
Abstract
Drought, rising demand for water, declining water resources, and mismanagement have put society at serious risk. Therefore, it is essential to provide appropriate solutions to increase water productivity (WP). As an element of research, this study presents a hybrid machine learning approach and investigates its potential for estimating date palm crop yield and WP under different levels of subsurface drip irrigation (SDI). The amount of applied water in the SDI system was compared at three levels of 125% (T1), 100% (T2), and 75% (T3) of water requirement. The proposed ACVO-ANFIS approach is composed of an anti-coronavirus optimization algorithm (ACVO) and an adaptive neuro-fuzzy inference system (ANFIS). Since the effect of irrigation factors, climate, and crop characteristics are not equal in estimating the WP and yield, the importance of these factors should be measured in the estimation phase. To fulfill this aim, ACVO-ANFIS employed eight different feature combination models based on irrigation factors, climate, and crop characteristics. The proposed approach was evaluated on a benchmark dataset that contains information about the groves of Behbahan agricultural research station located in southeast Khuzestan, Iran. The results explained that the treatment T3 advanced data palm crop yield by 3.91 and 1.31%, and WP by 35.50 and 20.40 kg/m3, corresponding to T1 and T2 treatments, respectively. The amount of applied water in treatment T3 was 7528.80 m3/ha, which suggests a decrease of 5019.20 and 2509.6 m3/ha of applied water compared to the T1 and T2 treatments. The modeling results of the ACVO-ANFIS approach using a model with factors of crop variety, irrigation (75% water requirement of SDI system), and effective rainfall achieved RMSE = 0.005, δ = 0.603, and AICC = 183.25. The results confirmed that the ACVO-ANFIS outperformed its counterparts in terms of performance criteria.
Similar content being viewed by others
Introduction
Date palm scientifically known as Phoenix dactylifera L., is the sixth most important horticultural product in Iran, accounting for about 5.5% of its total horticultural production (Dehghanisanij and Salamati 2017; Agricultural statistics 2018). Due to the specific climatic conditions such as drought, increasing demand for water, decreasing water resources in the southern regions of Iran, implementation of new pressurized irrigation systems and using fertilization in groves seem necessary. The realization of sustainable agriculture in any region requires efficient water management strategies. One of the efficient irrigation systems that have performed positively is the subsurface drip irrigation (SDI) system (Ahmed Mohammed et al. 2020; Mohammed et al. 2021a, b; Alnaim et al. 2022). The main objective of the SDI system is to increase water productivity (WP) (Dehghanisanij and Salamati 2017). Scientific studies show that using the SDI method reduces water consumption by 25–50% for row crops and citrus orchards compared with surface drip irrigation (Davis 1967). In the SDI method, soil moisture during the crop growth period is close to the field capacity (FC) and the crop receives its required water without consuming large energy (Al Wahaibi 2018; Ahmed Mohammed et al. 2020; Mohammed et al. 2021a, b).
The rising demand for agricultural products and difficulties in accessing farm data demonstrate the need to use appropriate models to estimate crop yields and WP. Most input parameters of crop models are not available in Iran. Crop management, crop nutrition, irrigation, soil characteristics, and climatic conditions are among the factors influencing the estimation of yield and energy consumption. Due to the impossibility of simultaneously studying the effects of irrigation, soil, and climate on the crop, efficient WP and yield estimation methods are required (Golabi et al. 2013). Powerful statistical techniques and neural networks have led to the development of yield and WP estimation models (Safari et al. 2019; Bagheri et al. 2012).
Researchers in simulating variables such as the amount of weekly evapotranspiration (Landeras et al. 2009), daily evaporation (Piri et al. 2009), predicting air temperature (Smith et al. 2009), solar radiation (Mubiru 2008), predicting the performance of pressurized irrigation systems (Ababaei and Verdinejad 2013), have used artificial neural networks (ANNs). In recent years, artificial intelligence (AI) methods are powerful alternatives to calculate the yield and WP parameters. Table 1 lists some of the recent studies that employed meta-heuristic algorithms to estimate WP and yield parameters.
Determining the harvest time is one of the main decisions of harvest management. Harvesting sooner or later than optimum date will lead to a reduction in revenue. The purpose of this study is to evaluate the ability of intelligent hybrid approaches based on artificial intelligence in estimating WP and date palm crop yield under SDI for planning at harvest time. It is also possible to select the best possible features from the factors affecting the date palm crop yield using the proposed hybrid approach, and the modeling process using these features.
