
Abstract
With the emergence of the Programmable Web paradigm, the World Wide Web is evolving into a Web of Services, where data and services can be effectively reused across applications. Given the wide diversity and scale of published Web services, the problem of service discovery is a big challenge for service-based application development. This is further compounded by the limited availability of intelligent categorization and service management frameworks. In this paper, an approach that extends service similarity analysis by using morphological analysis and machine learning techniques for capturing the functional semantics of real-world Web services for facilitating effective categorization is presented. To capture the functional diversity of the services, different feature vector selection techniques are used to represent a service in vector space, with the aim of finding the optimal set of features. Using these feature vector models, services are classified as per their domain, using ensemble machine learning methods. Experiments were performed to validate the classification accuracy with respect to the various service feature vector models designed, and the results emphasize the effectiveness of the proposed approach.
Similar content being viewed by others

1 Introduction
Service-oriented computing (SOC) is a distributed computing paradigm that employs fundamental computing entities called services, as constituent elements in developing complex business systems [29]. As per SOC concepts, a business landscape comprised of service-centric applications, called service-oriented architecture (SOA), allows reorganization of business applications and infrastructure as a set of reusable services. In domains such as e-commerce, e-government and B2B,Footnote 1 Web services are the most popular way of achieving service orientation. Web services use the XMLFootnote 2 standard for encapsulating the data to be exchanged between diverse business platforms. Further, XML-based protocols are also used for data transfer (SOAPFootnote 3) and for describing the service capabilities (WSDLFootnote 4). In business ecosystems, most applications are complex, which means that full service orientation can help in designing new applications faster, using existing functionality exposed as services [1]. Hence, the main advantage of a service-oriented application development is that services can be exposed as discoverable software components, thus promoting reusability.
For service-based application development, a designer either creates new services or tries to find appropriate existing services for performing the individual tasks as per a defined business workflow. The process of finding existing services, capable of performing a particular task, is called service discovery [14]. Despite considerable research effort in simplifying this process, service discovery is still challenging due to primarily keyword-based search for appropriate services. A unified service registry such as the Universal Business Registry is no longer available, and Web services are currently available in some service portals such as ProgrammableWeb and BioCatalogue or directly from service providers’ websites [21]. These service portals mostly provide keyword searching and manual categorization, due to which finding the most relevant services for a given task is still challenging. There may be several services already developed by third-party developers which may be very well suited for the given task that did not even appear in the search results due to these issues.
The problem of adding semantics and machine understanding to Web service capabilities to support automated dynamic discovery, matchmaking, composition and recommendation [9] has remained an area of active research interest. The primary motivation for semanticizing data and services on the Web is to facilitate seamless interoperation and knowledge discovery over the Web [2, 12]. However, at present, semantically enhanced published services are very few and the task of adding semantics to those lacking may prove to be quite a monumental job, in terms of time and cost. Therefore, alternate methods that are not dependent on the immediate availability of semantic markup, but can still overcome the problems associated with keyword-based service discovery, are the need of the day.
In this paper, we use different feature vectors selection techniques to represent a service document in vector space, with the aim of finding the most relevant set of features for a particular service. We proposed a novel process for effectively extracting the structural features of a service from its service description for the purpose of tag generation and tag-based service clusteringFootnote 5. We extended this mechanism for the extraction and formal representation of the functional semantics of services, for use in the process of multiple feature vector generation. Using the obtained feature vectors, services available in a repository can be categorized as per their domain. Various machine learning algorithms such as maximum entropy models, Näive Bayes and Support Vector Machines (SVM) have been widely used to automatically solve classification problems. Ensemble methods of machine learning have been proposed that can put together multiple base estimators to obtain better classification accuracy than the individual base algorithms by themselves. Experiments have been performed to validate the accuracy of classification with respect to the various feature vector generation approaches, and each of the classifiers used and the results are presented. The main contributions of this paper are summarized below:
-
An approach that extends the technique proposed in [16] for extracting the functional semantics of Web services from their service descriptions for generation of multiple service feature vectors is presented.
-
Hybrid feature selection techniques that use the extracted functional semantics for effectively capturing the representative features of each individual service are discussed.
-
Ensemble machine learning algorithms are used to classify services in domain-specific categories.
-
Experimental validation of the classification accuracy with respect to the various feature vector generation approaches and classifier ensembles.
The remainder of this paper is organized as follows. In Sect. 2, we discuss relevant literature in the area of semantics-based Web service discovery and classification. Section 3 presents a detailed discussion on the various processes and components of the proposed approach. In Sect. 4, we present the experimental evaluation of the proposed methodology and observed results. We describe the relevance of techniques discussed in this paper to other data science applications dealing with large-scale unstructured/semi-structured data in Sect. 5, followed by conclusion and references.
2 Related work
Many researchers have proposed ideas for addressing the issues associated with the large volume of services and their functional diversity through automated categorization techniques. Many of the initial approaches focused on first classifying service descriptions to a particular concept, which was then used to generate annotations for the service. Oldham et al. [27] developed a framework called Meteor-S Web Service Annotation Framework (MWSAF) that employs graph matching techniques for categorizing WSDL documents into classes. Each WSDL is first represented as a graph using its XML Document Object Model (DOM) structure. This formal representation is then compared with ontology concepts relevant to the document category, based on which services are classified. Patil et al. [30] proposed to convert the syntactic definitions of Web services to semantic concepts through annotation and classified various services into classes based on a semantic concept mapping technique. However, the authors used only 24 services to evaluate their technique. Heß et al. [13] proposed a service annotation tool called Assam that uses the syntactic service descriptions and machine learning techniques such as SVM and Näive Bayes Classifier to classify services. They used a small dataset of 391 services and achieved an accuracy of 60 %.
