
Abstract
Since sequential recommendation can effectively capture the user’s dynamic interaction pattern according to the user’s historical interaction, it plays one of the important roles in the field of recommendation systems. Nowadays, the sequential recommendation models based on deep learning approaches have achieved good results in reality due to their excellent performance in information retrieval and filtering. However, there are still some challenges that still should be overcome of them. A major disadvantage of them is that they are only considering users’ short-time interests while ignoring their long-term preferences. Moreover, they are incapable of considering the influence of time information in the original interaction sequence, which could be helpful to fully extract various patterns via the different temporal embedding forms. Therefore, this paper proposes a novel model named multi-temporal sequential recommendation model based on the fused learning preference named MTSR-FLP in short. In the proposed framework, this paper adopts an MLP-based state generation module to consider the user’s long-term preferences and the short-time interests simultaneously. In particular, the proposed MTSR-FLP model designs a global representation learning approach to obtain the user’s global preference, and a local representation learning approach to capture the users’ local preference via its historical information. Moreover, the proposed model develops a multiple temporal embedding scheme to encode the positions of user–item interactions of a sequence, in which multiple kernels are utilized for the absolute or relative timestamps to establish unique embedding matrices. Finally, compared with other advanced sequence recommendation models on five public real-world datasets, the experimental results show that the proposed MTSR-FLP model has improved the performance of HR@10 from the 6.68% through 31.10% and NDCG@10 from the 8.60% through 42.54%.
Similar content being viewed by others

1 Introduction
A recommendation system is an effective and powerful tool to address information overload by making users easily capture information in terms of their preferences and allowing online platforms to widely publicize the information they produce. Different from traditional recommendation systems, such as content-based and collaborative filtering systems, which prefer focusing on the user’s static historical interactions and assume that all user–item interactions in the historical sequence are equally important, sequential recommendation (SR) systems aimed at catching the dynamic preferences of users from their historical interaction. Therefore, SR is more consistent with real-world situations to obtain more accurate results with more information considered.
Generally, the conventional SR methods are classified into traditional machine learning approaches and deep learning-based approaches. The traditional machine learning (ML) approaches are mainly exploited to build up the sequence data, such as k-means, Markov chains, and matrix decomposition [1,2,3,4]. Especially, matrix factorization (MF) can obtain users’ long-term preferences through various sequences [5]. Nowadays, the sequential recommendation models based on the deep learning approaches have achieved relatively good results in reality due to their excellent performance in information retrieval and filtering, mainly including convolutional neural networks (CNNs) [6] and recurrent neural networks (RNNs) [7]. This is because DL-based SR approaches utilize a much longer sequence which is beneficial to the semantic information of the whole sequence [8]. In addition, DL-based SR approaches also have achieved much better performance for both the sparse data and different length sequences.
However, there are still some challenges that still should be overcome in the above DL-based SR approaches. A major disadvantage of them is that they are only considering users’ short-time interests while ignoring their long-term preferences. Moreover, they are incapable of considering the influence of time information in the original interaction sequence, which could have been helpful to fully extract various patterns by finding different temporal embedding forms. Therefore, this paper aims to propose a deep learning-based sequential recommendation system. It utilizes both the global preference and the local preference of users with the multi-temporal embedding to encode both absolute and relative positions of a user–item interaction, and simulates the real-time recommendation environment.
This paper proposes a novel model named multi-temporal sequential recommendation model based on the fused learning preference named MTSR-FLP. The proposed MTSR-FLP model consists of four parts: multi-temporal embedding learning; local representation learning; global representation learning; item similarity gating module. First, the multi-temporal embedding learning module is the most important and innovative in the proposed model. It is well designed especially to address the timestamp information with the construction of the multiple temporal embedding, which will be sent to the local representation learning module, named LRL in short. Moreover, the local representation learning module is developed via the framework of the SASRec model [9], which infers the multiple temporal embedding with the different weight and their aggregations, to obtain the local preference of users. Afterward, in the global representation learning module, named GRL in short, a novel location-based attention layer has been developed to obtain the final global learning representation of all users. Finally, the proposed model designs a novel item similarity gating module, which is critical in coordinating the local preference of the specific user and the global preference of all users. Meanwhile, it considers the influence of candidate items by calculating the similarity of candidate items and recently interacted items.
The main contributions of the proposed MTSR-FLP model are described as follows: (1) the proposed model develops a multiple temporal embedding scheme to encode the positions of user-item interactions of a sequence; (2) to capture the local representation of a user via his historical information, the MTSR-FLP model proposes a local representation learning module; (3) to effectively capture the user’s global preference, the proposed model designs a global representation learning module; (4) compared with the four traditional models on five public datasets, experimental results demonstrated that the proposed model had better performance regarding the effectiveness and feasibility of the sequence recommendation.
The rest of this paper is organized as follows. Section 2 briefly introduces the recent development of sequential recommendation based on deep learning and temporal recommendation. Section 3 describes the specific details of the proposed model and the procedures of its training. Experimental results on five public datasets and comparison with existing models are analyzed in Sect. 4. Finally, Sect. 5 gives a conclusion of the paper study and the directions for future work.
2 Related Work
2.1 DL-Based Sequential Recommendation
Recently, many researchers utilize DL-based sequential recommendation (SR) models to obtain nonlinear and dynamic features. In particular, DL models based on the RNNs are nearly the first to be incorporated into sequential modeling, which naturally models sequences step-by-step [10, 11]. Moreover, GRU4Rec model [12] has been proposed to effectively extract the position information between adjacent sequences, and GRU4Rec+ model [13] adopts various sampling strategies and loss functions. However, these models are more dependent on the user’s recent interactions, weakening the training efficiency Afterward, some researchers utilized CNNs-based models to address the vanishing gradient issue resulting from the RNNs-base SR models. For example, Caser model [5] learns sequence patterns using convolutional filters on the local sequences with the dense users’ behavior data. A simple convolutional generative network is proposed to learn high-level representation from both short- and long-range item dependencies [14].
