
Abstract
This research investigates the applicability of an ANN and genetic algorithms for modeling and multiobjective optimization of the thermal conductivity and viscosity of water-based spinel-type MnFe2O4 nanofluid. Levenberg-Marquardt, quasi-Newton, and resilient backpropagation methods are employed to train the ANN. The support vector machine (SVM) method is also presented for comparative purposes. Experimental results demonstrate the efficacy of the developed ANN with the LM-BR training algorithm and the 3-10-10-2 structure for the prediction of the thermophysical properties of nanofluids in terms of the significantly superior accuracy compared to developing the correlation and employing SVM regression. Moreover, the genetic algorithm is implemented to determine the optimal conditions, i.e., maximum thermal conductivity and minimum nanofluid viscosity, based on the developed ANN.
Similar content being viewed by others

Introduction
Researchers have studied nanofluids flow for over two decades. Nanofluids with nanoparticles (the size of which is usually less than 100 nm) have many applications in bioengineering, aerospace, microfluidics, mechanical engineering, chemical engineering, electronic packing, and renewable energy systems1,2,3,4,5. Among the existing nanoparticles, magnetic nanoparticles (such as CoFe2O4, MnZnFe2O4, MnFe2O4, Fe2O3, Fe3O4, Co and Fe) have attracted special attention due to their remarkable features. As a result, various studies have been conducted regarding the flow, heat, and mass transport behavior of these types of nanofluids under magnetic fields6,7,8,9, and it has been found that their thermal performances are significantly dependent on the magnetic field.
Numerous studies have been conducted on the thermophysical properties of different types of nanofluids10,11,12,13,14,15,16,17,18. Some researchers have focused on the thermophysical analysis of magnetic nanofluids. Toghraie et al.19 investigated the viscosity of Fe3O4 nanofluids for 0.1–3 vol.% concentrations at 20–55 °C. It was found that the viscosity is directly proportional to the concentration of nanoparticles and inversely proportional to their temperature. They reported a maximum improvement of approximately 130% in viscosity ratios for 3 vol.% Fe3O4 nanoparticles. In another study, Wang et al.20 studied the viscosity of 0.5–5% Fe3O4 nanofluids under an applied magnetic field with different strengths of 0–300 G at 20–60 °C; they developed a new correlation to predict viscosity as a function of magnetic induction, nanofluid temperature, and concentration. Sundar et al.21 performed an experimental and theoretical study on the thermophysical properties of 0.0–2.0 vol.% Fe3O4 nanofluids at 20–60 °C. They revealed that the thermophysical parameters were positive functions of the nanoparticle content. However, the improvement in viscosity with increasing nanoparticle content was found to be higher than that of thermal conductivity. They also developed new models to predict the thermophysical properties of Fe3O4 nanofluids; these have satisfactory accuracy without the help of the Maxwell and Einstein equations. Recently, Amani et al.22,23 experimentally evaluated the thermal conductivity and viscosity of MnFe2O4 nanofluids with concentrations of 0.25–3.0 vol.% under a magnetic field of 100–400 G at 20–60 °C. It was shown that the thermal conductivity improved at elevated temperatures in cases without a magnetic field, while it decreased in the presence of applied magnetic fields with increasing temperature. On the other hand, the viscosity was found to have an inverse relation with temperature in cases with and without a magnetic field. Maximum increases of 1.36 and 1.75 in the thermal conductivity and viscosity ratios were achieved under a 400 G magnetic field at 3 vol.% nanoparticles and 40 °C. Similar trends for the viscosity of Fe3O4 nanofluids were reported by Malekzadeh et al.24 within the concentration range of 0–1.0 vol.% under an external magnetic field at 25–45 °C. The thermal conductivity of NiFe2O4 nanoparticles was considered by Karimi et al.25, and the highest improvement of 17.2% was observed for 2 vol.% nanoparticles at 55 °C.
From the predictive ability of models proposed via the traditional methods in previous investigations, one can realize that the classical methods cannot provide very accurate predictions. In this regard, artificial neural networks (ANNs) are among the methods which have recently grabbed the attention of many investigators due to their simplicity, extensive capacity, and high processing speed. In particular, various studies have been conducted on the application of ANNs for predicting the thermophysical features of nanofluids26. Esfe et al.27,28,29 conducted several investigations on designing an ANN that could predict the thermal conductivity and viscosity of different types of nanofluids from input experimental data, including temperature and volume fraction. They evaluated the thermophysical properties of various nanofluids separately, such as Al2O3/water-EG (40:60), TiO2/water, and SWCNTs-MgO/EG, in their studies. The comparison between the performance of the ANN model and the results obtained from experimental data disclosed that the neural network can more accurately predict the thermophysical properties of the studied nanofluids. Afrand et al.30,31,32,33 evaluated the thermophysical properties of water-based Fe3O4, MgO, MWCNT, and functionalized CNT nanofluids with different concentrations and temperatures and proposed that ANNs could precisely predict the experimental results. Bahiraei and Hangi34 investigated the thermophysical properties of Fe3O4 nanofluids at 0–4 vol.% concentrations and for temperatures ranging from 25–60 °C. They developed a model for thermal conductivity and viscosity using a neural network and revealed that the ANN is very capable of accurately predicting the thermophysical properties of nanofluids. In another study, a 5-input ANN model was employed by Ahmadloo and Azizi35 to predict the thermal conductivity of 15 different water-, transformer-oil-, and EG-based nanofluids. Their model had a mean absolute percent error and R2 value of 1.44% and 0.993, respectively, indicating its reasonable accuracy. Later, Vafaei et al.36 employed an ANN to predict the thermal conductivity ratio of the MgO-MWCNTs/EG hybrid nanofluid. They conducted an optimization procedure and showed that an ANN with 12 neurons in the hidden layer resulted in the most accurate prediction, in which the highest deviation was 0.8%. Some other researchers also focused on the optimization of thermophysical properties obtained via ANN modeling. For instance, multiobjective optimization of the thermophysical properties of DWCNT/water, Al2O3/water-EG (40:60), and ND-Co3O4/water-EG (60:40) was performed by Esfe et al.37,38,39, who implemented the modified non-dominated sorting genetic algorithm (NSGA-II). Neural network modeling of the experimental results was performed to obtain the values of viscosity and thermal conductivity. For the optimization process, the nanofluid concentration and temperature design variables were employed to maximize the thermal conductivity and minimize the viscosity of the nanofluid. The optimal results showed that the optimum viscosity and thermal conductivity occur at the maximum temperature.
