
Abstract
Urban hydrological monitoring is essential for analyzing urban hydrology and controlling storm floods. However, runoff monitoring in urban areas, including flood inundation depth, is often inadequate. This inadequacy hampers the calibration of hydrological models and limits their capacity for early flood warning. To address this limitation, this study established a method for evaluating the depth of urban floods using image recognition and deep learning. This method utilizes the object recognition model YOLOv4 to identify submerged objects in images, such as the legs of pedestrians or the exhaust pipes of vehicles. In a dataset of 1,177 flood images, the mean average precision for water depth recognition reached 89.29%. The study also found that the accuracy of flood depth recognition by YOLOv4 is influenced by the type of reference object submerged by the flood; the use of a vehicle as the reference object yielded higher accuracy than using a person. Furthermore, image augmentation with Mosaic technology effectively enhanced the accuracy of recognition. The developed method extracts on-site, real-time, and continuous water depth data from images or video data provided by existing traffic cameras. This system eliminates the need for installing additional water gauges, offering a cost-effective and immediately deployable solution.
Similar content being viewed by others
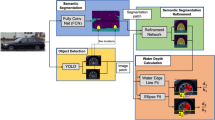

1 Introduction
Urban flooding presents escalating challenges for sustainable development worldwide (Hammond et al. 2015). The frequency and severity of flood damage are on the rise, attributed to the effects of climate change and rapid urbanization (Chen et al. 2015; Yin et al. 2015; Jamali et al. 2018).
Urban hydrology provides a basis to estimate the inundated areas and damage of urban floods (Fletcher et al. 2013; Ichiba et al. 2018). The prevalence of impervious surfaces in cities reduces precipitation infiltration and, simultaneously, increases the speed of surface water flow during a storm (Lee and Brody 2018; Yu et al. 2018; Feng et al. 2021). Consequently, these conditions afford only a limited time for warning and evacuating people possibly caught by the flash floods. Furthermore, urban flash floods are particularly destructive due to the higher exposure of people and expensive infrastructures in cities (Jamali et al. 2018; Singh et al. 2018).
Several hydrological models have been developed for urban flood simulations, among which models such as the Storm Water Management Model and MIKE FLOOD are widely applied worldwide (Mignot et al. 2019; Bulti and Abebe 2020; Guo et al. 2021; Babaei et al. 2018; Bai et al. 2018; Li et al. 2018; Nigussie and Altunkaynak 2019). These models enable the prediction of inundated areas in cities, which is essential for urban flood early warnings (Rangari et al. 2019; Seenu et al. 2020). However, there is a critical gap in model calibration and validation due to a lack of measured data of floodwater depths across urban areas. The primary challenges are the limited coverage of monitoring spots and the relatively high cost for maintaining the gauging equipment (Arshad et al. 2019; Moy De Vitry et al. 2019; Li et al. 2019). Moreover, urban areas present numerous and scattered waterlogging locations owing to various low-lying facilities or underground infrastructures, such as subway stations and traffic tunnels. Therefore, it becomes quite costly to monitor distributed flood inundations using a traditional sensor-based system in these scattered locations. Consequently, comprehensive monitoring networks that cover urban flood depths extensively remain scarce globally (Wang et al. 2018).
In the quest to acquire more comprehensive flood depth data within urban areas, a plethora of new technologies has been adopted over the past decade. These include remote sensing (Rong et al. 2020), social media or crowdsourcing data retrieval (Kankanamge et al. 2020), deep learning (Chia et al. 2023; Faramarzzadeh et al. 2023), and and object recognition in flood imagery (Jiang et al. 2019; Bhola et al. 2019; Park et al. 2021). Barz et al. established a method using content-based image retrieval technology and an artificial intelligence method to identify "flood" and "non-flood" events from a dataset of about 100,000 online images (Barz et al. 2019). Vlad et al. developed a deep learning classifier that detected flooding events by analyzing text published by online news outlets (Vlad et al. 2019). While these approaches have introduced novel insights into urban flood monitoring, achieving accurate and continuous data on floodwater levels at specific locations remains a challenge. To enhance the practicality of flood images, high-resolution photographs from water level gauges captured by video surveillance systems have been utilized to deduce water level data through identification technology (Lv et al. 2018; Jiang et al. 2020). Furthermore, Basnyat and Gangopadhyay developed a low-cost, low-power cyber-physical system prototype using a Raspberry Pi camera to detect the rising water level using image processing and text recognition techniques (Basnyat et al. 2018). This innovation has the potential to enable the widespread implementation of a flash flood detection system that requires minimal human supervision. Yet, the deployment of such systems in urban locales faces constraints, particularly due to the necessity for installing on-site water level gauges and camera systems at heavily trafficked urban locations (Yang et al. 2014).
