
Abstract
Objective
To assess the methodological issues in prediction models developed using electronic medical records (EMR) and their early-stage clinical impact on the HIV care continuum.
Methods
A systematic search of entries in PubMed and Google Scholar was conducted between January 1, 2010, and January 17, 2022, to identify studies developing and deploying EMR-based prediction models. We used the CHARMS (Critical Appraisal and Data Extraction for Systematic Reviews of Prediction Modeling Studies), PROBAST (Prediction Model Risk of Bias Assessment Tool), and TRIPOD (Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis) statements to assess the methodological issues. In addition, we consulted reporting guidelines for early-stage clinical evaluation of decision support systems to assess the clinical impact of the models.
Results
The systematic search yielded 35 eligible articles: 24 (68.6%) aimed at model development and 11 (31.4%) for model deployment. The majority of these studies predicted an individual's risk of carrying HIV (n = 12/35, 34.3%), the risk of interrupting HIV care (n = 9/35), and the risk of virological failure (n = 7/35). The methodological assessment for those 24 studies found that they were rated as high risk (n = 6/24), some concerns (n = 14/24), and a low risk of bias (n = 4/24). Several studies didn't report the number of events (n = 14/24), missing data management (n = 12/24), inadequate reporting of statistical performance (n = 18/24), or lack of external validation (n = 21/24) in their model development processes. The early-stage clinical impact assessment for those 9/11-deployed models showed improved care outcomes, such as HIV screening, engagement in care, and viral load suppression.
Conclusions
EMR-based prediction models have been developed, and some are practically deployed as clinical decision support tools in the HIV care continuum. Overall, while early-stage clinical impact is observed with those deployed models, it is important to address methodological concerns and assess their potential clinical impact before widespread implementation.
Systematic review registration: PROSPERO CRD42023454765.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Background
The human immune-deficiency virus (HIV) care continuum goes from diagnosis to viral suppression [1]. Thirty-nine million people globally have HIV, and 630,000 die from Acquired Immunodeficiency Syndrome (AIDS)-related illnesses annually [2]. The current goal is to end the epidemic by 2030 [3]. In order to achieve the epidemic goal, EMR-based predictive approaches and proactive interventions are key solution platforms [4,5,6]. EMRs are computerized platforms for storing and processing patients’ medical data [7]. They offer opportunities for risk prediction models that can be used for prediction model development, which can help identify high-risk HIV individuals [8,9,10].
EMR-based models have been used as clinical decision support (CDS) and have shown improvement in HIV care outcomes [11]. However, there are several methodological concerns during model development and validation [12, 13]. Previous systematic reviews indicated that almost all diagnostic and prognostic risk-predicting models were rated at high or unclear risk of bias, mostly because of non-representative sample size, improper handling of missing data, and inadequate reporting of model performance [14,15,16,17]. Often, prediction modeling studies did not fully address bias related to missing data, which is a common occurrence in EMR data [10], and external validation was rare [14].
On the other hand, the deployment of EMR-based models has demonstrated improvement in HIV care continuum outcomes [18], i.e., increased HIV screening [19,20,21,22], identified high risk and facilitated the re-linkage [23, 24], improved retention in care [25, 26], and improved viral suppression [27]. However, there is limited knowledge about their validity and usefulness. Therefore, a systematic study aimed to review methodological issues and the early-stage clinical impact of EMR-based prediction in the HIV care continuum.
2 Methods
This systematic review was guided by the “Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) statement for reporting [28]. We also used the guidance for conducting a systematic review of prognosis studies [29]. A proposal for the systematic review was registered on PROSPERO CRD42023454765.
2.1 Eligibility criteria
Studies were included if they were: (1) original articles and published in English between January 1st, 2010 and January 17th, 2022; (2) used structured EMR systems for prediction model development, validation, or update; (3) aimed at predicting any risk related to HIV care conditions (e.g., not other diseases); (4) deployed as clinical decision-support tools in HIV care settings, which allowed us to provide an early-stage clinical impact.
We excluded studies if they: (1) used unstructured EMR data or electronic clinical notes; (2) targeted non-HIV care or disease; (3) were population-level EMR-based risk prediction models like models predicting the incidence of HIV infection; (4) were not original research (e.g., systematic review); and (5) had no full text available.
