
Abstract
Dyslexia is a learning disorder caused by difficulties in the brain’s processing of letters and words. This study used EEG recordings to detect dyslexia at a young age. EEG recordings of 53 individuals, including 29 dyslexic and 24 normal individuals, were collected while they were engaged in two distinct mental activities known as the N-Back task and the Oddball task. Predictors were extracted using several methods and reduced using Principal Component Analysis (PCA). A relief-based strategy was applied to select predictors, and Support Vector Machine (SVM) classifier was used to achieve an average accuracy of 79.3% for dyslexia detection, which is better than the performance of its predecessors. The results indicate that EEG recordings and machine learning methods could be useful for identifying dyslexia in children.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Dyslexia affects one in five people, and among those with learning problems, 80–90% have a reading disability as a result of dyslexia. Dyslexia is the most common of all neuro-cognitive problems [1]. Rudolf Berlin, an ophthalmologist in Stuttgart, Germany, invented the name "dyslexia" in 1887, combining the words "difficult to read" (from the English dys) and "to read" (from the Latin legere) [2]. The diagnosis of dyslexia is driven by the fact that it hampers a person’s ability to understand and process language, with mild to severe symptoms. Dyslexia is a global problem that affects people of all ages and walks of life. Even though there have been improvements in diagnosing, understanding, and teaching methods, too many dyslexics are still not recognized and taught. It is not possible to cure dyslexia because it is a condition that affects a person for their entire life and cannot be eradicated [1]. However, dyslexic people can achieve great success with early identification, screening, evidence-based reading intervention, and accommodations. Our goal is to identify dyslexic children at an early age, most likely when they first enroll in school, in the hopes of protecting their professional future. The medical community can find that this detection technique, in addition to the conventional methods, is a beneficial tool for a higher level of accuracy. We have received funding under IEEE SPS- HAC to develop an early-detection dyslexia system for children aged 8–10 years. This system will help the medical community, the government in policy-making, and the children in the local region.
Electroencephalography (EEG), Electromyography (EMG), and Electrocardiography (ECG), as well as many other electro-biological measurements, are frequently used as body neuroimaging for in-depth research on specific organs and the conditions associated with them. Electroencephalography is a medical scanning technique that reads electrical activity stimulated by brain structures using metal electrodes and conductive media and displays the results as an electroencephalogram. Electroencephalography is defined as a technique that reads electroencephalograms. An EEG reading is a non-invasive procedure that uses event-related potentials to identify specific brain signals [3]. Action potentials are the end result of local current flows (called ion exchanges) that happen when a stimulus turns on neurons. These current flows occur across the neuronal membrane. Scanning of the electroencephalogram (EEG) is considered one of the most influential methods in the field of neuroscience due to its capacity to reflect both normal and abnormal activity.
2 Research review
Psycho-educational questionnaires are typically used to identify dyslexia. These surveys measure achievement, Intelligent Quotient (IQ), phonological processing, reading ability, and vocabulary expansion [4]. In other words, they measure students’ cognitive abilities. The most prevalent tests are Woodcock-Johnson III (WJ-III) [5], Comprehensive Test of Phonological Processing [6], and Peabody Picture Vocabulary Test: Third Edition (PPVT-III) [7]. Due to the wide diversity of observed behavioral patterns, formative evaluation is difficult, time-consuming, and unsuitable for many participants. Thus, researchers in this field are developing novel approaches for identifying dyslexia through data science.
k-means clustering, ANN, and fuzzy logic classifiers were used to identify dyslexia from Gibson test of brain skills records of 80 children aged eight to twelve [8]. A dataset is applied to the corresponding classifier block after minimal preprocessing. There are 62 dyslexic children out of a total of 80, demonstrating a class imbalance that does not ensure the outcome indicated for real-time data.
Statistical attributes for each individual, activity, and frequency sub-band in a channel are computed in [9]. 17 dyslexic and 15 non-dyslexic adults were included in this investigation. The participants’ EEGs were recorded while they did two different tasks. One task was to read a passage, and the other was to name as many colors as they could from a color card on a computer screen as quickly as they could. In a color-based test, the Cubic Support Vector Machine classifier achieved 75% accuracy. The left parieto-occipital and parieto-occipital were the most significant regions for the passage reading test and the colour identification task, respectively.