Other works proposed approaches for adding semantics to syntactic service descriptions. Corella and Castells [6] proposed an approach for semantically classifying services based on a metric called Normal Similarity Score (NSS). NSS computes the similarity between a set of service-specific terms and a limited set of predefined categories. Saha et al. [32] used a two-stage approach where the services are represented as tensors using a Tensor Space Model, and then, rough set-based classification scheme is applied for categorizing the services. The rough sets are used to combine individual service tensors’ information during classification.
Yang and Zhou [40] performed the process of semiautomatic Web service classification after representing the extracted WSDL elements in a digital vector form and then using C4.5 classifiers to test the accuracy for single element and multiple element-based classification. Own and Yahyaoui [28] proposed a rough set-based classification technique for the QWS Web service dataset, which also provides a service’s Quality of Service (QoS) values. They used the concepts of rough set theory to reduce the QoS attribute set of Web services to a lesser and more relevant dimension, after which services were mapped to predefined categories. Varguez-Moo et al. [36] used Näive Bayes classifier for performing classification of SAWSDL service descriptions and reported good results by evaluating the performance with respect to QoS parameters.
The problems associated with manual categorization of Web services can be dealt by automating the process by using unsupervised classification and supervised clustering methods. Various unsupervised machine learning approaches such as k-means, fuzzy c-mean, expectation maximization clustering, quality threshold clustering, kernel k-mean clustering and density-based clustering have been proposed and successfully applied to Web service clustering. Liu and Wong [23] used text mining techniques to generate a representative feature vector for a set of services and then clustered the documents based on similarity computed using a Grand similarity measure. They used Normalized Google Distance (NGD) [5] to compute this similarity. In our earlier work [16], we proposed a crawler-based system for gathering service descriptions available on the Web for building a scalable service repository. Similarity analysis techniques were used for extracting service features and automatically generate relevant tags for each service. These tags and the pair-wise service similarity values were used for clustering services using hierarchical clustering, and for optimizing time and precision of service discovery.
Crasso et al. [7] used a query-by-example approach for recommending services for discovery. They combined machine learning and text mining approaches to automatically classify services using their semantic descriptions. Katakis et al. [17] combined both interface details and the semantic annotation of OWL-SFootnote 6 service advertisements. This extended feature vector was given as input to Näive Bayes classifier. Wang et al. [37] used a hierarchical classification as per the UNSPSC taxonomy to automatically categorize services based on the captured domain-specific terms. They used Support Vector Machines to classify the documents, by treating the UNSPSC taxonomy as a multi-level tree, where each of non-leaf nodes (parent class) corresponds to a subclassification system.
In many of these approaches, we observed that the inherent semantic information that can be captured from a service description was neglected. Service descriptions are primarily XML artifacts with natural language element names and service providers often provide a natural language documentation of a service’s capabilities. To capture the inherent domain-specific terms of a service document for clustering, models such as Vector Space Model (VSM) [34] and Tensor Space Model (TSM) [22] that use document-specific feature vectors for conducting the clustering process have been used [7, 39]. However, choosing only those features that best represent the document’s domain is critical for attaining good accuracy and best performance time-wise. To this end, techniques such as feature reduction and feature selection can be used for effectively identifying the most relevant and smallest dimension feature set for a given document. The proposed methodology uses a hybrid approach where the merits of multiple feature vectors are analyzed to determine the best possible feature set, for performing service classification. The performance of base machine learning algorithms against that of ensemble classifiers is also compared.
3 Proposed methodology
The proposed approach consists of three major stages—(1) Web Service Functional Semantics Extraction, (2) Web Service Feature Modeling and (3) Web Service Classification. In the first phase, we use the preliminary methods described in our work [16] for preprocessing the service description files using natural language processing (NLP) and dynamic programming techniques. These processes have been described in greater detail in Sect. 3.1. In Sect. 3.2, we describe the process of feature modeling to capture the service functionalities in detail. The concept of feature reduction and semantics is also used to identify and capture the most relevant features for each service. Finally, the process of service classification with machine learning ensembles using the various service feature vector models is discussed in Sect. 3.3.
3.1 Web service functional semantics extraction
3.1.1 WSDL parsing and element extraction
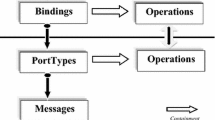
The first phase of the proposed approach deals with the extraction of the functional semantics of each service, which is contained within its service description. The WSDL service descriptions provided in the service dataset OWL-S service retrieval test collection (OWL-S TC4) were used for the experiments. For every service in the dataset, the WSDL DOM tree is parsed to extract all its component elements. Since each WSDL has some common elements such as the XML tag structure and namespace declarations, these are automatically removed by using a regular expression and pattern matching. The opening and closing tags of each element are also removed, and the phrases that are left over after this processing are the natural language names of the WSDL elements such as types, input and output messages, operations and portTypes. The service name and the documentation is also captured from the WSDL file. For example, for the sample WSDL for the service ‘StockQuote’ provided by W3C,Footnote 7 the input/output messages are named as ‘GetLastTradePriceInput’ & ‘GetLastTradePriceOutput’ and the corresponding operation name is ‘GetLastTradePrice.’ Many datatypes are provided, one of which is named as ‘TradePriceRequest.’ During element name extraction, these are extracted after parsing and are used for term token generation.
3.1.2 Term token generation
Once WSDL element names are obtained, these are processed further to extract term tokens from each element. For each of the natural language phrases extracted, we need to determine the splitting positions in order to obtain the individual words. It is a common practice to name the service elements are per standard naming conventions, with an emphasis on the functionality of the service element. Hence, standard programmatic naming conventions, such as combining multiple words and using camel case/pascal case to distinguish the individual words, are commonly used by most service designers. For correctly capturing the name of each service element, certain rules referred to as token generation rules are defined
-
Case 1:
Standard naming conventions were followed.
