
Abstract
CT diagnosis has been widely used in clinic because of its special diagnostic value. The image resolution of CT imaging system is constrained by X-ray focus size, detector element spacing, reconstruction algorithm and other factors, which makes the generated CT image have some problems, such as low contrast, insufficient high-frequency information, poor perceptual quality and so on. To solve the above problems, a super-resolution reconstruction method of CT image based on multi-scale attention mechanism is proposed. First, use a 3 × 3 and a 1 × 1 convolution layer extracting shallow features. In order to better extract the high-frequency features of CT images and improve the image contrast, a multi-scale attention module is designed to adaptively detect the information of different scales, improve the expression ability of features, integrate the channel attention mechanism and spatial attention mechanism, and pay more attention to important information, retain more valuable information. Finally, sub-pixel convolution is used to improve the resolution of CT image and reconstruct high-resolution CT image. The experimental results show that this method can effectively improve the CT image contrast and suppress the noise. The peak signal-to-noise ratio and structural similarity of the reconstructed CT image are better than the comparison method, and has a good subjective visual effect.
Similar content being viewed by others


1 Introduction
X-ray computed tomography (CT) is one of the most popular medical imaging methods for screening, diagnosis and image-guided intervention. High resolution CT (HRCT) imaging can enhance the fidelity of radiological features. However, the image resolution of CT imaging system is limited by X-ray focus size, detector element spacing, reconstruction algorithm and other factors. It is difficult to obtain CT images with high resolution in clinical application, which makes it a great challenge to use CT images directly for accurate diagnosis. The super-resolution reconstruction algorithm can effectively improve the resolution of medical images and obtain high-resolution medical images with high contrast and rich detail information. Therefore, the super-resolution (SR) method in the field of CT has attracted extensive attention [37, 41].
Super resolution reconstruction has important application prospects in military, medicine, public security and so on. The existing image super-resolution reconstruction methods mainly include interpolation based methods [38], reconstruction based methods [2, 23, 39] and learning based methods [12, 27, 28]. Interpolation based methods mainly include bicubic interpolation, nearest neighbor interpolation and bilinear interpolation. This kind of method estimates unknown pixels with adjacent pixels, which is simple and fast. However, this kind of method simply calculates between pixels according to the pre-defined conversion function, does not consider the image degradation model, and reconstructs the image blur and distortion, It can’t be directly applied to CT image super-resolution reconstruction. The reconstruction methods include iterative back projection method, convex set projection method and maximum a posteriori probability estimation method. Starting from the degradation model of image, it is assumed that the high-resolution image is a low-resolution image after appropriate motion transformation, blur and noise. This method constrains the generation of super-resolution images by extracting the key information from low resolution images and combining the prior knowledge of unknown super-resolution images. Relying on limited prior knowledge leads to poor reconstruction effect. In recent years, learning based methods have gradually become a research hotspot. This kind of method uses a large number of training data to learn some corresponding relationship between low-resolution image and high-resolution image, and then predicts the high-resolution image corresponding to the low-resolution image according to the learned mapping relationship, so as to realize the super-resolution reconstruction process of the image. Common learning based methods include manifold learning, sparse coding and other shallow learning methods [4] and deep learning methods. Yang et al. Proposed sparse representation [4, 28], Timofte et al. Combined sparse dictionary with neighborhood embedding, and proposed fixed neighborhood regression method and anchored neighborhood regression method [35, 36]. The shallow learning method improves the computational efficiency, but because the learning ability of the shallow learning method to the feature parameters is limited, it can’t adaptively adjust the algorithm parameters, has poor flexibility, and the effect of image reconstruction is poor. Deep learning method can adaptively learn more expressive features from the training set, which has become a research hotspot. In 2014, Dong et al. [6] first proposed super-resolution reconstruction (SRCNN) method based on convolutional neural network, For an input low-resolution image, SRCNN first enlarges it to the target size using bicubic interpolation, then uses a three-layer convolution neural network to fit the nonlinear mapping between low-resolution image and high-resolution image, and finally takes the output result of the network as the reconstructed high-resolution image. Compared with the above traditional methods, good reconstruction results are obtained. However, due to only three-layer convolution, simple network structure and poor generalization ability, it is unable to fully extract the detailed features of CT images. In 2016, Kim et al. [13] proposed a 20 layer deep convolution neural network (VDSR). Through residual learning, the network training efficiency was improved and the reconstruction quality was greatly improved. However, with the deepening of the network, the