
Abstract
The present study uses various statistical tools to understand the behaviour of PM2.5 and PM10 in the Kanjikode industrial area of Southern India. Annual PM2.5 and PM10 average concentrations in 2018–2020 were three times more than the World Health Organization–specified standards (5 and 15 µg m−3). The statistical distribution analysis suggested well-fitted lognormal and gamma distributions of 24-h average PM2.5 concentrations and gamma distributions of 24-h average PM10 concentrations. Trend analysis observed a notable monotonic increasing trend for 24-h average PM2.5 concentrations with an increasing magnitude of 0.43 µg m−3 per annum. A downward trend was found for 24-h average PM10 concentrations, with a decreasing magnitude of 0.2 µg m−3 per year. Extreme event analysis of PM2.5 and PM10 has provided the highest concentration levels expected in the coming 10 years, 193 and 165 µg m−3, respectively, higher than the Indian National Ambient Air Quality Standards and considered a public health threat. The health risk assessment by AirQ + emphasized that more than 15, 34, and 27 premature deaths caused by total mortality in 2018, 2019, and 2020 could have been prevented if PM2.5 concentrations in the Kanjikode industrial area did not exceed 10 μg m−3. Statistical analysis and health risk assessment suggested adopting various constructive and multipronged approaches to reduce pollution levels and develop a health risk management plan in the industrial region.
Similar content being viewed by others
1 Introduction
Air pollution has been one of India’s persistent environmental issues in recent years. Poor air quality is a substantial health and environmental concern that impacts well-being, hampers development, and incurs steep economic costs. As an emerging economic country in South Asia, India’s rapid industrialization and urbanization have led to extreme air pollution in urban and rural areas. The World Health Organization (WHO) reported that, in India, 14 of the 15 cities worldwide have the most severe air pollution. Northern India has experienced more severe air pollution episodes than southern India due to spatial heterogeneity and diverse meteorological conditions (PHFI, 2017). In 2019, household air pollution and particulate matter contributed to 1.67 million deaths in India, accounting for 17·8% (Pandey et al., 2021). Seventy-seven percent of India’s population lives in places where the annual PM2.5 concentration is above 40 μg m−3, the standard set by the Indian National Ambient Air Quality Standards (NAAQS) (Balakrishnan et al., 2019). No state in India has met the annual PM2.5 standard limit of 10 μg m−3 set by the WHO. India’s ambient air pollution sources are classified into vehicular exhaust households; small, medium, and large-scale industries; agriculture; power plants; waste and biomass burning; and construction and demolition activities. India’s populace has been breathing higher levels of toxic air, due to which they have experienced increased mortality and disease burden (Balakrishnan et al., 2019; Botle et al., 2020; Dwivedi et al., 2022; Gangadharan & Nambi, 2020; Masih et al., 2019; Pandey et al., 2021; Rohra et al., 2020).
Central and State Pollution Control Boards (CPCB and SPCBs) evaluated 88 industrial clusters and identified them as polluted areas, illustrating India’s air, water, and land pollution (SoE, 2021). The dissemination of daily levels of air pollutants, particularly in industrial areas, is essential for individuals suffering from illnesses from air pollution exposure. Knowledge of the statistical distribution of air quality data is necessary for predicting high pollutant concentrations, so that action can be planned and taken by related agencies and governments to tackle high pollutant events in future years. The ambient air pollutant levels varied with emission source strength and meteorological conditions. Previous studies have used distributions such as normal, lognormal, Weibull, gamma, and exponential distributions to fit the ambient air quality parameters (Giavis et al., 2009; Gulia et al., 2017; Lu & Fang, 2002; Mishra et al., 2021; Yang et al., 2012). Trend analysis is a helpful method for assessing variations in pollutant concentrations over time and may also be used to demonstrate the effectiveness of policy initiatives (Pandolfi et al., 2016; Sicard et al., 2021). The most common component of many statistical approaches researchers use is analyzing and correlating trends in pollutant data and meteorological parameters. Site-specific monitoring and source apportionment techniques can act as management and decision-making tools. Extreme event analysis (EVA) provides a statistical model to quantify the probability of extreme events, such as air pollution and the highest concentration of air pollutants, using return value analysis in a time of interest (Martins et al., 2017; Masseran et al., 2016). Extreme concentrations of air pollutants affect air quality and cause health hazards.
Studies have reported the adverse health effects of air pollution, focusing on long-term (chronic) and short-term (acute) exposures. The health of vulnerable and susceptible individuals (e.g., the elderly, women, and children) can be affected even on days with low levels of air pollution. Air pollution has many health effects, including respiratory and cardiovascular disorders, cancer, premature death, hypertension, and cognitive impairment. Many researchers worldwide have used the AirQ + model developed by the WHO to evaluate the long- and short-term health impacts of ambient air pollutants (Amoatey et al., 2020; Manojkumar & Srimuruganandam, 2021; Miri et al., 2016; Omidi Khaniabadi et al., 2019).
The present study investigates the statistical distributions and trends in the 24-h PM2.5 and PM10 concentrations measured in an industrial area of southern India. The Python-based pyMannKendall package was used to identify the trend in PM concentrations over the monitoring period. Additionally, we computed the return value of PM concentrations in a period of interest by applying threshold modelling, a Python package for modelling excesses over a threshold using the Generalized Pareto Distribution. Moreover, we explored the influence of meteorological parameters on pollutant concentrations. Furthermore, we estimated long-term health impacts such as total mortality and mortality due to chronic obstructive pulmonary disease (COPD), ischemic heart disease (IHD), lung cancer (LC), and stroke due to PM2.5.
2 Methodology
2.1 Study Area
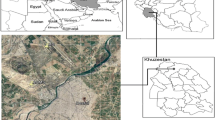
Kanjikode, with an area of 16.88 km2 and a population of more than 50,000 people, is located 13 km east of Palakkad town, one of the major industrial areas in Kerala, India. Kanjikode is an industrial hub in the Palakkad District of Kerala, India. Due to many electric furnace–based industries, air quality degradation in the Kanjikode area has been observed (MOEF 2022). Various companies, such as PPS Steel (Kerala) Pvt. Ltd., Pepsi, Indian Telephone Industries Limited (ITI), Patspin India Ltd., United Breweries, Rubfila International Ltd., Bharat Earth Movers Limited (BEML), and Saint-Gobain India Pvt. Ltd. (SEFPRO), are located in this region (Fig. 1). There are nearly 48 industries in this region, including manufacturing units for steel, cement, paint color, distilleries, fertilizers, textiles, and chemicals. Industrial emissions in Kanjikode vary based on the activities carried out in various industries (Table S3). High-volume samplers, such as APM 460BL, were used to collect 24-h PM10 samples, and fine-volume samplers (APM 550) were used to collect 24-h PM2.5. PM10 and PM2.5 sampling was conducted on the rooftop of a building with a height of 20 m located in SEPR Refractories (SEFPRO). The monitoring station located in the study area was at least 250–300 m away from the major polluting sources (stacks, roads). SEFPRO is a 100% subsidiary of Saint-Gobain SEFPRO and one of the leading manufacturers of fused cast and sintered refractories for glass furnaces. The two main processes in this industry are sintering and fusion. A total of 232 samples were collected during 2018 (winter—16, summer—24, southwest monsoon—33, northeast monsoon—27), 2019 (winter—19, summer—18, southwest monsoon—21, northeast monsoon—14), and 2020 (winter—18, summer—15, southwest monsoon—18, northeast monsoon—9).

