
Abstract
Macroscopic equations arising out of stochastic particle systems in detailed balance (called dissipative systems or gradient flows) have a natural variational structure, which can be derived from the large-deviation rate functional for the density of the particle system. While large deviations can be studied in considerable generality, these variational structures are often restricted to systems in detailed balance. Using insights from macroscopic fluctuation theory, in this work we aim to generalise this variational connection beyond dissipative systems by augmenting densities with fluxes, which encode non-dissipative effects. Our main contribution is an abstract theory, which for a given flux-density cost and a quasipotential, provides a decomposition into dissipative and non-dissipative components and a generalised orthogonality relation between them. We then apply this abstract theory to various stochastic particle systems—independent copies of jump processes, zero-range processes, chemical-reaction networks in complex balance and lattice-gas models—without assuming detailed balance. For macroscopic equations arising out of these particle systems, we derive new variational formulations that generalise the classical gradient-flow formulation.
Similar content being viewed by others


1 Introduction
When studying an evolution equation, it is often helpful to know if it has an associated variational structure, in order to obtain physical insight and tools for mathematical analysis. An important example of such a structure is a gradient flow or dissipative system; in this case the structure consists of an energy functional and a dissipation mechanism, and the evolution equation is completely characterised by a corresponding minimisation problem involving these two objects. From a thermodynamic point of view, such a variational structure is often related to random fluctuations of an underlying microscopic particle system via a large-deviation principle — examples include the Boltzmann–Gibbs–Helmholtz free energy and the Onsager–Machlup theory.
It has recently become clear that macroscopic equations are always dissipative (called gradient flows) if the underlying microscopic stochastic system is in detailed balance.Footnote 1 The energy functional and the dissipation mechanism for such macroscopic equations are then uniquely derived by an appropriate decomposition of the large-deviation rate functional associated to the microscopic systems [1,2,3,4]. These observations have provided a canonical approach to constructing a variational structure for such macroscopic equations. In addition to having a clear physical interpretation, these variational structures have been used to isolate interesting features of the macroscopic equations and study singular-limit problems arising therein.
So far, this approach has largely been limited to particle systems in detailed balance and corresponding macroscopic dissipative systems. Since a large deviation study is possible far beyond detailed balance, this leads to the following natural question.
Do the large deviations of the underlying particle systems provide a variational structure beyond detailed balance?
While this is a hard question to answer in general, considerable progress has been made in the case of some specific systems in two seemingly independent directions.
One direction that is tailored to allow for non-dissipative effects is the study of so-called FIR inequalities, first introduced for the many-particle limit of Vlasov-type nonlinear diffusions [5], independent particles on a graph [6] and chemical reactions [7, Sec. 5]. These inequalities bound the free-energy difference and Fisher information by the large-deviation rate functional, providing a useful tool to study singular-limit problems and to derive error estimates [8, 9]. Strictly speaking, these inequalities are not variational structures in the sense that they do not fully determine the macroscopic dynamics. However, in this paper we will construct a variational structure which generalises these inequalities and completely characterises the macroscopic dynamics.
Another direction of generalising dissipative systems is by using Macroscopic Fluctuation Theory (MFT) [10]. The main idea here is to consider, in addition to the usual density of the particle system, the particle fluxes at the microscopic level, and to study the large deviations of these fluxes. Consequently using time-reversal arguments, MFT explicitly captures the dissipative and non-dissipative effects in the system. However, most MFT literature has been devoted to diffusive scaling of particle systems and corresponding quadratic rate functions. Such rate functions define a Hilbert space with a natural orthogonal decomposition into dissipative and non-dissipative components. Recently non-quadratic rate functions and connections to MFT have been explored in the case of independent particles on a graph [11] and chemical reaction networks [7], but a general MFT for non-quadratic rate functions is largely open.
Spurred on by these exciting new developments, we provide a partial but affirmative answer to the question posed above. The basis of our analysis is an abstract action functional \((\rho ,j)\mapsto \int _0^T\!\mathcal {L}(\rho (t),j(t))\,dt\). This functional will correspond to the large deviations of random particle systems, but this identification is not necessary for our analysis; in this sense our approach is purely macroscopic. Inspired by FIR-inequalities and MFT, we set up an abstract theory whose central outcome will be a series of decompositions of the integrand \(\mathcal {L}\) into distinct dissipative and non-dissipative components. These decompositions generalise: (1) the connection between large deviations and dissipative systems from [3] to include non-dissipative effects, (2) the known cases of FIR inequalities [6] to a general setting, and (3) MFT to non-quadratic action functions.
Finally we apply this abstract theory to the density-flux large-deviation rate functional for various stochastic particle systems without assuming detailed balance, and derive new variational formulations for the corresponding macroscopic equations.
1.1 Summary of Results
Abstract results. Consider the macroscopic densities and fluxes \([0,T]\ni t \mapsto (\rho (t),j(t))\) that are evolving according to a coupled system of evolution equations of the form
Here “\(\mathop {{\textrm{div}}}\nolimits \)” will often denote the usual continuous or discrete divergence. In the abstract content of this paper we replace \(\mathop {{\textrm{div}}}\nolimits \) by a more general operator, but to keep the presentation short and intuitive, we simply write \(\mathop {{\textrm{div}}}\nolimits \) throughout this introduction. The \(j^0\) is a given operator mapping densities to fluxes, and is called the zero-cost flux for the following reason. In addition to the evolution (1.1) we are given an action functional
where the non-negative cost function \(\mathcal {L}\) has the crucial property that for any \((\rho ,j)\),
and hence the action (1.2) is minimised by the trajectory (1.1b). Typically, the first equation (1.1a) is a continuity equation, the coupled equations (1.1) describe the macroscopic dynamics arising from a microscopic stochastic particle system and (1.2) is the corresponding large-deviation rate functional.
Although writing the flux explicitly in (1.1b) instead of directly studying \({\dot{\rho }}(t)=-\mathop {{\textrm{div}}}\nolimits j^0(\rho (t))\) might seem superfluous at first sight, it is motivated by the fact that fluxes can encode information on non-dissipative, for instance divergence-free, effects in the system. Consequently, while studying densities is usually sufficient for dissipative systems [3, 12,13,14,15] (see Sect. 1.2 below for more details), the inclusion of fluxes is better suited to describe non-dissipative effects at the macroscopic level [10, 16].
Our abstract theory requires the existence of three objects: a sufficiently regular density-flux cost function \(\mathcal {L}(\rho ,j)\), an operator that will play the role of divergence and as such defines the continuity equation (1.1a) and a non-negative quasipotential \(\mathcal {V}\) associated to \(\mathcal {L}\). The basis of our approach will be the decomposition
where \(F(\rho ):=-{d_j}\mathcal {L}(\rho ,0)\) is called the driving force and \(\Psi \) and its convex dual \(\Psi ^*\) the dissipation potentials, see Theorem 2.9 for details. This decomposition is standard in the literature [3, 11, 16] and corresponds to a (possibly nonlinear) force-flux response relation \(j={d_\zeta }\Psi ^*(\rho ,F(\rho ))\) for the zero-cost dynamics; it includes gradient flows as a special case as discussed in Sect. 1.2.1.
Borrowing ideas from MFT, we uniquely decompose this driving force into a symmetric and antisymmetric part
On a macroscopic level, these notions of (anti)symmetry (defined in Sect. 2.3) are consistent with the time-reversal symmetry of Markov processes in the context of MFT and large deviations. In particular, if the microscopic system is in detailed balance, then \(F(\rho )={F^{\textrm{sym}}}(\rho )\) and the (macroscopic) dynamics is purely dissipative, i.e. described by a gradient flow driven by a quasipotential \(\mathcal {V}\) [3]. It turns out that even for systems that are not in detailed balance, the symmetric force \(F^\textrm{sym}\) always relates to such a \(\mathcal {V}\), which can be defined in terms of the cost \(\mathcal {L}\) (see Definition 2.6) and is a natural Lyapunov functional for the system. In particular, the symmetric part \({F^{\textrm{sym}}}(\rho )\) is a conservative force driven by the quasipotential (energy) \(\mathcal {V}\).
More generally, from a physical point of view, a purely dissipative system is thermodynamically closed, so that the work done is related to the free energy or quasipotential via
or formulated locally in time for the power
Thus for non-closed systems one can think of \({F^{\textrm{sym}}}(\rho )\) as an internally generated force and the remainder, \({F^{\textrm{asym}}}(\rho )\), as the force exerted by the system upon the environment. While
can be understood as expressions of power or rates of work, in general there is no reason to expect these to be exact differentials.
In our main result, Theorem 2.29, we relate the cost function \(\mathcal {L}\) to the three powers from (1.5) and (1.6). The crucial concept here will be the tilted cost \(\mathcal {L}_G(\rho ,j)\); these are modified versions of \(\mathcal {L}\) where the driving force \(F(\rho )\) is replaced by a different covector field \(G(\rho )\), see Definition 2.14. Consequently, the zero-cost flux of \(\mathcal {L}_G\) will be a modified dynamics, different from (1.1b). We shall use these to derive the following three dempositions of \(\mathcal {L}\), for any \(\lambda \in [0,1]\)
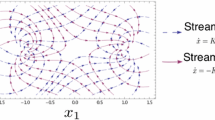
The parameter \(\lambda \) can be used to switch between different forces. Of particular interest is the case \(\lambda =\frac{1}{2}\), where the decompositions (1.7b) and (1.7c) can be seen as two different ways to split \(\mathcal {L}\) into purely dissipative and purely non-dissipative components. Indeed, the modified cost \(\mathcal {L}_{{F^{\textrm{sym}}}}\) is related to a purely dissipative system that can be formalised as a gradient flow (see Sect. 1.2.1). By contrast, we interpret the zero-cost flux of \(\mathcal {L}_{{F^{\textrm{asym}}}}\) as purely non-dissipative. Although the variational structure and physical interpretation of \(\mathcal {L}_{{F^{\textrm{asym}}}}\) remains an open question (see discussion in Sect. 6), we show for certain examples that its zero-cost behaviour corresponds to a purely Hamiltonian macroscopic evolution. This idea is clearly illustrated by Fig. 1, where we plot the phase diagram for the zero-cost flux associated with \(\mathcal {L}_F\), \(\mathcal {L}_{{F^{\textrm{sym}}}}\) and \(\mathcal {L}_{{F^{\textrm{asym}}}}\) in the case of independent Markov jump particles on a three-point state space. For details on this example see Sects. 2.6 and 4.

