
Abstract
Recently, Bomze et al. introduced a sparse conic relaxation of the scenario problem of a two stage stochastic version of the standard quadratic optimization problem. When compared numerically to Burer’s classical reformulation, the authors showed that there seems to be almost no difference in terms of solution quality, whereas the solution time can differ by orders of magnitudes. While the authors did find a very limited special case, for which Burer’s reformulation and their relaxation are equivalent, no satisfying explanation for the high quality of their bound was given. This article aims at shedding more light on this phenomenon and give a more thorough theoretical account of its inner workings. We argue that the quality of the outer approximation cannot be explained by traditional results on sparse conic relaxations based on positive semidenifnite or completely positive matrix completion, which require certain sparsity patterns characterized by chordal and block clique graphs respectively, and put certain restrictions on the type of conic constraint they seek to sparsify. In an effort to develop an alternative approach, we will provide a new type of convex reformulation of a large class of stochastic quadratically constrained quadratic optimization problems that is similar to Burer’s reformulation, but lifts the variables into a comparatively lower dimensional space. The reformulation rests on a generalization of the set-completely positive matrix cone. This cone can then be approximated via inner and outer approximations in order to obtain upper and lower bounds, which potentially close the optimality gap, and hence can give a certificate of exactness for these sparse reformulations outside of traditional, known sufficient conditions. Finally, we provide some numerical experiments, where we asses the quality of the inner and outer approximations, thereby showing that the approximations may indeed close the optimality gap in interesting cases.
Similar content being viewed by others

1 Introduction
Recently, in [5], the authors considered the scenario problem of a two-stage stochastic version of the standard quadratic optimization problem given by
where \(\Delta \subset \mathbb {R}^{n_1+n_2}\) is the unit simplex, and \(p_i,\ i \in [1\!:\!S]\) are probabilities of certain scenarios occurring. This optimization problem can be exactly reformulated into a copositive optimization problem based on Burer’s reformulation presented in [6]. The reformulation forces a lifting of the space of variables into a space of dimension \(O((n_1+Sn_2)^2)\), which makes this reformulation entirely impractical for the purposes of stochastic optimization since the number of scenarios S is typically very high and the copostive optimization problem has to be approximated with semidefinite optimization problems, which are known to scale poorly. In an effort to circumvent this issue, the authors introduced a copositive relaxation that merely requires \(O(S(n_1+n_2)^2)\) variables and showed empirically that the approximating SDPs are practical even if the number of scenarios is high. Somewhat surprisingly, they observed that the quality of the solutions they found did not substantially differ from the bound obtained by employing the traditional copositive reformulation. In fact they state that the difference was small enough to possibly be an artifact of numerical inaccuracies of the sdp-solver. Aside from an exactness result for a niche case of (2St3QP) no theoretical explanation for this phenomenon was provided. The present article is chiefly motivated by the question: why does the cheap relaxation perform so well? While we were not able to fully answer this question, we are still able to provide valuable theoretical insights that amount to a novel, practical approach to sparse conic reformulations. In short we introduce a generalization of the set-completely positive matrix cones that yield conic relaxations that are sparse to begin with, and which can, much like the traditional set-completely positive matrix cones, be approximated in order to generate lower and upper bounds, that may certify optimality in case the gap between them is zero.
To set up our exposition, we will now introduce a more general quadratic optimization problem and discuss some important context, specifically copositive optimization and sparse conic reformulations based on matrix completion. To begin with, the class optimization problems in question is given by:
where \({{\mathcal {K}}}_0\subseteq \mathbb {R}^{n_1},\ {{\mathcal {K}}}_i\subseteq \mathbb {R}^{n_2},\ i \in [1\!:\!S]\), are closed, convex cones, \(\textsf{A}\in {{\mathcal {S}}}^{n_1}\) (i.e. symmetric matrices of order \(n_1\)), \(\ {\textbf{a}}\in \mathbb {R}^{n_1}\), \(\textsf{B}_i\in \mathbb {R}^{n_1\times n_2},\ \textsf{C}_i\in {{\mathcal {S}}}^{n_2},{\textbf{c}}_i\in \mathbb {R}^{n_2},\ i \in [1\!:\!S]\) and \(\textsf{F}_i\in \mathbb {R}^{m_i\times n_1},\ \textsf{G}_i\in \mathbb {R}^{m_i\times n_2},\ {{\textbf{r}}}_i\in \mathbb {R}^{m_i},\ i \in [1\!:\!S]\). Further, \(Q_{j}(\cdot ):\mathbb {R}^{n_1+Sn_2} \rightarrow \mathbb {R},\ j\in [1\!:\!K]\) are quadratic functions that do not involve bilinear terms between \({\textbf{y}}_i\) and \({\textbf{y}}_j\) for \(i\ne j\). The special structure in place here is that \({\textbf{y}}_i\) does not interact with \({\textbf{y}}_j\) in a bilinear fashion in neither the constraints nor the objective, and the statement stays true even if the linear constraints are squared.
This setup encompasses not only (2St3QP), but general two-stage stochastic conic QCQPs over finitely supported distributions, which are important since they are used to approximate two-stage stochastic conic QCQPs with infinite support. In the context of two-stage stochastic optimization, S would be the number of scenarios and \({\textbf{y}}_i\) would be variables specific to scenario i. Hence, the special structure in (1) is native to all two-stage stochastic QCQPs regardless of the structure of the nominal QCQP.
Under some well known regularity conditions on the functions \(Q_{i}(.)\) (see [7, 9, 13]) our structured QCQP can be reformulated into a conic optimization problem with \({{\mathcal {O}}}\left( (n_1+Sn_2)^2\right) \) variables. This reformulation takes the form:
for appropriate linear functions \(\hat{Q}_{ij}\) with \(\hat{Q}_{ij}({\textbf{x}},{\textbf{x}}{\textbf{x}}^\textsf{T},{\textbf{y}}_1,{\textbf{y}}_1{\textbf{x}}^\textsf{T},{\textbf{y}}_1{\textbf{y}}_1^\textsf{T},\dots ,{\textbf{y}}_S,{\textbf{y}}_S{\textbf{x}}^\textsf{T},{\textbf{y}}_S{\textbf{y}}_S^\textsf{T}) = Q_{ij}({\textbf{x}},{\textbf{y}}_1,\dots ,{\textbf{y}}_S)\), with \(\circ \) denoting the elementwise multiplication of vectors, and the set-completely positive matrix cone is define as
for a closed, convex cone \({{\mathcal {K}}}\subseteq \mathbb {R}^n\). For example, \(\mathcal {CPP}(\mathbb {R}^n)\) is the positive semidefinite matrix cone, denoted by \({{\mathcal {S}}}^n_+\), and \(\mathcal {CPP}(\mathbb {R}^n_+)\) is the classical completely positive matrix cone, extensively discussed in [1]. In the literature, optimization over the set-completely positive cone and its dual, the set-copositive matrix cone is colloquially referred to as copositive optimization. In general, set-completely positive matrix cones are intractable and have to be approximated. For example, it is well known that
where \({{\mathcal {N}}}^n\) is the cone of nonnegative \(n\times n\) matrices and \(\mathcal {DNN}^n\) is called the doubly nonnegative matrix cone. In the above set containment, equality holds whenever \(n\le 4\).
While many tractable approximations do exist, be it based on positive semidefinite, second order cone or linear programming constraints, they all have in common that their complexity increases exponentially with the approximations quality. Even simple approximations, such as \(\mathcal {DNN}^n\), typically involve semidefinite constraints of the same order as the set-completely positive constraint. As a result the above reformulation is often impractical. Especially in the context of stochastic optimization, where the number of scenarios S is typically very high, the size of the psd-constraints, which is of the order \({{\mathcal {O}}}\left( (n_1+Sn_2)^2\right) \), becomes prohibitive.
Following the basic idea of the authors in [5], we can obtain a lower dimensional relaxation by replacing the conic constraint by S smaller conic constraints given by
where \(\textsf{Y}_{i,i}\) was relabeled \(\textsf{Y}_i\) and \(\textsf{Y}_{i,j}, \ i \ne j\) were dropped from the model, so that the number of variables is now \({{\mathcal {O}}}\left( S(n_1+n_2)^2\right) \), therefore linear in S. The cost we have to pay is that the resulting optimization problem is not necessarily equivalent to (2) and hence to (1), as the conic constraints are clearly a relaxation of the conic constraint of the exact reformulation. It is, however, this relaxation which performed so inexplicably well when it was applied in [5].
In searching for an explanation of this performance, one may turn to the literature on sparse reformulations of conic optimization problems. Results in this field are typically based on theorems on matrix completion. The central question in that area is, when a given matrix with non-specified entries, so called partial matrices, can be completed to a matrix in \(\mathcal {CPP}({{\mathcal {K}}})\). This is useful in the context of solving a conic optimization problem: if the problem data is sparse so that some of the entries of the matrix variable only appear in the conic constraint, one can check if the removal of that entries leaves a partial matrix for which one can give sufficient conditions so that it is completable to a matrix that fulfills the original conic constraint. If such conditions are available, they replace the conic constraint and the spurious entries of the matrix can be dropped entirely. The result is what we will call a sparse reformulation of the original conic problem. These reformulations can reduce the number of variables substantially, which eases the computational burden so that otherwise unmanageable problems become viable.
The classical text on such an approach is [19], where the conic constraint to be massaged is an sdp-constraint. Their approach utilizes the fact that a partial matrix, where the non-specified entries exhibit the so called chordal sparsity pattern can always be completed to a psd-matrix provided all fully specified, principle submatrices are positive semidefinite. The framework was applied in various contexts such as robust optimization [16] or optimal power flow [10, 18]. In [20] the authors harnessed sparsifications of SDPs computationally by exploiting properties of the ADMM algorithm. Another approach was recently put forward by [12], who applied classical \(\mathcal {CPP}(\mathbb {R}^n_+)\)-completion results derived in [8] in the context of copositive optimization. Their approach necessitates the presence of so called block-clique sparsity patterns in the problem data, owing to the fact that partial matrices with block-clique specification pattern can be completed to matrices in \(\mathcal {CPP}(\mathbb {R}^n_+)\) whenever the fully specified, principle submatrices are completely positive. On a related note, [2] explored sparse convex reformulations of binary quadratic optimization problems based on matrix completion where the set of matrices of interest was not some version of \(\mathcal {CPP}\) but the so called Boolean Quadratic Polytope, i.e. the convex hull of matrices \({\textbf{x}}{\textbf{x}}^\textsf{T}\) where \({\textbf{x}}\in \left\{ 0,1 \right\} ^n\). Interestingly, completion results for this subset of \(\mathcal {CPP}(\mathbb {R}^n_+)\) seem to be stronger than for general matrices in this cone, which bolsters our hope of finding stronger completion results for other such subsets as well.
