
Abstract
Digital image watermarking has become a valuable tool for preventing unauthorized use and alteration of digital images due to technological advancements. A fundamental difficulty in digital image watermarking is to provide resilience against geometrical assault while retaining a sufficient degree of imperceptibility and security. This study presents an efficient authentication scheme for digital image watermarking on medical images benefiting from both techniques: Support Vector Machine (SVM) and Lifting Wavelet Transform (LWT). In this article, we use two strategies, where SVM is used first to separate the Region of Interest (ROI) from the Non-Region of Interest (NROI) in the medical image. Then LWT is applied to embed watermark information within the NROI part of the medical image (Cover Image). Moreover, we have applied a shared secret key to enhancing the robustness of the proposed scheme. The method is tested on an extensive image database to see how it performs under different situations. The research looked into the various experimental analyses to establish the acceptability of the existing scheme. The simulation is performed to measure the imperceptibility and robustness using various evaluation metrics.
Similar content being viewed by others

1 Introduction
The pandemic of COVID-19 has emphasized the significance of the internet and multimedia technology. We have become more agnostic to internet communication technologies. We have to use the internet to share private information like health information, bank data, credit card data, or family photographs in our day-to-day lives. Nowadays, sharing this essential personal or commercial data over the internet is a high-risk activity. It is straightforward to access, vulnerable to tampering, unauthorized use, and copyright violations may happen easily as the information is transmitted over an untrusted digital platform. To defend against unauthorized access and usage, authentication, data integrity, and confidentiality are needed in the field of multimedia security. So the user needs a trustworthy platform or application through which one can easily share their personal information without any doubt. A machine learning and watermarking joint venture may provide an effective solution in this scenario. In this research, we proposed a reversible watermarking scheme (RWS) with the help of Support Vector Machine (SVM) [9] and lifting wavelet transform (LWT) to enhance the security, robustness and provide authenticity and data integrity.
Medical images are more typical than any other ordinary images since they store patients’ information for diagnosis purposes. Such images need more security and confidentiality as total diagnosis depends on them. In tele-medicine applications, transmitting a medical image via an open channel demands strong security and copyright protection. So we always have to take care of these images while embedding the secret information into them. To do so, we have classified a medical image into two regions: (i) an important part of the medical image used for diagnosis purposes is known as the Region of Interest (ROI), and (ii) the rest part of the image, which is not so essential, is known as the Non-Region of Interest (NROI). A small mis-classification may cause big trouble in extracting essential information from the patient. In statistical learning theory, SVM is a new class of machine learning methods that may be used as an image classifier. A few researchers [1, 29] have applied SVM to medical image watermarking schemes in the transform domain.
Watermarking in medical images can be stepped up in three stages; the first stage can be described as the classification of NROI and ROI. The second stage is watermark embedding in the host image. The last stage is the extraction of watermark information. SVM can play an important role in the classification stage as a machine-learning algorithm used for classification problems. On the other hand, the transform domain methods such as Singular Value Decomposition (SVD), Discrete Cosine Transform (DCT), Discrete Wavelet Transform (DWT), Integer Wavelet Transform (IWT), and Lifting Wavelet Transform (LWT) are robust against various attacks in the embedding and extraction processes. However, among all these schemes, the lifting wavelet transform has the unique property that it can transform the pixel values into some integer values, which might be useful for a reversible model.
In this current work, we have proposed a new watermarking model for medical image using SVM and LWT. Here, SVM is used to predict the regions in the MR images where the watermark image is embedded using a novel watermarking scheme. In our proposed model, double-layer security is introduced to ensure the robustness of embedded data. The embedded data is scrambled using a unique key, and a transform domain-based hybrid watermarking technique is applied to embed the scrambled data into the coefficients of the host image. This proposed scheme exploits the feature of reversibility of LWT and randomization properties of the secret key.
1.1 Contributions of this article
The contributions are summarize as follows:
-
(a)
In our proposed watermark embedding, we employ the concept of optimization for selecting the ROI and NROI parts of the cover image.
