
Abstract
Practice is an essential means by which humans and animals engage in cognitive activities. Intelligent tutoring systems, with a crucial component of modelling learners’ cognitive processes during learning and optimizing their learning strategies, offer an excellent platform to investigate students’ practice-based cognitive processes. In related studies, modelling methods for cognitive processes have demonstrated commendable performance. Furthermore, researchers have extended their investigations using decision-theoretic approaches, such as a partially observable Markov decision process (POMDP), to induce learning strategies by modelling the students’ cognitive processes. However, the existing research has primarily centered around the modelling of macro-level instructional behaviors rather than the specific practice selection made by the students within the intricate realms of cognitive domains. In this paper, we adapt the POMDP model to represent relations between the student’s performance on cognitive tasks and his/her cognitive states. By doing so, we can predict his/her performance while inducing learning strategies. More specifically, we focus on question selection during the student’s real-time learning activities in an intelligent tutoring system. To address the challenges on modelling complex cognitive domains, we exploit the question types to automate parameter learning and subsequently employ information entropy techniques to refine learning strategies in the POMDP. We conduct the experiments in two real-world knowledge concept learning domains. The experimental results show that the performance of the learning strategies induced by our new model is superior to that of other learning strategies. Moreover, the new model has good reliability in predicting the student’s performance. Utilizing an intelligent tutoring system as the research platform, this article addresses the modelling and strategy induction challenges of practice-based cognitive processes with intricate structures, aiming to tutor students effectively. Our work provides a new approach of predicting the students’ performance as well as personalizing their learning strategies.
Similar content being viewed by others


Introduction
Practice is an essential means by which humans and animals engage in cognitive activities. As an interactive platform, intelligent tutoring system (ITS) facilitates researchers in investigating learners’ cognitive processes within specific domains of knowledge. ITSs offer researchers data support, while the research outcomes reciprocally aid ITSs in providing personalized learning strategies to the learners. In such ITS applications, one of the most important components is to model the learners’ cognitive process when they are learning a subject of interest, based on which the learning strategies can be induced within the ITS.
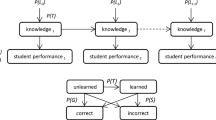
In this article, we focus on one a general learning scenario where students expect to improve their knowledge learning by practicing questions. Figure 1 shows how a student repeats the process of “choose a question - answer the question - proofread the answer,” which is often called “practice-based learning,” to improve his/her knowledge. The students may correct their misunderstanding of knowledge concepts by proofreading their answers and choose the next question from available questions. To improve the learning outcomes, we aim to develop students’ learning strategies through modelling their cognitive process in the learning. More specifically, our objective is to investigate the patterns of changes in students’ comprehension of domain knowledge with varying practice behaviors during cognitive processes so as to recommend questions to the students (i.e., learning strategies).

Practice-based learning. Students repeat the process of “choose a question - answer the question - proofread the answer” to improve their knowledge learning
Based on ITS, most of the recent research on dealing with learning strategy induction adopts reinforcement learning (RL) based techniques [1, 2] as well as their improvements, e.g., hierarchical reinforcement Learning (HRL) [3, 4], deep reinforcement learning (DRL) [5,6,7,8] and so on. However, the induction techniques are model-free and do not explicitly represent how learners understand the knowledge concepts in the learning process. In other words, the RL-based methods do not model the students’ learning process and the resulting strategies may become unexplainable, which compromises evidence-based learning for the students. Another most relevant approach refers to knowledge tracing (KT) model that describes the students’ cognitive process in the learning [9,10,11,12]. Specifically, given the students’ answer records and relevant information of the answered questions (such as the involved knowledge concepts and question contents), the KT method can capture the dynamics of the students’ knowledge states (mastery level of each knowledge concept). It estimates a student’s current knowledge state and subsequently predict the student’s performance on answering a new question. However, the KT techniques do not provide learning strategies to the students, e.g., selecting a new question from a question bank.
In contrast, Rafferty et al. [13] started a decision-theoretic approach using partially observable Markov decision process (POMDP) [14] and modelled the learners’ learning process with the purpose of inducing learning strategies in ITS. This approach was implemented in a personalized robot to assist the students’ learning [15]. A POMDP model is often used to optimize a sequence of decisions in a partial observable environment where the environmental states can’t be directly observed and the decisions need to be made upon possible observations from the environment. The actual states of the environments can be inferred by the received observations and the optimal decisions are to maximize rewards accumulated over the decision-making time steps.
A POMDP model can represent the students’ learning process and explain the learning strategies. The POMDP applications are still very rudiment in ITS since they assume the known model parameters, which is often subjective, in the students’ knowledge learning. Hence, in this article, we adopt the decision-theoretic approach, like the POMDP model, and improve the techniques for inducing the students’ learning strategies in ITS. More specifically, we will focus on the POMDP modelling and solution techniques given available data of the students’ learning activities.
As elaborated in Fig. 1, a student updates his/her knowledge states, which model levels of the mastery of knowledge concepts, in the process of answering the questions and proofreading the answers. As the student is practicing a number of correlated knowledge concepts, a question is always relevant to multiple knowledge concepts and a large number of potential questions exist in an ITS. The complexity of learning and solving a POMDP model lies in the increasing combinations of knowledge concept states as well as the number of available questions. In particular, we build the POMDP model by learning its parameters from the data that describes how students response to the selected questions based on their knowledge, and the data is naturally sparse since a knowledge concept is not relevant to all the questions or vice versa.
Once we build the POMDP model, we solve the model through the well-developed dynamic programming method [16] so as to optimize the students’ learning strategy which, more specifically, is to select a good question (answering which can best improve the students’ knowledge) from the question bank. We observe that there are often multiple questions that yield optimal learning strategies. In other words, selecting different questions may help achieve similar learning outcomes that are measured by the learners’ understanding of multiple knowledge concepts. Consequently, it would be the case that the learners either completely master one knowledge concept or understand multiple knowledge concepts with similarly good levels. From a pedagogical perspective, it is better to understand clearly about what exact knowledge the students have achieved within a learning period of time [17]. Hence, we make a further step to optimize the action selection in the POMDP model. We choose the question that leads to the largest reduction of the uncertainty on the students’ knowledge states. We propose an information-theoretic approach, e.g., information entropy [18], to measure different actions on reducing the uncertainty of the knowledge states in the POMDP solution. Our main contributions in this research are summarized below.
