
Abstract
The deep forest presents a novel approach that yields competitive performance when compared to deep neural networks. Nevertheless, there are limited studies on the application of deep forest to time series classification (TSC) tasks, and the direct use of deep forest cannot effectively capture the relevant characteristics of time series. For that, this paper proposes time series cascade forest (TSCF), a model specifically designed for TSC tasks. TSCF relies on four base classifiers, i.e., random forest, completely random forest, random shapelet forest, and diverse representation canonical interval forest, allowing for feature learning on the original data from three granularities: point, subsequence, and summary statistics calculated based on intervals. The major contribution of this work, is to define an ensemble and deep classifier that significantly outperforms the individual classifiers and the original deep forest. Experimental results show that TSCF outperforms other forest-based algorithms for solving TSC problems.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Time series is a continuous collection of data with a temporal relationship that presents unique classification challenges compared to traditional data. In recent years, numerous methods dedicated to time series classification (TSC) have emerged. For example, dynamic time warping (DTW) and its variants have been shown to be competitive similarity measures in solving TSC problems [1,2,3]. Shapelets [4], discriminating and interpretable subsequences found within time series, are generally used as the basis for decision tree node splitting, with proven advantages in improving accuracy. Calculating summary statistics based on intervals [5, 6] is also one of the main TSC methods, which find discriminating features on different intervals by randomly extracting intervals in sequences and calculating various statistics.
Decision trees’ performance has made them a popular choice for classification tasks, leading researchers to propose several forest-based TSC algorithms. Traditional methods, such as random forest (RF) and completely random forest (CRF), consider the original time series at the point-level and select a single attribute in the decision tree node, that is, a point in the time series as the splitting basis. Generalized random shapelet forest (RSF) [7] randomly selects both the training data and subsequences to construct the basic decision trees, which focuses on feature learning at the subsequence-level. Time series forest (TSF) [5], on the other hand, summarizes the interval statistics as input for decision trees. However, TSF only uses three simple summary statistics: the mean; standard deviation; and slope. Canonical interval forest (CIF) [6] combines TSF and Catch22 [8], including 25 features to sample randomly. Diverse representation canonical interval forest (DrCIF) [9], as an extension of CIF, extracts intervals from three representations of time series and uses 29 statistics to form a pool of feature candidates. Nonetheless, the forest-based methods above only consider a single granularity feature of time series, i.e., point, subsequence, or summary statistics. As such, each algorithm overlooks time series characteristics demonstrated by other granularities, resulting in limitations in classification accuracy.
The gcForest [10] uses forests to emulate neural network connectivity and has fewer hyperparameters than deep neural networks (DNNs). The model’s structure has two modules: multi-grained scanning, which extracts features using varying-sized windows, and cascade forest, a layer-by-layer processing system with two RFs and two CRFs. We conducted experiments using gcForest on UCR datasets,Footnote 1 but it did not outperform existing forest-based methods. Although gcForest considers information of different granularities through sliding windows with different sizes, it fails to fully consider the characteristics of the time series itself, i.e., temporal order, slope information, similarity between different time series, etc. Examining how to enhance the performance of gcForest to meet the needs of TSC tasks is a crucial topic warranting our attention.
Considering the challenges mentioned above, our aim is to improve the forest-based approach by embedding forest-based classifiers suitable for TSC based on the cascade structure of gcForest. This paper proposes a novel forest-based ensemble algorithm called time series cascade forest (TSCF). TSCF integrates four base classifiers, including RF, CRF, RSF, and DrCIF. By using them, while ensuring the diversity of the model, multi-granular feature learning of time series is realized. Our main contributions are as follows.
-
We propose a deep forest model specifically designed to solve the TSC task, which embeds four forest-based classifiers into cascade layers to form the cascade forest.
-
The model implements multi-granular feature learning by considering point-level features, discriminative subsequences, different statistics for phase dependent intervals.
-
Experiments on 113 UCR datasets show that TSCF outperforms existing forest-based methods and is highly competitive with other baselines.
The structure of this paper is as follows. In Sect. 2 we review various categories of relevant studies. In Sect. 3 we detail the individual classifiers in TSCF and its overall architecture. In Sect. 4 we first present and analyse experimental comparisons of TSCF and the current state-of-the-art in TSC, then compare TSCF and its variants, and perform ablation experiments. Finally, in Sect. 5 we summarise our conclusions and discuss future work.
2 Related Work
In this section, we present a non-exhaustive review of the state-of-the-arts in TSC algorithms, grouping them as distance-based, shapelet-based, interval-based, dictionary-based, hybrid, and deep learning methods based on our research needs.
Distance-based methods utilize various distance calculation techniques to measure the similarity/dissimilarity between two time series. The DTW-based nearest neighbor classifier serves as a popular baseline for comparison. For the improvement of DTW, considerations such as the first derivative [1], imposing a penalty [3], and the local slope [2] have been explored. There are also several other distance measures, for example, move-split-merge (MSM) [11] transforms any time series into any other time series by three fundamental operations: move, split, and merge. The elastic ensemble (EE) [12] integrates the nearest neighbor classifiers based on 11 distance measures and proves that this ensemble method is better than any single composition method and DTW. Shape dynamic time warping (shapeDTW) [13], which enhances DTW by taking point-wise local structural information into consideration.
