
Abstract
Resource and logistical constraints limit the frequency and extent of environmental observations, particularly in the Arctic, necessitating the development of a systematic sampling strategy to maximize coverage and objectively represent environmental variability at desired scales. A quantitative methodology for stratifying sampling domains, informing site selection, and determining the representativeness of measurement sites and networks is described here. Multivariate spatiotemporal clustering was applied to down-scaled general circulation model results and data for the State of Alaska at 4 km2 resolution to define multiple sets of ecoregions across two decadal time periods. Maps of ecoregions for the present (2000–2009) and future (2090–2099) were produced, showing how combinations of 37 characteristics are distributed and how they may shift in the future. Representative sampling locations are identified on present and future ecoregion maps. A representativeness metric was developed, and representativeness maps for eight candidate sampling locations were produced. This metric was used to characterize the environmental similarity of each site. This analysis provides model-inspired insights into optimal sampling strategies, offers a framework for up-scaling measurements, and provides a down-scaling approach for integration of models and measurements. These techniques can be applied at different spatial and temporal scales to meet the needs of individual measurement campaigns.
Similar content being viewed by others

Introduction
The Arctic contains vast amounts of frozen water in the form of sea ice, snow, glaciers, and permafrost. Extended areas of permafrost in the Arctic contain soil organic carbon that is equivalent to twice the size of the atmospheric carbon pool, and this large stabilized carbon store could be released by widespread thawing of permafrost, resulting in a positive feedback to climate warming (Schuur et al. 2008). The Intergovernmental Panel on Climate Change (IPCC) Fourth Assessment Report (AR4) has documented strong evidence for warming of the Earth’s climate over the last century and has attributed the increase in global temperatures primarily to the rising anthropogenic greenhouse gas burden (IPCC 2007). Climate warming is projected to continue with broad implications for sensitive ecosystems and globally important climate feedbacks (Anisimov et al. 2007). Warming is projected to be especially pronounced at high latitudes and accompanied by significant regional impacts. Evidence of Arctic-wide responses are already being observed (Hinzman et al. 2005). Despite these potential implications, the Arctic has a limited record of low density observations. The Arctic Climate Impact Assessment (ACIA) (2005) emphasized the need for studies of the complex and interacting processes of the atmosphere, sea ice, ocean, and terrestrial systems to improve the interpretation of past climate and projections of future climate. The Committee on Designing an Arctic Observing Network (2006) identified critical needs and gaps for observations in the Arctic. It recommended an Arctic Observing Network to satisfy current and future scientific needs and offered recommendations on key physical, biogeochemical, and human dimensions variables to monitor.
Conducting systematic and continuous field observations and long term monitoring are challenging, particularly in the Arctic. Resource and logistical constraints limit the frequency and extent of observations, necessitating the development of a systematic sampling strategy that objectively represents environmental variability at the desired spatial scale. Statistical design of the network, particularly the location of sampling sites, is critical for maximizing the representativeness of the sampled data, given a fixed number of sampling locations. A methodology that provides a quantitative framework for stratifying sampling domains, informing site selection, and determining the representativeness of measurements is required to ensure that observations are well distributed across geographic and environmental data space. This information is needed for up-scaling and extrapolating point measurements to a larger landscape with similar environmental characteristics. This study addresses these needs by developing a quantitative methodology, based on the concept of ecoregions, for objectively delineating sampling domains, identifying optimal sampling locations for these domains, and quantifying representativeness of sites and measurements. This methodology is applied at the landscape scale to inform the design of a sampling network for the U.S. Department of Energy’s Next Generation Ecosystem Experiment (NGEE) Arctic project in the State of Alaska. The National Science Foundation’s (NSF’s) National Ecological Observatory Network (NEON) adopted an objective, data-based methodology to define 20 optimal sampling domains across the conterminous United States (Schimel et al. 2007; Keller et al. 2008). An extension of that same methodology was applied both across space and through time to support identification of measurement sites and provide a framework for scaling measurements and model parameters for the NGEE Arctic project.
Quantitative delineation of ecoregions
Ecoregions
Ecoregions have been widely used to stratify geographic domains into nearly homogeneous land areas with respect to their geophysical, biological, and climatic characteristics. Since ecoregions are designed to correspond well with biome distributions and species ranges, they are frequently used as a framework for studying ecosystem structure and function. Qualitative and generalized ecoregion maps of the United States and the world have traditionally been developed by experts for studying ecosystem behavior or to define units for land management (Bailey and Hogg 1986; Omernik 1987; Olson and Dinerstein 2002; Bailey 2009). Hargrove and Hoffman (1999) used cluster analysis for quantitative delineation of ecoregions using a set of nine environmental characteristics for the conterminous United States at a resolution of 1 km2, and subsequently demonstrated its application for sampling network design, environmental niche modeling, and comparison of global model predictions (Hargrove and Hoffman 2004; Hoffman et al. 2005). Krohn et al. (1999) applied clustering to create hierarchical biophysical regions for Maine at a 21 km2 resolution. Jensen et al. (2001) used agglomerative clustering for hierarchical classification of sub-watersheds in the Columbia River Basin using 19 indirect biophysical variables. In this study, we used k-means cluster analysis to delineate ecoregions having nearly equal within-region heterogeneity for two time periods: the present (2000–2009) and the future (2090–2099). While species ranges are expected to correspond well with ecoregions under equilibrium conditions, species responses to transient climate conditions underlying dynamic ecoregions are difficult to predict. Assuming the environmental changes are slow enough, that habitats are sufficiently connected to enable migration, and that significant adaptations do not occur, future instantiations of ecoregions in new geographic areas are likely to support the same plant and animal communities as they do in the present.
Multivariate spatiotemporal clustering (MSTC)
The k-means algorithm (Hartigan 1975) clusters a dataset of n observation vectors \((\vec{X}_1,\;\vec{X}_2,\ldots,\;\vec{X}_n)\) into a user-selected number of groupings or clusters (k), equalizing the full multi-dimensional variance across clusters. The algorithm begins by calculating the Euclidean distance of each observation to the initial centroid vectors \((\vec{C}_1,\;\vec{C}_2,\ldots,\;\vec{C}_n)\) and classifies or assigns each observation to its nearest centroid. Each centroid vector is recalculated as the vector mean of all observations assigned to it. This classification and re-calculation process is iteratively repeated until fewer than some fixed proportion of observations change their cluster assignment between iterations. In the algorithm used here, convergence is assumed once fewer than 0.05 % of the observations change cluster assignments. The results of the k-means algorithm are sensitive to the choice of initial centroids. Various heuristics may be employed for their selection, such as choosing initial centroids to have an even distribution within data space or to be spread along the edges of the distribution of observations. In this study, a multi-stage refinement method based on the work of Bradley and Fayyad (1998) is employed.
