
Abstract
Langmuir volume constant and Langmuir pressure constant are parameters used in determining the nature of Langmuir isotherm. They are the basis for determining the adsorption capacity of any coal samples at different pressure and temperature and also the amount of gas released from these coal samples. The parameters of coal such as moisture, volatile matter, ash content, fixed carbon composition, vitrinite, semi-vitrinite, liptinite, Inertinite, mineral matter, mean and depth are used to relate with Langmuir isotherm constants and estimate sorption capacity. Due to the multiplicity of effective parameters and complexities of these parameters prediction of sorption capacity of coal using the regression analysis is not suitable. In this paper, artificial neural network (ANN) has been proposed to analysis these parameters and to learn which coal sample has more sorption capacity can be. In this paper, a correlation has been formed with parameters of coal samples from different coal mines with the help of regression analysis and ANN tool.
Similar content being viewed by others


Introduction
Coal bed methane has become the major natural gas resources which are extracted from coal beds. The methane gas is stored in micro pores in coal matrix in adsorbed form by the process of adsorption. The reservoir volume is comparatively larger than volume of a cleat or fracture system and hence free gas only accounts for a small fraction of the gas stored in coal (Diamond and Levine 1981). As a result, the desorption isotherm often describe the pressure volume relationship. Releasing of adsorbed gas can usually be described by Langmuir isotherm. Langmuir isotherm is the most frequently used isotherm which describes release of adsorbed gas. It is the most commonly used technique to describe gas adsorption by coal (Crosdale et al. 1998). It even provides the information about gas saturation and desorption pressure (Busch and Gensterblum 2011; Bae and Bhatia 2006). Attachment of gas to the surface of the coal, and covering the gas as a single layer of gas are the assumption of Langmuir adsorption isotherm. At low pressure, a greater volume of gas can be stored through sorption by compression mechanism (Scott 2002).
The productivity of methane can be increased from coal beds reservoir by simulation. Reservoir simulation provides information on the behavior of the reservoir in various production injection scenarios. Different techniques are used to calculate the uncertainties linked with reservoir parameters. CBM requires an ability to transfer the experience to the unique challenges and characteristics of coal for maximizing recovery. Among this Langmuir adsorption model is the most general model being used to quantify the amount of gas adsorption on an adsorbent as a function of partial pressure or concentration at a certain temperature. Langmuir isotherm has comprises of mainly two constants, the Langmuir volume constant and Langmuir pressure constant. The Langmuir Volume is the maximum amount of gas that can be adsorbed to coal at infinite pressure. As the pressure increases to infinity, the gas content in the plot of Langmuir isotherm asymptotically approaches the Langmuir volume (Fig. 1a). Whereas, the pressure at which one half of the Langmuir volume adsorbed is called Langmuir pressure or critical desorption pressure (Crosdale et al. 1998). As seen in (Fig. 1b), it changes the curvature of the line and thus affects the shape of the isotherm. So, Langmuir equation is being used as a simple method in CBM industry and reservoir simulation approaches for determination of amount of gas adsorbed on the surface. The equation is
where V L is Langmuir volume constant (LVC), P L is Langmuir pressure constant (LPC) and p is the pressure at which adsorption is calculating. The variation in LVC and LPC are cause of difference in nature of Langmuir isotherms.