Based on the discussion above, this article evaluates the applicability of ANNs and genetic algorithms for modeling as well as the multiobjective optimization of the thermal conductivity and viscosity of water-based spinel-type MnFe2O4 nanofluids. The experimental data used in this research are presented in refs22,23. Three distinctive methods for training the ANN, including the Levenberg–Marquardt, quasi-Newton, and resilient backpropagation approaches, are evaluated, and various structures are considered. For comparison purposes, the support vector machine (SVM) is also employed for the problem under study. Furthermore, a genetic algorithm is employed to find the optimal cases (i.e., the highest thermal conductivity and the relatively lowest viscosity). Afterward, the Pareto front and several optimal conditions are introduced.
This article is composed of five main sections. Section 2 presents the experimental procedure conducted to obtain the input data for modeling. Section 3 briefly introduces the current state-of-the-art regression methods, including the ANN, as well as different training algorithms and SVM regression. Section 4 gives the multicriteria optimization, for which the genetic algorithm is utilized. Section 5 discusses and analyzes the predictive ability of various regression models, including the ANN, along with different training methods and structures, developing correlations, and support vector regression (SVR). This section also discusses the optimal results of the developed ANN for practical applications. Section 6 provides some remarks regarding the future and familiarizes readers with several current state-of-the-art methods that may potentially be able to provide more reliable training and reproducibility of results. Finally, Section 7 concludes the research by offering some final remarks.
Experimental setup and procedure
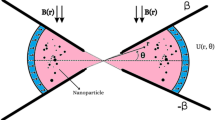
Figure 1 depicts a schematic view of the employed setup for the nanofluid thermal conductivity (k) and viscosity (µ) measurements. As shown, the apparatus was composed of thermal conductivity/viscosity measurement devices, a magnetic field generator, a data acquisition system, and a temperature bath. A Brookfield DV-I PRIME viscometer and a KD2 Pro (Decagon Devices Inc., USA) were used to determine the viscosity and thermal conductivity, respectively. A cylindrical container 100 mm in length and 22 mm in diameter was employed to hold the nanofluid.

Schematic diagram of the setup.
A uniform magnetic field was generated by placing the container in the middle of the two legs of the U-shaped zinc ferrite core, which was wrapped with copper wire to convert the U-shaped core into a magnet. A Gauss meter, along with a microcontroller programming tool, were employed to measure and control the intensity of the applied magnetic field.
The chemical co-precipitation approach40 was implemented to synthesize the manganese ferrite nanoparticles. Moreover, XRD, SEM, and VSM tests were conducted to evaluate the phase, size, and magnetic properties of nanoparticles. Details regarding the synthesis procedure as well as the hysteresis curve, SEM image and XRD pattern of the synthesized MnFe2O4 nanoparticles are presented in refs22,23. Accordingly, the synthesized nanoparticles were spherical, brown, and contained superparamagnetic particles with zero coercivity, a saturation magnetization of 15.79 emu/g, a density of 4870 kg/m3, and an average diameter of 20 nm. The nanofluid was stabilized via 90-min ultrasonic processing. For the experiments, the volume fraction of nanoparticles ranged from 0.25% to 3%, the temperature ranged from 20 °C to 60 °C, and the strength of the magnetic field varied from 100 to 400 G.
Statistical Methods
This section concerns various structures and evaluates three distinctive methods for training the ANN: the Levenberg-Marquardt, quasi-Newton, and resilient backpropagation approaches. For comparison purposes, the SVM is also employed for the problem under study.
Artificial neural network
For several years, the high precision, ability to solve complicated equations and significant benefits of the high speed of ANNs have led many researchers to employ these techniques for various scientific topics. ANNs are based on the human brain and comprise layers and neurons. They can be characterized by a transfer function (which converts the inputs to outputs), a learning algorithm (which defines biases and weights on the connections), and the architecture (which provides the connection between the neurons and layers).
To model the thermal conductivity and dynamic viscosity of the MnFe2O4/water nanofluid (output of the network) as a function of nanofluid temperature, concentration and an applied magnetic field (input of the network), the multilayer perceptron ANN shown in Fig. 2 is implemented.

Structure of the employed ANN.
The multilayer perceptron ANN consists of multiple layers with several neurons in each layer. The neurons in a layer are related to each other via weight coefficients. The relation between output and input variables in the network is determined by updating the biases and weights.
First, to train the network, the required data must be generated. Next, the optimal structure must be found by evaluating various structures of the neural network. Finally, the data that were not previously implemented for training the network must be employed to test the neural network. The coefficient of determination (R2) and mean square error (MSE) are calculated to evaluate the performance of the ANN. The MSE and R2 values can be calculated as follows:
where n is the amount of data, y exp represents the experimental values, and y pred denotes the values predicted by the neural network.
