
Abstract
Minimizing errors in wind resource analysis brings significant reliability gains for any wind power generation project. The characterization of the wind regime is one of fundamental importance, and the two parameters Weibull distribution is the most applied function for it. This study aims to determine the scale and shape factor in an attempt to establish acceptable criteria to a better utilization of wind power in the states of Pernambuco and Rio Grande do Sul, which is a national prominence in the use of renewable sources for electricity generation in Brazil. The following heuristic optimization algorithms were applied: Harmony Search, Cuckoo Search Optimization, Particle Swarm Optimization and Ant Colony Optimization. The fit tests were performed with data from the Brazilian Federal Government’s SONDA (National System of Environmental Data Organization) project, referring to Triunfo, Petrolina and São Martinho da Serra, states of Pernambuco and Rio Grande do Sul, cities in the northeast and south regions of Brazil, during the period of 1 year. The tests were made in 2006 and 2010, all at 50 m from ground level. The results were analyzed and compared with those obtained by the maximum likelihood method, moment method, empirical method and equivalent energy method, methods that presented significant results in regions with characteristics similar to the regions studied in this study. The performance of each method was evaluated by the RMSE (root mean square error), MAE (mean absolute error), R\(^2\) (coefficient of determination) and WPD (wind production deviation) tests . The statistical tests showed that ACO is the most efficient method for determining the parameters of the Weibull distribution for Triunfo and São Martinho da Serra and CSO is the most efficient for Petrolina.
Similar content being viewed by others
Introduction
Search for energy forms that reduce or eliminate the carbon dioxide emission to the atmosphere has encouraged the renewable energy sector development, with the wind energy being highlighted. According to the World Wind Energy Association, the installed capacity of wind power in the world reached 486.661 MW at the end of 2016, 54.846 MW more than in 2015, representing a growth rate of 11.8%.
Wind resource analysis is a key step in the wind power generation projects development. Reducing errors in this step brings significant reliability gains for the project. One of the most important information in the wind resource analysis is the characterization of the wind regime according to a probability distribution, which aims to transform the discrete data collected in a measurement campaign into continuous data. In this procedure, velocities are grouped in intervals and a probability distribution function is fitted to this histogram. Depending on the wind conditions, the curve to be adjusted may follow the Gauss, Rayleigh or, more commonly, two parameters k and c Weibull distributions [35].
One of the challenges in applying the Weibull distribution to represent the region wind regime is the estimation of the parameters k and c, and an adjustment must be obtained with the smallest possible error. Dorvlo [12] used the Chi-square method to determine the Weibull parameters in four locations in Oman and Saudi Arabia. Silva [32] presented the equivalent energy method, where the parameters are found from the square error minimization power. Akdag and Dinler [1] proposed the energy pattern factor method, with which it would be possible to determine the k and c parameters from the power density and average velocity. Rocha et al. [28] dealt with the analysis and comparison of seven numerical methods for the assessment of effectiveness in determining the parameters for the Weibull distribution, using wind data collected for Camocim and Paracuru cities in the northeast region of Brazil. Also in the Brazilian northeastern region, Andrade et al [3] compared the graphical method, moment, pattern energy, maximum likelihood, empirical and equivalent energy and evaluated the efficiency through the predicted and measured power available.
However, in some cases, these methods cannot represent satisfactorily the wind speed distribution. Therefore, a favorable condition for the study of the heuristic method applications has been applied in more recent studies in the field of wind energy. Rahmani et al. [27] estimated, applying the Particle Swarm Optimization, the wind speed and the power produced in the Binaloud Wind Farm. Barbosa [6] estimated the Weibull curve parameters through the Harmony Search for two Brazilian regions. Wang et al. [36] used the Cuckoo Search Optimization and Ant Colony Optimization methods to evaluate wind potential and predict wind speed in four locations in China. Gonzlez et al. [17] presented a new approach for optimizing the layout of offshore wind farms comparing the behavior of two metaheuristic optimization algorithms, the genetic algorithm and Particle Swarm Optimization. Hajibandeh et al. [18] used the multicriteria multi-objective heuristic method to propose a new model for wind energy and DR integration, optimizing supply and demand side operations by the time to use (TOU) or incentive with the emergency DR program (EDRP), as well as combining TOU and EDRP together. Salcedo-Sanz et al. [29] addressed a problem of representative selection of measurement points for long-term wind energy analysis, as the objective of selecting the best set of N measurement points, such that a measure of wind energy error reconstruction is minimized considering a monthly average wind energy field, for which the metaheuristic algorithm, Coral Reef Optimization with Substrate Layer, was used, which is an evolutionary type method capable of combining different search procedures within a single population. Faced with the inconsistent relationship between China’s economy and the distribution of wind power potential that caused unavoidable difficulties in wind power transport and even network integration, Jiang et al. [19] studied, by optimization methods, among them the Cuckoo Search and the Particle Swarm, the establishment of an integrated electric energy system with low-speed wind energy. Marzband et al. [23] used four heuristically optimized optimization algorithms to implement a market structure based on transactional energy, to ensure that market participants can obtain a higher return.