-
(b)
We exploit the properties of HVS to find all the possible functional dependencies that were not taken care of previously. We also investigate the problem with respect to the robustness properties and constraints of a watermarking system.
-
(c)
We use SVM to make the watermarking scheme imperceptible with respect to HVS.
-
(d)
We deploy LWT to achieve robustness against a series of attacks instead of a single attack, which is a much more desirable scenario.
-
(e)
Improve the embedding capacity of the scheme which is more required for recent medical image application.
1.2 Abbreviations
The notation and abbreviations used in this article are given in the Table 1.
The rest of the paper is structured as follows: A literature survey has been conducted in Section 2. Section 3 describes some preliminary information. The developed watermark embedding and extraction algorithms are defined in Section 4. Section 5 describes the experimental results obtained with the proposed framework and the performance comparisons with some state-of-the-art techniques. Finally, conclusions with potential for future work are drawn in Section 6.
2 Literature review
Singh et al. [29] presented a DWT-SVD-based watermarking scheme in which the watermark is encrypted and encoded using ECC, which provides robustness and imperceptibility to the proposed model; however, it increases the computational complexity to some extent. Roy et al. [24] proposed a new steganographic scheme using the video frame segmentation method. They compress the areas and embed secret data in those compact regions using a region selection approach followed by a dimensionality reduction procedure called principal component analysis (PCA). This PCA is utilized as a best-fit vector, minimizing the average square distance between the pixel values and that vector. Their experimental results demonstrated that they achieved high embedding capacity and improved visual quality. Furthermore, the suggested approach enhances resilience by allowing the receiver to extract the secret message even after certain known channel intrusions. In 2021, Ji and Cheng [12] developed an adaptive multisensor image fusion method based on monogenic features. The proposed method extracts the monogenic features of source images, adopts different similarity measure to divide monogenic features into different regions, and chooses different fusion rules to realize adaptive fusion. In 2021, Singh et al. [30] proposed a cutting-edge multi-focus image fusion method for real-time monitoring. The efficiency of the image fusion process is increased by using a wavelet-based hybrid solution, a multi-step image fusion methodology, and the noise diffusion concept. In 2022, Cheng et al. [3] proposed a Convolutional Neural Network framework to extract and evaluate the suspicious skin region for automatic extraction and evaluation of dermoscopy images. In 2022, Gaffar [7] suggested a new image steganography method with poor embedding capacity or susceptible embedded images. The suggested approach provides high embedding capacity and image secrecy based on the Golden Ratio and Non-Subsampled Contourlet Transform (GRNSCT) model. A two-level NSCT (Non-Subsampled Contourlet Transform) produces the large embedding capacity, while a deck of cards shuffling approach is used to ensure anonymity. Key sensitivity, histogram, and information entropy are some of the security assessment metrics used to analyze the resilience of embedded images. The experimental results show the embedding capacity of up to 24 bpp with a PSNR of up to 42.38 dB.
3 Prerequisite
This research proposes a reversible watermarking scheme using SVM and LWT. This section will go over the related background of SVM and LWT.
3.1 SVM
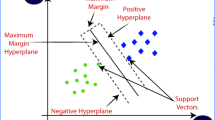
In statistical learning theory, SVM is a new class of supervised machine learning methods that can be used for regression or classification problems, but generally, it is used for classification issues. In this classification algorithm, each data item is plotted as a point in the n-dimensional feature space of things with the value of a particular coordinate; then, a classification is performed to distinguish the two classes by finding the best hyperplane depicted in Fig. 1. The margin defines the utmost breadth of two parallel lines to the hyperplane, which does not contain any data points within the parallel slabs; The data points nearby to the separating hyperplane are named support vectors; these support vector points lie on the edge of the slab; a square represents data points of category positive, and a circle represents data points of category negative. The classification of ROI and NROI regions in a medical image is an important procedure for embedding the watermark in the non-essential portion, but it can be overcome using SVM as a classifier that avoids any distortion to the diagnosis part of the image. So, such a classification technique can facilitate the schematic watermarking methodology. Ramly et al. [23] suggested a watermarking scheme using SVM and SS. SVM has been used for the classification of ROI and NROI in medical images, whereas Spread Spectrum has been used for embedding and extraction of patient information. However, embedding has been done in the spatial domain, and no attacks have been performed on the proposed model. Yen and Wang [38] proposed a new technique for watermarking using a supervised machine learning algorithm. The watermark is inserted by unsymmetrically tuning the blue channels of the surrounding pixels and central since embedding has been performed in the spatial domain, which is not robust against several image processing attacks.