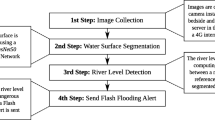
Given the above limitations, this study aims to develop an innovative method that can obtain continuous data of urban inundation depths at a specific location during a flash flood. Image-recognition technology is applied to recognize flood level figures from traffic photos during floods by identifying the relative position of the water surface to the reference objects in the water, including people and vehicles passing through the water. The primary innovation of the article lies in the establishment of a new method for image recognition of surface water depth. Compared to traditional methods that utilize sensors for monitoring and numerical models for acquiring flood inundation depths, the method proposed in this study is cost-effective and computationally efficient, making it more suitable for providing flood inundation depth data over large spatial extents. Moreover, the proposed method could provide real-time data of inundated water levels by analyzing images from existing traffic surveillance cameras in road networks. As traffic surveillance cameras are widespread in cities globally, this method might be practical for expanding urban flood monitoring and providing timely early warning.
2 Materials and Methods
2.1 Data
A total of 1,177 images of flooded streets with pedestrians or vehicles were utilized for water depth identification. The image resolutions varied from 142 × 107 pixels to 4613 × 2595 pixels. These images were acquired through Google Search using keywords such as “urban waterlogging” and “urban floods.” Some of these photos were sourced from traffic cameras. Complex and challenging scenarios, including those featuring nighttime, muddy water, and splashes caused by vehicle movement, were considered in the selection of the flood photos.
According to the VOC (visual object class) data set framework developed by the PASCAL organization, the images were converted into a standard data set for flood depth recognition. PASCAL (Pattern Analysis, Statistical Modeling and Computational Learning) is a network organization funded by the EU, which has developed public datasets of images and annotations, together with standardized evaluation software (Everingham et al. 2010). PASCAL VOC is one of the widely used visual datasets that employs a strictly normalized framework (Gauen et al. 2017) to identify the size, object class, and coordinates of bounding boxes in the images. In this study, the 1177 images were annotated to 2095 objects and seven categories using the VOC format with the aid of the software LabelImg (Yakovlev and Lisovychenko 2020). The seven categories were defined based on the positions of people or vehicles as they were submerged by floodwater, as detailed in Table 1.
2.2 Target Detection Algorithm
The “you only look once” (YOLO) algorithm was employed in this study to extract features and detect objects in the flood images using a deep convolutional neural network. Y OLO is favored for object detection due to its rapid image processing capabilities. It integrates feature extraction, object classification, and bounding box regression in a single pass through the neural network (Redmon et al. 2016). Unlike two-stage algorithms such as the Faster-RCNN with multiple steps for generating the candidate area of the input image and extracting features for the image recognition through different neural networks, YOLO skips the generation of a candidate area and completes the detection in one step. This endows YOLO with a markedly higher computational speed while maintaining adequate precision (Zou et al. 2019), aligning with the objectives of this study for real-time flood depth variation monitoring.
YOLO performs object detection by estimating the likelihood that each bounding box within an image grid pertains to predefined categories, employing a convolutional neural network (CNN) alongside a regression method. First, YOLO processes the full image by dividing it into a grid, typically of size 7 × 7, and then uses this grid as the input for the neural network. Subsequently, it proposes two potential bounding boxes for each cell of the grid, with each box having the capacity to classify objects across n categories. Every bounding box is characterized by five parameters: the x-coordinate (x) and y-coordinate (y) of the box's center, the box's width (w), height (h), and the confidence score (c), which is the probability of the box containing an object of interest, ranging between 0 and 1. Consequently, the network output, known as the YOLO Head, is a tensor with the dimensions of (7, 7, 2 * 5 + n). For instance, within a dataset encompassing 20 object categories, the YOLO output would be a tensor of dimensions (7, 7, 30). Here, the first two dimensions, a 7 × 7 matrix, signify the count of feature grids derived, while the final dimension of 30 is the product of the two bounding boxes per cell and the five parameters per box, coupled with the 20 class probabilities (2 × 5 + 20).