For geographic or spatial stratification applications, observation vectors consist of map cells, the dimensions of which are the biological or geophysical characteristics or variables under consideration. In this case, the k-means algorithm produces geographic regions with nearly equal heterogeneity with respect to the variance of these environmental characteristics. For spatiotemporal partitioning, observation vectors consist of map cells at different time periods, and the resulting regions maintain their equalized heterogeneity across variables for all time periods considered together. Hoffman and Hargrove (1999) developed a parallel version of the k-means algorithm for use on clusters of inexpensive personal computers (Hargrove et al. 2001), and this code was used in a meta-computing environment to cluster data using multiple supercomputers across the Internet (Mahinthakumar et al. 1999). Hoffman et al. (2008) later implemented improvements to accelerate convergence, handle empty cluster cases, and obtain initial centroids through a scalable implementation of the Bradley and Fayyad (1998) method. Kumar et al. (2011) extended this work to develop a fully distributed, highly scalable k-means parallel clustering tool for analysis of very large data sets, which was employed in the study presented here.
Input data layers
Selection of input data layers reflects a compromise between desirability and availability. Characteristics influencing the distribution, primary production, and reproduction of species include climate factors, topography, permafrost characteristics, edaphic or soil properties, disturbances, and community composition. Detailed and gridded data on soil factors, disturbances, and community composition is sparse or completely unavailable for the State of Alaska. However, climate is a primary driver controlling species ranges and affecting these secondary environmental factors. Therefore, we have chosen to demonstrate the utility of this analysis method using modeled climatic variables and permafrost properties and observed topography. As observations of soil properties and disturbances become available, they can easily be incorporated into future analyses as additional input data layers. This analysis used a set of 37 environmental characteristics shown in Table 1, from down-scaled general circulation model (GCM) results and observational data for the State of Alaska at a nominal resolution of 2 × 2 km2. These data were used to define a collection of ecoregions at multiple levels of division across two time periods for Alaska. Model results were averaged for the present (2000–2009) and the future (2090–2099). This analysis combined temperature, precipitation, and related bio-climatic projections from a five-model composite data set of down-scaled GCM results for the A1B emissions scenario (Nakićenović et al. 2000) described by Walsh et al. (2008); corresponding snow and permafrost projections from the Geophysical Institute Permafrost Lab (GIPL) 1.3 permafrost dynamics model forced with the composite GCM results (Romanovsky and Marchenko 2009); limnicity data based on the National Hydrography Dataset (NHD), pre-processed by Arp and Jones (2009); and elevation from the Shuttle Radar Topography Mission 30 (SRTM30) data set. SRTM30 is a combination of data from the SRTM and U.S. Geological Survey’s GTOPO30 data set. Since the SRTM mission was only able to map up to ~60.25°N latitude, values above this point in the SRTM30 data set are completely from GTOPO30. The same limnicity and elevation data were used for both time periods. Because the units of measurement differ between variables, all data were standardized such that each variable had a mean of zero and a standard deviation of one prior to clustering to equalize the contribution from each predictor.
Alaska ecoregions
Nowacki and Brock (1995) and Gallant et al. (1995) produced ecoregion maps for the State of Alaska using two different expert-based methodologies, strongly focused on land form. Later, Nowacki et al. (2001) produced a “unified” ecoregion map—combining the two expert-based techniques—by considering limited data and in consultation with experienced ecologists, biologists, geologists, and regional experts. While useful for some purposes, such qualitative maps are based on the subjective expertise of the person or group developing them and suffer from various limitations (Hudson 1992; Zhou 1996). The question of whether ecoregions can or should be developed using quantitative statistical methods or should rely upon human expertise has been a matter of debate among geographers (McMahon et al. 2001). In this study, MSTC was applied to derive ecoregions based on climate and topographic factors for the present and the future at multiple levels of division. The climate and topographic factors discussed in the "Input data layers" section describe the environmental conditions of each map cell and are the most important drivers controlling vegetation and primary production. Thus, groupings or clusters of similarly characterized map cells delineated based on these variables define unique ecoregions. As demonstrated by Hargrove and Hoffman (2004), both present and projected future climate factors were included in the same analysis so that groups of similar cells were objectively determined across space and through time. MSTC provides a basis for comparison of environmental conditions in the future with those in the present. Ecoregions constructed through this analysis may grow or shrink in spatial area and may shift across the landscape. At high levels of division or under extreme environmental change conditions, some present-day ecoregions may become extinct in the future (i.e., shrink to zero spatial area), while others may exist only in the future (i.e., have no analog in the present). This quantitative delineation of ecoregions across space and through time facilitates assessment of the magnitude of change between present and future environmental conditions and enables the evaluation of the ecological implications of climate change scenarios. From a conservation perspective, this methodology maps changing habitats and species at risk from climate change (Saxon et al. 2005). From a field sampling perspective, this methodology identifies regions fostering potentially vulnerable ecosystems or supporting large and vulnerable carbon stores that may be sensitive to climate change (McGuire et al. 2009; Chapin et al. 2010). Such ecoregions warrant intense observation and benefit from careful, quantifiable, and defensible sampling network design strategies.