Unfortunately, none of these results are able to explain the phenomenon we seek to investigate and we will spend a full section on discussing their shortcomings and what we can still learn from them about our object of interest. We will argue that, unless \({{\mathcal {K}}}= \mathbb {R}^n\), the required sparsity patterns are, outside of some limited special cases, not the ones present in (2), where the sparsity pattern takes the form of an arrow-head. Also, in cases where \({{\mathcal {K}}}\) is neither the positive orthant nor the full space, completion results are, to the best of our knowledge, entirely absent from literature.
1.1 Contribution
In an effort to remedy these shortcomings, we propose a new approach to sparse conic reformulations. Rather than treating completability of a matrix as an abstract concept we identify a cone that is isomorphic to the cone of completeable partial matrices with arrowhead sparsity pattern, denoted \(\mathcal {CMP}\), as a generalization of the set-completely positive matrix cone. We show that the geometry of this cone can be used in order to derive a lower dimensional alternative to the exact reformulation (2). Much the same way one uses inner and outer approximations in order to solve copositive optimization problems, we derive inner and outer approximations of \(\mathcal {CMP}\) in order to obtain upper and lower bounds to this new conic optimization problem. Numerical experiments show that in practice these approximations exhibit interesting beneficial properties.
1.2 Outline
The rest of the article is organized as follows: In Sect. 2 we will give a short discussion on existing approaches to sparse conic optimization and discuss the limitations that ultimately make these techniques unfit to tackle sparse reformulations of (2). Hence, we develop an alternative approach in Sect. 3, based on the aforementioned convex cone \(\mathcal {CMP}\). This new type of convex reformulation motivates a strategy to sparse optimization that is analogous to classical copositive optimization techniques, where difficult conic constraints are approximated via inner and outer approximations. In Sect. 4 we present many such approximations and discuss their limitations. Finally, we asses the efficacy of our approach in extensive numerical experiments.
1.3 Notation
Throughout the paper matrices are denoted by sans-serif capital letters (e.g. \(\textsf{O}\) will denote the zero matrix, where the size will be clear from the context), vectors by boldface lower case letters (e.g. \({\textbf{o}}\) will denote the zero vector, \({\textbf{e}}_i\) will denote a vector of zeros with a one at the i-th coordinate) and scalars (real numbers) by simple lower case letters. Sets will be denoted using calligraphic letters, e.g., cones will often be denoted by \({{\mathcal {K}}}\). We use \({{\mathcal {S}}}^n\) to indicate the set of symmetric matrices and \({{\mathcal {S}}}^n_+\)/\({{\mathcal {S}}}^n_-\) for the sets of positive-/negative-semidefinite symmetric matrices, respectively. Moreover, we use \({{\mathcal {N}}}_n\) to denote the set of entrywise nonnegative, symmetric matrices. We also use the shorthand notation \([l\!:\!k]{:=}\left\{ l,l+1,\dots ,k-1,k \right\} \subseteq \mathbb {N}\). For a given set \({{\mathcal {A}}}\) we denote its convex hull by \(\textrm{conv}({{\mathcal {A}}})\). For a convex set \({{\mathcal {C}}}\), the set of generators of its extreme rays and points is given by \(\textrm{ext}({{\mathcal {C}}})\). Also, for a cone \({{\mathcal {K}}}\subseteq \mathbb {R}^n\) we denote as
its dual cone. We also make use of the Frobenius product of two appropriately sized matrices \(\textsf{A}\) and \(\textsf{B}\) defined as \(\textsf{A}\bullet \textsf{B}{:=}\textrm{trace}(\textsf{A}^\textsf{T}\textsf{B})\), which can be interpreted as the sum of the inner products of the columns of \(\textsf{A}\) and \(\textsf{B}\).
2 Classical approaches to sparse conic optimization and why they fail
As stated in the introduction, there are already many approaches for utilizing sparsity patterns in conic optimization problems. At the core of these results lie matrix completion theorems, which we will discuss shortly. But in order to state them we must introduce some essential terms first.
A graph \(G =(\mathcal {V},{{\mathcal {E}}})\) is given by its set of vertices \(\mathcal {V}= \left\{ v_1,\dots ,v_n \right\} \) and its set of edges \({{\mathcal {E}}}\subseteq \left\{ \left\{ v,u \right\} :v,u\in \mathcal {V} \right\} \), both of which are finite. A subgraph \(T = (\mathcal {V}_T,{{\mathcal {E}}}_T)\) of a graph G is a graph such that \(\mathcal {V}_T\subseteq \mathcal {V}\) and \({{\mathcal {E}}}_T\subseteq {{\mathcal {E}}}\). Vertex \(v_j\) is adjacent to \(v_j\) and vice versa if \(\left\{ v_i,v_j \right\} \in {{\mathcal {E}}}\). If \(e= \{v_i,v_j\}\in {{\mathcal {E}}}\) then \(v_i\) and \(v_j\) are incident on e. A graph where all vertices are adjacent to one another is called a complete graph. A path that connects vertex \(v_i\) with \(v_j\) is given by a sequence of edges so that \(\left\{ \{v_i,v_{k_1}\},\dots ,\{v_{k_{p-1}},v_j\} \right\} \subseteq {{\mathcal {E}}}\), \(v_{k_i}\) are distinct and \(p>1\) is the length of that path. A graph is connected if any two vertices have a connecting path. A graph that is not connected is disconnected. A cycle is path that connects a vertex v to itself. A chord of a cycle with length greater than 3 is an edge that connects two vertexes who are incident on two different edges of the cycle. A graph is chordal if every cycle with length greater 3 has a chord. A collection of vertices in \(\mathcal {V}\) that induce a subgraph of G that is complete is called a clique. A block B of a graph is a subgraph that is connected, has no disconnected subgraph that is obtained by removing just one vertex and its adjacent edges (i.e. a cut vertex) from B, and is not contained in any other subgraph with these two properties. A block-clique graph is a graph whose blocks are cliques.
A partial matrix of order n is a matrix whose entries in the i-th row and the j-th column are determined if and only if \((i,j)\in {{\mathcal {I}}}\subseteq [1\!:\!n]^2\) and are undetermined otherwise. A matrix is said to be partial positive semidefinite/ completely positive/ doubly nonnegative if and only if every fully determined principal submatrix is positive semidefinite/ completely positive/ doubly nonnegative. A partial matrix is positive semidefinite/ completely positive/ doubly nonnegative completable if we can specify the undetermined entries so that the fully specified matrix is semidefinite/ completely positive/ doubly nonnegative.
The specification graph of partial matrix \(\textsf{A}\) of order n is a graph \(G(\textsf{A})\) with vertices \(\mathcal {V}= \left\{ v_i:i\in [1\!:\!n] \right\} \) and edges \({{\mathcal {E}}}\) such that \(\left\{ v_i,v_j \right\} \in {{\mathcal {E}}}\) if and only if the entry \(a_{ij}\) is specified. A symmetric matrix with \(G(\textsf{A}) = G\) is called a symmetric matrix realization of G.
The following three theorems give the key results on matrix completion as far as this text is concerned:
Theorem 1
All partial positive semidefinite symmetric matrix realizations of a graph G are positive semidefinite completable if and only if G is chordal.
Proof
See [1, Theorem 1.39]. \(\square \)
Theorem 2
Every partial completely positive matrix realization of a graph G is completely positive completable if and only if G is a block-clique graph
Proof
See [1, Theorem 2.33]. \(\square \)
Theorem 3
Every partial doubly nonnegative matrix realization of a graph G is doubly nonnegative completable if and only if G is a block-clique graph
Proof
See [8]. \(\square \)
These theorems can be used in order to establish that a constraint on a high-dimensional matrix, say \(\textsf{X}\), can be replaced by a number of constraints on certain principal submatrices of \(\textsf{X}\) without increasing the feasible set. This is achieved by showing that values for the submatrices of \(\textsf{X}\) that fulfill the latter constraints can be completed to a full evaluation of \(\textsf{X}\) that fulfills the original larger constraint. For the sake of illustration we present the following toy example.
Example 1
Consider the optimization problem
where \((\textsf{Q})_{ij} = (\textsf{B})_{ij} = 0\) if \(|i-j|>1\), the remaining entries of \(\textsf{B}\) equal one and those of \(\textsf{Q}\) are arbitrary. The entries of \(\textsf{X}\) that are outside the inner band of width 1 are not present in neither the equality constraint nor the objective. Consider the relaxation of (4) where the psd-constraints is replaced by
and the entries of \(\textsf{X}\) outside of the inner band are dropped from the problem. Clearly, we obtain a relaxation of the original problem since the new condition is necessary for the \(\textsf{X}\) to be positive semidefinite. Also, the fact that we dropped entries of \(\textsf{X}\) can be thought of as a replacement of the matrix \(\textsf{X}\) by a partial matrix, say \(\textsf{X}_{*}\), whose entries outside the inner band are not specified. In this case the specification graph of \(\textsf{X}_{*}\) is easily checked to be chordal, as it doesn’t contain any cycles at all. Hence, if all fully specified submatrices of \(\textsf{X}_{*}\) are positive semidefinite, i.e. (5) holds, then it can be completed to positive semidefinite matrix by Theorem 1. The resulting matrix would be feasible for (4) with the same objective function value, so that the relaxation turns out to be lossless.
One may attempt to similarly derive a sparse reformulation of (8) by invoking the completion results we discussed above. This would necessitate to show that a partial matrix of the following form
can be completed to a set-completely positive matrix whenever the submatrices
Note, that this would coincide with the model in [5], which we discussed in the introduction, so that the matrix completion theory is a promising contender for the desired explanation for the effectiveness of the model. The strategy appears feasible at first, at least for the case where \({{\mathcal {K}}}_i\) are nonnegative orthants given that in this case, completion results are readily available. Unfortunately it is futile, since the arrowhead structure is not block-clique outside of narrow special cases, as we will now show.
Lemma 4
Let \(S>1\) and consider a partial matrix where the specified entries exhibit an arrow-head structure, i.e.
where \( \textsf{X}\in {{\mathcal {S}}}^{n_1},\ \textsf{Y}_{i,i}\in {{\mathcal {S}}}^{n_2},\ \textsf{Z}_i\in \mathbb {R}^{n_2\times n_1}, \ i \in [1\!:\!S],\) and let \(G_{spec}\) be its specification graph. Then \(G_{spec}\) is chordal. If \(n_1\in \left\{ 0,1 \right\} \) then \(G_{spec}\) is also a block-clique graph, which is not the case otherwise.
