
Abstract
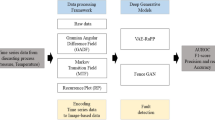
Microelectronics production failure analysis is an important step in improving product quality and development. In fact, the understanding of the failure mechanisms and therefore the implementation of corrective actions on the cause of the failure depend on the results of this analysis. These analyses are saved under textual features format. Then such data need first to be preprocessed and vectorized (converted to numeric). Second, to overcome the curse of dimensionality caused by the vectorisation process, a dimension reduction is applied. A two-stage variable selection and feature extraction is used to reduce the high dimensionality of a feature space. We are first interested in studying the potential of using an unsupervised variable selection technique, the genetic algorithm, to identify the variables that best demonstrate discrimination in the separation and compactness of groups of textual data. The genetic algorithm uses a combination of the K-means or Gaussian Mixture Model clustering and validity indices as a fitness function for optimization. Such a function improves both compactness and class separation. The second work looks into the feasibility of applying a feature extraction technique. The adopted methodology is a Deep learning algorithm based on variational autoencoder (VAE) for latent space disentanglement and Gaussian Mixture Model for clustering of the latent space for cluster identification. The last objective of this paper is to propose a new methodology based on the combination between variational autoencoder (VAE) for the latent space disentanglement, and genetic algorithm (GA) to find, in an unsupervised way, the latent variables allowing the best discrimination of clusters of failure analysis data. This methodology is called VAE-GA. Experiments on textual datasets of failure analysis demonstrate the effectiveness of the VAE-GA proposed method which allows better discrimination of textual classes compared to the use of GA or VAE separately or the combination of PCA with GA (PCA-GA) or a simple Auto-encoders with GA (AE-GA).






Similar content being viewed by others


Data availibility
All data, models, and code generated or used during the study appear in the submitted article and are provided upon request by contacting Abbas Rammal via email: abbas.rammal@emse.fr.
References
Abualigah L, Khader A, AlBetar M (2016) Unsupervised feature selection technique based on genetic algorithm for improving the text clustering, 2005. In: Paper Presented at the 7th International Conference on Computer Science and Information Technology, pp 13–14
Ani A (2005) Ant colony optimization for feature subset selection. Trans Eng Comput Technol 4:35–389
Ayad A (2013) Parametric analysis for genetic algorithms handling parameters. Alex Eng J 52:99–111
Bazu M, Bajenescu T (2011) A practical guide for manufacturers of electronic components and systems. failure analysis: a practical guide for manufacturers of electronic components and systems. Chennai, John Wiley and Sons
Bharti K, Singh P (2015) Hybrid dimension reduction by integrating feature selection with feature extraction method for text clustering. Expert Syst Appl 42:3105–3114
Calinski T, Harabasz J (1974) A dendrite method for cluster analysis. Commun Stat theor Methods 3:1–27
Centner V, Massart D, de Noord O, de Jong S, Vandeginste B, Sterna C (1996) Elimination of uninformative variables for multivariate calibration. Anal Chem 68(21):3851–3858
Chawdhry P, Roy R, Pant R (2012) Soft computing in engineering design and manufacturing. Springer, Berlin, Heidelberg
Dai B, Wipf D (2019) Diagnosing and enhancing vae models, 2019. Paper Presented at the International Conference on Learning Representations arXiv:1903.05789
Davies D, Boldin D (1979) A cluster separation measure. IEEE Trans Pattern Anal Mach Intel 2:224–227
Deep K, Thakury M (2007) A new mutation operator for real coded genetic algorithms. Appl Math Comput 193:211–230
Derksen S, Keselman H (1992) Backward forward and stepwise automated subset selection algorithms: Frequency of obtaining authentic and noise variables. Br J Math Stat Psychol 45(2):265–282
Dunn J (1974) Well-separated clusters and optimal fuzzy partitions. J Cybernet 4:95–104
Efron B (1979) Bootstrap methods: another look at the jackknife. Ann Stat 7:1–26
Ezukwoke K, Toubakh H, Hoayek A, Batton-Hubert M, Boucher X, Gounet P (2021) Intelligent fault analysis decision flow in semiconductor industry 4.0 using natural language processing with deep clustering, 2021. In: Paper Presented at the 17rd International Conference on Automation Science and Engineering, pp 23–27
Forrest S (1993) Genetic algorithms: principles of natural selection applied to computations. Science 261:872–878
Galvão R, Araújo M, Fragoso W, Silva E, José G, Soares S, Paiva H (2008) A variable elimination method to improve the parsimony of mlr models using the successive projections algorithm. Chemom Intell Lab Syst 92(1):83–91
Güney A, Bozdogan H, Arslan O (2021) Robust model selection in linear regression models using information complexity. J Comput Appl Math 398:113679
Gonçalves J, Mendes M, Resende M (2005) A hybrid genetic algorithm for the job shop scheduling problem. Eur J Oper Res 167:77–953
Hinterding R (1995) Gaussian mutation and self-adaption for numeric genetic algorithms, 1995. In: Paper Presented at the IEEE International Conference on Evolutionary Computation