Since the attention mechanisms have an advantage in their proper hierarchical structure, some DL-based models utilize them to solve sequential recommendation problems. For example, as an entire and famous attention mechanism, the Transformer model [15] computes representations of its input and output without RNNs or CNNs, which makes the Transformer more parallelizable and faster to be trained with superior translation quality. However, the Transformer model does not directly utilize the position information in the sequence and cannot extract local features [16]. In addition, some SR models have been developed through the self-attention mechanism. For example, SASRec [9] not only can uncover the long-term user's preference but also can predict the next recommended item mainly based on the recently interacted items. Bert4Rec [17] captures the correlation of items in both left-to-right and right-to-left directions to obtain a better sequence representation of user sequence. LSSA [18] deals with both long-term preferences and sequential dynamics based on a long and short-term self-attention network. However, they are limited to only capturing the sequential patterns between consecutive interactive items, ignoring the complex relationships between the high-order interactions.
Recently, graph neural networks (GNNs) have been widely utilized to model high-order transformation relationships in the area of SR. For example, NGCF [19] and LightGCN [20] argue that graph-based models can effectively deal with collaborative data and are critical in presenting user/item embedding. SRGNN [21] converts the sequence data into graph-structured data with the gated GNNs to perform message propagation on graphs. GCE-GNN [22] utilizes a GNN model for the session graph to learn item embedding with a session-aware attention mechanism. GC–MC [23] proposes a graph convolutional matrix completion (GC–MC) framework from the perspective of link prediction on graphs. However, the GC–MC framework only models the user’s direct scoring of items in a convolutional layer. CTDNE [24] defines a temporal graph to learn the dynamic embedding of nodes. However, most of these GNN-based models only capture sequential transition patterns based on items’ locations and identities, while ignoring the influence of contextual features such as time intervals, which will cause the models to fail to learn appropriate sequence representations.
Inspired by the SASRec [9], which has the advantages of not only uncovering the long-term user’s preference but also predicting the next recommended item mainly based on the recently interacted items, the proposed model utilizes the SASRec as the framework of the local representation learning layer. Different from the SASRec, the proposed local representation learning module infers the multiple temporal embedding with the different weight and their aggregations, to improve the performance of the local preference of users. In addition, the paper has not utilized the GNNs so the proposed model has a disadvantage at the high-order transformation relationships in some areas of the SR.
2.2 Temporal Recommendation
Since user preferences are dynamic in the SR problems, it is essential to capture temporal information. Originally, matrix factorization (MF) has often been utilized in temporal recommendation systems due to its relatively high accuracy and scalability [25]. However, it is difficult for the rating prediction of new users via the MF. Collaborative filtering-based (CF) approaches also have been proven of success in modeling temporal information [26]. However, some linear approaches are unsuitable for the more complex dynamics of temporal changes, and the transition matrix usually is homogeneous for all users [27]. In addition, it is impractical for large datasets due to their time-consuming performance and so on.
Afterward, there are also deep learning-based models in temporal recommendation systems, which encode temporal interval signals into the user preference representations to predict the user’s future actions. For example, Time-LSTM [28] combined the LSTM model with several time gates to achieve better performance of the time intervals in users’ interaction sequences. Zhang et al. [29] introduced a self-attention mechanism into the sequence-sense recommendation model that represented the user’s temporal interest. CTA model [30] utilized multiple-parameter kernel functions to address the temporal information as an attention mechanism [31]. Tang and Wang [10] combined a convolutional sequence embedding model with Top-N sequential recommendation as a way for a temporal recommendation. TiSASRec [32] is the absolute positions of items and the time intervals between them in a sequence. Moreover, TASER [33] proposes a temporal-aware network based on absolute and relative time patterns. KDA [34] utilizes the temporal decay functions of various relations between items to explore the time drift of their relation interactions.
In addition, some GNN-based temporal SR models have been proposed recently. For example, RetaGNN model [35] improves the inductive and transferable performance of the SR by encoding the sub-graphs resulting from the user-item pairs. Moreover, DSPR [36] proposes a novel sequential POI recommendation approach to capture the real-time impact and absolute time. DRL-SRe [37] obtains the dynamic preferences based on the global user-item graph for each time slice that deploys an auxiliary temporal prediction task over consecutive time slices. TARec [38] captures the user’s dynamic preferences based on the combination of an adaptive search-based module and a time-aware module.
Inspired by TiSASRec model [32], this paper seeks to utilize multi-scale temporal information embeddings based on the absolute and relative time patterns to comprehensively capture the diverse patterns of users’ behavior. However, self-attention operations and global preference learning have been integrated with the time-aware into the proposed model to improve the performance of the SR.
3 The MTSR-FLP Model
In this section, the paper proposes the MTSR-FLP model, i.e., fusing the global and the local preference of users with self-attention networks based on the multi-temporal embedding for the sequential recommendation. Without loss of generality, the paper has a recommendation system with implicit feedback given by a set of users to a set of items. Therefore, the entire recommendation process can be defined as follows.
-
Multiple temporal embeddings
-
Convert the \(\mathrm{T}= \left\{{\mathrm{t}}_{1}; \, {\mathrm{t}}_{2}; \, \dots ; \, {\mathrm{t}}_{\mathrm{L}}\right\}\in {\mathbb{R}}^{\left|\mathrm{I}\right|}\) into absolute embedding by combining \({\mathrm{E}}^{\mathrm{Day}}\in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \mathrm{d}}\) and \({\mathrm{E}}^{\mathrm{Pos}} \in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \mathrm{d}}\), which contain the information of the index and the time information of each item in sequence, respectively.
-
Convert the \(\mathrm{T}= \{{\mathrm{t}}_{1}; \, {\mathrm{t}}_{2}; \, \dots ; \, {\mathrm{t}}_{\mathrm{L}}\}\in {\mathbb{R}}^{\left|\mathrm{I}\right|}\) into relative embedding \({\mathrm{E}}^{\mathrm{Sin}}\in {\mathbb{R}}^{\left|\mathrm{l}\right|\times |\mathrm{l}|\times \mathrm{d}}\), \({\mathrm{E}}^{\mathrm{Exp}} \in {\mathbb{R}}^{\left|\mathrm{I}\right|\times |\mathrm{l}|\times \mathrm{d}}\) and \({\mathrm{E}}^{\mathrm{Log}} \in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \left|\mathrm{I}\right|\times \mathrm{d}}\), which present different temporal information to a greater extent.