Proof
We start out by showing that \(G_{spec}\) is chordal in general. We group the nodes of the specification graph into \(S+1\) groups where the first group \(g_0 = \left\{ 1,\dots n_1 \right\} \) are the nodes that correspond to the first \(n_1\) rows of the matrix and whose internal edges are specified by the north west entries \(\textsf{X}\). The second group \(g_1 = \left\{ n_1+1,\dots ,n_1+n_2 \right\} \) corresponds to the rows \(n_1+1\) to \(n_1+n_2\) whose internal edges are specified by the blocks \(\textsf{Y}_{2,2}\) and whose external edges, connecting to neighbors outside of \(g_1\), are specified by \(\textsf{Z}_1\). The construction of the remaining groups proceeds accordingly. We will now show that any cycle of length greater 3 must have a chord. Note that all the groups are cliques since the blocks \(\textsf{Y}_{i,i}\) are fully specified. Thus, a cycle of length greater than 3 must have a chord if it is entirely contained in one of the groups. We therefore only need to consider cycles that are not entirely contained in one group. Also, any member of \(g_0\) is a neighbor to any other node in the graph since the blocks \(\textsf{Z}_i, \ i \in [1\!:\!S]\) are fully specified. Thus, if a vertex v of \(g_0\) is visited by a cycle, then the edge to any other node in the cycle that is not the predecessor of v gives a chord. A cycle that visits more than one group needs to visit \(g_0\) since the other groups are not connected to one another and thus has a chord.
If \(n_1=1\) then \(g_0\) is a singleton. A block cannot contain just vertices from multiple \(g_i, \ i \in [1\!:\!S]\) since these groups are pairwise disconnected. A connection can only be established by adding \(g_0\) but then the single node in \(g_0\) is a cut vertex, i.e. the subgraph can become disconnected by deleting a single node and its adjacent edges. Hence, a block of \(G_{spec}\) must be a subgraph formed from the union of \(g_0\) and one \(g_i,\ i \in [1\!:\!S]\) and the respective edges. A subgraph formed from all the nodes of such a union, say T, cannot be contained in any other block since the construction of such a block would require to add nodes from a third group. Thus, T is a block, but it is also a clique since the \(q_i\) is a clique and the node in \(g_0\) is adjacent to all the members of \(g_i\).
If \(n_1 = 0\) then \(G_{spec}\) consists of S subgraphs that are cliques and pairwise disconnected, hence they are blocks.
Otherwise, the entire graph is its only block since it cannot become disconnected by deleting a single node and its adjacent edges, but this block is not a clique since \(g_i, \ i \in [1\!:\!S]\) have no inter-group edges. \(\square \)
As a consequence of the lemma, the traditional route for sparse conic reformulations provides little insight: If \({{\mathcal {K}}}_i\) are positive orthants the completion theorems are not applicable since (2) lacks the proper sparsity pattern. Also in that case, we cannot compare the \(\mathcal {DNN}\) relaxations of (2) and its sparse relaxation based on (3), since the same sparsity pattern would be required. If \({{\mathcal {K}}}_i\) are neither the positive orthant nor the full space, we do not even have any completion results to begin with.
Still, the present methodology allows for at least some insight into the benefits of working with (3), namely in the form of the following performance guarantee.
Theorem 5
Let \(\textrm{val}(SDP)\) be the optimal value of problem (2) after \(\mathcal {CPP}(\mathbb {R}_+\times _{i=0}^S{{\mathcal {K}}}_i)\) is replaced by \({{\mathcal {S}}}^{n_1+Sn_2+1}_+\) and let \(\textrm{val}(R)\) be that optimal value after replacing the full conic constraint with the conic constraints in (3). We have \(\textrm{val}(SDP)\le \textrm{val}(R)\) and the statement also holds if we replace the cones \( \mathcal {CPP}(\mathbb {R}_+\times {{\mathcal {K}}}_0\times {{\mathcal {K}}}_i),\ i\in [1\!:\!S]\) in (3) by any other subsets of \({{\mathcal {S}}}^{n_1+n_2+1}_+\).
Proof
Clearly, the two problems have the same objective function, so we only need to compare the feasible sets. Let \(\left( \textsf{X},\textsf{Y}_1,\dots ,\textsf{Y}_S,\textsf{Z}_i,\dots ,\textsf{Z}_S,{\textbf{x}},{\textbf{y}}_1,\dots ,{\textbf{y}}_S\right) \) be such that
and the linear constraints in (2) are fulfilled, i.e. we have a feasible solution for the optimization problem defining \(\textrm{val}(R)\). The setinclusion holds since, \(\mathcal {CPP}({{\mathcal {K}}}_A)\subseteq \mathcal {CPP}({{\mathcal {K}}}_B)\) whenever \({{\mathcal {K}}}_A\subseteq {{\mathcal {K}}}_B\), and \({{\mathcal {S}}}^n_+ =\mathcal {CPP}(\mathbb {R}^n)\). All we need to show, is that, after setting \(\textsf{Y}_{i,i} = \textsf{Y}_i,\ i \in [1\!:\!S]\), we can find \(\textsf{Y}_{i,j}, \ i \ne j\) such that we can construct a positive semidefinite matrix. By Theorem 1 it suffices to show that the specification graph of the partial matrix where \(\textsf{Y}_{i,j},\ i\ne j\) are not specified is a chordal graph and that all fully specified principal submatrices are positive semidefinite. So consider the partial matrix
Since in all but the first two columns (we use this word now referring to literal columns in the above representation) have unspecified blocks one can only obtain fully specified principal submatrices if one deletes all but one of the partially specified columns and all but the respective rows (again in the literal sense). The so obtained blocks are precisely the blocks in (6) and are thus positive semidefinite. The chordality of the specification graph follows from Lemma 4. This completes the proof. \(\square \)
The theorem states that our sparse, hence low dimensional, relaxation is at least as strong as the fully dimensional SDP-relaxation and thus gives a theoretical performance guarantee. It also applies to relaxations of (3) such as the \(\mathcal {DNN}\)-relaxation since \(\mathcal {DNN}^n\subseteq {{\mathcal {S}}}^n_+\).
Remark 1
We could have arrived at Lemma 4by using the results in [11] who describe a chordality-detection procedure for SDPs with chordal sparsity pattern. The chordality of the arrow head matrices was also observed in [2, 20]. However, it is more convenient for the reader if this technical detail is proved here directly. It is nonetheless important to note that the above result is not the first of its kind, but can be obtained directly from known results in literature. Still, to the best of our knowledge, the context in which we use this technique is original.
Remark 2
At this point we would also like to highlight a specific shortcoming of the above completion theorems. An inattentive reading of their claims might give the false impression that, as an example, for a partial psd-matrix to be completable, it needs to have a chordal specification graph. This assessment is incorrect. A partial psd-matrix \(\textsf{M}\) may have a specification graph \(G(\textsf{M})\) that is not chordal, while still being psd-completeable. All the theorem says is that not all partial psd-matrices with specification graph \(G(\textsf{M})\) are psd-completable. But that does not exclude the possibility that some still can be completed. This is significant, since for a sparse relaxation to be exact it suffices that its optimal set contains just one appropriately completable matrix. To additionally require that all other feasible matrices, or more so, all matrices with the same sparsity pattern are completable is needlessly restrictive, which explains part of the inflexibility of the classical machinery.
3 An alternative approach to sparse reformulations
We have seen that the classical approach to sparse reformulations is limited in several capacities. It is restrictive with respect to the cones \({{\mathcal {K}}}_i\) and it is inflexible with respect to the sparsity structure, such that it is ultimately ill-equipped to tackle sparse reformulations of (2). We therefore propose and alternative strategy, where we provide a convex-conic reformulation of (1) based on a generalization of \(\mathcal {CPP}\) that rests on a lifting of the space of variables into a space that is of lower dimension than required for the classical \(\mathcal {CPP}\)-reformulation (2). Hence, the reformulation is already sparse, which comes at the price of having to optimize over a new, complicated cone. This, however, is just a new guise of an old problem in copositive optimization, and we will meet in a, thus, familiar fashion: by providing inner and outer approximations, that provide upper and lower bounds on the problem whose gap is hopefully small or even zero. In order to achieve this we will first introduce some necessary concepts, that will allow us to state and proof our main reformulation result. After that, we close this section with a detailed description of our approach.
3.1 The space of connected components \({{\mathcal {S}}}_n^{S,k}\) and the cone of completable, completely positive, connected components \(\mathcal {CMP}\)
We define
i.e. the set of vectors of S symmetric matrices of order n connected by a component of order k, which we call the space of connected components. In order to distinguish elements of \({{\mathcal {S}}}_n^{S,k}\) from normal matrices we use san-serif letters braced by rectangular braces, for example \(\left[ \textsf{A}\right] \). Note, that \({{\mathcal {S}}}_n^{S,k}\) is isomorphic to the space of arrowhead matrices by the isomorphism
where for the inverse we have
Thus, \({{\mathcal {S}}}_n^{S,k}\) is a vector space with a natural inner product \(\left[ \textsf{A}\right] \odot \left[ \textsf{B}\right] {:=}\Gamma \left( \left[ \textsf{A}\right] \right) \bullet \Gamma \left( \left[ \textsf{A}\right] \right) \), sum \(\left[ \textsf{A}\right] \oplus \left[ \textsf{B}\right] {:=}\Gamma \left( \left[ \textsf{A}\right] \right) +\Gamma \left( \left[ \textsf{A}\right] \right) \) and scalar multiplication \(\lambda \left[ \textsf{A}\right] {:=}\Gamma ^{-1}\left( \lambda \Gamma \left( \left[ \textsf{A}\right] \right) \right) \). For notational convenience we will expand the meaning of the inverse \(\Gamma ^{-1}\) so that it is applicable to non-arrowhead matrices as well, where the nonzero off-diagonal blocks are treated as though they were blocks of zeros as in the definition above. Also, we define a second, analogous isomorphism \(\Gamma _*(\cdot )\) that maps into the space of partial matrices where the blocks of zeros in the definition of \(\Gamma (\cdot )\) are not specified. We also will use the shorthand notation
The central object we are interested in is the following subset of \({{\mathcal {S}}}_n^{S,k}\):
where \({{\mathcal {K}}}_0\subseteq \mathbb {R}^{k},\ {{\mathcal {K}}}_i\subseteq \mathbb {R}^{n-k},\ i \in [1\!:\!S]\) are convex cones, which we refer to as ground cones. We often use \(\mathcal {CMP}\) without its arguments as a colloquial term, in case the respective ground cones are not important to, or clear from, the context at hand. The same is true for all abbreviations of its inner and outer approximations that will be discussed later in the text.
We call \(\mathcal {CMP}\) the cone of completable, completely positive, connected components and we will justify that name in a latter section. Further, we define \(\textrm{gen} \mathcal {CMP}\) to be the set of its generators, i.e. the set we obtain by omitting the \({{\,\textrm{conv}\,}}\)-operator in the definition of \(\mathcal {CMP}\). We also like to note, that for the case \(S = 1\) the cone \(\mathcal {CMP}\) reduces to \(\mathcal {CPP}\), with its ground cone given by \({{\mathcal {K}}}_0\times {{\mathcal {K}}}_1\). Further, if \(k=n\) the ground cone reduces to \({{\mathcal {K}}}_0\), so that \(\mathcal {CMP}\) can be seen as a generalization of \(\mathcal {CPP}\). However, we will see later in the text, that in fact a certain type of correspondence holds between the two objects (see Remark 3).
