
Abstract
Nonlinear partial differential equations (PDEs) are used to model dynamical processes in a large number of scientific fields, ranging from finance to biology. In many applications standard local models are not sufficient to accurately account for certain non-local phenomena such as, e.g., interactions at a distance. Non-local nonlinear PDE models can accurately capture these phenomena, but traditional numerical approximation methods are infeasible when the considered non-local PDE is high-dimensional. In this article we propose two numerical methods based on machine learning and on Picard iterations, respectively, to approximately solve non-local nonlinear PDEs. The proposed machine learning-based method is an extended variant of a deep learning-based splitting-up type approximation method previously introduced in the literature and utilizes neural networks to provide approximate solutions on a subset of the spatial domain of the solution. The Picard iterations-based method is an extended variant of the so-called full history recursive multilevel Picard approximation scheme previously introduced in the literature and provides an approximate solution for a single point of the domain. Both methods are mesh-free and allow non-local nonlinear PDEs with Neumann boundary conditions to be solved in high dimensions. In the two methods, the numerical difficulties arising due to the dimensionality of the PDEs are avoided by (i) using the correspondence between the expected trajectory of reflected stochastic processes and the solution of PDEs (given by the Feynman–Kac formula) and by (ii) using a plain vanilla Monte Carlo integration to handle the non-local term. We evaluate the performance of the two methods on five different PDEs arising in physics and biology. In all cases, the methods yield good results in up to 10 dimensions with short run times. Our work extends recently developed methods to overcome the curse of dimensionality in solving PDEs.
Similar content being viewed by others


1 Introduction
In this article, we derive numerical schemes to approximately solve high-dimensional non-local nonlinear partial differential equations (PDEs) with Neumann boundary conditions. Such PDEs have been used to describe a variety of processes in physics, engineering, finance, and biology, but can generally not be solved analytically, requiring numerical methods to provide approximate solutions. However, traditional numerical methods are for the most part computationally infeasible for high-dimensional problems, calling for the development of novel approximation methods.
The need for solving non-local nonlinear PDEs has been expressed in various fields as they provide a more general description of the dynamical systems than their local counterparts [1,2,3]. In physics and engineering, non-local nonlinear PDEs are found, e.g., in models of Ohmic heating production [4], in the investigation of the fully turbulent behavior of real flows [5], in phase field models allowing non-local interactions [6,7,8,9], or in phase transition models with conservation of mass [10, 11]; see [1] for further references. In finance, non-local PDEs are used, e.g., in jump-diffusion models for the pricing of derivatives where the dynamics of stock prices are described by stochastic processes experiencing large jumps [3, 12,13,14,15,16,17,18]. Penalty methods for pricing American put options such as in Kou’s jump-diffusion model [19, 20], considering large investors where the agent policy affects the assets prices [15, 21], or considering default risks [22, 23] can further introduce nonlinear terms in non-local PDEs. In economics, non-local nonlinear PDEs appear, e.g., in evolutionary game theory with the so-called replicator-mutator equation capturing continuous strategy spaces [24,25,26,27,28] or in growth models where consumption is non-local [29]. In biology, non-local nonlinear PDEs are used, e.g., to model processes determining the interaction and evolution of organisms. Examples include models of morphogenesis and cancer evolution [30,31,32], models of gene regulatory networks [33], population genetics models with the non-local Fisher–Kolmogorov–Petrovsky–Piskunov (Fisher–KPP) equations [34,35,36,37,38,39,40], and quantitative genetics models where populations are structured on a phenotypic and/or a geographical space [41,42,43,44,45,46,47,48]. In such models, Neumann boundary conditions are used, e.g., to model the effect of the borders of the geographical domain on the movement of the organisms.
Real world systems such as those just mentioned may be of considerable complexity and accurately capturing the dynamics of these systems may require models of high dimensionality [47], leading to complications in obtaining numerical approximations. For example, the number of dimensions of the PDEs may correspond in finance to the number of financial assets (such as stocks, commodities, exchange rates, and interest rates) in the involved portfolio; in evolutionary dynamics, to the dimension of the strategy space; and in biology, to the number of genes modelled [33] or to the dimension of the geographical or the phenotypic space over which the organisms are structured. Standard approximation methods for PDEs such as finite difference approximation methods, finite element methods, spectral Galerkin approximation methods, and sparse grid approximation methods all suffer from the so called curse of dimensionality [49], meaning that their computational costs increase exponentially in the number of dimensions of the PDE under consideration.
Numerical methods exploiting stochastic representations of the solutions of PDEs can in some cases overcome the curse of dimensionality. Specifically, simple Monte Carlo averages of the associated stochastic processes have been proposed a long time ago to solve high-dimensional linear PDEs, such as, e.g., Black–Scholes and Kolmogorov PDEs [50, 51]. Recently, two novel classes of methods have proved successful in dealing with high-dimensional nonlinear PDEs, namely deep learning-based and full history recursive multilevel Picard approximation methods (in the following we will abbreviate full history recursive multilevel Picard by MLP). The explosive success of deep learning in recent years across a wide range of applications [52] has inspired a variety of neural network-based approximation methods for high-dimensional PDEs; see [53,54,55,56,57,58,59] for a survey of this field of research. One class of such methods is based on reformulating the PDE as a stochastic learning problem through suitable Feynman–Kac formulas, cf., e.g., [60,61,62,63,64,65]. In particular, the deep splitting scheme introduced in [65] relies on splitting the differential operator into a linear part (which is reformulated using a suitable Feynman–Kac formula) and a nonlinear part and in that sense belongs to the class of splitting-up methods [66,67,68]. The PDE approximation problem is then decomposed along the time axis into a sequence of separate learning problems. The deep splitting approximation scheme has proved capable of computing reasonable approximations to the solutions of nonlinear PDEs in up to 10000 dimensions. On the other hand, the MLP approximation method, introduced in [69,70,71], utilizes the Feynman–Kac formula to reformulate the PDE problem as a fixed point equation. It further reduces the complexity of the numerical approximation of the time integral through a multilevel Monte Carlo approach. However, neither the deep splitting nor the MLP method can, until now, account for non-localness and Neumann boundary conditions.
The goal of this article is to overcome these limitations and thus we generalize the deep splitting method and the MLP approximation method to approximately solve non-local nonlinear PDEs with Neumann boundary conditions. We handle the non-local term by a plain vanilla Monte Carlo integration and address Neumann boundary conditions by constructing reflected stochastic processes. While the MLP method can, in one run, only provide an approximate solution at a single point \(x \in D\) of the spatial domain \(D\subseteq \mathbb {R}^d\) where \(d\in \mathbb {N}=\{1,2,\dots \}\), the machine learning-based method can in principle provide an approximate solution on a full subset of the spatial domain D (however, cf., e.g., [72,73,74] for results on limitations on the performance of such approximation schemes). We use both methods to solve five non-local nonlinear PDEs arising in models from biology and physics and cross-validate the results of the simulations. We manage to solve the non-local nonlinear PDEs with reasonable accuracy in up to 10 dimensions.
For an account of classical numerical methods for solving non-local PDEs, such as finite differences, finite elements, and spectral methods, we refer the reader to the recent survey [2]. Several machine-learning based schemes for solving non-local PDEs can also be found in the literature. In particular, the physics-informed neural network and deep Galerkin approaches [75, 76], based on representing an approximation of the whole solution of the PDE as a neural network and using automatic differentiation to do a least-squares minimization of the residual of the PDE, have been extended to fractional PDEs and other non-local PDEs [77,78,79,80,81]. While some of these approaches use classical methods susceptible to the curse of dimensionality for the non-local part [77, 78], mesh-free methods suitable for high-dimensional problems have also been investigated [79,80,81].
The literature also contains approaches that are more closely related to the machine learning-based algorithm presented here. Frey and Köck [82, 83] propose an approximation method for non-local semilinear parabolic PDEs with Dirichlet boundary conditions based on and extending the deep splitting method in [65] and carry out numerical simulations for example PDEs in up to 4 dimensions. Castro [84] proposes a numerical scheme for approximately solving non-local nonlinear PDEs based on [64] and proves convergence results for this scheme. Finally, Gonon and Schwab [85] provide theoretical results showing that neural networks with ReLU activation functions have sufficient expressive power to approximate solutions of certain high-dimensional non-local linear PDEs without the curse of dimensionality.
There is a more extensive literature on machine learning-based methods for approximately solving standard PDEs without non-local terms but with various boundary conditions, going back to early works by Lagaris et al. [86, 87] (see also [88]), which employed a grid-based method based on least-squares minimization of the residual and shallow neural networks to solve low-dimensional ODEs and PDEs with Dirichlet, Neumann, and mixed boundary conditions. More recently, approximation methods for PDEs with Neumann (and other) boundary conditions have been proposed using, e.g., physics-informed neural networks [78, 89, 90], the deep Ritz method (based on a variational formulation of certain elliptic PDEs) [91,92,93], or adversarial networks [94].
The remainder of this article is organized as follows. Section 2 discusses a special case of the proposed machine learning-based method, in order to provide a readily comprehensible exposition of the key ideas of the method. Section 3 discusses the general case, which is flexible enough to cover a larger class of PDEs and to allow more sophisticated optimization methods. Section 4 presents our extension of the MLP approximation method to non-local nonlinear PDEs, which we use to obtain reference solutions in Sect. 5. Section 5 provides numerical simulations for five concrete examples of (non-local) nonlinear PDEs.
2 Machine learning-based approximation method in a special case
In this section, we present in Framework 2.11 in Sect. 2.3 below a simplified version of our general machine learning-based algorithm for approximating solutions of non-local nonlinear PDEs with Neumann boundary conditions proposed in Sect. 3 below. This simplified version applies to a smaller class of non-local heat PDEs, specified in Sect. 2.1 below. In Sect. 2.10 we present some elementary results related to the reflection of straight lines on the boundaries of a suitable subset \(D\subseteq \mathbb {R}^d\) where \(d\in \mathbb {N}\). These serve to elucidate and justify the notations introduced in Framework 2.10 which in turn will be used to describe time-discrete reflected stochastic processes that are employed in our approximations throughout the rest of the article. The simplified algorithm described in Sect. 2.3 below is limited to using neural networks of a particular architecture that are trained using plain vanilla stochastic gradient descent, whereas the full version proposed in Framework 3.1 in Sect. 3.2 below is formulated in such a way that it encompasses a wide array of neural network architectures and more sophisticated training methods, in particular Adam optimization, minibatches, and batch normalization. Stripping away some of these more intricate aspects of the full algorithm is intended to exhibit more acutely the central ideas in the proposed approximation method.
The simplified algorithm described in this section as well as the more general version proposed in Framework 3.1 in Sect. 3.2 below are based on the deep splitting method introduced in Beck et al. [65], which combines operator splitting with a previous deep learning-based approximation method for Kolmogorov PDEs [62]; see also Beck et al. [53, Sections 2 and 3] for an exposition of these methods.
2.1 Partial differential equations (PDEs) under consideration
Let \( T \in (0,\infty ) \), \( d \in \mathbb {N}\), let \(D\subseteq \mathbb {R}^d\) be a sufficiently regular closed set, letFootnote 1\( \textbf{n} :\partial _D\rightarrow \mathbb {R}^d \) be a suitable outer unit normal vector field associated to \(D\), let \(g\in C(D, \mathbb {R})\), let \(\nu _x :\mathcal {B}(D) \rightarrow [0,1]\), \(x \in D\), be probability measures, let \(f :\mathbb {R}\times \mathbb {R}\rightarrow \mathbb {R}\) be measurable, let \(u=(u(t,x))_{(t,x)\in [0,T]\times D}\in C^{1,2}([0,T]\times D,\mathbb {R})\) have at most polynomially growing partial derivatives, assumeFootnote 2 for every \(t\in (0,T]\), \(x\in \partial _D\) that \(\langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\), and assume for every \(t\in [0,T]\), \(x\in D\) that \(u(0,x)=g(x)\), \(\int _D|{f(u(t,x),u(t,\textbf{x})) } | \, \nu _x(\textrm{d}\textbf{x}) < \infty \), and
Our goal in this section is to approximately calculate under suitable hypotheses the solution \(u:[0,T]\times D\rightarrow \mathbb {R}\) of the PDE in (1).
2.2 Reflection principle for the simulation of time discrete reflected processes
Lemma 2.1
Let \(d\in \mathbb {N}\), let \(D\subseteq \mathbb {R}^d\), let \(x,y,\mathfrak {c}\in \mathbb {R}^d\) satisfy
and assume \(\mathfrak {c}\notin \{x,y\}\). Then \(\mathfrak {c}\in \partial _D\).
Proof of Lemma 2.1
Throughout this proof let \(t\in [0,1]\) satisfy
Observe that (2) and (3) imply that
This and the assumption that \(\mathfrak {c}\notin \{x,y\}\) show that
Combining this with (3) ensures that for every \(s\in [0,t)\) it holds that
Next observe that (3) and (5) imply that for every \(\varepsilon \in (0,\infty )\) there exists \(s\in [t,t+\varepsilon )\) such that
Combining this with (4), (5) and (6) shows that \(\mathfrak {c}\in \partial _D\). The proof of Lemma 2.1 is thus complete. \(\square \)
Lemma 2.2
Let \(d\in \mathbb {N}\), \(x,n\in \mathbb {R}^d\) and assume \(\Vert {n} \Vert =1\). Then
-
(i)
it holds that \(\Vert {n-x} \Vert = \Vert {n+x-2\langle {x,n} \rangle n} \Vert \) and
-
(ii)
it holds that \(\Vert {x-2\langle {x,n} \rangle n} \Vert =\Vert {x} \Vert \).