Layout of monitoring location in Kanjikode industrial area
2.2 Statistical Distribution Analysis
Characterizing the probability distribution of PM data is necessary for predicting the average concentration and probability of exceeding the standard limit set by the Indian NAAQS. The present study evaluated normal, lognormal, Weibull, gamma, and exponential distributions of the measured 24-h PM2.5 and PM10 concentrations. These distribution parameters (scale, shape, and location) were computed using the maximum likelihood estimation (MLE) method. The goodness-of-fit tests used to assess the best fit in the present study were the Kolmogorov–Smirnov (K-S), modified Kolmogorov–Smirnov, and Anderson–Darling (A-D) tests. A probability plot was used to identify the best fit of a dataset that followed a given distribution. After identifying the best distribution model, we used the cumulative distribution function to calculate the exceeding probabilities. The algorithms for parameter estimation by MLE and goodness of fit tests are provided in the supplementary information (S1).
2.3 Trend Analysis
The Mann–Kendall (M–K) test (Kendall, 1970; Mann, 1945) is a nonparametric test that is extensively used to find notable trends in temporal data (Bari et al., 2016). The slope estimator method was proposed by Theil (1992) and Sen (1968) to assess the magnitude of monotonic trends. Theil-Sen trend estimator is suitable for nonparametric data because of its insensitivity to anomalies, and it might be applied in severely skewed datasets. The test produced a p-value for the significance level and a slope value with a 95% confidence interval. The python-based pyMannKendall package was used for trend analysis in the present study (Hussain and Mahmud 2019).
2.4 Extreme Value Analysis
Generalized Pareto distribution (GPD) is commonly used in extreme event analysis (EVA). This approach uses the data above a predetermined threshold value and evaluates all data over the threshold without selecting a set of minimum or maximum values. The likelihood of the return level of the adverse environmental state was calculated using the fitted GPD model represented in Eq. (1). The probability of the return level is an essential measure of the likelihood of air pollution occurrences for a specific period.
\(x\) denotes the excess over a given threshold value. The maximum-likelihood approach was used to estimate the shape (ξ) and scale parameters (β), which determine the distribution. The threshold provides a simple but essential component for a correct fit; it defines the point at which an occurrence is excessive (Martins et al., 2017). A recurrence interval, also known as a return period, can be used to estimate the probability of an event with an extreme level of pollutants. The danger of an air pollution event can be inferred from this indicator based on the return level over a considerable amount of time. In this study, threshold modelling, a Python package, was used to choose, fit the threshold, and estimate the return value of PM concentrations at a time of interest (Lemos et al., 2020; Masseran et al., 2016).
2.5 Health Risk Estimation
The WHO developed AirQ + , which quantifies the health impact of ambient PM concentrations (WHO, 2018). The burden of diseases, such as mortality, morbidity, and risk assessment, can be studied using AirQ + . The long-term impacts of ambient PM2.5 were assessed in this study using AirQ + software (Version 2.1.1). This study used the values of input factors such as pollution concentration and population. In addition, to execute the AirQ + programme, relative risk, disease-specific or health endpoint incidence, and cut-off values should be known. A log-linear methodology was used in AirQ + to generate relative risk levels. The baseline incidence values (per 100,000 individuals) for each health outcome derived from previous studies were as follows: Total mortality = 1013, lung cancer = 22, COPD mortality = 106, and stroke mortality, 70 (Amoatey et al., 2020; Maji et al., 2017; Manojkumar & Srimuruganandam, 2021). The attributable proportions, number of attributable excess cases, and number of attributable cases (per 1 lakh population) were calculated using a 95% confidence interval. The mathematical expressions used for calculating health risk estimation are given in the supplementary information (S2).
3 Results and Discussion
3.1 Seasonal Characteristics of PM in the Kanjikode Industrial Area
The boxplot of PM2.5 for 2018–2020 showed that 75% of the data were within the standard limit prescribed by Indian NAAQS (60 µg m−3). Twenty-four-hour average PM2.5 concentrations for 1 day in 2018 and 4 days in 2019 exceeded 60 µg m−3. Annual PM2.5 concentrations of the Kanjikode industrial area were 3, 4.8, and 3.5 times more than the WHO-specified limit (5 µg m−3) in 2018, 2019, and 2020, respectively. The dataset showed that 50% of the PM2.5 concentration followed the range of 5–18 µg m−3, 10–28 µg m−3, and 9–40 µg m−3 in 2018, 2019, and 2020, respectively (Fig. 2). The maximum 24-h average PM2.5 concentration was observed to be 73 µg m−3, 167 µg m−3, and 55 µg m−3 in 2018, 2019, and 2020, respectively. The distribution of the time-series data exhibited high kurtosis (K) and skewness (S), which are considered frequency distribution moves away from a normal distribution (Hair et al., 2017). The high K, high S, and less interquartile range (IQR) of the PM2.5 dataset in the winter season of 2019 (K = 2.2; S = 4.3; IQR = 27.8), summer seasons in 2018 (K = 1.5; S = 2; IQR = 15.1), 2019 (K = 5.8; S = 2; IQR = 14), southwest monsoon seasons in 2018 (K = 12.9; S = 3.2; IQR = 7.4), 2020 (K = 6.2; S = 2.1; IQR = 6.7), and northeast monsoon season in 2018 (K = 1.5; S = 1.5; IQR = 14) indicated the PM2.5 data has heavy tails. Also, this dataset was characterized by larger mean values than the median, indicating the occurrence of extreme quantities during this period. Previous studies observed a similar trend (He et al., 2020; Liu et al., 2019; Zhai & Chen, 2018). The 24-h average PM2.5 concentration was higher in the southwest monsoon and winter. The 24-h average PM2.5 dataset demonstrated significant differences regarding the kurtosis and skewness of the data reflected in seasonal PM2.5 level variations.