-
We formulate a practice-based cognitive process through a POMDP model that represents how the learners update their cognitive states;
-
We automate the POMDP modelling and improve the model learning from the learners’ learning activity data through structuring potential relations of multiple knowledge concepts;
-
We solve the POMDP model to optimize the learning strategies and propose an information entropy-based technique to refine the strategies;
-
We demonstrate the utility of using the POMDP planning techniques in two real-world knowledge concept learning domains.
The remaining sections of this paper are organized as follows. “Related Works” section introduces the related cognitive modelling research and “Background Knowledge” section presents background knowledge on POMDP and its solutions. In “POMDP Solutions to Inducing Learning Strategies” section, we elaborate the learning strategy induction through the POMDP model and present additional applications of this new approach. “Experimental Results” section demonstrates the performance of our method in experiments, and “Conclusion” section summarizes our work and discusses further research.
Related Works
We proceed to review modelling approaches for practice-based cognitive processes, specifically KT, as well as decision-theoretic approaches for employing cognitive models in ITS.
Knowledge Tracing
KT methods are often used to describe the cognitive patterns of learners in a practice-based cognitive process. Based on Hidden Markov Model (HMM) [19], Bayesian knowledge tracing (BKT) [9] is the earliest KT method and builds temporal models of cognitive processes in student learning. It models a student’s state as a set of binary variables (mastered or non-mastered), and the observation of the state is the right or wrong of the student’s answer. A number of limitations exist in BKT. First, the problem of model degradation occurs that parameter values violate the model’s conceptual meaning (e.g., a student being more likely to get a correct answer if he does not know a skill than if he does). Second, BKT is only suitable for modelling the learning process for a single knowledge concept and can not deal with a complex knowledge concept structure. Third, as an HMM, since the impact of question selection on the student’s state is not considered, BKT can not be applied to optimize the question selection.
Inspired by BKT, Baker et al. [20] introduced relations among continuous data and proposed a contextual guess and slip model, which solved the model degradation problem. This model contextually estimates the probability that a student obtained a correct answer by guessing, or an incorrect answer by slipping, within BKT. Pardos and Hefferman [21] recognized the different difficulty of the same knowledge concept in different questions and proposed a new knowledge model that incorporates the difficulty levels. Käser et al. [22] introduced dynamic Bayesian networks to BKT (DBKT) and represented hierarchical relationships between different knowledge concepts in a learning domain. This work improves the BKT accuracy in predicting student performance, but can not explain possible reasons of the changing of the students’ knowledge states.
With the growing attention on deep learning techniques, Piech et al. [23] were the first to propose deep knowledge tracing (DKT). Different from traditional BKT models, DKT does not require the explicit encoding of domain knowledge, and can capture more complex representations of student knowledge. Moreover, DKT may be adopted for intelligent curriculum design and allow straightforward interpretation and discovery of structures of student tasks.
Subsequently, Yang and Cheung [24] proposed an effective method to pre-process the heterogeneous features and integrated the learned features implicitly to the original DKT model. Liu et al. [10] proposed a general exercise-enhanced recurrent neural network framework by exploring both students’ learning records and the text content of corresponding learning resources (EKT). Each student’s state was simply summarized into an integrated vector, which was traced with a recurrent neural network and a bidirectional LSTM [25] was designed to learn the encoding of each exercise from its content. Pandey and Srivastava [11] proposed a relation-aware self-attention mechanism for knowledge tracing task (RKT), which modelled a student’s interaction history and predicted his performance on the next exercise. RKT considers contextual information that is obtained from past exercises and the student’s behavior. Ghosh et al. [12] proposed attentive knowledge tracing (AKT), which integrated flexible attention-based neural networks with a series of interpretable model components.
The KT techniques explore potential causes that lead to the changing of learners’ states in the learning, but do not provide learning strategies to the learners. In this article, we will show how the improved POMDP method can function as what the KT does in addition to providing learning strategies to the learners.
Intelligent Tutoring Systems
In ITS research, while model-free strategy induction methods [1,2,3,4,5,6,7,8] demonstrate certain efficacy, the lack interpretability therefore compromising learners’ evidence-based learning. To overcome this limitation, researchers aim to bridge cognitive models with recommendation systems to model learners’ cognitive processes [26]. Model-based decision-theoretic approaches not only have the capabilities of KT methods but also can be used to induce learning strategies. Rafferty et al. [13] first formulated the problem of inducing learning strategies as a POMDP model and explored the effect of selecting learning activities under different student models. Subsequently, Wang [27] developed a learning technique that enables a POMDP-based ITS to enhance its teaching capabilities online. Subsequently, he [28] further developed techniques to improve efficiency in computing the Bellman equation. Ramachandran et al. [15] designed the assistive tutor POMDP (AT-POMDP) to provide personalized supports to students for practicing a difficult math concept over several tutoring sessions. Nioche et al. [29] extended the model-based approaches by introducing a modular framework that combined an online inference mechanism (tailored to each learner) with an online planning method that took the learner’s temporal constraints into account.
In this article, we will ground our research on the POMDP model, and automate the model learning in a complex cognitive domain and subsequently improve the solution method.
Background Knowledge
This section briefly reviews background knowledge of our research mainly involving some basic components – POMDP [14], dynamic programming [16], and information entropy [18]. Among the components, POMDP is our basic framework, dynamic programming is a general technique for solving POMDP, and information entropy serves as the theoretical foundation for further optimizing strategies.
A POMDP Model
POMDP is a generalized Markov decision process (MDP) in a partially observable environment. It assumes that the system dynamics are determined by MDP and the environmental states can not be directly observed. On the contrary, the distribution of states can be inferred based on the received observations. Formally, POMDP is a seven-tuple \(\left( S, A, T, R, \Omega , O, \gamma \right)\), where S is a set of states, A is a set of actions, T is a transaction function between states, \(\Omega\) is a set of observations, O is an observation function, R: \(S\times {}A\rightarrow {}\mathbb {R}\) is a reward function, and \(\gamma \in \left[ 0,1\right]\) is a discount factor.
