
Abstract
As an emerging trend in big data science, applications based on the Quantified-Self (QS) engage individuals in the self-tracking of any kind of biological, physical, behavioral, or environmental information as individuals or groups. There are new needs and opportunities for recommender systems to develop new models/approaches to support QS application users. Recommender systems can help to more easily identify relevant artifacts for users and thus improve user experiences. Currently recommender systems are widely and effectively used in the e-commerce domain (e.g., online music services, online bookstores). Next-generation QS applications could include more recommender tools for assisting the users of QS systems based on their personal self-tracking data streams from wearable electronics, biosensors, mobile phones, genomic data, and cloud-based services. In this paper, we propose three new recommendation approaches for QS applications: Virtual Coach, Virtual Nurse, and Virtual Sleep Regulator which help QS users to improve their health conditions. Virtual Coach works like a real fitness coach to recommend personalized work-out plans whereas Virtual Nurse considers the medical history and health targets of a user to recommend a suitable physical activity plan. Virtual Sleep Regulator is specifically designed for insomnia (a kind of sleep disorder) patients to improve their sleep quality with the help of recommended physical activity and sleep plans. We explain how these proposed recommender technologies can be applied on the basis of the collected QS data to create qualitative recommendations for user needs. We present example recommendation results of Virtual Sleep Regulator on the basis of the dataset from a real world QS application.
Similar content being viewed by others


1 Introduction
It is a well-known fact that the average human lifetime is increasing. Living longer implies the risk of age related health problems that reduce significantly the quality of life. Therefore, many people need to improve and maintain their independence, capabilities, health status as well as their physical, cognitive, mental and social wellbeing. Modern mobile and sensor technologies enable the recording of all kinds of data related to a person’s daily lifestyle, such as exercises, steps taken, body weight, food consumption, blood pressure, cigarettes smoked. This type of self-data tracking is often referred as the Quantified-Self concept (Swan 2012). Empowering and motivating people for physical activities is a major challenge. This becomes especially crucial when it comes to the health and the physical condition of an individual (Swan 2012).
Recent works have shown that tracking measurements such as step counts, spent calories and body weight are very effective in lifestyle changes by motivating a person to engage in physical exercise (McGrath and Scanaill 2013). Additionally, by tracking measurements over time, he/she gets insights regarding his/her progress and he/she is able to experience the direct relation between his efforts and the actual outcome. For instance, going for jogging twice a week leads to a decrease of body fat percentage (Munson and Consolvo 2012).
As an emerging topic, the Internet of Things (IoT) (Atzori et al. 2010; Greengard 2015; Miorandi et al. 2012) represents a networked infrastructure of connected different types of devices. In this context, a huge amount of services and applications is created which makes the identification of the relevant ones a challenging task.
Several IoT solutions have been proposed to implement various Quantified-Self applications in the areas of health care and assisted living (Maglogiannis et al. 2016; Menychtas et al. 2016; Wei 2014). AGILEFootnote 1 is an EU-funded project aiming to build a modular hardware and software gateway for IoT with support for protocol interoperability, device and data management, IoT applications execution, and external cloud communication. The main concept behind AGILE is to enable users to easily build IoT applications and control connected devices through a modular IoT gateway and a set of full stack (OS, runtime and applications) IoT software components. One of five pilot projects of AGILE is Quantified-Self which is an IoT enabled m-health (mobile health) system based on the AGILE gateway environment.
In the AGILE project, we have developed new recommendation approaches especially useful in IoT scenarios (Felfernig et al. 2016a, 2017; Valdez et al. 2016). Recommender systems (Jannach et al. 2010) suggest items (alternatives, solutions) which are potential interests for a user. Examples of related questions are: which book should be purchased?, which test method should be applied?, which method calls are useful in a certain development context? or which applications are of potential interest for the current user? A recommender system can be defined as any system that guides a user to interesting or useful objects for the user in a large space of possible options or that produces such objects as output (Felfernig and Burke 2008).
In this paper, we propose three new recommendation approaches on the basis of Quantified-Self:
Virtual Coach,
Virtual Nurse, and
Virtual Sleep Regulator.
Virtual Coach is developed to motivate the users of Quantified-Self by recommending new activities on the basis of their demographic information and past activities. On the other hand, Virtual Nurse helps chronic patients for reach their targets by recommending an activity plan on the basis of their medical history. We have implemented our proposed Virtual Coach approach and evaluated the test results of Virtual Coach based on our real-world dataset. Virtual Sleep Regulator provides walking and sleeping time recommendations for insomnia patients in order to improve their sleep qualities. Insomnia (Fox 1999; Zammit et al. 1999) is a sleep disorder that is characterized by difficulty falling and/or staying asleep. These people can not have a good quality sleep easily.
The remainder of this paper is organized as follows. First of all, we introduce details about the QS concept in Sect. 2. Then, we provide a short overview of basic recommendation approaches (Sect. 3). In Sect. 4, we give an overview of the state of the art in recommendation technologies in IoT enabled m-health. In Sect. 5, we introduce an example QS application Agile Quantified-Self, thereafter, in Sect. 6, we explain our proposed recommendation approaches based on real-world datasets from Quantified-Self. Finally, in Sect. 7, we conclude our work with discussions of our proposed approaches and issues for future work.
2 Quantified self
The Quantified Self (QS) concept refers to the use of technologies for collecting data about peoples’ daily activities. Smartphone apps, physical activity trackers, biometric sensors, and IoT devices allow people to monitor important aspects of their daily lives, such as their physical activity, heart rate, and mood, with the aim to learn more about themselves, improve their well-being and adopt a healthier lifestyle. In this context, the user is capable of not only storing their data to a location of their choice, such as their own server or private cloud, but also sharing their data with whomever they choose, such as their social circle or their physician. However, the process of sharing this data remains complex, mainly due to the fact that each vendor uses different communication mechanisms and requires a separate application for the persistent storage and visualization of data.