Shapelet-based approaches concentrate on distinctive local features of time series, which can be categorized into two types. The first uses shapelets [4] as a basis for decision tree node splitting. In addition to the previously mentioned RSF [7], random pairwise shapelets forest (RPSF) [14], unlike RSF which selects one shapelet at the node for splitting, uses a pair of shapelets from different classes to construct trees. To enhance the selection accuracy and calculation speed of shapelets, researchers have formulated several improved methods by using intelligent caching and exploiting a random projection technique on the symbolic aggregate approximation representation to search shapelet candidates. To optimize time complexity, the algorithm learns about shapelets in close proximity to the optimal ones [15] and employs local fisher discriminant analysis [16]. The second type is shapelet transformation (ST) initially proposed in [17]. Data are transformed into a new feature space by calculating the distance between the original data and the selected k best shapelet candidates, which is adaptive to different classifiers.
In addition to the TSF, CIF and DrCIF mentioned above, interval-based methods also include random interval features (RIF) [18], which does not use time domain intervals but two transformed representations of data, including RIF_ACF for autocorrelation-transformed data and RIF_PS for the power spectrum-transformed data. Unlike TSF, random interval spectral ensemble (RISE) [19] only randomly selects an interval for each base classifier, and then calculates the periodogram and auto-regression function based on the interval and stitches them into feature vectors and then builds trees. Supervised time series forest (STSF) [20] has supervised extraction intervals and screens the intervals that can be preserved with Fisher scores. There are also time series bag of features (TSBF) [21], learned pattern similarity (LPS) [22], etc.
Dictionary-based methods extracts words from a time series through a sliding window and classifies them based on those words. Bag of symbolic Fourier approximation symbols (BOSS) [23] transforms a time series into an unordered set of symbolic Fourier approximation (SFA) words. Word extraction for time series classification (WEASEL) [24] proposes a specific feature transformation method to learn a smaller but more discriminating feature set from time series.
Hybrid methods incorporate multiple perspectives of the time series. The hierarchical vote collective of transformation ensembles (HIVE-COTE) [18] is a various ensemble containing five classifiers each from a different representation. Numerous hybrid methods, such as random convolutional kernel transform (ROCKET) [25], time series combination of heterogeneous and integrated embeddings forest (TS-CHIEF) [26] and Catch22 [8], have also been developed for TSC. Interested researchers could refer to [27] for a detailed survey of the traditional method for TSC.
Deep learning, specifically DNNs, has been widely used in TSC problems. Time leNet (t-leNet) [28] first uses a convolutional neural network with temporal convolutions for TSC. Another effective approach is the multi-scale convolutional neural network (MCNN) [29] that downsamples the original sequence in the multi-scale and multi-frequency domains. Furthermore, fully convolutional neural networks (FCN), residual networks (ResNet) [30], time warping invariant echo state networks (TWIESN) [31], and InceptionTime [32] are all successfully applied to TSC. For a more comprehensive overview of deep learning methods for TSC, we recommend interested researchers refer to [33].
3 Time Series Cascade Forest
In this section we will elaborate TSCF in detail, starting with the problem definition, followed by the four forest-based classifiers that build up the model, and then the overall structure and complexity analysis. The running process of TSCF is described in Algorithms 1 and 2.
3.1 Problem Definition
Given a set of time series \( D= \{ S_{i}\}_{i=1}^m \) of m instances with labels Y, where each time series \(S_{i} = \{x_j^{i}\}_{j=1}^{n}\) has n ordered real-valued observations and a discrete class label y from a range of c possible values. A classifier is a function or mapping from the space of possible inputs to a probability distribution over the class variable values. We consider the problem of univariate and equal length time series. The goal of TSCF is to learn the class probability vector \(aug=\left\{ v_{1}, v_{2}, v_{3}, v_{4}\right\} \), where \(v_{1}\), \(v_{2}\), \(v_{3}\), and \(v_{4}\) represent the prediction probability of RF, CRF, RSF [7], and DrCIF [9], respectively. Classification accuracy is reported by comparing the maximum value of the mean of the four class vectors of the last layer to the true class label.
3.2 Forest-Based Classifiers
Since the combination of RF, CRF, RSF, and DrCIF enables the learning of multi-granular features of time series from different perspectives, they are selected as the base classifiers for constructing our TSCF. Details are described as follows.
-
(1)
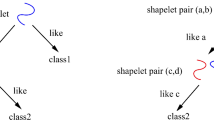
The RF in TSCF is an integration of traditional decision trees and increases the speed of tree building through parallel techniques. For the node splitting of each decision tree, as shown in Fig. 1a, \(\sqrt{n}\) point-level features of the time series are randomly selected. The split attribute of the node is the smallest Gini index selected from the \(\sqrt{n}\) selected attributes.
$$\begin{aligned} {\text {Gini }}(D)=1-\sum _{k=1}^{K}\left( \frac{\left| C_{k}\right| }{|D|}\right) ^{2}, \end{aligned}$$(1)where \(C_{k}\) is the subset of samples in D belonging to class k, and K is the number of classes. Gini index allows the RF to learn distinguishable point features present in time series.
-
(2)
The CRF comprises totally random trees, each of which randomly selects a point-level feature for splitting at every node as shown in Fig. 1a. Compared to the RF, it has a higher level of randomness and does not consider the splitting criterion. We selected two forests at the point-level. The CRF enhances the randomness of the model and both use parallel tree building technology, which can reduce the model training time.
-
(3)
In RSF [7], the shapelet acts as a discriminating subsequence of the time series that allows the model to learn subsequence-level features. Suppose that the shapelet is defined as \(S_{p,q}^{m}=\left\{ x_{p}^{m},x_{p+1}^{m},...,x_{p+q-1}^{m} \right\} \), m represents the shapelet from the \(m^{th}\) series, p is the start position and q is the length of shapelet, where \(1\le p\le n-q+1\). For each node of the decision tree, the length of the shapelet q and its starting point are randomly determined. In each node, RSF randomly selects s shapelet candidates and then chooses the one with the largest information gain as the final splitting basis as shown in Fig. 1b.
-
(4)
The last base classifier is DrCIF [9], an interval based TSC algorithm. DrCIF extracts intervals from three representations, including the primitive series, the first order difference series, and the periodograms of the entire series. The algorithm steps of DrCIF are as follows: Firstly, randomly select k intervals from three representations, and the starting point and length of each interval are randomly selected. a out of the pool of 29 feature candidates (i.e. mean, standard-deviation, slope, median, inter-quartile range, min, max, and Catch22) are randomly selected to calculate summary statistics for each interval. Then, these features are concatenated into \(3\cdot k\cdot a\) length vector \(f_{i}\) for each series \(S_{i}\), and the new dataset \( F= \{ f_{i}\}_{i=1}^m \) is used to build the time series tree [5], as shown in Fig. 1c.