-
Rule 1:
term tokens are generated by considering capital letters as the start of a new token.
-
Rule 2:
term tokens are generated by considering special characters as token separators.
-
Rule 3:
Elements containing words with contiguous capital letters are considered as a single token, as these mostly represent acronyms (e.g., ‘SMS,’ ‘SSN’ and ‘ISBN’).
-
Rule 1:
-
Case 2:
Standard naming conventions have not been followed. If no capital letters or special characters mark the beginning of a new word in the element name, proper splitting positions cannot be found. If these are used as features, they will result in incorrect similarity values. Algorithm 2 is used to correctly extract terms from such element names.

For finding the correct splitting positions for WSDL element names and obtaining the constituent terms, the element names are processed as shown in Algorithm 1. Once all the term tokens are extracted, any stop words are filtered out. For example, the name of the service ‘Academic-degreeScholarship’ is a feature and will result in the term tokens ‘academic,’ ‘degree’ and ‘scholarship.’ Similarly, the service’s operations are also considered as a feature, so after splitting, an operation named ‘getAcademic-degreeType,’ will result in ‘get,’ ‘academic,’ ‘degree’ and ‘type.’ Finally, stop words such as ‘get,’ ‘type’ are discarded.
During preprocessing, we found that standard naming conventions were not followed while naming the elements of several service descriptions in the dataset. For example, the service ‘Citycountryaccommodation’ does not have any camel-case representation in its name and element names. It is then impossible to determine the correct splitting positions using rules (1) through (3). If such unkempt element name are considered as a single token, then the semantic relatedness between service terms cannot be calculated, which will adversely affect classification accuracy. Hence, to generate the correct tokens from these types of names, a separate procedure has to be followed. For the given example, the term needs to be split into the tokens ‘city,’ ‘country’ and ‘accommodation.’ For this, a dynamic programming approach was designed, to correctly select the splitting positions. This exploits the concept of relative word frequencies based on Zipf’s law [26], to identify valid English words.
Algorithm 2 shows the approach used for determining correct splitting positions for badly named WSDL elements. According to Zipf’s law, ‘the probability of encountering the rth most common word in the English language is given roughly by \(P(r) = \frac{0.1}{r}\) for r up to approximately 1000.’ As Zipf’s Law does not apply to low frequency words, the probability of a word of rank r in a dictionary of N words sorted by their relative word frequencies is given by \(\frac{1}{r\cdot \mathrm{log}\ N}\). This is used in the dynamic programming approach, for finding the word splitting positions for badly named service elements.

After preprocessing all service descriptions as per Algorithms 1 and 2, all possible service element names are processed and term tokens are generated. Next, a stop word removal is performed to remove common English words and the Porter Stemmer was used to perform stemming on the resultant terms to reduce the multiple derivatives of the same word (e.g., ‘process,’ ‘processing,’ ‘processes,’ etc. are the derivatives of the word ‘process.’ Stemming reduces all such features to a single feature ‘process’). In addition to this, words used commonly in the Web services domain referred to as function words (e.g., ‘service,’ ‘input,’ ‘output,’ ‘request,’ ‘response,’ ‘SOAP’ and ‘parameter’) are also filtered as they contribute very little to the context of a service. After this, a feature vector comprising of extracted terms is obtained for each service feature considered. These individual service term vectors together form the set of feature vectors for a particular service.
3.2 Web service feature modeling
To capture both the interface level features and the context level features of the service, multiple feature vector approaches were employed. The feature vectors obtained from each of these approaches are used for service classification, to comparatively evaluate their effectiveness. The different approaches used to generate the five different service vectors (SV) are described here:
-
1.
From service name and documentation tags (SV1)
The terms obtained by applying algorithm 1 (Algorithm 2 also has to be applied, in case of badly named service elements) on the service name and the contents of <documentation> tag of the WSDL document, form the feature vector model SV1 for each service. For each service i, SV1 is of the form,
$$\begin{aligned} {SV1}_i = \{t_{(i,1)}, t_{(i,2)}, \ldots . , t_{(i,|T|)}\} \end{aligned}$$where, |T| is the total number of terms obtained from the <documentation> tag of all services in the dataset. To obtain the relative ranking of these features which are highly relevant for a given service, the term frequency/inverse document frequency (Tf–idf) technique is applied. Tf–idf helps in computing the importance of a particular term in a given service when compared to its importance in other services in the dataset. Tf–idf values are computed as per Eqs. (1) through (3).
$$\begin{aligned} TF(t)= & {} \frac{\hbox {Number}~\hbox {of}~\hbox {times}~\hbox {term}~\mathbf t ~\hbox {appears}~\hbox {in}~\mathbf d }{\hbox {Total}~\hbox {number}~\hbox {of}~\hbox {terms}~\hbox {in}~\mathbf d } \end{aligned}$$(1)$$\begin{aligned} IDF(t)= & {} \ln {\left( {\frac{\hbox {Number}~\hbox {of}~\hbox {documents}~\mathbf D }{\hbox {Number}~\hbox {of}~\hbox {documents}~\hbox {with}~\hbox {term}~\mathbf t }}\right) } \nonumber \\\end{aligned}$$(2)$$\begin{aligned} Tf{-}{idf}= & {} \left( 0.5 + \frac{tf}{tf_{max}}\right) \cdot log\left( 0.5 + \frac{D}{df}\right) \end{aligned}$$(3)Here, tf is the term frequency of a term t in the given WSDL document d, \(tf_{max}\) is the highest frequency of any term in the WSDL document d, df is the frequency of occurrence of the term t in other WSDL documents and D is the total number of WSDL documents in the dataset. Using the computed values for each term, a Tf–idf matrix is built to compute the relative importance of each term word in the service document.