Consider the setting of independent and irreducible Markov jump particles on a three-point state space with generator \(Q:=[[-3,2,1],[1,-3,2],[2,1,-3)]]\) and invariant measure \(\pi =(\frac{1}{3},\frac{1}{3},\frac{1}{3})\). Phase portrait for the (zero-cost) trajectories \(\rho (t)\) associated to a \(\mathcal {L}(\rho (t),j(t))=0\); b \(\mathcal {L}_{F^{\textrm{sym}}}(\rho (t),j(t))=0\); c \(\mathcal {L}_{F^{\textrm{asym}}}(\rho (t),j(t))=0\). Here \(\rho _i\) is the mass at point i and we do not plot \(\rho _3\) since \(\sum _i\rho _i=1\). The zero-cost trajectories for \(\mathcal {L}_{F^{\textrm{sym}}}\) and \(\mathcal {L}_{F^{\textrm{asym}}}\) follow a purely dissipative and Hamiltonian dynamics respectively
The middle terms in the right hand side of (1.7) are inspired by [6, Def. 1.5], [7, Sec. 5], and are called generalised Fisher informations. For \(\lambda \in [0,1]\) and covector fields \(G=F,{F^{\textrm{sym}}},{F^{\textrm{asym}}}\), they are defined as
where \(\mathcal {H}\) is the convex dual of \(\mathcal {L}\). The terminology is motivated by the fact that (see Proposition 2.18)
which in the case \(G={F^{\textrm{sym}}}\) is the time derivative or dissipation rate of the quasipotential along the zero-cost path, i.e. in the limit \(\lambda \rightarrow 0\), \(\mathcal {R}^\lambda _{F^{\textrm{sym}}}\) coincides with the classical Fisher information [6]. The non-negativity of the generalised Fisher informations in (1.7) is essential, since it shows that the three powers in (1.5) and (1.6) are non-negative along the zero-cost flux, thus generalising the second law of thermodynamics.
Scope. To highlight the minimal underlying structure required to obtain the decompositions (1.7), analysis will be carried out in a general abstract setting.
This implies that our results can be applied to a broad range of models: the cost function \(\mathcal {L}\) does not need to be associated to large deviations, \((\rho ,j)\) do not need to refer to actual densities and fluxes, and we will replace the \(\mathop {{\textrm{div}}}\nolimits \)-operator by a general operator \(\phi \) with minimal assumptions, see Definition 2.3. In theory, after properly setting up the spaces, the only requirements of analysis will be the cost function \(\mathcal {L}\) together with a continuity equation, which need not necessarily be of divergence-type. However for specific applications, explicit calculations are restricted to cost functions \(\mathcal {L}\) for which the associated quasipotential \(\mathcal {V}\) is known. For the purpose of this paper, we define the quasipotential in terms of a Hamilton-Jacobi-Bellman equation (Definition 2.6), and solve it for a number of examples. For cost functions that are derived from large deviations, this definition coincides with the large-deviation rate functional of the invariant measure (see Theorem 3.7). However we reiterate that the abstract definition is purely macroscopic and does not require connections to large deviations.
Application. All three decompositions (1.7) are power balances, split into purely dissipative and purely non-dissipative powers in a physically consistent way. From a mathematical perspective, this generalises ideas from dissipative systems to a larger class of systems which include non-dissipative effects. For dissipative systems (\({F^{\textrm{asym}}}(\rho )\equiv 0\)) these decompositions coincide with the variational formulation of a gradient flow (see Sect. 1.2.1). However, our abstract theory only requires a suitably convex cost \(\mathcal {L}\) and quasipotential \(\mathcal {V}\) for the decompositions (and therefore the corresponding variational ideas) to hold. Lyapunov functions, Fisher informations and dissipation potentials are central ingredients in gradient-flow theory and often difficult to discern in non-dissipative systems (for instance the laws of non-reversible Markov processes). This work provides explicit formulae for these objects in terms of the cost and the quasipotential.
For the zero-cost dynamics (1.1), our results imply that the three powers \(\langle F,j\rangle , \langle F^\textrm{asym},j\rangle \) and \(\langle F^\textrm{asym},j\rangle \) are always non-positive, and in particular that \(\mathcal {V}\) is a Lyapunov functional with an explicit expression for its decay (rather than merely an upper bound).
By contrast, the decay (1.4) of the quasipotential \(\mathcal {V}\) is bounded by a FIR inequality, which connect the cost to the quasipotential and Fisher information. These inequalities are crucial in studying singular limits in non-dissipative systems, for instance to prove compactness of densities and fluxes in suitable topologies. However they are only available in a limited setting. It turns out that since the modified cost functions \(\mathcal {L}_G\) in (1.7) are non-negative, the FIR inequalities naturally arise from these decompositions and therefore we provide a universal recipe to arrive at such inequalities. In fact, the decompositions (1.7) explicitly characterise the gap in the FIR inequalities. For more details see Sect. 1.2.3.
The aforementioned gap in the inequalities corresponds to the \(\mathcal {L}_{G}\) on the right-hand side of (1.7). This new term exactly characterises the effects of non-dissipative effects in the variational structure and the corresponding macroscopic evolution. This is especially revealing for jump processes where we find that purely non-dissipative systems (\({F^{\textrm{sym}}}(\rho )\equiv 0\)) correspond to Hamiltonian-type structures.
From a physical standpoint, the decompositions (1.7) can be interpreted as a novel combination of gradient flows and Hamiltonian systems, in a similar spirit to GENERIC (see Sect. 1.2.2). However, we stress that all of our examples – apart from the lattice gas model – cannot be cast into the GENERIC framework. This work also provides a framework to study physically relevant ‘open-boundary’ jump-process systems (see a recent application in [17]).
Finally these decompositions also have numerical implications since numerical schemes inspired by gradient-flow structures of evolution equations have gained importance [18] in recent years. Numerical schemes often add artificial non-reversibility to speed-up convergence to equilibrium, but their analysis is tricky except in special situations [19]. The decompositions (1.7) explicitly characterise the role of Fisher informations and antisymmetric forces and a natural goal would be to optimise this force to speed up convergence.
Examples. Above we discussed the abstract framework and theory derived from it; this theory is purely macroscopic in that we do not require any connection to particle systems and large deviations. In the latter part of this paper we apply this abstract theory to several microscopic particle systems.
First, we focus on independent Markov jump particles on a finite graph as a guiding example throughout this paper, and generalise the results of [11]. Second, we study zero-range processes in a scaling which leads to an ordinary differential equation (ODE) in the limit. Third, we study chemical reaction networks in complex balance [20] and generalise the results in [7]. In all these three examples the macroscopic dynamics are ODEs and the large-deviation principle yields an exponential rate functional. Finally, we focus on the setting of particles that hop on a lattice in a diffusive limit, which leads to a drift-diffusion equation as the macroscopic evolution. These particles can either be independent random walkers or interact via exclusion. In this setting, the large-deviation principle yields a quadratic rate functional, and we recover the classical MFT results [10].
Boundary issues and global-in-time decompositions. The decompositions (1.7) do not involve time, and therefore when considering trajectories \(t\mapsto (\rho (t),j(t))\), they should be considered as local-in-time or instantaneous decompositions of \(\mathcal {L}(\rho (t),j(t))\) at time t. Naively, one would simply integrate in time to obtain global decompositions of the rate functional \(\int _0^T\!\mathcal {L}(\rho (t),j(t))\,dt\) for arbitrary trajectories \((\rho ,j)\). This argument is formal since, strictly speaking, the decompositions (1.7) hold only for \(\rho \), j for which the required terms are defined. More precisely, it turns out that the forces F, \({F^{\textrm{sym}}}\) and \({F^{\textrm{asym}}}\) are well-defined only on a proper subset of the domain of definition for the modified cost functions \(\mathcal {L}_G\) and generalised Fisher informations \(\mathcal {R}^\lambda _G\). This issue is often ignored in the MFT literature.
This issue becomes clear in the various examples we consider. For instance when dealing with independent jump processes on a finite lattice \(\mathcal {X}\), the large-deviation cost is well defined for any trajectory in the space of probability measures i.e., \(\rho (t)\in \mathcal {P}(\mathcal {X})\) (see Example 2.1), whereas the symmetric force is only well-defined for trajectories in the space of strictly positive probability measures, i.e., \(\rho (t)\in \mathcal {P}_+(\mathcal {X})\) (see (2.29)). This difference in the domains arises due to the logarithm present in the definition of the symmetric force. Such issues are typically dealt with by first extending the domains of definition of the forces involved by appropriately regularising them, second by proving the decompositions on these extended domains, and finally passing to the limit in the regularisations (see for instance the proof of [6, Thm. 1.6]). Although we expect that similar arguments can be applied to (1.7) to arrive at global-in-time decompositions, in this first study we focus on local-in-time results.
1.2 Related Work
As mentioned earlier, this work connects and generalises existing literature in various directions. Barring fairly recent works [7, 11, 21] which deal with particular examples, the connections between MFT, dissipative systems and FIR inequalities have largely been unexplored in the literature. Not all of these works consider fluxes, and so we will also make use of a ‘contracted’ cost function,
where the velocity u is a placeholder for \({\dot{\rho }}(t)\) and \(-\mathop {{\textrm{div}}}\nolimits \) is the abstract operator that maps fluxes to velocities as in (1.1a). This construction is consistent with the notion of contraction in large deviations (see Example 2.1). Since \({\hat{\mathcal {L}}}(\rho ,-\mathop {{\textrm{div}}}\nolimits j^0(\rho ))=0\), we refer to \(u^0(\rho ):= -\mathop {{\textrm{div}}}\nolimits j^0(\rho )\) as the zero-cost velocity.
1.2.1 Dissipative/Gradient Systems
In the case of dissipative systems \(F={F^{\textrm{sym}}}\) and \({F^{\textrm{asym}}}=0\), and choosing \(\lambda =\tfrac{1}{2}\) in the decomposition (1.7b) leads to
which also corresponds to (1.3) with \({F^{\textrm{asym}}}=0\). This decomposition of \(\mathcal {L}\) is exactly the characterisation of dissipative systems in the density-flux setting [16, 21]; see Sect. 2.6 for a further elaboration.
Using (1.5), \({F^{\textrm{sym}}}=-\frac{1}{2}\nabla d\mathcal {V}\) (see Corollary 2.21 for definition) and applying the contraction (1.9), we switch to the density setting
where \({\hat{\Psi }}\) is the contraction of \(\Psi \) and \({\hat{\Psi }},{\hat{\Psi }}^*\) are convex duals of each other (see [21, Thm. 3] for details).
The identity (1.11) is the standard decomposition of the density cost function that characterises a dissipative system or generalised gradient flow in the following sense. For the zero-cost velocity, the left-hand side satisfies \({\hat{\mathcal {L}}}(\rho ,u^0(\rho ))=0\), and the right-hand side of (1.11) is the Energy–Energy-Dissipation identity (EDI) [22,23,24], which is equivalent by convex duality to
where \(d_\xi \) is the derivative with respect to the second argument. In the special case when \({\hat{\Psi }}^*(\rho ,\xi )=\tfrac{1}{2}\langle K(\rho )\xi ,\xi \rangle \) is a quadratic form with an inverse metric tensor \(K(\rho )\) of a manifold, we arrive at the usual gradient-flow representation of the zero-cost velocity on that manifold
This connection between generalised gradient flows and the symmetry \(F={F^{\textrm{sym}}}\) at the level of densities has been explored more directly in [3], where it was shown that this symmetry holds if \({\hat{\mathcal {L}}}\) corresponds to the large-deviation principle of a Markov process in detailed balance. The density-flux formulation (1.10) of a dissipative system with quadratic dissipation has also been investigated extensively in the literature, see for instance [10, 16, 21]. Since we derived this decomposition from (1.7a) and (1.7b), these two decompositions can be thought of as the natural generalisations of the EDI to non-dissipative systems.
1.2.2 GENERIC
The GENERIC framework is specifically designed as a coupling between dissipative and non-dissipative effects in a thermodynamically consistent way [25,26,27]. Although originally meant to describe evolution equations, recent work has also studied the following natural connection between GENERIC and large deviations from a variational perspective (see (1.11)),
where the Poisson structure \(\mathbb {J}\) and energy \(\mathcal {E}\) define the Hamiltonian part of the dynamics, and additional non-interaction conditions are required to ensure that the zero-cost velocity
dissipates \(\mathcal {V}\) and conserves \(\mathcal {E}\).
Such a connection is discussed in [28] in the particular setting of weakly interacting diffusions and more recently in the context of hypocoercivity [29]. More generally, the recent paper [30] shows that (1.13) can only hold if the underlying microscopic system consists of stochastic dynamics in detailed balance combined with a deterministic drift. The drift may be replaced by stochastic fluctuations as long as they appear deterministic on the large-deviation scale [21], but any larger scale fluctuations that are not in detailed balance will break down the GENERIC structure. Therefore, the class of large-deviation cost functions with a GENERIC structure is rather limited.
By contrast, the decompositions (1.7) always hold as soon as the quasipotential \(\mathcal {V}\) is identified. The crucial difference is that our decompositions are based on a decomposition of forces, i.e.
rather than a decomposition of fluxes or velocities as in GENERIC (1.14). Furthermore, generalised orthogonality between \({F^{\textrm{sym}}}\) and \({F^{\textrm{asym}}}\) (see Sect. 2.4) is a natural analogue of the non-interaction conditions used in GENERIC.
1.2.3 FIR Inequalities
Using \(\mathcal {L}_{F-2\lambda {F^{\textrm{sym}}}}\ge 0\) and \({F^{\textrm{sym}}}=-\tfrac{1}{2}\nabla d\mathcal {V}\) (as above) in the decomposition (1.7b), we find
Since \(\nabla \) is the dual of \(-\mathop {{\textrm{div}}}\nolimits \), using the contraction principle (1.9) and the definition of the Fisher information (1.8) it follows that (see Corollary 2.34 for details)
where \({\hat{\mathcal {H}}}\) is the convex dual of \({\hat{\mathcal {L}}}\). This is a local-in-time version of the FIR inequality.
Assume that a smooth trajectory \([0,T]\ni t\mapsto \rho (t)\) satisfies (1.15) for every t. Substituting \(u={\dot{\rho }}\), formally applying the chain rule \(\langle d\mathcal {V}(\rho ),{\dot{\rho }}\rangle = \tfrac{d}{dt}\mathcal {V}(\rho )\), and integrating in time over [0, T] we arrive at the F(“free energy”)-I(“rate functional”)-R(“Fisher information”) inequality [6, Thm. 1.6]
Therefore, the decomposition (1.7b) can be thought of as a generalisation of [6] in various ways. First, (1.7b) holds fairly generally (in the abstract framework) and can be applied to systems well beyond independent copies of Markov jump processes studied in [6]. Second, (1.7b) exactly characterises the gap in the inequality (1.15) via \(\mathcal {L}_{F-2\lambda {F^{\textrm{sym}}}}\) which we discarded in this discussion due to its non-negativity. And third, a different version of the FIR inequality can also be derived from (1.7c).
It should be noted that the FIR inequalities have been used in the literature as a priori estimates to study singular limits, and we expect that the decomposition (1.7b) and inequality (1.15) will serve the same purpose for a considerably larger class of systems. However, in this paper we limit ourselves to the local-in-time decompositions (1.7b) as opposed to the global-in-time inequality (1.16) discussed in [6], since moving from local to global descriptions is a nontrivial technical step outside the scope of this work.
1.2.4 MFT and (non-)Quadratic Cost Function
As stated earlier, most MFT literature is concerned with the diffusive scaling of underlying stochastic particle systems which converge to diffusion-type macroscopic partial differential equations and corresponds to quadratic cost functions of the form [10]
Crucial arguments in MFT are based on the fact that the dissipative and the non-dissipative effects are orthogonal in this Hilbert space, i.e.
However, even the simple example of independent particles on a finite graph (see Example 2.1) yields a non-quadratic cost function \(\mathcal {L}\), and the aforementioned orthogonality arguments break down. In [11] (for independent jump processes) and [7] (for chemical reactions) these ideas are ported to the non-quadratic setting by introducing a generalised notion of orthogonality, where the pairing is no longer bilinear, and rather satisfies a relation of the form
By contrast, the abstract theory that we develop is not necessarily based on such orthogonality relations, although we do borrow many notions such as time-reversed cost-functions and forces from MFT. However we will show that within our framework, one can also construct a generalised orthogonality pairing \(\theta _\rho \) (fully characterised by \(\mathcal {L}\)) that satisfies (1.17), and coincides with the bilinear pairings \(\langle \cdot ,\cdot \rangle _\rho \) in case of quadratic cost functions and with \(\theta _\rho (\cdot ,\cdot )\) from [7, 11] in the case of specific non-quadratic cost functions. This will be the content of Sect. 2.4.
1.3 Summary of Notation and Outline of the Article
\(\mathcal {X}\) | Finite graph with strict ordering | Ex. 2.1 |
\(\mathcal {X}^2/2\) | Half the edges on a finite graph \(\mathcal {X}\) | (2.2) |
\(s(\cdot |\cdot )\) | Relative Boltzmann function (integrand/summand in relative entropy) | (2.7) |
\(\mathcal {Z},\mathcal {W},\phi \) | State-flux triple | Def. 2.3 |
\(T\mathcal {Z}\), \(T^*\mathcal {Z}\) | Tangent and cotangent bundle associated to \(\mathcal {Z}\) | |
\(T_\rho \mathcal {Z}\), \(T_\rho ^*\mathcal {Z}\) | Tangent and cotangent space at \(\rho \in \mathcal {Z}\) | |
\(\mathcal {L}\), \(\mathcal {H}\) | L-function and its convex dual | Def. 2.5 |
\({\hat{\mathcal {L}}}\), \({\hat{\mathcal {H}}}\) | Contracted L-function and its convex dual | (2.40) |
\(\mathcal {V}\) | Quasipotential | Def. 2.6 |
\(d{\mathcal {F}}\) | Gateaux derivative of a functional \({\mathcal {F}}\) | |
\(\chi {}^{\textsf{T}}\) | transpose or adjoint operator \(\chi {}^{\textsf{T}}:{\mathcal {M}}^*\rightarrow {\mathcal {N}}^*\) for \(\chi :{\mathcal {N}}\rightarrow {\mathcal {M}}\) | |
\({{\,\textrm{Dom}\,}}(A)\) | domain of an operator A | |
F | Driving force | Def. 2.10 |
\(\Psi ^*\), \(\Psi \) | Dissipation potential and its dual | Def. 2.10 |
\({\hat{\Psi }}^*\), \({\hat{\Psi }}\) | Contracted dissipation potential and its dual | (2.42) |
\(\mathcal {L}_G\), \(\mathcal {H}_G\) | Tilted L-function and its convex dual | Def. 2.14 |
\({{\,\textrm{Dom}\,}}_\textrm{symdiss}(A)\) | Subset of \({{\,\textrm{Dom}\,}}(A)\) where the dissipation potential is symmetric | (2.18) |
\(\mathcal {R}^{\lambda }_{\zeta }\) | Generalised Fisher information | Def. 2.17 |
| Reversed L-function and its convex dual | Def. 2.19 |
\({F^{\textrm{sym}}}\), \({F^{\textrm{asym}}}\) | Symmetric and antisymmetric force | Cor. 2.21 |
\(\mathcal {M}({\mathcal {X}})\), \(\mathcal {M}_a({\mathcal {X}})\) | Space of signed measures on \({\mathcal {X}}\) (with total mass a) | (2.8) |
\(\mathcal {P}({\mathcal {X}})\) | Space of probability measures on \( {\mathcal {X}}\) | |
\({\mathcal {P}}_+({\mathcal {X}})\) | Space of strictly positive probability measures on a discrete state space \( {\mathcal {X}}\) | |
\(\nabla ,\mathop {{\textrm{div}}}\nolimits \) | Continuous gradient and divergence | |
(Throughout introduction: general operator \(\mathop {{\textrm{div}}}\nolimits =d\phi _\rho \)) | ||
\(\mathop {{\overline{\nabla }}}\nolimits ,\mathop {{\overline{\mathop {{\textrm{div}}}\nolimits }}}\nolimits \) | Discrete gradient and divergence | (2.4) |
\({\mathbb {1}}_x\) | Indicator function associated to \(\{x\}\) |
 ,
, 
In Sect. 2 we present the abstract framework and theory. In Sect. 4 we analyse the zero-cost velocity for the antisymmetric L-function in the setting of independent particles on a finite graph. In Sect. 5 we apply the abstract theory to various stochastic particle systems and conclude with discussion in Sect. 6. In Sect. 3 we connect (and thereby motivate) the abstract ideas developed in Sect. 2 to large deviations.
2 Abstract Theory
In the introduction we worked with the large-deviation cost; we now work with its abstraction, the so-called the L-functionFootnote 2. In what follows we first introduce the L-function and other key ingredients of the abstract framework in Sect. 2.1. Using these objects we introduce dissipation potentials, tilted L-functions and Fisher information in Sect. 2.2. Using time-reversal-type arguments from MFT, in Sect. 2.3 we introduce time-reversed L-functions, symmetric and antisymmetric forces, and in Sect. 2.4 we introduce a generalised notion of orthogonality satisfied by these forces. Section 2.5 contains various decompositions of the L-function and in Sect. 2.6 we study the symmetric and antisymmetric L-function. Throughout this section we will use the guiding example of Independent Markovian Particles on a Finite Graph (IPFG), which we now introduce.
Example 2.1
(IPFG) Let \(\mathcal {X}\) be a finite graph with strict ordering, i.e., a complete order on the nodes in which no two nodes are equal. Consider n independent Markovian particles \(X_1(t),\ldots X_n(t)\) on \(\mathcal {X}\), with irreducible generator \(Q\in \mathbb {R}^{\mathcal {X}\times \mathcal {X}}\). The empirical measure (also called discrete particle density), defined as \(\rho ^{\scriptscriptstyle {(n)}}(t):=n^{-1}\sum _{i=1}^n\delta _{X_i(t)}\), is a Markov process on \(\mathbb {R}^\mathcal {X}\) with generator
where \({\mathbb {1}}_x\) is the indicator function for \(x\in \mathcal {X}\). With a suitable initial condition, Varadarajan’s Theorem implies that the random process \(\rho ^{\scriptscriptstyle {(n)}}\) converges in the many-particle limit \(n\rightarrow \infty \) to the deterministic solution of the ODE
In addition to the empirical measure, we will also track the number of jumps through each edge, which characterises the flux over an edge. For reasons that will be clarified in Sect. 2.2, it is important to consider net fluxes (over the usual one-sided fluxes), defined on half of the edges (for this purpose we impose an arbitrary ordering < on the finite set \(\mathcal {X}\))
More precisely, the so-called integrated net flux \(W^{\scriptscriptstyle {(n)}}_{xy}(t)\) over the edge connecting \(x,y\in \mathcal {X}\), is defined as the difference between the number of jumps from \(x\rightarrow y\) and in the opposite direction from \(y\rightarrow x\) in the time interval [0, t], all rescaled by \(\frac{1}{n}\). Then the pair \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t))\) is again a Markov process, now in \(\mathbb {R}^\mathcal {X}\times \mathbb {R}^{\mathcal {X}^2/2}\) with the generator
This process converges as \(n\rightarrow \infty \) to the solution of the macroscopic system
where the operator
is the discrete divergence for net fluxes. Indeed the system (2.3) is of the form (1.1).
In the many-particle limit (\(n\rightarrow \infty \)), the random fluctuations around the mean behaviour decay fast due to averaging effects. The unlikeliness to observe an atypical flux for large but finite n is quantified by the large-deviation principle, formally written as
where the \(\mathcal {L}\) is given by [31, 32] (the flux j is a placeholder for \(\dot{w}\))
which uses the Boltzmann function
Here \(\mathcal {I}_0\) is the large-deviation rate functional corresponding to the initial distribution of \(\rho ^{\scriptscriptstyle {(n)}}(0)\). Indeed \(\mathcal {L}(\rho ,j)\) is non-negative and minimised by (2.3). Due to the contraction principle [33, Thm. 4.2.1], the infimum is taken over all non-negative one-way fluxes \((j^+_{xy})_{x<y}\) and \((j^+_{yx}-j_{yx})_{x>y}\).
Applying the contraction principle, the empirical measure satisfies the following large-deviation principle, where \({\hat{\mathcal {L}}}\) is related to \(\mathcal {L}\) via (1.9),
2.1 Abstract Framework
Although at first sight the general setup in this section may seem heavy, it appears naturally in various specific systems. We illustrate this via our guiding example.
Example 2.2
(IPFG) There are two natural manifolds associated to the example of independent particles on a finite graph \(\mathcal {X}\) which we now introduce. Let
including vectors with negative coordinates. The states/densities \(\rho \) lie in the manifold \(\mathcal {Z}:=\mathcal {M}_1(\mathcal {X})\). Due to the constraint on total mass, \(\mathcal {Z}\) is a \((|\mathcal {X}|-1)\)-dimensional hyperplane in \(\mathbb {R}^{\mathcal {X}}\), with corresponding local tangent, cotangent spaces and Euclidean pairing between them given by
where \(a\cdot b\) is the usual dot product in Euclidean spaces. Cotangents are defined modulo the orthogonal space \((\mathcal {M}_0(\mathcal {X}))^\perp = \textrm{span}\{(1,1,\ldots ,1)\}\), and lead to \(\langle \xi +c(1,\ldots ,1),u\rangle =\xi \cdot u+c\sum _{x\in \mathcal {X}}u_x=\xi \cdot u\). The integrated net fluxes w simply lie in the Euclidean “flux space” manifold \(\mathcal {W}:=\mathbb {R}^{\mathcal {X}^2/2}\) (recall (2.2)) with local tangent and cotangent spaces \(T_w\mathcal {W}=T_w^*\mathcal {W}=\mathbb {R}^{\mathcal {X}^2/2}\), again paired together with the Euclidean inner product.
Between the two manifolds above we define the map \(\phi :\mathcal {W}\rightarrow \mathcal {Z}\) as
where \(\mathop {{\overline{\mathop {{\textrm{div}}}\nolimits }}}\nolimits \) is the discrete divergence from (2.4), \(\mathop {{\overline{\nabla }}}\nolimits _{xy}\xi :=\xi _y-\xi _x\) and \(\rho _0\in \mathcal {Z}\) is an arbitrary but fixed reference measure. Hence the continuity equation can be abstractly written as \(u=d\phi _w j \in T_{\phi [w]}\mathcal {Z}\) for \(j\in T_w\mathcal {W}\). It will be important that the operator \(\phi \) is surjective. For an arbitrary \(\mu \in \mathcal {M}_1(\mathcal {X})\), the difference \(\mu -\rho ^0\in \mathcal {M}_0(\mathcal {X})\).
Note that the underlying dynamics (2.3) as well as any path with \(\mathcal {J}(\rho ,w)<\infty \) conserves the total mass as well as the non-negativity of \(\rho (t)\), so that the states will in fact be restricted to the simplex \(\mathcal {P}(\mathcal {X})\subset \mathcal {M}_1(\mathcal {X})\subset \mathbb {R}^\mathcal {X}\) of probability measures on \(\mathcal {X}\) (i.e., coordinate-wise non-negative vectors in \(\mathbb {R}^{\mathcal {X}}\) which sum to one). However, we always work with the full manifold \(\mathcal {M}_1(\mathcal {X})\) so that derivatives and the (co)tangent spaces are well defined without needing to worry about boundaries, boundary points etc. Instead we set \(\mathcal {L}(\rho ,j)=\infty \) whenever \(\rho \) lies on (or outside of) the boundary \(\partial \mathcal {P}(\mathcal {X})\) and the flux \(j\in T_\rho \mathcal {W}\) pushes the state in the outward direction. Indeed, the functional \(\mathcal {J}(\rho ,w)\) and cost \(\mathcal {L}(\rho ,j)\) from Example 2.1 are defined for all \(\rho \in \mathcal {Z}=\mathbb {R}^\mathcal {X}\), but for any path with \(\mathcal {J}(\rho ,w)<\infty \), the densities are contained in \(\mathcal {P}(\mathcal {X})\).
For the above example \(d\phi _w,d\phi {}^{\textsf{T}}_w\) and the (co)tangent spaces \(T_w\mathcal {W},T_w^*\mathcal {W}\) do not depend on w. In practice, \(d\phi _w,d\phi {}^{\textsf{T}}_w\) and \(T_w\mathcal {W},T_w^*\mathcal {W}\) might depend on w, but only through the corresponding state \(\rho =\phi [w]\), as for example in a contuinity equation of the form \(v=-\mathop {{\textrm{div}}}\nolimits (\rho j)\). By a slight abuse of notation we shall therefore write \(d\phi _\rho ,d\phi {}^{\textsf{T}}_\rho \) and \(T_\rho \mathcal {W},T_\rho ^*\mathcal {W}\) for \(\rho \in \mathcal {Z}\). In particular, this allows us to write \(\mathcal {L}:T\mathcal {W}\rightarrow \mathbb {R}\cup \{\infty \}\), so that \(\mathcal {L}=\mathcal {L}(\rho ,j)\) for \((\rho ,j)\in T\mathcal {W}\).
Inspired by these observations we now introduce the state-flux triple, L-function and the quasipotential, which are the key ingredients in the abstract framework.
Definition 2.3
([21, Sec. 4.1]) A triple \((\mathcal {Z},\mathcal {W},\phi )\) is called a state-flux triple if
-
(i)
The state-space \(\mathcal {Z}\) and the flux-space \(\mathcal {W}\) are differentiable Banach manifolds, with corresponding local tangent Banach spaces \(T_\rho \mathcal {Z}\) and \(T_w\mathcal {W}\).
-
(ii)
\(\phi :\mathcal {W}\rightarrow \mathcal {Z}\) is a surjective differentiable operator \(\phi :\mathcal {W}\rightarrow \mathcal {Z}\).
-
(iii)
\(T_w\mathcal {W}\) depends on w only through \(\rho =\phi [w]\), so that by a slight abuse of notation we can replace \(T_w\mathcal {W}\) by \(T_\rho \mathcal {W}\) and write \(T\mathcal {W}:=\{(\rho ,j):\rho \in \mathcal {Z}, j\in T_\rho \mathcal {W}\}\).
-
(iv)
\(\phi \) has a linear bounded differential that depends on w only through \(\rho =\phi [w]\), so that by a slight abuse of notation we write \(d\phi _\rho : T_\rho \mathcal {W}\rightarrow T_\rho \mathcal {Z}\).
The Banach structure should be seen as a reference norm only, that we use to define Gateaux derivatives, the Banach dual spaces \(T_\rho ^*\mathcal {W}, T_\rho ^*\mathcal {Z}\) and the duality pairings \(_{T_\rho ^*\mathcal {Z}}\langle \cdot ,\cdot \rangle _{T_\rho \mathcal {Z}}\), \(_{T_\rho ^*\mathcal {W}}\langle \cdot ,\cdot \rangle _{T_\rho \mathcal {W}}\) (where we omit the indices since it will be clear to which spaces the elements belong). Analogously we write \(T^*\mathcal {W}:=\{(\rho ,\zeta ):\rho \in \mathcal {Z}, \zeta \in T_\rho ^*\mathcal {W}\}\) and \(T^*\mathcal {Z}:=\{(\rho ,\xi ):\rho \in \mathcal {Z}, \xi \in T_\rho ^*\mathcal {Z}\}\). The differential \(d\phi _\rho \) corresponds to a continuity equation \(u=d\phi _\rho j\), where \(d\phi _\rho \) is usually minus a divergence operator or some generalisation thereof. The assumption that \(d\phi \) is bounded, ensures the existence of a well-defined adjoint. In order to avoid confusion with convex duality, we will denote adjoint operators by \(\textsf{T}\), e.g. \(d\phi _\rho {}^{\textsf{T}}:T_\rho ^*\mathcal {Z}\rightarrow T_\rho ^*\mathcal {W}\).
Remark 2.4
Our state-flux triple is essentially identical to the framework of [34]; there \(\mathcal {Z}\) is called the ‘base manifold’, \(T\mathcal {W}\) is called the ‘total manifold’, and the differential \(d\phi :T\mathcal {W}\rightarrow T\mathcal {Z}\) is called the ‘anchor map’. \(\square \)
Definition 2.5
For any \(\mathcal {S}\subseteq \mathcal {Z}\) define
A mapping \(\mathcal {L}:T_\mathcal {S}\mathcal {W}\rightarrow \mathbb {R}\cup \{\infty \}\) is called an L-function on \(\mathcal {S}\), if for all \(\rho \in \mathcal {S}\):
-
(i)
\(\inf \mathcal {L}(\rho ,\cdot )=0\),
-
(ii)
there exists a unique \(j^0(\rho )\in T_\rho \mathcal {W}\), called the zero-cost flow, which satisfies \(\mathcal {L}\big (\rho ,j^0(\rho )\big )=0\),
-
(iii)
\(\mathcal {L}(\rho ,\cdot )\) is convex and lower semicontinuous (with respect to the Banach norm on \(T_\rho \mathcal {W}\)).
While this definition allows for flexibility in the domain, throughout this paper we will reserve the symbol \(\mathcal {L}\) for L-functions on the full space \({\mathcal {S}}=\mathcal {Z}\). From Sect. 2.2 onwards we will encounter functions \(\mathcal {L}_G\) that are only defined on proper subsets of \(\mathcal {Z}\) (see Remark 2.8 below). The inclusion of \(\infty \) in the codomain of \(\mathcal {L}\) is essential to encode forbidden fluxes as discussed in Example 2.2.
By lower semicontinuity and convexity, \(\mathcal {L}(\rho ,\cdot )\) is its own convex bidual with respect to the second variable [35, Prop. 3.56], i.e. there exists an \(\mathcal {H}:T^*_\mathcal {S}\mathcal {W}\rightarrow \mathbb {R}\cup \{\infty \}\) such that
It is easy to see that \(\mathcal {L}\) is an L-function if and only if for any \(\rho \in \mathcal {Z}\), \(\mathcal {H}(\rho ,0)=0\), \(\mathcal {H}(\rho ,\cdot )\) is convex, lower semicontinuous, proper and bounded from below by an affine function. Typically \(\mathcal {L}(\rho ,0)<\infty \), so that \(\mathcal {H}(\rho ,\cdot )\) is bounded from below.
We are now ready to introduce the following notion of the quasipotential.
Definition 2.6
A function \(\mathcal {V}:\mathcal {Z}\rightarrow \mathbb {R}\cup \{\infty \}\) is called a quasipotential (corresponding to \(\mathcal {L}\)) if
-
(i)
\(\inf \mathcal {V}=0\),
-
(ii)
for any \(\rho \in \mathcal {Z}\) where \(\mathcal {V}\) is Gateaux differentiable, we have
$$\begin{aligned} \mathcal {H}\big (\rho ,d\phi _\rho {}^{\textsf{T}}d\mathcal {V}(\rho )\big )=0. \end{aligned}$$(2.12)
We stress that this notion of a quasipotential is only related to the convex dual \(\mathcal {H}\) of some abstract function \(\mathcal {L}\), where a priori no stochastic particle system is involved. Both nowhere differentiable functions and the zero function are quasipotentials by definition, and our results are true but mostly trivial in this setting. In all the examples we consider, (2.12) will have at least one non-trivial solution and in fact this definition is consistent with the usual definition from statistical physics when large deviations are involved (see Sect. 3.2). We envisage that (2.12) should be understood in the sense of viscosity solutions, however it is not clear how one can define a viscosity solution in the general setup of this section.
Example 2.7
(IPFG) In Example 2.1, the processes \(X_1(t),X_2(t),\ldots \) are irreducible and \(\mathcal {X}\) is finite which ensures the existence of an invariant measure \(\pi \in \mathcal {P}_+(\mathcal {X})\) (the space of strictly positive probability measures). Consequently, the n-particle density \(\rho ^{\scriptscriptstyle {(n)}}(t)\) admits an invariant measure \(\Pi ^{\scriptscriptstyle {(n)}}\in \mathcal {P}(\mathbb {R}^\mathcal {X})\), where
By Sanov’s theorem, the large-deviation rate functional corresponding to \(\Pi ^{\scriptscriptstyle {(n)}}\) is
where \(s(\cdot \mid \cdot )\) is defined in (2.7), and hence \(\mathcal {V}\) is indeed the quasipotential corresponding to \(\mathcal {L}\) in the classical large-deviation sense (see Theorem 3.7).
This can also be checked macroscopically by verifying (2.12), without invoking any connection to large deviations of a microscopic particle system. To check this, we first calculate the convex dual of the L-function (2.6):
Note that while \(\mathcal {V}(\cdot )\) would be nowhere differentiable as a functional on \(\mathbb {R}^\mathcal {X}\), it is differentiable at all \(\rho \in \mathcal {P}_+(\mathcal {X})\) (which is a subset of the manifold \(\mathcal {M}_1(\mathcal {X})\) introduced in Example 2.2) since \(\pi _x>0\) for every \(x\in \mathcal {X}\) with Gateaux derivative
so that \(d\phi _\rho d\mathcal {V}(\rho ) = \mathop {{\overline{\nabla }}}\nolimits d\mathcal {V}(\rho ) = \big ( \log (\rho _y/\pi _y) - \log (\rho _x/\pi _x) \big )_{x<y} \in T_\rho ^*\mathcal {W}\). In fact by the chain rule, \(\mathop {{\overline{\nabla }}}\nolimits d\mathcal {V}(\rho )\) can also be interpreted as the (classical) derivative of \(\mathcal {V}(\phi [w])\) with respect to \(w\in \mathbb {R}^{\mathcal {X}^2/2}\); this also explains why the constants c do not play a role after taking the discrete gradient. We then check that \(\mathcal {V}\) is a quasipotential by concluding that at all points of differentiability of \(\mathcal {V}\) (i.e. for \(\rho \in \mathcal {P}_+(\mathcal {X})\)) using \(Q{}^{\textsf{T}}\pi =0\) and \(\sum _y Q_{xy}=0\) we find
where the third and fourth equality follows by interchanging the indices in the second terms of the summation.
Remark 2.8
Most of the analysis that follows will be carried out locally for fixed \(\rho \). Therefore the \(\rho \)-dependencies in \(\mathcal {L}(\rho ,j)\) and \(d\phi _\rho \) do not play a role in the calculations. We however include the dependency for two reasons. First, for almost all practical applications, \(\mathcal {L}\) and \(d\phi _\rho \) will depend on \(\rho \), either explicitly or implicitly through the domains of definition \(T_\rho \mathcal {W}, T_\rho \mathcal {Z}\). Second, even though writing the \(\rho \)-dependency is standard in the literature, so far practically all literature on the topic completely ignores the problems at the boundaries, where \(\mathcal {V}\) may cease to be differentiable due to the appearance of \(\log 0\). Our paper is one of the first to make completely precise claims in regards to domain of definitions for various objects involved by very carefully identifying all points \(\rho \) for which our results hold; this also motivates the definition of L-functions on subsets \(\mathcal {S}\). \(\square \)
2.2 Dissipation Potentials, Tilted L-Functions and Fisher Information
While the concept of a dissipation potential is standard [36,37,38], the connection to convex analysis [3] and the application to flux spaces is more recent [11, 21, 31, 39, 40]. Classically, a dissipation potential \(\Psi (\rho ,j)\) is convex, lower semicontinuous in the second variable, and satisfies \(\inf \Psi (\rho ,\cdot )=0=\Psi (\rho ,0)\). To define the dissipation potential in our context, we first present the following basic result on \(\mathcal {L}\), which was originally derived in the context of gradient flows [3, Lem. 2.1 & Prop. 2.1], where the driving force is the derivative of a certain free energy. As in the literature [7, 11, 31, 39,40,41], the setting with fluxes allows for more general driving forces. We first focus on a driving force \({\hat{\zeta \in }} T_\rho ^*\mathcal {W}\) for a fixed \(\rho \); and later introduce it as a \(\rho \)-dependent force field \(F(\rho )\).
Theorem 2.9
([3, Prop. 2.1(i)]) Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\) and fix \(\rho \in \mathcal {Z}\). For any \({\hat{\zeta \in }} T_\rho ^*\mathcal {W}\) and convex lower-semicontinuous \(\Psi (\rho ,\cdot ):T_\rho \mathcal {W}\rightarrow \mathbb {R}\cup \{\infty \}\) with convex dual \(\Psi ^*\), the following statements are equivalent
-
(i)
\(\inf \Psi (\rho ,\cdot )=0=\Psi (\rho ,0)\), and for any \(j\in T_\rho \mathcal {W}\)
$$\begin{aligned} \mathcal {L}(\rho ,j)=\Psi (\rho ,j) + \Psi ^*(\rho ,{\hat{\zeta }}) - \langle {\hat{\zeta }}, j\rangle . \end{aligned}$$(2.13) -
(ii)
\(-{\hat{\zeta \in \partial \mathcal {L}}}(\rho ,0)\) with
$$\begin{aligned} \Psi ^*(\rho ,\zeta )=\mathcal {H}(\rho ,\zeta -{\hat{\zeta }}) - \mathcal {H}\big (\rho ,-{\hat{\zeta }}\big ). \end{aligned}$$(2.14)
We would like to define the driving force as \(F(\rho )={\hat{\zeta }}\) and the dissipation potential \(\Psi (\rho ,j)\) as above. However these exist uniquely only if the subdifferential \(\partial \mathcal {L}(\rho ,0)\) consists of a singleton, i.e. \(\mathcal {L}(\rho ,\cdot )\) is Gateaux differentiable at 0, which motivates the following definitions.
Definition 2.10
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). Define
and recall the definition of the restricted (co)tangent spaces (2.10). The driving force F and dissipation potentials (corresponding to \(\mathcal {L}\)) are defined as
Note that, \(\Psi ^*\) as defined in (2.16) indeed satisfies \(\inf \Psi ^*(\rho ,\cdot )=0=\Psi ^*(\rho ,0)\), since \(-F\) is a minimiser of \(\mathcal {H}(\rho ,\cdot )\) by (2.15), and consequently \(\inf \Psi (\rho ,\cdot )=0=\Psi (\rho ,0)\) which makes \(\Psi \) a dissipation potential. Furthermore combining Theorem 2.9 with Definition 2.10, for any \((\rho ,j)\in T_{{{\,\textrm{Dom}\,}}(F)}W\) we have the decomposition
In what follows we will make use of
The following lemma states that the dissipation potential is indeed symmetric in \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)\).
Lemma 2.11
([3, Prop. 2.1(ii)]) Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)\) the following statements are equivalent
-
(i)
\(\mathcal {H}\big (\rho ,\zeta -F(\rho )\big ) = \mathcal {H}\big (\rho ,-\zeta -F(\rho )\big )\) for all \(\zeta \in T^*_\rho \mathcal {W}\),
-
(ii)
\(\mathcal {L}(\rho ,j) = \mathcal {L}(\rho ,-j) -2\langle F(\rho ),j\rangle \) for all \(j\in T_\rho \mathcal {W}\),
-
(iii)
\(\Psi ^*(\rho ,\zeta )=\Psi ^*(\rho ,-\zeta )\) for all \(\zeta \in T^*_\rho \mathcal {W}\),
-
(iv)
\(\Psi (\rho ,j)=\Psi (\rho ,-j)\) for all \(j\in T_\rho \mathcal {W}\).
Example 2.12
(IPFG) In practice the force (2.15) is more easily calculated via the equivalent statement \({d_\zeta }\mathcal {H}(\rho ,-F(\rho ))=0\). Since \(\xi =\frac{1}{2} \log \frac{d}{c}\) minimises \(\xi \mapsto c (e^\xi -1)+d(e^{-\xi }-1)\), we find
This definition of the driving force has been introduced in [11, Sec. 2.2]. Using (2.16), the dissipation potentials are given by
These dissipation potentials are indeed symmetric (since \(\cosh \) is even), and therefore \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)={{\,\textrm{Dom}\,}}(F)\). Note that, while a priori \(\Psi \) and \(\Psi ^*\) are only defined for strictly positive probability measures, they can easily be extended to the full space \(\mathcal {Z}=\mathcal {P}(\mathcal {X})\). For instance, the observation that \(\lim _{a\rightarrow 0} a \cosh ^*(\tfrac{x}{a})=0\) if \(x=0\) and \(+\infty \) otherwise, offers a trivial extension of \(\Psi \) to \(\mathcal {Z}\), which also reflects the idea “vanishing jump rates guarantee vanishing fluxes”.
We note that the Hamiltonian corresponding to one-way fluxes is given by
for which the corresponding driving force does not exist at all, i.e., \({{\,\textrm{Dom}\,}}(F^\mathrm {one\text {-}way})=\emptyset \) (also see [31, Rem. 4.10]). Hence one can only construct a meaningful macroscopic fluctuation theory for net fluxes. This further justifies the net-flux approach used in this paper, as opposed to the one-way fluxes typically used for Markov jump processes.
Remark 2.13
In the IPFG example above and all the examples considered in Sect. 5, \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)={{\,\textrm{Dom}\,}}(F)\), i.e., the dissipation potential is symmetric. However, in general \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)\) may be an (empty) subset of \({{\,\textrm{Dom}\,}}(F)\) as the following construction shows. Consider \(\mathcal {Z}=\mathcal {W}=\mathbb {R}\) and \(\phi =\textrm{id}\). Let \(\mathcal {H}(\rho ,\zeta )=-\zeta +e^\zeta -1\), which corresponds to a real-valued Markov process with generator \((\mathcal {Q}^{\scriptscriptstyle {(n)}}f)(\rho ,w):= -\partial _\rho f(\rho ,w)-\partial _w f(\rho ,w) + n(f(\rho +\tfrac{1}{n},w+\tfrac{1}{n})-f(\rho ,w))\). Then \(F\equiv 0\) and clearly \(\mathcal {H}(\rho ,-\zeta -F(\rho ))\ne \mathcal {H}(\rho ,\zeta -F(\rho ))\), which implies that \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)=\emptyset \). \(\square \)
So far we have dealt with L-functions on \(\mathcal {Z}\). Using (2.14), we now introduce L-functions defined on subsets of \(\mathcal {Z}\). For a given \(\mathcal {L}\) and an appropriate cotangent field \(G(\rho )\), using (2.14) we can define a (\(G\)-tilted) L-function \(\mathcal {L}_G\) defined on a subset of \(\mathcal {Z}\). We call this a ‘tilted’ L-function since its definition is motivated by tilted Markov processes (see Sect. 3.1). Although, technically \(G\) is a cotangent field, in this paper we will often refer to it as a force field due to physical considerations.
Definition 2.14
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(G:{{\,\textrm{Dom}\,}}(G)\rightarrow T_{{{\,\textrm{Dom}\,}}(G)}^*\mathcal {W}\) with \({{\,\textrm{Dom}\,}}(G)\subseteq \mathcal {Z}\), the tilted function \(\mathcal {H}_G:T_{{{\,\textrm{Dom}\,}}(F)\cap {{\,\textrm{Dom}\,}}(G)}^*\mathcal {W}\rightarrow \mathbb {R}\cup \{\infty \}\) is defined as
and \(\mathcal {L}_G:T_{{{\,\textrm{Dom}\,}}(F)\cap {{\,\textrm{Dom}\,}}(G)}\mathcal {W}\rightarrow \mathbb {R}\cup \{\infty \}\) denotes its convex dual in the second variable.
Lemma 2.15
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). The tilted function \(\mathcal {L}_G\) is an L-function on \({{\,\textrm{Dom}\,}}(F)\cap {{\,\textrm{Dom}\,}}(G)\), and satisfies the decomposition
The two equalities follow by using convex duality and (2.13), (2.14) with \({\hat{\zeta }}=F\). For special choices of \(G(\rho )\) we obtain
Example 2.16
(IPFG) For any force field \(G(\rho )\in \mathbb {R}^{\mathcal {X}^2/2}\) we have
We now define the notion of generalised Fisher information which was introduced in Sect. 1.1.
Definition 2.17
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(\rho \in \mathcal {Z}\), \(\zeta \in T_\rho ^*\mathcal {W}\), and \(\lambda \in [0,1]\), the generalised Fisher information is
As discussed in Sect. 1.1, it is important to choose \(\lambda \) and \(\zeta \) such that \(\mathcal {R}^\lambda _\zeta \) is non-negative, as this guarantees that the corresponding powers are non-negative along the zero-cost flux. The following result explores the set of force fields for which this is true (also see Fig. 2).
Proposition 2.18
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(\rho \in \mathcal {Z}\) we have
-
(i)
The set \(\{\zeta \in T_\rho ^*\mathcal {W}: \mathcal {R}^{\frac{1}{2}}_\zeta (\rho )\ge 0\}\) is convex and includes \(\zeta =0\).
-
(ii)
In particular, if \(\zeta \in T_\rho ^*\mathcal {W}\) such that
$$\begin{aligned} \mathcal {R}^{\frac{1}{2}}_\zeta (\rho ) \ge 0, \end{aligned}$$(2.23)then for any \(\lambda \in [0,1]\)
$$\begin{aligned} \mathcal {R}^{\lambda }_{\frac{1}{2}\zeta }(\rho )\ge 0. \end{aligned}$$(2.24) -
(iii)
For any \(\zeta \in T_\rho ^*\mathcal {W}\) we have
$$\begin{aligned} \lim \limits _{\lambda \downarrow 0} \tfrac{1}{\lambda } \mathcal {R}^{\lambda }_\zeta (\rho ) = 2\langle \zeta ,j^0(\rho ) \rangle . \end{aligned}$$(2.25)where \(j^0\) is the zero-cost flux for \(\mathcal {L}\) (see Definition 2.5).
Proof
-
(i)
Since \(\mathcal {L}\) is an L-function, \(\mathcal {H}(\rho ,\cdot )\) is convex with \(\mathcal {H}(\rho ,0)=0\) and the assertion follows.
-
(ii)
Using convexity, \(-\mathcal {R}^{\lambda }_{\frac{1}{2}\zeta }(\rho )=\mathcal {H}(\rho ,-\lambda \zeta )=\mathcal {H}(\rho ,-\lambda \zeta +(1-\lambda )0)\le \lambda \mathcal {H}(\rho ,-\zeta ) + (1-\lambda )\mathcal {H}(\rho ,0)\le 0\).
-
(iii)
By definition of L-functions, \(\mathcal {L}(\rho ,\cdot )\) has unique minimiser \(j^0(\rho )\), which is equivalent to \(\partial \mathcal {H}(\rho ,0)=\{j^0(\rho )\}=\{{d_\zeta }\mathcal {H}(\rho ,0)\}\). The claim then follows from the definition of the Gateaux derivative.
\(\square \)
Note that [6, Thm. 1.7] is a special case of this result for the IPFG example. Following [6], we call \(\mathcal {R}^\lambda \) the generalised Fisher information since it generalises the classical notion of Fisher information as the dissipation rate of free energy along the solutions of the zero-cost flux of the L-function. This property follows by using (2.25) with appropriate choices for \(\zeta \). In the next section we construct \(\zeta \) for which \( \mathcal {R}^{\frac{1}{2}}_\zeta (\rho )= 0\) and the above result can be applied.
2.3 Reversed L-Function, Symmetric and Antisymmetric Forces
Inspired by the notion of time-reversibility in MFT we now introduce the reversed L-function which will then be used to define symmetric and antisymmetric forces. From now on we assume that \(\mathcal {V}\) is a quasipotential associated to \(\mathcal {L}\) in the sense of Definition 2.6.
Definition 2.19
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(\rho \in \mathcal {Z}\) where \(\mathcal {V}\) is Gateaux differentiable and any \(j\in T_\rho \mathcal {W}\), we define the reversed L-function as