Interpretation of the model’s multi-granular feature learning
3.3 Overall Structure
Inspired by gcForest, TSCF employs a cascade structure, as illustrated in Fig. 2. The original gcForest contains multi-grained scanning and cascade forest. In TSCF, since the four forests each perform feature learning on the data from three granularities, the multi-grained scanning module is no longer needed.

Illustration of TSCF method. Each layer of the cascade consists of a RF, a CRF, a RSF, and a DrCIF. Suppose there are three classes to be classified. Each forest outputs a three-dimensional class vector, which concatenates with the original input time series as re-representation
The establishment process of cascade forest is shown in Algorithm 1. First, the first cascade layer (line 1, as detailed in Algorithm 2) is built to obtain the class vectors generated by the four forests, i.e., \(v_1\), \(v_2\), \(v_3\), and \(v_4\), and then \(aug = (\left| \right| _{i=1}^{4} v_{i})\), where \(\left| \right| _{i=1}^{4}\) is the concatenation operation from class vector \(v_{1}\) to class vector \(v_{4}\). Then, we record the classification accuracy obtained by this layer as pivot (line 2). The class vector aug obtained by the previous layer is then stitched with the original time series and used as the input to the next cascade layer (lines 4–5). The new accuracy rate of newpivot obtained at each layer is compared with the previous pivot (lines 7–13), and if the accuracy of the two consecutive layers is no longer improved (lines 11–12), the training will be automatically terminated to obtain the final model. The final classification accuracy of the model is the ratio between the class corresponding to the maximum value after averaging the last layer of class vectors and the real labels Y.
Given an instance, each forest will generate an estimate of the class distribution by calculating the percentage of training examples of different classes of related instances on the leaf node, and then stitching together the class vectors obtained by all trees in the same forest to calculate the average. The estimated class distribution forms a class vector, which is then stitched with the original data vector to obtain a new feature representation and input to the next layer for continued training. For example, suppose there are three classes, each of the four forests will produce a three-dimensional class vector. Therefore, the next layer will receive 12 (= 3 \(\times \) 4) enhanced features.

