In parallel machine scheduling, a size of a job is defined as the number of machines that are simultaneously required for its processing. This paper considers a scheduling problem in which the set of jobs consists of jobs of two sizes: the conventional jobs (each job requires a single machine for its processing) and parallel jobs (each job to be simultaneously processed on more than one machine). The processing times are controllable, and they have to be chosen from given intervals in order to guarantee the existence of a preemptive schedule in which all jobs are completed by a common deadline. The objective is to minimize the total compression cost which reflects possible reductions in processing times. Unlike problems of classical scheduling with conventional jobs, the model under consideration cannot be directly handled by submodular optimization methods. We reduce the problem to maximizing the total weighted work of all jobs parametrized with respect to total work of the parallel jobs. The solution is delivered by separately finding the breakpoints for the maximum total weighted work of the parallel jobs and for the maximum total weighted work of the conventional jobs. This results in a polynomial-time algorithm that is no slower than needed to perform sorting of jobs’ parameters.
One of the main assumptions of the classical scheduling theory is that each job is not processed on more than one machine at a time. This assumption leads to a range of scheduling models that have found numerous applications in industry and services. However, during the last thirty years there has been a considerable volume of studies of various scheduling models in which a job can be (or even must be) processed on several machines simultaneously. The main application area of models of this type is the scheduling of computational tasks on computer systems of parallel architecture.
Formally, in scheduling on (identical) parallel machines, we are given a set \(N=\{1,2,\ldots ,\)\(n\}\) of jobs/tasks to be processed on \(m\ge 2\) machines/processors of set \({\mathcal {M}}=\{M_{1},M_{2},\ldots ,\)\(M_{m}\}\). It takes p(j) time units to process a job \(j\in N.\) Preemption is allowed, i.e., the processing of any job j can be interrupted and resumed later; the total length of time intervals of processing job j must be equal to \( p\!\left( j\right) \). The following variants of scheduling models can be distinguished:
Classical: each job can be processed preemptively on any machine, but only one at a time;
Dedicated: for each job \(j\in N\) a set of machines, traditionally denoted by \(fixed( j) \subseteq {\mathcal {M}}\), is given and the job must be preemptively processed on all machines of this set simultaneously;
Rigid (also known as non-moldable): for each job \(j\in N\) a number of machines, traditionally denoted by size(j), where \(1\le size(j)\le m\), is given and at any time of its processing the job must be preemptively processed on exactly \(size\left( j\right) \) machines simultaneously;
Non-Rigid (also known as malleable and moldable): for each job \(j\in N\), its size is not fixed in advance, and a job is allowed to be preemptively processed on any number of machines, but its actual processing time depends on the number of these machines.
By contrast with the classical model for which all jobs are conventional, i.e., of size one, in the last three models listed above some jobs require (or are allowed to use) more than one machine. We call such jobs parallel jobs or multi-processor jobs. See the monograph (Drozdowski, 2009) for a comprehensive exposition of scheduling with multi-processor jobs.
The main scheduling model studied in this paper belongs to the class of the rigid models. In fact, we focus on a restricted model, in which conventional jobs are processed by one machine and all parallel jobs have the same size \( \Delta \), where \(1<\Delta \le m\).
Let S be a schedule that is feasible for a certain scheduling model. The completion time of job \(j\in N\) is denoted by C(j). Assuming that the processing times p(j) are fixed, the following feasibility problems are of interest: to check whether there exists a schedule in which all jobs are completed by a given deadline D. Using the accepted scheduling notation, we denote these problems on m parallel identical machines by \(P\left| pmtn,C(j)\le D\right| -\) for the classical model and by \(P\left| pmtn,size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D\right| -\) for the model with parallel jobs of two sizes. Each of these problems is known to be solvable in O(n) time; see (McNaughton, 1959) for the classical model and Błažewicz et al. (1986) for the model with parallel jobs of two sizes. Notice that if the sizes of jobs are arbitrary, the problem is still solvable in O(n) provided the number of machines m is fixed (Jansen & Porkolab, 2003).
In a more general setting, the processing times p(j) are not fixed, but should be chosen by a decision-maker from a given interval [l(j), u(j)]. Selecting actual processing time p(j) implies compression of the longest processing time u(j) by the amount \(x(j)=u(j)-p(j)\). Compression may decrease the completion time of each job j but incurs additional cost w(j)x(j).
A wide range of the problems of scheduling with controllable processing times (SCPT) has been studied, see the most recent surveys (Shabtay & Steiner, 2007) and Shioura et al. (2018). For problems relevant to this paper, the goal is to minimize the total compression cost \(\sum _{j\in N}w(j)x(j)\) for a schedule in which all jobs complete by a common deadline D. In particular, the problem on m identical parallel machines that we denote by \( P\left| pmtn,p(j)=u(j)-x(j),C(j)\le D\right| \sum w(j)x(j)\) is solvable in O(n) time (Jansen & Mastrolilli, 2004). The best known polynomial-time algorithms for more general problems, that allow job-dependent release dates and/or deadlines and machine speeds are developed in McCormick (1999); Shioura et al. (2013, 2015, 2016); see also the survey (Shioura et al., 2018). Methods for solving speed scaling scheduling problems for the energy-aware environment are presented in Shioura et al. (2017). All these algorithms are designed by adapting methods of submodular optimization.
All prior results on the problems with changeable processing times deal with the models of the classical type, i.e., those with the jobs of size one. The notable exception is scheduling multi-processor jobs on machines with changeable speeds; see (Kononov & Kovalenko, 2020a, b; Li, 1999, 2012).
Rigid tasks are typical for modern distributed systems, which allow users to formulate their specific resource requirements in terms of the CPU cores, GPU’s, memory, input/output devices, etc. In a Gantt chart, rigid jobs are usually represented by two-dimensional rectangles, where size(j) represents the requirement of job j in terms of resource utilization and p(j) represents the job execution time. As stated in the survey (Lopes & Menasce, 2016), the study of rigid jobs is among most popular research directions.
Scenarios which combine the two features, task rigidness and controllability, arise, for example, in scientific computation. Users of scientific computation software, such as MAGMA (MAGMA, 2022), PETSc (PETSc, 2022), or ScaLAPACK (ScaLAPACK, 2022), are required to specify their resource requirement size(j). A certain level of flexibility in computation time p(j) is usually admitted. A solution of a higher precision is expected if computation time is \(p(j)>l(j)\). The penalty for delivering a less accurate solution, compared to a solution found during the maximum computation time u(j), is measured as w(j)x(j). The associated scheduling problem combines then the features of scheduling with controllable processing times and rigid parallel tasks, with pre-specified resource requirements size(j) for all jobs, \(j\in N\).
Other scenarios of similar nature arise in the context of audio and video streaming, location analysis of moving objects, or temperature/humidity analysis of controlled environments. For these domains, getting a timely approximate result before the deadline is a preferred option compared to a delayed result of higher quality.
The ability to control processing times can be part of the service level agreement between a user and a resource provider. Such an agreement reflects an obligation of a resource provider to commit size(j) resources during the time u(j) for processing task j; it also regulates a penalty (w(j)x(j) in our model) payable by the resource provider if job j gets required resources not for the time u(j), but for a shorter time p(j); the latter situation happens if the job is terminated earlier by the resource provider due to the adopted overload management policy.
The main objective of this paper is to verify to which extend the methods used for solving the SCPT problems with conventional jobs can be applied to handling the models which include the parallel jobs. In particular, we would like to see whether the techniques of submodular optimization can be used, directly or partly, for solving the SCPT problems with parallel jobs, even in the basic case of jobs of two sizes.
We present a polynomial-time algorithm for the problem with multi-processor jobs of two sizes that have to be completed before a common deadline and the total compression cost is to be minimized. Combining the earlier used pieces of notation, we denote this problem by \(P\left| pmtn,p(j)=u(j)-x(j),size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le \right. \left. D\right| \sum w(j)x(j)\). Interestingly, the submodular optimization toolkit, elaborated in our earlier study, is applicable for the special cases of this problem, if either \(size(j)=1\) or \(size(j)=\Delta \) for all jobs N, but not for the combined problem, with two types of jobs. As we show in this paper, the combined problem brings substantial algorithmic challenges; still the submodular optimization methods are helpful in the development of a fast algorithm. Our study can be considered as the first step toward developing the solution methods for the general problem, with jobs of different sizes.
In Sect. 2, we demonstrate that, unlike many SCPT problems of the classical setting, the problem with parallel jobs cannot be directly formulated as a linear programming problem with submodular constraints. An algorithm to handle the problem is outlined in Sect. 3. Sections 4 to 9 present detailed analysis of various parts of the algorithm. Further improvements for some components of the algorithm are presented in Appendix A. Section 10 contains concluding remarks.
2 Formulations and links to submodular optimization
For a problem with the jobs of two sizes, a job of a size 1 will be called a 1-job, while a job of size \(\Delta \) will be called a \(\Delta \)-job. Let \( N_{1}\) and \(N_{\Delta }\) denote the set of all 1-jobs and the set of all \( \Delta \)-jobs, respectively, \(N=N_{1}\cup N_{\Delta }\).
Throughout this paper, for an n-dimensional vector \({\textbf{p}} =(p(1),p(2),\ldots ,p(n))\in {\mathbb {R}}^{N}\) of processing times and a set \( X\subseteq N\) define
In scheduling theory, the processing capacity function is a set-function \(\varphi (X)\) defined for any subset of jobs \(X\subseteq N\) and it represents the total capacity of the machines available for processing the jobs of set X. It is widely used, not only for the problems with fixed processing times, but also for the SCPT problems (Shioura et al., 2018).
In the classical setting, i.e., when each job is a 1-job, the function \( \varphi (X)\) is essentially equal to the length of all time intervals within which the jobs of set X can be processed. This means that for a problem with fixed processing times a feasible schedule exists if and only if for each set X of jobs their total work does not exceed the available processing capacity. Thus, a feasible schedule exists if and only if the inequality
holds for all sets \(X\subseteq N\); see (Horn, 1974). For example, in the classical problem \(P\left| pmtn,C(j)\le D\right| -\) with m parallel identical machines and a common deadline D, each job of a set \( X\subseteq N\) must be completed by time D, and we have that
$$\begin{aligned} \varphi (X)=\min \left\{ \left| X\right| ,m\right\} D. \end{aligned}$$
More general feasibility problems on parallel machines, including the problems with job-dependent release dates and machine speeds can be found in Shioura et al. (2013, 2015); see also the survey (Shioura et al., 2018).
Let us try to derive the processing capacity function for the feasibility problem P|pmtn, \(\ size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D|-\) and formulate the condition for the existence of a feasible schedule. For a set \( X\subseteq N\) of jobs, let \(X_{1}=N_{1}\cap X\) and \(X_{\Delta }=N_{\Delta }\cap X\) be the sets of all 1-jobs and of all \(\Delta \)-jobs, respectively, in X. Then the total processing requirement, i.e., the length of all intervals during which the jobs of set X have to be processed on the machines is given by \(p(X_{\Delta })\Delta +p(X_{1})\). On the other hand, the total duration of the intervals that are available for this processing is given by
However, a simple argument which defines the total processing requirement and the processing capacity in terms of lengths of the relevant intervals cannot be extended from a classical settings with 1-jobs only to the setting with parallel jobs. Indeed, for problem \(P\left| pmtn,size(j)\in \left\{ 1,\Delta \right\} ,C(j)\right. \left. \le D\right| -\) the condition that the inequality
holds for any set \(X=X_{1}\cup X_{\Delta }\subseteq N\) is a necessary condition for the existence of a feasible schedule, but not a sufficient condition.
To illustrate this, consider the following instance of \(P\left| pmtn,size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D\right| -\) with \( m=3 \), \(n=3\) jobs and \(D=\Delta =2\); each job is a 2-job of unit length, i.e., \(N=N_{\Delta }=\left\{ 1,2,3\right\} \) and \(p\left( j\right) =1\) for \( j\in N\). Clearly, for this instance a feasible schedule in which all jobs complete by time \(D=2\) does not exist. But if we check the conditions (2.2) for a set \(X\subseteq N=\left\{ 1,2,3\right\} \), we obtain the inequalities
which all hold, provided that \(p\left( j\right) =1\), \(j\in N.\)
Notice that for the instances with \(\Delta \)-jobs only, we may assume that the number of machines is a multiple of \(\Delta \) and any of the extra machines is empty in any feasible schedule and can be removed. Thus, if in the example above the third machine is removed, checking the conditions (2.2) does not lead to the contradiction.
