
Abstract
Machine learning techniques have to date not been widely used in population-environment research, but represent a promising tool for identifying relationships between environmental variables and population outcomes. They may be particularly useful for instances where the nature of the relationship is not obvious or not easily detected using other methods, or where the relationship potentially varies across spatial scales within a given study unit. Machine learning techniques may also help the researcher identify the relative strength of influence of specific variables within a larger set of interacting ones, and so provide a useful methodological approach for exploratory research. In this study, we use machine learning techniques in the form of random forest and regression tree analyses to look for possible connections between drought and rural population loss on the North American Great Plains between 1970 and 2020. In doing so, we analyzed four decades of population count data (at county-size spatial scales), monthly climate data, and Palmer Drought Severity Index scores for Canada and the USA at multiple spatial scales (regional, sub-regional, national, and county/census division levels), along with county level irrigation data. We found that in some parts of Saskatchewan and the Dakotas − particularly those areas that fall within more temperate/less arid ecological sub-regions − drought conditions in the middle years of the 1970s had a significant association with rural population losses. A similar but weaker association was identified in a small cluster of North Dakota counties in the 1990s. Our models detected few links between drought and rural population loss in other decades or in other parts of the Great Plains. Based on R-squared results, models for US portions of the Plains generally exhibited stronger drought-population loss associations than did Canadian portions, and temperate ecological sub-regions exhibited stronger associations than did more arid sub-regions. Irrigation rates showed no significant influence on population loss. This article focuses on describing the methodological steps, considerations, and benefits of employing this type of machine learning approach to investigating connections between drought and rural population change.
Similar content being viewed by others


Introduction
Droughts are a common environmental hazard in dryland agricultural regions, and have wide-ranging socio-economic effects on rural communities that include, but are not limited to, loss of household incomes, food insecurity, and physical and mental health challenges (Edwards et al., 2015; Gautier et al., 2016; Hermans & Garbe, 2019; Keshavarz et al., 2013; Sena et al., 2014; Udmale et al., 2014). The human impacts of drought are context specific and vary according to the duration and severity of the drought event, the sensitivity of land-use practices and economic systems in exposed areas, the capacity of local populations to adjust and adapt, and the compounding effects of wider socio-economic processes (Chen et al., 2014; Mapedza & McLeman, 2019). Subsistence farmers, pastoralists, landless laborers, and rural households with low incomes are especially vulnerable to the impacts of drought and, when other adaptation options are exhausted, some or all members of the household may need to migrate out of affected areas temporarily or indefinitely (Afifi et al., 2014; Chapagain & Gentle, 2015; De Silva & Kawasaki, 2018; Gautier et al., 2016; Hermans & Garbe, 2019; Kabir et al., 2018; Marzieh Keshavarz et al., 2013; Venot et al., 2010).
It has long been understood that household vulnerability to droughts and other natural hazards is inversely related to the capacity of households, communities, and governments to adapt (Adger, 2006; Smit & Wandel, 2006), and that the potential for involuntary migration or displacement declines as adaptive capacity improves (McLeman, 2014). Indeed, most documented examples of drought migration and displacement in recent years have occurred in low-income and, to a lesser extent, middle-income countries that have large rural populations and limited institutional adaptive capacity (Mapedza & McLeman, 2019). On the North American Great Plains, large-scale migration events occurred during droughts between the late 1800s through the 1930s (Gregory, 1989; Hurt, 1981; McLeman, 2006; McLeman et al., 2008; Warrick, 1980), but became less common in later decades of the twentieth century due to agricultural restructuring, changing land management practices, technological innovations, greater government support for farming, and insurance regimes (Gutmann et al., 2005; Polsky & Easterling, 2001; Warrick, 1980; White, 1998).
This begs the question of whether droughts today have any influence on rural migration and population patterns on the Great Plains. It may be that they no longer have any influence at all or, alternatively, the influence has become so subtle that it is simply less obvious or less easily detected than was once the case. A small number of previous studies reviewed in the next section which were conducted using methods based on regression modeling suggest that droughts have had a weak or virtually undetectable influence on rural population patterns in the US Great Plains since the 1970s, except for certain age cohorts in counties with low irrigation rates. For the Canadian portion of the Great Plains, no previous studies on drought-population linkages have been done for periods since the 1930s. We wanted to conduct a closer investigation whether rural population changes anywhere, and at any spatial scale within the entire Canada-US Great Plains region, show an association with drought conditions between 1970 and 2010 (the decades for which we had complete census data for both countries at the start of the project). Rather than replicating regression-based approaches done in previous studies and extending these to Canada, where they had not been previously used, we chose an automated machine-learning based approach that has not been widely used in population and environment research previously.
Specifically, to do this, we used random forest models (Breiman, 2001) to identify possible locations and decades where rural population change within the study region shows a possible response to drought conditions and used regression tree analysis (Lewis, 2000) to identify the relative contribution of specific climatic factors or measures (e.g., temperature, precipitation, elements reflected in Palmer Drought Severity Index scores) in specific years to the observed rural population outcomes. Using machine learning methods for this study provided advantages over methods used in previous studies, including the ability to process enormous amount of data efficiently for multiple spatial and temporal scales; to conduct exploratory analyses of multiple covariates and identify potential relationships among variables that are not immediately obvious because their connections are subtle, complex or non-linear, and; to estimate the relative contribution of individual climatic variables in specific years to the population outcomes identified in a given time period and spatial unit.
Our findings are generally consistent with previous studies done in the USA and suggest that droughts had a relatively weak − but not entirely undetectable − effect on rural population patterns across the Great Plains region between 1970 and 2010, with the 1980s being the decade where no significant influence was detected at all, anywhere across or within the region. We did detect specific periods and sub-regional areas where drought conditions may have contributed to rural population loss − specifically, rural areas in parts of Saskatchewan and the Dakotas in the 1970s and 1990s − were able to identify specific years within those decades where precipitation shortfalls and/or monthly PDSI scores had the strongest association with the observed population outcomes. These areas where the drought-population change association was strongest are primarily located in wetter, more temperate parts of the wider Great Plains ecoregion, which contrasts with the well-documented drought-related population changes observed in arid parts of the Great Plains in the first half of the twentieth century.
This is, to our knowledge, the first time environmental impacts on population patterns have been assessed for the entire Great Plains region as a whole; for understandable reasons relating to data availability and comparability, past research has focused on either the US or Canadian areas, but not both. Subsequent sections of this article describe in detail the methodological steps we used to analyze climate and population data for the region, to provide insights for researchers who may wish to apply these methods to other topics in environmental migration research. We provide sample geovisualizations of our model outputs and describe our findings with respect to the previous research. As background, we first review existing research on the relationship between drought and population patterns on the Great Plains.
Previous research on drought impacts on Great Plains population patterns
While much has been written about the population impacts of historical droughts on the Great Plains, especially those of the Dust Bowl/Great Depression era (Cunfer, 2005; Gilbert & McLeman, 2010; Gregory, 1989; Hurt, 1981; Laforge & McLeman, 2013; McLeman, 2006; McLeman & Ploeger, 2012; McLeman et al., 2010; McWilliams, 1942; Reuveny, 2008; Worster, 1979), only a small number of researchers have assessed the influence of drought in subsequent decades, and these have focused exclusively on the USA. Warrick (1980) described key decades of drought on the US portion of the Great Plains − the 1890s, 1910s, 1930s, 1950s, and 1970s − and used population data from the US census and farm transfer data from the US Department of Agriculture to identify locations that experienced population loss. In doing so, he found that population change during the 1950s was not especially different from that which occurred in the relatively drought-free decades of the 1940s and 1960s, a finding he attributed to two factors: increasing resilience of farmers and an intervention by the US government in 1954 to pour hundreds of millions of dollars of relief funds into drought-stricken areas. The author noted an increase in farm ownership transfers in the early 1970s, but did not assess if these were directly attributable to drought.