-
-
Local learning representation
-
Input matrix \({\mathrm{X}}^{(0)}\) = \(\{{\mathrm{x}}_{1};{\mathrm{x}}_{2};\dots ;{\mathrm{x}}_{\mathrm{L}}\}\) \(\in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \mathrm{d}}\) is obtained, in which the absolute position embedding matrix \({\mathrm{E}}^{\mathrm{Abs}} = \{{\mathrm{a}}_{1};{\mathrm{a}}_{2};\dots ;{\mathrm{a}}_{\mathrm{L}}\}\in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \mathrm{d}}\) to the embedding item matrix \(\mathrm{E }\in {\mathbb{R}}^{|\mathrm{I}|\times \mathrm{d}}\).
-
Input the matrix \({\mathrm{X}}^{(0)}\) into stacked self-attentive blocks (SAB) to get the output of the \({\mathrm{b}}^{\mathrm{th}}\) block as the \({\mathrm{X}}^{\left(\mathrm{b}\right)}={\mathrm{SAB}}^{\left(\mathrm{b}\right)}\left({\mathrm{X}}^{\left(\mathrm{b}-1\right)}\right)\mathrm{ b}\in \left\{\mathrm{1,2},\dots ,\mathrm{B}\right\}\).
-
-
Global learning representation
-
The global representation of the sequences is formalized as \(\mathrm{y}=\mathrm{LBA}\left(\mathrm{E}\right)=\mathrm{softmax}\left({\mathrm{q}}^{\mathrm{S}}{\left(\mathrm{EW}{\mathrm{^{\prime}}}_{\mathrm{K}}\right)}^{\mathrm{T}}\right)\mathrm{EW}{\mathrm{^{\prime}}}_{\mathrm{V}}\).
-
-
Item similarity gating
-
The specific computing equation is formalized as
$$\mathrm{g}=\upsigma \left(\left[{\mathrm{m}}_{\mathrm{sl}},\mathrm{y},{\mathrm{m}}_{\mathrm{i}}\right]{\mathrm{W}}_{\mathrm{G}}+{\mathrm{b}}_{\mathrm{G}}\right),$$
-
where \(\mathrm{y}\) represents the global representation, \({\mathrm{m}}_{\mathrm{sl}}\) is the recently interacted item embedding vector, and \({\mathrm{m}}_{\mathrm{i}}\) is the candidate item embedding vector. \({\mathrm{W}}_{\mathrm{G}}\) and \({\mathrm{b}}_{\mathrm{G}}\) are weight and bias separately.
3.1 MTSR-FLP Model Overview
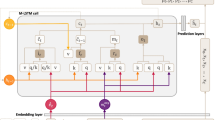
As shown in Fig. 1, the MTSR-FLP model mainly consists of four layers as follows: multi-temporal embedding learning; local representation learning; global representation learning; item similarity gating. Moreover, the entire algorithm of the MTSR-FLP model is described in Algorithm 1. The roles of the four components of the proposed model are described as follows:

The framework of the MTSR-FLP model

First, the multi-temporal embedding plays an important role in making full use of the temporal information of the user by constructing multiple temporal embeddings. In addition, the temporal embeddings are classified as two different forms of embedding vectors by the calculation way. Then, the paper utilizes a specific gate mechanism to integrate one form of embedding vectors as the absolute embeddings and integrate the other form of embedding vectors as the relative embeddings.
Second, the local representation learning layer mainly utilizes the self-attention mechanism, the absolute embeddings, and the relative embeddings learned in the multi-temporal embedding learning module to learn the local representation of the specific user.
Third, the global representation learning layer also utilizes all users’ historical sequence to capture the global preference of all users using the attention mechanism which is modified based on the self-attention mechanism.
Finally, the item similarity gating layer balances the global representation and the local representation using gate mechanism.
As shown in Table 1, there are the symbolic representations of the diagram in Fig. 1.
3.2 Multi-temporal Embedding Learning Module
To address timestamp information, this module makes the following improvements:
-
(1)
The construction of multiple temporal embeddings: \({E}^{Exp}\), \({E}^{Log}\), \({E}^{Sin}\), \({E}^{Day}\), and \({E}^{Pos}.\)
-
(2)
The construction of absolute embedding by combining \({E}^{Day}\) and \({E}^{Pos}\).
-
(3)
The construction of relative embedding by combining \({E}^{Exp}\), \({E}^{Log}\), and \({E}^{Sin}\).
3.2.1 Time Series Embedding
In the user’s historical sequence, each item is clicked by the user at a specific time, so time information is more important for recommendation.
The paper converts the \(T= \left\{{t}_{1};{t}_{2};\dots ;{t}_{L}\right\}\in {\mathbb{R}}^{\left|I\right|}\) into \({E}^{Day}\in {\mathbb{R}}^{\left|I\right|\times d}\) and \({E}^{Pos} \in {\mathbb{R}}^{\left|I\right|\times d}\). The \(d\) denotes the hidden vector dimension. \({E}^{Pos}\) contains the information on the index of each item in a sequence. \({E}^{Day}\) contains the time information of each item in a sequence. Compared with \({E}^{Timestamp}\), the \({E}^{Day}\) is more reasonable. Since \({E}^{Day}\) can save more storage space compared with \({E}^{Timespamp}\) using one day as a time interval, in the meantime it can take advantage of the time information of users’ historical sequence.
In addition, the paper maintains a learnable embedding matrix \({M}^{D}\in {R}^{\left|D\right|\times d}\), where \(|D|\) is the time interval by taking a day as a unit of measure between the earliest clicked item and the latest clicked item in uses’ historical sequence. Position embedding is a learnable positional embedding, where \({M}^{P}\in {R}^{|l|\times d}\), where \(|l|\) represents the length of the sequence. In this paper, the paper defines \(|l|\) as 50.