Feature selection in [10] was done using a Relief algorithm. From a sample of 32 pupils in classes 6 or 7, temporal, statistical, and frequency structural factors were extracted. SVM classifier with 10-fold cross-validation claims 79% accuracy. Furthermore, research is being done to identify the vital brain region for diagnosing dyslexia. An entire feature matrix has been applied to the feature selection block, and then cross-validation has been conducted, which can introduce bias into the classifier. In the proposed work, predictor selection was exclusively used on the training dataset in order to circumvent the biasing issue.
An analysis of the classifier’s results’ sensitivity (76.47%) and specificity (66.7%) confirmed the findings of the investigation into anterior-frontal lobe channels as the distinct brain signal-generating lobes AF7, AF3, AF4, and AF8. In order to differentiate the brainwave patterns of dyslexics and controls, researchers are beginning to use typing challenges as an innovative method and a contemporary alternative to writing. The frontal lobe channels F3, F4, F5, F6, and Fz appeared as the most significant EEG channels for producing unique brainwave patterns that are specific to typing difficulties in individuals who are dyslexic. This breakthrough was made possible by the use of a multi-channel EEG system. This conclusion was reached based on an analysis of sensitivity and specificity. When attempting to generate brainwave patterns, it is necessary to investigate particular EEG channels depending on the domain selected [11].
Instead of recording the electrical activity of the brain with an EEG, the authors of [12] collected the handwriting of sixth-grade students and divided it into two parts. Part one was an open-ended creative writing prompt in which parents were asked to submit a photograph of their child’s handwriting. Two samples were collected from students who had dyslexia, and fifteen samples were collected from students who did not have dyslexia. In the second section, children were asked to write down words and a paragraph read by parents or researchers in order to collect a controlled data set. The collection included 63 samples from students who did not have dyslexia as well as 9 samples from students who did have dyslexia. During the pre-processing phase, they split each image into text lines and then made fifty random patches for each line. The CNN model was utilized for classification, and the results obtained through validation with a 5-fold CV method demonstrate an accuracy of 55.7%.
The authors of [13] recorded an Event-Related Potential (ERP) for the N-Back task, Spatial N-Back task, and Oddball task, and extracted 43 different features for each channel and subject. In total, 30 children between the ages of 7 and 12 have been taken into consideration for this study-15 dyslexic and 15 controlled adolescents. An SVM classifier using a cross-validation approach was employed to evaluate the accuracy, and the highest accuracy of 73% was achieved. The correlation-based methodology was utilized to group channels. This paper’s authors have provided a data set containing 53 children. We are able to achieve superior results compared to their findings.
Our proposed endeavor aims to confront these challenges by pioneering an innovative approach to dyslexia identification. Harnessing contemporary data science methodologies, which encompass feature selection, and leveraging the insights gained from previous research, our primary objective is to elevate the precision and effectiveness of dyslexia diagnosis. By building upon the foundations laid by earlier studies and honing the methodologies, our aspiration is to make a meaningful contribution to the ongoing advancements in the field, ultimately providing a more efficient and accurate means of identifying dyslexia.
3 Methodology
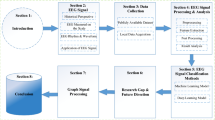
The block diagram of Fig. 1 is a framework that illustrates the flow for the detection of dyslexic children, and the subsequent sections explain each block in further detail.

Framework for detection of dyslexia based on EEG Signals
3.1 Dataset and stimuli
Researchers of [14] concluded that the total number of participants could range from 30 to 50 using Altman’s Nomogram sample size calculation, considering a power of 0.80 (p-value significance of 0.05) and a standardized difference value between 0.8 and 1.0 (Cohen’s d effect size). Due to a lack of awareness among parents of dyslexic children, getting parental permission to record their child’s EEG is a common stumbling block. For this reason, there are relatively limited participants taking part. Despite all of these limitations, we are able to manage a dataset from researchers of [15], which consists of 53 students (24 normal and 29 dyslexic), between the age of 7 and 12. The dyslexic group has a Raven Intelligence score of 94, while the control group has a Raven Intelligence score of 96.