Proof of Lemma 2.2
Throughout this proof let \(y\in \mathbb {R}^d\) satisfy
Observe that the assumption that \(\Vert {n} \Vert =1\) implies that
This ensures that for every \(a,b\in \mathbb {R}\) it holds that
Hence, we obtain that
This proves item (i). Next note that (10) implies that
This demonstrates item (ii). The proof of Lemma 2.2 is thus complete. \(\square \)
Lemma 2.3
Let \(d\in \mathbb {N}\), let \(D\subseteq \mathbb {R}^d\) be a closed set, let \(\mathfrak {c}:(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(\textbf{n}:\partial _D\rightarrow \{x\in \mathbb {R}^d:\Vert {x} \Vert =1\}\) and \(\mathscr {R}:(\mathbb {R}^d)^2\rightarrow (\mathbb {R}^d)^2\) satisfy for every \(x,y\in \mathbb {R}^d\) that
and let \(x_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0=\mathbb {N}\cup \{0\}\), and \(y_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), satisfy for every \(n\in \mathbb {N}\) that
(cf. Lemma 2.1). Then
-
(i)
it holds for every \(n\in \mathbb {N}\) that \( x_n = \mathfrak {c}(x_{n-1},y_{n-1}) \),
-
(ii)
it holds for every \(n,k\in \mathbb {N}_0\) with \(x_n\in D\) that \(x_{n+k}\in D\),
-
(iii)
it holds for every \(n,k\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\in \{x_{n-1},y_{n-1}\}\) that \( (x_{n+k},y_{n+k}) = (x_n,y_n) \),
-
(iv)
it holds for every \(n\in \mathbb {N}\) that \( \Vert {x_n-y_{n-1}} \Vert = \Vert {x_n-y_n} \Vert \),
-
(v)
it holds that
$$\begin{aligned} \sum _{i=0}^\infty \Vert {x_i - x_{i+1}} \Vert \le \Vert {x_0 - y_0} \Vert . \end{aligned}$$(16)
Proof of Lemma 2.3
First, observe that (14) and (15) imply item (i). Moreover, note that (13) ensures that for every \(v,w\in \mathbb {R}^d\) with \(v\ne w\) and \(\mathfrak {c}(v,w)=w\) it holds that
The assumption that D is a closed set hence shows that for every \(v,w\in \mathbb {R}^d\) with \(v\ne w\) and \(\mathfrak {c}(v,w)=w\) it holds that \( w \in D \). Combining this and the fact that for every \(v\in \mathbb {R}^d\) it holds that \(\mathfrak {c}(v,v)=v\) with Lemma 2.1 and the assumption that D is a closed set proves that for every \(v\in D\), \(w\in \mathbb {R}^d\) it holds that
Item (i) and induction hence establish item (ii). Next observe that (14) and (15) imply that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1}) = x_{n-1}\) it holds that
Induction therefore ensures that for every \(n\in \mathbb {N}\), \(k\in \mathbb {N}_0\) with \(\mathfrak {c}(x_{n-1},y_{n-1}) = x_{n-1}\) it holds that
In addition, note that (14) and (15) show that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1}) = y_{n-1}\) it holds that
Hence, we obtain that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1}) = y_{n-1}\) it holds that
This and (20) demonstrate that for every \(n,k\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1}) = y_{n-1}\) it holds that
Combining this with (20) establishes item (iii). In the next step we observe that (14) and (15) ensure that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\in \{x_{n-1},y_{n-1}\}\) it holds that \(y_n = y_{n-1}\). Therefore, we obtain that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\in \{x_{n-1},y_{n-1}\}\) it holds that
Next note that Lemma 2.1, item (ii) in Lemma 2.2 (applied for every \(v\in \mathbb {R}^d\), \(w\in \{u\in \mathbb {R}^d:\mathfrak {c}(v,u)\notin \{v,u\}\}\) with \(d\curvearrowleft d\), \(x\curvearrowleft w-\mathfrak {c}(v,w)\), \(n\curvearrowleft \textbf{n}(\mathfrak {c}(v,w))\) in the notation of Lemma 2.2), and (14) show that for every \(v,w,u,z\in \mathbb {R}^d\) with \(\mathfrak {c}(v,w)\notin \{v,w\}\) and \((u,z) = \mathscr {R}(v,w)\) it holds that
This, item (i), and (15) prove that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
Combining this with (24) establishes item (iv). Moreover, observe that item (i) and (13) ensure that for every \(n\in \mathbb {N}\) there exists \(t\in [0,1]\) such that \(x_n=x_{n-1}+t(y_{n-1}-x_{n-1})\). This and item (iv) show that for every \(n\in \mathbb {N}\) there exists \(t\in [0,1]\) such that
Combining this with induction proves that for every \(n\in \mathbb {N}\) it holds that
This implies item (v). The proof of Lemma 2.3 is thus complete. \(\square \)
Proposition 2.4
Let \(d\in \mathbb {N}\), let \(\mathfrak {c}:(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(\mathscr {R}:(\mathbb {R}^{ d })^2 \rightarrow ( \mathbb {R}^{ d })^2 \) satisfy for every \(x,y \in \mathbb {R}^d\) that
and let \(x_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), and \(y_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), satisfy for every \(n\in \mathbb {N}\) that
Then there exists \(N\in \mathbb {N}_0\) such that for every \(n\in \mathbb {N}_0\cap [N,\infty )\) it holds that
Proof of Proposition 2.4
Throughout this proof let \(t_n\in [0,1]\), \(n\in \mathbb {N}_0\), satisfy for every \(n\in \mathbb {N}_0\) that
Note that Lemma 2.1 (applied for every \(n\in \{m\in \mathbb {N}:\mathfrak {c}(x_{m-1},y_{m-1})\notin \{x_{m-1},y_{m-1}\}\}\) with \(d\curvearrowleft d\), \(D\curvearrowleft \{x\in \mathbb {R}^d:\Vert {x} \Vert \le 1\}\), \(x\curvearrowleft x_{n-1}\), \(y\curvearrowleft y_{n-1}\), \(\mathfrak {c}\curvearrowleft \mathfrak {c}(x_{n-1},y_{n-1})\) in the notation of Lemma 2.1) implies that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
Next observe that item (i) in Lemma 2.1, (29), and (33) show that for every \(n\in \mathbb {N}\) it holds that
This and (30) ensure that for every \(n\in \mathbb {N}\), \(t\in \mathbb {R}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
Combining this, (34), and (35) with item (i) in Lemma 2.2 (applied for every \(t\in \mathbb {R}\), \(n\in \{m\in \mathbb {N}:\mathfrak {c}(x_{m-1},y_{m-1})\notin \{x_{m-1},y_{m-1}\}\}\) with \(d\curvearrowleft d\), \(x\curvearrowleft t(y_{n-1}-x_{n})\), \(n\curvearrowleft x_{n}\) in the notation of Lemma 2.2) establishes that for every \(n\in \mathbb {N}\), \(t\in \mathbb {R}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
In the next step we note that (33) implies that for every \(n\in \mathbb {N}_0\), \(t\in [0,t_n]\) with \(t_n>0\) it holds that
The fact that for every \(s\in [0,1)\), \(t\in [0,\tfrac{s}{1-s}]\) it holds that \(s-t(1-s)\in [0,s]\) and (35) hence ensure that for every \(n\in \mathbb {N}\), \(t\in [0,1]\) with \(t_{n-1}\in (0,1)\) and \(t\le \tfrac{t_{n-1}}{1-t_{n-1}}\) it holds that
Combining this with (37) shows that for every \(n\in \mathbb {N}\), \(t\in [0,1]\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) and \(t\le \tfrac{t_{n-1}}{1-t_{n-1}}\) it holds that
Hence, we obtain that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
Furthermore, note that (35) implies that for every \(n\in \mathbb {N}_0\) with \(\mathfrak {c}(x_{n},y_{n})\notin \{x_{n},y_{n}\}\) it holds that
Item (iv) in Lemma 2.3, (35), and (41) therefore establish that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) and \(\mathfrak {c}(x_{n},y_{n})\notin \{x_{n},y_{n}\}\) it holds that
Moreover, observe that (42) ensures that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
Combining this and (43) with item (v) in Lemma 2.3 demonstrates that there exists \(n\in \mathbb {N}_0\) such that \(\mathfrak {c}(x_n,y_n)\in \{x_n,y_n\}\). Combining this with item (iii) in Lemma 2.3 establishes that there exists \(N\in \mathbb {N}_0\) such that for every \(n\in \mathbb {N}_0\cap [N,\infty )\) it holds that
The proof of Proposition 2.4 is thus complete. \(\square \)
Lemma 2.5
Let \(d\in \mathbb {N}\), for every \(k\in \{1,2,\dots ,d\}\) let \(\mathfrak {a}_k^0\in \mathbb {R}\), \(\mathfrak {a}_k^1\in (\mathfrak {a}_k^0,\infty )\), let \(D=[\mathfrak {a}_1^0,\mathfrak {a}_1^1]\times [\mathfrak {a}_2^0,\mathfrak {a}_2^1]\times \cdots \times [\mathfrak {a}_d^0,\mathfrak {a}_d^1]\subseteq \mathbb {R}^d\), let \(e_1=(1,0,0,\dots ,0)\), \(e_2=(0,1,0,\dots ,0)\), \(\dots \), \(e_d=(0,\dots ,0,0,1)\in \mathbb {R}^d\), let \(\textbf{n}:\partial _D\rightarrow \mathbb {R}^d\) satisfy for every \(x=(x_1,\dots ,x_d)\in \partial _D\), \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:x_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) that
let \(\mathfrak {c}:(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(\mathscr {R}:(\mathbb {R}^d)^2\rightarrow (\mathbb {R}^d)^2\) satisfy for every \(x,y\in \mathbb {R}^d\) that
for every \(a\in \mathbb {R}\), \(b\in (a,\infty )\) let \(r_{a,b}:\mathbb {R}\rightarrow \mathbb {Z}\) satisfy for every \(x\in (-\infty ,a)\), \(y\in (b,\infty )\) that
let \(\mathfrak {r}:\mathbb {R}^d\rightarrow \mathbb {N}_0\) satisfy for every \(x=(x_1,\dots ,x_d)\in \mathbb {R}^d\) that
and let \(u\in \mathbb {R}^d\), \(x=(x_1,\dots ,x_d),\,y=(y_1,\dots ,y_d),\,c=(c_1,\dots ,c_d),\,v=(v_1,\dots ,v_d)\in \mathbb {R}^d\) satisfy \(c=\mathfrak {c}(x,y)\notin \{x,y\}\) (cf. Lemma 2.1). Then
-
(i)
it holds that \( c\in \partial _D=\{z=(z_1,\dots ,z_d)\in D:(\exists \,k\in \{1,2,\dots ,d\}:z_k\in \{\mathfrak {a}_k^0,\mathfrak {a}_k^1\})\} \),
-
(ii)
it holds for every \(i,k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) that
$$\begin{aligned} v_i = {\left\{ \begin{array}{ll} y_i &{} :i\ne k\\ 2c_k-y_k &{}:i=k, \end{array}\right. } \end{aligned}$$(51) -
(iii)
it holds that
$$\begin{aligned} \mathfrak {c}(u,v) = u \qquad \text {or}\qquad \mathfrak {r}(v)<\mathfrak {r}(y) , \end{aligned}$$(52)and
-
(iv)
it holds for every \(k\in \{1,2,\dots ,d\}\) with \(\{k\} = \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) that
$$\begin{aligned} x_k\ne y_k ,\qquad \mathfrak {c}(u,v) \ne u ,\qquad \text {and}\qquad \mathfrak {r}(v)<\mathfrak {r}(y) . \end{aligned}$$(53)
Proof of Lemma 2.5
Throughout this proof let \(t\in [0,1]\) satisfy
Note that Lemma 2.1 and the assumption that \(c\notin \{x,y\}\) imply item (i). Next observe that (46) ensures that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_k^0,\mathfrak {a}_k^1\}\}\) it holds that
This, (48), and the assumption that \(c\notin \{x,y\}\) show that for every \(i,k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) it holds that
Hence, we obtain item (ii). Next note that (47) implies that for every \(k\in \{1,2,\dots ,d\}\) with \(x_k=y_k\) it holds that \(x_k=c_k=y_k \). Item (ii) therefore demonstrates that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) and \(x_k=y_k\) it holds that
Moreover, observe that the assumption that \(c=\mathfrak {c}(x,y)\notin \{x,y\}\), (47), and (54) ensure that
The fact that \(D\subseteq \mathbb {R}^d\) is a closed, convex set, (54), and the assumption that \(c\ne y\) hence proves that for every \(s\in (t,1]\) it holds that
In addition, note that (48) implies that
This, (57), (58), and (59) show that for every \(k\in \{1,2,\dots ,d\}\), \(s\in (0,1]\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) and \(x_k=y_k\) it holds that
Hence, we obtain that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) and \(x_k=y_k\) it holds that
Next observe that (47) and (58) ensure that for every \(k\in \{1,2,\dots ,d\}\) with \(x_k\ne y_k\) it holds that
Furthermore, note that (58) implies that
This and (63) show that for every \(k\in \{1,2,\dots ,d\}\) with \(x_k\ne y_k\) and \(c_k=\mathfrak {a}_k^0\) it holds that
Combining this with item (ii), (49), and (50) proves that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\), \(x_k\ne y_k\), and \(c_k=\mathfrak {a}_k^0\) it holds that
In addition, observe that (64) and (63) imply that for every \(k\in \{1,2,\dots ,d\}\) with \(x_k\ne y_k\) and \(c_k=\mathfrak {a}_k^1\) it holds that
Combining this with item (ii), (49), and (50) shows that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\), \(x_k\ne y_k\), and \(c_k=\mathfrak {a}_k^1\) it holds that
This and (66) establish that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) and \(x_k\ne y_k\) it holds that
Combining this with (62) proves item (iii). Next note that the fact that for every \(z=(z_1,\dots ,z_d)\in D\), \(k\in \{1,2,\dots ,d\}\) with \(z_k\notin \{\mathfrak {a}_k^0,\mathfrak {a}_k^1\}\) it holds that \(z_k\in (\mathfrak {a}_k^0,\mathfrak {a}_k^1)\) implies that for every \(k\in \{1,2,\dots ,d\}\) with \(c_k\notin \{\mathfrak {a}_k^0,\mathfrak {a}_k^1\}\) there exists \(T\in (0,\infty )\) such that for every \(t\in [0,T]\) it holds that
Moreover, observe that (47) demonstrates that for every \(k\in \{1,2,\dots ,d\}\) it holds that
This and (64) show that for every \(k\in \{1,2,\dots ,d\}\) with \(c_k\in \{\mathfrak {a}_k^0,\mathfrak {a}_k^1\}\) it holds that
This and item (ii) ensure that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) and \(c_k=\mathfrak {a}_k^0\) it holds that
In addition, observe that item (ii) and (72) demonstrate that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) and \(c_k=\mathfrak {a}_k^1\) it holds that
Combining this and (73) proves that for every \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) there exists \(T\in (0,\infty )\) such that for every \(t\in [0,T]\) it holds that
This and (70) establish that for every \(k\in \{1,2,\dots ,d\}\) with \(\{k\}=\{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) there exists \(T\in (0,\infty )\) such that for every \(t\in [0,T]\) it holds that
Moreover, note that item (ii) and the assumption that \(c\ne y\) show that \( v\ne \mathfrak {c}(x,y) \). Combining this and (76) with (47) and (60) shows that for every \(k\in \{1,2,\dots ,d\}\) with \(\{k\}=\{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) it holds that
This and (62) imply that for every \(k\in \{1,2,\dots ,d\}\) with \(\{k\}=\{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) it holds that
Combining this with (69) proves that for every \(k\in \{1,2,\dots ,d\}\) with \(\{k\}=\{l\in \{1,2,\dots ,d\}:c_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) it holds that
This, (77), and (78) establish item (iv). The proof of Lemma 2.5 is thus complete. \(\square \)
Lemma 2.6
Let
 satisfy for every
\(k\in \mathbb {N}\),
\(x\in [-k-\nicefrac 12,-k+\nicefrac 12)\),
\(y\in [-\nicefrac 12,\nicefrac 12]\),
\(z\in (k-\nicefrac 12,k+\nicefrac 12]\) that
satisfy for every
\(k\in \mathbb {N}\),
\(x\in [-k-\nicefrac 12,-k+\nicefrac 12)\),
\(y\in [-\nicefrac 12,\nicefrac 12]\),
\(z\in (k-\nicefrac 12,k+\nicefrac 12]\) that

let \(a\in \mathbb {R}\), \(b\in (a,\infty )\), and let \(r:\mathbb {R}\rightarrow \mathbb {Z}\) satisfy for every \(x\in \mathbb {R}\) that
Then it holds for every \(x\in (-\infty ,a)\), \(y\in (b,\infty )\) that
Proof of Lemma 2.6
Observe that (80) and the fact that for every \(x\in (0,b-a]\) it holds that \(k+\tfrac{x}{b-a}-\tfrac{1}{2}\in (k-\tfrac{1}{2},-k+\tfrac{1}{2}]\) ensure that for every \(k\in \mathbb {N}\), \(x\in (0,b-a]\) it holds that
Moreover, note that (80) and the fact that for every \(x\in (0,b-a]\) it holds that \(-k+\tfrac{1}{2}-\tfrac{x}{b-a}\in [-k-\tfrac{1}{2},-k+\tfrac{1}{2})\) imply that for every \(k\in \mathbb {N}\), \(x\in (0,b-a]\) it holds that
Next observe that (83) and (84) show that for every \(k\in \mathbb {N}_0\), \(x\in (0,b-a]\) it holds that
This and the fact that for every \(x\in (-\infty ,a)\) there exist \(k\in \mathbb {N}_0\), \(y\in (0,b-a]\) such that \(x = a-k(b-a)-y\) prove that for every \(x\in (-\infty ,a)\) it holds that
Furthermore, note that (83) and (84) ensure that for every \(k\in \mathbb {N}_0\), \(x\in (0,b-a]\) it holds that
This and the fact that for every \(x\in (b,\infty )\) there exist \(k\in \mathbb {N}_0\), \(y\in (0,b-a]\) such that \(x = b+k(b-a)+y\) demonstrate that for every \(x\in (b,\infty )\) it holds that
This and (86) establish (82). The proof of Lemma 2.6 is thus complete. \(\square \)
Corollary 2.7
Let \(d\in \mathbb {N}\), for every \(k\in \{1,2,\dots ,d\}\) let \(\mathfrak {a}_k^0\in \mathbb {R}\), \(\mathfrak {a}_k^1\in (\mathfrak {a}_k^0,\infty )\), let \(D=[\mathfrak {a}_1^0,\mathfrak {a}_1^1]\times [\mathfrak {a}_2^0,\mathfrak {a}_2^1]\times \cdots \times [\mathfrak {a}_d^0,\mathfrak {a}_d^1]\subseteq \mathbb {R}^d\), let \(e_1=(1,0,0,\dots ,0)\), \(e_2=(0,1,0,\dots ,0)\), \(\dots \), \(e_d=(0,\dots ,0,0,1)\in \mathbb {R}^d\), let \(\textbf{n}:\partial _D\rightarrow \mathbb {R}^d\) satisfy for every \(x=(x_1,\dots ,x_d)\in \partial _D\), \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:x_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) that
let \(\mathfrak {c}:(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(\mathscr {R}:(\mathbb {R}^d)^2\rightarrow (\mathbb {R}^d)^2\) satisfy for every \(x,y\in \mathbb {R}^d\) that
let \(x_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), and \(y_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), satisfy for every \(n\in \mathbb {N}\) that
and let \(N\in \mathbb {N}\cup \{\infty \}\) satisfy
(cf. Lemma 2.1). Then
-
(i)
it holds that \(N<\infty \) and
-
(ii)
it holds for every \(n\in \mathbb {N}\cap [N,\infty )\) that \( (x_n,y_n) = (x_N,y_N) \).
Proof of Corollary 2.7
Throughout this proof let
 satisfy for every
\(k\in \mathbb {N}\),
\(u\in [-k-\nicefrac 12,-k+\nicefrac 12)\),
\(v\in [-\nicefrac 12,\nicefrac 12]\),
\(w\in (k-\nicefrac 12,k+\nicefrac 12]\) that
satisfy for every
\(k\in \mathbb {N}\),
\(u\in [-k-\nicefrac 12,-k+\nicefrac 12)\),
\(v\in [-\nicefrac 12,\nicefrac 12]\),
\(w\in (k-\nicefrac 12,k+\nicefrac 12]\) that

for every \(a\in \mathbb {R}\), \(b\in (a,\infty )\) let \(r_{a,b}:\mathbb {R}\rightarrow \mathbb {Z}\) satisfy for every \(z\in \mathbb {R}\) that
and let \(\mathfrak r:\mathbb {R}^d\rightarrow \mathbb {N}_0\) satisfy for every \(z=(z_1,\dots ,z_d)\in \mathbb {R}^d\) that
Observe that Lemma 2.6 shows that for every \(a,b,w,z\in \mathbb {R}\) with \(w<a<b<z\) it holds that
Item (iii) in Lemma 2.5 and (92) therefore establish that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) and \(\mathfrak {c}(x_n,y_n)\notin \{x_n,y_n\}\) it holds that
The fact that for every \(z\in \mathbb {R}^d\) it holds that \(\mathfrak {r}(z)\in \mathbb {N}_0\) and (93) hence imply that
Moreover, note that item (iii) in Lemma 2.3 ensures that for every \(n\in \mathbb {N}\cap [N,\infty )\) it holds that
The proof of Corollary 2.7 is thus complete.
Lemma 2.8
Let \(\lfloor {\cdot } \rfloor :\mathbb {R}\rightarrow \mathbb {Z}\) satisfy for every \(k\in \mathbb {Z}\), \(x\in [k,k+1)\) that
let \(a\in \mathbb {R}\), \(b\in (a,\infty )\), and let \(\mathscr {R}:\mathbb {R}\rightarrow [0,1]\) and \(\mathscr {S}:\mathbb {R}\rightarrow [a,b]\) satisfy for every \(x\in \mathbb {R}\) that
Then
-
(i)
it holds for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) that
$$\begin{aligned} \mathscr {S}(a+2k(b-a)+x) = a+x = \mathscr {S}(b-(2k+1)(b-a)-x) \end{aligned}$$(103)and
-
(ii)
it holds for every \(x\in \mathbb {R}\) that \(\mathscr {S}(2a-x) = \mathscr {S}(x) = \mathscr {S}(2b-x) \).
Proof of Lemma 2.8
First, observe that (101) and (102) imply that for every \(k\in \mathbb {Z}\), \(x\in [0,1)\) it holds that
Combining this with (102) shows that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a)\) it holds that
Furthermore, note that (101) and (102) ensure that for every \(k\in \mathbb {Z}\), \(x\in [0,1)\) it holds that
This and (102) imply that for every \(k\in \mathbb {Z}\) it holds that
Combining this with (105) shows that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) it holds that
Next observe that (106) and (102) prove that for every \(k\in \mathbb {Z}\), \(x\in (0,b-a]\) it holds that
Moreover, note that (104) and (102) imply that for every \(k\in \mathbb {Z}\) it holds that
Combining this with (109) demonstrates that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) it holds that
This and (108) establish item (i). In the next step we observe that item (i) shows that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) it holds that
Furthermore, note that item (i) ensures that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) it holds that
Moreover, observe that item (i) implies that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) it holds that
In addition, note that item (i) shows that for every \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) it holds that
Combining this, (112), (113), and (114) with the fact that for every \(y\in \mathbb {R}\) there exist \(k\in \mathbb {Z}\), \(x\in [0,b-a]\) such that \(y\in \{a+2k(b-a)+x,b-(2k+1)(b-a)-x\}\) establishes item (ii). The proof of Lemma 2.8 is thus complete. \(\square \)
Corollary 2.9
Let \(d\in \mathbb {N}\), for every \(k\in \{1,2,\dots ,d\}\) let \(\mathfrak {a}_k^0\in \mathbb {R}\), \(\mathfrak {a}_k^1\in (\mathfrak {a}_k^0,\infty )\), let \(D=[\mathfrak {a}_1^0,\mathfrak {a}_1^1]\times [\mathfrak {a}_2^0,\mathfrak {a}_2^1]\times \cdots \times [\mathfrak {a}_d^0,\mathfrak {a}_d^1]\subseteq \mathbb {R}^d\), let \(e_1=(1,0,0,\dots ,0)\), \(e_2=(0,1,0,\dots ,0)\), \(\dots \), \(e_d=(0,\dots ,0,0,1)\in \mathbb {R}^d\), let \(\textbf{n}:\partial _D\rightarrow \mathbb {R}^d\) satisfy for every \(x=(x_1,\dots ,x_d)\in \partial _D\), \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:x_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) that
let \(\mathfrak {c}:(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(\mathscr {R}:(\mathbb {R}^d)^2\rightarrow (\mathbb {R}^d)^2\) satisfy for every \(x,y\in \mathbb {R}^d\) that
let \(\lfloor {\cdot } \rfloor :\mathbb {R}\rightarrow \mathbb {Z}\) satisfy for every \(k\in \mathbb {Z}\), \(z\in [k,k+1)\) that \(\lfloor {z} \rfloor = k \), let \(\mathfrak {r}:\mathbb {R}\rightarrow [0,1]\) satisfy for every \(z\in \mathbb {R}\) that
for every \(a,b\in \mathbb {R}\) let \(\,r_{a, b}:\mathbb {R}\rightarrow [a,b]\) satisfy for every \(z\in \mathbb {R}\) that \(\,{r_{a, b}}(z) = (b-a)\mathfrak {r}\big ({\tfrac{z-a}{b-a}}\big ) + a \), let \(\mathscr {S}:\mathbb {R}^d\rightarrow D\) satisfy for every \(z=(z_1,\dots ,z_d)\in \mathbb {R}^d\) that
let \(x_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), and \(y_n\in \mathbb {R}^d\), \(n\in \mathbb {N}_0\), satisfy for every \(n\in \mathbb {N}\) that
and assume for every \(n\in \mathbb {N}\) that
(cf. Lemma 2.1). Then there exists \(N\in \mathbb {N}\) such that for every \(n\in \mathbb {N}\cap [N,\infty )\) it holds that
Proof of Corollary 2.9
Throughout this proof let \(N\in \mathbb {N}\cup \{\infty \}\) satisfy
Note that Corollary 2.7 proves that
-
(A)
it holds that \( N<\infty \) and
-
(B)
it holds for every \(n\in \mathbb {N}\cap [N,\infty )\) that \((x_n,y_n)=(x_N,y_N)\).