This notion of the reversed L-function is motivated by the large-deviations of time-reversed Markov processes (see Sect. 3.3 for details). Note that we use the name reversed L-function as opposed to time-reversed L-function since there is no time variable in this abstract framework.
The following result states that  is indeed an L-function, and discusses the driving force and dissipation potential associated to it.
is indeed an L-function, and discusses the driving force and dissipation potential associated to it.
Proposition 2.20
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(\rho \in \mathcal {Z}\) where \(\mathcal {V}\) is Gateaux differentiable we have
-
(i)
The convex dual of
 is
is  .
. -
(ii)
If
 is the zero-cost flux in the sense that
is the zero-cost flux in the sense that  , then
, then  , and it is unique if \(\mathcal {H}(\rho ,\cdot )\) is Gateaux differentiable at \(d\phi _\rho {}^{\textsf{T}}d\mathcal {V}(\rho )\). Furthermore
, and it is unique if \(\mathcal {H}(\rho ,\cdot )\) is Gateaux differentiable at \(d\phi _\rho {}^{\textsf{T}}d\mathcal {V}(\rho )\). Furthermore  is an L-function on \(\{\rho \in \mathcal {Z}:\mathcal {V}\text { is Gateaux differentiable in }\rho \}\) and \(\mathcal {V}\) is a quasipotential corresponding to
is an L-function on \(\{\rho \in \mathcal {Z}:\mathcal {V}\text { is Gateaux differentiable in }\rho \}\) and \(\mathcal {V}\) is a quasipotential corresponding to  .
. -
(iii)
Additionally, if \(\rho \in {{\,\textrm{Dom}\,}}(F)\) (recall Definition 2.10), then the driving force and dissipation potentials corresponding to
 are given by
are given by 
 is
is  .
. is the zero-cost flux in the sense that
is the zero-cost flux in the sense that  , then
, then  , and it is unique if
, and it is unique if  is an L-function on
is an L-function on  .
. are given by
are given by 
Proof
-
(i)
Follows by a straightforward calculation of the convex dual.
-
(ii)
Using the Fermat’s rule
 , and therefore
, and therefore  . Using Definition 2.19 and since \(\mathcal {L}\) is an L-function,
. Using Definition 2.19 and since \(\mathcal {L}\) is an L-function,  is convex, lower semicontinuous and using (2.12) satisfies
is convex, lower semicontinuous and using (2.12) satisfies  . Consequently
. Consequently  is an L-function on \({{\,\textrm{Dom}\,}}({F^{\textrm{sym}}})\) (see (2.26) below) and \(\mathcal {V}\) is a quasipotential associated to
is an L-function on \({{\,\textrm{Dom}\,}}({F^{\textrm{sym}}})\) (see (2.26) below) and \(\mathcal {V}\) is a quasipotential associated to  .
. -
(iii)
Using (2.15) we find

and using (2.16) we find

Consequently
 .
.
 , and therefore
, and therefore  . Using Definition
. Using Definition  is convex, lower semicontinuous and using (
is convex, lower semicontinuous and using ( . Consequently
. Consequently  is an L-function on
is an L-function on  .
.

 .
.\(\square \)
Motivated by this result, we decompose the driving force F (recall (2.15)) into a symmetric and antisymmetric part with respect to the reversal, i.e.  and
and  . The following result summarises these ideas.
. The following result summarises these ideas.
Corollary 2.21
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). Define
and
Then for any \(\rho \in {{\,\textrm{Dom}\,}}(F^\textrm{asym})\),

Note that while we make use of the reversed L-function to construct the symmetric and antisymmetric force, it does not explicitly appear in their definition. In the case of zero antisymmetric force, i.e. \({F^{\textrm{asym}}}(\rho )=0\), the driving forces satisfy  , which is the setting of dissipative systems (see Sect. 2.6).
, which is the setting of dissipative systems (see Sect. 2.6).
Example 2.22
(IPFG) We have

The expression \(\frac{\pi _{x}}{\pi _{y}} Q_{xy}\) is the generator matrix for a single time-reversed jump process [42, Thm. 3.7.1]. Again, beware that a priori  and
and  are only defined on \(\mathcal {Z}= {{\,\textrm{Dom}\,}}(F)\), but can be continuously extended to \(\mathcal {P}(\mathcal {X})\) in a straightforward manner.
are only defined on \(\mathcal {Z}= {{\,\textrm{Dom}\,}}(F)\), but can be continuously extended to \(\mathcal {P}(\mathcal {X})\) in a straightforward manner.
The symmetric and antisymmetric (with respect to the reversal) components of the driving force are (also see [11])
with \({{\,\textrm{Dom}\,}}(F)={{\,\textrm{Dom}\,}}({F^{\textrm{sym}}})={{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})=\mathcal {P}_+(\mathcal {X})\). Note that for reversible Markov chains, i.e., those satisfying detailed balance, \(F^\textrm{asym}=0\).
Recall the generalised Fisher information \(\mathcal {R}^{\lambda }_\zeta \) from Definition 2.17, and that we are looking for force fields that make this quantity non-negative. The following result shows that \(\mathcal {R}^{\frac{1}{2}}_\zeta (\rho )=0\) for \(\zeta =2F(\rho ),2F^\textrm{sym}(\rho )\), \(2F^\textrm{asym}(\rho )\). This will be crucial to derive the key decompositions of \(\mathcal {L}\) in Sect. 2.5.
In this result we make use of (analogous to (2.18)),
Note that \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym})\subseteq {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)\) since \({{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})\subseteq {{\,\textrm{Dom}\,}}F\).
Lemma 2.23
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). We have
-
(i)
\(\forall \rho \in {{\,\textrm{Dom}\,}}(F): \ \mathcal {R}^{\frac{1}{2}}_F(\rho ) \ge 0\) and \(\forall \rho \in {{\,\textrm{Dom}\,}}_{\textrm{symdiss}}(F): \ \mathcal {R}^{\frac{1}{2}}_{2F}(\rho )= 0\),
-
(ii)
\(\forall \rho \in {{\,\textrm{Dom}\,}}(F^\textrm{sym}): \ \mathcal {R}^{\frac{1}{2}}_{2{F^{\textrm{sym}}}}(\rho ) =0\),
-
(iii)
\(\forall \rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym}): \ \mathcal {R}^{\frac{1}{2}}_{2{F^{\textrm{asym}}}}(\rho ) =0\).
Proof
-
(i)
Since \(-F\) minimises \(\mathcal {H}\), it follows that \(\mathcal {H}(\rho ,-F)=\inf \mathcal {H}(\rho ,\cdot )\le \mathcal {H}(\rho ,0)=-\inf \mathcal {L}(\rho ,\cdot ) = 0\), and therefore \(\mathcal {R}^{\frac{1}{2}}_F(\rho ) = -\mathcal {H}(\rho ,-F)\ge 0\). If the dissipation potential is symmetric, the choice \(\zeta =-F(\rho )\) in Lemma 2.11(i) gives \(\mathcal {R}^{\frac{1}{2}}_{2F}(\rho ) = \mathcal {H}\big (\rho ,-2F(\rho )\big )=\mathcal {H}(\rho ,0)=0\).
-
(ii)
The claim follows since (2.12) holds for all \(\rho \in {{\,\textrm{Dom}\,}}(F^\textrm{sym})\).
-
(iii)
With
 in Lemma 2.11(i) we find \(\mathcal {H}\big (\rho ,-2F^\textrm{asym}(\rho )\big ) = \mathcal {H}\big (\rho ,-2F^\textrm{sym}(\rho )\big )=0\).
in Lemma 2.11(i) we find \(\mathcal {H}\big (\rho ,-2F^\textrm{asym}(\rho )\big ) = \mathcal {H}\big (\rho ,-2F^\textrm{sym}(\rho )\big )=0\).
 in Lemma
in Lemma \(\square \)
Figure 2 is a schematic diagram of force fields \(\zeta \) for which \(\mathcal {R}^\lambda _\zeta \) is non-negative. Note that, while there are various possibilities for such \(\zeta \), we focus on \(\zeta =2F(\rho ),2F^\textrm{sym}(\rho ),2F^\textrm{asym}(\rho )\) since they correspond to the physically relevant powers defined in (1.5) and (1.6).