The EEG signals, sampled at a rate of 250 Hz, were recorded using 19 channels while children were exposed to two different stimuli. Students were asked to complete the N-Back task while their EEG were being recorded during the first stimulus. This mental exercise is commonly used to assess a person’s capacity for working memory. Students were given a series of shapes to identify, and if the preceding shape was repeated, they had to press enter. Three minutes of EEG recordings were made for this stimulation.
To concentrate on the P300 event-related potential (ERP), another stimulus called the Oddball Task was applied. The recording took place for approximately seven minutes. At the top or bottom of the screen, random shapes can appear. Children have to press the space bar if it appears at the top of the screen and do nothing if it appears at the bottom.
3.2 Pre-processing
Pre-processing procedures in a sequence include; line noise elimination (notch filter), a minimum phase causal band pass filter with a bandwidth of 0.1–50 Hz, removal of artifacts, and Independent Component Analysis (ICA) to separate a mixture of data into its constituent channels [16]. The pre-processed EEG data is then partitioned into non-overlapping 1-second segments in order to consider it stationary [13].
3.3 Predictor extraction
The uniqueness of the input data is extracted during predictor extraction, which improves the accuracy of previously trained models. In this step of the general framework, the unnecessary data is taken away, which makes the data less complex. Consequently, it accelerates training and inference.
3.3.1 Extraction of zero, second and fourth order power moments
An EEG trace g[i] in the time domain with P samples and \(f_s\) sampling frequency can be transformed into a frequency domain signal G[f] using the discrete Fourier transform. Using Parseval’s Theorem, the following expression can be used to get the power spectrum Z[f] without phase from a time-domain signal g[i].
The symmetric spectrum produced by the Fourier transform includes both positive and negative frequencies. Since Power Spectral Density (PSD) is derived from a signal in the time domain, we can’t have direct access to PSD and must therefore include the entire frequency spectrum. Incorporating both positive and negative frequencies will eliminate all atypical occurrences of all odd-order moments [17]. The moment h of order n of the power spectral density Z[f] is defined as follows:
In the preceding equation, when \(n=0\), the outcome is Parseval’s Theorem, and for non-zero values of n, the time-differentiation property of the Fourier transform can be exploited.
Zero order moment The zero order moment gives an indication of the overall power in the frequency domain, which is represented by the expression.
Second order moment The first order difference signal \(g'[i]\) can be utilized to get the second order moment using the equation:
Second order moment is regarded to be Hjorth’s second moment.
Fourth order moment The ‘fatness’ of the outer tails of power spectral density Z[f] is defined as the fourth moment, which is represented by the equation,
The process for deriving predictors based on the moments is depicted schematically in Fig. 2 and explained in detail beneath.

Schematic of the predictor extraction procedure
3.4 Predictor extraction based on power spectrum moments
The following predictors are derived using power spectrum moments [18].
Hjorth mobility: It is stated as a ratio per unit of time and can alternatively be considered the average frequency [18]. The ratio will only depend on the shape of the curve since all of these quantities are proportional to the mean amplitude. This indicates that it estimates the average relative slope.
Hjorth complexity: It is a measurement of the signal’s resemblance to a perfect sinusoidal signal. It is stated as the number of standard gradients obtained in the average time taken by the mobility to generate one standard amplitude [17]. To account for non-linearity, this parameter will express any divergence from the sinusoidal graph as an increase in variance over unity.
Zero crossings: This predictor is able to capture the temporal changes in an EEG signal. The number of zero crossings in a given amount of time is expressed as follows [18]:
Number of extrema:It detects the amplitude fluctuations of an EEG signal. The formula that gives the number of extrema that occur per unit of time is:
Mean zero up-crossing duration: The spectral disturbances can be detected using a mean zero up-crossing duration, which can be calculated using
Mean peak-to-peak duration: Amplitude and time variations are both capable of being simultaneously captured by a mean peak-to-peak duration, which is then expressed as
On the basis of the diagram depicted in Fig. 2, six predictors stated above are extracted. These predictors will form a vector denoted by \(m = [m_1,m_2,...m_6]\). A time-domain EEG signal g is logarithmically scaled and represented as \(g_1=log(g2)\). The predictor vector \(n = [n_1, n_2,... n_6]\) is the result of extracting all six predictors for this transformed signal \(g_1\). The final six generated features are extracted as the orientation of the two vectors specified by the similarity measure defined below.
