
Abstract
Nitrogen (N) is an important nutrient for crop growth. However, the overuse of N fertilizers has led to a series of devastating global environmental issues. Recent studies show that multiple datasets have been created for agricultural N fertilizer application with varied temporal or spatial resolutions, nevertheless, how to synchronize and use these datasets becomes problematic due to the inconsistent temporal coverages, spatial resolutions, and crop-specific allocations. Here we reconstructed a comprehensive dataset for crop-specific N fertilization at 5-arc-min resolution (~10 km by 10 km) during 1961–2020, including N application rate, types, and placements. The N fertilization data was segmented by 21 crop groups, 13 fertilizer types, and 2 fertilization placements. Comparison analysis showed that our dataset is aligned with previous estimates. Our spatiotemporal N fertilization dataset could be used for the land surface models to quantify the effects of agricultural N fertilization practices on food security, climate change, and environmental sustainability.
Similar content being viewed by others


Background & Summary
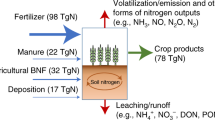
Nitrogen (N) is one of the most essential nutrients for crop production. Since the development of the Haber-Bosch process, the consumption of synthetic N fertilizers has increased exponentially to meet the food demand of growing human population1,2. However, excess N fertilizers are escaping into the environment, via a cascade of processes through atmospheric, aquatic, marine and terrestrial pools3,4. For example, agricultural N pollutants due to emitting, run-offs and leaching could result in severe air pollution (i.e., fine particle matter and aerosols)5,6, global climate change (i.e., ozone depletion in the stratosphere)7,8, eutrophication9 and compromised water quality in surface and groundwater aquatic ecosystems10,11, biodiversity loss12 as well as acidification in terrestrial ecosystems13. In order to assess the effect of N fertilization, which was defined as N application rate, types (including synthetic N fertilizers, manure and crop residues) and placement, on the environment at different scales (especially for a globally large scale), diverse datasets of agricultural N fertilization practices segmented by various temporal and spatial resolutions are urgently needed.
N fertilization has been considered as an important input in multiple models, e.g., the Organising Carbon and Hydrology In Dynamic Ecosystems model (ORCHIDE-Crop)6 and PKU-NRUNOFF model14 require crop-specific N inputs, the Soil & Water Assessment Tool (SWAT)15 and the Magnitude And Seasonality of Agricultural Emissions model for NH3 (MASAGE_NH3 models)16 require fertilizer types as input data besides. More importantly, the DeNitrification-DeComposition model (DNDC)17,18 and the flux upscaling model for N2O emissions19 simultaneously need crop-specific N inputs, fertilizer types, and application placement as input data. Generally, the country-level N fertilizer applied to agriculture could be obtained from the Food and Agriculture Organization of the United Nations (FAO)20 and the International Fertilizer Association (IFA)21, which have been widely used in global and national research. However, detailed geospatial distributions, which are usually required in many process-based models, are unavailable from these international statistics. Crop-specific N fertilizer application rate at a resolution of 5 arc-min was firstly generated by Mueller et al.22, whereas this study only focused on the rates for the year 2000. The related dataset was further expanded to a period of 1961–2013 at a relatively lower resolution of 0.5 degree × 0.5 degree and segmented by NH4+ and NO3− forming N fertilizers23.Moreover, Wang et al.24 extended the temporal period of N application rate data into the year 1961–2014, but only into two categories (i.e., upland crops and paddy rice) through aggregating administrative-unit statistic data. Meanwhile, a 5-arc-min gridded global dataset pertaining to global manure N production and application in cropland during 1860–2015 was reconstructed by Zhang et al.25. Historic anthropogenic N inputs to terrestrial biosphere with 5 arc-min during 1960–2019 were also reconstructed, including annual rates of synthetic N fertilizer, manure application, and atmospheric N deposition on cropland, pasture, and rangeland26. It is noted that most current research and datasets mainly focus on N fertilization inputs instead of N fertilizer types and N fertilization placement. Moreover, those datasets did not show long-term and high-resolution patterns of crop-specific N fertilization (rate, type, placement) and were not at uniform spatial resolutions or with consistent allocation algorithms, making it impossible to use them together.
To provide input data for the land surface models for assessing the effects of agricultural N fertilization practices on food security, climate change and ecosystem health, we developed a new global crop-specific N fertilization dataset. This newly developed N fertilization dataset covers not only more than one single fertilization rate but also crop-specific N application rate, N fertilizer types, as well as N application placement at a spatial resolution of 5 arc-min in the past six decades. This dataset was developed based on multiple statistical datasets (e.g., the FAOSTAT20, the IFASTAT21, and the EUROSTAT27), empirical estimates as well as gridded dataset (e.g., gridded harvested area from the EARTHSTAT28, gridded N application for Wang et al.24 and Zhan et al.29 and gridded climate data from Climatic Research Unit (CRU)30). This dataset also combines previous datasets at different spatial and temporal scales to reconstruct the important components of N fertilization (i.e., rate, type and placement) by crop types. The uncertainties of crop-specific N application rate were estimated and further comparison between our new N fertilization dataset and existing N fertilization datasets were also analyzed. The limitations that users should be aware and the future research priorities to build a more accurate and comprehensive N fertilization dataset were also discussed in the “Usage Notes”.
Methods
A comprehensive crop-specific N fertilization dataset was reconstructed across the global agricultural soils, including the N application applied to twenty-one crops groups with different fertilizer types and application methods. The N fertilization was defined as N application of synthetic N fertilizers, crop residues and manure to cropland in this study. The N application amount can be quantified as below:
where Namountcro,f,p,y,g (kg N) is N application amount of fertilizer type f applied by placement p to crop cro in grid g in the year y. Hareacro,y,g (ha) is harvested area of crop cro in grid g in the year y. Nratecro,y,g (kg N ha−1) is N application rate (N application amount per harvested area) of crop cro in grid g in the year y. FerRatiof,y,g (%) is the percentage of fertilizer f inputs to total N application amount in grid g in the year y. Placementcro,f,p,y,g (%) is the percentage of surface placement p (or deep placement) inputs to total inputs of fertilizer f applied to crop cro in grid g in the year y. It’s noteworthy that crops were aggregated into 21 crop groups according to Zhan et al.29. The detailed methods for generating each individual item were described as below, respectively. The workflow of methods is presented in Fig. 1. Main variables used in equations see Table 1. Main data used for developing this new crop-specific N fertilization dataset are listed in Table 2.

Workflow for developing the crop-specific N application dataset.