One of the reasons for the successful development of fast algorithms for the SCPT problems on parallel machines in the classical settings is that for most environment the problem of minimizing total compression cost can be written as a linear programming (LP) problem over a region related to a submodular polyhedron.
For completeness, below we briefly discuss the relevant issues, some of which will be applied in the remainder of this paper. We mainly follow a comprehensive monograph on submodular optimization (Fujishige, 2005), see also (Katoh & Ibaraki, 1998) and Schrijver (2003).
Definition 1
(Fujishige, 2005) A set-function \(\varphi :2^{N}\rightarrow {\mathbb {R}}\) is called submodular if the inequality
holds for all sets \(X,Y\in 2^{N}\). For a submodular function \(\varphi \) defined on \(2^{N}\) such that \(\varphi (\emptyset )=0\), the pair \( (2^{N},\varphi )\) is called a submodular system on N, while \( \varphi \) is referred to as its rank function.
Definition 2
(Fujishige, 2005) For a submodular system \((2^{N},\varphi )\), polyhedra
where \(\varphi (X)\) is the processing capacity function, \({\textbf{p}}\in {\mathbb {R}}^{N}\) is a vector of decision variables, \(\textbf{w}\in {\mathbb {R}} _{+}^{N}\) is a non-negative weight vector, and \(\textbf{l,u}\in {\mathbb {R}} ^{N}\) are vectors of upper and lower bounds on the components of vector \({ \textbf{p}}\), respectively. This problem serves as a mathematical model for many SCPT problems to minimize total compression cost, including problem \( P\left| pmtn,p(j)=u(j)-x(j),C(j)\le D\right| \sum w(j)x(j)\) and many of its extensions. This is due to the fact that the values of p(j) are actual processing times in a feasible schedule and minimizing total compression cost
is equivalent to maximizing total weighted processing time or total weighted work\(\sum _{j\in N}w(j)p(j)\).
If in problem (2.3) set-function \(\varphi :2^{N}\rightarrow {\mathbb {R}}\) is submodular and \(\varphi (\emptyset )=0\), then the feasible region of problem (2.3) is a submodular polyhedron intersected with a box (Shioura et al., 2018), and the problem can be solved by various tools of submodular optimization, including the classical greedy algorithm and a recent decomposition algorithm developed in Shioura et al. (2015).
Unfortunately, the submodular optimization toolkit available for solving the SCPT in the classical settings, with the jobs of size 1 only, cannot be used directly even for a relatively simple problem \(P\left| pmtn,p(j)=u(j)-x(j),size(j)\in \right. \left. \left\{ 1,\Delta \right\} ,C(j)\le D\right| \sum _{j\in N}w(j)x(j)\). One reason for that is that there is no known reformulation of the corresponding feasibility problem in terms of capacity set-functions.
Suppose, however, such a formulation is known with respect to a capacity function \(\varphi \), which is submodular. The problem can be written as an LP problem similar to (2.3); however, the feasible region will not be a submodular polyhedron, since the coefficients in the left-hand side of some constraints are different from 0 and 1.
For illustration, consider an instance of problem \(P\left| pmtn,\right. \left. size(j)\in \left\{ 1,2\right\} ,C(j)\le D\right| -\) with \(m=2\) machines, \(n=3\) jobs and \(\Delta =2\) such that \(N_{\Delta }=\left\{ 1\right\} \) and \(N_{1}=\left\{ 2,3\right\} \). The capacity function \(\varphi \) is such that \(\varphi \left( X\right) =2D\) for \(X=\left\{ 1\right\} \) and all sets X with \(\left| X\right| \ge 2,\) while \(\varphi \left( \left\{ j\right\} \right) =D\) for \(j\in \left\{ 2,3\right\} \). The set of constraints that describe a feasible region is written as
Thus, in order to solve problem \(P|pmtn,p(j)=u(j)-x(j),size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D|\sum _{j\in N}w(j)x(j)\) we need to develop an alternative approach, which cannot be completely based on previously known techniques of submodular optimization.
We also assume that a sequence \(\sigma =(\sigma (1),\sigma (2),\ldots ,\sigma (n_{1}))\) is a permutation of jobs in \(N_{1}\) satisfying the condition
are available. Notice that these assumptions can be satisfied in \(O(n\log n)\) time.
We may assume that \(u(j)\le D\) for each \(j\in N\); otherwise, the upper bounds can be reduced to D. Let \(p(1),p(2),\ldots ,p(n)\) be the variables that represent the values of the actual processing times such that \(l(j)\le p(j)\le u(j)\) for each \(j\in N\).
We introduce a parameter \(\lambda \), equal to total work of the \(\Delta \)-jobs, i.e.,
Provided that total work of \(\Delta \)-jobs is equal to \(\lambda \) and the deadline D is observed, introduce the following functions of parameter \( \lambda \):
\(W_{\Delta }(\lambda )\), the maximum total weighted work of \(\Delta \)-jobs;
\(W_{1}(\lambda )\), the maximum total weighted work of 1-jobs;
\(W(\lambda )\), the maximum total weighted work of all jobs.
The structure of the problem allows us to employ the following approach to finding \(W\!\left( \lambda \right) \). First, we consider the \(\Delta \)-jobs alone and find their maximum total work \(W_{\Delta }(\lambda )\); see Sect. 4. Then, keeping the structure of the corresponding schedule for processing the \(\Delta \)-jobs, we add the 1-jobs and maximize \( W_{1}(\lambda )\), see Sect. 5. As a result, \(W(\lambda )=W_{\Delta }(\lambda )+W_{1}(\lambda )\). Note that the schedule for \(\Delta \)-jobs is constructed in such a way that it does not create restrictions on finding the maximum total weighted work \(W_{1}(\lambda )\) for 1-jobs, as it leaves room for scheduling 1-jobs in the most favorable way.
As mentioned in Sect. 2, the problem of minimizing total compression cost is equivalent to the problem of maximizing total weighted work, i.e., to maximizing \(W(\lambda )\) over the appropriate range of \(\lambda \)-values. In the following sections, we describe an algorithm for finding \(\lambda =\lambda ^{*}\) that maximizes the function \( W(\lambda )\); as soon as the value \(\lambda ^{*}\) is obtained, we can also obtain the corresponding optimal processing times \(p^{*}(j)\) of jobs \(j\in N\).
Below we present an outline of the proposed algorithm. In Sects. 4, 5, and 6, we show that for a given \( \lambda \), the function value \(W(\lambda )\) can be computed in O(n) time, provided that the sorted lists of the input parameters w(j), u(j), and l(j) are given. We also show that each function \(W_{\Delta }(\lambda )\), \( W_{1}(\lambda )\), and \(W(\lambda )\) is a piecewise-linear concave function. Therefore, an optimal value of \(\lambda \) that maximizes \(W(\lambda )\) is achieved at some breakpoint of that function, and we describe how to search for such a breakpoint.
Any breakpoint of \(W(\lambda )\) is either a breakpoint of \(W_{\Delta }(\lambda )\) or a breakpoint of \(W_{1}(\lambda )\). We classify all breakpoints of \(W(\lambda )\) into two types: major breakpoints and minor breakpoints.
Major breakpoints consist of breakpoints of \(W_{\Delta }(\lambda )\), plus some additional points (see Sect. 4 for details). We show in Sect. 4 that all major breakpoints can be obtained in \(O(n_{\Delta })\) time. Major breakpoints split the domain of the parameter \(\lambda \) into intervals, and we want to find an interval that contains \(\lambda ^{*}\), an optimal value of \(\lambda \). We show in Sect. 7 that by using binary search, we can find in \( O(n\log n_{\Delta })\) time at most two candidates for such interval.
Minor breakpoints consist of breakpoints of function \(W_{1}(\lambda )\). We show in Sect. 8 that for any single interval defined by the major breakpoints, the number of the minor breakpoints in the interval is \(O(n_{1})\). In Sect. 8, we present an \( O((n_{1})^{2})\)-time algorithm for finding all minor breakpoints. Then, we apply binary search to find a minor breakpoint that maximizes the function value \(W(\lambda )\), which is a global maximizer of \(W(\lambda )\), and this operation can be done in \(O(n\log n_{1})\) time.
In total, function \(W(\lambda )\) can be maximized in \(O(n\log n+(n_{1})^{2})\) time.
Theorem 1
Problem P|pmtn, \(p(j)=u(j)-x(j)\), \(size(j)\in \left\{ 1,\Delta \right\} \), \(C(j)\le D|\)\(\sum _{j\in N}w(j)x(j)\) can be solved in \( O(n\log n+(n_{1})^{2})\) time.
It is easy to see that the lower bound on the time complexity of the algorithm that solves this scheduling problem is \(O(n\log n)\), and the bound \(O((n_{1})^{2})\) for computing the minor breakpoints is the bottleneck to achieve the best possible time bound. In Appendix A, we present a faster algorithm for computing the minor breakpoints and show that it runs in \( O(n_{1}\log n_{1})\) time. This makes it possible to solve our scheduling problem in \(O(n\log n)\) time.
Theorem 2
Problem P|pmtn, \(p(j)=u(j)-x(j)\), \(size(j)\in \left\{ 1,\Delta \right\} \), \(C(j)\le D|\)\(\sum _{j\in N}w(j)x(j)\) can be solved in \( O(n\log n)\) time.
In the following sections, we explain each part of the outlined algorithm in detail.
4 Analysis of total weighted work of parallel jobs
In this section, we show that \(W_{\Delta }(\lambda )\), an optimal total weighted work of the \(\Delta \)-jobs, provided that their total work is equal to \(\lambda \), is a piecewise-linear concave function with \(O(n_{\Delta })\) breakpoints, and it can be computed in \(O(n_{\Delta })\) time. It is assumed that all \(\Delta \)-jobs are numbered in non-increasing order of their weights, in accordance with (3.1).
Notice that in a feasible schedule the total work \(\lambda \) of \(\Delta \)-jobs is contained in the interval \([\underline{\lambda },\overline{\lambda } ]\), where
For a fixed \(\lambda \in [\underline{\lambda },\overline{\lambda }]\), the function value \(W_{\Delta }(\lambda )\) is equal to the optimal value of the following linear programming problem:
The feasible region of problem (4.2) is a base polyhedron intersected with a box, and the problem can be solved by a greedy algorithm. The algorithm considers the jobs in the order of their numbering and each job j is assigned the largest value of \(p\!\left( j\right) \) which does not affect the previous assignments. For \(j=0,1,\ldots ,n_{\Delta }\), we define
Provided that \(\lambda \in [\lambda _{q-1},\lambda _{q}]\), \(1\le q\le n_{\Delta }\), an optimal solution to problem (4.2), can be found by computing actual processing times \(p^{*}(j)\), \(j\in N_{\Delta }\), by
For any given \(\lambda \in [\underline{ \lambda },\overline{\lambda }]\), the function value \(W_{\Delta }(\lambda )\) can be computed in \(O(n_{\Delta })\) time.
It follows from formula (4.3) that function \(W_{\Delta }(\lambda )\) is piecewise-linear and its slope is decreasing in \(\lambda \) as \(\lambda \) changes within \([\underline{\lambda },\overline{\lambda }]\). Therefore, the following is valid.
Lemma 2
Function \(W_{\Delta }(\lambda )\) is a piecewise-linear concave function.
We see that breakpoints of the function \(W_{\Delta }(\lambda )\) are given by
In addition to these points, we consider the set of points
$$\begin{aligned} \{rD\mid r \text{ is } \text{ integer, }\ \underline{\lambda }\le rD\le \overline{ \lambda }\}. \end{aligned}$$
The points in the union of these two sets are called the major breakpoints of function \(W(\lambda )\). In the following discussion, we often consider a closed interval \(I=[\lambda ^{\prime },\lambda ^{\prime \prime }]\) given by two consecutive major breakpoints \(\lambda ^{\prime }\) and \(\lambda ^{\prime \prime }\); we call such an interval a major interval.
By definition, major breakpoints consist of breakpoints of \(W_{\Delta }(\lambda )\) and additional points rD; due to these additional points, any major interval I satisfies the condition that
$$\begin{aligned} I\subseteq [rD,(r+1)D]\qquad \text{ for } \text{ some } \text{ integer } \,\, r. \end{aligned}$$
(4.4)
This means that if \(\lambda \in [\lambda ^{\prime },\lambda ^{\prime \prime }]\), where \([\lambda ^{\prime },\lambda ^{\prime \prime }]\) is a major interval, then all \(\Delta \)-jobs can be processed by using the same number of groups of \(\Delta \) machines. This property makes it easier to analyze the function \(W_{1}(\lambda )\) in Sect. 8.