3.2 Main result: a new type of convex reformulation, with reduced dimension
The derivation of our main result relies heavily on the very general framework from [13], for achieving convex reformulations for a large array of problems. In the following paragraphs we will give a small and simplified account of their results in order to make the derivation of our main result as transparent as possible. The two theorems we discuss shortly are specializations of theorems in [13], which we prove here for the readers convenience. To distinguish this more abstract discussion from the rest of the paper, and to highlight the special role of the sets we are about to introduce, we diverge from the convention of denoting sets via calligraphic capital letters and use blackboard bold capital letters.
We start out be investigating a more general question. So, let \(\mathbb {V}\) be a vector space of dimension n. For a (possibly nonconvex) cone \(\mathbb {K}\subseteq \mathbb {V}\), and vectors \(\textsf{Q},\textsf{H}_0\in \mathbb {V}\) and a convex set \(\mathbb {J}\subseteq \textrm{conv}(\mathbb {K})\). We want to know when we have the equality:
Defining \(\mathbb {H}{:=}\left\{ \textsf{X}:\langle \textsf{H}_0, \textsf{X} \rangle = 1 \right\} \), we can equivalently ask for conditions for the equality
The following theorem gives an answer based on convex geometry.
Theorem 6
For \(\mathbb {H},\mathbb {K},\mathbb {J}\) as above, assume that \(\mathbb {H}\cap \mathbb {J}\ne \emptyset \) is bounded and that \(\mathbb {J}\) is a face of \(\textrm{conv}(\mathbb {K})\). Then \(\textrm{conv}(\mathbb {H}\cap \mathbb {K}\cap \mathbb {J}) =\mathbb {H}\cap \mathbb {J}\).
Proof
For the "\(\subseteq \)"-inclusion, since \(\mathbb {H}\cap \mathbb {K}\cap \mathbb {J}\subseteq \mathbb {H}\cap \mathbb {J}\) and the latter set is convex, there is nothing left to show. For the converse, let \(\textsf{X}\in \mathbb {H}\cap \mathbb {J}\). Then \(\textsf{X}\in \textrm{conv}(\mathbb {K})\) since \(\mathbb {J}\subseteq \textrm{conv}(\mathbb {K})\), so that \(\textsf{X}= \sum _{i=1}^{n}\textsf{X}_i\) with \( \textsf{X}_i \in \mathbb {K}{\setminus }\left\{ \textsf{O} \right\} \) but also \(\textsf{X}_i \in \mathbb {J}\) since \(\mathbb {J}\) is a face of \(\textrm{conv}(\mathbb {K})\) so that \(\textsf{X}_{i}\in \mathbb {K}\cap \mathbb {J}\). Now, \(\langle \textsf{H}_0, \textsf{X}_{i} \rangle >0\) since \(\mathbb {H}\cap \mathbb {J}\ne \emptyset \) is bounded. Define \(\lambda _{i} = \langle \textsf{H}_0, \textsf{X}_{i} \rangle .\) We have \(\langle \textsf{H}_0, \textsf{X} \rangle = \sum _{i}\langle \textsf{H}_0, \textsf{X}_{i} \rangle = \sum _{i}\lambda _{i} = 1\) and \(\lambda _{i}^{-1}\textsf{X}_{i}{=:}{\bar{\textsf{X}}}_{i} \in \mathbb {K}\cap \mathbb {J}\) and thus \(\textsf{X}= \sum _{i}\lambda _{i} {\bar{\textsf{X}}}_{i} \in \textrm{conv}(\mathbb {H}\cap \mathbb {K}\cap \mathbb {J})\). \(\square \)
This theorem motivates the search for a condition that lets us identify faces of convex cones, which are provided in the following theorem.
Theorem 7
Assume that \(\mathbb {J} = \left\{ \textsf{X}\in \textrm{conv}(\mathbb {K}):\langle \textsf{A}_i, \textsf{X} \rangle = 0,\ i \in [1\!:\!m] \right\} \) and define \(\mathbb {J}_p {:=} \left\{ \textsf{X}\in \textrm{conv}(\mathbb {K}):\langle \textsf{A}_i, \textsf{X} \rangle = 0,\ i \in [1\!:\!p] \right\} \) so that \(\mathbb {J}_m=\mathbb {J}\) and \(\mathbb {J}_0=\textrm{conv}(\mathbb {K})\).
If \(\textsf{A}_p \in \mathbb {J}_{p-1}^*,\ {p} \in [1\!:\!m]\) then \(\mathbb {J}\) is a face of \(\textrm{conv}(\mathbb {K})\).
Proof
Since a face of a face a convex set is itself a face of that set, the claim will follow by induction if we can show that
So let \(\mathbb {J}_p\ni \textsf{X}= \textsf{X}_1+\textsf{X}_2\) with \(\textsf{X}_i\in \mathbb {J}_{p-1},\ i \in \left\{ 1,2 \right\} \). We have \(\langle \textsf{A}_p, \textsf{X}_i \rangle \ge 0\) since \(\textsf{A}_p \in \mathbb {J}_{p-1}^*\) so that \(0 = \langle \textsf{A}_p, \textsf{X} \rangle = \langle \textsf{A}_p, \textsf{X}_1 \rangle +\langle \textsf{A}_p, \textsf{X}_2 \rangle \) implies that actually \(\langle \textsf{A}_p, \textsf{X}_i \rangle =0\) and we indeed have \(\textsf{X}_i\in \mathbb {J}_p,\ i\in \left\{ 1,2 \right\} \). \(\square \)
Based on the above theorems, it is quite straight forward to prove the classical result from [6], at least for the case where the linear portion of the set is bounded, with \(\mathbb {K} = \textrm{ext}\mathcal {CPP}(\mathbb {R}_+\times {{\mathcal {K}}})\) and \(\mathbb {J}\) equal to the feasible set of the conic reformulation (we omit laying out the details here, but the steps required are equivalent to the ones laid out in the proof of Theorem 8). A natural question is, whether we can execute a similar strategy for proving the exactness of a conic reformulation of reduced dimension by replacing the cone of extreme rays of \(\mathcal {CPP}({{\mathcal {K}}})\) with another appropriately structured object as our choice for \(\mathbb {K}\).
In the following theorem we show that by choosing \(\mathbb {K} =\textrm{gen}\mathcal {CMP}\left( \left( \mathbb {R}_+\times {{\mathcal {K}}}_0\right) ,{{\mathcal {K}}}_1,\dots ,{{\mathcal {K}}}_S\right) \) and \(\mathbb {J}\) and \(\mathbb {H}\) appropriately we can use Theorem 6 in order to obtain an exact conic reformulation of (1).
Theorem 8
Considering (1), assume \({{\mathcal {F}}}_i~{:=}~\left\{ \left( {\textbf{x}}^\textsf{T},{\textbf{y}}_i^\textsf{T}\right) \in {{\mathcal {K}}}_0\times {{\mathcal {K}}}_i:\textsf{F}_i{\textbf{x}}+\textsf{G}_i{\textbf{y}}_i = {{\textbf{r}}}_i \right\} \) are nonempty bounded sets. Further, assume that
Then (1) is equivalent to the following conic optimization problem:
where \([\textsf{C}],[\textsf{H}_0],[\textsf{F}_i]\in {{\mathcal {S}}}_{n_1+n_2+1}^{S,n_1+1}, \ i\in [1\!:\!S]\) are defined as
and \(\hat{Q}_{j}(\cdot ):{{\mathcal {S}}}^{S,n_1+1}_{n_1+n_2+1} \rightarrow \mathbb {R}\) are linear functions such that
Proof
Consider the following equivalences
Invoking Theorem 6, we specify
and we need to show that
is a face of \(\mathcal {CMP}\left( \left( \mathbb {R}_+\times {{\mathcal {K}}}_0\right) ,{{\mathcal {K}}}_1,\dots ,{{\mathcal {K}}}_S\right) \). By Theorem 7, this will follow if we can show that \([\textsf{F}_i]\odot [\textsf{X}]\ge 0, \ \forall [\textsf{X}]\in \mathcal {CMP}\left( \left( \mathbb {R}_+\times {{\mathcal {K}}}_0\right) ,{{\mathcal {K}}}_1,\dots ,{{\mathcal {K}}}_S\right) ,\ i \in [1\!:\!S]\) and that \(\hat{Q}_{j}([\textsf{X}])\ge 0,\ j \in [1\!:\!K]\) whenever \([\textsf{X}]\) fulfills the homogeneous and conic constraints in the description of the feasible set of the conic optimization problem. We will first show, that the statement of the theorem would hold if the quadratic constraints were omitted. Indeed for any of the \([\textsf{F}_i]\) and any \([\textsf{X}]\in \textrm{gen}\mathcal {CMP}\left( \left( \mathbb {R}_+\times {{\mathcal {K}}}_0\right) ,{{\mathcal {K}}}_1,\dots ,{{\mathcal {K}}}_S\right) \) we have
To complete the first part of the argument we need to show that the feasible set is bounded. To this end we consider its recession cone which by [17, Corollary 8.3.3.] is given by
Take an arbitrary \(\left[ \textsf{X}\right] \in 0^+{{\mathcal {F}}}\), then
Thus, for any \(i \in [1\!:\!S]\) and \(l\in [1\!:\!k]\) we have \(\textsf{F}_i{\textbf{x}}_l+\textsf{G}_i{\textbf{y}}^i_l = {\textbf{o}}\) and \(\left( 0,{\textbf{x}}_l,{\textbf{y}}^i_l\right) \in \mathbb {R}_+\times {{\mathcal {K}}}_0\times {{\mathcal {K}}}_i\) so that we have a element of the recession cone of \({{\mathcal {F}}}_i\), which only contains the origin by the boundedness assumption, so that \(\left[ \textsf{X}\right] = \left[ \textsf{O}\right] \). So far our arguments imply that
is a face of \(\mathbb {K}\), hence its extreme points correspond to extreme rays of \(\mathbb {K}\) by Theorem 6, that is \(\textrm{gen}\mathcal {CMP}\left( \left( \mathbb {R}_+\times {{\mathcal {K}}}_0\right) ,{{\mathcal {K}}}_1,\dots ,{{\mathcal {K}}}_S\right) \). But then (7) implies that \(\hat{Q}_{j}([\textsf{X}])\ge 0,\ j\in [1\!:\!K]\) whenever \([\textsf{X}]\in \hat{\mathbb {J}}\) so that by Theorem 7 the set \(\mathbb {J}\) is a face of \(\mathbb {K}\) and our theorem follows from Theorem 6. \(\square \)
While the above representation of the conic problem is convenient for the application of Theorems 6 and 7 and the statement of the proof, we can use [7, Proposition 3] in order to present it in a more familiar form:
Before discussing this new type of conic reformulation, we want to point out, that there is a another way to prove Theorem 8. First, we make the following observation:
Theorem 9
The partial matrix
is completable to a matrix in \(\mathcal {CPP}({{\mathcal {K}}}_0\times _{i=1}^S{{\mathcal {K}}}_i)\) if and only if there are decompositions
hence, if and only if
Proof
Given said decompositions we can create a matrix
is the desired completion of \(\textsf{M}_*\). Conversely, if \(\textsf{M}_{*}\) has a completion \(\textsf{M}\in \ \mathcal {CPP}(\times _{i=0}^{S}{{\mathcal {K}}}_i)\) then by definition of the latter cone we have
so that
\(\square \)
Remark 3
The theorem is easily derived, but it highlights the key difficulty for the construction of a completion of the arrow-head arrangement of a set of matrix blocks connected by a common submatrix \(\textsf{X}\). If all of the blocks have representations as convex-conic combinations (i.e. nonnegative linear combinations) where the parts of the representations that form the connecting \(\textsf{X}\)-component are identical for all blocks, obtaining the completion is simply a matter of concatenating the individual factors of the decompositions. However, there is no guarantee that decompositions that are coordinated in this manner do exist. Nonetheless, we can now clearly see the correspondence between \(\mathcal {CMP}\) and \(\mathcal {CPP}\) hinted at, at the end of Sect. 3.1: From any matrix in \(\mathcal {CPP}\), if its ground cone is given by \(\times _{i=0}^S{{\mathcal {K}}}_i\), one can carve out an arrow head shaped partial matrix \(\textsf{M}_*\) so that \(\Gamma _{*}^{-1}(\textsf{M}_*)\) is an element of \(\mathcal {CMP}\). Conversely, such an element uniquely corresponds to a partial arrow head matrix that can be completed to at least one element of \(\mathcal {CPP}\).