Contour lines of a possible concave function \(\zeta \mapsto \mathcal {R}^{\frac{1}{2}}_{\zeta }(\rho )\) for a fixed \(\rho \), where the superlevel set \(\{\zeta \in T_\rho ^*\mathcal {W}:\mathcal {R}^{\frac{1}{2}}_{\zeta }(\rho )\ge 0\}\) is depicted in gray. By Definitions 2.10 and 2.17, \(F(\rho )\) is a maximiser for \(\zeta \mapsto \mathcal {R}^{\frac{1}{2}}_{\zeta }(\rho )\), and assuming \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}({F^{\textrm{asym}}})\), Lemma 2.23 says that \(2F(\rho )\), \(2{F^{\textrm{sym}}}(\rho )\) and \(2{F^{\textrm{asym}}}(\rho )\) all lie on the 0-contour line. By the convexity of the superlevel set \(\{\mathcal {R}^{\frac{1}{2}}_\zeta (\rho )\ge 0\}\) (see Proposition 2.18), any convex combination \(\zeta \) between 0 and \(2F(\rho )\), \(2{F^{\textrm{sym}}}(\rho )\) or \(2{F^{\textrm{asym}}}(\rho )\), drawn by the three lines, yield non-negative \(\mathcal {R}^{\frac{1}{2}}_\zeta (\rho )\ge 0\)
Remark 2.24
For all \(\rho \in {{\,\textrm{Dom}\,}}(F^\textrm{asym})\), we can write the reversed function as a tilting in the sense of (2.20)

Using (2.21), the corresponding reversed L-function then satisfies

where we have used  . \(\square \)
. \(\square \)
2.4 Generalised Orthogonality
Before we continue with deriving the main decompositions (1.7) of the L-function, we elaborate further on the decomposition of the driving force F into the symmetric force \({F^{\textrm{sym}}}\) and antisymmetric force \({F^{\textrm{asym}}}\), and investigate the natural question whether these forces are orthogonal in some sense. It turns out that they are indeed orthogonal in a generalised sense, and using this notion of orthogonality we can already derive decompositions (1.7) for \(\lambda =\frac{1}{2}\). As discussed in the introduction, in MFT the dissipation potentials are often squares of appropriate Hilbert norms \(\Vert \cdot \Vert _{\rho }\), and in that setting one can write
where \(\langle \cdot ,\cdot \rangle _{\rho }\) is the inner product induced by the norm. Typically \({F^{\textrm{sym}}}\) and \({F^{\textrm{asym}}}\) are orthogonal in the sense that \(\langle {F^{\textrm{sym}}},{F^{\textrm{asym}}}\rangle _{\rho }=0\). We reiterate these ideas in Sect. 5.3 which deals with the classical MFT setting of lattice gases. However this orthogonality relation is specific to the quadratic setting. A generalised notion of orthogonality was introduced in [11] for non-quadratic dissipation potential (2.19) corresponding to independent Markov chains which have \(\cosh \)-type structure (see Example 2.12) and this principle was further generalised to chemical reaction networks in [7] (see Sect. 5.2 for details). Based on these results, we now provide a notion of generalised orthogonality which applies to arbitrary dissipation potentials arising within the abstract framework of this section (and does not require any specific structure).
Definition 2.25
For any \(\rho \in {{\,\textrm{Dom}\,}}(F)\) and \(\zeta ^2 \in T^*_{\rho }\mathcal {W}\), define the modified dissipation potential \(\Psi ^*_{\zeta ^2}:T^*_{\rho }\mathcal {W}\rightarrow {\mathbb {R}}\cup \{\infty \}\) and the generalised orthogonality pairing \(\theta _\rho :T^*_{\rho }\mathcal {W}\times T^*_{\rho }\mathcal {W}\rightarrow {\mathbb {R}}\cup \{\infty \}\) as
where we have used (2.16) to arrive at the equalities.
The following result collects the properties of \(\Psi _{\zeta ^2}\) and \(\theta _\rho \) clarifying the notion of orthogonality in the abstract framework. Recall the definition of \({{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym})\) from (2.30).
Proposition 2.26
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(\rho \in {{\,\textrm{Dom}\,}}(F)\), \(\Psi _{\zeta ^2}^*(\rho ,\cdot )\) is convex, lower semicontinuous and \(\inf \Psi ^*_{\zeta ^2}(\rho ,\cdot )=0=\Psi _{\zeta ^2}^*(\rho ,0)\). Furthermore, for any \(\zeta ^1,\zeta ^2\in T_\rho ^*\mathcal {W}\), the dissipation potential \(\Psi ^*\) admits the decomposition
Moreover the generalised orthogonality pairing satisfies
and therefore we have
Proof
The convexity, lower semicontinuity of \(\Psi _{\zeta ^2}^*\) follows from the convexity, lower semicontinuity of \(\Psi ^*\) and \(\Psi _{\zeta ^2}^*(\rho ,0)=0\) follows from the definition. Using convexity of \(\Psi ^*\) we find
and therefore \(\inf \Psi ^*_{\zeta ^2}(\rho ,\cdot )=0\). The two decompositions follow immediately by adding \(\Psi ^*_{\zeta ^2}\) and \(\theta _\rho \). Using Lemma 2.23 we find
where the second decomposition additionally requires that \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym})\). \(\square \)
From the general decomposition (2.17) and the generalised orthogonality result above, we can already provide two distinct decompositions of \(\mathcal {L}\), as derived in [7, Cor. 4.3] for the case of chemical reactions.
Corollary 2.27
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). Then for all \((\rho ,j)\in T_{{{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})}\mathcal {W}\),
and for all \((\rho ,j)\in T_{{{\,\textrm{Dom}\,}}_\textrm{symdiss}({F^{\textrm{asym}}})}\mathcal {W}\),
In both decompositions, we may interpret the first three terms as an L-function with a modified force, the fourth term as a Fisher information, and the last term as a power (see Remark 2.32 for details).
Example 2.28
(IPFG) Using Definition 2.25 we have (see also [11])
2.5 Decomposing the L-Function
We now present decompositions of the L-function, which are the main results of the abstract theory presented so far. Using \(G=F,{F^{\textrm{sym}}},{F^{\textrm{asym}}}\) in (2.21) and encoding convex combinations via the parameter \(\lambda \), we arrive at three distinct decompositions of \(\mathcal {L}\); this corresponds to all the points on the three lines depicted in Fig. 2.
Theorem 2.29
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). It admits the following decompositions
-
(i)
For any \(\rho \in {{\,\textrm{Dom}\,}}_{\textrm{symdiss}}(F)\), \(j\in T_\rho \mathcal {W}\) and \(\lambda \in [0,1]\),
$$\begin{aligned} \mathcal {L}(\rho ,j)= & {} \mathcal {L}_{(1-2\lambda )F}(\rho ,j) + \mathcal {R}^\lambda _F(\rho ) - 2\lambda \langle F(\rho ),j\rangle \nonumber \\{} & {} \quad \text { with } \mathcal {R}^\lambda _F(\rho )\ge 0. \end{aligned}$$(2.32) -
(ii)
For any \(\rho \in {{\,\textrm{Dom}\,}}(F^\textrm{asym})\), \(j\in T_\rho \mathcal {W}\) and \(\lambda \in [0,1]\),
$$\begin{aligned} \mathcal {L}(\rho ,j)= & {} \mathcal {L}_{F-2\lambda F^\textrm{sym}}(\rho ,j) + \mathcal {R}^\lambda _{{F^{\textrm{sym}}}}(\rho ) - 2\lambda \langle F^\textrm{sym}(\rho ),j\rangle \nonumber \\{} & {} \quad \text { with }\mathcal {R}^\lambda _{{F^{\textrm{sym}}}}(\rho )\ge 0. \end{aligned}$$(2.33) -
(iii)
For any \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym})\), \(j\in T_\rho \mathcal {W}\) and \(\lambda \in [0,1]\),
$$\begin{aligned} \mathcal {L}(\rho ,j)= & {} \mathcal {L}_{F-2\lambda F^\textrm{asym}}(\rho ,j) + \mathcal {R}^\lambda _{{F^{\textrm{asym}}}}(\rho ) - 2\lambda \langle F^\textrm{asym}(\rho ),j\rangle \nonumber \\{} & {} \quad \text {with }\mathcal {R}^\lambda _{{F^{\textrm{asym}}}}(\rho )\ge 0. \end{aligned}$$(2.34)
Proof
The decompositions follow directly from Lemma 2.15. The non-negativity of the Fisher informations follows from Proposition 2.18 and Lemma 2.23. \(\square \)
Remark 2.30
The decomposition (2.32) holds for \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F)\). Since by Lemma 2.23(i), \(\mathcal {R}_F^{\frac{1}{2}}(\rho )\ge 0\) for any \(\rho \in {{\,\textrm{Dom}\,}}(F)\), we also have the following decomposition for any \(\rho \in {{\,\textrm{Dom}\,}}(F)\), \(j\in T_\rho \mathcal {W}\) and \(\lambda \in [0,\tfrac{1}{2}]\)
The non-negativity of \(\mathcal {R}^\lambda _{F}(\rho )\) follows by repeating the proof of Proposition 2.18(ii) for \(\lambda \in [0,\tfrac{1}{2}]\). \(\square \)
The following result exhibits the significance of the choices \(\lambda =\tfrac{1}{2},1\), and that the decompositions for other values can be seen as generalisations.
Corollary 2.31
(\(\lambda =\tfrac{1}{2},1\)) With the choice \(\lambda =\tfrac{1}{2}\), the decompositions (2.32), (2.33) and (2.34) respectively become
With the choice \(\lambda =1\), the decompositions (2.32), (2.33) and (2.34) respectively become

where  satisfy the relations (2.28).
satisfy the relations (2.28).
The second equality in (2.35) follows from (2.22) and (2.16) where we use \(\mathcal {H}(\rho ,0)=0\) and the Fisher-information term vanishes by Lemma 2.23. A careful analysis of the zero-cost flux for \(\mathcal {L}_{{F^{\textrm{sym}}}}\) and \(\mathcal {L}_{{F^{\textrm{asym}}}}\) will be presented in Sect. 2.6 and Sect. 4.
Remark 2.32
Using (2.17), we see that (2.36) and (2.37) are the same decompositions as those in Corollary 2.27 which use generalised orthogonality, and that the two corresponding Fisher informations are in fact modified dissipation potentials (as introduced in Sect. 2.4)
This also explains the non-negativity of these Fisher informations for \(\lambda =\frac{1}{2}\). \(\square \)
Example 2.33
(IPFG) Decompositions (2.32), (2.33) and (2.34) hold with the tilted L-functions
and the corresponding Fisher informations
While non-negativity of these Fisher informations is guaranteed by construction, it can also be proven directly by using \((1-\lambda ) a+\lambda b \ge a^{1-\lambda }b^\lambda \). For \(\lambda =\frac{1}{2}\), all three Fisher informations are of the form \({\mathop {\mathrm {\sum \!\sum }}\limits }_{x\ne y}(\sqrt{\cdot }-\sqrt{\cdot })^2\); interpreting the difference as an abstract discrete gradient, this is reminiscent of the usual Fisher information in continuous space \(\frac{1}{2}\int \!(\nabla \sqrt{\rho (x)})^2\,dx\).
These decompositions provide new variational characterisations for the IPFG example, which coincide with the classical gradient-flow structure for Markov chains satisfying detailed balance (see Sect. 2.6) and lead to the FIR inequality as a special case (see Example 2.35 below). The decomposition (2.33) with \(\lambda =\frac{1}{2}\) was first discussed in [11, Cor. 4].
All three L-functions \(\mathcal {L}_{(1-2\lambda )F}\), \(\mathcal {L}_{F-2\lambda F^\textrm{sym}}\) and \(\mathcal {L}_{F-2\lambda F^\textrm{asym}}\) are the large-deviation cost functions for processes with altered jump rates. In particular, \(\mathcal {L}_{F^\textrm{sym}}=\mathcal {L}_{F-F^\textrm{asym}}\) is the large-deviation cost function corresponding to the jump process with jump rates for a particle to jump from x to y given by

where we write  for the jump rate of a single time-reversed jump process [42, Thm. 3.7.1]. The linearity in \(\rho _x\) reflects that the system consists of independent Markov particles with generator
for the jump rate of a single time-reversed jump process [42, Thm. 3.7.1]. The linearity in \(\rho _x\) reflects that the system consists of independent Markov particles with generator  [31, 32].
[31, 32].
Similarly, \(\mathcal {L}_{F^\textrm{asym}}=\mathcal {L}_{F-F^\textrm{sym}}\) is the large-deviation cost function corresponding to a system with jump rates for one particle to jump from x to y given by [43]

