
Abstract
In this paper, we propose a first-order non-negative integer-valued autoregressive (INAR(1)) model with one-misrecorded Poisson (OMP) marginal via a combination of the generalized binomial thinning and mixture Pegram operators for zero-inflated and one deflated count time series. The suggested model is suitable for multimodal, equi- and over-dispersed data modeling. It contains two particular cases: the mixture of Pegram and thinning of a first-order integer-valued autoregressive (MPT(1)) with Poisson and one-misrecorded Poisson. The distribution of the innovation term is derived as a mixture of degenerate distributions at 0 and 1, and two Poisson distributions with certain parameters. Regression and several statistical properties of the proposed model are discussed. We investigate the distribution of the runs (the lengths of zeros and ones). The parameters of the model are estimated using the maximum-likelihood, modified Yule–Walker, and modified conditional least squares methods. The estimation of the parameters, their behavior, and their performance are presented through a simulation study. Two practical data sets on the monthly cases of criminal records and weekly sales are applied to check the proposed process’s performance against other relevant INAR(1) models, showing its capabilities in the challenging case of over-dispersed count data. Furthermore, the proposed model discusses data forecasting.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction and basics
In the recent years, there has been a lot of interest in modeling and forecasting the temporal dependence and evolution of time series of low counts. Integer-valued time series arise in many applications, such as queueing systems, finance, reliability theory, medicine, and epidemiology, among others. The non-negative integer-valued autoregressive (INAR) model was developed by Al-Osh and Alzaid (1987) based on the binomial thinning operator introduced by Steutel and van Harn (1979) and McKenzie (1985). The INAR process has undergone numerous generalizations and modifications thanks to the efforts of many authors, including Alzaid and Al-Osh (1990), Al-Osh and Aly (1992), and Alzaid and Al-Osh (1993). Models based on the negative binomial thinning operator were also constructed and taken into consideration (Aly and Bouzar 1994; Ristić et al. 2009; Ristić and Nastić 2012). All of the models previously described have one common feature, which is considering on independent counting random variables to the thinning operation. The assumption of independence simplifies the computations and enables obtaining simple, not complex, models with nice characteristics. However, the fundamental drawback of such models is that they cannot be used in practice with data that do not support this assumption. For example, it is reasonable to expect some dependence between the survival or bankruptcy of some big companies in the economy, or it is logical to expect that the occurrence of some natural disasters affects the appearance or non-appearance of some other disasters in meteorology, etc. Therefore, a model with dependent counting sequences is needed to be established. Brännäs and Hellström (2001), Ristić et al. (2013), Ilić (2016), and Nastić et al. (2017) introduced thinning operators with dependent counting series. In this paper, the proposed model is based on the generalized thinning with dependent Bernoulli counting series and Pegram’s mixture operators that were introduced by Ilić (2016) and Biswas and Song (2009), respectively.
The generalized binomial thinning operator is defined as follows:
Definition 1.1
(Generalized binomial thinning operator with a dependent Bernoulli counting series, GBT) As in Ilić (2016), the GBT operator \(\alpha \ \star _{\vartheta }\) was defined as
where X is a non-negative integer-valued random variable (RV), \(0 \le 1-\alpha \le \vartheta \), and \(\vartheta \in (0,1] \).
Ilić (2016) defined the first-order dependent counting INAR model [NDCINAR(1)] based on the GBT operator \((\star _{\vartheta })\) as
where \(\{\xi _{t}\}\) is a sequence of i.i.d. RVs such that \(Cov(\xi _{t}, X_{s})=0\) for \(s < t\). For more details about this operator and its properties, see Ilić (2016).
Pegram (1980) introduced the discrete AR(p) that looks like ARMA models and permits some of the serial correlations to be negative. Biswas and Song (2009) used the Pegram operator to define the discrete ARMA model.
Khoo et al. (2017) introduced an INAR process with Poisson marginal via mixing the binomial thinning that consists of independent Bernoulli counting series, with the mixture Pegram operators (abbreviated MPT), and Khoo (2016) handled the MPT(1) process with some discrete marginal distributions, such as binomial, geometric, and negative binomial. Shirozhan and Mohammadpour (2018) and Shirozhan et al. (2019) presented the INAR(1) process with Poisson and geometric marginal distributions by combining the mixture Pegram with the generalized binomial thinning, which was based on the Bernoulli dependent counting series (Ristić et al. 2013).
The models based on combining the mixture Pegram and thinning operators are easy to interpret, have a simple form, and are more flexible in terms of the range of correlation. They are appropriate for any discrete marginal distributions, including infinite and finite divisible distributions, unlike the models based on the thinning operator, which are applied only for infinite range distributions, and also applied to the multimodal data.
The conditional variance of the INAR(1) based on the independent counting series is linear in \(X_{t}\), but for a Pegram model, it is a quadratic function like the INAR(1) with dependent counting series. Therefore, the quadratic property is not satisfied for INAR(1) with independent counting series. This property implies large values of variance, which may be appropriate to model over-dispersed data. The one-misrecorded Poisson distribution—also known as a simple modified Poisson distribution or a Cohen Poisson distribution—forms the basis of the proposed model and is introduced in the following definition.
Definition 1.2
(The one-misrecorded Poisson) The one-misrecorded Poisson distribution, abbreviated as (OMP), of a RV X with parameters \(\lambda >0, , \ 0\le \phi \le 1\), has the probability mass function (p.m.f.)
The OMP was invented by Cohen (1960) to model the data (or misclassified data) that contain errors in reporting one as a zero, or it sometimes happens that a few of the observations taking value one are misclassified and reported as zero. \(\phi \) is the probability of misclassification, or the proportion of ones reported as zeros. The OMP distribution has its application in situations where the true values of ones are erroneously recorded as zeros with probability \(\phi \), while values of two and more are recorded correctly from a Poisson. For example, when determining the number of defects per unit or item examined, an inspector may make an error by reporting units that actually contain a single defect as being perfect or defect-free. The OMP is reduced to a Poisson distribution when \(\phi =0\), the equi-dispersion case. Also, all the observations falling into class one will be reported as zero when \(\phi =1\).
For the OMP distribution, the corresponding probability generating function (p.g.f.), mean, variance, second, third, and fourth moments are, respectively, given by
Therefore, the Fisher index of dispersion (variance to mean ratio) is obtained as follows:
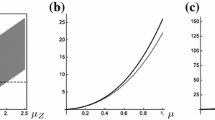
where \(D(\phi ,\lambda )=\frac{\lambda \phi e^{-\lambda }(2-\phi e^{-\lambda })}{(1-\phi e^{-\lambda })}.\) \(D(\phi ,\lambda )\) increases as \(\phi \) increases from 0 to 1 and the degree of over-dispersion increases. The value of function \(D(\phi ,\lambda )=0\) for large values of \(\lambda \) or for \(\phi =0\). The behavior of this function can be seen graphically in Fig. 1.

Behavior of the function \(D(\phi ,\lambda )\) on the index dispersion
We can say that the OMP distribution is zero-inflated (there is an excess of zeros) and one-deflated (there are fewer ones than expected), according to the two definitions given by Ahmad (1968):
The first definition is that a class in a distribution will be said to be inflated if some of the observations falling in other classes are erroneously misclassified in this class.
The second definition is that a class in a distribution will be said to be deflated if some of the observations falling in the class are erroneously misclassified in another class.
Also, according to Johnson et al. (2005), pages (211 and 353), in describing the modified distribution’s zero probability, we can conclude that if \(\phi _{0}=\lambda \phi e^{-\lambda } > 0\), then the Poisson’s zero probability is increased (zero-inflation), while the Poisson’s one probability is decreased for \(\phi _{1}=-\lambda \phi e^{-\lambda } < 0\) (one-deflation).
Moreover, according to Puig and Valero (2006), a random variable X is zero-inflated when its proportion of zeros is greater than the proportion of zeros of a Poisson variate with the same expectation; zero inflation can be studied in a standard way using the zero-inflation index, \(I_{\textrm{Zero}}\), as
The value of function \(Z(\lambda ,\phi )=-1\) for \(\phi =0\) and any value of \(\lambda \), and this implies that \(I_{\textrm{Zero}}=0\), consequently, X is a Poisson distribution. The value of \(Z(\lambda ,\phi )\) is greater than -1 since \(Z(\lambda ,\phi )\) increases as \(\phi \) increases from 0 to 1. In particular, the behavior of the function \(Z(\lambda , \phi )\) is shown graphically in Fig. 2. As a result, the values of \(I_{\textrm{Zero}} > 0\) and from the plot in Fig. 2, we conclude that \(I_{\textrm{Zero}}\in (0,1)\), which indicates zeroinflation (an excess of zero with respect to a Poisson distribution).