2.2 Literature search
We searched the PubMed database and Google Scholar. In addition, we conducted a backward citation search, checking the references of identified papers, and a forward citation search using Google Scholar, which discovered papers referencing the identified papers. We used the guidance for formulating a review question for a systematic review of prediction models provided by the checklist for critical appraisal and data extraction for systematic reviews of prediction modeling studies (CHARMS) [30]. Key items for searching strategy and study eligibility criteria for systematic review followed the PICO (population, intervention, comparison, and outcome) guidance used in therapeutic studies [30, 31]. For our easy search strategy, we categorized the formulated PICO question into three concepts: (a) electronic medical records; (b) risk prediction model; and (c) HIV continuum care outcomes. Finally, all these three concepts are combined with the “AND” logical operator. The detailed search query used in PubMed is available [see Additional File 1].
2.3 Study selection
After we checked for any duplicates, two independent reviewers (TE and AD) conducted the study selection process in three stages. In the first stage, titles and abstracts were screened to identify papers for full-text screening. In the second stage, the selected papers were reviewed in full following inclusion and exclusion criteria. The disagreements between the two independent reviewers were resolved based on reaching a consensus to have a list of papers for a full-text review. In the third stage, we conducted a full-text paper review for eligibility. Finally, at this stage, we listed the final full-text reviewed articles for data extraction and inclusion for qualitative analysis.
2.4 Data extraction process
Two authors (TE and AD) independently extracted the data. For articles aimed at model development and validation, we used a spreadsheet and extracted the data using a CHARMS checklist [30]. For those studies aimed at model development, we extracted information on the first author, year of publication, the clinical context of the model, study setting, modeling methods, EMR data source, sample size including number of events, number of predictors, missing data management, outcome predicted, validation type including technique used, and evaluation metrics. Further, we extracted information on whether the authors evaluated the models with clinical utility metrics such as decision curve analysis (DCA) and net benefit [32]. For the articles aimed at model deployment, we extracted information on the first author, year of publication, methods of model presentation to end users, model application, and early-stage clinical impact, independently of the study design chosen [33].
2.5 Risk of bias assessment
We appraised the presence of bias in the model development and validation using the “prediction model risk of bias assessment tool (PROBAST)” [34]. Two investigators (TE and AD) independently assessed the risk of bias (ROB). It contained 20 signaling questions in four domains: 2 questions related to participants, 3 questions related to predictors, 6 questions about outcomes, and 9 questions related to the statistical analysis domain. These questions were answered as "yes," “probably yes," “probably no," "no," or “no information." ROB is rated as low, high, or has some concerns. If a domain contains at least one question answered with “no” or “probably no," it is rated as high-risk. If all the questions contained in a domain were signaled with “yes” or “probably yes," the domain is rated as low-risk. When all domains are at low risk, the overall risk of bias is considered to be low risk; when at least one domain is high risk, the overall risk of bias is rated as high risk. If some concern for bias was noted in at least one domain and it was low for all others, it is rated as having some concern for bias. The summary of judgment for ROB was visualized using a web application for visualizing risk-of-bias assessments built on the Robes R package [35].
2.6 Synthesis and analysis
We performed a qualitative synthesis by consulting the statement of the “Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD)” [36], CHARMS checklist [30], and PROBAST [34]. In addition, the reporting guideline for the early-stage clinical evaluation of the decision support system was used for the clinical impact evaluations [33]. Study characteristics were counted and tabulated, and descriptive statistics, including proportions, medians, and interquartile ranges, were used. The findings are presented in tables, figures, and the text.
2.7 Patient and public involvement
In this study, there was no patient involvement in terms of formulating review questions or measuring outcomes, or in study design or implementation. Patients did not provide suggestions on recording or interpreting the results. There are no plans to disseminate study results to patients or relevant communities.
3 Results
Of the 7760 identified articles, 7684 were excluded after the title and abstract screening according to the aforementioned criteria. The majority were excluded due to the title of the modeling studies being different from HIV continuum care settings. Then, upon the consensus of independent reviewers (TE and AD), 76 were considered potentially relevant. These 76 papers were screened in full text, and another 41 were excluded, of which 13 were unstructured EMR-based modeling studies, 14 were not focused on HIV care, 11 were systematic reviews, and 3 had no full text available. Finally, 35 were included for data extraction and qualitative analysis, of which 24 (68.6%) were aimed at model development and 11 (31.4%) were aimed at model deployment (Fig. 1). Thirty-one (88.6%) were from high-income countries, of which 26 (74.3%) were from the United States of America, and 4 (11.4%) reported from middle-income countries and low-income countries. In terms of research trends, there has been a gradual increase in the number of studies using EMR-based prediction modeling and deploying it as a clinical decision support tool in primary HIV continuum care. Thirteen of the thirty-five full-text reviewed articles were published between 2014 and 2017, ten (28.5%) between 2018 and 2021, and four (11.4%) between 2010 and 2013 (see Additional File 2).