The paper also converts the \(\mathrm{T}= \{{\mathrm{t}}_{1};{\mathrm{t}}_{2};\dots ;{\mathrm{t}}_{\mathrm{L}}\}\in {\mathbb{R}}^{\left|\mathrm{I}\right|}\) into \({E}^{Sin}\in {\mathbb{R}}^{\left|\mathrm{l}\right|\times |\mathrm{l}|\times \mathrm{d}}\), \({E}^{Exp} \in {\mathbb{R}}^{\left|\mathrm{I}\right|\times |\mathrm{l}|\times \mathrm{d}}\) and \({E}^{Log} \in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \left|\mathrm{I}\right|\times \mathrm{d}}\). This paper uses different time embeddings to utilize different temporal information to a greater extent. First, this paper defines a temporal differences matrix as \(\mathrm{D}\in {\mathbb{R}}^{\mathrm{N}\times \mathrm{N}}\), in which the element is defined as \({\mathrm{d}}_{\mathrm{ab}}=\frac{{\mathrm{t}}_{\mathrm{a}}-{\mathrm{t}}_{\mathrm{b}}}{\tau }\), where \(\tau\) is the adjustable unit time difference; in the \({\mathrm{E}}^{\mathrm{Sin}},\) the paper converts the difference \({\mathrm{d}}_{\mathrm{ab}}\) to a latent vector \({\overrightarrow{\uptheta }}_{\mathrm{ab}}\in {\mathbb{R}}^{1\times \mathrm{h}}\), as shown in Eq. (1):
where \({\overrightarrow{\theta }}_{\mathrm{ab},\mathrm{c}}\) is the \({\mathrm{c}}^{\mathrm{th}}\) value of the vector \({\overrightarrow{\theta }}_{\mathrm{ab}}\). In the above equation, \(\mathrm{freq}\) and \(\mathrm{h}\) are adjustable parameters. Similarly, in the \({\mathrm{E}}^{\mathrm{Exp}}\), the paper converts \({\mathrm{d}}_{\mathrm{ab}}\) to \({\overrightarrow{\mathrm{e}}}_{\mathrm{ab}}\) and \({\overrightarrow{\mathrm{l}}}_{\mathrm{ab}}\) respectively, and the superposition of these vectors gives \({\mathrm{E}}^{\mathrm{Exp}}\) and \({\mathrm{E}}^{\mathrm{Log}}\) respectively, as shown in Eq. (2):
3.2.2 Absolute and Relative Embeddings Calculation
The calculation of absolute embeddings and relative embeddings is shown in Fig. 2. Here, \({E}^{Day}\) and \({E}^{Pos}\) are not simply addition operations to get the absolute embeddings, however, the paper calculates the different weights of the \({E}^{Day}\) and \({E}^{Pos}\), then the paper adds them together via their weights. The specific calculation is described in Eq. (3):
where \([.,.]\) denotes the ternary concatenation operation, \({W}_{day\_pos}\in {\mathbb{R}}^{2d\times 1}\) and \({b}_{day\_pos} \in {\mathbb{R}}^{1\times 1}\). To restrict each element in \(\alpha\) from 0 to 1, the paper utilizes the sigmoid activation function \(\sigma \left(z\right)=1/(1+{e}^{-z})\). Then, the paper adds \({E}^{Day}\) to \({E}^{Pos}\) to obtain \({E}^{Abs}\). The calculation procession is formalized in Eq. (4):

Absolute and relative embeddings
In the end, the paper can get the absolute embedding \({E}^{Abs}\in {\mathbb{R}}^{\left|I\right|\times d}\).Meanwhile, the paper calculates the relative embeddings with the same approaches of above. First, the paper can calculate \(\beta\) to balance the \({E}^{Exp}\) and \({E}^{Log}\). This calculation process is described in Eqs. (5, 6):
where \({W}_{\mathrm{sin}\_log}\in {\mathbb{R}}^{2d\times 1}\), \({b}_{\mathrm{sin}\_log} \in {\mathbb{R}}^{\left|I\right|\times \left|I\right|\times 1}\). Then, we add \({E}^{Sin}\) to \({E}^{Log}\) to obtain \({E}^{Sin\_Log}\) using weight \(\beta\):
Second, the paper calculates the weight \(\upgamma\) using a method in Eq. (7):
where \({W}_{\mathrm{sin}\_\mathrm{log}\_exp}\in {\mathbb{R}}^{2d\times 1}\), \({b}_{\mathrm{sin}\_\mathrm{log}\_exp} \in {\mathbb{R}}^{\left|I\right|\times \left|I\right|\times 1}\). Finally, the paper adds \({E}^{Sin\_log}\) to \({E}^{Exp}\) to obtain the relative embeddings \({E}^{Rel}\in {\mathbb{R}}^{\left|I\right|\times \left|I\right|\times 1}\) by weight \(\gamma\) in Eq. (8):
3.3 Local Learning Representation Module
Based on the SASRec model [9], the output vector \(\mathrm{x}\) from the top self-attentive block is used as the local learning representation for the user's dynamic preferences in a sequence. Due to the importance of the absolute positions of a user-item interaction of a sequence, the paper adds the absolute position embedding matrix \({\mathrm{E}}^{\mathrm{Abs}} = \{{\mathrm{a}}_{1};{\mathrm{a}}_{2};\dots ;{\mathrm{a}}_{\mathrm{L}}\}\in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \mathrm{d}}\) to the embedding item matrix \(\mathrm{E }\in {\mathbb{R}}^{|\mathrm{I}|\times \mathrm{d}}\) 33. In the end, an input matrix \({\mathrm{X}}^{(0)}\) = \(\{{\mathrm{x}}_{1};{\mathrm{x}}_{2};\dots ;{\mathrm{x}}_{\mathrm{L}}\}\) \(\in {\mathbb{R}}^{\left|\mathrm{I}\right|\times \mathrm{d}}\) is obtained. The specific process is formalized as shown in Eq. (9):
Afterward, the paper inputs the matrix \({\mathrm{X}}^{(0)}\) into stacked self-attentive blocks (SAB) to get the output of the \({\mathrm{b}}^{\mathrm{th}}\) block which is defined as shown in Eq. (10):
Next is the omission of the normalization layer with residual connections, where each self-attentive block is considered as a self-attentive layer (・), and then the results are fed into the feed forward layer, and values are calculated as shown in Eqs. (11–14):
Here, \(X\) is the input matrix containing absolute positional information, Q \(=X{W}_{Q}\),\(K=X{W}_{K}\),\(V=X{W}_{V}\), in which\({W}_{Q}\), \({W}_{K}\) and \({W}_{V}\) present different weight matrixes. To consider the influence of each interaction pairs in the sequence, the paper uses relative embedding\({E}^{Rel}\). Moreover, the weight \(\partial\) is introduced to balance the effect of the absolute embeddings and the relative embeddings. In Eq. (14), \({W}_{\mathrm{abs}\_\mathrm{rel}}\in {\mathbb{R}}^{2d\times 1}\) and\({b}_{abs\_rel} \in {\mathbb{R}}^{d\times 1}\), \([.,.]\) denotes the ternary concatenation operation, \(\sigma\) is the sigmoid function. Using the method, the paper can control the influence of the relative embeddings.
