
Abstract
Unsupervised sentence embedding learning is a fundamental task in natural language processing. Recently, unsupervised contrastive learning based on pre-trained language models has shown impressive performance in sentence embedding learning. This method aims to align positive sentence pairs while pushing apart negative sentence pairs to achieve semantic uniformity in the representation space. However, most previous literature leverages a random strategy to sample negative pairs, which suffers from the risk of selecting uninformative negative examples (e.g., easily distinguishable examples, anisotropic representations), thus greatly affecting the quality of learned representations. To address this issue, we propose nmCSE, a negative mining contrastive learning method for sentence embedding. Specifically, we introduce distance moderation and spatial uniformity as two properties of informative negative examples, and devise distance-based weighting and grid sampling as two strategies to preserve these properties, respectively. Our proposal outperforms the random strategy across seven semantic textual similarity datasets. Furthermore, our method can easily be adapted to other contrastive learning scenarios (e.g., vision), and does not introduce significant computational overhead.










Similar content being viewed by others


Data availibility
The datasets used in this paper are public. We have provided the corresponding reference of each dataset.
Code availability
The code can be obtained by contacting the corresponding author.
Notes
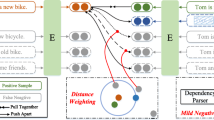
Distance moderation is an explicit property thus we don’t have to verify it.
References
Agirre, E., Banea, C., Cardie, C., Cer, D., Diab, M., Gonzalez-Agirre, A., Guo, W., Lopez-Gazpio, I., Maritxalar, M., Mihalcea, R., et al. (2015). Semeval-2015 task 2: Semantic textual similarity, english, spanish and pilot on interpretability. In Proceedings of the 9th international workshop on semantic evaluation (SemEval 2015) (pp. 252–263).
Agirre, E., Banea, C., Cardie, C., Cer, D.M., Diab, M.T., Gonzalez-Agirre, A., Guo, W., Mihalcea, R., Rigau, G., & Wiebe, J. (2014). Semeval-2014 task 10: Multilingual semantic textual similarity. In SemEval@ COLING (pp. 81–91).
Agirre, E., Banea, C., Cer, D., Diab, M., Gonzalez Agirre, A., Mihalcea, R., Rigau Claramunt, G., & Wiebe, J. (2016). Semeval-2016 task 1: Semantic textual similarity, monolingual and cross-lingual evaluation. In SemEval-2016. 10th international workshop on semantic evaluation; 2016 Jun 16–17 (pp. 497–511). Association for Computational Linguistics.
Agirre, E., Cer, D., Diab, M., & Gonzalez-Agirre, A. (2012). Semeval-2012 task 6: A pilot on semantic textual similarity. In * SEM 2012: The first joint conference on lexical and computational semantics—Volume 1: Proceedings of the main conference and the shared task, and volume 2: Proceedings of the sixth international workshop on semantic evaluation (SemEval 2012) (pp. 385–393).
Agirre, E., Cer, D., Diab, M., Gonzalez-Agirre, A., & Guo, W. (2013). * SEM 2013 shared task: Semantic textual similarity. In Second joint conference on lexical and computational semantics (* SEM), volume 1: Proceedings of the main conference and the shared task: Semantic textual similarity (pp. 32–43).
Cer, D., Diab, M., Agirre, E., Lopez-Gazpio, I., & Specia, L. (2017). Semeval-2017 task 1: Semantic textual similarity multilingual and cross-lingual focused evaluation. In The 11th international workshop on semantic evaluation (SemEval-2017) (pp. 1–14).
Chopra, S., Hadsell, R., LeCun, Y. (2005). Learning a similarity metric discriminatively, with application to face verification. In: 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 1, pp. 539–546. IEEE
Chuang, Y.-S., Dangovski, R., Luo, H., Zhang, Y., Chang, S., Soljačić, M., Li, S.-W., Yih, W.-t., Kim, Y., & Glass, J. (2022). DiffCSE: Difference-based contrastive learning for sentence embeddings. arXiv preprint arXiv:2204.10298
Chuang, C.-Y., Robinson, J., Lin, Y.-C., Torralba, A., & Jegelka, S. (2020). Debiased contrastive learning. Advances in Neural Information Processing Systems, 33, 8765–8775.
Conneau, A., & Kiela, D. (2018). Senteval: An evaluation toolkit for universal sentence representations. In Proceedings of the eleventh international conference on language resources and evaluation (LREC 2018).
Cui, Y., Zhou, F., Lin, Y., & Belongie, S. (2016). Fine-grained categorization and dataset bootstrapping using deep metric learning with humans in the loop. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1153–1162).
Daniel (2022). How to plot \(N\) points on the surface of a \(D\)-dimensional sphere roughly equidistant apart? Mathematics Stack Exchange. https://math.stackexchange.com/q/4403884 (version: 2022-03-15).