Considering the presented works, this study aims to analyze four heuristic optimization methods and compare them with four other deterministic numerical methods, to suggest which is the most efficient to determine the parameters of the Weibull probability distribution curve for Petrolina, Triunfo and São Martinho da Serra regions.
Weibull distribution
Wind speed is a random variable, and it is useful to use statistical analysis to determine the wind potential of a region [2, 9, 35]. Commonly, the two parameters Weibull distribution is the one that presents the best fit and is therefore the most used to estimate this potential. [8, 22].
The Weibull distribution for the velocity v is expressed by the probability density function, wind velocity frequency curve, shown in Eq. 1. Equation 2 expresses its cumulative probability function [10, 24].
where c is the scaling factor with unit \(m \cdot s^{-1}\), k is the shape factor (dimensionless) and F(v) denotes the probability of velocities smaller than or equal to v.
Among the methods already studied with the purpose of Weibull curves estimating parameters for the regions studied in this paper, or with similar characteristics, the maximum likelihood method, moment method, empirical method and the equivalent energy method were shown to be the most effective [3, 5, 28].
Maximum likelihood method (MLM)
In the maximum likelihood method, numerical iterations are required to determine the Weibull distribution parameters [15]. In this method [28], the parameters k and c are determined according to the Eqs. 3 and 4.
where n is the number of observed data and \(v_{i}\) is the wind speed measured in the interval i.
Moment method (MM)
The moment method may be used as an alternative to the maximum likelihood method and it is recommended when the mean and standard deviation of the elements are known and are initially on an appropriate scale [21]. In this case [28], the k and c parameters are determined by Eqs. 5 and 6.
where \({\bar{v}}\), \(\sigma\), \(\varGamma\) are, respectively, the average wind speed, the standard deviation of the observed wind speed data, and the gamma function.
Empirical method (EM)
The empirical method [10, 28] is considered a simplified form of the moment method, in which the determination of the k parameter follows Eq. 7 and the c parameter Eq. 8.
where \({\bar{v}}\) and \(\sigma\) are, respectively, the mean wind speed and the standard deviation of the observed wind speed data.
Equivalent energy method (EEM)
The equivalent energy method seeks the equivalence between the energy density of the observations and the theoretical Weibull curve. For this, the k parameter is estimated from the third moment of the velocity, by minimizing the square error related to the adjustment, represented by Eq. 9 and the c parameter is adjusted by using Eq. 10 [3, 32].
Heuristic methods
Heuristics encompasses a set of methods where, to solve a problem, the variables in question use the experience gained over the iterations. Heuristic methods combine different concepts intelligently to explore the search space, so that learning strategies are used to structure information and find efficient and almost optimal solutions [25]. Many of the heuristic approaches depend on probabilistic decisions made during the algorithm run. The main difference against pure random search is that in heuristic algorithms, randomness is not used blindly but intelligently and biased [34]. It is valid to emphasize that every optimization procedure searches for the best result of a function for the desired scenario. This function is called the objective function. In this paper, the objective function is the one presented in Eq. 11, which represents the minimization of the square error sum applied to the frequency of occurrence values found by the curve adjusted by the method and the observed frequency of occurrence in the histogram of the data.
where n is the number of histogram velocity intervals and \(f_{\mathrm{adjustment}}\) and \(f_{\mathrm{observed}}\) are the occurrence frequencies from the adjusted curve and that observed in the histogram, respectively.
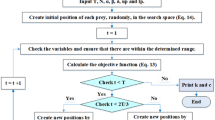
Harmony search (HS)
The Harmony Search is a heuristic algorithm based on the analogy of the artificial phenomenon of a musical group in search of the best harmony. This search occurs by the combination of existing elements and the generation of new elements that are combined to form possible solutions [16]. The search process begins with the formation of a harmony memory (HM), by the memorization of a series of possible solutions, denominated harmonies. At each iteration, a new harmony is formed and compared to the harmonies stored in the HM. The algorithm is presented by the following steps [4]:
-
1.
initialize the HARMONY MEMORY;
-
2.
improvise a new harmony from HM;
-
3.
if the new harmony is better than the minimum harmony in HM, include the new harmony in HM and exclude the minimum harmony from HM. If not, the new harmony is excluded;
-
4.
if the stopping criteria are not satisfied, go to step 2.
Figure 1 shows the flowchart of the Harmony Search algorithm, summarizing all steps described previously.