-
2.
From input/output messages and operation names (SV2)
SV2 of each service is comprised of the terms successfully extracted from the names of the <input> and <output> message of the <portType> tag and also the <operation> names. For each service i, its SV2 is of the form
$$\begin{aligned} {SV2}_i = \{u_{(i,1)}, u_{(i,2)}, \ldots . , u_{(i,|U|)}\} \end{aligned}$$where |U| is the total number of terms obtained from the different terms explained above, for all services in the corpus. To obtain the relative ranking of these features which are highly relevant for a given service, again, Tf–idf technique is applied as discussed earlier.
After the generation of SV1 and SV2, a feature reduction technique called Principal Component Analysis (PCA) [38] is applied to reduce the dimension of the resultant feature space (explained in Sect. 3.2.1). After PCA, the reduced feature set obtained for both SV1 and SV2 are used to generate SV3, SV4 and SV5.
-
3.
Semantic SV1 (SV3)
For the generation of SV3, the reduced feature set of SV1 is used. The extended service vector of SV1 is obtained by using NLTK’s WordNet package to determine each term’s synsets and morphological variants such as hyponyms and hypernyms (referred to as SV3 of each service).
-
4.
Semantic SV2 (SV4)
SV4 is generated by a process similar to that of SV3, by applying WordNet concepts to the terms in the reduced SV2 (referred to as SV4 of each service).
-
5.
Merging SV3 and SV4 (SV5)
Finally, the last service vector model uses all the features of the service obtained from its various interface elements after semantic analysis (SV3 and SV4), and uses this for the classification (referred to as SV5 of each service).
3.2.1 Dimensionality reduction of SV1 and SV2 feature sets
The SV1 and SV2 feature list obtained for each service represents its multi-dimensional feature vector, i.e., each term represents a dimension as indicated by the ranked Tf–idf value of the term in the corpus considered [33]. However, even for a small-sized service collection, the number of distinct terms obtained from all documents can result in several hundred such terms or dimensions. Using all these terms as features not only is computationally intensive, but can also affect the accuracy of classification and ultimately, service retrieval performance. Determining an optimal set of most relevant terms that represent a service’s functionality to the highest extent possible is thus very important. This can be achieved by applying dimensionality reduction techniques such as Singular Value Decomposition (SVD) [19] and PCA [38], for deducing the optimal feature set for each service. In this paper, we use the PCA technique for achieving a low-dimensional feature vector for each service.
PCA is an applied linear algebra technique that uses an iterative process of orthogonal transformations for identifying the uncorrelated variables (principal components) of possibly correlated variables from the original dataset [38]. Each orthogonal transformation is defined such that the first set of uncorrelated variables (called the first principal component) represents the highest diversity (variance) in the considered dataset. The second principal component is the one with the highest diversity possible, under the constraint that it is orthogonal to the first principal component. The principal components are orthogonal because they are the eigenvectors of the covariance matrix, which is symmetric. This process is continued and ultimately results in p principal components for a d-dimensional term space, where \(p \le d\).
The procedure followed for performing PCA on the processed services is described next.
-
For the given dataset, the d-dimensional mean vector is computed as
$$\begin{aligned} \bar{X} = \frac{1}{n}{\sum _{i=1}^{n} (X_i)} \end{aligned}$$(4) -
Then, the covariance values between each pair of dimensions are computed and represented as the covariance matrix. Covariance values between two dimensions X and Y can be computed using Eq. (5) as below.
$$\begin{aligned} Cov(X,Y) = \frac{\sum _{i=1}^{n} (X_i - \bar{X}) (Y_i - \bar{Y})}{n-1} \end{aligned}$$(5)where \(X_i\) are the set of terms in the any two dimensions in the d-dimensional data, \(\bar{X}\) and \(\bar{Y}\) are the mean.
-
The eigenvectors and corresponding eigenvalues are now computed from the covariance matrix.
-
Finally, the eigenvectors are ranked from highest to lowest eigenvalue and the top k eigenvectors are chosen as the most significant features.
For computing principal components, the covariance matrix for the considered dataset is first computed, using which the eigenvalues are calculated. Based on eigenvectors (principal components) obtained from the largest eigenvalues, we reconstruct the new data matrix with a lower dimension. The optimum number of attributes was obtained at a variance value of 0.95, and all attributes with the variance value less than this value were selected. Finally, the reduced service feature vectors SV1 and SV2 were obtained. After PCA, the reduced SV1 and SV2 are considered for the generation of SV3, SV4 and SV5.
3.3 Web service classification
Web service classification is the process of automatically categorizing a service to one or more predefined categories based on its feature vectors and similarity [25]. Supervised classification consists of two phases—training and classification. During the training phase, a part of the categorized document dataset (services) is taken, based on which the classifier is trained to learn the classes. Then, during the classification phase, this classifier deduces one or more categories for a new document with varied accuracy levels. As service descriptions are natural language artifacts, there are dependencies between the category of a Web service and its description, in terms of the terminology chosen by the service designer and the classifier uses this latent information to categorize services into functionally similar groups with certain accuracy.
As it is, the class prediction accuracy of a single classifier is dependent on its ‘inductive bias’ and generalization error, as different classifiers may pick different patterns in the input data to make the classification [8]. The objective of using ensemble learning techniques is to integrate the combined predictions of different base machine learning classifiers, to achieve a better model that can reduce the limitations of an individual classifier. We analyzed the classification accuracy with both based estimators such as Multinomial Näive Bayes (MNB) and Support Vector Machines (SVM) and ensemble methods such as Bagging Classifier, Random Forests Classifier and AdaBoost Classifier on the service dataset. We used the scikit-learn machine learning library for Python [31].