To improve flexibility, \({W}_{1}\), \({W}_{2}\) are the weights, and \({b}_{1}\), \({b}_{2}\) are biases of the two convolution layers. In the above equations, \(1\in {\mathbb{R}}^{d\times 1}\) is a unit vector, and \(\Delta\) is a unit lower triangular matrix to be used as a mask, preserving only the transformation of the previous step. Meanwhile, the paper introduces a layer of normalization to normalize the output and dropout to avoid over-fitting, in which specific usage of layer normalization and dropout is the same as those in the SASRec [9].
3.4 Global Representation Learning Layer
Inspired by the paper [39], the paper proposes a novel attention module, called the location-based attention layer LBA (・), to obtain the global learning representation of all users. In particular, the user u’s preference for interaction item s is generated in step \(l+1\) as a uniform aggregation of other interaction item representations, so the predicted ratings can be considered as the factorial similarity between user u’s historical item and candidate item s, as shown in Eq. (15):
In this paper, to calculate the most representative feature representation of all items in all sequences, the paper introduces \({q}^{S}\in {\mathbb{R}}^{1\times \mathrm{d}}\) as the query vector, rather than an average weighted aggregation. The \({q}^{S}\) is different from \(Q\) in Eq. (12). This is because this module aims to calculate all users’ global preferences instead of individual preferences.
The global representation of the sequences is formalized in Eq. (16):
where \(E\) is the initial input matrix and \(W{\mathrm{^{\prime}}}_{K}\), \(W{\mathrm{^{\prime}}}_{V}\) are the learnable weight matrixes, similar to \({W}_{Q}\),\({W}_{K}\),\({W}_{V}\).
The dropout layer in the training process can avoid over-fitting and generalize the global representation in all steps, and then obtain the final global representation of all users' matrix \(Y\), as shown in Eq. (17):
3.5 Item Similarity Gating Layer
Designing the item similarity gating module has two main reasons. First, the global representation and the local representation are all important to the final recommendation. The paper must distinguish the importance between the global learning representation and the local learning representation. Second, the problem of uncertainty in users’ intent in SR when user sees candidate items commonly exists.
Inspired by the NAIS [40], the paper designs a novel item similarity gating module which is critical in coordinating the local preference of the specific user and the global preference of all users. Meanwhile, it considers the influence of candidate items by calculating the similarity of candidate items and recently interacted items. The specific computing equation is formalized as follows in Eq. (18):
where \(y\) represents the global representation, \({m}_{sl}\) is the recently interacted item embedding vector, and \({m}_{i}\) is the candidate item embedding vector. \({W}_{G}\) and \({b}_{G}\) are weight and bias separately. The paper utilizes the sigmoid function as the activation function.
At step \(l\) of the sequence, the final representation \({z}_{i}\) is the weighted sum of the related local learning representation \({x}_{i}\) and the global learning representation \(y\), as shown in Eq. (19):
where \(\otimes\) is the broadcast operation in TensorFlow.
The final prediction of the item \(i\) preference to be the \({(\mathrm{i}+1)}^{\mathrm{th}}\) item in the sequence is shown in Eq. (20):
MTSR-FLP is trained using the Adam optimizer, which loss function is shown in Eq. (21):
in which \({\mathrm{r}}_{\mathrm{l}+1,\mathrm{j}}^{\mathrm{u}}\) is the negative sample’s possibility as the \({(\mathrm{i}+1)}^{\mathrm{th}}\) item in the sequence, and \(\updelta \left({\mathrm{s}}_{\mathrm{l}+1}^{\mathrm{u}}\right)\) is used as eliminating the influence of padding items. If \({\mathrm{s}}_{\mathrm{l}+1}^{\mathrm{u}}\) is a padding item, \(\updelta \left({\mathrm{s}}_{\mathrm{l}+1}^{\mathrm{u}}\right)\) will be 0, otherwise, it will be 1.
4 Experimental Results and Analysis
4.1 Experimental Environment
The related experiments environment of the proposed model is based on versions Python 3.6 and above and torch 1.10.0 or higher, and the running environment version requires Anaconda 3-2020.02 and above. The main data packages include cuda 10.2, cudnn10.2, torch = = 1.10.0 + cu102, networkx = = 2.5.1, numpy = = 1.19.2, pandas = = 1.1.5, six = = 1.16.0, scikit-learn = = 0.24.2, and space = = 3.4.0. The hardware environment of this model is processor Intel Xeon Gold 5218, GPU is Rtx 3060 and memory is 32 GB DDR4.
This paper verifies the proposed model performance under strong generalization conditions by dividing all users into training/testing sets in the ratio of eight to two. In the user’s historical sequence, the last item in the user’s historical sequence is used in the testing set, and other items are used in the training set. During the process of training, the model is evaluated using the following two commonly used metrics. This paper conducts experiments on five real-world datasets—Beauty [41], Games [42], Steam [43], Foursquare [44] and Tmall [45]. The specific statistics are shown in Table 2. The optimal values of the nine parameters shown in Table 3 are the conclusions drawn through experimental comparison.
4.2 Evaluation Indicators
4.2.1 Click-Through Rate
This paper uses click-through rate (HR) to evaluate the percentage of recommended items that incorporate the correct item for at least one user interaction, and the metric is calculated as shown in Eq. (22):
in which \(\updelta \left(\cdot \right)\) is the indicator function and equal to 1 if \(\left|{\widehat{\mathrm{I}}}_{\mathrm{u},\mathrm{N}}\cap {\mathrm{T}}_{\mathrm{u}}\right|>0\).