Observe that Lemma 2.1 and (122) ensure that for every \(n\in \mathbb {N}_0\) with \(\mathfrak {c}(x_{n},y_{n})\notin \{x_{n},y_{n}\}\) it holds that
Item (iv) in Lemma 2.5 therefore establishes that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that
Furthermore, note that the assumption that \(x\in D\backslash \partial _D\) and (117) imply that
Combining this and (126) with (124) and item (A) shows that
The fact that D is a closed set and (117) therefore demonstrate that \( y_{N-1}\in D \). This, (118), and items (A) and (B) prove that for every \(n\in \mathbb {N}\cap [N,\infty )\) it holds that
In the next step we observe that item (ii) in Lemma 2.8 establishes that for every \(k\in \{1,2,\dots ,d\}\), \(z\in \mathbb {R}\) it holds that
Item (ii) in Lemma 2.5 and (121) therefore imply that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\notin \{x_{n-1},y_{n-1}\}\) it holds that \(\mathscr {S}(y_n) = \mathscr {S}(y_{n-1}) \). Combining this and the fact that for every \(n\in \mathbb {N}\) with \(\mathfrak {c}(x_{n-1},y_{n-1})\in \{x_{n-1},y_{n-1}\}\) it holds that \(y_n=y_{n-1}\) with induction demonstrates that for every \(n\in \mathbb {N}\) it holds that
In addition, note that item (i) in Lemma 2.8 ensures that for every \(a\in \mathbb {R}\), \(b\in (a,\infty )\), \(z\in [a,b]\) it holds that \(\,{r_{a, b}}(z) = z \). Hence, we obtain that for every \(z\in D\) it holds that
Combining this with (129) and (131) establishes that for every \(n\in \mathbb {N}\cap [N,\infty )\) it holds that
The proof of Corollary 2.9 is thus complete. \(\square \)
Framework 2.10
(Reflection principle for the simulation of time discrete reflected processes) Let \(d \in \mathbb {N}\), let \(D\subseteq \mathbb {R}^{ d }\) be a sufficiently regular closed set, let \( \textbf{n} :\partial _D\rightarrow \mathbb {R}^d \) be a suitable outer unit normal vector field associated to \(D\), let \(\mathfrak {c} :(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(\mathscr {R} :(\mathbb {R}^{ d })^2 \rightarrow ( \mathbb {R}^{ d })^2 \) satisfy for every \(x,y \in \mathbb {R}^d\) that
let \(P :(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d\) satisfy for every \(x,y \in \mathbb {R}^d\) that \(P(x,y) = y\), let \(\mathcal {R}_{n} :(\mathbb {R}^d)^2 \rightarrow ( \mathbb {R}^{ d } )^2\), \(n \in \mathbb {N}_0\), satisfy for every \(n \in \mathbb {N}_0 \), \(x,y \in \mathbb {R}^d\) that \(\mathcal {R}_0(x,y) = (x,y)\) and \(\mathcal {R}_{ n + 1 }(x,y) = \mathscr {R}( \mathcal {R}_{n} (x,y ) ) \), and let \(R :(\mathbb {R}^d)^2 \rightarrow \mathbb {R}^d \) satisfy for every \(x,y\in \mathbb {R}^d\) that
(cf. Lemma 2.1).
Note that in Framework 2.10 above, for every \(d\in \mathbb {N}\), every closed set \(D\subseteq \mathbb {R}^d\) with a smooth boundary \(\partial _D\), every suitable outer unit normal vector field \(\textbf{n}:\partial _D\rightarrow \mathbb {R}^d\), and every \(a\in D\backslash \partial _D\), \(b\in \mathbb {R}^d\backslash D\) we have
-
(i)
that \(\mathfrak c(a,b)\) is the point closest to a on the line segment from a to b which lies on \(\partial _D\) and
-
(ii)
that \(\mathscr {R}(a,b)\) is the reflection of b on the hyperplane through \(\mathfrak c(a,b)\) tangent to \(\partial _D\) (cf. Fig. 1).
In view of this, we can, roughly speaking, think of R(a, b) as the point where a particle that travels a length of \(\Vert {b-a} \Vert \) starting in a going towards b and getting reflected every time it hits the boundary of D, ends up; cf. Fig. 1.

Two illustrations for Framework 2.10. The diagram on the left shows the reflection of a line segment from a to b on a hyperplane with unit normal vector n. The diagram on the right illustrates the recursive definition of the functions \(\mathcal R_n:(\mathbb {R}^d)^2\rightarrow (\mathbb {R}^d)^2\), \(n\in \mathbb {N}_0\), and \(R:(\mathbb {R}^d)^2\rightarrow \mathbb {R}\) defined in Framework 2.10 in the case where \(d=2\) and \(D\subseteq \mathbb {R}^d\) is a closed rectangle
Also, observe that in Framework 2.10 above, we have used the vague notions of “sufficiently regular set” and “suitable outer unit normal vector field”. Corollaries 2.7 and 2.9 and Proposition 2.4 above provide more information on two particular special cases of the construction in Framework 2.10. More specifically, we consider the conditions satisfied in (at least) the following two cases:
-
(a)
The case where \(D=\{x\in \mathbb {R}^d:\Vert {x} \Vert = 1\}\) and where \(\textbf{n}:\partial _D\rightarrow \mathbb {R}^d\) satisfies for every \(x\in \partial _D=\{x\in \mathbb {R}^d:\Vert {x} \Vert =1\}\) that \(\textbf{n}(x) = x\). Note that in this case, Proposition 2.4 demonstrates that the limit in (136) exists.
-
(b)
The case where for every \(k\in \{1,2,\dots ,d\}\) there exist \(\mathfrak {a}_k^0\in \mathbb {R}\), \(\mathfrak {a}_k^1\in (\mathfrak {a}_k^0,\infty )\) such that \(D=[\mathfrak {a}_1^0,\mathfrak {a}_1^1]\times [\mathfrak {a}_2^0,\mathfrak {a}_2^1]\times \cdots \times [\mathfrak {a}_d^0,\mathfrak {a}_d^1]\), where \(e_1=(1,0,0,\dots ,0)\), \(e_2=(0,1,0,\dots ,0)\), \(\dots \), \(e_d=(0,\dots ,0,0,1)\in \mathbb {R}^d\), and where \(\textbf{n}:\partial _D\rightarrow \mathbb {R}^d\), satisfies for every \(x=(x_1,\dots ,x_d)\in \partial _D=\{x=(x_1,\dots ,x_d)\in D:(\exists \, k\in \{1,2,\dots ,d\}:x_k\in \{\mathfrak {a}_k^0,\mathfrak {a}_k^1\})\}\), \(k\in \{1,2,\dots ,d\}\) with \(k=\min \{l\in \{1,2,\dots ,d\}:x_l\in \{\mathfrak {a}_l^0,\mathfrak {a}_l^1\}\}\) that
$$\begin{aligned} \begin{aligned} \textbf{n}(x) = {\left\{ \begin{array}{ll} -e_k&{}:x_k=\mathfrak {a}_k^0\\ e_k&{}:x_k=\mathfrak {a}_k^1. \end{array}\right. } \end{aligned} \end{aligned}$$(137)Note that in this case, Corollary 2.7 demonstrates that the limit in (136) exists and Corollary 2.9 shows how the function R can be practically computed (up to a zero set).
2.3 Description of the proposed approximation method in a special case
Framework 2.11
(Special case of the machine learning-based approximation method) Assume Framework 2.10, let \(T,\gamma \in (0,\infty )\), \(N,M,K \in \mathbb {N}\), \(g \in C^2(\mathbb {R}^d,\mathbb {R})\), \(\mathfrak d,\mathfrak {h} \in \mathbb {N}\backslash \{1\}\), \(t_0,t_1,\ldots ,t_N\in [0,T]\) satisfy \(\mathfrak {d} = \mathfrak {h}(N+1)d(d+1)\) and
let \(\tau _0, \tau _1, \dots ,\tau _N \in [0,T]\) satisfy for every \(n \in \{0,1,\dots ,N\}\) that \(\tau _n= T-t_{N-n}\), let \(f :\mathbb {R}\times \mathbb {R}\rightarrow \mathbb {R}\) be measurable, let \((\Omega ,{\mathcal {F}},\mathbb {P},(\mathcal {F}_t)_{t\in [0,T]})\) be a filtered probability space, let \(\xi ^{m}:\Omega \rightarrow \mathbb {R}^d\), \(m\in \mathbb {N}\), be i.i.d. \(\mathcal {F}_0\)/\(\mathcal {B}(\mathbb {R}^d)\)-measurable random variables, let \(W^{m}:[0,T]\times \Omega \rightarrow \mathbb {R}^d\), \(m\in \mathbb {N}\), be i.i.d. standard \((\mathcal {F}_t)_{t\in [0,T]}\)-Brownian motions, for every \(m\in \mathbb {N}\) let \(\mathcal {Y}^{m}:\{0,1,\ldots ,N\}\times \Omega \rightarrow \mathbb {R}^d\) be the stochastic process which satisfies for every \(n\in \{0,1,\ldots ,N-1\}\) that \(\mathcal {Y}^{m}_0 = \xi ^{m}\) and
let \( \mathcal {L} :\mathbb {R}^d \rightarrow \mathbb {R}^d \) satisfy for every \( x = ( x_1, \dots , x_d ) \in \mathbb {R}^d \) that
for every \( \theta = ( \theta _1, \dots , \theta _{ \mathfrak {d} } ) \in \mathbb {R}^{ \mathfrak {d} }\), \(k, l, v \in \mathbb {N}\) with \(v + l (k + 1 ) \le \mathfrak {d}\) let \( A^{ \theta , v }_{ k, l } :\mathbb {R}^k \rightarrow \mathbb {R}^l \) satisfy for every \( x = ( x_1, \dots , x_k )\in \mathbb {R}^k \) that
let \({\mathbb {V}}_n:\mathbb {R}^{\mathfrak {d}}\times \mathbb {R}^d\rightarrow \mathbb {R}\), \(n\in \{0,1,\ldots ,N\}\), satisfy for every \(n\in \{1,2,\ldots ,N\}\), \(\theta \in \mathbb {R}^{\mathfrak {d}}\), \(x \in \mathbb {R}^d\) that \({\mathbb {V}}_0(\theta ,x) = g(x)\) and
let \(\nu _x :\mathcal {B}( D)\rightarrow [0,1]\), \(x \in D\), be probability measures, for every \(x \in D\) let \(Z^{ n, m }_{ x, k } :\Omega \rightarrow D\), \(k, n, m \in \mathbb {N}\), be i.i.d. random variables which satisfy for every \( A \in \mathcal {B}( D) \) that \(\mathbb {P}( Z_{ x, 1 }^{ 1, 1 } \in A ) = \nu _x( A )\), let \(\Theta ^{n}:\mathbb {N}_0\times \Omega \rightarrow \mathbb {R}^{\mathfrak {d}}\), \(n \in \{0,1,\ldots ,N\}\), be stochastic processes, for every \(n \in \{1,2,\ldots ,N\}\), \(m\in \mathbb {N}\) let \(\phi ^{n,m}:\mathbb {R}^{\mathfrak {d}}\times \Omega \rightarrow \mathbb {R}\) satisfy for every \(\theta \in \mathbb {R}^{\mathfrak {d}}\), \(\omega \in \Omega \) that
for every \(n\in \{1,2,\ldots ,N\}\), \(m\in \mathbb {N}\) let \(\Phi ^{n,m}:\mathbb {R}^{\mathfrak {d}}\times \Omega \rightarrow \mathbb {R}^{\mathfrak {d}}\) satisfy for every \(\theta \in \mathbb {R}^{\mathfrak {d}}\), \(\omega \in \Omega \) that \(\Phi ^{n,m}(\theta ,\omega ) = (\nabla _{\theta }\phi ^{n,m})(\theta ,\omega )\), and assume for every \(n\in \{1,2,\ldots ,N\}\), \(m\in \mathbb {N}\) that
As indicated in Sect. 2.1 above, the algorithm described in Framework 2.11 computes an approximation for a solution of the PDE in (1), i.e., a function \(u\in C^{1,2}([0,T]\times D,\mathbb {R})\) which has at most polynomially growing derivatives, which satisfies for every \(t\in (0,T]\), \(x\in \partial _D\) that \( \langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\) and which satisfies for every \(t\in [0,T]\), \(x\in D\) that \(u(0,x)=g(x)\), \(\int _D|{f(u(t,x), u(t,\textbf{x})) } | \, \nu _x(\textrm{d}\textbf{x}) < \infty \), and
Let us now add some explanatory comments on the objects and notations employed in Framework 2.11 above. The algorithm in Framework 2.11 decomposes the time interval [0, T] into N subintervals at the times \(t_0,t_1,t_2,\dots ,t_{N}\in [0,T]\) (cf. (138)). For every \(n\in \{1,2,\dots ,N\}\) we aim to approximate the function \(\mathbb {R}^d\ni x\mapsto u(t_n,x)\in \mathbb {R}\) by a suitable (realization function of a) fully-connected feedforward neural network. Each of these neural networks is an alternating composition of \(\mathfrak h-1\) affine linear functions from \(\mathbb {R}^d\) to \(\mathbb {R}^d\) (where we think of \(\mathfrak h\in \mathbb {N}\backslash \{1\}\) as the length or depth of the neural network), of \(\mathfrak h-1\) instances of a d-dimensional version of the standard logistic function, and finally of an affine linear function from \(\mathbb {R}^d\) to \(\mathbb {R}\). Every such neural network can be specified by means of \((\mathfrak h-1)(d^2+d)+d+1\le \mathfrak hd(d+1)\) real parameters and so \(N+1\) of these neural networks can be specified by a parameter vector of length \(\mathfrak d=\mathfrak h(N+1)d(d+1)\in \mathbb {N}\). Note that \(\mathcal L:\mathbb {R}^d\rightarrow \mathbb {R}^d\) in Framework 2.11 above denotes the d-dimensional version of the standard logistic function (cf. (140)) and for every \(k,l,v\in \mathbb {N}\), \(\theta =(\theta _1,\dots ,\theta _{\mathfrak d})\in \mathbb {R}^{\mathfrak d}\) with \(v+kl+l\le \mathfrak d\) the function \(A^{\theta ,v}_{k,l}:\mathbb {R}^k\rightarrow \mathbb {R}^l\) in Framework 2.11 denotes an affine linear function specified by means of the parameters \(\theta _{v+1},\theta _{v+2},\dots ,\theta _{v+kl+l}\) (cf. (141)). Furthermore, observe that for every \(n\in \{1,2,\dots ,N\}\), \(\theta \in \mathbb {R}^{\mathfrak d}\) the function
denotes a neural network specified by means of the parameters \(\mathfrak {h}nd(d+1)+1, \mathfrak {h}nd(d+1)+2,\dots ,(\mathfrak {h}n+\mathfrak {h}-1)d(d+1)+d+1\).
The goal of the optimization algorithm in Framework 2.11 above is to find a suitable parameter vector \(\theta \in \mathbb {R}^{\mathfrak {d}}\) such that for every \(n\in \{1,2,\dots ,N\}\) the neural network \(\mathbb {R}^d\ni x\mapsto \mathbb {V}_n(\theta ,x)\in \mathbb {R}\) is a good approximation for the solution \(\mathbb {R}^d\ni x\mapsto u(t_n,x)\in \mathbb {R}\) to the PDE in (145) at time \(t_n\). This is done by performing successively for each \(n\in \{1,2,\dots ,N\}\) a plain vanilla stochastic gradient descent (SGD) optimization on a suitable loss function (cf. (144)).
Observe that for every \(n\in \{1,2,\dots ,N\}\) the stochastic process \(\Theta ^n:\mathbb {N}_0\times \Omega \rightarrow \mathbb {R}^{\mathfrak {d}}\) describes the successive estimates computed by the SGD algorithm for the parameter vector that represents (via \(\mathbb {V}_n:\mathbb {R}^{\mathfrak {d}}\times \mathbb {R}^d\rightarrow \mathbb {R}\)) a suitable approximation to the solution \(\mathbb {R}^d\ni x\mapsto u(t_n,x)\in \mathbb {R}\) of the PDE in (145) at time \(t_n\). Next note that \(M\in \mathbb {N}\) in Framework 2.11 above denotes the number of gradient descent steps taken for each \(n\in \{1,2,\dots ,N\}\) and that \(\gamma \in (0,\infty )\) denotes the learning rate employed in the SGD algorithm. Moreover, observe that for every \(n\in \{1,2,\dots ,N\}\), \(m\in \{1,2,\dots ,M\}\) the function \(\phi ^{n,m}:\mathbb {R}^{\mathfrak {d}}\times \Omega \rightarrow \mathbb {R}\) denotes the loss function employed in the \(m\hbox {th}\) gradient descent step during the approximation of the solution of the PDE in (145) at time \(t_n\) (cf. (143)). The loss functions employ a family of i.i.d. time-discrete stochastic processes \(\mathcal Y^m:\{0,1,\dots N\}\times \Omega \rightarrow \mathbb {R}^d\), \(m\in \mathbb {N}\), which we think of as discretizations of suitable reflected Brownian motions (cf. (139)). In addition, for every \(n\in \{1,2,\dots ,N\}\), \(m\in \{1,2,\dots ,M\}\), \(x\in D\) the loss function \(\phi ^{n,m}:\mathbb {R}^{\mathfrak {d}}\times \Omega \rightarrow \mathbb {R}\) employs a family of i.i.d. random variables \(Z^{n,m}_{x,k}:\Omega \rightarrow D\), \(k\in \mathbb {N}\), which are used for the Monte Carlo approximation of the non-local term in the PDE in (145) whose solution we are trying to approximate. The number of samples used in these Monte Carlo approximations is denoted by \(K\in \mathbb {N}\) in Framework 2.11 above.