QS is targeting data acquisition on aspects of a person’s daily life in terms of inputs (e.g., food consumed, quality of surrounding air), states (e.g., mood, arousal, blood oxygen levels), and performance (mental and physical activities) through a modern, health centric, social and mobile enabled, communication platform that resides in the gateway (in terms of collecting and visualizing data). The application is developed using the AGILE environment and uses the communication modules of the gateway to collect data from self-tracking devices of users: wristbands or smart watches, weighting scales, oximeters, and blood pressure monitors. In addition, the cloud integration modules are exploited for periodically importing activity data and biosignals from other providers and applications through their public APIs (Menychtas et al. 2016; Panagopoulos et al. 2017).
According to Swan (2013), QS is starting to be a mainstream phenomenon as 60% of U.S. adults are currently tracking their weight, diet, or exercise routine, and 33% are monitoring other factors such as blood sugar, blood pressure, headaches, or sleep patterns. Further, 27% of U.S. Internet users track health data online, 9% have signed up for text message health alerts, and there are 40,000 smartphone health applications available. Diverse publications have covered the quantified self movement and it was a key theme at CES 2013, a global consumer electronics trade show. Commentators at a typical industry conference in 2012, Health 2.0, noted that more than 500 companies were making or developing self-management tools, up 35% from the beginning of the year, and that venture financing in the commensurate period had risen 20%. At the center of the quantified self movement is, appropriately, the Quantified Self community, which in October 2012 comprised 70 worldwide meet-up groups with 5,000 participants having attended 120 events since the community formed in 2008Footnote 2. At the “show-and-tell” meetings, self-trackers come together in an environment of trust, sharing, and reciprocity to discuss projects, tools, techniques, and experiences. There is a standard format in which projects are presented in a simplified version of the scientific method, answering three questions: “What did you do?” “How did you do it?” and “What did you learn?” The group’s third conference was held at Stanford University in September 2012 with over 400 attendees. Other community groups address related issues, for example Habit DesignFootnote 3, a U.S.-based national cooperation for sharing best practices in developing sustainable daily habits via behavior-change psychology and other mechanisms (Swan 2013).
A variety of quantified self-tracking projects have been conducted, and a few have been selected and described here to give an overall sense of the diverse activity. One example is design student Lauren Manning’s year of food visualization, where every type of food consumed was tracked over a one-year period and visualized in different infographic formats.Footnote 4 Another example is Rosane Oliveira’s multiyear investigation into diabetes and heart disease risk, using her identical twin sister as a control, and testing vegan dietary (not consuming animal products, not only meat but also eggs and dairy products) and metabolism markers such as insulin and glucose.Footnote 5
The range of tools used for QS tracking and experimentation extends from the pen and paper of manual tracking to spreadsheets, mobile applications, and specialized devices. Standard contemporary QS devices include pedometers, sleep trackers and fitness trackers. The Quantified Self web siteFootnote 6 listed over 500 tools, mostly concerning exercise, weight, health, and goal achievement. Unified tracking for multiple activities is available in mobile applications such as Track and ShareFootnote 7 and Daily TrackerFootnote 8. Many QS solutions pair the device with a web interface for data aggregation, infographic display, and personal recommendations and action plans. At present, the vast majority of QS tools do not collect data automatically and require manual user data input. A recent emergence in the community is tools created explicitly for the rapid design and conduct of QS experiments, including the Personal Analytics Companion (PACO)Footnote 9 and studycureFootnote 10.
Consequently, QS projects are becoming an interesting data management and manipulation challenge for big data science in the areas of data collection, integration, and analysis. Therefore, recommender technologies are also becoming very important in many QS applications.
3 Basic recommendation approaches
In the IoT context, recommender systems can support scenarios such as the recommendation of apps, services, sensor equipment, and IoT workflows (Felfernig et al. 2016b). In this section, we introduce basic recommendation algorithms. For a detailed discussion of recommendation algorithms we refer to Jannach et al. (2010).
Collaborative filtering (Konstan et al. 1997) is based on the idea of word of mouth promotion, i.e., the opinion of users with similar preferences plays a major role in a decision. These users are also denoted as nearest neighbors, i.e., users with similar preferences compared to the current user. The first step of a collaborative filtering recommender is to identify the k-nearest neighborsFootnote 11 and to extrapolate from the ratings of these users the preferences of the current user.
Content-based filtering (Pazzani and Billsus 1997) is based on the assumption of monotonic personal interests. For example, users interested in the topic Internet of Things are typically not changing their interest profile from one day to another but will also be interested in the topic in the (near) future. The basic approach of content-based filtering is to compare the content of already consumed items with new items that can potentially be recommended to the user, i.e., to find items that are similar to those already consumed (and positively rated) by the user.
Knowledge-based recommendation (Burke 2000; Felfernig and Burke 2008) does not rely on item ratings and textual item descriptions but on deep knowledge about the offered items represented in terms of constraints, rules, or similarity metrics. Such deep knowledge (semantic knowledge) describes an item in more detail and thus allows for a different recommendation approach. The current user articulates his/her requirements in terms of item property specifications which are internally as well represented as rules (constraints). Constraints are interpreted and the resulting items are presented to the user. Such items can also be interpreted as cases (consistent with the constraints) which are recommended to the current user as solutions for his/her current requirements (problem setting). The underlying recommendation process is also denoted as case-based recommendation (a kind of knowledge-based recommendation approach) (Felfernig and Burke 2008).
Utility-based recommendation (Felfernig and Burke 2008) is based on the idea that – given a set of items—item ranking is determined on the basis of multi-attribute utility theory (MAUT) (Winterfeldt and Edwards 1986). In this case, each item is evaluated with regard to a set of interest dimensions. In the context of optimizing the used data transfer protocols, example dimensions could be efficiency (measured in terms of transfer rates) and economy (measured in terms of costs for data connections). Utility-based recommendation is often combined with knowledge-based recommendation since item ranking is needed after constraints (rules) have pre-selected the items of potential relevance for the user. In this context, customer-individual preferences can also be learned by analyzing existing user interaction data (Jannach et al. 2010).