In the current study, supervised learning is considered, along with the involved sets of input/output data pattern pairs. Thus, the ANN must be trained to produce the actual outputs pursuant of the instances. The backpropagation algorithm is chosen as the method of training.
The pace of different training methods depends on the error goal, the number of biases and weights in the network, the number of data points in the training set, and generally the kind of problem. These factors should be considered to find the fastest training method for a particular problem among various types of backpropagation algorithms. The fastest reduction in the performance function can be attained by updating the network weights and biases in the orientation of the negative gradient. This is the simple utilization of backpropagation training, in which the iterations can be expressed as follows:
where α k represents the learning rate and g k and x k denote the gradient and vector, respectively, of the current weights and biases.
Such simple backpropagation training algorithms are not appropriate for practical problems because they are usually too slow. There are some other algorithms that employ some methods such as the standard numerical optimization methods (e.g., Levenberg-Marquardt (LM) and Quasi-Newton approaches) or heuristic techniques (e.g., the resilient backpropagation technique (Rprop)). In this regard, the present research aims to evaluate the accuracy of the aforementioned methods to train the ANN. These methods are described in the following.
Resilient backpropagation (Rprop) algorithm
In this approach, the sigmoid transfer function, i.e., the squashing function, is employed in the hidden layers to create a finite output range from a compressed infinite input. In fact, as the input becomes large, the slopes of these functions must approach zero. When the steepest descent is applied to train a multilayer network with these functions, it causes a problem. This problem occurs because the very small gradient value causes small alterations in the weights and biases. This phenomenon occurs even when the magnitudes of weights and biases are far from their optimal value. Therefore, the objective of the Rprop training algorithm is to remove these detrimental influences from the partial derivative values. Manhattan learning rules with specific modifications have been used as the basic principle of Rprop41. Eqs (4) and (5) represent the increasing variation in and update of the weight magnitudes for a specific iteration and the next iteration, respectively.
A particular magnitude for the update of each weight, i.e., \({{\rm{\Delta }}}_{ij}^{(t-1)}\) between neurons of layers i and j at the (t − 1)th instant of time, is introduced in the Rprop algorithm. The evolution of these update values is based on the sight of the local error function, E. \(\frac{\partial {E}^{(t)}}{\partial {W}_{ij}}\) represents the gradient information at i over all patterns of the training set. Next, the new update values, \({{\rm{\Delta }}}_{ij}^{(t)}\), must be determined in terms of the error function topology. Eq. (6) shows how this is carried out using a sign-dependent adaptation procedure:
where 0 < η − < 1 < η +. The update magnitude for each weight and bias is a positive function of η + when the sign of the performance function derivative remains constant through two successive iterations with respect to that weight. The update magnitude is a negative function of η − when the sign of the derivative varies from the previous iteration with respect to that weight. Moreover, the update value remains the same if the derivative is zero.
Quasi-Newton model
According to the previous discussions, the steepest reduction in the performance function can be attained by updating the network weights and biases along the negative gradient. However, it was proven that the fastest decrease in the performance function does not necessarily lead to the fastest convergence. Indeed, the implementation of a search along conjugate directions in the conjugate gradient algorithms can result in faster convergence compared to the fastest reduction directions. An alternative to the conjugate gradient algorithms is Newton’s method, which has the following basic step:
where A k (the Hessian matrix) represents a second derivative of the performance function at the current weight and bias values. Although using Newton’s methods results in faster convergence compared to using the conjugate gradient approaches, computing the Hessian matrix for feedforward neural networks is complicated and expensive. On the other hand, quasi-Newton approaches are another type of algorithm based on Newton’s method, in which evaluating the second derivatives is not required. In this approach, the Hessian matrix approximation in every iteration is updated and used for evaluation in terms of the gradient. The Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm is the most commonly used algorithm in published investigations using the quasi-Newton approach. Although this algorithm commonly converges within fewer iterations, it requires greater storage and more computations in every iteration compared to the conjugate gradient techniques. Indeed, a Hessian approximation with dimensions of n2 × n2 must be stored, where n represents the number of weights and biases.
Bayesian regularization based on the Levenberg-Marquardt model
A standard method for nonlinear optimization is the Levenberg-Marquardt algorithm, which was employed to train the ANN as a third method. In the LM algorithm, there is no need for the Hessian matrix computation, as it has been developed to approach second-order training speeds similar to those of the quasi-Newton methods. The Hessian matrix can be defined by:
and the gradient is calculated using:
where J and e are the Jacobian matrix and network errors, respectively. The Jacobian matrix consists of the first derivative of network errors regarding the biases and weights, which can be determined using a standard back-propagation technique. The calculation of a Jacobian matrix is less intricate than that of a Hessian matrix. The estimation of a Hessian matrix is employed by the Levenberg-Marquardt algorithm as follows:
The estimation of the Hessian matrix converts it into a gradient descent with a minor step size by considering ξ as a large value, while it becomes Newton’s approach when ξ is zero. It is desired to shift towards Newton’s approach due to the speed and accuracy of this method near an error minimum. Therefore, the reduction of ξ leads to decrementing the performance function after each successful step, and when an increment of the performance function is needed, ξ is increased.
Assigning the optimum performance ratio is a challenging problem in regularization. If this parameter is considered to be very small, the accuracy of the network’s prediction regarding the trained data diminishes, and if the ratio is regarded as being too large, overfitting may occur. One procedure for the determination of the optimum regularization parameters is the Bayesian framework for training the ANN as the optimal method. Random variables with specified distributions are assigned to the network biases and weights. Then, a statistical technique is implemented to estimate the regularization parameters (l).