problems of gradient explosion and network degradation became more and more obvious. In 2017, Ledig [15] et al. Proposed SRGAN and applied the generative adversarial network (GAN) to super-resolution reconstruction for the first time. The reconstructed image has good visual effect, but the network training is unstable. In 2018, Zhang [40] and others proposed the residual channel attention mechanism to pay more attention to useful information and improve network performance. The above super-resolution reconstruction method based on depth learning has achieved good reconstruction results, but because CT images are different from natural images, the super-resolution reconstruction method of natural images cannot be directly applied to the super-resolution reconstruction of CT images. This paper summarizes the shortcomings of existing CT image super-resolution reconstruction as follows: (1) CT image has low contrast and insufficient high-frequency details. The above methods can’t make full use of the global and local feature information of the image, resulting in the unclear detail texture of the reconstructed CT image [7, 11]. (2) Medical images are an important basis for doctors to screen and diagnose, and the existing super-resolution reconstruction methods may introduce unnecessary noise, which can’t ensure the pathological invariance of CT images, affecting doctors’ accurate diagnosis [30, 32, 33, 42]. In order to overcome the shortcomings of existing methods to reconstruct CT images, a super-resolution reconstruction method based on multi-scale feature fusion is proposed in this paper. The contributions of this paper are summarized as follows:
-
(1)
A super-resolution reconstruction method of CT image based on multi-scale attention mechanism is proposed, which can fully extract the useful information of CT image, improve the image contrast and reconstruct high-quality CT image without introducing noise.
-
(2)
Aiming at the problems of low contrast and insufficient high-frequency information of CT images, 1 × 1、3 × 3、5 × 5 three convolution kernels with different sizes can adaptively detect CT image features of different scales, which enhances the feature extraction ability of the network.
-
(3)
In order to make the network pay more attention to useful information, this paper combines spatial attention mechanism and channel attention mechanism to improve the sensitivity of the network to more important features in CT images, which can effectively improve the contrast of CT images and enhance detailed features.
2 Related work
2.1 Super-resolution reconstruction
Super resolution reconstruction (SR) refers to the reconstruction of a high-resolution image from one or more low-resolution images. The main task is to increase the high-frequency information of the image by reconstruction and restore the detail information lost in the process of converting low-resolution image into high-resolution image. In the task of super-resolution reconstruction, low resolution images are generally degraded by fuzzy processing and down sampling, and the reconstruction process is the inverse process of image degradation. The main difficulty is how to ensure that high-resolution images are generated without losing high-frequency information.
2.2 Multiscale feature fusion
Human vision processes image information from different scales. Therefore, in deep learning, many image processing algorithms adopt a method similar to human vision to extract and fuse features from different scales, so that the network can obtain receptive fields of different sizes, capture information at different scales, and effectively improve the network performance [1].
As an important part in the field of computer vision, super-resolution reconstruction also needs to extract image information of different scales as a priori knowledge to better learn the corresponding relationship between low-resolution image and high-resolution image, so as to reconstruct high-quality high-resolution image. In 2018, Li et al. applied multiscale to super-resolution reconstruction and proposed multi-scale residual network (MSRN) [16], which can adaptively extract features of different scales and obtain good reconstruction results.
2.3 Attention mechanism
When the computing power is limited, the attention mechanism in neural network allocates computing resources to more important tasks. In recent years, attention mechanism has been widely used in deep neural networks [10, 24, 25, 31, 34]. Hu et al. [9] proposed SENet to learn the correlation between channels, and achieved significant performance improvement in image classification. Zhang et al. [40] introduced the attention mechanism into the super-resolution reconstruction task. The overall process of channel attention mechanism is shown in Fig. 1.

Channel attention module structure
By modeling the interdependence between feature channels, the features of each channel are adaptively rescaled, so as to improve the expression ability of the network. Experiments show that the attention mechanism can make the network pay attention to more useful information and improve the ability of discrimination learning.
2.4 Video object segmentation
Video object segmentation can be defined as a binary labeling problem that separates the foreground object from the background region. Video object segmentation is generally the most significant and key object in the whole video sequence. Region similarity (IOU of segmentation results), contour accuracy and time-domain stability are used to evaluate the segmentation effect. From the degree of supervision, it is divided into three categories: unsupervised segmentation, semi supervised segmentation and supervised segmentation [3, 17,18,19,20,21,22]. At present, the combination of apparent information and motion information is the mainstream research direction of video object segmentation.