Hybrid recommendation (Burke 2002) is based on the idea of combining basic recommendation approaches in such a way that one helps to compensate the weaknesses of the other. For example, when combining content-based filtering with collaborative recommendation, content-based recommendation helps to recommend items which were not rated up-to-now. If a user has already consumed some items (e.g., purchased some IoT apps), the content description of a new item can be compared with the descriptions of items already purchased by the user. If the new item is similar to some of the already consumed ones (e.g., installed apps), it can be recommended to the user. Hybrid recommendation can also combine recommendation approaches to increase prediction quality. Combining the recommendations of different algorithms, for example, on the basis of a voting mechanism, can help to significantly increase prediction quality (Jannach et al. 2010).
Group recommender systems (Felfernig et al. 2018) are based on the idea that recommendations are not determined for single users but for a whole group, i.e., not a single user but the whole group should be satisfied with the given recommendation (e.g., a group decision regarding a smart home solution). Recommendations in this context are often determined on the basis of group decision heuristics (Masthoff 2011). For example, least misery is a heuristic that recommends items which minimize the misery of all group members. In contrast, most pleasure tries to maximize the pleasure of individual group members. Also in the context of group recommender systems, hybrid approaches can be developed, i.e., individual group recommendation heuristics can be combined with each other.
4 Existing applications of recommender systems in health-IoT
IoT-based applications enable a deeper understanding for recommender systems which can primarily be explained by the availability of heterogeneous information sources (Amato et al. 2013; Frey et al. 2015; Yao et al. 2016). Thanks to this ongoing IoT revolution, huge amounts of data are being collected in clinical databases representing patients’ health states. Sensor-based internet-enabled devices equipped with radio frequency identification (RFID) (Want 2006) tags and other communication enablers (Chen et al. 2012) are opening up exciting new ways of innovative recommendation applications in the health domain. Hence, required digital information is already available for patient-oriented decision making. This means, when this data can be used by recommendation algorithms, very important results can be obtained (Chen et al. 2012).
Casino et al. (2015) show how recommender systems could be used to provide healthcare services within the context of a smart city in which citizens collaborate with the city to improve their quality of life. It is observed that many citizens perform physical activities in the city, namely walking, running, and cycling. With the aim to promote these healthy habits, it would be desirable to count with a system that could dynamically adapt to the needs of the citizens. The system would consider real-time constraints and information from several sources: (1) citizens’ preferences, (2) citizens’ health conditions and, (3) real-time information provided by the smart city infrastructure. They propose the design of a system that fulfills the following properties:
Citizens can obtain recommendations of routes that best fit their needs and preferences using regular smartphones. No other special devices are required.
The system will be dynamic and collaborative, and it will adapt to real-time environmental changes.
Citizens will be allowed to contribute with their sensing capabilities, knowledge and experience to the system. Also they can inform about dangerous situations.
Citizens can provide the system with new routes.
In the area of patient health monitoring, Sharma and Kaur (2017) discuss how web-based tools can be used for dissemination of health related information and for providing a better quality of care to patients. It concludes that patients are more probable to follow advice from peers and patients with similar diseases.
Anumala and Busetty (2015) propose a distributed health platform using IoT devices. User health goals are specified and home smart appliances (e.g., microwave oven, smart TV) are all involved in monitoring the user health goals. However, their model does not support users in decision making.
Datta et al. (2015) propose the application of IoT for personalized healthcare in smart homes. An IoT architecture is presented which enables such healthcare services. Continuous monitoring of physical parameters and processing of the medical data form the basis of smarter, connected and personalized healthcare. The core functionalities of the IoT architecture are exposed using Restful web services.
On the other hand, we also observe recommender systems in traditional healthcare systems (without IoT usage). These approaches (Hu et al. 2016; Schäfer et al. 2017; Valdez et al. 2016) generally use the data stored in the centralize personal health records (PHR). PHR management systems may fail to satisfy the individual medical information needs of their users. Personalized recommendations could solve this problem. In Wiesner and Pfeifer (2010), a ranking procedure based on a health graph is proposed which enables a match between entries of a PHR management system and health information artifacts. This way, the user of such a system can obtain individualized health information he might be interested in. Nursing care plan recommender systems can provide clinical decision support, nursing education, clinical quality control, and serve as a complement to existing practice guidelines (Duan et al. 2011). Based on rule-based expert system, recommending clinical examinations for patients or physicians is also possible (Pattaraintakorn et al. 2007).
Recent researches also include recommender systems in QS applications. Schäfer (2016) proposed a decision support system that engages users with in- and output functionalities, such as gamified/ automated data insertion and intrigues him with avatar-based self-quantification or explanations. It also motivates users by personalizing on specific user needs and applying social pressure to ensure long term habit development. The system provides both crowd based and expert based recommendations, as well as hybrid recommendations tailored to the users needs and contexts.
This paper differs from all cited above in that we aim to achieve an effective decision making system in QS applications by utilizing both physical activity and health monitoring data. Our proposed recommendation approaches can answer a wide range of QS user questions, such as which new biosignal sensors to buy?, which new apps to install?, when to go for a walk?, how long to go for a walk?, when to go to sleep?. This means, our proposed approaches are helping QS application users in multi-dimensions. For example, in this paper, we propose a recommender called Virtual Sleep Regulator which recommends a daily walking and sleeping plan for insomnia patients (people with sleep disorder) based on their and similar users’ QS data. As far as we know, there is not such a QS application based recommendation approach up to now to support these insomnia patients. Therefore, our proposed recommender approaches aims to carry the recommendation systems in QS applications one step further than the state-of-the-art.
5 An example QS application: AGILE quantified-self
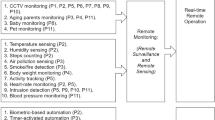
In this paper, we describe and test our recommendation approaches on the basis of AGILE Quantified-Self (see Fig. 1). Within the frame of AGILE Quantified-Self, AGILE gateway addresses this issue by creating a single point of communication for these devices, to facilitate their integration into QS concept, and provide advanced functionalities for the utilization and secure sharing of the acquired data, demonstrating the applicability of AGILE in home/personal use (Menychtas et al. 2017).

