
Abstract
Cross-domain recommendation (CDR) has become an important research direction in the field of recommender systems due to the increasing demand for personalized recommendations across different domains. However, CDR faces multiple challenges, including data sparsity, popularity bias, and long-tail problems. To address these challenges, we propose a novel framework that combines graph contrastive embedding and multi-head cross-attention transfer for cross-domain recommendation, called GCE-MCAT. Specifically, in the pre-training process, we generate more uniform user and item embeddings through contrastive learning, effectively solving the problem of inconsistent data embedding space distribution and recommendation popularity bias. Moreover, we propose a multi-head cross-attention transfer mechanism that allows the model to extract user common and specific domain features from multiple perspectives and perform cross-domain bidirectional knowledge transfer. Finally, we propose a cross-domain feature fusion mechanism that dynamically assigns weights to common user features and specific domain features. This enables the model to more effectively learn common user interests. We evaluate the proposed framework on three real-world CDR datasets and show that GCE-MCAT consistently and significantly improves recommendation performance compared to state-of-the-art methods. In particular, the proposed framework has demonstrated remarkable effectiveness in addressing long-tail distribution and enhancing recommendation novelty, providing users with more diversified recommendations and reducing popularity bias.
Similar content being viewed by others

1 Introduction
Today, recommendation systems have been widely used in many businesses such as e-commerce, video streaming websites and social networks [1]. In these businesses, personalized recommendations have become an indispensable online service by predicting users/interests in items through fully utilizing their historical interactions [2]. With the enrichment of recommendation scenarios and the continuous expansion of recommendation scale, the severity of data sparsity and long-tail problems in recommendation systems has also increased. These problems pose great challenges to the performance of recommendation systems, especially when user-item interactions are very sparse [3].
To solve the problem of domain data sparsity in recommendation systems, cross-domain recommendation has become an effective solution. Cross-domain recommendation [4] can improve the recommendation accuracy in sparse domains by utilizing information from rich domains. Dual-target CDR [5,6,7] allows knowledge transfer and mutual promotion between source and target domains. For instance, if a user watches and rates works by the same director on a movie website (source domain), we can also recommend books related to that director on a book website (target domain). If a user browses and rates multiple detective novels on a book website (source domain), we can also recommend suspense movies to the user on a movie website (target domain). However, most existing cross-domain recommendation works still do not consider the long-tail distribution of user-item interaction data [8].
It is well-known that popular items receive significantly more exposure than niche items, leading to a “rich get richer” phenomenon, commonly referred to as the “80/20 rule.” As shown in Fig. 1, “Titanic,” starring Leonardo, is a famous romantic movie that includes a lot of user feedback, while “Revolutionary Road,” also starring him, is not well-known. This indicates that the distribution of user-item interaction data is highly imbalanced, with a small fraction of popular items dominating the majority of user attention, as compared to niche items. On the other hand, the majority of items are long-tail items that receive very limited user interactions [9]. This results in the under-recommendation of long-tail items, as conventional recommendation models trained on such data are more likely to overfit to popular items [10]. Furthermore, it is important to consider the impact of the long-tail distribution on cross-domain recommendation systems. In cross-domain recommendation, where recommendations are made across different domains or categories, the long-tail distribution can have significant implications. The under-recommendation of long-tail items can lead to limited diversity in recommendations and hinder the exploration of niche items in different domains. Therefore, understanding and addressing the challenges posed by the long-tail distribution in cross-domain recommendation systems is crucial for improving recommendation accuracy and user satisfaction. This causes the recommendation model to often ignore more suitable long-tail items and only retrieve popular items, which is not friendly to people with niche interests and is not conducive to the growth of recommendation system users.

Long-tail Problem
In such cases, we need to consider how to deal with the long-tail problem and popularity bias problem to improve the performance of recommendation systems. Researchers have proposed many DNN-based CDR methods [11,12,13] to better capture user preferences. For example, EMCDR [14] is a classic embedding mapping method that establishes a mapping function by aligning user representations. In addition, deep learning-based CDR methods [15, 16] can solve the long-tail problem and popularity bias problem in recommendation systems by introducing new data representations. These methods use deep neural networks to model users and items, thus learning the relationship between users and items. Compared with traditional matrix factorization-based collaborative filtering algorithms [17], these deep learning-based methods can better handle data sparsity and nonlinear relationships, thus having better performance on long-tail problems and popularity bias problems. In addition to deep learning-based methods, some contrastive learning recommendation models [18, 19] can also be applied to solve long-tail problems and popularity bias problems. A large number of experiments in SimGCL [20] have shown that the uniformity of representation distribution is the key point for performance improvement. Chen et al. [21] believe that learning more uniformly distributed user/item representations can alleviate popularity bias.
In this paper, our goal is to improve the recommendation performance of both rich and sparse domains through CDR, and to provide users with diversified recommendations to reduce popularity bias. This task mainly faces the following three challenges.
-
Challenge 1: The inconsistent distribution of data embedding space leads to popularity bias and long-tail problems. Long-tail items lack feedback, so their feature distribution is inconsistent compared to popular items with rich feedback. Therefore, how to generate more representative user and item embeddings for a single domain to reduce popularity bias in recommendations becomes an important issue.
-
Challenge 2: Most CDR methods only consider transferring shared features of common users without considering user-specific domain preference features. And sometimes the specific preferences of the source domain provide useless information for the target domain, which can cause negative transfer and damage the recommendation performance of the target domain. Therefore, it is equally important to effectively extract domain-specific features and extract common domain features.
-
Challenge 3: Directly aggregating domain-shared features and domain-specific features during training ignores that they represent different semantic transfer knowledge representations.
To address these challenges, we propose a cross-domain recommendation framework that combines graph contrastive embedding and multi-head cross-attention transfer, called GCE-MCAT. First, during the pre-training process, we generate more balanced user and item embeddings through contrastive learning. Specifically, on the basis of the graph encoder, random uniform noise is added to the original representation to construct positive examples for representation-level data augmentation. Then, different views are contrasted to learn more balanced feature representations. Second, we propose a multi-head cross-attention transfer mechanism that allows the model to extract common and domain-specific features of users from multiple perspectives and perform bidirectional knowledge transfer. Finally, we propose a cross-domain feature fusion mechanism that can dynamically allocate weights to common user features and domain-specific features. This allows the model to more effectively learn the interest preferences of common users.
In this paper, our contributions are as follows:
-
(1)
We propose a cross-domain recommendation framework that combines graph contrastive embedding and multi-head cross-attention transfer, called GCE-MCAT. Through contrastive learning, we generate more balanced user and item embeddings during pre-training. This allows the model to effectively address the problem of inconsistent data embedding space distribution and reduce popularity bias in recommendations.