It is easy to see that the number of breakpoints of the function \(W_{\Delta }(\lambda )\) is at most \(n_{\Delta }+2\). We have
since by assumption \(u(j)\le D\) holds for \(j\in N_{\Delta }\). Hence, if \( rD\le \overline{\lambda }\), then we have \(r\le n_{\Delta }\), and this implies that
$$\begin{aligned} |\{rD\mid r \text{ is } \text{ integer, }\ \underline{\lambda }\le rD\le \overline{ \lambda }\}|\le n_{\Delta }. \end{aligned}$$
Thus, the number of the major breakpoints is \(O(n_{\Delta })\).
The procedure below computes all major breakpoints of function \(W(\lambda )\) and outputs them as an increasing list.
Procedure ComputeMajor
Step 1.:
Compute \(\underline{\lambda }\) and \(\overline{\lambda }\) by (4.1). Set \(\lambda _{0}:=\underline{\lambda }\).
Step 2.:
For \(j=1, 2, \ldots , n_\Delta \), set \(\lambda _{j}:=\lambda _{j-1}+u( j) -l(j)\).
Step 3.:
Let \(j^{\prime }\) (respectively, \(j^{\prime \prime }\)) be the smallest (respectively, the largest) integer j such that \(\lambda _{j}\in \left( \underline{\lambda },\overline{\lambda }\right) \).
Step 4.:
Let \(r^{\prime }\) be the smallest integer such that \( r^{\prime }D\ge \underline{\lambda }\). Let \(r^{\prime \prime }\) be the largest integer such that \(r^{\prime \prime }D\le \overline{\lambda }\).
Step 5.:
Merge the sorted lists \(\underline{\lambda },\lambda _{j^{\prime }},\lambda _{j^{\prime }+1},\ldots ,\lambda _{j^{\prime \prime }},\overline{\lambda }\) and \(r^{\prime }D,(r^{\prime }+1)D,\ldots ,r^{\prime \prime }D\), eliminate duplicates (if any), and output the merged sorted list.
It is easy to see that Procedure ComputeMajor requires \(O(n_\Delta )\) time. Hence, we obtain the following lemma.
Lemma 3
The number of major breakpoints of function \( W(\lambda )\) is \(O(n_{\Delta })\), and all major breakpoints can be found in \( O(n_{\Delta })\) time.
To illustrate various algorithmic aspects of the paper, we will use the instance of P|pmtn, \(p(j)=u(j)-x(j)\), \(size(j)\in \left\{ 1,\Delta \right\} \), \(C(j)\le D|\)\(\sum _{j\in N}w(j)x(j)\) presented below.
Example 1. There are 6 jobs to be processed on 5 machines so that they all should be completed by time \(D=7\). The parameters of the jobs are given in Table 1.
It is assumed that \(\Delta =2\) and each job of set \(N_{\Delta }=\left\{ J_{1},J_{2},J_{3}\right\} \) requires two machines for its processing, while each job of set \(N_{1}=\left\{ J_{4},J_{5},J_{6}\right\} \) is conventional. Notice that the jobs of each of these two sets are numbered in decreasing order of their weights.
In accordance with Procedure ComputeMajor, we find \(\underline{\lambda }=6\) and \(\overline{\lambda }=\min \left\{ 15,14\right\} =14.\) We also compute \( \lambda _{0}=6\), \(\lambda _{1}=8\), \(\lambda _{2}=13\) and \(\lambda _{3}=15\). Determine \(j^{\prime }=1\) and \(j^{\prime \prime }=2\), as well as \(r^{\prime }=1\) and \(r^{\prime \prime }=2\). The list of the major breakpoints is given by \(\left( 6,7,8,13,14\right) .\)
To illustrate (4.3), take, e.g., \(\lambda \in \left[ \lambda _{1},\lambda _{2}\right] \), and compute \(W_{\Delta }\left( \lambda \right) =w\left( 1\right) u\left( 1\right) +w\left( 3\right) l\left( 3\right) +w\left( 2\right) \big (\lambda -\lambda _{1}+l\)\(\big ( 2\big )\big )=20+3+3\left( \lambda -7\right) =3\lambda +2\). In particular for \(\lambda =10,\) we have that \(W_{\Delta }\left( \lambda \right) =32\) and the corresponding optimal processing times of the \(\Delta \)-jobs are \(p^{*}\left( 1\right) =4\), \(p^{*}\left( 3\right) =3\) and \(p^{*}\left( 2\right) =3\); notice that the sum of these processing times is equal to \( \lambda =10\).
5 Analysis of total weighted work of 1-jobs
In this section, we show that \(W_1(\lambda )\) is a piecewise-linear concave function.
5.1 Explicit formula for \(W_1(\lambda )\)
Let \(\lambda \in \left[ \underline{\lambda },\overline{\lambda }\right] \) be a taken value of total work of the \(\Delta \)-jobs. To determine the maximum total weighted work \(W_{1}(\lambda )\) of the 1-jobs, we consider the case that \(rD<\lambda \le (r+1)D\), where \(r=\lfloor \lambda /D\rfloor \).
For \(\lambda \) in this range, the \(\Delta \)-jobs are assigned to r groups of \(\Delta \) machines, occupying these machines fully in [0, D], and additionally the remaining load of the \(\Delta \)-jobs equal to \(\lambda -rD\) is assigned to another group of \(\Delta \) machines. Time \(D-(\lambda -rD)=(r+1)D-\lambda \) left on each of the machines of the latter group has to be used to process the 1-jobs. Note that leaving only one group of \( \Delta \) machines partially loaded is the best possible configuration for scheduling 1-jobs. Thus, to determine \(W_{1}(\lambda )\) we need to solve a problem with controllable processing times to maximize weighted processing time of 1-jobs, provided that \(\Delta \) machines are only available in the interval \(\left[ 0,d\right] \), where \(d=(r+1)D-\lambda \), while the remaining \(m^{\prime }=m-(r+1)\Delta \) machines are available in the interval \(\left[ 0,D\right] \). We say that the \(\Delta \) machines that are available in the interval [0, d] are restricted, and the remaining \(m^{\prime }\) machines are unrestricted.
Example 2. For illustration of what we want to achieve, take the same instance as in Example 1. Assume that \(\lambda =10\). The processing times of the size 2 jobs are as found in Example 1. We see that \(r=1\), i.e., we can build a schedule in which one group of two machines is busy in the interval \(\left[ 0,7\right] \) and one group is busy for three time units, e.g., in the interval \(\left[ 4,7\right] \). More specifically, machines \( M_{1}\) and \(M_{2}\) simultaneously process job \(J_{1}\) in the time interval \( \left[ 0,4\right] \) and job \(J_{2}\) in \(\left[ 4,7\right] \), while machines \( M_{3}\) and \(M_{4}\) are restricted and simultaneously process job \(J_{3}\) in the interval \(\left[ 4,7\right] \).
Since \(r=1\) and \(m^{\prime }=1\), we deduce that for the processing of the conventional jobs \(J_{4}\), \(J_{5}\) and \(J_{6}\) we may use the restricted machines \(M_{3}\) and \(M_{4}\), each available in the interval \(\left[ 0,d \right] =\left[ 0,4\right] \), and the unrestricted machine \(M_{5}\) available in the interval \(\left[ 0,7\right] .\)
Our goal is to maximize the total weighted work \(W_{1}\left( \lambda \right) \) of the conventional jobs. Further in this section we explain how to achieve this in general by formulating and solving the corresponding problem with submodular constraints. Before we do this, we use our small size example to illustrate the logic behind such an approach. Job 4 has the largest weight and we should try to give it the largest actual processing time, i.e., \(p^{*}\left( 4\right) =6.\) This means that job \(J_{4}\) is processed on one of the restricted machines, e.g., on \(M_{3}\) in the interval \(\left[ 0,4\right] \), and on the unrestricted machine \(M_{5}\) for 2 time units within the interval \(\left[ 4,7\right] \), e.g., in the interval \( \left[ 4,6\right] \). To process jobs \(J_{5}\) and \(J_{6}\) we have 9 time units: the interval \(\left[ 0,4\right] \) on each machine \(M_{4}\) and \(M_{5}\) plus one time unit on \(M_{5}\) after time 4. Thus, job \(J_{5}\) can be processed for at most 5 units, e.g., in \(\left[ 0,4\right] \) on machine \( M_{4}\) and in \(\left[ 6,7\right] \) on machine \(M_{5}\), while job \(J_{6}\) is processed in \(\left[ 0,4\right] \) on \(M_{5}\). See Fig. 1 for the corresponding schedule. We see that \(W_{1}\left( \lambda \right) =5\times 6+2\times 5+1\times 4=44\). The total weighted work for this example \(W\left( \lambda \right) =W_{\Delta }\left( \lambda \right) +W_{1}\left( \lambda \right) =10+44.\)
In Example 2, we have just solved the problem of a small size using a common sense reasoning. However, it should be clear that we need a solid mathematical technique to solve the problem in the general case.
We will employ the technique similar to that used in Shioura et al. (2013), based on the ideas of submodular optimization. The problem of maximizing the total weighted work for the conventional jobs can be formulated in terms of the linear programming (LP) problem of type (2.3) as
where \(\varphi \) is an appropriate processing capacity function. For a given \(\lambda \), the optimal value of this LP problem is equal to \(W_{1}(\lambda ) \).
To derive the function \(\varphi \), observe that the required processing capacity depends on the cardinality of a chosen set \(X\subseteq N_{1}\) of jobs. If \(0\le |X|\le m^{\prime }\), then all these jobs can be processed on the unrestricted machines, at most one for each job. If \(m^{\prime }<|X|<m^{\prime }+\Delta \), then we can fully use the available capacity on the \(m^{\prime }\) unrestricted machines and additionally a required number of the restricted machines. If \(m^{\prime }+\Delta \le |X|\le n_{1}\), then we can use all machines with available capacity. Thus, the capacity function can be written as
Under the conditions of Example 2, for \(\left| X\right| =1\) we have the unrestricted machine to process a single job in the interval \(\left[ 0,D \right] =\left[ 0,7\right] \). On the other hand, for \(\left| X\right| =2\) two jobs can be processed on the unrestricted machine in \( \left[ 0,7\right] \) and on one of the restricted machines in \(\left[ 0,d \right] =\left[ 0,3\right] .\)
Notice that in (5.2) we stress that the capacity function depends on both, the chosen set X and the small deadline d. Although d is fixed in problem (5.1), for our further purposes it is useful to emphasis the dependence on d.
It is not difficult to prove that \(\varphi \) is a submodular function for each fixed d; see (Shakhlevich & Strusevich, 2008; Shioura et al., 2018) for details of the proof techniques that can be used for this purpose. Thus, the feasible region for problem (5.1) is a submodular polyhedron intersected with a box.
In our previous work, on multiple occasions we have applied the result proved in Shakhlevich et al. (2009) that an LP problem of the form (5.1) reduces to maximizing the same objective function over a base polyhedron with the rank function defined by
Such a reduction allows us to apply the most well-known result of submodular optimization which says that this problem can be solved by a greedy algorithm, that delivers components \(p^{*}(j)\), \(j\in N_{1}\), of an optimal solution in a closed form.
For the sequence \(\sigma =(\sigma (1),\sigma (2),\ldots ,\sigma (n_{1}))\) defined by (3.2), introduce the sets
Using formula (5.6), we prove that function \(W_{1}(\lambda ) \) is a piecewise-linear concave function. For this purpose, we rewrite functions \(\varphi (X,d)\) and \(\varphi _{l}^{u}(X,d)\), which are functions of the parameter d, as functions of the parameter \(\lambda \).