Now, it is clear that the following optimization problem is equivalent to (2):
but the latter constraint holds whenever the conic constraint in (9) holds. Thus, we can close the relaxation gap between (9) and (1) by appealing to Burer’s reformulation and Theorem 9. However, we believe it is valuable to have a direct proof that is solely based on the geometry of \(\mathcal {CMP}\) and does not explicitly reference matrix completion. Firstly, we avoid referencing something abstract, namely completability, by invoking something relatively concrete, i.e. the geometry of the respective convex cone. Secondly, the proof shows that the homogenized feasible set of (9) is a face of the respective instance of \(\mathcal {CMP}\), which may be a useful insight for future investigations of this object. Finally, the proof is a somewhat unexpected application of the theory laid out in [13], which may inspire similar approaches to convex reformulations where a desired property, in our case completability, is inscribed in the structure of the cone \(\mathbb {K}\).
To summarize, the reformulation we obtained is similar to the one obtainable from [6] in that it is a linear-conic optimization problem over an appropriately structured convex cone. The advantage of our reformulation is that the number of variables is \(S(n_1+n_2)(n_1+n_2+1)/2\), while for the traditional approach this number would be \((n_1+Sn_2)(n_1+Sn_2+1)/2\), which is a bigger number if S is big enough. However, similarly to \(\mathcal {CPP}\), we cannot directly optimize over \(\mathcal {CMP}\) since no workable description is yet known for this novel object. We therefore propose the following strategy.
3.3 A new strategy for sparse conic reformulations
As stated before, optimizing over \(\mathcal {CMP}\) necessitates the applications of appropriate inner and outer approximations of that cone. On the one hand, we thus look for necessary conditions \([\textsf{M}]\in {{\mathcal {S}}}^{S,k}_n\) has to meet lest completing \(\Gamma _{*} \left( [\textsf{M}]\right) \) to a matrix in the respective \(\mathcal {CPP}\)-cone is impossible, and we denote the subset of connected components that meet these conditions by \({{\mathcal {C}}}_{nes}\supseteq \mathcal {CMP}\). On the other hand we look for subsets \({{\mathcal {C}}}_{suf}\subseteq \mathcal {CMP}\), in other words, we look for sufficient conditions on a connected component \([\textsf{M}]\in {{\mathcal {S}}}^{S,k}_n\) so that \(\Gamma _{*} \left( [\textsf{M}]\right) \) is in fact completable.
As we will show in the next section such necessary and/or sufficient conditions can be formulated in terms of \(\mathcal {CPP}\) constraints. Such constraints are again intractable in general so we need an additional step in order to take advantage of these approximations. Set-compeltely positive matrix cones are very well studied objects and strong inner and outer approximations feature prominently in the existing literature (see [3] for extensive discussion). These approximations can thus be used to find tractable approximations of \({{\mathcal {C}}}_{suf}\) and \({{\mathcal {C}}}_{nes}\). More precisely, whenever we describe \({{\mathcal {C}}}_{nes}\) via set-completely postive constraints, we can loosen these constraints via tractable outer approximation of \(\mathcal {CPP}\) as to obtain a new set \({{\mathcal {C}}}_{outer}\supseteq {{\mathcal {C}}}_{nes}\). Conversely, replacing \(\mathcal {CPP}\) in the description \({{\mathcal {C}}}_{suf}\) with a tractable inner approximation we obtain an inner approximation \({{\mathcal {C}}}_{inner}\subseteq {{\mathcal {C}}}_{suf}\). In total we get:
hence, tractable inner and outer approximations of \(\mathcal {CMP}\).
The two step nature of our proposed approximation procedure stems from the fact that there are two sources of difficulty that necessitate resorting to approximations. The first one is the requirement of completability, which is addressed by the inner two of the above inclusions. The second one is the requirement of set-completely positivity, addressed by the outer two of the above inclusions.
Hence, whenever we approximately solve (9) by replacing \(\mathcal {CMP}\) by its tractable inner and outer approximations we incur a relaxation gap that consists of two components. The portion of the gap that results from a failure of meeting the completability requirement we henceforth refer to as completability gap, while the portion of the gap the stems from the approximation error caused by the relaxation of the \(\mathcal {CPP}\) constraints will be refered to as the completepositivity gap.
In the next section we will mostly be concerned with narrowing the completability gap by providing promising examples for \({{\mathcal {C}}}_{nes}\) and \({{\mathcal {C}}}_{suf}\). Also, most of the discussion in the rest of the article will focus on the quality of this gap. We will, however, also provide some references to approximations of \(\mathcal {CPP}\), in order to give some orientation on how to narrow the completepositivity gap as well. In the section on our numerical experiments we will also show some strategies on how to bypass this gap entirely, albeit in limited cases.
4 Inner and outer approximations of \(\mathcal {CMP}\) based on set-completely positive matrix cones
Our goal in this section is to identify conditions on an element \([\textsf{M}] \in {{\mathcal {S}}}^{S,k}_n\) that are either sufficient or necessary for \(\Gamma _*([\textsf{M}])\) to have a set-completely positive completion. In the following discussion we will show that many such conditions can be given in terms of set-completely positive cone constraints.
4.1 An outer approximation via necessary conditions
For a vector of ground cones \(\bar{{{\mathcal {K}}}} {:=}\left( {{\mathcal {K}}}_0,\dots ,{{\mathcal {K}}}_S\right) \), we define yet another generalization of the set-completely positive matrix cone
for which we can prove the following.
Theorem 10
We have that \(\mathcal {CPI}\left( \bar{{{\mathcal {K}}}}\right) \supseteq \mathcal {CMP}\left( \bar{{{\mathcal {K}}}}\right) \).
Proof
By setting \(\textsf{X}= {\textbf{x}}{\textbf{x}}^\textsf{T},\ \textsf{Z}_i = {\textbf{y}}_i{\textbf{x}},\ \textsf{Y}_i = {\textbf{y}}_i{\textbf{y}}_i^\textsf{T}\) we see that the generators of \(\mathcal {CMP}\) are contained in \(\mathcal {CPI}\) and by convexity \(\mathcal {CMP}\) itself is contained. \(\square \)
We thus have an outer approximations of \(\mathcal {CMP}\) in terms of set-completely positive matrix blocks, which is convenient for approximately optimizing of over \(\mathcal {CMP}\) since set-completely positive optimization is a well researched field.
4.2 Inner approximations via sufficient conditions
We define
While it is not immediately obvious, the above cone is in fact a subset of \(\mathcal {CMP}\). In fact the generators of \(\mathcal {CPS}\) are a subset of the generators of \(\mathcal {CMP}\) as we will now show.
Theorem 11
\(\mathcal {CPS}\left( \bar{{{\mathcal {K}}}}\right) \subseteq \mathcal {CMP}\left( \bar{{{\mathcal {K}}}}\right) \) if \({{\mathcal {K}}}_i, \ i \in [1\!:\!S]\) contain the origin.
Proof
Let \([\bar{\textsf{X}}] \in \mathcal {CPS}\), we need to to show that
for some fixed \(r\in \mathbb {N}\). The important aspect is that the decomposition of the \(\textsf{X}\)-component does not change across \(i \in [1\!:\!S]\). We have
We can set \(r = \sum _{i=1}^Sr_i\) and we have \(\textsf{X}= \sum _{i=1}^S\textsf{W}_i = \sum _{i=1}^S\sum _{k=1}^{r_i} {\textbf{w}}_i^k({\textbf{w}}_i^k)^\textsf{T}\) so that
with
where the last inclusion holds, since \({{\mathcal {K}}}_i\) contain the origin. \(\square \)
For obtaining a second approximation, we can use a slight generalization of known results on matrix completion to obtain another inner approximation for the case \({{\mathcal {K}}}_0=\mathbb {R}^{n_1}_+\). We define
and
Then we can prove the containment
Theorem 12
\(\mathcal {CBC}\left( \bar{{{\mathcal {K}}}}\right) \subseteq \mathcal {CMP}\left( \bar{{{\mathcal {K}}}}\right) \) for \({{\mathcal {K}}}_0=\mathbb {R}^{n_1}_+\).
Proof
Since convex cones are closed under addition the statement will follow if we show that \(\mathcal {CBC}_k\left( \bar{{{\mathcal {K}}}}\right) \subseteq \mathcal {CMP}\left( \bar{{{\mathcal {K}}}}\right) \) for any \(k\in [1\!:\!n_1]\). For an element of \(\mathcal {CBC}_k\) consider the partial matrix
If \(x=0\) then it follows that \({\textbf{z}}_i = {\textbf{o}}, \ i \in [1\!:\!S]\) in which case a completion of \(\textsf{M}\) to a matrix in \(\mathcal {CPP}(\mathbb {R}_+\times _{i=1}^S{{\mathcal {K}}}_i)\) is easily constructed by concatenating the zero vector with the decompositions of \(\textsf{Y}_i= \bar{\textsf{Y}}_i\bar{\textsf{Y}}_i^\textsf{T}, \ \bar{\textsf{Y}}_i\in {{\mathcal {K}}}_i^{r_i}, \ i \in [1\!:\!S]\), where we can insert columns of zeros in case \(r_i\) are not all identical. Thus, we can assume \(x=1\). We will proof that \(\textsf{M}\) can still be completed to a member in \(\mathcal {CPP}(\mathbb {R}_+\times _{i=1}^S{{\mathcal {K}}}_i)\). The desired inclusion then follows since zero rows and columns can be added in order to obtain a member of \(\mathcal {CPP}(\mathbb {R}_+^{n_1}\times _{i=1}^S{{\mathcal {K}}}_i)\).