We can interpret \(\mathcal {L}_{F^\textrm{asym}}(\rho ,j)\) as the flux large-deviation cost function corresponding to a system of interacting particles with jump rates \(n\kappa _{xy}^\textrm{asym}(\rho )\) [44]. It should be noted that the usual large-deviation proof techniques break down in this particular case due to the non-uniqueness of solution to the limiting antisymmetric ODE (see Proposition 4.2).
The next corollary connects the decomposition (2.33) to an (abstract-)FIR inequality (recall Sect. 1.2.3) only defined on the state-space \(\mathcal {Z}\) and with no dependence on the flux-space \(\mathcal {W}\). In order to make this connection we introduce the contracted L-function \(\hat{\mathcal {L}}:T_\rho \mathcal {Z}\rightarrow {\mathbb {R}}\cup \{\infty \}\) defined as
The definition of \({\hat{\mathcal {L}}}\) is inspired by the contraction principle in large-deviation theory, where \({\hat{\mathcal {L}}}\) is the large-deviation rate functional only on the state space (recall Example 2.1). This connection will be further clarified in Proposition 3.4.
Corollary 2.34
(FIR inequality) Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\). For any \(\rho \in {{\,\textrm{Dom}\,}}(F^\textrm{asym})\), \(u\in T_\rho \mathcal {Z}\) and \(\lambda \in [0,1]\) we have
where \({\hat{\mathcal {L}}}\) (with convex dual \({\hat{\mathcal {H}}}\)) is defined in (2.40) and \(\mathcal {R}^\lambda _{{F^{\textrm{sym}}}}(\rho )=-{\hat{\mathcal {H}}}(\rho ,\lambda d\mathcal {V})\).
Proof
Using convex duality and (2.40) it follows that \(\mathcal {R}^\lambda _{{F^{\textrm{sym}}}}(\rho )=-\mathcal {H}(\rho ,\lambda d\phi {}^{\textsf{T}}_\rho d\mathcal {V})=-{\hat{\mathcal {H}}}(\rho ,\lambda d\mathcal {V})\). Using (2.33) and the definition of \({F^{\textrm{sym}}}\) (2.27) we find
where the second equality follows since \(\langle d\phi {}^{\textsf{T}}_\rho \eta ,j\rangle = \langle \eta ,d\phi _\rho j\rangle \) and the inequality follows since tilted L-functions are non-negative by definition (see Lemma 2.15 & Definition 2.5). \(\square \)
Example 2.35
(IPFG) We now comment on the connection with the FIR inequality in [6]. Let \(\rho \in C^1([0,T];{{\,\textrm{Dom}\,}}({F^{\textrm{sym}}}))\), where we have abused notation so that \(\rho \) is now a trajectory, and recall that \({{\,\textrm{Dom}\,}}({F^{\textrm{sym}}})=\mathcal {P}_{+}(\mathcal {X})\). Since \({\dot{\rho }}(t)\in T_{\rho (t)}\mathcal {Z}\), using Corollary 2.34, for any \(t\in [0,T]\) and \(\lambda \in [0,1]\) we have
where we have used \(\langle d\mathcal {V}(\rho (t)),{\dot{\rho }}(t) \rangle = \frac{d}{dt}\mathcal {V}(\rho (t))\). Integrating in time, which is allowed since \(\rho \) is a sufficiently smooth curve, we find
This is exactly the FIR inequality in [6, Thm. 1.6], although this paper has two crucial generalisations. First, using approximation arguments, in [6] the class of admissible curves is extended to \(\rho \in AC([0,T];\mathcal {Z})\), i.e., absolutely continuous curves in \(\mathcal {Z}=\mathcal {P}(\mathcal {X})\) instead of \(\mathcal {P}_+(\mathcal {X})\) discussed above (recall the discussion in Sect. 1.2.3). Second, in [6] the relative entropy \(\textrm{RelEnt}(\rho (t)|\mu (t))\) with respect to any time-dependent solution \(\mu \) of the corresponding macroscopic dynamics (which is the forward Kolmogorov equation)
is used as opposed to the quasipotential \(\mathcal {V}(\rho )=\textrm{RelEnt}(\rho (t)|\pi )\), where \(\pi \) is the invariant measure of (2.41). We believe that this generalisation from the invariant measure \(\pi \) to any time dependent solution \(\mu (t)\) is a feature of the linear forward Kolmogorov equations (similar results also hold for linear Fokker-Planck equations [45, Thm. 1.1], [8, Thm. 4.18] arising from diffusion processes), and cannot be expected to hold in the setup of our paper where we are interested in nonlinear macroscopic equations. This is also the case for nonlinear diffusion processes [5, Thm. 2.3].
2.6 Symmetric and Antisymmetric L-Functions
In this section we focus on the two terms \(\mathcal {L}_{F^{\textrm{sym}}}\) and \(\mathcal {L}_{F^{\textrm{asym}}}\) in the decompositions (2.37) and (2.36) respectively. Observe that \(\mathcal {L}=\mathcal {L}_{F^{\textrm{sym}}}\) if \({F^{\textrm{asym}}}=0\), and therefore \(\mathcal {L}_{F^{\textrm{sym}}}\) corresponds to a system with a purely symmetric force. The relation between such systems with gradient flows is well known and follows from the theory in the previous sections, but for completeness we will make this connection explicit here. Similarly, \(\mathcal {L}_{F^{\textrm{asym}}}\) corresponds to a system with a purely antisymmetric force; in the level of abstraction of our current paper such systems are less understood. Motivated by our analysis in Sect. 4 and the examples in Sect. 5 we conjecture below that these L-functions are related to Hamiltonian systems.
We first discuss the purely symmetric case. Note that when particle systems and large-deviations are involved, \(\mathcal {L}_{F^{\textrm{sym}}}\) is the large-deviation cost function of a microscopic system in detailed balance (see Corollary 3.11). In what follows we will make use of the contracted dissipation potential \({\hat{\Psi }}:T_\rho \mathcal {Z}\rightarrow {\mathbb {R}}\cup \{\infty \}\) defined as
Corollary 2.36
(EDI) Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\) and \(\rho \in {{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})\). For any \(j\in T_\rho \mathcal {W}\) we have
and for any \(u\in T_\rho \mathcal {Z}\) we have
where \({\hat{\mathcal {L}_{F^{\textrm{sym}}}}}\), \({\hat{\Psi }}\) are defined in (2.40), (2.42) and \({\hat{\Psi }}^*(\rho ,\xi )=\Psi ^*(\rho ,d\phi _\rho {}^{\textsf{T}}\xi )\) is the convex dual of \({\hat{\Psi }}\). Additionally if \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym})\), then for any \(j\in T_\rho \mathcal {W}\) and \(u\in T_\rho \mathcal {Z}\) we have the symmetry relations
Proof
Using \({F^{\textrm{asym}}}=0\) we have \(F(\rho )={F^{\textrm{sym}}}(\rho )\), and the decomposition (2.43) then follows from (2.36) since \(\mathcal {L}_0(\rho ,j)=\Psi (\rho ,j)\) (see (2.22)), \(\mathcal {R}^\frac{1}{2}_{{F^{\textrm{sym}}}}(\rho )=\Psi ^*(\rho ,{F^{\textrm{sym}}}(\rho ))\) and using the definition of \({F^{\textrm{sym}}}\) (2.27). The decomposition (2.44) follows by applying the infimum in (2.40) to (2.43) and noting that by definition of convex duality \({\hat{\Psi }}^*(\rho ,\xi )=\Psi ^*(\rho ,d\phi {}^{\textsf{T}}\xi )\) for any \(\xi \in T^*_\rho \mathcal {Z}\). The first symmetry relation follows by Lemma 2.11(ii) and the second symmetry relation following by taking the infimum of the first symmetry relation on both sides. \(\square \)
Note that the decomposition (2.43) also follows from (2.37) by using (2.13), but for \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}({F^{\textrm{asym}}})\). Let us first comment on the contracted symmetric function \({\hat{\mathcal {L}_{F^{\textrm{sym}}}}}\). Clearly, its zero-cost velocity \(u^0(\rho )\) satisfies the EDI
which is equivalent by convex duality to a generalised gradient flow (1.12). Summarising Corollaries 3.11 and 2.36, if a microscopic system is in detailed balance, the large-deviation cost function \(\mathcal {L}=\mathcal {L}_{F^{\textrm{sym}}}\) has a purely symmetric force, and hence induces a generalised gradient flow. This connection between gradient flows and detailed balance was first discussed in this generality in [3]. For the IPFG example, the second symmetry relation in (2.45) correspond to the classical gradient structure for finite-state Markov chains in detailed balance [3, Sec. 4.1] and the decomposition (2.43) is the corresponding flux formulation of the gradient structure for this example [31, Sec. 4.5]. Note that, strictly speaking (2.43) is not a gradient flow in the density-flux space. However a careful rewriting allows us to see \(\mathcal {L}_{F^{\textrm{sym}}}\) as a gradient flow, as summarised in the following remark.
Remark 2.37
With \(\mathcal {L}^\mathcal {W}_{F^{\textrm{sym}}}(w,j):=\mathcal {L}_{F^{\textrm{sym}}}(\phi [w ],j)\), and applying the chain rule \(d_w\mathcal {V}^\mathcal {W}(w)=d\phi _{\phi [w ]}{}^{\textsf{T}}d_\rho \mathcal {V}(\phi [w])\), we arrive at
In this formulation \(\mathcal {L}_{{F^{\textrm{sym}}}}\) is indeed a gradient flow in the density-flux space [21]. \(\square \)
As far as we are aware, the purely antisymmetric cost \(\mathcal {L}_{F^{\textrm{asym}}}\) has not been studied in the literature, and we could not produce rigorous results for it in the abstract setting of this section. However, as will be discussed in forthcoming sections, we are able to show that for certain examples the zero-cost velocity associated to \(\mathcal {L}_{F^{\textrm{asym}}}\) is non-dissipative, in the sense that one can associate a non-trivial conserved energy and a skew-symmetric operator to it, which motivates the following conjecture.
Conjecture 2.38
Let \(\mathcal {L}\) be an L-function on \(\mathcal {Z}\) and \({\hat{\mathcal {L}}}_{{F^{\textrm{asym}}}}\) be the contracted L-function corresponding to \({\hat{\mathcal {L}}}_{{F^{\textrm{asym}}}}\), i.e.
Then there exists an energy \(\mathcal {E}:\mathcal {Z}\rightarrow \mathbb {R}\) and a skew-symmetric operator \(\mathbb {J}:\rho \mapsto (T_\rho ^*\mathcal {Z}\rightarrow T_\rho \mathcal {Z})\) such that the zero-cost velocity of \({\hat{\mathcal {L}_{F^{\textrm{asym}}}}}\) can be written as
Clearly, the skew-symmetry of \(\mathbb {J}(\rho )\) implies that the energy \(\mathcal {E}(\rho (t))\) will be conserved along solutions of \({\dot{\rho }}(t)=\mathbb {J}(\rho (t))D\mathcal {E}(\rho (t))\). In fact, for the IPFG and lattice gas examples, the corresponding \(\mathbb {J}\) even satisfies the Jacobi identity, so that the purely antisymmetric velocity has a Hamiltonian structure (see Sections 4, 5.3 for details).
3 Formal Connection With Large Deviations
In Sect. 2 we focussed on the purely macroscopic setting. In this section we motivate the abstract structures introduced therein by connecting them to Markov processes and their large deviations. Although the results presented in this section are largely known in the literature in specific settings, we include them here in a more general setting to provide rationale for the abstract framework discussed in the last section. While these results are formal due to the level of generality at which we work, they can be made rigorous case by case.
Throughout this section we assume a microscopic dynamics described by a sequence of Markov processes \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) defined on \(\mathcal {Z}\times \mathcal {W}\). Typically, \(\rho ^{\scriptscriptstyle {(n)}}(t)\) is the empirical measure, concentration or density corresponding to \(\mathcal {O}(n)\) particles, and \(W^{\scriptscriptstyle {(n)}}(t)\) is the integrated/cumulative particle flux (recall Example 2.1 and see Sect. 5 for further examples). For now, we assume a fixed deterministic initial condition \(\rho ^{\scriptscriptstyle {(n)}}(0)\) for the empirical measure; this will be relaxed later on. We always assume that the initial condition for the flux satisfies \(W^{\scriptscriptstyle {(n)}}(0)=0\) almost surely, since the particles have not moved yet at initial time. For any \(t\ge 0\), the integrated flux \(W^{\scriptscriptstyle {(n)}}(t)\) contains all information required to reconstruct the current state of the system, i.e., almost surely
Equivalently, if the random paths allow for a notion of (measure-valued) time-integration, we write
We assume that the sequence \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) satisfies a law of large numbers, whereby the microscopic process \(\big (\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) converges to a macroscopic, deterministic trajectory \((\rho (t),w(t))\), which satisfies an equation of the form (1.1), where at this stage we are only interested in the instantaneous flux \(j=\dot{w}\). Consequently, the corresponding path probability measures \(\mathbb {P}^{\scriptscriptstyle {(n)}}={{\,\textrm{law}\,}}(\rho ^{\scriptscriptstyle {(n)}},W^{\scriptscriptstyle {(n)}})\) will concentrate on that path \((\rho ,w)\) as \(n\rightarrow \infty \).
Finally we assume that the sequence \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) satisfies a corresponding large-deviation principle in \(\mathcal {Z}\times \mathcal {W}\), which can be formally written as
This large-deviation principle characterises the exponentially vanishing probability of paths starting from the fixed deterministic initial conditions which do not converge to the macroscopic path \((\rho ,w)\). The function \(\mathcal {L}\) is non-negative and its zero-cost flux corresponds to the macroscopic path, since for that path \(\mathbb {P}^{\scriptscriptstyle {(n)}} \sim 1\).
In what follows, we first focus on the classical technique for proving the aforementioned large-deviation statement, which motivates the tilted L-function introduced in Lemma 2.15. Consequently we motivate the Definition 2.6 of the quasipotential via the large deviations of invariant measures, and the Definition 2.19 of the reversed L-function using time-reversal.
3.1 Tilting, Contraction and Mixture
Rigorous proofs of large-deviation principles for Markov processes tend to be rather technical. We nevertheless briefly review the classical proof technique, since it is closely related to the macroscopic framework introduced in Sect. 2.2. For an example of this technique see [46, Chap. 10].
Formal Theorem 3.1
Let \(\mathcal {Q}^{\scriptscriptstyle {(n)}}\) be the generator of the Markov process \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t))\), define
and let the limit \(\mathcal {H}(\rho ,\zeta )=\lim _{n\rightarrow \infty }\mathcal {H}^{\scriptscriptstyle {(n)}}(\rho ,w,\zeta )\) exist and be dependent on w only via the relation \(\rho =\phi [w]\). Then the process \((\rho ^{\scriptscriptstyle {(n)}},W^{\scriptscriptstyle {(n)}})\) satisfies the large-deviation principle (3.1) with
The assumption that \(\mathcal {H}\) depends on w only via \(\rho =\phi [w]\) will generally be justified if the noise only depends on the state \(\rho \) of the system.
Main proof technique
In order to derive the large deviations (3.1) for a given, atypical path \((\rho ,w)\), one changes the probability measure \(\mathbb {P}^{\scriptscriptstyle {(n)}}\) to a tilted probability measure \(\mathbb {P}^{\scriptscriptstyle {(n)}}_\zeta \). The tilting is defined via a time-dependent force field \(\zeta (t)\) to be chosen later, and the Radon-Nikodym derivative is explicitly given by (see [47] for the generator of the tilted process and related technical details)
One can then (formally) estimate, for a small ball \(\mathcal {B}_\varepsilon (\rho ,w)\) around the given atypical path \((\rho ,w)\),
We choose \(\zeta (t)\) to be optimum in \(\sup _{{\hat{\zeta }}}\langle {\hat{\zeta }},\dot{w}(t)\rangle -\mathcal {H}(\rho (t),{\hat{\zeta }})\). It turns out that with this choice, the tilted probability \(\mathbb {P}^{\scriptscriptstyle {(n)}}_\zeta \) will concentrate on the given path \((\rho ,w)\) and therefore the final term in the right hand side vanishes (even for small \(\varepsilon \)), which results in
\(\square \)
Remark 3.2
On this formal level we do not specify the precise topological space in which the large-deviation principle holds; typically one can choose the Skorohod space \(D(0,T;\mathcal {Z}\times \mathcal {W})\), possibly requiring weaker topologies on \(\mathcal {Z}\times \mathcal {W}\). However, this topological setting does not influence the geometric picture of Sect. 2.1. We also stress that although the described proof strategy is classic, there are known cases were it fails [48]. A different proof technique is developed in [49], but the main argument described above are the same. \(\square \)
Following similar arguments one can derive the large deviations of the tilted measures.
Corollary 3.3
For a given path \(\zeta (t)\), the tilted probability \(\mathbb {P}^{\scriptscriptstyle {(n)}}_\zeta \) from (3.2) satisfies the large-deviation principle
where \(\mathcal {L}_{\zeta }\) is the convex dual of
The proof follows from the same arguments as Formal Theorem 3.1, with (3.2) replaced by
Note that \(\mathcal {H}_{\zeta -F}\) is exactly as in (2.14) and consequently we interpret the tilted L-functions introduced in Definition 2.14 as the large-deviation cost functions for the tilted probability measures.
From the Formal Theorem 3.1, one immediately obtains the following large-deviation principle for the state by applying the contraction principle [33, Thm. 4.2.1], which motivates the definition (1.9)Footnote 3
Proposition 3.4
Assume that the large-deviation principle (3.1) holds for the pair \((\rho ^{\scriptscriptstyle {(n)}},W^{\scriptscriptstyle {(n)}})\). Then the large-deviation principle also holds for \(\rho ^{\scriptscriptstyle {(n)}}\), i.e.,
Moreover, \({\hat{\mathcal {H}}}(\rho ,\xi ):=\sup _{{\dot{\rho }}\in T_\rho \mathcal {Z}} \langle \xi ,{\dot{\rho }}\rangle - {\hat{\mathcal {L}}}(\rho ,{\dot{\rho }})=\mathcal {H}(\rho ,d\phi _\rho {}^{\textsf{T}}\xi )\).
So far we have assumed that the initial condition \(\rho ^{\scriptscriptstyle {(n)}}(0)\) is fixed and deterministic. If the initial condition is random then we have the following result, which will be useful in what follows.
Proposition 3.5
(Mixing [50]) Assume that the large-deviation principle (3.1) holds for the pair \((\rho ^{\scriptscriptstyle {(n)}},W^{\scriptscriptstyle {(n)}})\) with a deterministic initial condition. If the initial condition is replaced by a sequence \(\rho ^{\scriptscriptstyle {(n)}}(0)\in \mathcal {Z}\) which satisfies the large-deviation principle
for some functional \(\mathcal {I}_0:\mathcal {Z}\rightarrow [0,\infty ]\) and \(W^{\scriptscriptstyle {(n)}}(0)=0\) almost surely, then the pair \((\rho ^{\scriptscriptstyle {(n)}},W^{\scriptscriptstyle {(n)}})\) with random initial condition \(\rho ^{\scriptscriptstyle {(n)}}(0)\in \mathcal {Z}\) satisfies the large deviation principle
Remark 3.6
The abstract framework introduced in Sect. 2.1 automatically fixes the state \(\rho (0)=\phi [0]\), which coincides with deterministic initial conditions in context of large deviations. Strictly speaking, to work with varying random initial conditions would require additional flexibility in the abstract framework. This can be achieved by either replacing the mapping \(\phi \) (recall Definition 2.3) by a family of mappings \((\phi _{\rho (0)})_{\rho (0)}\), or by keeping a fixed reference state \(\phi [0]\), and redefining the initial integrated flux as \(w(0)\in \phi ^{-1}[\rho (0)]\), exploiting the surjectivity of \(\phi \). To keep the notation simple, we stick to the setup of a deterministic initial condition, and with a slight abuse of notation always tacitly assume that \(\rho (t)=\phi [w(t)]=\phi _{\rho (0)}(w(t))\). \(\square \)
3.2 Quasipotential
We now motivate Definition 2.6 of the quasipotential \(\mathcal {V}\). The following result is largely known in the literature, see for instance [51, Sec. 2.2], [52, Sec. 3.3], [53, Sec. 4] and [54, Cor. 2], although it is not often made explicit at the level of generality used in this section.
Theorem 3.7
Assume that the Markov process \(\rho ^{\scriptscriptstyle {(n)}}(t)\) satisfies the large-deviation principle (3.4) and has an invariant measure \(\Pi ^{\scriptscriptstyle {(n)}}\in \mathcal {P}(\mathcal {Z})\) that satisfies the large-deviation principle
where \(\mu ^{\scriptscriptstyle {(n)}}\) denotes a random variable distributed with \(\Pi ^{\scriptscriptstyle {(n)}}\). Then we have
-
(i)
$$\begin{aligned} \displaystyle \mathcal {V}(\mu ) \equiv \inf _{\begin{array}{c} {\hat{\rho \in }} C^1_b([0,T];\mathcal {Z}):\\ {\hat{\rho }}(T)=\mu \end{array}} \left\{ \mathcal {V}\big ({\hat{\rho }}(0)\big ) + \int _0^T\!{\hat{\mathcal {L}}}\big ({\hat{\rho }}(t),\dot{{\hat{\rho }}}(t)\big )\,dt \right\} \quad \text { for any } T\ge 0, \end{aligned}$$(3.7)
-
(ii)
\(\displaystyle \mathcal {H}\big (\mu ,d\phi _\mu {}^{\textsf{T}}d\mathcal {V}(\mu )\big )= {\hat{\mathcal {H}}}\big (\mu ,d\mathcal {V}(\mu )\big )\equiv 0\),
where \({\hat{\mathcal {L}}},{\hat{\mathcal {H}}}\) are defined in Proposition 3.4.
Note that (3.7) implies that \(\mathcal {V}\) is always a Lyapunov function along the zero-cost dynamics, which can also be deduced from the decomposition (2.33).
Formal proof
For arbitrary \(T>0\) and fixed deterministic initial condition \(\rho ^{\scriptscriptstyle {(n)}}(0)=\rho (0)\), the state \(\rho ^{\scriptscriptstyle {(n)}}_T\) satisfies the large-deviation principle [33, Thm. 4.2.1],
By definition the invariant measure is invariant under the transition probability, i.e., for any \(T>0\),
Hence the large-deviation functional of the left-hand side is equal to the large-deviation rate of the right-hand side, which using a mixing argument [50] is given by
which proves the first claim. From here on the arguments are purely macroscopic. We proceed by noting that
which has the form of the value function from classical control theory, and hence solves the Hamilton-Jacobi-Bellman equation
We have already shown that \(\Xi _T\equiv \mathcal {V}\) does not depend on T, and therefore \({\dot{\Xi }}_T(\rho )\equiv 0\), which proves the second claim. \(\square \)
Remark 3.8
Strictly speaking, \(\mathcal {V}\) should be a viscosity solution of the Hamilton-Jacobi-Bellman (3.9) and hence also of the stationary version Theorem 3.7(ii). However, it is not precisely clear to us which boundary conditions should be imposed in the definition of the viscosity solution. This issue is particularly challenging since most classical Hamilton-Jacobi-Bellman theory is developed for quadratic \({\hat{\mathcal {H}}}\) only. Therefore, Theorem 3.7(ii) should be seen as formal. We remind the reader that a viscosity solution \(\mathcal {V}(\rho )\) is a solution in the classical sense at points of differentiability. At least on a formal level, this already suffices for the applications in this paper. \(\square \)
Remark 3.9
In Theorem 3.7(ii) we do not require that the invariant measure is unique, neither do we claim that the quasipotential \(\mathcal {V}(\rho )\) will be unique. In particular, we do not require stable points \(\pi \in \mathcal {Z}\) for which \({\hat{\mathcal {L}}}(\pi ,0)=0\) to be unique. In case of uniqueness, the quasipotential from Theorem 3.7(ii) will also satisfy the classical definition of the quasipotential [55]
In case of multiple stable points, one usually defines a family of non-equilibrium quasipotentials indexed by the stable points [55]. Any one of these will also satisfy Theorem 3.7(ii), which is sufficient for our purpose. Therefore the abstract theory from Sect. 2 can be constructed with any of these quasipotentials. \(\square \)
3.3 Time Reversal
In the following proposition we relate the large-deviation rate functions for Markov processes and their time-reversed counterparts, which motivates the notion of reversed L-function introduced in Definition 2.19. Since the proof below is standard in MFT, we only outline the proof idea for completeness.
Proposition 3.10
([10, Sec. II.C], [31, Sec. 4.2]) Let \(\big (\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) be a Markov process with random initial distribution \(\Pi ^{\scriptscriptstyle {(n)}}\) for \(\rho ^{\scriptscriptstyle {(n)}}(0)\) and \(W^{\scriptscriptstyle {(n)}}(0)=0\) almost surely, where \(\Pi ^{\scriptscriptstyle {(n)}}\in \mathcal {P}(\mathcal {Z})\) is the invariant measure of \(\rho ^{\scriptscriptstyle {(n)}}(t)\). Define the time-reversed processFootnote 4

Assume that \(\Pi ^{\scriptscriptstyle {(n)}}\) satisfies a large-deviation principle (3.6), \(\big (\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) with deterministic initial condition satisfies a large-deviation principle (3.1) with cost function \(\mathcal {L}\), and  with deterministic initial condition satisfies a large-deviation principle (3.1) with cost function
with deterministic initial condition satisfies a large-deviation principle (3.1) with cost function  . Then for any \((\mu ,j)\in \mathcal {Z}\times \mathcal {W}\),
. Then for any \((\mu ,j)\in \mathcal {Z}\times \mathcal {W}\),  is related to \(\mathcal {L}\) and \(\mathcal {V}\) via the relation
is related to \(\mathcal {L}\) and \(\mathcal {V}\) via the relation

Proof
Note that if \(\rho ^{\scriptscriptstyle {(n)}}(0)\) is distributed according to \(\Pi ^{\scriptscriptstyle {(n)}}\), then so is  , and if \(W^{\scriptscriptstyle {(n)}}(0)=0\) almost surely, then
, and if \(W^{\scriptscriptstyle {(n)}}(0)=0\) almost surely, then  almost surely as well. Since
almost surely as well. Since

using Proposition 3.5, we find for all paths \((\rho ,w)\),

Since the equality above holds for any \(T>0\), we can write

for any \(\rho (0)\) and \(\dot{w}(0)\) (assuming sufficient regularity on  ). The claimed result then follows by choosing any path \(\rho ,w\) for which \(\rho (0)=\mu \) and \(\dot{w}(0)=j\). \(\square \)
). The claimed result then follows by choosing any path \(\rho ,w\) for which \(\rho (0)=\mu \) and \(\dot{w}(0)=j\). \(\square \)
A special and important case of the previous result pertains to detailed balance.
Corollary 3.11
Let \(\big (\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t)\big )\) and  be as in Proposition 3.10. If, under initial distribution \(\Pi ^{\scriptscriptstyle {(n)}}\in \mathcal {P}(\mathcal {Z})\) of \(\rho ^{\scriptscriptstyle {(n)}}(0)\) and
be as in Proposition 3.10. If, under initial distribution \(\Pi ^{\scriptscriptstyle {(n)}}\in \mathcal {P}(\mathcal {Z})\) of \(\rho ^{\scriptscriptstyle {(n)}}(0)\) and  and
and  almost surely,
almost surely,