3.4.1 Slow wave index
This will be an extremely important predictor for the N-Back task and the Oddball task, whose primary rhythms will be either delta (\(\delta \)), theta (\(\theta \)), or alpha (\(\alpha \)). As a result of their low-frequency range, \(\delta \), \(\theta \), and \(\alpha \) are characterized as “Slow Waves". Band-pass FIR digital filters were utilized to enable the sub-band decomposition process. This method aimed to partition the input signal into discrete frequency components or sub-bands, extracting and isolating specific frequency ranges of interest. Slow Wave Index is determined by determining relative spectral power by examining only these three rhythms [15]. If the power spectral density of the delta band, theta band, and the alpha band is defined by \(\delta _P\), \(\theta _P\), and \(\alpha _P\) respectively, then their respective Slow Wave Indices can be designated as \(SW_\delta \), \(SW_\theta \), and \(SW_\alpha \) and represented as
3.4.2 Average band-power
The Fast Fourier Transform (FFT) is the most common method for decomposing the EEG signal into frequency components, and the magnitude-squared of the FFT is typically employed to calculate the power spectral density (periodogram). A wide range of analyses can be carried out using the power spectrum density, but this paper will focus on the average band power, which is a single number that summarises the contribution of the given frequency band to the overall signal power [19]. This could be especially beneficial in a machine-learning method, in which users frequently want to extract key data aspects and have a single number that represents a particular element of the data.
3.5 Principal component analysis (PCA)
Dimensionality reduction is a technique intended to solve the dimension issue. Dimensionality reduction approaches can only be employed to filter a small number of training-critical predictors; principal component analysis (PCA) comes into play here. PCA is a dimension reduction technique that identifies correlations and patterns in a data collection so that it can be turned into a significantly reduced data set without sacrificing crucial information. When a high correlation is discovered between distinct variables, a determination is made regarding the reduction of data sizes while preserving significant data [20]. This strategy is essential for addressing complex data-driven problems requiring massive data sets.
3.6 Cross validation
To assess a machine learning model’s performance and gauge its effectiveness, cross-validation is a prevalent technique in ML applications. It aids in comparing and selecting a suitable model for a certain predictive modeling issue. Cross-validation is a potent technique for identifying the optimal model for a particular task since it has a lower bias than other approaches used to calculate the model’s efficiency ratings [21]. Cross-validating a model can be accomplished through a variety of approaches. These strategies all share a common structure, which is outlined below:
-
Divide the data set into two sections: training and testing.
-
Establish the model using the training data.
-
Using a test set of data to assess the model’s accuracy.
-
Complete k iterations of steps 1–3.
This research employs a ‘stratified’ k-fold cross-validation strategy, which divides the data set into k folds such that each fold contains nearly the same proportion of samples from each target class [21].
3.7 Predictor selection
In many instances involving machine learning, the number of predictors that can be used to describe an input object may be exceedingly high. The majority of supervised learning does not perform well in these contexts due to a number of constraints, including high dimensionality (over-fitting), outliers, extended training times, etc. It is vital to utilize predictor selection strategies prior to training a model [22]. Moreover, adopting predictor selection strategies offers other benefits: minimizing the training error, less intricate and hence easier to understand, higher efficiency if the appropriate subset is selected, and decreased training time.
Relief algorithm and its variations are capable of discovering predictor dependencies in performance evaluation filter algorithms. Instead of searching through predictor combinations, these algorithms leverage the concept of closest neighbors to generate predictor statistics that implicitly account for connections. In addition, Relief Algorithms preserve the core properties of filter algorithms, i.e., they are reasonably quick and the derived predictors are independent of the induction process [23]. For these reasons, the Relief group of techniques is often applied as a predictor subset selection method in the preprocessing stage prior to learning a model. Relief strategies focus on the attribute’s capacity to distinguish between identical cases in the real world when measuring its quality. An algorithm 1 outlines the fundamental steps for implementing the Relief method for predictor selection.