At each time step, the environment is in the state \(s\in {}S\). The agent takes the action \(a\in {}A\), which causes the environment state s to be changed into the new state \(s'\) with the probability of \(T\left( s'\mid {}s,a\right)\). At the same time, the agent receives the observation \(o\in \Omega\), which depends on the new environmental state, with the probability of \(O\left( o\mid {}s'\right)\) (or sometimes \(O\left( o\mid {}s,a\right)\)), and the reward \(R\left( s,a\right)\). By repeating the above process, the agent aims to choose the actions that maximize its expected rewards, \(E\left[ \sum _{t=0}^{\infty }\gamma ^{t}r_t\right]\), which is discounted by \(\gamma\) over the time steps.
Dynamic Programming
Dynamic programming (DP) is a general method to solve POMDP. Roughly speaking, if we aim to solve a given problem, we need to solve its different parts (i.e., sub-problems), and then get the solution of the original problem based on the solutions of the sub-problems. In general many sub-problems are very similar. For this reason, DP attempts to solve each sub-problem only once, thereby reducing the amount of computation. Once the solution of a given sub-problem has been achieved, it is stored so that the solution of the same sub-problem can be directly queried in the next time. DP is particularly useful when the number of repetitive sub-problems increases exponentially with respect to the input size.
As the POMDP model is shown in Fig. 2, the current state of the environment \(s_{t}\) depends on the last state \(s_{t-1}\) and action \(a_{t-1}\). The current observation \(o_{t}\) depends on the current state \(s_{t}\) and the current action \(a_{t}\).

A general four-(time)step POMDP with the transaction function \(T(s_{t}|s_{t-1}, a_{t-1})\), the observation function \(O(o_{t}|s_{t}, a_{t})\) and the reward function \(R(s_{t}, a_{t})\)
In a POMDP model, a belief or belief state b(s) is a probability distribution over the environmental states \(s\in S\). Given the initial belief \(b_0(s_0)\), we can update the belief \(b_{t}(s_{t})\) recursively in Eq. 1 once the agent takes an action and receives an observation.
Upon the current belief state \(b_{t}(s_{t})\), the optimal strategy \(\pi ^{*}(b_{t})\) is to choose the action with the highest action value
where the action value is calculated as
where the next belief state \(b_{t+1}\) updated with Eq. 1 is determined by the current belief state \(b_{t}\), the current action \(a_{t}\), and the current observation \(o_{t}\).
The belief state value \(V_{t}(b_{t})\) is the value of the action that maximizes the next belief state value therefore leading to the recursive computation in the dynamic programming in Eq. 4.
Information Entropy
As a belief state is precisely a probability distribution of a POMDP state space, various types of information entropy can be used to quantify the state information in POMDP. In this article, we use the Shannon entropy as a measurement of the uncertainly of random variables. For the belief state b(s), its entropy is calculated in Eq. 5. If the belief state contains a large amount of uncertainty, the SE value tends to be high.
Relative entropy, also named KL divergence, is a measurement of the distance between two probability distributions, which in statistics corresponds to a logarithmic expectation of the likelihood ratio. The relative entropy of two belief states b and \(b'\) is defined below.
The KL divergence is generally used to measure how far the hypothesized distribution \(b'\) is away from the true distribution b. Each observation leads to an updated belief in POMDP and the observation may bring more information into the new belief. Hence, the KL divergence can be used to measure the amount of reduced uncertainty due to the received observations in POMDP.
POMDP Solutions to Inducing Learning Strategies
We proceed to present our new approach using POMDP to model a practice-based cognitive process. In this section, we will elaborate how POMDP models the cognitive process of learners’ learning, including the model specification, the constraints-based simplification of POMDP parameter learning, and how an information entropy-based dynamic programming (IE-DP) works in optimizing learning strategy for learners. In addition, we will show how our solutions can be used as a KT technique to predict the students’ performance on understanding knowledge states.
Modelling Cognitive Process Through POMDP
We will propose a general POMDP specification to model the student’s cognitive process of learning knowledge concepts through answering questions in the learning process. To facilitate the POMDP model construction, we develop a new parameter learning technique.
A POMDP Specification
In the learning process, answering questions is an important means of improving students’ knowledge, which also provides a valid observation on deciding the selection of a new question. Given a question bank with N questions and K knowledge concepts involving with all the questions, Table 1 shows a general specification of a POMDP model while Fig. 3 exhibits a four-step POMDP model that structures relations among the student’s knowledge state s, the question selection a and the answer observation o.

One POMDP model that plans the learning over four time steps and represents the cognitive process of students’ learning
It should be noted that the reward only appears when the POMDP terminates. The specification of the reward is determined by a specific learning goal. For example, if students are expected to master as many knowledge concepts as possible and the importance of each knowledge concept is considered to be the same, the reward is
where T is the total number of decision steps (equal to the number of questions to be answered) and \(KC(s_T)\) the number of mastered knowledge concepts in the state \(s_T\).
POMDP Parameter Learning
To build a POMDP model, we need to specify all the parameters, including the transaction function T, the observation function O and the reward function R, based on available domain knowledge. The reward values are determined by the student’s learning objectives as mentioned above. The remain is to specify conditional probabilities in both the transaction and observation functions. The probability values can be either manually specified by a domain expert with sufficient knowledge about the students’ learning in a specific problem domain, or automatically learned through available data recording the students’ learning activities including questions answered by the students, knowledge concepts and their relations to the questions, and so on. In this paper, we focus on learning the parameters from available learning activity data.
Given a question bank with N questions and K knowledge concepts, the number of the states is \(2^{K}\) and the number of observations is 2N. Consequently, the sizes of the transaction and observation functions become \(2^{2K+1}\times {}N\) and \(2^{K+1}\times {}N\) respectively, which leads to intractable computational complexity in learning the POMDP parameters. To address this challenge, we proceed to exploit relations among knowledge concepts through the development of question types.