Parton et al. (2007) assessed population trends for US Great Plains counties from 1900 to 2000, subdividing these into three categories: metropolitan/urban counties, rural counties with predominantly irrigated farmland, and rural counties where farmland was typically not irrigated. The authors observed little difference in population trends for any of these categories in the 1950s or the 1970s, decades in which significant drought events occurred (Lockeretz, 1978; Wilhite, 1983). They instead described three longer-term population trends: a continuous population decline in non-irrigated counties that began in the 1940s and stabilized by the 1990s; a slow trend of population increase in irrigated rural counties over that same time period; and, steady growth in urban populations beginning in the 1940s that has continued for the remainder of the century, to the point where urbanites now outnumber rural dwellers on the US plains. The authors further noted that over the course of the twentieth century, linkages between population and agricultural productivity weakened due to technological advances in farming, but that heavily irrigated counties likely had more labor market opportunities than non-irrigated counties, thus explaining the divergence in population trends between the two.
Gutmann et al. (2005) examined the relationship between environment and population trends on the US Great Plains from 1930 to 1990, using as their dependent variable estimates of net migration rates derived from decennial census data. Their independent variables included annual values for temperature and precipitation derived from a dataset gridded at a half-degree latitude/longitude scale; county elevation and area covered in water (as proxies for environmental amenities that might attract migrants) taken from US Geological Survey data; and employment, population size, and gender data from the US census. Using a multistage analysis that started with basic regression models comparing temperature and precipitation variables with county-level migration outcomes, they found that hot temperatures were generally associated with net out-migration, but that precipitation variables showed less association. As additional non-climatic variables were added into the analysis, the strength of the climate-migration relationship weakened, with employment and educational variables exhibiting much greater importance in explaining migration patterns. The association between drought conditions and migration patterns was significant in the decades of the 1930s, the 1950s (possibly spilling over into the 1960s), and, to a much smaller extent in the 1970s, but the overall strength of the relationship declined over time. No significant relationship between climatic variables and migration was seen in data for the 1980s or 1990s.
A final study of note was done by Feng et al. (2012), who investigated possible associations between weather-related declines in crop yields and population change between 1970 and 2009 in US states where corn and soybeans are important crops, including the Great Plains states of Kansas, Nebraska, North Dakota, and South Dakota. Using time-adjusted regression analyses, the authors identified a statistically significant association between county-level net outmigration and weather-related crop yield shocks, an effect that is likely filtered through impacts on local employment opportunities. When migration patterns were further assessed by age cohorts, the authors found the drought-yield-migration relationship to be statistically significant only for people under the age of forty-five, and that for people over age sixty, there is no association at all. The strongest association is for people between the ages of fifteen and twenty-nine, further reinforcing the likelihood of the causal link to changes in employment opportunities. Worth noting is that in this study, the calculated yield declines could be caused by excessive precipitation events as well as by extreme heat or drought.
Cumulatively, these studies suggest that in the US portion of the Great Plains, the influence of drought on population patterns at the county level has been declining since the 1930s, and that by the 1970s the influence had become very subtle, though not completely absent. When droughts have occurred in recent decades, the observed influence was strongest in rural counties with low levels of irrigation, with migration typically being undertaken by young people in response to the subsequent changes in employment availability.
Far less published research is available for the relationship between drought and rural population patterns in the Canadian portions of the Great Plains − known in Canada as “The Prairies.” This region experienced significant drought events in the 1890s, 1910s, 1930s, 1960s, 1980s, and 1999–2005 (Hanesiak et al., 2011) but quantitative studies of the population impacts are limited to droughts that occurred in the 1930s, conducted using GIS models that combined census data with customized drought indices (McLeman & Ploeger, 2012; McLeman et al., 2010). The general arc of rural population patterns in the Canadian Prairies is comparable to that of the US Great Plains. By the late 1800s, most original Indigenous occupants of the region had been displaced to reserve lands through a series of numbered treaties (Starblanket, 2019). A system of “homesteading” based on the US model was instituted, leading to an in-migration beginning in the 1880s of people of European origin to establish family farms based on a grid-shaped, range-and-township survey method (Richtik, 1975). Rural population growth began first in the more temperate areas of the Prairies and eventually spread into the drier south-central regions, prompted by World War I-era rises in commodity prices, with the region’s rural population numbers peaking at approximately 1.3 million by the mid-1930s (Carlyle, 1994). Winnipeg was at that time the only urban center of significant size in the Prairies. The combined effects of severe droughts and the economic hardships of the Great Depression led to significant outmigration from rural areas, especially in drier parts of the region, and started a trend of steady rural population decline over the next four decades (Carlyle, 1994; Jones, 1991; Marchildon et al., 2008). Meanwhile, urban populations in the Prairies grew rapidly from the 1950s onward, driven in large part by oil and gas development in Alberta and Saskatchewan (Davies, 1990).
Since the 1970s, the rate of rural population decline on the Canadian Prairies has slowed, with rural areas within commuting distance of urban centers experiencing population growth associated with new housing developments (Davies, 1990). In rural areas more distant from urban centers, population densities are generally low, and a pattern consistent with those seen in the USA has emerged, with farms becoming fewer and larger, and the average age of residents becoming older (Dandy & Bollman, 2008; Parson, 1999). A close review of existing scholarly literature found no studies assessing the role of environmental factors in general, and drought in particular, in observed rural population trends and settlement patterns in western Canada for the last 50 years.
In addition to filling the missing gap with respect to analyzing the drought-population change relationship in Canada, we describe in the following sections how we build upon existing studies of the US region by using machine learning to add granularity to the association between rural population loss and specific climatic factors in particular years, comparing the influence of climate factors across multiple scales, and factoring in decadal changes in irrigation rates. We also compare findings between Canada and the USA. We provide considerable detail in our methodological steps given the relative newness of this approach for population-environment research.
Methodology
Rather than replicate methods used in previous studies, we chose to explore associations between drought and rural population change on the Great Plains from 1970 to 2010 (1971 to 2011 in the case of Canada, given census dates) using an approach that combined random forest machine learning algorithms and regression tree analysis. Such an approach has not been used previously to assess population-environment interactions for the Great Plains study region or for drought-related population change more generally; to our knowledge, this approach has been used in population-environment research in only a small number of cases, Best et al. (2020) study of cyclone-related displacements in Bangladesh being the best example. Such an approach is time consuming, especially in the early stages of preparing data for analysis, and requires familiarity with programming (ideally R language), but it allows the researcher to conduct exploratory analyses of very large datasets with multiple covariates, and to identify potential relationships among variables that are not immediately obvious because their connections are subtle, complex, or non-linear. In addition, this approach provides an indication of the strength of the influence of particular variables on model outputs relative to others. Compared with other regression methods where the researcher chooses the variables to be tested for connectivity, this is a data-driven method where the algorithms suggest to the researcher where the connections may exist.
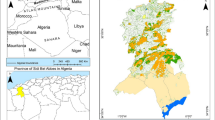
Delineation of the study area was done using the US Environmental Protection Agency ecoregion categorization, which uses geology, landform, soil, vegetation, climate, land use, wildlife, and hydrological characteristics to identify twelve mutually exclusive continental ecoregions (Omernik & Griffith, 2014). The Great Plains were in this way divided into three ecological sub-regions for analysis: the South-Central Semi-Arid Prairies, West-Central Semi Arid Prairies, and the Temperate Prairies. ArcGIS was used to create customized maps to visualize our findings, with Fig. 1 illustrating the study area, its ecological sub-regions, and the area underlain by the Ogallala aquifer, which is heavily used for irrigation − a variable identified by Parton et al. (2007) as being a relevant factor in drought-population linkages.