PRISMA flow chart displays the process of study identification, screening, and inclusion
3.1 Outcomes predicted in the HIV care continuum
Twelve (34.3%) studies predicted individual risk of carrying HIV [19,20,21,22, 37,38,39,40,41,42,43,44]; 9 (25.7%) predicted risk of interrupting HIV care [23,24,25,26, 45,46,47,48,49]; 7 (20.0%) predicted risk of virological failure [27, 50,51,52,53,54,55]; 2 (5.7%) predicted phenotype of HIV-1/2 infection [56, 57]; others predicted patients newly diagnosed with HIV infection [58], clinical status of HIV patients [59], CD4 count change [60], comorbidity burden [61] and risk of readmission and death [62] [Fig. 2].

Outcomes predicted in the HIV care continuum by all the included studies (n = 35)
3.2 Model development
We conducted appraisals for those 24 studies aimed at model development and validation. Of which 15 (62.5%) were diagnostic models aimed at predicting the current risk of having an event of interest outcomes [37,38,39,40,41,42,43, 51, 54, 56,57,58,59, 61, 62], and 9 (37.5%) were prognostic models aimed at predicting the future risk of event occurrence in the HIV care continuum [45,46,47,48, 50, 52, 53, 55, 60]. Regarding participants used in modeling, 14 (58.3%) studies used EMRs from multi-center sites for model development and validation, while 10 (41.7%) studies used EMR data from a single site. In around two-fifths of model development studies, 11 (45.8%) were derived using machine learning algorithms, 9 (37.5%) used generalized linear models such as logistic regression and Cox regression algorithms, and 5 (20.8%) used chart review-based algorithm classification [Table 1]. The median sample size for model development was 2633 (interquartile range: 795, 138, 806). Seven studies (29.2%) used a sample size of less than 1000. The median number of predictors was 20 (interquartile range: 12, 94), with only 7 studies using 50 or more predictors and 4 studies using fewer than 10 predictors (see Additional File 2).
3.3 Model validation and performance metrics
A vital stage in any predictive modeling process is model validation. The majority of the modeling studies that were included carried out internal validation, i.e., 12 (50%) of them then employed cross-validation techniques followed by sample splitting [4 (16.7%)] and bootstrapping [3 (12.5%)]. Four of those studies (16.7%) used more than one type of validation technique (Table 1). As for the model performance measures, 14 (58.3%) used the c-statistic, or area under the receiver operating characteristic curve (AUC), to evaluate the discrimination of the model. Other assessment measures, such as sensitivity and positive predictive value (PPV), were given in addition to c-statistics. Sensitivity was reported in 11 (45.8%), and PPV was measured in 8 (33.3%) prediction modeling studies. Six (25%) papers were evaluated using model calibration, and one of them reported an F1 score along with an AUC. Decision curve analysis (DCA) was not reported in any of the included studies to evaluate clinical value by taking clinical implications into account (see an additional file 2).
3.4 Risk of bias assessment
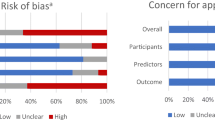
Figure 3 shows a risk of bias assessment according to PROBAST for those 24 model development and validation studies (except for the eleven studies aimed at model deployment). Six (25%) were rated at high risk of bias, 14 (58.3%) were rated at some concern about the risk of bias, and 4 (16.7%) were rated at low risk of bias. The majority of 20 (83.3%) studies expressed some concern about the risk of bias in the statistical analysis domain (see Additional File 3). For instance, 14 (58.3%) studies did not report the number of events used in model development, 12 (50%) did not consider or report missing data management, 4 (16.7%) did not report validation techniques, and 21 (87.5%) did not conduct external validation. Similarly, 10 (41.6%) studies did not report model discrimination performance, 18 (75%) did not report model calibration, and none measured clinical performance using decision analytics. For more details on this, see an additional file 2.