Finally, for sufficiently large \(N,M,K\in \mathbb {N}\) and sufficiently small \(\gamma \in (0,\infty )\) the algorithm in Framework 2.11 above yields for every \(n\in \{1,2,\dots ,N\}\) a (random) parameter vector \(\Theta ^n_M:\Omega \rightarrow \mathbb {R}^{\mathfrak d}\) which represents a function \(\mathbb {R}^d\times \Omega \ni (x,\omega )\mapsto \mathbb V_n(\Theta ^n_M(\omega ),x)\in \mathbb {R}\) that we think of as providing for every \(x\in D\) a suitable approximation
3 Machine learning-based approximation method in the general case
In this section we describe in Framework 3.1 in Sect. 3.2 below the full version of our deep learning-based method for approximating solutions of non-local nonlinear PDEs with Neumann boundary conditions (see Sect. 3.1 for a description of the class of PDEs our approximation method applies to), which generalizes the algorithm introduced in Framework 2.11 in Sect. 2.3 above and which we apply in Sect. 5 below to several examples of non-local nonlinear PDEs.
3.1 PDEs under consideration
Let \( T \in (0,\infty ) \), \( d \in \mathbb {N}\), let \(D\subseteq \mathbb {R}^d\) be a closed set with sufficiently smooth boundary \(\partial _D\), let \( \textbf{n} :\partial _D\rightarrow \mathbb {R}^d \) be an outer unit normal vector field associated to \(D\), let \( g:D\rightarrow \mathbb {R}\), \( \mu :D\rightarrow \mathbb {R}^d \), and \( \sigma :D\rightarrow \mathbb {R}^{ d \times d } \) be continuous, let \(\nu _x :\mathcal {B}(D) \rightarrow [0,1]\), \(x \in D\), be probability measures, let \( f :[0,T] \times D\times D\times \mathbb {R}\times \mathbb {R}\rightarrow \mathbb {R}\) be measurable, let \( u= (u(t,x))_{(t,x)\in [0,T]\times D}\in C^{1,2}([0,T]\times D,\mathbb {R}) \) have at most polynomially growing partial derivatives, assume for every \(t\in [0,T]\), \(x\in \partial _D\) that \( \langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\), and assume for every \(t\in [0,T]\), \(x\in D\) that \(u(0,x)=g(x)\), \(\int _D\big |{f\big ({t,x,\textbf{x}, u(t,x),u(t,\textbf{x}) }\big ) }\big | \, \nu _x(\textrm{d}\textbf{x}) < \infty \), and
Our goal is to approximately calculate under suitable hypotheses the solution \(u:[0,T]\times D\rightarrow \mathbb {R}\) of the PDE in (148).
3.2 Description of the proposed approximation method in the general case
Framework 3.1
(General case of the machine learning-based approximation method) Assume Framework 2.10, let \(T \in (0,\infty )\), \(N, \varrho , \mathfrak {d}, \varsigma \in \mathbb {N}\), \((M_n)_{n\in \mathbb {N}_0}\subseteq \mathbb {N}\), \((K_n)_{n\in \mathbb {N}}\subseteq \mathbb {N}\), \((J_m)_{m \in \mathbb {N}} \subseteq \mathbb {N}\), \(t_0,t_1,\ldots ,t_N\in [0,T]\) satisfy
let \(\tau _0, \tau _1, \dots ,\tau _N \in [0,T]\) satisfy for every \(n \in \{0, 1, \dots , N\}\) that \(\tau _n= T-t_{N-n}\), let \(\nu _x :\mathcal {B}( D)\rightarrow [0,1]\), \(x \in D\), be probability measures, for every \(x \in D\) let \(Z^{ n, m,j }_{ x, k } :\Omega \rightarrow D\), \(k, n, m, j \in \mathbb {N}\), be i.i.d. random variables which satisfy for every \( A \in \mathcal {B}( D) \) that \(\mathbb {P}( Z_{ x, 1 }^{ 1, 1,1 } \in A ) = \nu _x( A )\), let \(f:[0,T] \times D\times D\times \mathbb {R}\times \mathbb {R}\rightarrow \mathbb {R}\) be measurable, let \(( \Omega , {\mathcal {F}}, \mathbb {P}, ( \mathcal {F}_t )_{ t \in [0,T] } )\) be a filtered probability space, for every \(n \in \{1,2,\ldots ,N\}\) let \(W^{n,m,j} :[0,T] \times \Omega \rightarrow \mathbb {R}^d\), \(m,j \in \mathbb {N}\), be i.i.d. standard \(( \mathcal {F}_t )_{ t \in [0,T] }\)-Brownian motions, for every \(n \in \{1, 2, \ldots ,N\}\) let \(\xi ^{n,m,j}:\Omega \rightarrow \mathbb {R}^d\), \(m, j \in \mathbb {N}\), be i.i.d. \( \mathcal {F}_0\)/\(\mathcal {B}(\mathbb {R}^d)\)-measurable random variables, let \(H:[0,T]^2\times \mathbb {R}^d\times \mathbb {R}^d\rightarrow \mathbb {R}^d\) be a function, for every \(j\in \mathbb {N}\), \(\textbf{s}\in \mathbb {R}^\varsigma \), \(n\in \{0, 1, \dots ,N\}\) let \( {\mathbb {V}}^{j,\textbf{s}}_n:\mathbb {R}^{\mathfrak {d}}\times \mathbb {R}^d\rightarrow \mathbb {R}\) be a function, for every \( n \in \{1,2, \ldots ,N\}\), \( m,j \in \mathbb {N}\) let \(\mathcal {Y}^{n,m,j}:\{0,1,\ldots ,N\}\times \Omega \rightarrow \mathbb {R}^d\) be a stochastic process which satisfies for every \(k\in \{0,1,\ldots ,N-1\}\) that \(\mathcal {Y}^{n,m,j}_0 = \xi ^{ n, m, j }\) and
let \(\Theta ^{n}:\mathbb {N}_0\times \Omega \rightarrow \mathbb {R}^{\mathfrak {d}}\), \(n \in \{0, 1, \dots , N\}\), be stochastic processes, for every \(n\in \{1,2,\ldots ,N\}\), \(m\in \mathbb {N}\), \(\textbf{s}\in \mathbb {R}^{\varsigma }\) let \(\phi ^{n,m,\textbf{s}}:\mathbb {R}^{\mathfrak {d}}\times \Omega \rightarrow \mathbb {R}\) satisfy for every \(\theta \in \mathbb {R}^{\mathfrak {d}}\), \(\omega \in \Omega \) that
for every \(n\in \{1,2,\ldots ,N\}\), \(m\in \mathbb {N}\), \(\textbf{s}\in \mathbb {R}^{\varsigma }\) let \(\Phi ^{n,m,\textbf{s}}:\mathbb {R}^{\mathfrak {d}}\times \Omega \rightarrow \mathbb {R}^{\mathfrak {d}}\) satisfy for every \(\omega \in \Omega \), \(\theta \in \{\vartheta \in \mathbb {R}^{\mathfrak {d}}:(\mathbb {R}^{\mathfrak d}\ni \eta \mapsto \phi ^{n,m,\textbf{s}}(\eta ,\omega )\in \mathbb {R})\) is differentiable at \(\vartheta \}\) that
let \(\mathcal {S}^n:\mathbb {R}^{\varsigma }\times \mathbb {R}^{\mathfrak {d}}\times (\mathbb {R}^d)^{\{0,1,\ldots ,N\}\times \mathbb {N}}\rightarrow \mathbb {R}^{\varsigma }\), \(n\in \{1,2,\ldots ,N\}\), be functions, for every \(n\in \{1,2,\ldots ,N\}\), \(m\in \mathbb {N}\) let \(\psi ^n_m:\mathbb {R}^{\varrho }\rightarrow \mathbb {R}^{\mathfrak {d}}\) and \(\Psi ^n_m:\mathbb {R}^{\varrho }\times \mathbb {R}^{\mathfrak {d}}\rightarrow \mathbb {R}^{\varrho }\) be functions, and for every \(n\in \{1,2,\ldots ,N\}\) let \(\mathbb {S}^{n}:\mathbb {N}_0\times \Omega \rightarrow \mathbb {R}^{\varsigma }\) and \(\Xi ^{n}:\mathbb {N}_0\times \Omega \rightarrow \mathbb {R}^{\varrho }\) be stochastic processes which satisfy for every \(m\in \mathbb {N}\) that
In the setting of Framework 3.1 above we think under suitable hypotheses for sufficiently large \(N \in \mathbb {N}\), sufficiently large \((M_n)_{n\in \mathbb {N}_0} \subseteq \mathbb {N}\), sufficiently large \((K_n)_{n\in \mathbb {N}} \subseteq \mathbb {N}\), every \(n \in \{0, 1, \dots , N\}\), and every \(x \in D\) of \( \mathbb {V}^{1,\mathbb {S}_{M_n}^n}_n(\Theta ^n_{M_n},x) :\Omega \rightarrow \mathbb {R}\) as a suitable approximation
of \(u(t_n,x)\) where \( u=(u(t,x))_{(t,x)\in [0,T]\times \mathbb {R}^d}\in C^{1,2}([0,T]\times \mathbb {R}^d,\mathbb {R}) \) is a function with at most polynomially growing derivatives which satisfies for every \(t\in (0,T]\), \(x\in \partial _D\) that \( \langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\) and which satisfies for every \(t\in [0,T]\), \(x\in D\) that \(u(0,x)=g(x)\), \(\int _D\big |{f\big ({t,x,\textbf{x}, u(t,x), u(t,\textbf{x}) }\big ) }\big | \, \nu _x(\textrm{d}\textbf{x}) < \infty \), and
(cf. (148)). Compared to the simplified algorithm in Framework 2.11 above, the major new elements introduced in Framework 3.1 are the following:
-
(a)
The numbers of gradient descent steps taken to compute approximations for the solution of the PDE at the times \(t_n\), \(n\in \{1,2,\dots ,N\}\), are allowed to vary with n, and so are specified by a sequence \((M_n)_{n\in \mathbb {N}_0}\subseteq \mathbb {N}\) in Framework 3.1 above.
-
(b)
The numbers of samples used for the Monte Carlo approximation of the non-local term in the approximation for the solution of the PDE at the times \(t_n\), \(n\in \{1,2,\dots ,N\}\), are allowed to vary with n, and so are specified by a sequence \((K_n)_{n\in \mathbb {N}_0}\subseteq \mathbb {N}\) in Framework 3.1 above.
-
(c)
The approximating functions \(\mathbb V^{j,\textbf{s}}_n\), \((j,\textbf{s},n)\in \mathbb {N}\times \mathbb {R}^\varsigma \times \{0,1,\dots ,N\}\), in Framework 3.1 above are not specified concretely in order to allow for a variety of neural network architectures. For the concrete choice of these functions employed in our numerical simulations, we refer the reader to Sect. 5.
-
(d)
For every \(m\in \{1,2,\dots ,M\}\) the loss function used in the \(m\hbox {th}\) gradient descent step may be computed using a minibatch of samples instead of just one sample (cf. (151)). The sizes of these minibatches are specified by a sequence \((J_m)_{m\in \mathbb {N}}\subseteq \mathbb {N}\).
-
(e)
Compared to Framework 2.11 above, the more general form of the PDEs considered in this section (cf. (156)) requires more flexibility in the definition of the time-discrete stochastic processes \(\mathcal Y^{n,m,j}:\{0,1,\dots ,N\}\times \Omega \rightarrow \mathbb {R}^d\), \((n,m,j)\in \{1,2,\dots ,N\}\times \mathbb {N}\times \mathbb {N}\), which are specified in Framework 3.1 above in terms of the Brownian motions \(W^{n,m,j}:[0,T]\times \Omega \rightarrow \mathbb {R}^d\), \((n,m,j)\in \{1,2,\dots ,N\}\times \mathbb {N}\times \mathbb {N}\), via a function \(H:[0,T]^2\times \mathbb {R}^d\times \mathbb {R}^d\rightarrow \mathbb {R}^d\) (cf. (150)). We refer the reader to (181) in Sect. 5.1 below, (183) in Sect. 5.2 below, (185) in Sect. 5.3 below, (206) in Sect. 5.4 below, and (211) in Sect. 5.5 below for concrete choices of H in the approximation of various example PDEs.
-
(f)
For every \(n\in \{1,2,\dots ,N\}\), \(m\in \mathbb {N}\) the optimization step in (154) in Framework 3.1 above is specified generically in terms of the functions \(\psi ^n_m:\mathbb {R}^{\varrho }\rightarrow \mathbb {R}^{\mathfrak {d}}\) and \(\Psi ^n_m:\mathbb {R}^{\varrho }\times \mathbb {R}^{\mathfrak {d}}\rightarrow \mathbb {R}^{\varrho }\) and the random variable \(\Xi ^n_m:\Omega \rightarrow \mathbb {R}^{\varrho }\). This generic formulation covers a variety of SGD based optimization algorithms such as Adagrad [95], RMSprop, or Adam [96]. For example, in order to implement the Adam optimization algorithm, for every \(n\in \{1,2,\dots ,N\}\), \(m\in \mathbb {N}\) the random variable \(\Xi ^n_m\) can be used to hold suitable first and second moment estimates (see (175) and (176) in Sect. 5 below for the concrete specification of these functions implementing the Adam optimization algorithm).
-
(g)
The processes \(\mathbb {S}^n:\mathbb {N}_0\times \Omega \rightarrow \mathbb {R}^{\varsigma }\), \(n\in \{1,2,\ldots ,N\}\), and functions \(\mathcal {S}^n:\mathbb {R}^{\varsigma }\times \mathbb {R}^{\mathfrak {d}}\times (\mathbb {R}^d)^{\{0,1,\dots ,N\}\times \mathbb {N}}\rightarrow \mathbb {R}^\varsigma \), \(n\in \{1,2,\dots ,N\}\), in Framework 3.1 above can be used to implement batch normalization; see [97] for details. Loosely speaking, for every \(n\in \{1,2,\dots ,N\}\), \(m\in \mathbb {N}\) the random variable \(\mathbb {S}^n_m:\Omega \rightarrow \mathbb {R}^\varsigma \) then holds mean and variance estimates of the outputs of each layer of the approximating neural networks related to the minibatches that are used as inputs to the neural networks in computing the loss function at the corresponding gradient descent step.
4 Multilevel Picard approximation method for non-local PDEs
In this section we introduce in Framework 4.1 in Sect. 4.1 below our extension of the full history recursive multilevel Picard approximation method for approximating solutions of non-local nonlinear PDEs with Neumann boundary conditions. The MLP method was first introduced in E et al. [71] and Hutzenthaler et al. [69] and later extended in a number of directions; see E et al. [98] and Beck et al. [53] for recent surveys. We also refer the reader to Becker et al. [99] and E et al. [70] for numerical simulations illustrating the performance of MLP methods across a range of example PDE problems.
In Sect. 4.2 below, we will specify five concrete examples of (non-local) nonlinear PDEs and describe how Framework 4.1 can be specialized to compute approximate solutions to these example PDEs. These computations will be used in Sect. 5 to obtain reference values to compare the deep learning-based approximation method proposed in Sect. 3 above against.
4.1 Description of the proposed approximation method
Framework 4.1
(Multilevel Picard approximation method) Assume Framework 2.10, let \(c,T\in (0,\infty )\), \(\mathfrak {I}= \bigcup _{n\in \mathbb {N}} \mathbb {Z}^n\), \(f \in C([0,T]\times D \times D \times \mathbb {R}\times \mathbb {R},\mathbb {R})\), \(g\in C(D,\mathbb {R})\), \(u \in C([0,T]\times D, \mathbb {R})\), assume \(u\vert _{[0,T)\times D}\in C^{1,2}([0,T)\times D,\mathbb {R})\), let \(\nu _x :\mathcal {B}( D)\rightarrow [0,1]\), \(x \in D\), be probability measures, for every \(x \in D\) let \( Z^{\mathfrak {i}}_{ x } :\Omega \rightarrow D\), \(\mathfrak {i}\in \mathfrak {I}\), be i.i.d. random variables, assume for every \( A \in \mathcal {B}( D) \), \(\mathfrak {i}\in \mathfrak {I}\) that \(\mathbb {P}( Z_{ x }^{ \mathfrak {i}} \in A ) = \nu _x( A )\), for every \(r_1\in [-\infty ,\infty )\), \(r_2\in [r_1,\infty ]\) let \( \phi _{r_1,r_2} :\mathbb {R}\rightarrow \mathbb {R}\) satisfy for every \(y \in \mathbb {R}\) that
let \((\Omega ,\mathcal {F}, \mathbb {P})\) be a probability space, let \({\mathcal {V}}^\mathfrak {i}:\Omega \rightarrow (0,1),\) \(\mathfrak {i}\in \mathfrak {I}\), be independent \(\mathcal {U}_{(0,1)}\)-distributed random variables, let \(V^\mathfrak {i}:[0,T]\times \Omega \rightarrow [0,T]\), \(\mathfrak {i}\in \mathfrak {I}\), satisfy for every \(t\in [0,T]\), \(\mathfrak {i}\in \mathfrak {I}\) that
let \(W^\mathfrak {i}:[0,T]\times \Omega \rightarrow \mathbb {R}^d\), \(\mathfrak {i}\in \mathfrak {I}\), be independent standard Brownian motions, assume \(({\mathcal {V}}^\mathfrak {i})_{\mathfrak {i}\in \mathfrak {I}}\) and \((W^\mathfrak {i})_{\mathfrak {i}\in \mathfrak {I}}\) are independent, let \(\mu :\mathbb {R}^{d} \rightarrow \mathbb {R}^{d}\) and \(\sigma :\mathbb {R}^{d}\rightarrow \mathbb {R}^{d\times d}\) be globally Lipschitz continuous, for every \(x\in \mathbb {R}^{d}\), \(\mathfrak {i}\in \mathfrak {I}\), \(t\in [0,T]\) let \(X^{x,\mathfrak {i}}_{t} = (X^{x,\mathfrak {i}}_{t,s})_{s\in [t,T]} :[t,T] \times \Omega \rightarrow \mathbb {R}^d\) be a stochastic process with continuous sample paths, let \((K_{n,l,m})_{n,l,m\in \mathbb {N}_0} \subseteq \mathbb {N}\), for every \(\mathfrak {i}\in \mathfrak {I}\), \(n,M \in \mathbb {N}_0\), \(r_1\in [-\infty ,\infty )\), \(r_2\in [r_1,\infty ]\) let \(U^\mathfrak {i}_{n,M,r_1,r_2}:[0,T]\times \mathbb {R}^d\times \Omega \rightarrow \mathbb {R}^k\) satisfy for every \(t\in [0,T]\), \(x\in \mathbb {R}^d\) that
assume for every \(t \in [0,T)\), \(x \in \partial _D\) that \( \langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\), and assume for every \(t\in [0,T)\), \(x \in D\) that \(\Vert {u(t,x)} \Vert \le c(1+\Vert {x} \Vert ^{c})\), \(u(T,x) = g(x)\), and
4.2 Examples for the approximation method
Example 4.2
(Fisher–KPP PDEs with Neumann boundary conditions) In this example we specialize Framework 4.1 to the case of certain Fisher–KPP PDEs with Neumann boundary conditions (cf., e.g., Bian et al. [36] and Wang et al. [40]).