Flowchart of the HS algorithm
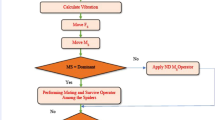
Cuckoo search optimization (CSO)
Cuckoos are birds with an aggressive breeding strategy. Some species such as Ani and Guira cuckoos place their eggs in communal nests, and sometimes remove other species’ eggs to increase the hatching probability of their own eggs. Other species lay their eggs in nesting host birds (often of other species). New World brood-parasitic Tapera species have evolved in such a way that the female parasitic cuckoos are often very specialized in the mimicry of the color and pattern of the eggs of a few chosen host species. This ability reduces the probability of their eggs being abandoned and thus increasing their reproductivity [26].
The CSO has its origin inspired by the behavior of the cuckoo in the process of finding nests, in which a nest is a possible solution. First, an initial population of nests is randomly generated. Later, new solutions are generated via Lévy flights. and from these the best solutions are stored in comparison to the current solutions. There are several ways to implement the distribution of Lévy distribution, the simplest is the Mantegna\('\)s algorithm [37], and its distribution takes the form presented by Eq. 12 [20].
where \(X_i^{(t)}\) is the previous solution from which the new solution \(X_i^{(t+1)}\) has been generated, \(\alpha _0\) is a constant, usually 0.01, \(X_{\mathrm{best}}^{(t)}\) represents the best actual solution, u and v are drawn from normal distributions, \(\beta\) is the scale factor which has an assigned value of 1.5 and \(\phi\) is calculated according to Eq. 13, where \(\varGamma\) is the gamma function.
Then, the solution subset is discarded according to the probability of detection \(P_a\) \(\in\) [0,1] and new solutions are obtained, according to Eq. 14, with the same quantity of solutions abandoned [20, 30].
In Eq. 14, r is a uniformly distributed random number from 0 to 1, and \(X_{(i,c)}\) and \(X_{(i,k)}\) denote the two random solutions of the ith generation.
Figure 2 shows the flowchart of the Cuckoo Search Optimization algorithm, summarizing all steps described previously.