Summary of risk of bias assessment according to BROBAST for studies aimed at model development and validation (n = 24)
3.5 Early-stage clinical impact
In the second part of this systematic review, we assessed the early-stage clinical impact. Out of 35 included, 11 (31.4%) studies deployed EMR-based prediction tools in the HIV care continuum [19,20,21,22,23,24,25,26,27, 44, 49]. These tools are used as clinical decision support by generating EMR-based alerts when triggered by the predefined risk level or criteria and/or preparing a work list that assigns patients to their risk category. Five (45.5%) studies deployed EMR-based models to identify individuals at high risk of carrying HIV and who are eligible for screening [19,20,21,22, 44]. According to the preliminary reports, four of these models increased screening rates in HIV care practices [19,20,21,22], while one study did not impact the test rate [44]. Similarly, 5 (45.5%) were deployed to identify HIV patients who were at high risk of interrupting HIV care or losing care [23,24,25,26, 49], and one study was deployed to predict HIV patients at high risk of treatment failure [27]. According to the preliminary reports, all of these models lowered the rate of care interruption [23,24,25,26, 49] and improved viral load suppression [27]. [Table 2].
4 Discussion
This systematic review showed that within the past decade, at least 35 studies were published on EMR-based modeling studies in HIV care settings. The majority of these models predicted the individual risk of carrying HIV, the risk of interrupting HIV care, and the risk of virological failure. The finding was supported by the work of Ridgway and colleagues. Accurate EMR-based models have been developed to predict individual diagnoses of HIV, care attendance, and viral suppression [11]. This could be due to the increased interest in prediction model development and its potential applications as clinical decision support, followed by the rise of EMRs in healthcare settings [16]. The other argument could be narrated as the need for risk stratification. Since resources are getting scarce and a classical, “one-size-fits-all” intervention strategy is clinically inefficient, researchers are looking for a solution like predicting and stratifying patients into risk levels and tailoring intervention for those who may benefit most [9, 63].
We appraised those 24 studies aimed at model development and identified common methodological pitfalls, mostly because of the lack of a reported number of events for the outcome of interest and not considering or reporting the missing data. In addition, several modeling studies did not report important statistical performance, such as discrimination, calibration, and clinical performance. Other systematic reviewers also reported similar problems in prediction modeling studies [10, 17, 64]. These methodological issues can limit the generalizability of the prediction models or reduce their performance when applied to new patient populations or to other care settings [65]. Even though several pitfalls can be encountered during prediction model development and validation, measures for discrimination (e.g., area under a curve) and calibration (e.g., showing a calibration curve) are key aspects of statistical performance [13, 66]. Furthermore, before the actual use of EMR-based predictive models as clinical decision support, it’s important to assess clinical consequences using decision curve analysis and the net benefit [13, 32].
Another key factor in our systematic review was the early-stage clinical impact of EMR-based prediction models deployed independently of methodological concerns. The early-stage clinical impact of these models was increased HIV screening rates, linkage to care, a lowered rate of care interruption, and improved engagement in HIV care and treatment. A previous study by Ridgway JP and colleagues also reported that EMR-based clinical decision support tools had been effectively utilized to improve HIV care continuum outcomes [11]. For instance, some of the included studies reported that using an EMR-driven clinical decision support tool had increased monthly HIV screening from 7 to 550 monthly average HIV screens [19] and increased linkage to care from 15 to 100% [21]. Similarly, it lowered the loss of follow-up in HIV care by 10% [49], improved the clinical appointment visit by 3.8% [67], and increased the likelihood of achieving viral suppression by 15% [27]. However, reporting of the early-stage clinical impact is inadequate to promote the impact of EMR-based models in HIV care settings. Thus, further investigation may be needed to evaluate the potential and actual clinical impact on improving decisions and patient outcomes [13].
This systematic review has some limitations. Firstly, it only includes peer-reviewed journal articles published in English, which may introduce language and publication bias. Secondly, searching only in the PubMed database and Google Scholar might increase publication bias. However, to minimize this, we search for backward and forward citations in Google Scholar. Thirdly, due to variations in the definitions of predicted HIV continuum care outcomes and a lack of uniformity of model performance measurements across different studies, which make reasonable comparisons challenging, we were unable to quantitatively assess effects on specific clinical domains across studies and conducted a meta-analysis.
5 Conclusions
EMR-based prediction models have been developed, and some of them are practically deployed as clinical decision support in the HIV care continuum. The majority of these models have predicted the patient’s risk of carrying HIV, the risk of interrupting HIV care, and the risk of treatment or virological failure. However, the methodological assessment shows that most studies were at high risk of bias or some concerns. Several studies did not report the number of events, missing data management, and inadequate reports of statistical performance. Rare modeling studies conduct external validation. On the other hand, the early-stage clinical impact findings show that almost all of those deployed models have improved HIV care continuum outcomes.
5.1 Recommendations and policy implications
Firstly, the common recommendations are to take methodological concerns into account in the model development process to improve the predictive ability. Secondly, models should be externally validated in other care settings or in new patient populations to test their predictive performance. Lastly, while there is early-stage clinical impact observed with EMR-based predictive models in HIV care settings, it is important to assess clinical consequences before widespread implementation.