Typical Langmuir volume and pressure curve
Parameters like moisture content, ash content, carbon composition mineral matter etc., influence the gas adsorption characteristics of a coal seam (Crosdale et al. 1998; Bustin and Clarkson 1998). In this paper, both linear and nonlinear mathematical models like multivariate regression analysis (MVRA) and artificial neural network (ANN), respectively have been used to predict Langmuir constants using coal proximate and macerals properties like moisture, volatile matter, ash content, fixed carbon composition, vitrinite, semi-vitrinite, liptinite, inertinite, mineral matter, mean and depth as input parameters. The main objective of this study is to develop intelligent models to predict the maturity of coal and coal having best adsorption capacity to store maximum methane gas.
Basheer and Najjar (1996) investigated the feasibility of utilizing the concept of neural nets in developing networks for predicting the breakthrough curves of fixed-bed adsorbers (Basheer and Najjar 1996). They observed close agreement between the breakthrough curves predicted by the developed neural network and those obtained from the mathematically based adsorption model (HSDM). Naseri et al. (2012) predicted hydrocarbon gas viscosity and density using two neural networks. They trained and tested the two networks separately to predict gas viscosity and gas density (Naseri et al. 2012).
Coveney et al. (1996) used the approach to predict oil field cement compositions, particle- size distributions, and thickening-time curves from the diffuse reflectance infrared Fourier transform spectrum of neat cement powders (Coveney et al. 1996). Soroush et al. (2014) utilized a novel mathematical model of least squares support vector machine (LSSVM) for accurate prediction of adsorption isotherm considering variables like temperature, pressure and type of adsorbents (Soroush et al. 2014). They showed that the LSSVM model is capable to predict adsorption isotherm with an acceptable statistical parameters of 2.3058 % and 0.9995 for AARD % and R 2, respectively.
Study area and data set
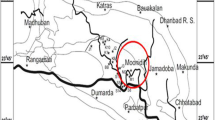
The data sets in this study is taken from a previous study (Dutta et al. 2011). Fourteen coal samples were collected from different parts of the country (Fig. 2). India’s major coal mining and CBM exploration activities are concentrated in these regions. Eight samples are from the Raniganj coalfield, four from the Jharia coalfield, and the remaining two are from the South Karanpura Coalfield. The analysis was carried out on dry samples. The moisture content represents the residual moisture of the samples. The ash content in Indian coal is usually high. Ash content of the samples ranges from 10 to 48 % which strongly reduces the sorption capacity of a coal. Coals from Raniganj formation have higher moisture and lower ash content than the other coal samples. Volatile matter content is high in all samples and their value ranges from 32 to 45 %.The Vitrinite, Inertinite, Liptinite are a type of macerals (organic substance). Their values can be known by the method of reflectance. Maturity of the coal samples and composition of carbon & hydrogen is known by vitrinite reflectance (Ro).

Location of coal samples from coalfields in India (Dutta et al. 2011)
The value of vitrinite reflectance varies from 0.61 to 1.94 % indicating that the coals are bituminous. Coals of South Karanpura coals are most mature followed by the coal from Jharia, Barakar formation, and Raniganj formation. All Raniganj and Barakar formation coals are bright as they have high vitrinite content whereas the other coals are dull due to high inertinite content. The data for different coalfields have been shown in Table 1.
Multivariate regression analysis
To quantify the relationship between two groups of variables, regression analysis is used to fit a model to the observed data. The fitted model may then be used either to merely describe the relationship between the two groups of variables, or to predict new values.
The aim of multivariate regressions is to study about the correlation between several independent or predictor variables and a dependent variable to get the best-fit equation. It solves the data sets by performing least squares fit. It constructs and solves the simultaneous equations by creating the regression matrix, and then solving for the co-efficient using the backslash operator.
A linear transformation of the X variables is made so that minimum value of the sum of squared deviations of the observed and predicted Y is obtained. The computations become more complex as the interrelationships among all the variables must be taken into account in the weights assigned to the variables.
The prediction of Y is accomplished by the following equation:
Here, ‘b’ values are regression weight and they are computed in a way that minimizes the sum of squared deviations \(\mathop \sum \limits_{i = 1}^{N} (Y_{i} - Y_{i}^{{\prime }} )^{2}\) in the same manner as in simple linear regression.
Artificial neural networks
Artificial neural network are the structures consisted of interconnected adaptive simple processing elements that can perform massive parallel computation for data processing and knowledge representation. It works in the same way as the human brain works with complex network, which is performed by extensively connecting various processing units (Zhang et al. 1998). Same as the biological nervous system, ANN has neurons which act as a connector and data transfer among layers. A neural network predict an output pattern when it recognizes a given input pattern (Weigend et al. 1990; Poli and Jones 1994). Each neurons has n inputs and calculates its output ‘a’ using equation
where p i are the ith input, w i are the ith weight, b is the bias and f is the activation or transfer function for the neuron. Different type of activation function like linear function, step function, sigmoid function can be used in ANN. In this paper, sigmoid function is considered as an activation function.
Many neurons can be combined in a layer and these layers together form a particular network. The role of layers in multilayer network is different. The layer that results in network output is called output layer. The layers that are between input layer and output layer are called hidden layer. There can be more than one hidden layer in any network and this produces different types of ANNs (Fig. 3.)