Block diagram of SVM
3.2 Lifting Wavelet Transform (LWT)
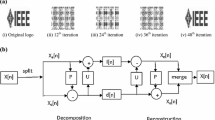
In recent years, the LWT, proposed by Sweldens [34], has become a powerful tool for image analysis due to the faster and more efficient implementation of LWT than traditional wavelet transform [14]. It gives better results than traditional wavelet in the fields of image compression [6], image de-noising [32], pattern recognition [18], feature extraction [10] and watermarking [16, 37]. The detailed mathematical description of the lifting scheme is described in [5, 34]. The lifting-based wavelet transforms save time and have a better frequency localization feature that overcomes the shortcomings of traditional wavelets. The basic idea behind lifting wavelets is to design a new wavelet with better features based on a simple wavelet. The lifting wavelet transform is a substitute for the discrete wavelet transform. A lifting scheme is used to produce second-generation wavelets, which are not necessarily translations and dilation of one particular function. Three steps are involved in assembling wavelets using a lifting scheme, viz. Split, Predict, and Update. The split-phase splits data into odd and even sets. An even set is used to anticipate an odd set in the predict step. The predict phase ensures polynomial cancellation in high pass. The update phase will use wavelet coefficients to modernize the even set and calculate the scaling function. Figure 2 shows the lifting wavelet transform scheme. The lifting scheme allows faster implementation of the wavelet transform.

Block diagram of integer wavelet transform
Decomposition of a signal using LWT involves three steps: splitting, prediction, and update shown in Fig. 3 are described as:

Signal Decomposition in lifting wavelet transform
Split
divide the original signal x[n] into non overlapping even and odd samples, that is, xe[n] (even samples) and xo[n] (odd samples) where,
Predict
if even and odd samples are correlated, then one can be the predictor of the other. To predict x0[n] we use xe[n] samples defined as:
Where d[n] is the difference between the original sample and its predicted value defined as a high-frequency component, and P(.) is the predictor operator.
Update
with the help of update operator U(.) and detail signal d[n], we can update the even samples. Then the low-frequency components l[n], which represent the rough shape of the original signal are obtained as:
4 Proposed watermarking scheme
4.1 Image classification
In this classification stage of the proposed model, the pixels of the medical host image are characterized into ROI and NROI to perform embedding. In an SVM classification model, the labeled predictor data is used to build a trained model. Various SVM kernel functions are available to find adequate predictive precision, which requires the parameters to be set for better accuracy. After training the model, it is cross-validated using the test data set. For instance, the host medical image is partitioned into two parts: ROI and NROI. The trained SVM model utilizes the available dataset to manage its related parameters, i.e., weight vector and bias, which are mainly used to reduce the mis-classification between ROI and NROI. ROI is basically used for diagnosis purposes, whereas NROI does not have more significance. Therefore, a small mis-classification in the selection of ROI & NROI can cause big trouble in diagnosis.
In the proposed scheme, a model has been created after performing the SVM algorithm on image datasets. The ROI and NROI of the host medical image are predicted using the same model (Fig. 4).