Data availability
All data generated and analysed during this study is included in this manuscript and its additional files. The detailed search query (Additional File 1), the complete methodological characteristics of model development (Additional File 2), and the risk of bias assessment for studies (Additional File 3) can be found as additional files.
Abbreviations
- AIDS:
-
Acquired immunodeficiency syndrome
- CDS:
-
Clinical decision support
- CHARMS:
-
Critical appraisal and data extraction for systematic reviews of prediction modeling studies
- EMRs:
-
Electronic medical records
- HIV:
-
Human Immunodeficiency Virus
- PRISMA:
-
Preferred Reporting Items for Systematic Reviews and Meta-Analyses
- PROBAST:
-
Prediction model risk of bias assessment tool
- ROB:
-
Risk of bias
- TRIPOD:
-
Transparent Reporting of a multivariable prediction model for Individual Prognosis or Diagnosis
References
Centers for Disease Control and Prevention (CDC). Understanding the HIV Care Continuum. 2022. https://www.cdc.gov/hiv/pdf/library/factsheets/cdc-hiv-care-continuum.pdf.
United Nations Programme on HIV/AIDS (UNAIDS). Global HIV & AIDS statistics—Fact sheet. 2023. https://www.unaids.org/en/resources/fact-sheet.
Frescura L, Godfrey-Faussett P, Feizzadeh AA, El-Sadr W, Syarif O, Ghys PD, et al. Achieving the 95 95 95 targets for all: a pathway to ending AIDS. PLoS ONE. 2022;17(8): e0272405.
Cascini F, Santaroni F, Lanzetti R, Failla G, Gentili A, Ricciardi W. Developing a data-driven approach in order to improve the safety and quality of patient care. Front Public Health. 2021;9: 667819.
Gao J, Moran E, Higgins DSJ, Mecher C. Predicting high-risk and high-cost patients for proactive intervention. Med Care. 2022;60(8):610–5.
Gilkey MB, Marcus JL, Garrell JM, Powell VE, Maloney KM, Krakower DS. Using HIV risk prediction tools to identify candidates for pre-exposure prophylaxis: perspectives from patients and primary care providers. AIDS Patient Care STDs. 2019;33(8):372–8.
What Is An EMR? About EMR Systems—Electronic Medical Records . Healthcare IT Skills. 2020. https://healthcareitskills.com/what-is-an-emr-ehr/.
Rothman B, Leonard JC, Vigoda MM. Future of electronic health records: implications for decision support: future of electronic health records. Mt Sinai J Med J Transl Pers Med. 2012;79(6):757–68.
Agency for Clinical Innovation (N.S.W.). Patient identification and selection handbook : NSW guide to risk stratification / NSW Agency for Clinical Innovation. Version 1. Agency for Clinical Innovation Chatswood, NSW; 2015. https://collection.sl.nsw.gov.au/record/74VKzEJDjR7O.
Goldstein BA, Navar AM, Pencina MJ, Ioannidis JPA. Opportunities and challenges in developing risk prediction models with electronic health records data: a systematic review. J Am Med Inform Assoc. 2017;24(1):198–208.
Ridgway JP, Lee A, Devlin S, Kerman J, Mayampurath A. Machine learning and clinical informatics for improving HIV care continuum outcomes. Curr HIV/AIDS Rep. 2021;18(3):229–36.
Jin Y, Kattan MW. Methodologic issues specific to prediction model development and evaluation. Chest. 2023;S0012–3692(23):00945–55.
Binuya MAE, Engelhardt EG, Schats W, Schmidt MK, Steyerberg EW. Methodological guidance for the evaluation and updating of clinical prediction models: a systematic review. BMC Med Res Methodol. 2022;22(1):316.
Bellou V, Belbasis L, Konstantinidis AK, Tzoulaki I, Evangelou E. Prognostic models for outcome prediction in patients with chronic obstructive pulmonary disease: systematic review and critical appraisal. BMJ. 2019;4(367): l5358.
Huang H, Dong J, Wang S, Shen Y, Zheng Y, Jiang J, Zeng B, Li X, Yang F, Ma S, He Y, Lin F, Chen C, Chen Q, Lv H. Prediction model risk-of-bias assessment tool for coronary artery lesions in Kawasaki disease. Front Cardiovasc Med. 2022;13(9):1014067.
Goldstein BA, Navar AM, Pencina MJ. Risk prediction with electronic health records: the importance of model validation and clinical context. JAMA Cardiol. 2016;1(9):976–7.