Software architecture of Quantified-Self on the basis of the AGILE gateway
As illustrated in Fig. 1, each user of the Quantified-Self application is provided with a set of activity tracking devices and biosignals sensors (such as oximetersFootnote 12, blood pressure monitorsFootnote 13 or glucometersFootnote 14), to monitor their daily physical activity and physical condition. All activity data and biosignal measurements are stored locally, on the user’s gateway. Users are able to visualize and manage their data, create reports and export the data from the gateway. Furthermore, they can even import past data from other cloud services they might have used before, such as FitbitFootnote 15 and GoogleFitFootnote 16. In parallel, motion and lifestyle data can be processed and analyzed on the gateway, so as personalized recommendations are sent to the user’s smart phone in order to encourage them to reach their physical activity goals. Moreover, users are able to share their activity data and achievements with certain people/users from their social circle, including relatives, friends and most importantly their physicians.
In this paper, we explain and test our recommendation approaches on the basis of AGILE Quantified-Self which requires the integration of several m-health and IoT elements (see Fig. 1), where proposed applications are orchestrated around the AGILE Gateway (Menychtas et al. 2017). The gateway connects to the home network and through the gateway’s management user interface, the owner has access to all provided features, such as reporting and visualization tools, can manage (store/view/edit) their data and define an access policy to share data with their social network contacts. Wearable activity trackers and medical sensors automatically communicate with the gateway whenever within range, and upload the most recent data. Integration with cloud platforms allows data synchronization between the gateway and the owner’s online profile, which enables the user to access their data through a web application. In addition, health and activity data can be downloaded to the gateway from the owner’s personal accounts on relevant platforms.
Since the implementation of the aforementioned application is ongoing and the number of users who are currently using it is limited, an extended dataset from an established m-health solution (Menychtas et al. 2016; Panagopoulos et al. 2017) has been used as the knowledge base for our recommender. The main dataset consists of the “biosignal” measurements of patients and elders, which are acquired directly from the biosignal sensors that users are equipped with. Supported biosignal sensors are the following: activity trackers, pulse oximeters, blood pressure monitors, weighing scales, spirometers, glucometers, and thermometers. These sensors measure the following biosignal types: step count, heart rate (bpm), oxygen saturation (%), blood pressure (mmHg), FEV1 (L), peak flow (L/min), blood glucose levels (mg/dL), and body temperature (Celsius). It should be noted that the modular design that has been followed, enables the potential integration of additional devices in the same application, which may require different operational workflows and communication patterns.
The biosignals’ dataset includes approximately half million records of the aforementioned biosignals from one hundred users in a time frame of three years. Besides the biosignal data, the knowledge base includes information for users’ demographics (gender, age, location), as well as their personal health record (lab results, medication and allergies). In order to ensure the smooth communication between the different components of the system (and for the smooth data integration with external systems), well established data models have been used. Therefore, in the proposed approach, all components and workflows which require data exchange and/or storage follow the Fast Healthcare Interoperability Resources Specification (FHIR)Footnote 17.
6 Proposed recommendation approaches in quantified-self
The utilization of recommendation technologies is essential for improving the health conditions of individuals. Users of IoT enabled m-health applications can get recommendations for new activity plans, IoT enabled m-health devices, applications, healthy nutritions. All these recommendations help users to enhance their life style and reach their targeted health conditions easier than before. These recommendations indeed play an important role like a personal trainer or personal coach.
We explain our proposed three recommendation approaches for IoT enabled m-health applications based on our QS application Agile Quantified-Self in the following subsections.
6.1 Virtual coach
In order to motivate subscribers/users for sport activities, Virtual Coach collects demographic information (age, location, physical condition, medical history, and chronic diseases) of each user. It stores user profiles on its online server and a recommender engine calculates the similarities between users based on their demographic data. Using the similar users’ information, a new activity plan (how often, what to measure, which activities) or a new IoT device (e.g., a wristband, a step counter watch) can be recommended to users.
In this case, a recommender engine uses collaborative filtering as the recommendation technology to find similarities between users. Virtual Coach recommends new activities or new devices to users based on these similarities.
There are several similarity metrics in the context of collaborative filtering scenarios for determining nearest neighbors (Jannach et al. 2010). For the purposes of our example, we use a simplified formula that supports the identification of k-nearest neighborsFootnote 18 (see Formula 1 Felfernig et al. 2019).
When Formula 1 is applied to the example of Table 1, property in Formula 1 is standing for demographics and devices of users. Thus, for the seven properties (age, gender, location, chronic diseases, oximeter, wristband, BPM (hearth beats per minute) device) of each user, the calculation result of eval(user_a) − eval(user_b) for the \(i^{th}\) property is 0 if their values are same, otherwise it is 1. For instance, for the first property age, the calculation result of eval(\(user_1\)) − eval(\(user_2\)) is 1, because age of \(user_1\) is young whereas age of \(user_2\) is middle. Since they do not have the same values, their difference is 1. For another instance, for the sixth property wristband, the calculation result of eval(\(user_1\)) − eval(\(user_2\)) is 1, because the usage of oximeter of \(user_1\) is \(\checkmark\) whereas for \(user_3\) it is \(\checkmark\). Since they have the same values, when \(property = 5\), the result of eval(\(user_1\)) - eval(\(user_3\)) is 0.
In order to find a recommendation for the active user \(user_x\) in Table 1, we first find the nearest neighbor based on demographics. The user \(user_1\) is the most similar user to the active user \(user_x\). Consequently, a collaborative recommender suggests new devices to the current user which have been used by the nearest neighbor (e.g., an oximeter device is recommended to \(user_x\)).
6.2 Virtual nurse
Virtual Nurse motivates different types of chronic patients (e.g., diabetes, asthma, cancer, cardiovascular) to reach their targets on the basis of a recommended plan. It collects the measured data of patients and checks their health conditional targets. If the measured values are very far from their expected (target) values, then some specific recommendations can be placed for those patients. The recommendations should be personalized and related to the base line of each user’s data, which will be permanently updated.