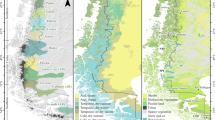
Expert-derived ecoregion maps are static and have boundaries based on subjective consideration of geographic properties and expert judgment. In contrast, statistically derived ecoregions can vary with time and are delineated in the data space or state space representing all the characteristics under consideration. Moreover, the state space resolution can be varied by selecting different values of k, the level of division in the clustering algorithm. Figure 1a, b contain maps of the ten quantitatively defined, most-different Alaskan ecoregions for the present and future, respectively. The cluster centroid of each ecoregion represents the mean value of all the characteristics or state variables for that ecoregion. Tables 2 and 3 show the ten centroid values of all 37 state variables, as well as the land area and percent land area for both the present and future time periods. Increasing the selected number of clusters in the k-means algorithm allows the definition of a larger number of more specifically defined, less generalized ecoregions. For example, Fig. 1c, d contain maps of the 20 quantitatively defined, most-different Alaskan ecoregions for the present and future, respectively. By continuing to increase the level of division, the state space resolution can be further increased. Maps of Alaska were produced for k = 5, 10, 20, 50, 100, 200, 500, and 1000 ecoregions (Hoffman et al. 2013). To demonstrate the additional state space resolution provided by higher levels of division, maps of 50 and 100 ecoregions for the present and future are shown in Fig. 2. Since cluster centroids are calculated in the 37-dimensional state space, they may not actually exist in geographic space. However, the map cell closest to the calculated centroid in state space is easily identified. This cell is called the realized centroid for the ecoregion, and it best represents the combination of environmental conditions for the entire ecoregion. The location of these representative realized centroids is indicated by the blue dot in each ecoregion in Figs. 1 and 2.

The 10 (a, b) and 20 (c, d) most-different quantitatively defined ecoregions for the State of Alaska in the present (a, c) and future (b, d) decades were derived from 37 variables and are shown using random colors. Realized centroids, map locations most closely approximating the mean value within an ecoregion of all the 37 variables, are indicated by the blue dot in each ecoregion

The 50 (a and b) and 100 (c and d) most-different quantitatively defined ecoregions for the State of Alaska in the present (a and c) and future (b and d) decades were derived from 37 variables and are shown using random colors. Realized centroids, map locations most closely approximating the mean value within an ecoregion of all the 37 variables, are indicated by the blue dot in each ecoregion
Ecoregions defined quantitatively may or may not correspond well to expert-derived ecoregions (Hargrove et al. 2006). Table 4 shows the spatial overlap or correspondence between the ten quantitatively defined MSTC Ecoregions and the eight dominantly associated Level 2 ecological groups consisting of the 32 ecoregions defined by Nowacki et al. (2001). As expected, strongly distinctive or orographically constrained ecoregions, like Arctic Tundra, have a high degree of correspondence. As shown in Table 4, nearly 96 % of MSTC ecoregion 3 overlaps with the Arctic Tundra Level 2 ecological group defined by Nowacki et al. (2001), and 93 % of their Arctic Tundra group overlaps with MSTC ecoregion 3. Meanwhile, MSTC ecoregion 4 intersects multiple Level 2 ecological groups but most dominantly corresponds to the Bering Taiga group with <48 % overlap. Because ten MSTC ecoregions are intersected with eight Level 2 ecological groups, MSTC ecoregions appear to subdivide two Level 2 ecological groups and the percent area overlap of MSTC ecoregions on Level 2 ecological groups is usually larger than the percent area overlap of Level 2 ecological groups on MSTC ecoregions. A quantitative goodness-of-fit method that explicitly accounts for the degree of spatial correspondence between categorical maps with different numbers of categories (Hargrove et al. 2006) can be used to further explore this sort of correspondence analysis.
Alaska exhibits wide ranging heterogeneity in environmental conditions, which can be resolved by selecting larger numbers of clusters in the MSTC algorithm. While MSTC is a non-hierarchical procedure, inherently hierarchical relationships within the combinations of state variables automatically emerge when increasing the level of division. For example, at a level of division of k = 10, the North Slope of Alaska is represented by a single ecoregion (#3) corresponding to the Arctic Tundra Level 2 ecological group (Fig. 3a). The North Slope is divided into two ecoregions (#5 and #13) corresponding to the Brooks Range and Beaufort Coastal Plains ecoregions defined by Nowacki et al. (2001) at a level of division of k = 20 (Fig. 3b). By further increasing the level of division to k = 50, the North Slope is divided into five different ecoregions (#32, 33, 34, 35, and 40) corresponding to the Intermontane Boreal ecological group, high- and low-elevation Brooks Range, Brooks Foothills, and Beaufort Coastal Plains ecoregions defined by Nowacki et al. (2001) (Fig. 3c). Even more specialized ecoregions can be resolved by further increasing the desired level of division in the MSTC algorithm (Fig. 2).

A hierarchy of increasingly specific ecoregions for the North Slope of Alaska emerge by increasing the level of division in the MSTC algorithm. MSTC cluster numbers are shown and the spatially corresponding Level 2 ecological group or ecoregion defined by Nowacki et al. (2001) is identified
Mapping sensitive environments
Evidence of environmental change in the Arctic and resulting impacts on aquatic productivity and biodiversity, terrestrial ecosystems, and local economies were highlighted by Anisimov et al. (2007). Increased shrub abundance has been observed in Alaska (Sturm et al. 2001, 2005; Tape et al. 2006). During the last 50 years, the tree line along the Arctic to sub-Arctic boundary has moved 10 km northward and 2 % of Alaskan tundra on the Seward Peninsula has been replaced by forests. Ecoregions derived for the present and future (Fig. 1) show a similar northward shift, indicating a dramatic change in environmental conditions due to a warming climate by the end of this century, as projected by models using the A1B emissions scenario (Nakićenović et al. 2000). By tracking changes in the spatial area and migration of ecoregions statistically derived from a hypervolume of environmental gradients (Hutchinson 1957), this objective approach for mapping landscapes undergoing environmental change can be applied to predict shifts in species ranges and constrain estimates of changes in the carbon balance of sensitive environments.
Figure 4a shows the percent area distribution of each ecoregion, at the k = 10 level of division, for the present and future time periods. Correspondence between these MSTC Ecoregions and Nowacki et al. (2001) Level 2 ecological groups is shown in Table 4. A significant decrease in the area of Ecoregion #3, representing most of the North Slope of Alaska as shown in Fig. 3a, is observed. This contemporary Arctic Tundra environment is predicted to be reduced to about 0.78 % of its present area by the end of the century. About 76 % of the area will be replaced by conditions typical of the warmer Bering Tundra environment (Ecoregion #2). Meanwhile, the Bering Tundra (Ecoregion #2) environment moves northward by the end of the century and more than doubles in areal extent. About 70 % of its current area, especially over the Seward Peninsula, will change to conditions similar to contemporary Bering Taiga (Ecoregion #4). In the future, the Bering Taiga (Ecoregion #4) environment decreases in extent by 32 % and migrates northward. Under increased temperatures and reduced permafrost conditions, the present-day Aleutian Mountains (Ecoregion #7) environmental conditions are predicted to replace 65 % of Bering Taiga (Ecoregion #4), and Alaska Range Transition (Ecoregion #10) environmental conditions are expected to replace 28 % of Bering Taiga (Ecoregion #4). Aleutian Mountain (Ecoregion #7) and Alaska Range Transition (Ecoregion #10) environments, which exist in the southern coastal regions of Alaska, are expected to grow in extent northward and occupy a larger portion of Alaska. Alaska Range Transition (Ecoregion #10) environmental conditions are also expected to replace about 75 % of the Intermontane Boreal (Ecoregion #5) environment in the future, which will be reduced to 18 % of its current area by the end of the century. While similar trends of large scale northward migrations and changes in the areal extents of the environments discussed above are observed at 20 and higher levels of divisions, these ecoregion refinements highlight the changes that are occurring in smaller, more uniquely defined environments.