Assume Framework 4.1, let \(\epsilon \in (0,\infty )\), assume for every \(t \in [0,T]\), \(x,\textbf{x} \in D\), \(y,\textbf{y} \in \mathbb {R}\), \(v \in \mathbb {R}^d\) that \(g(x)= \exp \big (- \tfrac{1}{4}\Vert {x} \Vert ^2\big )\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v = \epsilon v\), and \(f(t,x,\textbf{x},y,\textbf{y})= y(1-y)\), and assume that for every \(x\in \mathbb {R}^{d}\), \(\mathfrak {i}\in \mathfrak {I}\), \(t\in [0,T]\), \(s\in [t,T]\) it holds \(\mathbb {P}\)-a.s. that
The solution \(u:[0,T]\times D\rightarrow \mathbb {R}\) of the PDE in (160) then satisfies that for every \(t\in [0,T)\), \(x\in \partial _D\) it holds that \(\langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\) and that for every \(t\in [0,T)\), \(x\in D\) it holds that \(u(T,x) = \exp (- \tfrac{1}{4}\Vert {x} \Vert ^2)\) and
Example 4.3
(Non-local competition PDEs) In this example we specialize Framework 4.1 to the case of certain non-local competition PDEs (cf., e.g., Doebeli and Ispolatov [47], Berestycki et al. [38], Perthame and Génieys [37], and Génieys et al. [42]).
Assume Framework 4.1, let \(\mathfrak s,\epsilon \in (0,\infty )\), assume for every \(x \in \mathbb {R}^d\), \(A \in \mathcal {B}(\mathbb {R}^d)\) that \(\nu _x(A) = \pi ^{-\nicefrac {d}{2}}\mathfrak {s}^{-d}\int _A \exp \bigl (-\mathfrak {s}^{-2}\Vert {x - \textbf{x}} \Vert ^2\bigr )\,\textrm{d}\textbf{x}\), assume for every \(t \in [0,T]\), \(v,x,\textbf{x} \in \mathbb {R}^d\), \(y,\textbf{y} \in \mathbb {R}\) that \(g(x)= \exp (- \tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v = \epsilon v\), and \(f(t,x,\textbf{x},y,\textbf{y})= y(1 -\textbf{y}\pi ^{\nicefrac {d}{2}}\mathfrak {s}^d)\), and assume that for every \(x\in \mathbb {R}^{d}\), \(\mathfrak {i}\in \mathfrak {I}\), \(t\in [0,T]\), \(s\in [t,T]\) it holds \(\mathbb {P}\)-a.s. that
The solution \(u:[0,T]\times \mathbb {R}^d \rightarrow \mathbb {R}\) of the PDE in (160) then satisfies that for every \(t\in [0,T)\), \(x\in \mathbb {R}^d\) it holds that \(u(T,x) = \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\) and
Example 4.4
(Non-local sine-Gordon PDEs) In this example we specialize Framework 4.1 to the case of certain non-local sine-Gordon type PDEs (cf., e.g., Hairer and Shen [9], Barone et al. [6], and Coleman [8]).
Assume Framework 4.1, let \(\mathfrak s,\epsilon \in (0,\infty )\) , assume for every \(x \in \mathbb {R}^d\), \(A \in \mathcal {B}(\mathbb {R}^d)\) that \(\nu _x(A) = \pi ^{-\nicefrac {d}{2}}\mathfrak {s}^{-d}\int _A \exp \left( -\mathfrak {s}^{-2}\Vert {x - \textbf{x}} \Vert ^2\right) \,\textrm{d}\textbf{x}\), assume for every \(t \in [0,T]\), \(v,x,\textbf{x} \in \mathbb {R}^d\), \(y,\textbf{y} \in \mathbb {R}\) that \(g(x)= \exp (- \tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v = \epsilon v\), and \(f(t,x,\textbf{x},y,\textbf{y})= \sin (y) -\textbf{y}\pi ^{\nicefrac {d}{2}}\mathfrak {s}^d\), and assume that for every \(x\in \mathbb {R}^{d}\), \(\mathfrak {i}\in \mathfrak {I}\), \(t\in [0,T]\), \(s\in [t,T]\) it holds \(\mathbb {P}\)-a.s. that
The solution \(u:[0,T]\times \mathbb {R}^d \rightarrow \mathbb {R}\) of the PDE in (160) then satisfies that for every \(t\in [0,T)\), \(x\in \mathbb {R}^d\) it holds that \(u(T,x) = \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\) and
Example 4.5
(Replicator-mutator PDEs) In this example we specialize Framework 4.1 to the case of certain d-dimensional replicator-mutator PDEs (cf., e.g., Hamel et al. [26]).
Assume Framework 4.1, let \(\mathfrak {m}_1, \mathfrak {m}_2, \dots ,\mathfrak {m}_d, \mathfrak {s}_1, \mathfrak {s}_2, \dots , \mathfrak {s}_d,\mathfrak {u}_1, \mathfrak {u}_2,\dots ,\mathfrak {u}_d \in \mathbb {R}\) , let \(a :\mathbb {R}^d \rightarrow \mathbb {R}\) satisfy for every \(x \in \mathbb {R}^d\) that \(a(x) = -\frac{1}{2}\Vert {x} \Vert ^2\), assume for every \(x \in \mathbb {R}^d\), \(A \in \mathcal {B}(\mathbb {R}^d)\) that \(\nu _x(A) = \int _{A\cap [-\nicefrac 12,\nicefrac 12]^d} \textrm{d}{\textbf{x}}\), assume for every \(t \in [0,T]\), \(v= (v_1,\dots ,v_d),\,x = (x_1,\dots ,x_d)\in \mathbb {R}^d\), \(\textbf{x} \in \mathbb {R}^d\), \(y,\textbf{y} \in \mathbb {R}\) that \(g(x)= (2\pi )^{-\nicefrac {d}{2}} \big [{\prod _{ i = 1 }^d |{\mathfrak {s}_i} |^{-\nicefrac {1}{2}}}\big ] \exp \big ({-\sum _{i = 1}^d \, \frac{(x_i - \mathfrak {u}_i )^2}{2\mathfrak {s}_i}}\big )\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x)v=(\mathfrak {m}_1 v_1, \dots , \mathfrak {m}_d v_d)\), and
and assume that for every \(x\in \mathbb {R}^{d}\), \(\mathfrak {i}\in \mathfrak {I}\), \(t\in [0,T]\), \(s\in [t,T]\) it holds \(\mathbb {P}\)-a.s. that
The solution \(u:[0,T]\times \mathbb {R}^d \rightarrow \mathbb {R}\) of the PDE in (160) then satisfies that for every \(t\in [0,T)\), \(x = (x_1,\dots ,x_d) \in \mathbb {R}^d\) it holds that \(u(T,x)= (2\pi )^{-\nicefrac {d}{2}}\big [{ \prod _{ i = 1 }^d |{\mathfrak {s}_i} |^{-\nicefrac {1}{2}}}\big ] \exp \big ({-\sum _{i = 1}^d \, \frac{(x_i - \mathfrak {u}_i )^2}{2\mathfrak {s}_i}}\big )\) and
Example 4.6
(Allen–Cahn PDEs with conservation of mass) In this example we specialize Framework 4.1 to the case of certain Allen–Cahn PDEs with cubic nonlinearity, conservation of mass, and no-flux boundary conditions (cf., e.g., Rubinstein and Sternberg [10]).
Assume Framework 4.1, let \(\epsilon \in (0,\infty )\) , assume for every \(x \in D\), \(A \in \mathcal {B}(D)\) that \(\nu _x(A) = \int _A \textrm{d}\textbf{x}\), assume for every \(t \in [0,T]\), \(x,\textbf{x} \in D\), \(y,\textbf{y} \in \mathbb {R}\), \(v \in \mathbb {R}^d\) that \(g(x)= \exp (- \tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v = \epsilon v\), and \(f(t,x,{\textbf{x}},y,{\textbf{y}})= y - y^3 - (\textbf{y} - {\textbf{y}}^3)\), and assume that for every \(x\in \mathbb {R}^{d}\), \(\mathfrak {i}\in \mathfrak {I}\), \(t\in [0,T]\), \(s\in [t,T]\) it holds \(\mathbb {P}\)-a.s. that
The solution \(u:[0,T]\times D\rightarrow \mathbb {R}\) of the PDE in (160) then satisfies that for every \(t\in [0,T)\), \(x\in \partial _D\) it holds that \(\langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\) and that for every \(t\in [0,T)\), \(x\in D\) it holds that \(u(T,x) = \exp (- \tfrac{1}{4}\Vert {x} \Vert ^2)\) and
5 Numerical simulations
In this section we illustrate the performance of the machine learning-based approximation method proposed in Framework 3.1 in Sect. 3.2 above by means of numerical simulations for five concrete (non-local) nonlinear PDEs; see Sects. 5.1, 5.2, 5.3, 5.4, and 5.5 below. In each of these numerical simulations we employ the general machine learning-based approximation method proposed in Framework 3.1 with certain 4-layer neural networks in conjunction with the Adam optimizer (cf. (175) and (176) in Framework 5.1 below and Kingma and Ba [96]).
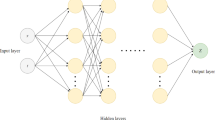
More precisely, in each of the numerical simulations in Sects. 5.1, 5.2, 5.3, 5.4, and 5.5 the functions \({\mathbb {V}}^{j,\textbf{s}}_n:\mathbb {R}^{\mathfrak d}\times \mathbb {R}^d\rightarrow \mathbb {R}\) with \( n \in \{ 1, 2, \dots , N\} \), \( j \in \{ 1, 2, \dots , 8000 \} \), \( \textbf{s} \in \mathbb {R}^{\varsigma }\) are implemented as N fully-connected feedforward neural networks. These neural networks consist of 4 layers (corresponding to 3 affine linear transformations in the neural networks) where the input layer is d-dimensional (with d neurons on the input layer), where the two hidden layers are both \((d+50)\)-dimensional (with \(d+50\) neurons on each of the two hidden layers), and where the output layer is 1-dimensional (with 1 neuron on the output layer). We refer to Fig. 2 for a graphical illustration of the neural network architecture used in the numerical simulations in Sects. 5.1, 5.2, 5.3, 5.4, and 5.5.

Graphical illustration of the neural network architecture used in the numerical simulations. In Sects. 5.1, 5.2, 5.3, 5.4, and 5.5 we employ neural networks with 4 layers (corresponding to 3 affine linear transformations in the neural networks) with d neurons on the input layer (corresponding to a d-dimensional input layer), with \(d + 50\) neurons on the 1st hidden layer (corresponding to a \((d+50)\)-dimensional 1st hidden layer), with \(d + 50\) neurons on the 2nd hidden layer (corresponding to a \((d+50)\)-dimensional 2nd hidden layer), and with 1 neuron on the output layer (corresponding to a 1-dimensional output layer) in the numerical simulations
As activation functions just in front of the two hidden layers we employ, in Sects. 5.1, 5.2, 5.3, and 5.4 below, multidimensional versions of the hyperbolic tangent function
and we employ, in Sect. 5.5 below, multidimensional versions of the ReLU function
In addition, in Sects. 5.1, 5.2, and 5.4 we use the square function and \( \mathbb {R}\ni x \mapsto x^2 \in \mathbb {R}\) as activation function just in front of the output layer and in Sects. 5.3 and 5.5 we use the identity function \( \mathbb {R}\ni x \mapsto x \in \mathbb {R}\) as activation function just in front of the output layer. Furthermore, we employ Xavier initialization to initialize all neural network parameters; see Glorot and Bengio [100] for details. We did not employ batch normalization in our simulations.
Each of the numerical experiments presented below was performed with the Julia library HighDimPDE.jl on a NVIDIA TITAN RTX GPU with 1350 MHz core clock and 24 GB GDDR6 memory with 7000 MHz clock rate where the underlying system consisted of an AMD EPYC 7742 64-core CPU with 2TB memory running Julia 1.7.2 on Ubuntu 20.04.3.
The algorithms proposed in Framework 3.1 and Sect. 4.1 have been implemented as a Julia library named HighDimPDE, which belongs to the SciML software ecosystem. The library is listed in the official registry of general Julia packages, and its source code can be accessed at https://github.com/SciML/HighDimPDE.jl. The exact source code we used for the simulations in this section is available from two sources: It is included (along with the source code of the library) in the arXiv version of this article available at https://arxiv.org/abs/2205.03672 where the source files can be downloaded by choosing “Other sources” under “Download” and then following the link “Download sources” (or using the URL https://arxiv.org/e-print/2205.03672). Additionally, the specific Julia source code used for the simulations in this section can be found in a dedicated Github repository located at https://github.com/vboussange/HighDimPDE_examples.
Framework 5.1
Assume Framework 3.1, assume \(\mathfrak {d}=(d+50)(d+1)+ (d+50)(d+51)+(d+51)\), let \(\varepsilon ,\beta _1,\beta _2\in \mathbb {R}\), \((\gamma _m)_{m\in \mathbb {N}}\subseteq (0,\infty )\) satisfy \(\varepsilon =10^{-8}\), \(\beta _1 = \tfrac{9}{10}\), and \(\beta _2 = \tfrac{999}{1000}\), let \(g:D \rightarrow \mathbb {R}\), \(\mu :D\rightarrow \mathbb {R}^d\), and \(\sigma :D\rightarrow \mathbb {R}^{d\times d}\) be continuous, let \(u=(u(t,x))_{(t,x) \in [0,T]\times D} \in C^{1,2}([0,T]\times D,\mathbb {R})\) have at most polynomially growing partial derivatives, assume for every \(t\in (0,T]\), \(x\in \partial _D\) that \( \langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\), assume for every \(t\in [0,T]\), \(x\in D\), \(j \in \mathbb {N}\), \(\textbf{s} \in \mathbb {R}^\varsigma \) that \(u(0,x)=g(x) = \mathbb V^{ j, \textbf{s} }_0( \theta , x )\), \(\int _D\big |{f\big ({t,x,\textbf{x}, u(t,x),u(t,\textbf{x}) }\big ) }\big | \, \nu _x(\textrm{d}\textbf{x}) < \infty \), and
assume for every \(m\in \mathbb {N}\), \(i\in \{0,1,\ldots ,N\} \) that \( J_m = 8000\), \( t_i = \tfrac{iT}{N} \), and \( \varrho = 2 \mathfrak {d} \), and assume for every \(n \in \{1,2,\dots ,N\}\), \(m\in \mathbb {N}\), \(x=(x_1, \ldots , x_{\mathfrak {d}})\), \(y=(y_1, \ldots , y_{\mathfrak {d}})\), \(\eta = ( \eta _1, \ldots , \eta _{\mathfrak {d}} )\in \mathbb {R}^{\mathfrak {d}}\) that
and
In Sects. 5.1, 5.2, 5.3, 5.4, and 5.5 below, we use the machine learning-based approximation method in Framework 5.1 to approximately calculate the solutions to a variety of PDEs with a non-local term and/or Neumann boundary conditions in dimension \(d\in \{1,2,5,10\}\) and with time horizon \(T\in \{\nicefrac 15,\nicefrac 12,1\}\). We evaluate these approximations by comparing them to a reference solution. Specifically, in Sects. 5.1, 5.2, 5.3, and 5.5 we use the multilevel Picard approximation method presented in Framework 4.1 to compute an approximation for \(u(T,(0,\dots ,0))\) which we use as the reference solution to approximate the unknown exact solution \(u(T,(0,\dots ,0))\). For the PDEs treated in Sect. 5.4 we can compute the exact solution directly and use this exact solution as the reference solution. In all cases, we run the simulation 5 times, for each value of d and for each value of T, thus obtaining 5 independent realizations of the random variable \( {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},(0,\ldots ,0)) \). We use these to approximately compute and report, in Tables 1, 2, 3, 4, and 7 below, the mean
the standard deviation
the relative \(L^1\)-approximation error
the standard deviation
of the relative \(L^1\)-approximation error, as well as the average of the runtimes of the 5 independent runs. This runtime is measured from the start of the training of the first neural network until the end of the training of the final neural network (note that the time required for the evaluation of the neural networks is negligible).
5.1 Fisher–KPP PDEs with Neumann boundary conditions
In this subsection we use the machine learning-based approximation method in Framework 5.1 to approximately calculate the solutions of certain Fisher–KPP PDEs with Neumann boundary conditions (cf., e.g., Bian et al. [36] and Wang et al. [40]).
Assume Framework 5.1, let \(\epsilon \in (0,\infty )\) satisfy \(\epsilon = \tfrac{1}{10}\), assume \(d\in \{1,2,5,10\}\), \(D = [-\nicefrac {1}{2},\nicefrac {1}{2}]^d\), \(T\in \{\nicefrac {1}{5},\nicefrac {1}{2},1\}\), \(N=10\), \(K_1 = K_2 = \ldots = K_N= 1\), and \(M_1 = M_2 = \ldots = M_N = 500\), assume for every \(n,m,j\in \mathbb {N}\), \(\omega \in \Omega \) that \(\xi ^{n,m,j}(\omega )=(0,\dots ,0)\), assume for every \(m \in \mathbb {N}\) that \(\gamma _m = 10^{-2}\), and assume for every \(s,t \in [0,T]\), \(x,\textbf{x} \in D\), \(y,\textbf{y} \in \mathbb {R}\), \(v \in \mathbb {R}^d\) that \(g(x)= \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v =\epsilon v\), \(f(t,x,\textbf{x},y,\textbf{y} )= y(1-y)\), and
(cf. (139) and (150)). The solution \(u:[0,T]\times D\rightarrow \mathbb {R}\) of the PDE in (174) then satisfies that for every \(t\in (0,T]\), \(x\in \partial _D\) it holds that \(\langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\) and that for every \(t\in [0,T]\), \(x\in D\) it holds that \(u(0,x) = \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\) and
In (182) the function \(u:[0,T]\times D\rightarrow \mathbb {R}\) models the proportion of a particular type of alleles in a biological population spatially structured over D. For every \(t\in [0,T]\), \(x\in \mathbb {R}^d\) the number \(u(t,x) \in \mathbb {R}\) describes the proportion of individuals with a particular type of alleles located at position \(x = (x_1, \dots , x_d) \in \mathbb {R}^d\) at time \(t \in [0,T]\).