Materials and methods
Case study
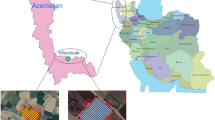
This study was conducted at Behbahan agricultural research station located in Khuzestan, Iran. This station is situated 5 km northeast of Behbahan city at 30° 35'N and 50° 16'E. Its area is 64 hectares; 62 hectares are arable land. Figure 1 shows the geographical location of the study area.

Geographical location of the study area (Ghorbani et al. 2021)
Methodology
This study was conducted in the form of a randomized complete block design with three replications for 3 years (2013–2016). For irrigation management, SDI system at three levels based on water requirements of 125% (T1), 100% (T2), and 75% (T3) and two palm varieties (Khasi and Zahedi) were considered as main plots and sub-plots, respectively. Date palms were planted as offshoots in 1990. The primary method of irrigating the palms was surface irrigation. In 2013, date palms were equipped with surface and subsurface drip irrigation. The placement of date palms (at planting time) has been implemented in three repetitions. In other words, at the time of planting, the station of date palms was implemented as treatment and replication. Then, SDI treatment was implemented for date palms. Therefore, the date palms are placed in the main plots, and the different irrigation levels treatment placed in the sub-plots. The SDI was 16 mm polyethylene pipes equipped with 4 l/h−1 inline pressure compensative emitters 70 cm apart. The subsurface drip pipes were installed 40 cm below the soil surface, one meter from the trunk of the palm tree on each side of the row. The trees received 48 l/h−1 through the SDI method since 12 emitters belong to each tree. At the inlet of each SDI line, sensitive flow meters whose resolution was one-tenth of a liter were installed. Installation depth, distance of emitters from each other and tree trunks were determined based on international results and soil texture. The average applied water in T1, T2, and T3 treatments was measured as 1264.80, 1003.88, and 752.88 mm during 3 years, respectively. Zahedi and Khasi varieties are harvested in the form of Khalal and Tamr, respectively. The Zahedi variety is harvested earlier than the Khasi variety (about 10–15 days). Irrigation operation is stopped at the time of harvesting of both varieties. The yield of each tree in each treatment was calculated once all trees had been harvested and weighed. MSTATC statistical software was used to analyze physical characteristics and percentages of fruit moisture and total sugar. The fruit moisture was determined in a vacuum dryer at a temperature of 70 °C according to the AOAC standard method (AOAC 1990). The amount of total sugar and regenerating sugar was determined by Fehling's method (Hosseini 1990). Duncan's multiple range test was used to compare the means of different treatments.
Irrigation scheduling
The Penman–Monteith equation was used to calculate reference evapotranspiration based on daily data of Behbahan synoptic meteorological station (Allen et al. 1998). Irrigation time was calculated by monitoring the daily meteorological information. Irrigation interval was set at daily. Based on the conducted studies and the FAO 56 model, the crop coefficient was determined (Norouzi and Zolfibavareyani 2010). In Table 2, date crop coefficients during the growing season are presented.
The results of water sample analysis and soil physical and chemical properties are presented in Tables 3 and 4. All measurements and laboratory tests which performed in this study are in accordance with scientific and international standards, such as soil texture determination (ASTM 2007), volumetric soil moisture monitoring (Devices 2008) and water quality analysis (EPA). Table 5 shows the average water consumption of different treatments.
Pe: Effective rainfall; T1: 125% water requirement (in SDI system); T2: 100% water requirement (in SDI system); T3: 75% water requirement (in SDI system); Total T1, T, and T3: Applied Water (Irrigation water + Pe).
Water productivity was calculated as follows (Howell 2001):
where Y denotes the economical yield (kg ha−1) measured base on the delivered product to the market, ET shows the evapotranspiration (mm), I indicated irrigation water measured using a volumetric flow meters (mm), P indicates a wetted area (%), Dp indicates deep percolation (mm), Roff shows surface runoff (mm), and ΔS shows a change in soil moisture (mm).