-
(2)
To enable the model to extract common and domain-specific features of users from multiple perspectives, we propose a multi-head cross-attention transfer mechanism. In addition, we propose a cross-domain feature fusion mechanism that can dynamically allocate weights to common user features and domain-specific features. This allows the model to more effectively learn the interest preferences of common users.
-
(3)
We conduct experiments on three real-world CDR datasets and evaluate model performance. Through extensive experiments, our model consistently and significantly improves performance. To further investigate the effectiveness of each component in the GCE-MCAT model, we conduct a comprehensive ablation study and analysis. In addition, to verify the model’s improvement on long-tail distribution and the enhancement of recommendation novelty, we also conduct long-tail experiments and novelty analysis.
2 Related Work
2.1 Cross-Domain Recommendation
Cross-domain recommendation methods are an effective way to solve the problem of data sparsity [22, 23]. Single-target CDR [24] is a cross-domain recommendation method that transfers knowledge from the source domain to the target domain through transfer learning to better learn user preferences. This method has achieved great success in solving cold start problems and improving recommendation performance [25]. For example, EMCDR [14] solves the cold start problem in the target domain by learning the mapping function between user embeddings in the source and target domains. Singh and Gordon [26] uses a collective matrix factorization model for cross-domain recommendation, and Loni et al. [17] considers interactions with specific types of items as constituting specific domains and allows interaction information from auxiliary domains to be recommended in the target domain.
However, the disadvantage of single-target CDR is that it only focuses on the performance of one domain and ignores the performance of another domain [27]. In contrast, dual-target CDR pursues better performance in both domains at the same time. This method can not only use knowledge from the source domain to improve the recommendation performance of the target domain, but also use knowledge from the target domain to improve the recommendation performance of the source domain. This method has also achieved great success in solving data sparsity problems and improving recommendation performance [28].
Hu et al. [29] achieves cross-domain dual knowledge transfer by introducing cross connections between two base networks. Hu et al. [5] uses an adaptive embedding sharing strategy to combine and share cross-domain common user embeddings, thereby improving the recommendation performance of both domains at the same time. DDTCDR [6] uses latent orthogonal mapping to extract user preferences from multiple domains and iteratively transfers information between two related domains. GA-DTCDR [30] constructs a heterogeneous graph of two domains based on their information and combines common user embeddings of both domains using element attention mechanism. Liu et al. [31] combines high-order feature propagation in graph structure with transfer learning to solve top K problem in cross-domain recommendation. Cao et al. [32] proposed two mutual information-based separation regularizers to separate domain-shared information and domain-specific information. Zhao et al. [33] improve dual-target recommendation performance by perceiving cross-domain similarity between entities and aligning user interests. CATCL [34] combines cross-attention and contrastive learning for dual-target cross-domain recommendation. Compared to previous work, we have introduced a graph-based contrastive learning approach in the graph modeling process, which better captures the features and correlations of cross-domain recommendation. Additionally, instead of using traditional attention mechanism transfer techniques, our method utilizes cross-domain self-attention mechanisms and cross-domain feature fusion methods to model domain-shared information and domain-specific information.
2.2 Contrastive Learning in Recommendation
Contrastive learning is an unsupervised learning method that originated from metric learning [35]. It maps similar samples to nearby embedding spaces and different samples to distant embedding spaces, thereby learning better feature representations. Recently, contrastive learning has made great strides in the fields of CV [36, 37], NLP [38, 39], and recommendation systems [19, 40]. In the field of computer vision, Chen et al. [35] is a classic contrastive learning model that constructs positive and negative examples by cropping and flipping images, representing image content through an Encoder, and mapping embeddings to projection space through a Projector.
In recommendation systems, contrastive learning can be used to train embeddings for users and items for use in recommendation tasks. Specifically, contrastive learning measures the similarity between two samples using the similarity between their embedding vectors. These samples can be users, items or other entities. The goal of contrastive learning is to map similar samples to adjacent spaces and different samples to distant spaces. Since CL can not only solve the data sparsity problem in recommendation systems, but also play a significant role in alleviating popularity bias and other issues, some work has emerged that combines CL with recommendation systems. Lin et al. [40] introduces potential neighbors of users or items from graph structure and semantic space into the contrastive objective. Xia et al. [41] proposed a self-supervised training strategy based on contrastive learning to learn user interest embeddings from unlabeled session data.
Contrastive learning methods have also been used in sequential recommendation [42, 43], session recommendation [19], cross-domain recommendation [44, 45] and other directions. Sun et al. [42] transfers the cloze objective from language modeling to sequential recommendation by predicting randomly masked items in the sequence with surrounding context. Chen et al. [43] learns the user’s intention distribution function from unlabeled user behavior sequences and optimizes the sequence recommendation model by considering the learned intention in contrastive self-supervised learning (SSL). Xia et al. [19] use a session-based graph to enhance two views that show intra- and inter-session connectivity, allowing encoders to recursively use different connectivity information to generate underlying true samples and supervise each other through contrastive learning. Xia et al. [44] effectively improves matching performance in CDR by designing a diversified preference network and intra- and inter-domain contrastive learning tasks. Xia et al. [34] uses contrastive learning and cross-attention mechanisms to improve dual-domain performance. COAST [33]improves dual-domain recommendation performance by utilizing contrastive learning and gradient alignment techniques to perceive cross-domain similarity between entities and align user interests.
However, mainstream contrastive learning methods often overlook the inconsistent distribution of data embedding, leading to issues such as popularity bias and long-tail problems. To address this, we propose a novel approach that leverages contrastive learning to generate more balanced user and item embeddings by considering different feature perspectives within each domain. This enables our model to effectively capture user preference representations, enhancing recommendation performance.
3 Proposed Model
3.1 Problem Definition
We consider two relevant domains and let \(D_{{\text{A}}} \) represent domain A and \(D_{{\text{B}}} \) represent domain B, respectively. Let \(U=\{u_1,u_2,....u_m\}\) and \(V=\{v_1,v_2,....v_n\}\) represent the set of users and the set of items, respectively, where m and n denote the number of users and items, the set of items for \(D_{{\text{A}}} \) and \(D_{{\text{B}}} \) is denoted as \(V_A\) and \(V_B\), the set of users is denoted as \(U_{{\text{A}}} \) and \(U_{{\text{B}}} \), and the set of overlapping users of the two domains is denoted as \(U_{{\text{C}}} \). The \(y_{ij}\in R\) represents the rated interactions between users and items, and the user-item interaction matrix is defined as \(R_A\in R^{M\times N}\) in \(D_{{\text{A}}} \) and \(R_{{\text{B}}} \in R^{M\times N}\) in \(D_{{\text{B}}} \). The goal of this paper is to simultaneously improve the recommendation performance of both domains \(D_{{\text{A}}} \) (\(D_{{\text{B}}} \)). Specifically, a function is learned to predict the user’s rating \({\hat{y}}_{i j}^a \) (\({\hat{y}}_{i j}^b\)) of the items to be interacted with based on the user’s historical interaction records in both domains, which is used to rank the Top K items.