The patient medical data includes the personalized models that shows the behavioral responses of the patients versus the coach interventions to discover best-practices and measure adherence. The recommender could act as a decision support system that gathers information from the patient, finds an activity plan that matches with the available objectives and offers a personalized list. A physician might intervene (semi-supervised recommendation) to select the collected information that are more related with the well-being of the patient. In this case, the recommender engine uses Content-based Filtering as the recommendation technology to find a related plan based on the user data. Virtual Nurse recommends new activity plans to users based on their actual and expected measurements.
A simplified example of a related recommendation approach is given in Table 2. When applying a content-based filtering based approach, recommended items (plans) are determined on the basis of the similarity of the patient’s targets and available plans. Similar to collaborative filtering, there are different types of similarity metrics (Jannach et al. 2010). For the purposes of our examples, we introduce a simplified formula that supports the identification of, for example, relevant plans for the patient-1 (see Formula 2 Felfernig et al. 2019).
Formula 2 determines the similarity on the basis of the targets of plans and targets of patient-1. For instance, the similarity between targets of patient-1 and targets of plan-3 is calculated as 0.33 where \(\#(targets(patient-1) \cap targets(plan-3))=1\) since there is only one common target which is decreasing the hearth-rate and \(\#(targets(patient-1) \cup targets(plan-3))=3\) where all targets include systolic blood pressure, hearth-rate, and weight. In our example of Table 2, targets of plan-1 has the highest similarity with targets of patient-1, therefore targets of plan-1 is recommended to patient-1.
6.3 Virtual sleep regulator
Chronic insomnia, defined as difficulty initiating or maintaining sleep, awakening too early in the morning, or non-restorative sleep, is the most common sleep disorder among adults. Though exercise has long been assumed to improve sleep, surprisingly little research has been conducted on the effect of exercise on chronic insomnia.
Related studies (Guilleminault et al. 1995; Passos et al. 2011, 2010; Reid et al. 2010) show that exercise significantly improves the sleep of people with chronic insomnia. The only study that looked at the effects of a single exercise session found that about of moderate-intensity exercise (e.g., walking) reduced the time it took to fall asleep and increased the length of sleep of people with chronic insomnia compared to a night in which they did not exercise. However, in the same study, vigorous exercise (e.g., running) or lifting weights did not improve sleep. Similar results have been found for studies that examined the effects of long-term exercise on sleep in adults with insomnia. In these studies, after 4 to 24 weeks of exercise, adults with insomnia fell asleep more quickly, slept slightly longer, and had better sleep quality than before they began exercising.Footnote 19
Virtual Sleep Regulator helps insomnia patients to improve their sleep qualities. It uses collaborative filtering techniques to recommend an appropriate walking/sleeping plan for the patients.
6.3.1 Recommendation technology
We used collaborative filtering approach to recommend a steps & sleep plan for users based on the recommendable activities of other users’. As aforementioned, the first step of a collaborative filtering recommender is to identify the k-nearest neighborsFootnote 20 and to extrapolate from the ratings of these users the preferences of the current user.
We have used the collaborative filtering recommendation library of Apache-Mahout (Schelter and Owen 2012). Apache Mahout is an Apache-licensed, open source library for scalable machine learning. It is well known for algorithm implementations that run in parallel on a cluster of machines. Besides that, Mahout offers one of the most mature and widely used frameworks for non-distributed Collaborative Filtering. We give an overview of this framework’s functionality, API and featured algorithms. At the heart of Collaborative filtering applications lie user-item interactions. Mahout models those as a < user,item,value > triple. Mahout’s recommenders expect interactions between users and items as input. The easiest way to supply such data to Mahout is in the form of a textfile, where every line has the format < user,item,value >. Here userID and itemID refer to a particular user and a particular item, and value denotes the strength of the interaction (e.g., the rating given to a movie). An example of Mahout data file is shown in Table 3. Based on the ratings of users for the movies, for the user with userID=2, the movie with the itemID=12 can be recommended (due to the similarities between the ratings of users userID=1 and userID=2).
6.3.2 Dataset
From 26 users, during six months, we have collected number of steps (see Table 4) and quality of sleep (see Table 5) data. In Table 4, each row is identified with a unique Activity ID and the duration of each activity is 5 minutes. Number of steps are the taken steps during a 5 minutes period which starts at given Date/time.
In Table 5, each row is identified with a unique Activity ID and the duration of each activity is 5 minutes. Quality of Sleep is the measured sleep quality during a 5 minutes period which starts at given Date/time. Sleep Quality domain is [\(-10,-20,-30,-40\)] where \(-40\) is the highest quality (the deepest) sleep whereas \(-10\) is the lowest quality (the lightest) sleep.
Based on these two datasets, we generated a < user,item,value > triple style dataset (see Table 6). In order to do this, we have defined attributes of users as items. All the item values are scaled in [1..5]. For example, gender of user is defined as item ID = 1 with values [1.0 (if gender = female), 3.0 (if gender = other), 5.0 (if gender = male)]. Age of user is defined as item ID = 2 with values [1.0 (if age < 20), 2.0 (if 20 \(<=\) age > 40), 3.0 (if 40 \(<=\) age > 60), 4.0 (if 60 \(<=\) age > 80), 5.0 (if age \(>=80\))]. Other items are the steps and sleep results of users during a day which are encoded according to Table 3 with values [1.0 (if sleep quality \(>-10\)), 2.0 (if \(-10>=\) sleep quality \(<-20\)), 3.0 (if \(-20>=\)sleep quality \(<-30\)), 4.0 (if \(-30>=\) sleep quality \(<-40\)), 5.0 (if sleep quality \(=<-40\))] where 5.0 means the deepest sleep and 1.0 is the lightest.
As shown in Table 7, the steps and sleep plan of a day is encoded as an item ID which holds number of steps, durations of steps (hours) and durations of sleeps (hours). The first character in the item ID is ignored since it is used for padding (to avoid the cases where the item ID starts with 0, because initial 0s are ignored by the recommender). The first row (Enc.) shows the encoding in the item ID and the second row (Act.) holds the actual corresponding values in number of steps or hours. The actual number of steps are calculated by adding 1 to the number of steps before multiplying with 2000. The actual duration of steps is calculated by adding 1 to the duration of steps. The actual duration of sleep is directly taken as the duration of sleep.