Crop-specific harvested areas
The gridded crop-specific harvested area (ha) for the year 1961–2020 (Hareacro,y,g) was integrated from gridded harvested area in the year 2000 from the EARTHSTAT28 and country-level statistics of crop-specific harvested area during the period of 1961–2020 from the FAOSTAT20. The historical areas of arable land and permanent crops (here referred to cropland areas), were also included from the History Database of the Global Environment (HYDE version 3.2)31 to identify the spatial distributions of cropland and to map the statistics of harvested areas onto a grid.
The gridded harvested area from the EARTHSTAT28 is relatively detailed and covers a wide range of crop types, which was developed based on agricultural census and survey information of 175 crops from the 22,050 political units reasonably obtainable for 206 countries during 1997–2003. Thus, we developed crop-specific gridded harvested area based on this dataset. First, the harvested area of 136 crops (accounting for 92.9% of total harvested area) from the EARTHSTAT28 were integrated into 21 crop groups and administrative units (i.e., county/district, a lower level subdivision than state or province) according to Zhan et al.29 and political boundaries from the GADM32, respectively. Note that, arable forage crops (such as green maize, alfalfa) or temporary and permanent grasslands are not included in this study. Details for crop information see Table 3.
Then, the national harvested area from the FAOSTAT20 was then used to extend the harvested area from the EARTHSTAT28 (as a reference map for the distribution of harvested area) in the year 2000 to the period of 1961–2020. The harvested area can be extended by the following equation:
where, Hareacro,y,i is harvested area of crop cro in the county/district i in the year y. HareaMcro,2000,i is harvested area in the county/district i around the year 2000 from the EARTHSTAT28. HareaFAOcro,y,j is harvested area of crop cro in the country j from the FAOSTAT20. Here, we assumed that the annual changes within each county/district (i) of country (j) were consistent with the annual changes in that respective country. The harvested area of the countries, which experienced political disintegration, was distributed to individual newly-formed countries using the ratio derived from the harvested area in the first year after disintegration.
Thirdly, the crop-specific harvested area for each county/district during the period of 1961–2020 (Hareacro,y,i) was mapped onto a grid by spatially disaggregating it using the dynamic cropland distribution from the HYDE3.231. The HYDE3.231 provided distribution and area croplands for a long time series (annual time-step after the year 2000 to 2017 and a decadal time-step during 1700–2000). The mapping of the gridded crop-specific harvested area was in proportion to the cropland area of each grid in each county/district, which can be calculated as below:
where, Hareacro,y,g is the harvested area of crop cro in grid g. Carearice,y,g and Careaupland,y,g are cropland area of rice and upland for grid g from the HYDE3.231, respectively. Carearice,y,i and Careaupland,y,i are total calculated cropland area of rice and upland for county/district i from the HYDE3.231. Due to the cropland area from the HYDE3.231 was available only up to the year 2017 and at decadal time-step before the 1990s, we assumed that the cropland area after the year 2017 was the same as that in 2017 and the cropland area before the year 2000 was constant in each decade. Lastly, to be comparable with that from the FAOSTAT20, the disaggregated gridded dataset was matched by the total crop-specific harvested area of each country from the FAOSTAT20.
Crop-specific N application rate
The gridded crop-specific N application rate (including synthetic N fertilizers (SN), crop residues (CR) and manure (MA)) for the year 1961–2020 (Nratecro,y,g) was derived from the gridded N application amount in 1961–2014 developed by Wang et al.24, the country level N consumption for agriculture from the FAOSTAT20 (including SN, CR, and MA), the country-level crop-specific fertilizer consumption from FUBC33 and the N application rate for 21 crop groups from Zhan et al.29.
Due to its high spatial and temporal resolution, the gridded N application amount in 1961–2014 provided by Wang et al.24 was used as a reference dataset to develop the crop-specific N application rate. Firstly, the gridded N application amount (divided into SN, CR, and MA) from Wang et al.24 was integrated into the GADM administrative units32 such as county, district or equivalent that is a lower level subdivision than state or province. Then, SN, MA, and CR application amount from the FAOSTAT20 spanning the period from 1961–2020 were utilized to extend and calibrate the above aggregated N application amount. Since the N application amount from the FAOSTAT20 includes both the cropland use and the other agricultural uses (e.g., pasture), we separated fertilizer use applied to croplands for each county/district based on the country-scale crop-wise proportion34, by assuming the same proportion of cropland use within a certain country. The calculation was described as below:
Where NamountWf,y,i is N application amount of fertilizer f (SN, MA or CR) for county/district i in the year y (from 2015 to 2020). NamountWf,2014,i is N application amount of fertilizer f (SN, MA or CR) developed by Wang et al.24 for county/district i in 2014. NamountFAOf,y,j and NamountFAOf,2014,j is application amount of fertilizer f (SN, MA or CR) from FAOSTAT20 for country j in the year y and 2014.
Note that, total N application amount from Wang et al.24 was on average 12% lower than the FAOSTAT20 that removed the pasture synthetic-fertilizer application, due to the reduced amount of SN application. Thus, we corrected SN application amount from Wang et al.24 to the FAOSTAT20. CR and MA application amount were consistent with Wang et al.24. Then, the total N application amount (Namountf,y,i) of this dataset was obtained and the calculation was described as below:
Then, since gridded crop-specific N application rate of SN, MA, and CR from Zhan et al.29 were only available in 2000, we assumed that the N application rate changed at the same ratio for all crops across all the time during 1961–2020 according to Zhang et al.35. We used the same calculation as Zhang et al.35 to calculate the N application rate of fertilizer f (SN, MA, and CR) applied to crop cro for county/district i in the year y (Nratecro,f,y,i).
where Nratecro,f,y,i is N application rate of fertilizer f (SN, MA, CR) applied to crop cro for county/district i in the year y. NrateZcro,f,2000,i is N application rate of fertilizer f (SN, MA, CR) applied to crop cro for county/district i in the year 2000 from Zhan et al.29. Namountf,y,i is N application amount of each county/district obtained from Eq. (5). NamountWf,y,i and Hareacro,y,g was obtained above.
Lastly, to minimize the uncertainties of crop-specific N application rate, we calibrated crop-specific N application rate after the year 2003 using country-level N synthetic fertilizer consumption reported by the Fertilizer Use By Crop (FUBC)33 for the years 2006, 2007, 2010, 2014 and 2018. Thus, the above-derived crop-specific synthetic N application rate (Nratecro,SN,y0,i) multiplied with the crop-specific harvested area (Hareacro,y0,i) was used to achieve crop-specific N application amount, and then synthetic N crop-specific amount of each crop group belongs to crop group cro2 was summed up by county/district i and corrected with the country-level N synthetic fertilizer consumption by crop group cro2 from the FUBC33. The calculation was described below:
where NconFUBCcro2,SN,y0,j is SN fertilizer consumption from FUBC33 to the 11 crop groups in the year 2006, 2007, 2010, 2014, 2018.