3.2 Model Overview
As shown in Fig. 2, our proposed model GCE-MCAT consists of five main modules: input layer, graph contrastive embedding layer, multi-head cross-attention layer, cross-domain feature fusion, and output layer.

Overview of GCE-MCAT
3.3 Graph Contrastive Embedding Layer
A typical process for CL-based recommendation models is to first expand the user-item bipartite graph with structural perturbations and then maximize the consistency of node representation between different graph augmentations. The current state-of-the-art CL-based recommendation model SGL [46] uses node dropout, edge dropout and random walk in the graph structure to create different node views. Inspired by SimGCL model, we adopt a similar data augmentation approach to generate different contrast views as a way to generate a smoother and more uniform feature representation. The basic idea is to add random uniform noise to the embedding space to create the contrast views. Applying different random noise creates differences between the contrast views while still retaining learnable invariance due to the controlled magnitude. Based on the above graph contrastive learning, we generate user and item embedding matrices for each domain through pre-training, respectively. Graph contrastive embedding layer includes four main components, i.e., data augmentation, contrastive learning, multi-task training.
3.3.1 Data Augmentation
Since the dropout-based graph augmentation is intractable and ineffective, we discard this augmentation method and choose a simpler and more effective graph-free augmentation method. Specifically, this approach adds random uniform noise to the original representation for representation-level data augmentation, which results in a more uniform distribution of the embedding space.
Given a node i and its representation \(e_i\) in the d-dimensional embedding space, we can achieve the following representation-level augmentation:
where \(H(\cdot )\) is the encoder function that encodes the connection information into a representation. \(\delta ^{\prime }\) and \(\delta ^{\prime \prime }\) are the randomly generated noise vectors. We use LightGCN [47] as a graph encoder to perform convolution operations on the input graph data to capture node preferences by propagating information between neighboring nodes. At each layer, different scaled random noise is applied to the current node embedding. We consider the views of the same node as positive samples of each other (i.e., \(z_{i}^{'}\) and \(z_{i}^{''}\)), the views of any different nodes as negative samples of each other (i.e., \(z_{i}^{'}\) and \(z_{j}^{''}\)).
We restrict the noise \(\delta \) magnitude to the size of the radius r of a hypersphere. If the noise added to the \(z_i\) influences excessively, it will cause the augmented samples to lose the similar features to the original samples. Therefore, we need to control that the direction of \(z_i\) and its augmented representations \(z_{i}^{'}\) and \(z_{i}^{''}\) do not deviate excessively. As shown in Eq. (3), \(\bar{\delta }\) contains the direction of the three within a certain range. These restrictions do not allow for large deviations in \(z_i\) that lead to a reduction in the number of valid positive samples. The augmented representation retains most of the personalized feature information of the original representation since the noise added is relatively light. In the augmented embedding space, similar instances are closer together, and different instances are more uniformly distributed.
3.3.2 Contrastive Learning
Formally, we use the contrastive loss InfoNCE [37] to achieve consistency among different views of the same node and diversity among different nodes. The contrastive loss function for user u is represented as follows:
where \({\mathcal {B}}\) denotes a set of users in a batch, \(z_{u}^{'}\) and \(z_{u}^{''}\) represent two different feature representations for user u, and \(\tau \) is a temperature parameter. The objective of this loss function is to better distinguish \(z_{u}^{'}\) and \(z_{u}^{''}\) from each other and separate them from the features of other users. Specifically, the numerator in this formula represents the similarity between \(z_{u}^{'}\) and \(z_{u}^{''}\), while the denominator represents the sum of similarities between \(z_{u}^{'}\) and \(z_{v}^{''}\) for all users in a batch, calculated using the softmax function. The goal of the contrastive loss function is to make the feature vectors of the same user in different contexts as close as possible while separating the feature vectors of different users as far as possible. Maximizing the similarity between the two feature vectors of the same user can make the extracted features more consistent and reliable in different contexts. Minimizing the similarity between feature vectors of different users can increase the discriminability of the model, thereby better distinguishing the features of different users.
Similarly, the InfoNCE loss function for item i is represented as:
For each item i, this loss function learns the item representation by maximizing the similarity between positive and negative examples and minimizing the similarity between item i and other negative examples. Specifically, the numerator \(\exp \left( \frac{z_i^{\prime \top } z_i^{\prime \prime }}{\tau }\right) \) represents the similarity between the positive example and item i, while the denominator \(\sum _{j \in {\mathcal {B}}} \exp \left( \frac{z_i^{\prime \top } z_j^{\prime \prime }}{\tau }\right) \) represents the sum of similarities between negative examples and item i. Therefore, the entire formula represents the goal of maximizing the similarity between positive examples and item i while minimizing the similarity between item i and other negative examples. By minimizing this loss function, we can learn item representations that effectively distinguish the similarities between different items.
3.3.3 Multi-Task Training
We use a multi-task training strategy to jointly optimize the recommendation task and contrastive learning task:
where \(\Theta \) is the parameter of \({\mathcal {L}}_{\text{ main } }\), \(\lambda _1\) and \(\lambda _2\) are contrastive learning rates used to adjust the ratio of \({\mathcal {L}}_{\text{ main } }\) and \({\mathcal {L}}_{\text{ cl }}\) loss, \(\lambda _3\) is the hyperparameter controlling L2 regularization. \(\lambda _1 {\mathcal {L}}_{c l}^U\) and \(\lambda _2 {\mathcal {L}}_{c l}^I\) are the user contrastive loss and item contrastive loss, respectively, which enhance the recommendation performance by constraining the feature vectors of users and items to be closer among similar users. \(\lambda _3\Vert \Theta \Vert _2^2\)is the regularization term used to control the complexity of the model and prevent overfitting. \({\mathcal {L}}_{\text{ main } }\) is the main loss, which trains the model by maximizing the ranking of correct items, using the Bayesian Personalized Ranking (BPR) loss:
where O is a triplet (u, i, j) representing that user u rates item i higher than item j, \(z_u\), \(z_i\), and \(z_j\) are the latent vector representations of user u, item i, and item j, respectively, and \(\sigma \) is the sigmoid function. The goal of this loss function is to maximize the difference between high-rated items and low-rated items during the training process, thus improving the performance of the recommendation system. We can obtain user and item embeddings generated by graph contrastive learning after multi-task joint training, denoted as \(Z_u^a\), \(Z_v^a\), \(Z_u^b\), \(Z_v^b\) on \(D_{{\text{A}}} \) and \(D_{{\text{B}}} \), respectively.