Wynants L, Van Calster B, Collins GS, Riley RD, Heinze G, Schuit E, et al. Prediction models for diagnosis and prognosis of COVID-19: systematic review and critical appraisal. BMJ. 2020;7(369): m1328.
Lee TC, Shah NU, Haack A, Baxter SL. Clinical implementation of predictive models embedded within electronic health record systems: a systematic review. Informatics. 2020;7(3):25.
Lin J, Mauntel-Medici C, Heinert S, Baghikar S. Harnessing the power of the electronic medical record to facilitate an opt-out HIV screening program in an urban academic emergency department. J Public Health Manag Pract. 2017;23(3):264–8.
Tapp H, Ludden T, Shade L, Thomas J, Mohanan S, Leonard M. Electronic medical record alert activation increases hepatitis C and HIV screening rates in primary care practices within a large healthcare system. Prev Med Rep. 2020;17: 101036.
Burrell CN, Sharon MJ, Davis S, Feinberg J, Wojcik EM, Nist J, et al. Using the electronic medical record to increase testing for HIV and hepatitis C virus in an Appalachian emergency department. BMC Health Serv Res. 2021;21(1):524.
Marcelin JR, Tan EM, Marcelin A, Scheitel M, Ramu P, Hankey R, et al. Assessment and improvement of HIV screening rates in a Midwest primary care practice using an electronic clinical decision support system: a quality improvement study. BMC Med Inform Decis Mak. 2016;4(16):76.
Lubelchek RJ, Fritz ML, Finnegan KJ, Trick WE. Use of a real-time alert system to identify and re-engage lost-to-care HIV patients. JAIDS J Acquir Immune Defic Syndr. 2016;72(2):e52–5.
Ridgway JP, Almirol E, Schmitt J, Wesley-Madgett L, Pitrak D. A clinical informatics approach to reengagement in HIV care in the emergency department. J Public Health Manag Pract. 2019;25(3):270–3.
Shade SB, Steward WT, Koester KA, Chakravarty D, Myers JJ. Health information technology interventions enhance care completion, engagement in HIV care and treatment, and viral suppression among HIV-infected patients in publicly funded settings. J Am Med Inform Assoc. 2015;22(e1):e104–11.
Herwehe J, Wilbright W, Abrams A, Bergson S, Foxhood J, Kaiser M, et al. Implementation of an innovative, integrated electronic medical record (EMR) and public health information exchange for HIV/AIDS. J Am Med Inform Assoc. 2012;19(3):448–52.
Puttkammer N, Simoni JM, Sandifer T, Chéry JM, Dervis W, Balan JG, et al. An EMR-based alert with brief provider-led ART adherence counseling: promising results of the InfoPlus adherence pilot study among Haitian adults with HIV initiating ART. AIDS Behav. 2020;24(12):3320–36.
Page MJ, Moher D, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD, et al. PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ. 2021;29: n160.
Damen JAA, Moons KGM, van Smeden M, Hooft L. How to conduct a systematic review and meta-analysis of prognostic model studies. Clin Microbiol Infect. 2023;29(4):434–40.
Moons KGM, de Groot JAH, Bouwmeester W, Vergouwe Y, Mallett S, Altman DG, et al. Critical appraisal and data extraction for systematic reviews of prediction modelling studies: The CHARMS Checklist. PLoS Med. 2014;11(10): e1001744.
Riley RD, Moons KGM, Snell KIE, Ensor J, Hooft L, Altman DG, et al. A guide to systematic review and meta-analysis of prognostic factor studies. BMJ. 2019;30(364): k4597.
Vickers AJ, Van Calster B, Steyerberg EW. Net benefit approaches to the evaluation of prediction models, molecular markers, and diagnostic tests. BMJ. 2016;25(352): i6.
Vasey B, Nagendran M, Campbell B, Clifton DA, Collins GS, Denaxas S, et al. Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI. Nat Med. 2022;28(5):924–33.
Moons KGM, Wolff RF, Riley RD, Whiting PF, Westwood M, Collins GS, et al. PROBAST: a tool to assess risk of bias and applicability of prediction model studies: explanation and elaboration. Ann Intern Med. 2019;170(1):W1-33.
McGuinness LA, Higgins JPT. Risk-of-bias VISualization (robvis): an R package and Shiny web app for visualizing risk-of-bias assessments. Res Synth Methods. 2020. https://doi.org/10.1002/jrsm.1411.
Moons KGM, Altman DG, Reitsma JB, et al. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): explanation and elaboration. Ann Intern Med. 2015;162(1):W1–73.