Finally, the county-level crop-specific N application rate (divided into SN, CR, and MA) summed up to generate the total N application rate and then was resampled into 5 arc-min resolution assuming that N application rate of each grid in a county/district was equal to the N application rate of this county/district, thus the crop-specific N application rate in each grid (Nratecro,y,g) was obtained.
N fertilizer types
The gridded percentage of different N fertilizer type inputs to total N application amount for the year 1961–2020 (FerRatiof,y,g) was integrated from country- and continent-scale annual fertilizer consumption surveys provided by the IFASTAT21 and N application amount (Namountf,y,i) developed above. We sorted N fertilizers into 13 types, include anhydrous ammonia (AA), ammonium nitrate (AN), ammonium sulphate (AS), calcium ammonium nitrate (CAN), nitrogen solutions (NS), other N straight (ONS), Urea, ammonium phosphate (AP), N K compounds (NK), N P K compounds (NPK), other NP (ONP), crop residues (CR) and manure (MA).
Consumption of each synthetic fertilizer type was available from both the IFASTAT21 and the FAOSTAT20. However, about 5.87% and 59.3% of the values from the IFASTAT21 and the FAOSTAT20, respectively, was missing. Hence, we chose to apply fertilizer consumption data from the IFASTAT due to the lesser missing values. Consumption of SN fertilizers for 1962–1972 from the IFASTAT is missing for all countries and regions. Moreover, the data is also missing from countries that have experienced political disintegration, especially in the years following it. As for data from the FAOSTAT20, missing data spread all over the period 1961–2020, especially for the developing countries. The missing data from the IFASTAT21 was filled by the multiple data imputation method (e.g., “Amelia”) for time-series cross-section datasets proposed by King et al.36, which were used by Nishina et al.23 to fill the missing fertilizer consumption data from the FAOSTAT. Covariates (e.g., the national GDP (from the World Bank37), population (from the FAOSTAT20), and cropland area (from the FAOSTAT20)) were chosen to apply the “Amelia” algorithm for imputation of the missing values as Nishina et al.23. R package “Amelia” was used for statistical imputation and settings, which is ideal in handling national-based time-series and cross-sectional data with advanced statistical imputation protocol23. More details see Nishina et al.23.
Then, the calculation for the percentage of each N fertilizer type inputs to total N application amount can be sorted into two classifications. For crop residues and manure, the percentage can be directly obtained with the ratio of crop residue and manure inputs amount and total N application amount. For the remaining 11 synthetic fertilizers, the percentage was calculated through multiplying the consumption proportion of each synthetic fertilizer to the total synthetic N fertilizer from the IFASTAT by the proportion of synthetic fertilizer inputs to total N application amount obtained above.
The percentage of each fertilizer consumption can be calculated as following equations:
where, FerRatiof,y,i is the percentage of fertilizer f inputs to total N application amount in the county/district i in the year y. Namountf,y,i, NamountSN,y,i, Namounttotal,y,i was generated above, which represents N application amount of fertilizer f (MA or CR), SN and all fertilizers for county/district i in the year y, respectively. FerIFAf,y,co and FerIFAtotal,y,co is the consumption amount of synthetic fertilizer f and total synthetic fertilizer in the country or region m in the year y from the IFASTAT21, respectively.
Lastly, the percentages of each fertilizer were resampled into 5 arc-min resolution to obtain the percentages of each fertilizer in each grid (FerRatiof,y,g).
N application placement
The gridded percentage of different N fertilizer types applied with deep placement (or surface placement) inputs to total input applied to different crop (Placementcro,f,deep,y,g and Placementcro,f,surface,y,g) for the year 1961–2020 was quantified based on fertilizer type, tillage practice, and base-topdressing application ratio, as referred to Zhan et al.29. and can be calculated by the following equations.
where, Placementcro,f,deep,y,g and Placementcro,f,surface,y,g is the percentage of fertilizer f applied with deep placement and surface placement inputs to total inputs applied to crop cro in grid g in the year y, respectively. NoTillcro,y,g is non-tillage ratio for crop cro in grid g in the year y. 0.7 is base-topdressing application ratio from Nishina et al.23.
Anhydrous ammonia and N solutions, commonly injected, were placed deep or totally infiltrated into soils38. All manure and crop residues were assumed to be applied before sowing or transplanting, thus the incorporation of manure and crop residues was linearly correlated to the tillage fraction39. For the rest synthetic fertilizer, if it was applied as base fertilizers, the proportion of incorporation or deep application should be positively related to the fraction of non-tillage (zero tillage or direct drilling during planting) in high-income countries. Because in developed countries, the non-tillage was mainly achieved through mechanized seeding and fertilization practices40,41. However, when the synthetic fertilizer was applied during the top-dressing process if applicable, we assumed that broadcasting techniques were applied42. It is noteworthy that the gridded non-tillage fraction for each crop during the period of 1961–2020 (NoTillcro,y,g) was specially developed, including the obtain of national or sub-national non-tillage area and its downscaling to grid and crop.
We firstly calculated the national non-tillage fraction during the period of 1961–2020 with the regression model provided by Zhan et al.29, which fitted the relationship between the cropland area per capita of the rural population (i.e., a proxy of the spatial variation of labor availability for tillage activity) and country-level non-tillage fractions (46 countries from the FAOSTAT20 and EUROSTAT27 databases, as well as China (2000−2016)43 and the United States of America (1989−2008)44). National cropland area per capita of rural population for prediction can be obtained from the FAOSTAT20. Then the national non-tillage area can be calculated through multiplying the above-mentioned fraction and the cropland area from the HYDE3.231. Specially, data of non-tillage area by province (or state) for China (2000–2016)43 and the USA (1989–2008)44 were publicly available and can be used directly; for the rest year, the sub-national non-tillage area was obtained by downscaling the above predicted national non-tillage area.
Then, the national non-tillage area was downscaled to grid and crop following the methods by Porwollik et al.41, with the gridded and country-scale datasets (including the harvested area of irrigated crops and rain-fed crops from the SPAM2005 and the SPAM201045,46 field size47, income (World Bank37), water erosion48, and aridity (calculated by potential evapotranspiration and precipitation from the CRU TS V4.0630)). Firstly, potential non-tillage area was allocated based on crop type, field size and local income. The potential non-tillage area was assumed that derived from the cropland of 11 rain-fed annual crops (Soybean, Wheat, Maize, Barley, Rapeseed, Sunflower, Sorghum, Cotton, Milled, Groundnut, Vegetables) in grid cells reporting dominant large field size in low-income countries and all field sizes in high-income countries49,50,51.