Figure 4b shows the percent area distribution of k = 20 ecoregions for the present and future time periods. In addition to areal extent, changes and geographic redistribution of ecoregions between the present and future, at this level of division one present-day ecoregion ceases to exist in the future (i.e., becomes extinct) while another ecoregion exists only in the future (i.e., is born) and has no analog in the present. Ecoregion #13 (Fig. 5a), which represents the most northern portion of Arctic Tundra on the North Slope, becomes extinct in the future due to projected climate change. Ecoregions #2 and #17, which presently occupy the Seward Peninsula and nearby coasts (Fig. 5b), replace Ecoregion #13 in the future (Fig. 5c). Approximately 46 % of the area of Ecoregion #13 is replaced by Ecoregion #2 and 53 % is replaced by Ecoregion #17. Under this climate change scenario, the ecoregions replacing the extinct region in the future have characteristically higher precipitation, higher temperatures, earlier thaw dates, later freeze dates, a longer growing season, increased active layer depth, and higher ground surface temperatures. At the end of the century, much of the Seward Peninsula and nearby coasts are occupied by an entirely new combination of environmental conditions, defined by Ecoregion #1, which has no analog in the present (Fig. 5d). This new ecoregion, which appears only in the future time period, represents an environment with higher precipitation and temperature, an increased growing season length, increased active layer depth, and higher soil temperatures.

At k = 20, MSTC ecoregions migrate across the landscape, one becomes extinct, and one comes into existence between the present and future
As the level of division is increased in the MSTC algorithm, more specialized ecoregions are delineated. As a result, the number of present-day ecoregions that become extinct and the number of non-analog future ecoregions will both increase. Identification of regions representing new combinations of environment conditions that did not previously occur together is important for forecasting species range distributions, conservation planning, and climate change impacts on biodiversity (Fitzpatrick and Hargrove 2009).
Site selection
Selection of sampling locations for long term monitoring of ecosystem properties and processes should be guided by an objective, quantitative, systematic, and defensible methodology. Instead, sampling locations in large-scale networks have often been established in opportunistic, political, or logistically-driven ways, resulting in unquantified representation of heterogeneity, biased sampling, uncharacterized uncertainty, and undirected network growth. Finite resources and logistical constraints limit the spatiotemporal frequency and extent of environmental observations, necessitating the development of a systematic sampling strategy to objectively represent environmental variability at the desired spatial scale. An appropriately designed observation strategy should be employed to quantitatively delineate sampling domains, sites, and frequencies. The NSF’s NEON adopted the objective, data-based methodology described above to define 20 optimal sampling domains across the conterminous United States (Schimel et al. 2007; Keller et al. 2008). Accurate characterization of the landscape and translation of data collected in the field and laboratory into useful datasets, process algorithms, and model parameters requires classification of the landscape into discrete units based on ecological, hydrological, and geological properties. In much the same way that ecologists develop ecoregions, geologists often classify landscape areas into geomorphological units based on their geophysical and hydrological features. For complex and evolving landscapes featuring interacting vegetation and geomorphological dynamics responding to changes in climate, such as in the Arctic, these stratification concepts may be unified to produce biogeomorphic units at relevant spatial scales for landscape characterization, identification of ecological and geomorphological processes, assessing the representativeness of measurements, and providing a framework for scaling measurements and model parameters to larger domains.
An important aspect of site selection and the up- and down-scaling approach to integration of models, observations, and process studies is the estimation of representativeness. The MSTC methodology described above for landscape characterization offers useful metrics for indicating the representativeness of sites, measurements, and model parameters, assuming the environmental characteristics included in the analysis covary with the measured variables. Hargrove et al. (2003) described this technique for understanding the representativeness of a sampling network based on a suite of environmental gradients considered to be useful proxies for the characteristics being measured. Maps identifying poorly represented regions can be produced, suggesting where new measurements should be taken to maximize sampling network coverage. As discussed in the "Alaska ecoregions" section, since the cluster centroid represents the mean value of all the state variables in an ecoregion, the realized centroid for an ecoregion is the location that best represents the combination of environmental conditions of the entire ecoregion. Therefore, statistically defined realized centroids, indicated by blue dots in each ecoregion in Figs. 1 and 2, are the optimal sampling locations for each ecoregion. Logistical constraints—including accessibility, availability of electric power and telecommunications infrastructure, and geologic stability—may prevent establishment of sampling sites at such optimal locations, particularly in an Arctic environment. Nevertheless, the MSTC Ecoregion framework provides a means for quantifying the representativeness of measurements taken at sub-optimal locations, either within an ecoregion or across any larger domain for which the desired state variables are available.
Quantifying representativeness
While most in situ field measurements are made at relatively small, individual geographic points, ecosystem processes operate at many scales. To utilize limited point measurements at larger spatial and temporal scales for input to or evaluation of process modeling or for estimating landscape-scale characteristics, the representativeness of those measurements must be quantified in the context of a heterogeneous and evolving landscape. A useful representativeness metric is one that can inform the selection of sampling locations, up-scaling of point measurements, down-scaling of remote sensing data, and extrapolation of measurements to unsampled domains. This requires that the underlying variables used to define ecoregions covary with the point measurements (i.e., the surrogate variables have and maintain predictive power). The representativeness metric described by Hargrove et al. (2003) provides a unit-less, relative measure of the dissimilarity between the ecoregion of interest, which may contain a sampling site, and any other ecoregion. It is calculated as the Euclidean distance between two ecoregion centroids within the standardized n-dimensional state space. Ecoregions with similar combinations of environmental conditions will have centroids located near to each other in state space. Therefore, the Euclidean distance between those centroids will be small, representing a low dissimilarity or high representativeness measure. Meanwhile, ecoregions with very different combinations of environmental conditions will have centroids located far from each other in state space, resulting in a large Euclidean distance between them. Such ecoregions will have a high dissimilarity or low representativeness measure. To best capture the natural heterogeneity at the scale of interest, this ecoregion-based representativeness should be calculated using MSTC Ecoregions with a large number of divisions (i.e, a large value of k).