then  .
.
For the applications that we have in mind, the condition (3.10) holds precisely when \(\rho ^{\scriptscriptstyle {(n)}}(t)\) is in detailed balance with respect to \(\Pi ^{\scriptscriptstyle {(n)}}\), see for example [31, Prop. 4.1]. The relation  is the time-reversal symmetry from [3], which implies that \(\mathcal {L}\) induces a gradient flow, or \({F^{\textrm{asym}}}=0\) in the context of this paper.
is the time-reversal symmetry from [3], which implies that \(\mathcal {L}\) induces a gradient flow, or \({F^{\textrm{asym}}}=0\) in the context of this paper.
4 Zero-cost Velocity for IPFG Antisymmetric L-Function
In Sect. 2.6 we argued that the both the purely symmetric flux and velocity are dissipative, that is, they are generalised gradient flows of the energy \(\frac{1}{2}\mathcal {V}\) (and \(\frac{1}{2}\mathcal {V}^\mathcal {W}\) respectively). Moreover, \(\mathcal {L}_{F^{\textrm{sym}}}\) defines the variational structure of those gradient flows via the equalities (2.43) and (2.46).
The interpretation of \(\mathcal {L}_{F^\textrm{asym}}\) is more complicated. In general \(\mathcal {L}_{F^\textrm{asym}}\) will not have \(\mathcal {V}\) as its quasipotential, and using Lemmas 2.11 and 2.15 for any \(\rho \in {{\,\textrm{Dom}\,}}_\textrm{symdiss}(F^\textrm{asym})\) and \(j\in T_\rho \mathcal {W}\) it satisfies the time-reversal relation
This relation in fact holds for any tilted L-function, but \(-F^\textrm{asym}\) can be interpreted as the time-reversed counterpart of \(F^\textrm{asym}\) in the sense that  (see Remark 2.24). Formally this means that time-reversal reverses the fluxes, which is a physical indication that \(\mathcal {L}_{F^\textrm{asym}}\) might correspond to Hamiltonian dynamics, as proposed in Conjecture 2.38.
(see Remark 2.24). Formally this means that time-reversal reverses the fluxes, which is a physical indication that \(\mathcal {L}_{F^\textrm{asym}}\) might correspond to Hamiltonian dynamics, as proposed in Conjecture 2.38.
In this section we illustrate this principle for the IPFG example with L-function \(\mathcal {L}\) from Example 2.3. As far as we are aware this is has not been studied in the literature, and as a first step we will focus solely on the trajectories of the zero-cost velocity \(u(t)={\dot{\rho }}(t)=u^0(\rho (t))\) of \(\mathcal {L}_{F^\textrm{asym}}\), largely ignoring fluxes as well as the variational structure.
Let \((\rho ,j)\) satisfy \(\mathcal {L}_{F^\textrm{asym}}\big (\rho (t),j(t)\big )=0\) or equivalently \(j(t)\in \partial \Psi ^*\big (\rho (t),F^\textrm{asym}(\rho (t))\big )\), where the subdifferential is with respect to the second variable. Substituting \(\lambda =\tfrac{1}{2}\) in \(\mathcal {L}_{F-2\lambda {F^{\textrm{sym}}}}\) (defined in Example 2.33), for any \(x\in \mathcal {X}\), \(\rho :[0,T]\rightarrow \mathcal {P}(\mathcal {X})\) satisfies the ODEFootnote 5
Introducing the change of variables \(\omega _x(t):=\sqrt{\rho _x(t)}\), the zero-cost velocity (4.1) transforms into a linear ODE with a matrix \(A\in {\mathbb {R}}^{\mathcal {X}\times \mathcal {X}}\), i.e.
Solutions to this equation have a nice geometric interpretation, see Figure 3 for an example in three dimensions. Clearly, \(|\omega (t)|_2^2=|\rho (t)|_1=1\) and so the solutions are confined to the unit sphere \(S^{\mathcal {X}-1}\). On the other hand, the matrix A is skewsymmetric with imaginary eigenvalues and represents rotations around the axis \(\sqrt{\pi }\), implying that the solutions are confined to a plane perpendicular to \(\sqrt{\pi }\). Therefore, solutions \(\omega (t)\) lie on the intersection of these planes with the unit sphere, resulting in periodic orbits that conserve the distance of the plane to the origin. In the following result we show that this transformed system is indeed a Hamiltonian system with a suitable energy and Poisson structure which satisfies the Jacobi identity (see Lemma A.1 for a useful alternative characterisation of the Jacobi identity in our context).
Proposition 4.1
The ODE (4.2) admits a Hamiltonian structure \(({\mathbb {R}}^{\mathcal {X}\times \mathcal {X}},{\tilde{\mathcal {E}}},{\widetilde{\mathbb {J}}})\), i.e. \({\dot{\omega }} = {\widetilde{\mathbb {J}}}(\omega )\nabla {\tilde{\mathcal {E}}}(\omega )\), where the linear energy \({\tilde{\mathcal {E}}}:{\mathbb {R}}^{\mathcal {X}}\rightarrow {\mathbb {R}}\) and Poisson structure \({\widetilde{\mathbb {J}}}:{\mathbb {R}}^{\mathcal {X}}\rightarrow {\mathbb {R}}^{\mathcal {X}\times \mathcal {X}}\) are given by
Here \(\omega \cdot v\) is the standard Euclidean inner product and \(\omega \otimes v\) is the outer product of vectors \(\omega ,v\).
Proof
In Appendix A we present a Hamiltonian structure for a general class of ODEs, which includes the transformed system (4.2). The proof of Proposition 4.1 follows directly from Theorem A.2 with the choice \(d=|\mathcal {X}|\), \(\omega _*=\sqrt{\pi }\) and observing that \(|\omega _*|^2=\sum _x \pi _x = 1\) and \(A\sqrt{\pi }=A^T\sqrt{\pi }=0\) since \(\pi \) is the invariant solution corresponding to the original dynamics (4.1). \(\square \)
We would now like to transform the Hamiltonian structure of the transformed ODE (4.2) back to obtain a Hamiltonian structure for the original non-linear equation (4.1). This transforms the positive octant of the sphere in Fig. 3 to the simplex in Fig. 1(c). However, transforming back via \(\omega _x(t)=\sqrt{\rho }_x(t)\) is valid only if \(\omega _x(t)\ge 0\) for every \(x\in \mathcal {X}\). In the following result we state the criterion for this to hold.
Proposition 4.2
Define the threshold
the energy \(\mathcal {E}:{\mathbb {R}}^{\mathcal {X}}\rightarrow {\mathbb {R}}\) and the Poisson structure \(\mathbb {J}:{\mathbb {R}}^{\mathcal {X}}\rightarrow {\mathbb {R}}^{\mathcal {X}\times \mathcal {X}}\) as
where A is defined in (4.2). If the energy of the initial distribution \(\rho ^0\in \mathcal {P}(\mathcal {X})\) for the ODE (4.1) satisfies \(0\le \mathcal {E}(\rho ^0)<\sigma \), then (4.1) has a unique solution and admits a Hamiltonian structure \(({\mathbb {R}}^{\mathcal {X}\times \mathcal {X}},\mathcal {E},\mathbb {J})\), i.e., \({\dot{\rho }} = \mathbb {J}(\rho )\nabla \mathcal {E}(\rho )\). If the energy of the initial distribution satisfies \(\mathcal {E}(\rho ^0)\ge \sigma \), then (4.1) has non-unique, non-energy-conserving solutions.
Proof
We first analyse the critical case, where the periodic orbit \(\omega (t)\) of (4.2) touches one of the boundaries of \(S^{\mathcal {X}-1}\cap \mathbb {R}^\mathcal {X}_{\ge 0}\). The energy level of such an orbit can be calculated by solving the constrained minimisation problem
Assume \(x\in \mathcal {X}\) is optimal. For the interior minimisation problem, the optimal \(\omega \) with \(\omega _x=0\) solves
where the Lagrange multiplier \(\lambda \ge 0\) is such that the constraint \(|\omega |_2^2=1\) holds. It follows that \(\omega _y=\sqrt{\pi _y}/\sqrt{1-\pi _x}\), and so \({\tilde{\mathcal {E}}}(\omega )=1-\sqrt{1-\pi _x}=:\sigma \), yielding the critical case.
Using Proposition 4.1 we thus find that if \(\mathcal {E}(\rho ^0)={\tilde{\mathcal {E}}}(\omega ^0)<\sigma \), the solution \(\omega (t)\) of the linear system satisfies \({\tilde{\mathcal {E}}}(\omega (t))={\tilde{\mathcal {E}}}(\omega ^0)\) and remains positive (coordinate-wise), so that \(\rho (t)=\sqrt{\omega (t)}\) solves (4.1), and has the corresponding transformed Hamiltonian structure. Note that this is possible since Poisson structures are preserved by coordinate transformations [56, Sec. 4.2]. The uniqueness of the thus constructed solution \(\rho (t)\) follows since \(\sqrt{\rho _x(t)\rho _y(t)}\) is strictly bounded away from zero, and therefore the right hand side of (4.1) is Lipschitz.
Now we show the non-uniqueness when \(\mathcal {E}(\rho ^0)\ge \sigma \), for simplicity with \(|\mathcal {X}|=3\) only. The idea is to use the argument above to construct an energy-conserving solution until time \(t_1\) it hits a boundary, say \({\hat{x}}=0\), a solution that moves along the boundary until an arbitrary time but sufficiently large time \(t_1+\delta >0\), and an energy-conserving solution that moves away from the boundary again. See Fig. 1(c). More precisely, let \(\omega ^0_x=\sqrt{\rho ^0_x}\) and define
Here \(t_1:=\min \{t\ge 0:(e^{\tfrac{1}{2} A t}\omega ^0)_{{\hat{x}}}=0\}\), \(\omega ^1:=e^{\tfrac{1}{2} A t_1}\omega ^0\) and \(\omega ^2:=e^{\tfrac{1}{2} A (t_1+\delta )}\omega ^1\), and \({\bar{A}}_{xy}:= A_{xy}{\mathbb {1}}_{\{x,y\ne {\hat{x}}\}}\). Note that \(\delta >0\) must be large enough so that outgoing instead of incoming characteristics cross the boundary \({\hat{x}}=0\) and small enough that the corners in the simplex are avoided. It is easily checked that \(\rho (t)\) is continuously differentiable and satisfies the ODE (4.1). Since \(\delta >0\) is arbitrary we have constructed an infinite number of solutions. \(\square \)