Behavior of the function \(Z(\phi ,\lambda )\) on the zero index
Practical over-dispersed INAR(1) processes have been presented in the literature, such as the negative binomial INAR(1) process (McKenzie 1986) and the compound Poisson INAR(1) process (Schweer and Weiß 2014). These over-dispersed classes of INAR(1) models fail when the data set contains a large number of zeros. To analyze count data with excess zeros, Jazi et al. (2012) and Barreto-Souza (2015) introduced INAR(1) with zero-inflated Poisson (ZIP) innovations and zero-modified geometric INAR(1) models, respectively. The over-dispersed and zero-inflated INAR(1) models, however, fail when a data set contains both a large number of zeros and ones, which occurs frequently in practice, for example, in the number of patients with a rare disease in various areas, the monthly counts of Computer-Aided Dispatch (CAD) drug calls, etc. Furthermore, the illustrative examples in Sect. 4 show real-life data examples with excesses of zero-and-one. So that a change in the p.m.fs. for modeling zero-and-one observation is necessary. Qi et al. (2019), Mohammadi et al. (2022a, 2022b) introduced INAR(1) models with zero-and-one inflated Poisson (ZOIP), Poisson–Lindely (ZOIPL), and geometric (ZOIG) that are useful tools for capturing the characteristics of such count data. In these processes, the authors assume that the innovation term has a zero-and-one inflated distribution.
The main aim of this paper is to construct an INAR(1) process for modeling over-, equi-dispersed, and multimodality data by assuming that the main time series \(\{X_{t}\}\) follows the OMP distribution based on combining the GBT and mixture Pegram operators. Also, the proposed process can be used to model zero-inflated and one-deflated data, and the misclassification of ones as zeros (errors in recording at one or one-misrecorded data).
This paper is constructed as follows: In Sect. 2, an extension or generalization of the MPT(1) model based on a dependent Bernoulli counting series with OMP distribution (OMP-EMPT(1)) is defined, and some properties of the innovation process and its p.m.f. are derived. Also, several statistical and conditional properties of the model, including conditional and joint distributions and jumps, are shown, along with a study of the distribution of zeros and ones in the proposed process. In Sect. 3, the parameters of the process are estimated via the maximum-likelihood (ML), modified conditional least-squares (MCLS), and modified Yule–Walker (MYW) methods. Also, the performance of the estimates is checked via a simulation study. In Sect. 4, we provide two real-life data sets to model over-dispersed data, illustrating the performance of the process throughout the goodness-of-fit statistics. Also, the model’s adequacy is checked by the mean logarithmic score, benchmark chart, and non-randomized probability integral transform (PIT). The predictive capacity of the proposed model is checked through forecasting.
2 Construction of the model and its statistical properties
This section is implemented as follows: An extension of the MPT(1) with OMP marginal distribution is constructed using a generalized binomial thinning (abbreviated as OMP-EMPT(1)). The p.m.f. for the innovation term of the model is obtained. The bivariate p.g.f., conditional p.g.f., conditional mean and variance, \(k-\)step-ahead conditional mean and variance, transition probability, autocorrelation function, and the number of zeros and ones in the model are discussed.
The proposed model is defined as follows:
Definition 2.1
(Extended MPT(1) with OMP, OMP-EMPT(1)) The OMP-EMPT(1) \(\{X_{t}\}\) is defined as
also, this model can be expressed as
where \("\alpha \star _{\vartheta }"\) refers to the GBT operator, and \(\{\xi _{t}\}\) is a sequence of i.i.d. RVs such that \(\vartheta \in (0,1]\), \(p\in (0,1)\), \(\ 0\le 1-\alpha \le \vartheta \), \(\lambda >0\), and \(\phi \in [0,1]\).
Remark 2.1
Note the following sub-models:
-
When \(\vartheta =1-\alpha \), the GBT is reduced to binomial thinning, and hence, the MPT(1) with OMP marginal, OMP-MPT(1), process is obtained, which has not been discussed before.
-
When \(\phi =0\) and \(\vartheta =1-\alpha \), the constructed process is reduced to the MPT(1) with Poisson distribution that is given by Khoo et al. (2017).
2.1 Probability distribution of the innovation term
The following proposition provides the distribution of the innovation process:
Proposition 2.1
The p.m.f. for \({\xi _{t}}\) has the following representations:
for \(\lambda >0\), \(\vartheta \in (0,1]\), \(\alpha \in [0,1]\), and \(0\le 1-\alpha \le \vartheta \). The condition
where \(C_{1}\) and \(C_{2}\) are defined as
is necessary for the p.m.f. of the innovation process \(\xi _{t}\) in Eq. (2.1) to be well defined and non-negative for any j.
Proof
By using the definition of \((1-\vartheta )\circ X=\sum _{i=1}^{X}Z_{i}\), where \(Z_{i}\sim Ber((1-\vartheta ))\), as a result the p.g.f. of \((1-\vartheta )\circ X\) is given by \(G_{(1-\vartheta )\circ X}=G_{X}(\vartheta +(1-\vartheta )s)\). First, we get the p.g.f. of the innovation process \(\{\xi _{t}\}\) as a mixture representation of ones to the \(\{X_{t}\}\) as follows:
For this purpose, the p.g.f. of \(\{X_{t}\}\) given by Definition (2.1) has the expression
Hence, the p.g.f. of the innovation process \(\{\xi _{t}\}\) is
From Eq. (2.5), it can be noted that \(\textbf{G}_{\xi _{t}}(1)=1\) and \(\textbf{G}_{\xi _{t}}(0)=p(\xi _{t}=0)\) with (2.2).
Using Eq. (2.5), the innovation process \(\{\xi _{t}\}\) has a mixture distribution of degenerate distributions at 0 and 1, \(Poisson(\lambda )\) and \(Poisson((1-\vartheta )\lambda )\) with mixing weights \(\frac{\lambda \phi e^{-\lambda }(1-p\alpha )}{1-p}, -\frac{\lambda \phi e^{-\lambda }(1-p\alpha )}{1-p}, \frac{1-p(1-\frac{1-\alpha }{\vartheta })}{1-p}\), and \(\frac{-p(\frac{1-\alpha }{\vartheta })}{1-p}\), respectively. Hence, the p.m.f. of \(\xi _{t}\) is represented by equation’s system given in Eq. (2.1). Finally, we demonstrate as follows that this function is a p.m.f.
By the definition of generalized mixture of the distribution functions (Mohammadpour et al. 2018), the sum of preceding mixing weights equals 1, and hence, it follows that \(\sum _{j=0}^{\infty }P(\xi _{t}=j)=1.\)
The following step will demonstrate and confirm that the system of equations outlined in Eq. (2.1) yields non-negative probabilities under the condition specified in by Eq. (2.1). For each \(j=0, 1, 2, \ldots \), we aim to prove that \(P(\xi _{t}=j)\ge 0\) as outlined below.
When \(j=0\), ensuring \(P(\xi _{t}=0)\ge 0\) is achieved through solving the subsequent inequality
consequently,
Upon solving the aforementioned inequality for p, the following result is obtained:
In the case of \(j=1\), the condition \(P(\xi _{t}=1)\ge 0\) is satisfied if
therefore, we have
Following the resolution for the preceding inequality, the condition for p is determined to be
Finally, when \(j=2,\ 3,\ 4,\ \ldots \), the condition \(P(\xi _{t}=j)\ge 0\) is satisfied if
or equivalently
Consequently, the condition for p will be
Let us assume that
Hence, it is evident that \(C_{3}\) increases with an increase in j, reaching its minimum at \(j = 2\). This is depicted in Fig. 3 and supported by the numeric findings (conditions, confirmation numeric values, and folder of plots) available at https://drive.google.com/drive/folders/1oDmUr-vuSw98V9eYDmIsLbKA6Ha35J1t?usp=sharing. Hence, \(C_{3}\) is consistently greater than or equal to \(C_{2}\) or \(C_{1}\), leading to the conclusion that \(\min (C_{1},C_{2},C_{3})=\min (C_{1},C_{2})\). \(\square \)
Remark 2.2
Taking the minimum of \(C_{1}\) and \(C_{2}\) guarantees that the p.m.f. of \(\xi _{t}\) is non-negative for \(j=0,\ 1,\ 2,\ \ldots \).
From the numeric results and the graphs of the two conditions (\(C_{1}\) and \(C_{2}\)), the minimum is changed from \(C_{1}\) to \(C_{2}\), and this means that there is an inflection point or intersection point of the two conditions. By setting \(C_{1}=C_{2}\), the value of the intersection point, \(\phi \), can be obtained as follows:
\(\phi _{0}\) is considered as an inflection point between the two conditions, and at \(\phi _{0}\), we have \( C_{1}=C_{2}\). Figure 4 illustrates the two conditions, \(C_{1}\) and \(C_{2}\), plotted under the specified intervals for \(\phi \), with \(0\le \phi \le \phi _{0}\) and \(\phi _{0}\le \phi \le 1,\) and for \(\lambda = 0.5,\ 1, \ 5,\ 10\), \(\alpha =0.83\), and \(\vartheta =0.21\). The illustrations in Fig. 4, coupled with the confirmation numeric values file (https://drive.google.com/file/d/1-hHVIoHLUMZUn2Z9o-AxghExHADjzHPY/view?usp=drive_link), demonstrate that:
-
When \(\phi <\phi _{0}\), \(C_{1}\) becomes the minimum. Therefore, p should be within the interval \(0\le p\le C_{1}\).
-
When \(\phi >\phi _{0}\), \(C_{2}\) becomes the minimum. Thus, p should be within the interval \(0 \le p\le C_{2}\).
-
If \(\phi =\phi _{0}\), then \(C_{2}=C_{1}=C\). Hence, p should be within the interval \(0 \le p\le C\).
Remark 2.3
-
If \(\phi =0\), then \(\min (C_{1},C_{2})=C_{1}\), which implies that p falls within the interval \(0\le p\le C_{1}\). The condition in Eq. (2.2) is reduced to that proposed by Khoo et al. (2017) for the case where \(\phi =0\) and \(\vartheta =1-\alpha \), in the context of the MPT(1) with Poisson distribution, which is a sub-model of the proposed model.
-
If \(\phi =1\), then \(\min (C_{1},C_{2})=C_{2}\) and consequently \(0\le p\le C_{2}\).
As a visual illustration of the p.m.f. under the mentioned conditions:
For \(\lambda =10;\alpha =0.83;\vartheta =0.21\), the p.m.f. of the innovation process, \(\xi _{t}\), is shown in:
-
Figure 5a with \(\phi =\phi _{0}=0.02679988802\) and \(C_{1}=C_{2}=0.1805334165\), so p must be in the range \(0\le p\le 0.1805334165\).
-
Figure 6a with \(\phi =0.5>\phi _{0}\) and taking \(p\le C2\), i.e., \(p\le 0.1000412914\). For \(\lambda =1;\alpha =0.6;\vartheta =0.5\), the p.m.f of \(\xi _{t}\) is represented in:
-
Figure 5a with \(\phi =\phi _{0}=0.5596162930\) and \(C_{1}=C_{2}=0.8408782799\), so \(0\le p\le 0.8408782799\).
-
Figure 6b with \(\phi =0.7>\phi _{0}\) and taking \(p\le C2\), i.e., \(p\le 0.6826117049\).