The YOLO algorithm was initially developed and subsequently upgraded to its third iteration by Redmon (Redmon and Farhadi 2018). The fourth generation, YOLOv4, was introduced by Alexey Bochkovskiy in 2020 (Bochkovskiy et al. 2020), and this version was employed in the current study. YOLOv4 consists of three components: the backbone, feature enhancement, and prediction. In the backbone, the model extracts three feature layers from the image using five residual networks after adjusting the image to a fixed resolution using CSPDarknet53 (Wang et al. 2020). The three feature layers are subsequently transferred to the feature enhancement part, known as the neck, where they are processed to produce three predictive layers that form the YOLO head. The YOLO head, within the prediction component, is responsible for the final object classification and image recognition tasks.
In this study, three feature layers with the shapes (13, 13), (26, 26), and (52, 52) were adopted to extract the feature from an image with the shape (416, 416) through pooling technology of the CNN, as shown in Fig. 1. Each cell within the feature layers was encased by three alternative bounding boxes with seven categories. As previously described, every bounding box is defined by five specific parameters. Consequently, the output dimensions of the YOLO heads correspond to (13, 13, 22), (26, 26, 22), and (52, 52, 22), respectively. Here, the third dimension, with a value of 22, is computed by summing the product of the bounding boxes' count and the parameters per box with the probability values for each category's association, resulting in 3 × 5 + 7.

Network of "You Only See Once" Version 4 (YOLOv4)
In addition, YOLOv4 employs the activation function Mish (Misra 2019) instead of LeakyRelu (Maas et al. 2013) used in YOLOv3. Mish function has the advantage of a lower bound compared to LeakyReLU, thereby enhancing the model's regularization effect. Moreover, the non-monotonic nature of Mish allows it to retain small negative values, which aids in stabilizing the gradient flow within the network. Its infinitely continuous and smoothly curved nature also contributes to the improvement of result quality. Although utilizing the Mish function demands more computational resources than LeakyReLU functions, it is beneficial for enhancing the model's accuracy. The activation functions are illustrated in Fig. 1.
2.3 Model Training, Validation and Test
In this study, the input data were randomly partitioned into a training set (81% of data), a validation set (9% of data) and a test set (10% of data). The test set remained unused during the training process. YOLOv4 was trained through the transfer learning method, wherein the initial parameters, including the initial weights of the CNN, were adopted from the existing dataset VOC2007 (Everingham et al. 2010). Transfer learning is recognized as a practical scheme in the training process, which can use generic features from other larger training datasets. This reduces the time required for training the model. The VOC2007 dataset contains about 500,000 annotated images categorized into 20 object classes, offering a sufficiently large and diverse foundation to provide the CNN utilized in this study with initial weights.
For the model training in this study, two hundred epochs were set. Initially, a frozen learning approach with a learning rate of 1e-3 was implemented for the first 90 epochs, followed by regular learning with a learning rate of 1e-4 for the subsequent epochs. Frozen learning did not change the initial parameters of the networks in the backbone part, and only generated minor adjustments to other networks during the training (Brock et al. 2017). In contrast, regular learning involved modifying the parameters across all networks within the model. The utilization of frozen learning facilitates a reduction in training time by leveraging existing network parameters from prior datasets, like VOC2007. However, due to the static nature of the backbone networks during frozen learning, the model tends not to converge after only a few epochs. Consequently, regular `learning was employed thereafter to ensure further model convergence. Additionally, a reduced learning rate was applied in regular learning to minimize the risk of overfitting.
The convergence curve of the model training is shown in Fig. 2. A stabilization in the decrease of training loss was observed after 70 epochs, attributable to the unchanged network structure during the frozen learning phase. Subsequently, with the cessation of frozen learning, a further reduction in training loss occurred, continuing until the 150th epoch.

Convergence curve of the model training
2.4 Indicators for Performance Assessment
Mean average precision (mAP) was used in this study to evaluate the accuracy of flood image recognition. It is a metric that is extensively applied in object detection and classification (Zou et al. 2019). The mAP was computed using the precision and recall indicators of the modeling results. Precision is the ratio of correctly predicted positive observations to the total predicted positive observations, and recall is the ratio of correctly predicted positive observations to all actual positives, as shown in the Eqs. 1 and 2.
where TP (true positive) represents the number of samples that are correctly recognized or classified, FP (false positive) represents the number of samples that are recognized incorrectly, and FN (false negative) represents the number of unrecognized results.