Based on the converted steps/sleep quality dataset in Table 6, we request two recommendations from the recommender for the user with userID = 20 and the recommender finds the nearest neighbor. The most similar user (nearest neighbor) to userID = 20 is userID = 19, because they both have same gender (gender is represented with itemID = 1 and both users have value = 1.0 which means both are female) and same age group (age group is represented with itemID = 2 and both users have value = 1.0 which means both are younger than 20). Therefore the items with highest ratings (values) of userID = 19 are recommended to userID = 20 which are 1020000700 (value = 5.0) and 1000000800 (value = 5.0).
6.3.3 Interface
As shown in Fig. 2, the user dashboard of Quantified-Self presents recommendation results from Virtual Sleep Regulator based on the demographics (age and gender) and the current activities (the total number of steps taken during the day and the sleep quality values) of the user. The recommendations are provided based on the similar users data and this data grows continuously with new activity data. Therefore, the output of the system evolves with the new data coming from all the users of this system.

An instance of the user dashboard of Quantified-Self with recommendation results from Virtual Sleep Regulator
The web API of Virtual Sleep Regulator provides a human readable version of these recommendation results in JSON (JavaScript Object Notation) format as follows:
{“intro1”: “Recent scientific works show that Insomnia (a sleep disorder)
can be solved with a personal physical activity plan.”,
“intro2”: “Therefore, according to your profile, for a high quality sleep,
we recommend you several walking and sleeping plans as below:”,
“activityRecommendation_list”: [
{ “steps1”: “take 2000 steps in 1 hours before noon”,
“steps2”: “take 6000 steps in 1 hours in the afternoon”,
“steps3”: “take 2000 steps in 1 hours in the evening”,
“sleep1”: “sleep 7 hours between 00:00-12:00”,
“sleep2”: “sleep 0 hours between 12:00-18:00”,
“sleep3”: “sleep 0 hours between 18:00-24:00” },
{ “steps1”: “take 2000 steps in 1 hours before noon”,
“steps2”: “take 8000 steps in 2 hours in the afternoon”,
“steps3”: “take 2000 steps in 1 hours in the evening”,
“sleep1”: “sleep 8 hours between 00:00-12:00”,
“sleep2”: “sleep 0 hours between 12:00-18:00”,
“sleep3”: “sleep 0 hours between 18:00-24:00” } ]}
7 Performance evaluations
In the previous section, we have introduced the user interface of Virtual Sleep Regulator. However, we could not yet test this interface with a dataset of real users. Therefore, in this section, we have evaluated the performance (in terms of prediction accuracy) of other two proposed methods: Virtual Nurse and Virtual Coach. The performance indicator Prediction Accuracy (Erdeniz et al. 2019) has a generic definition in recommender systems as provided in the following paragraph.
Prediction accuracy (\(\pi\)) A recommended product can be purchased by the customer or not. If the recommended product is purchased, then it is considered as a correct recommendation CR, otherwise it is not a correct recommendation IR. As shown in Formula 3, the prediction accuracy of a recommender is calculated by dividing the number of correct recommendations by the number of total recommendations.

Evaluation datasets
In order to evaluate the prediction accuracy of our method, first we have removed a device/activity plan from the dataset (see Fig. 3) of each patient. Then, we have calculated recommendations for those patients with sparse datasets. Finally, we have compared the recommended item with the removed item from patient’s dataset to calculate the accuracy.

Evaluation results
As seen in Fig. 4, Virtual Coach can find the most accurate recommendations for Patient #3, because Patient#3 uses many common devices with other patients. Virtual Nurse can find the most accurate recommendations for Patient #4, because Patient#4 has the richest dataset (incl. allergies and medications) among other patients. According to our evaluation results, our health-IoT recommender helps users/patients to improve their health conditions by providing highly accurate recommendations (\(\ge\) 0.75).
8 Further research issues
The lessons learned during the design and implementation of the proposed recommender approaches can be grouped in several further research issues as stated in the following paragraphs.
Datasets for evaluation purposes The development of recommendation technologies for QS applications is a rather young discipline and research in the field would strongly profit from the availability of more QS datasets that enable corresponding tests of, for example, the prediction quality of recommendation algorithms.
Scalability and privacy In many scenarios, recommendation algorithms, especially the ones based on collaborative filtering approaches, can be deployed in the cloud which has no serious limitations regarding computational resources. Typical examples of such a setting are the recommendation of QS apps (e.g., located on some sort of application marketplace) and the recommendation of QS devices (e.g., located on an online store). However, for recommendation functionalities that employs sensitive data (e.g., medical data of users), the recommendation system (e.g., Virtual Nurse) and the related content-based dataset (e.g., activity plan options) should be located directly on the local IoT gateway for privacy issues.
Distributed data analysis The distributed nature of the Internet of Things and corresponding high amounts of collected data from QS applications are challenging existing data analysis methods (Stolpe 2016). While approaches to big data analytics (Chen et al. 2015; Sun et al. 2016) often follow the paradigm of parallel and high-performance computing, analysis approaches in IoT gateways based QS application scenarios are often limited, for example, in terms of bandwidth and energy supply. This is the major motivation for decentralized analysis algorithms that often have to work (partly) on QS devices.
Group recommender systems Compared to traditional group recommender systems, QS application scenarios increase the number of relevant dimensions in the corresponding datasets. For example, in group-based scenarios (e.g., a group of tourists interested in a city round trip recommendation) example dimensions are not only related to the items to be recommended (e.g., tourist destinations) but also to additional dimensions such as information about health status of group members (e.g., according to the heart rate data of group members, some group members may need a short break rather than further walking).