Our proof involves merely a slight adaptation of the argument used for the completion of partial completely positive matrices given in [8], who considered the case where \({{\mathcal {K}}}_i\) are all positive orthants. We show that such an assumption is unnecessary. Let us proceed by induction and start by showing that the first \((2n_2+1)\times (2n_2+1)\) principal submatrix of \(\textsf{M}\) can be completed to a matrix in \(\mathcal {CPP}\left( \mathbb {R}_+\times {{\mathcal {K}}}_1\times {{\mathcal {K}}}_2\right) \). After a permutation, this matrix can be written as
where we replaced the unspecified entries by \(\textsf{X}\). Observe that the submatrices
so that
Let us define \(m_1m_2\) vectors as follows:
Then the matrix \(\sum _{k,l}{\textbf{v}}_{lk}{\textbf{v}}_{lk}^\textsf{T}\) is the matrix \(\bar{\textsf{M}}\) with \(\textsf{X}={\textbf{z}}_2{\textbf{z}}_1^\textsf{T}\). Hence, after undoing the perturbation, we generate the desired completion. For the j-th induction step we can repeat the argument with \({{\mathcal {K}}}_1\) replaced by \(\times _{i=1}^{j-1}{{\mathcal {K}}}_1\) and \({{\mathcal {K}}}_2\) replaced by \({{\mathcal {K}}}_j\). \(\square \)
Finally, we present a simple, yet, as we will see in the numerical experiments, very effective inner approximation, which is applicable whenever \({{\mathcal {K}}}_i\in \left\{ \mathbb {R}^{n_2}_+,\ \mathbb {R}^{n_2} \right\} , \ i \in [1\!:\!S]\). Again, we express it as the sum of simpler cones given by
We can then define
about which the following statement is easily proved.
Theorem 13
We have \(\mathcal {DDC} \left( \bar{{{\mathcal {K}}}}\right) \subseteq \mathcal {CMP}\left( \bar{{{\mathcal {K}}}}\right) \) if \({{\mathcal {K}}}_i\in \left\{ \mathbb {R}^{n_2}_+,\ \mathbb {R}^{n_2} \right\} , \ i \in [1\!:\!S]\).
Proof
Since \(\mathcal {CMP}\) is convex, it is enough to proof that \(\mathcal {DDC}_{s,k} \left( \bar{{{\mathcal {K}}}}\right) \subseteq \mathcal {CMP}\left( \bar{{{\mathcal {K}}}}\right) \) for any \(k\in [1\!:\!n_2], \ s \in [1\!:\!S]\). For any \([\textsf{M}]\in \mathcal {DDC}_{s,k} \left( \bar{{{\mathcal {K}}}}\right) \) the required completion of \(\Gamma _{*}([\textsf{M}])\) is easily obtained by filling out the unspecified entries with zeros. \(\square \)
Note, that the statement remains true if we merely work with a selection of \(\mathcal {DDC}_{k,s}\) in order to alleviate some of the numerical burden.
All these inner and outer approximations we now discussed represent an effort to tackle the completability gap. But, as we laid out at the beginning of this section, they all have it in common that they are constructed using set-completely positive matrix cones, over which we cannot optimize directly. In this text we will discuss some instances where the completepositivity gap can be bypassed conveniently, so that we can focus on assessing the extent of the completability gap.
4.2.1 Limitations of the inner approximations of \(\mathcal {CMP}\)
We will now critically asses the strength of the inner approximations discussed above. Of course, an obvious limitation of \(\mathcal {CBC}\) and \(\mathcal {DDC}\) is that the \(\textsf{X}\) and the \(\textsf{Y}_i\) components respectively can only be diagonal matrices. In case of \(\mathcal {CBC}\), this has some undesirable consequences when approximating an exact reformulation of (1) based on Theorem 8.
Obviously, if \(\mathcal {CMP}\) is replaced by \(\mathcal {CBC}\), then \({\textbf{x}}= {\textbf{o}}\), since these values reside in off-diagonal of the north-west blocks. But then Theorem 8 implies that \({\textbf{x}}\) is the convex combination of some \({\textbf{x}}_j,\ j \in [1\!:\!k]\) that are part of a feasible solution to (1). Since the feasible set is bounded we get \({\textbf{x}}_j= {\textbf{o}}\) as well, which eventually yields \(\textsf{Z}_i = \sum _{j=1}^{k}\lambda _j{\textbf{y}}^i_j{\textbf{x}}_j^\textsf{T}= \textsf{O}\), so that the approximations eliminates these components entirely.
A similar deficiency can be identified for \(\mathcal {CPS}\). To see this, note the from the proof of Theorem 11 we have that all extreme rays of \(\mathcal {CPS}\) are in fact rank one, in the sense that all matrix components are rank one matrices. In other words the generators of \(\mathcal {CPS}\) are a subset of the generators of \(\mathcal {CMP}\). Hence, if \(\mathcal {CMP}\) is replaced by \(\mathcal {CPS}\) in (8) the extreme points of the feasible set can be shown to be rank one as well, by invoking a similar argument as in Theorem 8. If \(\textsf{Y}_i,{\textbf{y}}_i, \textsf{W}_i, \ i \in [1\!:\!S]\) are part of feasible extremal solution of the respective approximation we get
where \(w_0^i\) are the north-west entries of \(\textsf{W}_i,\ i \in [1\!:\!S]\). By Schur complementation we get \({{\mathcal {S}}}^{n_{2}}_+ \ni w_0^i\textsf{Y}_i-{\textbf{y}}_i{\textbf{y}}_i^\textsf{T}= w_0^i{\textbf{y}}_i{\textbf{y}}_i^\textsf{T}-{\textbf{y}}_i{\textbf{y}}_i^\textsf{T}\), for any fixed \(i \in [1\!:\!S]\), which implies that either \(w^0_i = 1\) or \({\textbf{y}}_i = {\textbf{o}}\). Thus, the approximations based on \(\mathcal {CPS}\) eliminates all but one of the \(\textsf{Y}_i\) components and as a consequence all but one of the \(\textsf{Z}_i\) components. Depending on the model at hand, this can be an advantage as we will see in the numerical experiments in Sect. 5. However, in case \((\textsf{F}_i,\ \textsf{G}_i, {{\textbf{r}}}_i)\) is identical across \(i \in [1\!:\!S]\), the approximations actually eliminates all \(\textsf{Y}_i\) and \(\textsf{Z}_i\) components. To see this, consider that in said case we have that \({{\,\textrm{diag}\,}}(\textsf{G}_i\textsf{Y}_i\textsf{G}_i^\textsf{T}) = \textsf{O}\) for one i forces the same for all i, which by boundedness implies \(\textsf{Y}_i = \textsf{O}\), entailing \(\textsf{Z}_i = \textsf{O}\) for all \(i \in [1\!:\!S]\).
Despite these limitations we have found instances of (1) where the inner approximations yield favorable results. We will discuss these instances in the next section, where we conduct numerical experiments assessing the efficacy of the inner and outer approximations.
5 Numerical experiments
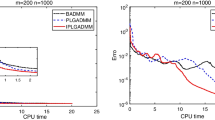
As discussed in the introduction, the authors of [5] tried to solve (2St3QP) using copositive reformulations, where they compared the traditional model akin to (2), with what we can now conceptualize as the \(\mathcal {CPI}\) relaxation of the \(\mathcal {CMP}\) reformulation of (2St3QP). For both models, they used their respective \(\mathcal {DNN}\) relaxations in order to produce solutions. For the purpose of certifying optimality, they exploited the fact that either relaxation also produces feasible solutions, hence upper bounds, since both leave the original space of variables in tact. For many instances, these bounds alone closed the optimality gap, but for some gaps persisted, even though they were narrowed by extensive polishing procedures, about which we will not go into detail here. What we are setting out to do in this section is revisiting these instances and new variants of them, in order to see if the bounds we introduced in this article can further narrow the optimality gap.
In what follows we will use Mosek 9.2 as a conic optimization solver, and Gurobi 9.1 as a global optimization solver, to both of which we interface via the YALMIP environment in Matlab (see [14]). All experiments were run on a Intel Core i5-9300 H CPU with 2.40GHz and 16GB of ram.
In our experiments consider the following problem
with the following specifications for \({{\mathcal {F}}}\):
where \(\bar{{\textbf{y}}} {:=}\left( {\textbf{y}}_1,\dots ,{\textbf{y}}_S\right) \).
The data for the objective functions coefficients were generated using the same two approaches as in [5]. Next to setting \(p_i = 1/S, \ i \in [1\!:\!S]\), the following two schemes for generating the problem data have been implemented:
-
Scheme 1: For the first one, we sample \(n_1+n_2\) points from the unit square. The first \(n_1\) points are fixed and their mutual distances are used to populate the entries in \(\textsf{A}\). For the other \(n_2\) points we assume that they are only known to lie in square with side length \(2\varepsilon \), where their position follows a uniform distribution. For these points S samples are generated and for the s-th sample, the distances between them and the first \(n_1\) points populate the entries of \(\textsf{C}_s\) and \(\textsf{B}_s\) respectively.
-
Scheme 2: For the second one, we choose \(A_{ij} \sim \mathcal {U}_{\left\{ 0,1 \right\} }\), \(B_{ij}\sim \mathcal {U}_{[0:10]}\), \(C_{ij} \sim \mathcal {U}_{[0,0.1]}\), independently of each other, where \(\mathcal {U}_{\mathcal {M}}\) is the uniform distribution with support \(\mathcal {M}\).
It was observed in [5] that Scheme 2 consistently produced instances where the gap generated via the \(\mathcal {CPI}\)-approximation was large. Note, that in the experiments there, the authors focused exclusively on \({{\mathcal {F}}}_1\).
We will now proceed with a discussion of the different instances of \({{\mathcal {F}}}_i, \ i \in [1\!:\!{3}]\), where we present the respective conic reformulations/relaxations and the inner and outer approximations of its sparse counterpart. Regarding the inner approximations, note that one could combine them by using Minkowski sums of the different cones. However, for a given problem there will only ever be one non-redundant approximation. The reason is that the linear functions attain the optimum at an extreme point of the feasible set and the extreme rays of a sum of cones are a subset of the extreme rays of the individual cones. Thus, for every \({{\mathcal {F}}}_i, \ i \in [1\!:\!{3}]\) we will discuss the merits of only one specific inner approximation at a time. The lower bounds will be obtained by using \(\mathcal {CPI}\) by default. The focus of the discussion will be the quality of the bounds obtained. Specifically, we are interested in assessing the completability gap, which necessitates guaranteeing a completepositivity gap of zero. We will discuss how the latter was achieved case by case.
5.1 Using \(\mathcal {DDC}\) under \({{\mathcal {F}}}_1\)
By choosing \({{\mathcal {F}}}= {{\mathcal {F}}}_1\) we are recovering the scenario problem for the two-stage stochastic standard quadratic optimization problem introduced in [5]. In the experiments conducted there, a conic lower bound was used that is equivalent to the outer approximation of (8) based on \(\mathcal {CPI}\). Since the original space of variables is preserved, the conic relaxation also yielded an upper bound that conveniently closed the optimality gap for all instances generated by sc heme 1. However, the gaps generated by the \(\mathcal {CPI}\)-approximation were typically large.