Study area: Great Plains and ecological sub-regions, based on Omernik and Griffith (2014)
Population data
American census data for the study area were obtained via the IPUMS National Historic Geographic Information System online archive hosted by the University of Minnesota. The US census reports population at 10-year intervals for years ending in zero, providing county-level data for the years 1970–2010 inclusive (2020 census data were not available at the time we conducted this project). With the exception of a single suburban Colorado county, county boundaries did not change during the study period. The next step in the data processing workflow was to remove from the population dataset counties that have urban or large suburban populations, which we identified by using county-level Rural–Urban Continuum Codes produced by the US Department of Agriculture (US Department of Agriculture Economic Research Service, 2020). The Continuum was first published in 1974, with successive updates every tenth year starting in 1983, and assigns codes to counties on a nine-point scale according to their population and/or proximity to an urban metropolitan area as is defined by the US Office of Management and Budget (Table 1). A total of 912 counties overlapped with the study area shown in Fig. 1, of which 808 were initially classified as “Non-Metro” (i.e., codes 4–9 on the continuum), a number that declined to 727 by the 2003 update. Counties that appeared with codes 1–3 were removed from the dataset, and data for those that switched from 4 to 3 during the study period were removed for the relevant decades.
Unlike the USA, Canadian census data for rural populations are not linked to county or other municipal boundaries but are instead reported according to a hierarchy of spatial units known as census consolidated subdivisions (CCSs) whose boundaries have shifted multiple times over the last half-century based on adjustments made by the government agency responsible for census taking. Each CCS consists of a collection of villages, towns, and their surrounding rural areas with prescribed boundaries, but CCSs have no specific grounding in political boundaries as do US counties. We used for this project population counts from 1971 to 2011 inclusive for all CCS that overlay the Canadian portion of the Great Plains ecoregion. The CCS is distinct from census units used for urban population counts, the latter being recorded as census metropolitan areas (CMAs). Suburban areas immediately adjacent to CMAs can sometimes be recorded as CCS, and so for this study, we removed all CMA-adjacent CCS with a density of 400 or more inhabitants per square kilometer, so as to eliminate CCSs that are likely to be suburban in nature, thereby selecting only those census units roughly comparable to US non-metro counties (a list of these units is provided in the Supplementary Materials). An initial challenge in conducting this project was that CCS boundaries and their corresponding data were not previously digitized for the entire study period. As a result, several weeks of labor and numerous manual steps were required to prepare the Canadian population data for this study. These steps are detailed in the Supplementary Materials for this article, and the final population dataset has been made available online for use by other researchers.
Climate data
We were particularly interested in investigating the impacts of agricultural drought on rural population change over the study period. “Agricultural drought” is defined by the American Meteorological Society as, “Conditions that result in adverse crop responses, usually because plants cannot meet potential transpiration as a result of high atmospheric demand and/or limited soil moisture” (American Meteorological Society, 2012). A variety of indices have been used to estimate agricultural drought potential on the Great Plains, each with its strengths and weaknesses (Bonsal et al., 2011; Tian et al., 2018; Zargar et al., 2011). Those that contain a measure of temperature in their calculation, such as the Palmer Drought Severity Index (PDSI) and the Standardized Precipitation and Evapotranspiration Index (SPEI) are most relevant for population impact research; we made this conclusion on the basis of Gutmann et al. (2005) observation that rural population decline is responsive to extreme temperatures but exhibits multi-directional outcomes in response to precipitation. Similarly, modeling work has shown that the combination of extreme heat with precipitation shortfall had a strong association with rural population decline in western Canada in the 1930s (McLeman et al., 2010; McLeman & Ploeger, 2012). Research by Colston et al. (2019) on farmers’ perceptions of drought risks on the southern Great Plains emphasizes the importance of the timing of precipitation and heat relative to the farming or grazing system calendar in determining the severity of a drought’s impacts.
Based on the above, we selected and assessed four sets of climatic variables for the study period in our machine learning analyses: extreme heat conditions each summer, as indicated by the number of degree days per year where maximum daily temperature is greater than 30 °C, a temperature threshold above which common cash crops on the Great Plains show rapidly diminishing yield curves (Schlenker & Roberts, 2009); total annual precipitation received in the period April to August, when moisture is most needed by crops; annual averages of monthly PDSI scores for April through August; and, a combination of the three preceding variables in which each is given equal weighting, and which we refer to for the remainder of this article as a Drought Potential Index (DPI).
The first two sets of variables (extreme heat and April–August precipitation) are mutually exclusive, while the third set − the monthly PDSI score − contains the first two sets within a much larger suite of data. PDSI is an index for calculating meteorological drought based on a water balance model, but it has limitations that mean it is not always an accurate predictor of agricultural drought. For example, PDSI values are sensitive to anomalous precipitation amounts received in a given month, the effects of which can persist in PDSI calculations for multiple subsequent months (Alley, 1984). The thresholds for various categories of drought within the PDSI are somewhat arbitrarily established, as are assumptions about relationships between precipitation, stored soil moisture, groundwater recharge, and surface run-off; as a result, PDSI scores often do not accurately reflect growing season conditions on the ground in a given location (Guttman et al., 1992). We thus experimented by creating our own drought prediction index (DPI) as a fourth set of variables for analysis, by combining the monthly values for each of the first three sets of variables (i.e., PDSI, extreme heat, and summer precipitation) weighting each one equally in each spatial unit. In doing so, we attempted to capture the meteorological characteristics of water availability in a given location predicted by the PDSI while emphasizing specific combinations of extreme heat and precipitation shortfalls that have high potential to stimulate crop and pasture damage during the growing season. We emphasize that the DPI was our own creation with which we wanted to experiment for this particular project on the chance that it might offer greater predictive power than the more familiar PDSI, and it is not a measure that has been used elsewhere.
Multiple open source datasets were drawn upon to acquire the necessary data for these four sets of variables, and for each set the spatial scale was resampled to a standardized spatial unit of 10 km by 10 km. For the first two sets, temperature and precipitation data for Canada were taken from the gridded NRCANmet climatology dataset (Hutchinson et al., 2009). These data have a resolution of 10 km2 and were created using thin-plate splines (ANUSPLIN) to generate continuous datasets for minimum temperature, maximum temperature, and precipitation from weather station records. Temperature and precipitation data for the USA were derived from the US Historical Climatology Network (USHCN), which has 341 stations on the US Great Plains with continuous daily reporting histories. Data for the study period for each US station were converted to Celsius and millimeters. To convert these point-source data into surface pixels to be distributed across the study area, we used an inverse distance weighting interpolation to create gridded cells of 10 km by 10 km. This method would not be suitable for areas with rapid elevation changes, interspersed biomes, or large amounts of surface water, but is acceptable for the geography of the Great Plains.