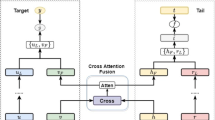
Cross-Attention mechanism
3.4 Multi-Head Cross-Attention
In order to better connect users from different fields, capture the association between cross-domain user preferences, and promote the learning of knowledge that can be shared across domains, we adopt a multi-head cross-attention mechanism. By using shared users with interaction history to learn the potential factors of user preferences in two domains, all items can be fully expressed in a shared space, even if there are few or no items shared in different domains. Figure 3 shows a diagram of the cross-attention mechanism.
In \(D_{{\text{A}}} \), we use the user embedding vector \(Z_u^a\) generated by graph contrastive learning to represent three vectors projected by queries \(\textrm{Q}_u^{(a)} \in R^{N \times d_k}\), keys \(\textrm{K}_u^{(a)} \in R^{N \times d_k}\), and values \(\textrm{V}_u^{(a)} \in R^{N \times d_k}\), where \(d_k\) represents their dimension. Their calculation formulas are as follows:
where \(W_q^{(a)}\),\(W_k^{(a)}\),\(W_v^{(a)}\) are trainable matrices in \(D_{{\text{A}}} \). Similarly, we can obtain \(W_q^{(b)}\),\(W_k^{(b)}\),\(W_v^{(b)}\) on \(D_{{\text{B}}} \), and thus obtain three vectors \(Q_u^{(b)}\),\(K_u^{(b)}\),\(V_u^{(b)}\) on \(D_{{\text{B}}} \).
where Eq. (9) calculates the cross-attention score of domain A. The query vector \(Q_u^{(a)}\) comes from \(D_{{\text{A}}} \), and the key vector \(K_u^{(b)}\) and value vector \(V_u^{(b)}\) come from \(D_{{\text{B}}} \). This formula calculates the attention distribution from domain A to domain B, and then applies the attention weight to the value vector \(V_u^{(b)}\) to generate cross-domain feature representation. Equation (10) is similar to Eq. (9), which can calculate the attention distribution from domain B to domain A. The query vector \(Q_u^{(b)}\) comes from \(D_{{\text{B}}} \), and the key vector \(K_u^{(a)}\) and value vector \(V_u^{(a)}\) come from \(D_{{\text{A}}} \). This operation enables the model to cross-fuse and extract features from different domains.
By using a single-head cross-attention mechanism, we can further extend it to a multi-head cross-attention mechanism, which allows the model to fuse and extract cross-domain features from multiple perspectives. The equation for computing multi-head cross-attention is as follows:
where h represents the number of heads. \(W_i^{(a)}, W_i^{(b)}, W_i^{(v)} \in {\mathbb {R}}^{d_k \times d_{k, h}}\) are the matrix parameters used to split the input vectors into heads, where \(d_{k,h}\) represents the dimension of the query/key vectors for each head. \(W^{(c)} \in {\mathbb {R}}^{h d_v \times d_v}\) is the matrix parameter used to concatenate the heads, where \(d_v\) is the dimension of the value vectors. Concat is used to form the final output by combining all the heads. CrossAttention(Q, K, V) represents the single-head attention function. By using this function, the cross-attention scores for each head, \(head_i\), can be computed, and the outputs of all the heads can be concatenated to form the final output. In the multi-head cross-attention mechanism, we can obtain multiple attention heads by using different sets of query, key, and value vectors. This can increase the model’s expressive power and improve its performance. Using Eq. (11), we can obtain the multi-head attention scores for domain A, denoted as \(H_u^{(a)}\). Similarly, we can obtain the multi-head attention scores for domain B, denoted as \(H_u^{(b)}\).
3.5 Cross-Domain Feature Fusion
We fuse the multi-head cross-domain attention scores with the domain-specific embedding of both domains to obtain domain-shared features and domain-specific features. The calculation formula is as follows:
where \(\lambda ^a\) and \(\lambda ^b\) are hyperparameters within the range of [0, 1]. In Eq. (11), we can obtain the cross-attention scores \(H_u^a\),\(H_u^b\). We use the hyperparameters \(\lambda ^a\) and \(\lambda ^b\) to control the retention ratio of user features in the corresponding domain. For example, when \(\lambda ^a\) = \(\lambda ^b\) = 1.0, it indicates that 100\(\%\) of the user features in \(D_{{\text{A}}} \) and \(D_{{\text{B}}} \) are retained, so the user features have the greatest specificity in these two domains. When \(\lambda ^a\) = \(\lambda ^b\)= 0.5, the specificity of user features disappears and the same user has the same features in both domains.
Finally, we use the element-wise attention component to combine domain-shared and domain-specific features. It tends to have different proportions of common and specific domain features learned from the two domains. We denote the combination of user common and specific domain features embedding \({\widetilde{U}}^a\) and \({\widetilde{U}}^b\) of \(D_{{\text{A}}} \) and \(D_{{\text{B}}} \) as:
where \(\odot \) is the element multiplication, \(W^a \in R^{N\times k}\), \(W^b \in R^{N \times k}\) are the weight matrices of the attention network on \(D_{{\text{A}}} \) and \(D_{{\text{B}}} \), respectively.
3.6 Model Training
In the output layer, we obtain the predicted value of \({\hat{y}}_{i j}^a\) by the consine function cosine function:
where \(U_i^a\) and \(V_j^a\) are the user embedding and item embedding trained by MLP layer, \(\left\| U_i^a\right\| \) and \(\left\| V_j^a\right\| \) are the normalized embeddings, respectively. Similarly, we can also obtain the predicted value \({\hat{y}}^b\) the \(D_{{\text{B}}} \).
We use the cross-entropy loss function as the objective function in \(D_{{\text{A}}} \) to train our model, which is defined as follows:
where \(y^{a+}\) is the set of observed interaction histories, and \(y^{a-}\) is the set of randomly sampled non-observed interactions. \(\lambda \) is the hyperparameter that controls the regularization strength to avoid overfitting. \(\left\| U_{M L P}^a\right\| _F^2+\left\| V_{M L P}^a\right\| _F^2\) is the regularizer.
4 Experiments
In this section, we first describe the experimental setup, including the datasets, evaluation metrics, parameter settings, and baseline models. We then conduct an extensive analysis of the experimental results. The questions studied are as follows:
- RQ1::
-
How is the performance of GCE-MCAT compared to the baseline model?
- RQ2::
-
How do the different design modules (i.e., CL-based embedding layer, multi-head cross-attention mechanism) contribute to the performance of the model?
- RQ3::
-
Does CL-based embedding help to improve the long-tail problem?
- RQ4::
-
How does the GCE-MCAT model perform in terms of novelty?