An algorithm of Relief
The difference in predictor P value between two occurrences \(F_1\) and \(F_2\), where \(F_1=Z_n\) and \(F_2\) are either H or M, has been determined using the \(diff(P,{F_1},{F_2})\) operator to update the weights. The following equation represents this operator.
3.8 Support vector machine (SVM)
SVM belongs to the field of supervised learning and can be utilized to solve classification challenges. This method generates the optimal decision boundary to divide n-dimensional space into distinct classes in order to place novel data points in the correct class category. This boundary is known as the hyperplane. When creating the hyperplane, SVM finds the most extreme vectors possible. These points are known as support vectors [24]. The hyperplane can be represented by a single straight line if the dataset only contains two data attributes. There are two types of SVM: linear and non-linear. Linear SVM uses a straight line to make one decision out of two distinct groups for a new dataset. In a non-linear SVM with a high-dimensional feature space, data points are partitioned using non-linear boundaries. Non-linear SVM with Radial Basis Function (RBF), Polynomial, and Multilayer Perceptron (MLP) Kernels [25] is the focus of this paper.
4 Simulation results
An EEG recording of N subjects doing two distinct tasks, namely the N-Back task and the Oddball Task, has been acquired. Considering data on any given activity and extracting a subset for one channel, the retrieved data is further pre-processed and grouped into 1-second intervals. The sampling frequency of \(f_s\) Hz and the presence of M samples in a single channel suggest that T groups are represented by the integer expression \(M/f_s\). For each 1-second interval, a total of 14 predictors are extracted: 6 based on moments of the power spectrum, 3 slow wave indices, and 5 average band-power predictors. For a single channel of EEG data, the \(T*14=V\) predictors are formed by combining all of these predictors together for each 1-second group. Now, this procedure is done for each channel, and the predictors are concatenated; if there are C channels, the final predictor vector will include \(V*C=K\) columns for each individual. The final dimension of the predictor matrix will be \(N \times K\). The size of this predictor matrix can be regarded as quite huge in order to apply predictor selection. PCA has been applied to the data in order to shrink the size of data. The PCA algorithm is utilized in order to extract the top \((N -1) = 52\) features. This is possible due to the fact that N objects can be separated linearly into \((N-1)\) or a lower-dimensional feature space [26]. This reduced predictor set is sent to the k-fold cross-validation block, which divides it into 10 folds, 9 of which are utilized for training and 1 for testing. This research use 10-fold ‘stratified’ cross-validation to ensure that there is no class imbalance in any fold. The training set will be applied to the predictor selection block, which will determine the predictors that are most suitable.
The predictor importance of each feature can be estimated using the model’s feature importance attribute. Predictor importance assigns a value to each predictor, with a higher score indicating that the predictor is more important or relevant to the output variable. Predictor ranks are assigned based on the predictor score; these scores are computed using the Relief algorithm, which was discussed in a previous section. In this work, we examine the top 25 percent of predictors according to their score rankings. Figure 3 shows that the top 25% of predictors have significant score values; predictors with scores below that are not chosen since they are insignificant. Following selection, the predictor matrix is given to the SVM model, and the test set is reduced using the indices provided by the predictor selection block. SVM with non-linear kernels RBF Kernel (\(\sigma =1\)), Polynomial Kernel (\(Order=3\)), and MLP Kernel (\(k_1=0.1\) and \(k_2=-0.1\)) [27] are evaluated.

Predictive Score for the ReliefF Method during N-Back task
A comparison of accuracy for the N-Back task and Oddball task using three different kernels are shown in Table 1 while taking into account various scenarios, such as results without using PCA block, results using PCA block alone, and results using PCA block combined with Predictor Selection based on Relief method with \(k=10\). The N-Back task produces better results, as can be seen from Table 1. Table 2 compares the N-Back task, predictor selection using the ReliefF algorithm for various values of k, and SVM Recursive Feature Elimination (SVM-RFE).
5 Discussion
The dataset utilized in this study was sourced from the research conducted by the authors of [15]. In their work, the authors employed features obtained from a comprehensive feature extraction process, which included a selection of optimal features for classification. These features encompassed a range of statistical measures such as RSP features, mean, standard deviation, skewness, and kurtosis, as well as hjorth and AR parameters.