-
1.
Näive Bayes [24] is a class of supervised classifiers that apply Bayes’ theorem to given data, naively assuming that the features are independent. Multinomial NB (MNB) implements the Näive Bayes algorithm for multinomially distributed data and is well suited for classifying documents represented as word or frequency vectors.
-
2.
Support Vector Machine (SVM) [15] is a supervised learning method that uses the concept of hyperplanes for classifying high-dimensional data. They provide different kernel functions for use in the decision function, which can be customized for different types of data.
Ensemble methods which differ based on the way the predictions of the underlying individual machine learning algorithms used are combined. Two categories can be identified—averaging (e.g., Bagging, Random Forests) and boosting (e.g., AdaBoost, Gradient Tree Boosting). Three different ensemble methods were used.
-
1.
In the Bagging Classifier, each classifier in the ensemble is trained on a random redistribution of the training set [3]. That is, for training a classifier, N samples are selected randomly with replacement as the training set, from the original dataset of size N. Due to the random selection, there may or may not be overlap between each training sample, or some samples may even be left out all together. This effectively means that each individual classifier’s result is generated with a different random sampling of the training set.
-
2.
Random Forests [4] is an ensemble of multiple decision trees. Each decision tree is constructed by using a random subset of the training data, and each can vote for the most popular class label during a classification problem, thus making Random Forests a majority voting-based classifier.
-
3.
The AdaBoost [11] or Adaptive Boosting classifier performs classification by fitting one classifier on the original dataset. In the later stages, additional copies of that classifier are applied to the same dataset, but the weights of incorrectly classified instances are adjusted such that subsequent classifiers focus more on difficult cases, so as to achieve better accuracy.
In summary, in averaging methods, several base estimators work independently and the final result is given as the average of all estimators results. Boosting-based techniques arrange their constituent classifiers sequentially such that the ultimate result is the cumulative effect of each. Hence, we use both base machine learning estimators (MNB and SVM) and ensemble approaches (Bagging, Random Forests and AdaBoost) for Web service classification, on the different service feature vector models proposed, and analyze their effect on classification accuracy.
4 Experimental evaluation and results
For experimental evaluation of the proposed approach for service classification, we used OWL-S TC4Footnote 8 dataset. This dataset provides a collection of 1076 Web service descriptions from 9 different domains such as communication (58 services), economy (359 services), education (285 services), food (34 services), geography (60 services), medical (73 services), simulation (16 services), travel (165 services) and weapon (40 services).
Table 1 provides details of the five different service vector models (described in Sect. 3.2) and their composition. These service vector models were used for classifying the service dataset using various classifiers (MNB, SVM, Bagging, Random Forests and AdaBoost Classifier). The classification accuracy was determined using 10-fold cross-validation [20]. Here, the dataset is divided into 10 parts with a homogeneous distribution of classes. Out of the 10 parts, one is retained for testing while 9 parts were used for training. This process is performed 10 times with different testing partitions each time.
Different metrics were used to evaluate the service classification performance. Each classifier’s accuracy is calculated by taking the average of 10 accuracy scores for each fold during cross-validation. The classification accuracy itself is calculated as per Eq. (6). Precision gives the number of positive predictions of the classifier with respect to the total number of positive class values predicted and is given by Eq. (7). Recall (also called Sensitivity or the True Positive (TP) rate) is a measure of the number of positive predictions with respect to the number of positive class values in the test data and is computed using Eq. (8). F-measure or F1-score is a metric which is the harmonic mean of the precision and recall performance of the classifier [given by Eq. (9)].
The proposed feature vector schemes are comparatively evaluated by using the above metrics. In addition, the ROC curves for each classifier were plotted, and the area under the curve (AUC) was observed as a measure for effectiveness of each classifier. These results are discussed in the following sections.
4.1 Effect of dimension reduction on classification accuracy
The effect of dimensionality reduction on the service vectors is evaluated by comparing the accuracy of classification before and after applying PCA. Table 2 shows the number of features obtained for SV1 and SV2 before and after PCA. The feature space was reduced significantly after the application of PCA for both SV1 and SV2. While Random Forests and SVM achieved the highest accuracy using SV1 and SV2 before PCA, MNB showed the worst performance. Bagging and AdaBoost classifiers achieved an accuracy of 70–77 % before PCA. Random Forests is an ensemble approach that works with a randomly selected set of features per iteration. So, it can be inferred that some subsets of features tended to have higher accuracy than other subsets.
Table 3 shows the comparison between accuracy obtained when SV1 and SV2 were given as input to the classifiers before PCA and after PCA. It can be observed that the accuracy of classification increased by a margin of 4–11 % when PCA was applied for dimension reduction of SV1 and SV2. Though the Bagging classifier achieved the highest accuracy of 86 %, SVM also performed well at 85 % accuracy, despite being a base estimator. This shows that SVM can deal with multi-dimensional data very well and achieve good accuracy for both low- and high-dimensional data. The accuracy obtained for service classification using each classifier for the dataset before and after dimensionality reduction is shown in Fig. 1a, b.

Service classification accuracy before and after PCA. a For service vector SV1. b For service vector SV1
4.2 Comparison of classification accuracy for various service vector models
Experiments were performed using each of feature vector models to classify the service dataset. The classification results pertaining to all five classifiers is presented in Table 3. It was seen that ensemble methods outperformed Multinomial Näive Bayes by more than 18–20 %. However, SVM achieved an accuracy comparable to Bagging Classifier, despite being a base estimator. As SVMs are constructed to adhere to the Structural Risk Minimization (SRM) principle [35], they are able to capture the inherent data characteristics better. This, in turn, minimizes the upper bound on the generalization error, thus making SVMs efficient despite the dimensionality of the feature space.