First, we structure relations among K knowledge concepts so as to reduce the state space S. In a general cognitive process, cognitive tasks within the same problem domain often exhibit a sequential order. For instance, in the process of learning to walk, humans typically master the ability to stand upright before progressing to walking; thus, “standing” serves as a prerequisite cognitive task for “walking.” Similarly, conventional learning processes often dictate the sequence in which students acquire a set of knowledge concepts. A student progresses from basic to advanced knowledge concepts. For example, before learning “absolute value,” students generally have to learn “opposite number” and “number axis,” of which the reason is that under a normal circumstance, students can understand “absolute value” only if they have mastered “opposite number” and “number axis.” On the other hand, these hierarchical relations among knowledge concepts are well managed in ITS since they are formally defined in learning pathways in subject study [30].
We use an acyclic directed graph, \(G=(V, D)\), to structure relations among K knowledge concepts, where V contains a set of nodes, \(V=\{v_1,..., v_K\}\), each of which represents a specific knowledge concept, and D contains a set of arcs (d) and an arc \(d(v_i, v_j)\) links two nodes from the parent node \(v_i\) to the child \(v_j\) where \(v_i\) is the pre-required knowledge concept to learning \(v_j\). A knowlege concept can only be mastered if all of its pre-required ones are achieved. Hence, this relation constrains the learning order of the knowledge concepts thereby reducing the state space in POMDP. For example, Fig. 4 structures the relations among three knowledge concepts X, Y and Z where X and Y are parent nodes of Z. Each node has a binary state (0,1) and the number of combinations of all the knowledge states is up to 8. By exploiting the relations in Fig. 4, the number of states is reduced to 5 as compared in Table 2.

Shrink the state space through relations among X, Y and Z as X and Y are pre-required knowledge concepts of Z
Subsequently, we categorize N questions by considering how the questions are linked to relevant knowledge concepts. In general, a question is designed to help students improve the understanding of knowledge concepts. Inspired by this observation, we classify a number of questions into one question type if all of them are linked to the same set of knowledge concepts. In other words, the action set A is reduced when some of the actions corresponding to the questions are merged into one representative action. More specifically, if two actions (\(a^{0}\) and \(a^{1}\)) have the same type, the two transaction probabilities are equal, e.g., \(T(s'\mid {}s,a^{0})=T(s'\mid {}s,a^{1})\). Thus, we do not need to learn the transaction function of a large size in POMDP.
The reduction of the number of states and actions makes it tractable that the transaction and observation functions can be learned in POMDP. In this work, we identify the knowledge concepts’ relations and question types through domain knowledge in available datasets. In general, they are either well defined by a tutor, or automatically learned from the students’ learning records, which currently attracts increasing research attention [31] and is out of the scope of this article.
New POMDP Solutions
Once we have built a POMDP model, we can use a well-developed DP method to solve the model and obtain an optimal learning strategy. The DP method solves the POMDP model by updating the belief state through Eq. 1 and computing the value function recursively through Eqs. 3 and 4. The solutions provide optimal actions (Eq. 2) given possible observations at each time step therefore composing the optimal learning strategy over the entire decision-making horizon. According to the POMDP structure in Fig. 3, we rewrite Eq. 3 as follows
where the final belief state value is equal to the reward below.
In addition, it is known that multiple optimal learning strategies, e.g., actions replaced by others at some time step, exist in solving a POMDP model. This is because different actions may produce the same reward values by following the computation in Eqs. 8 and 9. Intuitively, a student may achieve identical learning targets by selecting and answering different questions. It is more likely to happen when a larger number of question types exist in a question bank. We make a further step to exploit the benefit of selecting different actions in optimizing learning strategies.
Selecting actions to optimize a learning strategy is a main objective in solving a POMDP model, which is equivalent to maximizing final outcomes of knowledge states. Meanwhile, another important function is to reduce the uncertainty of the student’s knowledge states, which benefits the understanding of learning strategies and makes more precise, subsequent decisions. This function is typically considered in computerized adaptive testing [32].
To refine the action selection in optimizing the learning strategy induction, we introduce two methods to choose a question through measuring the uncertainty reduced by a list of possible questions. We can update the current belief states b(s) in a POMDP model given a possible action (a question to be selected) and an observation (the received answers).
Subsequently, we can compute the amount of uncertainty that the new (updated) belief states \(b'(s)\) brings to b(s) through either the Shannon entropy or KL divergence measurement as the metric of question selection (QSM).
If the Shannon entropy is selected as QSM, we compute the entropy value in Eq. 11 and aim to select the question that minimizes the Shannon entropy in Eq. 12.
If the KL divergence is chosen as QSM, we select the question that maximizes the KL divergence as computed in Eqs. 13 and 14.
An Example
We use a concrete example to illustrate the POMDP solutions. Given a question bank with five questions, three knowledge concepts, and the structure of the knowledge concepts in Fig. 4, we have the state space
the action space
and the observation space
Let the initial belief state be
Among the five actions, the actions \(a^{0}\) and \(a^{1}\) are related to the knowledge concept X, the actions \(a^{2}\) and \(a^{3}\) are related to the knowledge concept Y, and the action \(a^{4}\) is related to the knowledge concept Z. The transaction and observation functions are shown in Tables 3 and 4 respectively.
Given the constraints in “POMDP Parameter Learning” section, the transaction probabilities of the actions related to the same knowledge concept are the same; however, the observation probabilities of the actions may be different. This is due to the fact that the difficulty of the questions related to the same knowledge concept could be different.
Based on the above settings, we simulate the interaction between a student and an ITS using the POMDP model. According to the initial belief state, we randomize an initial student as \(s^{3}=(1,0,1)\), and compute the action values for each action (following Eqs. 8 and 9) below
We then observe that the actions \(a^2\) and \(a^3\) have the same action values and either of them can be included in the optimal learning strategy. If we use the Shannon entropy measurement to refine the strategy, we compute the entropy values (following Eqs. 10–12) as follows.
Hence, the action \(a^{3}\) is selected as the next action since it leads to the largest reduction of the uncertainty in the belief states.