Conditions \(C_{1}, C_{2}\), and \(C_{3}\) at \(j=2,3,4\); \(\lambda =0.1 \ to \ 10;\ \alpha =0.83;\ \vartheta =0.21\)

The conditions \(C_{1}\) and \(C_{2}\)

PMF of the innovation process at \(\phi =\phi _{0}\), \(C_{1}=C_{2}=C\), and \(p\le C\)

PMF of the innovation process at \(\phi >\phi _{0}\) and \(p\le C_{2}\)
Consequently, based on the aforementioned proposition, the mean, variance, and the second and third moments of \(\{\xi _{t}\}\) are provided as follows, respectively:
and
2.2 Conditional properties of the process, joint distributions, and jumps
Regression properties are useful for estimating unknown parameters as well as forecasting future values. In particular, the conditional expectation is used for the conditional least-squares estimation method, k-step-ahead expectation for forecasting the future values of time series data, and a conditional probability function for the maximum-likelihood estimation method. The joint distributions are used to check the model’s time reversibility.
Let \(\{X_{t}\}\) be a stationary OMP-EMPT(1) process, then the conditional probability generating function (c.p.g.f.) and its corresponding conditional probability (one-step transition probability) function are as follows:
where \(P(\xi _{t}=i)\), the p.m.f. of \(\{\xi _{t}\}\) is given by Eq. (2.1), t=0, 1, 2, \(\ldots \), and \(|s|\le 1\), and \(I_{\{j\}}\) is the indicator function with a degenerate random variable defined as
Proposition 2.2
Let \(\{X_{t}\}\) be a stationary OMP-EMPT(1) process, then
-
1.
The one-step-ahead conditional expectation is
$$\begin{aligned} E(X_{t+1}|X_{t})=p\alpha X_{t}+(1-p\alpha )\lambda (1-\phi e^{-\lambda }), \end{aligned}$$(2.16) -
2.
The k-step-ahead conditional expectation is formulated as
$$\begin{aligned} E(X_{t+k}|X_{t})=(p\alpha )^{k} X_{t}+(1-(p\alpha )^{k})\lambda (1-\phi e^{-\lambda }). \end{aligned}$$(2.17) -
3.
The one-step-ahead conditional variance is
$$\begin{aligned} Var(X_{t+1}|X_{t})= & {} p[(2\alpha -\alpha \vartheta +\vartheta -1) -p\alpha ^{2}]X^{2}_{t}\nonumber \\{} & {} +p[(1-\alpha )(1-\vartheta )-2\alpha \lambda (1-p\alpha )(1-\phi e^{-\lambda })]X_{t}\nonumber \\{} & {} +((1-p\alpha )\lambda (1-\phi e^{-\lambda })(1-\lambda (1-p\alpha )(1-\phi e^{-\lambda }))\nonumber \\{} & {} +\lambda ^{2}(1+p+p\alpha (-2+\vartheta )-p\vartheta ). \end{aligned}$$(2.18) -
4.
The k-step-ahead conditional variance is given as
$$\begin{aligned} Var(X_{t+k}|X_{t})= & {} (p\textbf{A}_{\textbf{0}})^{k}X^{2}_{t} +p^{k}\textbf{B}_{\textbf{0}}\left( \frac{\textbf{A}_{\textbf{0}}^{k} -\alpha ^{k}}{\textbf{A}_{\textbf{0}}-\alpha }\right) X_{t}\nonumber \\{} & {} +((1-p\alpha )\lambda (1-\phi e^{-\lambda })+\lambda ^{2} (1-p\textbf{A}_{\textbf{0}}))\left( \frac{1-(p\textbf{A}_{\textbf{0}})^{k}}{1-p\textbf{A}_{\textbf{0}}}\right) \nonumber \\{} & {} +\left( \frac{(1-p\alpha )\lambda (1-\phi e^{-\lambda })}{\textbf{A}_{\textbf{0}}-\alpha }\right) \textbf{B}_{\textbf{0}}\left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{p\textbf{A}_{\textbf{0}}-1} -\frac{(p\alpha )^{k}-1}{p\alpha -1}\right) \nonumber \\{} & {} -((p\alpha )^{k} X_{t}+(1-(p\alpha )^{k})\lambda (1-\phi e^{-\lambda }))^{2}, \end{aligned}$$(2.19)
where \(\textbf{A}_{\textbf{0}}= (2\alpha -\alpha \vartheta +\vartheta -1)\), \(\textbf{B}_{\textbf{0}}=(1-\alpha )(1-\vartheta )\).
Proof
The proof of Proposition 2.2 is given in Appendix A.1. \(\square \)
The autocovariance, autocorrelation, and partial autocorrelation functions at lag k of \(\{X_{t}\}\) are, respectively, given as follows:
Remark 2.4
-
The unconditional mean and variance of the OMP-EMPT(1) process are obtained by taking the limit of Eqs. (2.17) and (2.19) at \(k\longrightarrow \infty \), that is
$$\begin{aligned}{} & {} \lim _{k\rightarrow \infty }E(X_{t+k}|X_{t})=\lambda (1-\phi e^{-\lambda })=E(X_{t}), \end{aligned}$$(2.24)$$\begin{aligned}{} & {} \lim _{k\rightarrow \infty }Var(X_{t+k}|X_{t}) = [(1-p\alpha )\lambda (1-\phi e^{-\lambda }) +\lambda ^{2}(1-p\textbf{A}_{\textbf{0}})] \left( \frac{1}{1-p\textbf{A}_{\textbf{0}}}\right) \nonumber \\{} & {} \qquad +\left( \frac{(1-p\alpha )\lambda (1-\phi e^{-\lambda })}{\textbf{A}_{\textbf{0}}-\alpha }\right) \textbf{B}_{\textbf{0}}\left( \frac{-1}{p\textbf{A}_{\textbf{0}}-1} -\frac{-1}{p\alpha -1}\right) -(\lambda (1-\phi e^{-\lambda }))^{2}\nonumber \\{} & {} \quad =\frac{\lambda (1-\phi e^{-\lambda })(1-p\alpha )}{1-p \textbf{A}_{\textbf{0}}}+\lambda ^{2}-\frac{\lambda (1-\phi e^{-\lambda }) (1-p\alpha )\textbf{B}_{\textbf{0}}}{-\textbf{B}_{\textbf{0}}(p\textbf{A}_{\textbf{0}}-1)}\nonumber \\{} & {} \qquad + \frac{\lambda (1-\phi e^{-\lambda })(1-p\alpha )\textbf{B}_{\textbf{0}}}{-\textbf{B}_{\textbf{0}}(p\alpha -1)}-(\lambda (1-\phi e^{-\lambda }))^{2}\nonumber \\{} & {} \quad =\lambda ^{2}-(\lambda (1-\phi e^{-\lambda }))^{2} +\frac{(1-p\alpha )\lambda (1-\phi e^{-\lambda })}{1-p\textbf{A}_{\textbf{0}}}[1-1]+\lambda (1-\phi e^{-\lambda })\nonumber \\{} & {} \quad =\lambda ^{2}+\lambda (1-\phi e^{-\lambda })(1-\lambda (1-\phi e^{-\lambda }))=Var(X_{t}). \end{aligned}$$(2.25) -
From Eq. (2.19), it is concluded that the \(k-\)step-ahead conditional variance, \(Var(X_{t+k}|X_{t})\), depends on \(X^{2}_{t}\), that is, quadratically depends on the past of the process, and the coefficient of this dependence is \((p\textbf{A}_{\textbf{0}})^{k}-(p\alpha )^{2k}\). Thus, if \(\vartheta \ne 0\) and \(\alpha \in (0,1)\), which is a general case, then large values of variance could be expected when the process reaches some significant realizations. This goes with the fact that \(Var(X_{t})\) is approximated by \(Var(X_{t + k}|X_{t})\) for large values of k. Therefore, OMP-EMPT(1) model provides a very convenient property in the application to over-dispersed data.
-
The process is stationary, since the mean, variance, and autocovariance are finite and independent of time.
-
The autocorrelation and partial autocorrelation functions can be thought as model specification tools. When \(k\longrightarrow \infty \) in Eq. (2.21), the autocorrelation function decays exponentially to zero. Also, we have from Eq. (2.22), and noting that \(\beta (1) = p\alpha \), the PACF of OMP-EMPT(1) cuts off after lag 1. As a result, it could be remarked that the OMP-EMPT(1) model is an autoregressive process of order one.
The joint p.g.f. of two consecutive observations of this process, \(X_{t}\) and \(X_{t-1}\), is
It is clear from Eq. (2.26) that \(\textbf{G}_{\textbf{X}_{\textbf{t}-\textbf{1}}, \textbf{X}_{\textbf{t}}}(s_{1},\ s_{2})\) is not symmetric in \(s_{1}\) and \(s_{2}\), implying that the process is not time-reversible, and thus, the joint distribution of \((X_{t-1},X_{t})\) is not equal to the joint distribution of \((X_{t},X_{t-1})\).
The joint probability function of \(X_{t-1},\ X_{t}\) is
where \(P(X_{t}=j|X_{t-1}=i)\) is the one-step transition probability function given by Eq. (2.13) and \(P(X_{t-1}=i)\) is the marginal probability distribution defined by Eq.(1.2).
The adequacy or sufficiency of the fitted models can be checked by jumps (see Weiß (2009)). The jump process is also used to construct control charts that show changes in the serial dependence structure. The p.g.f. of the jump process, \(J_{t}\equiv X_{t}-X_{t-1}\), for \(t\ge 2\) is obtained by replacing \(s_{1}\) and \(s_{2}\) by \(u^{-1}\) and u, respectively, in Eq. (2.26), as
Utilizing Eq. (2.28) and the definition of the jump process, it is determined that the mean, variance, autocovariance, and autocorrelation of \(J_{t}\) are, respectively, specified by
2.3 Distribution of zeros and ones
The run is defined by Mood (1940), as a succession of similar events that are preceded and succeeded by different events, and the length of the run is determined by its number. The distribution of runs has been extensively studied in the context of i.i.d. set-ups, and a well-known application of runs is the runs test in non-parametric hypothesis testing. Jacobs and Lewis (1978) introduced the distribution of the run length for a stationary discrete autoregressive process of first-order. The expected time of its stay in state i at a stress after entering the process at state i from another state j can be evaluated using the run length. The expected length of zeros and ones will be discussed in two different ways. Let \(\{X_{t}\}\) be the OMP-EMPT(1) process, for a fixed state \(i\in \{0,1,2,\ldots \}\), suppose \(\mathcal {N}_{i}=\inf \{n\ge 1: X_{n}\ne i\}-1\), \(\mathcal {N}_{i}\) is the run length of state i starting at time 1, where the length can be \(0, 1, 2, \cdots \). Then, the survival function, probability of \(\mathcal {N}_{i}\) greater than or equal to n, of \(\mathcal {N}_{i}\) is
and \(P(\mathcal {N}_{i}=0)=P(X_{1}\ne i)=1-P(X_{1}=i)\), where \(P(X_{1}=i)\) and \(P(i|i)=P(X_{n}=i|X_{n-1}=i) =p(1-\frac{1-\alpha }{\vartheta })I_{\{i\}}+p\frac{1-\alpha }{\vartheta }(1-\vartheta )^{i}+(1-p)P(\xi _{n}=i)\) are, respectively, the stationary distribution and conditional distribution of the process given by Eqs. (1.3) and (2.13).