CascadeForestClassifier(D, Y, t, s)

ClassificationCascadeLayer(X, Y, t, s)
3.4 Complexity Analysis
For the proposed TSCF, the number of layers is N, and the number of decision trees in each forest is t. For a set of time series has m instances with length n, the time complexity of RF and CRF is \(O(tmn\log (m))\) and O(tmn), respectively. The computational cost for RSF is \(O(tm^{2}sn^{2}\log (msn^{2}))\), where s is the number of shapelet candidates. Note that the time complexity of DrCIF is \(O(tmn\log (n))\). Therefore, the computational cost of each layer in TSCF depends on the highest time complexity of the four forests, that is \(O(tm^{2}sn^{2}\log (msn^{2}))\). Finally, multiplied by the number of layers N, the time complexity of TSCF should be \(O(Ntm^{2}sn^{2}\log (msn^{2}))\).
4 Experiments
In this section, we first describe the datasets and baseline methods used in our experiments, and then outline the parameter settings before evaluating the performance of TSCF in terms of accuracy and visualization. The source code of TSCF and more detailed experimental results of TSCF and other time series classification algorithms are available on our anonymous website https://anonymous.4open.science/r/Time-series-cascade-forest-D1DB.
4.1 Datasets and Baseline Methods
Experiments are conducted on 113 of the 128 public UCR datasets that are widely used in TSC studies. We have removed data with unequal length series or missing values, because most approaches cannot handle these scenarios. We experiment with a 4.10 GHz Intel Core i7-8750 H PC machine with 24 Gigabytes of memory. We use the open source software tool sktimeFootnote 2 and its deep learning variant sktime-dlFootnote 3 that contain implementations of the majority of the existing algorithms we have compared.
Twenty-one different baselines are compared against, which are grouped into the following seven clusters.
-
Distance-based methods employ similarity measures to quantify the distance between two series, such as EE [12] and shapeDTW [13].
-
Shapelet-based methods distinguish differences between categories by extracting discriminating shapelets from time series, such as ST [17].
-
Interval-based methods select one or more phase dependent intervals of the series and then using summary measures calculated by intervals as features, such as RISE [19].
-
Dictionary-based methods form frequency counts of repetition of subseries, then use the histograms to build classifiers, such as BOSS [23] and WEASEL [24].
-
Hybrid methods combine two or more of the single approaches, such as HIVE-COTE V2 [9], ROCKET [25], TS-CHIEF [26], and Catch22 [8].
-
Deep learning methods employ nerual networks to TSC tasks, such as InceptionTime [32], FCN, MLP, and ResNet [30].
-
The classifiers use forests as the basic classification structure, TSF [5], RSF [7], RPSF [14], Proximity Forest (PF) [34], STSF [20], CIF [6], and DrCIF [9].
We compare them separately with the TSCF. The results of the HIVE-COTE V2, TS-CHIEF, InceptionTime, and RPSF experiments were obtained directly from the official UCR website or the literature, and other methods were re-evaluated on 113 datasets, and the results are available on our supporting website. All experimental results are averaged over ten runs on the test set.
4.2 Parameter Analysis
Parameter settings have an important impact on the accuracy of the model. For the proposed TSCF, there are three factors, including the number of trees per forest t and the number of shapelet candidates for each node in RSF s. Due to the large number of datasets, we randomly selected 6 datasets from 113 UCR datasets with different numbers of time series instances, series lengths, and classes for experiments, including BME, CBF, Chinatown, DiatomSizeReduction, GunPoint, and MoteStrain, evaluated by 5-fold cross-validation on the training set. Figure 3 shows their classification accuracies across changes in \(t\in \left\{ 25,50,75,100,125 \right\} \) and \(s\in \left\{ 5,10,15,20,25 \right\} \).
As shown in Fig. 3, we can observe different trends in different datasets, and half of these datasets fluctuate moderately. Observing the dataset that is more sensitive to changes and considering the impact on training time, we set the parameters \(t=50\) and \(s=15\).