4.2.2 Normalized Discounted Cumulative Gain
The paper takes the normalized discounted cumulative gain (NDCG@10) because it takes into account the location of correctly recommended items, and is calculated as shown in Eq. (23):
where \({\widehat{\mathrm{i}}}_{\mathrm{u},\mathrm{k}}\) denotes the \({\mathrm{k}}^{\mathrm{th}}\) item recommended to user \(u\), and \(Z\) is a normalization constant indicating the discounted cumulative gain (NDCG@10) of the ideal case, which is the maximum possible value of NDCG@10.
4.3 Baseline Model
The following baseline models are utilized to be compared with the proposed MTSR-FLP model in this paper:
-
BPRMF [46]: a standard recommendation model based on MF via pairwise loss.
-
FISM [47]: another popular model learning the similarity matrix between items.
-
GRU4Rec [1]: one of the earliest improved RNN models based on deep learning via an additional sampling strategy land twice loss function for sequence recommendation.
-
SASRec [9]: a popular sequential recommendation model using a self-attention network.
4.4 Experimental Results
As shown in Table 4, the MTSR-FLP model achieves better results in both HR@10 and NDCG@10 compared with other sequence recommendation models. The performance comparison of MTSR-FLP and SASRec is shown in Figs. 3 and 4.

SASRec model and MTSR-FLP model on five different datasets performance on HR@10. The blue dotted line represents MTSR-FLP and the red dotted line represents the SASRec model. It can be seen that under the evaluation index of NDCG@10, MTSR-FLP performs better than the SASRec model in the five datasets

SASRec model and MTSR-FLP model on five different datasets performance on NDCG@10. It can be seen that under the evaluation index of NDCG@10, MTSR-FLP performs better than the SASRec model in the five datasets
From Figs. 3 and 4, the MTSR-FLP’s performance in five datasets is much better than those of the SASRec. In the foursquare dataset, the performance SASRec is better than MTSR-FLP. This might because that the results are influenced by over-fitting with the longer training time.
4.5 Ablation Study
As shown in Table 5, model-1 is the proposed model, the other models have different attention factors including absolute embeddings, relative embeddings, and calculating approaches. The performances of models with different settings are described in Table 6.
In the model-2, the paper defines \({E}^{Pos}\) as the absolute embedding, \({E}^{Exp}\) as the relative embedding. Since model-2 has only one absolute embedding and one relative embedding, the \({E}^{Abs}\) is the same as \({E}^{Pos}\) and the \({E}^{Rel}\) is the same as \({E}^{Exp}\). In other words, the absolute embedding calculation block and the relative embedding calculation block are useless. Therefore, Eq. (12) is replaced by Eq. (24):
Compared with Eq. (12), there is no parameter \(\partial\) which means model-2 does not consider the negative influence of relative embeddings. Model-3 is similar to the model-2 except that \({E}^{Exp}\) is replaced with \({E}^{Sin}\).
In model-4, the paper uses \({E}^{Pos}\) as absolute embedding and uses \({E}^{Exp}\) and \({E}^{Log}\) as the relative embeddings, in which \({E}^{Abs}\) is same as \({E}^{Pos}\), so the absolute embedding calculation block is useless. The relative embedding calculation block is different from that of the proposed model. First, the paper concatenates the \({E}^{Sin}\mathrm{ and }{ E}^{Log}\) together to get \({E}^{Rel}\). Then, the paper feds \({E}^{Rel}\) into the feed forward neural network to get the final \({E}^{Rel}\). Model-4 does not consider the negative influence of the relative embeddings. This can be formalized by following Eq. (25):
The performance of different settings of the model is shown in Table 6. To highlight the training performance, the paper depicts the results in Fig. 5. From the Fig. 5 the proposed model performs best in almost all datasets on HR@10 and NDCG@10. The specific training process is shown below. The paper can see the proposed model’s performance is better than the model with other settings in almost all datasets.

The performance of MTSR-FLP with different settings. In both HR@10 and NDCG@10, Model-1 performed very well. Except for Tmall datasets, Model-1 outperforms other models on the other four datasets
The specific training process is shown in Figs. 6 and 7. It is easy to see that the proposed model’s performance is better than the model with other settings in almost all datasets. The analysis of ablation experimental results is described as follows.
-
Model-1 vs. Model-2 and Model-3. In the training process, the paper can see the performance of Model-1 is better than Model-2 and Model-3 in most datasets. The reason for this is that Model-1 only uses \({E}^{Exp}\) as relative embedding and the Model-2 only use \({\mathrm{E}}^{\mathrm{Log}}\) as relative embedding, but the proposed model use\({E}^{Exp}\), \({E}^{Log}\), and \({E}^{Sin}\) as relative embeddings. Therefore, the proposed model uses more information than Model-2 and Model-3.
-
Model-2 vs Model-3. In different datasets, the performance of Model-2 and Model-3 is different. This is mainly because the \({E}^{Exp}\) and \({E}^{Sin}\) capture different time information. If the paper uses \({E}^{Exp}\) as relative embedding, a large time gap can quickly decay to zero. But if the paper uses \({E}^{Sin}\) as relative embedding, the relative embedding only captures periodic occurrences. Time information is different in different datasets, so the performance in different datasets is different.
-
Model-4 vs Model-2 and Model-3. Compared with Model-2 and Model-3, Model-4 performs worse than Model-2 and Model-3. Though Model-4 uses more information than Model-2 and Model-3, combining \({E}^{Exp}\) and \({E}^{Log}\) using feed forward network causes over-fitting.
-
Model-1 vs Model-2, Model-3 and Model-4. From Table 6, it can be seen that the performance of Model-2, Model-3, and Model-4 in datasets foursquare is worse than the proposed model. In these models, they do not consider the negative influence of relative embedding. But in this datasets, relative time information is useless.

The performance in different HR@10 for MTSR-FLP models with different settings. Model-2 performed well on the first datasets. Model-1 outperformed the other models on the remaining four datasets

The performance in different epochs of NDCG@10 for MTSR-FLP models with different settings
5 Conclusion
This paper proposes a novel MTSR-FLP model for the sequence recommendation. In particular, the paper integrates attention mechanisms, including multi-temporal embeddings self-attention network, and a factorial item similarity, to improve the performance of the SR. In particular, the multiple temporal embedding provides the absolute embeddings and relative embeddings for the self-attention network using temporal information and multiple encoding functions, where different attention heads handle different temporal embeddings. Meanwhile, this paper also designs a gating module for modulating local and global representations, considering the relationship between candidate items, recent interacted items, and all user’s global preferences to cope with possible uncertainty in user intent.