Ethayarajh, K. (2019). How contextual are contextualized word representations? Comparing the geometry of BERT, ELMO, and GPT-2 embeddings. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) (pp. 55–65).
Fang, H., Wang, S., Zhou, M., Ding, J., & Xie, P. (2020). Cert: Contrastive self-supervised learning for language understanding. arXiv preprint arXiv:2005.12766
Gao, T., Yao, X., Chen, D. (2021). SimCSE: Simple contrastive learning of sentence embeddings. In Empirical methods in natural language processing (EMNLP).
Giorgi, J. M., Nitski, O., Wang, B., & Bader, G. D. (2021). Declutr: Deep contrastive learning for unsupervised textual representations. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing, ACL/IJCNLP (pp. 879–895).
Hadsell, R., Chopra, S., & LeCun, Y. (2006). Dimensionality reduction by learning an invariant mapping. In 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR 2006), 17–22 June 2006, New York, NY, USA (pp. 1735–1742).
Harwood, B., Kumar, B. G. V., Carneiro, G., Reid, I., & Drummond, T. (2017). Smart mining for deep metric learning. In Proceedings of the IEEE international conference on computer vision (pp. 2821–2829).
Henaff, O. (2020). Data-efficient image recognition with contrastive predictive coding. In International conference on machine learning (pp. 4182–4192). PMLR.
Karpukhin, V., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., & Yih, W.-T. (2020). Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) (pp. 6769–6781).
Kenton, J. D. M.-W. C., & Toutanova, L. K. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of NAACL-HLT (pp. 4171–4186).
Leonardelli, E., Uma, A., Abercrombie, G., Almanea, D., Basile, V., Fornaciari, T., Plank, B., Rieser, V., & Poesio, M. (2023). SemEval-2023 task 11: Learning with disagreements (LeWiDi). arXiv preprint arXiv:2304.14803
Li, B., Zhou, H., He, J., Wang, M., Yang, Y., & Li, L. (2020). On the sentence embeddings from pre-trained language models. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) (pp. 9119–9130).
Lin, T.-Y., Goyal, P., Girshick, R., He, K., & Dollár, P. (2017). Focal loss for dense object detection. In Proceedings of the IEEE international conference on computer vision (pp. 2980–2988).
Liu, F., Jiao, Y., Massiah, J., Yilmaz, E., & Havrylov, S. (2022). Trans-encoder: Unsupervised sentence-pair modelling through self- and mutual-distillations. In The tenth international conference on learning representations, ICLR 2022, virtual event, April 25–29, 2022.
Logeswaran, L., & Lee, H. (2018). An efficient framework for learning sentence representations. In International conference on learning representations.
Marelli, M., Menini, S., Baroni, M., Bentivogli, L., Bernardi, R., & Zamparelli, R. (2014). A sick cure for the evaluation of compositional distributional semantic models. In Proceedings of the ninth international conference on language resources and evaluation (LREC’14) (pp. 216–223).
Meng, Y., Xiong, C., Bajaj, P., Bennett, P., Han, J., Song, X., et al. (2021). COCO-LM: Correcting and contrasting text sequences for language model pretraining. Advances in Neural Information Processing Systems, 34, 23102–23114.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781
Oh Song, H., Xiang, Y., Jegelka, S., & Savarese, S. (2016). Deep metric learning via lifted structured feature embedding. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4004–4012).
Oord, A. V. D., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748
Paun, S., Artstein, R., & Poesio, M. (2022). Statistical methods for annotation analysis. Springer.
Peters, M. E., Neumann, M., Iyyer, M., Gardner, M., Clark, C., Lee, K., & Zettlemoyer, L. (2018). Deep contextualized word representations. In Proceedings of NAACL-HLT (pp. 2227–2237).
Real, L., Rodrigues, A., Vieira e Silva, A., Albiero, B., Thalenberg, B., Guide, B., Silva, C., de Oliveira Lima, G., Câmara, I. C., Stanojević, M., et al. (2018). SICK-BR: A Portuguese corpus for inference. In Proceedings of the Computational processing of the Portuguese language: 13th international conference, PROPOR 2018, Canela, Brazil, September 24–26, 2018 (Vol. 13, pp. 303–312). Springer.
Reimers, N., & Gurevych, I. (2019). Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) (pp. 3982–3992).
Robinson, J., Chuang, C.-Y., Sra, S., & Jegelka, S. (2021). Contrastive learning with hard negative samples. In International conference on learning representations (ICLR).
Schroff, F., Kalenichenko, D., & Philbin, J. (2015) Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 815–823).
Su, J., Cao, J., Liu, W., & Ou, Y. (2021). Whitening sentence representations for better semantics and faster retrieval.