Secondly, a logit model combined four predictors (including crop mix, field size, water erosion, and aridity) was developed to determine the probability of non-tillage occurrence per grid cell as well as the spatial distribution of country-level non-tillage area. Crop mix was defined as the ratio of the area sum of 11 non-tillage suitable crop types over the sum of total cropland area per grid cell, thus we assumed an increasing probability for non-tillage area occurrence in grid cells with an increasing cultivated area share of non-tillage suitable crop types. Farm size is highly positively correlated with the share of non-tillage area on arable land, with the coefficient of determination r2 = 0.66 (p < 0.001, slope = 0.116)41, thus non-tillage was thus assumed highly probable for cropland in grid cells with large fields (here serving as a spatial proxy for large farm size and mechanization). Besides, non-tillage was considered to be suitable for arable production under arid conditions, due to less aeration, more stable pores, and soil aggregates compared to soils managed with conventional tillage50,51. Moreover, erosion levels as allocation criteria, non-tillage was regarded as suitable for crop production in areas with elevated erosion levels to protect the soil surface50,52,53,54. The probability of no-tillage in a grid cell (NTAg) was derived through the following equation:
where n represents the input datasets of water erosion, aridity, crop mix (the ratio of sum of harvested area of no-tillage suitable crop types over the sum of total harvested area per grid cell), and field size (proxy for farm size), kn refers to the slope value, xmidn to the central points of each of the logit curves, and vxn to grid cell values of the referring input dataset. Values of kn and xmidn are directly derived from Porwollik et al.41.
Thirdly, the abovementioned projected national or sub-national non-tillage area was downscaled to all grid cells suitable for non-tillage in this country based on the gridded probability. According to the non-tillage probability, the grid cell in this country was sorted in decreasing order, which was further selected as non-tillage until the added potential non-tillage area (calculated as grid area multiplied by the probability) reached the projected country-level non-tillage area threshold. Lastly, crop-specific non-tillage area per grid (NoTillcro,y,g) was attained by disaggregating the non-tillage area of per grid cell according to the proportion of harvested area occupied by each crop in this grid.
Uncertainty analysis
A Monte Carlo simulation method was utilized to estimate the uncertainty for N application rate. To generate a proper estimate interval, here we mainly accounted for the uncertainties related to the assumption that the crop-specific N application rate changed at the same ratio for all crop types across all the time during 1961–2020. Thus, to estimate the uncertainty around the mean changing ratio of N application rate by crop and by region, we derived standard deviation, coefficient variations (CV) of each crop group for 24 regions or countries from 5-year (i.e. 2006, 2007, 2010, 2014, 2018) crop-specific fertilizer use reported by the Fertilizer Use By Crop (FUBC)33. Then, we run 1,000 iterations for each crop by randomly varying the annual change ratio by coefficient variations with normal distributions, so that the 95% prediction interval as well as standard deviation could be constructed. Undoubtedly, if there is a large inter-annual variation in N application rate for a particular crop in a region, the uncertainty associated with the estimated N application rate will be correspondingly high.
Data Records
The gridded N application data by crops, fertilizer, and placement from 1961 to 2020 and the gridded harvested area (1961–2020) are available at National Tibetan Plateau/Third Pole Environment Data Center55. The dataset extend from 180°E to 180°W longitude and 90°S to 90°N latitude at a resolution of 5 arc-min for the temporal period 1961–2020 in standard WGS84 coordinate system. The dataset is provided in Hierarchical Data Format (HDF5) format, which can be read by many tools (i.e., IDL, MATLAB).
The gridded N application data by crops, fertilizer, and placement are stored in the file “N_rate_{‘Crop name’}_1961–2020.h5”, while {‘Crop name’} represents each crop group listed in Table 4. The file contains 26 records named by {‘Fertilizer type name’_‘Placement name’}, while {‘Fertilizer type name’_‘Placement name’} represents each fertilizer type with two kinds of fertilization placements listed in Table 4. In addition, to calculate the N application amount by crop, the gridded harvested area was summarized in the file “Harvested_area_1961–2020.h5”, containing 21 crop groups named by {‘Crop name’}. The unit of N application rate was kg N per hectare of harvested area and unit of the harvested area was hectare per 5-arc-min grid cell.
Crop-specific N application
Crop-specific N application in the 1960s (average from 1961 to 1970) and 2010s (average from 2011 to 2020) were shown in Fig. 2. The average N application rate applied to cropland was 44.6 kg N ha−1 yr−1 in the 1960s, mainly in Europe and USA. Average N application rate for maize (49.2 kg N ha−1 yr−1), wheat (61.8 kg N ha−1 yr−1), vegetables and fruits (67.7 kg N ha−1 yr−1) were relatively higher than for other crops. In the 2010s, average N application rate increased to 100.9 kg N ha−1 yr−1, and the hotspots also shifted from Europe and the USA to China. The N application rate between 1961 and 2020 for rice, vegetables and fruits showed the highest growth rate, increasing by 237.6%, 175.6%, and 252.3%, respectively, compared to wheat (152.2%), maize (141.3%), other cereals (86.8%), and rest of crops (34.1%).

Spatial pattern of crop-specific N application rate (kg N per hectare of harvested area) applied to cropland in the 1960s and 2010s.
N fertilizer types
The spatial pattern of the N application for each fertilizer was illustrated in Fig. 3. In the1960s, the N application rate of manure and crop residues was about 26.1 kg N ha−1 yr−1, and the hotspots were mainly in USA, Europe and south America. Hotspots of synthetic fertilizers varied depending on the fertilizer types. For urea, nitrate fertilizers and compound fertilizers, the hotspots were mainly distributed in Eastern Europe, while for other synthetic fertilizers were mainly in Southeastern China and Middle Europe. Anhydrous ammonia and N solutions were mainly applied in Middle USA. Both the N application rate and spatial pattern of different N-consumed fertilizers changed significantly after five decades, e.g., the contributions of synthetic fertilizers grew from 41.5% to 64.4%. Urea as the most important synthetic-N fertilizers, with an average N application rate more than 100 kg N ha−1 yr−1, shared 31.0% of global N fertilizer consumption in 2010s and were mainly distributed in China, India and Pakistan. The hotspots of compound fertilizers and manure and crop residues also expanded to China, while the hotspots of nitrate fertilizers, other synthetic fertilizers, anhydrous ammonia and N solutions didn’t change much.

Spatial pattern of N application rate for different fertilizers (kg N per hectare of harvested area) applied to cropland. Fertilizers include Urea, nitrate fertilizers (ammonium nitrate (AN) and calcium ammonium nitrate (CAN)), compound fertilizers (ammonium phosphate (AP), N K compounds (NK), N P K compounds (NPK), other NP (ONP)), AA&NS (anhydrous ammonia (AA) and N solutions (NS)), other synthetic fertilizers (other N straight (ONS) and ammonium sulphate (AS)) and MA&CR (manure (MA) and crop residues (CR)).