3 Proposed model
3.1 Network architecture
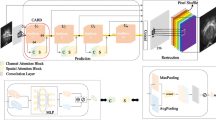
Because the existing super-resolution reconstruction methods can’t extract and reconstruct the features of CT images with low contrast and insufficient high-frequency information, and can’t fully extract the deep features of CT images, resulting in blurred details and unclear texture of the reconstructed CT images, so that doctors can not directly use the reconstructed CT images for screening and diagnosis. To solve the above problems, a CT image super-resolution reconstruction method combining attention mechanism and multi-scale feature fusion is proposed in this paper. Convolution kernels of different sizes are introduced to adaptively extract features of different scales, pay more attention to important information through spatial and channel attention mechanism, enhance the expression ability of features, and use sub-pixel convolution to improve the resolution and avoid the chessboard effect. The network structure of this paper is shown in Fig. 2.

The multi-scale feature fusion network structure diagram based on attention mechanism is divided into shallow feature extraction module, deep feature extraction module and feature reconstruction module
As shown in Fig. 2, the network takes the low resolution (LR) image as the input, and first passes through a 3 × 3 and 1 × 1 convolution to extract the shallow features of CT images. Then, the deep features are extracted through the multi-scale attention module, and three different scale convolution kernels are introduced to fully extract the deep features of CT images. Finally, the sub-pixel convolution is used to improve the resolution of CT images and obtain high-resolution CT images.
3.2 Feature extraction module
Firstly, the high-resolution (LR) CT image is sampled by bicubic interpolation to obtain the input low-resolution CT image as the input of the network. Then, the shallow features of CT image are extracted through a 3 × 3 convolution layer and a 1 × 1 convolution layer, and then extracts the deep detail features of CT through multiple multi-scale attention modules (MSAB). In the real scene, the image structure and context information are contained in the features of different scales, so that the detailed features of the image can’t be fully extracted by using a single scale, while the high-frequency details hidden in the images of different scales can be fully mined by using multi-scale feature fusion network, so as to obtain good reconstruction results. The MSAB module is shown in Fig. 3.

MSAB module architecture
The structure of the nth MSAB module is shown in Fig. 3. Including conv 5 × 5,Conv 3 × 3,Conv 1 × 1 represents three convolution kernels of different sizes. Concat represents channel fusion of the features extracted by three convolution kernels of different sizes. Channel Attention represents channel attention mechanism, get a channel descriptor of c × 1 × 1. Spatial Attention represents spatial attention mechanism, get an 1 × H × W size characteristic graph.
MSAB is mainly composed of multi-scale feature fusion part, spatial attention unit and channel attention unit. The output of the n-1th MSAB module is the input of the n th MSAB. Firstly, the features of different scales are extracted in parallel through convolution of three different scales, of which the 1 × 1 convolution layer can retain the features of the previous layer, and the deepest features still retain the details extracted from the shallow layer during fusion. Then enter the channel attention (CA) unit and spatial attention mechanism (SA) unit in parallel. Finally, the two parts of features are fused through Concat operation, use 1 × 1 convolution layer to adjust the number of channels. Finally, the nth MSAB output is obtained by adding the jump structure to the input of MSAB.
Through the attention mechanism, we can pay more attention to important information, so as to fully extract useful information and reconstruct high-quality CT images. Because channel attention mechanism and spatial attention mechanism have different effects on recovering high-frequency information, this paper combines channel attention mechanism and spatial attention mechanism to adaptively adjust the network, make the network pay more attention to important information and extract more valuable features. The structure of CA unit and SA unit is shown in Fig. 4 (a) and (b).

(a) channel attention mechanism, (b) spatial attention mechanism
3.2.1 Multiscale feature fusion module
Deep network can greatly improve the quality of image reconstruction, but with the deepening of the network, more training skills will be introduced and more computing resources will be used. In order to avoid using deeper networks and ensure the full extraction of detailed features of CT images, we use convolution kernels of different scales, so that different channels can share information and detect features of different scales.