We substitute \(m^{\prime }=m-(r+1)\Delta \) into the formula (5.2) and obtain
Since this formula is dependent on the parameter r, we write here \(\varphi (X,d)=\varphi _{r}(X,d)\), and define the function \(\widetilde{\varphi } (X,\lambda )\) by
it follows from (5.7) that function \(\widetilde{\varphi } (X,\lambda )\) is linear in the interval \((rD,(r+1)D]\). In the rest of this proof, we show that for \(r=0,1,2,\ldots ,\lfloor m/\Delta \rfloor -2\), \( \widetilde{\varphi }(X,\lambda )\) is continuous and concave at the point \( \lambda =(r+1)D\). For this purpose, we fix an integer r, \(r\in \{0,1,2,\ldots ,\lfloor m/\Delta \rfloor -2\}\), and show that the following two properties hold:
the slope of \(\widetilde{\varphi }(X,\lambda )\) in the interval \(\lambda \in (rD,(r+1)D]\) is no smaller than the slope of \( \widetilde{\varphi }(X,\lambda )\) in the interval \(\lambda \in (( r+1) D,(r+2)D].\)
Depending on the cardinality of set X, we have five cases to consider. The cases arise when we assume different positions of \(|X|+(r+1)\Delta \) and \( |X|+(r+2)\Delta \) regarding m and \(m+\Delta \).
so that Property A holds. Besides, the slope of \(\widetilde{\varphi } (X,\lambda )\) is zero for \(\lambda \in (rD,(r+1)D]\) and is equal to \( -(|X|-m+(r+2)\Delta )<0\) for \(\lambda \in ((r+1)D,(r+2)D]\), so that Property B also holds.
Case 3:\(|X|+(r+1)\Delta \le m,\ m+\Delta \le |X|+(r+2)\Delta \).
so that Property A holds. Besides, the slope of \(\widetilde{\varphi } (X,\lambda )\) is zero for \(\lambda \in (rD,(r+1)D]\) and is equal to \(-\Delta <0\) for \(\lambda \in ((r+1)D,(r+2)D]\), so that Property B also holds.
Case 4:\(m<|X|+(r+1)\Delta<m+\Delta <|X|+(r+2)\Delta \).
so that Property A holds. Besides, the slope of \(\widetilde{\varphi } (X,\lambda )\) is \(-(|X|-m+(r+1)\Delta )\) for \(\lambda \in (rD,(r+1)D]\) and is equal to \(-\Delta \) for \(\lambda \in ((r+1)D,(r+2)D]\). Since \( -(|X|-m+(r+1)\Delta )>-\Delta \) by the assumption that defines this case, we conclude that Property B also holds.
Since \(\widetilde{\varphi }(Y,\lambda )\) is piecewise-linear concave in \( \lambda \), for each set \(Y\subseteq N_{1}\) the function \(\widetilde{\varphi } (Y,\lambda )+u(X\setminus Y)-l(Y\setminus X)\) is a piecewise-linear concave function in \(\lambda \), which implies that the function \(\widetilde{\varphi } _{l}^{u}(X,\lambda )\) is also a piecewise-linear concave function in \( \lambda \), since the minimum of several piecewise-linear concave functions is also a piecewise-linear concave function. It follows from (5.6) that
This shows that \(W_{1}(\lambda )\) is a weighted sum of piecewise-linear concave functions, which implies the following statement.
Lemma 5
Function \(W_{1}(\lambda )\) is a piecewise-linear concave function.
6 Computation of \(W_1(\lambda )\)
In this section, we present an algorithm that for a given \(\lambda \) computes the value of \(W_{1}(\lambda )\) in \(O(n_{1})\) time under the assumptions made at the beginning of Sect. 3.
Let r be the integer with \(\lambda \in (rD,(r+1)D]\). It follows from (5.6) that in order to compute \(W_{1}(\lambda )\) it suffices to compute the function values \(\varphi _{l}^{u}(N_{t}(\sigma ),d)\), where \(d=(r+1)D-\lambda \). We introduce the sets
that contain all subsets of the ground set \(N_{1}\) with exactly v elements; for completeness we define \({\mathcal {Y}}_{0}=\left\{ \emptyset \right\} \). Combining (5.2) and (5.3) and using the identity \(u(X{\setminus } Y)=u(X)-u(X\cap Y)\), define
By (5.6), to compute the function value \(W_{1}(\lambda )\), we need to compute the smallest of the values \(\psi ^{\prime }(X,d)\), \(\psi ^{\prime \prime }(X,d)\) and \(\psi ^{\prime \prime \prime }(X,d)\) for \( X=N_{t}(\sigma )\), where \(0\le t\le n_{1}\). Algorithm ComputeW1 that performs this computation is presented below.
To compute \(\psi ^{\prime }(X,d)\) for a given set \(X\subseteq N_{1}\), observe that this function does not depend on d and the minimum in the right-hand side is sought for among the differences between v multiples of D and the sum of v numbers, each being either a u-value or an l -value. It follows from \(D\ge u(j)\ge l(j),\)\(j\in N_{1}\), that the minimum in the right-hand side is achieved by \(v=0\), i.e.,
Thus, all required values \(\psi ^{\prime }(N_{t}(\sigma ),d)\), \(t=0,1,\ldots ,n_{1}\), can be easily computed. See Step 1 of Algorithm ComputeW1 below.
For \(\psi ^{\prime \prime \prime }(X,d)\), the maximum in the right-hand side is attained by \(v=n_{1}\), so that
and all required values \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\), \( t=0,1,\ldots ,n_{1}\), can be easily computed. See Step 2 of Algorithm ComputeW1 below.
We now consider function \(\psi ^{\prime \prime }(X,d)\). In the right-hand side of (6.3) the minimum is sought for among the differences of v multiples of d and the sum of v numbers, each equal to some u-value or some l-value, and the minimum is attained if these u- and l-values are greater than d. Formally, for a given set X, define
i.e., for each fixed d, the set \(\overline{Y}(X,d)\) is the set-minimizer that is smallest with respect to inclusion. Hence, if \(m^{\prime }<| \overline{Y}(X,d)|<m^{\prime }+\Delta \), then (6.3) implies that
The lemma below shows that if the set \(\overline{Y}(X,d)\) does not satisfy the condition \(m^{\prime }<|\overline{Y}(X,d)|<m^{\prime }+\Delta \), then the function \(\psi ^{\prime \prime }(X,d)\) can be ignored in computing \( \varphi _{l}^{u}(X,d)\).
Lemma 6
Suppose that either \(\left| \overline{Y}(X,d)\right| \ge m^{\prime }+\Delta \) or \(\left| \overline{Y}(X,d)\right| \le m^{\prime }\) holds. Then,
We show that \(\psi ^{\prime \prime }(X,d)\ge \psi ^{\prime }(X,d)\) or \(\psi ^{\prime \prime }(X,d)\ge \psi ^{\prime \prime \prime }(X,d)\) holds. Since \(\overline{Y}(X,d)\) satisfies (6.8), it follows that
where the last inequality follows from the assumption \(|\overline{Y} (X,d)|~\ge m^{\prime }+\Delta \) and from the non-negativity of u(j) and l(j). Hence, we have \(\psi ^{\prime \prime }(X,d)\ge \psi ^{\prime \prime \prime }(X,d)\).
Suppose now that \(|\overline{Y}(X,d)|\le m^{\prime }\). By (6.3), (6.6), and (6.9), we have
where the second inequality follows from \(l(j)\le u(j)\le D\) for \(j\in N\), while the last inequality follows from \(d\le D\) and from the assumption \(| \overline{Y}(X,d)|\le m^{\prime }\). Hence, we have \(\psi ^{\prime \prime }(X,d)\ge \psi ^{\prime }(X,d)\). \(\square \)
The lemma above implies that for each \(t=0,1,\ldots ,n_{1}\), in order to determine \(\varphi _{l}^{u}(N_{t}(\sigma ),d)\), the value of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) must be compared to the smaller of \(\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) only if \(m^{\prime }<\overline{Y}(N_{t}(\sigma ),d)<m^{\prime }+\Delta \).
The algorithm for computing the value \(W_1(\lambda )\) is presented below.
Algorithm ComputeW1
Step 0.:
Let r be the integer such that \(rD<\lambda \le (r+1)D\). Set \(d:=(r+1)D-\lambda \), \(m^{\prime }:=m-\left( r+1\right) \Delta \).
Step 1.:
For \(t=0,1,\ldots ,n_{1}\), set \(\psi _{t}^{\prime }:=U_{t}\), where \(U_{t}\) is given by (3.3).
Step 2.:
For \(t=0,1,\ldots ,n_{1}\), set \(\psi _{t}^{\prime \prime \prime }:=Dm^{\prime }+d\Delta -(L_{n_{1}}-L_{t})\), where \(L_{t}\) is given by (3.3).
Output the value \(\sum _{t=1}^{n_{1}}(w(\sigma (t))-w(\sigma (t+1)))\varphi _{l}^{u}(N_{t}(\sigma ),d)\).
It is easy to see that the running time of Algorithm ComputeW1 is \(O(n_1)\).
Lemma 7
For any \(\lambda \in [\underline{\lambda }, \overline{ \lambda }]\), the function value \(W_1(\lambda )\) can be computed in \(O(n_1)\) time.
7 Search by major breakpoints
In this section, we describe how to find up to two consecutive major intervals of \(\lambda \), which is total work of the \(\Delta \)-jobs, that contain an optimal value of \(\lambda ^{*}\) that maximizes function \( W\left( \lambda \right) \). The running time of the presented search algorithm is \(O(n\log n_{\Delta })\).
We know from Sect. 4 that function \(W_{\Delta }(\lambda )\) is concave, and from Sect. 5 that function \(W_{1}(\lambda )\) is concave. Thus, the overall function \(W(\lambda )\) is concave, as it is the sum of these two functions. Hence, we have the following properties of an optimal value \(\lambda =\lambda ^{*}\) that maximizes the function value \(W(\lambda )\):
For any two real numbers \(\lambda ^{\prime }\) and \(\lambda ^{\prime \prime }\) such that \(\lambda ^{\prime }<\lambda ^{\prime \prime }\),
if \(W(\lambda ^{\prime })=W(\lambda ^{\prime \prime })\), then there exists an optimal \(\lambda ^{*}\) such that \(\lambda ^{\prime }\le \lambda ^{*}\le \lambda ^{\prime \prime }\), since \(W(\lambda )\le W(\lambda ^{\prime })\) for \(\lambda \le \lambda ^{\prime }\) and \(W(\lambda )\le W(\lambda ^{\prime \prime })\) for \(\lambda \ge \lambda ^{\prime \prime }\);
if \(W(\lambda ^{\prime })>W(\lambda ^{\prime \prime })\), then there exists an optimal \(\lambda ^{*}\) such that \(\lambda ^{*}\le \lambda ^{\prime \prime }\), since \(W(\lambda )\le W(\lambda ^{\prime \prime })\) for \(\lambda \ge \lambda ^{\prime \prime }\);
if \(W(\lambda ^{\prime })<W(\lambda ^{\prime \prime })\), then there exists an optimal \(\lambda ^{*}\) such that \(\lambda ^{*}\ge \lambda ^{\prime }\), since \(W(\lambda )\le W(\lambda ^{\prime })\) for \(\lambda \le \lambda ^{\prime }\).
This justifies the application of binary search for determining a rough location of the global optimum of function \(W(\lambda )\). Such an algorithm is outlined below. The algorithm calls Procedure ComputeMajor described in Sect. 4, which outputs a sorted list of the major breakpoints.
For a given interval \(I=[\lambda ^{\prime },\lambda ^{\prime \prime }]\) of \( \lambda \)-values, the increment\(\delta (I)\) of function \(W(\lambda )\) is defined as the difference \(W(\lambda ^{\prime \prime })-W(\lambda ^{\prime })\) of the function values computed at the endpoints of the interval.
Algorithm SearchMajor
Step 1.:
Call Procedure ComputeMajor to compute the sorted list of the major breakpoints. Suppose that the total number of the found major breakpoints is \(g+1\). Denote the corresponding major intervals by \( I_{1},I_{2},\ldots ,I_{g}.\)
Step 2.:
Compute the increments \(\delta (I_{1})\) and \(\delta (I_{g})\) of function \(W(\lambda )\). If \(\delta (I_{1})\le 0\), then output the interval \(I_{1}\) and stop. If \(\delta (I_{g})\ge 0\), then output the interval \(I_{g}\) and stop. Otherwise, go to Step 3.
Step 3.:
Perform binary search among the major intervals with a purpose of finding two consecutive intervals \(I^{\prime }\) and \(I^{\prime \prime }\), one with a positive increment \(\delta (I^{\prime })\) and the other with a negative increment \(\delta (I^{\prime \prime })\). Set \( k^{\prime }:=1\) and \(k^{\prime \prime }:=g\).