Seasonal variation of 24-h average PM2.5 concentration during 2018–2020
Twenty-four-hour average PM10 concentrations exceeded 100 µg m−3 in 29, 2, and 8 days in 2018, 2019, and 2020, respectively. The annual average PM10 concentrations in the study area were 5.3, 3.6, and 3.5 times more than the WHO-specified limits (15 µg m−3) in 2018, 2019, and 2020, respectively. The dataset showed that 50% of the PM10 concentration followed the concentration range between 49 and 102 µg m−3, 32 and 69 µg m−3, and 25 and 83 µg m−3 in 2018, 2019, and 2020, respectively (Fig. 3). The 24-h average PM10 concentration was higher in the winter, northeast monsoon, and summer seasons. The high K, high S, and less IQR of the PM10 dataset in the summer season (K = 3.1; S = 1.6; IQR = 40.5) and southwest monsoon seasons (K = 1.1; S = 0.9; IQR = 16.7) in 2018, winter season in 2019 (K = 8.5; S = 2.5; IQR = 24), and north-east season (K = 2.9; S = 1.6; IQR = 8.1) in 2020 indicated the occurrence of extreme PM10 concentrations during this period.

Seasonal variation of 24-h average PM10 concentration during 2018–2020
The processes in manufacturing industries including crushing, grinding, sieving, and mixing various materials to produce monolithic refractories were reported to emit elevated levels of PM in the atmosphere (Kuenen et al., 2019; MSME, 2010). Fugitive dust emissions may occur during the handling and transportation of raw materials. Industrial stack emissions also led to higher particulate matter (PM) emissions.
3.2 Statistical Distribution and Trend Analysis of PM Concentrations
Statistical distributions of atmospheric concentrations were used to assess the degree of compliance of a region with ambient air quality standards. The present study performed a statistical distribution analysis for the 24-h average PM2.5 to find the representative distributions. Goodness-of-fit tests used for assessing the best fit in the present study were Kolmogorov–Smirnov (K-S), modified Kolmogorov–Smirnov, and Anderson–Darling (A-D) test. Lognormal distributions with a significance level of 0.05 were better with actual data with lower K-S, K-S modified, and A-D test statistics for 2018–2020 (Table 1). PM2.5 concentrations followed gamma distributions in 2019 and 2020 (Table 1). Smaller K-S, K-S modified, and A-D test statistics signify a better fit with the actual data (McHugh, 2013). The lognormal distribution analysis of the 24-h average PM2.5 dataset predicted a 2.8%, 7.9%, and 7.7% probability of 24-h average PM2.5 concentration exceeding 60 µg m−3 in 2018, 2019, and 2020, respectively. In 2018, 2019, and 2020, the probability of PM2.5 concentration exceeding the prescribed limit (WHO 24-h standard limit: 15 µg m−3) was 32.1%, 52%, and 55%, respectively. The estimates of the location (µ) and scale (σ) of lognormal distributions are shown in Table 2. As demonstrated in Table 2, the values of σ were similar from 2018 to 2020, indicating that the meteorological parameters remained similar for the 3 years. The probability distributions of PM2.5 concentration showed a unimodal distribution. Past studies have reported well-fitted lognormal and gamma distributions of 24-h average PM2.5 concentration in megacities across the globe (Gulia et al., 2017; Lu & Fang, 2002; Mishra et al., 2021). The probability-probability (P-P) plots are provided in supplementary Figures (S1-S3) (supplementary information (S3)). The analysis results of various modified M–K tests and Theil-Sen slope estimation of the 24-h average PM2.5 dataset of 2018–2020 are provided in Table S1 (supplementary information (S4)). A significant monotonic increasing trend (Seasonal M–K test result: tau (τ) = 0.15, p-value = 0.002) was found for 24-h average PM2.5 concentration with an increasing magnitude of 0.43 µg m−3 per annum during 2018–2020 (Fig. 4). This increasing trend may be attributed to the various industrial activities in the study area. Industrial operations were not restricted during the COVID-19 lockdown in 2020. A similar increasing monotonic trend for PM2.5 was observed in an industrial location in Brisbane, Australia (Lorelei de Jesus et al., 2020) and urban areas of NY, USA (Masiol et al., 2019).