The results obtained for the service vectors SV3, SV4 and SV5, which were enhanced by using WordNet concepts to provide the semantic relatedness between service terms, are presented in Table 4. Among ensemble methods, Random Forests classifier achieved the best accuracy for SV3 and SV5. As SV3, SV4 and SV5 are all service vectors that take semantic relatedness into consideration, the classification accuracy improved by about 4–10 % when compared to the syntactic service vectors SV1A and SV2A. Similar results were observed for the Bagging and AdaBoost classifiers. Random Forests again achieved the highest accuracy of 93 % for SV5, which contains the semantic relatedness values obtained from all the interface elements of the WSDL. Both Bagging and AdaBoost achieved better accuracy in the range of 4–7 % for the semantic service vectors, when compared to that obtained for SV1A and SV2A. Figure 2 summarizes the results obtained for each service feature vector approach for the various base and ensemble classifiers considered for the experiments.
4.3 Classification accuracy for syntactic versus semantic service vector models
To analyze the effect on classification accuracy when the purely syntactic features and semantic features are used, an experiment using SV1A + SV2A (reduced syntactic feature set) and SV5 (final semantic feature set) was performed. The service vector {SV1A + SV2A} represents the reduced feature set obtained from all the service elements such as service name, documentation text, input/output messages, operations and portTypes, thus representing the entire interface details of the service directly. The service vector SV5 represents the semantic relatedness values of the reduced service terms obtained from all the service elements, thus representing the service interface details in an enhanced manner.
Table 4 summarizes the results of this experiment. It can be seen that for all classifier approaches, the classification accuracy is better when the final semantic vector is used to represent the service. In all cases, the semantic vector approach outperforms the syntactic vector approach by 4–8 %. Figure 3 depicts the results for classification accuracy for both approaches.

Classification accuracy for different service vector approaches

Classification accuracy for syntactic and semantic service vector models
4.4 Precision, recall and F-measure
Each classifier algorithm learns on the training data and saves a trained model, which is hence used to predict the probabilities of the occurrence of each class for each test instance. Tables 5 and 6 present each classifier’s performance statistics for the reduced syntactic feature vector approach (SV1A + SV2A) and the semantic feature vector (SV5) approach, in terms of True Positive (TP) rate, False Positive (FP) rate, Precision, Recall, F-measure, ROC area and PRC area. The ROC curves were plotted for each service vector approach (syntactic vs. semantic) for all classifiers, and are shown in Figs. 4 and 5.

ROC plot for reduced syntactic feature vector (SV1A + SV2A) model

ROC plot for semantic feature vector (SV5) model
As illustrated by the ROC plot, the Multinomial Näive Bayes classifier displayed the worst classifying performance and had the least AUC, while the F-measure value indicates satisfactory precision-recall performance, for both the syntactic and semantic feature vector approaches. SVM performed well for both feature vector approaches, and showed an F-measure value of above 0.85. The best performance for both feature vector approaches was achieved by Random Forests classifier, with a ROC area of more than 0.95 and F-measure values of more than 0.92.
To summarize, the five feature vector models used for formally representing the service functional semantics were designed such that all morphological variants of the phrases used in the service description are captured. It was seen that ensemble methods outperformed Multinomial Näive Bayes by more than 18–25 %, while SVM achieved a classification accuracy comparable to AdaBoost classifier, despite being a base estimator. Among ensemble methods, Random Forests achieved the best accuracy for the service vector SV3 and SV5. As SV3, SV4 and SV5 are all service vectors that take semantic relatedness into consideration the classification accuracy improved by about 4–10 % when compared to the syntactic service vectors SV1A and SV2A. At 93 %, Random Forests performed the best for the final semantic feature vector SV5, which contained the semantic relatedness values obtained from all the interface elements of the WSDL.
5 Relevance to data science applications
Today, the volume of publicly available Web services has been reported to double every three years as per Li et al.’s [21] report. Some researchers [10, 18, 21] report that there are more than 20,000 published services on the Web, most with WSDL-based service descriptions, without any associated semantics. While some of these are published in existing UDDI registries and service portals, most are hosted on their publishers’ servers. This makes a service hosted on the provider’s server truly distributed and distant, especially as the exact URL where it is hosted is unknown, most often than not. Another major challenge is the task of correctly and intelligently inferring the domain details of published Web services.
In UDDIs and service portals, the task of categorizing a service into relevant categories is delegated to the service provider. UDDIs use standard taxonomies such as UNSPSC for defining the categories into which a service can categorized, and these are organized hierarchically. Some of the core problems associated with adopting such standard taxonomies for a specialized domain such as Web services is that most are extremely large, consisting of thousands of categories, within multiple hierarchical levels. The placement of a service under the most suitable category requires a considerable amount of knowledge of the taxonomy, the service characteristics, the application domain, the overall organization of the repository, implicit guidelines, etc. in order to make good classification decisions. Service portals such as ProgrammableWeb and BioCatalogue actually allow service providers to create their own categories to describe the domain of their services, without adhering to a finite set of category terms. Since UDDIs and service portals still allow publishers to classify their services themselves, this can often lead to suboptimal classification and sometimes, misclassification.