Two phase diagram of Watermarking
4.2 Watermark embedding
The embedding scheme of our proposed scheme has been described in this section. The basic block diagram of the proposed scheme has been described in Fig. 5. At first, a cover image of size (M × N) is considered input. As in the previous section, we have already discussed selecting the ROI and NORI parts of an image using SVM. Now these ROI and NORI pixel positions are stored in two different arrays, say, αr and αnr and the pixel values are stored in two separate arrays, say, βr and βnr respectively. Here, only the NROI part of the image is our major concern. Now apply lifting wavelet transform (LWT) to the images and collect all the LWT coefficients lying in the NROI part of the images. Now select any shared secret key (κ) and generate a 512-bit string using the standard SHA-512 encryption algorithm. Hence, input the watermark logo (W ) and generate the watermark bit stream (BW). Hence, κ is XORed with the BW to generate an encrypted watermark (γ). Now the γ is embedded into the NROI part on the cover image using Rule Table-1 given in Fig. 5. Here, T can randomly be chosen from the each blocks using the formula: T = Cmin mod 8. Basically, a shared secret key is used to scramble the watermark bit. We have embedded 4 bits of watermark information within four pixels of the cover image for each iteration. This process will carry forward for all other NROI positions. After embedding all the γ bits into the cover image, apply inverse LWT to generate the watermarked image (WI). The Algorithmic framework for embedding has been provided in Algorithm 1.

Block diagram of proposed watermarking scheme

Embedding algorithm.
4.3 Watermark extraction
The extraction process of the watermark information has been described in this section. At first, we consider the watermarked image (WI) of size (M × N) as an input. Now a selection of ROI and NORI parts of the watermarked image has been made using SVM as described in Section 3.1. Now these ROI and NORI pixel positions are stored in two different arrays, say, \(\alpha ^{\prime }_{r}\) and \( \alpha ^{\prime }_{nr} \) and the pixel values are stored in two separate arrays, say, \(\beta ^{\prime }_{r}\) and \(\beta ^{\prime }_{nr} \) respectively. Here, only the NROI part of the images is our major concern, as only this portion was used to embed the watermark information. Now apply the lifting wavelet transform (LWT) to the watermarked image and extract the LWT coefficients. Split the coefficients into 2×2 non-overlapping blocks and collect the \( C_{\max \limits } \) and \( C_{\min \limits } \) values from the blocks. Hence, compare \(C_{\max \limits } \) and \( (C_{\max \limits }-1) \), if they are the same, then extract 0; otherwise, extract 1 and store them into an array \(\gamma ^{\prime }\). This \(\gamma ^{\prime }\) is just like an encrypted watermark bit. Select the shared secret key (κ) and generate a 512-bit string using the standard SHA-512 encryption algorithm. Now extract the original watermark bits by XORing \(\gamma ^{\prime }\) with κ. In this way, the watermark logo can be easily generated from the watermark information. Finally, we can easily verify or validate the cover document from the extracted watermark information. The Algorithmic framework for extraction has been provided in Algorithm 2.

Extraction algorithm.
5 Experimental results and comparisons
Many approaches and metrics are available for a subjective and objective assessment of the performance of watermarking systems. In general, objective analysis corresponds to performance benchmarks that do not require the presence of the examiner, and these tests may be carried out according to certain guidelines. The detailed descriptions are described in the following subsections. For the experiment, an Intel Core i7-8565U CPU 1.80 GHz processor, 16 GB, 512 GB SDD, DDR3 Memory, Matlab version 21a, and JAVA 8 software are used for the experiment. The proposed method is applied to Sagittal T2-weighted fat-suppressed Dynamic Contrast-Enhanced Magnetic Resonance Imaging (DCE-MRI) of the breast collected from [4, 17, 36]. The size of the images is (256 × 256). The SVM was trained with 40 MR images and tested with 10 MR images. These fifty (50) images are considered the cover image, and a gray-scale image of size (165 × 165) as the logo image. Here, breast lesional regions are the ROIs, and other regions are the NROIs. A standard dataset is considered with 50 images of size (256 × 256) as cover image and a gray-scale image of size (165 × 165) as logo image. Furthermore, we have increased the size of the dataset to 100, 150, and 200. We have trained the SVM with 80, 120, and 160 training MR images, and tested the SVM model with 20, 30, and 40 testing MR images and evaluated the performance of the proposed model accordingly.