According to the observation and transaction functions, we randomly generate the answer as \(o_{0}=o^{7}=1_{a^{3}}\), and the state of the student is kept as \(s^{3}=(1,0,1)\). We then update the belief state (Eq. 1) as
For the new belief state \(b_{1}(s_{1})\), we compute the action values (Eqs. 8 and 9) as
Hence, the action \(a^{4}\) is selected as the next action. According to the observation function and transaction function, we repeat the random generation of the answer as \(o_{0}=o^{8}=0_{a^{4}}\), and the state of the student is transferred to \(s^{4}=(1,1,1)\). After that, the belief state (Eq. 1) is updated as
From the above process, we notice that the student incrementally improves his/her knowledge by answering the questions (given by the strategies provided by the POMDP model), and the ITS has a more accurate estimation of the student’s ability through the student’s answering records.
Algorithm Summary and Discussion
We summarize the process of POMDP-based solutions, namely IE-DP, to the learning strategy induction in Algorithm 1. Given available data records D, we learn the transaction and observation functions to build the POMDP model \(\lambda =(S,A,T,R,\Omega ,O,\gamma )\) through the well-known Baum-Welch algorithm [33]. To reduce the model complexity, we exploit the relational structures of the states S when learning the model (line 1). Then, we use the dynamic programming method to solve the POMDP model by following Eqs. 8 and 9 (lines 2–4). Once we identify the actions that have identical values, we proceed to use either the Shannon entropy or KL divergence to select the action in the optimal learning strategy according to Eqs. 10–14 (lines 6–8).

IE-DP
We shall notice that we can induce different learning strategies by specifying the reward function R in the POMDP model. Table 5 shows three examples of the reward functions when the solutions aim for different learning outcomes.
For example, if the learning goal is to learn as many knowledge concepts as possible, all the knowledge concepts can be assigned with the same importance coefficient. If the learning goal is to focus on mastering the basic knowledge concepts first, the more basic knowledge concepts are assigned with larger importance coefficients. If the learning goal is to master all the knowledge concepts, the states representing mastering all knowledge concepts can be assigned with the importance coefficients of larger than zero, and each of other states is assigned with zero.
As we mention in “Related Works” section, one of the very popular works in ITS is to predict students’ knowledge states through various KT methods. We proceed to show that the POMDP-based approach can perform as what the KT techniques do. The POMDP method presents the belief state calculated from the historical answer records (Eq. 1). Furthermore, as we use 0 and 1 to indicate whether the student has mastered a certain knowledge concept or not, we can convert the belief state into the probability that the student masters each knowledge concept, and use the probability value as the student’s proficiency in the knowledge concept. Below is one example to illustrate the conversion. Given the knowledge concept structure in Fig. 4, the state space is
Suppose the belief state is
the student’s proficiency of mastering each knowledge concept can be calculated below
Additionally, we can use a vector to represent the proficiency of each knowledge concept as
Hence the new POMDP method can induce the optimal learning strategies and simultaneously predict the student’s proficiency of the knowledge concepts of interest. We will further confirm the performance in the experiments.
Experimental Results
In this section, we conduct a series of experiments to demonstrate the performance of the POMDP method, namely IE-DP, on the learning strategy induction. In addition, we will show the new method can also be used to predict the student’s performance from the learning records.
Data and Knowledge Concepts
We use two real-world datasets, including the public dataset ASSIST (Non Skill-Builder data 2009-10) [34] and the private dataset Quanlang provided by the education company QuanlangFootnote 1. ASSIST is an open dataset that was gathered in the school year 2009–2010 by the ASSISTments online tutoring systemsFootnote 2. Quanlang contains the data from the middle schools that have partnerships with the Quanlang education company. Each dataset contains answer logs of students. We briefly summarize these datasets in Table 6.
The details of ASSIST can be found in the aforementioned website while we briefly introduce Quanlang here. Table 7 shows some examples of the students’ records and Table 8 elaborates the attributes in the dataset. We mainly use the attributes of seq_id, account_no, exam_id, knowledge_concept_id and is_right in our experiments.
To conduct the experiments, we retrieved five subsets (KCS1 - KCS5) from the two large datasets by considering possible relations of knowledge concepts as shown in Table 9. We obtained the knowledge structures, which is shown in Fig. 5, either from the information supplied in the ASSIST website or from the Quanlang lecturers.

Knowledge concept structures of the five subdatasets. The records of KCS1 and KCS2 are from QuanLang while the records of KCS3, KCS4 and KCS5 are from ASSIST
We implemented our methods and other baseline methods through Python 3.8 on an Ubuntu server with a Core i9-1090K 3.7GHz, a GeForce RTX 3090 and 128 GB memory.
Experiment 1: Evaluations on Learning Strategy Induction
As we aim to demonstrate the performance of inducing effective learning strategies through the IE-DP methods, we first learned the POMDP parameters, such as the transaction and observation functions, through the Baum-Welch algorithm [33]. After we learned the POMDP models, we solved the models to obtain the learning strategies through either the IE-DP method or their variations. Finally, we simulated the interactions between the students who answer the questions and the ITS from which the questions were selected according to the learning strategies provided by our models. We conducted 10, 000 simulations and reported the average performance of the simulated students. We compared all the learning strategy induction methods below.
-
DP, as introduced in “Dynamic Programming” section, is the traditional method for solving POMDP and provides ground-truth for the POMDP solutions [16].
-
GREEDY strategy is a simplistic DP of which the decision horizon is 1. It aims to maximize the reward for only one time step.
-
IE\(_{\varvec{SE}}\)-DP and IE\(_{\varvec{KL}}\)-DP are the new IE-DP methods based on the POMDP models as implemented in Algorithm 1 where the Shannon entropy and the KL divergence are used to refine the learning strategies respectively.
-
Student strategy is retrieved from the students’ answer records [35]. We use a decision tree to compose the learning strategies based on what the students provide to answer the selected questions.
-
Random strategy is an excessive assignment tactic. The ITS randomly selects one question from the question bank which the student is to answer at each step.
-
LeitnerTutor selects the questions by examining the students’ proficiency on knowledge concepts [36]. The probability that a question is selected is reduced if the student has correctly answered the question involving the same knowledge concept; otherwise, the selection chance is increased.
-
ThresholdTutor presents questions based on the student’s correct rates on answering the possible questions [37], of which the threshold value is set as 0.5 in our experiments.