We rescaled the extreme heat and summer precipitation data to a 10-point scale for each 10 km by 10 km grid pixel. Annualized growing season precipitation amounts and extreme heat day counts for each spatial unit were sorted into deciles, with a score of 10 being assigned to deciles with the greatest number of high heat days and lowest precipitation values, and a score of one given to years with the fewest hot days/highest amounts of precipitation. So, for example, Clearwater County, Minnesota recorded no days above 30 °C in 2009, resulting in it being given a score of 1 for temperature for that year. With these two sets of variables, certain areas of the Plains inevitably score higher than others year after year, on average; central Texas will in most years record more extremely hot days than central Saskatchewan, and eastern South Dakota will usually record more summer rain than eastern Colorado. Agricultural producers have adapted practices to local conditions over the last century-plus, meaning that crop choices and land use practices in central Texas reflect the typically dry conditions found there and differ from crop choices and land use practices in eastern South Dakota or central Saskatchewan. The decile ranking approach allows for easy identification of years when summer temperatures or precipitation were anomalous in a given year relative to average conditions for each 10 × 10 grid cell.
For the third set of variables, monthly PDSI scores for the study period were obtained from NOAA’s National Centers for Environmental Information online portal. The spatial unit for these data is the “climate division,” a unit larger than a county but smaller than a state, with each state having between six and ten climate divisions. The average annual PDSI scores for the months of April to August for each climate division were transferred to annual rasters (i.e., sets of cells with data arranged in rows and columns) aligned with the precipitation and temperature data. PDSI values for the Canadian section of the study area were acquired from TerraClimate, a moderate-spatial resolution dataset (1/24°, ~ 4 km) (Abatzoglou et al., 2018). PDSI scores are centered on zero, with negative scores indicating dry conditions and positive values indicating wet conditions. To make calculations easier, we converted the PDSI into an inverted 10-point scale, with scores of − 5 or lower (i.e., severe dryness) given a score of 10 and PDSI scores of + 5 or more (i.e., especially wet) being given a score of 1, and values between these extremes ranked accordingly.
To create the fourth set of variables − the customized DPI mentioned previously − we summed the other three variables for each 10 × 10 km cell (i.e., weighted-sum model), with those that scored close to zero interpreted as being very unlikely to have experienced drought conditions in a given year, while those closer to a maximum score of 30 were interpreted as having had a very high potential for drought. We use the term drought “potential” deliberately, since the actual vegetative stress at farm levels depends on a range of additional, local level factors, such as soil characteristics, stored moisture from preceding winters, crop choices, land management practices and so forth.
The results described in the “Results” section are from model runs where we also elected to include farm-level irrigation data for each county/CCS taken from Canadian and US agricultural censuses over the study period. As will be shown, irrigation data were subsequently found to have little influence on model outcomes.
As is evident from the preceding descriptions, to conduct spatially explicit modeling across multiple decades, domain sources, and natural and administrative jurisdictions in this way and for such large spatial units necessitated significant data processing before analysis could begin. A particularly time-consuming aspect was that source data for climate for this project were at a variety of spatial scales and needed to be standardized to a common spatial fabric of 10 km × 10 km pixels across the entire study area. It took the equivalent of 4 months of full-time work by a graduate researcher to prepare the population and climate data before we could begin to run our models. The standardized datasets we created for this project are available from the authors for use by other researchers.
Random forest algorithm and regression tree analysis
In this project, we used random forests to identify the climatic variables that have robust predictive potential, and regression trees to identify the specific associations between the individual climatic variables and population decline in each decade from 1970 to 2010. We repeated our analyses at multiple spatial scales, starting with the entire Great Plains region, followed by a separate analysis for each of the four ecological sub-regions shown in Fig. 1, the USA and Canadian portions of the entire study region and, for the two ecological sub-regions that span the border, a separate analysis for each part. This created a total of 10 regional/sub-regional spatial units that we analyzed to see whether the strength of any drought-population loss relationships identified with this method varied according to political and/or ecological characteristics within the study region.
R software packages were used for both the random forest and regression tree analyses: randomForest (Liaw & Wiener, 2002) and rpart (Therneau et al., 2019). Random forest creates an ensemble of independent, unpruned, bagged regression trees using a boot-strap sample of the dataset from which variable importance is decided based on a voting system (Breiman, 1996). Each tree that emerges from the random forest is based on a random subset of approximately 2/3 of the data supplied for the dependent variable, and each split within each tree is decided based on a random subset of independent variables using the method described below (Breiman, 2001). For this analysis, each model iteration was run using 1000 trees and 25 variables at each split.Footnote 1 Overfitting was addressed by allowing regression trees to grow to their maximum depth and subsequently pruning trees (i.e., removing splits at terminal nodes) by minimizing the cross-validation error (detailed below).
Four measures of importance were used to identify the top-ranked variables within each set: mean square error increase, node purity increase, and two properties derived from the construction of individual trees, namely mean minimal depth and “times a root” (Paluszynska, 2017). Mean square error increase refers to the increase of mean squared error of predictions after the values of an individual independent variable have been permuted. Node purity increase is measured by the decrease in the sum of squares based on splitting an independent variable in a way that creates a high variance between semi-supervised learning (SSL) nodes and semi-supervised regression (SSR) nodes and a small variance within each node itself. The premise behind using mean minimal depth and “times a root” is that the variables most responsible for partitioning large samples of the population will most frequently appear closest to the root of the regression tree. Node levels are numbered based on their distance from the root, with the root being numbered as zero. “Times a root” is a count of the number of times an independent variable is used to split the dataset, while mean minimal depth is calculated by averaging the depth of the first node for each variable across all trees (Ehrlinger, 2015). Our analysis ran random forest models for rural population decline for each decade from 1970/1971 to 2010/2011 for counties/CCDs in each of the 10 regional/sub-regional units in the study area using each of the three climate-related variables (extreme heat, growing season precipitation, and PDSI) and the DPI that combines all three. This created a total of 40 separate models, as shown in Table 2. The random forest analysis allowed us to isolate those specific ecological regions/sub-regions and decades where climate variables and population loss showed potential association based on the R2 values, with those of 0.25 or lower being interpreted as suggesting that little or no association exists. As can be seen in the table, in the decades of the 1970s, 1990s and 2000-2010 models returned R2 values greater than 0.25 at the spatial scale of the Great Plains as a whole, with the sub-regional models for those decades suggesting that these outcomes were driven disproportionately by population losses in the temperate ecoregion. This is elaborated upon in the “Results” section below.
The next step was to identify which specific variables in a given decade/region were most responsible for the outcome. To do this, the 15 top-ranked importance variables from each random forest model output were used as inputs for regression tree analysis to identify the strength of association between population change and specific climatic variables. Regression trees are a flexible, non-parametric method capable of detecting non-linear relationships within a dataset. Data are split according to predetermined decision rules to create subsets of the dependent variable using recursive partitioning, creating trees with decision nodes and leaf nodes. For continuous data, ANOVA is used to find optimal splits of the dependent variable based on intervals of predictor variables. Splits are chosen that reduce the overall node impurity, which is measured as the total sum of squared deviations from node centers. We followed accepted best practice by allowing regression trees to grow to their maximum depth and subsequently pruning trees based on the lowest cross-validation accuracy estimate. To assess the regression tree outputs, the primary splits of each tree were visually examined to determine whether leaf nodes with the highest levels of population loss were associated with climatic (and/or irrigation) variables. Boxplots were generated to determine whether leaf nodes met the mapping criteria for each variable, and trees that exhibited four or five of these criteria were then mapped. Figure 2 provides an illustration of these processes.