(a)
If \(k^{\prime }+1=k^{\prime \prime }\), then output intervals \( I_{k^{\prime }}\) and \(I_{k^{\prime \prime }}\) and stop. Otherwise, go to Step 3(b).
(b)
Set \(k:=\lfloor \frac{1}{2}(k^{\prime }+k^{\prime \prime })\rfloor \) and compute the increment \(\delta (I_{k})\) of function \( W(\lambda )\).
(c)
If \(\delta (I_{k})=0\), then output the interval \(I_{k}\) and stop. If \(\delta (I_{k})>0\), then update \(k^{\prime }:=k\) and return to Step 3(a). Otherwise (i.e., \(\delta (I_{k})<0\)), update \(k^{\prime \prime }:=k\) and return to Step 3(a).
In Algorithm SearchMajor, Steps 1 and 2 can be done in O(n) time by Lemmas 1, 3, and 7. Since the number of major breakpoints is \(O(n_{\Delta })\) by Lemma 3, the number of iterations of binary search in Step 3 is \(O(\log n_{\Delta })\). Each iteration in Step 3 can be implemented in O(n) time by Lemmas 1 and 7. Thus, the overall time complexity of Algorithm SearchMajor is \(O(n\log n_{\Delta })\).
Algorithm SearchMajor outputs either a single major interval or two consecutive major intervals. The endpoints of each of these intervals are major breakpoints of function \(W(\lambda )\), and the global maximum of function \(W(\lambda )\) is achieved within these intervals. Notice that within each of major intervals the function \(W_{\Delta }(\lambda )\) is linear. In order to find the global maximum of \(W(\lambda )\), we need to closely inspect the behavior of the function \(W_{1}(\lambda )\) over each of the found major intervals. As established in Sect. 5, the function \(W_{1}(\lambda )\) is piecewise-linear over each of these intervals, and we need to determine its breakpoints, which we call minor breakpoints. The next sections present details for finding and handling minor breakpoints.
8 Minor breakpoints
Consider I, one of the major intervals found by running Algorithm SearchMajor. In what follows we explain how to determine the minor breakpoints of function \(W(\lambda )\) within interval I, i.e., the breakpoints of function \(W_{1}(\lambda )\) within I.
Remark
The algorithm presented in this section does not find exactly the set of all minor breakpoints in I, but rather finds its superset, i.e., the set obtained by the algorithm contains all minor breakpoints and may contain some points that are not minor breakpoints. This is sufficient for our purpose of finding an optimal \( \lambda ^{*}\) that maximizes the function \(W(\lambda )\) since \(\lambda ^{*}\) is contained in the set of minor breakpoints and therefore in the set computed by the algorithm.
8.1 Classification of breakpoints
We can represent function \(W_{1}(\lambda )\) by using function \(\varphi _{l}^{u}(N_{t}(\sigma ),d)\) as follows. The chosen major interval I is contained in the interval \([rD,(r+1)D]\) for some integer r (see (4.4)). Then, we have \(d=(r+1)D-\lambda \), and (5.6) implies that
This shows that all breakpoints of \(W_{1}(\lambda )\) in the major interval I can be obtained by finding all breakpoints of functions \(\varphi _{l}^{u}(N_{t}(\sigma ),d)\) for \(t=1,2,\ldots ,n_{1}\) within the interval [0, D]. In the remainder of this section, we focus on the latter problem.
Recall that \(\varphi _{l}^{u}(N_t(\sigma ), d)\) can be represented as
with the functions \(\psi ^{\prime }(N_t(\sigma ), d)\), \(\psi ^{\prime \prime }(N_t(\sigma ), d)\) and \(\psi ^{\prime \prime \prime }(N_t(\sigma ), d)\) given by (6.6), (6.3), and (6.7), respectively, with \( X = N_t(\sigma )\). That is,
While the functions \(\varphi _{l}^{u}(N_t(\sigma ), d), \psi ^{\prime }(N_t(\sigma ),d), \psi ^{\prime \prime }(N_t(\sigma ),d), \psi ^{\prime \prime \prime }(N_t(\sigma ), d)\) are defined on the finite interval [0, D], in the following we extend the domain of the functions to the infinite interval \((- \infty , + \infty )\) to simplify the discussion. For our purpose, we just compute all breakpoints of the function \(\varphi _{l}^{u}(N_t(\sigma ), d)\) and then take those contained in the interval [0, D].
Since the functions \(\psi ^{\prime }(N_t(\sigma ), d)\) and \(\psi ^{\prime \prime \prime }(N_t(\sigma ), d)\) are linear, the breakpoints of function \( \varphi _{l}^{u}(N_t(\sigma ), d)\) can be classified into four types:
Type 1: breakpoints of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\); Type 2: intersection points of \(\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\), Type 3: intersection points of \(\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\); Type 4: intersection points of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\).
Here, intersection points of two functions of the argument d are defined as the values of d for which both functions are equal. It is easy to see that for each integer t, a Type 2 breakpoint is uniquely determined since both \(\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) are linear functions. We will show that for each integer t, Type 3 and Type 4 breakpoints are also uniquely determined.
In our analysis of the minor breakpoints, let \(\mathcal {B=}\left( \bar{\beta } _{1},\bar{\beta }_{2},\ldots ,\bar{\beta }_{2n_{1}}\right) \) be a non-increasing sequence of the values l(j) and \(u\left( j\right) \), \(j\in N_{1}\). Such a sequence, which we call the \({\mathcal {B}}\)-sequence can be obtained in \(O(n_{1}\log n_{1})\) time. We assume that the \({\mathcal {B}} \)-sequence is available before starting the computation of minor breakpoints.
For each t, \(0\le t\le n_{1}\), let \({\mathcal {B}}_{t}\) be a sequence that contains the values of u(j) for \(j\in N_{t}(\sigma )\) and the values of l(j) for \(j\in N_{1}{\setminus } N_{t}(\sigma )\). For \(z=1,2,\ldots ,n_{1}\), let \(\beta _{z}^{(t)}\) denote the z-th largest number in sequence \( {\mathcal {B}}_{t}\). Notice that the sequence \(\beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{n_{1}}^{(t)}\) is a sub-sequence of the \(\mathcal {B }\)-sequence.
8.2 Type 1 and Type 2 breakpoints
We first consider the Type 1 breakpoints and show that those breakpoints are defined by either u-values or l-values.
Using the sequence \(\beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{n_{1}}^{(t)}\), function \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) of the form (8.2) can be rewritten as
For \(t=0,1,\ldots ,n_{1}\) and \(v=m^{\prime }+1,m^{\prime }+2,\ldots ,m^{\prime }+\Delta -1\), if \(d\in I_{v}^{(t)}\) then \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)=\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\). Moreover, the breakpoints of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d) \) are given by \(\beta _{z}^{(t)}\), \(z=m^{\prime }+2,m^{\prime }+3,\ldots ,m^{\prime }+\Delta -1\).
Note that \(\beta _{m^{\prime }+1}^{(t)}\) is not a breakpoint of \( \psi ^{\prime \prime }(N_{t}(\sigma ),d)\) within the interval \(I_{m^{\prime }+1}^{(t)}\), as parameter v in (8.4) takes the minimum value \( m^{\prime }+1\) for any \(d>\beta _{m^{\prime }+2}^{(t)}\).
Proof
Since \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) is a piecewise-linear concave function, it suffices to show that for each integer \(\hat{v}=m^{\prime }+1,m^{\prime }+2,\ldots ,m^{\prime }+\Delta -2\), if \(d=\beta _{\hat{v}+1}^{\left( t\right) }\) then we have
To prove the first equality in (8.5), we show that at \( d=\beta _{\hat{v}+1}^{\left( t\right) }\), for any v, \(m^{\prime }<v<m^{\prime }+\Delta \), the linear function \(\psi _{{v}}^{\prime \prime }(N_{t}(\sigma ),d)\) has the same or larger value than \(\psi _{\hat{v} }^{\prime \prime }(N_{t}(\sigma ),d)\). For \(v\in \{m^{\prime }+1,m^{\prime }+2,\ldots ,m^{\prime }+\Delta -2\}\), it holds that
Since the values \(\beta _{z}^{(t)}\) are non-increasing with respect to z, we have \(\sum _{z=\hat{v}+1}^{v}(\beta _{\hat{v}+1}^{(t)}-\beta _{z}^{(t)})\ge 0\) if \(v\ge \hat{v}\) and \(\sum _{z=v+1}^{\hat{v}}(\beta _{z}^{(t)}-\beta _{\hat{v}+1}^{\left( t\right) })\ge 0\) if \(v<\hat{v}\). Hence, Eq. (8.6) implies that \(\psi _{{v} }^{\prime \prime }(N_{t}(\sigma ),d)\ge \psi _{\hat{v}}^{\prime \prime }(N_{t}(\sigma ),d)\).
The second equality in (8.5) follows immediately from (8.6) in the case \(v=\hat{v}+1\) since
By the lemma above, all Type 1 breakpoints of \(\varphi _{l}^{u}(N_{t}(\sigma ),d)\) for \(t=0,1,2,\ldots ,n_{1}\) belong to the sequence \({\mathcal {B}}\) and they can be computed in \(O(n_{1})\) time.
For \(t=0,1,\ldots ,n_{1}\), a Type 2 breakpoint of \(\varphi _{l}^{u}(N_{t}(\sigma ),d)\) is the intersection of two linear functions \( \varphi ^{\prime }(N_{t}(\sigma ),d)\) and \(\varphi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\), i.e., the point
recall the definitions of \(U_{t}\) and \(L_{t}\) in (3.3). Therefore, the Type 2 breakpoints for all t can be also obtained in \( O(n_{1})\) time.
8.3 Type 3 and Type 4 breakpoints
We first show that for each t, Type 3 and Type 4 breakpoints are uniquely determined.
Lemma 9
For each \(t=0,1,\ldots ,n_{1}\), the intersection points of \(\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\), as well as of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) are uniquely determined.
Proof
To prove the claim, we use the following fundamental property of a continuous function:
for a continuous and strictly increasing function \(f: {{\mathbb {R}}} \rightarrow { {\mathbb {R}}}\) such that \(\lim _{d \rightarrow + \infty } f(d)= + \infty \) and \(\lim _{d \rightarrow - \infty } f(d)= - \infty \), a solution of the equation \(f(d)=0\) is uniquely determined.
We show that the continuous functions \(f(d) = \psi ^{\prime \prime }(N_{t}(\sigma ), d) - \psi ^{\prime }(N_{t}(\sigma ), d)\) and \({\tilde{f}}(d) = \psi ^{\prime \prime \prime }(N_{t}(\sigma ), d) - \psi ^{\prime \prime }(N_{t}(\sigma ), d)\) satisfy the conditions above.
By (8.1), (8.2), and (8.3), the slope of \(\psi ^{\prime }(N_{t}(\sigma ),d)\) is zero, the slope of \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) is \(\Delta \), and the slope of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) is between 1 and \(\Delta -1\). Hence, the functions \(f(d)=\psi ^{\prime \prime }(N_{t}(\sigma ),d)-\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\tilde{f}(d)=\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)-\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) are strictly increasing and satisfy
For \(t=0,1,\ldots ,n_{1}\), denote by \(\gamma ^{(t)}\) the (unique) intersection point of \(\psi ^{\prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\), i.e., \(\gamma ^{(t)}\) is a Type 3 breakpoint. We now present an algorithm for finding the Type 3 breakpoints. The idea of our algorithm is simple. Recall the representation of function \( \psi ^{\prime \prime }(N_{t}(\sigma ),d)\) and the definition of the intervals \(I_{v}^{(t)}\) used in Lemma 8. To compute \(\gamma ^{(t)}\), for each integer v from \(m^{\prime }+\Delta -1\) down to \( m^{\prime }+1\) we compute the intersection point \(\gamma _{v}^{(t)}\) of two linear functions \(\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime }(N_{t}(\sigma ),d)\). The intersection point \(\gamma _{v}^{(t)}\) is given as
i.e., is the sum of v largest elements in sequence \( {\mathcal {B}}_{t}\). We have \(\gamma ^{(t)}=\gamma _{v}^{(t)}\) if the intersection point \(\gamma _{v}^{(t)}\) is contained in the interval \( I_{v}^{(t)}\), and such v always exists.
Algorithm ComputeGamma1
Step 0.:
Compute \(\beta _{1}^{(0)},\beta _{2}^{(0)},\ldots ,\beta _{m^{\prime }+\Delta -1}^{(0)}\), and \(\Theta _{m^{\prime }+\Delta -1}^{(0)}\). Set \(t:=0\).