Figure 6 shows some of the original images and their corresponding mask images after applying SVM.

Original and their corresponding Mask images
Figure 7 shows the Watermarked image (Marked_MRI#4) after embedding the watermark logo image (Watermark) into the cover image (MRI#4) and also shows the watermark logo image after extraction.

Watermark Image before embedding and after extraction
5.1 Capacity
Capacity is another significant aspect in medical image watermarking that should be considered when evaluating the overall effectiveness of the proposed approach. It is the amount of information encoded in the host image, represented in bits per pixel (BPP) units. Table 2 shows that the capacity (in BPP) achieved with our technique is 0.99 bpp. The capacity can be calculated by using the (4).
5.2 Visual quality measures
The following performance metrics are used to measure the visual quality of a watermarking system.
5.2.1 Peak Signal to Noise Ratio (PSNR)
The PSNR (Peak Signal to Noise Ratio) is used to assess the image deterioration induced by including the secret image within the cover image. It is expressed by the (5).
Where the Mean Square Error (MSE), it is defined as (6)
Where, I(i,j) and SI(i,j) are the pixel intensities of original and watermarked images of size (m × n) respectively.
5.2.2 Structural Similarity Index Measure (SSIM)
In addition to PSNR, SSIM is applied to evaluate how the host image (I) and the watermarked image (SI) can be distinguished from one another. SSIM calculates the degree of resemblance between two images by comparing three different parameters: luminance, contrast, and structure. The SSIM of I and SI is defined as given in (7).
where,
where, δI and δSI represent the luminance of the respective images. If the luminance of both images is the same, i.e., δI = δSI, the maximum value of α is one. Similarly, if the contrast of both images is the same, the maximum value of β is also 1 whereas the structural comparison, i.e., γ measures the correlation coefficients between the host and watermarked images. Here, σI and σSI represent the standard deviation, and σI.SI represents the covariance factors of host and watermarked images.
5.3 Robustness analysis
To find the robustness of the scheme we need to find some experimental results in terms of BER and NCC which are given in the following subsections.
5.3.1 Bit Error Rate (BER)
Bit Error Rate (BER) is used to measure the robustness of the analysis between the original secret (W ) and extracted watermark (\(W^{\prime }\)) images with a size (m × n). BER is expressed using (11):
5.3.2 Normalized Correlation Coefficients (NCC)
The Normalized Correlation Coefficients (NCC) metric assesses the robustness of the watermarking scheme. It calculates the correlation coefficients between the retrieved watermark (\(W^{\prime }\)) and the original one (W ) initially placed. The NCC is expressed as the (12):
The NCC value is defined on the interval [0, 1] with unity as the ideal value.
From Table 2, one can easily find out that the considered cover image is of size (256 × 256), which means there are a total 65,536 data points used for the classification purpose using the SVM model. In Table 2, it is observed that from the total of ten images, the minimum number of NROI pixel values is 61,690 for image “Mask2”. Moreover, the payload for the grayscale image will be in the range of 0.9572 − 0.993 bpp, whereas the embedding capacity of our proposed scheme is in the range of 61,690 to 65,491 bits.
Table 3 represents the experimental results of PSNR, Capacity, Payload, SSIM, and NCC. For any standard image processing experiment, an image with a PSNR value greater than 30 dB is considered a good quality image. From Table 3, it is clear that the PSNR for the proposed scheme is approximately 64 dB. The watermarked image is undetectable to the human visual system (HVS).
Moreover, to justify the robustness of the proposed scheme, we have found the experimental results on SSIM and NCC. The average SSIM and NCC results for the ten images are approximately 98% and 99%, respectively, which is very acceptable to demonstrate robustness. Our proposed algorithm provides a good trade-off between imperceptibility, embedding capacity, and robustness.