Felsen UR, Bellin EY, Cunningham CO, Zingman BS. Development of an electronic medical record-based algorithm to identify patients with unknown HIV status. AIDS Care. 2014;26(10):1318–25.
Ahlström MG, Ronit A, Omland LH, Vedel S, Obel N. Algorithmic prediction of HIV status using nation-wide electronic registry data. EClinicalMedicine. 2019;5(17): 100203.
Kramer JR, Hartman C, White DL, Royse K, Richardson P, Thrift AP, et al. Validation of HIV-infected cohort identification using automated clinical data in the department of veterans affairs. HIV Med. 2019;20(8):567–70.
Krakower DS, Gruber S, Hsu K, Menchaca JT, Maro JC, Kruskal BA, et al. Development and validation of an automated HIV prediction algorithm to identify candidates for pre-exposure prophylaxis: a modeling study. Lancet HIV. 2019;6(10):e696-704.
Marcus JL, Hurley LB, Krakower DS, Alexeeff S, Silverberg MJ, Volk JE. Use of electronic health record data and machine learning to identify candidates for HIV pre-exposure prophylaxis: a modeling study. Lancet HIV. 2019;6(10):e688–95.
Gruber S, Krakower D, Menchaca JT, Hsu K, Hawrusik R, Maro JC, Cocoros NM, Kruskal BA, Wilson IB, Mayer KH, Klompas M. Using electronic health records to identify candidates for human immunodeficiency virus pre-exposure prophylaxis: an application of super learning to risk prediction when the outcome is rare. Stat Med. 2020;39(23):3059–73.
Duthe JC, Bouzille G, Sylvestre E, Chazard E, Arvieux C, Cuggia M. How to identify potential candidates for HIV pre-exposure prophylaxis: an AI algorithm reusing real-world hospital data. Stud Health Technol Inform. 2021;27(281):714–8.
Naito T, Endo K, Fukushima S, Suzuki M, Fukui Y, Saita M, et al. A preliminary analysis of the performance of a targeted HIV electronic medical records alert system: a single hospital experience. J Infect Chemother. 2021;27(1):123–5.
Woodward B, Person A, Rebeiro P, Kheshti A, Raffanti S, Pettit A. Risk prediction tool for medical appointment attendance among HIV-infected persons with unsuppressed viremia. AIDS Patient Care STDs. 2015;29(5):240–7.
Pence BW, Bengtson AM, Boswell S, Christopoulos KA, Crane HM, Geng E, et al. Who will show? Predicting missed visits among patients in routine HIV primary care in the United States. AIDS Behav. 2019;23(2):418–26.
Ramachandran AA, Kumar A, Koenig H, De Unanue A, Sung C, Walsh J, et al. Predictive analytics for retention in care in an urban HIV clinic. Sci Rep. 2020;10(1):6421.
Pettit AC, Bian A, Schember CO, Rebeiro PF, Keruly JC, Mayer KH, et al. Development and validation of a multivariable prediction model for missed HIV health care provider visits in a large US clinical cohort. Forum Infect Dis. 2021. https://doi.org/10.1093/ofid/ofab130.
Sohail M, Rastegar J, Long D, Rana A, Levitan EB, Reed-Pickens H, et al. Data for care (D4C) Alabama: clinic-wide risk stratification with enhanced personal contacts for retention in HIV care via the Alabama Quality Management Group. JAIDS J Acquir Immune Defic Syndr. 2019;82(3):S192–8.
Robbins GK, Johnson KL, Chang Y, Jackson KE, Sax PE, Meigs JB, et al. Predicting virologic failure in an HIV clinic. Clin Infect Dis. 2010;50(5):779–86.
Evans DH, Fox MP, Maskew M, McNamara L, MacPhail P, Mathews C, et al. CD4 criteria improve the sensitivity of a clinical algorithm developed to identify viral failure in HIV-positive patients on antiretroviral therapy. J Int AIDS Soc. 2014;17(1):19139.
Benitez AE, Musinguzi N, Bangsberg DR, Bwana MB, Muzoora C, Hunt PW, et al. Super learner analysis of real-time electronically monitored adherence to antiretroviral therapy under constrained optimization and comparison to non-differentiated care approaches for persons living with HIV in rural Uganda. J Int AIDS Soc. 2020;23(3): e25467.
Gebrezgi MT, Fennie KP, Sheehan DM, Ibrahimou B, Jones SG, Brock P, et al. Development and validation of a risk prediction tool to identify people with HIV infection likely not to achieve viral suppression. AIDS Patient Care STDS. 34(4):157–65.