Step 1.:
Compute the value \(\gamma ^{(t)}\) as follows:
Step 1-1.:
Set \(v:=m^{\prime }+\Delta -1\).
Step 1-2.:
Compute the intersection point \(\gamma _{v}^{(t)}\) of the two linear functions \(\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\) and \( \psi ^{\prime }(N_{t}(\sigma ),d)\) by (8.7).
Step 1-3.:
If \(\gamma _{v}^{(t)}\in I_{v}^{(t)}\), then set \(\gamma ^{(t)}:=\gamma _{v}^{(t)}\) and go to Step 2 (Note: if \(v=m^{\prime }+1\), then the condition \(\gamma _{v}^{(t)}\in I_{v}^{(t)}\) must hold). Otherwise, set \(\Theta _{v-1}^{(t)}:=\Theta _{v}^{(t)}-\beta _{v}^{(t)}\), \( v:=v-1\), and go to Step 1-2.
Step 2.:
If \(t=n_{1}\), then stop. Otherwise, go to Step 3.
We explain implementation details of the algorithm and analyze its running time.
In Steps 0 and 3, we compute \(\beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{m^{\prime }+\Delta -1}^{(t)}\), which can be done easily in \( O(n_{1}) \) time by using the \({\mathcal {B}}\)-sequence since \(\beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{m^{\prime }+\Delta -1}^{(t)}\) is a sub-sequence of the \({\mathcal {B}}\)-sequence. The value \(\Theta _{m^{\prime }+\Delta -1}^{(0)}\) is initially computed in \(O(n_{1})\) time, and then updated in Step 3 in constant time by using the following formula:
Steps 1-1, 1-2, and 1-3 can be done in constant time. Since the number of iterations in Step 1 is \(O(\Delta )\), Step 1 requires \(O(\Delta )\) time in total.
Steps 2 and 4 can be done in constant time.
Since Steps 1–4 are repeated \(O(n_{1})\) times, the running time of Algorithm ComputeGamma1 is \(O((n_{1})^{2})\).
Now, we present an algorithm for finding the Type 4 breakpoints, which is similar to Algorithm ComputeGamma1 for finding the Type 3 breakpoints. For \( t=0,1,\ldots ,n_{1}\), we denote by \(\alpha ^{(t)}\) the (unique) intersection point of \(\psi ^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\), i.e., \(\alpha ^{(t)}\) is a Type 4 breakpoint.
To compute \(\alpha ^{(t)}\), for each integer v from \(m^{\prime }+\Delta -1\) down to \(m^{\prime }+1\) we compute the intersection point \(\alpha _{v}^{(t)}\) of two linear functions \(\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\) and \( \psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\). The intersection point \( \alpha _{v}^{(t)}\) is given as
We have \(\alpha ^{(t)}=\alpha _{v}^{(t)}\) if the intersection point \(\alpha _{v}^{(t)}\) is contained in the interval \(I_{v}^{(t)}\), and such v always exists.
Algorithm ComputeAlpha1
Step 0.:
Compute \(\beta _{1}^{(0)},\beta _{2}^{(0)},\ldots ,\beta _{m^{\prime }+\Delta -1}^{(0)}\). Also, compute \(\Upsilon _{0}\) and \(\Theta _{m^{\prime }+\Delta -1}^{(0)}\) by (8.10) and (8.8 ), accordingly. Set \(t:=0\).
Step 1.:
Compute the value \(\alpha ^{(t)}\) as follows:
Step 1-1.:
Set \(v:=m^{\prime }+\Delta -1\).
Step 1-2.:
Compute the intersection point \(\alpha _{v}^{(t)}\) of the two linear functions \(\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\) and \( \psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) by (8.9).
Step 1-3.:
If \(\alpha _{v}^{(t)}\in I_{v}^{(t)}\), then set \(\alpha ^{(t)}=\alpha _{v}^{(t)}\) and go to Step 2 (Note: if \(v=m^{\prime }+1 \), then the condition \(\alpha _{v}^{(t)}\in I_{v}^{(t)}\) must hold). Otherwise, set \(\Theta _{v-1}^{(t)}:=\Theta _{v}^{(t)}-\beta _{v}^{(t)}\), \( v:=v-1\), and go to Step 1-2.
Step 2.:
If \(t=n_{1}\), then stop. Otherwise, go to Step 3.
Set \(\Upsilon _{t+1}:=\Upsilon _{t}+u(\sigma (t+1))-l(\sigma (t+1))\), \(t:=t+1\), and go to Step 1.
\(\square \)
As in the analysis for Algorithm ComputeGamma1, we can show that the running time of Algorithm ComputeAlpha1 is \(O((n_{1})^{2})\). In Appendix A, we will present a faster algorithm for computing the Type 3 and Type 4 breakpoints.
9 Search by minor breakpoints
Let \(I^{*}\) be a major interval, and suppose that we find (a superset of) all minor breakpoints \(\mu _{1},\mu _{2},\ldots ,\mu _{s}\) contained in the major interval \(I^{*}\); for convenience, we denote by \(\mu _{0}\) and \(\mu _{s+1}\) the left and right endpoints of the interval \(I^{*}\). By the result in Sect. 8, we have \(s=O(n_{1})\). In this section, we show that some \(\mu _{k}\in I^{*}\) that maximizes the function value \(W(\lambda )\) can be found in \(O(n\log n_{1})\) time.
The approach of the algorithm described below is essentially the same as the one used in Sect. 7. Since the function \(W(\lambda )\) is concave, we have the following properties for an optimal value \(\lambda =\lambda ^{*}\) that maximizes the function value \(W(\lambda )\) within the interval \(I^{*}\).
For any consecutive minor breakpoints \(\mu ^{\prime }<\mu ^{\prime \prime }\) in the interval \(I^{*}\), one of the following holds:
if \(W(\mu ^{\prime })=W(\mu ^{\prime \prime })\), then both of \(\mu ^{\prime }\) and \(\mu ^{\prime \prime }\) are optimal since \(W(\lambda )\le W(\mu ^{\prime })\) for \(\lambda \le \mu ^{\prime }\), \(W(\lambda )=W(\mu ^{\prime })=W(\mu ^{\prime \prime })\) for \(\lambda \in [\mu ^{\prime },\mu ^{\prime \prime }]\), and \(W(\lambda )\le W(\mu ^{\prime \prime })\) for \(\lambda \ge \mu ^{\prime \prime }\).
if \(W(\mu ^{\prime })>W(\mu ^{\prime \prime })\), then there exists an optimal \(\lambda ^{*}\) such that \(\lambda ^{*}\le \mu ^{\prime }\) since \(W(\lambda )\le W(\mu ^{\prime })\) for \(\lambda \ge \mu ^{\prime }\);
if \(W(\mu ^{\prime })<W(\mu ^{\prime \prime })\), then there exists an optimal \(\lambda ^{*}\) such that \(\lambda ^{*}\ge \mu ^{\prime \prime }\) since \(W(\lambda )\le W(\mu ^{\prime \prime })\) for \(\lambda \le \mu ^{\prime \prime }\).
Notice that for any consecutive minor breakpoints \(\mu ^{\prime }<\mu ^{\prime \prime }\), function \(W(\lambda )\) is linear in the interval \([\mu ^{\prime },\mu ^{\prime \prime }]\).
This justifies the application of binary search for determining an optimal \( \lambda =\lambda ^{*}\) that maximizes the function \(W(\lambda )\) in the interval \(I^{*}\). Recall the definition of an increment \(\delta (I)\) of the function \(W(\lambda )\) for an interval \(I=[\mu ^{\prime },\mu ^{\prime \prime }]\) of \(\lambda \)-values, as defined in Sect. 7.
Algorithm Minor
Step 1.:
Find an increasing sequence \(\mu _{1},\mu _{2},\ldots ,\mu _{s}\) of real numbers containing all minor breakpoints of \(W(\lambda )\) in interval \(I^{*}\). Also, let \(\mu _{0}\) and \(\mu _{s+1}\) be the left and right endpoints of the interval \(I^{*}\), respectively. The values \(\mu _{0},\mu _{1},\ldots ,\mu _{s+1}\) split the interval \(I^{*}\) into intervals \(I_{1},I_{2},\ldots ,I_{s+1}\), where \(I_{k}=\left[ \mu _{k-1},\mu _{k}\right] \), \(1\le k\le s+1\).
Step 2.:
Compute the increments \(\delta (I_{1})\) and \(\delta (I_{s+1})\) of function \(W(\lambda )\). If \(\delta (I_{1})\le 0\), then output the value \( \lambda ^{*}=\mu _{0}\) and stop. If \(\delta (I_{s+1})\ge 0\), then output the value \(\lambda ^{*}=\mu _{s+1}\) and stop. Otherwise, go to Step 3.
Step 3:
Perform binary search among the found intervals with a purpose of finding two consecutive intervals \(I^{\prime }\) and \(I^{\prime \prime }\), one with a positive increment \(\delta (I^{\prime })\) and the other with a negative increment \(\delta (I^{\prime \prime })\). Start with \(k^{\prime }=1\), \(k^{\prime \prime }=s+1\).
(a)
If \(k^{\prime }+1=k^{\prime \prime }\), then output the value \(\mu _{k^{\prime }}\) and stop. Otherwise, go to Step 3(b).
(b)
Compute \(k=\left\lfloor \frac{1}{2}(k^{\prime \prime }+k^{\prime })\right\rfloor \) and the increment \(\delta (I_{k})\) of function \(W(\lambda ) \).
(c)
If \(\delta (I_{k})=0\), then output the value \(\mu _{k}\) (or \(\mu _{k-1}\)) and stop. If \(\delta (I_{k})>0\), then update \(k^{\prime }=k\) and return to Step 3(a). Otherwise (i.e., \(\delta (I_{k})<0\)), update \(k^{\prime \prime }=k\) and return to Step 3(a).
In Algorithm Minor, Step 1 can be done in \(O( (n_{1})^{2})\) time by the results presented in Sect. 8. Step 2 can be done in O(n) time by Lemmas 1 and 7. The number of iterations of binary search in Step 3 is \(O(\log n_1)\). Each iteration in Step 3 can be implemented in O(n) time by Lemmas 1 and 7. Thus, the overall time complexity of Algorithm Minor is \(O(n \log n_1 + (n_{1})^{2})\).
The results presented in this section imply that after the major intervals that contain an optimal value of \(\lambda \) are found, that optimal value can be found in \(O(n \log n_1 + (n_{1})^{2})\) time. This concludes the proof of Theorem 1, that states that the scheduling problem \( P|pmtn,p(j)=u(j)-x(j),size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D|\sum _{j\in N}w(j)x(j)\) can be solved in \(O(n\log n+(n_{1})^{2})\) time.
10 Conclusions
The main result of this paper is an \(O\left( n\log n\right) \)-time algorithm for minimizing total compression cost on identical parallel machines, provided that the processing times of the jobs are controllable and each job either requires one machine or \(\Delta >1\) machines for its processing. Although the problem does not admit a direct reformulation in terms of submodular optimization, some techniques developed in our prior research (Shioura et al., 2018) still appear to be useful; see, e.g., Sect. 5. This paper shows that even in a fairly simple settings, with only two sizes of the jobs, considerable technical efforts are required to design a fast algorithm.
The problems that combine the presence of parallel jobs and controllable processing times have been insufficiently studied. We hope that this work will initiate systematic studies in this area, and that will lead to establishing fairly general methodological principles.
Data Availability
No data are associated with this article.
References
Błažewicz, J., Drabowski, M., & Węglarz, J. (1986). Scheduling multiprocessor tasks to minimize schedule length. IEEE Transactions on Computers, C-35, 389–393.
Drozdowski, M. (2009). Scheduling for Parallel Processing. London: Springer.
Jansen, K., & Mastrolilli, M. (2004). Approximation schemes for parallel machine scheduling problems with controllable processing times. Computers and Operations Research,31, 1565–1581.
Jansen, K., & Porkolab, L. (2003). Computing optimal preemptive schedules for parallel tasks: Linear programming approaches. Mathematical Programming Series A,95, 617–630.
Katoh, N., & Ibaraki, T. (1998). Resource allocation problems. In D.-Z. Du & P. M. Pardalos (Eds.), Handbook of Combinatorial Optimization (Vol. 2, pp. 159–260). Dordrecht: Kluwer.