Parameter analysis
4.3 Classification Performance
In this section, we demonstrate that TSCF is competitive in term of classification accuracy contrast to state-of-the-art algorithms.
4.3.1 Compared with Forest-Based Benchmark Methods
We first compare benchmark forest-based methods, such as TSF [5], RSF [7], RPSF [14], PF [34], CIF [6], DrCIF [9], STSF [20], and gcForest [10] with our TSCF. Figure 4 shows the accuracy comparison between TSCF and the other 8 forest-based classifiers, and areas below the diagonal line indicate that TSCF is better.

Accuracy comparison between TSCF and other forest-based classifiers
It is clear that TSCF shows outstanding performance. Compared with TSF, RSF, RPSF, PF, CIF, DrCIF and STSF, TSCF performs better on 90, 94, 51, 97, 55, 71, 64 out of 113 (or 112/77) datasets, respectively. In addition, TSCF outperforms the original gcForest on 95 datasets. A more detailed version of the number of Wins/Draws/Losses is indicated by the W/D/L in the bottom-right corner of Fig. 4.
Figure 5 shows the critical difference (CD) diagram [35, 36] over the average ranks of the tested forest-based classification methods. The classifier with the lowest (best) rank lies in the upper right corner. The group of classifiers that are not significantly different is connected by a bar. The average ranking of TSCF is 2.7257 which is the lowest and there are no significant difference between the TSCF, CIF, and STSF. TSCF performs significantly better than DrCIF, RPSF, TSF, RSF, and PF.
From the experimental results, it can be proved that the direct use of gcForest for TSC tasks does not perform as well as existing forest-based methods, and the classifier that is more suitable for TSC based on its cascade structure combination can significantly improve the classification accuracy and perform better than the existing forest-based methods.

CD diagram for comparisons among TSCF and other forest-based classifiers
Specific experimental results for TSCF and the 8 methods are shown in Table 1. The average accuracy of TSCF on 113 datasets is 0.839, followed by CIF with 0.832. For the 1-to-1 comparison on a single dataset, the accuracy is improved by more than 10\(\%\) on 6 datasets compared with CIF, such as the accuracy of PigAirwayP and PigCVP is increased by 144.39\(\%\) and 51.64\(\%\), respectively. The experimental results of RPSF came from their paper [14], which was not re-evaluated because it was written in Java and took a long time to train. The other methods are the result of re-runs, because each classifier in TSCF contains 50 trees, so the number of decision trees in several other forest-based methods is set to 200 (=50\(\times \)4) for direct comparison with TSCF.
4.3.2 Compared with Distance/Shapelet/Interval/Dictionary-Based Methods
In addition to the forest-based methods, there are many traditional methods based on distance/shapelet/interval/dictionary to solve TSC problems. We compare TSCF with six related benchmarks. EE [12] and shapeDTW [13] are distance-based methods. Shapelet-based method we select ST [17]. RISE [19] is interval-based approaches. The dictionary-based methods we consider are BOSS [23] and WEASEL [24].
The analysis in Figs. 6 and 7 reveals that TSCF performs significantly better than these six methods. The experimental accuracy results for TSCF and other methods are available on our anonymous website.