- RQ5::
-
How does GCE-MCAT perform under different parameter settings?
4.1 Experimental Setup
4.1.1 Datasets
To evaluate our proposed model against the state-of-the-art baseline, we chose three real datasets in the movie, book, and music domains of the Douban website (see Table 1) for our experiments.Footnote 1 For the three datasets (douban_movie, douban_book and douban_music), we retain the users and items that had at least five interactions, and we transformed the user’s rating to 0 or 1, indicating whether the user interacted with the item or not. This filtering strategy has been widely used in existing approaches [48]. With different combinations of domains, we constructed two CDR tasks, movie-book, and movie-music (see Table 2). We validate the recommendation performance of our model in the CDR scenario with dual-target CDR experiments in rich and sparse domains.
4.1.2 Evaluation Metrics
In this paper, we use a ranking-based evaluation strategy, the leave-one-out evaluation, which has been widely used in the literature. For each test user, we selected the most recent interaction with the test item as the test interaction and randomly selected 99 unobserved interactions for the test user, and then ranked the test items among the 100 items. Hit ratio (HR), normalized discounted cumulative gain (NDCG) and recall are the three evaluation metrics of this strategy, which are defined as follows:
where N represents the total number of users, hits(i) indicates whether the true interaction value of the i-th user is present in the recommendation list, where 1 denotes presence and 0 denotes absence. pi represents the position of the true interaction value of the i-th user in the recommendation list. R(u) represents the list of recommended items for user u, and T(u) represents the set of items that are truly recommended to user u. HR@N is the rate at which the test sample ranks in the N-th position of the ranked list, while NDCG@N measures the quality of a particular ranking that assigns high scores to the top-ranked hits. Recall@N evaluates the proportion of relevant items that are correctly recommended within the top N positions of the ranked list. In this paper, H@10 and N@10 represent HR@10 and NDCG@10, respectively. We use HR@10 and NDCG@10 to evaluate the performance of our models and other comparison models, Recall@10 and NDCG@10 to evaluate the performance of the long-tail experiment, and use the novelty metric to verify the novelty of the model.
4.1.3 Parameters Settings
For the pre-trained CL-based embedding, we used Adam with a learning rate of 5e-4 to optimize the model. We empirically set the temperature t to 0.2 and the contrastive learning rate to 1e-4. The batch size is set to 512. In addition, to train our model GCE-MCAT, we randomly select seven negative samples for each observed positive sample to generate the training dataset, use Adam as the optimizer to train the neural network, and set the maximum number of training epochs to 50, the initial learning rate to 1e-4, the regularization factor \(\lambda \) to 1e-3, and the batch size to 4096. The L2 penalty is set to 10–3 to avoid overfitting. Furthermore, we set d = 128 for the embedding size of all the methods.
4.1.4 Comparison Methods
-NeuMF [45] is a neural network architecture that uses collaborative filtering methods to model the latent features of users and items.
-DMF [49] is a neural network-based CF model that uses a deep architecture to learn low-dimensional factors of users and items.
-DTCDR [5] performs dual-target cross-domain recommendation by transferring the domain-shared features of common users of both domains.
-DDTCDR [6] introduces potential orthogonal mapping functions through dual learning mechanism to transfer user similarity across domains.
-GA-DTCDR [30] generate graph embedding using rating and review information and use attention mechanism to achieve cross-domain knowledge transfer.
-BiTGCF [31] extends LightGCN to the CDR task. It first generates user/item representations for each domain using two linear graphical encoders, and then fuses the user representations using a feature transfer layer.
-DisenCDR [32] separates domain-shared information from domain-specific information based on two separating regularizers of mutual information.
-CATCL [34] uses contrastive learning to generate more uniform user-item embeddings, and introduces a cross-attention mechanism to extract shared and domain-specific feature representations of users.
4.2 RQ1: Performance Comparisons
For RQ1, we conducted experiments on two cross-domain recommendation tasks. The experimental results are shown in Table 3. Bold scores are the best in each column, while underlined scores are the best among all baselines. Improvement denotes the improvement versus best baseline results. We observed the following results: First, we can see that the GCE-MCAT model achieved the best results on all metrics in both datasets. Compared to other models, it achieved an improvement rate of 0.76 and 4.09, 2.96 and 0.58% (in Movie and Book dataset) and 0.84 and 3.40, 7.39 and 0.47% (in Movie and Music dataset) in terms of HR@10 and NDCG@10, respectively. This result validates the advantages provided by the GCE-MCAT model through graph contrastive learning and multi-head cross-attention transfer.
In the single-domain recommendation models, NeuMF performed poorly on all four evaluation metrics compared to other models. It seems to struggle in capturing the complex relationships between users and items in both domains. DMF performed better than NeuMF but still worse than most other models. It uses a deep architecture to learn low-dimensional factors of users and items but may not be able to effectively capture domain-specific features. In most cases, single-domain recommendation methods (e.g., NeuMF, DMF) performed worse than all cross-domain recommendation models on these three datasets. This demonstrates that transferring knowledge from the source domain to the target domain can indeed improve recommendation performance.
Among cross-domain recommendation models, CATCL achieved the best baseline performance and performed well on both Movie and Book and Movie and Music datasets. GA-DTCDR generated graph embeddings using rating and review information and achieved cross-domain knowledge transfer through attention mechanism. DisenCDR separated domain-specific information and domain-shared information using two mutually informative separable regularizers, both of which had good effects in cross-domain recommendation. DDTCDR performed well in the Movie and Book task but performed poorly in the Movie and Music task. This model introduced a potential orthogonal mapping function through the dual learning mechanism to achieve cross-domain transfer of user similarity, but may not handle specific issues in music recommendation very well. The BI-TGCF model performed well in the Movie and Music task, with an HR@10 metric of 0.4141. This model first used two linear graph encoders to generate user/item representations for each domain and then fused the user representations using a feature transfer layer. Its performance was relatively good in this task, but still lower than other models.
4.3 RQ2: Ablation Study
To investigate the impact of each component of GCE-MCAT, we considered the following variants of GCE-MCAT:
-
(1)
GCE-MCAT_Embed: In this variant, we used regular embeddings instead of graph contrastive embeddings. To evaluate the quality of the embeddings, we compared this variant with GCE-MCAT.
-
(2)
GCE-MCAT_LightGCN: In this variant, we used embeddings generated by LightGCN instead of regular embeddings. It performs neighborhood aggregation without distinguishing various relationships between nodes.
-
(3)
GCE-MCAT_SGL: In this variant, we compared the components of our model using graph contrastive embeddings generated by the SGL model instead of CL-based embeddings.
-
(4)
GCE-MCAT_MLP: This variant does not perform knowledge transfer between source and target domains, but instead directly sends the graph contrastive embeddings to the MLP layer for training.