In this research, Bayesian regularization based on the LM method is applied to train the network. It can be inferred that the LM approach is selected for network training and that Bayesian regularization is implemented to improve the network generalizations. Bayesian regularization was comprehensively described by Penny and Roberts42 and Mahapatra and Sood43.
Support vector machine
Support vector machines (SVMs) are machine learning methods employed for regression and classification. Support vector regression (SVR) produces nonlinear boundaries by constructing a linear boundary in a large and transformed version of the feature space. Unlike NNs, SVR does not suffer from the local minima problem, as model parameter estimation involves solving a convex optimization problem44.
Multiobjective Optimization
Previous studies have shown that the thermal conductivity and viscosity of MnFe2O4/water magnetic nanofluids are significantly dependent upon the nanoparticle concentration, temperature and applied magnetic field22,23. The results demonstrate that the presence of nanoparticles augments the thermal conductivity and viscosity of nanofluids compared to pure water due to the significant heat conduction of nanoparticles. In particular, various factors result in an increase in thermal conductivity, i.e., the dispersion of nanoparticles into water, including Brownian motion, the congregation of nanoparticles, the formation of a layer of fluid molecules next to the nanoparticle surfaces, and the formation of nanoparticle complexes and collisions between them. Moreover, the increase in nanofluid viscosity with increasing nanoparticle concentration is due to the strengthening of the internal shear influences of nanoparticles. In fact, scattering nanoparticles inside the base fluid leads to the formation of larger clusters due to the Van der Waals forces. These nanoclusters hinder the movements of layers of the fluid on each other, which results in an increase in viscosity. Moreover, the viscosity exponentially decreases by increasing the temperature, and the thermal conductivity varies directly with temperature. This nonlinear relationship between viscosity and temperature is due to the attenuation of interparticle and intermolecular adhesion forces as a result of increasing the temperature. Thermal conductivity enhancements can be mainly regarded as increases in interactions between the nanoparticles and Brownian motion. Furthermore, it was observed that the thermal conductivity and viscosity increase with intensifying magnetic field strength. Application of a magnetic field causes the suspension of particles in the direction of the magnetic line, which results in the formation of chainlike structures. This phenomenon increases the flow resistance, and due to the distribution and morphology of chainlike clusters, the viscosity and thermal conductivity increase. It was revealed that the variable parameters have different influences on the thermophysical behaviors of a nanofluid. Therefore, optimizing the thermophysical properties of the MnFe2O4/water magnetic nanofluid is essential for heat transferring purposes. In this study, ANN optimization is conducted to evaluate the optimum conditions of variables to achieve the highest thermal conductivity and the lowest viscosity for the MnFe2O4/water nanofluid. Accordingly, with the help of a genetic algorithm, a multiobjective optimization is implemented in this work. The outlines of the genetic algorithm are as follows:
-
(1)
The initial phase of the algorithm is to create a random initial population.
-
(2)
The second phase is to create a sequence of new populations using the individuals in the current generation.
-
(3)
If one of the stopping criteria is met, the algorithm stops (see Table 1).
Table 1 Stopping criteria for the optimization process.
Additionally, coupled with the genetic algorithm, a promise programming decision-making method is employed to simplify the process of selection between optimal cases, as these cases have no preference for each other. In this regard, a single-objective optimization can be conducted instead of a multiobjective one, in which after combining the objective functions, and on the basis of their relative importance, the optimal values are measured. Eq. (11) represents the compromised function (D b ), which must be minimized.
In Eq. (11), Z and W represent the objective functions that must be maximized and minimized, respectively. Moreover, the superscripts “−” and “*” represent the best and the worst values for each objective function, respectively. The parameter b, where 1 ≤ b ≤ ∞, represents the distance parameter. In this work, b = 2. The relative importance of the objective functions is represented by the coefficient α in Eq. (11). Based on which output is most pivotal, the optimal point will change.
Results and Discussion
Model comparison
The primary objective of this work is to develop specific models for the accurate prediction of the thermophysical properties of water-based MnFe2O4 nanofluids under a magnetic field, as the conventional models are not able to provide desirable accuracy in predicting nanofluid viscosity and thermal conductivity. In the current work, a multilayer perceptron ANN is applied to the experimental data22,23 (to model the thermophysical properties as a function of the applied magnetic field) and to the nanofluid temperature and concentration (see Fig. 2). In this regard, 175 data points are used, among which 125 points are used to train the ANN and the other 50 points are used to test the ANN to ensure its reliability and validity. The viscosity data ranges from 0.00047 to 0.00164, and the data of thermal conductivity ranges between 0.598 and 0.817. The relative difference between these ranges may pose some problems during ANN training. To compensate for this issue, the data are preliminarily processed and normalized within [−1, 1]. However, the corresponding modeling is also compared to that of non-preprocessed data.
A comparative study of the predictive ability of the Rprop, BFGS and LM-BR techniques used to train the ANN is also conducted. The results are presented in Table 2, which involves 1500 epochs for every network. This study examines single- and two-layered network structures that include, respectively, 12 and 8 neurons in every hidden layer. It is observed that the normalization of the data improves the predictability of single- and two-layered networks. Thus, the normalized data are implemented to find the optimal model.