While Hargrove et al. (2003) calculated representativeness in the context of ecoregions, this same approach can be applied to every map cell projected individually onto the n-dimensional state space used to perform the cluster analysis that produced MSTC Ecoregions. This point-based representativeness metric captures the full range of heterogeneity in the combinations of environmental conditions, providing a continuously varying measure of dissimilarity for every map cell with respect to a map cell of interest, which may contain a sampling location. When a single ecoregion centroid or map cell of interest is considered, a map of site representativeness can be produced. However, multiple ecoregions or map cells of interest may be considered simultaneously, for instance, to provide a quantitative measure of the representativeness of an array or network of sampling sites. The result is a map of network representativeness for which the dissimilarity measure for every ecoregion centroid or map cell is the Euclidean distance between that point and the nearest ecoregion centroid or map cell of interest (i.e., the minimum value from a stack of site representativeness maps, one for each ecoregion centroid or map cell containing a measurement site). This representativeness metric, whether ecoregion- or point-based, can be calculated not only between different geographic points in space, but also between different (or the same) geographic points through time. For example, the Euclidean distance between the present combination of environmental conditions and those of the future for any single map cell represents a measure of the magnitude of environmental change over time. Therefore, with this metric it is possible to calculate not only the present-day representativeness of measurements from a site, but also the future representativeness of those present-day measurements, based on future projections of the state variables used in the analysis.
Site representativeness
Due to significant logistical constraints when working in the Arctic, a set of eight potential sites were identified as candidates for measurements, long term monitoring and potential manipulative experiments for the U.S. Department of Energy’s NGEE Arctic project in the State of Alaska: Barrow, Council, Atqasuk, Ivotuk, Kougarok, Prudhoe Bay, Toolik Lake, and Fairbanks. Because of available support infrastructure, Barrow was selected as an initial location for collecting field measurements. To adequately capture the heterogeneity of environmental gradients, an ecoregion-based representativeness analysis employed ecoregion maps at the k = 1,000 level of division. Figure 6a shows the present-day representativeness of the monitoring site at Barrow for the present period. In this map, white to light gray land areas are well-represented by the Barrow location, while dark gray to black land areas are poorly represented by Barrow. The Arctic Tundra of the North Slope is well represented by the Barrow site, but the representativeness drops rapidly at the Brooks Range, which experiences different climate conditions driven by high topography. If a field researcher were attempting to select one additional sampling location to provide optimal coverage of the environments within the state of Alaska, that next site should be chosen within the darkest land areas shown in the map. Once a new candidate site has been selected, a new map of representativeness can be generated with simultaneous consideration of both sites. Using this relative representativeness metric, optimal sampling locations can be chosen to maximize the coverage of environmental conditions for any domain at any scale for which sufficient state variable data are available.

Ecoregion-based representativeness maps of present-day Barrow for the present and future time periods. White to light gray land areas are well-represented by Barrow, while dark gray to black land areas are poorly represented by Barrow
Since climate model projections for the future were included in the MSTC procedure, the future representativeness of the present-day Barrow-containing ecoregion can also be mapped (Fig. 6b). Since the climate is projected to change significantly, the future representativeness of the present-day ecoregion is relatively lower, which is indicated by darker colors in Fig. 6b as compared with Fig. 6a. Such changes in representativeness are especially large in the Northern Arctic Coastal Plains since this Arctic Tundra is projected to warm significantly and has been identified as a sensitive environment ("Mapping sensitive environments" section). Similarly, Fig. 7a, b contain maps of the present and future representativeness of present-day Barrow, respectively, calculated using the point-based representativeness method. As expected, the large-scale pattern of maps in Fig. 7 is the same as that of the maps in Fig. 6, but the maps in Fig. 7 show more detail and are less generalized than those in Fig. 6. Point-based site representativeness maps for each of the eight candidate sites for the present time period are shown in Fig. 8.

Point-based representativeness maps of present-day Barrow for the present and future time periods. White to light gray land areas are well-represented by Barrow, while dark gray to black land areas are poorly represented by Barrow

Point-based representativeness for eight potential present-day NGEE Arctic sites for the present time period. White to light gray land areas are well-represented by the site, while dark gray to black land areas are poorly represented by the site
Since the representativeness metric—or measure of dissimilarity—can be computed between any two map locations, a table quantitatively characterizing dissimilarity of the eight individual candidate sampling locations may be useful for site selection purposes. Table 5 shows point-to-point dissimilarity values for the eight candidate sampling locations for the present time period. Of those locations, Barrow and Fairbanks are the most dissimilar, having a dissimilarity value of 12.16. Atqasuk and Prudhoe Bay are the most similar of the sites. Both Atqasuk and Prudhoe Bay are near-coastal sites at the northern extent of the North Slope; therefore, the environmental conditions are expected to be similar. In addition, according to Table 5, the Prudhoe Bay site is most similar to Barrow, while the Council site is the most dissimilar to Barrow, ignoring Fairbanks. This example analysis suggests that if Barrow were the first sampling site selected, Council may be a strong candidate for a second site in the northern half of the State of Alaska because of its dissimilarity to Barrow. Similarly, Table 6 shows point-to-point dissimilarity values for the eight candidate sampling locations for the future time period. While the dissimilarity values for the future are similar to those of the present, it is apparent that some sites become more similar while others become less similar. For example, Barrow and Council become less dissimilar in the future (i.e., their dissimilarity value of 9.13 in the present changes to 8.87 in the future), indicating that the environmental conditions in Barrow and Council are more different in the present than they are projected to be in the future.