Using the stationary and Markov properties of the proposed process, and based on the expression of the survival function of \(\mathcal {N}_{i}\) given by Eq.(2.33), the p.m.f. of \(\mathcal {N}_{i}\) is obtained as
Therefore, based on the previous expression for the p.m.f. of \(\mathcal {N}_{i}\) given by Eq. (2.34), the expected run length of state i is given by
The p.g.f. of \(\mathcal {N}_{i}\) is
For the OMP-EMPT(1) process, the transition probability functions from zero to zero and non-zero are, respectively, given by
and
Also, the transition probability functions from one to one and non-one are, respectively, given by
and
Using Eq. (2.35), the expected length of the runs of zeros and ones, the number of zeros between two non-zero values, and the number of ones between two non-one values of the process can be, respectively, derived as
Using Eq. (2.33), the survival functions of \(\mathcal {N}_{0}\) and \(\mathcal {N}_{1}\) are, respectively, given by
and
Using the stationarity of the process, as in Barreto- Souza W (2015), and Eq. (2.34), the p.m.f. for the number of zeros and ones is given as follows, respectively:
for \(n\ge 2\) and \(P(\mathcal {N}_{0}=1)=P(X_{1}\ne 0| X_{0}=0)={\delta }_{0}\).
for \(n\ge 2\) and \(P(\mathcal {N}_{1}=1)=P(X_{1}\ne 1| X_{0}=1)={\eta }_{1}\). Based on Eq. (2.36), the p.g.f. for \(\mathcal {N}_{0}\) and \(\mathcal {N}_{1}\) are, respectively, given by
and
Remark 2.5
-
1.
The expected run length of zeros and ones in the process, as in Jazi et al. (2012) and Barreto-Souza (2015), can be determined in a different way, because the run length of zeros and ones has a geometric distribution with probabilities \({\delta }_{0}\) and \({\eta }_{1}\), that is, \(P(\mathcal {N}_{0}=n)={\delta }_{0}(1-{\delta }_{0})^{n-1}, n\ge 1\), where \({\delta }_{0}\) is given by Eq. (2.38) and \(P(\mathcal {N}_{1}=n)={\eta }_{1}(1-{\eta }_{1})^{n-1}, n\ge 1\), where \({\eta }_{1}\) is given by Eq. (2.40), respectively. The expected run length zeros and ones are calculated as
$$\begin{aligned} E(\mathcal {N}_{0})=\frac{1}{\begin{array}{c}1-p\left( 1-\frac{1-\alpha }{\vartheta }\right) I_{\{0\}}-p\frac{1-\alpha }{\vartheta }-\lambda \phi e^{-\lambda }(1-p\alpha )\\ {[}+p\frac{1-\alpha }{\vartheta } e^{-\lambda (1-\vartheta )}- e^{-\lambda }\left( 1-p\left( 1-\frac{1-\alpha }{\vartheta }\right) \right) ]\end{array}}, \end{aligned}$$(2.47)and
$$\begin{aligned} E(\mathcal {N}_{1})=\frac{1}{\begin{array}{c}1-p\left( 1-\frac{1-\alpha }{\vartheta }\right) I_{\{1\}}-p\frac{1-\alpha }{\vartheta }(1-\vartheta )+\lambda \phi e^{-\lambda }(1-p\alpha )\\ {[}+p\frac{1-\alpha }{\vartheta } e^{-\lambda (1-\vartheta )}\lambda (1-\vartheta )-\lambda e^{-\lambda }\left( 1-p\left( 1-\frac{1-\alpha }{\vartheta }\right) \right) ]\end{array}}. \end{aligned}$$(2.48) -
2.
The expected run length for the MPT(1) with Poisson marginal is obtained by setting \(\phi =0\) and \(1-\alpha =\vartheta \) in Eqs. (2.41 and 2.42) or Eqs. (2.47 and 2.48).
3 Estimation of parameters and a simulation study
In this section, the unknown parameters of the OMP-EMPT(1) model will be estimated based on the maximum-likelihood (ML), modified Yule–Walker (MYW), and modified conditional least-squares (MCLS) methods. Suppose that \(\Theta =(\alpha ,\vartheta ,\phi ,\lambda ,p)^{T}\) is the vector of parameters that will be estimated using a realization \({X_{1},X_{2},\ldots ,X_{n}}\) from the process, where n is the sample size.
3.1 Maximum-likelihood estimation
The considered maximum-likelihood (ML) estimators take into account the temporal dependence between time series ordered records. The ML function of the considered realization is given by
The corresponding log-likelihood function can be written as
where \(P(X_{j}=x_{j}|X_{j-1}=x_{j-1})\) is the one-step transition probability given by Eq. (2.13) and \(p_{x_{1}}\) is given by Eq. (1.3). The maximum-likelihood (ML) estimator of \(\Theta \) is the value \(\hat{\Theta }_{\textrm{ML}}=(\hat{\alpha }_{\textrm{ML}},\hat{\vartheta }_{\textrm{ML}}, \hat{\phi }_{\textrm{ML}},\hat{\lambda }_{\textrm{ML}},\hat{p}_{\textrm{ML}})^{T}\), which maximizes the log-likelihood function in Eq. (3.1). The ML estimators are computed using the numerical methods found in most statistical software to solve the nonlinear system obtained from \(\frac{\partial l(\Theta ;x)}{\partial \Theta }=0\). To maximize the log-likelihood function of the proposed process, the optim function in R software is used.
3.2 Modified Yule–Walker estimation
The Modified Yule–Walker (MYW) estimators are computed via a combination of Yule–Walker estimators and ML estimators that have been introduced by Miletić Ilić et al. (2018). The MYW estimators of the parameters \(\alpha , p, \lambda , \phi , \theta \) are based on the sample values of \(\rho _{X}(1), E(X^{2}_{t})-E(X_{t}),E(X_{t}),Cov(X^{2}_{t},X_{t-1})\). Recall that \(\rho _{X}(1)=Corr(X_{t},X_{t-1})=p\alpha \), \(E(X_{t})=\lambda (1-\phi e^{-\lambda })\) and \(E(X^{2}_{t})=\lambda ^{2}+\lambda (1-\phi e^{-\lambda })\). Using the earlier sample values, the estimators for \(\alpha , p, \lambda ,\) and \(\phi \) are obtained as
where \(\widehat{p}_{\textrm{ML}}\) is the ML estimator of p and it is used as the initial estimator of the parameter. Then, the YW estimator of p is given by
To estimate the parameter \(\vartheta \), first, the \(Cov(X^{2}_{t},X_{t-1})\) is computed
using Eqs. (1.8), (1.7), and (1.6) for \(E(x^{3}_{t-1}), E(X^{2}_{t-1})\) and \(Var(X_{t})\), then
By solving the previous equation to \(\vartheta \), then the YW estimator of the parameter \(\vartheta \) is obtained as
where \(\widehat{M}_{1}\) and \(\widehat{V}_{1}\) are defined as
and \(\widehat{C}\) is the estimator of \(Cov(X^{2}_{t},X_{t-1})\) given by
3.3 Modified conditional least-squares estimation
In this section, the unknown parameters of the proposed model are estimated by modified conditional least-squares (MCLS). The MCLS is presented by Miletić Ilić et al. (2018) and Karlsen and TjøStheim (1988) to estimate the parameters, and it is based on a combination of CLS and ML estimators. The parameters \(\alpha ,\ \vartheta ,\ p,\ \phi , \ \text {and}\ \lambda \) are estimated by the two-step CLS method. The first step is estimating the parameters \(\alpha , p, \phi , \ \text {and,}\ \lambda \) by minimizing the function \(Q_{n}(\alpha ,\ p,\ \phi ,\ \lambda )\)
the estimators are then obtained by solving the system of equations: \(\frac{\partial Q_{n}(\Theta )}{\partial (\alpha ,\ p,\ \phi ,\ \lambda )^{T} }=0\) and combining the CLS method with the ML approach. Because the parameters \(\alpha \) and p cannot be separable and because when the \(Q_{n}\) function is differentiated with respect to \(\phi \) and \(\lambda \), they lead to the same estimated equation, the method of moments is used to estimate one of these parameters. With this, we use the CLS to derive the estimators of \(\alpha \), \(\phi ,\) and p and suppose that \(\lambda \) will be estimated using the method of moments; also, we have that \(\frac{\partial Q_{n}(\Theta )}{\partial (\alpha ,\ p,\ \phi )^{T} }=0\), then the estimators of \(\alpha \), \(\lambda \), p and \(\phi \) are, respectively, given by
where \(\widehat{p}_{\textrm{ML}}\) is the ML estimator of the parameter p used as the initial estimate of the parameter. Thus, the \(\widehat{p}_{\textrm{cls}}\) is given by
Consequently, we get
The calculations for the expressions in Eqs. (3.2), (3.3), and (3.4) are provided in Appendix A.2.
In the second step, the CLS estimator of the parameter \(\vartheta \) is obtained using the method introduced by Karlsen and TjøStheim (1988) by minimizing the function
where \(E(X_{t}|X_{t-1})\) and \(Var(X_{t}|X_{t-1})\) are given by (2.16) and (2.18), respectively. Therefore, by solving the equation \(\frac{\partial \mathcal {S}_{n}(\vartheta )}{\partial \vartheta }=0\), the estimator of \(\vartheta \) is given by
where
and
Remark 3.1
The OMP-EMPT(1) process is an irreducible Feller chain, stationary, strictly stationary, and ergodic. The proof of these properties is similar to the ones in Khoo et al. (2017), Shirozhan and Mohammadpour (2018), Nastić et al. (2012), and Schweer and Weiß (2014).
3.4 Simulation
Some simulated trajectories of the OMP-EMPT(1) process for sample size \(n=100\) and \(\lambda =0.5,\ 1.5,\ 5\) with \(\alpha =0.5; \vartheta =0.6; p=0.2; p=0.02; \phi =0.5\), and \(\alpha =0.7;\vartheta =0.3; p=0.1; \phi =0.7\) are presented in Fig. 7. From these simulated series, one can conclude that the proposed process is stationary, and for lower values of \(\lambda \), the number of ones and zeros increases. When \(\lambda \) is large, the number of zeros and ones decreases, resulting in larger values for the sample path. The details of the simulations and how the innovation process \(\xi _{t}\) has been simulated are shown by the R code for simulated series at \(n=100\); \(\alpha =0.5;\vartheta =0.6;p=0.2;\lambda =1.5;\phi =0.5\); see Appendix A.3.