Irrigation method
Subsurface drip irrigation
Subsurface drip irrigation system could be a low-pressure, tall proficiency water system framework that employs buried dribble tubes or dribble tape to meet trim water needs. These innovations have been a portion of inundated agribusiness since the 1960s; with the innovation progressing quickly within the final three decades. This is often particularly reasonable for dry, semi-arid, hot, and blustery regions with restricted water supply, particularly on sandy soils (Camp et al. 2000). Figure 2 shows the cross section of the subsurface drip irrigation method (Li et al. 2020).

Cross section of the subsurface drip irrigation method
Yield and WP estimation methodology based on intelligent methods
Anti-coronavirus optimization algorithm (ACVO)
ACVO is a multi-agent swarm intelligence strategy which is inspired by the containment protocols considered to reduce the spread of the COVID-19 (Emami 2022). Figure 3 shows the flowchart of the ACVO algorithm.

Flowchart of the ACVO algorithm
This algorithm is a population-based algorithm which begins its work with a population of solutions. The algorithm is equipped with three operators including social distancing, quarantine, and isolation. The algorithm moves the persons around the solution space and hopefully causes the persons to converge to the global optimum of the cost function. The main principle behind the algorithm is to direct the persons to a safe location in the solution space where the disease transmission is minimal and health protocols are well followed.
In the population creation step, the algorithm generates a collection of solutions. Each solution in the population is referred to as a person. In the social distancing stage, the algorithm attempts to create a safe distance between people in the population.
In the quarantine phase, the suspected individuals with COVID-19 should be monitored to determine whether they are infected or not. In the ACVO, the individuals suspected of having the COVID-19 are those ones that attain low fitness in optimization phase. The suspected individuals should be quarantined for a while to determine the effect of the virus on them. To simulate the quarantine process, the algorithm first selects q number of the weakest individuals to form the quarantine list. Then, the algorithm randomly selects some variables from each suspected individual and mutates their values. At the end of the quarantine phase, if the fitness of a suspected individual is equal to or greater than its fitness on the first day of quarantine, then the individual is returned as healthy, otherwise, the individual should be isolated.
In the isolation phase, the algorithm aims to treat infected people so that they can recover their health. The algorithm injects some variables of the fittest healthy individual into the infected individuals. To fulfill this aim, some variables of the best-fit individual are randomly selected and combined with the corresponding variables of the infected individuals. This issue improves the fitness of infected individuals and moves them toward global optimum.
The three phases of social distancing, quarantine, and isolation are applied to the population for predetermined times to improve the fitness of population. Finally, the healthiest individual is considered as the optimal solution to the optimization problem.
Adaptive neuro-fuzzy inference system (ANFIS)
The ANFIS, first introduced by Jang (1993), is an efficient kind of multilayer feed-forward ANNs developed based on fuzzy inference system (FIS). ANFIS integrates and makes full use of the advantages of both ANNs and FIS in a unified framework. It is highly adaptive and fast to learn, reflects a nonlinear process structure, and requires less memory. Classical prediction methods are sometimes not able to deal with uncertainty in data (Alarifi et al. 2019). ANFIS is an efficient predictor under such cases. The FIS is build according to the if–then rules, thus the relationship between input and output variables can be identified by regulations and handled uncertainty can be handled easily.
Figure 4 shows the typical architecture of the ANFIS network comprising five layers with two inputs and one output. There five include fuzzification, implication, normalization, defuzzification, and combination. In the ANFIS structure, the nodes are divided into two categories: fixed and adaptable. The nodes of layers 1 and 4 are adaptive, while the nodes of layers 2, 3, and 4 are fixed nodes. The parameters in adaptive nodes can be learnt by optimization algorithms.

The basic structure of ANFIS
To explain the working principle of each layer, we take two fuzzy if–then rules into account as follows:
where R shows each rule, x, y are the inputs variables, Ai and Bi are fuzzy sets, and f is the output of the system. The parameters \(p_{i}\), \(q_{i}\) and \(r_{i}\) are consequent variables that should be determined during the training phase.
In the fuzzification phase, the values of the crisp input variables are modified by membership functions. In this layer, each node generates a membership value of a linguistic label. The node function of the ith node may be membership functions such as linear, Gaussian, trapezoidal, triangular or other types. The node function of the ith node (Oi) using in the Gaussian form can be defined as follows:
where \(c_{i}\) and \(\sigma_{i}\) are respectively the center and width of the ith fuzzy set Ai or Bi. These parameters affecting the membership function's shape and should be tuned during the model optimization phase.
