
Abstract
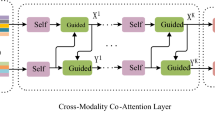
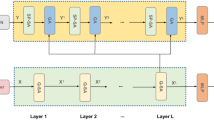
Current visual question answering (VQA) has become a research hotspot in the computer vision and natural language processing field. A core solution of VQA is how to fuse multi-modal features from images and questions. This paper proposes a Multimodal Bi-direction Guided Attention Network (MBGAN) for VQA by combining visual relationships and attention to achieve more refined feature fusion. Specifically, the self-attention is used to extract image features and text features, the guided-attention is applied to obtain the correlation between each image area and the related question. To obtain the relative position relationship of different objects, position attention is further introduced to realize relationship correlation modeling and enhance the matching ability of multi-modal features. Given an image and a natural language question, the proposed MBGAN learns visual relation inference and question attention networks in parallel to achieve the fine-grained fusion of the visual features and the textual features, then the final answers can be obtained accurately through model stacking. MBGAN achieves 69.41% overall accuracy on the VQA-v1 dataset, 70.79% overall accuracy on the VQA-v2 dataset, and 68.79% overall accuracy on the COCO-QA dataset, which shows that the proposed MBGAN outperforms most of the state-of-the-art models.











Similar content being viewed by others

References
Wang Q, Deng H, Wu X, Yang Z, Liu Y, Wang Y, Hao G (2023) LCM-Captioner: A lightweight text-based image captioning method with collaborative mechanism between vision and text. Neural Netw. https://doi.org/10.1016/j.neunet.2023.03.010
Jiang W, Li Q, Zhan K, Fang Y, Shen F (2022) Hybrid attention network for image captioning. Displays 73:102238. https://doi.org/10.1016/j.displa.2022.102238
Tian Y, Ding A, Wang D, Luo X, Wan B, Wang Y (2023) Bi-Attention enhanced representation learning for image-text matching. Pattern Recognition 140:109548
Dongqing Wu, Li H, Tang Y, Guo L, Liu H (2022) Global-guided asymmetric attention network for image-text matching. Neurocomputing 481:77–90. https://doi.org/10.1016/j.neucom.2022.01.042
Zhang L, Liu S, Liu D, Zeng P, Li X, Song J, Gao L (2020) Rich visual knowledge-based augmentation network for visual question answering. IEEE Trans Neural Netw Learn Syst 32(10):4362–4373
Zeng P, Zhang H, Gao L, Song J, Shen H (2022) Video question answering with prior knowledge and object-sensitive learning[J]. IEEE Trans Image Process 31:5936–5948
Zhang H, Zeng P, Yuxuan Hu, Qian J, Song J, Gao L (2023) Learning visual question answering on controlled semantic noisy labels. Pattern Recogn 138:109339
Peng L, Yang Y, Wang Z, Huang Zi, Shen HT (2022) MRA-Net: improving VQA Via multi-modal relation attention network. IEEE Trans Pattern Anal Mach Intell 44(1):318–329. https://doi.org/10.1109/TPAMI.2020.3004830
Chen C, Han D, Chang C-C (2022) CAAN: Context-Aware attention network for visual question answering. Pattern Recogn 132:108980
Yu D, Gao X, Xiong H (2018) Structured semantic representation for visual question answering. In: 2018 25th IEEE International Conference on Image Processing (ICIP), 2286–2290. https://doi.org/10.1109/icip.2018.8451516
Wu J, Ge F, Shu P, Ma L, Hao Y(2022) Question-Driven Multiple Attention(DQMA) Model for Visual Question Answer. International Conference on Artificial Intelligence and Computer Information Technology (AICIT), 1–4. https://doi.org/10.1109/AICIT55386.2022.9930294
Guan W, Wu Z, Ping W (2022) Question-oriented cross-modal co-attention networks for visual question answering. 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), 2022, 401–407. https://doi.org/10.1109/ICCECE54139.2022.9712726
Wang F, An G (2022) Visual Question Answering based on multimodal triplet knowledge accumulation. In: 2022 16th IEEE International Conference on Signal Processing (ICSP), 81–84. https://doi.org/10.1109/ICSP56322.2022.9965282
Liu L, Wang M, He X, Qing L, Chen H (2022) Fact-based visual question answering via dual-process system. Knowledge-Based Syst. https://doi.org/10.1016/j.knosys.2021.107650
Yang Z, Garcia N, Chu C, Otani M, Nakashima Y, Takemura H (2021) A comparative study of language transformers for video question answering. Neurocomputing 445:121–133. https://doi.org/10.1016/j.neucom.2021.02.092