Accuracy comparison between TSCF and distance/shapelet/interval/dictionary-based benchmark classifiers

CD diagram for the average ranking comparison among TSCF and distance/shapelet/interval/dictionary-based classifiers
4.3.3 Compared with Hybrid Benchmark Methods
In this section, we try to analyze TSCF with state-of-the-art hybrid methods. Hybrid methods include HIVE-COTE V2 [9], ROCKET [25], TS-CHIEF [26], and Catch22 [8]. As shown in Figs. 8 and 9, although our method is worse than HIVE-COTE V2 and TS-CHIEF, it is competitive with ROCKET and better than Catch22. In addition, TSCF consists of only four forest-based classifiers and each forest contains 50 trees. But, TS-CHIEF uses PF, BOSS, and RISE as node splitting functions for 500 decision trees, which is more complex than TSCF, taking into account distance, dictionary, and interval-based spectral features. HIVE-COTE V2 contains four component classifiers: the dictionary based temporal dictionary ensemble (TDE); the interval based DrCIF; an adaptation of ROCKET and the latest version of ST. Therefore, TSCF’s performance not exceeding the two of them is to be expected. Since TSCF uses DrCIF as a base classifier, and the 29 summary statistics in DrCIF include Catch22, TSCF’s classification ability is better than Catch22.

Accuracy comparison between TSCF and hybrid classifiers

CD diagram for the comparison among TSCF and hybrid classifiers
4.3.4 Compared with Deep Learning Benchmark Methods
We compared four deep learning models, which are InceptionTime [32], FCN [37], MLP [38], and ResNet [30] with TSCF. As shown in Figs. 10 and 11, TSCF is competitive with InceptionTime, and do better performance than FCN, MLP and ResNet. This proves that the construction of deep forests based on the cascade structure of gcForest can obtain performance comparable to DNNs.

Accuracy comparison between TSCF and deep learning classifiers

CD diagram for the comparison among TSCF and deep learning classifiers
4.4 Variants of TSCF
We include several variants of the proposed TSCF. For the four forest-based classifiers used in TSCF, we conducted different combinations, including: (1) replacing DrCIF with PF; (2) one each for RF and CRF, two for RSF; (3) one each for RF and CRF, two for DrCIF; (4) two RSFs and two DrCIFs.
As shown in Table 2, the experiment was conducted on 25 datasets. The results showed that TSCF has better classification performance (0.899 in average). Compared with other combinations of the four forest-based classifiers, the accuracy of TSCF is the highest, which validates the effectiveness of multi-granular representation learning of time series.
4.5 Ablation Study
We implement ablation studies to understand the contribution of four different base classifiers. The settings are summarized as follows: (1) w/o RF means abandoning the RF classifier, only using the other three models; (2) w/o CRF represents not using the CRF; (3) w/o RSF indicates deleting the RSF module; (4) w/o DrCIF denotes only using RF, CRF, and RSF to constitute a cascade layer; (5) w/o C means that the output of each layer in the model does not concatenate the original time series, and is directly used as the input to the next layer.
Table 3 shows the average accuracy of TSCF and its ablation variants on 25 datasets, and it turns out that all four base classifiers combined with TSCF contribute to the whole, allowing TSCF to achieve better performance than individuals. Among them, the existence of DrCIF improved model performance by 2.860%, and RSF by 1.011%. RF and CRF are also indispensable roles, which can increase the diversity of models and sample randomness. From w/o C, we can conclude that after the training of each layer, it is necessary to concatenate the output of this layer with the original time series as the input to the next layer. In this way, the layer-by-layer classifier can further learn from the original data after obtaining the learning results of the previous layer. Overall, all variants of the model perform slightly worse than the full TSCF, which also proves the effectiveness of each base classifier.
4.6 Visualization
We visualized the learned representation to show that TSCF effectively captures the underlying structure among different classes of time series. In this section, we randomly selected 5 of the 113 UCR datasets, including Meat, UMD, Mallat, MoteStrain, and Symbols. First, we use the t-SNE visual algorithm [39] to compare the learned representations. As shown in Fig. 12, each column represents the test result of a dataset. The first row is a visualization of the original data. The second is the representation of gcForest. The last is our method. For gcForest and TSCF, we used the splicing class vectors of the four forests output by the last layer as the representations learned by the model and then used them as the input of t-SNE visualization. Figure 12 shows that TSCF can learn class embeddings with larger inter-class distances and compact intra-classes distributions. These results also illustrate the effectiveness of TSCF in learning data characteristics from different granularities. Then, we analyse the learned representation of TSCF with a heatmap. Figure 13 indicates that TSCF can learn distinguishable features among different classes.