Firstly, three convolutions with different scales are used to extract detailed features in parallel, and then the features extracted with different convolution cores are superimposed through concat operation. At this time, the number of channels is increased by 3 times, and finally through 1 × 1. Reduce the dimension by convolution, keep the number of channels consistent with the input, and complete multi-scale feature fusion.
3.2.2 CA unit
The channel attention mechanism is originally used to solve the task of image classification. If it is directly applied to the low-level visual task of image super-resolution reconstruction, the effect is poor. Therefore, the channel attention mechanism of sensing image contrast is adopted in this paper.
As shown in Fig. 4 (a), after multi-scale feature fusion, the weight of each channel is readjusted through CA unit to give higher weight to important information and suppress redundant information. [40] The input of CA module is represented by O = [o1, o2, ⋯, oc], represents c characteristic graphs with size H × W. Firstly, the standard deviation and mean value of the feature map are calculated through the Contract operation, and the method of perceived image contrast is used to represent the global information of each layer of the feature map. The process is shown as follows:
Where zc represents the c-th element of the output, HGC(⋅) represents the Contrast function, H and W respectively represent the height and width of the characteristic graph, and oc(i, j) represents the value of the c-th characteristic graph at position (i, j). Then through two 1 × 1 convolution, relu activation function and sigmoid function that gating mechanism, reduces and increases the dimension, and adjusts the weight of each channel. The process is shown as follows:
Where SCA represents the final weight of each channel, f(⋅) represents sigmoid operation, δ(⋅) represents Relu function, WU and WD represent the weights of the two 1 × 1 convolutions respectively, and finally multiply the weight SCA corresponding to the original feature for scaling input. The process is shown as follows:
Through CA unit, the network can adaptively adjust the weight of each channel and give more weight to important information, so as to retain more important information.
3.2.3 SA unit
Through the CA mechanism, the global information is compressed into each channel through GCP, the spatial information of each feature map is removed, and the spatial position of the information distribution of the input image and the information distribution of the feature map has changed. Therefore, the spatial attention (SA) unit is introduced as complementary in this paper, so as to pay more attention to the information that is difficult to reconstruct. So as to reconstruct high-quality CT images.
The specific refinement of SA unit is shown in Fig. 4 (b). The specific operations of SA are shown as follows:
Where f(⋅) represents sigmoid operation, δ(⋅) represents Relu function, and W1, W2 represent the weights of the two 1 × 1 convolutions respectively. Finally, the obtained weight SSA is multiplied by the original feature O, and the weight is redistributed to obtain a new feature map OSA. The process is represented as follows:
3.3 Loss function
Pixel level loss is used to measure the similarity between SR image and original HR image, which can ensure that the generated SR image is closer to HR image in pixel value. We use L1 loss function as the loss function in this paper. The loss function is defined as follows:
The error of the value of the corresponding pixel position of the generated between HR image and real HR.
3.4 Reconstruction module
The common up sampling methods mainly include bicubic interpolation, deconvolution and sub-pixel convolution [26]. The bicubic interpolation method has small amount of sampling calculation and simple algorithm, so the operation speed is fast. However, it only uses the gray value of the pixel closest to the sampling point to be measured as the gray value of the sampling point without considering the influence of other adjacent pixels. Therefore, after resampling, the gray value has obvious discontinuity, the loss of image quality is large, and obvious mosaic and saw tooth phenomena will occur. Using deconvolution, a large number of zeros will be added in the up sampling process, resulting in the chessboard effect of the reconstructed CT image. Therefore, sub-pixel convolution is used for up sampling in this paper.
Subpixel convolution includes two processes: convolution and rearrangement. If n times up sampling is carried out, the number of convolution cores of subpixel convolution is r2 (r = n). The feature map corresponds to r2 channels, and they are rearranged into a r × r region, corresponding to a r × r sub block in the high-resolution image. In the process of amplification, the interpolation function is hidden in the previous convolution layer and can be learned automatically, only changing the image size in the last layer helps to reduce the amount of parameters and time complexity.
4 Experiment
The experimental environment is windows 10 operating system, using pytorch deep learning framework. The hardware configuration is CPU inter (R) core (TM) i7-6500u @ 2.50ghz, 8 g memory, GPU is NVIDIA geforce GTX 1060, and CUDA 10.0 + cudnn 7.1 is used for GPU acceleration. Using the Adam [14] optimization algorithm, set it to 0.9, set it to 0.999, set the momentum parameter to 0.9, the batch size to 16, iterate 1000 epochs, initialize the learning rate of all layers to 1e-4, and reduce it twice every 100 cycles.