In this section we will test whether the gap can also be improved by using the inner approximations introduced here.
Due to the limitations discussed in Sect. 4.2.1, the only inner approximation that is meaningfully applicable here is the one based on \(\mathcal {DDC}\). Thus, the approximation will involve \(Sn_2\) constraints involving \(\mathcal {CPP}(\mathbb {R}^{n_1+1}_+\times \mathbb {R}_+)\). In case \(n_1+2\le 4\) these constraints can be represented via semidefinite constraints, since \(\mathcal {CPP}(\mathbb {R}^n_+) = {{\mathcal {S}}}^n_+\cap {{\mathcal {N}}}^n{=:}\mathcal {DNN}^n\) whenever \(n\le 4\), so that the completepositivity gap can be conveniently bypassed. If \(n_1+2>4\) the relaxation based on \(\mathcal {DNN}\) is an outer approximation of \(\mathcal {DDC}\), which itself is an inner approximation of \(\mathcal {CMP}\) so that we cannot qualify the resulting approximation as neither outer nor inner. However, the original space of variables stays in tact regardless so that in cases where \(n_1+2>4\) we can still obtain another upper bound that potentially narrows the optimality gap.
5.2 Using \(\mathcal {CPS}\) under \({{\mathcal {F}}}_2\)
The model encodes selecting one out of S groups of variables to be nonzero and optimizing the objective using just these variables. The activation and deactivation of the different groups is modeled via the variable \({\textbf{x}}\), so that \(n_1 = S\) in this model. While there are more straightforward ways of encoding this process, the one presented here is the one for which the conic bounds behaved most favorably.
In order to obtain a \(\mathcal {CMP}\) reformulation for computing \(v({{\mathcal {F}}}_2)\) via Theorem 8 we would have to do some prior adaption of the problem. First of all, \(x_i\in \{0,1\}, i \in [1\!:\!S]\) can be reformulated as quadratic constraints \(x^2_i-x_i =0\), so that in order for the assumptions of the theorem to hold, we would have to introduce redundant constraints and additional variables given by \(x_i+s_i = 1,\ s_i\ge 0, \ i \in [1\!:\!S]\). Secondly, in order for \({\textbf{y}}_ix_i=0\) to fulfill said assumptions we would have to split each \({\textbf{y}}_i\) into a positive and a negative component and enforce the constraints for both components. Lastly, the quadratic constraints would need to be absorbed into a second order cone constraint. Due to the introduction of this many variables, we would have no chance at bypassing the completepositivity gap. Thus, we will merely work with the the following \(\mathcal {CMP}\) based relaxation:
When working with the \(\mathcal {CPS}\) based upper bound, we obtain a problem with S conic constraints involving \(\mathcal {CPP}(\mathbb {R}_+^{n_1+1}\times \mathbb {R}^{n_2})\). Here we can use a result from [15, Theorem 1], which states that
This allows us to bypass the completepositivity gap whenever \(n_1+1 \le 4\).
However, while the above problem is clearly a lower bound, we cannot proof that it is tight based on the theory we have discussed in this text. Thus, when we calculate the optimal values obtained based on inner and outer approximations of \(\mathcal {CMP}\) we merely bound the optimal value of the the \(\mathcal {CMP}\) relaxation. Nonetheless, the space of original variables \({\textbf{x}}\) and \({\textbf{y}}_i, \ i \in [1\!:\!S]\) stays in tact for any of these approximations so that we can obtain upper bounds to the original problem and hence a valid optimality gap. It is however not as straight forward as in the previous model since the values of \({\textbf{x}}\) and \({\textbf{y}}_i, \ i \in [1\!:\!S]\) obtained from approximations of the \(\mathcal {CMP}\) relaxation do not necessarily fulfill the nonlinear constraints in \({{\mathcal {F}}}_2\), as their counterparts in the relaxation are only imposed on the lifted variables.
We therefore have to employ some rounding in order to obtain feasible solutions. In order for \({\textbf{x}}\) to be feasible for \({{\mathcal {F}}}_2\) all entries have to be equal to one except for a single one, say the j-the entry, that is equal to zero. Also, all \({\textbf{y}}_i, \ i \in [1\!:\!S]{\setminus }\left\{ j \right\} \) are zero so that \({\textbf{y}}_j^\textsf{T}{\textbf{y}}_j = 1\). For a solution obtained from a relaxation we therefore round the smallest entry of \({\textbf{x}}\), again say the j-th entry, down to zero, while the rest is rounded up to one. Similarly, all \({\textbf{y}}_i\) are set to zero except for \({\textbf{y}}_j\). We obtain a feasible value for this variable by dividing it by its norm so that eventually \({\textbf{y}}_j^\textsf{T}{\textbf{y}}_j = 1\) holds.
We also want to point out that in this specific case the rounding procedure can actually improve the upper bound obtained from \({\textbf{x}}\) and \({\textbf{y}}_i, \ i \in [1\!:\!S]\) compared to their infeasible pre-rounding values. This is counter intuitive at first, since usually, when we take optimal solutions of a relaxation, we have to sacrifice some performance in order to turn them into feasible solutions of the original problem. However, this intuition leads us astray in this instance. Remember that \({\textbf{x}}\) and \({\textbf{y}}_i, \ i \in [1\!:\!S]\) do not appear in the objective of the \(\mathcal {CMP}\) relaxation and its approximations. They are just some values that are needed in order to make the optimal choices one the other variables feasible and that do not have any specific relation with the optimal value of the approximation itself beyond that. Thus, changing these variables may take their implied objective function value of the original problem in either direction.
5.3 Using \(\mathcal {CBC}\) under \({{\mathcal {F}}}_3\)
In order to bypass the weakness of \(\mathcal {CBC}\) outlined in Sect. 4.2.1 we will work with a simplified, sparse, conic reformulation given by
Note, that we cannot apply Theorem 8 directly here since the single quadratic constraint does not fulfill the assumption of the theorem as it can, after the constant is put on the left-hand side, take both positive and negative values over the remaining feasible set. However, the fact that this is in fact a valid reformulation and not just a lower bound can be deduced from Theorem 6 by choosing \(\mathbb {H}\) to be the hyperplane corresponding to the one linear constraint that is present in (15), and \(\mathbb {J}\) to be all of \(\mathcal {CMP}\). The boundedness of \(\mathbb {J}\cap \mathbb {H}\) follows from the fact that the identity matrix \(\textsf{I}\) is positive definite. In this reformulation \({\textbf{x}}\) is absent so that the problem lined out in Sect. 4.2.1 is mute. Of course, this comes at the cost, of having merely a single upper bound given by the optimal solution of the \(\mathcal {CBC}\) approximation. However, since \({{\mathcal {K}}}_i= \mathbb {R}^{n_2}, \ i \in [1\!:\!S]\) we can use the fact that \(\mathcal {CPP}(\mathbb {R}_+\times \mathbb {R}^n) = {{\mathcal {S}}}^n_+\) (see [4, Section 2]) in order to close the completepositivity gap regardless of the dimension of the problem. We also like to note, that in our experiments, the lower bound was often very close to zero, which leads to optimality gaps being reported as \(\infty \). In order to avoid this inconvenience we added 1 as a constant to the objective function.
5.4 Design of the experiments and results
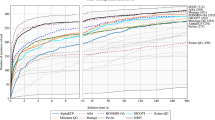
Based on the models discussed above we conducted three experiments. In the first one, we wanted to assess the quality of the bounds obtained from our approximations. This was done by evaluating the global optimality gaps obtained from these bounds, but also by comparing these gaps to the global optimality gaps that a benchmark solver, namely Gurobi, can produce in a reasonable amount of time. Gurobi is a commercial solver that employs branch and bound and related strategies to solve QCQPs globally, which makes it a good benchmark for our procedures, as they produce bounds on the global solution as well.
As it turned out that the conic bounds can be calculated very time efficiently, we conducted a second experiment where we set the time limit for Gurobi to the time it took for the conic approach to produce the respective optimality gaps. This allows us to assess a potential gain in efficiency for global solvers, if they employed the bounds derived in this text as a pre-solving step.
Finally, we compared the sparse bounds with the bounds obtained from relaxations of the full model, i.e. the model where the full \(\mathcal {CPP}\) constraint was present, as in (2), rather than its sparse counterpart based on \(\mathcal {CMP}\). In [5], these experiments have been conducted for instances of \({{\mathcal {F}}}_1\), where the authors observed close to no gap between the full models and the sparse models. We repeat these experiments for instances of \({{\mathcal {F}}}_2\) and \({{\mathcal {F}}}_3\) to test whether this phenomenon persists, but also to test whether the advantage of the sparse models with respect to computation time is also maintained for the inner approximations.
5.5 Quality of the bounds
For each of the models we generated two types of instances. For the first one we choose the dimension of the problem such, that the completepositivity gap could be bypassed and one where that is not the case. For the latter instances, we worked with outer approximations of the respective set-completely positive constraints. Hence, the \(\mathcal {CPI}\) relaxation was further relaxed, so that the resulting problem can be qualified as a valid lower bound. The relaxation of the inner approximation does not allow for such a qualification, since we obtain lower bound to an upper bound. However, the relaxation yields valid upperbounds as a byproduct since the original space of variables stays in tact for all but the \(\mathcal {CBC}\) approximation of \({{\mathcal {F}}}_3\). However, for the latter the completepositivity gap can be bypassed regardless of the dimension of the problem data. For every choice on \((n_1,n_2,S)\) and \({{\mathcal {F}}}_i, \ i = 1,2,3\) we generated 10 instances from scheme 1 and 2 respectively. For every instance we calculated the \(\mathcal {CPI}\) lower bound, the bounds and approximations based on the respective inner approximations, and in addition we used upper and lower bounds achieved by Gurobi within a 5 min time limit (Tables 1, 2, 3).
The results are summarized in Table 4. The “instance-types” are indicated by a quadruple of the form \(n_1\_ n_2\_S\_ s\), where \(s\in \left\{ 1,2 \right\} \) indicates the scheme by which we constructed the instances. In the multi-column "Conic Gaps" we report the average gap between the \(\mathcal {CPI}\) lower bound and the feasible solution generated from the \(\mathcal {CPI}\) bound (UB), the optimal value of the inner approximations (I) and the feasible solution generated from the latter approximations (IUB). Note, that we also considered instances of sizes for which we could not guarantee that the completepositivity gap is eliminated. In these cases the bounds based on the inner approximations are not valid upper bounds, since they stem from relaxations of inner approximations. For these cases we still report the gaps, but they appear in the table in parenthesis. However, we do like to mention at this point that these "invalid upper bounds" never fell below any of the lower bounds we calculated, which suggests that the completepositivity gap is small at least for our experiments. For "Gurobi Gaps" we calculate these gaps with respect to the lower bound found by Gurobi instead of the one obtained from \(\mathcal {CPI}\). In addition we present the gap between the \(\mathcal {CPI}\) based lower bound and the upperbound generated by Gurobi (O), and we also report the optimality gap obtained by Gurobi itself within the 5 min time limit (G). All the gaps are reported in percentages relative to the respective lower bound. Finally, in the last two multi-columns, we count the number of times the conic and the Gurobi gaps were smaller then \(0.01\%\), at which point we consider the instance solved.