The implication phase in layer 2 is responsible to compute the firing weight of rules as follows:
Layer 3 performs strength normalization for each fuzzy rule as below
The variable wi is the firing weight of the ith fuzzy rule calculated in implication phase.
Layer 4 is devoted to defuzzification phase. Each node at this layer computes a linear function as follows:
where \(\overline{W}_{i}\) is the output of layer 3. The coefficients of \(p_{i}\), \(q_{i}\) and \(r_{i}\) are identified during training phase by minimizing the following equations.
Layer 5 is in charge of combining the output of layer 4 as follows:
ACVO-ANFIS
Two kinds of structural parameters in ANFIS model are antecedent and consequent parameters that need to be tuned. To optimally tune these parameters, researchers usually used gradient-based methods. The main drawback of gradient-based methods is that they frequently get stuck in local optimality often with slow convergence rate. An efficient alternative is meta-heuristic algorithms that easily can reach to global optimum with high convergence rate. As an element of research, in this paper, we used ACVO algorithm to optimally tune the antecedent and consequent parameters of the ANFIS model. Figure 5 shows the working principle of the proposed ACVO-ANFIS approach.

Flowchart of the proposed ACVO-ANFIS approach
Data normalization
To avoid negative effect of different scales of variables on estimation models, it is necessary to correct the data through preprocessing. The data were normalized as follows:
where, xi is the observed value and x is the normal data corresponding to xi. Modeling data were randomly divided into two parts, 80% for the training and 20% for the model test.
Results and discussion
Datasets used
Seven important factors that affect the WP and yield of date palm are irrigation type (I), average temperature (T), average relative humidity (RHavg), sunshine (Rn), minimum wind speed (Umin), crop variety (V), and effective rainfall (Pe). Since these factors are not of equal importance and may be associated with uncertainty, in intelligent models, the selection of important factors is essential. Table 6 and Fig. 6 present the effective and best-performing factors in estimating WP and yield.

Some input factors in estimating WP and yield
Performance criteria
This section describes the performance criteria, the case study used to evaluate the proposed approach and its counterparts, the comparison algorithms, and the process of feature selection. Four criteria including root-mean-squared error (RMSE), standard deviation (δ), and Akaike information criterion (AICc) (Emami et al. 2021) were used to evaluate the performance of the proposed method. Table 7 presents the mathematical formulation of these measures.
In Eqs. (13–15), \(j_{i}\) and \(i_{i}\) are the observed and predicted values, respectively. \(\overline{j}\) and \(\overline{i}\) are average of observed and predicted values. k is the number of parameters, n is number of samples, and \(\sigma_{\varepsilon }\) is the residuals’ standard deviation.
Quantity features
Table 8 summarizes the combined analysis of variance (ANOVA) of quantitative features of the date palm. The statistical results justify that there was no significant difference between irrigation levels, crop variety, the interaction of irrigation levels and cultivar in fruit weight, fruit flesh to kernel weight ratio, and yield. The results of the ANOVA analysis of WP confirmed that there was a significant difference between irrigation treatments at the level of 5% probability, while there was no significant difference between the two date varieties. The results of mutual analysis of ANOVA of year and crop variety showed that in all quantitative features, there is a significant difference at the level of 1% probability.