4.1 Datasets
This paper uses the 3Dircadb data set, which contains the CT volume of venous phase of 20 patients. By slicing the CT volume, the image is transformed into png format. In order to make full use of the data, we enhance the data by randomly flipping, rotating and adding gaussian noise. 4000 of them are selected as our data set, recorded as C1, 3600 are randomly selected as the training set CC and 400 as the test set CT1. The novel coronavirus pneumonia image recognition dataset CTCOVID released by MathorCup competition is published in this paper. 100 samples were randomly selected as test set CT2. The original CT image is sampled 2, 3 and 4 times by bicubic interpolation to obtain the corresponding low resolution CT image. Some data sets are shown in Fig. 5.

Partial dataset samples
4.2 Evaluation indexes
This paper uses the two most common image quality evaluation indexes peak signal-to-noise ratio (PSNR) [8] and structural similarity (SSIM) [29] to evaluate the model. PSNR is calculated based on the error between corresponding pixels. The larger the value, the smaller the image distortion and the higher the image quality, in dB. The PSNR expression is as follows:
Where, n represents the number of bits per pixel, MSE represents mean square error, and the MSE expression is as follows:
Where X(i, j) and Y(i, j) respectively represent the pixel value where the pixel coordinates in HR image and SR image are (i, j), and H and W respectively represent the height and width of the image.
SSIM measures image quality from three aspects: brightness, contrast and structure. The higher the value, the higher the image similarity. SSIM expression is as follows:
Where, the representative HR image represents the reconstructed SR image, μX and μY represent the average value of and, σX and σY represent the standard deviation of and, σXY represents the covariance of and, C1 and C2 represent constants.
4.3 Experimental results and analysis
In order to verify the effectiveness of the proposed method, this paper tests on the test set CT1. In order to further verify the generalization of the proposed network, we add the CT2 test set for further testing. It is mainly compared with bicubic, srcnn, srgan and San [5] methods to qualitatively evaluate the reconstruction effect from two aspects of PSNR and SSIM. All experiments were conducted in the same environment, and the source code published by the author was used for retraining and testing. The obtained PSNR and SSIM values are shown in Table 1.
Table 1 shows the average values of PSNR and SSIM obtained by experiments on CT1 and CT2 using different super-resolution reconstruction algorithms. The best results are displayed in bold. It can be seen from the data in Table 1 that the method in this paper can obtain good reconstruction results under different reconstruction ratios, and both PSNR and sism achieve good results. The test results of CT1 show that when the reconstruction ratio is 4, the PSNR of this method is about 4.15db higher than bicubic, and the SSIM is about 0.097 higher. The reconstruction results are further improved by using the deep learning method. Among them, srcnn method can not fully extract the deep features of CT images due to its shallow network and small amount of calculation, resulting in poor test results. Srgan method uses the generation of countermeasure network to reconstruct CT images, which may introduce unnecessary noise and affect the reconstruction quality. The second-order attention mechanism is used in San, which greatly improves the reconstruction effect compared with other methods. However, because San only uses a single-scale convolution kernel, it can not fully extract the features of different scales, resulting in the lack of high-frequency information of the reconstructed CT image. In order to further verify the universality of this method, relevant experiments are carried out on CT2. From the CT2 test results, it can be seen that this method also reaches the optimal, which further proves the generalization of this method. By evaluating the model size and test time, it can be seen that the amount of parameters in this paper is much smaller than SRGAN and SAN. Although SRCNN has small amount of parameters and fast test time, the reconstruction effect is poor.
In order to further prove the effectiveness of this method from a subjective point of view, this paper randomly selects two CT images from test set CT1 and test set CT2 for triple and quadruple reconstruction. For more intuitive comparison, this paper selects the location of possible lesions for labeling and amplification. The reconstruction results are shown in Figs. 6 and 7.