For each choice of \(d\in \{1,2,5,10\}\) and \(T\in \{\nicefrac 15,\nicefrac 12,1\}\) we approximate the unknown value \(u(T,(0,\dots ,0))\) by computing 5 independent realizations of \( {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},(0,\ldots ,0)) \). We report in Table 1 approximations of the mean and the standard deviation of this random variable as well as approximations of the relative \( L^1 \)-approximation error and the uncorrected sample standard deviation of the approximation error (see the discussion below Framework 5.1 for more details). For the latter two statistics, the reference value which is used as an approximation for the unknown value \(u(T,(0,\ldots ,0))\) of the exact solution of the PDE in (182) is computed via the MLP approximation method for non-local nonlinear PDEs in Framework 4.1 as described in Example 4.2 (cf. Beck et al. [101, Remark 3.3]). More precisely, we apply Example 4.2 with \(d\in \{1,2,5,10\}\), \(T\in \{\nicefrac 15, \nicefrac 12, 1\}\), \(D=[-\nicefrac 12,\nicefrac 12]^d\), \(\epsilon =\frac{1}{10}\) in the notation of Example 4.2 and we use the mean of 5 independent realizations of \(U^{(0)}_{5,5,0,\infty }(0,(0,\dots ,0))\) as the reference value.
5.2 Non-local competition PDEs
In this subsection we use the machine learning-based approximation method in Framework 5.1 to approximately calculate the solutions of certain non-local competition PDEs (cf., e.g., Doebeli and Ispolatov [47], Berestycki et al. [38], Perthame and Génieys [37], and Génieys et al. [42]).
Assume Framework 5.1, let \(\mathfrak s,\epsilon \in (0,\infty )\) satisfy \(\mathfrak {s} = \epsilon =\tfrac{1}{10}\), assume \(d\in \{1,2,5,10\}\), \(D= \mathbb {R}^d\), \(T\in \{\nicefrac {1}{5},\nicefrac {1}{2},1\}\), \(N=10\), \(K_1 = K_2 = \cdots = K_N= 1\), and \(M_1 = M_2 = \cdots = M_N = 500\), assume for every \(n,m,j\in \mathbb {N}\), \(\omega \in \Omega \) that \(\xi ^{n,m,j}(\omega )=(0,\dots ,0)\), assume for every \(m \in \mathbb {N}\) that \(\gamma _m = 10^{-2}\), and assume for every \(s,t \in [0,T]\), \(v,x,\textbf{x}\in \mathbb {R}^d\), \(y,\textbf{y} \in \mathbb {R}\), \(A \in \mathcal {B}(\mathbb {R}^d)\) that \(\nu _x(A) = \pi ^{-\nicefrac {d}{2}}\mathfrak {s}^{-d}\int _A \exp \big (-\mathfrak {s}^{-2}\Vert {x - \textbf{x}} \Vert ^2\big )\,\textrm{d}\textbf{x}\), \(g(x)= \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v=\epsilon v\), \(f(t,x,\textbf{x},y,\textbf{y})= y(1 - \textbf{y} \mathfrak {s}^d\pi ^{\nicefrac {d}{2}})\), and
(cf. (139) and (150)). The solution \(u:[0,T]\times \mathbb {R}^d \rightarrow \mathbb {R}\) of the PDE in (174) then satisfies that for every \(t\in [0,T]\), \(x\in \mathbb {R}^d\) it holds that \(u(0,x)=\exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\) and
In (184) the function \(u:[0,T]\times \mathbb {R}^d\rightarrow \mathbb {R}\) models the evolution of a population characterized by a set of d biological traits under the combined effects of selection, competition, and mutation. For every \(t\in [0,T]\), \(x\in \mathbb {R}^d\) the number \(u(t,x) \in \mathbb {R}\) describes the number of individuals with traits \(x = (x_1, \dots , x_d) \in \mathbb {R}^d\) at time \(t \in [0,T]\).
For each choice of \(d\in \{1,2,5,10\}\) and \(T\in \{\nicefrac 15,\nicefrac 12,1\}\) we approximate the unknown value \(u(T,(0,\dots ,0))\) by computing 5 independent realizations of \( {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},(0,\ldots ,0)) \). We report in Table 2 approximations of the mean and the standard deviation of this random variable as well as approximations of the relative \( L^1 \)-approximation error and the uncorrected sample standard deviation of the approximation error (see the discussion below Framework 5.1 for more details). For the latter two statistics, the reference value which is used as an approximation for the unknown value \(u(T,(0,\ldots ,0))\) of the exact solution of the PDE in (184) is computed via the MLP approximation method for non-local nonlinear PDEs in Framework 4.1 as described in Example 4.3 (cf. Beck et al. [101, Remark 3.3]). More precisely, we apply Example 4.3 with \(d\in \{1,2,5,10\}\), \(T\in \{\nicefrac 15, \nicefrac 12, 1\}\), \(D=\mathbb {R}^d\), \(\mathfrak s=\epsilon =\frac{1}{10}\) in the notation of Example 4.3 and we use the mean of 5 independent realizations of \(U^{(0)}_{5,5,0,\infty }(0,(0,\dots ,0))\) as the reference value.
5.3 Non-local sine-Gordon type PDEs
In this subsection we use the machine learning-based approximation method in Framework 5.1 to approximately calculate the solutions of non-local sine-Gordon type PDEs (cf., e.g., Hairer and Shen [9], Barone et al. [6], and Coleman [8]).
Assume Framework 5.1, let \(\mathfrak s,\epsilon \in (0,\infty )\) satisfy \(\mathfrak {s} = \epsilon =\tfrac{1}{10}\), assume \(d\in \{1,2,5,10\}\), \(D= \mathbb {R}^d\), \(T\in \{\nicefrac {1}{5},\nicefrac {1}{2},1\}\), \(N=10\), \(K_1 = K_2 = \cdots = K_N= 1\), and \(M_1 = M_2 = \cdots = M_N = 500\), assume for every \(n,m,j\in \mathbb {N}\), \(\omega \in \Omega \) that \(\xi ^{n,m,j}(\omega )=(0,\dots ,0)\), assume for every \(m \in \mathbb {N}\) that \(\gamma _m = 10^{-3}\), and assume for every \(s,t \in [0,T]\), \(v,x,\textbf{x} \in \mathbb {R}^d\), \(y,\textbf{y} \in \mathbb {R}\), \(A \in \mathcal {B}(\mathbb {R}^d)\) that \(\nu _x(A) = \pi ^{-\nicefrac {d}{2}}\mathfrak {s}^{-d}\int _A \exp \big (-\mathfrak {s}^{-2}\Vert {x - \textbf{x}} \Vert ^2\big )\,\textrm{d}\textbf{x}\), \(g(x)= \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x) v = \epsilon v\), \(f(t,x,\textbf{x},y,\textbf{y})= \sin (y) - \textbf{y} \pi ^{\nicefrac {d}{2}}\mathfrak {s}^d\), and
(cf. (139) and (150)). The solution \(u:[0,T]\times \mathbb {R}^d \rightarrow \mathbb {R}\) of the PDE in (174) then satisfies that for every \(t\in [0,T]\), \(x\in \mathbb {R}^d\) it holds that \(u(0,x)=\exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\) and
For each choice of \(d\in \{1,2,5,10\}\) and \(T\in \{\nicefrac 15,\nicefrac 12,1\}\) we approximate the unknown value \(u(T,(0,\dots ,0))\) by computing 5 independent realizations of \( {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},(0,\ldots ,0)) \). We report in Table 3 approximations of the mean and the standard deviation of this random variable as well as approximations of the relative \( L^1 \)-approximation error and the uncorrected sample standard deviation of the approximation error (see the discussion below Framework 5.1 for more details). For the latter two statistics, the reference value which is used as an approximation for the unknown value \(u(T,(0,\ldots ,0))\) of the exact solution of the PDE in (186) is computed via the MLP approximation method for non-local nonlinear PDEs in Framework 4.1 as described in Example 4.4 (cf. Beck et al. [101, Remark 3.3]). More precisely, we apply Example 4.4 with \(d\in \{1,2,5,10\}\), \(T\in \{\nicefrac 15, \nicefrac 12, 1\}\), \(D=\mathbb {R}^d\), \(\mathfrak s=\epsilon =\frac{1}{10}\) in the notation of Example 4.4 and we use the mean of 5 independent realizations of \(U^{(0)}_{5,5,-\infty ,\infty }(0,(0,\dots ,0))\) as the reference value.
5.4 Replicator-mutator PDEs
In this subsection we use both the machine learning-based approximation method in Framework 5.1 and the MLP approximation method in Framework 4.1 to approximately calculate the solutions of certain replicator-mutator PDEs describing the dynamics of a phenotype distribution under the combined effects of selection and mutation (cf., e.g., Hamel et al. [26]). The solutions to the PDEs we are trying to approximate in this subsection can be represented explicitly (cf., e.g., Lemma 5.2 below). The gives us the opportunity to compare the performance of the two approximation methods presented here and it also allows us to evaluate the capability of the machine learning-based approximation method in Framework 5.1 to produce approximations on an entire subset of the domain.
Exact solutions. The following results, Lemma 5.2 below, give an explicit representation of the exact solutions of certain replicator-mutator PDEs. In (190) the function \(u:[0,T]\times \mathbb {R}^d\rightarrow \mathbb {R}\) models the evolution of the phenotype distribution of a population composed of a set of d biological traits under the combined effects of selection and mutation. For every \(t\in [0,T]\), \(x\in \mathbb {R}^d\) the number \(u(t,x) \in \mathbb {R}\) describes the number of individuals with traits \(x = (x_1, \dots , x_d) \in \mathbb {R}^d\) at time \(t \in [0,T]\). The function a models a quadratic fitness function.
Lemma 5.2
Let \(d \in \mathbb {N}\), \(\mathfrak {u}_1,\mathfrak {u}_2, \dots ,\mathfrak {u}_d\in \mathbb {R}\), \(\mathfrak {m}_1,\mathfrak {m}_2, \dots ,\mathfrak {m}_d, \mathfrak {s}_1,\mathfrak {s}_2, \dots ,\mathfrak {s}_d \in (0,\infty )\), let \(a :\mathbb {R}^d \rightarrow \mathbb {R}\) satisfy for every \(x \in \mathbb {R}^d\) that \(a(x) = -\frac{1}{2} \Vert {x} \Vert ^2\), for every \(i \in \{1,2,\dots ,d\}\) let \(\mathfrak {S}_i :[0,\infty ) \rightarrow (0,\infty )\) and \(\mathfrak {U}_i :[0,\infty ) \rightarrow \mathbb {R}\) satisfy for every \(t \in [0,\infty )\) that
and let \(u :[0,\infty ) \times \mathbb {R}^d \rightarrow \mathbb {R}\) satisfy for every \(t \in [0,\infty )\), \(x = (x_1,\dots ,x_d)\in \mathbb {R}^d\) that
Then
-
(i)
it holds that \(u \in C^{1,2}([0,\infty )\times \mathbb {R}^d,\mathbb {R})\),
-
(ii)
it holds for every \(x = (x_1,\dots ,x_d)\in \mathbb {R}^d\) that
$$\begin{aligned} u(0,x) = (2\pi )^{-\nicefrac {d}{2}} \left[ {\prod _{ i = 1 }^d |{\mathfrak {s}_i} |^{-\nicefrac {1}{2}}}\right] \exp \bigg (-\sum _{i = 1}^d \frac{(x_i - \mathfrak {u}_i )^2}{2\mathfrak {s}_i}\bigg ),\nonumber \\ \end{aligned}$$(189)and
-
(iii)
it holds for every \(t \in [0,\infty )\), \(x = (x_1,\dots ,x_d)\in \mathbb {R}^d\) that
$$\begin{aligned} \big ({\tfrac{\partial }{\partial t}u}\big ) (t,x) = u(t,x)\Bigg (a(x) - \int _{\mathbb {R}^d} u(t,\textbf{x})\, a(\textbf{x}) \, \textrm{d}\textbf{x}\Bigg ) + \sum _{i=1}^{d} \tfrac{1}{2} |{\mathfrak {m}_i} |^2\big ({\tfrac{\partial ^2 }{\partial x_i^2} u}\big ) (t,x) . \end{aligned}$$(190)
Proof of Lemma 5.2
First, note that the fact that for every \(i \in \{1,2,\dots ,d\}\) it holds that \(\mathfrak {S}_i \in C^{\infty }([0,\infty ),(0,\infty ))\), the fact that for every \(i \in \{1,2,\dots ,d\}\) it holds that \(\mathfrak {U}_i \in C^{\infty }([0,\infty ),\mathbb {R}) \), and (188) establish item (i). Moreover, observe that the fact that for every \(i \in \{1,2,\dots ,d\}\) it holds that \(\mathfrak {S}_i(0) = \mathfrak {s}_i\), the fact that for every \(i \in \{1,2,\dots ,d\}\) it holds that \(\mathfrak {U}_i(0) = \mathfrak {u}_i\), and (187) prove item (ii). Next note that (188) ensures that for every \(t \in [0,\infty )\), \(x = (x_1,\dots ,x_d)\in \mathbb {R}^d\) it holds that
The product rule hence implies that for every \(t \in [0,\infty )\), \(x = (x_1,\dots ,x_d)\in \mathbb {R}^d\) it holds that
The chain rule, the product rule, and (191) therefore show that for every \(t \in [0,\infty )\), \(x = (x_1,\dots ,x_d)\in \mathbb {R}^d\) it holds that
Moreover, observe that (187), the chain rule, and the product rule ensure that for every \(i \in \{1, \dots ,d\}\), \(t \in [0,\infty )\) it holds that
and
Combining this with (193) implies that for every \(i \in \{1, 2,\dots ,d\}\), \(t \in [0,\infty )\) it holds that
Furthermore, note that (191) and the product rule show that for every \(i \in \{1,2, \dots ,d\}\), \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
The product rule therefore assures that for every \(i \in \{1,2, \dots ,d\}\), \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
Hence, we obtain that for every \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
Next observe that (191) and Fubini’s theorem ensure that for every \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
This and the fact that for every \(i \in \{1,2, \dots , d\}\), \(t \in [0,\infty )\) it holds that
imply that for every \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
Next observe that the integral transformation theorem demonstrates that for every \(i \in \{1,2, \dots ,d\}\), \(t \in [0,\infty )\) it holds that
Combining this with (202) ensures that for every \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
This and (199) demonstrate that for every \(t \in [0,\infty )\), \(x = (x_1, \dots ,x_d)\in \mathbb {R}^d\) it holds that
Combining this with (196) proves item (iii). The proof of Lemma 5.2 is thus complete. \(\square \)
Machine-learning based approximations. Assume Framework 5.1, let \(\mathcal D\subseteq \mathbb {R}^d\), \(\mathfrak {m}_1,\mathfrak {m}_2,\dots ,\mathfrak {m}_d,\mathfrak {s}_1,\mathfrak {s}_2,\dots ,\mathfrak {s}_d,\mathfrak {u}_1, \mathfrak {u}_2, \dots ,\mathfrak {u}_d,\mathfrak t \in \mathbb {R}\) satisfy for every \(k \in \{1,2,\dots ,d\}\) that \(\mathfrak {m}_k = \tfrac{1}{10}\), \(\mathfrak {s}_k = \tfrac{1}{20}\), \(\mathfrak {u}_k = 0\), and \(\mathfrak t=\tfrac{1}{50}\), assume \(d\in \{1,2,5,10\}\), \(D= \mathbb {R}^d\), \(T\in \{\nicefrac 1{10},\nicefrac {1}{5},\nicefrac {1}{2}\}\), \(N=10\), \(K_1 = K_2 = \cdots = K_N= 1\), let \(a\in C(\mathbb {R}^d,\mathbb {R})\), \(\delta \in C(\mathbb {R}^d,(0,\infty ))\) satisfy for every \(x \in \mathbb {R}^d\) that \(a(x) = -\frac{1}{2}\Vert {x} \Vert ^2\), and assume for every \(s,t \in [0,T]\), \(v= (v_1,\dots ,v_d),\,x = (x_1,\dots ,x_d)\in \mathbb {R}^d\), \(\textbf{x} \in \mathbb {R}^d\), \(y,\textbf{y} \in \mathbb {R}\), \(A\in \mathcal {B}(\mathbb {R}^d)\) that \(\nu _x(A)=\int _{A\cap \mathcal D}\delta (\textbf{x})\,\textrm{d}\textbf{x}\), \(g(x)= (2\pi )^{-\nicefrac {d}{2}}\big [{ \prod _{ i = 1 }^d |{\mathfrak {s}_i} |^{-\nicefrac {1}{2}}}\big ] \exp \big ({-\sum _{i = 1}^d \frac{(x_i - \mathfrak {u}_i )^2}{2\mathfrak {s}_i}}\big )\), \(\mu (x)=(0,\dots ,0)\), \(\sigma (x)v=(\mathfrak {m}_1 v_1, \dots , \mathfrak {m}_d v_d)\), \(f(t,x,\textbf{x},y,\textbf{y}) = y(a(x)-\textbf{y a}(\textbf{x})[\delta (\textbf{x})]^{-1})\), and
(cf. (139) and (150)). The solution \(u:[0,T]\times \mathbb {R}^d \rightarrow \mathbb {R}\) of the PDE in (174) then satisfies that for every \(t\in [0,T]\), \(x = (x_1, \dots , x_d) \in \mathbb {R}^d\) it holds that
and
For Table 4, we approximate for each choice of \(d\in \{1,2,5,10\}\) and \(T\in \{\nicefrac 15,\nicefrac 12,1\}\) the value \(u(T,(0,\dots ,0))\) by computing 5 independent realizations of \( {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},(0,\ldots ,0)) \). We report in Table 4 approximations of the mean and the standard deviation of this random variable as well as approximations of the relative \( L^1 \)-approximation error and the uncorrected sample standard deviation of the approximation error (see the discussion below Framework 5.1 for more details). For the latter two statistics, the reference value \(u(T,(0,\ldots ,0))\) has been calculated using Lemma 5.2 above which provides an explicit representation of the exact solution of the PDE in (208).
In Table 5 we report statistics on the capability of the approximation method in Framework 3.1 to approximate the solution of the PDE in (208) on an entire subset of the domain. More specifically, for Table 5, we approximate for each choice of \(d\in \{1,2,5,10\}\) and \(T\in \{\nicefrac 1{10},\nicefrac 15,\nicefrac 12\}\) the function \([-1,1]^d\ni x\mapsto u(T,x)\in \mathbb {R}\) by computing 5 independent realizations of \( [-1,1]^d\ni x\mapsto {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},x)\in \mathbb {R}\). We report in Table 4 an estimate of the \(L^2\)-approximation error
and of the standard deviation
of the error. The integrals appearing in (209) and (210) have been computed by means of a standard Monte Carlo approximation using the exact solution of the PDE as provided by Lemma 5.2 above.