N application placement
Crop-specific N application rate by deep placement in the 1960s and 2010s were displayed in Fig. 4. The average N application rate applied by deep placement enhanced from 28.0 kg N ha−1 yr−1 in the 1960s to 41.3 kg N ha−1 yr−1 in the 2010s, while the hotspots were mainly in southern USA, southeast of South America, northwestern Europe and Australia during 1961–2020. N application rate by deep placement for most of crops has increased (64.7% for wheat, 64.4% for rice, 68.9% for maize, 46.9% for other cereals, 63.6% for vegetables and fruits and 132.9% for oil crops) during 1961–2020.

Spatial pattern of crop-specific N application rate (kg N per hectare of harvested area) applied by deep placement in the 1960s and 2010s.
Technical Validation
To check the spatiotemporal consistency and plausibility between the newly developed global crop-specific N fertilization dataset and previous datasets, we did a comprehensive comparison analysis, including the uncertainty analysis, direct validation analysis against various available data, etc.
Firstly, we utilized Monte Carlo simulations to quantify the uncertainties of crop-specific N application rate derived from the assumption, that the N application rate changed at the same ratio for all crops all the time. The 95% confidence intervals of crop-specific N application rate by crop, regions, and years can be gained, and are shown in Figs. 5, 6. Globally, uncertainties of wheat, rice, maize, sugar crops and vegetables&fruits at 95% confidence interval accounted for ±27.9%, ±31.5%, ±24.4%, ±25.1%, ±35.0% of average N application rate during 1961–2020, respectively (Fig. 5). Uncertainties of other cereals, oil crops, and rest of crops were larger (±42.0%, ±50.8% and ±80.0%), however, the three together only accounting for 34.9% of the total N application amount (Fig. 5). In addition, the spatial patterns of uncertainties related to the crop-specific N application rate were also generated (Fig. 6). Spatial heterogeneity of uncertainties was striking, regardless of crop types. For the vast majority of regions, the standard deviation (SD) of crop-specific N application rate were within acceptable limits, but in specific regions and for specific crops, the SD of the N application rate exceeded 20 kg N ha−1 yr−1 (Fig. 6). However, it is worth noting that N application rate tended to be higher in these regions and crops, such as China, Russia, and Australia for wheat; China and South Asia for rice; and the USA, China, and South America for maize. As a result, the coefficient of variation (CV) for these regions is relatively low, usually below 20%, despite the high standard deviation. Nevertheless, regions with both high SD and high CV, such as vegetables and fruits in USA, Russia and South America; maize in India and Southwest America; sugar crops in China, may have relatively large uncertainties, and caution should be exercised when using the N application rate of these crop groups in these regions. Despite the large uncertainties in certain regions and crop groups, it is important to note that the regions with large uncertainties (>20 kg N ha−1) and large CV (>25%) only contributed 8.9% of the total N application amount due to limited crop cultivation in these regions. This means that although we made very ambitious assumptions, the result looks reasonable due to the relatively low overall uncertainty.

Uncertainties of global N application rate (kg N ha−1) for 8 crop groups. The grey color area in each panel shows the 95% confidence interval of N application rate estimates by Monte Carlo simulations, whereas the average value is presented by a black line.

Spatial pattern of uncertainties related to N application rate (kg N ha−1) for 8 crop groups in 2010s.
Crop-specific N application rate from 2003 onwards was adjusted to match the crop-specific N fertilizer use from the FUBC33 report, which likely reduced uncertainties after 2000. As for the year before 2000, country-level fertilizer use data from the first to fifth FUBC report for the years 1978–2001 were extracted to validate the data. To determine the differences in the N application rate from this dataset with respect to the FUBC33 report, we calculated the country-wise relative difference Dif (%) as equation below:
Where Nratecro,y,j is N application rate of crop cro in the country j in the year y. Nrate_FUBCcro,y,j is corresponding N application rate from FUBC33.
The mean and SD for Dif of 8 crops groups and 9 countries or regions were presented here (Fig. 7). In most of the regions except for South Asia, the mean Dif between our estimates and the FUBC report was contained in the range of ±50%. Large values of the mean Dif were observed for some crops, such as vegetables and fruits in China (Dif = 50.4%), other crops in Canada (Dif = 70.9%), sugar crops in Africa (Dif = 53.0%), rice in Europe (Dif = −63.0%). N application rate for South Asia in this study might be underestimated due to most of the mean Dif for 8 crop groups lower than 0.

Relative differences between crop-specific N application rate in this dataset with data from the first to fifth FUBC report for the year during 1978–2001. The box plots show the range of relative differences, whereas numbers besides the box plots represents sample size of country-year.
Finally, we evaluated the reasonability of our results on a regional scale, with the historical N application statistics of USA and China from the United States Department of Agriculture (USDA)56 and the Cost and Income of Chinese Farm Produce (NDRCC 2003, 202257,58), respectively. The N application rate for wheat in this study was relatively close to the USDA record (Fig. 8). However, for the USA, the N application rate for maize was 32.8% lower than the USDA record during 1964–2018, whereas those for cotton and soybean were 24.1% and 35.3% higher during 1964–2000, respectively. For China, our estimates for wheat, rice, maize, and potatoes are generally in agreement with the NDRCC record, with differences within the range of ±20% (Fig. 9). The estimated N application rate for vegetables and fruits were close to the records from the NDRCC before the year 2000, but after that, it was significantly lower (−13.8% and −36.4%). In general, the narrow differences between this study and regional statistic reflects that our crop-specific N application rate is relatively reasonable in regions.

A comparison of N application rate between data reported by the United States Department of Agriculture (USDA) and this dataset.

A comparison of N application rate between data reported by Cost and Income of Chinese Farm Produce (NDRCC) and this dataset.
In addition, we verified the reliability of the Amelia methods in the imputation of missing data by using national N fertilizer use by different types from the FAOSTAT20. Though, there were missing data from the FAOSTAT20, we still found 858 records of 69 countries during 1962–1972 overlapped the data filled by the Amelia approach. We directly compared the consumption of urea, ammonium nitrate and ammonium sulphate filled by Amelia method with those records from the FAOSTAT20. The scatter plots showed that the consumptions of these three N fertilizers per harvested area (kg N ha−1) were relatively close to the FAOSTAT20 (Fig. 10). However, there are also some estimates that are not accurate, such as urea for New Zealand, ammonium nitrate for Germany, Italy and Norway. Although the consumption of different N fertilizer types is missing for a few years from the IFASTAT21, the IFASTAT21 provides the total N fertilizer consumption amount for these years. Thus, we also calculated the summed-up N fertilizer consumption rate of different N fertilizer types filled by the Amelia methods and directly compared it with the IFASTAT21. It was confirmed that the total N fertilizer consumption rate filled by Amelia method in this study was very close to that from the IFASTAT21, except for Norway and Nepal.