Comparison of the reconstruction effects of different algorithms with reconstruction scale factor of 3 on test set CT1

Comparison of the reconstruction effects of different algorithms with reconstruction scale factor of 4 on test set CT2
Figure 6 shows the effect of three times magnification using different super-resolution reconstruction methods on test set CT1, and Fig. 7 shows the effect of four times magnification using different super-resolution reconstruction methods on test set CT2. Taking Fig. 6 as an example, the CT image reconstructed by bicubic method is fuzzy as a whole, and the reconstructed image effect is poor. The effect of CT image reconstruction by deep learning method has been significantly improved. Compared with bicubic and SRCNN, the reconstruction quality of CT image reconstructed by SRGAN has been further improved, and the texture is clearer. However, additional noise is introduced, which can’t ensure the pathological invariance of CT image, which will affect the diagnosis of doctors in serious cases. The high-frequency information of CT images reconstructed by San method is insufficient, and doctors can’t make accurate diagnosis directly through the images reconstructed by this method. Compared with other methods, this method can not only ensure the pathological invariance of CT images, but also obtain more valuable information and good reconstruction effect.
CT image super-resolution is a very professional field. It is not convincing to evaluate it only through PSNR and SSIM. Therefore, we invited two doctors to conduct subjective visual evaluation on the reconstructed CT image. Both doctors believe that the CT image reconstructed by this method has the best light transmittance, and there are obvious differences between normal tissue and lesion location, It can better reflect the density value of the diseased part. Comprehensive comparison shows that the visual effect of this reconstruction method is better than other methods.
5 Ablation study
5.1 Model depth analysis
Network depth is an important factor affecting the reconstruction effect. The deeper the network, the more texture features are extracted, so as to obtain better reconstruction effect. However, with the deepening of the network, the difficulty of model training also increases, and the gradient may disappear in serious cases. In order to obtain the optimal performance, this paper analyzes the model depth. We trained models with different depths (d = 2, 3, 4, 5, 6, 7, 8 and 9). Table 2 shows the relationship between the number of MSAB used and PSNR and reconstruction speed, in which the magnification is 3.
It can be seen from the data in Table 2 that the performance of the deep network is better than that of the shallow network, but it will increase the time cost. When using 8 MSAB modules, the network shows the best performance, but there is little difference from the PSNR when using 4 MSAB modules, but the time consumption increases greatly. Moreover, when using 4 MSAB modules, the PSNR has tended to be stable, with a difference of 0.05db and a time difference of 4.2 s compared with the PSNR when using 8 MSAB modules, If you continue to increase MSAB, will get a small performance improvement, but it will greatly increase the computing cost. In order to balance the two factors of performance and speed, this paper finally selects four MSAB modules.
5.2 Multiscale attention module
In order to further verify the role of channel attention mechanism and spatial attention mechanism in this paper, this paper removes SA module, CA module, SA and CA module respectively on the network subject, and compares the CA and SA modules in this paper with the attention mechanism in Bam recently proposed. The results are shown in Table 3, where the magnification is 2.
It can be seen from the data in Table 3 that the simultaneous use of channel spatial attention mechanism can effectively improve the reconstruction effect and obtain better performance. CA module and SA module play different roles. The combination of the two makes the effect the best. CA module redistributes weights to each channel, which can effectively retain useful information and suppress redundant information. However, the global spatial information is compressed into each channel, ignoring the spatial information in the feature map. Different spatial locations represent different information. By adding SA module, we can pay more attention to the information that is difficult to reconstruct. Compared with the recently proposed attention mechanism in BAM [25], this paper also has some advantages. The reason is that the attention mechanism used in this paper is mainly to solve the low-level visual task of super-resolution reconstruction, which can better solve the problems of low contrast and poor perceptual quality of CT images. Therefore, this paper combines the channel spatial attention mechanism to obtain better performance.
It can be seen from Fig. 8 that the details of the network without attention mechanism are blurred, and some artifact information appears, which cannot ensure the pathological invariance of CT images. Using CA module and SA module alone improves the quality of CT image to a certain extent, but the restored details are not ideal. Due to the superior performance of BAM, it also improves the reconstruction quality of CT image, and the attention mechanism we designed is aimed at CT image, so we obtain the best visual effect.