Given the above indicators, the mAP can be calculated as follows:
where AP (average precision) represents the area under the precision-recall curve of the prediction results referring to each category. n is the total number of categories. r is the value of recall from Eq. 2p (r) represents the Precision-Recall curve. The y-axis of p(r) is the maximum value of the corresponding precision when the value of recall increases from 0 to 1 at a given interval, such as 0.1.
3 Results
The results of flood recognition from the street images are presented in Fig. 3. As shown in the figure, the reference objects—vehicles and pedestrians—are enclosed within bounding boxes, with the identified category of water depth displayed at the top of each box. In this way, the flood water depth can be extracted by real-time image recognition using street photos or surveillance videos from traffic cameras. It must be emphasized that this method is not appropriate for severe urban flooding, as it depends on the relative position between the water surface and the reference object. When the floodwater level exceeds the height of the reference object, the model's accuracy is likely to be impaired.

Examples of flood depth recognitions
The precision, recall, and AP of the flood recognition from test set are shown in Table 2. he mAP (mean Average Precision) of the model's predictions reached 89.29%, demonstrating a satisfactory performance of the model in identifying the submerged depths of the reference objects. The AP for the predictions in the categories of Car-roof and Car-pipe was 98.81% and 98.63%, respectively, indicating that the most accurate performance of the flood depth recognition from the image dataset in this study was in identifying water levels reaching the car's roof and exhaust pipe. The AP for the categories "Car-handle" and "Person-leg" was 92.47% and 90.44%, respectively, representing the second-best performances in the flood depth recognition.
The AP of seven categories and the number of labeled objects in each category are shown in Fig. 4. The dataset consisted of a total of 2,095 objects. Out of these, 1,885 objects were used for model training and validation, while the remaining 210 objects were reserved for test purposes. The category "Per-leg" had the highest number of objects in the training and validation set, with a total of 494 objects. There were 67 objects belonging to the "Per-leg" category in the test set. Compared to the Per-leg category, the Car-pipe category had a fewer number of objects, with 342 objects in the training and validation set, and 30 objects in the test set. However, the AP of the Car-pipe was 98.63% and was higher than the AP of the Per-leg category, which was only 90.44%. In addition, the Per-waist category had the fewest number of objects but the second lowest AP. The AP was not only affected by the number of objects but also by the feature extractions of the objects. This finding was supported by other studies using the dataset VOC2007, in which the objects were classified into 20 categories with various APs. In previous studies, objects with relatively clearer contours and more regular shapes, such as cars and trains, achieved higher recognition APs. Conversely, irregularly shaped objects, such as humans, cats, and dogs, had lower APs (Wang et al. 2013). This is consistent with the results of this study. When a car was used as the reference object for the flood submerged depth, the AP of the flood recognition was higher than when using the human body as the inundated reference. This is because objects with clear contours and regular shapes are more easily identifiable, thus having features more easily extracted in image recognition.

AP and number of labeled objects of the predictions
4 Discussion
4.1 Performances of Frozen Learning and Regular Learning
The performances of frozen learning and regular learning on inundated depth recognition were analyzed by observing the changes in the mAP and the loss during the learning process using these different learning methods. The mAP and the loss values are shown at every 50 epochs during the learning process in Table 3. At 200 epochs, the mAP of regular learning was higher than that of frozen learning. The loss of regular learning was less than that of frozen learning. This indicates that the performance of regular learning was better than that of frozen learning. In addition, a further improvement of the model performance was observed by using a combined learning method, which employed frozen learning in the first 90 epochs and switched to regular learning for the subsequent epochs.
4.2 Impacts of Training Technologies
Three technologies were utilized in the deep learning process for image processing and model training to analyze their impact on enhancing image recognition performance for flood depths. These technologies include the Mosaic (Bochkovskiy et al. 2020), label smoothing (Szegedy et al. 2016), and cosine annealing (Loshchilov and Hutter 2016), which are currently widely used in image recognition. Mosaic is an image augmentation technique that combines four images through cropping and blending to fully utilize the dataset (Hao and Zhili 2020). Label smoothing is a regularization technique that introduces noise to the labels, helping to mitigate overfitting (Müller et al. 2019). Cosine annealing, characterized by periodic learning rate decreases and resets, aids in avoiding local optima during the training process by allowing for larger learning rate resets (Gotmare et al. 2018).