Hinterding R, Michalewicz Z, Peachey T (1996) Self-adaptive genetic algorithm for numeric functions. Parallel Probl Solv Nat 1141:420–429
Jolliffe I (2002) Principal component analysis. Springer, Berlin, Heidelberg
Lee JH, Chan S, Jang JS (2010) Process-oriented development of failure reporting, analysis, and corrective action system. J Qual Reliab Eng 2010:8
Liu L, Kang J, Yu J, Wang Z (2005) A comparative study on unsupervised feature selection methods for text clustering, 2005. In: Paper Presented at the International Conference on Natural Language Processing and Knowledge Engineering, pp 30–31
Lore K, Akintayo A, Sarkar S (2017) A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit 61:650–662
Mehmood T, Liland K, Snipen L, Sæbog S (2012) A review of variable selection methods in partial least squares regression. Chemom Intel Lab Syst 118:62–69
Mikolov T, Sutskever I, Chen K, Corrado G, Dean J (2013) Distributed representations of words and phrases and their compositionality. In: Burges CJ, Bottou L, Welling M, Ghahramani Z, Weinberger KQ (eds) An overview and empirical comparison of natural language processing (NLP) models and an introduction to and empirical application of autoencoder models in marketing. Curran Associates Inc
Mitchell M (1995) Genetic algorithms: an overview. Complexity 1:31–39
Pakhira M, Bandyopadhyay S, Maulik U (2004) Validity index for crisp and fuzzy clusters. Pattern Recognit 37:487–501
Picek S, Goluba M (2010) Comparison of a crossover operator in binary-coded genetic algorithms. WSEAS Trans Comput 9:1064–1073
Ranjini A, Zoraida B (2013) Analysis of selection schemes for solving job shop scheduling problem using genetic algorithm. Int J Res Eng 2:775–779
Reynolds D (2009) Gaussian mixture models. Springer, Boston, US
Rong X (2014) word2vec parameter learning explained. arXiv e-prints
Rousseeuw P (1987) Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20:53–65
San Martin G, López Droguett E, Meruane V, das Chagas Moura M (2019) Deep variational auto-encoders: a promising tool for dimensionality reduction and ball bearing elements fault diagnosis. Struct Health Monitor 18:1092–1128
Shamsinejadbabki P, Saraee M (2012) A new unsupervised feature selection method for text clustering based on genetic algorithms. J Intel Inf Syst 38:1–16
Shankar V, Parsana S (2022) An overview and empirical comparison of natural language processing (nlp) models and an introduction to and empirical application of autoencoder models in marketing. J Acad Mark Sci 50(6):1324–1350
Sivanandam S, Deepa S (2008) Introduction to genetic algorithms. Springer, Berlin, Germany
Song C, Liu F, Huang Y, Wang L, Tan T (2013) Auto-encoder based data clustering. Springer, Berlin, Heidelberg
Song W, Li C, Park C (2009) Genetic algorithm for text clustering using ontology and evaluating the validity of various semantic similarity measures. Expert Syst Appl 36:9095–9104
Starczewski A (2017) A new validity index for crisp clusters. Pattern Anal Appl 20:687–700
Teknomo K (2006) K-means clustering tutorials. Medicine 100:3
Thashina S (2020) Email based spam detection. International Journal of Engineering and Technical Researchs, 9
Uguz H (2011) A two-stage feature selection method for text categorization by using information gain, principal component analysis and genetic algorithm. Knowl Based Syst 24(7):1024–1032
Uysal A, Gunal S (2014) Text classification using genetic algorithm oriented latent semantic features. Expert Syst Appl 41:5938–5947
Wyse N, Dubes C, Jain A (1980) A critical evaluation of intrinsic dimensionality algorithms
Xie X, Beni G (1991) A validity measure for fuzzy clustering. IEEE Trans Pattern Anal Mach Intel 13:841–847
Yangn M, Yang Y, Su T (2014) An efficient fitness function in genetic algorithm classifier for landuse recognition on satellite images. Sci World J. https://doi.org/10.1155/2014/264512
Yilmaz S, Toklu S (2020) A deep learning analysis on question classification task using word2vec representations. Neural Comput Appl 32:2909–2928
Acknowledgements
This study was carried out by Mines Saint-Etienne in partnership with STMicroelectronics Reliability and Failure Analysis Lab in Grenoble, France.
Funding
This project has been funded with the support of european project FA4.0.
Author information
Authors and Affiliations
Contributions
All named authors contributed equally to the construction of the paper. A.R. designed the structure of this article and managed to run the new algorithms and interpreted the results. A.H. and M.B. contributed in the explanation of mathematical methods and discussion of the results. He also reviewed the article for faults and added some other explanations and also revised the manuscript for linguistic check and some other explanations. K.E. were responsible of the data collection and illustration part. They gathered data from different sources and check for its reliability. Authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no competing interests.
Ethical approval
Not applicable.
Consent to participate
Not applicable.
Consent to publish
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rammal, A., Ezukwoke, K., Hoayek, A. et al. Unsupervised approach for an optimal representation of the latent space of a failure analysis dataset. J Supercomput 80, 5923–5949 (2024). https://doi.org/10.1007/s11227-023-05634-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-023-05634-0