
Abstract
Katyusha momentum is a famous and efficient alternative acceleration method that used for stochastic optimization problems, which can reduce the potential accumulation error from the process of randomly sampling, induced by classical Nesterov’s acceleration technique. The nature idea behind the Katyusha momentum is to use a convex combination framework instead of extrapolation framework used in Nesterov’s momentum. In this paper, we design a Katyusha-like momentum step, i.e., a negative momentum framework, and incorporate it into the classical variance reduction stochastic gradient algorithm. Based on the built negative momentum-based framework, we proposed an accelerated stochastic algorithm, namely negative momentum-based stochastic variance reduction gradient (NMSVRG) algorithm for minimizing a class of convex finite-sum problems. There is only one extra parameter needed to turn in NMSVRG algorithm, which is obviously more friendly in parameter turning than the original Katyusha momentum-based algorithm. We provided a rigorous theoretical analysis and shown that the proposed NMSVRG algorithm is superior to the SVRG algorithm and is comparable to the best one in the existing literature in convergence rate. Finally, experimental results verify our analysis and show again that our proposed algorithm is superior to the state-of-the-art-related stochastic algorithms.

Similar content being viewed by others
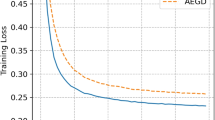
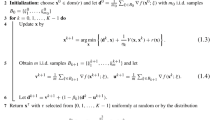

References
Allen-Zhu, Z.: Katyusha: the first direct acceleration of stochastic gradient methods. J. Mach. Learn. Res. 18(221), 1–51 (2018)
Allen-Zhu, Z.: Katyusha X: Simple momentum method for stochastic sum-of-nonconvex optimization. In: Jennifer, D., Andreas, K. (eds.) Proceedings of the 35th International Conference on Machine Learning, vol. 80, pp. 179–185 (2018)
Beck, A.: First-Order Methods in Optimization. In: MOS-SIAM, Series on Optimization. SIAM, Philadelhia (2017)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Image Sci. 2(1), 183–202 (2009)
Bottou, L.: Large-scale machine learning with stochastic gradient descent. In: Proceedings of Computational Statistics. pp. 177–186 (2010)
Cevher, V., Vu, B.C.: On the linear convergence of the stochastic gradient method with constant step-size. Optim. Lett. 13, 1177–1187 (2019)
Defazio, A., Bach, F., Lacoste-Julien, S.: SAGA: a fast incremental gradient method with support for non-strongly convex composite objectives. In: Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 27, pp. 1–9 (2014)
Ghadimi, S., Lan, G.: Stochastic first and zeroth order methods for nonconvex stochastic programming. SIAM J. Optimi. 23(4), 2341–2368 (2013)
Ghadimi, S., Lan, G.: Accelerated gradient methods for nonconvex nonlinear and stochastic programming. Math. Program. 156, 59–99 (2016)
Ghadimi, S., Lan, G.: Unified convergence analysis of stochastic momentum methods for convex and non-convex optimization. arXiv:1604.03257v2 (2016)
Johnson, R., Zhang, T.: Accelerating stochastic gradient descent using predictive variance reduction. In: Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 26, pp. 315–323 (2013)
Klein, S., Pluim, J., Staring, M., Viergever, M.A.: Adaptive stochastic gradient descent optimisation for image registration. Int. J. Comput. Vis. 81, 227–239 (2009)
Lan, L.: An optimal method for stochastic composite optimization. Math. Program. 133, 365–397 (2012)
Le Roux, N., Schmidt, M., Bach, F.: A stochastic gradient method with an exponential convergence rate for finite training sets. In: Burges, C.J.C., Bottou, L., Welling, M., Ghahramani, Z., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 25, pp. 1–9 (2012)
Lin, Z., Li, H., Fang, C.: Accelerated Optimization for Machine Learning: First-Order Algorithms. Springer, Singapore (2020)