Increasing trend of 24-h average PM2.5 concentrations during 2018–2020
The statistical distributions of the 24-h average PM10 dataset showed that gamma distributions with a significance level of 0.05 were a better fit with actual data with lower K-S, K-S modified, and A-D test statistics for 2018–2020 (Table 3). In comparison, no distributions were detected for the 24-h average PM10 dataset in 2020. The gamma distribution analysis of the 24-h average PM10 dataset predicted 24.5%, 5.5%, and 9.3% probabilities of PM10 concentrations exceeding 100 µg m−3 in 2018 and 2019, respectively. The probabilities of PM10 concentrations exceeding the prescribed limit (WHO standard limit: 45 µg m−3) in 2018, 2019, and 2020 were 85%, 58%, and 51%, respectively. The P-P plots are provided in supplementary figures (S4-S6) (supplementary information (S3)). The analysis results of various modified Mann–Kendall tests and Theil-Sen slope estimation of the 24-h average PM10 dataset of 2018–2020 are provided in Table S2 (supplementary information (S4)). Trend analysis of the PM10 dataset showed a decreasing trend (Modified M–K Hamed Rao approach test result: tau (τ) = − 0.3, p-value = 0.002) with a low rate of 0.2 µg m−3 per annum during 2018–2020 (Fig. 5). The downward trend may be attributed to the reduction in road resuspension brought on by COVID-19’s restrictions on vehicle mobility in the study area.

The decreasing trend of 24-h average PM10 concentrations during 2018–2020
3.3 Extreme Value Analysis and Return Level of PM Concentrations
This study applied extreme value analysis (EVA) to estimate the probability of exceedance and return values of PM10 and PM2.5, which can be anticipated in the coming years. Threshold selection is the basis for performing EVA using the peak-over-threshold (POT) method based on GPD. Mean residual life (MRL), parameter stability, and return level plots were used in the present study to establish the threshold.
The MRL plot in Fig. 6 indicates the threshold region between 40 and 45, where the linearity condition is required for threshold selection. The parameter stability plot in Fig. 7 indicates that the stability region appears to be confined between 40 and 45. The distribution became unstable after a threshold value of 45, indicating a lack of sufficient exceedances. The return value stability plot (Fig. 8) can be used as an additional check to investigate the sensitivity and stability of the GPD model to the threshold value. The return level plot showed the return value for the given return period (100 years) and thresholds (40 to 42). The return value between threshold values of 40.25 to 41.25 appeared to be constant for both Gen Pareto and exponential distributions. Based on these analyses, the threshold value for PM2.5 data was 41 in the present study. Maximum likelihood estimated the GPD parameters-shape (ξ) = 0.47 and scale (β) = 8 based on the threshold value of 41 with standard errors of 0.2 and 2.3, respectively. The diagnostic plots of the fitted GPD are shown in Fig. 9. The goodness-of-fit in the probability, quantile, and probability density plots seems convincing, though not perfect, as accurate. Thus, the fitted GPD model is reliable for estimating the return levels of PM2.5, for different return periods and predicting extreme events exceeding the prescribed standards and the risk of exposure to such extreme events. The return values estimated for the return periods (1–1000 years) with 95% confidence intervals (Fig. 10). Since shape (ξ) > 0, the distribution is unbounded with a concave shape (Coles, 2001), as depicted in Fig. 10. The return value of the PM2.5 concentration in the 100th year was 602 µg m−3. The return value of PM2.5 in the 10th year will be 193 µg m−3, with PM2.5 concentrations ranging from 71 to 650 µg m−3.

MRL plot for 24-h PM2.5 concentrations during 2018–2020

Parameter estimates against the threshold for 24-h PM2.5 concentrations during 2018–2020

Return value plot for the threshold stability for 24-h PM2.5 concentrations during 2018–2020

Diagnostic plots for threshold excess model fitted to 24-h PM2.5 concentrations during 2018–2020

Return level plots for 24-h PM2.5 concentrations in future
EVA was also performed for the PM10 data, as previously explained. The MRL parameter stability and return level plots are shown in Figs. 11, 12 and 13. Based on these plots, a threshold value of 122 was selected for PM10 in this study. The diagnostic plots of the fitted GPD shown in Fig. 14 indicate the reliability of the model in estimating the return levels. The maximum likelihood estimated the distribution parameters-shape (ξ) = − 1.13 and scale (β) = 49.71 with standard errors of 0.5 and 0.03, respectively. The return level plot indicates that the plotted curve asymptotes to infinity because of the negative value of the shape parameter corresponding to the distribution with a short bounded upper tail (Coles, 2001). The return value of PM10 concentration in the 100th year was 144–223 µg m−3. The return value of the PM10 concentration in the 100th year was 166 µg m−3. The return value of PM10 in the 10th year was 165 µg m−3, and the PM10 concentration varied between 144 and 180 µg m−3 (Fig. 15).