Three different training algorithms are evaluated to determine which is the most appropriate method for training the ANN. The comparative results, which were obtained based on the number of iterations, are presented in Table 3. In this regard, a sum squared error of 10−4 is considered to be the termination condition for training the single- and two-layered networks. The selected numbers of neurons in single- and two-layered networks are 12 and 8 in each layer, respectively.
An Rprop algorithm requires minimal storage and computation and does not need a line search. For instance, it is observed that 3270 epochs occurred in the two-layer network for Rprop, indicating that poor convergence was achieved. On the other hand, it can be seen that although convergence was achieved in fewer epochs for the BFGS algorithm, this algorithm requires more storage and computations compared to Rprop. Moreover, the LM-BR algorithm achieved the desired convergence in fewer epochs compared to Rprop and BFGS. Therefore, one can conclude that the LM-BR training method is the most suitable method. It is worth mentioning that these findings are specific to this situation and may not be typical for other applications.
To determine the most appropriate topology for different problems, there is no general or established technique, except for some preliminary suggestions to predict the optimal numbers of layers and neurons. Therefore, past experiences are employed to determine the topology and structure via trial-and-error methods. The predictability of the ANN significantly depends on the numbers of neurons and layers; a large number of them can decrease the generalization capability of an ANN, and too few of them can delay the training process. In this contribution, a total of 12 structures are assessed: networks with either one or two hidden layers with 2, 4, 6, 8, 10, and 12 neurons.
The ability to predict the viscosity and thermal conductivity using different structures is presented in Tables 4 and 5. Although the pivotal results for selecting the optimal case are those including the test data set (the more suitable the network, the more appropriate the prediction of unseen data), in Tables 4 and 5, the performance parameters of the training and test data are provided. The case of 1500 epochs is assumed to terminate the algorithms.
From assessing the ANN, it is found that the network with two hidden layers and 10 neurons in every layer results in the least difference between network outputs and experimental data and thus provides the best performance (highlighted in Tables 4 and 5). The corresponding MSE values of 5.86E-06 and 8.56E-07 and R2 values of 0.997 and 0.994 for the test data are obtained for thermal conductivity and viscosity prediction, respectively. The values of MSE and R2 indicate the excellent predictive ability of the model within the domain under study. The slight differences between the errors demonstrate the appropriate generalization of the network and proper data division into two parts, which can be referred to as the application of the BR feature.
The comparison of the experimental results with those extracted using this model is shown in Fig. 3 for the test data. It can be seen, without conducting any further experiments, that the model is capable of satisfactorily predicting the viscosity and thermal conductivity of the MnFe2O4 nanofluid at various temperatures from 20 to 60 °C and nanoparticle concentrations from 0.25 to 3 vol.% under the absence and presence of a magnetic field with an intensity of 100 to 400 G.

Previously, Amani et al.22,23 proposed new correlations between thermal conductivity and viscosity using a nonlinear regression method with R2 values of approximately 0.96 and 0.90, respectively. However, when comparing the values of R2 obtained in this study, it is found that the ANN model is much more accurate and, consequently, is a very powerful tool for determining the thermophysical properties in the studied problem.
Linear regression remains one of the most important regression methods. This is because linear models have apparent advantages due to their simplicity. Linear models include not only least square regressions but also many other techniques, including the LASSO (least absolute shrinkage and selection operator), the PLS (partial least square), and the SVM. Therefore, it may be worthwhile to spend more time using a linear regression or methods with good interpretations to understand more about their applicability to problems such as those under study. In this regard, and for comparison purposes, the SVM method is also compared with the ANN using the experimental dataset to demonstrate the efficacy of these models for further practical applications. SVM regression is implemented using the STATISTICA® v.12 software. The comparison of the predictive ability of the ANN with that of the SVM is presented in Table 6. It can be seen that the ANN outperforms the SVR and that the MSE and R2 values of the ANN predicted outputs are better than those of the SVM for both training and testing. Thus, it is observed that the ANN has superior performance in terms of developing new correlations of prediction accuracy for the calculated datasets and performs better in terms of statistical measurements and efficiency compared to other machine learning methods, such as the SVM.
It should be noted that for practical applications, the more accurate prediction is much more desirable. Moreover, the higher production cost of nanofluids may hinder the application of nanofluids in industry and make the accurate prediction of nanofluid properties more crucial. Therefore, it can be concluded that ANN is the most accurate prediction model when applying practical applications, such as cooling or heating systems containing nanofluids.
Optimization of ANN for practical applications
The experimental results show that each of the applied magnetic fields and the nanofluid temperature (T) and concentration (φ) have their particular influence on the thermophysical properties of the nanofluid. For example, when the nanofluid concentration is increased, the thermal conductivity, as well as the nanofluid viscosity, increases, which may be uneconomical due to the increment of the latter property22,23. Thus, a multiobjective optimization is needed to achieve a combination of parameters with the least viscosity, μ, and highest thermal conductivity, k, of the MnFe2O4/water nanofluid. In this regard, the genetic algorithm is employed to optimize the model obtained from the ANN. The Pareto diagram and 17 optimal cases obtained via the optimization are shown in Fig. 4 and Table 7.

Values of objective functions corresponding to the optimal performance points (Pareto diagram).