The t-SNE visualization of original, gcForest, and TSCF (from top to bottom) representation space on 5 datasets. Different colors represent different classes in each subgraph, and each dot represents one instance

The heatmap visualization of representations learned by TSCF on 5 datasets. Each column in the subgraph represents a class in the dataset
5 Conclusion
This paper proposes TSCF, an ensemble model based on the deep forest for TSC tasks. TSCF performs feature learning on the original time series at point-level, subsequence-level, and the summary statistics of intervals, using four different forests to capture more sequence information. The extensive evaluation of TSCF demonstrates its effectiveness, and visualization of learned representations validates its capability to capture different granularities of time series. Based on the framework of TSCF, other base classifiers for point, subsequence and interval-level can be considered for multi-granular representation learning in practical applications, such as TSF [5], RPSF [14], etc. Our future work will focus on including more efficient base classifiers to enhance the performance of cascade forests.
While TSCF exhibits the capability to learn from time series data at various granularities, it is constrained by the practice of concatenating the learning outcomes of the forest with the original sequence, serving as the input for the subsequent layer. Furthermore, each layer necessitates a reiteration of learning on the raw data, incurring a time overhead. In future endeavors, it is imperative to explore strategies for efficiently processing data within the cascading structure and establishing effective data transmission mechanisms between layers. This is essential to enable the classifier to consistently and comprehensively grasp the distinctive features of the data.
References
Pazzani MJ, et al (2001) Derivative dynamic time warping. In: Proceedings of the 2001 SIAM international conference on data mining. Society for Industrial and Applied Mathematics
Yuan J, Lin Q, Zhang W, et al (2019) Locally slope-based dynamic time warping for time series classification. In: Proceedings of the 28th ACM international conference on information and knowledge management, pp 1713–1722
Jeong YS, Jeong MK, Omitaomu OA (2011) Weighted dynamic time warping for time series classification. Pattern Recogn 44(9):2231–2240
Ye L, Keogh E (2009) Time series shapelets: a new primitive for data mining. In: Proceedings of the 15th ACM SIGKDD international conference on knowledge discovery and data mining, pp 947–956
Deng H, Runger G, Tuv E et al (2013) A time series forest for classification and feature extraction. Inf Sci 239:142–153
Middlehurst M, Large J, Bagnall A (2020) The canonical interval forest (CIF) classifier for time series classification. In: 2020 IEEE international conference on big data (Big Data), IEEE, pp 188–195
Karlsson I, Papapetrou P, Boström H (2016) Generalized random shapelet forests. Data Min Knowl Disc 30:1053–1085
Lubba CH, Sethi SS, Knaute P et al (2019) catch22: canonical time-series characteristics: Selected through highly comparative time-series analysis. Data Min Knowl Disc 33(6):1821–1852
Middlehurst M, Large J, Flynn M et al (2021) Hive-cote 2.0: a new meta ensemble for time series classification. Mach Learn 110(11–12):3211–3243
Zhou ZH, Feng J (2019) Deep forest. Natl Sci Rev 6(1):74–86
Stefan A, Athitsos V, Das G (2012) The move-split-merge metric for time series. IEEE Trans Knowl Data Eng 25(6):1425–1438
Lines J, Bagnall A (2015) Time series classification with ensembles of elastic distance measures. Data Min Knowl Disc 29:565–592
Zhao J, Itti L (2018) shapedtw: shape dynamic time warping. Pattern Recogn 74:171–184
Yuan J, Shi M, Wang Z et al (2022) Random pairwise shapelets forest: an effective classifier for time series. Knowl Inf Syst 64:1–32
Grabocka J, Schilling N, Wistuba M, et al (2014) Learning time-series shapelets. In: Proceedings of the 20th ACM SIGKDD international conference on knowledge discovery and data mining, pp 392–401
Zhang Z, Zhang H, Wen Y et al (2018) Discriminative extraction of features from time series. Neurocomputing 275:2317–2328
Lines J, Davis LM, Hills J, et al (2012) A shapelet transform for time series classification. In: Proceedings of the 18th ACM SIGKDD international conference on knowledge discovery and data mining, pp 289–297