MRL plot for 24-h PM10 concentrations during 2018–2020

Parameter estimates against the threshold for 24-h PM10 concentrations during 2018–2020

Return value plot for the threshold stability for 24-h PM10 concentrations during 2018–2020

Diagnostic plots for threshold excess model fitted to 24-h PM10 concentrations during 2018–2020

Return level plots for 24-h PM10 concentrations in future
EVA analysis of PM2.5 and PM10 has provided the highest concentration levels expected in the coming years, higher than the NAAQS and considered a public health threat. A similar trend and extreme episodes were observed for PM2.5 and PM10 concentrations measured in the metropolitan areas of São Paulo and Rio de Janeiro, Southern America (Martins et al., 2017).
3.4 Meteorology Dynamics on PM Concentrations
Meteorological parameters influence the ambient PM concentration, including wind direction, speed, relative humidity, and temperature. The wind is an essential meteorological parameter that can transport and disperse pollutants in the ambient atmosphere. Previous studies have highlighted that low wind speeds cause stagnation of pollutants near the emission source, and higher wind speeds transport pollutants away from the emission source (Ji et al., 2012; Kim Oanh & Leelasakultum, 2011; Peter & Nagendra, 2021). According to the Beaufort scale, light air (0.5–1.5 ms−1), light breeze (1.6–3.3 ms−1), gentle breeze (3.4–5.5 ms−1), and moderate breeze (5.5–7.9 ms−1) were observed during the study period. The analysis in Table 4 showed the elevated levels of both 24-h PM2.5 and PM10 during the wind speed of 1.6–3.3 ms−1. The predominant wind direction in the industrial area ranged from SSW-W (210°–270°) from March to September (Fig. S7-S9 in Supplementary Information (S5)). The wind direction at the monitoring site was ENE-SSE (90°–150°) from November to February (Fig. S7–S9). The data showed elevated levels of both 24-h PM2.5 and PM10 in the wind direction of ESE (120°), impacting the air quality of the nearby residential area. Spearman correlation analysis showed that wind speed was negatively correlated with PM10 (− 0.34) and a very weak correlation with PM2.5 (0.06) (Fig. 16).