As shown in Table 9, treatment T3 (75% water requirement) with WP = 0.698 kg/m3 is superior to treatments T1 and T2. This is likely due to the efficient water utilization of the functional absorbent root zoon (Alnaim et al. 2022). The SSDI system with 75% water requirement is the most appropriate choice for date palm irrigation in arid and semi-arid regions due to its positive effect on WP and yield without changing the chemical quality of the soil (Alnaim et al. 2022). Plant nutrient uptake can be increased and enhanced by appropriate water use within tree systems (Manzoor Alam 1999; Bainbridge 2006; Ahmed Mohammed et al. 2020). The reduction of irrigation water has improved the physical properties of the date palm fruit (Alnaim et al. 2022). Ahmed Mohammed et al. (2020) reported that the SDI system significantly increased data palm crop yield and fruit quality, which is consistent with the results of the present study. Rastegar and Zargari (2011), Alihouri and Tishezan (2011), and Mohebbi and Alihouri (2013), reported that the highest WP was achieved for treatments in which 25% less irrigation was applied. In a similar study, Ahmed Mohammed et al. (2020) concluded that the SDI system has a positive effect on the efficiency of applied water and increasing data palm crop yield in arid and semi-arid regions. Sarhadi and Sharif (2017), showed that the lowest amount of drying damage of date bunch was with the highest applied water, which was consistent with the results of the present study. The length of the fruit has a negative relationship with the amount of applied water. In other words, the reduction of applied water increased the length of the fruit (Sarhadi and Sharif 2017). Alikhani-Koupaei et al. (2018), showed that reducing applied water was effective in increasing fruit sugar content. The number of clusters and fruit moisture had a positive and significant effect at the level of 5% probability on WP. The negative effect of cluster drying on WP was consistent with the results of Sarhadi and Sharif (2017). In Table 8, the values with common letters in a column are not significantly different (p < 0.05). The results of this study on WP are consistent with the findings of Mohebbi and Alihouri (2013) and Farzamnia and Ravari (2005). 25% decrease in the water requirement of date palm crop yield did not have any influential changes on WP compared to yield. Mohebbi (2005) and Saleh et al. (2014) showed that applied water of more than 65% of the water requirement caused a decrease in WP, which is consistent with the results of the present study. The superiority of the treatment T3 compared to T1 and T2 treatments can be related to the overestimation of evaporation–transpiration estimation models. Several researchers are trying to provide unknown methods for estimating water requirements or correcting the usual methods, such as Penman–Monteith equation (Schymanski and Or 2017; McColl 2020).
Modeling results
The results of selecting the desired features using the ACVO-ANFIS hybrid approach indicate that the model φ8 with factors of crop variety (V), irrigation (75% water requirement of SDI system), and effective rainfall (Pe), with values of RMSE = 0.005, δ% = 0.603, and AICC = 83.25, have the greatest impact on yield and WP. Table 10 presents the results obtained with the ACVO-ANFIS approach. Sensitivity examination appeared that after irrigation, crop variety, and effective rainfall parameters, the average temperature (T), minimum wind speed (Umin), and sunshine hours (Rn) parameters are additionally fundamental in estimating the yield and WP. Dehghanisanij et al. (2021), reported that irrigation-fertilizer parameters (PMDI, F) and crop variety (V) is the most effective parameters in estimating the yield and WP of tomato crops. In a similar study, Sadras and Calvino (2001), showed that irrigation is the most important parameter in estimating soybean and corn yields. Kaul et al. (2005) introduced available water as the most effective parameter in estimating crop yield. Montazer et al. (2010) reported irrigation and rainfall parameters as the most important parameters in estimating wheat yield.
Next, modeling of WP and yield estimates was performed by considering irrigation, effective rainfall, and crop variety factors as inputs of the ACVO-ANFIS approach (Figs. 7 and 8).

a, b Comparison of predicted Yield with observed values a ACVO-ANFIS on test dataset b ACVO-ANFIS on the training dataset

a, b Comparison of predicted WP with observed values a ACVO-ANFIS on the training dataset b ACVO-ANFIS on test dataset
According to the results, it is clear that the predicted and observed values are in good agreement, which indicates the good performance of the ACVO-ANFIS hybrid approach. Jayashree et al. (2016), predicted sugarcane yield using a fuzzy-neural network (FNN) with a genetic algorithm (GA), imperialist competitive algorithm (ICA), and particle swarm optimization (PSO), the results of which are consistent with the present study.
Comparison approaches
There are a few approaches in yield and WP estimation using intelligent methods. The proposed ACVO-ANFIS is compared with five state-of-the-art approaches including season's optimization-support vector regression (SO-SVR) (Dehghanisanij et al. 2021), Gaussian process regression algorithm (GPR), (Sharifi 2021), random forest (RF) (Prasad et al. 2021), genetic algorithm-back propagation neural network (GA-BP) (Gu et al. 2017), and ANN (Abrougui et al. 2019). The results rendered by the ACVO-ANFIS approach and other counterparts are compared in Table 11. The results indicate the high efficiency of the ACVO-ANFIS approach with RMSE of 0.005 compared to other similar methods. In general, the ACVO algorithm is a fast convergence algorithm, and surpasses the coequal algorithms in optimizing the ANFIS parameters and thus estimating the data palm crop yield and WP. However, the ACVO-ANFIS approach needs to be parameterized, and the performance of ACVO-ANFIS is scarcely less than perfection. It is suggested that in future analyses, ACVO algorithm be combined with SVR, ANN and other neural network models to increase accuracy and provide generalizable results. Hence, in future analyses, it was offered to combine the ACVO algorithm with SVR, ANN, and other models to improve errors and supply generalizable results.