Lopes, R. V., & Menasce, D. (2016). A taxonomy of job scheduling on distributed computing systems. IEEE Transactions on Parallel and Distributed Systems,27, 3412–3428.
Sha, L., Abdelzaher, T., Årzén, K.-E., Cervin, A., Baker, T., Burns, A., Buttazzo, G., Caccamo, M., Lehoczky, J., & Mok, A. K. (2004). Real time scheduling theory: a historical perspective. Real-Time Systems,28, 101–155.
Shakhlevich, N. V., & Strusevich, V. A. (2008). Preemptive scheduling on uniform parallel machines with controllable job processing times. Algorithmica,51, 451–473.
Shakhlevich, N. V., Shioura, A., & Strusevich, V. A. (2009). Single machine scheduling with controllable processing times by submodular optimization. International Journal of Foundations of Computer Science,20, 247–269.
Shioura, A., Shakhlevich, N. V., & Strusevich, V. A. (2013). A submodular optimization approach to bicriteria scheduling problems with controllable processing times on parallel machines. SIAM Journal on Discrete Mathematics,27, 186–204.
Shioura, A., Shakhlevich, N. V., & Strusevich, V. A. (2015). Decomposition algorithms for submodular optimization with applications to parallel machine scheduling with controllable processing times. Mathematical Programming Series A,153, 495–534.
Shioura, A., Shakhlevich, N. V., & Strusevich, V. A. (2016). Application of submodular optimization to single machine scheduling with controllable processing times subject to release dates and deadlines. INFORMS Journal on Computing,28, 148–161.
Shioura, A., Shakhlevich, N. V., & Strusevich, V. A. (2017). Machine speed scaling by adapting methods for convex optimization with submodular constraints. INFORMS Journal on Computing,29, 724–736.
Shioura, A., Shakhlevich, N. V., & Strusevich, V. A. (2018). Preemptive models of scheduling with controllable processing times and of scheduling imprecise computation: A review of solution approaches. European Journal of Operational Research,266, 795–818.
This work is supported by the project EP/T01461X/1 “Algorithmic Support for Massive Scale Distributed Systems” funded by the Engineering and Physical Sciences Research Council (EPSRC). The first author is partially supported by the Grant 18K11177 of the Japanese Society for the Promotion of Science (JSPS) KAKENHI. The first version of this paper was written when the second author was at the University of Greenwich, London, U.K.
Author information
Authors and Affiliations
Department of Industrial Engineering and Economics, Tokyo Institute of Technology, Tokyo, 152-8550, Japan
Akiyoshi Shioura
Welling, Kent, UK
Vitaly A. Strusevich
School of Computing, University of Leeds, Leeds, LS2 9JT, UK
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Faster algorithm for finding the Type 3 and Type 4 breakpoints
Appendix A: Faster algorithm for finding the Type 3 and Type 4 breakpoints
Algorithm Minor from Sect. 9 locates the optimal value \(\lambda ^{*}\) in a major interval \(I^{*}\) in \(O(n\log n+(n_{1})^{2})\) time. The term \((n_{1})^{2}\) is responsible for finding the Type 3 breakpoints \(\gamma ^{(0)},\gamma ^{(1)},\ldots ,\gamma ^{(n_{1})}\) and the Type 4 breakpoints \(\alpha ^{(0)},\alpha ^{(1)},\ldots ,\alpha ^{(n_{1})}\) according to the algorithms from Sect. 8.3. Here we present improved algorithms for finding the Type 3 and Type 4 breakpoints and show that each of them runs in \(O(n_{1}+m\log m)\) time. These results prove Theorem 2, which states that the problem \( P|pmtn,p(j)=u(j)-x(j),size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D|\sum _{j\in N}w(j)x(j)\) can be solved in \(O(n\log n)\) time.
1.1 A1 Monotonicity properties of minor breakpoints
Type 3 and Type 4 breakpoints have the following monotonicity, which will be used in developing an efficient algorithm for computing those breakpoints.
For an integer t, \(0\le t<n_{1}\), we show that \(\alpha ^{(t)}\le \alpha ^{(t+1)}\) holds. By the definitions of \(\alpha ^{(t)}\) and \(\alpha ^{(t+1)}\), we have
Below we show that \(\xi _{t}\ge 0\). Recall that the value of \(\beta _{z}^{(t)}\) (respectively, \(\beta _{z}^{(t+1)}\)) is the z-th largest number in \({\mathcal {B}}_{t}\) (respectively, in \({\mathcal {B}}_{t+1}\)), and the sequence \({\mathcal {B}}_{t+1}\) is obtained from \({\mathcal {B}}_{t}\) by the removal of \(l(\sigma (t+1))\) and the insertion of \(u(\sigma (t+1))\). Hence, we have to examine the following three possibilities:
Case 1:\(l(\sigma (t+1))\) is contained in the sequence \(( \beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{v(t+1)}^{(t)}) \), and \(u(\sigma (t+1))\) is contained in the sequence \(( \beta _{1}^{(t+1)},\beta _{2}^{(t+1)},\ldots ,\beta _{v(t+1)}^{(t+1)}) .\)
In this case, we have \(\xi _{t}=0\), since \((\beta _{1}^{(t+1)},\beta _{2}^{(t+1)},\ldots ,\beta _{v(t+1)}^{(t+1)})\) is obtained from \((\beta _{1}^{(t)},\)\(\beta _{2}^{(t)},\ldots ,\)\(\beta _{v(t+1)}^{(t)})\) by the removal of \(l(\sigma (t+1))\) and the insertion of \(u(\sigma (t+1)).\)
Case 2:\(l(\sigma (t+1))\) is not contained in the sequence \(( \beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{v(t+1)}^{(t)}) \), but \(u(\sigma (t+1))\) is contained in the sequence \(( \beta _{1}^{(t+1)},\beta _{2}^{(t+1)},\ldots ,\beta _{v(t+1)}^{(t+1)}) \).
In this case, we have \(\xi _{t}\ge 0\) since \(l(\sigma (t+1))\le \beta _{v(t+1)}^{(t)}\) and \((\beta _{1}^{(t+1)},\beta _{2}^{(t+1)},\ldots ,\beta _{v(t+1)}^{(t+1)})\) is obtained from \((\beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{v(t+1)}^{(t)})\) by the removal of \(\beta _{v(t+1)}^{(t)}\) and the insertion of \(u(\sigma (t+1)).\)
Case 3:\(l(\sigma (t+1))\) is not contained in the sequence \(( \beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{v(t+1)}^{(t)}) \), and \(u(\sigma (t+1))\) is not contained in the sequence \(( \beta _{1}^{(t+1)},\beta _{2}^{(t+1)},\ldots ,\beta _{v(t+1)}^{(t+1)}) \).
In this case, we have \(\xi _{t}=0\) since the sequences \((\beta _{1}^{(t)},\beta _{2}^{(t)},\ldots ,\beta _{v(t+1)}^{(t)})\) and \((\beta _{1}^{(t+1)},\)\(\beta _{2}^{(t+1)},\ldots ,\)\(\beta _{v(t+1)}^{(t+1)})\) coincide.
Thus, in any case, \(\xi _{t}\ge 0\) holds. This, together with (A1.6), implies that \(\alpha ^{(t)}-\alpha ^{(t+1)}\le 0 \), since \(v(t+1)-m^{\prime }-\Delta <0\). \(\square \)
For an integer t, \(0\le t<n_{1}\), we show that \(\gamma ^{(t)}\le \gamma ^{(t+1)}\) holds. By the definitions of \(\gamma ^{(t)}\) and \(\gamma ^{(t+1)}\), we have
By the definitions of \(\beta _{z}^{(t)}\) and \(\beta _{z}^{(t+1)}\), we have that \(\beta _{z}^{(t)}\le \beta _{z}^{(t+1)}\) for each z, which implies that \(\sum _{z=1}^{\tilde{v}(t)}\left( \beta _{z}^{(t+1)}-\beta _{z}^{(t)}\right) \ge 0\). Since \(\tilde{v}(t)-m^{\prime }>0\) in (A1.12), we have \(\gamma ^{(t+1)}-\gamma ^{(t)}\ge 0\), as required. \(\square \)
1.2 A2 An improved algorithm
We present a faster algorithm for computing the Type 4 minor breakpoints \( \alpha ^{(t)}\), \(t=0,1,\ldots ,n_{1}\); the Type 3 minor breakpoints can be found in a similar way and the details of the corresponding algorithm are omitted.
The idea for the faster algorithm is as follows. Recall that to find the value \(\alpha ^{(t)}\), Algorithm ComputeAlpha1 computes the values \(\alpha _{z}^{(t)}\) for \(z=m^{\prime }+\Delta -1,m^{\prime }+\Delta -2,\ldots ,m^{\prime }+1\) and checks whether \(\alpha _{z}^{(t)}\) is contained in the interval \(I_{z}^{(t)}\); if \(\alpha _{z}^{(t)}\in I_{z}^{(t)}\) then \(\alpha ^{(t)}=\alpha _{z}^{(t)}\) holds. We, however, know that \(\alpha ^{(t)}\ge \alpha ^{(t-1)}\) by Lemma 10. This implies that it suffices to check whether one of the following conditions holds:
where v is an integer such that \(\alpha ^{(t-1)}\in I_{v}^{(t)}\). Besides, instead of computing the values \(\beta _{z}^{(t)}\) for all z, \(m^{\prime }<z<m^{\prime }+\Delta \), in advance at the beginning of each iteration, we compute the values one by one, when necessary.
For \(t=1,2,\ldots ,n_{1}\), let \(v(t-1)\) denote the maximum integer \(v\in \{m^{\prime }+1,\ldots ,m^{\prime }+\Delta -1\}\) such that \(\alpha ^{(t-1)}\in I_{v}^{(t-1)}\). To compute \(v(t-1)\), define the sequence
Similarly, for \(t=1,2,\ldots ,n_{1}\), denote by \(v^{\prime }(t)\) the maximum integer \(v\in \{m^{\prime }+1,\ldots ,m^{\prime }+\Delta -1\}\) such that \( \alpha ^{(t-1)}\in I_{v}^{(t)}\). To compute \(v^{\prime }(t)\), define the sequence
For \(t=1,2,\ldots ,n_{1}\), we have \(v^{\prime }(t)\in \{v(t-1),v(t-1)+1\}\).
Proof
Recall that \(v(t-1)\) (respectively, \(v^{\prime }(t)\)) is defined via the length of the sequence \({\mathcal {S}}\) (respectively, of \({\mathcal {S}}^{\prime }\)). By the definition of the values \( \beta _{z}^{(t-1)}\) and \(\beta _{z}^{(t)}\), we have the following three possibilities for the relationship between the sequences \({\mathcal {S}}\) and \( {\mathcal {S}}^{\prime }\).
Case 1: \({\mathcal {S}}^{\prime }={\mathcal {S}}\);
Case 2: \({\mathcal {S}}^{\prime }\) is obtained from \({\mathcal {S}}\) by the insertion of \(u(\sigma (t));\)
Case 3: \({\mathcal {S}}^{\prime }\) is obtained from \({\mathcal {S}}\) by the insertion of \(u(\sigma (t))\) and the removal of \(l(\sigma (t))\).
In Cases 1 and 3, we have \(v^{\prime }(t)=v(t-1)\), while in Case 2, we have \( v^{\prime }(t)=v(t-1)+1\), if \(v(t-1)=\left| {\mathcal {S}}\right| \ge m^{\prime }+1\), or \(v^{\prime }(t)=v(t-1)=m^{\prime }+1\), if \( v(t-1)=m^{\prime }+1>\left| {\mathcal {S}}\right| \). \(\square \)
We describe below a faster algorithm for computing \(\alpha ^{(t)}\). While we compute the value \(\alpha ^{(0)}\) in the same way as in Algorithm ComputeAlpha1, we compute the values \(\alpha ^{(t)}\) for \(t=1,2,\ldots , n_1\) using the idea explained above.
Algorithm ComputeAlpha2
Step 0.:
Compute \(\beta _{1}^{(0)},\beta _{2}^{(0)},\ldots ,\beta _{m^{\prime }+\Delta -1}^{(0)}\). Also, compute \(\Upsilon _{0}\) and \(\Theta _{m^{\prime }+\Delta -1}^{(0)}\), by (8.10) and (8.8 ), accordingly. Set \(t:=0\).