After the simulations, we record the final states of the 10, 000 students and calculate the distribution over the final states below.
where \(n_{s_T}\) is the number of students whose final states are \(s_{T}\), and N is the number (10,000) of students in the simulations. To compare the performance of the aforementioned eight methods, we use three measurements in the comparison.
-
Proficiency of each knowledge concept achieved by all the students is calculated as
$$\begin{aligned} pro(k)={\sum }_{s_{T}\in {}S}ml(s_{T},k)P(s_{T}) \end{aligned}$$where k is the \(k^{th}\) knowledge concept and \(ml(s_{T},k)\) is the mastery level (0 or 1) of the \(k^{th}\) knowledge concept at the state \(s_{T}\).
-
AVE is the average number of knowledge concepts mastered by all the students.
$$\begin{aligned} AVE={\sum }_{s_{T}\in {}S}KC(s_{T})P(s_{T}) \end{aligned}$$ -
VAR is the variance of the number of knowledge concepts mastered by all the students.
$$\begin{aligned} VAR={\sum }_{s_{T}\in {}S}[AVE-KC(s_{T})]^{2}P(s_{T}) \end{aligned}$$
Table 10 shows the results when all the methods are used to induce the learning strategies for the 10,000 students.
For each dataset (KCS1-KCS5), we report the distribution of the final states, e.g., state(W, X, Y, Z) in KCS1, in the POMDP models, which is shown in the top panel of every section for each dataset in the table. For example, after the students conduct the learning by following the strategies provided by the DP method in KCS1, they have the probability of 0.5761 on \(state(1_{W},1_{X},1_{Y},1_{Z})\), which represents all the four knowledge concepts are mastered.
Table 11 presents the statistical significance of the performance differences among the learning strategies for each dataset. The critical value for the two-tailed t-test with a significance level of 0.05 and freedom degrees of 19,998 is 1.96. Values less than 1.96 are denoted in bold. Based on the above metrics, we conclude that the learning strategies induced by IE\(_{SE}\)-DP and IE\(_{KL}\)-DP methods are better than others. We will elaborate on this in detail in the following.
Based on the distribution of the final states, we calculate the proficiency as shown in the example in “Algorithm Summary and Discussion” section. We report the students’ proficiency of mastering each knowledge concept, e.g., W, X, Y and Z in KCS1. In most of the knowledge concepts (W, X and Y), both the IE\(_{SE}\)-DP and IE\(_{KL}\)-DP methods provide the better learning strategies to the students since they have shown good understandings (above 0.8). As for the knowledge concept Z, which can only be mastered if all other knowledge concepts are mastered in KCS1, students tutored by the IE-DP strategies are more likely to master this knowledge concept.
In terms of the second measurement (AVE), the IE\(_{SE}\)-DP and IE\(_{KL}\)-DP methods perform better than others (except compared to the GREEDY in KCS5), as indicated by the bold numbers in the table. For example, in the dataset KCS4, both the methods help the students grasp almost all the knowledge concepts (around 4.27). It is worth noting that the GREEDY strategy performs better than the DP strategy in KCS3, and the best in KCS5. Since there are many actions to select at each step and the long-term rewards of actions are considered, we approximate the action value when applying the DP and the IE-DP methods (e.g., the FIB method [38] is adopted to approximate the action value in our experiments). While the GREEDY method only considers the immediate rewards of the actions, of which the precise calculation is easy to do. When the long-term rewards of actions are not estimated well, it may appear that the performance of the GREEDY strategy is better as indicated by the case of KCS5.
We also notice that, through using the learning strategies provided by the IE\(_{SE}\)-DP and IE\(_{KL}\)-DP methods, the students have stable performance as shown in the small VAR values. From a pedagogical point of view, refining the questions through either the Shannon entropy or KL divergence makes ITS more accurate in estimating student states, which helps students master knowledge concepts step-by-step. From a computational viewpoint, for questions with the same long-term rewards, we prefer to choose a question with the smallest reward variance.
In some cases (KCS1 and KCS2), there is no obvious difference between the performance of the Student and the Random strategies. The Student strategy is summarized from the answer records, which is mainly the homework assigned by teachers to students. In order to take care of all students, the homework often covers all knowledge concepts but is not targeted, which limits some students in doing special exercises on the knowledge concepts they have not mastered.
The performance of LeitnerTutor and ThresholdTutor is unstable. The two strategies are more suitable for learning scenarios where knowledge concepts are weakly related, such as vocabulary memory.
Case Analysis: Taking the KCS1 example, we introduce the interaction process between the POMDP-based ITS and a student in detail. For the student with no answer record at all, the ITS needs to give a reasonable estimate of the initial state. A natural thought is that for a person without any information, his/her state can be regarded as the average level of the population. It is consistent that the POMDP parameters learned through Baum-Welch algorithm include the distribution of the students’ initial states, which can be regarded as the initial belief state. For KCS1, the student’s initial belief state is
where the corresponding states are (0, 0, 0, 0), (1, 0, 0, 0), (1, 0, 1, 0), (1, 1, 0, 0),(1, 1, 1, 0) and (1, 1, 1, 1). As the first radar chart shown in Fig. 6, we might as well convert it into the mastery of each knowledge concept

The details of the student’s cognitive process. The initial belief state is the average level of the population. Given the initial belief, the ITS system calculates the optimal action by IE-DP and updates the beliefs as the students answer the questions
For this belief state, the expected reward of each action is
For these actions, we choose the optimal action is \(a^{221}\) by using Shannon entropy as the refinement metric. If the student answers this question correctly, the answer sequence is updated as \([(a^{221},1)]\), and the belief state is updated as (0.00, 0.00, 0.00, 0.10, 0.02, 0.88). As shown in Fig. 6, assuming that four questions are answered in the process, we repeat the above operations of action selection, belief state update, and recording the action and observation at each step. From step 1 to step 3, the estimation of the student’s state varies greatly, of which the reason is that the ITS lacks sufficient information (answer records) to judge the student’s knowledge states. The main factor affecting the belief state at these steps is the observation function.