The applicability of various technologies was analyzed by comparing the model mAP across different application scenarios using eight individual or combined technologies, as detailed in Table 4. In scenario 1, where none of the aforementioned, the mAP of the modeling under this scenario was only 67.58%. After using Mosaic, label smoothing, and cosine annealing separately, the mAP increased to 72.14%, 70.94%, and 70.48%, respectively. The most significant improvement compared to scenario 1 was observed in scenario 2, where Mosaic alone was used. However, in scenarios 5 and 6, where Mosaic was combined with label smoothing and cosine annealing, the mAP reached 71.92% and 67.53%, respectively. The mAP decreased when Mosaic was used in conjunction with label smoothing and cosine annealing, compared to its solitary application. Mosaic alone demonstrated the greatest efficacy in enhancing the mAP for flood depth recognition in this study. This is in alignment with prior research involving YOLOv4, where Mosaic was shown to enhance the accuracy of image recognition (Bochkovskiy et al. 2020).
4.3 Impacts of Activation Functions
DarknetConv2D serves as the foundational convolutional block in residual networks. It comprises three fundamental components: convolution, normalization, and the activation function. The activation function is critical, significantly affecting the performance of deep learning models by impacting both accuracy and computational speed. In this study, the effects of two activation functions, Mish and LeakyRelu, were evaluated by measuring the mean average precision (mAP) and frames per second (FPS), where a higher FPS denotes a faster speed of image recognition. The results are shown in Table 5. The YOLOv4 model utilizing Mish typically achieved higher mAP results compared to that using LeakyReLU. However, the FPS of the model with Mish was 30.49, which was less than that of LeakyRelu. This indicates that Mish operated at a slower speed in image recognition. These findings align with previous research, which indicated that while Mish experiences a greater reduction in detection speed compared to LeakyReLU, it offers superior accuracy (Wang et al. 2021). Despite these differences, it's noteworthy that both activation functions demonstrate impressive prediction speeds, averaging merely 32.8 and 28.6 ms per image for Mish and LeakyReLU, respectively.
5 Conclusion
An image recognition method for detecting urban flood inundation was established in this study by employing the YOLOv4 deep learning network combined with transfer training techniques. In the images, vehicles and pedestrians submerged by floodwaters were used as reference objects to gauge flood water depth. The model categorized images with discernible flood water levels into four categories: 'Car-none', 'Car-pipe', 'Car-handle', and 'Car-roof'. These categories indicate that the floodwater depth in the image was below 5 cm, or had reached the vehicle’s exhaust pipe, door, or roof, respectively. Similarly, for images involving pedestrians, the model classified the flood depth into three categories: 'Per-none', 'Per-leg', and 'Per-waist', signifying that the floodwater depth was below 5 cm, or had reached a person’s leg or waist, respectively. The results demonstrated that the YOLOv4 model's precision for flood depth recognition can reach up to 89.29%, with an impressive recognition speed of 30.49 frames per second (FPS).
It was also found that the accuracy of flood depth recognition by YOLOv4 is influenced by the type of reference object submerged. Recognition accuracy was higher when using vehicles as reference objects compared to people, attributable to vehicles' regular shapes and fixed positions, which facilitate easier identification. Furthermore, the study explored the impact of various transfer learning techniques on flood depth recognition. It was found that a hybrid approach, combining frozen learning with regular learning, yielded better results than employing each technique in isolation. Additionally, the implementation of image augmentation with Mosaic technology was effective in enhancing the model's recognition accuracy.
The proposed YOLOv4 model boasts high accuracy and rapid processing speeds in determining flood water depths from images, utilizing vehicles and pedestrians as reference markers. This capacity allows the model to leverage images or video data from existing traffic cameras to ascertain flood depths during storms, thus facilitating the acquisition of on-site, real-time, and continuous water depth measurements. Data on flood depths garnered through this approach can serve a dual purpose: they can be instrumental in the verification and calibration of urban hydrological models, and they can also provide timely flood inundation information essential for early warning systems in urban settings.
Availability of Data and Materials
The data that support the findings of this study are available from the corresponding author upon reasonable request.