The average imperceptibility and robustness results of the proposed scheme for various train and test image dataset are tabulated in Table 5. Here, we have increased the size of the dataset to 100, 150, and 200 to check the acceptability of our proposed model. We have trained the SVM with 80, 120, and 160 training MR images, and tested the SVM model with 20, 30, and 40 testing MR images and evaluated the performance of the proposed model accordingly. From the tabulated data, it is clearly visible that with the variation of test dataset the model can sustain with the good imperceptibility and robustness.
The proposed technique is compared with some current state-of-the-art methods shown in Table 4. The comparison is based on PSNR and SSIM. From this table, it is clear that the PSNR is better in the proposed scheme than the listed methods. The better SSIM value also proves the robustness of the proposed scheme (Table 5).
5.4 Multi-criteria decision analysis
Multi-Criteria Decision Analysis (MCDA) [2] has been conducted using a well-known method, namely Technique for Order of Preference by Similarity to Ideal Solution (TOPSIS), and this philosophy in the selection of the best algorithm/method based on a set of performance measurement metrics is adopted from the study [22, 26,27,28]. Here, multiple criteria are PSNR and SSIM. Table 6 provides the ranks obtained from the TOPSIS technique. The proposed method has achieved the highest ranking, indicating that our proposed scheme provides better performance considering both PSNR and SSIM than other schemes. It is also worth noting that the existing scheme from Ghosal et al. [8] gets placed at the bottom of the list.
Table 7 depicts the PSNR difference in various scaling factors. We have considered ten breast images with rising factors of 10%, 20%, 40%, and 80%. In general, the average PSNR value for the original image is 66.737 dB. But for the scaling factors of 10%, 20%, 40%, and 80%, the average PSNR values become 62.749 dB, 55.809 dB, 48.786 dB, and 41.865 dB, respectively, which means that the watermarked image can still be undetectable to the human visual system.
We have also tested the proposed scheme under various attacking scenarios like Salt & Paper Noise, Cropping, Filtering, Gaussian Noise, JPEG Compression, Histogram Equalization, and Rotation (90∘), and the results are reported in Table 9. From this table, it is clear that the PSNR value for the extracted watermark image is more than 30 dB for all cases except JPEG compression and rotation, which means that the watermark image can be easily detectable by the HVS system.
The Table 8 shows the tabulated results of NCC values in various attacking condition (Salt & pepper noise, JPEG compression and Median filtering). The tabulated results show the superiority of the proposed scheme over other existing schemes in terms of robustness.
5.5 Computational complexity
The time required to embed and extract the watermark data into a cover image is analysed here. The asymptotic time complexity of the proposed scheme is O(mn) considering the size of the medical image is of m × n. More quantitative values are required to implement the algorithm for real-world applications. So, the actual CPU time of embedding and extraction algorithm are collected by implementing the algorithms using MATLAB and Python. The average embedding time of the proposed scheme is 3.05s and 2.98s and average extraction time is 2.65s and 2.54s when implemented using MATLAB and Python respectively (Table 9).
6 Conclusion with potential future works
Medical images or diagnostic information are transmitted from one place to another using a wired or wireless medium in the healthcare industry. Therefore, the transmission of such information requires more security. The proposed model ensures imperceptibility and robustness of medical images against attacks like salt and pepper noise, Gaussian noise, and jpeg compression. When SVM and double-layer security are used together, they strengthen the proposed model against several attacks on image processing. The watermark information is embedded in the NROI portion of the medical image. The NROI portion varies from image to image depending upon the type of the medical image. As the NROI section or the embedding positions are not predefined for every image, it is very difficult for an attacker to extract valuable patient information embedded in secret information.
The outcomes from this experiment prove the high imperceptibility and better robustness of the proposed steganographic scheme. Here, the average SSIM value is 0.9999, and the PSNR value is 67 dB (approx), which is more than the acceptable value. The results of the proposed embedding method ensure some potential applications of the proposed scheme in telemedicine. However, the proposed model has high initial computation complexity due to the SVM model building, which needs improvement.