Conclusion
In this study, a hybrid approach based on the ANFIS and ACVO algorithm was proposed to estimate date palm yield and WP under different levels of drip irrigation. The training of the proposed model was performed using data collected from Behbahan agricultural research station. In ACVO-ANFIS, eight models were used to determine the most efficient parameters in estimating and yield and WP. The statistical analysis demonstrated that there is no significant difference between irrigation levels, crop variety, and the interaction of irrigation levels and cultivar in fruit weight, fruit flesh to kernel weight ratio, and yield. The results of selecting the desired features using the ACVO-ANFIS hybrid approach indicate that the model φ8 with factors of crop variety (V), irrigation (75% water requirement of SDI system), and effective rainfall (Pe), with values of RMSE = 0.005, δ% = 0.603, and AICC = 83.25, have the greatest impact on data palm crop yield and WP. In comparison, the ACVO-ANFIS approach performed better than the practical methods. The results proved that the proposed ACVO-ANFIS approach has promising performance in estimating the yield and WP parameters. The output of the ACVO-ANFIS approach can be developed as a user-friendly mobile application. One of the promising research directions is to test the proposed approach with a large dataset to identify its strengths and weaknesses. Another work is to enhance the operators of the ACVO algorithm to improve the estimation performance of the ACVO-ANFIS approach.
Data availability
The data that support the findings of this study are openly available.
References
Ababaei B, Verdinejad V (2013) Estimating hydraulic performance of pressurized irrigation system using artificial neural networks and nonparametric regression. J Water Soil 27:769–779
Abrougui K, Gabsi K, Mercatoris B, Khemis C, Amami R, Chehaibi S (2019) Prediction of organic potato yield using tillage systems and soil properties by artificial neural network (ANN) and multiple linear regressions (MLR). Soil Tillage Res 190:202–208
Agricultural statistics (2018) Volume 3: Horticultural Products. Crop year 2017–18. Ministry of Jihad Agriculture, Deputy of Planning and Economy. Office of Statistics and Information Technology.
Ahmed Mohammed ME, Refdan Alhajhoj M, Ali-Dinar HM, Munir M (2020) Impact of a novel water-saving subsurface irrigation system on water productivity, photosynthetic characteristics, yield, and fruit quality of date palm under arid conditions. Agronomy 10(9):1265
Al Wahaibi, H. S. (2018). Effects of drip subsurface irrigation system on date palm production and water productivity. 12th Gulf Water Conference, Manama, Bahrain, pp 28–30
Alarifi IM, Nguyen HM, Bakhtiyari AN, Asadi A (2019) Feasibility of ANFIS-PSO and ANFIS-GA Models in Predicting Thermophysical Properties of Al2O3-MWCNT/Oil Hybrid Nanofluid. Materials (Basel), 12.
Alihouri M, Tishehzan P (2011) The following watering schedule- Strategic Plan palm sector in the country. Kerdegar Press, Ahvaz, pp 61–52.
Alikhani-Koupaei M, Fatahi R, Zamani Z, Salimi S (2018) Effects of deficit irrigation on some physiological traits, production and fruit quality of ‘Mazafati’ date palm and the fruit wilting and dropping disorder. Agric Water Manag 209:219–227
Allen RG, Pereira LS, Raes D, Smith M (1998) Crop evapotranspiration: Guidelines for computing cropwater requirements. FAO Irrigation and Drainage Paper 56, Rome, Italy.
Alnaim MA, Mohamed MS, Mohammed M, Munir M (2022) Effects of automated irrigation systems and water regimes on soil properties, water productivity, yield and fruit quality of date palm. Agriculture 12(3):343
ASTM (2007) Standard D422-63: standard test method for particle-size analysis of soils. ASTM International, West Conshohocken
Bagheri S, Gheysari M, Ayoubi S, Lavaee N (2012) Silage maize yield prediction using artificial neural networks. J Plant Prod 19:77–96
Bainbridge DA (2006) Deep pipe irrigation. The Overstory# 175; Permanent Agriculture Resources: Holualoa, HI, USA, p 6. 78.