Sample regression tree output: splitting of county-level rural population loss data for the temperate ecoregion of the USA between 1970 and 1980, using summer precipitation for 1974. Explanatory note: the figure depicts regression tree output for counties in the temperate ecoregion of the US Great Plains for the decade 1970 to 1980. Node 1 (the root node) shows the average rural county-level population change during the decade (i.e., − 6%), the sample size (i.e., n = 153 counties), and the percent of the sample accounted for at this node (i.e., 100%). The sum of precipitation between April and August in 1974 (i.e., PrSum_04_08_1974) is used to split the data in node 1 using ANOVA into leaf nodes 2 and 3. The key threshold for calculating the split was 316.731 mm, with 24 of the 153 counties being sent to node 2, which then has an average population loss of 12%. The remaining 129 counties from the dataset are sent to node 3, which then has an average population loss of 4.8%. The boxplots illustrate variations within each node and between nodes 2 and 3
Results
Association between climate variables and rural population loss by region and decade
Detailed results from our models at regional and sub-regional scales are presented in Tables 3 through 5. For ease of reading, these are presented as, in order, results for the Great Plains ecoregion and its sub-regions irrespective of political boundaries (Table 3), results for Canada (Table 4), and results for the USA (Table 5). The random forest R-squared values for our models ranged from − 0.17 to 0.56 and in the regression tree models ranged from near zero to 0.51, but in both cases were generally quite low. As a reminder, low R-squared values suggest a weak association between the climate/irrigation variables and rural population losses in a given region in a given decade, meaning that the observed population change was likely driven by variables not included in the models. To facilitate analysis and discussion, regions/decades that returned a random forest R-squared value of 0.25 or greater are highlighted in bold.
Overall, the R-squared values of most models were highest in the decade of the 1970s and lowest in the first decade of the 2000s, which is consistent with previous studies reviewed in the “Previous research on drought impacts on Great Plains population patterns” section above. We find that the random forest results in each decade for the Great Plains as a whole tended to have higher R-squared values than sub-regional models, and that sub-regional models showed greater variance within each decade, suggesting that particular regions contribute more than others to the results observed at larger spatial scales. For most decades, US models tend to generate higher R-squared values than Canadian models, with the exception of the 1970s, where the model for the Canadian portion of the Great Plains as a whole had a higher value than the US portion. This latter outcome likely reflects the fact that the ratio of census units in the temperate ecoregion relative to those in semi-arid sub-regions in Canada is much higher as compared with the USA.
The 1970s was the only decade in which an ecological sub-region other than the temperate sub-region returned a high R-squared value, that being the western semi-arid region shared between Canada and the USA. The temperate ecoregion as a whole returned R-squared values greater than 0.25 in all decades but the 1980s, but once disaggregated by country, the R-squared values remain higher than 0.25 for both Canada and the USA in the 1970s, but only for the US portion in 1990s. In the first decade of the 2000s, random forest R-squared values at the largest scale regional model are exactly at the 0.25 cut-off we selected for discussion; consistent with other decades, the temperate zone model returns the highest R-squared value among sub-regional models, with the USA and Canadian portions having roughly equal, lower R-squared values. Even in the 1980s, where random forest models for the study region return relatively low R-squared results at all scales, the temperate ecoregion models tended to have higher R-squared values than other sub-regions. The overall pattern is that, within the vast spatial unit that is the Great Plains, the greatest potential for a positive association between drought and rural population loss over the last 50 years has been within the temperate, easternmost counties and census subdivisions, where precipitation levels tend to be generally higher than in the more arid regions to the west and south.
Our models also provide results across the four decades for each of the approximately 1200 individual counties and Canadian census subdivisions (these are not tabulated in this article for practical reasons but are available in electronic form from the authors). Figure 3 is a composite map illustrating county/CCD-level results of the models from the temperate ecoregions of Canada and the USA for the 1970s and for the US temperate ecoregion for the 1990s, models which all have relatively high random forest R-squared values. As can be seen in the map, the association between drought and rural population loss was not random or uniform within these ecological sub-regions but was the strongest in counties in the western part of the temperate zone, at or near the transition to the semi-arid areas of the Dakotas and Saskatchewan.

Counties/rural census units showing R2 values > 0.25 for models of the temperate sub-region for 1970s and 1990s. Counties in Canada and the US are distinguished by color changes (red and blue for USA, yellow for Canada)
To gauge the accuracy of the models, we calculated the residual error between the observed decadal population loss for all rural counties/CCS and the population loss predicted by the random forest model for the US portion of the temperate ecoregion for the 1970s, which had the highest sub-regional R-squared value. As can be seen in Fig. 4, the residual errors are generally small for counties through the central portion of the ecoregion, including the eastern part of South Dakota where R-squared values are relatively high. This is consistent with empirical evidence from a separate study by McLeman et al. (2021a, 2021b) which identified a strong drought-population loss association in this same area in the 1970s. Conversely, there is a notable concentration of counties showing large residual errors (in terms of both underestimation and overestimation) in western and central North Dakota and central South Dakota, with a more random distribution in other parts of this ecoregion. Further research would be needed to disentangle the underlying causes of this outcome; we suspect it reflects the large spatial sizes and relatively small absolute population numbers in those counties, as well as differences in land-use (i.e., more ranching than row cropping) and the considerable expansion of oil and gas extraction activities since the 1970s within the ecoregion.

Residual error of random forest model for US temperate ecoregion for the 1970s
Relative importance of specific variables
The right-most columns of Tables 3, 4, and 5 show the relative contribution of specific variables to the observed population outcomes in each model as calculated by our regression tree analysis. Focusing on the results for the random forest models that returned R-squared values above 0.25, a number of general patterns can be observed. In models for the Great Plains as a whole, for the Canadian portion of the Great Plains, and for the Canadian and American temperate regions, climatic variables in the middle years of the census period tended to have the strongest influence on the model outcomes (as a reminder, censuses in Canada are taken 1 year later than in the USA). As one scales down to the sub-regional models, the mix of contributing variables changes, but the timing remains roughly the same. For example, in modeling results for the Great Plains region as a whole, the two drought indices for 1974, high heat in 1976 and 1978, and low summer precipitation in 1979 have the greatest influence. The two drought indices also have a strong influence on our model results for the Canadian portion of the Great Plains that same decade. However, the sub-regional models all point to the temperate ecoregion as being where the climate variables are most influential, and at that scale, the summer precipitation values make a greater contribution.
Another pattern is that the same climatic value often appears in successive years, suggesting a cumulative effect. For example, in the US part of the temperate ecoregion, the results show a strong influence of low levels of precipitation in three consecutive years, 1973 through 1975. This model output is generally consistent with empirical evidence reported by McLeman et al. (2021b) in their study of droughts in eastern South Dakota in the 1970s, although the authors of that study found that the fourth consecutive year of low precipitation (1976) had the most proximate causal effects on socio-economic impacts that in turn affected rural population movements for certain age cohorts (a point we return to in our discussion below). In the Canadian part of the temperate ecoregion, low levels of summer precipitation in 1976, 1977, and 1979 collectively have a strong influence. In the 1990s, the US temperate ecoregion exhibits the strongest rural population responses, with low summer precipitation in six of the 10 years being the main contributor.
We included two variables reflecting farm-level irrigation rates for each county/CCS in the model runs shown in Tables 3, 4, and 5: the percentage of farms irrigated at the start of each decade and the change in irrigation rates from one decade to the next, with data taken from Canadian and US agricultural censuses. These irrigation variables did not have any observed influence on outcomes in models with high random forest R-squared values, which is not entirely surprising, given that those regions tend to have relatively low percentages of farms that use irrigation. It is in the more arid sub-regions of the Plains (where counties tend to have small absolute population counts) that irrigation variables show up in the regression trees as having an effect on the results; again, these are regions where random forest models suggest the selected suite of climatic variables have minimal influence on rural population losses.