Comparison of country-level consumption per harvested area (kg N ha−1) of different fertilizer types during 1962–1972. Panel (a–c) represent comparison per ha of harvested area of urea, ammonium nitrate and ammonium sulphate filled by Amelia approach against official data from the FAOSTAT20, respectively. Panel (d) represents comparisons of sum of fertilizer consumption per ha of harvested area filled by Amelia approach against total fertilizer consumption from the IFASTAT21. Each point represents the fertilizer consumption of a specific country in a particular year.
Lastly, although the data about fertilization placement was scarce, the comparison for regional scale (i.e., China) demonstrated that the values obtained by our estimation methods were consistent with that obtained by Adalibieke et al.42 (Fig. 11). It was noteworthy that the temporal trends about the percentage of N fertilization with the deep placement were close between these two studies, except in the year after 2000. Possible explanation is that the calculation of fertilization placement related to tillage fraction and fertilizer type in this study ignored some specific issues (e.g., the implementation of “Agricultural Cost-saving and Efficiency-increasing Program”, which encouraged the implement of deep fertilization machine to enhance fertilizer use efficiency and save agricultural cost for field crops), while the survey data can reflect more about the reality.

Comparison for the percentage of deep placement in China during 1980–2017 between this study and Adalibieke et al.42.
Overall, despite the inevitable uncertainties in our dataset, the analysis indicated that our data was aligned reasonably well with other existing multiple data sources or estimates provided by previous studies (including the FUBC33 report, USDA56, NDRCC57,58, FAOSTAT20 and so on). Needless to say, uncertainties related to this dataset can be easily reduced in the future as new underlying datasets become available or existing datasets are updated.
Usage Notes
Our dataset provides a gridded estimate of the global crop-specific N application by fertilizer types and placements during the period of 1961–2020. Moreover, N application amount of each crop groups, NH4+ and NO3− application can also be obtained from this dataset. For example, N application amount could be calculated by N application rate multiplied by harvested area. NH4+ and NO3− application in synthetic N fertilizer could be calculated by N application of each fertilizer multiplied by composition of N types (i.e., NH4+ or NO3−).
However, there were several limitations that users should be aware when using this dataset. First, the historical cropland spatial and temporal distribution patterns provided by the HYDE3.231 are inconsistent with the one from satellite-derived land use (e.g. China and India59,60) or national census (e.g. USA61) at regional scale. Therefore, the downscaling of crop-specific harvested area from cropland area might be biased, so did the calculation of the N application amount. Second, no significant interannual difference was assumed to the relative proportion of N application rate by each crop. The crop-specific N application rate was determined by the spatial patterns of N application amount over the study period and the relative proportion among crops, which is against the reality and survey data from FUBC33. We acknowledged the existence of this assumption and assessed the uncertainty quantitatively, however, we believe that uncertainty associated with this assumption will be reduced as new relevant data available. Third, this study aimed to provide a dataset about N fertilization practices by crop, however, we cannot obtain the data for the proportion of different types of N fertilizers applied by crop for such a long-term period from the current statistic data. Fourth, due to the lack of mechanical sowing and fertilization data, we assumed that fertilizers in non-tillage regions with high-income were deeply applied through fertilizer spreaders. While in reality, mechanical sowing and fertilization is more achievable than the conservation tillage (i.e., non-tillage), which means that cropland with tillage practice may be equipped with fertilizer spreaders and thus the percentages of N fertilization with deep placement are underestimated40. In addition, in our study, the non-tillage area was downscaled by crop type and the relationship between field size and non-tillage practices adoption, whereas the temporal coverage of field size was only available in the year 2015, assuming it constant during 1961–202041. Thus, the non-tillage area in our study could be underestimated, since the field size has been increasingly associated with the economic growth and mechanization level62. Furthermore, the mechanical fertilization with deep placement in this study was also potentially underestimated. Furthermore, based on the analysis of uncertainties, the use of the N application rate for other cereals, oil crops, and rest of crops should be cautious, as well as the N application rate before the year 2000, the consumption of urea for New Zealand, and ammonium nitrate for Germany, Italy, and Norway. Lastly, although not quantified in this paper, we must acknowledge that other uncertainties arise from the use of multiple data sources and methodological choices, which can be considered in future studies.
Nevertheless, our study extended the crop-specific N fertilization for a long period of time and also provided a comprehensive dataset about N fertilization including N application rate, N fertilizer types and N fertilization placement simultaneously at uniform spatiotemporal resolution. In addition, we revealed a uniform approach using public and available datasets and methodologies to reconstruct N fertilization dataset over a relative long period of time. Such dataset can also be easily further updated when new underlying datasets and the update of existing datasets become available in the future.
Future directions of this study could focus on the conducting of finer scale and crop-specific surveys and reporting data on agricultural N fertilization practices. For example, the proportions of N fertilizers applied with different types varied by crops and geospatial distribution. The current survey data on different types of N fertilizer consumption from the IFASTAT21 and FAOSTAT20 are available at country-level and without dividing by detailed crop type. In comparison, the IFASTAT21 provided years of country-level N consumption data by crop types but not by fertilizer types. Therefore, continuous survey data of crop-specific N fertilizer consumption with different types at sub-national scales are necessary and critical for further improvement of our dataset. Moreover, application frequency and application timing are also crucial parts of agricultural N fertilization practices, suggesting that including the development of fertilizer application frequency and timing datasets could also be beneficial to improve our dataset. Last but not least, we can take advantage of satellite data and use machine learning and/or other comprehensive data fusion methods to improve the accuracy and precision of agricultural N fertilization practices63.
Code availability
Codes used in MATLAB 2020a and RStudio to deal with the dataset and plot the figures are available at available at National Tibetan Plateau/Third Pole Environment Data Center55.
References
Erisman, J. W., Sutton, M. A., Galloway, J., Klimont, Z. & Winiwarter, W. How a century of ammonia synthesis changed the world. Nature Geoscience 1, 636–639, https://doi.org/10.1038/ngeo325 (2008).
Lu, C. & Tian, H. Global nitrogen and phosphorus fertilizer use for agriculture production in the past half century: shifted hot spots and nutrient imbalance. Earth System Science Data 9, 181–192, https://doi.org/10.5194/essd-9-181-2017 (2017).
Galloway, J. N., Bleeker, A. & Erisman, J. W. in Annual Review of Environment and Resources, Vol 46, 2021 Vol. 46 Annual Review of Environment and Resources (eds Gadgil, A. & Tomich, T. P.) 255–288 (2021).
Schlesinger, W. H. & Bernhardt, E. S. Biogeochemistry: an analysis of global change. (Academic press, 2020).