Neural network
Before interpreting new information a network first has to be trained. Back-propagation algorithm is the most versatile and robust technique among all available algorithms. It provides the most efficient learning method for multilayer perception (MLP) neural networks. In the feed forward back-propagation neural network (BPNN), received inputs are forwarded through the entire next layer to obtain the outputs (Benardos and Vosniakos 2007; Rumelhart and McClelland 1986).
The number of hidden layers and the number of neurons in the hidden layers can be changed according to the problem to be solved. The number of input and output neurons is the same as the number of input and output variables. In network training, data is processed through the input layer to hidden layer and then from hidden layer to output layer. In this layer, the output is compared to the measured values (the ‘‘true’’ output) and the difference (error) is processed back through the network (backward pass) by updating individual weights of the connections and biases of individual neurons. Training pair represent the input and output data in the form of vectors. The above-mentioned process is repeated for all training pairs in the dataset, until the network error reaches to minimum. Root mean square error (RMSE) is usually used to calculate the error. The error can usually be calculated using the root mean squared error (RMSE) (Zhang et al. 1998).
In the paper, nonlinear sigmoid function (LOGSIG, TANSIG) and linear function (POSLIN, PURELIN) are used as transfer functions. The logarithmic sigmoid function (LOGSIG) is defined as (Zhang et al. 1998)
Whereas the tangent sigmoid function (TANSIG) is defined as (Bustin and Clarkson 1998)
where e x is the weighted sum of the inputs for a processing unit.
The sample values of proximate and macerals parameters are considered to be as input data and sample values of Langmuir volume constant and Langmuir pressure constant are taken as target data (Table 2).
Result and discussion
Multivariate regression (MVRA) analysis to predict LVC and LPC
Proximate/macerals and LVC/LPC data sets have been used as independent and dependent variable, respectively to develop MVRA predicting model.
Checking multicollinearity problem
When the correlations among the independent variables is strong, multicollinearity problems occur. This increases the standard errors of the coefficients leading to an erroneous conclusion of multivariate regression analysis. Pearson’s correlation values of Moisture, Volatile matter, Ash, Fixed carbon, Vitrinite, Semi-vitinite, Litinite, Intertinite, Mineral matter, Mean Ro % and Depth with LVC are 0.6821, 0.0431, 0.1116, 0.2349, 0.6884, −0.1131, −0.3168, −0.6681, −0.2426, −0.2766, 0.0267 and with LPC are 0.6132, 0.0938, −0.4454, 0.2859, 0.4018, 0.127, 0.283, −0.2789, −0.3851, −0.5604 and −0.5215, respectively. Since, the correlations among the independent variables is not strong multicollinearity problem can be neglected and is under controlled conditions.
Two multivariate linear equation for LVC and LPC, respectively are obtained. R (coefficient of correlation) values for LVC and LPC are 0.9515 and 0.7596, respectively. R values provide a normalized measurement of the linear relation of two variables in data samples. The value of R is such that −1 < R < + 1. The + and − signs are used for positive linear correlations and negative linear correlations, respectively. The values near to 1 imply that it corresponds to linear relationship. A correlation greater than 0.8 is generally described as strong relation.
and
Figure 4a, b indicates that although coefficient of correlation (R) is high between measured and predicted values of both LVC and LPC but the percentage error is quite high. This indicates that coefficient of correlation (R) is not a sufficient criteria to determine the predictive capability of a model. Hence, another statistical criteria need to be introduced.

a Pearson’s product–moment correlation (R) between measured and predicted LVC values using MVRA, b Pearson’s product–moment correlation (R) between measured and predicted LPC values using MVRA
Artificial neural network
In this paper, a nonlinear modeling approach ANN has been used to predict LVC and LPC governing the nature of Langmuir isotherms which associate the adsorption of methane gas molecules on a coal surface to gas pressure or concentration at a fixed temperature. ANN architect have been optimally optimized and the optimized model parameters have been determined using internal and external validation techniques. Internal validation has been implemented using the tenfold cross validation technique, whereas, external validation has been performed using a sub-set of data (15 %). The average values of RMSE in cross validation and training data for ANN were: 0.94 and 0.87, respectively. The network has been developed with 80 % datasets used for training, 15 % for validation and 5 % for testing.
Common issues with the ANN application are to define optimum number of hidden layers, the number of neurons in these layers, functional relations between input and output parameters, learning algorithm and to avoid over-fitting (Verma and Singh 2013). Although Hecht-Nielsen (Hecht-Nielsen 1987) and Kaastra and Boyd (Kaastra and Boyd 1996) have proposed empirical techniques to determine the optimum architecture of ANN but a heuristic approach is needed because the suitable numbers of layers and neurons may even change with different simulations for the same problem.
To determine the optimal model parameters, a criterion of minimum RMSE value (training and validation) was used. To determine the optimal architecture, the neural network with two and three hidden layer has been considered for carrying out parametric simulation (Table 3). In each hidden layer, number of neurons has been varied to determine the optimum model based on minimum value of RMSE. The RMSE is more sensitive to the larger relative errors caused by the low valued so that it offers a balanced evaluation of the goodness of fit of the model. The perfect model will have a value approaching to zero. To determine the optimum network, RMSE was calculated for different combination of networks as shown in Table 3. The basic formula for determining the RMSE is:
where, T i is measured output (Target), O i is the predicted output and N represent the number of input–output data pairs. The network with architecture 11–15–10–2 with transfer function ‘logsig–logsig–purelin’ has been found to have the minimum RMSE and is considered as the optimum model (Table 3). Figures 5, 6 shows network view of optimum model.