In the present study, we have used MR images. In the future, we intend to study the proposed model in other modalities of biomedical imaging such as Ultra-Sound (US), Computed Tomography (CT), Positron Emission Tomography (PET), etc. Furthermore, we intend to use Deep Learning (DL) models in place of SVM to generate NROIs from medical images in the future.
Data Availability
Open Source
References
An FP, Je Liu (2021) Medical image segmentation algorithm based on multilayer boundary perception-self attention deep learning model. Multimedia Tools Appl 80(10):15017–15039
Brown SD, Tauler R, Walczak B (2020) Comprehensive chemometrics: chemical and biochemical data analysis. Elsevier
Cheng X, Kadry S, Meqdad MN, Crespo RG (2022) CNN supported framework for automatic extraction and evaluation of dermoscopy images. J Supercomput:1–18
Clark K, Vendt B, Smith K et al (2022) The Cancer Imaging Archive (TCIA): Maintaining and Operating a Public Information Repository. J Digit Imaging 26:1045–1057. https://doi.org/10.1007/s10278-013-9622-7
Daubechies I, Sweldens W (1998) Factoring wavelet transforms into lifting steps. J Fourier Anal Appl 4(3):247–269
Fan W, Chen J, Zhen J (2005) SPIHT algorithm based on fast lifting wavelet transform in image compression. In: International conference on computational and information science. Springer, pp 838–844
Gaffar A, Joshi AB, Singh S, Srivastava K (2022) A high capacity multi-image steganography technique based on golden ratio and non-subsampled contourlet transform. Multimedia Tools Appl:1–28
Ghosal SK, Mandal JK, Sarkar R (2018) High payload image steganography based on Laplacian of Gaussian (LoG) edge detector. Multimed Tools Appl 77(23):30403–30418
Haykin S (2001) Neural networks and learning machines. 3rd edn. PHI
Huang Y, Liu C, Zha XF, Li Y (2009) An enhanced feature extraction model using lifting-based wavelet packet transform scheme and sampling-importance-resampling analysis. Mechanic Syst Signal Process 23(8):2470–2487
Jeevitha S, Amutha Prabha N (2020) Effective payload and improved security using HMT Contourlet transform in medical image steganography. Health Technol 10(1):217–229
Ji X, Cheng X (2020) An adaptive multisensor image fusion method based on monogenic features. IEEE Sensors J 21(14):15598–15606
Kadhim IJ, Premaratne P, Vial PJ (2020) High capacity adaptive image steganography with cover region selection using dual-tree complex wavelet transform. Cogn Syst Res 60:20–32
Kathirvalavakumar T, Ponmalar E (2013) Self organizing map and wavelet based image compression. International Journal of Machine Learning and Cybernetics. 4(4):319–326
Kumar V, Kumar D (2018) A modified DWT-based image steganography technique. Multimed Tools Appl 77(11):13279–13308
Lei B, Soon Y, Zhou F, Li Z, Lei H (2012) A robust audio watermarking scheme based on lifting wavelet transform and singular value decomposition. Signal Process 92(9):1985–2001
Lingle W, Erickson BJ, Zuley ML, Jarosz R, Bonaccio E, Filippini J et al (2022) Radiology data from the cancer genome atlas breast invasive carcinoma collection [TCGA-BRCA] Lingle, W., Erickson, B., Zuley, M., Jarosz, R., Bonaccio, E., Filippini, J., and Gruszauskas, N., Radiology data from the cancer genome atlas breast invasive carcinoma [tcga-brca] collection, The Cancer Imaging Archive (2016)
Mehta R, Rajpal N, Vishwakarma VP (2017) A robust and efficient image watermarking scheme based on lagrangian SVR and lifting wavelet transform. Int J Mach Learn Cybern 8(2):379–395
Muhuri PK, Ashraf Z, Goel S (2020) A novel image steganographic method based on integer wavelet transformation and particle swarm optimization. Appl Soft Comput 92:106257
Parah SA, Ahad F, Sheikh JA, Bhat GM (2017) Hiding clinical information in medical images: a new high capacity and reversible data hiding technique. J Biomed Inf 66:214–230