Sample paths of OMP-EMPT(1) process
A Monte Carlo simulation study is performed for different parameter values and different sample sizes to evaluate the performance of the ML, MYW, and MCLS estimators. The mean square errors (MSE) and empirical biases were calculated over 100 replications with the sample sizes \(n=100, 500, 1000, 5000\) to evaluate the performance of the estimates and check their properties. The true values of the parameters in the simulations are: \((\alpha ,\vartheta ,\phi ,\lambda ,p)= (0.7,0.3,0.01,1,0.1),\ (0.4,0.6,0.1,1,0.1)\), (0.5, 0.6, 0.2, 0.5, 0.5), and (0.5, 0.6, 0.2, 1, 0.5). Using this simulation, Tables 1 and 2 show the bias and MSE (in brackets) of the estimates of different parameter values \((\alpha ,\vartheta ,\phi ,\lambda ,p)\) and through different sample sizes. From these tables, we conclude that the MSEs and biases are reduced by increasing the sample sizes for the three methods. The estimation using using the ML approach is better than MYW and MCLS. The ML-estimated parameters converged to their true values faster. Furthermore, we can conclude that the MLEs have the smallest MSE for all parameters and thus give the best performance, as expected.
4 Real-life data analysis, model selection, diagnostic tools, and forecasting
In this section, the usefulness and applicability of the OMP-EMPT(1) process are shown using two real-life data sets. The assessment of the adequacy of the models proposed and fitted to the data under analysis is a critical step in any statistical investigation. In the literature, several methods for model validation and diagnostics in discrete-valued time series have been proposed. These methods are broadly classified as follows: model comparisons using information criteria and scores; residual-based methods; and predictive distribution-based methods.
4.1 Data and model selection based on information criteria
The application of the proposed process is investigated using economic and crime data sets:
-
The first data set represents \(n=242\) weekly sales of a particular soap product in a supermarket, obtained from a database provided by the Kilts Center for Marketing, Graduate School of Business of the University of Chicago (available at http://research.chicagobooth.edu/marketing/databases/dominicks/categories/soa.aspx; the product is ‘Zest White Water 15 oz’, with code 3700031165), or data can also be accessed from https://drive.google.com/drive/folders/165XirSF7gKiACX-Mg0Ho16QZ0J0KlqIe?usp=sharing.
-
The second data set represents \(n=142\) monthly counts of liquor law violations, reported in the 12th police car beat in Pittsburgh Plus, reported in a period from January 1990 to October 2001, and obtained from the Crime data section of the Forecasting Principles site http://www.forecastingprinciples.com or it can be obtained by https://drive.google.com/drive/folders/1b4a1Z2y9MPSFl1e3uMMmWc8zC-kjYVxU?usp=sharing. Table 3 displays some descriptive statistics for the two data sets. The time series, sample autocorrelation, partial autocorrelation functions (SACF and SPACF, respectively), and empirical p.m.f. for the weekly sales counts and monthly counts of liquor law violations are displayed in Figs. 8 and 9, respectively. From these plots, we conclude that a first-order autoregressive model may be appropriate for the two data sets, as the first autocorrelation is more significant than the other and the SPACF cuts off after lag one. Moreover, the behavior of the two data sets indicates that they may be stationary, and we confirm that result using the test of stationarity. The stationarity of the data is justified throughout the Augmented Dickey–Fuller (ADF) test based on the p-value of the ADF test; the stationarity of the data is supported, and the null hypothesis (non-stationary) is rejected.
The empirical p.m.f. displayed in black in Figs. 8d and 9d, while gray bars refer to the fitted OMP distribution below. From these figures, the empirical p.m.f. and the estimated OMP p.m.f. are close to each other.
As can seen in Table 3, the sample variance is greater than the sample mean for the data sets; therefore, they are over-dispersed. Schweer and Weiß (2014) proposed an over-dispersion test that is used to check this assumption, with a test statistic based on the empirical dispersion index \(\hat{I}_{x}=\frac{S^{2}}{\overline{X}}\), where \(S^{2}\) and \(\overline{X}\) are, respectively, the sample variance and mean. The null hypothesis \(H_{0}:x_{1},\ldots , x_{n}\) is derived from an equi-dispersed PINAR(1) process (Al-Osh and Alzaid 1987), while the alternative \(H_{1}:x_{1},\ldots , x_{n}\) stems from an over-dispersed INAR(1) process, with a level of significance of \(\beta _{0}=0.05\). If the observed value of \(\hat{I}_{x}\) exceeds the critical value \(1+z_{1-\beta _{0}}\sqrt{\frac{2(1+\alpha ^{2})}{n(1-\alpha ^{2})}}\), or if the p-value \(1-\Phi \left( \sqrt{\frac{n(1-\alpha ^{2})}{2(1+\alpha ^{2})}}\times (\hat{I}_{x}-1)\right) \) falls below \(\beta _{0}\), the null hypothesis is rejected, where \(z_{1-\beta _{0}}\) and \(\Phi (.)\) represents the \((1-\beta _{0})-\) quantile and the distribution function of the standard normal distribution, respectively, and \(\alpha =\hat{\rho }(1)\). The considered data sets are empirically over-dispersed, with dispersion indices, \(\hat{I}_{x}\) given in Table 3. By applying the over-dispersion test, the critical values and the p-values for the weekly sales and monthly liquor law violations counts are (1.165164, 1.232448) and (0.000,0.000), respectively. Therefore, the data sets stem from an over-dispersed INAR(1) process.
For comparison purposes, the two data sets are used to compare the proposed process, OMP-EMPT(1), with the following relevant INAR(1) models: PINAR(1) (Al-Osh and Alzaid 1987), Pegram AR(1) model with Poisson marginal (Biswas and Song 2009), Poisson MPT(1) (Khoo et al. 2017), MPDBPINAR(1) (Shirozhan and Mohammadpour 2018). We use the following goodness-of-fit statistics: the Akaike information criterion (AIC), the Hannan–Quinn information criterion (HQIC), and the corrected Akaike information criterion (AICc), where the best model has the ones with the lowest values. The results of these goodness-of-fit statistics and ML estimates with their standard error (S.E.) are displayed in Tables 4 and 5. These tables show that the values of the AIC, HQIC, and AICc are the smallest for the OMP-EMPT(1) process. Hence, we conclude that the proposed model works well for the two data sets. Also, we can conclude that the OMP-EMPT(1) model is significantly better than the Poisson-MPT(1) model for explaining both data sets, as we have \(\hat{\phi }=0.3185468,\ 0.6040971\), i.e., the proportion of ones that were misclassified as zeros in the process does not equal zero for the considered data sets. When \(\hat{\phi }=0.6040971\), this means that most ones are misclassified and reported as zeros, and this implies a zero inflation as seen in Fig. 9d. This means that when determining the number of weekly sales or liquor violations per unit, an inspector may make an error by reporting units that actually contain one item or one person as having no item or no one, respectively. The R script that was used to fit the data to the OMP-EMPT(1) model is included in the Appendix A.4.