Peng L, An G, Ruan Q (2022) Transformer-based Sparse Encoder and Answer Decoder for Visual Question Answering. In: 2022 16th IEEE International Conference on Signal Processing (ICSP), 120–123. https://doi.org/10.1109/ICSP56322.2022.9965298
Yu Z, Yu J, Cui Y, Tao D, Tian Q (2019) Deep modular co-attention networks for visual question answering. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 6281–6290. https://doi.org/10.1109/cvpr.2019.00644
Bin Y, Yang Y, Zhou J, Huang Z, Shen HT(2017) Adaptively attending to visual attributes and linguistic knowledge for captioning. In: Proceedings of the 25th ACM international conference on multimedia, 1345–1353
Tasse FP, Kosinka J, Dodgson N (2015) Vqa: Visual question answering. In: Proceedings of the IEEE international conference on computer vision, 2425–2433. https://doi.org/10.1109/ICCV.2015.279
Fukui A, Park DH, Yang D, Rohrbach A, Darrell T (2016) Multimodal compact bilinear pooling for visual question answering and visual grounding. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 457–468. https://doi.org/10.18653/v1/D16-1044
Qian Y, Yuncong Hu, Wang R, Feng F, Wang X (2022) Question-driven graph fusion network for visual question answering. IEEE Int Conf Multimed Expo (ICME) 2022:1–6. https://doi.org/10.1109/ICME52920.2022.9859591
Zhou Yu, Jun Yu, Xiang C, Fan J, Tao D (2018) Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans Neural Netw Learn Syst 29(12):5947–5959. https://doi.org/10.1109/tnnls.2018.2817340
Ben-Younes H, Cadene R, Cord M, Thome N (2017) Mutan: Multimodal tucker fusion for visual question answering. In: Proceedings of the IEEE international conference on computer vision, 2631–2639. https://doi.org/10.1109/iccv.2017.285
Yu Z, Yu J, Fan J, Tao D (2017) Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In: Proceedings of the IEEE international conference on computer vision, doi: https://doi.org/10.1109/iccv.2017.202
Zhang W, Jing Yu, Zhao W, Ran C (2021) DMRFNet: deep multimodal reasoning and fusion for visual question answering and explanation generation. Inform Fusion 72:70–79. https://doi.org/10.1016/j.inffus.2021.02.006
Lao M, Guo Y, Nan P, Chen W, Liu Y, Lew MS (2021) Multi-stage hybrid embedding fusion network for visual question answering. Neurocomputing 423:541–550. https://doi.org/10.1016/j.neucom.2020.10.071
Zhang W, Jing Y, Wang Y, Wang W (2021) Multimodal deep fusion for image question answering. Knowledge-Based Syst 212:106639. https://doi.org/10.1016/j.knosys.2020.106639
Kim J-J, Lee D-G, Jialin W, Jung H-G, Lee S-W (2021) Visual question answering based on local-scene-aware referring expression generation. Neural Netw 139(158):167. https://doi.org/10.1016/j.neunet.2021.02.001
Sharma H, Jalal AS (2021) Visual question answering model based on graph neural network and contextual attention. Image and Vis Comput 110:104165. https://doi.org/10.1016/j.imavis.2021.104165
Peng, L., Yang, Y., Wang, Z., Wu, X. and Huang, Z (2019) Cra-net: Composed relation attention network for visual question answering. In: Proceedings of the 27th ACM International Conference on Multimedia, 1202–1210. https://doi.org/10.1145/3343031.3350925
Yang Z, He X, Gao J, Deng L, Smola A (2016) Stacked attention networks for image question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 21–29. https://doi.org/10.1109/cvpr.2016.10
Anderson P, He X, Buehler C, Teney D, Johnson M, Gould S, Zhang L (2018) Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 6077–6086. https://doi.org/10.1109/cvpr.2018.00636
Lu J, Yang J, Batra D, Parikh D (2016) Hierarchical question image co-attention for visual question answering. Adv Neural Inform Process Syst. https://doi.org/10.48550/arXiv.1606.00061
Kim J-H, Jun J, Zhang B-T (2018) Bilinear attention networks. Adv Neural Inform Process Syst. https://doi.org/10.48550/arXiv.1805.07932
Nguyen DK, Okatani T (2018) Improved fusion of visual and language representations by dense symmetric co-attention for visual question answering. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 6087–6096. https://doi.org/10.1109/CVPR.2018.00637
Li RY, Kaabar MK, Wu Z (2022) A Lightweight Visual Question Answering Model based on Semantic Similarity. In Proceedings of the 2021 4th International Conference on Machine Learning and Machine Intelligence (MLMI '21). 71–76. https://doi.org/10.1145/3490725.3490736
Guo Z, Han D (2020) Multi-modal explicit sparse attention networks for visual question answering. Sensors 20(23):6758. https://doi.org/10.3390/s20236758