Kamal S, Urata J, Cavassini M, Liu H, Kouyos R, Bugnon O, et al. Random forest machine learning algorithm predicts virologic outcomes among HIV-infected adults in Lausanne, Switzerland using electronically monitored combined antiretroviral treatment adherence. AIDS Care. 2021;33(4):530–6.
Puttkammer N, Zeliadt S, Balan JG, Baseman J, Destine R, Domercant JW, et al. Development of an electronic medical record based alert for risk of HIV treatment failure in a low-resource setting. PLoS ONE. 2014;9(11): e112261.
Paul DW, Neely NB, Clement M, Riley I, Phelan M, Kraft M, et al. Development and validation of an electronic medical record (EMR)-based computed phenotype of HIV-1 infection. J Am Med Inform Assoc. 2018;25(2):150–7.
May SB, Giordano TP, Gottlieb A. A phenotyping algorithm to identify people with HIV in electronic health record data (HIV-Phen): development and evaluation study. JMIR Form Res. 2021;5(11): e28620.
Goetz MB, Hoang T, Kan VL, Rimland D, Rodriguez-Barradas M. Development and validation of an algorithm to identify patients newly diagnosed with HIV infection from electronic health records. AIDS Res Hum Retroviruses. 2014;30(7):626–33.
Mitchell M, Hedt BL, Eshun-Wilson I, Fraser H, John MA, Menezes C, et al. Electronic decision protocols for ART patient triaging to expand access to HIV treatment in South Africa: A cross-sectional study for development and validation. Int J Med Inf. 2012;81(3):166–72.
Kebede M, Zegeye DT, Zeleke BM. Predicting CD4 count changes among patients on antiretroviral treatment: application of data mining techniques. Comput Methods Prog Biomed. 2017;152:149–57. https://doi.org/10.1016/j.cmpb.2017.09.017.
Yanga X, Zhanga J, Chena S, Yang X, Zhang J, Chen S, Weissman S, Olatosi B, Li X. Utilizing electronic health record data to understand comorbidity burden among people living with HIV: a machine learning approach. AIDS. 2021;35(Suppl 1):S39–51.
Nijhawan AE, Clark C, Kaplan R, Moore B, Halm EA, Amarasingham R. An electronic medical record-based model to predict 30-day risk of readmission and death among HIV-infected inpatients. J Acquir Immune Defic Syndr. 2012;61(3):349–58.
Operational Research and Evaluation Unit, NHS England. Risk stratification: learning and impact study . New care models. 2017. https://imperialcollegehealthpartners.com/wp-content/uploads/2018/07/ORE__Risk_stratification_learning_and_impact_study.pdf.
Li L, Li X, Li W, Ding X, Zhang Y, Chen J, et al. Prognostic models for outcome prediction in patients with advanced hepatocellular carcinoma treated by systemic therapy: a systematic review and critical appraisal. BMC Cancer. 2022;22(1):750.
Siontis GCM, Tzoulaki I, Castaldi PJ, Ioannidis JPA. External validation of new risk prediction models is infrequent and reveals worse prognostic discrimination. J Clin Epidemiol. 2015;68(1):25–34.
Alba AC, Agoritsas T, Walsh M, Hanna S, Iorio A, Devereaux PJ, et al. Discrimination and calibration of clinical prediction models: users’ guides to the medical literature. JAMA. 2017;318(14):1377–84.
Adams JA, Whiteman K, McGraw S. Reducing missed appointments for patients with HIV: an evidence-based approach. J Nurs Care Qual. 2020;35(2):165–70. https://doi.org/10.1097/NCQ.0000000000000434.
Acknowledgements
Abebaw Gebeyehu's (Ph.D.) help with constructing the title and reviewing is gratefully acknowledged.
Funding
Authors state no funding involved.
Author information
Authors and Affiliations
Contributions
TE: designing, screening the articles, performing the data extraction, data analysis, interpretation of the results, and writing of the manuscript; WD: design, data analysis, interpretation of the results, revision of the manuscript; GT: data analysis, interpretation of the results, revision of the manuscript; AD: screening the articles, performing the data extraction, revision of the manuscript; AA: critical revision of this manuscript. All authors approved the final manuscript, including the authorship list.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Endebu, T., Taye, G., Addissie, A. et al. Electronic medical record-based prediction models developed and deployed in the HIV care continuum: a systematic review. Discov Health Systems 3, 25 (2024). https://doi.org/10.1007/s44250-024-00092-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44250-024-00092-8