Flowchart of the CSO algorithm
Particle swarm optimization (PSO)
In a PSO system, each particle “flies” through the multidimensional search space, adjusting its position in space according to its own experience, however, also considering the experience of the neighboring particle. A particle uses the best position found by itself and the best position of its neighbors to position itself toward an ideal solution. The effect is that the particles “fly” toward a global optimum, while still investigating an area around the best current solution [14]. For each particle k positioned in a two-dimensional plane and for each iteration i, the positions and the best individual results \((x_k^{\mathrm{best}},y_k^{\mathrm{best}})\) are recorded. Then, the best result among the k particles is recorded \((x_{\mathrm{global}}^{\mathrm{best}},y_{\mathrm{global}}^{\mathrm{best}})\). Each particle’s movement will be proportional to the distance between the current position of the particle and the resulting point of the weighted average between the best individual position of the particle and the best position of the swarm, according to Eqs. 15 and 16 [13].
where
In these, \(\lambda\), \(\mu\), \(\eta\) and \(\epsilon\) are random numbers belonging to the set [0, 1] and \(\omega\) is the particle inertia term, defined by Eq. 19 [31].
where m is the maximum number of iterations.
Figure 3 shows the flowchart of the Particle Search Optimization algorithm, summarizing all steps described previously.

Flowchart of the PSO algorithm
Ant colony optimization (ACO)
In an ant colony, the communication between individuals, or between the individuals and the environment, is based on the pheromone produced by them. The trail pheromone is a specific type of pheromone that some ant species use to mark paths on the ground. When detecting pheromone trails, forage ants may follow the path trodden by other ants to the food source. The first ants when sniffing the pheromone tend to choose, probabilistically, the trails marked with stronger concentrations of pheromone. The second group of ants will notice more intense the shortest path due to the shorter evaporation time. With the continuation of this procedure by all the ants, at one point in this process, one of the paths stands out for being the most frequented, being indicated by the intensity of ants’ pheromone and density superior to the others. At this point, the best path found by the ants is defined. This behavior inspired the optimization method by ant colonies [11].
In the ACO method, the parameters k and c of the Weibull curve form a Cartesian plane that is divided into N equal parts. The center point of each new area will be an ordered pair (k, c) where the curve fit will be evaluated [5]. The probability of occurrence of each reticulum is defined by Eq. 20.
where \(\tau _r\) is the pheromone intensity for the reticle r.
Each ant is then randomly positioned in the plane through a roulette draw, where each slice of the roulette represents a reticle and is defined by the probability of occurrence. The visited quadrants are indicated by the pheromone deposit according to Eq. 21. At each iteration, the amount of the hormone is also reduced at a constant rate to simulate the hormone volatility, according to Eq. 22.
where \(\tau _{i, r}\) is the pheromone intensity for the reticle r, at iteration i, \({\mathrm{err}}_f\) is the error evaluated by the ant f, \(\mu\) is the deposition constant and \(\rho\) is the evaporation constant [33].
While the iterations follow up, some reticles will be more attractive to ants because they have a large amount of pheromone, this attraction being symbolized by the larger slices of the roulette, until most of the ants follow the same path.
Figure 4 shows the flowchart of the Ant Colony Optimization algorithm, summarizing all steps described previously.

Flowchart of the ACO algorithm
Parameters applied to the heuristic methods
Each heuristic method depends on a certain number of parameters, with its adjustment being necessary to reduce the computational time response that leads to convergence to the optimal values. The parameters applied here, presented in Table 1, were extracted from the works whose authors used the proposed methods in wind energy applications [6, 7, 27, 36].
Statistical tests
The performance evaluation of the applied methods was realized by the following tests:
Root mean square error (RMSE) (Eq, 23):
Mean absolute error (MAE) (Eq. 24):
Determination coefficient R\(^2\) (Eq. 25):
where n is the number of observations, \(y_i^{\mathrm{calculated}}\) is the frequency of Weibull, \({\bar{y}}_i^{\mathrm{measured}}\) is the mean wind speed and \(y_i^{\mathrm{measured}}\) is the frequency of observations.
The percentage value of the wind production deviation (WPD) between the obtained Weibull probability distribution curve and the data histogram was evaluated as in Eq. 26.
where \(\rho\) is the specific mass of the air, v is the wind speed, \(\varGamma\) is the gamma function and k and c are the estimated Weibull curve parameters.
Wind site data processing
The data of each location were separated into intervals with a variation of 1 m/s, and to fit the interval, the velocity should be higher than the lower value of the interval and less than or equal to the upper value, except the first interval where: 0 m/s \(\le\) V \(\le\) 1 m/s. Once separated, the data size within each interval was evaluated, and this amount of each interval was divided by the data size, thus generating a relative frequency value for each interval. The data is validated by a SONDA project methodology, which does not change the databases, eliminating data considered invalid by the process. However, this only indicates the data considered as suspicious for the user to decide whether or not to use them. Data collected by the SONDA project for the Triunfo, Petrolina and São Martinho da Serra accounted for a total of 52,560 for the three stations, although, after the processing, a total of 52,560, 52,514 and 52,366 data were considered, representing a use of 100%, 99.91% and 99.63%. (Figs. 5, 6, 7, 8, 9, 10)
Results and discusssion
The results of the statistical tests for the TRI23 station located in Triunfo, PTR11 station located in Petrolina and SMS08 located in São Martinho da Serra are presented in Tables 2, 3 and 4. Figures 5, 8, 11, 6, 9 and 12 present the Weilbull distribution curves for deterministic numerical methods and heuristic methods. Figures 7 and 13compare the results obtained by ACO and the EM for Triunfo and São Martinho da Serra and Figure 10 compares the results obtained by CSO and the EM for Petrolina