Table 7 shows a full matrix of point-to-point dissimilarity values for the eight candidate sites between the present and the future. This table quantifies the dissimilarity of present-day sites to those same sites in the future. For this list of widely dispersed locations, the environmental conditions for any single site in the present will be most like the environmental conditions for that same site in the future. Therefore, the smallest dissimilarity values are along the diagonal in Table 7. The largest value on the diagonal is for the Barrow site, indicating that environmental conditions at Barrow are projected to change more than at any other candidate site. In addition, this table shows that environmental conditions at Barrow in the future are more similar to those at Council in the present (8.38) than are the conditions at Barrow in the present to Council in the future (9.67). This result is consistent with the MSTC Ecoregion migration shown in Fig. 5. This point-to-point analysis through time is a novel method for quantifying relationships between sampling locations and how those relationships evolve over time due to environmental change.
Network representativeness
A monitoring network often consists of a geographically distributed constellation of measurement sites or may be locations where samples are collected for further analysis in the laboratory. Quantifying the representativeness of the network as a whole is important for optimal network design to avoid unnecessary duplication and to maximize the coverage of the monitoring network. By combining multiple maps of site representativeness for every sampling location, and calculating the minimum value for every map cell, maps of network representativeness are produced. Figures 9a, b contain maps of ecoregion-based network representativeness for all eight candidate sampling sites for the present and future time periods, respectively. Similarly, Fig. 10a, b contain maps of point-based network representativeness for the same eight candidate sampling sites for the present and future time periods, respectively. White to light gray land areas are well-represented by the network of sites, while dark gray to black land areas are poorly represented by the network of sites. If the objective were to maximize the coverage of all environments in the State of Alaska, the next sampling location should be chosen within the darkest land areas shown in the map. Most of Alaska is well represented by this network of eight sampling locations.

Representativeness maps for a network of eight sites for the present and future time periods. White to light gray land areas are well-represented by the network of sites, while dark gray to black land areas are poorly represented by the network of sites

Representativeness maps for a network of eight sites for the present and future time periods. White to light gray land areas are well-represented by the network of sites, while dark gray to black land areas are poorly represented by the network of sites
Conclusions
Systematic sampling strategies are essential for understanding ecosystem responses to climate change and informing model development. In the harsh Arctic environment—where climate change appears to be most rapidly affecting sensitive ecosystems and vulnerable, carbon-rich permafrost—filling critical gaps in observations is expensive and technically challenging. To fully explore the regional and global implications of climate change in the Arctic, global Earth System Models must capture the important processes and feedbacks. Such models must be developed based on a rich body of observational data as representative as possible of multiple spatial and temporal scales. Meanwhile, finite resources and logistical constraints place restrictions on the number of sampling sites, spatial extent, frequency, and types of measurements that can be collected. This study proposes a quantitative, data-based methodology for stratifying sampling domains, informing site selection, and determining the representativeness of measurement sites and sampling networks.
Multivariate spatiotemporal clustering, based on k-means cluster analysis, was applied to down-scaled GCM results and observational data for the State of Alaska at a nominal resolution of 4 km2 to define a set of ecoregions at multiple levels of division across two decadal time periods. Maps of ecoregions for the present (2000–2009) and future (2090–2099) were produced, showing how combinations of 37 environmental conditions are distributed across Alaska and how these combinations shift as a result projected climate change in the 21st century. Using this statistical approach, optimal sampling locations, called realized centroids, were identified for each ecoregion at every level of division. In addition, the resulting geographic shifts and changes in areal distribution of ecoregions suggested that some environments may disappear, many will be redistributed, and new ones will appear in the coming century. This analysis provides insights into the identification of the most sensitive and potentially vulnerable Arctic ecosystems. The Euclidean distance within the 37-dimensional state space used for MSTC provides a metric for representativeness. Gray-scale maps of representativeness, showing the similarity of every map cell to a list of eight candidate samples locations near town sites in Alaska, were produced for each site. Tables quantitatively characterizing the similarity of candidate sampling locations to each other across space and through time were generated. These tables are useful for understanding the strength of the environmental gradients between sites and how those gradients may change based on model projections of the future. Taken together, these analysis products provide model-inspired insights into optimal sampling strategies across space and through time, and these same techniques can be applied at different spatial and temporal scales to meet the needs of individual measurement or monitoring campaigns.
The representativeness of a sampling network is best maximized before the network is deployed. Even if additional “optimized” sites are added to an existing network, it will require many more additions to approach the theoretical maximum representativeness for a given number of initial sites. It is difficult, with only the sequential addition of new optimized sites, to achieve the same representativeness once some sampling sites have been established. Representativeness resulting from such network “repairs” rarely ever equal the representativeness of a network initially designed de novo with that same number of sampling sites. Even if the network is to be constructed in stages, it is best to design site placement using the final, ultimate complement of sites and to operate sub-optimally until the full network can be completed. Otherwise, many more sites will have to be added to the existing network to achieve the same representativeness than could otherwise have been designed in initially.
Cluster analysis and n-dimensional data space regressions offer quantitative methods for up-scaling and extrapolating measurements to land areas within and beyond the sampling domain and provide a down-scaling approach to the integration of models, observations, and process studies. The success of these methods depends upon selecting appropriate surrogate environmental characteristics that covary with the observations and parameters that will be up- or down-scaled. The accuracy of the up-scaled data will be higher for areas represented well by the monitoring network and lower for areas that are poorly represented. At a large scale, these techniques are useful for delineating distinct, broad regions and optimal measurement sites. However, this methodology can also be applied at finer spatiotemporal scales, with inclusion of other geophysical characteristics and remote sensing data, to inform measurement frequency and site selection within these broader ecoregions.