In addition, there are some directions to improve the proposed model. First, although this paper has tried deep learning and self-attention network models, more strategies might be worth trying to improve the performance of SR. In the near future, the paper will try integrating some new attention mechanisms, such GNNs, and generative adversarial networks (GANs) into the MTSR-FLP model. Second, future works should capture the multi-dimension information of items and the users in the SR, which can be utilized to further classify recommendation items and the users. In addition, more detailed time feature information also needs to be obtained to improve the accuracy of the SR. Finally, the paper will utilize new datasets to evaluate and improve the performance of the proposed model.
Data Availability
Data sharing is not applicable to this article as no real-world datasets were acquired or analyzed during the current study.
References
Hidasi, B., Karatzoglou, A., Baltrunas, L., Tikk, D., Japa.: Session-based recommendations with recurrent neural networks (2015) Doi: https://doi.org/10.48550/arXiv.1511.06939
Le, DT., Lauw, HW., Fang, Y.: Modeling contemporaneous basket sequences with twin networks for next-item recommendation. (2018) Doi: https://doi.org/10.24963/ijcai.2018/474
Chen, X., Xu, H., Zhang, Y., et al.: Sequential Recommendation with User Memory Networks. In: Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining (2018) Doi: https://doi.org/10.1145/3159652.3159668
Jannach, D., Ludewig, M.: When Recurrent Neural Networks meet the Neighborhood for Session-Based Recommendation. In: Proceedings of the Eleventh ACM Conference on Recommender Systems; 2017. Doi: https://doi.org/10.1145/3109859.3109872
He, R., McAuley, J.: Fusing similarity models with markov chains for sparse sequential recommendation. In: Paper presented at: 2016 IEEE 16th International Conference on Data Mining (ICDM)2016. Doi: https://doi.org/10.1109/ICDM.2016.0030
Zhang, S., Yao, L., Sun, A., Tay, Y.: Deep learning based recommender system. ACM Comput. Surv. 52(1), 1–38 (2019). https://doi.org/10.1145/3285029
He, X., He, Z., Du, X., Chua, T-S.: Adversarial Personalized Ranking for Recommendation. In: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval (2018) Doi: https://doi.org/10.1145/3209978.3209981
Wang, S., Cao, L., Wang, Y., Sheng, Q.Z., Orgun, M.A., Lian, D.: A survey on session-based recommender systems. ACM Comput. Surv. 54(7), 1–38 (2022). https://doi.org/10.1145/3465401
Kang, W-C., McAuley, J.: Self-Attentive Sequential Recommendation. In: 2018 IEEE International Conference on Data Mining (ICDM) (2018) Doi: https://doi.org/10.1109/ICDM.2018.00035
Feng, F., He, X., Wang, X., Luo, C., Liu, Y., Chua, T-SJAToIS.: Temporal relational ranking for stock prediction (2019) 37(2): 1-30. Doi: https://doi.org/10.1145/3309547
Wu, C.-Y., Ahmed, A., Beutel, A., Smola, AJ., Jing, H.: Recurrent recommender networks. In: Paper presented at: Proceedings of the tenth ACM international conference on web search and data mining (2017) Doi: https://doi.org/10.1145/3018661.3018689
Hidasi, B., Karatzoglou, A., Baltrunas, L., Tikk, D.: Session-based recommendations with recurrent neural networks. In ICLR (2016). https://doi.org/10.48550/arXiv.1511.06939
Hidasi, B., Karatzoglou, A.: Recurrent neural networks with top-k gains for session-based recommendations. In: Proceedings of the 27th ACM International Conference on Information and Knowledge Management (CIKM) (2018) p. 843–852. Doi: https://doi.org/10.1145/3269206.3271761
Yuan, F., Karatzoglou, A., Arapakis, I., Jose, J.M., He, X.: A simple convolutional generative network for next item recommendation. Paper Present (2019). https://doi.org/10.1145/3289600.3290975
Vaswani, A., Shazeer, N., Parmar, N., et al.: Attention is all you need. Paper presented at: Advances in neural information processing systems (2017) Doi: https://doi.org/10.48550/arXiv.1706.03762
Devlin, J., Chang, M. W., Lee. K., et al.: Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018) Doi: https://doi.org/10.48550/arXiv.1810.04805
Fei, S., Jun, L., Jian, W., Changhua, P., Xiao, L., Wenwu, O., Peng, J.: BERT4Rec: sequential recommendation with bidirectional encoder representations from transformer. CIKM. (2019). https://doi.org/10.1145/3357384.3357895
Chengfeng, Xu., Feng, J., Zhao, P., Zhuang, F., Wang, D., Liu, Y., Sheng, V.S.: Long and short-term self-attention network for sequential recommendation. Neurocomputing 423(2021), 580–589 (2021). https://doi.org/10.1016/j.neucom.2020.10.066
Xiang, W., Xiangnan, H., Meng, W., Fuli F., Tat-Seng, C.: Neural Graph Collaborative Filtering. In SIGIR. (2019) 165–174. Doi: https://doi.org/10.1145/3331184.3331267
He, X., Deng, K., Wang, X., Li, Y., Zhang, Y., Wang, M.: Lightgcn: simplifying and powering graph convolution network for recommendation. ACM (2020). https://doi.org/10.1145/3397271.3401063
Shu, W., Yuyuan, T., Yanqiao, Z., Liang, W., Xing, X., Tieniu, T.: Session-Based Recommendation with Graph Neural Networks. In AAAI. 8 pages (2019) Doi: https://doi.org/10.1609/aaai.v33i01.3301346
Wang, Z., Wei, W., Cong, G., Li, X.-L., Mao, X.-L, Qiu, M.: Global Context Enhanced Graph Neural Networks for Session-based Recommendation. In: Proceedings of the 43nd International ACM SIGIR Conference on Research and Development in Information Retrieval, (2020) pp. 169–178. Doi: https://doi.org/10.1145/3397271.3401142
Rianne van den Berg, Thomas N. Kipf, and Max Welling.: Graph convolutional matrix completion. arXiv:1706.02263. Retrieved from https://arxiv.org/abs/1706.02263 (2017) Doi: https://doi.org/10.48550/arXiv.1706.02263