It should be noted that there is no preference between the above optimum conditions and no specific criteria to select among them. Selection among these optimal points depends on the designer’s point of view. For some purposes, the priority is an elevated thermal conductivity, while in other situations, the lowest nanofluid viscosity is more desirable. Thus, a compromise programming decision-making approach is implemented to simplify the process of selecting between these conditions. In this technique, the combination of objective functions converts the problem into a single-objective optimization. As previously seen in Eq. (15), the relative importance of the objective function is represented by the coefficient α, and in this regard, only one optimal condition can be found for each value of α. Since this problem is a two-objective situation, Eq. (11) has been converted into Eq. (12), as follows:
where α 1 and α 2 represent the importance of the thermal conductivity and viscosity objective functions, respectively. According to Eq. (12), the current situation is solved for various α 1 and α 2 combinations, where the sum of these coefficients must equal to one. Table 8 presents the values of the affected parameters, including the applied magnetic field intensities and nanofluid temperatures and concentrations corresponding to the optimal points, for different values of α.
According to the results, the maximum thermal conductivity and minimum viscosity of the MnFe2O4/water nanofluid are obtained at the highest temperature (60 °C). Since increasing the magnetic field intensity (B) along with the nanoparticle concentration results in elevating the viscosity of the nanofluid, the concentration and magnetic field intensity have their lowest values in the first row of the table (when the importance of viscosity is considered to be 1). On the other hand, the concentration and magnetic field intensity have their highest values in the last row of the table (when the importance of thermal conductivity is considered to be 1). Furthermore, it can be seen that in the middle rows of the table, where thermal conductivity and viscosity have almost equal importance, magnetic fields with medium intensities in the presence of nanoparticles with medium concentrations are the optimal cases, indicating the desirable conditions for the cases in which thermal conductivity and viscosity are equally important.
Future Works
The aim of many machine learning methods is to update a set of parameters to optimize an objective function. Adaptive gradient algorithms (AdaGrad) and adaptive moment estimations (Adam) are the current state-of-the-art methods. AdaGrad is a modified stochastic gradient descent with a per-parameter learning rate; it was first published in 201145. This algorithm increases the learning rate for sparser parameters and decreases the learning rate for less sparse ones. This strategy often improves convergence performance over standard stochastic gradient descent in settings where data are sparse and sparse parameters are more informative. One of AdaGrad’s main benefits is that it eliminates the need to manually tune the learning rate, and AdaGrad’s main weakness is its accumulation of the squared gradients in the denominator. Adam is an algorithm for first-order gradient-based optimizations of stochastic objective functions based on adaptive estimates of lower-order moments. The method is straightforward to implement, is computationally efficient, has few memory requirements, is invariant to diagonal rescaling of the gradients, and is well suited for problems that are large in terms of data and/or parameters. The method is also appropriate for nonstationary objectives and problems with very noisy and/or sparse gradients. The hyperparameters have intuitive interpretations and typically require little tuning. Empirical results demonstrate that Adam works well in practice and is favorably comparable to other stochastic optimization methods46. These methods provide more reliable training and reproducibility of results, and it is strongly recommended that one employs these algorithms for engineering prediction purposes.
Conclusions
The primary focus of this work is the optimization of water-based MnFe2O4 nanofluids to enhance thermal conductivity and decrease nanofluid viscosity. Using the artificial neural network, target functions are determined with the aim of discussing the experimental results of the thermophysical properties of nanofluids. In the current research, the input data for neural networks include the magnetic field intensity and the nanofluid temperature and concentration. The Rprop, BFGS and BR-LM algorithms are examined to train the ANN, and it is found that the developed ANN with the BR-LM method and the 3-10-10-2 structure yields the best performance. Using the ANN, MSE values of 5.86E-06 and 8.56E-07 and R2 values of 0.997 and 0.994 for the test data are obtained for thermal conductivity and viscosity prediction, respectively, indicating a significantly high accuracy of the ANN model compared to the prediction ability of previously proposed correlations obtained via nonlinear regression22,23. The SVM method is also compared to the ANN in terms of predictive capability for the problem under study. It is found that the ANN outperforms the SVR and is highly recommended for the prediction of the thermophysical features of magnetic nanofluids under an external magnetic field.
Furthermore, the optimal cases are considered in this study. In this regard, multiobjective optimizations using a genetic algorithm are applied to the developed model, resulting in the introduction of 17 optimal cases. A compromise programming decision-making method is also used to simplify the process of selecting between cases. Accordingly, the study proposes the optimum conditions for different importance levels of the objective functions.
References
Jung Lee, H., Bai, S.-J. & Seok Song, Y. Microfluidic Electrochemical Impedance Spectroscopy of Carbon Composite Nanofluids. Sci. Rep. 7, 722 (2017).
Amani, M., Amani, P., Kasaeian, A., Mahian, O. & Yan, W.-M. Two-phase mixture model for nanofluid turbulent flow and heat transfer: Effect of heterogeneous distribution of nanoparticles. Chem. Eng. Sci. 167, 135–144 (2017).
Mahian, O., Kianifar, A., Kalogirou, S. A., Pop, I. & Wongwises, S. A review of the applications of nanofluids in solar energy. Int. J. Heat Mass Transf. 57, 582–594 (2013).
Mahian, O. et al. Nanofluids effects on the evaporation rate in a solar still equipped with a heat exchanger. Nano Energy 36, 134–155 (2017).
Ameri, M., Amani, M. & Amani, P. Thermal performance of nanofluids in metal foam tube: Thermal dispersion model incorporating heterogeneous distribution of nanoparticles. Adv. Powder Technol. 28, 2747–2755 (2017).
Amani, M., Ameri, M. & Kasaeian, A. Investigating the convection heat transfer of Fe3O4 nanofluid in a porous metal foam tube under constant magnetic field. Exp. Therm. Fluid Sci. 82, 439–449 (2017).
Amani, M., Ameri, M. & Kasaeian, A. The Experimental Study of Convection Heat Transfer Characteristics and Pressure Drop of Magnetite Nanofluid in a Porous Metal Foam Tube. Transp. Porous Media 116, 959–974 (2017).