These problems are quite challenging as service data primarily contain natural language terms and are semi-structured. This is an interesting data science problem requiring extensive intelligent processing and management for supporting varied tasks such as service discovery, service selection, service matchmaking and composition. The proposed service functional semantics extraction methodology is based on NLP techniques, to process explicitly available data (service’s functional elements) and discover latent knowledge (service domain/context). Each data artifact can have multiple facets (or distinguishing features) and capturing those that represent it most is very important to discover the best knowledge. The proposed hybrid feature selection approaches are specifically applied to services to deduce their most representative features which can then be used to discover its domain information using machine learning algorithms. Hence, the major contributions of our work can be readily adapted to suit other types of semi-structured such as XML documents, Web Server Logs and sensor data. These can also be applied to unstructured data such as HTML Web pages, online news items, blogs articles and user comments/ratings to automatically process them and extract their latent knowledge for applications such as sentiment analysis and market trend analysis. Some possible data science problems where the discussed techniques can be adopted for are discussed in the following section.
5.1 Some use-case scenarios
The techniques described in this work can be easily adapted to suit other types of unstructured and semi-structured data.
-
1.
Online news is a fitting example for big data, due to its high volume, velocity, volume, value and need for veracity. The published articles are primarily semi-structured and are formatted using XHTML tags. The techniques that are discussed in this paper for extracting the functional semantics of a service can be modified to process the natural language content of a sports news article, and obtain those representative features that can distinguish it from articles on other topics. The hybrid feature selection techniques and models that were designed and compared can be used to rank these features so that this process can help achieve highest accuracy. It can also be used to automatically classify news articles into relevant categories, so that users can have easy personalized access to news of their choice. News articles from multiple sources on the same topic can be clustered together using their representative features to verify claims and glean truthful facts.
-
2.
In case of Web server logs of a particular Web site, intelligent processing techniques similar to those described in this paper can be applied to categorize similar user sessions based on their specific usage patterns to provide better user experience while browsing the Web site. Analyzing the usage pattern and browsing behavior of users can also help in improving the navigational structure of the Web site or provide collaborative filtering or product recommendation features to users.
-
3.
Streaming social media data has become the source for large-scale knowledge that can be used in applications ranging from political leaning to product market perceptions. With the continuous real-time streaming of data and its high volume, it becomes impractical and time consuming for a human to analyze and classify each observed behavior manually. If one can automatically identify distinguishing patterns and classify this behavior using an efficient classification algorithm, it would be very beneficial. Ongoing research work on bias detection, rumor identification, sentiment analysis, community detection, influence estimation, etc. use NLP techniques for determining the most representative features of each tweet, so that they can be categorized accordingly. In this, techniques similar to the feature selection and optimization processes discussed in this paper can prove to be helpful.
-
4.
Healthcare analytics is another example which can benefit from the semantics-based intelligent techniques described in this paper. Currently the most prevalent application for real-time healthcare analytics is for Clinical Decision Support (CDS). These programs analyze clinical information at the point of care and support health providers as they make prescriptive decisions. These real-time systems are active knowledge systems, which use two or more items of patient data to generate case-specific advice. As patient health reports are available in the form of Electronic Health Records (EHR) stored in structured and semi-structured form, the presented techniques can be adapted to extract and analyze pertinent health data.
6 Conclusion and future work
In this paper, a data science-based approach for Web service classification based on morphological analysis and machine learning techniques was proposed. NLP techniques are used for capturing the functional semantics of real-world Web services for facilitating effective categorization. To capture the functional diversity of the services, different feature vector selection techniques were used to represent services in vector space, with the aim of finding the most relevant set of features for a particular service, for use during classification. Experimental results indicated that the combined feature vector that captures the semantic relatedness between service terms helped achieve nearly 93 % accuracy during service classification. It was also found that the Ensemble methods performed better than base estimators such as Multinomial Näive Bayes and SVM for the proposed combined vector approach.
For further improvement, we intend to explore the application of other ensemble methods to further improve the accuracy of service classification. Other service vector models and semantic relatedness measures can be explored to handle cases when multi-context terms exist. Another issue is automatically managing any new services added to the repository, instead of a static dataset. We intend to explore avenues for autonomic management and online categorization as these new changes occur, using swarm intelligence-based clustering techniques such as Ant Colony Optimization (ACO) and Particle Swarm Optimization (PSO), that are well suited for dynamic data clustering.
Notes
Business-to-Business Systems.
Extensible Markup Language.
Simple Object Access Protocol.
Web Service Description Language.
Proposed in an earlier publication ‘Similarity analysis of service descriptions for efficient Web service discovery’ published in the proceedings of IEEE DSAA’2014. The current work uses an extended version of the technique proposed in the DSAA paper.
Web Ontology Language for Services.
OWL-S test collection, version 4. Available online at http://projects.semwebcentral.org/projects/owls-tc/.