Sample path, SPACF, SACF, and PMF of the number of weekly sales

Sample path, SACF, SPACF, and PMF of the number of monthly liquor law violations counts
4.2 Diagnostic tools and model adequacy
In this subsection, we check the model’s adequacy throughout the logarithmic scoring rule, non-randomized probability integral transform (PIT), and benchmark chart.
Scoring rules can be used to assess a model’s relative performance within a given group of competing models. In decision analysis, scoring rules are frequently used to evaluate the accuracy of probabilistic predictions by assigning a numerical score based on the predictive distribution and observed data. To compare the observation \(x_{t}\) realized at time t with the conditional distribution \(p_{.|x_{t-1}}\) based on the previous observation, typical scoring rules are of the form \(s(p_{.|x_{t-1}},x_{t})\), with smaller score values indicating better agreement. The mean score \(\frac{1}{T-1}\sum _{t=2}^{T} s(p_{.|x_{t-1}},x_{t})\) is used to evaluate the model’s overall predictive performance with respect to the time series \(x_{1}, \cdots , x_{T}\). There are many scoring rules, such as quadratic, logarithmic, ranked probability, and spherical scores, to select the model with the smallest value of its mean. For the two data sets, we compute the logarithmic score defined as
which corresponds to the conditional log-likelihood calculation defined by Eq. (2.13). Table 6 shows the mean logarithmic score (\(\overline{S_{ls}}\)) for the proposed fitted process and the competing models of the two data series. The mean score recommends the OMP-EMPT(1) model among the competitive INAR models.
The adequacy of the proposed fitted model is checked using the jumps \(J_{t}=X_{t}-X_{t-1},\) for \(t=2,\ 3,\ \cdots ,\ n\), \(E(J_{t})\), and \(Var(J_{t})\), which are given by Eq.(2.29) and Eq.(2.30), respectively. Figures 10 and 11a represent the jumps against time (Shewhart control chart) of the two data sets with \(\pm 3\sigma _{J}\) limits chosen as the benchmark chart as proposed by Weiß (2009), where \(\sigma _{J} =\sqrt{Var(J_{t})}=3.072668,\ \text {and}\ 1.288924\), respectively. The Shewhart control chart for the two considered data sets indicates that there is no particular point causing a huge impact in the model and implies that the proposed model fits the two data sets well. If a model is suitable for the data series, the non-randomized probability integral transform (PIT) histogram, Czado et al. (2009), should be uniform. Figures 10 and 11b show the PIT for the two data sets, indicating that the PIT histogram is close to uniform and that the proposed model fits the two data sets well, i.e., the model is adequate for these data series.

Jumps against time and PIT of fitted OMP-EMPT(1) for weekly sales

Jumps against time and PIT of fitted OMP-EMPT(1) for monthly liquor law violations counts