Erisman, J. W. & Schaap, M. The need for ammonia abatement with respect to secondary PM reductions in Europe. Environmental Pollution 129, 159–163, https://doi.org/10.1016/j.envpol.2003.08.042 (2004).
Wu, X. et al. ORCHIDEE-CROP (v0), a new process-based agro-land surface model: model description and evaluation over Europe. Geoscientific Model Development 9, 857–873, https://doi.org/10.5194/gmd-9-857-2016 (2016).
Clark, M. A. et al. Global food system emissions could preclude achieving the 1.5 degrees and 2 degrees C climate change targets. Science 370, 705–708, https://doi.org/10.1126/science.aba7357 (2020).
Hauglustaine, D. A., Balkanski, Y. & Schulz, M. A global model simulation of present and future nitrate aerosols and their direct radiative forcing of climate. Atmospheric Chemistry and Physics 14, 11031–11063, https://doi.org/10.5194/acp-14-11031-2014 (2014).
Elser, J. J. et al. Shifts in Lake N:P Stoichiometry and Nutrient Limitation Driven by Atmospheric Nitrogen Deposition. Science 326, 835–837, https://doi.org/10.1126/science.1176199 (2009).
Erisman, J. W. et al. Consequences of human modification of the global nitrogen cycle. Philosophical Transactions of the Royal Society B-Biological Sciences 368, https://doi.org/10.1098/rstb.2013.0116 (2013).
Fowler, D. et al. The global nitrogen cycle in the twenty-first century. Philosophical Transactions of the Royal Society B-Biological Sciences 368, https://doi.org/10.1098/rstb.2013.0164 (2013).
Eskelinen, A., Harpole, W. S., Jessen, M. T., Virtanen, R. & Hautier, Y. Light competition drives herbivore and nutrient effects on plant diversity. Nature 611, 301–305, https://doi.org/10.1038/s41586-022-05383-9 (2022).
Guo, J. H. et al. Significant Acidification in Major Chinese Croplands. Science 327, 1008–1010, https://doi.org/10.1126/science.1182570 (2010).
Hou, X. et al. Spatial patterns of nitrogen runoff from Chinese paddy fields. Agriculture Ecosystems & Environment 231, 246–254, https://doi.org/10.1016/j.agee.2016.07.001 (2016).
Gassman, P. W., Reyes, M. R., Green, C. H. & Arnold, J. G. The soil and water assessment tool: Historical development, applications, and future research directions. Transactions of the Asabe 50, 1211–1250 (2007).
Paulot, F. et al. Ammonia emissions in the United States, European Union, and China derived by high-resolution inversion of ammonium wet deposition data: Interpretation with a new agricultural emissions inventory (MASAGE_NH3. Journal of Geophysical Research-Atmospheres 119, 4343–4364, https://doi.org/10.1002/2013jd021130 (2014).
Li, C. S., Frolking, S. & Frolking, T. A. A model of nitrous oxide evolution from soil driven by rainfall events: 1. Model structure and sensitivity. Journal of Geophysical Research-Atmospheres 97, 9759–9776, https://doi.org/10.1029/92jd00509 (1992).
Li, C. S., Frolking, S. & Frolking, T. A. A model of nitrous oxide evolution from soil driven by rainfall events: 2. Model applications. Journal of Geophysical Research-Atmospheres 97, 9777–9783, https://doi.org/10.1029/92jd00510 (1992).
Cui, X. et al. Global mapping of crop-specific emission factors highlights hotspots of nitrous oxide mitigation. Nature Food 2, 886–893, https://doi.org/10.1038/s43016-021-00384-9 (2021).
FAOSTAT Data:Food and Agriculture Organization https://www.fao.org/faostat/en/#home (2023).
IFASTAT Data:International Fertilizer Association https://www.ifastat.org (2023).
Mueller, N. D. et al. Closing yield gaps through nutrient and water management. Nature 490, 254–257, https://doi.org/10.1038/nature11420 (2012).
Nishina, K., Ito, A., Hanasaki, N. & Hayashi, S. Reconstruction of spatially detailed global map of NHNH4+ and NO3− application in synthetic nitrogen fertilizer. Earth System Science Data 9, 149–162, https://doi.org/10.5194/essd-9-149-2017 (2017).
Wang, Q. et al. Data-driven estimates of global nitrous oxide emissions from croplands. National Science Review 7, 441–452, https://doi.org/10.1093/nsr/nwz087 (2020).
Zhang, B. et al. Global manure nitrogen production and application in cropland during 1860–2014: a 5 arcmin gridded global dataset for Earth system modeling. Earth System Science Data 9, 667–678, https://doi.org/10.5194/essd-9-667-2017 (2017).
Tian, H. et al. History of anthropogenic Nitrogen inputs (HaNi) to the terrestrial biosphere: a 5 arcmin resolution annual dataset from 1860 to 2019. Earth System Science Data 14, 4551–4568, https://doi.org/10.5194/essd-14-4551-2022 (2022).
EUROSTAT https://ec.europa.eu/eurostat/statistics-explained/images/0/0f/Tilled_arable_area_by_tillage_practice%2C_EU-27%2C_IS%2C_NO%2C_CH%2C_ME_and_HR%2C_2010.png (2023).
Monfreda, C., Ramankutty, N. & Foley, J. A. Farming the planet: 2. Geographic distribution of crop areas, yields, physiological types, and net primary production in the year 2000. Global Biogeochemical Cycles 22, https://doi.org/10.1029/2007gb002947 (2008).
Zhan, X. et al. Improved Estimates of Ammonia Emissions from Global Croplands. Environmental Science & Technology 55, 1329–1338, https://doi.org/10.1021/acs.est.0c05149 (2021).
Harris, I., Osborn, T. J., Jones, P. & Lister, D. Version 4 of the CRU TS monthly high-resolution gridded multivariate climate dataset. Scientific Data 7, https://doi.org/10.1038/s41597-020-0453-3 (2020).
Goldewijk, K. K., Beusen, A., Doelman, J. & Stehfest, E. Anthropogenic land use estimates for the Holocene - HYDE 3.2. Earth System Science Data 9, 927–953, https://doi.org/10.5194/essd-9-927-2017 (2017).
GADM. Database of Global Administrative Areas https://gadm.org/download_world.html.
Ludemann, C. I., Gruere, A., Heffer, P. & Dobermann, A. Global data on fertilizer use by crop and by country. Scientific Data 9, https://doi.org/10.1038/s41597-022-01592-z (2022).
Lassaletta, L., Billen, G., Grizzetti, B., Anglade, J. & Garnier, J. 50 year trends in nitrogen use efficiency of world cropping systems: the relationship between yield and nitrogen input to cropland. Environmental Research Letters 9, https://doi.org/10.1088/1748-9326/9/10/105011 (2014).