References
Anisimov OA, Vaughan DG, Callaghan TV, Furgal C, Marchant H, Prowse TD, Vilhjálmsson H, Walsh JE (2007) Polar regions (Arctic and Antarctic). In: Parry ML, Canziani OF, Palutikof JP, van der Linden PJ, Hanson CE (eds) Climate change 2007: impacts, adaptation and vulnerability. Cambridge University Press, Cambridge, pp 653–685
Arp Christopher D, Jones Benjamin M (2009) Geography of Alaska lake districts: identification, description, and analysis of lake-rich regions of a diverse and dynamic state. Scientific investigations report 2008-5215. U.S. Geological Survey, 4210 University Dr., Anchorage, Alaska 99508
Bailey RG (2009) Ecoregions of the United States. In: Ecosystem geography, statistics for social and behavioral sciences. Springer New York, pp 93–114. ISBN 978-0-387-89516-1. doi:10.1007/978-0-387-89516-1_7
Bailey RG, Hogg HC (1986) A world ecoregions map for resource reporting. Environ Conserv 13(3):195–202. doi:10.1017/S0376892900036237
Bradley PS, Fayyad UM (1998) Refining initial points for k-means clustering. In: ICML ’98: Proceedings of the fifteenth international conference on machine learning, Morgan Kaufmann Publishers Inc., San Francisco, pp 91–99. ISBN 1-55860-556-8
Chapin FS, McGuire AD, Ruess RW, Hollingsworth TN, Mack MC, Johnstone JF, Kasischke ES, Euskirchen ES, Jones JB, Jorgenson MT, Kielland K, Kofinas GP, Turetsky MR, Yarie J, Lloyd AH, Taylor DL (2010) Resilience of Alaska’s boreal forest to climatic change. Can J For Res 40(7):1360–1370. doi:10.1139/X10-074
Fitzpatrick MC, Hargrove WW (2009) The projection of species distribution models and the problem of non-analog climate. Biodivers Conserv 18(8):2255–2261. doi:10.1007/s10531-009-9584-8
Gallant AL, Binnian EF, Omernik JM, Shasby MB (1995) Ecoregions of Alaska. Professional paper 1567, U.S. Geological Survey
Hargrove WW, Hoffman FM, Law BE (2003) New analysis reveals representativeness of the AmeriFlux Network. Eos Trans AGU 84(48):529,535. doi:10.1029/2003EO480001
Hargrove WW, Hoffman FM (1999) Using multivariate clustering to characterize ecoregion borders. Comput Sci Eng 1(4):18–25. doi:10.1109/5992.774837
Hargrove WW, Hoffman FM (2004) Potential of multivariate quantitative methods for delineation and visualization of ecoregions. Environ Manag 34(Supplement 1):S39–S60. doi:10.1007/s00267-003-1084-0
Hargrove WW, Hoffman FM, Sterling T (2001) The do-it-yourself supercomputer. Sci Am 265(2):72–79
Hargrove WW, Hoffman FM, Hessburg PF (2006) Mapcurves: a quantitative method for comparing categorical maps. J Geogr Syst 8(2):187–208. doi:10.1007/s10109-006-0025-x
Hartigan JA (1975) Clustering algorithms. Wiley, New York
Hinzman LD, Bettez ND, Bolton W, Chapin F, Dyurgerov M, Fastie C, Griffith B, Hollister R, Hope A, Huntington H, Jensen A, Jia G, Jorgenson T, Kane D, Klein D, Kofinas G, Lynch A, Lloyd A, McGuire A, Nelson F, Oechel W, Osterkamp T, Racine C, Romanovsky V, Stone R, Stow D, Sturm M, Tweedie C, Vourlitis G, Walker M, Walker D, Webber P, Welker J, Winker K, Yoshikawa K (2005) Evidence and implications of recent climate change in Northern Alaska and other Arctic regions. Clim Change 72(3):251–298. ISSN 0165-0009. doi:10.1007/s10584-005-5352-2
Hoffman FM, Hargrove WW (1999) Multivariate geographic clustering using a Beowulf-style parallel computer. In: Arabnia HR (eds) Proceedings of the international conference on parallel and distributed processing techniques and applications (PDPTA ’99), vol III. CSREA Press, Las Vegas, pp 1292–1298. ISBN 1-892512-11-4
Hoffman FM, Kumar J, Mills RT, Hargrove WW, Thornton PE, Wullschlegar SD (2013) A geospatiotemporal analysis method for site selection for Next Generation Ecosystem Experiments (NGEE). Technical Memorandum ORNL/TM-2013/196, Oak Ridge National Laboratory
Hoffman FM, Hargrove WW, Mills RT, Mahajan S, Erickson DJ, Oglesby RJ (2008) Multivariate Spatio-Temporal Clustering (MSTC) as a data mining tool for environmental applications. In: Sàànchez-Marrè M, Béjar J, Comas J, Rizzoli AE, Guariso G (eds) Proceedings of the iEMSs fourth biennial meeting: international congress on environmental modelling and software society (iEMSs 2008), pp 1774–1781. ISBN 978-84-7653-074-0
Hoffman FM, Hargrove WW, Erickson DJ, Oglesby RJ (2005) Using clustered climate regimes to analyze and compare predictions from fully coupled general circulation models. Earth Interact 9(10):1–27. doi:10.1175/EI110.1
Hudson BD (1992) The soil survey as paradigm-based science. Soil Sci Soc Am J 56(3):836–841. doi:10.2136/sssaj1992.03615995005600030027x
Hutchinson GE (1957) Concluding remarks. In Cold Spring Harb Symp Quant Biol 22:415–427. Reprinted in 1991: Classics in theoretical biology. Bull Math Biol 53:193–213
IPCC (2007) Summary for policymakers. In: Solomon S, Qin D, Manning M, Chen Z, Marquis M, Averyt KB, Tignor M, Miller HL (eds) Climate change 2007: the physical science basis. Contribution of working group I to the fourth assessment report of the intergovernmental panel on climate change, Cambridge University Press, Cambridge. ISBN 978-0-521-88009-1 hardback; 978-0-521-70596-7 paperback
Jensen ME, Goodman IA, Bourgeron PS, Poff NL, Brewer CK (2001) Effectiveness of biophysical criteria in the hierarchical classification of drainage basins. J Am Water Resour Assoc 37:1155–1167
Keller M, Schimel DS, Hargrove WW, Hoffman FM (2008) A continental strategy for the National Ecological Observatory Network. Front Ecol Environ 6(5):282–284. http://dx.doi.org/10.1890/1540-9295%282008%296%5B282%3AACSFTN%5D2.0.CO%3B2. Special issue on continental-scale ecology
Krohn WB, Boone RB, Painton SL (1999) Quantitative delineation and characterization of hierarchical biophysical regions of Maine. Northeast Nat 6(2):139–164