Weibull curve adjustment for TRI23-deterministic numerical methods

Weibull curve adjustment for TRI23-heuristic methods

Weibull curve adjustment for TR23 station in Triunfo

Weibull curve adjustment for PTR11-deterministic numerical methods

Weibull curve adjustment for PTR11-heuristic methods

Weibull curve adjustment for PTR11 station in Petrolina

Weibull curve adjustment for SMS08—deterministic numerical methods

Weibull curve adjustment for SMS08—heuristics methods

Weibull curve adjustment for SMS08 station in São Martinho da Serra
Graphically, it was observed that the methods EM, MLM, MM, ACO, CSO, PSO and HS, to determine the shape parameter k and the scale parameter c of the Weibull distribution, presented a better curve fit with the histogram of the wind speed for the cities Triunfo, Petrolina and São Martinho da Serra. Moreover, it was further observed that the heuristic methods Ant Colony Optimization and Cuckoo Search Optimization were completely adequate to estimate the Weibull parameters. This fact was clearly validated by means of the statistical tests, i.e., RMSE, MAE and R\(^2\), and by the WPD test. Tables 2, 3 and 4 show the statistical tests results for all deterministic and heuristic methods and WPD test considered in the analysis. It was also observed from the statistical and wind production deviation analysis that the values of RMSE, MAE, R\(^2\) and WPD have low variation magnitudes to each other for all the methods.
It can be concluded that the ACO method for Triunfo and São Martinho da Serra and the CSO method for Petrolina have a good performance, since the results among all the used methods obtained the lowest values of RMSE, MAE and WPD, highlighting the WPD test values less than 2%, which was below the acceptable limit for the wind production deviation. It can also be concluded that the EEM for Triunfo, Petrolina and São Martinho da Serra has the worst performance, since it obtained the highest values of RMSE and MAE, and the lowest value of R\(^2\) among all methods, although this method presented great performance of the WPD test, since it obtained negligible values of wind production deviation. Among the heuristic methods, PSO for Triunfo and São Martinho da Serra had the worst performance, since it obtained WPD value higher than 2%.
Conclusion
The following conclusions can be drawn from the preceding analysis:
-
1.
Graphically, the EEM method was the least effective to fit Weibull distribution curves for wind speed data from the region of Pernambuco and Rio Grande do Sul, respectively, using the data analyzed for the cities of Triunfo, Petrolina and São Martinho da Serra.
-
2.
Regarding the parameter k, it was observed that its values range from 2 to 3 for the cities of Triunfo, Petrolina and São Martinho da Serra, showing less constancy of the wind speed for that location. The values of c for Petrolina and São Martinho da Serra cities range from 3 to 6 and for Triunfo range 13 to 16 for the mean wind speed occurring in those aforementioned places.
-
3.
Ant Colony Optimization was an efficient method to determine the Weibull distribution parameters, k and c, for Triunfo and São Martinho da serra, and Cuckoo Search Optimization was an efficient method for Petrolina.
-
4.
A suggestion for future work is to evaluate more periods of time and use the predicted values for k and c to calculate the average wind speed and its standard deviation to achieve a rank for each method.
References
Akdag, S.A.: Dinler: a new method to estimate weibull parameters for wind energy applications. Energy Convers. Manag. 50(7), 1761–1766 (2009)