Zhang, X. et al. Managing nitrogen for sustainable development. Nature 528, 51–59, https://doi.org/10.1038/nature15743 (2015).
King, G., Honaker, J., Joseph, A. & Scheve, K. Analyzing incomplete political science data: An alternative algorithm for multiple imputation. American Political Science Review 95, 49–69, https://doi.org/10.1017/s0003055401000235 (2001).
World Bank: World Development indicators- historical classification by income https://datahelpdesk.worldbank.org/knowledgebase/articles/906519-world-bank-country-and-lending-groups (2023).
Bouwman, A. F., Boumans, L. J. M. & Batjes, N. H. Estimation of global NH3 volatilization loss from synthetic fertilizers and animal manure applied to arable lands and grasslands. Global Biogeochemical Cycles 16, https://doi.org/10.1029/2000gb001389 (2002).
Lutz, F., Stoorvogel, J. J. & Muller, C. Options to model the effects of tillage on N2O emissions at the global scale. Ecological Modelling 392, 212–225, https://doi.org/10.1016/j.ecolmodel.2018.11.015 (2019).
Jaleta, M., Baudron, F., Krivokapic-Skoko, B. & Erenstein, O. Agricultural mechanization and reduced tillage: antagonism or synergy? International Journal of Agricultural Sustainability 17, 219–230, https://doi.org/10.1080/14735903.2019.1613742 (2019).
Porwollik, V., Rolinski, S., Heinke, J. & Mueller, C. Generating a rule-based global gridded tillage dataset. Earth System Science Data 11, 823–843, https://doi.org/10.5194/essd-11-823-2019 (2019).
Adalibieke, W. et al. Decoupling between ammonia emission and crop production in China due to policy interventions. Global Change Biology 27, 5877–5888, https://doi.org/10.1111/gcb.15847 (2021).
CAMI:China Agricultural Machinery Industry Yearbook for China (Statistics of Agricultural Mechanization from 2000 to 2017) https://data.cnki.net/v3/trade/Yearbook/Single/N2022030117?zcode=Z032 (2023).
CTIC: The Conservation Technology Information Center data for USA (National Crop Residue Management Survey form 1989 to 2008).
International Food Policy Research, I. MapSPAM (ed Institute International Food Policy Research) (Harvard Dataverse, 2019).
International Food Policy Research, I. & International Institute for Applied Systems, A. (eds Institute International Food Policy Research & Analysis International Institute for Applied Systems) (Harvard Dataverse, 2016).
Lesiv, M. et al. Estimating the global distribution of field size using crowdsourcing. Global Change Biology 25, 174–186, https://doi.org/10.1111/gcb.14492 (2019).
Borrelli, P. et al. An assessment of the global impact of 21st century land use change on soil erosion. Nature Communications 8, https://doi.org/10.1038/s41467-017-02142-7 (2017).
Giller, K. E. et al. Beyond conservation agriculture. Frontiers in Plant Science 6, https://doi.org/10.3389/fpls.2015.00870 (2015).
Kassam, A., Friedrich, T., Shaxson, F. & Pretty, J. The spread of Conservation Agriculture: justification, sustainability and uptake. International Journal of Agricultural Sustainability 7, 292–320, https://doi.org/10.3763/ijas.2009.0477 (2009).
Pittelkow, C. M. et al. When does no-till yield more? A global meta-analysis. Field Crops Research 183, 156–168, https://doi.org/10.1016/j.fcr.2015.07.020 (2015).
Basso, B., Ritchie, J., Grace, P. & Sartori, L. Simulating tillage impacts on soil biophysical proprerties using the SALUS model. 3, 1–10 (2006).
Govaerts, B. et al. Conservation agriculture and soil carbon sequestration: between myth and farmer reality. Critical Reviews in Plant Science 28, 97–122 (2009).
Schmitz, P. M., Mal, P. & Hesse, J. W. The importance of conservation tillage as a contribution to sustainable agriculture: A special case of soil erosion. (Inst. für Agribusiness, 2015).
Wulahati, A., Cui, X., Cai, H., You, L., Zhou, F. Global crop-specific nitrogen fertilization dataset in 1961-2020. National Tibetan Plateau/Third Pole Environment Data Center, https://doi.org/10.11888/Terre.tpdc.300446 (2023).
USDA: United States Department of Agriculture https://www.ers.usda.gov/data-products/fertilizer-use-and-price.aspx (2023).
NDRCC (National Development and Reform Commission of China). Statistics of cost and income of Chinese farm produce since the establishment of the nation from 1950–1997 (2023).
NDRCC (National Development and Reform Commission of China). Statistics of cost and income of Chinese farm produce. https://data.stats.gov.cn/easyquery.htm?cn=C01 (2023).
Liu, M. & Tian, H. China’s land cover and land use change from 1700 to 2005: Estimations from high-resolution satellite data and historical archives. Global Biogeochemical Cycles 24, https://doi.org/10.1029/2009gb003687 (2010).
Tian, H., Banger, K., Bo, T. & Dadhwal, V. K. History of land use in India during 1880-2010: Large-scale land transformations reconstructed from satellite data and historical archives. Global and Planetary Change 121, 78–88, https://doi.org/10.1016/j.gloplacha.2014.07.005 (2014).
Yu, Z. & Lu, C. Historical cropland expansion and abandonment in the continental US during 1850 to 2016. Global Ecology and Biogeography 27, 322–333, https://doi.org/10.1111/geb.12697 (2018).
Wu, Y. et al. Policy distortions, farm size, and the overuse of agricultural chemicals in China. Proceedings of the National Academy of Sciences of the United States of America 115, 7010–7015, https://doi.org/10.1073/pnas.1806645115 (2018).
You, L. & Sun, Z. Mapping global cropping system: Challenges, opportunities, and future perspectives. Crop and Environment 1, 68–73, https://doi.org/10.1016/j.crope.2022.03.006 (2022).
Acknowledgements
This study was supported by the National Natural Science Foundation of China (42225102, 41977082, F.Z.; 42207378, X.Q.C.). We acknowledge Dr. Kazuya Nishina and Dr. Vera Porwollik for providing the codes for the methodology of Amelia and downscaling the country-level no-tillage area, respectively. Besides, we also thankful to Steffen Fritz for sharing the field size dataset.
Author information
Authors and Affiliations
Contributions
F.Z. designed the study. W.A. and X.Q.C. constructed and analyzed the data. W.A., X.Q.C. and F.Z. drafted the paper. All co-authors reviewed and commented on the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Adalibieke, W., Cui, X., Cai, H. et al. Global crop-specific nitrogen fertilization dataset in 1961–2020. Sci Data 10, 617 (2023). https://doi.org/10.1038/s41597-023-02526-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41597-023-02526-z

{kind=link}