References
Arshad B, Ogie R, Barthelemy J, Pradhan B, Verstaevel N, Perez P (2019) Computer vision and iot-based sensors in flood monitoring and mapping: A systematic review. Sensors (Switzerland) 19(22):5012. https://doi.org/10.3390/s19225012
Babaei S, Ghazavi R, Erfanian M (2018) Urban flood simulation and prioritization of critical urban sub-catchments using SWMM model and PROMETHEE II approach. In: Physics and chemistry of the earth, vol 105. lsevier Ltd, pp 3–11. https://doi.org/10.1016/j.pce.2018.02.002
Bai Y, Zhao N, Zhang R, Zeng X (2018) Storm water management of low impact development in urban areas based on SWMM. Water (Switzerland) 11(1):33. https://doi.org/10.3390/w11010033
Barz B, Schröter K, Münch M, Yang B, Unger A, Dransch D, Denzler J, E-pRINT PR (2019) Enhancing flood impact analysis using interactive retrieval of social media images
Basnyat B, Roy N, Gangopadhyay A (2018) A flash flood categorization system using scene-text recognition. In: 2018 IEEE International Conference on Smart Computing (SMARTCOMP). pp 147–154
Bhola PK, Nair BB, Leandro J, Rao SN, Disse M (2019) Flood inundation forecasts using validation data generated with the assistance of computer vision. J Hydroinf 21(2):240–256. https://doi.org/10.2166/hydro.2018.044
Bochkovskiy A, Wang CY, Liao HYM (2020) Yolov4: Optimal speed and accuracy of object detection. ArXiv Preprint ArXiv:2004.10934
Brock A, Lim T, Ritchie JM, Weston N (2017) Freezeout: Accelerate training by progressively freezing layers. ArXiv Preprint ArXiv:1706.04983
Bulti DT, Abebe BG (2020) A review of flood modeling methods for urban pluvial flood application. In: Modeling Earth Systems and Environment. In: Modeling earth systems and environment, vol 6, Issue 3. Springer Science and Business Media Deutschland GmbH, pp 1293–1302. https://doi.org/10.1007/s40808-020-00803-z
Chen Y, Zhou H, Zhang H, Du G, Zhou J (2015) Urban flood risk warning under rapid urbanization. Environ Res 139:3–10. https://doi.org/10.1016/j.envres.2015.02.028
Chia MY, Koo CH, Huang YF, Di Chan W, Pang JY (2023) Artificial intelligence generated synthetic datasets as the remedy for data scarcity in water quality index estimation. Water Resour Manage 1–6. https://doi.org/10.1007/s11269-023-03650-6
Everingham M, Van Gool L, Williams CKI, Winn J, Zisserman A (2010) The pascal visual object classes (VOC) challenge. Int J Comput Vision 88(2):303–338. https://doi.org/10.1007/s11263-009-0275-4
Faramarzzadeh M, Ehsani MR, Akbari M, Rahimi R, Moghaddam M, Behrangi A, Klöve B, Haghighi AT, Oussalah M (2023) Application of machine learning and remote sensing for gap-filling daily precipitation data of a sparsely gauged basin in East Africa. Environ Process 10(1):8. https://doi.org/10.1007/s40710-023-00625-y
Feng B, Zhang Y, Bourke R (2021) Urbanization impacts on flood risks based on urban growth data and coupled flood models. Nat Hazards 106(1):613–627. https://doi.org/10.1007/s11069-020-04480-0
Fletcher TD, Andrieu H, Hamel P (2013) Understanding, management and modelling of urban hydrology and its consequences for receiving waters: A state of the art. Adv Water Resour 51:261–279. https://doi.org/10.1016/j.advwatres.2012.09.001
Gauen K, Dailey R, Laiman J, Zi Y, Asokan N, Lu YH, Thiruvathukal GK, Shyu ML, Chen SC (2017) Comparison of visual datasets for machine learning. In: 2017 IEEE International Conference on Information Reuse and Integration (IRI). pp 346–355
Gotmare A, Keskar NS, Xiong C, Socher R (2018) A closer look at deep learning heuristics: Learning rate restarts, warmup and distillation. ArXiv Preprint ArXiv:1810.13243
Guo K, Guan M, Yu D (2021) Urban surface water flood modelling-a comprehensive review of current models and future challenges. In: Hydrology and earth system sciences, vol 25, issue 5. Copernicus GmbH, pp 2843–2860. https://doi.org/10.5194/hess-25-2843-2021
Hammond MJ, Chen AS, Djordjević S, Butler D, Mark O (2015) Urban flood impact assessment: A state-of-the-art review. Urban Water J 12(1):14–29. https://doi.org/10.1080/1573062X.2013.857421