Optimum ANN Network with typical feed-forward back propagation

Proposed ANN network for the LVC and LPC
The performance of LVC and LPC predicting models has been evaluated using different statistical criteria parameters: the root mean square error (RMSE), Pearson’s product–moment correlation (R), the Nash–Sutcliffe coefficient of efficiency (E f). Apart from above criteria, t and F tests will be done between measured and predicted values of LVC and LPC.
Pearson’s product–moment correlation (R) and Nash–Sutcliffe model efficiency coefficient (E f)
Pearson’s product–moment correlation coefficient, also known as r, R, or Pearson’s r, is a measure of the strength and direction of the linear relationship between two variables that is defined as the (sample) covariance of the variables divided by the product of their (sample) standard deviations. Nash–Sutcliffe model efficiency coefficient (E f) is same as coefficient of determination (R 2) used in linear regression whose values ranges between—\(\infty\) and 1.0. When the value is 1 it indicates the perfect fit. Efficiency can be define mathematically as
where T i is measured output (Target), O i is the predicted output from ANN and \({\bar{T}}_{i}\) is the mean measured output. An efficiency of 1 (E f = 1) resembles to a perfect match of measured output with the predicated output. An efficiency of 0 (E f = 0) tells that the model predictions are as accurate as the mean of the observed data, whereas an efficiency less than zero (E f < 0) occurs when the observed mean is a better predictor than the model or, in other words, when the residual variance (described by the numerator in the expression above), is larger than the data variance (described by the denominator).
Figure 7a, b illustrates the measured and predicted LVC and LPC on 1:1 slope line with standard error bars. All predicted data points are very near to the 1:1 slope line. This clearly indicates the potential of ANN for the prediction of LVC and LPC for Indian coals. Here, Pearson’s product–moment correlation (R) is as high as 0.9827 and 0.9123 for LVC and LPC, respectively, whereas, RMSE is as low as 0.00065 and 0.0007 for LVC and LPC, respectively.