Discussion and conclusions
This project provides insights on the relationship between drought and rural population losses on the Great Plains in recent decades and illustrated how machine learning techniques offer opportunities to tease out more details about environmental influences on populations than can be generated through traditional regression analysis methods. In terms of the relationship between drought and rural population loss, the R-squared values from our models suggest that nowhere in the Great Plains during the period 1970 to 2011 was drought the primary driver of rural population loss. Rather, in particular clusters of counties and rural census divisions in the temperate ecoregion, rural population losses were influenced to a certain extent by unusually low levels of precipitation in the mid-1970s, with a smaller area in North Dakota possibly having a similar experience in the 1990s. Even in those limited cases, it is very likely that drought acted in concert with other factors to stimulate population movements. These results are consistent with and extend previous studies done in the USA showing that, although rural population losses have occurred across large areas of the Great Plains since the 1970s, droughts have played a minimal causal role. It is probably not a coincidence that the temperate ecoregions were more likely than other ecoregions within the Plains to have experienced population losses potentially attributable to droughts. These are areas where lack of precipitation and soil moisture is an infrequent hazard, and as a result, irrigation rates have historically been low. In the semi-arid regions farther west and south, precipitation levels in most years are near or below the minimum thresholds for common crops, and since the 1950s landowners have adapted through irrigation, by planting drought tolerant crops, or using the land for grazing and fodder crops (McLeman et al., 2014).
None of the counties that overlay the Ogallala aquifer exhibited significant drought-associated population losses according to our models. Our regression tree analyses showed that irrigation variables we selected had no influence in areas where the random forest model identified an association between the climatic variables and population loss. This is consistent with Parton et al. (2007) study suggesting that rural population change in irrigated counties on the Great Plains is largely driven by non-climatic factors such as labor markets. The southern, arid portions of the Great Plains of “Dust Bowl” fame showed no significant association between drought and population change between 1970 and 2010 in our models; neither did the arid Palliser’s Triangle region of southeastern Alberta and southwestern Saskatchewan that is also infamous for Depression-era drought migration (Jones, 1991). Today, these areas are relatively sparsely populated, with land use and economic activity having shifted decades ago from crop farming to grazing, oil and gas exploration, and other less drought-sensitive activities.
Our models show the importance of sub-regional differences in ecological and political terms. At the largest spatial scale − the Great Plains as a whole − the random forest R-squared values for each decade tended to be high relative to those for sub-regional models for the same decades. At that spatial scale, hot days and drought indices had the strongest association with overall population losses, consistent with the findings of Gutmann et al. (2005). However, more detailed insights emerge when individual ecological regions are considered on their own. The climatic influence on rural population loss is disproportionately greater in the temperate region, and summer precipitation emerges as a more noticeable influence. By scaling down farther to the county or CCS, the models are able to provide further refinement and can identify clusters of counties that have the strongest influence on the sub-regional picture. There are observable differences in R-squared values for most American and Canadian models at the regional and sub-regional scales, pointing to an important avenue for future research in trying to identify and distinguish the non-climatic factors that underlay such outcomes. Using the same methodology, one might also choose to include in the models data about job markets, agricultural output, land use, non-agricultural economic activity, or any number of other possible causal variables − so long as one has the necessary data available at relevant spatial scales and is able to invest the time to prepare it for analysis. There are also other types of data beyond those we used that might be used to capture the occurrence of drought or land degradation, such as normalized difference in vegetation index or other remotely sensed data (see Hermans & McLeman, 2021 for review). Again, the limits to doing so are the availability and quality of such data and the time resources available to the researcher to prepare it for modeling.
This study is one of the first to explore the suitability of using random forests and regression tree models for assessing drought impacts on rural population change. Machine-based learning approaches such as these offer many additional benefits for the researcher beyond those derived from regression analyses and other quantitative approaches traditionally used in population-environment research (see Fussell et al., 2014 for review). Once the researcher has identified a variable of interest − in this case, rural population loss − the models can identify potential causal associations with other variables within large datasets, including those that are not immediately obvious or not anticipated by the researcher. As we have shown, the data can be readily analyzed and associations identified across a range of spatial scales, with the resulting models informing the researcher where and when there is a relatively strong association − such as in the 1970s, in particular areas of the Great Plains temperate ecoregion − and where there is little or none, such as in areas of the Plains with high irrigation rates. Of particular value to this study was the additional ability to identify the relative contributions of specific climate variables and specific years to the model outcomes. So, for example, we found that for the US temperate ecoregion, low precipitation in the mid-1970s and early 1990s was the main climatic factor contributing to rural population losses.
Perhaps the greatest overall benefit from this approach is that it suggests where (and when) to look when one is not sure where to start. For example, before we started this project, we did not know that severe drought conditions in the mid-1970s were associated with rural population change in eastern South Dakota − something that would obviously have been known to people who lived in that area during that decade, but much less well known to anyone else. This initial identification through the modeling described above led us to conduct a more detailed analysis of eastern South Dakota by adding additional census data to the models for county-level population age characteristics by gender for the period 1970–2010, and to follow up with additional geospatial analyses plus archival and qualitative field research. The results, reported in McLeman et al. (2021b) showed that the mid-1970s drought did not affect all age cohorts equally, but that young men of working age in specific counties showed the most significant response. This raises an important point in that the population outcome explored in the present article − decadal population loss in rural areas − is a very coarse one, and that just as additional causal variables might be added to the mix of data being analyzed, so too might additional data for possible outcome variables, such as data on gender, age, education, or other demographic characteristics. The main consideration for the researcher is the amount of time needed to acquire and prepare the necessary data for the selected study area, which is why we limited our initial efforts to decadal population loss.
Temporal and spatial resolution of data are important considerations for this method in population-environment research. In our case, census data are much coarser in temporal and spatial terms than climate data, with the 10-year interval between censuses being a notable limitation. Research elsewhere has suggested there may be a lag time of up to 36 months between the onset of a drought and any observable change in rural migration patterns in response to it (Nawrotzki & DeWaard, 2016). Decadal census counts are consequently more likely to reflect a change in population numbers in response to droughts that occur in the middle period of the census interval than droughts that coincide with the census count or occur just before or after it. For that reason, our models have a built-in possibility of type II errors. While these methods appear to work well for studying population responses to drought hazards and population responses in the Great Plains ecoregions, future research is needed to determine if this method would be useful for examining population responses to other types of climate hazards that are spatially dispersed and/or have a rapid onset.
This type of research method should not be undertaken without significant computing skills and resources, and with plenty of time available to prepare data prior to beginning the actual model runs. Computer hardware needs to be robust enough to manage and process large volumes of data; on computers with 6 GB RAM and 2.4 GHZ CPU, a single model run took approximately 15 min, but only after many months of code development and experimentation. The work needed to prepare the raw data for analysis was made especially laborious due to a lack of prior digitization of much of the Canadian census data; researchers working in other countries may experience similar challenges. Selection and preparation of the climate data was in our case speeded by easy online availability of high-quality datasets from environment agencies in the two countries and our own past experience in geospatial modeling of drought in the Great Plains region. For studies in other countries or regions, data availability could be less straightforward, and the selection of climate data should be informed by knowledge of land use and socio-economic systems in the study area, and tailored to these as much as possible. We created extra work for ourselves in creating and experimenting with a customized drought potential index, for in reviewing the results we found that it differed little from the PDSI in terms of its predictive power, and that neither index had greater predictive power than the precipitation and temperature variables we selected. This may be a relevant consideration for research where PDSI or other drought index data are not available.