Comparison of reconstruction effects using different attention mechanisms
6 Conclusion
Aiming at the shortcomings of CT image super-resolution reconstruction methods, this paper proposes a multi-scale attention mechanism super-resolution reconstruction method, which uses convolution kernels of different sizes to extract the features of CT images, can extract the features of different scales, obtain richer texture information, and improve the expression ability of features. By combining the channel spatial attention mechanism, Pay more attention to important information, suppress noise, and ensure the case invariance of CT images while retaining more valuable information. Compared with other advanced super-resolution reconstruction algorithms, the experimental results show that this method has achieved good results in objective indicators and subjective visual effects. Finally, the network depth and attention mechanism are discussed to optimize the effect of this method. Due to the limited information provided by a single image, the effect of reconstructed CT image is limited. Therefore, in the future, we can try multi frame image super-resolution reconstruction method to reconstruct high-quality CT image, which provides a favorable premise for doctors to make accurate diagnosis.
References
Anwar S, Khan S, Barnes N (2020) A deep journey into super-resolution: a survey. ACM Comput Surv 53(3):1–34
Baker S, Kanade T (2002) Limits on super-resolution and how to break them. IEEE Trans Pattern Anal Mach Intell 24(9):1167–1183
Cai W, Zhai B, Liu Y, Liu R, Ning X (2021) Quadratic polynomial guided fuzzy C-means and dual attention mechanism for medical image segmentation. Displays 70:102106. https://doi.org/10.1016/j.displa.2021.102106
Chang H, Yeung DY, Xiong Y (2004) Super-resolution through neighbor embedding//Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition,. CVPR
Dai T, Cai J, Zhang Y, Xia S, Zhang L (2019) Second-order attention network for single image super-resolution, 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 11057–11066. https://doi.org/10.1109/CVPR.2019.01132
Dong C., Loy C., He K., Tang X., (2014) Learning a deep convolutional network for image super-resolution, In: European Conference on Computer Vision (ECCV), 8692, 184–199. https://doi.org/10.1007/978-3-319-10593-2_13
Feng C, Fu H, Yuan S (2021) Multi-Contrast MRI Super-Resolution via a Multi-Stage Integration Network. arXiv:2105.08949
Horé A, Ziou D (2010) Image quality metrics: PSNR vs. SSIM// 20th International Conference on Pattern Recognition, ICPR 2010, Istanbul, Turkey, 23–26.
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. Proceedings of the IEEE conference on computer vision and pattern recognition, 7132-7141
Hu X, Ren W, LaMaster J et al (2020) Face super-resolution guided by 3d facial priors, European Conference on Computer Vision. Springer, Cham, 763–780. https://doi.org/10.1007/978-3-030-58548-8_44
Kang E, Chang W, Yoo J (2018) Deep convolutional Framelet Denosing for low-dose CT via wavelet residual network. IEEE Trans Med Imaging 37(6):1358–1369. https://doi.org/10.1109/TMI.2018.2823756
Kim K, Kwon Y (2010) Single-image super-resolution using sparse regression and natural image prior. IEEE Trans Pattern Anal Mach Intell 32(6):1127–1133
Kim J, Lee JK, Lee KM (2016) Deeply-recursive convolutional network for image super-resolution, in proc. IEEE Conf Comput Vis Pattern Recognit:1637–1645
Kingma D, Ba J (2014) Adam: a method for stochastic optimization, computer science. arXiv preprint arXiv:1412.6980
Ledig C, Theis L, Huszar F, Caballero J (2017) Photo-realistic single image super-resolution using a generative adversarial network. IEEE Conf Comput Vis Pattern Recognit (CVPR):105–114. https://doi.org/10.1109/cvpr.2017.19
Li J., Fang F., Mei K., Zhang G, (2018) Multi-scale Residual Network for Image Super-Resolution, European Conference on Computer Vision(ECCV), 11212, 527–542
Liao X, Li K, Zhu X, Liu KJR (2020) Robust detection of image operator chain with two-stream convolutional neural network. IEEE J Sel Top Signal Process 14(5):955–968. https://doi.org/10.1109/JSTSP.2020.3002391
Liao X, Yin J, Chen M, Qin Z (2020) Adaptive payload distribution in multiple images steganography based on image texture features. IEEE Trans Dependable Secure Comput 19:897–911. https://doi.org/10.1109/TDSC.2020.3004708
