
Abstract
Introduction
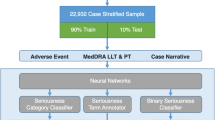
As part of routine safety surveillance, thousands of articles of potential interest are manually triaged for review by safety surveillance teams. This manual triage task is an interesting candidate for automation based on the abundance of process data available for training, the performance of natural language processing algorithms for this type of cognitive task, and the small number of safety signals that originate from literature review, resulting in its lower risk profile. However, deep learning algorithms introduce unique risks and the validation of such models for use in Good Pharmacovigilance Practice remains an open question.
Objective
Qualifying an automated, deep learning approach to literature surveillance for use at AstraZeneca.
Methods
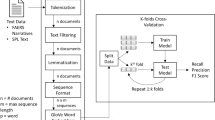
The study is a prospective validation of a literature surveillance triage model, comparing its real-world performance with that of human surveillance teams working in parallel. The biggest risk in modifying this triage process is missing a safety signal (resulting in model false negatives) and hence model recall is the main evaluation metric considered.
Results
The model demonstrates consistent global performance from training through testing, with recall rates comparable to that of existing surveillance teams. The model is accepted for use specifically for those products where non-inferiority to the manual process is rigorously demonstrated.
Conclusion
Characterizing model performance prospectively, under real-world conditions, allows us to thoroughly examine model consistency and failure modes, qualifying it for use in our surveillance processes. We also identify potential future improvements and recognize the opportunity for the community to collaborate on this shared task.



Similar content being viewed by others

References
Landhuis E. Scientific literature: information overload. Nature. 2016;535(7612):457–8.
Huysentruyt K, et al. Validating intelligent automation systems in pharmacovigilance: insights from good manufacturing practices. Drug Saf. 2021;44(3):261–72.
Ball R, Dal Pan G. “Artificial Intelligence” for pharmacovigilance: ready for prime time? Drug Saf. 2022;45(5):429–38.
Pinheiro LC, Kurz X. Artificial intelligence in pharmacovigilance: a regulatory perspective on explainability. Pharmacoepidemiol Drug Saf. 2022;31(12):1308–10.
Liu X, et al. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: the CONSORT-AI extension. Nat Med. 2020;26(9):1364–74.
Danysz K, et al. Artificial intelligence and the future of the drug safety professional. Drug Saf. 2019;42(4):491–7.
European Medicines Agency and Heads of Medicines Agencies, Guideline on good pharmacovigilance practices (GVP). Module VI – Collection, management and submission of reports of suspected adverse reactions to medicinal products (Rev 2). 2017.
McHugh ML. Interrater reliability: the kappa statistic. Biochem Med (Zagreb). 2012;22(3):276–82.
Newcombe RG. Two-sided confidence intervals for the single proportion: comparison of seven methods. Stat Med. 1998;17(8):857–72.
Beltagy IP, Matthew E. Cohan, Arman, Longformer: the long-document transformer. arXiv, 2020. https://doi.org/10.48550/arXiv.2004.05150.
Liu Y, et al. RoBERTa: a robustly optimized BERT pretraining approach. 2019. arXiv pre-print server.
Rokach L. Ensemble-based classifiers. Artif Intell Rev. 2010;33(1–2):1–39.
Pharmaspectra, Insightmeme. https://insightmeme.com/. Accessed 25 Oct 2023.
Elsevier, Embase. https://embase.com/. Accessed 25 Oct 2023.
Wu E, et al. How medical AI devices are evaluated: limitations and recommendations from an analysis of FDA approvals. Nat Med. 2021;27(4):582–4.
D’Agostino RBSR, Massaro JM, Sullivan LM. Non-inferiority trials: design concepts and issues—the encounters of academic consultants in statistics. Stat Med. 2003;22(2):169–86.
Rothmann MD, Wiens BL, Chan ISF. Design and analysis of non-inferiority trials. Chapman & Hall/CRC biostatistics series. Boca Raton: Chapman & Hall/CRC; 2012. p. 438 (xvi).
Haviland MG. Yates’s correction for continuity and the analysis of 2 x 2 contingency tables. Stat Med. 1990;9(4):363–7 (discussion 369-83).
Sedgwick P. Multiple hypothesis testing and Bonferroni’s correction. BMJ. 2014;349: g6284.
US Food and Drug Administration. International Conference on Harmonisation; choice of control group and related issues in clinical trials; availability. Fed Regist. 2001;66(93): p. 24390-1.
US Food and Drug Administration. Guidance for industry non-inferiority clinical trials. March 2010. https://downloads.regulations.gov/FDA-2010-D-0075-0002/attachment_1.pdf.
Kaul S, Diamond GA. Good enough: a primer on the analysis and interpretation of noninferiority trials. Ann Intern Med. 2006;145(1):62–9.
Canales L, et al. Assessing the performance of clinical natural language processing systems: development of an evaluation methodology. JMIR Med Inform. 2021;9(7): e20492.
McCambridge J, Witton J, Elbourne DR. Systematic review of the Hawthorne effect: new concepts are needed to study research participation effects. J Clin Epidemiol. 2014;67(3):267–77.
Malikova MA. Practical applications of regulatory requirements for signal detection and communications in pharmacovigilance. Ther Adv Drug Saf. 2020;11:2042098620909614.
Vela D, et al. Temporal quality degradation in AI models. Sci Rep. 2022;12(1):11654.
Yu LX, et al. Understanding pharmaceutical quality by design. AAPS J. 2014;16(4):771–83.
Gao T, Yao X, Chen D. SimCSE: simple contrastive learning of sentence embeddings. 2021. arXiv pre-print server.
Fazi MB. Beyond human: deep learning, explainability and representation. Theory Cult Soc. 2021;38(7–8):55–77.
Acknowledgments
This work was supported by AstraZeneca colleagues including Alex Kiazand, David Greatrex, and Maria Lägnert Hammar and the authors thank Mark Cherry, Denise Baker, Arundhati Ghosh, Charles Lee, Mel Mistretta, and Ryan McGowan for their GVP and regulatory guidance. The authors also thank the US Food and Drug Administration Artificial Intelligence/Machine Learning working group for the opportunity to present this work and the helpful feedback received during its development. Finally, the authors thank the reviewers for their support and very helpful critique.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Funding
This study was funded by AstraZeneca.
Conflict of Interest
All authors are employees of AstraZeneca and may hold stock or stock options or restricted shares.
Availability of Data
The datasets generated or analyzed during the current study are available from the corresponding author on reasonable request; proprietary and/or sensitive safety data are not available for disclosure.
Ethical Approval
Not applicable.
Consent to Participate
Not applicable.
Consent for Publication
Not applicable.
Code Availability
The authors regret that we are unable to share the model prediction software, as it depends on commercial services and proprietary source code.
Author Contributions
Conception and design: DC, RH, VP, AI, DD, and NS. Collection and assembly of data: JP and MD. Data analysis and interpretation: JP, MD, DC, AI, DD, and NS. Manuscript writing: JP, DC, RH, AI, DD, and NS. Accountable for all aspects of the work: All authors.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Park, J., Djelassi, M., Chima, D. et al. Validation of a Natural Language Machine Learning Model for Safety Literature Surveillance. Drug Saf 47, 71–80 (2024). https://doi.org/10.1007/s40264-023-01367-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40264-023-01367-4