Step 1.:
Compute the values \(\alpha ^{(0)}\) and v(0) as follows:
Step 1-1.:
Set \(v:=m^{\prime }+\Delta -1\).
Step 1-2.:
Compute the intersection point \(\alpha _{v}^{(0)}\) of the two linear functions \(\psi _{v}^{\prime \prime }(N_{0}(\sigma ),d)\) and \( \psi ^{\prime \prime \prime }(N_{0}(\sigma ),d)\) by (8.9).
Step 1-3.:
If \(\alpha _{v}^{(0)}\in I_{v}^{(0)}\), then set \(\alpha ^{(0)}:=\alpha _{v}^{(0)}\), \(v(0):=v\), and go to Step 2 (Note: if \( v=m^{\prime }+1\), then the condition \(\alpha _{v}^{(0)}\in I_{v}^{(0)}\) must hold). Otherwise, set \(\Theta _{v-1}^{(0)}:=\Theta _{v}^{(0)}-\beta _{v}^{(0)}\) and \(v:=v-1\), and go to Step 1-2.
Step 2.:
Set \(\Upsilon _{1}:=\Upsilon _{0}+u(\sigma (1))-l(\sigma (1))\) and \(t:=1\). Go to Step 3.
Step 3.:
Compute the value \(\alpha ^{(t)}\) as follows:
Step 3-1.:
Compute the values \(v^{\prime }(t)\), \(\beta _{v^{\prime }(t)}^{(t)}\), and \(\Theta _{v^{\prime }(t)}^{(t)}\) (details will be given later).
Step 3-2.:
Compute the intersection point \(\alpha _{v^{\prime }(t)}^{(t)}\) of the two linear functions \(\psi _{v^{\prime }(t)}^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) by (8.9).
Step 3-3.:
If \(v^{\prime }(t)=m^{\prime }+1\), or \(v^{\prime }(t)\ge m^{\prime }+2\) and \(\alpha ^{(t-1)}\le \alpha _{v^{\prime }(t)}^{(t)}\le \beta _{v^{\prime }(t)}^{(t)}\), then set \(\alpha ^{(t)}:=\alpha _{v^{\prime }(t)}^{(t)}\), \( v(t):=v^{\prime }(t)\), and go to Step 4. Otherwise, set \(v:=v^{\prime }(t)\) and go to Step 3-4.
Step 3-4.:
Compute the value \(\beta _{v-1}^{(t)}\) (details will be given later). Set \(\Theta _{v-1}^{(t)}:=\Theta _{v}^{(t)}-\beta _{v}^{(t)}\) and \(v:=v-1\).
Step 3-5.:
Compute the intersection point \(\alpha _{v}^{(t)}\) of the two linear functions \(\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) by (8.9).
Step 3-6.:
If \(v=m^{\prime }+1\), or \(v\ge m^{\prime }+2\) and \(\alpha _{v}^{(t)}\in I_{v}^{(t)}\), then set \(\alpha ^{(t)}:=\alpha _{v}^{(t)}\), \( v(t):=v\), and go to Step 4.Otherwise, go to Step 3-4.
Step 4.:
If \(t=n_{1}\), then stop. Otherwise, set \(\Upsilon _{t+1}:=\Upsilon _{t}+u(\sigma (t+1))-l(\sigma (t+1))\), \(t:=t+1\), and go to Step 3.
It is not difficult to see that the algorithm above computes the values \( \alpha ^{(t)}\) correctly. The most important part in Algorithm ComputeAlpha2 is the computation of values \(v^{\prime }(t)\), \(\beta _{v^{\prime }(t)}^{(t)} \), and \(\Theta _{v^{\prime }(t)}^{(t)}\) in Step 3-1 and \(\beta _{v-1}^{(t)}\) in Step 3-4. It is easy to compute these values in \(O(n_{1})\) time, as in Algorithm ComputeAlpha1, which leads to the same running time as before. To reduce the running time, we use a heap \({\mathcal {H}}\), which, at the beginning of Step 3, is a multi-set
at the beginning of Step 3,\(\bullet \)\(v^{\prime }(t)\) is equal to \(\max \left\{ \left| {\mathcal {H}} \right| ,m^{\prime }+1\right\} \), where \(\left| {\mathcal {H}} \right| \) is the size of \({\mathcal {H}}\),\(\bullet \)\(\Theta _{v^{\prime }(t)}^{(t)}\) is the total sum of the values in \({\mathcal {H}}\),\(\bullet \)\(\beta _{v^{\prime }(t)}^{(t)}\) is the minimum value in \(\mathcal { H}\).
Hence, the values \(v^{\prime }(t)\) and \(\Theta _{v^{\prime }(t)}^{(t)}\) can be obtained in constant time by maintaining the size of \({\mathcal {H}}\) and the total sum of the values in \({\mathcal {H}}\). The value \(\beta _{v^{\prime }(t)}^{(t)}\) can be obtained in constanttime as well.
To compute the value \(\beta ^{(t)}_{v-1}\) in Step 3-4, we delete the minimum value from \({\mathcal {H}}\) so that the new minimum value in \({\mathcal {H}}\) is equal to \(\beta ^{(t)}_{v-1}\). This can be done in \(O(\log n_1)\) time.
After computing the value \(\alpha ^{(t)}\) in Step 3, we need to update the heap \({\mathcal {H}}\), which can be done easily as follows. At this point, \( {\mathcal {H}}\) is represented by the multi-set
it follows that if \(l(\sigma (t+1))\ge \alpha ^{(t)}\) then the value \( l(\sigma (t+1))\) is currently in \({\mathcal {H}}\) and it should be deleted. Additionally, if \(u(\sigma (t+1))\ge \alpha ^{(t)}\), the value \(u(\sigma (t+1))\) is added to \({\mathcal {H}}\). In this way, we can update the heap \( {\mathcal {H}}\) in \(O(\log n_{1})\) time.
We give a detailed implementation of Algorithm ComputeAlpha2, where Steps 0 and 1 are the same as before and omitted.
Step 2.:
Set \(\Upsilon _{1}:=\Upsilon _{0}+u(\sigma (1))-l(\sigma (1))\). Let \({\mathcal {H}}\) be the heap which is represented by the multi-set \(\{\beta _{z}^{(0)}\mid 1\le z\le n_{1},\ \beta _{z}^{(0)}\ge \alpha ^{(0)}\}\). If \(l(\sigma (1))\ge \alpha ^{(0)}\), then delete the value \(l(\sigma (1))\) from \({\mathcal {H}}\).If \(u(\sigma (1))\ge \alpha ^{(0)}\), then add the value \(u(\sigma (1))\) to \( {\mathcal {H}}\). Set \(t:=1\) and compute \(v^{\prime }(1):=\max \left\{ \left| {\mathcal {H}}\right| ,m^{\prime }+1\right\} \), the sum \(\Theta _{v^{\prime }(1)}^{(1)}\) of the elements in \({\mathcal {H}}\) and its minimum element \(\beta _{v^{\prime }(1)}^{(1)}\). Go to Step 3.
Step 3.:
Using the current heap \({\mathcal {H}}\) and the values \( v^{\prime }(t)=\max \left\{ \left| {\mathcal {H}}\right| ,m^{\prime }+1\right\} \), \(\Theta _{v^{\prime }(t)}^{(t)}\) equal to the total sum elements of \({\mathcal {H}}\) and the minimum element \(\beta _{v^{\prime }(t)}^{(t)}\), compute the value \(\alpha ^{(t)}\) as follows:
Step 3-1.:
Compute the intersection point \(\alpha _{v^{\prime }(t)}^{(t)}\) of the two linear functions \(\psi _{v^{\prime }(t)}^{\prime \prime }(N_{t}(\sigma ),d)\) and \(\psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) by (8.9).
Step 3-2.:
If \(v^{\prime }(t)=m^{\prime }+1\), or \(v^{\prime }(t)\ge m^{\prime }+2\) and \(\alpha ^{(t-1)}\le \alpha _{v^{\prime }(t)}^{(t)}\le \beta _{v^{\prime }(t)}^{(t)}\), then set \(\alpha ^{(t)}:=\alpha _{v^{\prime }(t)}^{(t)}\), \( v(t):=v^{\prime }(t)\), and go to Step 4. Otherwise, set \(v:=v^{\prime }(t)\) and go to Step 3-3.
Step 3-3.:
Determine the interval I with the endpoints being the two smallest elements in the heap (to be used in Step 3-5). To do this, store the minimum value in \({\mathcal {H}}\), which is \(\beta _{v}^{(t)}\), as \( c^{\prime }\). Delete that minimum value \(c^{\prime }\) from \({\mathcal {H}}\) and update \(\Theta _{v-1}^{(t)}:=\Theta _{v}^{(t)}-c^{\prime }\). Store the minimum value in the updated heap \({\mathcal {H}}\), which is \(\beta _{v-1}^{(t)} \), as \(c^{\prime \prime }\) and define \(I=\left[ c^{\prime },c^{\prime \prime }\right] \). Set \(v:=v-1\).
Step 3-4.:
Compute the intersection point \(\alpha _{v}^{(t)}\) of the two linear functions \(\psi _{v}^{\prime \prime }(N_{t}(\sigma ),d)\) and \( \psi ^{\prime \prime \prime }(N_{t}(\sigma ),d)\) by (8.9).
Step 3-5.:
If \(v=m^{\prime }+1\), or \(v\ge m^{\prime }+2\) and \(\alpha _{v}^{(t)}\in I\), then set \(\alpha ^{(t)}:=\alpha _{v}^{(t)}\), \(v(t):=v\), and go to Step 4. Otherwise, go to Step 3-3.
Step 4.:
If \(t=n_{1}\), then stop. Otherwise, go to Step 5.
Step 5.:
Set \(\Upsilon _{t+1}:=\Upsilon _{t}+u(\sigma (t+1))-l(\sigma (t+1))\). If \(l(\sigma (t+1))\ge \alpha ^{(t)}\), then delete the value \(l(\sigma (t+1))\) from \({\mathcal {H}}\). If \(u(\sigma (t+1))\ge \alpha ^{(t)}\), then add the value \(u(\sigma (t+1))\) to \({\mathcal {H}}\). For the obtained heap, appropriately update the size, the total sum and the minimum element.Set \(t:=t+1\) and go to Step 3.
We analyze the time required to each steps. As in Algorithm ComputeAlpha1, Steps 0 and 1 can be done in \(O(n_{1})\) time and Step 4 requires O(1) time. Step 2 requires \(O(n_{1}\log n_{1})\) time for initializing the heap \( {\mathcal {H}}\), and Step 5 requires \(O(\log n_{1})\) time for deletion/insertion in the heap \({\mathcal {H}}\).
We now analyze the time required in Step 3 for each \(t=1,2,\ldots ,n_{1}\). It is easy to see that each of Steps 3-1 – 3-5 can be done in \(O(\log n_{1}) \) time. The number of iterations of Steps 3-3, 3-4 and 3-5 is equal to \(v^{\prime }(t)-v(t)\). Hence, Step 3 for each t requires \(O((v^{\prime }(t)-v(t)+1)\log n_{1})\) time. This implies that the total running time of Algorithm ComputeAlpha2 is
where the last inequality is by \(v(0)\le n_{1}\) and \(v(n_{1})\ge 0\). \(\square \)
This concludes the proof of Theorem 2, stating that the problem \( P|pmtn,p(j)=u(j)-x(j),size(j)\in \left\{ 1,\Delta \right\} ,C(j)\le D|\sum _{j\in N}w(j)x(j)\) can be solved in \(O(n\log n)\) time.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
Shioura, A., Strusevich, V.A. & Shakhlevich, N.V. Preemptive scheduling of parallel jobs of two sizes with controllable processing times.
J Sched27, 203–224 (2024). https://doi.org/10.1007/s10951-023-00782-w

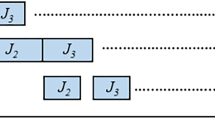



 is the sum of v largest elements in sequence \( {\mathcal {B}}_{t}\). We have \(\gamma ^{(t)}=\gamma _{v}^{(t)}\) if the intersection point \(\gamma _{v}^{(t)}\) is contained in the interval \( I_{v}^{(t)}\), and such v always exists.
is the sum of v largest elements in sequence \( {\mathcal {B}}_{t}\). We have \(\gamma ^{(t)}=\gamma _{v}^{(t)}\) if the intersection point \(\gamma _{v}^{(t)}\) is contained in the interval \( I_{v}^{(t)}\), and such v always exists.