Actual and predicted values of weekly sales

Actual and predicted values of monthly liquor law violations counts
4.3 Forecasting
The minimum mean square error is one of the most common procedures for optimally forecasting future values of a model. The conditional mean finds a forecast, \(\hat{X}_{t+k}\) of \(X_{t+k}\) that minimizes the expected squared error given a sample. Using Eqs. (2.16) and (2.17), the one- and k-step-ahead forecasts of \(X_{t+1}\) and \(X_{t+k}\) are, respectively, given by
where \(\hat{X}_{1}=(1-(p\alpha ))\lambda (1-\phi e^{-\lambda })\) and
In practice, the parameters \(p, \alpha , \lambda \), and \(\phi \) are replaced by their ML estimates. Therefore
and
The two actual data sets and their predicted values in the classical way using Eq. (4.2) are displayed and plotted in Figs. 12 and 13 to show the predictive ability of the OMP-EMPT(1) process, where \(\hat{\alpha }, \hat{\phi }, \hat{p}, \ \text {and} \ \hat{\lambda }\) are presented in Tables 4 and 5. From these figures, we observe that the predicted values are close to the original ones in the data sets, indicating that the OMP-EMPT(1) process can provide a good forecast for these data sets.
Data Availability
The application section of this research cites the URLs to the used data sets, and the authors can provide the data upon request.
References
Ahmad M (1968) Truncated multivariate Poisson distributions. Iowa State University, Iowa
Al-Osh MA, Aly E-EA (1992) First order autoregressive time series with negative binomial and geometric marginals. Commun Stat Theory Methods 21(9):2483–2492
Al-Osh M, Alzaid AA (1987) First-order integer-valued autoregressive (INAR (1)) process. J Time Ser Anal 8(3):261–275
Aly E-EA, Bouzar N (1994) On some integer-valued autoregressive moving average models. J Multivar Anal 50(1):132–151
Alzaid A, Al-Osh M (1990) An integer-valued pth-order autoregressive structure (INAR(p)) process. J Appl Probab 27(2):314–324
Alzaid AA, Al-Osh M (1993) Some autoregressive moving average processes with generalized Poisson marginal distributions. Ann Inst Stat Math 45(2):223–232
Barreto-Souza W (2015) Zero-modified geometric INAR (1) process for modelling count time series with deflation or inflation of zeros. J Time Ser Anal 36(6):839–852
Biswas A, Song PX-K (2009) Discrete-valued ARMA processes. Stat Probab Lett 79(17):1884–1889
Brännäs K, Hellström J (2001) Generalized integer-valued autoregression. Econom Rev 20(4):425–443
Cohen AC Jr (1960) Estimating the parameters of a modified Poisson distribution. J Am Stat Assoc 55(289):139–143
Czado C, Gneiting T, Held L (2009) Predictive model assessment for count data. Biometrics 65(4):1254–1261
Ilić AVM (2016) A geometric time series model with a new dependent Bernoulli counting series. Commun Stat Theory Methods 45(21):6400–6415
Jacobs PA, Lewis PA (1978) Discrete time series generated by mixtures. I: Correlational and runs properties. J R Stat Soc Ser B (Methodol) 40(1):94–105
Jazi MA, Jones G, Lai C-D (2012) First-order integer valued AR processes with zero inflated Poisson innovations. J Time Series Anal 33(6):954–963
Johnson NL, Kotz S, Kemp AW (2005) Univariate discrete distributions. Wiley, New York
Karlsen H, TjøStheim D (1988) Consistent estimates for the NEAR (2) and NLAR (2) time series models. J R Stat Soc Ser B (Methodol) 50(2):313–320
Khoo WC (2016) Statistical modelling of time series of counts for a new class of mixture distributions/Khoo Wooi Chen. PhD thesis, University of Malaya
Khoo WC, Ong SH, Biswas A (2017) Modeling time series of counts with a new class of INAR (1) model. Stat Pap 58(2):393–416
McKenzie E (1985) Some simple models for discrete variate time series 1. JAWRA J Am Water Resour Assoc 21(4):645–650
McKenzie E (1986) Autoregressive moving-average processes with negative-binomial and geometric marginal distributions. Adv Appl Probab 18(3):679–705
Miletić Ilić AV, Ristić MM, Nastić AS, Bakouch HS (2018) An INAR (1) model based on a mixed dependent and independent counting series. J Stat Comput Simul 88(2):290–304
Mohammadi Z, Sajjadnia Z, Bakouch H, Sharafi M (2022a) Zero-and-one inflated Poisson–Lindley INAR (1) process for modelling count time series with extra zeros and ones. J Stat Comput Simul 92(10):2018–2040
Mohammadi Z, Sajjadnia Z, Sharafi M, Mamode Khan N (2022b) Modeling medical data by flexible integer-valued AR (1) process with zero-and-one-inflated geometric innovations. Iran J Sci Technol Trans A Sci 46(3):891–906
Mohammadpour M, Bakouch HS, Shirozhan M (2018) Poisson–Lindley INAR (1) model with applications. Braz J Probab Stat 32(2):262–280
Mood AM (1940) The distribution theory of runs. Ann Math Stat 11(4):367–392
Nastić AS, Ristić MM, Bakouch HS (2012) A combined geometric INAR (p) model based on negative binomial thinning. Math Comput Model 55(5–6):1665–1672
Nastić AS, Ristić MM, Ilić AVM (2017) A geometric time-series model with an alternative dependent Bernoulli counting series. Commun Stat Theory Methods 46(2):770–785
Pegram G (1980) An autoregressive model for multilag Markov chains. J Appl Probab 17(2):350–362
Puig P, Valero J (2006) Count data distributions: some characterizations with applications. J Am Stat Assoc 101(473):332–340
Qi X, Li Q, Zhu F (2019) Modeling time series of count with excess zeros and ones based on INAR (1) model with zero-and-one inflated Poisson innovations. J Comput Appl Math 346:572–590
Ristić MM, Nastić AS (2012) A mixed INAR (p) model. J Time Ser Anal 33(6):903–915
Ristić MM, Bakouch HS, Nastić AS (2009) A new geometric first-order integer-valued autoregressive (NGINAR (1)) process. J Stat Plann Inference 139(7):2218–2226
Ristić MM, Nastić AS, Miletić Ilić AV (2013) A geometric time series model with dependent Bernoulli counting series. J Time Ser Anal 34(4):466–476
Schweer S, Weiß CH (2014) Compound Poisson INAR (1) processes: stochastic properties and testing for overdispersion. Comput Stat Data Anal 77:267–284
Shirozhan M, Mohammadpour M (2018) A new class of INAR (1) model for count time series. J Stat Comput Simul 88(7):1348–1368
Shirozhan M, Mohammadpour M, Bakouch HS (2019) A new geometric INAR (1) model with mixing Pegram and generalized binomial thinning operators. Iran J Sci Technol Trans A Sci 43(3):1011–1020
Steutel FW, van Harn K (1979) Discrete analogues of self-decomposability and stability. Ann Probab 7(5):893–899
Weiß CH (2009) Jumps in binomial AR (1) processes. Stat Probab Lett 79(19):2012–2019
Acknowledgements
The authors express their thanks to the referees and the editor for careful reading of the article and providing valuable comments. Their efforts enabled us to improve the paper in a constructive way.
Funding
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
There is no conflict of interest.
Additional information
Communicated by Clémentine Prieur.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
A Appendix
A Appendix
1.1 A.1 Proof of Proposition 2.2
Proof
-
1.
The one-step-ahead conditional expectation is calculated as
$$\begin{aligned} E(X_{t+1}|X_{t})= & {} pE(\alpha \star _{\vartheta }X_{t}|X_{t})+(1-p)E(\xi _{t+1}|X_{t}) \\= & {} p\alpha X_{t}+(1-p)\mu _{\xi _{t}}. \end{aligned}$$ -
2.
By using mathematical induction, the \(k-\)step-ahead conditional expectation is given as follows: For \(k=1\), as determined by Eq. (2.16); similarly, \(k=2\)
$$\begin{aligned} E(X_{t+2}|X_{t})= & {} E_{X_{t+1}|X_{t}}(E(X_{t+2}|X_{t+1})) \\= & {} E_{X_{t+1}|X_{t}}((p\alpha X_{t+1}+(1-p)\mu _{\xi _{t+2}})|X_{t+1}) \\= & {} p\alpha E(X_{t+1}|X_{t})+(1-p)\mu _{\xi _{t}}\\= & {} (p\alpha )^{2}X_{t}+(1-p)\mu _{\xi _{t}}(1+p\alpha ), \end{aligned}$$where \(\mu _{\xi _{t}}\) is given by Eq. (2.9).
Now, suppose that the \((k-1)-\)step-ahead conditional expectation is
$$\begin{aligned} E(X_{t+k-1}|X_{t})= & {} (p\alpha )^{k-1}X_{t}+(1-p) \mu _{\xi _{t}}\frac{1-(p\alpha )^{k-1}}{1-p\alpha }. \end{aligned}$$Hence, the \(k-\)step-ahead conditional expectation is obtained as follows:
$$\begin{aligned} E(X_{t+k}|X_{t})= & {} E_{X_{t+1}|X_{t}}(E(X_{t+k}|X_{t+1})) \\= & {} E\left[ \left( (p\alpha )^{k-1}X_{t+1}+(1-p)\mu _{\xi _{t+1}} \frac{1-(p\alpha )^{k-1}}{1-p\alpha }\right) |X_{t}\right] \\= & {} (p\alpha )^{k-1}[p\alpha X_{t}+(1-p)\mu _{\xi _{t}}] +(1-p)\frac{1-(p\alpha )^{k-1}}{1-p\alpha }\mu _{\xi _{t+1}}\\= & {} (p\alpha )^{k}X_{t}+(1-p)\mu _{\xi _{t}}\left[ (p\alpha )^{k-1} +\frac{1-(p\alpha )^{k-1}}{1-p\alpha }\right] . \end{aligned}$$ -
3.
The one-step-ahead conditional variance is computed as follows:
$$\begin{aligned} Var(X_{t+1}|X_{t})=E(X^{2}_{t+1}|X_{t})-(E(X_{t+1}|X_{t}))^{2}. \end{aligned}$$Thus, the expression for \(E(X^{2}_{t+1}|X_{t})\) is calculated to get \(Var(X_{t+1}|X_{t})\)
$$\begin{aligned} E(X^{2}_{t+1}|X_{t})= & {} pE((\alpha \star _{\vartheta }X_{t})^{2}|X_{t})+(1-p)E(\xi ^{2}_{t+1}|X_{t})\nonumber \\= & {} p[(2\alpha -\alpha \vartheta +\vartheta -1)X^{2}_{t}+(1-\alpha ) (1-\vartheta )X_{t}]+(1-p)E(\xi ^{2}_{t}). \nonumber \\ \end{aligned}$$(A.1)Hence
$$\begin{aligned} Var(X_{t+1}|X_{t})= & {} p[(2\alpha -\alpha \vartheta +\vartheta -1)X^{2}_{t}+(1-\alpha )(1-\vartheta )X_{t}]\\{} & {} +(1-p)E(\xi ^{2}_{t})-(p\alpha X_{t}+(1-p)\mu _{\xi _{t}})^{2}, \end{aligned}$$using Eqs. (2.16), (2.9), and (2.11) for \(E(X_{t+1}| X_{t}), \mu _{\xi },\) and \(E(\xi ^{2})\), respectively, then
$$\begin{aligned} Var(X_{t+1}|X_{t})= & {} p[(2\alpha -\alpha \vartheta +\vartheta -1) -p\alpha ^{2}]X^{2}_{t}\\{} & {} +p\left[ (1-\alpha )(1-\vartheta )-2\alpha (1-p) \frac{\lambda (1-p\alpha )(1-\phi e^{-\lambda })}{1-p}\right] X_{t}\\{} & {} +(1-p)\left( \frac{(1-p\alpha )\lambda (1-\phi e^{-\lambda }) +\lambda ^{2}(1+p+p\alpha (-2+\vartheta )-p\vartheta )}{1-p}\right) \\{} & {} -(1-p)^{2}\left( \frac{\lambda (1-p\alpha ) (1-\phi e^{-\lambda })}{1-p}\right) ^{2}. \end{aligned}$$After some simplification, the one-step conditional variance in Eq. (2.18) is derived.
-
4.
To compute the k-step conditional variance, \(Var(X_{t+k}|X_{t})\), first compute the expression \(E(X^{2}_{t+k}|X_{t})\). The first-step of the conditional second moment that is given by Eq. (A.1) can be written as follows: by setting \(\textbf{A}_{\textbf{0}}=(2\alpha -\alpha \vartheta +\vartheta -1)\) and \(\textbf{B}_{\textbf{0}}=(1-\alpha )(1-\vartheta )\):
$$\begin{aligned} E(X^{2}_{t+1}|X_{t})= & {} p\textbf{A}_{\textbf{0}}X^{2}_{t}+p\textbf{B}_{\textbf{0}}X_{t}+(1-p)E(\xi ^{2}_{t}). \end{aligned}$$For \(k=2\):
$$\begin{aligned} E(X^{2}_{t+2}|X_{t})= & {} E(E(X^{2}_{t+2}|X_{t+1})|X_{t})\\= & {} pE((\alpha \star _{\vartheta }X_{t+1})^{2}|X_{t})+(1-p)E(\xi ^{2}_{t})\\= & {} p[E((\textbf{A}_{\textbf{0}}X^{2}_{t+1}+\textbf{B}_{\textbf{0}}X_{t+1})|X_{t})]+(1-p)E(\xi ^{2}_{t})\\= & {} (p\textbf{A}_{\textbf{0}})^{2}X^{2}_{t}+p^{2}\textbf{B}_{\textbf{0}}(\textbf{A}_{\textbf{0}}+\alpha )X_{t}+(1-p)(1+p\textbf{A}_{\textbf{0}})E(\xi ^{2}_{t})+(1-p)p\textbf{B}_{\textbf{0}}\mu _{\xi _{t}}. \end{aligned}$$For \(k=3\):
$$\begin{aligned} E(X^{2}_{t+3}|X_{t})= & {} E(E(X^{2}_{t+3}|X_{t+1})|X_{t})\\= & {} E([(p\textbf{A}_{\textbf{0}})^{2}X^{2}_{t+1}+p^{2}\textbf{B}_{\textbf{0}}(\textbf{A}_{\textbf{0}}+\alpha )X_{t+1}]|X_{t})\\{} & {} +(1-p)(1+p\textbf{A}_{\textbf{0}})E(\xi ^{2}_{t})+(1-p)p\textbf{B}_{\textbf{0}}\mu _{\xi _{t}}\\= & {} (p\textbf{A}_{\textbf{0}})^{3}X^{2}_{t}+p^{3}\textbf{B}_{\textbf{0}}X_{t} \left( \frac{\textbf{A}_{\textbf{0}}^{3}-\alpha ^{3}}{\textbf{A}_{\textbf{0}}-\alpha }\right) +(1-p)E(\xi ^{2}_{t}) \left( \frac{(p\textbf{A}_{\textbf{0}})^{3}-1}{(p\textbf{A}_{\textbf{0}})-1}\right) \\{} & {} +\frac{(1-p)\textbf{B}_{\textbf{0}}\mu _{\xi _{t}}}{(\textbf{A}_{\textbf{0}}-\alpha )} \left( \frac{(p\textbf{A}_{\textbf{0}})^{3}-1}{p\textbf{A}_{\textbf{0}}-1} -\frac{(p\alpha )^{3}-1}{p\alpha -1}\right) . \end{aligned}$$Hence, by continuing the procedure and observing the obtained formulas, it can be concluded that the conditional second moment for \(k-\)step, \(E(X^{2}_{t+k}|X_{t})\), is
$$\begin{aligned} E(X^{2}_{t+k}|X_{t})= & {} (p\textbf{A}_{\textbf{0}})^{k}X^{2}_{t}+p^{k} \textbf{B}_{\textbf{0}}X_{t}\left( \frac{\textbf{A}_{\textbf{0}}^{k} -\alpha ^{k}}{\textbf{A}_{\textbf{0}}-\alpha }\right) +(1-p)E(\xi ^{2}_{t}) \left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{(p\textbf{A}_{\textbf{0}})-1}\right) \nonumber \\{} & {} +\frac{(1-p)\textbf{B}_{\textbf{0}}\mu _{\xi _{t}}}{(\textbf{A}_{\textbf{0}}-\alpha )} \left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{p\textbf{A}_{\textbf{0}}-1} -\frac{(p\alpha )^{k}-1}{p\alpha -1}\right) . \end{aligned}$$(A.2)Therefore, using Eqs. (A.2) and (2.17) and the expression \(Var(X_{t+k}|X_{t})=E(X^{2}_{t+k}|X_{t})-(E(X_{t+k}|X_{t}))^{2}\), the conditional variance for \(k-\)step is obtained as
$$\begin{aligned}{} & {} Var(X_{t+k}|X_{t})\\{} & {} \quad =(p\textbf{A}_{\textbf{0}})^{k}X^{2}_{t}+p^{k} \textbf{B}_{\textbf{0}}X_{t}\left( \frac{\textbf{A}_{\textbf{0}}^{k}-\alpha ^{k}}{\textbf{A}_{\textbf{0}}-\alpha }\right) +(1-p)E(\xi ^{2}_{t}) \left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{(p\textbf{A}_{\textbf{0}})-1}\right) \\{} & {} \qquad +\frac{(1-p)\textbf{B}_{\textbf{0}}\mu _{\xi _{t}}}{(\textbf{A}_{\textbf{0}}-\alpha )} \left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{p\textbf{A}_{\textbf{0}}-1} -\frac{(p\alpha )^{k}-1}{p\alpha -1}\right) \\{} & {} \qquad -((p\alpha )^{k}X_{t}+(1-p)\mu _{\xi _{t}}\frac{(p\alpha )^{k}-1}{p\alpha -1})^{2}\\{} & {} \quad =((p\textbf{A}_{\textbf{0}})^{k}-(p\alpha )^{2k})X^{2}_{t}+(p^{k} \textbf{B}_{\textbf{0}}\left( \frac{\textbf{A}_{\textbf{0}}^{k} -\alpha ^{k}}{\textbf{A}_{\textbf{0}}-\alpha }\right) -2(p\alpha )^{k} \mu _{X}(1-(p\alpha )^{k}))X_{t}\\{} & {} \qquad + \left[ (1-p)E(\xi ^{2}_{t})\left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{(p\textbf{A}_{\textbf{0}})-1}\right) +\frac{(1-p\alpha ) \textbf{B}_{\textbf{0}}\mu _{X}}{(\textbf{A}_{\textbf{0}}-\alpha )} \left( \frac{(p\textbf{A}_{\textbf{0}})^{k}-1}{p\textbf{A}_{\textbf{0}}-1} -\frac{(p\alpha )^{k}-1}{p\alpha -1}\right) \right. \\{} & {} \qquad \left. -(\mu _{X}(1-(p\alpha )^{k}))^{2}\right] , \end{aligned}$$using \(E(\xi ^{2}_{t})\) that is given by Eq. (2.11) and \(\mu _{X}=\lambda (1-\phi e^{-\lambda })\), the \(k-\)step conditional variance for the process is obtained.
\(\square \)
1.2 A.2 Derivations of the CLS estimators for \(\alpha , \phi ,\) and \(\lambda \)
Proof
The CLS estimators given by the expressions in Eqs. (3.2), (3.4), and (3.3) are obtained as follows.
Recall that
with \(\mu _{X}=\lambda (1-\phi e^{-\lambda })\), then
and
Consequently, \(\frac{\partial Q_{n}(\Theta )}{\partial \Theta }=0,\) which implies
as a result, we have
We obtain that \((I)=0\) by rearranging it and substituting \(\widehat{\mu }_{X}\) inside the brackets as follows:
Using (II) and replacing \(\widehat{\mu }_{X}\), we obtain the estimator for \(\alpha \) as follows:
Therefore, as (II)=(I)=0;
by replacing p by some consistent estimators, \(\hat{p}_{\textrm{ML}}\), as an initial value, we obtain Eq. (3.2). Hence, the CLS estimator for p is given by
The parameter \(\lambda \) is estimated using the method of moments based on the following statistics:
Therefore, using the first and second sample means, we obtain the estimator of \(\lambda \) from the expression
Therefore, the expression in Eq. (3.3) is obtained as follows:
The estimator for \(\phi \) is obtained as
As a result, \(\widehat{\phi }\) is provided as
\(\square \)
1.3 A.3 R code for simulated series at \(n=100;\) \( \alpha =0.5; \vartheta =0.6; p=0.2; \lambda =1.5;\) \(\phi =0.5\)

1.4 A.4 R code that was used to fit the data to the OMP-EMPT(1) model

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gabr, M.M., Bakouch, H.S. & El-Hadidy, S.M. One-misrecorded Poisson INAR(1) model via two random operators with application to crime and economics data. Comp. Appl. Math. 43, 206 (2024). https://doi.org/10.1007/s40314-024-02668-9
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s40314-024-02668-9
Keywords
- Integer-valued time series
- Scoring rules
- Forecasting
- Simulation
- Dependent Bernoulli counting series
- Weekly sales
- Liquor law violations