Liu F, Liu J, Fang Z, Hong R, Hanqing Lu (2020) Visual question answering with dense inter-and intra-modality interactions. IEEE Trans Multimed 23:3518–3529. https://doi.org/10.1109/tmm.2020.3026892
Liu Y, Zhang X, Zhang Q, Li C, Huang F, Tang X, Li Z (2021) Dual self-attention with co-attention networks for visual question answering. Pattern Recognition 117:107956. https://doi.org/10.1016/j.patcog.2021.107956
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalantidis Y, Li L-J, Shamma DA, Bernstein MS, Fei-Fei Li (2017) Visual genome: connecting language and vision using crowdsourced dense image annotations. Int J Comput Vision 123(1):32–73. https://doi.org/10.1007/s11263-016-0981-7
Pennington J, Socher R, Manning C (2014) Glove: Global vectors for word representation. In: Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), 1532–1543. https://doi.org/10.3115/v1/d14-1162
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. Adv Neural Inform Process Syst. https://doi.org/10.48550/arXiv.1706.03762
Jing Yu, Zhang W, Yuhang Lu, Qin Z, Yue Hu, Tan J, Qi Wu (2020) Reasoning on the relation: enhancing visual representation for visual question answering and cross-modal retrieval. IEEE Trans Multimedia 22(12):3196–3209. https://doi.org/10.1109/tmm.2020.2972830
Miao Y, Cheng W, He S, Jiang H (2022) Research on visual question answering based on GAT relational reasoning. Neural Process Lett 54:1435–1448. https://doi.org/10.1007/s11063-021-10689-2
Han Y, Guo Y, Yin J, Liu M, Hu Y, Nie L (2021) Focal and Composed Vision-semantic Modeling for Visual Question Answering. Proceedings of the 29th ACM International Conference on Multimedia, 4528–4536. https://doi.org/10.1145/3474085.3475609
Liu Y, Guo Y, Yin J, Song X, Liu W, Nie L, Zhang M (2022) Answer questions with right image regions: a visual attention regularization approach. ACM Trans Multimedia Comput Commun Appl. https://doi.org/10.1145/3498340
Yirui W, Ma Y, Wan S (2021) Multi-scale relation reasoning for multi-modal visual question answering. Signal Process Image Commun 96(1):116319. https://doi.org/10.1016/j.image.2021.116319
Gao L, Zeng P, Song J, Liu X, Shen HT (2018) From pixels to objects: Cubic visual attention for visual question answering. Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence Main track. 906–912. https://doi.org/10.24963/ijcai.2018/126
Chen K, Wang J, Chen LC, Gao H, Xu W, Nevatia R (2015) Abc-cnn: An attention based convolutional neural network for visual question answering. arXiv preprint arXiv:1511.05960. https://doi.org/10.48550/arXiv.1511.05960
Noh H, Seo PH, Han B (2016) Image question answering using convolutional neural network with dynamic parameter prediction. In: Proceedings of the IEEE conference on computer vision and pattern recognition, 30–38. https://doi.org/10.1109/cvpr.2016.11
PLu P, Li H, Zhang W, Wang J, Wang X (2018) Co-attending free-form regions and detections with multi-modal multiplicative feature embedding for visual question answering. In: Proceedings of the AAAI Conference on Artificial Intelligence, 32. https://doi.org/10.1609/aaai.v32i1.12240
Qun Li Fu, Xiao BB, Sheng B, Hong R (2022) Inner knowledge-based Img2Doc scheme for visual question answering. ACM Trans Multimedia Comput Commun Appl. https://doi.org/10.1145/3489142
Voita E, Talbot D, Moiseev F, Sennrich R, Titov I (2019) Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 5797–5808. https://doi.org/10.18653/v1/P19-1580
Acknowledgements
This work is funded by the National Natural Science Foundation of China (62277008) and the Educational Informatization Project of Chongqing University of Posts and Telecommunications (xxhyf2022-08).
Author information
Authors and Affiliations
Contributions
Linqin Cai to carry out the design of experimental ideas; Hang Tian conducted data collection and analysis; Haodu Fan performed the visualization of the experimental results; Nuoying Xu and Kejia Chen designed the software and wrote the first draft of the paper. All authors contributed to the review and revision of the first draft.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Cai, L., Xu, N., Tian, H. et al. Multimodal Bi-direction Guided Attention Networks for Visual Question Answering. Neural Process Lett 55, 11921–11943 (2023). https://doi.org/10.1007/s11063-023-11403-0
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-023-11403-0