Amani, M., Ameri, M. & Kasaeian, A. The efficacy of magnetic field on the thermal behavior of MnFe2O4 nanofluid as a functional fluid through an open-cell metal foam tube. J. Magn. Magn. Mater. 432, 539–547 (2017).
Amani, P., Amani, M., Mehrali, M. & Vajravelu, K. Influence of quadrupole magnetic field on mass transfer in an extraction column in the presence of MnFe2O4 nanoparticles. J. Mol. Liq. 238, 145–154 (2017).
Soltanimehr, M. & Afrand, M. Thermal conductivity enhancement of COOH-functionalized MWCNTs/ethylene glycol–water nanofluid for application in heating and cooling systems. Appl. Therm. Eng. 105, 716–723 (2016).
Li, H. et al. Experimental investigation of thermal conductivity and viscosity of ethylene glycol based ZnO nanofluids. Appl. Therm. Eng. 88, 363–368 (2015).
Nemade, K. & Waghuley, S. A novel approach for enhancement of thermal conductivity of CuO/H2O based nanofluids. Appl. Therm. Eng. 95, 271–274 (2016).
Abdolbaqi, M. K., Azmi, W. H., Mamat, R., Sharma, K. V. & Najafi, G. Experimental investigation of thermal conductivity and electrical conductivity of BioGlycol–water mixture based Al2O3 nanofluid. Appl. Therm. Eng. 102, 932–941 (2016).
Afrand, M. Experimental study on thermal conductivity of ethylene glycol containing hybrid nano-additives and development of a new correlation. Appl. Therm. Eng. 110, 1111–1119 (2017).
Nikkam, N. et al. Experimental investigation on thermo-physical properties of copper/diethylene glycol nanofluids fabricated via microwave-assisted route. Appl. Therm. Eng. 65, 158–165 (2014).
Amiri, M., Movahedirad, S. & Manteghi, F. Thermal conductivity of water and ethylene glycol nanofluids containing new modified surface SiO2-Cu nanoparticles: Experimental and modeling. Appl. Therm. Eng. 108, 48–53 (2016).
Adhami Dehkordi, R., Hemmat Esfe, M. & Afrand, M. Effects of functionalized single walled carbon nanotubes on thermal performance of antifreeze: An experimental study on thermal conductivity. Appl. Therm. Eng. 120, 358–366 (2017).
Azmi, W. H., Abdul Hamid, K., Mamat, R., Sharma, K. V. & Mohamad, M. S. Effects of working temperature on thermo-physical properties and forced convection heat transfer of TiO2 nanofluids in water – Ethylene glycol mixture. Appl. Therm. Eng. 106, 1190–1199 (2016).
Toghraie, D., Alempour, S. M. & Afrand, M. Experimental determination of viscosity of water based magnetite nanofluid for application in heating and cooling systems. J. Magn. Magn. Mater. 417, 243–248 (2016).
Wang, L., Wang, Y., Yan, X., Wang, X. & Feng, B. Investigation on viscosity of Fe3O4 nanofluid under magnetic field. Int. Commun. Heat Mass Transf. 72, 23–28 (2016).
Syam Sundar, L., Singh, M. K. & Sousa, A. C. M. Investigation of thermal conductivity and viscosity of Fe3O4 nanofluid for heat transfer applications. Int. Commun. Heat Mass Transf. 44, 7–14 (2013).
Amani, M., Amani, P., Kasaeian, A., Mahian, O. & Wongwises, S. Thermal conductivity measurement of spinel-type ferrite MnFe2O4 nanofluids in the presence of a uniform magnetic field. J. Mol. Liq. 230, 121–128 (2017).
Amani, M. et al. Experimental study on viscosity of spinel-type manganese ferrite nanofluid in attendance of magnetic field. J. Magn. Magn. Mater. 428, 457–463 (2017).
Malekzadeh, A. & Pouranfard, A. Experimental Investigations on the Viscosity of Magnetic Nanofluids under the Influence of Temperature, Volume Fractions of Nanoparticles and External Magnetic. J. Appl. Fluid Mech. 9, 693–697 (2016).
Karimi, A., Sadatlu, M. A. A., Saberi, B., Shariatmadar, H. & Ashjaee, M. Experimental investigation on thermal conductivity of water based nickel ferrite nanofluids. Adv. Powder Technol. 26, 1529–1536 (2015).
Amani, M., Amani, P., Mahian, O. & Estellé, P. Multi-objective optimization of thermophysical properties of eco-friendly organic nanofluids. J. Clean. Prod. 166, 350–359 (2017).
Hemmat Esfe, M. et al. Estimation of thermal conductivity of Al2O3/water (40%)–ethylene glycol (60%) by artificial neural network and correlation using experimental data. Int. Commun. Heat Mass Transf. 74, 125–128 (2016).
Hemmat Esfe, M., Hassani Ahangar, M. R., Rejvani, M., Toghraie, D. & Hajmohammad, M. H. Designing an artificial neural network to predict dynamic viscosity of aqueous nanofluid of TiO2 using experimental data. Int. Commun. Heat Mass Transf. 75, 192–196 (2016).
Hemmat Esfe, M., Alirezaie, A. & Rejvani, M. An applicable study on the thermal conductivity of SWCNT-MgO hybrid nanofluid and price-performance analysis for energy management. Appl. Therm. Eng. 111, 1202–1210 (2017).