For \(|\mathcal {X}|=3\), the trajectories \(\omega (t)\) rotate around the \(\sqrt{\pi }\)-axis, and lie at the intersection of the two-dimensional sphere \(S^2\) and a plane perpendicular to the \(\sqrt{\pi }\)-axis. The transformation \(\rho _x=\sqrt{\omega }_x\) maps the (octant) sphere to the simplex of Fig. 1(c)
In the following remark we comment on the role of \(\lambda \ne \frac{1}{2}\) in \(\mathcal {L}_{F-2\lambda F^\textrm{sym}}\).
Remark 4.3
One can also study the zero-cost velocity associated to \(\mathcal {L}_{F-2\lambda F^\textrm{sym}}\) from (2.33) for \(\lambda \in (0,1)\). For \(\lambda <\frac{1}{2}\), the symmetric part is dominant and the trajectories spiral inwards towards \(\pi \), i.e., \(\pi \) is a spiral sink, and for \(\lambda >\frac{1}{2}\), the antisymmetric part is dominant and the trajectories spiral outwards from \(\pi \), i.e. \(\pi \) is a spiral source (compare with Fig. 1(c) for \(\lambda =\frac{1}{2}\)). \(\square \)
Remark 4.4
As pointed out to us by André Schlichting, the energy \(\mathcal {E}(\rho )=\frac{1}{2}\sum _{x\in \mathcal {X}}(\sqrt{\pi _x}-\sqrt{\rho _x})^2\) is exactly the squared Hellinger distance between \(\rho \) and the steady state \(\pi \). At this stage we do not know the physical meaning behind the Hellinger distance, but it appears naturally in the context of purely time-antisymmetric flows. \(\square \)
5 Examples
Throughout Sect. 2 we applied the abstract theory developed therein to the example of independent Markovian particles. We now apply the abstract theory to three examples of interacting particle systems. In Sect. 5.1 we consider the example of zero-range processes with an atypical scaling limit which leads to an ODE system in the limit as opposed to the usual parabolic scaling. Section 5.2 deals with the case of chemical reaction networks in complex balance. Finally in Sect. 5.3 we consider the case of lattice gases with parabolic scaling (which lead to diffusive systems).
For each of these examples we derive the decompositions in Theorem 2.29,
and explicitly calculate all the different terms. We stress that these decompositions were previously unknown for zero-range processes and chemical reactions; we include the lattice gas example to show that for quadratic cost functions our decompositions coincide with existing results in MFT.
We expect that by using approximation arguments similar to [6, Thm 1.6], [7, Sec. 5] and [57, Part II.A], one can derive global-in-time decompositions of the rate functionals \(\int _0^T\! \mathcal {L}(\rho (t),j(t))\,dt\); this is beyond the scope of the current paper.
5.1 Zero-Range Processes
Microscopic particle system. To simplify and unify notation, we first consider the irreducible Markov process on a finite graph \(\mathcal {X}\) from the IPFG example, with generator (represented by a matrix) \(Q\in \mathbb {R}^{\mathcal {X}\times \mathcal {X}}\), and assume that it has a unique and coordinate-wise positive invariant measure \(\pi \in \mathcal {P}_+(\mathcal {X})\). Similar to the setup in Example 2.1 we study the Markov process \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t))\) on \(\mathcal {P}(\mathcal {X})\times \mathcal {X}^2/2\), where \(\rho ^{\scriptscriptstyle {(n)}}(t)\) is the particle density of interacting particles and \(W^{\scriptscriptstyle {(n)}}(t)\) is the integrated net flux (both defined in Example 2.1). The interaction between the particles is such that the jump rate \(n\kappa _{xy}(\rho )\) from x to y only depends on the density at the source node x (“zero-range”), through a given family of functions \(\eta _x:[0,\infty )\rightarrow [0,\infty )\) via
For each x, the functions \(\eta _x\) are assumed to satisfy
-
(i)
\(\eta _x\) is strictly increasing,
-
(ii)
\(\eta _x(0)=0\) and \(\eta _x(1)=1\),
-
(iii)
\(\log \eta _x(z)\) is integrable near \(z=0\).
The condition \(\eta _x(0)=0\) ensures that \(\rho _x\ge 0\), i.e. there are no negative densities. The strict monotonicity of \(\eta \) implies that the macroscopic dynamics ((5.1) below) has a unique steady state. The condition \(\eta _x(1)=1\) ensures that \(\pi \) is this steady state, and is assumed only for convenience (see Remark 5.2 below). The integrability condition is necessary and sufficient for the large-deviation principle to hold [44]. Observe that the particular choice \(\eta _x\equiv \textrm{id}\) corresponds to the IPFG model.
The pair \(\big (\rho ^{\scriptscriptstyle {(n)}},W^{\scriptscriptstyle {(n)}}(t)\big )\) has the n-particle generator
As opposed to the typical diffusive scaling for zero-range processes [10], we keep the graph \(\mathcal {X}\) fixed. The many-particle limit for this process as \(n\rightarrow \infty \) is the solution to the ODE system [7, Sec. 3.1]
where \(\mathop {{\overline{\mathop {{\textrm{div}}}\nolimits }}}\nolimits \) is again the discrete divergence defined in (2.4). The Markov process \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t))\) satisfies a large-deviation principle with the rate functional (2.5) where the corresponding \(\mathcal {L}\) and its dual \(\mathcal {H}\) are now given by [43, 44, 58]
and \(s(\cdot \mid \cdot )\) is defined in (2.7).
State-flux triple and L-function. The manifolds \(\mathcal {Z},\mathcal {W}\) with the corresponding tangent and cotangent spaces and the map \(\phi :\mathcal {Z}\rightarrow \mathcal {W}\) with \(d\phi _\rho =-\mathop {{\overline{\mathop {{\textrm{div}}}\nolimits }}}\nolimits ,\ d\phi {}^{\textsf{T}}=\mathop {\mathop {{\overline{\nabla }}}\nolimits }\nolimits \) are exactly as in Example 2.2. It is easily checked that \(\mathcal {L}\) and \(\mathcal {H}\) are convex duals of each other, so that \(\mathcal {L}\) is indeed convex and lower semicontinuous.
Quasipotential. Define \(\mathcal {V}:\mathcal {Z}\rightarrow \mathbb {R}\cup \{\infty \}\) as
Note that \(\mathcal {V}\) depends on Q through the steady state \(\pi \) only. Moreover, the integral is well-defined due to the integrability condition on \(\eta _x\). This function can be found as the large-deviation rate of the explicitly known invariant measure \(\Pi ^{\scriptscriptstyle {(n)}}\) using Theorem 3.7, [46, Prop. 3.2] and [58, Sec. 4.1]. However, in the next proposition we show that it is the correct quasipotential without any reference to a microscopic particle system, in the macroscopic sense of Definition 2.6.
Proposition 5.1
The function \(\mathcal {V}\) defined in (5.3) satisfies \(\mathcal {H}(\rho ,d\phi {}^{\textsf{T}}d\mathcal {V}(\rho ))=0\) at all points of differentiability \(\rho \in \mathcal {P}_+(\mathcal {Z})\) of \(\mathcal {V}\).
Proof
At the points of differentiability of \(\mathcal {V}\) we have
where the fourth and fifth equality follows by exchanging indices and the final equality follows since \(Q{}^{\textsf{T}}\pi =0\). \(\square \)
Remark 5.2
If the condition \(\eta _x(1)=1\) is not satisfied then one can always construct \({\overline{Q}}\in \mathbb {R}^{\mathcal {X}\times \mathcal {X}}\), \({\overline{\pi }}\in \mathcal {P}_+(\mathcal {X})\) and a family \({\overline{\eta }}_x\) with \({\overline{\eta }}_x(1)=1\), such that \(\kappa _{xy}(\rho )={\overline{Q}}_{xy}{\overline{\pi }}_x {\overline{\eta }}_x\big (\frac{\rho _x}{{\overline{\pi }}_x}\big )\), \(\overline{Q}{}^{\textsf{T}}{\bar{\pi }}=0\), and \({\overline{\pi }}\) is the unique stable point of (5.1). To calculate these modified objects, we minimise \(\mathcal {V}(\rho )\) for \(\rho \in \mathcal {P}(\mathcal {X})\), which gives the minimiser
and define
It is easily checked that these modified objects satisfy all the properties described above, and one can work with these objects instead. \(\square \)
Dissipation potential, forces and orthogonality. As in Example (2.12), using Definition 2.10 the driving force is
with the dissipation potentials
Since \(\ell \mapsto \cosh (\ell )\) is an even function, using Lemma 2.11 it follows that \({{\,\textrm{Dom}\,}}_{\textrm{symdiss}}(F)={{\,\textrm{Dom}\,}}(F)\), i.e. the dissipation potential is symmetric.
Using Corollary 2.21 we find
with \({{\,\textrm{Dom}\,}}({F^{\textrm{sym}}})={{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})=\mathcal {P}_+(\mathcal {X})\). Observe that the expressions of \({F^{\textrm{sym}}}\) and \({F^{\textrm{asym}}}\) imply that their domains can be easily extended to \(\mathcal {P}_+(\mathcal {X})\) and \(\mathcal {P}(\mathcal {X})\) respectively; however the theory of Sect. 2 will not automatically be valid on that extension. Also note that \(F^\textrm{asym}_{xy}=0\) if the particle system satisfies detailed balance with respect to \(\pi \). The orthogonality relations in Proposition 2.26 apply with (see [7])
Decomposition of the L-function. The decompositions in Theorem 2.29 hold with the L-functions
and the corresponding Fisher informations
In particular, with \(\eta _x\equiv \textrm{id}\), we indeed arrive at the expressions in Example 2.33.
With the expressions above the zero-range model satisfies the FIR inequality from Corollary 2.34 for \(\lambda =\frac{1}{2}\), which is consistent with [7, Cor. 4.3] but also holds more generally for \(\lambda \in [0,1]\). We also mention that the zero-cost flux for the symmetric \(\mathcal {L}_{{F^{\textrm{sym}}}}\) satisfies EDI (see Corollary 2.36), i.e., it induces a gradient flow structure. We now turn our attention to its antisymmetric counterpart.
Zero-cost velocity for antisymmetric L-function. As in the IPFG case in Sect. 4, we now consider the zero-cost velocity associated to \(\mathcal {L}_{{F^{\textrm{asym}}}}\) which for any \(x\in \mathcal {X}\) solves the ODE
Note that the corresponding ODE for IPFG (4.1) follows with \(\eta _x\equiv \textrm{id}\). The geometric arguments of Sect. 4 cannot be fully repeated, because it is unclear how to transform (5.4) into a linear equation. However, by analogy to that section, we make an educated guess for the energy and the Poisson structure, which is summarised in the following result. We will make use of the following family of functions \(g_x:[0,1]\rightarrow \mathbb {R}\)
for every \(x\in \mathcal {X}\). Using these functions we now show that the Conjecture 2.38 holds for the zero-range process.
Proposition 5.3
Assume that \(\eta _x\) is such that \(g_x\) is well defined for any \(x\in \mathcal {X}\). Define the threshold
and the energy \(\mathcal {E}:\mathbb {R}^{\mathcal {X}}\rightarrow \mathbb {R}\cup \{\infty \}\) and the skew-symmetric matrix field \(\mathbb {J}:\mathbb {R}^{\mathcal {X}}\rightarrow \mathbb {R}^{\mathcal {X}\times \mathcal {X}}\) as
where A is defined in (5.4). If the energy of initial distribution \(\rho ^0\in \mathcal {P}(\mathcal {X})\) for the ODE (5.4) satisfies \(0\le \mathcal {E}(\rho ^0)<\sigma \), then (4.1) has a unique solution and \({\dot{\rho }} = \mathbb {J}(\rho )\nabla \mathcal {E}(\rho )\). If the energy of the initial distribution satisfies \(\mathcal {E}(\rho ^0)\ge \sigma \), then (5.4) has non-unique, non-energy-conserving solutions.
Proof
For any \(x\in \mathcal {X}\) we have
where the third equality follows since \(\sum _y \pi _y=1\) and \((A{}^{\textsf{T}}\sqrt{\pi })_y=0\) for any \(y\in \mathcal {X}\). Finally, note that (5.4) has unique solutions if the right hand side is Lipschitz, which follows if \(\rho _x>0\), since \(\eta _x(0)=0\), for every \(x\in \mathcal {X}\). The expression (5.5) for this threshold follows by solving
where \(\lambda _x\) in (5.5) is the Lagrange multiplier for the constraint \(\sum _{z\ne x}\rho _z =1\). The non-uniqueness of solutions follows if \(\mathcal {E}(\rho ^0)\ge \sigma \) due to non-Lipschitz right-hand side in (5.4). \(\square \)
The equation (5.4) may have an underlying Hamiltonian structure, but while the matrix field \(\mathbb {J}(\rho )\) proposed here is skew-symmetric, it generally does not satisfy the Jacobi identity.
5.2 Complex-Balanced Chemical Reaction Networks
Microscopic particle system. We now describe a particle system that is commonly used to model chemical reactions. For a detailed review of this particle system with motivation and connections to related particle systems see [20].
Let \(\mathcal {X}\) be a finite set of species, \(\textrm{R}\) be the finite set of reactions between the species, and let the vectors \(\gamma ^{\scriptscriptstyle {(r)}}\in \mathbb {R}^\mathcal {X}\) denote the net number of particles of each species that are created/annihilated during a reaction \(r\in \textrm{R}\). Furthermore, let \(\textrm{R}={\textrm{R}_{\textrm{fw}}}\cup {\textrm{R}_{\textrm{bw}}}\) such that each forward reaction \(r\in {\textrm{R}_{\textrm{fw}}}\) corresponds to a backward reaction \(\textrm{bw}(r)\in {\textrm{R}_{\textrm{bw}}}\), meaning that \(\gamma ^{\scriptscriptstyle {(\textrm{bw}(r))}} = -\gamma ^{\scriptscriptstyle {(r)}}\) for all \(r\in {\textrm{R}_{\textrm{fw}}}\).Footnote 6. The set \({\textrm{R}_{\textrm{fw}}}\) will play the role of \(\mathcal {X}^2/2\) from Example 2.1.
The microscopic model involves a finite volume V that controls the number of randomly reacting particles in the system. For a fixed V, we study the random concentration or empirical measure \(\rho _x^{\scriptscriptstyle {(V)}}(t)\), which is the number of particles belonging to species \(x\in \mathcal {X}\). Note that the total number of particles may not be conserved here, as opposed to the setting of Example 2.1. We also consider the integrated net reaction flux for \(r\in {\textrm{R}_{\textrm{fw}}}\),
Forward and backward microscopic reactions r take place with given microscopic jump rates \(V\kappa _r^{\scriptscriptstyle {(V)}}(\rho ^{\scriptscriptstyle {(V)}})\) and \(V\kappa _{\textrm{bw}(r)}^{\scriptscriptstyle {(V)}}(\rho ^{\scriptscriptstyle {(V)}})\) respectively. Typically these jump rates are modelled with combinatoric terms (B.2), see also [20]. Since our framework is purely macroscopic, the precise expressions for the microscopic jump rates are not relevant; the only crucial point is that both converge sufficiently strongly to macroscopic reaction rates \({\kappa _{r}}(\rho )\) and \({\kappa _{\textrm{bw}(r)}}(\rho )\). The pair \((\rho ^{\scriptscriptstyle {(V)}}(t), W^{\scriptscriptstyle {(V)}}(t))\) is a Markov process on \(\mathbb {R}^{\mathcal {X}}\times \mathbb {R}^{{\textrm{R}_{\textrm{fw}}}}\) with generator
Using the matrix notation \(\Gamma :=[\gamma ^{\scriptscriptstyle {(r)}}]_{r\in {\textrm{R}_{\textrm{fw}}}} \in \mathbb {R}^{\mathcal {X}\times {\textrm{R}_{\textrm{fw}}}}\), in the limit \(V\rightarrow \infty \) the pair \((\rho ^{\scriptscriptstyle {(V)}}, W^{\scriptscriptstyle {(V)}})\) converges to the solution of (see [60] and [7, Sec. 3.1])
The Markov process \((\rho ^{\scriptscriptstyle {(V)}}(t), W^{\scriptscriptstyle {(V)}}(t))\) satisfies a large-deviation principle (2.5) where \(\mathcal {L},\mathcal {H}\) are now given by (see [43, Thm. 1.1] and [7, Cor. 3.1])
and \(s(\cdot \mid \cdot )\) is defined in (2.7). As in the IPFG and zero-range models, the infimum over one-way fluxes \(j^+\) can be derived using the contraction principle.
We mention that at this level of generality one can already derive many interesting MFT properties, see [7]. After all, the IPFG and zero-range models fall within this class. However, in order to apply our framework and obtain explicit results, the quasipotential needs to be known. To this aim we make two crucial assumptions.
First, the system satisfies mass-action kinetics i.e. there exists stoichiometric vectors or complexes \(\alpha ^{\scriptscriptstyle {(r)}}\in \mathbb {R}^\mathcal {X}_{\ge 0}\) (encoding the number of reactants involved) and reaction constants \({c_{r}}>0\) for each \(r\in \textrm{R}\) such that
and the forward and backward rates satisfy, setting \(\rho ^{\alpha ^{\scriptscriptstyle {(r)}}}:=\prod _{x\in \mathcal {X}} \rho _x^{\alpha ^{\scriptscriptstyle {(r)}}_x}\),
Second, we assume that the system is in complex balance [59, Sec. 3.2] with respect to some \(\pi \in \mathbb {R}^\mathcal {X}_{>0}\), i.e.
where \(\mathbb {C}:=\{\alpha ^{\scriptscriptstyle {(r)}}:r\in \textrm{R}\}\) signifies the set of complexes. This immediately implies that \(\pi \) is a steady state of the macroscopic dynamics (5.6). Observe that complex balance w.r.t. \(\pi \) is a macroscopic notion, whereas detailed balance of the Markov process w.r.t. \(\Pi ^{\scriptscriptstyle {(V)}}\) is a microscopic notion. However, for reversible networks (see footnote 6) microscopic detailed balance corresponds to the macroscopic notion of detailed balance \({c_{r}}\pi ^{\alpha ^{\scriptscriptstyle {(r)}}} = {c_{\textrm{bw}(r)}}\pi ^{\alpha ^{\scriptscriptstyle {(\textrm{bw}(r))}}}\) [59, Th. 4.5], which is clearly a stronger than complex balance. Most importantly, whereas detailed balance corresponds to purely dissipative dynamics [3], complex balance allows for non-dissipative effects.
State-flux triple and L-function. Fix a reference or initial concentration \(\rho ^0\in \mathbb {R}^\mathcal {X}_{\ge 0}\) and recall the matrix notation \(\Gamma w = \sum _{r\in {\textrm{R}_{\textrm{fw}}}} \gamma ^{\scriptscriptstyle {(r)}} w_r\). The state space is the flat manifold of concentrations that can be produced from \(\rho ^0\) via reactions, with corresponding local (co)tangent spaces:
As in the case of IPFG and zero-range, we include negative concentrations to simplify the geometric setting; this set \(\mathcal {Z}\) is known in the literature as the stoichiometric compatibility class, whereas the subset of \(\mathcal {Z}\) of coordinate-wise non-negative concentrations is called the stoichiometric simplex.Footnote 7. Moreover, as in the previous examples, \(T_\rho \mathcal {Z}\) restricts the directions of \(\mathbb {R}^\mathcal {X}\) in which one can differentiate, and \(T_\rho ^*\mathcal {Z}\) appears as a quotient space. Indeed the Euclidean inner product between tangents \(u=\Gamma j\in {{\,\textrm{Ran}\,}}(\Gamma )\) and cotangents \(\xi \in \mathbb {R}^\mathcal {X}/{{\,\textrm{Ker}\,}}(\Gamma {}^{\textsf{T}})\) is again invariant under addition of vectors \(\nu \in {{\,\textrm{Ker}\,}}(\Gamma {}^{\textsf{T}})\), since \(_{T_\rho ^*\mathcal {Z}}\langle \xi +c\nu ,u\rangle _{T_\rho \mathcal {Z}}=(\xi +c\nu )\cdot \Gamma j)=\xi \cdot u\). The space \({{\,\textrm{Ker}\,}}(\Gamma {}^{\textsf{T}})\) encode the quantities (usually numbers of atoms) that are conserved under the reactions.
The flux space and its associated tangent and cotangent spaces are simply the Euclidean space
and the continuity map \(\phi :\mathcal {W}\rightarrow \mathcal {Z}\) and its differential are
Note that with this setup, \(\phi \) is indeed surjective. Again, \(\mathcal {L}\) is convex and lower semicontinuous since \(\mathcal {L}\) is its own convex bidual.
Quasipotential. The quasipotential is again the relative entropy with respect to the invariant measure,
Similar to Example 5.10, as a function on the state manifold \(\mathcal {Z}\), this quasipotential is differentiable on \(\mathcal {Z}_+:=\{\rho \in \mathcal {Z}:\rho >0 \text { (coordinate-wise)}\}\), with Gateaux derivative \(d\mathcal {V}(\rho )=\{(\log (\rho _x/\pi _x))_{x\in \mathcal {X}}+\xi : \xi \in {{\,\textrm{Ker}\,}}(\Gamma {}^{\textsf{T}})\}\).
Recall the relation between the quasipotential and the large-deviation rate functional for the invariant measure of the microscopic system from Theorem 3.7. Whereas in the IPFG model this relative entropy appears as the large-deviation rate functional for independent particles by Sanov’s Theorem, in the complex balance case this is the rate functional of the explicitly known invariant measure of the microscopic particle system [59, Thm. 4.1]. As in the previous examples, it can also be checked purely macroscopically that this is the correct quasipotential satisfying (2.12). In fact, it turns out that (2.12) is equivalent to complex balance; both directions of the equivalence will be shown in Theorem B.1 in Appendix B.
Remark 5.4
As mentioned in Sects. 1.1 and 3.2, the quasipotential \(\mathcal {V}\) is always a Lyapunov function along the zero-cost dynamics (1.1). For the case of chemical reactions this was worked out explicitly in [61]. \(\square \)
Dissipation potential, forces and orthogonality. The driving force is
recalling that \({\kappa _{r}}(\rho )={c_{r}}\rho ^{\alpha ^{\scriptscriptstyle {(r)}}}\) and \(\mathcal {Z}_+\) denote the positive concentrations in \(\mathcal {Z}\). The dissipation potentials are
Note that \({{\,\textrm{Dom}\,}}_{\textrm{symdiss}}(F)={{\,\textrm{Dom}\,}}(F)\), i.e., the dissipation potential is symmetric.
Following Corollary 2.21, the symmetric and antisymmetric forces are
with \({{\,\textrm{Dom}\,}}({F^{\textrm{sym}}})={{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})={{\,\textrm{Dom}\,}}(F)=\mathcal {Z}_+\). The orthogonality relations in Proposition 2.26 apply with
This notion of generalised orthogonality is consistent with the derivations in [7].
Decomposition of the L-function. The decompositions in Theorem 2.29 hold with the L-functions
with the corresponding Fisher informations
The zero-cost flux for \(\mathcal {L}_{{F^{\textrm{sym}}}}\) is related to a gradient flow by Corollary 2.36; this has been discussed in [31, Cor. 4.8]. As opposed to IPFG and zero-range examples, the construction of a Poisson structure for \(\mathcal {L}_{{F^{\textrm{asym}}}}\) is difficult in the chemical reaction setting due to the non-locality of the jump rates and the interplay with the stoichiometric vectors, and remains an open question.
5.3 Lattice Gases
In this section we focus on the typical setting of MFT [10]. We are given a nonnegative potential \(U\in C^\infty ({\mathbb {T}}^d;(0,\infty ))\), a covector field \(A\in C^\infty ({\mathbb {T}}^d;{\mathbb {R}}^d)\) and a ‘mobility’ \(\chi \in C^\infty (\mathbb {R};[0,\infty ))\). The lattice gas model is a discrete state-space particle system whose hydrodynamic limit is the following drift-diffusion equation on the torus \({\mathbb {T}}^d\)
As before \(\rho \in \mathcal {P}({\mathbb {T}}^d)\) is the limiting density of the particle system, but now \({\nabla },{{\,\mathrm{\mathop {{\textrm{div}}}\nolimits }\,}}\) denote the continuous differential operators in \(\mathbb {R}^d\). We assume that,Footnote 8
for some \(h: [0,\infty ) \rightarrow [0,\infty )\),
Most results about this class of models are well known; we present them here to show that our abstract theory is consistent with ‘classical’ MFT.
Microscopic particle system. Although the macroscopic framework works for general mobilities, we only describe two standard microscopic particle systems that give rise to different mobilities. For independent random walkers \(\chi (a) = a\), \(h(a) = a\log a - a + 1\) and for the simple-exclusion process \(\chi (a) = a(1-a)\), \(h(a)=\ a \log a + (1-a) \log (1-a)\). Since these two particle systems with limit (5.11) have been extensively studied in the literature, we only present the essential features here.
For both particle systems, the particles can jump to neighbouring sites on the lattice \(\mathbb {T}^d\cap (\frac{1}{n}\mathbb {Z})^d\). In order to pass to the hydrodynamic limit (5.11) and derive the corresponding large deviations, the state space will be embedded in the continuous torus. The first particle system consists of independent random walkers with drift. For any \(n\in \mathbb {N}\), the corresponding empirical measure-flux pair \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t))\) is a Markov process in \(\mathcal {P}(\mathbb {T}^d)\times \mathcal {M}(\mathbb {T}^d;\mathbb {R}^d)\) with generator (see [21])
This system can also be derived as the spatial discretisation of interacting stochastic differential equations, although in such continuous-space setting it becomes less straight-forward how to define particle fluxes.
The second particle system is the weakly asymmetric simple exclusion process (WASEP) which has been extensively studied in the MFT literature (see for instance [10, 62]). In this case the Markov process \((\rho ^{\scriptscriptstyle {(n)}}(t),W^{\scriptscriptstyle {(n)}}(t))\) has generator
Observe that in both generators, the flux w has a different scaling than the particle density \(\rho \). This is required to ensure that the discrete-space, finite-n continuity equation converges to the continuous-space continuity equation with differential operator \(-\mathop {{\textrm{div}}}\nolimits \).
Letting \(n\rightarrow \infty \) we arrive at the hydrodynamic limit (5.11) with \(\chi (a):=a\) for the first particle system and \(\chi (a):=a(1-a)\) for the second particle system. The corresponding large-deviation cost function and its dual are
Here \(L^2(\chi (\rho ))\) is the \(\chi (\rho )\)-weighted \(L^2\)-space on \(\mathbb {T}^d\) with \(\Vert f\Vert _{L^2(\chi (\rho ))}^2:=\int _{\mathbb {T}^d} f(x)^2 \chi (\rho (x))dx\) and \(\Vert \cdot \Vert _{L^2(1/\chi (\rho ))}\) is the dual norm to \(\Vert \cdot \Vert _{L^2(\chi (\rho ))}\). Note that \(\mathcal {L}\) is constructed by taking the convex dual of \(\mathcal {H}\) which is defined in terms of \(\Vert \cdot \Vert _{L^2(\chi (\rho ))}\). See [21, Sec. 5] for the large-deviations of the random walkers (with \(A=0\)), [46, Chap. 10] for exclusion process without fluxes, and [62, Thm. 2.1] for exclusion process with fluxes (with \(A=0\)).
State-flux triple and L-function. Apart from the fact that the state space is infinite-dimensional, the lattice gas example differs from the previous examples in a number of ways. First of all, in this setting, one actually has a microscopic state-flux triple \((\mathcal {Z}^n,\mathcal {W}^n,\phi ^n)\) that converges to the macroscopic one \((\mathcal {Z},\mathcal {W},\phi )\) in a suitable sense, see for example [31, Sec. 5]. For simplicity we only present the macroscopic structure. The second difference is that the cost (5.13) happens to be a quadratic functional, which induces a norm on the cotangent space. However as in the finite-dimensional examples, we regard such induced geometry to be a posteriori; one first needs a basic geometric setup in order to derive the dissipation potentials. Therefore we shall work with the following setting, and discuss the geometry induced by (5.13) in Remark 5.5.
For the state space we choose, analogous to (2.9) and (5.9),
For \(\chi (a)=a\) one might be tempted to choose \(\mathcal {Z}\) as the space of signed measures with total mass \(\int \!\rho ^0\,dx\), but then the quasipotential \(\mathcal {V}\) will fail to be differentiable.
For the flux space we choose the flat Banach manifold (see [63, Theorem 3.12])
and for the continuity operator the usual one:
As a validity check, this setup indeed satisfies \(\phi :\mathcal {W}\rightarrow \mathcal {Z}\), \(d\phi _\rho :T_\rho \mathcal {W}\rightarrow T_\rho \mathcal {Z}\) and \(d\phi _\rho {}^{\textsf{T}}:T_\rho ^*\mathcal {Z}\rightarrow T_\rho ^*\mathcal {W}\). Finally, \(\mathcal {L}\) is clearly convex and lower semicontinuous in the \(L^2_{1/\chi (\rho )}\)-norm.
Remark 5.5
A posteriori we could also choose the state-flux triple implied by the large deviations (5.13). Then \(\mathcal {Z}=(\mathcal {P}({\mathbb {T}}^d),{{\,\textrm{W}\,}}_2)\), the space of probability measures on the (compact) torus, endowed with the Wasserstein-2 metric \({{\,\textrm{W}\,}}_2\). For any \(\rho \in \mathcal {Z}\), the corresponding cotangent and tangent spaces and the associated norms are
with the standard (semi)norms from Wasserstein-2 geometry [64, Sec. 3.4.2]
The induced flux space is the metric space
And the continuity operator is again (5.14). This setup is slightly different from the standard Wasserstein geometry, where by convention the fluxes are defined so as to satisfy \({\dot{\rho }}=\mathop {{\textrm{div}}}\nolimits (\rho \, j)\), while in our context the fluxes satisfy \({\dot{\rho }} = \mathop {{\textrm{div}}}\nolimits j\).
However, this induced state-flux triple is formal, as \(\mathcal {Z}\) and \(\mathcal {W}\) are not Banach manifolds, and differentiability of the quasipotential \(\mathcal {V}\) becomes less straightforward. We therefore work with the simpler triple described above. \(\square \)
Quasipotential. The quasipotential \(\mathcal {V}:\mathcal {Z}\rightarrow \mathbb {R}\) is defined as, recalling (5.12),
Its Gateaux derivative in \(\mathcal {Z}\) is simply, recalling (2.26),
It is easy to verify that \(\mathcal {H}(\rho ,d\phi {}^{\textsf{T}}_\rho d\mathcal {V}(\rho ))=0\) and therefore \(\mathcal {V}\) is indeed a quasipotential in the sense of Definition 2.6. In the case \(\chi (a)=a\), \(\mathcal {V}\) is the relative entropy with respect to the Gibbs-Boltzmann measure \(\mu (dx)=Z^{-1}e^{-U(x)}\,dx\).
Dissipation potential, forces and orthogonality. Using Definition (2.10) the driving force is
The dissipation potential and its dual are
Observe that \({{\,\textrm{Dom}\,}}_{\textrm{symdiss}}(F)={{\,\textrm{Dom}\,}}(F)\), i.e., the dissipation potential is symmetric. Following Corollary 2.21, the symmetric and antisymmetric forces are