Parah SA, Ahad F, Sheikh JA, Loan NA, Bhat GM (2017) A new reversible and high capacity data hiding technique for E-healthcare applications. Multimed Tools Appl 76(3):3943–3975
Patra DK, Si T, Mondal S, Mukherjee P, Breast DCE-MRI (2021) Segmentation for lesion detection by multi-level thresholding using student psychological based optimization. Biomed Signal Process Cont 69:102925
Ramly S, Aljunid SA, Shaker Hussain H (2011) SVM-SS watermarking model for medical images. In: International conference on digital enterprise and information systems. Springer, pp 372–386
Roy S, Howlader J, Sanyal G (2022) A novel approach of data hiding in video using region selection and PCA. Multimedia Tools Appl 81(10):14553–14571
Sabbane F, Tairi H (2019) Medical image watermarking technique based on polynomial decomposition. Multimed Tools Appl 78(23):34129–34155
Si T, Bagchi J, Miranda PBC (2022) Artificial neural network training using metaheuristics for medical data classification: an experimental study. Exp Syst Appl:193:116423. https://doi.org/10.1016/j.eswa.2021.116423
Si T, Miranda P, Galdino JV, Nascimento A (2021) Grammar-based automatic programming for medical data classification: an experimental study. Artif Intell Rev. https://doi.org/10.1007/s10462-020-09949-9
Si T, Patra DK, Mondal S, Mukherjee P (2022) Breast DCE-MRI segmentation for lesion detection using chimp optimization algorithm. Exp Syst Appl:117481. https://doi.org/10.1016/j.eswa.2022.117481
Singh AK, Dave M, Mohan A (2015) Robust and secure multiple watermarking in wavelet domain. J Med Imaging Health Inf 5(2):406–414
Singh P, Diwakar M, Cheng X, Shankar A (2021) A new wavelet-based multi-focus image fusion technique using method noise and anisotropic diffusion for real-time surveillance application. J Real-Time Image Process 18(4):1051–1068
Singh A, Dutta MK (2017) Imperceptible watermarking for security of fundus images in tele-ophthalmology applications and computer-aided diagnosis of retina diseases. Int J Med Inf 108:110–124
Sree Sharmila T (2014) Ramar K. Efficient analysis of hybrid directional lifting technique for satellite image denoising. Signal, Image Video Process 8 (7):1399–1404
Subhedar MS, Mankar VH (2019) Image steganography using contourlet transform and matrix decomposition techniques. Multimed Tools Appl 78 (15):22155–22181
Sweldens W (1996) The lifting scheme: a custom-design construction of biorthogonal wavelets. Applied and computational harmonic analysis. 3(2):186–200
Thanki R, Borra S, Dwivedi V, Borisagar K (2017) An efficient medical image watermarking scheme based on FDCut–DCT. Eng Sci Technol, Int J 20(4):1366–1379
The cancer imaging archive: TCGA-BRCA (2022) Accessed: 02-03-2019. https://wiki.cancerimagingarchive.net/display/Public/TCGA-BRCA
Verma VS, Kumar JR (2015) Improved watermarking technique based on significant difference of lifting wavelet coefficients. Signal, Image Video Process 9(6):1443–1450
Yen SH, Wang CJ, et al. (2006) SVM Based watermarking technique. Journal of Applied Science and Engineering. 9(2):141–150
Funding
The authors declare that no funds, grants, or other support were received during the preparation of this manuscript.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design, material preparation, data collection and analysis.
Corresponding author
Ethics declarations
Ethics approval
Allowed
Consent to participate
Allowed
Consent for Publication
Allowed
Conflict of Interests
We declare that we do not have any commercial or associative interest that represents a conflict of interest in connection with the work submitted.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Pal, P., Chowdhuri, P. & Si, T. A novel watermarking scheme for medical image using support vector machine and lifting wavelet transform. Multimed Tools Appl 82, 41187–41206 (2023). https://doi.org/10.1007/s11042-023-15144-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-15144-z