Lines J, Taylor S, Bagnall A (2016) Hive-cote: The hierarchical vote collective of transformation-based ensembles for time series classification. In: 2016 IEEE 16th international conference on data mining (ICDM), IEEE, pp 1041–1046
Lines J, Taylor S, Bagnall A (2018) Time series classification with hive-cote: the hierarchical vote collective of transformation-based ensembles. ACM Trans Knowl Discov Data 12(5):1–35
Cabello N, Naghizade E, Qi J, et al (2020) Fast and accurate time series classification through supervised interval search. In: 2020 IEEE international conference on data mining (ICDM), IEEE, pp 948–953
Baydogan MG, Runger G, Tuv E (2013) A bag-of-features framework to classify time series. IEEE Trans Pattern Anal Mach Intell 35(11):2796–2802
Baydogan MG, Runger G (2016) Time series representation and similarity based on local autopatterns. Data Min Knowl Disc 30:476–509
Schäfer P (2015) The boss is concerned with time series classification in the presence of noise. Data Min Knowl Disc 29:1505–1530
Schäfer P, Leser U (2017) Fast and accurate time series classification with weasel. In: Proceedings of the 2017 ACM on conference on information and knowledge management, pp 637–646
Dempster A, Petitjean F, Webb GI (2020) Rocket: exceptionally fast and accurate time series classification using random convolutional kernels. Data Min Knowl Disc 34(5):1454–1495
Shifaz A, Pelletier C, Petitjean F et al (2020) Ts-chief: a scalable and accurate forest algorithm for time series classification. Data Min Knowl Disc 34(3):742–775
Middlehurst M, Schäfer P, Bagnall A (2023) Bake off redux: a review and experimental evaluation of recent time series classification algorithms. arXiv preprint arXiv:2304.13029
Le Guennec A, Malinowski S, Tavenard R (2016) Data augmentation for time series classification using convolutional neural networks. In: ECML/PKDD workshop on advanced analytics and learning on temporal data
Cui Z, Chen W, Chen Y (2016) Multi-scale convolutional neural networks for time series classification. arXiv preprint arXiv:1603.06995
He K, Zhang X, Ren S, et al (2016) Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Tanisaro P, Heidemann G (2016) Time series classification using time warping invariant echo state networks. In: 2016 15th IEEE international conference on machine learning and applications (ICMLA), IEEE, pp 831–836
Ismail Fawaz H, Lucas B, Forestier G et al (2020) Inceptiontime: finding alexnet for time series classification. Data Min Knowl Disc 34(6):1936–1962
Ismail Fawaz H, Forestier G, Weber J et al (2019) Deep learning for time series classification: a review. Data Min Knowl Disc 33(4):917–963
Lucas B, Shifaz A, Pelletier C et al (2019) Proximity forest: an effective and scalable distance-based classifier for time series. Data Min Knowl Disc 33(3):607–635
Benavoli A, Corani G, Demšar J et al (2017) Time for a change: a tutorial for comparing multiple classifiers through Bayesian analysis. J Mach Learn Res 18(1):2653–2688
Demšar J (2006) Statistical comparisons of classifiers over multiple data sets. J Mach Learn Res 7:1–30
Zhao B, Lu H, Chen S et al (2017) Convolutional neural networks for time series classification. J Syst Eng Electron 28(1):162–169
Wang Z, Yan W, Oates T (2017) Time series classification from scratch with deep neural networks: A strong baseline. In: 2017 international joint conference on neural networks (IJCNN), IEEE, pp 1578–1585
Van der Maaten L, Hinton G (2008) Visualizing data using t-SNE. J Mach Learn Res 9(11):2579–2605
Acknowledgements
This work was supported by the National Key R &D Program of China (No. 2022YFE0200400) and the Fundamental Research Funds for the Central Universities (No. 2022JBMC011).
Author information
Authors and Affiliations
Contributions
MD: Conceptualization, methodology, software, validation, formal analysis, investigation, data curation, writing-original draft, writing-review and editing, visualization. JY: formal analysis, resources, writing-reviewing and editing, supervision, project administration, funding acquisition. HL: writing-reviewing and editing, supervision, project administration. JW: investigation, data curation.
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Dai, M., Yuan, J., Liu, H. et al. TSCF: An Improved Deep Forest Model for Time Series Classification. Neural Process Lett 56, 13 (2024). https://doi.org/10.1007/s11063-024-11531-1
Accepted:
Published:
DOI: https://doi.org/10.1007/s11063-024-11531-1