When ITS obtains a good amount of information, it gives a precise assessment of the student’s states (step 3 to step 5). At step 3, the ITS considers that the student has mastered the knowledge concepts W and Y, but has not mastered the knowledge concepts X and Z. As the knowledge concept structure of KCS1 shows, the knowledge concept X is one of the pre-required knowledge concepts to the knowledge concept Z. Hence the ITS recommends the student to answer the question \(a^{445}\) first. After the student corrects the answer to the question \(a^{445}\), the ITS considers that the student has mastered the knowledge concept X through answering the question \(a^{445}\). Finally, the ITS recommends the question \(a^{110}\). Although the student’s answer to \(a^{110}\) is incorrect, the ITS believes that the student still has a certain probability to master the knowledge concept Z. From step 4 to step 5, since the information is sufficient, the main factor affecting the belief state is the transition function. In the interaction process, the ITS gradually understands the student’s state, and provides effective questions for improving the knowledge concept that the students did not master well.
Experiment 2: Evaluations on Students’ Performance Prediction
As elaborated in “Algorithm Summary and Discussion” section, the POMDP methods, where the IE-DP methods are rooted, can also be used to predict the student’s performance on mastering knowledge concepts. We proceed to compare the POMDP methods with the state-of-arts below.Footnote 3 We do not include EKT [10] and RKT [11] because the techniques require extra information, such as question texts, in the model development.
-
BKT [9] predicts the student’s performance on mastering a single knowledge concept.
-
DBKT [22] introduces dynamic Bayesian nets into BKT and makes it possible to represent the hierarchy and relationships between different skills of a learning domain.
-
AKT [12] couples flexible attention-based neural network models with a series of novel, interpretable model components inspired by cognitive and psychometric models.
We tested the performance of all the techniques through the data of KCS1-KCS5. For each set of knowledge concepts, we used \(90\%\) of the data to conduct the five-fold cross-validation in the model training and \(10\%\) in the final tests. We used four traditional metrics to demonstrate the prediction performance.
-
Prediction Accuracy (ACC) binarizes the predicted values and is the ratio of the number of samples, which are predicted correctly, to the total number of samples.
-
Area Under an ROC Curve (AUC): In a dataset with M positive samples and N negative samples. There are a total of \(M\times {}N\) pairs of samples. For these \(M\times {}N\) pairs of samples, AUC is the ratio of the number of sample pairs whose predicted value of the positive sample is greater than that of the negative sample to the total number of sample pairs. A large AUC value indicates a good prediction performance.
$$\begin{aligned} AUC=\frac{\sum {}I(P_{positive},P_{negative})}{M\times {}N} \end{aligned}$$where
$$\begin{aligned} I(P_{positive},P_{negative})= {\left\{ \begin{array}{ll} 1,\quad {}P_{positive}>P_{negative}, \\ 0.5,\quad {}P_{positive}=P_{negative} \\ 0,\quad {}P_{positive}<P_{negative}\\ \end{array}\right. } \end{aligned}$$ -
Mean Average Error (MAE) and Root Mean Squared Error (RMSE) measure the deviation of the predicted values from the true values.
$$\begin{aligned} \begin{aligned} MAE&=\frac{\sum {}|y_{true}-y_{predicted}|}{the\;number\;of\;samples} \\ RMSE&=\frac{\sqrt{\sum {}(y_{true}-y_{predicted})^{2}}}{the\;number\;of\;samples} \end{aligned} \end{aligned}$$
In Table 12, we observe that both the POMDP method and AKT perform better than BKT and DBKT in most cases. Compared to the best performance, the POMDP method has a very competitive performance. Specifically, the performance of POMDP-based model is, on average, \(0.53\%\sim {}2.37\%\) lower than the best one in ACC, \(0.82\%\sim {}2.36\%\) lower in AUC, \(0.31\%\sim {}2.55\%\) higher in MAE, and \(0.02\%\sim {}1.27\%\) higher in RMSE.
Although deep learning (adopted by AKT) is indeed better than Bayesian methods in predicting student performance, the deep learning based methods are facing a number of difficulty in inducing learning strategies: a)the deep learning based methods often involve state space that does not explicitly describe the students’ states; and b)defining the reward for completing a particular question is difficult in current DKT models, which makes it challenging to apply related planning methods for the induction of learning strategies.
In summary, the POMDP-based methods, such as the IE-DP techniques, can effectively solve the above challenges by structuring relations among multiple knowledge concepts. The techniques perform well in predicting the students’ performance while providing operational ways to induce learning strategies in ITS.
Conclusion
Modelling a cognitive process serves as a crucial approach to solve cognitive tasks. In this paper, utilizing ITS as the research platform, we introduce a novel approach to model a practice-based cognitive process and a new strategy induction method in ITS. We adopt the POMDP model to optimize the learning strategies and refine the strategies through information entropy techniques. The new approaches can interpret the students’ learning performance in knowledge concepts of interest while providing learning strategies. As the POMDP model is descriptive, it also offers space to personalize the learning strategies through defining reward functions in the model.
The existing research commonly assumes that the cognitive patterns of a group of learners within a specific cognitive domain can be represented by a single unified model. While this assumption is made to facilitate the model learning, it is evidently at odds with reality. In future research, we aim to model individual learners and personalize their learning strategies. Furthermore, we seek to extend the model update in a real-time interactive learning process.
Data Availability
The authors confirm that the data associated with the experiments can be available upon request.
Notes
In this comparison, we do not need to optimize the question selection as what is done in IE-DP because we directly use the action sequences in the students’ answer records. This is to ensure a fair comparison with other methods.
References
Tang X, Chen Y, Li X, Liu J, Ying Z. A reinforcement learning approach to personalized learning recommendation systems. Br J Math Stat Psychol. 2019;72:108–35.
Kubotani Y, Fukuhara Y, Morishima S. Rltutor: Reinforcement learning based adaptive tutoring system by modeling virtual student with fewer interactions. 2021. arXiv preprint arXiv:2108.00268.
Zhou G, Azizsoltani H, Ausin MS, Barnes T, Chi M. Hierarchical reinforcement learning for pedagogical policy induction, in: International conference on artificial intelligence in education, Springer. 2019. p. 544–556.
Zhou G, Yang X, Azizsoltani H, Barnes T, Chi M. Improving student-system interaction through data-driven explanations of hierarchical reinforcement learning induced pedagogical policies, in: Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization. 2020. p. 284–292.