Correlation between PM concentrations and meteorological parameters
The hygroscopic growth of PM is affected by ambient relative humidity (RH) and tends to result in the amalgamation, accumulation, and dry deposition of PM. The maximum RH was observed during the post-monsoon period, during the southwest monsoon, and low RH was observed during the summer in the study area. Relative humidity in this study is categorized in the ranges between 35 and 60%, 61 and 70%, 71 and 80%, and 81 and 94%. The data analysis indicated that both PM10 and PM2.5 had higher concentrations during RH, ranging between 35 and 71% (Table 5). Mcmurry and Stolzenburg (1989) observed that particle diameter increased (4–7%) even as RH increased to 85–90%, resulting in dry deposition of PM. Spearman correlation analysis showed that RH had a strong negative correlation with PM10 (− 0.6) and a moderate negative correlation with PM2.5 (− 0.3) (Fig. 16).
The ambient temperature significantly influenced the vertical air motion. The temperature in the study area ranges from 21 to 32 °C. Low temperatures were recorded during the monsoon season (July–September), and the maximum temperature was recorded during the summer (March–April). The data analysis showed that the temperature did not vary much throughout the year, which did not influence the PM concentration (Table 6). Correlation analysis showed a weak correlation between temperature and PM concentrations (Fig. 16).
3.5 Health Risk Assessment of PM 2.5
The AirQ + software was used to evaluate the health risks associated with exposure to PM2.5. Long-term health impacts such as total mortality, mortality due to chronic obstructive pulmonary disease (COPD), ischemic heart disease (IHD), lung cancer (LC), and stroke were evaluated in 2018, 2019, and 2020, respectively. The annual PM2.5 exposure concentration of 24.34 µg m−3 in 2019 was higher than that in 2020 (21.53 µg m−3) and 2018, (16.26 µg m−3). The annual PM2.5 average concentrations exceeded the WHO annual limit (5 μg m−3). The estimated proportions and number of attributable cases due to total mortality, COPD, IHD, LC, and stroke are depicted in Table 7. It was observed that PM2.5 exposure could induce higher mortality due to IHD and COPD. More than 15, 34, and 27 premature deaths caused by total mortality in 2018, 2019, and 2020, respectively, could have been prevented if PM2.5 concentrations in the Kanjikode industrial area did not exceed 10 μg m−3, as suggested by WHO standards in 2005. The authors collected the number of mortality cases due to stroke and lung cancer during the study period from the state government’s health centre in the study area (Table S4). Mortality due to ischemic heart disease (IHD) and chronic obstructive pulmonary disease (COPD) in this region has not been documented. Previous studies have reported strong relationships between long-term and short-term PM2.5 exposure and increased mortality and hospitalization due to respiratory or cardiovascular diseases (Amoatey et al., 2020; Hoek et al., 2013; Omidi Khaniabadi et al., 2019; Pala et al., 2021).
3.6 Control Measures for Air Pollution in Kanjikode Industrial Area—a Way Forward
The Kanjikode industrial area is home to many medium- and small-scale factories, including those producing steel, cement, paint colors, distilleries, fertilizers, textiles, and chemicals, contributing to elevated pollutant concentrations in the study area. Industrial point sources, such as the power sector, industrial boilers, and other industrial processes, individually contribute to local source emissions. Despite emphasizing industrial emissions, transportation sources emitted more pollutants than the power sector. Kanjikode is situated in a region where a national highway road connects two Indian states, where various transport operations and large vehicle movements are everyday activities. The present research suggests the following measures to curb air pollution from industrial areas:
-
Reducing air pollution using numerous technologies can destroy hazardous pollutants at the source of pollution. These technologies include regenerative thermal oxidizers, catalytic oxidizers, and rotary concentrators.
-
Adopting renewable energy alternatives, such as solar power and wind turbines, enables industries to be more self-sufficient and energy-sufficient.
-
Industries’ existing air pollution control measures should be adequately maintained and periodically inspected for performance.
-
Conventional vehicles should be substituted with electric vehicles to eliminate exhaust emissions.
-
Pavements and roads should be maintained regularly to reduce vehicle-induced resuspension of road dust.
-
To contain industrial pollutants, adequate industrial exhaust ventilation and green belts should be increased.
-
Stringent measures and policies should be implemented to reduce pollution, thus reducing occupational and environmental exposure to various toxic pollutants.
4 Conclusion
Industrial air pollution has long been a significant contributor to poor air quality and has been recognized as an exacerbating factor that induces health threats. The trend and statistical distribution analysis showed that the probability of exceedance and increasing trend of PM2.5 might be attributed to various industrial activities in the study area. Extreme event analysis of PM10 and PM2.5 has provided the highest concentration levels expected to be higher than NAAQS in the coming years and is considered a public health threat. AirQ + software developed by WHO evaluated long-term health impacts such as total mortality, chronic obstructive pulmonary diseases, ischemic heart disease, lung cancer, and stroke due to PM2.5 exposure. Increasing adequate green belts, improving road transportation, and conducting periodic monitoring of the performance of air pollution control technologies will curtail PM2.5 levels in the study area, thereby safeguarding public health.
Data Availability
Data will be made available on request.
References
Amoatey, P., Sicard, P., de Marco, A., & Khaniabadi, Y. O. (2020). Long-term exposure to ambient PM2.5 and impacts on health in Rome, Italy. Clinical Epidemiology and Global Health, 8(2), 531–535. https://doi.org/10.1016/j.cegh.2019.11.009