-
(5)
GCE-MCAT_Pooling: This variant uses pooling operations instead of multi-head cross-attention mechanisms for knowledge transfer.
-
(6)
GCE-MCAT_SingleCA: This variant uses a single-head cross-attention mechanism for feature fusion and transfer.
Based on Table 4 and the introduction of GCE-MCAT variants, we can analyze the impact of each component of GCE-MCAT. From the table, it can be observed that GCE-MCAT_Embed performs slightly worse than GCE-MCAT and other variants, particularly in terms of HR@10 and NDCG@10 metrics. This suggests that using graph contrastive embeddings is beneficial for performance improvement. Next, GCE-MCAT_LightGCN performs well in most experiments, indicating that neighborhood aggregation can improve the model’s performance. GCE-MCAT_SGL, which uses graph contrastive embeddings generated by the SGL model instead of CL-based embeddings, performs slightly worse than GCE-MCAT and other variants in most experiments. GCE-MCAT_MLP performs poorly in most experiments, indicating that knowledge transfer is necessary for performance improvement. GCE-MCAT_Pooling, which uses pooling operations instead of multi-head cross-attention mechanisms for knowledge transfer, performs poorly in most experiments. Finally, GCE-MCAT_SingleCA, which uses a single-head cross-attention mechanism for feature fusion and transfer, performs slightly worse than GCE-MCAT and other variants, particularly in terms of NDCG@10 metrics for Movie and Book and Movie and Music datasets. This suggests that multi-head cross-attention mechanisms are more suitable for feature fusion and transfer.

Comparison of Recall performance for different item groups

Comparison of NDCG performance for different item groups
4.4 RQ3: Effectiveness of the Long-Tail Recommendation
To verify the graph contrast learning embedding, we divided the test set into popular and long-tail items according to the popularity of the items. We define the top 20% of items as popular items and the rest as long-tail items. We divided the experimental data into three groups: the first group contains only long-tail items, the second group is an unfiltered data set, and the third group contains only popular items. Then, we tested two experimental tasks separately and checked the Recall@10 and NDCG@10 values of each group. The results of Recall@10 are shown in Fig. 4, and the results of NDCG@10 are shown in Fig. 5. From the experimental results, it can be seen that each model’s performance on popular items is always much higher than that on long-tail items, indicating that there is a significant difference between popular and long-tail items and their distribution is inconsistent. This difference may stem from the popularity difference between popular and long-tail items. Popular items usually have higher popularity and are more easily accepted and liked by users. Therefore, models are more likely to achieve good results when recommending popular items. In contrast, long-tail items usually have lower popularity and are more difficult to be accepted and liked by users. Therefore, it is more difficult for models to recommend long-tail items. Secondly, the results on Long-Tail, Entire and Hot datasets show that our model performs better than other comparison models and has a more significant advantage in recommending long-tail projects. This shows that graph contrast learning can train more balanced embedding representations, so that the model can achieve better results in long-tail recommendations. In addition, according to the experimental results, GA-DTCDR and LightGCN tend to recommend popular items but perform poorly in recommending long-tail items. This is due to the lack of uniformity in the feature representation learned by the model, resulting in popularity bias. CATCL performs well on Long-Tail and Entire datasets but performs poorly on hot datasets. This may be because the model focuses more on recommending long-tail projects while ignoring users’ general interests. Our model takes into account both long-tail and popular recommendations, breaking through information cocoons to bring users novel experiences while also allowing users to understand popular trends.

Novelty Experiment Result
4.5 RQ4: Novelty Comparison
In this section, we first introduce the novelty formula and then compare the novelty experimental results of three cross-domain recommendation models. In recommendation systems, novelty refers to the degree to which the recommended items or information in the results differ from the user’s past experiences or known preferences. It measures whether the recommendation system can introduce novel content that the user has not encountered before. Highly novel recommendations can bring new discoveries and enriching experiences to users. The calculation equation for novelty is as follows:
where u represents the user, i represents the item, R(u) represents the list of recommended items for user u, and P(i) represents the popularity of item i. The novelty index in the above formula is a measure of the popularity of the recommended items in the recommendation system. The numerator of the formula is the sum of the logarithms of the popularity of all recommended items for all users, and the denominator is the total number of recommended items for all users. The calculation method of this index is to take the logarithm of the popularity of all recommended items, sum them up, and then divide by the total number of recommended items, representing the average level of popularity of the recommended items in the recommendation system. It should be noted that the popularity of an item is correlated with its historical interaction data. If an item has less repetition in a user’s historical behavior, indicating lower popularity, recommending it can be considered to achieve higher novelty. Therefore, a lower novelty score indicates a higher level of novelty in the recommended list.
From the experimental results in Fig. 6, it can be seen that our model has higher novelty in both Task 1 and Task 2. In both tasks’ movie domain, the novelty is significantly higher than the other two models. This may be because our model adopts cross-domain graph contrastive learning, which can better learn the relationships between cross-domain items and thus generate more novel recommendations. In the book and music domains, the novelty of the model is similar, which may be because the items in the book and music domains have different characteristics and our model may not fully utilize cross-domain information to improve the novelty of recommendations, resulting in little difference in novelty.

Effect of \(\lambda \)
4.6 RQ5: Impact Factor Analysis
In this experiment, we analyzed the impact of hyperparameter \(\lambda \) on the experimental performance. We set \(\lambda = \lambda ^{(a)} = \lambda ^{(b)}\), with a step size of 0.1, in the range of [0.5, 1.0]. Figure 7 shows the experimental results of our model on the movie-book and movie-music tasks. It can be seen that both tasks achieve the best performance when \(\lambda \) is set to 0.8. Additionally, the model’s initial performance is ordinary when \(\lambda \) is 0.5, and the performance improves gradually with the increase of \(\lambda \). However, when \(\lambda \) is 1, the performance of both tasks declines. This indicates that the model needs to retain specific features of both domains and also needs to consider the proportion of feature preservation.
5 Future Directions and Prospects
While the proposed GCE-MCAT framework has shown promising results in addressing the challenges of cross-domain recommendation (CDR) tasks, there are several avenues for further research and development in this field.
-
(1)
Exploring additional contrastive learning techniques: In this paper, contrastive learning was employed to improve the balance of user and item embeddings. However, there are various other contrastive learning methods that could be explored to further enhance the quality of embeddings. Techniques such as InfoNCE loss, SimCLR, or MoCo could be investigated to achieve even better performance in CDR tasks.
-
(2)
Incorporating domain adaptation techniques: Cross-domain recommendation often involves transferring knowledge from one domain to another. To improve the transferability of the learned representations, domain adaptation techniques can be explored. Methods such as adversarial training, domain adversarial neural networks, or domain-invariant feature learning could be integrated into the GCE-MCAT framework to enhance its ability to handle domain shifts and improve recommendation performance across different domains.