Akpinar, E.K., Akpinar, S.: Determination of the wind energy potential for maden-elazig. Energy Convers. Manage. 45, 2901–2914 (2004)
Andrade, C.F., Neto, M.F.H., Rocha, P.A.C., Silva, M.E.V.: An efficiency comparison of numerical methods for determining weibull parameters for wind energy applications:a new approach applied to the northeast region of brazil. Energy Convers. Manage. 86, 801–808 (2014)
Askarzadeh, A., Zebarjadi, M.: Wind power modeling using harmony search with a novel parameter setting approach. J. Wind Eng. Ind. Aerodyn. 135, 70–75 (2014)
Azevedo, D.C.R.: Métodos heurísticos aplicados no ajuste de curvas de weibull em energia eólica. Master’s thesis, Mechanical Engineering Course, Mechanical Engineering Department, Federal University of Ceará, Fortaleza (2015)
Barbosa, H.P.: Utilização da busca harmônica no ajuste da curva de weibull aplicado a dados de vento. Master’s thesis, Mechanical Engineering Course, Mechanical Engineering Department, Federal University of Ceará, Fortaleza (2015)
Benhala, B., Bouattane, O.: Ga and aco techniques for the analog circuits design optimization. J. Theor. Appl. Inf. Technol. 64, 413–419 (2014)
Burton, T., Sharpe, D., Jenkins, N., Bossanyi, E.: Wind Energy Handbook. Wiley, Chichester (2001)
Celik, A.N.: A statistical analysis of wind power density based on the weibull and rayleigh models at the southern region of turkey. Renew. Energy 29, 593–604 (2003)
Chang, T.P.: Estimation of wind energy potential using different probability density functions. Appl. Energy 88, 1848–1856 (2011)
Dorigo, M., stützle, T.: Ant Colony Optimization. MIT Press, Cambridge, MA (2004)
Dorvlo, A.S.: Estimating wind speed distribution. Energy Convers. Manage. 43(17), 2311–2318 (2002)
Eberhart, R.C., kennedy, J. (eds.): A New Optimizer Using Particle Swarm Theory, vol. 1. Sixth International Symposium on, IEEE (1995)
Engelbrecht, A.P.: Computational Intelligence: An Introduction, 2nd edn. Wiley, Chichester (2007)
Fisher, R.A.: Frequency distribution of the values of the correlation coefficient in samples from an indefinitely large population. Biometrika 10, 507–521 (1915)
Geem, Z.W., kim, J.H., Loganathan, G.V.: A new heuristic optimization algorithm: harmony search. Simulation 76(2), 60–68 (2001)
González, J.S., García, A.L.T., Payán, M.B., Santos, J.R., Rodríguez, A.G.G.: Optimal wind-turbine micro-siting of offshore wind farms: A grid-like layout approach. Appl. Energy 200, 28–38 (2017)
Hajibandeh, N., Catalão, J.P.S., Shafie-khah, M., Osório, G.J., Aghaei, J.,.: A heuristic multi-objective multi-criteria demand response planning in a system with high penetration of wind power generators. Appl. Energy 212, 721–732 (2018)
Jiang, H., Wang, J., Wu, J., Geng, W.: Comparison of numerical methods and metaheuristic optimization algorithms for estimating parameters for wind energy potential assessment in low wind regions. Renew. Sustain. Energy Rev. 69, 1199–1217 (2017)
Jiang, P., Wang, Y., Wang, J.: Short-term wind speed forecasting using a hybrid model. Energy 119, 561–577 (2017)
Justus, C.G., Mikhail, A.: Height variation of wind speed and wind distribution statistics. Geophys. Res.Lett. 3, 261–264 (1976)
Manwell, J.F., McGowan, J.G., Rogers, A.L.: Wind Energy Explained : Theory, Ddesign, and Application, 2nd edn. Wiley, Chichester (2009)
Marzband, M., Fouladfar, M.H., Akorede, M.F., Lightbody, G., Pouresmaeil, E.: Framework for smart transactive energy in home-microgrids considering coalition formation and demand side management. Sustain. Cities Soc. 40, 136154 (2018)
Ohunakin, O.S., Adaramola, M.S., Oyewola, O.M.: Wind energy evaluation for electricity generation using wecs in seven selected locations in nigeria. Appli. Energy 88, 3197–3206 (2011)