References
Bachlechner, D., Siorpaes, K., Fensel, D., Toma, I.: Web service discovery-a reality check. In: 3rd European Semantic Web Conference, vol. 308 (2006)
Berners-Lee, T., Hendler, J., Lassila, O., et al.: The semantic web. Sci. Am. 284(5), 28–37 (2001)
Breiman, L.: Bagging predictors. Mach. Learn. 24(2), 123–140 (1996)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Cilibrasi, R.L., Vitanyi, P.: The google similarity distance. Knowl. Data Eng. IEEE Trans. 19(3), 370–383 (2007)
Corella, M.Á., Castells, P.: Semi-automatic semantic-based web service classification. In: Business Process Management Workshops, BPM 2006 International Workshops, pp. 459–470. Springer (2006)
Crasso, M., Zunino, A., Campo, M.: Easy web service discovery: a query-by-example approach. Sci. Comput. Program. 71(2), 144–164 (2008)
Dietterich, T.G.: Ensemble methods in machine learning. In: Kittler, J., Roli, F. (eds.) Multiple Classifier Systems, pp. 1–15. Springer, Berlin (2000)
Dustdar, S., Schreiner, W.: A survey on web services composition. Int. J. Web Grid Serv. 1(1), 1–30 (2005)
Fan, J., Kambhampati, S.: A snapshot of public web services. ACM SIGMOD Rec. 34(1), 24–32 (2005)
Freund, Y., Schapire, R.E.: A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 55(1), 119–139 (1997)
Hendler, J.: Agents and the semantic web. IEEE Intell. Syst. 2, 30–37 (2001)
Heß, A., Johnston, E., Kushmerick, N.: Assam: A tool for semi-automatically annotating semantic web services. In: International Semantic Web Conference, pp. 320–334. Springer (2004)
Hoschek, W.: The web service discovery architecture. In: Supercomputing, ACM/IEEE 2002 Conference, IEEE (2002)
Joachims, T.: Text categorization with support vector machines: Learning with many relevant features. In: European Conference on Machine Learning, pp. 137–142. Springer (1998)
Kamath, S., Ananthanarayana, V.: Similarity analysis of service descriptions for efficient web service discovery. In: Data Science and Advanced Analytics (DSAA), 2014 International Conference on, IEEE, pp. 142–148 (2014)
Katakis, I., Meditskos, G., Tsoumakas, G., Bassiliades, N., et al.: On the combination of textual and semantic descriptions for automated semantic web service classification. In: IFIP International Conference on Artificial Intelligence Applications and Innovations, pp. 95–104. Springer (2009)
Kim, S.M., Rosu, M.C.: A survey of public web services. In: International Conference on Electronic Commerce and Web Technologies, pp. 96–105. Springer (2004)
Klema, V., Laub, A.J.: The singular value decomposition: its computation and some applications. Autom. Control IEEE Trans. 25(2), 164–176 (1980)
Kohavi, R., et al.: A study of cross-validation and bootstrap for accuracy estimation and model selection. In: 14th International Joint Conference on Artificial Intelligence (IFCAI 1995), vol. 14, pp. 1137–1145 (1995)
Li, Y., Liu, Y., Zhang, L., Li, G., Xie, B., Sun, J.: An exploratory study of web services on the internet. In: IEEE International Conference on Web Services, pp. 380–387 (2007)
Liu, N., Zhang, B., Yan, J., Chen, Z., Liu, W., Bai, F., Chien, L.: Text representation: from vector to tensor. In: Fifth IEEE International Conference on Data Mining (ICDM’05), IEEE, pp. 4–10 (2005)
Liu, W., Wong, W.: Web service clustering using text mining techniques. Int. J. Agent-Oriented Softw. Eng. 3(1), 6–26 (2009)
McCallum, A., Nigam, K., et al.: A comparison of event models for naive bayes text classification. In: AAAI-98 Workshop on Learning for Text Categorization, Citeseer, vol. 752, pp. 41–48 (1998)
Nasir, J.A., Karim, A., Tsatsaronis, G., Varlamis, I.: A knowledge-based semantic kernel for text classification. In: 18th International Symposium on String Processing and Information Retrieval (SPIRE 2011), pp 261–266. Springer (2011)
Newman, M.E.: Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 46(5), 323–351 (2005)
Oldham, N., Thomas, C., Sheth, A., Verma, K.: Meteor-s web service annotation framework with machine learning classification. In: Cardoso, J., Sheth, A. (eds.) Semantic Web Services and Web Process Composition, pp. 137–146. Springer, Berlin (2005)
Own, H.S., Yahyaoui, H.: Rough set based classification of real world web services. Inf. Syst. Front. 17(6), 1–11 (2014)
Papazoglou, M.P.: Service-oriented computing: concepts, characteristics and directions. In: Web Information Systems Engineering, (WISE), IEEE, pp. 3–12 (2003)
Patil, A.A., et al.: Meteor-s web service annotation framework. In: 13th International Conference on World Wide Web, ACM, pp. 553–562 (2004)
Pedregosa, F., Varoquaux, G., et al.: Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830 (2011)
Saha, S., Murthy, C., Pal, S.K.: Classification of web services using tensor space model and rough ensemble classifier. In: An, A., Matwin, S., Ras, Z.W., Ślęzak, D. (eds.) Foundations of Intelligent Systems, pp. 508–513. Springer, Berlin (2008)
Salton, G., Buckley, C.: Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 24(5), 513–523 (1988)
Salton, G., Wong, A., Yang, C.S.: A vector space model for automatic indexing. Commun. ACM 18(11), 613–620 (1975)
Vapnik, V.: Principles of risk minimization for learning theory. In: Advances in Neural Information Processing Systems, pp. 831–838 (1992)
Varguez-Moo, M., Moo-Mena, F., Uc-Cetina, V.: Use of classification algorithms for semantic web services discovery. J. Comput. 8(7), 1810–1814 (2013)
Wang, H., Shi, Y., et al.: Web service classification using support vector machines. In: Tools with Artificial Intelligence (ICTAI), 22nd IEEE International Conference on, vol. 1, pp. 3–6 (2010)
Wold, S., et al.: Principal component analysis. Chemom. Intell. Lab. Syst. 2(1), 37–52 (1987)
Wu, J., Wu, Z.: Similarity-based web service matchmaking. In: Services Computing, 2005 IEEE International Conference on, IEEE, vol. 1, pp. 287–294 (2005)
Yang, J., Zhou, X.: Semi-automatic algorithm based on web service classification. Adv. Sci. Technol. Lett. 53, 88–91 (2014)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Kamath, S.S., Ananthanarayana, V.S. Semantics-based Web service classification using morphological analysis and ensemble learning techniques. Int J Data Sci Anal 2, 61–74 (2016). https://doi.org/10.1007/s41060-016-0026-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41060-016-0026-x