Afrand, M., Toghraie, D. & Sina, N. Experimental study on thermal conductivity of water-based Fe3O4 nanofluid: Development of a new correlation and modeled by artificial neural network. Int. Commun. Heat Mass Transf. 75, 262–269 (2016).
Afrand, M., Hemmat Esfe, M., Abedini, E. & Teimouri, H. Predicting the effects of magnesium oxide nanoparticles and temperature on the thermal conductivity of water using artificial neural network and experimental data. Phys. E Low-dimensional Syst. Nanostructures 87, 242–247 (2017).
Afrand, M., Ahmadi Nadooshan, A., Hassani, M., Yarmand, H. & Dahari, M. Predicting the viscosity of multi-walled carbon nanotubes/water nanofluid by developing an optimal artificial neural network based on experimental data. Int. Commun. Heat Mass Transf. 77, 49–53 (2016).
Afrand, M. et al. Prediction of dynamic viscosity of a hybrid nano-lubricant by an optimal artificial neural network. Int. Commun. Heat Mass Transf. 76, 209–214 (2016).
Bahiraei, M. & Hangi, M. An empirical study to develop temperature-dependent models for thermal conductivity and viscosity of water-Fe3O4 magnetic nanofluid. Mater. Chem. Phys. 181, 333–343 (2016).
Ahmadloo, E. & Azizi, S. Prediction of thermal conductivity of various nanofluids using artificial neural network. Int. Commun. Heat Mass Transf. 74, 69–75 (2016).
Vafaei, M. et al. Evaluation of thermal conductivity of MgO-MWCNTs/EG hybrid nanofluids based on experimental data by selecting optimal artificial neural networks. Phys. E Low-dimensional Syst. Nanostructures 85, 90–96 (2017).
Hemmat Esfe, M., Hajmohammad, H., Moradi, R. & Abbasian Arani, A. A. Multi-objective optimization of cost and thermal performance of double walled carbon nanotubes/water nanofluids by NSGA-II using response surface method. Appl. Therm. Eng. 112, 1648–1657 (2017).
Hemmat Esfe, M. et al. Optimization, modeling and accurate prediction of thermal conductivity and dynamic viscosity of stabilized ethylene glycol and water mixture Al2O3 nanofluids by NSGA-II using ANN. Int. Commun. Heat Mass Transf. 82, 154–160 (2017).
Hemmat Esfe, M. & Hajmohammad, M. H. Thermal conductivity and viscosity optimization of nanodiamond-Co3O4/EG (40:60) aqueous nanofluid using NSGA-II coupled with RSM. J. Mol. Liq. 238, 545–552 (2017).
Sharma, U. S., Sharma, R. N. & Shah, R. Physical and Magnetic Properties of Manganese Ferrite Nanoparticles. Int. J. Eng. Res. Appl. 4, 14–17 (2014).
Riedmiller, M. & Braun, H. A direct adaptive method for faster backpropagation learning: the RPROP algorithm. in IEEE International Conference on Neural Networks 586–591 (IEEE, 1993).
Penny, W. D. & Roberts, S. J. Bayesian neural networks for classification: how useful is the evidence framework? Neural Networks 12, 877–892 (1999).
Mahapatra, S. S. & Sood, A. K. Bayesian regularization-based Levenberg–Marquardt neural model combined with BFOA for improving surface finish of FDM processed part. Int. J. Adv. Manuf. Technol. 60, 1223–1235 (2012).
Bishop, C. Pattern recognition and machine learning. (springer, 2006).
Duchi, J., Hazan, E. & Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 12, 2121–2159 (2011).
Kingma, D. P. & Ba, J. Adam: A Method for Stochastic Optimization. (2014).
Acknowledgements
The authors are grateful to the respected reviewers for critically reviewing the manuscript and making important suggestions. The sixth author acknowledges the support provided by the “Research Chair Grant” National Science and Technology Development Agency (NSTDA), the Thailand Research Fund (TRF) and King Mongkut’s University of Technology Thonburi through the “KMUTT 55th Anniversary Commemorative Fund”. The fourth author would liketo thank the postdoc fellowship granted by KMUTT. The work of I. Pop has been supported from the grant PN-III-P4-ID-PCE-2016-0036, UEFISCDI, Romania.
Author information
Authors and Affiliations
Contributions
M. Amani and P. Amani collected the data and performed the data analysis. The results were discussed and interpreted by M. Amani, P. Amani, A. Kasaeian and O. Mahian. I. Pop and S. Wongwises conceived and supervised the study. The manuscript was written with contributions from all authors. In addition, all authors have approved the final version of this manuscript.
Corresponding authors
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Amani, M., Amani, P., Kasaeian, A. et al. Modeling and optimization of thermal conductivity and viscosity of MnFe2O4 nanofluid under magnetic field using an ANN. Sci Rep 7, 17369 (2017). https://doi.org/10.1038/s41598-017-17444-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-17444-5
This article is cited by
-
A web-based intelligent calculator for predicting viscosity of ethylene–glycol–based nanofluids using an artificial neural network model
Rheologica Acta (2024)
-
An optimised deep learning method for the prediction of dynamic viscosity of MXene-based nanofluid
Journal of the Brazilian Society of Mechanical Sciences and Engineering (2023)
-
System-dependent behaviors of nanofluids for heat transfer: a particle-resolved computational study
Computational Particle Mechanics (2023)
-
Comprehensive review on exergy analysis of shell and tube heat exchangers
Journal of Thermal Analysis and Calorimetry (2022)
-
Predicting the density of carbon-based nanomaterials in diesel oil through computational intelligence methods
Journal of Thermal Analysis and Calorimetry (2022)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