-
(3)
Leveraging advanced attention mechanisms: While the GCE-MCAT model utilizes multi-head cross-attention transfer, there are more advanced attention mechanisms that could be explored. Transformer-based models, such as the popular BERT or GPT architectures, have demonstrated remarkable success in various natural language processing tasks. Adapting these attention mechanisms to the CDR domain could potentially improve the model’s ability to capture intricate user-item relationships and further enhance recommendation accuracy.
-
(4)
Addressing privacy and data sparsity concerns: Privacy is a crucial concern when dealing with user data in recommendation systems. Exploring privacy-preserving techniques, such as federated learning or differential privacy, could help mitigate privacy risks while still enabling effective cross-domain recommendations. Additionally, data sparsity is a common challenge in recommendation systems, especially in cross-domain scenarios. Investigating techniques like knowledge graph integration, transfer learning, or hybrid recommendation approaches could help alleviate the sparsity issue and improve recommendation quality.
-
(5)
Evaluating the framework on larger-scale datasets: While the experiments in this paper were conducted on three real-world CDR datasets, further evaluation on larger-scale datasets would provide a more comprehensive understanding of the GCE-MCAT model’s performance. Scaling up the experiments to include more domains and diverse user preferences would help validate the model’s effectiveness in real-world scenarios.
In conclusion, the proposed GCE-MCAT framework lays a solid foundation for addressing the challenges of cross-domain recommendation systems. However, there is ample room for future research to explore advanced techniques, incorporate domain adaptation methods, leverage state-of-the-art attention mechanisms, address privacy and data sparsity concerns, and evaluate the framework on larger-scale datasets. These future directions and prospects will contribute to the advancement of cross-domain recommendation systems and enhance the overall user experience in diverse recommendation scenarios.
6 Conclusion
In this paper, we propose a cross-domain recommendation framework, named GCE-MCAT, which combines graph contrastive embedding and multi-head cross-attention transfer to tackle three major challenges faced by CDR task. Firstly, contrastive learning is employed to generate more balanced user and item embeddings during pre-training, effectively addressing the issue of inconsistent data embedding space distribution and reducing popularity bias in recommendations. Secondly, by utilizing multihead cross-attention transfer and cross-domain feature fusion mechanisms, the model can extract user features from multiple perspectives, including both common and specific domains, and dynamically allocate weights to more effectively learn the interest preferences of common users. Finally, experiments on three real-world CDR datasets demonstrate the significant improvement of the GCE-MCAT model in various metrics. Detailed ablation experiments and analyses are conducted to verify the effectiveness of each component of the model. Moreover, long-tail experiments and novelty analysis are performed to demonstrate the improvement of the model in enhancing long-tail distribution and recommendation novelty.
Data Availability
Our code will be publicly available on the github website after the paper is published.
References
Isinkaye FO, Folajimi YO, Ojokoh BA (2015) Recommendation systems: principles, methods and evaluation. Egyp Inf J 16(3):261–273
Tao Y, Gao M, Yu J, Wang Z, Xiong Q, Wang X (2022) Predictive and contrastive: dual-auxiliary learning for recommendation. arXiv preprint arXiv:2203.03982,
Cao J, Sheng J, Cong X, Liu T, Wang B (2022a) Cross-domain recommendation to cold-start users via variational information bottleneck. In: 2022 IEEE 38th international conference on data engineering (ICDE), IEEE, pp 2209–2223
Zhu F, Wang Y, Chen C, Zhou J, Li L, Liu G (2021) Cross-domain recommendation: challenges, progress, and prospects. In: IJCAI 2021 International joint conferences on artificial intelligence, pp 4721–4728
Zhu F, Chen C, Wang Y, Liu G, Zheng X (2019) Dtcdr: A framework for dual-target cross-domain recommendation. In: Proceedings of the 28th acm international conference on information and knowledge management, pp 1533–1542
Li P, Tuzhilin (2020) Ddtcdr: Deep dual transfer cross domain recommendation. In: WSDM International conference on web search and data mining , pp 331–339
Li P, Jiang Z, Que M, Hu Y, Tuzhilin A (2021) Dual attentive sequential learning for cross-domain click-through rate prediction. In: Proceedings of the 27th ACM SIGKDD conference on knowledge discovery and data mining, pp 3172–3180
Milojević S (2010) Power law distributions in information science: making the case for logarithmic binning. J Am Soc Inform Sci Technol 61(12):2417–2425
Yao T, Yi X, Cheng DZ, Yu F, Chen T, Menon A, Hong L, Chi EH, Tjoa S, Kang J, Ettinger E et al (2021) Self-supervised learning for large-scale item recommendations. In: Proceedings of the 30th ACM international conference on information and knowledge management, pp 4321–4330
Krishnan A, Sharma A, Sankar A, Sundaram H (2018) An adversarial approach to improve long-tail performance in neural collaborative filtering. In: International conference on information and knowledge management CIKM, pp 1491–1494
Zhu F, Wang Y, Chen C, Liu G, Orgun M, Wu J (2020) A deep framework for cross-domain and cross-system recommendations. arXiv preprint arXiv:2009.06215
Kanagawa H, Kobayashi H, Shimizu N, Tagami Y, Suzuki T (2019) Cross-domain recommendation via deep domain adaptation. In: Advances in information retrieval: 41st European conference on IR research, ECIR 2019, Cologne, Germany, April 14–18, 2019, Proceedings, Part II Springer, 41, pp 20–29
Li P, Tuzhilin A (2021) Dual metric learning for effective and efficient cross-domain recommendations. IEEE Trans Knowl Data Eng 35(1):321–334
Man T, Shen H, Jin X, Cheng X (2017) Cross-domain recommendation: an embedding and mapping approach. In IJCAI 17:2464–2470
Li J, Ke L, Huang Z, Shen HT (2019) On both cold-start and long-tail recommendation with social data. IEEE Trans Knowl Data Eng 33(1):194–208
Chen Z, Xiao R, Li C, Ye G, Sun H, Deng H (2020a) Esam: Discriminative domain adaptation with non-displayed items to improve long-tail performance. In Proceedings of the 43rd international ACM SIGIR conference on research and development in information Retrieval, pp 579–588
Loni B, Shi Y, Larson M, Hanjalic A (2014) Cross-domain collaborative filtering with factorization machines. In: Advances in Information Retrieval: 36th European conference on IR research ECIR, Springer, pp 656–661