9 Conclusions and future work
Applications based on the Quantified-Self (QS) engage individuals in the self-tracking of any kind of biological, physical, behavioral, or environmental information as individuals or groups. Based on the collected huge amount of self-tracking data, there are new needs for recommender systems to support QS application users. Recommender systems can help to more easily identify relevant artifacts for users and thus improve user experiences.
In this paper, we have proposed three recommendation approaches Virtual Coach, Virtual Nurse, and Virtual Sleep Regulator which help users/patients to improve their health conditions. This improvement is provided by appropriate device or sportive activity recommendations for users by Virtual Coach, activity plan recommendation for patients by Virtual Nurse, and walking/sleeping plan recommendation for patients by Virtual Sleep Regulator. We have explained these proposed approaches based on real-world datasets collected from a QS application AGILE Quantified-Self and also applied experimental evaluations on Virtual Coach and Virtual Nurse. Moreover, we have demonstrated how a JSON format and the corresponding user interface of a recommendation output of Virtual Sleep Regulator look like. Finally, we have discussed further research issues to motivate the researchers working in the domain of recommender systems for QS.
The proposed approaches in this paper are novel in QS and improve the user experience with helpful recommendations. State of the art applications in QS do not provide activity or sleep recommendations based on such datasets. For example, thanks to our novel bit-coded model for Virtual Sleep Regulator, we could obtain a standardized dataset of steps/sleep qualities of various users and utilize state of the art recommendation algorithms (collaborative filtering approaches). Since in the proposed methods, all employed algorithms are well known algorithms in recommendation systems, we provide neither long algorithms descriptions nor a performance comparison. As mentioned, we have used Apache Lucene (for content based filtering) and Apache Mahout (for collaborative filtering) Java libraries for calculation recommendations.
As future work, we would like to extend our approaches by employing various correlations based on more parameters in datasets. Therefore, we expect to obtain more complicated recommendations. For example, if we can also know jobs or working times of the users, we could recommend more accurate sleeping times to regulate the user’s sleeping quality.
Notes
AGILE (An Adaptive & Modular Gateway for the IoT) is an EU-funded H2020 project 2016–2018—see http://agile-iot.eu/.
k represents the number of users with similar ratings compared to the current user.
For simplicity we assume \(k=1\).
k represents the number of users with similar ratings compared to the current user.
References
Amato F, Mazzeo A, Moscato V, Picariello A (2013) A recommendation system for browsing of multimedia collections in the internet of things. In: Bessis N, Xhafa F, Varvarigou D, Hill R, Li M (eds) Internet of things and inter-cooperative computational technologies for collective intelligence, studies in computational intelligence, vol 460. Springer, New York
Anumala H, Busetty SM (2015) Distributed device health platform using internet of things devices. In: Data science and data intensive systems (DSDIS), 2015 IEEE international conference on IEEE, pp 525–531
Atzori L, Iera A, Morabito G (2010) The internet of things: a survey. Comput Netw 54:2787–2805
Burke R (2000) Knowledge-based recommender systems. Encycl Libr Inform Syst 69(32):180–200
Burke R (2002) Hybrid recommender systems: survey and experiments. UMUAI J 12(4):331–370
Casino F, Batista E, Patsakis C, Solanas A (2015) Context-aware recommender for smart health. In: Smart Cities Conference (ISC2), 2015 IEEE first international IEEE, pp 1–2
Chen H, Chiang RH, Storey VC (2012) Business intelligence and analytics: from big data to big impact. MIS Q 36(4):1165–1188.https://doi.org/10.2307/41703503
Chen F, Deng P, Wan J, Zhang D, Vasilakos A, Rong X (2015) Data mining for the internet of things: literature review and challenges. Int J Distrib Sens Netw. https://doi.org/10.1155/2015/431047
Datta SK, Bonnet C, Gyrard A, Da Costa RPF, Boudaoud K (2015) Applying internet of things for personalized healthcare in smart homes. In: Wireless and optical communication conference (WOCC), 2015 24th IEEE, pp 164–169
Duan L, Street WN, Xu E (2011) Healthcare information systems: data mining methods in the creation of a clinical recommender system. Enterp Inform Syst 5(2):169–181
Erdeniz SP, Felfernig A, Samer R, Atas M (2019) Matrix factorization based heuristics for constraint-based recommenders. In: Proceedings of the 34th ACM/SIGAPP symposium on applied computing ACM, pp 1655–1662
Felfernig A, Boratto L, Stettinger M, Tkalčič M (2018) Group recommender systems: an introduction. Springer, New York
Felfernig A, Burke R (2008) Constraint-based recommender systems: technologies and research issues. In: ACM international conference on electronic commerce (ICEC08), Innsbruck, Austria, pp 17–26
Felfernig A, Erdeniz SP, Azzoni P, Jeran M, Akcay A, Doukas C (2016a) Towards configuration technologies for iot gateways. In: 18th international configuration workshop
Felfernig A, Erdeniz SP, Azzoni P, Jeran M, Akcay A, Doukas, C (2016b) Towards configuration technologies for iot gateways. In: International workshop on configuration 2016 (ConfWS’16), Toulouse, France, pp 73–76
Felfernig A, Erdeniz SP, Jeran M, Akcay A, Azzoni P, Maiero M, Doukas C (2017) Recommendation technologies for iot edge devices. Proc Comput Sci 110:504–509
Felfernig A, Erdeniz SP, Uran C, Reiterer S, Atas M, Tran TNT, Azzoni P, Király C, Dolui K (2019) An overview of recommender systems in the internet of things. J Intell Inf Syst 52(2):285–309. https://doi.org/10.1007/s10844-018-0530-7
Fox KR (1999) The influence of physical activity on mental well-being. Public Health Nutr 2(3a):411–418
Frey R, Xu R, Ilic A (2015) A novel recommender system in IoT. In: 5th International conference on the internet of things (IoT 2015), Seoul, South Korea, pp 1–2