The classification results presented in this paper, involved the application of SVM and Bayes classifiers, demonstrating the effectiveness of their method in successfully distinguishing dyslexic children from healthy individuals. Notably, their study also explored the impact of electrode reduction on classification accuracy, achieving a classification accuracy rate of 70%.
When these findings are compared with the results of the proposed approach, an innovative approach was employed, involving the incorporation of novel predictors and predictor selection techniques. An average classification accuracy of 79.3% was attained through the proposed approach, which included the utilization of a 10-fold cross-validation methodology. This signifies a significant improvement when contrasted with the results reported in [15].
In [28, 29], the authors employed the Wavelet Scattering Transform and ensemble learning, respectively. While they achieved higher accuracy compared to our findings, it’s important to note that our approach is exclusively feature extraction-based. There are several advantages to feature extraction approaches over methods like the Wavelet Scattering Transform [30]:
-
Interpretability: Feature extraction methods are inherently more interpretable compared to the complex transformations involved in the Wavelet Scattering Transform and ensemble learning-based approaches. This means it is easier to discern which specific features are being learned and how they contribute to the model’s decision-making process. This interpretability is invaluable for debugging and gaining insights into the model’s behavior [31].
-
Flexibility: Feature extraction approaches offer versatility in handling various data types, such as images, text, and audio. In contrast, Wavelet Scattering Transform-based methods are primarily designed for image classification tasks. Therefore, feature extraction is a more adaptable choice when dealing with diverse data sources [32].
-
Efficiency: Feature extraction methods tend to be more efficient, particularly when working with limited datasets or in scenarios demanding real-time performance. The efficiency stems from the fact that feature extraction models typically have fewer parameters, making them quicker to train and less computationally demanding. This is especially advantageous when working with hardware that may not be as powerful [33].
In summary, feature extraction approach offers advantages in terms of interpretability, flexibility across different data types, and efficiency, making it a suitable choice for specific applications and use cases.
6 Conclusion and future scope
In this work, an EEG-based method for detecting dyslexia in early childhood has been provided. In addition to standard predictors such as slow-wave indices and average band power, novel predictors based on power spectrum moments have been extracted. In order to reduce the computational burden of the predictor selection block, the predictors are passed through the PCA block to reduce their dimensionality. Following the PCA block, features are grouped into folds using a ‘stratified’ k-Fold cross-validation method. Predictor selection has only been applied to training folds with the Relief method. On the basis of indices provided by the predictor selection step, the testing fold is reduced. To illustrate the influence of each block, accuracy results without PCA and predictor selection are provided. Accuracy values with only the PCA block are provided to demonstrate the significance of using the Prediction Selection block. A cubic polynomial kernel and relief-based predictor selection for nearest neighbors \(k=5\) were used to achieve an average classification accuracy of 79.3%. This accuracy was attained while students were doing the N-Back task. This is an improvement over the results of the peer group, which achieved a maximum accuracy of 72%. Other predictor selection approaches, such as SVM-RFE, and the relief algorithm’s results are also examined for various k values. The use of predictor selection improves the accuracy and speed of the dyslexia detection system. Observations show that doing the N-Back task instead of Oddball produces superior outcomes in this study’s testing conditions.
In the future, a novelty at the predictor level, as well as alternative approaches to predictor selection, can be studied to increase accuracy. Results can be enhanced by emphasizing other mental activities during which EEG can be recorded.
Data availability
The dataset employed in this research has been sourced with due permission from the authors of the research paper referenced as [15]. Researchers seeking access to this dataset for further investigations are kindly advised to establish direct contact with the aforementioned authors.
References
Dyslexia YCF. Creativity: Dyslexia FAQ. https://dyslexia.yale.edu/dyslexia/dyslexia-faq/. Accessed 21 Oct 2022.
Maunsell M. Dyslexia in a global context: a cross-linguistic, cross-cultural perspective. Latin Am J Content Lang Integr Learn. 2020;13:92–113. https://doi.org/10.5294/laclil.2020.13.1.6.
Yan Z, Zhou J, Wong W-F. Eeg classification with spiking neural network: smaller, better, more energy efficient. Smart Health. 2022;24: 100261. https://doi.org/10.1016/j.smhl.2021.100261.