Indeed the antisymmetric force \({F^{\textrm{asym}}}\) is again independent of \(\rho \).
The generalised orthogonality relations in Proposition 2.26 apply with
where \((\cdot ,\cdot )_{L^2(\chi (\rho ))}\) is the \(\chi (\rho )\)-weighted \(L^2\) norm. This shows that for quadratic dissipation potentials, the generalised expansion of Proposition 2.26 indeed collapses to the usual expansion of squares, i.e.:
Decomposition of the L-function. The decompositions in Theorem 2.29 hold with the L-functions
and the corresponding Fisher informations
The positivity of these Fisher informations is obvious from the definition. In this setting, the decompositions in Theorem 2.29 can be derived simply by expanding the squares in the L-function.
Repeating the calculations in Corollary 2.34 for \(\chi (a)=a\), we arrive at the local FIR equality for diffusion processes (with u as a placeholder for \({\dot{\rho }}\)) [6, Eq. (14)]
where the contracted L-function \({\hat{\mathcal {L}}}\) is defined in (2.40), the relative entropy with respect to \(\mu \) is defined as \(\textrm{RelEnt}(\cdot |\mu ):=\mathcal {V}(\cdot )\).
We now briefly comment on the symmetric and antisymmetric L-functions. Substituting \(\lambda =\tfrac{1}{2}\) in (5.16) and expanding the square we find
where we have used \(-2{F^{\textrm{asym}}}(\rho )={\nabla }d\mathcal {V}(\rho )\) and the definition of \(\Vert \cdot \Vert _{-1,\chi (\rho )}\). Using this decomposition of \(\mathcal {L}_{{F^{\textrm{sym}}}}\), the contracted symmetric L-function
admits the decomposition
where the contracted dissipation potential \({\hat{\Psi }}(\rho ,u) =\frac{1}{4} \Vert u\Vert ^2_{-1,\chi (\rho )}\) and its dual \({\hat{\Psi }}^*(\rho ,s)=\Vert s\Vert ^2_{1,\chi (\rho )}\) (recall abstract definition in (2.42)). The decomposition (5.17) is the standard Wasserstein-based EDI for the drift-diffusion equation (5.11) (see for instance [3, Sec. 4.2]).
Similarly, the purely antisymmetric L-function and its contraction read
with zero-cost velocity \(u^0(\rho )=-{{\,\mathrm{\mathop {{\textrm{div}}}\nolimits }\,}}(\chi (\rho )A)=-{\nabla }(\chi (\rho ))\cdot A\). While the corresponding evolution equation \({\dot{\rho }}(t)= {{\,\mathrm{\mathop {{\textrm{div}}}\nolimits }\,}}(\chi (\rho )A)\) preserves the energy
it is not clear if we can define an operator \(\mathbb {J}\) such that Conjecture 2.38 holds. However in the case \(A=J\nabla U\) where \(J\in \mathbb {R}^{d\times d}\) is a constant skew-symmetric matrix and \(\chi (a)=a\), we define the operator
Using the antisymmetry of J it follows that
i.e., \(\mathbb {J}\) is a skew-symmetric operator. Furthermore \(\mathbb {J}\) satisfies the Jacobi identity by an elementary but tedious calculation which we skip. Therefore the antisymmetric zero-cost velocity indeed evolves according to the standard Hamiltonian system (see for instance [28, Section 3.2]) with energy \(\mathcal {E}\) and Poisson structure \(\mathbb {J}\).
6 Conclusion and Discussion
In this paper we have presented an abstract macroscopic framework, which, for a given flux-density L-function, provides its decomposition into dissipative and non-dissipative components and a generalised notion of orthogonality between them. This decomposition provides a natural generalisation of the gradient-flow framework to systems with non-dissipative effects. Specifically we prove that the symmetric component of the L-function corresponds to a purely dissipative system and conjecture that the antisymmetric component corresponds to a Hamiltonian system, which has been verified in several examples. We then apply this framework to various examples, both with quadratic and non-quadratic L-functions.
We now comment on several related issues and open questions.
Why does the density-flux description work? While at the level of the evolution equations which are of continuity-type, the density-flux description does not offer any advantage (recall (1.1)), at the level of the cost functions it allows us to naturally encode divergence-free effects. This is clearly visible for instance in Theorem 2.29, where the evolutions corresponding to \(\mathcal {L}_{{F^{\textrm{sym}}}}\), \(\mathcal {L}_{{F^{\textrm{asym}}}}\) are dissipative and energy-preserving respectively, while the zero of the full L-function characterises the macroscopic evolution. A simple contraction argument allows us to retrieve the classical gradient-flow structure as well as the FIR inequalities in a fairly general setting, which further reveals the power of this description.
Antisymmetric force and L-function. While in the abstract theory the antisymmetric force \({F^{\textrm{asym}}}={F^{\textrm{asym}}}(\rho )\) is a function of \(\rho \in {{\,\textrm{Dom}\,}}({F^{\textrm{asym}}})\), in all the concrete examples studied in this paper, \({F^{\textrm{asym}}}\) is independent of \(\rho \). It is not clear to us if this is a general property of the antisymmetric force or a special characteristic of the examples studied in this paper.
In Sect. 2.6 we conjectured that the zero-velocity flux for the contracted antisymmetric L-function admits a Hamiltonian structure, which was concretely proved for IPFG and zero-range process in Proposition 4.2, 5.3 respectively. While this gives insight into the associated zero-flows, it is not clear if \(\mathcal {L}_{{F^{\textrm{asym}}}}\) admits a variational formulation akin to the gradient-flow structure for \(\mathcal {L}_{{F^{\textrm{sym}}}}\) discussed in Corollory 2.36.
Chemical-reaction networks. In Appendix B we provide a new interpretation of systems in complex balance as being exactly those systems which admit the relative entropy as the quasipotential. This also restricts the search for invariant measures of the CME without complex balance to measures that are not exponentially equivalent to the product-Poisson form. However, motivated by the example in that appendix, an interesting question would be to identify the class of systems which admit a rescaled relative entropy as their quasipotential.
Furthermore, the Hamiltonian structure of the zero-velocity for \(\mathcal {L}_{{F^{\textrm{asym}}}}\) in the chemical-reaction setting is open. As pointed out in Sect. 5.2, the non-locality of the jump rates for chemical-reaction networks offers a challenge as opposed to the local jump rates for IPFG and zero-range process.
Generalised orthogonality. The notion of generalised orthogonality as introduced in Sect. 2.4 allows us to decompose the L-function as in Theorem 2.29 for the special case \(\lambda =\frac{1}{2}\). However a natural question is whether this notion of orthogonality encoded via \(\theta _{\rho }\) can be generalised to allow for any \(\lambda \in [0,1]\). This would provide a deeper understanding of our main decomposition Theorem 2.29 as well as a clear interpretation of the Fisher information in terms of a modified dissipation potential.
Quasipotentials for multiple invariant measures. In Remark 3.9 we discussed the possibility of having multiple quasipotentials. On a macroscopic level, forcing uniqueness for non-quadratic Hamilton-Jacobi-Bellman equations is generally challenging. This is not merely a technical issue, since even on a microscopic level there may be multiple invariant measures; we have not pursued this possibility any further.
Global-in-time decompositions. In this paper we have focussed on the local-in-time description of the L-function as opposed to working with time-dependent trajectories. While it is not obvious how to generalise the various abstract results to allow for global-in-time descriptions, we expect that it can be worked out case by case for the examples presented in this paper. The main difficulty here is that the time-dependent trajectories are allowed to explore the boundary of the domain where the forces are not well-defined, and therefore an appropriate regularisation procedure is required to extend the domain of definition of these forces.
Acknowledgements. The authors are grateful to Alexander Mielke who provided the proof of the Hamiltonian structure for linear antisymmetric flows discussed in Appendix A, and to the participants of the discussions at the AIM workshop “Limits and control of stochastic reaction networks” who helped develop the results of Appendix B, in particular Daniele Cappelletti, Anne J. Shiu and Artur Stephan. Furthermore, the authors thank Jin Feng, Davide Gabrielli, Alberto Montefusco, Mark Peletier, Jim Portegies, Richard Kraaij and Péter Koltai for insightful discussions. US thanks Julien Reygner who first pointed out the possibility of a connection between FIR inequalities and MFT. This work was presented at the MFO Workshop 2038 ‘Variational Methods for Evolution’ and the authors would like to thank the participants for stimulating interactions.
The work of RP and MR has been funded by the Deutsche Forschungsgemeinschaft (DFG) through grant CRC 1114 “Scaling Cascades in Complex Systems”, Project C08. RP received further support from the Math+ excellence cluster through project EF4-10. The work of US was supported by the Alexander von Humboldt foundation and the DFG under Germany’s Excellence Strategy–MATH+: The Berlin Mathematics Research Center (EXC-2046/1)-project ID:390685689 (subproject EF4-4).
Data Availibility
Data sharing not applicable to this article as no datasets were generated or analysed during the current study.
Notes
In this paper we often use the terminology of dissipative systems interchangeably with gradient flows since in non-equilibrium systems the gradient-flow part arises purely due to dissipative effects characterised by the symmetric forces discussed below.
We use the terminology “L-function” from [3, Def. 1.1] as opposed to ‘Lagrangian’ or ‘cost’, since in practice \(\mathcal {L}\) need not correspond to a large-deviation principle, and it often plays a different role as the Lagrangian in mechanics.
In practice, the mapping from paths \((\rho ,w)\) to paths \(\rho \) is clearly continuous. In order to make the statement rigorous one only needs to show that the infimum can be moved inside the integral.
This construction requires a vector structure on \(\mathcal {W}\). For all applications that we have in mind this holds trivially, as long as we work with net fluxes (see the discussion in Example 2.12).
Although \(F^\textrm{asym}\) is only defined on the interior, this ODE can be defined on the whole domain by continuous extension of \({d_\zeta }\Psi ^*(\rho ,F^\textrm{asym})\).
This does not necessarily mean that each forward reaction \(\alpha ^{\scriptscriptstyle {(r)}}\rightarrow \alpha ^{\scriptscriptstyle {(\textrm{bw}(r))}}\) corresponds to a backward reaction \(\alpha ^{\scriptscriptstyle {(\textrm{bw}(r))}}\rightarrow \alpha ^{\scriptscriptstyle {(r)}}\), which is known in the literature as a reversible network [59, Def. 2.2] The difference between the two notions is clearly seen in the example at the end of our Appendix B.
Under the complex balance assumption the steady state \(\pi \) is unique and stable within such simplex [59, Thm. 3.2].
In order to make sure that the rate functional \(\int _0^T\!{\hat{\mathcal {L}}}(\rho (t),{\dot{\rho }}(t))\,dt=\infty \) whenever negative concentrations are reached, one should in fact require \(\chi (a)\equiv 0\) for all \(a\notin [0,1]\), and assume that \(\chi \) is continuous and smooth away from its zeros.
References
Adams, S., Dirr, N., Peletier, M.A., Zimmer, J.: From a large-deviations principle to the Wasserstein gradient flow: A new micro-macro passage. Commun. Math. Phys. 307, 791–815 (2011)
Adams, S., Dirr, N., Peletier, M.A., Zimmer, J.: Large deviations and gradient flows. Philos. Trans. Royal Soc. A 371(2005), 20120341 (2013)
Mielke, A., Peletier, M.A., Renger, D.R.M.: On the relation between gradient flows and the large-deviation principle, with applications to Markov chains and diffusion. Potential Anal. 41(4), 1293–1327 (2014)
Peletier, M.A., Redig, F., Vafayi, K.: Large deviations in stochastic heat-conduction processes provide a gradient-flow structure for heat conduction. J. Math. Phys. 55(9), 093301 (2014)
Duong, M.H., Lamacz, A., Peletier, M.A., Sharma, U.: Variational approach to coarse-graining of generalized gradient flows. Calc. Var. Partial Differ. Eqs. 56(4), 100 (2017)
Hilder, B., Peletier, M.A., Sharma, U., Tse, O.: An inequality connecting entropy distance, Fisher information and large deviations. Stoch. Process. Their Appl. 130(5), (2020)
Renger, D.R.M., Zimmer, J.: Orthogonality of fluxes in general nonlinear reaction networks. Discrete Cont. Dyn. Syst. 14(1), 205–217 (2021)
Duong, M.H., Lamacz, A., Peletier, M.A., Schlichting, A., Sharma, U.: Quantification of coarse-graining error in Langevin and overdamped Langevin dynamics. Nonlinearity 31(10), 4517–4566 (2018)
Peletier, M.A., Renger, D.R.M.: Fast reaction limits via \(\Gamma \)-convergence of the flux rate functional. J. Dyn. Differ. Eqs. 35, 865–906 (2023)
Bertini, L., De Sole, A., Gabrielli, D., Jona-Lasinio, G., Landim, C.: Macroscopic fluctuation theory. Rev. Modern Phys. 87(2), 593 (2015)
Kaiser, M., Jack, R., Zimmer, J.: Canonical structure and orthogonality of forces and currents in irreversible Markov chains. J. Stat. Phys. 170(6), 1019–1050 (2018)
Onsager, L.: Reciprocal relations in irreversible processes I. Phys. Rev. 37(4), 405–426 (1931)
Onsager, L.: Reciprocal relations in irreversible processes II. Phys. Rev. 38(12), 2265–2279 (1931)
Onsager, L., Machlup, S.: Fluctuations and irreversible processes. Phys. Rev. 91(6), 1505–1512 (1953)
Mielke, A., Patterson, R.I.A., Peletier, M., Renger, D.R.M.: Non-equilibrium thermodynamical principles for chemical reactions with mass-action kinetics. SIAM J. Appl. Math. 77(4), 1562–1585 (2017)
Maes, C.: Non-Dissipative effects in Nonequilibrium Systems. Springer, Cham, Switzerland (2018)
Renger, D.R.M., Sharma, U.: Untangling dissipative and Hamiltonian effects in bulk and boundary-driven systems. Phys. Rev. E 108(5), 054123 (2023)
Carrillo, J.A., Chertock, A., Huang, Y.: A finite-volume method for nonlinear nonlocal equations with a gradient flow structure. Commun. Comput. Phys. 17(1), 233–258 (2015)
Lelièvre, T., Nier, F., Pavliotis, G.A.: Optimal non-reversible linear drift for the convergence to equilibrium of a diffusion. J. Stat. Phys. 152(2), 237–274 (2013)
Anderson, D.F., Kurtz, T.G.: Continuous time Markov chain models for chemical reaction networks. In: Design and analysis of biomolecular circuits, p. 3–42. Springer, (2011)
Renger, D.R.M.: Gradient and GENERIC systems in the space of fluxes, applied to reacting particle systems. Entropy 20(8), 596 (2018)
Sandier, E., Serfaty, S.: Gamma-convergence of gradient flows with applications to Ginzburg-Landau. Commun. Pure Appl. Math. 57(12), 1627–1672 (2004)
Ambrosio, L., Gigli, N., Savaré, G.: Gradient Flows in Metric Spaces and in the Space of Probability Measures. Lectures in mathematics ETH Zürich, Birkhäuser (2008)
Rossi, R., Mielke, A., Savaré, G.: A metric approach to a class of doubly nonlinear evolution equations and applications. Ann. Scuola Norm. Super. Pisa-Cl. Sci. 7(1), 97–169 (2008)
Grmela, M., Öttinger, H.: Dynamics and thermodynamics of complex fluids I: Development of general formalism. Phys. Rev. E 56(6), 6620–6632 (1997)
Öttinger, H., Grmela, M.: Dynamics and thermodynamics of complex fluids II: Illustrations of general formalism. Phys. Rev. E 56(6), 6633–6655 (1997)
Öttinger, H.: Beyond Equilibrium Thermodynamics. Wiley, USA (2005)
Duong, M.H., Peletier, M.A., Zimmer, J.: GENERIC formalism of a Vlasov-Fokker-Planck equation and connection to large-deviation principles. Nonlinearity 26, 2951–2971 (2013)
Duong, M.H., Ottobre, M.: Non-reversible processes: GENERIC, hypocoercivity and fluctuations. Nonlinearity 36(3), 1617 (2023)
Kraaij, R., Lazarescu, A., Maes, C., Peletier, M.: Fluctuation symmetry leads to GENERIC equations with non-quadratic dissipation. Stoch. Process. Their Appl. 130(1), 139–170 (2020)
Renger, D.R.M.: Flux large deviations of independent and reacting particle systems, with implications for Macroscopic Fluctuation Theory. J. Stat. Phys. 172(5), 1291–1326 (2018)
Kraaij, R.: Flux large deviations of weakly interacting jump processes via well-posedness of an associated Hamilton-Jacobi equation. Bernoulli 27(3), 1496–1528 (2021)
Dembo, A., Zeitouni, O.: Large deviations techniques and applications, 38th edn. Springer Science & Business Media, Germany (2009)
Ajji, A., Chaouki, J., Esen, O., Grmela, M., Klika, V., Pavelka, M.: On geometry of multiscale mass action law and its fluctuations. Phys. D: Nonlinear Phenom. 445, 133642 (2023)
Peypouquet, J.: Convex Optimization in Normed Spaces - Theory, Methods and Examples. SpringerBriefs in Optimization. Springer International Publishing, New York, NY, U.S.A (2015)
Colli, P., Visintin, A.: On a class of doubly nonlinear evolution equations. Comm. Partial Differ. Eqs. 15(5), 737–756 (1990)
Luckhaus, S., Sturzenhecker, T.: Implicit time discretization for the mean curvature flow equation. Calc. Var. Partial Differ. Equ. 3(2), 253–271 (1995)
Mielke, A.: Formulation of thermoelastic dissipative material behavior using GENERIC. Contin. Mechan. Thermodyn. 23(3), 233–256 (2011)
Maes, C., Netočný, K.: Canonical structure of dynamical fluctuations in mesoscopic nonequilibrium steady states. Europhys. Lett. EPL. 82(3), 6 (2008)
Maes, C.: Frenetic bounds on the entropy production. Phys. Rev. Lett. 119(16), 160601 (2017)
Schnakenberg, J.: Network theory of microscopic and macroscopic behavior of master equation systems. Rev. Modern Phys. 48(4), 571–585 (1976)
Norris, J.R.: Markov chains. Cambridge University Press, Cambridge (1998)
Patterson, R.I.A., Renger, D.R.M.: Large deviations of jump process fluxes. Math. Phys. Anal. Geomet. 22(3), 21 (2019)
Agazzi, A., Andreis, L., Patterson, R.I.A., Renger, D.R.M.: Large deviations for Markov jump processes with uniformly diminishing rates. Stoch. Process. Their Appl. 152, 533–559 (2022)
Bogachev, V., Röckner, M., Shaposhnikov, S.: Distances between transition probabilities of diffusions and applications to nonlinear Fokker-Planck-Kolmogorov equations. J. Funct. Anal. 271(5), 1262–1300 (2016)
Kipnis, C., Landim, C.: Scaling limits of interacting particle systems. Springer, Berlin-Heidelberg, Germany (1999)
Palmowski, Z., Rolski, T.: A technique for exponential change of measure for Markov processes. Bernoulli 8(6), 767–785 (2002)
Heydecker, D.: Large deviations of Kac’s conservative particle system and energy nonconserving solutions to the Boltzmann equation: A counterexample to the predicted rate function. Annal. Appl. Probab. 33(3), 1758–1826 (2023)
Feng, J., Kurtz, T.G.: Large deviations for stochastic processes, volume 131 of Mathematical Surveys and Monographs. American Mathematical Society, (2006)
Biggins, J.: Large deviations for mixtures. Elect. Commun. Probab. 9, 60–71 (2004)
Bertini, L., De Sole, A., Gabrielli, D., Jona-Lasinio, G., Landim, C.: Macroscopic fluctuation theory for stationary non-equilibrium states. J. Stat. Phys. 107(3/4), (2002)
Bouchet, F.: Is the Boltzmann equation reversible? A large deviation perspective on the irreversibility paradox. J. Stat. Phys. 181(2), 515–550 (2020)
Borkar, V.S., Sundaresan, R.: Asymptotics of the invariant measure in mean field models with jumps. Stoch. Syst. 2(2), 322–380 (2013)
Jia, C., Jiang, D.-Q., Li, Y.: Detailed balance, local detailed balance, and global potential for stochastic chemical reaction networks. Adv. Appl. Probab. 53(3), 886–922 (2021)
Freidlin, M.I., Wentzell, A.D.: Random perturbations of Hamiltonian systems. Mem. Amer. Math. Soc., 109(523), (1994)
Mielke, A.: Hamiltonian and Lagrangian Flows on Center Manifolds, volume 1489 of Lecture Notes in Mathematics. With Applications to Elliptic Variational Problems. Springer, Berlin, Germany (1991)
Hoeksema, J.: Mean-field limits and beyond: Large deviations for singular interacting diffusions and variational convergence for population dynamics. PhD thesis, Eindhoven University of Technology, (2023)
Gabrielli, D., Renger, D.R.M.: Dynamical phase transitions for flows on finite graphs. J. Stat. Phys. 181(6), 2353–2371 (2020)
Anderson, D., Craciun, G., Kurtz, T.: Product-form stationary distributions for deficiency zero chemical reaction networks. Bull. Math. Biol. 72(8), 1947–1970 (2010)
Kurtz, T.: Solutions of ordinary differential equations as limits of pure jump Markov processes. J. Appl. Probab. 7(1), 49–58 (1970)
Anderson, D.F., Craciun, G., Gopalkrishnan, M., Wiuf, C.: Lyapunov functions, stationary distributions, and non-equilibrium potential for reaction networks. Bull. Math. Biol. 77(9), 1744–1767 (2015)
Bertini, L., De Sole, A., Gabrielli, D., Jona-Lasinio, G., Landim, C.: Large deviations of the empirical current in interacting particle systems. Theo. Probab. Appl. 51(1), 2–27 (2007)
Adams, R.A., Fournier, J.J.: Sobolev spaces. Elsevier, Netherlands (2003)
Peletier, M.A.: Variational modelling: Energies, gradient flows, and large deviations. arXiv preprint:arXiv:1402.1990, (2014)
Gao, Y., Liu, J.-G.: Revisit of macroscopic dynamics for some non-equilibrium chemical reactions from a hamiltonian viewpoint. J. Stat. Phys. 189(2), 22 (2022)
Funding
Open Access funding enabled and organized by CAUL and its Member Institutions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Christian Maes.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
Hamiltonian Structure for Linear Antisymmetric Flow
We learnt the arguments of Appendix A from Alexander Mielke.
We study the linear ODEs of the form
In Theorem A.2 we provide a complete characterisation of a natural Hamiltonian structure for these ODEs. In contrast to the typical settings of Hamiltonian systems, where \(A\in {\mathbb {R}}^{d\times d}\) is assumed to be skew-symmetric, here we assume the existence of an invariant vector \(\omega _*\) for the dynamics. The zero-cost antisymmetric flux for the IPFG system discussed in Sect. 4 is of the form (A.1).
The following lemma provides a useful alternative characterisation of the Jacobi identity for Poisson structures which will be used to prove Theorem A.2 below.
Lemma A.1
Define a (Poisson-like) bracket \(\{\cdot ,\cdot \}\) by
where \(\mathcal {G}_1,\mathcal {G}_2:{\mathbb {R}}^d\rightarrow {\mathbb {R}}\) are \(C^2\)-mappings, and the \(C^1\) matrix-valued function \(\omega \mapsto {\widetilde{\mathbb {J}}}(\omega )\in {\mathbb {R}}^{d\times d}\) is antisymmetric, i.e., \({\widetilde{\mathbb {J}}}{}^{\textsf{T}}=-{\widetilde{\mathbb {J}}}\). The bracket (A.2) satisfies the Jacobi identity if and only if for all smooth \(\mathcal {G}_1,\mathcal {G}_2,\mathcal {G}_3:{\mathbb {R}}^d\rightarrow {\mathbb {R}}\) and for all \(\omega \in \mathbb {R}^d\) we have
where \(\nabla {\widetilde{\mathbb {J}}}[v]\) is the matrix valued function with \((\nabla {\widetilde{\mathbb {J}}}[v])_{ij}(\omega ) = \sum _k v_k (\partial _{\omega _k} {\widetilde{\mathbb {J}}}(\omega )_{ij})\).
The proof follows by straightforward manipulation of the Jacobi identity. We now present the Hamiltonian structure for (A.1).
Theorem A.2
The linear ODE (A.1) admits the Hamiltonian system \(({\mathbb {R}}^d,{\tilde{\mathcal {E}}},{\widetilde{\mathbb {J}}})\) with the linear energy and the linear Poisson structure
for any \(c\in \mathbb {R}\). Consequently \({\dot{\omega }} = {\widetilde{\mathbb {J}}}(\omega )\nabla {\tilde{\mathcal {E}}}(\omega )\).
Proof
For any \(b\in {\mathbb {R}}^d\) we have
and inserting \(b=\omega _*\) in this relation and using \(A{}^{\textsf{T}}\omega _*=0\) it follows that \(\frac{1}{2}A\omega =-{\widetilde{\mathbb {J}}}(\omega )\omega _*={\widetilde{\mathbb {J}}}(\omega )\nabla {\tilde{\mathcal {E}}}(\omega )\). Since \({\widetilde{\mathbb {J}}}(\omega ){}^{\textsf{T}}= -{\widetilde{\mathbb {J}}}(\omega )\) by construction, we only need to prove the Jacobi identity (A.3) to prove this result. Using the linearity of \({\widetilde{\mathbb {J}}}\) we find \(\nabla {\widetilde{\mathbb {J}}}[v](\omega )={\widetilde{\mathbb {J}}}(v)\), and therefore for any \(\mathcal {F}\in {\mathbb {R}}^d\) we have
Using \(A\omega _*=0\) we find
Using the above two relations we arrive at
Setting \(\mathcal {F}_i = \nabla \mathcal {G}_i\) we can compute the remaining two terms on the left hand side of (A.3) by rotating the indices. \(\square \)
Complex Balance and Quasipotential Condition (2.12)
The results in this appendix were developed during discussions with the participants of the online AIM workshop “Limits and control of stochastic reaction networks”. This appendix explores the relation between the quasipotential for chemical reaction networks on the one hand (defined via (2.12)) and the notion of complex balance on the other. Interestingly, it turns out that complex balance is equivalent to having the relative entropy as the quasipotential.
Consider chemical-reaction networks satisfying mass-action kinetics (5.7) as explained in Sect. 5.2. To stress that these results are independent of the flux formulation and do not require a decomposition into forward and backward reactions, we will simply work with the density formulation (2.40), with the dual of the contracted L-function given by
The equation (2.12) for the quasipotential reads
The following result shows that the notion of complex balance is inherently connected to (B.1), in the case when the quasipotential is the relative entropy. This result has also appears in [65, Lemma 3.6].
Theorem B.1
The following two statements are equivalent.
-
1.
Complex balance (5.8) holds with respect to \(\pi \in \mathcal {Z}\).
-
2.
Equation (B.1) holds with \(\mathcal {V}(\rho )=\sum _{x\in \mathcal {X}} s(\rho _x\mid \pi _x)\).
Proof
We first prove the forward implication. Let \(\mathcal {V}(\rho )=\sum _{x\in \mathcal {X}} s(\rho _x\mid \pi _x)\) and calculate for \(\rho \in \mathbb {R}^\mathcal {X}_{>0}\)
where the final equality follows by choosing \(\psi _\alpha =(\tfrac{\rho }{\pi })^\alpha \) in the complex-balance condition (5.8).
Now we present the backward implication (proof due to Artur Stephan). Assume that (B.1) holds with \(\mathcal {V}(x)=\sum _{x\in \mathcal {X}} s(\rho _x\mid \pi _x)\). Sorting the expression with respect to the complexes, one obtains
Since all \(\alpha \in \mathbb {C}\) are distinct, the polynomial \(p(\tfrac{\rho }{\pi })\) can only be 0 for all \(\rho /\pi \in \mathbb {R}^\mathcal {X}_{>0}\) when all coefficients are zero. Hence \(A_\alpha =0\) for all \(\alpha \in \mathbb {C}\), which is equivalent to complex balance [59, Eq. (8)]. \(\square \)
The forward implication in Theorem B.1 can also be shown indirectly via the Chemical Master Equation (CME), describing the probability of the microscopic random particle system with jump rates
If complex balance holds with respect to \(\pi \in \mathcal {Z}\), then the CME is known to have the invariant measure of product-Poisson form [59, Thm. 4.1], i.e.
The large-deviation rate can be explicitly calculated using Stirling’s formula, which gives \(\lim _{V\rightarrow \infty } -\frac{1}{V}\log \Pi ^{\scriptscriptstyle {(V)}}(\rho )=\sum _{x\in \mathcal {X}} s(\rho _x\mid \pi _x)\), and so by Theorem 3.7 the equation (B.1) must hold.
Very little can be said about the invariant measures for the CME without the assumption of complex balance. However, the following is a straightforward consequence of Theorem B.1.
Corollary B.2
If complex balance does not hold, any invariant measure \(\Pi ^{\scriptscriptstyle {(V)}}\) of the CME will not be exponentially equivalent to the product-Poisson form (B.3), i.e., \(\Pi ^{\scriptscriptstyle {(V)}}\) and (B.3) will not have the same large-deviation rate.
The following simple example, constructed by Daniele Cappelletti and Anne J. Shiu, shows that an appropriately rescaled relative entropy can still be a quasipotential. Consider a simple birth-death process
for which the CME has the explicit invariant measure (for simplicity writing \(\rho :=\rho _\textsf{A}\))
where \(Z_V\) is the V-dependent normalisation constant. Note that the corresponding (zero-cost) reaction rate equation reads \(\dot{\rho }(t)=\kappa _b -\kappa _d \rho (t)^2\), which clearly has the steady state \(\pi :=\sqrt{\kappa _b/\kappa _d}\). The CME is in detailed balance with respect to \(\Pi ^{\scriptscriptstyle {(V)}}\), but the reaction network is not in complex balance w.r.t. \(\pi \). Again by Stirling’s formula and using the fact that \(\inf \mathcal {V}=0\), we find
Although the CME is in detailed balance, this result does not contradict the findings of [15], since this reaction network is not reversible in the sense of footnote 6.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Patterson, R.I.A., Renger, D.R.M. & Sharma, U. Variational Structures Beyond Gradient Flows: a Macroscopic Fluctuation-Theory Perspective. J Stat Phys 191, 18 (2024). https://doi.org/10.1007/s10955-024-03233-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10955-024-03233-8