Nguyen G. H., Lee J. B., Rossi R. A., Ahmed N. K., Koh E., Kim S.: “Continuous-Time Dynamic Network Embeddings” In: 12 Web Conference 2018—Companion of the World Wide Web Conference, WWW 2018, no. BigNet, pp. 969–976, 2018. Doi: https://doi.org/10.1145/3184558.3191526
Lo, Y.-Y., Liao, W., Chang, C-S., Lee, Y-CJIToCSS.: Temporal matrix factorization for tracking concept drift in individual user preferences (2017) 5(1): 156-168. Doi: https://doi.org/10.1109/TCSS.2017.2772295
Koren, Y.: Collaborative filtering with temporal dynamics. In: Paper presented at: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining2009. Doi: https://doi.org/10.1145/1557019.1557072
Dallmann, A., Grimm, A., Pölitz, C., Zoller, D., Hotho, AJapa.: Improving session recommendation with recurrent neural networks by exploiting dwell time (2017) Doi: https://doi.org/10.48550/arXiv.1706.10231
Zhu, Y., Li, H., Liao, Y., et al.: What to Do Next: Modeling User Behaviors by Time-LSTM. In: Paper presented at: IJCAI2017 Doi: https://doi.org/10.24963/ijcai.2017/504
Zhang, S., Tay, Y., Yao, L. et al.: Next item recommendation with self-attentive metric learning. Thirty-Third AAAI Conference on Artifcial Intelligence (2019), Doi: https://doi.org/10.48550/arXiv.1808.06414
Wu, J., Cai, R., Wang, H. Déjà, vu: A contextualized temporal attention mechanism for sequential recommendation. In: Paper presented at: Proceedings of The Web Conference 2020. Doi: https://doi.org/10.1145/3366423.3380285
Zhou, C., Bai, J., Song, J., et al.: Atrank: An attention-based user behavior modeling framework for recommendation. In: Paper presented at: Proceedings of the AAAI Conference on Artificial Intelligence2018. Doi: https://doi.org/10.1609/aaai.v32i1.11618
Li, J., Wang, Y., & McAuley, J.: Time interval aware self-attention for sequential recommendation. In: Proceedings of the 13th international conference on web search and data mining (pp. 322–330). (2020). Doi: https://doi.org/10.1145/3336191.3371786
Ye, W., Wang, S., Chen, X., Wang, X., Qin, Z., & Yin, D. (2020). Time matters: Sequential recommendation with complex temporal information. In: Proceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval (pp. 1459–1468). Doi: https://doi.org/10.1145/3397271.3401154
Wang, C., Ma, W., Zhang, M., Chen, C., Liu, Y., Ma, S.: Toward dynamic user intention: Temporal evolutionary effects of item relations in sequential recommendation ACM Transactions on Information Systems (TOIS), 39 (2020), pp. 1-33. Doi: https://doi.org/10.1145/3432244
Hsu,C., Li, C.-T.: Retagnn: Relational temporal attentive graph neural networks for holistic sequential recommendation. In: Proceedings of the web conference (2021) (pp. 2968–2979). Doi: https://doi.org/10.1145/3442381.3449957
Wang, H., Li, P., Liu, Y., Shao, J.: Towards real-time demand-aware sequential poi recommendation. Inf. Sci. 547, 482–497 (2021). https://doi.org/10.1016/j.ins.2020.08.088
Chen, Z., Zhang, W., Yan, J., Wang, G., & Wang, J. (2021). Learning dual dynamic representations on time-sliced user-item interaction graphs for sequential recommendation. In: Proceedings of the 30th ACM international conference on information & knowledge management (p. 231–240). Doi: https://doi.org/10.1145/3459637.3482443
Jin, J., Chen, X., Zhang, W., Huang, J., Feng, Z., & Yu, Y. (2022). Learn over past, evolve for future: Search-based time-aware recommendation with sequential behavior data. In: Proceedings of the ACM web conference 2022 (pp. 2451–2461). Doi: https://doi.org/10.1145/3485447.3512117
Cho, S.M., Park, E., Yoo, S.: MEANTIME: mixture of attention mechanisms with multi-temporal embeddings for sequential recommendation. Paper Present (2020). https://doi.org/10.1145/3383313.3412216
Lin, J., Pan, W,, Ming Z. FISSA: Fusing Item Similarity Models with Self-Attention Networks for Sequential Recommendation. Fourteenth ACM Conference on Recommender Systems; 2020. Doi: https://doi.org/10.1145/3383313.3412247
He,X., He, Z., Song, J., et al.: Nais: Neural attentive item similarity model for recommendation. (2018) 30(12): 2354–2366. Doi: https://doi.org/10.1109/TKDE.2018.2831682
Beauty. http://jmcauley.ucsd.edu/data/amazon/. Accessed 12 July 2023
Games. http://jmcauley.ucsd.edu/data/amazon/. Accessed 12 July 2023
Steam. https://cseweb.ucsd.edu/~jmcauley/datasets.html#steam_data. Accessed 12 July 2023
Foursquare. https://archive.org/download/201309_foursquare_dataset_umn. Accessed 12 July 2023
Tmall. https://tianchi.aliyun.com/dataset/. https://doi.org/10.48550/arXiv.1205.2618. Accessed 12 July 2023
Rendle, S., Freudenthaler, C., Gantner, Z., Schmidt-Thieme, LJ. BPR: Bayesian personalized ranking from implicit feedback (2012) Doi: https://doi.org/10.48550/arXiv.1205.2618
Acknowledgements
The authors would like to thank the anonymous reviewers for their comments which helped us to improve the quality of the paper.
Funding
This paper is supported by Key scientific research projects of colleges and universities in Henan Province (Grand No. 23A520054).
Author information
Authors and Affiliations
Contributions
All the authors have contributed to the design and evaluation of the schemes and the writing of the manuscript. All the authors have read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of Interest
The authors of the paper certify that they have no affiliations with or involvement in any organization or entity with any financial interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chen, J., Pan, L., Dong, S. et al. Multi-temporal Sequential Recommendation Model Based on the Fused Learning Preferences. Int J Comput Intell Syst 16, 143 (2023). https://doi.org/10.1007/s44196-023-00310-w
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-023-00310-w