Hao W, Zhili S (2020) Improved mosaic: Algorithms for more complex images. J Phys Conf Ser 1684(1):012094
Ichiba A, Gires A, Tchiguirinskaia I, Schertzer D, Bompard P, Ten Veldhuis MC (2018) Scale effect challenges in urban hydrology highlighted with a distributed hydrological model. Hydrol Earth Syst Sci 22(1):331–350. https://doi.org/10.5194/hess-22-331-2018
Jamali B, Löwe R, Bach PM, Urich C, Arnbjerg-Nielsen K, Deletic A (2018) A rapid urban flood inundation and damage assessment model. J Hydrol 564:1085–1098. https://doi.org/10.1016/j.jhydrol.2018.07.064
Jiang J, Liu J, Cheng C, Huang J, Xue A (2019) Automatic estimation of urban waterlogging depths from video images based on ubiquitous reference objects. Remote Sensing 11(5):587. https://doi.org/10.3390/rs11050587
Jiang J, Qin CZ, Yu J, Cheng C, Liu J, Huang J (2020) Obtaining urban waterlogging depths from video images using synthetic image data. Remote Sens 12(6):1014. https://doi.org/10.3390/rs12061014
Kankanamge N, Yigitcanlar T, Goonetilleke A, Kamruzzaman M (2020) Determining disaster severity through social media analysis: Testing the methodology with South East Queensland Flood tweets. Int J Disaster Risk Reduct 42:101360. https://doi.org/10.1016/j.ijdrr.2019.101360
Lee Y, Brody SD (2018) Examining the impact of land use on flood losses in Seoul, Korea. Land Use Policy 70:500–509. https://doi.org/10.1016/j.landusepol.2017.11.019
Li J, Zhang B, Mu C, Chen L (2018) Simulation of the hydrological and environmental effects of a sponge city based on MIKE FLOOD. Environ Earth Sci 77(2). https://doi.org/10.1007/s12665-018-7236-6
Li Y, Martinis S, Wieland M (2019) Urban flood mapping with an active self-learning convolutional neural network based on TerraSAR-X intensity and interferometric coherence. ISPRS J Photogramm Remote Sens 152:178–191. https://doi.org/10.1016/j.isprsjprs.2019.04.014
Loshchilov I, Hutter F (2016) Sgdr: Stochastic gradient descent with warm restarts. ArXiv Preprint ArXiv:1608.03983
Lv Y, Gao W, Yang C, Wang N (2018) Inundated areas extraction based on Raindrop Photometric Model (RPM) in surveillance video. Water (Switzerland) 10(10):1332. https://doi.org/10.3390/w10101332
Maas AL, Hannun AY, Ng AY (2013) Rectifier nonlinearities improve neural network acoustic models. Proc Icml 30(1):3
Mignot E, Li X, Dewals B (2019) Experimental modelling of urban flooding: A review. J Hydrol 568:334–342. https://doi.org/10.1016/j.jhydrol.2018.11.001. Elsevier BV
Misra D (2019) Mish: A self regularized non-monotonic neural activation function. 4(2):10–48550. ArXiv Preprint ArXiv:1908.08681
Moy De Vitry M, Kramer S, Dirk Wegner J, Leitao JP (2019) Scalable flood level trend monitoring with surveillance cameras using a deep convolutional neural network. Hydrol Earth Syst Sci 23(11):4621–4634. https://doi.org/10.5194/hess-23-4621-2019
Müller R, Kornblith S, Hinton GE (2019) When does label smoothing help? Adv Neural Inf Process Syst 32
Nigussie TA, Altunkaynak A (2019) Modeling the effect of urbanization on flood risk in Ayamama Watershed, Istanbul, Turkey, using the MIKE 21 FM model. Nat Hazards 99(2):1031–1047. https://doi.org/10.1007/s11069-019-03794-y
Park S, Baek F, Sohn J, Kim H (2021) Computer vision–based estimation of flood depth in flooded-vehicle images. J Comput Civ Eng 35(2):04020072. https://doi.org/10.1061/(ASCE)CP.1943-5487.0000956
Rangari VA, Umamahesh NV, Bhatt CM (2019) Assessment of inundation risk in urban floods using HEC RAS 2D. Model Earth Syst Environ 5(4):1839–1851. https://doi.org/10.1007/s40808-019-00641-8
Redmon J, Divvala S, Girshick R, Farhadi A (2016) You only look once: Unified, real-time object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 779–788
Redmon J, Farhadi A (2018). Yolov3: An incremental improvement. ArXiv Preprint ArXiv:1804.02767
Rong Y, Zhang T, Zheng Y, Hu C, Peng L, Feng P (2020) Three-dimensional urban flood inundation simulation based on digital aerial photogrammetry. J Hydrol 584:124308. https://doi.org/10.1016/j.jhydrol.2019.124308
Seenu PZ, Venkata Rathnam E, Jayakumar KV (2020) Visualisation of urban flood inundation using SWMM and 4D GIS. Spat Inf Res 28(4):459–467. https://doi.org/10.1007/s41324-019-00306-9