Greengard S (2015) The internet of things. MIT Press, Cambridge
Guilleminault C, Clerk A, Black J, Labanowski M, Pelayo R, Claman D (1995) Nondrug treatment trials in psychophysiologic insomnia. Arch Intern Med 155(8):838–844
Hu H, Elkus A, Kerschberg L (2016) A personal health recommender system incorporating personal health records, modular ontologies, and crowd-sourced data. In: Advances in social networks analysis and mining (ASONAM), 2016 IEEE/ACM international conference on IEEE, pp 1027–1033
Jannach D, Zanker M, Felfernig A, Friedrich G (2010) Recommender systems—an introduction. Cambridge University Press, Cambridge
Konstan J, Miller B, Maltz D, Herlocker J, Gordon L, Riedl J (1997) Grouplens: applying collaborative filtering to usenet news full text. Comm ACM 40(3):77–87
Maglogiannis I, Ioannou C, Tsanakas P (2016) Fall detection and activity identification using wearable and hand-held devices. Integr Comput Aided Eng 23(2):161–172
Masthoff J (2011) Group recommender systems. Recommender systems handbook, pp 677–702
McGrath MJ, Scanaill CN (2013) Wellness, fitness, and lifestyle sensing applications. In: Sensor technologies. Springer, New York, pp 217–248
Menychtas A, Doukas C, Tsanakas P, Maglogiannis I (2017) A versatile architecture for building iot quantified-self applications. In: 2017 IEEE 30th international symposium on computer-based medical systems (CBMS) IEEE, pp 500–505
Menychtas A, Tsanakas P, Maglogiannis I (2016) Automated integration of wireless biosignal collection devices for patient-centred decision-making in point-of-care systems. Healthc Technol Lett 3(1):34–40
Miorandi D, Sicari S, DePellegrini F, Chlamtac I (2012) Internet of things: vision, applications and research challenges. Ad Hoc Netw 10:1497–1516
Munson SA, Consolvo S (2012) Exploring goal-setting, rewards, self-monitoring, and sharing to motivate physical activity. In: Pervasive computing technologies for healthcare (PervasiveHealth), 2012 6th international conference on IEEE, pp 25–32
Panagopoulos C, Malli F, Menychtas A, Smyrli EP, Georgountzou A, Daniil Z, Gourgoulianis KI, Tsanakas P, Maglogiannis I (2017) Utilizing a homecare platform for remote monitoring of patients with idiopathic pulmonary fibrosis. In: GeNeDis 2016. Springer, New York, pp 177–187
Passos GS, Poyares D, Santana MG, D’Aurea CVR, Youngstedt SD, Tufik S, de Mello MT (2011) Effects of moderate aerobic exercise training on chronic primary insomnia. Sleep Med 12(10):1018–1027
Passos GS, Poyares D, Santana MG, Tufik S, Tú M et al (2010) Effect of acute physical exercise on patients with chronic primary insomnia. J Clin Sleep Med 6(03):270–275
Pattaraintakorn P, Zaverucha GM, Cercone N (2007) Web based health recommender system using rough sets, survival analysis and rule-based expert systems. In: International workshop on rough sets, fuzzy sets, data mining, and granular-soft computing. Springer, New York, pp 491–499
Pazzani M, Billsus D (1997) Learning and revising user profiles: the identification of interesting web sites. Mach Learn 27:313–331
Reid KJ, Baron KG, Lu B, Naylor E, Wolfe L, Zee PC (2010) Aerobic exercise improves self-reported sleep and quality of life in older adults with insomnia. Sleep Med 11(9):934–940
Schäfer H (2016) Personalized support for healthy nutrition decisions. In: Proceedings of the 10th ACM conference on recommender systems ACM, pp 455–458
Schäfer H, Hors-Fraile S, Karumur RP, Calero Valdez A, Said A, Torkamaan H, Ulmer T, Trattner C (2017) Towards health (aware) recommender systems. In: Proceedings of the 2017 international conference on digital health ACM, pp 157–161
Schelter S, Owen S (2012) Collaborative filtering with apache mahout. Proc. of ACM RecSys challenge
Sharma P, Kaur PD (2017) Effectiveness of web-based social sensing in health information dissemination—a review. Telemat Inform 34(1):194–219
Stolpe M (2016) The internet of things: opportunities and challenges for distributed data analysis. ACM SIGKDD Exlorations Newslett 18:15–34
Sun Y, Song H, Jara A, Bie R (2016) Internet of things and big data analytics for smart and connected communities. IEEE Access 4:766–773
Swan M (2012) Sensor mania! the internet of things, wearable computing, objective metrics, and the quantified self 2.0. J Sens Actuator Netw 1(3):217–253
Swan M (2013) The quantified self: fundamental disruption in big data science and biological discovery. Big Data 1(2):85–99
Valdez AC, Ziefle M, Verbert K, Felfernig A, Holzinger A (2016) Recommender systems for health informatics: state-of-the-art and future perspectives. In: Machine learning for health informatics. Springer, New York, pp 391–414
Want R (2006) An introduction to rfid technology. IEEE Pervasive Comput 5(1):25–33
Wei J (2014) How wearables intersect with the cloud and the internet of things: considerations for the developers of wearables. IEEE Consum Electron Mag 3(3):53–56
Wiesner M, Pfeifer D (2010) Adapting recommender systems to the requirements of personal health record systems. In: Proceedings of the 1st ACM international health informatics symposium ACM, p. 410–414
Winterfeldt D, Edwards W (1986) Decision analysis and behavioral research. Cambridge University Press, Cambridge
Yao L, Sheng Q, Ngu A, Li X (2016) Things of interest recommendation by leveraging heterogeneous relations in the internet of things. ACM Trans Internet Technol 16(9):1–25
Zammit GK, Weiner J, Damato N, Sillup GP, McMillan CA (1999) Quality of life in people with insomnia. Sleep: J Sleep Res Sleep Med 22 Suppl 2:S379-85
Acknowledgements
Open access funding provided by Graz University of Technology.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Ethical statement
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants involved in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Erdeniz, S.P., Menychtas, A., Maglogiannis, I. et al. Recommender systems for IoT enabled quantified-self applications. Evolving Systems 11, 291–304 (2020). https://doi.org/10.1007/s12530-019-09302-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12530-019-09302-8