Luo, Z., Chen, S., Qian, Y., Hou, Y.: Multi-stage stochastic gradient method with momentum acceleration. Signal Process. 188, 108201 (2021)
Mittelhammer, R.C.: Sampling, Sample Moments and Sampling Distributions. Mathematical Statistics for Economics and Business, Springer, New York (2013)
Nemirovski, A., Juditsky, A., Lan, G., Shapiro, A.: Robust stochastic approximation approach to stochastic programming. SIAM J. Optim. 19(4), 1574–1609 (2009)
Nesterov, Y.: A method of solving a convex programming problem with convergence rate. Sov. Math. Dokl. 27, 372–376 (1983)
Nesterov, Y.: Introductory Lectures on Convex Optimization: A Basic Course. Springer, Boston (2004)
Nesterov, Y.: Lectures on Convex Optimization, vol. 137. Springer, Berlin (2018)
Nguyen, L.M., Liu, J., Scheinberg, K., Taka, M.: SARAH: a novel method for machine learning problems using stochastic recursive gradient. In: Doina, P., Yee Whye, T. (eds.) The 34th International Conference on Machine Learning, vol. 70, pp. 2613–2621 (2017)
Nguyen, L.M., Scheinberg, K., Takac, M.: Inexact SARAH algorithm for stochastic optimization. Optim. Method Softw. 36(1), 237–258 (2021)
Nitanda, A.: Stochastic proximal gradient descent with acceleration techniques. In: Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 27, pp. 1574–1582 (2014)
Pham, N.H., Nguyen, L.M., Phan, D.T., Tran-Dinh, Q.: ProxSARAH: an efficient algorithmic framework for stochastic composite nonconvex optimization. J. Mach. Learn. Res. 21, 1–48 (2020)
Reddi, S.J., Sra, S., Poczos, B., Smola, A.: Fast incremental method for nonconvex optimization. arXiv:1603.06159v1 (2016)
Robbins, H., Monro, S.: A stochastic approximation method. Ann. Math. 22(3), 400–407 (1951)
Shalev-Shwartz, S., Zhang, T.: Stochastic dual coordinate ascent methods for regularized loss minimization. arXiv:1209.1873v2 (2013)
Shang, F., Jiao, L., Zhou, K., Cheng, J., Ren, Y., Jin, Y.: ASVRG: accelerated proximal SVRG. In: Zhu, J., Takeuchi, I. (eds.) Proceedings of Machine Learning Research, vol. 95, pp. 1–32 (2018)
Shapiro, A., Wardi, Y.: Convergence analysis of gradient descent stochastic algorithms. J. Optim. Theory Appl. 91(2), 439–454 (1996)
Shapiro, A., Wardi, Y.: Convergence analysis of stochastic algorithms. Math. Oper. Res. 21(3), 615–628 (1996)
Wu, Z., Li, M.: General inertial proximal gradient method for a class of nonconvex nonsmooth optimization problems. Comput. Optim. Appl. 73(1), 129–158 (2019)
Xiao, L., Zhang, T.: A proximal stochastic gradient method with progressive variance reduction. SIAM J. Optim. 24(4), 2057–2075 (2014)
Yang, Z., Wang, C., Zhang, Z., Li, J.: Accelerated stochastic gradient descent with step size selection rules. Signal Process. 159, 171–186 (2019)
Zavriev, S.K., Kostyuk, F.V.: Heavy-ball method in nonconvex optimization problems. Comput. Math. Model. 4, 336–341 (1993). https://doi.org/10.1007/BF01128757
Zhou, K., Shang, F., Cheng, J.: A simple stochastic variance reduced algorithm with fast convergence rates. In: Jennifer, D., Andreas, K. (eds.) Proceedings of the 35th International Conference on Machine Learning, vol. 80, pp. 5980–5989 (2018)
Acknowledgements
The authors would like to thank the editor and the anonymous referees for their valuable suggestions and comments which have greatly improved the presentation of this paper. This work is supported in part by the National Nature Science Foundation of China under Grant 61573014, the Fundamental Research Funds for the Central Universities under Grant JB210717 and the Fundamental Research Funds for the Central Universities under Grant YJS2215.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Liqun Qi.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
He, L., Ye, J. & Jianwei, E. Accelerated Stochastic Variance Reduction for a Class of Convex Optimization Problems. J Optim Theory Appl 196, 810–828 (2023). https://doi.org/10.1007/s10957-022-02157-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10957-022-02157-1