Kumar J, Mills RT, Hoffman FM, Hargrove WW (2011) Parallel k-means clustering for quantitative ecoregion delineation using large data sets. In: Sato M, Matsuoka S, Sloot PM, van Albada GD, Dongarra J (eds) Proceedings of the international conference on computational science (ICCS 2011), volume 4 of Procedia Comput. Sci. Elsevier, Amsterdam, pp 1602–1611 doi:10.1016/j.procs.2011.04.173
Mahinthakumar G, Hoffman FM, Hargrove WW, Karonis NT (1999) Multivariate geographic clustering in a metacomputing environment using globus. In: Supercomputing ’99: Proceedings of the 1999 ACM/IEEE conference on supercomputing (CDROM), Supercomputing ’99, ACM Press, New York. ISBN 1-58113-091-0. doi:10.1145/331532.331537
McGuire DA, Anderson LG, Christensen TR, Dallimore S, Guo L, Hayes DJ, Heimann M, Lorenson TD, Macdonald RW, Roulet N (2009) Sensitivity of the carbon cycle in the Arctic to climate change. Ecol Monogr 79(4):523–553. doi:10.1890/08-2025.1
McMahon G, Gregonis SM, Waltman SW, Omernik JM, Thorson TD, Freeouf JA, Rorick AH, Keys JE (2001) Developing a spatial framework of common ecological regions for the conterminous united states. Environ Manag 28(3):293–316. ISSN 0364-152X. doi:10.1007/s0026702429
Nakićenović N, Alcamo J, Davis G, de Vries B, Fenhann J, Gaffin S, Gregory K, Grübler A, Yong JT, Kram T, Lebre La Rovere E, Michaelis L, Mori S, Morita T, Pepper W, Pitcher H, Price L, Riahi K, Roehrl A, Rogner H-H, Sankovski A, Schlesinger M, Shukla P, Smith S, Swart R, van Rooijen S, Victor N, Dadi Z (2000) Special report on emissions scenarios. In: Nakićenović N, Swart R (eds) A special report of working group III of the intergovernmental panel on climate change. Cambridge University Press, Cambridge, pp 570. ISBN 92-9169-113-5
National Research Council Committee on Designing an Arctic Observing Network (2006) Towards an Integrated Arctic Observing Network. The National Academies Press. ISBN 9780309100526
Nowacki G, Brock T (1995) Ecoregions and subregions of Alaska, EcoMap Version 2.0. map, USDA Forest Service, Alaska Region, Juneau. Scale 1:5,000,000
Nowacki G, Spencer P, Fleming M, Brock T, Jorgenson T (2001) Ecoregions of Alaska: 2001. Open-file report 02-297 (map), U.S. Geological Survey
Olson DM, Dinerstein E (2002) The global 200: priority ecoregions for global conservation. Ann Mo Bot Garden 89(2):199–224. ISSN 00266493
Omernik JM (1987) Ecoregion of the conterminuous United States. Ann Assoc Am Geogr 77(1):118–125. doi:10.1111/j.1467-8306.1987.tb00149.x
Romanovsky VE, Marchenko S (2009) The GIPL permafrost dynamics model. Technical report, University of Alaska, Fairbanks, Alaska
Saxon E, Baker B, Hargrove W, Hoffman F, Zganjar C (2005) Mapping environments at risk under different global climate change scenarios. Ecol Lett 8:53–60. doi:10.1111/j.1461-0248.2004.00694
Schimel D, Hargrove W, Hoffman F, McMahon J (2007) NEON: a hierarchically designed national ecological network. Front Ecol Environ 5(2):59. http://dx.doi.org/10.1890/1540-9295%282007%295%5B59%3ANAHDNE%5D2.0.CO%3B2
Schuur EAG, Bockheim J, Canadell JG, Euskirchen E, Field CB, Goryachkin SV, Hagemann S, Kuhry P, Lafleur PM, Lee H, Mazhitova G, Nelson FE, Rinke A, Romanovsky VE, Shiklomanov N, Tarnocai C, Venevsky S, Vogel JG, Zimov SA (2008) Vulnerability of permafrost carbon to climate change: implications for the global carbon cycle. Bioscience 58(8):701–714, ISSN 0006-3568. doi:10.1641/B580807
Sturm M, Rachine C, Tape K (2001) Climate change: increasing shrub abundance in the Arctic. Nature 411(6837):546–547. doi:10.1038/35079180
Sturm M, Douglas T, Racine C, Liston GE (2005) Changing snow and shrub conditions affect albedo with global implications. J Geophys Res 110(G1):G01004. ISSN 0148-0227. doi:10.1029/2005JG000013
Tape K, Sturm M, Racine C (2006) The evidence for shrub expansion in Northern Alaska and the Pan-Arctic. Glob Change Biol 12(4):686–702. ISSN 1365-2486. doi:10.1111/j.1365-2486.2006.01128.x
The Arctic Climate Impact Assessment (ACIA) (2005) Arctic climate impact assessment. Cambridge University Press, Cambridge, ISBN 9780521865098
Walsh JE, Chapman WL, Romanovsky V, Christensen JH, Stendel M (2008) Global climate model performance over Alaska and Greenland. J Clim 21(23):6156–6174. doi:10.1175/2008JCLI2163.1
Zhou Y (1996) An ecological regionalization model based on NOAA/AVHRR data. Int Arch Photogramm Remote Sens, XXXI, Part B4:1001–1006
Acknowledgments
This research was partially sponsored by the Climate and Environmental Sciences Division (CESD) of the Office of Biological and Environmental Research (BER) within the U.S. Department of Energy (DOE) Office of Science. Additional support was provided by the U.S. Department of Agriculture (USDA) Forest Service, Eastern Forest Environmental Threat Assessment Center (EFETAC). The Next-Generation Ecosystem Experiments (NGEE Arctic) project is supported by the Office of Biological and Environmental Research in the DOE Office of Science. This research used resources of the Center for Computational Sciences at Oak Ridge National Laboratory, which is supported by the Office of Science of the U.S. Department of Energy under Contract No. DE-AC05-00OR22725. The submitted manuscript has been authored by a contractor of the U.S. Government under Contract No. DE-AC05-00OR22725. Accordingly, the U.S. Government retains a non-exclusive, royalty-free license to publish or reproduce the published form of this contribution, or allow others to do so, for U.S. Government purposes.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Hoffman, F.M., Kumar, J., Mills, R.T. et al. Representativeness-based sampling network design for the State of Alaska. Landscape Ecol 28, 1567–1586 (2013). https://doi.org/10.1007/s10980-013-9902-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10980-013-9902-0