Ju S. Identify critical pedagogical decisions through adversarial deep reinforcement learning, in: Proceedings of the 12th International Conference on Educational Data Mining (EDM 2019). 2019.
Huang Z, Liu Q, Zhai C, Yin Y, Chen E, Gao W, Hu G. Exploring multi-objective exercise recommendations in online education systems, in: Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019. p. 1261–1270.
SanzAusin M, Maniktala M, Barnes T, Chi M. Exploring the impact of simple explanations and agency on batch deep reinforcement learning induced pedagogical policies, in: International Conference on Artificial Intelligence in Education, Springer, 2020. p. 472–485.
Ausin MS, Maniktala M, Barnes T, Chi M. Tackling the credit assignment problem in reinforcement learning-induced pedagogical policies with neural networks, in: International Conference on Artificial Intelligence in Education, Springer. 2021. p. 356–368.
Corbett AT, Anderson JR. Knowledge tracing: Modeling the acquisition of procedural knowledge. User Model User-Adap Inter. 1994;4:253–78.
Liu Q, Huang Z, Yin Y, Chen E, Xiong H, Su Y, Hu G. Ekt: Exercise-aware knowledge tracing for student performance prediction. IEEE Trans Knowl Data Eng. 2019;33:100–15.
Pandey S, Srivastava J. Rkt: Relation-aware self-attention for knowledge tracing, in: Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020. p. 1205–1214.
Ghosh A, Heffernan N, Lan AS. Context-aware attentive knowledge tracing, in: Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2020. p. 2330–2339.
Rafferty AN, Brunskill E, Griffiths TL, Shafto P. Faster teaching via pomdp planning. Cogn Sci. 2016;40:1290–332.
Spaan MT. Partially observable markov decision processes, in: Reinforcement Learning, Springer, 2012;387–414.
Ramachandran A, Sebo SS, Scassellati B. Personalized robot tutoring using the assistive tutor pomdp (at-pomdp), in: Proceedings of the AAAI Conference on Artificial Intelligence. 2019:33;8050–8057.
Bellman R. Dynamic programming. Science. 1966;153:34–7.
Ebel RL, Frisbie DA. Essentials of educational measurement. 1972.
Núñez J, Cincotta P, Wachlin F. Information entropy, in: Chaos in Gravitational N-Body Systems, Springer. 1996. p. 43–53.
Baum LE, Petrie T. Statistical inference for probabilistic functions of finite state markov chains. Ann Math Stat. 1966;37:1554–63.
Baker RSJ, Corbett AT, Aleven V. More accurate student modeling through contextual estimation of slip and guess probabilities in bayesian knowledge tracing, in: International conference on intelligent tutoring systems, Springer. 2008. p. 406–415.
Pardos ZA, Heffernan NT. Kt-idem: Introducing item difficulty to the knowledge tracing model, in: International conference on user modeling, adaptation, and personalization, Springer, 2011. p. 243–254.
Käser T, Klingler S, Schwing AG, Gross M. Dynamic bayesian networks for student modeling. IEEE Trans Learn Technol. 2017;10:450–62.
Piech C, Bassen J, Huang J, Ganguli S, Sahami M, Guibas LJ, Sohl-Dickstein J. Deep knowledge tracing. Adv Neural Inf Process Syst. 2015;28.
Yang H, Cheung LP. Implicit heterogeneous features embedding in deep knowledge tracing. Cogn Comput. 2018;10:3–14.
Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. 1997;9:1735–80.
Angulo C, Falomir IZ, Anguita D, Agell N, Cambria E. Bridging cognitive models and recommender systems. Cogn Comput. 2020;12:426–7.
Wang F. Reinforcement learning in a pomdp based intelligent tutoring system for optimizing teaching strategies. Int J Inf Educ Technol. 2018;8:553–8.
Wang F, Handling exponential state space in a POMDP-based intelligent tutoring system, in,. IIAI 4th International Congress on Advanced Applied Informatics. IEEE. 2015;2015:67–72.
Nioche A, Murena P-A, dela Torre-Ortiz C, Oulasvirta A. Improving artificial teachers by considering how people learn and forget, in: 26th International Conference on Intelligent User Interfaces, 2021. p. 445–453.
Millán E, Descalço L, Castillo G, Oliveira P, Diogo S. Using bayesian networks to improve knowledge assessment. Comput Educ. 2013;60:436–47.
Roy S, Madhyastha M, Lawrence S, Rajan V. Inferring concept prerequisite relations from online educational resources, in: Proceedings of the AAAI conference on artificial intelligence. 2019:33;9589–9594.
vander Linden WJ, Glas CA. Elements of adaptive testing, 2010:10. Springer.
Baum LE, Petrie T, Soules G, Weiss N. A maximization technique occurring in the statistical analysis of probabilistic functions of markov chains. Ann Math Stat. 1970;41:164–71.
Feng M, Heffernan N, Koedinger K. Addressing the assessment challenge with an online system that tutors as it assesses. User Model User-Adap Inter. 2009;19:243–66.
Quinlan JR. Induction of decision trees. Mach Learn. 1986;1:81–106.
Leitner S. So lernt man lernen: Der Weg zum Erfolg, Nikol, 2011.
Khajah MM, Lindsey RV, Mozer MC. Maximizing students’ retention via spaced review: Practical guidance from computational models of memory. Top Cogn Sci. 2014;6:157–69.
Hauskrecht M. Value-function approximations for partially observable markov decision processes. 2011. arXiv preprint arXiv:1106.0234.
Funding
Professor Yifeng Zeng received the support from the EPSRC New Investigator Award (Grant No. EP/S011609/1). This work is also supported in part by the National Natural Science Foundation of China (Grants No. 61836005, 62176225 and 62276168) and Guangdong Natural Science Foundation (Grants No. 2023A1515010869).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Ethical Approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Conflict of Interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gao, H., Zeng, Y., Ma, B. et al. Improving Knowledge Learning Through Modelling Students’ Practice-Based Cognitive Processes. Cogn Comput 16, 348–365 (2024). https://doi.org/10.1007/s12559-023-10201-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12559-023-10201-z