Belouz K, Nourani A, Zereg S, Bencheikh A (2022) Prediction of greenhouse tomato yield using artificial neural networks combined with sensitivity analysis. Sci Hortic 293:110666
Camp CR, Lamm FR, Evans RG, Phene CJ (2000) Subsurface drip irrigation–Past, present and future. In: Proceedings of Fourth Decennial Nat’l Irrigation Symposium, pp 14–16.
Davis S (1967) Subsurface irrigation. Agr Eng 48:654–655
Dehghanisanij H, Salamati N (2017) Palm response to the implementation of surface and subsurface drip irrigation system. Iran J Soil Water Res 49:991–1001
Dehghanisanij H, Emami S, Achite M, Linh NTT, Pham QB (2021) Estimating yield and water productivity of tomato using a novel hybrid approach. Water 13:3615
Dehghanisanij H, Emami S, Khasheisiuki A (2022) Functional properties of irrigated cotton under urban treated wastewater using an intelligent method. Appl Water Sci 12:1–10
Devices DT (2008) User Manual for the Profile Probe type PR2. Delta-T Devices Ltd., Cambridge
Emami S, Choopan Y (2019) Estimation of barley yield under irrigation with wastewater using RBF and GFF models of artificial neural network. J Appl Res Water Wastewater 6:73–79
Emami S, Parsa J, Emami H, Abbaspour A (2021) An ISaDE algorithm combined with support vector regression for estimating discharge coefficient of W-planform weirs. Water Supply 21:3459–3476
Emami H (2022) Anti-coronavirus optimization algorithm. Soft Comput, pp 1–33.
Farzamnia M, Ravari Z (2005) The effect of deficit irrigation on yield and water use efficiency of Mazafati dates in Bam. J Agric Sci 28:79–86
Ghorbani A, Mansouri B, Baradaran M (2021). Effects of climate variables on the incidence of scorpion stings in Iran for five years. J Venomous Animals Toxins Including Tropical Dis, p. 27.
Golabi M, Karami B, Albaji M (2013) Sensitivity analysis of sugarcane yield using artificial neural networks. In: 4th national conference on irrigation and drainage network management. Faculty of Water Sciences Engineering. Shahid Chamran University of Ahvaz, pp 1917–1924.
Gu J, Yin G, Huang P, Guo J, Chen L (2017) An improved back propagation neural network prediction model for subsurface drip irrigation system. Comput Electr Eng 60:58–65
Howell TA (2001) Enhancing water use efficiency in irrigated agriculture. Agron J 93:281–289
Jang JSR (1993) ANFIS: adaptive-network-based fuzzy inference system. IEEE Trans Syst Man Cybern 23:665–685
Jayashree LS, Rajathi N, Thirumal A (2016) Precision agriculture: On the accuracy of multilevel and clustered ANFIS models for sugarcane yield categorization. In: IEEE Region 10 Annual International Conference, Proceedings/TENCON, pp 1983–1987.
Jeong JH, Jonathan P, Resop ND, Mueller DH, Fleisher KY, Ethan EB, Dennis JT et al (2016) Random forests for global and regional crop yield predictions. PLoS One 11:e0156571.
Kaul M, Hill RL, Walthall C (2005) Artificial neural networks for corn and soybean yield prediction. Agric Syst 85:1–18. https://doi.org/10.1016/j.agsy.2004.07.009
Lad AM, Bharathi KM, Saravanan BA, Karthik R (2022) Factors affecting agriculture and estimation of crop yield using supervised learning algorithms. Mater Today Proc 62(7):4629–4634
Landeras G, Ortiz-Barredo A, López JJ (2009) Forecasting weekly evapotranspiration with ARIMA and artificial neural network models. J Irrig Drain Eng 135:323–334
Li Y, Niu W, Cao X, Zhang M, Wang J, Zhang Z (2020) Growth response of greenhouse-produced muskmelon and tomato to subsurface drip irrigation and soil aeration management factors. BMC plant biology 20(1):1–15.
ManzoorAlam S (1999) Nutrient uptake by plants under stress conditions. Handb Plant Crop Stress 2:285–313
McColl KA (2020) Practical and theoretical benefits of an alternative to the Penman‐Monteith evapotranspiration equation. Water Resources Res 56(6):e2020WR027106.