As with all modeling-based studies of human–environment interactions, this type of approach benefits from ground truthing − that is, doing field work to assess whether the model predictions are reliable and using such findings in an iterative way to improve the models. We were able to do this for one area that the models identified as having experienced drought-related population change − the temperate ecoregion of South Dakota (McLeman et al., 2021b) − and for one non-irrigated area in eastern Colorado that experienced population losses during the study period but which the models did not associate with drought (McLeman, 2019). Additional field research planned for North Dakota and Saskatchewan had to be abandoned due to the COVID-19 pandemic.
We can, in summary, conclude that random forest and regression tree models are very useful for hindcasting exercises where the necessary climate and population data are available and could potentially be promising for such activities as making future projections − such as by substituting general circulation model data for observed temperature and precipitation data and population forecasts for census data − but further exploration is needed. Finally, we do not suggest this particular methodological approach is better or that the model outcomes are more precise than approaches used in previous studies done for population-environment linkages in the Great Plains; that would require considerably more analysis and one-to-one comparison between our model outputs and those generated in past studies to make an assessment of relative performance. For the time being, machine learning approaches should be seen as promising and complementary to longer tested methods.
Data availability
The data used in this study and the code for random forest/regression tree modeling are freely available to other researchers by contacting the authors.
Notes
When we use the term “model” in the remainder of this section, we refer specifically to population change in one of the ten ecological regions, sub-region, and political units of the Great Plains in one of the four decades between 1970 and 2010.
References
Abatzoglou, J. T., Dobrowski, S. Z., Parks, S. A., & Hegewisch, K. C. (2018). TerraClimate, a high-resolution global dataset of monthly climate and climatic water balance from 1958–2015. Scientific Data, 5(1), 170191.
Adger, W. N. (2006). Vulnerability. Global Environmental Change, 16(3), 268–281.
Afifi, T., Liwenga, E., & Kwezi, L. (2014). Rainfall-induced crop failure, food insecurity and out-migration in Same-Kilimanjaro. Tanzania. Climate and Development, 6(1), 53–60.
Alley, W. M. (1984). The Palmer Drought Severity Index: Limitations and assumptions. Journal of Climate and Applied Meteorology, 23(7), 1100–1109.
American Meteorological Society. (2012). Agricultural drought. Glossary of Meteorology. http://glossary.ametsoc.org/wiki/Agricultural_drought. Accessed 10 March 2020
Best, K. B., Gilligan, J. M., Baroud, H., Carrico, A. R., Donato, K. M., Ackerly, B. A., & Mallick, B. (2020). Random forest analysis of two household surveys can identify important predictors of migration in Bangladesh. Journal of Computational Social Science. https://doi.org/10.1007/s42001-020-00066-9
Bonsal, B. R., Wheaton, E. E., Chipanshi, A. C., Lin, C., Sauchyn, D. J., & Wen, L. (2011). Drought research in Canada: A review. Atmosphere-Ocean, 49(4), 303–319.
Breiman, L. (2001). Random forests. Machine Learning, 45, 5–32.
Breiman, L. (1996). Stacked regressions. Machine Learning, 24(1), 49–64.
Carlyle, W. J. (1994). Rural population change on the Canadian Prairies. Great Plains Research, 4, 65–87.
Chapagain, B., & Gentle, P. (2015). Withdrawing from agrarian livelihoods: Environmental migration in Nepal. Journal of Mountain Science, 12(1), 1–13.
Chen, H., Wang, J., & Huang, J. (2014). Policy support, social capital, and farmers’ adaptation to drought in China. Global Environmental Change, 24, 193–202.
Colston, N. M., Vadjunec, J. M., & Fagin, T. (2019). It is always dry here: Examining perceptions about drought and climate change in the Southern High Plains. Environmental Communication, 13(7), 958–974.
Cunfer, G. (2005). On the Great Plains: Agriculture and environment. Texas A&M University Press.
Dandy, K, & Bollman, R.D. (2008). Seniors in rural Canada. Rural and Small Town Canada Analysis Bulletin, 7(8). Statistics Canada, Ottawa, 56p.
Davies, W. K. D. (1990). What population turnaround?: Some Canadian Prairie settlement perspectives, 1971–1986. Geoforum, 21, 303–320.
De Silva, M. M. G. T., & Kawasaki, A. (2018). Socioeconomic vulnerability to disaster risk: A case study of flood and drought impact in a rural Sri Lankan community. Ecological Economics, 152, 131–140.
Edwards, B., Gray, M., & Hunter, B. (2015). The impact of drought on mental health in rural and regional Australia. Social Indicators Research, 121(1), 177–194. https://doi.org/10.1007/s11205-014-0638-2
Ehrlinger, J. (2015). ggRandomForests: Visually exploring random forests. https://cran.r-project.org/web/packages/ggRandomForests/index.html
Feng, S., Oppenheimer, M., & Schlenker, W. (2012). Climate change, crop yields, and internal migration in the United States. Cambridge MA. http://www.nber.org/papers/w17734
Fussell, E., Hunter, L. M., & Gray, C. (2014). Measuring the environmental dimensions of human migration: The demographer’s toolkit. Global Environmental Change, 28, 182–191.
Gautier, D., Denis, D., & Locatelli, B. (2016). Impacts of drought and responses of rural populations in West Africa: A systematic review. Wires Climate Change, 7(5), 666–681.
Gilbert, G., & McLeman, R. (2010). Household access to capital and its effects on drought adaptation and migration: A case study of rural Alberta in the 1930s. Population and Environment, 32(1), 3–26.
Gregory, J. N. (1989). American Exodus: The Dust Bowl migration and Okie culture in California. Oxford University Press.
Gutmann, M. P., Deane, G. D., Lauster, N., & Peri, A. (2005). Two population-environment regimes in the Great Plains of the United States, 1930–1990. Population and Environment, 27(2), 191–225.
Guttman, N. B., Wallis, J. R., & Hosking, J. R. M. (1992). Spatial comparability of the Palmer Drought Severity Index. JAWRA Journal of the American Water Resources Association, 28(6), 1111–1119.
Hanesiak, J. M., Stewart, R. E., Bonsal, B. R., Harder, P., Lawford, R., Aider, R., et al. (2011). Characterization and summary of the 1999–2005 Canadian Prairie drought. Atmosphere-Ocean, 49(4), 421–452.
Hermans, K., & Garbe, L. (2019). Droughts, livelihoods, and human migration in northern Ethiopia. Regional Environmental Change. https://doi.org/10.1007/s10113-019-01473-z
Hermans, K., & McLeman, R. (2021). Climate change, drought, land degradation and migration: Exploring the linkages. Current Opinion in Environmental Sustainability, 50, 236–244.
Hurt, R. D. (1981). The Dust Bowl: An agricultural and social history. Nelson-Hall.
Hutchinson, M. F., McKenney, D. W., Lawrence, K., Pedlar, J. H., Hopkinson, R. F., Milewska, E., & Papadopol, P. (2009). Development and testing of Canada-wide interpolated spatial models of daily minimum–maximum temperature and precipitation for 1961–2003. Journal of Applied Meteorology and Climatology, 48(4), 725–741.
Jones, D. C. (1991). Empire of Dust. University of Alberta Press.
Kabir, M. E., Davey, P., Serrao-Neumann, S., & Hossain, M. (2018). Seasonal drought thresholds and internal migration for adaptation: Lessons from Northern Bangladesh. In M. Hossain, R. Hales, & T. Sarker (Eds.), Pathways to a Sustainable Economy (pp. 167–189). Springer.
Keshavarz, M., Karami, E., & Vanclay, F. (2013). The social experience of drought in Iran. Land Use Policy, 30(1), 120–129.