Plot of a machine learning-based approximation of the solution of the replicator-mutator PDE in (208) in the case \(d=5\), \(T=\nicefrac 12\), and \(\mathcal D=\mathbb {R}^d\). The left-hand side shows a plot of \([-\nicefrac {1}{4}, \nicefrac {1}{4}] \ni x \mapsto {\mathbb {V}}_n^{1,0}(\Theta ^n_{M_n}(\omega ),(x, 0, \dots ,0)) \in \mathbb {R}\) for \(n\in \{0,1,2,3\}\) and one realization \(\omega \in \Omega \) where the functions \(\mathbb {R}^d\ni x\mapsto {\mathbb {V}}_n^{1,0}(\Theta ^n_{M_n}(\omega ),x)\in \mathbb {R}\) for \(n\in \{0,1,2,3\}\), \(\omega \in \Omega \) were computed via Framework 5.1 as an approximation of the solution of the PDE in (208) with \(d=5\), \(T=\nicefrac 12\), and \(\mathcal D=[-\nicefrac 12,\nicefrac 12]^d\) where we take \(M_1=M_2=\cdots =M_N=2000\), \(\gamma _1=\gamma _2=\cdots =\gamma _{2000}=\nicefrac {1}{200}\), and \(\delta =\mathbb {1}_{\mathbb {R}^d}\) and where we take \(\xi ^{n,m,j}:\Omega \rightarrow \mathbb {R}^d\), \(n, m, j \in \mathbb {N}\), to be independent \(\mathcal {U}_{[-\nicefrac {1}{2},\nicefrac {1}{2}]^d}\)-distributed random variables. The right-hand side of Fig. 3 shows a plot of \([-\nicefrac {1}{4}, \nicefrac {1}{4}] \ni x \mapsto u(t, (x, 0, \dots ,0)) \in \mathbb {R}\) for \(t\in \{0,0.05,0.1,0.15\}\) where u is the exact solution of the PDE in (208) with \(d=5\), \(T=\nicefrac 12\), and \(\mathcal D=\mathbb {R}^d\)
Figure 3 provides a graphical illustration of an approximation to a solution of the PDEs in (208) computed by means of the the method in Framework 5.1 compared to the exact solution. More specifically, in Fig. 3 we use the machine learning-based method in Framework 5.1 to approximate the solution \(u:[0,T]\times \mathbb {R}^d\rightarrow \mathbb {R}\) of the PDE in (208) above with \(d=5\), \(T=\nicefrac 12\), and \(\mathcal D=\mathbb {R}^d\). The right-hand side of Fig. 3 shows a plot of \([-\nicefrac {1}{4}, \nicefrac {1}{4}] \ni x \mapsto u(t, (x, 0, \dots ,0)) \in \mathbb {R}\) for \(t\in \{0,0.05,0.1,0.15\}\) where u is the exact solution of the PDE in (208) with \(d=5\), \(T=\nicefrac 12\), and \(\mathcal D=\mathbb {R}^d\) computed via (188) in Lemma 5.2 below. The left-hand side of Fig. 3 shows a plot of \([-\nicefrac {1}{4}, \nicefrac {1}{4}] \ni x \mapsto {\mathbb {V}}_n^{1,0}(\Theta ^n_{M_n}(\omega ),(x, 0, \dots ,0)) \in \mathbb {R}\) for \(n\in \{0,1,2,3\}\) and one realization \(\omega \in \Omega \) where the functions \(\mathbb {R}^d\ni x\mapsto {\mathbb {V}}_n^{1,0}(\Theta ^n_{M_n}(\omega ),x)\in \mathbb {R}\) for \(n\in \{0,1,2,3\}\), \(\omega \in \Omega \) were computed via Framework 5.1 as an approximation of the solution of the PDE in (208) with \(d=5\), \(T=\nicefrac 12\), and \(\mathcal D=[-\nicefrac 12,\nicefrac 12]^d\). For the approximation, we take \(M_1=M_2=\cdots =M_N=2000\), \(\gamma _1=\gamma _2=\cdots =\gamma _{2000}=\nicefrac {1}{200}\), and \(\delta =\mathbb {1}_{\mathbb {R}^d}\) and we take \(\xi ^{n,m,j}:\Omega \rightarrow \mathbb {R}^d\), \(n, m, j \in \mathbb {N}\), to be independent \(\mathcal {U}_{[-\nicefrac {1}{2},\nicefrac {1}{2}]^d}\)-distributed random variables. Note that the solution of the PDE in (208) in the case \(\mathcal D=[-R,R]^d\) with \(R\in (0,\infty )\) sufficiently large is a good approximation of the solution \(u:[0,T]\times \mathbb {R}^d\rightarrow \mathbb {R}\) of the PDE in (208) in the case \(\mathcal D=\mathbb {R}^d\) since we have that for every \(t\in [0,T]\) the value u(t, x) of the solution u of the PDE in (208) in the case \(\mathcal D=\mathbb {R}^d\) sufficiently quickly tends to 0 as \(\Vert {x} \Vert \) tends to \(\infty \).
MLP approximations.
For Table 6, we use the approximation method presented in Framework 4.1 to compute approximations of the PDEs in (208) by applying Example 4.5 with \(\mathfrak m_1=\mathfrak m_2=\cdots =\mathfrak m_d=\frac{1}{10}\), \(\mathfrak s_1=\mathfrak s_2=\cdots =\mathfrak s_d=\frac{1}{20}\), and \(\mathfrak u_1=\mathfrak u_2=\cdots =\mathfrak u_d=0\). We compute 5 independent realizations of \( U^{(0)}_{5,5,0,\infty }(0,(0,\dots ,0)) \) as approximations of the value at (0, x) of the solution u of the PDE in (166) in Example 4.5 above (note that this is the value at \((T,x)\in [0,T]\times \mathbb {R}^d\) of the solution u of the PDE in (208) above; cf., e.g., Beck et al. [101, Remark 3.3]). Based on these realizations, we report in Table 6 approximations of the mean and the standard deviation of the random variable \( U^{(0)}_{5,5,0,\infty }(0,(0,\dots ,0)) \) as well as approximations of the relative \( L^1 \)-approximation error and the uncorrected sample standard deviation of the approximation error. For the latter two statistics, the reference value has been calculated using Lemma 5.2 above which provides an explicit representation of the exact solution of the PDE in (208) above (and hence of the exact solution of the PDE in (166) in Example 4.5 above).
Comparison of the two methods.
In Fig. 4 below we compare the performance of the machine learning-based approximation method in Framework 5.1 to the MLP approximation method in Framework 4.1 when computing approximations to the solution of the PDE in (208) with \(d=5\), \(\mathcal D=[-1,1]^d\), and \(T=0.2\). A straightforward runtime comparison between these two methods is difficult, as the machine learning-based method is highly parallelizable, with our simulations running to a large part on the GPU, whereas the MLP approximation method cannot be parallelized as easily and in our simulations is performed entirely on the CPU. As a consequence, comparisons of the runtimes to a large degree reflect the relative performance of the GPU compared to the CPU of the test system. In Fig. 4 we instead use the number of evaluations of one-dimensional standard normal random variables as a proxy for the complexity and we plot this measure against the relative \(L^1\)-approximation error of the approximation method. For the MLP approximation method, we obtained the four different measurements by computing 5 realizations each of \( U^{(0)}_{n,n,0,\infty }(0,(0,\dots ,0)) \) for \(n\in \{2,3,4,5\}\). For the machine learning-based approximation method in Framework 5.1, we similarly obtained the four different measurements by computing 5 realizations each of \(\mathbb {V}^{1,0}_{N}(\Theta ^N_{M_N},(0,\dots ,0))\) varying the number of time steps (with \(N\in \{1,2,3,4\}\)), the number of neurons in each of the two hidden layers (with the number of neurons in each hidden layer chosen from \(\{10, 20, 30, 40\}\)), and the batch sizes (with \(\forall \,k\in \mathbb {N}:J_k=J_1\in \{10^1,10^2,10^3,10^4\}\)).

5.5 Allen–Cahn PDEs with conservation of mass
In this subsection we use the machine learning-based approximation method in Framework 5.1 to approximately calculate the solutions of certain Allen–Cahn PDEs with cubic nonlinearity, conservation of mass, and no-flux boundary conditions (cf., e.g., Rubinstein and Sternberg [10]).
Assume Framework 5.1, let \(\epsilon \in (0,\infty )\) satisfy \(\epsilon = \tfrac{1}{10}\), assume \(d\in \{1,2,5,10\}\), \(D= [-\nicefrac 12,\nicefrac 12]^d\), \(T\in \{\nicefrac {1}{5},\nicefrac {1}{2},1\}\), \(N=10\), \(K_1 = K_2 = \cdots = K_N= 5\), and \(M_1 = M_2 = \cdots = M_N = 500\), assume \(\xi ^{n,m,j}, n, m, j \in \mathbb {N}\), are independent \(\mathcal {U}_{D}\)-distributed random variables, assume for every \(m \in \mathbb {N}\) that \(\gamma _m =10^{-2}\), and assume for every \(s,t \in [0,T]\), \(x,\textbf{x}\in D\), \(y,\textbf{y} \in \mathbb {R}\), \(v\in \mathbb {R}^d\), \(A \in \mathcal {B}(D)\) that \(\nu _x(A) = \int _A \textrm{d}\textbf{x}\), \(g(x)= \exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\), \(\mu (x)=(0, \dots , 0)\), \(\sigma (x) v = \epsilon v\), \(f(t,x,\textbf{x},y,\textbf{y})= y - y^3 - \big ( \textbf{y} - \textbf{y}^3\big )\), and
(cf. (139) and (150)). The solution \(u:[0,T]\times D\rightarrow \mathbb {R}\) of the PDE in (174) then satisfies that for every \(t\in (0,T]\), \(x\in \partial _D\) it holds that \(\langle {\textbf{n}(x) ,(\nabla _x u)(t,x)} \rangle = 0\) and that for every \(t\in [0,T]\), \(x\in D\) it holds that \(u(0,x)=\exp (-\tfrac{1}{4}\Vert {x} \Vert ^2)\) and
For each choice of \(d\in \{1,2,5,10\}\) and \(T\in \{\nicefrac 15,\nicefrac 12,1\}\) we approximate the unknown value \(u(T,(0,\dots ,0))\) by computing 5 independent realizations of \( {\mathbb {V}}^{1,0}_N(\Theta ^N_{M_N},(0,\ldots ,0)) \). We report in Table 7 approximations of the mean and the standard deviation of this random variable as well as approximations of the relative \( L^1 \)-approximation error and the uncorrected sample standard deviation of the approximation error (see the discussion below Framework 5.1 for more details). For the latter two statistics, the reference value which is used as an approximation for the unknown value \(u(T,(0,\ldots ,0))\) of the exact solution of the PDE in (212) is computed via the MLP approximation method for non-local nonlinear PDEs in Framework 4.1 as described in Example 4.6 (cf. Beck et al. [101, Remark 3.3]). More precisely, we apply Example 4.6 with \(d\in \{1,2,5,10\}\), \(T\in \{\nicefrac 15, \nicefrac 12, 1\}\), \(D=[-\nicefrac 12,\nicefrac 12]^d\) in the notation of Example 4.6 and we use the mean of 5 independent realizations of \(U^{(0)}_{5,5,0,\infty }(0,(0,\dots ,0))\) as the reference value.

Influence of various hyperparameters on the performance of the machine learning-based approximation method
5.6 Influence of hyperparameters
For both the machine learning-based approximation method and the MLP approximation method proposed above, several hyperparameters need to be chosen. More precisely, for the machine learning-based approximation method described in Framework 3.1, we need, e.g., to decide on the number of discrete time steps used in the approximation (denoted by \(N\in \mathbb {N}\) in Framework 3.1 above), the numbers of samples used in the Monte Carlo approximation of the nonlocal term (denoted by \((K_n)_{n\in \mathbb {N}}\subseteq \mathbb {N}\) in Framework 3.1 above), the optimization algorithm used (represented by the functions \(\Psi ^n_m:\mathbb {R}^\varrho \times \mathbb {R}^{\mathfrak d}\rightarrow \mathbb {R}^\varrho \), \(n\in \{1,2,\dots ,N\}\), \(m\in \mathbb {N}\), in Framework 3.1 above), the batch sizes used in the optimization algorithm (denoted by \((J_m)_{m\in \mathbb {N}}\subseteq \mathbb {N}\) in Framework 3.1 above), and the architecture of the employed neural networks (i.e., in the case of fully connected feedforward neural networks, the number of hidden layers and the number of neurons in each hidden layer). For the MLP approximation method introduced in Framework 4.1 above, we need, e.g., to decide on the numbers of samples used in the Monte Carlo approximation of the nonlocal term (denoted by \((K_{n,l,m})_{n,l,m\in \mathbb {N}_0}\subseteq \mathbb {N}\) in Framework 4.1 above) and which iteration to use as an approximation of the unknown PDE solution (i.e., for which \(n,M\in \mathbb {N}_0\) to compute \(U^{(0)}_{n,M,r_1,r_2}(t,x)\) in (159) in Framework 4.1 above).
In Figs. 5 and 6 we examine the influence of some of these choices on the accuracy and runtime of the proposed approximation methods when computing approximate solutions to the replicator-mutator PDEs in (208) where \(d=5\), where \(\mathcal D=[-1,1]^d\), and where for every \(\textbf{x}\in \mathbb {R}^d\) it holds that \(\delta (\textbf{x})=2^{-d}\). More specifically, in Fig. 5 we show the effect on the \(L^1\)-approximation error and on the runtime of the machine learning-based approximation method in Framework 5.1 when varying, respectively (from left to right and top to bottom), the number of samples used in the Monte Carlo approximation of the nonlocal term, the batch size, the number of time steps, the number of neurons in each of the hidden layers, and the number of hidden layers. In Fig. 6 we show the effect on the \(L^1\)-approximation error and on the runtime of the MLP approximation method in Framework 4.1 (cf. Example 4.5) when varying, respectively (from left to right), the number of samples used to compute the Monte Carlo approximation of the nonlocal term and the number of iteration steps.

Influence of various hyperparameters on the performance of the MLP approximation method
Notes
Throughout this article we denote for every topological space \((X,\mathcal X)\) and every set \(D\subseteq X\) by \(\partial _D\) the set which satisfies \(\partial _D=\{x\in X:(\forall \,U\in \mathcal X:(x\in U \rightarrow (U\nsubseteq D\wedge U\nsubseteq X\backslash D)))\}\).
Throughout this article we denote by \(\langle {\cdot ,\cdot } \rangle :\big (\bigcup _{n\in \mathbb {N}} (\mathbb {R}^n\times \mathbb {R}^n)\big )\rightarrow \mathbb {R}\) and \(\Vert {\cdot } \Vert :\big (\bigcup _{n\in \mathbb {N}}\mathbb {R}^n\big )\rightarrow \mathbb {R}\) the functions which satisfy for every \(n\in \mathbb {N}\), \(v=(v_1,\dots ,v_n),\,w=(w_1,\dots ,w_n)\in \mathbb {R}^n\) that \(\langle {v,w} \rangle =\sum _{i=1}^n v_iw_i\) and \(\Vert {v} \Vert =\sqrt{\langle {v,v} \rangle }=\big [{\sum _{i=1}^n |{v_i} |^2}\big ]^{\nicefrac {1}{2}}\).