Usman OL, Muniyandi RC, Omar K, Mohamad M. Advance machine learning methods for dyslexia biomarker detection: a review of implementation details and challenges. IEEE Access. 2021;9:36879–97. https://doi.org/10.1109/ACCESS.2021.3062709.
Abu-Hamour B, Hmouz HA, Mattar J, Muhaidat M. The use of Woodcock–Johnson tests for identifying students with special needs-a comprehensive literature review. Proc Soc Behav Sci. 2012;47:665–73. https://doi.org/10.1016/j.sbspro.2012.06.714.
Dickens RH, Meisinger EB, Tarar JM. Test review: comprehensive test of phonological processing—2nd ed. (CTOPP-2) by Wagner, R. K., Torgesen, J. K., Rashotte, C. A., and Pearson, N. A. Can J School Psychol. 2015;30(2):155–62. https://doi.org/10.1177/0829573514563280.
Bell N, Lassiter K, Matthews T, Hutchinson M. Comparison of the peabody picture vocabulary test-third edition. J Clin Psychol. 2001;57:417–22. https://doi.org/10.1002/jclp.1024.
Al-Barhamtoshy HM, Motaweh DM. Diagnosis of dyslexia using computation analysis. In: 2017 International Conference on Informatics, Health & Technology (ICIHT), pp. 1–7 (2017). https://doi.org/10.1109/ICIHT.2017.7899141.
Perera H, Shiratuddin MF, Wong KW, Fullarton K. Eeg signal analysis of passage reading and rapid automatized naming between adults with dyslexia and normal controls. In: 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), pp. 104–108 (2017). https://doi.org/10.1109/ICSESS.2017.8342874.
Frid A, Manevitz LM. Design and selection of features under erp for correlating and classifying between brain areas and dyslexia via machine learning. In: 2020 International Joint Conference on Neural Networks (IJCNN), pp. 1–8; 2020. https://doi.org/10.1109/IJCNN48605.2020.9207715.
Perera P, Harshani H, Shiratuddin MF, Wong KW, Fullarton K. Eeg signal analysis of writing and typing between adults with dyslexia and normal controls. 2018.
Spoon K, Crandall DJ, Siek K. Towards detecting dyslexia in children’s handwriting using neural networks. 2019.
Kheyrkhah R, Setarehdan S. The effective brain areas in recognition of dyslexia. Int Clin Neurosci J. 2020;7:147–52. https://doi.org/10.34172/icnj.2020.16.
Perera H, Shiratuddin MF, Wong KW, Fullarton K. EEG signal analysis of real-word reading and nonsense-word reading between adults with dyslexia and without dyslexia. In: 2017 IEEE 30th International Symposium on Computer-Based Medical Systems (CBMS), pp. 73–78; 2017. https://doi.org/10.1109/CBMS.2017.108.
Kheyrkhah Shali R, Setarehdan SK. The impact of electrode reduction in the diagnosis of dyslexia. In: 2020 27th National and 5th International Iranian Conference on Biomedical Engineering (ICBME), pp. 118–125; 2020. https://doi.org/10.1109/ICBME51989.2020.9319431.
Rejer I, Górski P. Benefits of ica in the case of a few channel eeg. Annu Int Conf IEEE Eng Med Biol Soc. 2015;2015:7434–7. https://doi.org/10.1109/EMBC.2015.7320110.
Hjorth B. Eeg analysis based on time domain properties. Electroencephalogr Clin Neurophysiol. 1970;29(3):306–10. https://doi.org/10.1016/0013-4694(70)90143-4.
Al-Timemy A, Khushaba R, Bugmann G, Escudero J. Improving the performance against force variation of emg controlled multifunctional upper-limb prostheses for transradial amputees. IEEE Trans Neural Syst Rehabil Eng. 2016;24(6):650–61. https://doi.org/10.1109/TNSRE.2015.2445634.
Vallat R. Bandpower of an EEG signal. https://raphaelvallat.com/bandpower.html. Accessed 21 Oct 2022.
Edureka: principal component analysis tutorial for beginners in Python. https://www.edureka.co/blog/principal-component-analysis/. Accessed 21 Oct 2022.