Laforge, J., & McLeman, R. (2013). Social capital and drought-migrant integration in 1930s Saskatchewan. The Canadian Geographer, 57(4), 488–505.
Lewis, R. J. (2000). An introduction to classification and regression tree (CART) analysis. In Annual meeting of the society for academic emergency medicine, San Francisco, California (May 2000, Vol. 14).
Liaw, A., & Wiener, M. (2002). Classification and regression by randomForest. R News, 2(3), 18–22.
Lockeretz, W. (1978). The lessons of the Dust Bowl. American Scientist, 66(5), 560–569.
Mapedza, E., & McLeman, R. (2019). Drought risks in developing regions: challenges and opportunities. In Current Directions in Water Scarcity Research (Vol. 2, pp. 1-14). Elsevier.
Marchildon, G. P., Kulshreshtha, S., Wheaton, E., & Sauchyn, D. (2008). Drought and institutional adaptation in the Great Plains of Alberta and Saskatchewan, 1914–1939. Natural Hazards, 45, 391–411.
McLeman, R. (2006). Migration out of 1930s rural eastern Oklahoma: Insights for climate change research. Great Plains Quarterly, 26(1).
McLeman, R. (2014). Climate and human migration: Past experiences, future challenges. Cambridge University Press.
McLeman R. (2019). Drought adaptation when irrigation is not an option: The case of Lincoln Co., Colorado, USA. In Drought Challenges, Mapedza E, Tsegai D, Bruntrup M, Mcleman RBT-CD in WSR (eds).Elsevier; 311–323.
McLeman, R., Dupre, J., Berrang Ford, L., Ford, J., Gajewski, K., & Marchildon, G. (2014). What we learned from the Dust Bowl: Lessons in science, policy, and adaptation. Population and Environment, 35(4), 417–440.
McLeman, R., & Ploeger, S. K. (2012). Soil and its influence on rural drought migration: Insights from Depression-era Southwestern Saskatchewan. Canada. Population and Environment, 33(4), 304–332.
McLeman, R., Wrathall, D., Gilmore, E., Adams, H., Thornton, P., & Gemenne, F. (2021a). Conceptual framing to link climate risk assessments and climate-migration scholarship. Climatic Change, 165(24).
McLeman, R., Fontanella, F., Greig, C., Heath, G., & Robertson, C. (2021b). Population responses to the 1976 South Dakota drought: insights for wider drought migration research. Population, Space and Place. https://doi.org/10.1002/psp.2465
McLeman, R., Herold, S., Reljic, Z., Sawada, M., & McKenney, D. (2010). GIS-based modeling of drought and historical population change on the Canadian Prairies. Journal of Historical Geography, 36, 43–55.
McLeman, R., Mayo, D., Strebeck, E., & Smit, B. (2008). Drought adaptation in rural Eastern Oklahoma in the 1930s: Lessons for climate change adaptation research. Mitigation and Adaptation Strategies for Global Change, 13(4), 379–400.
McWilliams, C. (1942). Ill Fares the Land: Migrants and migratory labor in the United States. Little, Brown and Company.
Nawrotzki, R., & DeWaard, J. (2016). Climate shocks and the timing of migration from Mexico. Population and Environment, 38, 72–100.
Omernik, J. M., & Griffith, G. E. (2014). Ecoregions of the conterminous United States: Evolution of a hierarchical spatial framework. Environmental Management, 54(6), 1249–1266.
Paluszynska, A. (2017). randomForestExplainer: Explaining and visualizing random forests in terms of variable importance. https://github.com/ModelOriented/randomForestExplainer
Parson, H. E. (1999). Regional trends of agricultural restructuring in Canada. Canadian Journal of Regional Science, 22, 343–356.
Parton, W. J., Gutmann, M. P., & Ojima, D. (2007). Long-term trends in population, farm income, and crop production in the Great Plains. BioScience, 57(9), 737–747.
Polsky, C., & Easterling, W. E. (2001). Adaptation to climate variability and change in the US Great Plains: A multi-scale analysis of Ricardian climate sensitivities. Agriculture, Ecosystems and Environment, 85(1–3), 133–144.
Reuveny, R. (2008). Ecomigration and violent conflict: Case studies and public policy implications. Human Ecology, 36(1), 1–13.
Richtik, J. M. (1975). The policy framework for settling the Canadian West 1870–1880. Agricultural History, 49, 613–628.
Schlenker, W., & Roberts, M. J. (2009). Nonlinear temperature effects indicate severe damages to U.S. crop yields under climate change. Proceedings of the National Academy of Sciences, 106(37), 15594 LP – 15598.
Sena, A., Barcellos, C., Freitas, C., & Corvalan, C. (2014). Managing the health impacts of drought in Brazil. International Journal of Environmental Research and Public Health. https://doi.org/10.3390/ijerph111010737
Smit, B., & Wandel, J. (2006). Adaptation, adaptive capacity and vulnerability. Global Environmental Change, 16(3), 282–292.
Starblanket, G. (2019). The numbered treaties and the politics of incoherency. Canadian Journal of Political Science, 52, 443–459.
Therneau, T., Atkinson, B., Ripley, B. (2019). Rpart: Recursive partitioning and regression trees (version 4.1–15). https://CRAN.R-project.org/package=rpart
Tian, L., Yuan, S., & Quiring, S. M. (2018). Evaluation of six indices for monitoring agricultural drought in the south-central United States. Agricultural and Forest Meteorology, 249, 107–119.
Udmale, P., Ichikawa, Y., Manandhar, S., Ishidaira, H., & Kiem, A. S. (2014). Farmers’ perception of drought impacts, local adaptation and administrative mitigation measures in Maharashtra State, India. International Journal of Disaster Risk Reduction, 10, 250–269.
US Department of Agriculture Economic Research Service. (2020). Rural-Urban Continuum Codes. Data Products. https://www.ers.usda.gov/data-products/rural-urban-continuum-codes.aspx. Accessed 9 March 2020
Venot, J. P., Reddy, V. R., & Umapathy, D. (2010). Coping with drought in irrigated South India: Farmers’ adjustments in Nagarjuna Sagar. Agricultural Water Management, 97(10), 1434–1442.
Warrick, R. A. (1980). Drought in the Great Plains: A case study of research on climate and society in the USA. In J. Ausubel & A. K. Biswas (Eds.), Climatic constraints and human activities (pp. 93–123). Pergamon Press.
White, S. E. (1998). Migration trends in the Kansas Ogallala region and the internal colonial dependency model. Rural Sociology, 63(2), 253–271.
Wilhite, D. A. (1983). Government response to drought in the United States: With particular reference to the Great Plains. Journal of Climate and Applied Meteorology, 22, 40–50.
Worster, D. (1979). Dust Bowl: The southern plains in the 1930s. Oxford University Press.
Zargar, A., Sadiq, R., Naser, B., & Khan, F. I. (2011). A review of drought indices. Environmental Reviews, 19, 333–349.
Funding
This research was funded under Social Science and Humanities Research Council of Canada grant number 435‐2017‐0219.
Author information
Authors and Affiliations
Contributions
All authors contributed in roughly equal amounts to this manuscript, with author names reflecting their relative contributions.
Corresponding author
Ethics declarations
Human and animal rights and informed consent
This study did not have human or animal participants, and no ethical approvals were necessary.
Conflict of interest
The authors declare no conflicts of interest or competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
McLeman, R., Grieg, C., Heath, G. et al. A machine learning analysis of drought and rural population change on the North American Great Plains since the 1970s. Popul Environ 43, 500–529 (2022). https://doi.org/10.1007/s11111-022-00399-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11111-022-00399-9