Tian, Y., Krishnan, D., & Isola, P. (2020). Contrastive multiview coding. In European conference on computer vision (pp. 776–794). Springer
Tsai, Y.-H. H., Li, T., Ma, M. Q., Zhao, H., Zhang, K., Morency, L.-P., & Salakhutdinov, R. (2021). Conditional contrastive learning with kernel. In International conference on learning representations.
van den Oord, A., Li, Y., & Vinyals, O. (2018). Representation learning with contrastive predictive coding.
Van der Maaten, L., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(11).
Wang, T., & Isola, P. (2020). Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International conference on machine learning (pp. 9929–9939). PMLR.
Wang, B., Kuo, C.-C. J., Li, H. (2022). Just rank: Rethinking evaluation with word and sentence similarities. arXiv preprint arXiv:2203.02679
Wang, B., & Kuo, C.-C.J. (2020). SBERT-WK: A sentence embedding method by dissecting BERT-based word models. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 2146–2157.
Wijnholds, G., & Moortgat, M. (2021). SICK-NL: A dataset for Dutch natural language inference. In Proceedings of the 16th conference of the European chapter of the association for computational linguistics: Main volume (pp. 1474–1479).
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al. (2020). Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 conference on empirical methods in natural language processing: System demonstrations (pp. 38–45).
Wu, C.-Y., Manmatha, R., Smola, A. J., & Krahenbuhl, P. (2018). Sampling matters in deep embedding learning. In Proceedings of the IEEE international conference on computer vision (pp. 2840–2848).
Wu, Q., Tao, C., Shen, T., Xu, C., Geng, X., & Jiang, D. (2022). PCL: Peer-contrastive learning with diverse augmentations for unsupervised sentence embeddings. CoRR arXiv:2201.12093
Yan, Y., Li, R., Wang, S., Zhang, F., Wu, W., & Xu, W. (2021). Consert: A contrastive framework for self-supervised sentence representation transfer. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) (pp. 5065–5075).
Yan, Y., Li, R., Wang, S., Zhang, F., Wu, W., & Xu, W. (2021). ConSERT: A contrastive framework for self-supervised sentence representation transfer. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing, ACL/IJCNLP 2021 (pp. 5065–5075).
Yanaka, H., & Mineshima, K. (2022). Compositional evaluation on Japanese textual entailment and similarity. Transactions of the Association for Computational Linguistics, 10, 1266–1284.
Zhang, Y., He, R., Liu, Z., Bing, L., & Li, H. (2021). Bootstrapped unsupervised sentence representation learning. In Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing, ACL/IJCNLP 2021 (volume 1: long papers), virtual event, August 1–6, 2021 (pp. 5168–5180).
Zhang, Y., He, R., Liu, Z., Lim, K. H., & Bing, L. (2020). An unsupervised sentence embedding method by mutual information maximization. In Webber, B., Cohn, T., He, Y., & Liu, Y. (Eds.), Proceedings of the 2020 conference on empirical methods in natural language processing, EMNLP 2020, Online, November 16–20, 2020 (pp. 1601–1610).
Zheng, W., Chen, Z., Lu, J., & Zhou, J. (2019). Hardness-aware deep metric learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 72–81).
Zhou, K., Zhang, B., Zhao, W. X., & Wen, J.-R. (2022). Debiased contrastive learning of unsupervised sentence representations. In Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: Long papers) (pp. 6120–6130).
Funding
This work was supported by the Major Program of National Fund of Philosophy and Social Science of China (Grant No. 19ZDA345), National Natural Science Foundation of China (Grant No. 71804055), the Hebei Provincial Natural Science Foundation (Grant No. 2022CFB006), the China Postdoctoral Science Foundation 590 (Grant No. 2021M701368), and Fundamental Research Funds for the Central Universities (Grant No. CCNU21XJ039), Fundamental Research Funds for the Central Universities (Grant No. CCNU22QN016).
Author information
Authors and Affiliations
Contributions
QT proposed the main idea of the paper, conducted experiments and wrote the draft manuscript. XS participated in the experiments and visualization. GY participated in the design of experiments, reviewing and editing the manuscript. CW participated in the design of experiments, writing and editing the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing interests or conflict of interest that are relevant to the content of this paper.
Consent to participate
Not applicable. All experiments in this paper do not involve animals, plants, or human entities.
Consent for publication
Not applicable. The paper does not include data or images requiring permissions.
Ethics approval
Not applicable.
Additional information
Editor: Derek Greene.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
About this article

Cite this article
Tan, Q., Song, X., Ye, G. et al. An effective negative sampling approach for contrastive learning of sentence embedding. Mach Learn 112, 4837–4861 (2023). https://doi.org/10.1007/s10994-023-06408-8
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10994-023-06408-8