Singh P, Sinha VSP, Vijhani A, Pahuja N (2018) Vulnerability assessment of urban road network from urban flood. Int J Disaster Risk Reduct 28:237–250. https://doi.org/10.1016/j.ijdrr.2018.03.017
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp 2818–2826
Vlad GA, Bînă D, Onose C, Cercel DC (2019) Flood severity estimation in news articles using deep learning approaches. https://www.researchgate.net/publication/345843772
Wang CY, Bochkovskiy A, Liao HYM (2021) Scaled-yolov4: Scaling cross stage partial network. In: Proceedings of the IEEE/Cvf conference on computer vision and pattern recognition. pp 13029–13038
Wang CY, Liao HYM, Wu YH, Chen PY, Hsieh JW, Yeh IH (2020) CSPNet: A new backbone that can enhance learning capability of CNN. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp 390–391
Wang X, Yang M, Zhu S, Lin Y (2013) Regionlets for generic object detection. In: Proceedings of the IEEE international conference on computer vision. pp 17–24
Wang Y, Chen AS, Fu G, Djordjević S, Zhang C, Savić DA (2018) An integrated framework for high-resolution urban flood modelling considering multiple information sources and urban features. Environ Model Softw 107:85–95. https://doi.org/10.1016/j.envsoft.2018.06.010
Yakovlev A, Lisovychenko O (2020) An approach for image annotation automatization for artificial intelligence models learning. Aдaптивнi Cиcтeми Aвтoмaтичнoгo Упpaвлiння 1(36):32–40
Yang HC, Wang CY, Yang JX (2014) Applying image recording and identification for measuring water stages to prevent flood hazards. Nat Hazards 74(2):737–754. https://doi.org/10.1007/s11069-014-1208-2
Yin J, Ye M, Yin Z, Xu S (2015) A review of advances in urban flood risk analysis over China. In: Stochastic environmental research and risk assessment, vol 29, issue 3. Springer Science and Business Media, LLC, pp 1063–1070. https://doi.org/10.1007/s00477-014-0939-7
Yu H, Zhao Y, Fu Y, Li L (2018) Spatiotemporal variance assessment of urban rainstorm waterlogging affected by impervious surface expansion: A case study of Guangzhou, China. Sustainability (Switzerland) 10(10):3761. https://doi.org/10.3390/su10103761
Zou Z, Shi Z, Guo Y, Ye J (2019) Object detection in 20 years: A survey. ArXiv Preprint ArXiv:1905.05055
Acknowledgements
This study was financially supported by the National Natural Science Foundation of China (U2040206), (52179009) and (51909035).
Funding
National Natural Science Foundation of China, U2040206, Hang Zheng, 52179009, Hang Zheng, 51909035, Yueyi Liu.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Pengcheng Zhong, Yueyi Liu, Hang Zheng, Jianshi Zhao. The first draft of the manuscript was written by Pengcheng Zhong and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Ethics Approval
Submission of this article implies that the work described has not been published previously, that it is not under consideration for publication elsewhere, that its publication is approved by all authors and tacitly or explicitly by the responsible authorities where the work was carried out and that, if accepted, it will not be published elsewhere in the same form, in English or in any other language, including electronically without the written consent of the copyright holder.
Consent for Publication
Not applicable.
Informed Consent
Informed consent was obtained from all individual participants included in the study.
Competing Interests
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Highlights
• Water depth can be calculated by recognizing the flood image using deep learning.
• The method can identify submerged positions of pedestrians or vehicles in the image.
• The precision of the YOLOv4 model for flood depth recognition can reach 89.29%.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhong, P., Liu, Y., Zheng, H. et al. Detection of Urban Flood Inundation from Traffic Images Using Deep Learning Methods. Water Resour Manage 38, 287–301 (2024). https://doi.org/10.1007/s11269-023-03669-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11269-023-03669-9