Mohammed M, Sallam A, Munir M, Ali-Dinar H (2021a) Effects of deficit irrigation scheduling on water use, gas exchange, yield, and fruit quality of date palm. Agronomy 11(11):2256
Mohammed M, Riad K, Alqahtani N (2021b) Efficient iot-based control for a smart subsurface irrigation system to enhance irrigation management of date palm. Sensors 21:3942
Mohebbi AM, Alihouri M (2013) Effect of depth and irrigation method on productivity, yield and vegetative traits of Piarom palm. Water Res Agric 27:455–464
Mohebbi A (2005) The effect of irrigation water in two methods of surface and drip irrigation on the yield and quality traits of Peyaram dates. J Soil Water Sci 19(1):124–130 (In Farsi)
Montazer A, Azadeghan B, Shahraki M (2010) Assessing the efficiency of artificial neural network models to predict wheat yield and water productivity based on climatic data and seasonal water-nitrogen variables. Iran Water Res J 3:17–29
Mubiru J (2008) Predicting total solar irradiation values using artificial neural networks. Renew Energy 33:2329–2332
Norouzi M, Zolfibavareyani M (2010) Determination of water required dates drip irrigation system in the Bushehr province. J Water Res Agric 24:21–30
Piri J, Amin S, Moghaddamnia A, Keshavarz A, Han D, Remesan R (2009) Daily pan evaporation modeling in a hot and dry climate. J Hydrol Eng 14:803–811
Prasad NR, Patel NR, Danodia A (2021) Crop yield prediction in cotton for regional level using random forest approach. Spat Inf Res 29:195–206
Rashid M, Bari BS, Yusup Y, Kamaruddin MA, Khan N (2021) A comprehensive review of crop yield prediction using machine learning approaches with special emphasis on palm oil yield prediction. IEEE Access 9:63406–63439
Rastegar H, Zargari H (2011) Effects of water stress on yield and quality of Shahani date. In: 7th Congress of Horticultural Sciences. Iran, Isfahan University of Technology, pp 1608–1610.
Sadras VO, Calviño PA (2001) Quantification of grain yield response to soil depth in soybean, maize, sunflower, andwWheat. Agron J 93:577–583. https://doi.org/10.2134/agronj2001.933577x.
Safari F, Ramezani Etedali H, Kaviani A, Ababaei B (2019) Plausibility of training artificial neural networks with crop models to predict wheat phenology and yield. Nivar 43:101–112
Saleh M, Ismail D, Adel Al-Qurashi M, Awad A (2014) optimization of irrigation water use, yield, and quality of “NABBUT-SAIF” date palm under dry land conditions. Irrig Drain 63(1):29–37
Sarhadi J, Sharif M (2017) The role of optimal irrigation on reducing the complication of date cluster drought in light lands. In: The third national conference on farm water management, Karaj, Iran.
Schymanski SJ, Or D (2017) Leaf-scale experiments reveal an important omission in the Penman-Monteith equation. Hydrol Earth Syst Sci 21(2):685–706
Sharifi A (2021) Yield prediction with machine learning algorithms and satellite images. J Sci Food Agric 101:891–896
Shirdeli A, Tavassoli A (2015) Predicting yield and water use efficiency in saffron using models of artificial neural network based on climate factors and water. Saffron Agron Technol 3:121–131
Smith BA, Hoogenboom G, McClendon RW (2009) Artificial neural networks for automated year-round temperature prediction. Comput Electron Agric 68:52–61
Upadhya SM, Mathew S (2020) Implementation of fuzzy logic in estimating yield of a vegetable crop. J Phys Conf Ser 1427:012013
Zhang L, Traore S, Ge J, Li Y, Wang S, Zhu G, Fipps G (2019) Using boosted tree regression and artificial neural networks to forecast upland rice yield under climate change in Sahel. Comput Electron Agric 166:105031
Acknowledgements
We would like to thank the Agricultural Engineering Research Institute, Agricultural Research, Education and Extension Organization (AREEO), Karaj, Alborz, Iran, for assisting in conducting this study.
Funding
The author(s) received no specific funding for this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dehghanisanij, H., Salamati, N., Emami, S. et al. An intelligent approach to improve date palm crop yield and water productivity under different irrigation and climate scenarios. Appl Water Sci 13, 56 (2023). https://doi.org/10.1007/s13201-022-01836-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-022-01836-8