Balakrishnan, K., Dey, S., Gupta, T., Dhaliwal, R. S., Brauer, M., Cohen, A. J., et al. (2019). The impact of air pollution on deaths, disease burden, and life expectancy across the states of India: The Global Burden of Disease Study 2017. The Lancet Planetary Health, 3(1), e26–e39. https://doi.org/10.1016/S2542-5196(18)30261-4
Bari, S. H., Rahman, M. T. U., Hoque, M. A., & Hussain, M. M. (2016). Analysis of seasonal and annual rainfall trends in the northern region of Bangladesh. Atmospheric Research, 176–177, 148–158. https://doi.org/10.1016/j.atmosres.2016.02.008
Botle, A., Singhal, R. K., Basu, H., V, M., & Masih, J. (2020). Health risk assessment of heavy metals associated with Coarse and Quasi-accumulative airborne particulate matter in Mumbai City situated on the Western Coast of India. Environmental Technology and Innovation, 19. https://doi.org/10.1016/j.eti.2020.100857
Coles, S. (2001). An introduction to statistical modeling of extreme values. Springer, London. https://doi.org/10.1007/978-1-4471-3675-0
Dwivedi, S., Tewari-Singh, N., Masih, J., Taushiba, A., & Lawrence, A. (2022). Evaluation of indoor particulate matter and associated PAHs during the winter season in Northern India: A comprehensive impact of regional appearances. Journal of Hazardous Materials Advances, 8, 100195. https://doi.org/10.1016/j.hazadv.2022.100195
Gangadharan, P., & Nambi, I. M. (2020). The performance of Cu2+as dissolved cathodic electron-shuttle mediator for Cr6+reduction in the microbial fuel cell. Sustainable Environment Research, 30(1). https://doi.org/10.1186/s42834-020-00059-3
Giavis, G. M., Kambezidis, H. D., & Lykoudis, S. P. (2009). Frequency distribution of particulate matter (PM 10 ) in urban environments. Int. J. Environment and Pollution (Vol. 36).
Gulia, S., Nagendra, S. M. S., & Khare, M. (2017). Extreme events of reactive ambient air pollutants and their distribution pattern at urban hotspots. Aerosol and Air Quality Research, 17(2), 394–405. https://doi.org/10.4209/aaqr.2016.06.0273
Hair, J. F., Matthews, L. M., Matthews, R. L., & Sarstedt, M. (2017). PLS-SEM or CB-SEM: updated guidelines on which method to use “PLS-SEM or CB-SEM: updated guidelines on which method to use.” Organizational Research Methods, MIS Quarterly, and International Journal (Vol. 1).
He, J., Zhao, M., Zhang, B., Wang, P., Zhang, D., Wang, M., et al. (2020). The impact of steel emissions on air quality and pollution control strategy in Caofeidian, North China. Atmospheric Pollution Research, 11(7), 1238–1247. https://doi.org/10.1016/j.apr.2020.04.012
Hoek, G., Krishnan, R. M., Beelen, R., Peters, A., Ostro, B., Brunekreef, B., & Kaufman, J. D. (2013). Long-term air pollution exposure and cardio-respiratory mortality: A review. Environmental Health: A Global Access Science Source. https://doi.org/10.1186/1476-069X-12-43
Hussain, M., & Mahmud, I. (2019). pyMannKendall a python package for non parametric Mann Kendall family of trend tests. Journal of Open Source Software, 4(39). https://doi.org/10.21105/joss.01556
Ji, D., Wang, Y., Wang, L., Chen, L., Hu, B., Tang, G., et al. (2012). Analysis of heavy pollution episodes in selected cities of northern China. Atmospheric Environment, 50, 338–348. https://doi.org/10.1016/j.atmosenv.2011.11.053
Kendall, M. G. (1970). Rank Correlation Methods (4th ed.). Griffin.
Kim Oanh, N. T., & Leelasakultum, K. (2011). Analysis of meteorology and emission in haze episode prevalence over mountain-bounded region for early warning. Science of the Total Environment, 409(11), 2261–2271. https://doi.org/10.1016/j.scitotenv.2011.02.022
Kuenen, J., Most, P. van der, Rentz, O., Nunge, S., Trozzi, C., Pulles, T., & Appelman, W. (2019). Glass production 2019.
Lemos, I., Lima, A., & Duarte, M. (2020). Threshold modeling: A Python package for modeling excesses over a threshold using the Peak-Over-Threshold Method and the Generalized Pareto Distribution. Journal of Open Source Software, 5(46), 2013. https://doi.org/10.21105/joss.02013
Liu, H., Duan, Z., & Chen, C. (2019). A hybrid framework for forecasting PM2.5 concentrations using multi-step deterministic and probabilistic strategy. Air Quality Atmosphere and Health, 12(7), 785–795. https://doi.org/10.1007/s11869-019-00695-8
Lorelei de Jesus, A., Thompson, H., Knibbs, L. D., Kowalski, M., Cyrys, J., Niemi, J. v., et al. (2020). Long-term trends in PM2.5 mass and particle number concentrations in urban air: The impacts of mitigation measures and extreme events due to changing climates. Environmental Pollution, 263. https://doi.org/10.1016/j.envpol.2020.114500
Lu, H.-C., & Fang, G.-C. (2002). Estimating the frequency distributions of PM10 and PM2.5 by the statistics of wind speed at Sha-Lu, Taiwan. Science of the Total Environment, 298(1–3), 119–130. https://doi.org/10.1016/s0048-9697(02)00164-x
Maji, K. J., Dikshit, A. K., & Deshpande, A. (2017). Assessment of city level human health impact and corresponding monetary cost burden due to air pollution in India taking Agra as a model city. Aerosol and Air Quality Research, 17(3), 831–842. https://doi.org/10.4209/aaqr.2016.02.0067
Mann, H. B. (1945). Nonparametric tests against trend. Econometrica, 13(3), 245–259.
Manojkumar, N., & Srimuruganandam, B. (2021). Health effects of particulate matter in major Indian cities. International Journal of Environmental Health Research, 31(3), 258–270. https://doi.org/10.1080/09603123.2019.1651257
Martins, L. D., Wikuats, C. F. H., Capucim, M. N., de Almeida, D. S., da Costa, S. C., Albuquerque, T., et al. (2017). Extreme value analysis of air pollution data and their comparison between two large urban regions of South America. Weather and Climate Extremes, 18, 44–54. https://doi.org/10.1016/j.wace.2017.10.004
Masih, J., Nair, A., Gautam, S., Singhal, R. K., Basu, H., Dyavarchetty, S., et al. (2019). Chemical characterization of sub-micron particles in indoor and outdoor air at two different microenvironments in the western part of India. SN Applied Sciences, 1(2). https://doi.org/10.1007/s42452-019-0164-6
Masiol, M., Squizzato, S., Rich, D. Q., & Hopke, P. K. (2019). Long-term trends (2005–2016) of source apportioned PM2.5 across New York State. Atmospheric Environment, 201, 110–120. https://doi.org/10.1016/j.atmosenv.2018.12.038