Lyashenko V. Cross-validation in machine learning: how to do it right. 2020. https://neptune.ai/blog/cross-validation-in-machine-learning-how-to-do-it-right. Accessed 26 Jul 2022.
Urbanowicz RJ, Meeker M, La Cava W, Olson RS, Moore JH. Relief-based feature selection: introduction and review. J Biomed Informat. 2018;85:189–203. https://doi.org/10.1016/j.jbi.2018.07.014.
Dagli Y. Feature selection using Relief algorithms with python example. 2019. https://medium.com/@yashdagli98/feature-selection-using-relief-algorithms-with-python-example-3c2006e18f83 Accessed 26 Jul 2022.
Tiwari H. 6-Early prediction of heart disease using deep learning approach. In: Gupta D, Kose U, Khanna A, Balas VE, editors. Deep learning for medical applications with unique data, pp. 107–122. Academic Press, 2022. https://doi.org/10.1016/B978-0-12-824145-5.00014-9. https://www.sciencedirect.com/science/article/pii/B9780128241455000149.
Parmar SK, Ramwala OA, Paunwala CN. Performance evaluation of svm with non-linear kernels for eeg-based dyslexia detection. In: 2021 IEEE 9th Region 10 Humanitarian Technology Conference (R10-HTC), pp. 1–6. 2021. https://doi.org/10.1109/R10-HTC53172.2021.9641696.
Bobrowski L, Lukaszuk T. Selection of the linearly separable feature subsets. In: Rutkowski L, Siekmann JH, Tadeusiewicz R, Zadeh LA, editors. Artificial intelligence and soft computing—ICAISC 2004. Berlin, Heidelberg: Springer; 2004. p. 544–9.
Vora A, Paunwala CN, Paunwala M. Statistical analysis of various kernel parameters on svm based multimodal fusion. In: 2014 Annual IEEE India Conference (INDICON), pp. 1–5; 2014. https://doi.org/10.1109/INDICON.2014.7030414.
Parmar S, Paunwala C. A novel and efficient wavelet scattering transform approach for primitive-stage dyslexia-detection using electroencephalogram signals. Healthc Anal. 2023;3: 100194. https://doi.org/10.1016/j.health.2023.100194.
Zaree M, Mohebbi M, Rostami R. An ensemble-based machine learning technique for dyslexia detection during a visual continuous performance task. Biomed Signal Process Control. 2023;86: 105224. https://doi.org/10.1016/j.bspc.2023.105224.
Ono Y, Mitani Y. Evaluation of feature extraction methods with ensemble learning for breast cancer classification. In: 2022 IEEE 4th Global Conference on Life Sciences and Technologies (LifeTech), pp. 194–195; 2022. https://doi.org/10.1109/LifeTech53646.2022.9754789.
Yousefnezhad M, Hamidzadeh J, Aliannejadi M. Ensemble classification for intrusion detection via feature extraction based on deep learning. Soft Comput. 2021;25(20):12667–83. https://doi.org/10.1007/s00500-021-06067-8.
Parashivamurthy SPT, Rajashekararadhya SV. Recognition of Kannada character scripts using hybrid feature extraction and ensemble learning approaches. Cybernet Syst. 2023;1–36. https://doi.org/10.1080/01969722.2023.2175145.
Ren W, Han M. Classification of eeg signals using hybrid feature extraction and ensemble extreme learning machine. Neural Process Lett. 2019;50(2):1281–301. https://doi.org/10.1007/s11063-018-9919-0.
Acknowledgements
We are thankful to IEEE SPS- HAC for funding to establish an Early-Detection Dyslexia System for children aged 8 to 10.
Author information
Authors and Affiliations
Contributions
The authors of this work, SP and CP, have contributed equally to the research and preparation of this manuscript. Both authors were involved in the conception and design of the study, as well as the interpretation of the results. Additionally, they collaborated on the drafting and critical revision of the manuscript, ensuring its accuracy and scientific rigor. The division of work between the two authors was balanced, and their joint effort has significantly contributed to the quality and completeness of this work.
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that they have no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Parmar, S., Paunwala, C. Early detection of dyslexia based on EEG with novel predictor extraction and selection. Discov Artif Intell 3, 33 (2023). https://doi.org/10.1007/s44163-023-00082-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44163-023-00082-4