References
Kavallaris, N.I., Suzuki, T.: Non-local Partial Differential Equations for Engineering and Biology. Mathematics for Industry (Tokyo), vol. 31, p. 300. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-67944-0
D’Elia, M., Du, Q., Glusa, C., Gunzburger, M., Tian, X., Zhou, Z.: Numerical methods for nonlocal and fractional models. Acta Numer. 29, 1–124 (2020). https://doi.org/10.1017/S096249292000001X
Sunderasan, S.: Financial Modeling. In: Long-Term Investments, pp. 33–51. Routledge India, London (2020). https://doi.org/10.4324/9780367817909-3
Lacey, A.A.: Thermal runaway in a non-local problem modelling Ohmic heating. I. Model derivation and some special cases. Eur. J. Appl. Math. 6(2), 127–144 (1995). https://doi.org/10.1017/S095679250000173X
Caglioti, E., Lions, P.-L., Marchioro, C., Pulvirenti, M.: A special class of stationary flows for two-dimensional Euler equations: a statistical mechanics description. II. Comm. Math. Phys. 174(2), 229–260 (1995). https://doi.org/10.1007/BF02099602
Barone, A., Esposito, F., Magee, C.J., Scott, A.C.: Theory and applications of the sine-Gordon equation. La Rivista del Nuovo Cimento 1(2), 227–267 (1971). https://doi.org/10.1007/BF02820622
Gajewski, H., Zacharias, K.: On a nonlocal phase separation model. J. Math. Anal. Appl. 286(1), 11–31 (2003). https://doi.org/10.1016/S0022-247X(02)00425-0
Coleman, S.: Quantum sine-Gordon equation as the massive Thirring model. In: Bosonization, vol. 1, pp. 128–137. World Scientific, Singapore (1994). https://doi.org/10.1142/9789812812650_0013
Hairer, M., Shen, H.: The dynamical sine-Gordon model. Comm. Math. Phys. 341(3), 933–989 (2016). https://doi.org/10.1007/s00220-015-2525-3
Rubinstein, J., Sternberg, P.: Nonlocal reaction–diffusion equations and nucleation. IMA J. Appl. Math. 48(3), 249–264 (1992). https://doi.org/10.1093/imamat/48.3.249
Stoleriu, I.: Non-local models for solid-solid phase transitions. ROMAI J. 7(1), 157–170 (2011)
Merton, R.C.: Option pricing when underlying stock returns are discontinuous. J. Financ. Econ. 3(1–2), 125–144 (1976). https://doi.org/10.1016/0304-405X(76)90022-2
Chan, T.: Pricing contingent claims on stocks driven by Lévy processes. Ann. Appl. Probab. 9(2), 504–528 (1999). https://doi.org/10.1214/aoap/1029962753
Kou, S.G.: A jump-diffusion model for option pricing. Manag. Sci. 48(8), 1086–1101 (2002). https://doi.org/10.1287/mnsc.48.8.1086.166
Abergel, F., Tachet, R.: A nonlinear partial integro-differential equation from mathematical finance. Discr. Contin. Dyn. Syst. 27(3), 907–917 (2010). https://doi.org/10.3934/dcds.2010.27.907
Benth, F.E., Karlsen, K.H., Reikvam, K.: Optimal portfolio selection with consumption and nonlinear integro-differential equations with gradient constraint: a viscosity solution approach. Finance Stoch. 5(3), 275–303 (2001). https://doi.org/10.1007/PL00013538
Cruz, J.M.T.S., Ševčovič, D.: On solutions of a partial integro-differential equation in Bessel potential spaces with applications in option pricing models. Jpn. J. Ind. Appl. Math. 37(3), 697–721 (2020). https://doi.org/10.1007/s13160-020-00414-2
Cont, R., Tankov, P.: Financial Modelling with Jump Processes. Chapman & Hall/CRC Financial Mathematics Series, Boca Raton (2004)
Huang, J., Cen, Z., Le, A.: A finite difference scheme for pricing American put options under Kou’s jump-diffusion model. J. Funct. Spaces Appl. (2013). https://doi.org/10.1155/2013/651573
Gan, X., Yang, Y., Zhang, K.: A robust numerical method for pricing American options under Kou’s jump-diffusion models based on penalty method. J. Appl. Math. Comput. 62(1–2), 1–21 (2020). https://doi.org/10.1007/s12190-019-01270-1
Amadori, A.L.: Nonlinear integro-differential evolution problems arising in option pricing: a viscosity solutions approach. Differ. Integr. Equ. 16(7), 787–811 (2003)
Pham, H.: Continuous-time Stochastic Control and Optimization with Financial Applications. Stochastic Modelling and Applied Probability, vol. 61. Springer, Berlin (2009). https://doi.org/10.1007/978-3-540-89500-8
Henry-Labordère, P.: Counterparty Risk Valuation: A Marked Branching Diffusion Approach. arXiv:1203.2369 (2012)
Oechssler, J., Riedel, F.: Evolutionary dynamics on infinite strategy spaces. Econ. Theory 17(1), 141–162 (2001). https://doi.org/10.1007/PL00004092
Kavallaris, N.I., Lankeit, J., Winkler, M.: On a degenerate nonlocal parabolic problem describing infinite dimensional replicator dynamics. SIAM J. Math. Anal. 49(2), 954–983 (2017). https://doi.org/10.1137/15M1053840
Hamel, F., Lavigne, F., Martin, G., Roques, L.: Dynamics of adaptation in an anisotropic phenotype-fitness landscape. Nonlinear Anal. Real World Appl. 54, 103107 (2020). https://doi.org/10.1016/j.nonrwa.2020.103107
Alfaro, M., Carles, R.: Replicator-mutator equations with quadratic fitness. Proc. Am. Math. Soc. 145(12), 5315–5327 (2017). https://doi.org/10.1090/proc/13669
Alfaro, M., Veruete, M.: Evolutionary branching via replicator-mutator equations. J. Dynam. Differ. Equ. 31(4), 2029–2052 (2019). https://doi.org/10.1007/s10884-018-9692-9
Banerjee, M., Petrovskii, S.V., Volpert, V.: Nonlocal reaction–diffusion models of heterogeneous wealth distribution. Mathematics 9(4), 351 (2021). https://doi.org/10.3390/math9040351
Lorz, A., Lorenzi, T., Hochberg, M.E., Clairambault, J., Perthame, B.: Populational adaptive evolution, chemotherapeutic resistance and multiple anti-cancer therapies. ESAIM Math. Model. Numer. Anal. 47(2), 377–399 (2013). https://doi.org/10.1051/m2an/2012031
Chen, L., Painter, K., Surulescu, C., Zhigun, A.: Mathematical models for cell migration: A non-local perspective. Philos. Trans. R. Soc. B 375(1807), 20190379 (2020). https://doi.org/10.1098/rstb.2019.0379
Villa, C., Chaplain, M.A.J., Lorenzi, T.: Evolutionary dynamics in vascularised tumours under chemotherapy: Mathematical modelling, asymptotic analysis and numerical simulations. Vietnam J. Math. 49(1), 143–167 (2021). https://doi.org/10.1007/s10013-020-00445-9
Pájaro, M., Alonso, A.A., Otero-Muras, I., Vázquez, C.: Stochastic modeling and numerical simulation of gene regulatory networks with protein bursting. J. Theoret. Biol. 421, 51–70 (2017). https://doi.org/10.1016/j.jtbi.2017.03.017
Fisher, R.A.: The wave of advance of advantageous genes. Ann. Eugen. 7(4), 355–369 (1937). https://doi.org/10.1111/j.1469-1809.1937.tb02153.x
Hamel, F., Nadirashvili, N.: Travelling fronts and entire solutions of the Fisher-KPP equation in \({{\mathbb{R} }}^N\). Arch. Ration. Mech. Anal. 157(2), 91–163 (2001). https://doi.org/10.1007/PL00004238
Bian, S., Chen, L., Latos, E.A.: Global existence and asymptotic behavior of solutions to a nonlocal Fisher-KPP type problem. Nonlinear Anal. 149, 165–176 (2017). https://doi.org/10.1016/j.na.2016.10.017
Perthame, B., Génieys, S.: Concentration in the nonlocal Fisher equation: The Hamilton–Jacobi limit. Math. Model. Nat. Phenom. 2(4), 135–151 (2007). https://doi.org/10.1051/mmnp:2008029
Berestycki, H., Nadin, G., Perthame, B., Ryzhik, L.: The non-local Fisher-KPP equation: Travelling waves and steady states. Nonlinearity 22(12), 2813–2844 (2009). https://doi.org/10.1088/0951-7715/22/12/002
Houchmandzadeh, B., Vallade, M.: Fisher waves: An individual-based stochastic model. Phys. Rev. E 96(1), 012414 (2017). https://doi.org/10.1103/PhysRevE.96.012414
Wang, F., Xue, L., Zhao, K., Zheng, X.: Global stabilization and boundary control of generalized Fisher/KPP equation and application to diffusive SIS model. J. Differ. Equ. 275, 391–417 (2021). https://doi.org/10.1016/j.jde.2020.11.031
Burger, R., Hofbauer, J.: Mutation load and mutation-selection-balance in quantitative genetic traits. J. Math. Biol. 32(3), 193–218 (1994). https://doi.org/10.1007/BF00163878
Génieys, S., Volpert, V., Auger, P.: Pattern and waves for a model in population dynamics with nonlocal consumption of resources. Math. Model. Nat. Phenom. 1(1), 65–82 (2006). https://doi.org/10.1051/mmnp:2006004
Berestycki, H., Jin, T., Silvestre, L.: Propagation in a non local reaction diffusion equation with spatial and genetic trait structure. Nonlinearity 29(4), 1434–1466 (2016). https://doi.org/10.1088/0951-7715/29/4/1434
Nordbotten, J.M., Stenseth, N.C.: Asymmetric ecological conditions favor Red-Queen type of continued evolution over stasis. Proc. Natl. Acad. Sci. U.S.A. 113(7), 1847–1852 (2016). https://doi.org/10.1073/pnas.1525395113
Nordbotten, J.M., Levin, S.A., Szathmáry, E., Stenseth, N.C.: Ecological and evolutionary dynamics of interconnectedness and modularity. Proc. Natl. Acad. Sci. U.S.A. 115(4), 750–755 (2018). https://doi.org/10.1073/pnas.1716078115
Roques, L., Bonnefon, O.: Modelling population dynamics in realistic landscapes with linear elements: A mechanistic-statistical reaction–diffusion approach. PLoS ONE 11(3), 0151217 (2016). https://doi.org/10.1371/journal.pone.0151217
Doebeli, M., Ispolatov, I.: Complexity and diversity. Science 328(5977), 494–497 (2010). https://doi.org/10.1126/science.1187468
Nordbotten, J.M., Bokma, F., Hermansen, J.S., Stenseth, N.C.: The dynamics of trait variance in multi-species communities. R. Soc. Open Sci. 7(8), 200321 (2020). https://doi.org/10.1098/rsos.200321
Bellman, R.: Dynamic Programming. Princeton Landmarks in Mathematics. Princeton University Press, Princeton (2010)
Metropolis, N., Ulam, S.: The Monte Carlo method. J. Am. Stat. Assoc. 44(247), 335–341 (1949). https://doi.org/10.1080/01621459.1949.10483310
Bauer, W.F.: The Monte Carlo method. J. Soc. Ind. Appl. Math. 6(4), 438–451 (1958). https://doi.org/10.1137/0106028
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015). https://doi.org/10.1038/nature14539
Beck, C., Hutzenthaler, M., Jentzen, A., Kuckuck, B.: An overview on deep learning-based approximation methods for partial differential equations. Discr. Contin. Dyn. Syst. Ser. B 28(6), 3697–3746 (2023). https://doi.org/10.3934/dcdsb.2022238
Weinan, E., Han, J., Jentzen, A.: Algorithms for solving high dimensional PDEs: From nonlinear Monte Carlo to machine learning. Nonlinearity 35(1), 278–310 (2022). https://doi.org/10.1088/1361-6544/ac337f
Blechschmidt, J., Ernst, O.G.: Three ways to solve partial differential equations with neural networks—a review. GAMM-Mitteilungen 44(2), 202100006 (2021). https://doi.org/10.1002/gamm.202100006
Karniadakis, G.E., Kevrekidis, I.G., Lu, L., Perdikaris, P., Wang, S., Yang, L.: Physics-informed machine learning. Nat. Rev. Phys. 3(6), 422–440 (2021). https://doi.org/10.1038/s42254-021-00314-5
Cuomo, S., Di Cola, V.S., Giampaolo, F., Rozza, G., Raissi, M., Piccialli, F.: Scientific machine learning through physics-informed neural networks: Where we are and what’s next. J. Sci. Comput. 92(3), 88 (2022). https://doi.org/10.1007/s10915-022-01939-z
Yunus, R.B., Abdul Karim, S.A., Shafie, A., Izzatullah, M., Kherd, A., Hasan, M.K., Sulaiman, J.: An overview on deep learning techniques in solving partial differential equations. In: Abdul Karim, S.A. (ed.) Intelligent Systems Modeling and Simulation II, pp. 37–47. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-04028-3_4
Huang, S., Feng, W., Tang, C., Lv, J.: Partial differential equations meet deep neural networks: A survey. arXiv:2211.05567 (2022)
E, W., Han, J., Jentzen, A.: Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations. Commun. Math. Stat. 5(4), 349–380 (2017). https://doi.org/10.1007/s40304-017-0117-6
Han, J., Jentzen, A., E, W.: Solving high-dimensional partial differential equations using deep learning. Proc. Natl. Acad. Sci. U.S.A. 115(34), 8505–8510 (2018). https://doi.org/10.1073/pnas.1718942115
Beck, C., Becker, S., Grohs, P., Jaafari, N., Jentzen, A.: Solving the Kolmogorov PDE by means of deep learning. J. Sci. Comput. 88, 73–28 (2021). https://doi.org/10.1007/s10915-021-01590-0
Chan-Wai-Nam, Q., Mikael, J., Warin, X.: Machine learning for semi linear PDEs. J. Sci. Comput. 79(3), 1667–1712 (2019). https://doi.org/10.1007/s10915-019-00908-3
Huré, C., Pham, H., Warin, X.: Deep backward schemes for high-dimensional nonlinear PDEs. Math. Comp. 89, 1547–1579 (2020). https://doi.org/10.1090/mcom/3514
Beck, C., Becker, S., Cheridito, P., Jentzen, A., Neufeld, A.: Deep splitting method for parabolic PDEs. SIAM J. Sci. Comput. 43(5), 3135–3154 (2021). https://doi.org/10.1137/19M1297919
Cox, S., Neerven, J.: Pathwise Hölder convergence of the implicit-linear Euler scheme for semi-linear SPDEs with multiplicative noise. Numer. Math. 125(2), 259–345 (2013). https://doi.org/10.1007/s00211-013-0538-4
Gyöngy, I., Krylov, N.: On the splitting-up method and stochastic partial differential equations. Ann. Probab. 31(2), 564–591 (2003). https://doi.org/10.1214/aop/1048516528
Hochbruck, M., Ostermann, A.: Explicit exponential Runge–Kutta methods for semilinear parabolic problems. SIAM J. Numer. Anal. 43(3), 1069–1090 (2005). https://doi.org/10.1137/040611434
Hutzenthaler, M., Jentzen, A., Kruse, T., Nguyen, T.A., Wurstemberger, P.: Overcoming the curse of dimensionality in the numerical approximation of semilinear parabolic partial differential equations. Proc. A. 476(2244), 20190630 (2020). https://doi.org/10.1098/rspa.2019.0630
E, W., Hutzenthaler, M., Jentzen, A., Kruse, T.: On multilevel Picard numerical approximations for high-dimensional nonlinear parabolic partial differential equations and high-dimensional nonlinear backward stochastic differential equations. J. Sci. Comput. 79(3), 1534–1571 (2019). https://doi.org/10.1007/s10915-018-00903-0
E, W., Hutzenthaler, M., Jentzen, A., Kruse, T.: Multilevel Picard iterations for solving smooth semilinear parabolic heat equations. Partial Differ. Equ. Appl. 2(6), 80 (2021). https://doi.org/10.1007/s42985-021-00089-5
Heinrich, S.: Monte Carlo complexity of global solution of integral equations. J. Complex. 14(2), 151–175 (1998). https://doi.org/10.1006/jcom.1998.0471
Heinrich, S., Sindambiwe, E.: Monte Carlo complexity of parametric integration. J. Complex. 15(3), 317–341 (1999). https://doi.org/10.1006/jcom.1999.0508
Grohs, P., Voigtlaender, F.: Proof of the theory-to-practice gap in deep learning via sampling complexity bounds for neural network approximation spaces. Found. Comput. Math. (2023). https://doi.org/10.1007/s10208-023-09607-w
Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019). https://doi.org/10.1016/j.jcp.2018.10.045
Sirignano, J., Spiliopoulos, K.: DGM: A deep learning algorithm for solving partial differential equations. J. Comput. Phys. 375, 1339–1364 (2018). https://doi.org/10.1016/j.jcp.2018.08.029
Pang, G., Lu, L., Karniadakis, G.E.: fPINNs: Fractional physics-informed neural networks. SIAM J. Sci. Comput. 41(4), 2603–2626 (2019). https://doi.org/10.1137/18M1229845
Lu, L., Meng, X., Mao, Z., Karniadakis, G.E.: DeepXDE: A deep learning library for solving differential equations. SIAM Rev. 63(1), 208–228 (2021). https://doi.org/10.1137/19M1274067
Guo, L., Wu, H., Yu, X., Zhou, T.: Monte Carlo fPINNs: Deep learning method for forward and inverse problems involving high dimensional fractional partial differential equations. Comput. Methods Appl. Mech. Engrg. 400, 115523 (2022). https://doi.org/10.1016/j.cma.2022.115523
Al-Aradi, A., Correia, A., Jardim, G., de Freitas Naiff, D., Saporito, Y.: Extensions of the deep Galerkin method. Appl. Math. Comput. 430, 127287 (2022). https://doi.org/10.1016/j.amc.2022.127287
Yuan, L., Ni, Y.-Q., Deng, X.-Y., Hao, S.: A-PINN: Auxiliary physics informed neural networks for forward and inverse problems of nonlinear integro-differential equations. J. Comput. Phys. 462, 111260 (2022). https://doi.org/10.1016/j.jcp.2022.111260
Frey, R., Köck, V.: Deep neural network algorithms for parabolic PIDEs and applications in insurance and finance. Computation 10(11), 201 (2022). https://doi.org/10.3390/computation10110201
Frey, R., Köck, V.: Convergence analysis of the deep splitting scheme: the case of partial integro-differential equations and the associated FBSDEs with jumps. arXiv:2206.01597 (2022)
Castro, J.: Deep learning schemes for parabolic nonlocal integro-differential equations. Partial Differ. Equ. Appl. 3, 77 (2022). https://doi.org/10.1007/s42985-022-00213-z
Gonon, L., Schwab, C.: Deep ReLU neural networks overcome the curse of dimensionality for partial integrodifferential equations. Anal. Appl. (Singap.) 21(1), 1–47 (2023). https://doi.org/10.1142/S0219530522500129
Lagaris, I.E., Likas, A., Fotiadis, D.I.: Artificial neural networks for solving ordinary and partial differential equations. IEEE Trans. Neural Netw. 9(5), 987–1000 (1998). https://doi.org/10.1109/72.712178
Lagaris, I.E., Likas, A.C., Papageorgiou, D.G.: Neural-network methods for boundary value problems with irregular boundaries. IEEE Trans. Neural Netw. 11(5), 1041–1049 (2000). https://doi.org/10.1109/72.870037
McFall, K.S., Mahan, J.R.: Artificial neural network method for solution of boundary value problems with exact satisfaction of arbitrary boundary conditions. IEEE Trans. Neural Netw. 20(8), 1221–1233 (2009). https://doi.org/10.1109/TNN.2009.2020735
Sukumar, N., Srivastava, A.: Exact imposition of boundary conditions with distance functions in physics-informed deep neural networks. Comput. Methods Appl. Mech. Engrg. 389, 114333 (2022). https://doi.org/10.1016/j.cma.2021.114333
Wang, S., Perdikaris, P.: Deep learning of free boundary and Stefan problems. J. Comput. Phys. (2020). https://doi.org/10.1016/j.jcp.2020.109914
E, W., Yu, B.: The Deep Ritz method: A deep learning-based numerical algorithm for solving variational problems. Commun. Math. Stat. 6(1), 1–12 (2018). https://doi.org/10.1007/s40304-018-0127-z
Liao, Y., Ming, P.: Deep Nitsche method: Deep Ritz method with essential boundary conditions. Commun. Comput. Phys. 29(5), 1365–1384 (2021). https://doi.org/10.4208/cicp.OA-2020-0219
Chen, J., Du, R., Wu, K.: A comparison study of deep Galerkin method and deep Ritz method for elliptic problems with different boundary conditions. Commun. Math. Res. 36(3), 354–376 (2020). https://doi.org/10.4208/cmr.2020-0051
Zang, Y., Bao, G., Ye, X., Zhou, H.: Weak adversarial networks for high-dimensional partial differential equations. J. Comput. Phys. 411, 109409 (2020). https://doi.org/10.1016/j.jcp.2020.109409
Duchi, J., Hazan, E., Singer, Y.: Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 12(61), 2121–2159 (2011)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv:1412.6980 (2014)
Ioffe, S., Szegedy, C.: Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Bach, F., Blei, D. (eds.) Proceedings of the 32nd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 37, pp. 448–456. PMLR, Lille, France (2015). https://proceedings.mlr.press/v37/ioffe15.html
E, W., Han, J., Jentzen, A.: Algorithms for solving high dimensional PDEs: From nonlinear Monte Carlo to machine learning. Nonlinearity 35(1), 278–310 (2021). https://doi.org/10.1088/1361-6544/ac337f
Becker, S., Braunwarth, R., Hutzenthaler, M., Jentzen, A., Wurstemberger, P.: Numerical simulations for full history recursive multilevel Picard approximations for systems of high-dimensional partial differential equations. Commun. Comput. Phys. 28(5), 2109–2138 (2020). https://doi.org/10.4208/cicp.OA-2020-0130
Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Teh, Y.W., Titterington, M. (eds.) Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics. Proceedings of Machine Learning Research, vol. 9, pp. 249–256. PMLR, Chia Laguna Resort, Sardinia, Italy (2010). https://proceedings.mlr.press/v9/glorot10a.html
Beck, C., E, W., Jentzen, A.: Machine learning approximation algorithms for high-dimensional fully nonlinear partial differential equations and second-order backward stochastic differential equations. arXiv:1709.05963 (2017)
Acknowledgements
We gratefully acknowledge the helpful suggestions by an anonymous referee. This project has been partially funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) in the frame of the priority programme SPP 2298 ‘Theoretical Foundations of Deep Learning’ - Project no. 464123384. In addition, this project has been partially funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy EXC 2044-390685587, Mathematics Münster: Dynamics - Geometry - Structure.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interest statement
The authors declare that they have no competing interests regarding this manuscript.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Boussange, V., Becker, S., Jentzen, A. et al. Deep learning approximations for non-local nonlinear PDEs with Neumann boundary conditions. Partial Differ. Equ. Appl. 4, 51 (2023). https://doi.org/10.1007/s42985-023-00244-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42985-023-00244-0
Keywords
- Non-local
- Partial differential equation
- PDE
- Deep learning
- Neural networks
- Neumann boundary condition
- Reflected Brownian motion