Liao X, Yu Y, Li B, Li Z, Qin Z (2020) A new payload partition strategy in color image steganography. IEEE Trans Circuits Syst Video Technol 30(3):685–696. https://doi.org/10.1109/TCSVT.2019.2896270
Lu X, Wang W, Ma C et al (2019) See more, know more: unsupervised video object segmentation with co-attention siamese networks, proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3623-3632
Lu X, Wang W, Shen J, Crandall D, Luo J (2020) Zero-shot video object segmentation with co-attention Siamese networks. IEEE Trans Pattern Anal Mach Intell 44:2228–2242. https://doi.org/10.1109/TPAMI.2020.3040258
Lu X, Wang W, Shen J, Crandall DJ, van Gool L (2021) Segmenting objects from relational visual data. IEEE Trans Pattern Anal Mach Intell 44:7885–7897. https://doi.org/10.1109/TPAMI.2021.3115815
Michal I (1991) Improving resolution by image registration. CVGIP: Graph Models Image Process 53(3):231–239
Niu B, Wen W, Ren W et al (2020) Single image super-resolution via a holistic attention network, European conference on computer vision. Springer, Cham, 191–207. https://doi.org/10.1007/978-3-030-58610-2_12
Park J et al (2018) Bam: Bottleneck attention module. arXiv preprint arXiv:1807.06514
Shi W, Caballero J, Huszár F (2016) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE Computer Society, 1874-1883
Stark H, Oskoui P (1989) High-resolution image recovery from image-plane arrays, using convex projections. J Opt Soc Am A 6(11):1715–1726
Timofte R, De S, Van G, (2015) A+: adjusted anchored neighborhood regression for fast super-resolution, Asian conference on computer vision, 111-126. https://doi.org/10.1007/978-3-319-16817-3_8
Wang Z, Bovik AC, Sheikh HR et al (2004) Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans Image Process 13(4) (SSIM):600–612
Wang Y, Rahman SS, Arns CH (2018) Super resolution reconstruction of μ -CT image of rock sample using neighbour embedding algorithm. Phys A Stat Mech Appl 493:177–188
Wei X, Yu L, Tian S, Feng P, Ning X (2021) Underwater target detection with an attention mechanism and improved scale. Multimed Tools Appl 80:33747–33761. https://doi.org/10.1007/s11042-021-11230-2
Xu L, Zeng X, Huang Z, Li W (2020) Low-dose chest X-ray image super-resolution using generative adversarialnets with spectral normalization. Biomed Signal Process Control 55:101600
Yan Z, Li J, Lu Y (2015) Super resolution in CT. Int J Imaging Syst Technol 25(1):92–101
Yan Y, Ren W, Hu X, Li K, Shen H, Cao X (2021) SRGAT: single image super-resolution with graph attention network, in. IEEE Trans Image Process 30:4905–4918. https://doi.org/10.1109/TIP.2021.3077135
Yang J, Wright J, Huang T S, (2008) Image super-resolution as sparse representation of raw image patches// 2008 IEEE computer society conference on computer vision and pattern recognition (CVPR 2008), 24–26 June 2008, Anchorage, Alaska, USA.
Yang J, Wright J, Huang T, Ma Y (2010) Image super-resolution via sparse representation. IEEE Trans Image Process 19(11):2861–2873
You C, Li G, Yi Z (2020) CT super-resolution GAN constrained by the identical, residual, and cycle learning ensemble (GAN-CIRCLE). IEEE Trans Med Imaging 39(1):188–203
Zhang L, Wu X (2006) An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans Image Process 15(8):2226–2238
Zhang K, Gao X, Tao D (2012) Single image super-resolution with non-local means and steering kernel regression. IEEE Trans Image Process 21(11):4544–4556
Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y (2018) Image super-resolution using very deep Residual Channel attention networks. In: Ferrari V, Hebert M, Sminchisescu C, Weiss Y (eds) Computer vision – ECCV 2018. Lecture notes in computer science, pp 294–310. https://doi.org/10.1007/978-3-030-01234-2_18
Zhao C, Shao M, Carass A (2019) Applications of a deep learning method for anti-aliasing and super-resolution in MRI. Magn Reson Imaging 64:132–141
Zhao T, Hu L, Zhang Y, Fang J (2021) Super-resolution network with information distillation and multi-scale attention for medical CT image. Sensors 21(20):6870. https://doi.org/10.3390/s21206870
Funding
The authors are grateful for collaborative funding support from the State Key Research & Development Program of China (2018YFC1406203).
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Yin, J., Xu, SH., Du, YB. et al. Super resolution reconstruction of CT images based on multi-scale attention mechanism. Multimed Tools Appl 82, 22651–22667 (2023). https://doi.org/10.1007/s11042-023-14436-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-14436-8