Du H, Shi H, Zhao P, Wang D, Sheng VS, Liu Y, Liu G, Zhao L (2022) Contrastive learning with bidirectional transformers for sequential recommendation. In: Proceedings of the 31st ACM international conference on information and knowledge management, pp 396–405
Xia X, Yin H, Yu J, Shao Y, Cui L (2021a) Self-supervised graph co-training for session-based recommendation. In: Proceedings of the 30th ACM international conference on information and knowledge management CIKM, pp 2180–2190
Yu J, Yin H, Xia X, Chen T, Cui L, Nguyen QV (2022) Are graph augmentations necessary? simple graph contrastive learning for recommendation. In: Proceedings of the 45th international ACM SIGIR conference on research and development in information retrieval SIGIR, pp 1294–1303
Chen J, Dong H, Wang X, Feng F, Wang M, He X (2022) Bias and debias in recommender system: a survey and future directions. ACM Trans Inf Syst 41(3):1–39
Zhao C, Li C, Xiao R, Deng H, Sun A (2020) CATN: Cross-domain recommendation for cold-start users via aspect transfer network. In: Proceedings of the 43rd international ACM SIGIR conference on research and development in information Retrieval, pp 229–238
Li C, Xie Y, Yu C, Hu B, Li Z, Shu G, Qie X, Niu D (2023) One for all, all for one: Learning and transferring user embeddings for cross-domain recommendation. In: Proceedings of the 16th ACM international conference on web search and data mining, pp 366–374
Elkahky AM, Song Y, He X (2015) A multi-view deep learning approach for cross domain user modeling in recommendation systems. In: Proceedings of the 24th international conference on world wide web, pp 278–288
Wang Y, Feng C, Guo C, Chu Y, Hwang JN (2019) Solving the sparsity problem in recommendations via cross-domain item embedding based on co-clustering. In: Proceedings of the 12th ACM international conference on web search and data mining, pp 717–725
Singh AP, Gordon GJ (2008) Relational learning via collective matrix factorization. In: Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining SIGKDD, pp 650–658
Kang S, Hwang J, Lee D, Yu H (2019) Semi-supervised learning for cross-domain recommendation to cold-start users. In: Proceedings of the 28th ACM international conference on information and knowledge management, pp 1563–1572
Xu K, Xie Y, Chen L, Zheng Z (2021) Expanding relationship for cross domain recommendation. In: Proceedings of the 30th ACM international conference on information and knowledge management, pp 2251–2260
Hu G, Zhang Y, Yang Q (2018) Conet: Collaborative cross networks for cross-domain recommendation. In: Proceedings of the 27th ACM international conference on information and knowledge management CIKM, pp 667–676
Zhu F, Wang Y, Chen C, Liu G, Zheng X (2020b) A graphical and attentional framework for dual-target cross-domain recommendation. In IJCAI, pp 3001–3008
Liu M, Li J, Li G, Pan P (2020) Cross domain recommendation via bi-directional transfer graph collaborative filtering networks. In: Proceedings of the 29th ACM international conference on information and knowledge management CIKM, pp 885–894
Cao J, Lin X, Cong X, Ya J, Liu T, Wang B (2022b) Disencdr: Learning disentangled representations for cross-domain recommendation. In: Proceedings of the 45th International ACM SIGIR conference on research and development in information retrieval, pp 267–277
Zhao C, Zhao H, He M, Zhang J, Fan J (2023) Cross-domain recommendation via user interest alignment. arXiv preprint arXiv:2301.11467
Xiao S, Zhu D, Tang C, Huang Z (2023) CATCL: Joint cross-attention transfer and contrastive learning for cross-domain recommendation. In: Database systems for advanced applications: 28th international conference, DASFAA 2023, Tianjin, China, April 17–20, 2023, Proceedings, Part II, Springer, pp 446–461
Chen T, Kornblith S, Norouzi M, Hinton G (2020b) A simple framework for contrastive learning of visual representations. In: International conference on machine learning, PMLR, pp 1597–1607
Komodakis N, Gidaris, S (2018) Unsupervised representation learning by predicting image rotations. In: ICLR
Oord AV van den, Li Y, Vinyals O (2018) Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748
Lan Z, Chen M, Goodman S, Gimpel K, Sharma P, Soricut R (2019) A lite bert for self-supervised learning of language representations. In: ICLR, Albert
Devlin J, Chang MW, Lee K, Toutanova K (2019) Bert: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of NAACL-HLT, pp 4171–4186
Lin Z, Tian C, Hou Y, Zhao WX (2022) Improving graph collaborative filtering with neighborhood-enriched contrastive learning. In: Proceedings of the ACM web conference 2022, pp 2320–2329
Xia X, Yin H, Junliang Yu, Wang Q, Cui L, Zhang X (2021) Self-supervised hypergraph convolutional networks for session-based recommendation. In: Proceedings of the AAAI conference on artificial intelligence vol 35: pp 4503–4511
Sun F, Liu J, Wu J, Pei C, Lin X, Ou W, Jiang P (2019) Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. In: Proceedings of the 28th ACM international conference on information and knowledge management CIKM, pp 1441–1450
Chen Y, Liu Z, Li J, McAuley J, Xiong C (2022) Intent contrastive learning for sequential recommendation. In: Proceedings of the ACM web conference pp 2172–2182
Xie R, Liu Q, Wang L, Liu S, Zhang B, Lin L (2022) Contrastive cross-domain recommendation in matching. In: Proceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining SIGKDD, pp 4226–4236
He X, Liao L, Zhang H, Nie L, Hu X, Chua TS (2017) Neural collaborative filtering. In: WWW, pp 173–182
Wu J, Wang X, Feng F, He X, Chen L, Lian J, Xie X (2021) Self-supervised graph learning for recommendation. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval, pp 726–735
He X, Deng K, Wang X, Li Y, Zhang Y, Wang M (2020) Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval, pp 639–648
Yuan F, Yao L, Benatallah B (2019) DARec: deep domain adaptation for cross-domain recommendation via transferring rating patterns. In: IJCAI, pp 4227–4233
Xue HJ, Dai X, Zhang J, Huang S, Chen J (2017) Deep matrix factorization models for recommender systems. IJCAI. vol 17. Melbourne, Australia, pp 3203–3209
Acknowledgements
The preliminary version of this article has been published in DASFAA 2023 [34].
Funding
This study was funded by National Natural Science Foundation of China (No. 62271486 and No. 62071470) and the Postgraduate Research and Practice Innovation Program of Jiangsu Province (Grant No. SJCX23_1277).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by ShuoXiao, CT and ZH. The first draft of the manuscript was written by DZ and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflict of interests to declare that are relevant to the content of this article.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Xiao, S., Zhu, D., Tang, C. et al. Combining Graph Contrastive Embedding and Multi-head Cross-Attention Transfer for Cross-Domain Recommendation. Data Sci. Eng. 8, 247–262 (2023). https://doi.org/10.1007/s41019-023-00226-7
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-023-00226-7