Masseran, N., Razali, A. M., Ibrahim, K., & Latif, M. T. (2016). Modeling air quality in main cities of Peninsular Malaysia by using a generalized Pareto model. Environmental Monitoring and Assessment, 188(1), 1–12. https://doi.org/10.1007/s10661-015-5070-9
McHugh, M. L. (2013). The chi-square test of independence. Biochemia Medica, 23(2), 143–149. https://doi.org/10.11613/BM.2013.018
Mcmurry, P. H., & Stolzenburg, M. R. (1989). On the sensitivity of particle size to relative humidity for Los Angeles aerosols. Atmospheric Environment, 23(2), 497–507.
Ministry of Environment and Forests, Govt. of India. (2022). Pollution: Air – Status of Environment related issues: Kerala ENVIS Centre. http://www.kerenvis.nic.in/Database/Air_Pollution_835.aspx
Miri, M., Derakhshan, Z., Allahabadi, A., Ahmadi, E., Oliveri Conti, G., Ferrante, M., & Aval, H. E. (2016). Mortality and morbidity due to exposure to outdoor air pollution in Mashhad metropolis, Iran. The AirQ model approach. Environmental Research, 151, 451–457. https://doi.org/10.1016/j.envres.2016.07.039
Mishra, G., Ghosh, K., Dwivedi, A. K., Kumar, M., Kumar, S., Chintalapati, S., & Tripathi, S. N. (2021). An application of probability density function for the analysis of PM2.5 concentration during the COVID-19 lockdown period. Science of the Total Environment, 782. https://doi.org/10.1016/j.scitotenv.2021.146681
MSME. (2010). Project profile on monolithic refractories.
OmidiKhaniabadi, Y., Sicard, P., OmidiKhaniabadi, A., Mohammadinejad, S., Keishams, F., Takdastan, A., et al. (2019). Air quality modeling for health risk assessment of ambient PM10, PM2.5 and SO2 in Iran. Human and Ecological Risk Assessment, 25(5), 1298–1310. https://doi.org/10.1080/10807039.2018.1487277
Pala, K., Aykac, N., & Yasin, Y. (2021). Premature deaths attributable to long-term exposure to PM2.5 in Turkey. Environmental Science and Pollution Research, 28(37), 51940–51947. https://doi.org/10.1007/s11356-021-13923-5
Pandey, A., Brauer, M., Cropper, M. L., Balakrishnan, K., Mathur, P., Dey, S., et al. (2021). Health and economic impact of air pollution in the states of India: The Global Burden of Disease Study 2019. The Lancet Planetary Health, 5(1), e25–e38. https://doi.org/10.1016/S2542-5196(20)30298-9
Pandolfi, M., Alastuey, A., Pérez, N., Reche, C., Castro, I., Shatalov, V., & Querol, X. (2016). Trends analysis of PM source contributions and chemical tracers in NE Spain during 2004–2014: A multi-exponential approach. Atmospheric Chemistry and Physics, 16(18), 11787–11805. https://doi.org/10.5194/acp-16-11787-2016
Peter, A. E., & Nagendra, S. M. S. (2021). Dynamics of PM2.5 pollution in the vicinity of the old municipal solid waste dumpsite. Environmental Monitoring and Assessment, 193(5). https://doi.org/10.1007/s10661-021-09052-8
Pollution, A. (2017). Health in India: A review of the current evidence and opportunities for the future July 2017 (pp. 1–64). India: Public Health Foundation of India/Centre for environmental Health.
Rohra, H., Pipal, A. S., Tiwari, R., Vats, P., Masih, J., Khare, P., & Taneja, A. (2020). Particle size dynamics and risk implication of atmospheric aerosols in South-Asian subcontinent. Chemosphere, 249. https://doi.org/10.1016/j.chemosphere.2020.126140
Sen, P. K. (1968). Estimates of the regression coefficient based on Kendall’s tau. Journal of the American Statistical Association, 63(324), 1379–1389. https://doi.org/10.1080/01621459.1968.10480934
Sicard, P., Agathokleous, E., de Marco, A., Paoletti, E., & Calatayud, V. (2021). Urban population exposure to air pollution in Europe over the last decades. Environmental Sciences Europe, 33(1). https://doi.org/10.1186/s12302-020-00450-2
SoE. (2021). Industrial pollution: no respite quality of air, water and land has worsened in India’s industrial clusters between 2009 and 2018,finds CSE. Centre for Science and Environment. https://www.cseindia.org/industrial-pollution-no-respite-quality-of-air-water-and-land-has-worsened-in-india-10704. Accessed 30 September 2022
Theil, H. (1992). A rank-invariant method of linear and polynomial regression analysis. In Henri Theil’s Contributions to Economics and Econometrics: Econometric Theory and Methodology (Vol. 23, pp. 345–381). Springer, Dordrecht. https://doi.org/10.1007/978-94-011-2546-8_20
WHO. (2018). AirQ+: Software tool for health risk assessment of air pollution.
Yang, X., Lee, J., Barker, D. E., Wang, X., & Zhang, Y. (2012). Comparison of six particle size distribution models on the goodness-of-fit to particulate matter sampled from animal buildings. Journal of the Air and Waste Management Association, 62(6), 725–735. https://doi.org/10.1080/10962247.2012.671148
Zhai, B., & Chen, J. (2018). Development of a stacked ensemble model for forecasting and analyzing daily average PM2.5 concentrations in Beijing, China. Science of the Total Environment, 635, 644–658. https://doi.org/10.1016/j.scitotenv.2018.04.040
Acknowledgements
The authors thankfully acknowledge Krishnan M N, Environmental Engineer, Kerala State Pollution Control Board, Palakkad, for the ambient air quality data measured at Kanjikode Industrial area.
Author information
Authors and Affiliations
Contributions
Anju Elizbath Peter: data collection, conceptualization, methodology, data interpretation, and writing of the original draft. Monish Raj: methodology, data interpretation, writing—original draft. Praveena Gangadharan: writing—review and editing—original draft. Athira P: writing—review and editing the original draft. S.M. Shiva Nagendra: writing—review and editing—original draft.
Corresponding author
Ethics declarations
Ethics Approval
Not applicable.
Consent to Participate
Not applicable.
Consent to Publish
Not applicable.
Competing Interests
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Peter, A.E., Raj, M., Gangadharan, P. et al. Trends, Extreme Events and Long-term Health Impacts of Particulate Matter in a Southern Indian Industrial Area. Water Air Soil Pollut 234, 303 (2023). https://doi.org/10.1007/s11270-023-06302-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11270-023-06302-y