Osman, I.H., Laporte, G.: Metaheuristics: a bibliography. Ann. Op. Res. 63, 513–628 (1996)
Payne, R.B., Sorenson, M.D., Klitz, K.: The Cuckoos. Oxford University Press, New York (2005)
Rahmani, R., Yusof, R., Mahmoudian, M.S., Mekhilef, S.: Hybrid technique of ant colony and particle swarm optimization for short term wind energy forecasting. J. Wind Eng. Ind. Aerodyn. 123, 163–170 (2013)
Rocha, P.A.C., Souza, R.C., Andrade, C.F., Silva, M.E.V.: Comparison of seven numerical methods for determining weibull parameters for wind energy generation in the northeast region of Brazil. Appl. Energy 89(1), 395–400 (2012)
Salcedo-Sanz, S., García-Herrera, R., Camacho-Gómez, C., Aybar-Ruíz, A., Alexandre, E.: Wind power field reconstruction from a reduced set of representative measuring points. Appl. Energy 228, 1111–1121 (2018)
Sanajaoba, S., Fernandez, E.: Maiden application of cuckoo search algorithm for optimal sizing of a remote hybrid renewable energy system. Renew. Energy 96, 1–10 (2016)
Secchi, A.R., Biscaia Jr.E.C.: Otimização de processos. Class notes. Federal University of Rio de Janeiro, Rio de Janeiro, RJ (2012)
Silva, G.R.: Características de vento da região nordeste, análise, modelagem e aplicações para projetos de centrais eólicas. Master’s thesis, Federal University of Pernambuco, Recife (2003)
Socha, K.: Ant colony optimisation for continuous and mixed-variable domains. Ph.D. thesis, Universite Libre de Bruxelles, Av. Franklin D. Roosevelt 50, 1050 Brussels, Belgium (2009)
Stutzle, T.: Local search algorithms for combinatorial problemsanalysis, algorithms and new applications. Ph.D. thesis, Department of Computer Science, Technical University of Darmstadt, Darmstadt, Augustin, Germany (1999)
Wais, P.: Two and three-parameter weibull distribution in available windpower analysis. Renew. Energy 103, 15–29 (2017)
Wang, Z., Wang, C., Wu, J.: Wind energy potential assessment and forecasting research based on the data pre-processing technique and swarm intelligent optimization algorithms. Sustainability 8(11), 1191 (2016)
Yang, X.S.: Nature-Inspired: Metaheuristic Algorithms, 2nd edn. Luniver Press, Beckington, UK (2010)
Acknowledgements
This research was jointly supported by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES) and the Conselho Nacional de Desenvolvimento Científico e Tecnológico (CNPq), Brazilian governmental agencies.
Author information
Authors and Affiliations
Contributions
The authors Carla Ferreira de Andrade, Lindemberg Ferreira dos Santos, Marcus V. Silveira Macedo, Paulo A. Costa Rocha and Felipe Ferreira Gome declare to be responsible for the elaboration of the manuscript titled “Four heuristic optimization algorithms applied to wind energy: determination of Weibull curve parameters for three Brazilian sites”. The second and third authors participated in the elaboration of the project, data collection, data analysis and article writing, the fifth author participated in the elaboration of the computational algorithm and the first and fourth authors guided all the steps of the work and participated in the review and writing of the project and the article.
Corresponding author
Ethics declarations
Conflict of interest
On behalf of all the authors, the corresponding author states that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Freitas de Andrade, C., Ferreira dos Santos, L., Silveira Macedo, M.V. et al. Four heuristic optimization algorithms applied to wind energy: determination of Weibull curve parameters for three Brazilian sites. Int J Energy Environ Eng 10, 1–12 (2019). https://doi.org/10.1007/s40095-018-0285-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40095-018-0285-5