a Pearson’s product–moment correlation (R) between measured and predicted LVC values using ANN, b Pearson’s product–moment correlation (R) between measured and predicted LPC values using ANN
The coefficient of correlation is a statistical measure of how well the regression line is close to the observed data and a coefficient of ± 1 indicates that the regression line perfectly fits the observed data. Nash–Sutcliffe model efficiency coefficient (E f) for LVC and LPC comes out to be 0.9610 and 0.7056, respectively which shows that prediction is not close to mean and shows the versatile nature of ANN prediction. Nash–Sutcliffe model efficiency coefficients (E f) for LVC and LPC using MVRA are −344.5627 and −633.2961 respectively. The negative values of E f for LVC and LPC prediction using MVRA means that observed mean is a better predictor than the MVRA model and hence proves the superiority of ANN over MVRA Tables 4, 5.
T and F test
The significance of Pearson’s product–moment correlation (R) can be tested by T test and F test. The significance of R is determined by the t test by assuming that both measured and predicted variables are normally distributed and the observations are chosen randomly. So for both LVC and LPC, the two variables are the measured and predicted values obtained from ANN model. The F Test is used to test the null hypothesis that the variances of two samples are equal. P (probability) value is more than 0.05 so variance are assumed to be equal in case of LVC whereas in case of LPC the p value is less than 0.05, so variance is assumed to be not equal. Further, t test is performed for equal and unequal variance for both cases, respectively. Since the p value (two tail) for t test is more than 0.05, this provides evidence to accept the null hypothesis of equal and unequal means, respectively. The observed difference between the sample means is not convincing enough to say that the average of measured and predicted values differ significantly Table 6.
Conclusion
In this study, ANN model was efficiently used to predict the methane adsorption parameters like Langmuir volume constant and Langmuir pressure constants of sub-bituminous to high-volatile bituminous Indian Gondwana coals. This application demonstrated more accuracy in comparison with the statistical methods. It can be concluded that ANN is a useful resource to enhance and determine sorption capacity of methane gas in Indian Gondwana coal.
In this paper, multivariate regression model and a multilayer perception (MLP) neural network is developed and used to predict sorption capacity through Langmuir isotherm. The ANN architecture is optimum when 11 neurons in input layers, 2 hidden layers (15 neurons & 10 neurons) and 2 neurons in output layers are considered. ANN showed high correlation values and less RMSE, whereas MVRA showed less correlation values and high RMSE. Also, E f value for ANN prediction was found to be better as compared to MVRA. Relationships between measured and predicted values are statistically significant according to the Student’s t test with 95 % safety.
Based on the study, it is can be established that the ANN seems to be the better option for better prediction of Langmuir constants of Indian Gondwana coals. ANN can be used to predict the Langmuir constants prior to conducting complicated adsorption/desorption experiment on coal samples and accordingly pressure in the well can be adjusted for efficient recovery of methane from reservoirs. The use of ANN/MVRA is also an economical technology in analysis of adsorption. The cost of a typical adsorption desorption equipment for gas ranges from 80,344 USD to 160,688 USD. While, the cost of developing ANN/MVRA algorithm costs is very insignificant as compared to adsorption desorption equipment.
Abbreviations
- ANN:
-
Artificial neural network
- BPNN:
-
Back-propagation neural network
- CBM:
-
Coal bed methane
- LPC:
-
Langmuir pressure constant
- LVC:
-
Langmuir volume constant
- MLP:
-
Multilayer perception
- MVRA:
-
Multivariate regression analysis
- RMSE:
-
Root mean square error
References
Bae JS, Bhatia SK (2006) High-pressure adsorption of methane and carbon dioxide on coal. Energy Fuels 20(6):2599–2607
Basheer I, Najjar Y (1996) Predicting dynamic response of adsorption columns with neural nets. J Comput Civ Eng 10(1):31–39
Benardos PG, Vosniakos GC (2007) Optimizing feed-forward artificial neural network architecture. Eng Appl Artif Intel 20:365–382
Busch A, Gensterblum Y (2011) CBM and CO2-ECBM related sorption processes in coal. Rev, Int J Coal Geol 87:49–71
Bustin RM, Clarkson CR (1998) Geological controls on coalbed methane reservoir capacity and gas content. Int J Coal Geol 38(1–2):3–26
Coveney PV, Fletcher P, Hughes TL (1996) Using artificial neural networks to predict the quality and performance of oil-field cements. AI Mag 17(4):41–53
Crosdale PJ, Beamish BB, Valix M (1998a) Coalbed methane sorption related to coal composition. Int J Coal Geol 35(1–4):147–158
Crosdale PJ, Beamish BB, Valix M (1998b) Coalbed methane sorption related to coal composition. Int J Coal Geol 35:147–158
Diamond WP, Levine JR (1981) Direct method determination of the gas content of coal: procedures and results. US Bureau of Mines Report of Investigations, RI 8515
Dutta P, Bhowmik S, Das S (2011) Methane and carbon dioxide sorption on a set of coals from India. Int J Coal Geol 85:289–299
Hecht-Nielsen R (1987) Kolmogorov’s mapping neural network existence theorem. In: The 1st IEEE International Conference on Neural Networks, San Diego, CA, USA, pp 11–14
Kaastra I, Boyd M (1996) Designing a neural network for forecasting financial and economic time series. Neurocomputing 10(3):215–236
Naseri A, Yousefi SH, Sanaei A, Gharesheikhlou A (2012) A neural network model and an updated correlation for estimation of dead crude oil viscosity. Braz J Pet Gas 6(1):031–041
Poli I, Jones RD (1994) A neural net model for prediction. J Am Stat Assoc 89:117–121
Rumelhart D, McClelland J (1986) Parallel distributed processing. MIT Press, Cambridge
Scott AR (2002) Hydrogeologic factors affecting gas content distribution in coalbeds. Int J Coal Geol 50(1–4):363–387
Soroush E, Mesbah M, Shokrollahi A, Bahadori A, Ghazanfari MH (2014) Prediction of methane uptake on different adsorbents in adsorbed natural gas technology using a rigorous model. Energy Fuels 28(10):6299–6314
Verma AK, Singh TN (2013) A neuro-fuzzy approach for prediction of longitudinal wave velocity. Neural Comput Appl 22:1685–1693
Weigend S, Huberman BA, Umelhart DE (1990) Predicting the future: a connectionist approach. Int J Neural Syst 1:193–209
Zhang G, Patuwo BE, Hu MY (1998) Forecasting with artificial neural networks: The state of the art. Int J Forecast 14:35–62
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article

Cite this article
Verma, A.K., Sirvaiya, A. Intelligent prediction of Langmuir isotherms of Gondwana coals in India. J Petrol Explor Prod Technol 6, 135–143 (2016). https://doi.org/10.1007/s13202-015-0157-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13202-015-0157-y