For the experiments on \({{\mathcal {F}}}_1\) we see that the phenomenon already documented in [5] persists: instances from scheme 1 are regularly solved via \(\mathcal {CPI}\) alone, while that is not the case for the scheme 2 instances. However, for these instances the solutions from the \(\mathcal {DDC}\) approximation yield excellent bounds, revealing that both approximations are very good, albeit not quite good enough to solve the instances on a \(0.01\%\) tolerance threshold. The feasible solutions produced by via \(\mathcal {DDC}\) are only slightly better, than the ones produced by \(\mathcal {CPI}\), and sometimes even worse. We also note that \(\mathcal {CPI}\) on average yields a much better lower bound than Gurobi does within the time limit, sometimes even certifying optimality of Gurobi’s feasible solution. The upper bound provided by \(\mathcal {DDC}\) performs worse to Gurobi’s upperbound, when measured relative to Gurobi’s lower bound.
Regarding \({{\mathcal {F}}}_2\), we see that the conic gaps were narrowed quite substantially by the inner approximation and regularly closed. Gurobi on its own performed similarly except for the largest instance types, for which it was outperformed quite substantially. What is remarkable is the fact that the upper bounds of the approximations of the \(\mathcal {CMP}\) relaxation seem to also upper bound Gurobi’s lower bounds. Conversely, Gurobi’s upper bounds seem to live close to the \(\mathcal {CPI}\) based lower bounds on average. This might indicate that the \(\mathcal {CMP}\) relaxation may in fact be tight despite the fact that Theorem 8 is not applicable. We hope we can address this phenomenon in future research. Again, instances from scheme 2 seemed to be a greater challenge. Note that the smallest gaps are regularly produced by the feasible solution of the inner approximation.
Finally we can see that for \({{\mathcal {F}}}_3\) the upper bound based on \(\mathcal {CBC}\), unfortunately, performed quite poorly, which is surprising, given that the derivation of \(\mathcal {CBC}\) is the one that is closest to classical results in matrix completion. On the brighter side, we see that the \(\mathcal {CPI}\) produced good lower bounds that narrow the gap to Gurobi’s feasible solution better than Gurobi itself.
We also recorded the average time spent on the different approaches in Table 5. We decomposed these running times into the time the respective solver used to produce the bounds (solver time), the internal model-building time reported by Yalmip (yalmip time) and the time our implementation used for building the model that is passed to Yalmip (model time). We like to point out a couple of things. Firstly, for the majority of the instance types Gurobi ran into the time limit on average. Also, on average the \(\mathcal {DDC}\) approximations are more demanding for Mosek than the other approximations. Still, the models were solved quite quickly, certainly quicker than 5 min. Hence, our methods can produce good bounds with reasonable effort. Finally we would like to point out that there are also spikes in the model time for some of the inner approximations. This, however, is an artifact of our implementation that can potentially be avoided with better programming.
5.6 Restricting Gurobi’s time limit to the conic solution time
For this experiment we used the same setup as in the previous section, but this time Gurobi’s time limit was set to the time it took the conic solver to produce both the solutions of the inner and the outer approximations. This was done on a per instance basis, but the average solution times can be gathered from Table 5. The results are summarized in Table 1, where the nomenclature is as in the previous section.
The first thing, that stands out is that we omitted results on \({{\mathcal {F}}}_3\) and on the larger instances of \({{\mathcal {F}}}_2\). For these instances Gurobi was not able to obtain optimality gaps within the time limit because it could not find a feasible solution and/or was not able to produce a lower bound. The issue was not resolved even after the time limit was expanded by several seconds. For the gaps marked with an asterisk in Table 1, the same issue was present, but was resolved by expanding the time limit by an additional second. Of course this biases the respective results in favor of Gurobi, but we decided to include these results anyway, since the question what a slight loosening of the time limit could achieve is also interesting.
From the results we did include we see several things. First, we observe that the gaps produced via the conic approach were often much better than what Gurobi could achieve in the same time. Only in some of the instances of \({{\mathcal {F}}}_2\) did Gurobi show an advantage, but only in cases where Gurobi operated under an extended time limit. Moreover, the feasible solutions generated by the conic approach were of better quality on average than the ones produced by Gurobi. It is therefore highly plausible, that a conic pre-solver could benefit the running time of global solvers such as Gurobi.
5.7 Comparing the sparse and the full conic models
In our final experiments, we calculated the lower bounds obtained from relaxations of the full model (2), where the entire completely positive constraint was present, rather than its sparse surrogate. In cases where the original space of variables was preserved, we also calculated the associated upper bounds. For models \({{\mathcal {F}}}_2\) and \({{\mathcal {F}}}_3\) we considered the full model to be given by (13) and (15) where the \(\mathcal {CMP}\) constraint was replaced by the respective full \(\mathcal {CPP}\) constraint. These conic constraints were approximated using [15, Theorem 1] as depicted in (14), where the completely positive constraints on the submatrices were relaxed to doubly nonnegative constraints. The results are summarized in Table 2.
In the first column (M) we report the gap between the lower bound from the full model and the lower bound based on \(\mathcal {CPI}\). The second one (F) gives the gap between the lower bound of the full model and the upper bound associated with the feasible solution that the full model produced. The other two columns (UB, I) are calculated as in the other experiments. The final two columns report the number of times the optimality gap of the full model was worse than the one produced by either \(\mathcal {CPI}\) alone (UB) or by \(\mathcal {CPI}\) and the respective inner approximation (I).
We see that there is almost no difference between the lower bounds generated by the full and the sparse models. This is an observation already made for \({{\mathcal {F}}}_1\) in [5], and it is replicated here for \({{\mathcal {F}}}_2\) and \({{\mathcal {F}}}_3\) as well. However, for the upper bounds the picture is more complicated. For instances of \({{\mathcal {F}}}_1\) generated with scheme 1 the upper bounds from the full model and \(\mathcal {CPI}\) are similar while the upper bounds from the inner approximation lack behind. But the latter at least sometimes produces superior upperbounds when it comes to instances produced by scheme 2. For instances of \({{\mathcal {F}}}_2\) the upperbounds produced by the sparse models are often better than what the full model is capable of producing. For \({{\mathcal {F}}}_3\) no upperbounds were produced by the full model since the space of the original variables is absent. Thus, we also omitted the other upper bounds since there was nothing to compare them to.
As in [5], we again see that the bounds based on \(\mathcal {CPI}\) can be computed much faster than the bounds from the full model. This holds true for the newly tested instances of \({{\mathcal {F}}}_2\) and \({{\mathcal {F}}}_3\) as well. On top of that, the same holds true for the inner approximations to the point where it is almost always faster to evaluate both the inner and the outer sparse approximations than it is to solve the full model. Disadvantages exist for the overall model building time, but this is a matter of implementation that is avoidable, at least in principle, by better implementations.
6 Conclusion
In this text we presented a new approach to sparse conic optimization based on a generalization of the set-completely positive matrix cone, which was motivated by the study of the two-stage stochastic standard quadratic optimization problem. Using innner and outer approximations of said cone allows for certificates of exactness of a sparsification outside of traditional matrix completion approaches. We demonstrate in numerical experiments, that this approach can close or at least narrow the optimality gap in interesting cases. We think that this provides a proof of concept that may motivate future research. Interesting questions remain, for example, about the quality of the inner approximations and whether they can be proven to be exact for special cases.
Data availability
The datasets generated and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Berman, A., Shaked-Monderer, N.: Completely Positive Matrices. World Scientific, Singapore (2003)
Bettiol, E., Bomze, I., Létocart, L., Rinaldi, F., Traversi, E.: Mining for diamonds-Matrix generation algorithms for binary quadratically constrained quadratic problems. Comput. Oper. Res. 142, 105735 (2022)
Bomze, I., Dür, M., Teo, C.-P.: Copositive optimization. Optima Newsl. Math. Optim. Soc. 89(1), 2–8 (2012)
Bomze, I., Gabl, M.: Interplay of non-convex quadratically constrained problems with adjustable robust optimization. Math. Methods Oper. Res. 93, 115–151 (2021)
Bomze, I.M., Gabl, M., Maggioni, F., Pflug, G.C.: Two-stage stochastic standard quadratic optimization. Eur. J. Oper. Res. 299(1), 21–34 (2022)
Burer, S.: On the copositive representation of binary and continuous nonconvex quadratic programs. Math. Program. 120(2), 479–495 (2009)
Burer, S.: Copositive programming. In: Handbook on Semidefinite, Conic and Polynomial Optimization, pp. 201–218. Springer (2012)
Drew, J.H., Johnson, C.R.: The completely positive and doubly nonnegative completion problems. Linear Multilinear Algebra 44(1), 85–92 (1998)
Eichfelder, G., Povh, J.: On the set-semidefinite representation of nonconvex quadratic programs over arbitrary feasible sets. Optim. Lett. 7(6), 1373–1386 (2013)
Fan, L., Aghamolki, H. G., Miao, Z., Zeng, B.: Achieving SDP tightness through SOCP relaxation with cycle-based SDP feasibility constraints for AC OPF. arXiv preprint arXiv:1804.05128, (2018)
Fukuda, M., Kojima, M., Murota, K., Nakata, K.: Exploiting sparsity in semidefinite programming via matrix completion I: general framework. SIAM J. Optim. 11(3), 647–674 (2001)
Kim, S., Kojima, M., Toh, K.-C.: Doubly nonnegative relaxations are equivalent to completely positive reformulations of quadratic optimization problems with block-clique graph structures. J. Glob. Optim. 77, 513–541 (2020)
Kim, S., Kojima, M., Toh, K.-C.: A geometrical analysis on convex conic reformulations of quadratic and polynomial optimization problems. SIAM J. Optim. 30(2), 1251–1273 (2020)
Löfberg, J.: Yalmip: a toolbox for modeling and optimization in matlab. In: Proceedings of the CACSD Conference, Taipei, Taiwan (2004)
Natarajan, K., Teo, C.-P.: On reduced semidefinite programs for second order moment bounds with applications. Math. Programm. 161(1), 487–518 (2017)
Padmanabhan, D., Natarajan, K., Murthy, K.: Exploiting partial correlations in distributionally robust optimization. Math. Program. 186(1), 209–255 (2021)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (2015)
Sliwak, J., Anjos, M., Létocart, L., Maeght, J., Traversi, E.: Improving clique decompositions of semidefinite relaxations for optimal power flow problems. arXiv preprint arXiv:1912.09232, (2019)
Vandenberghe, L., Andersen, M.S.: Chordal graphs and semidefinite optimization. Found. Trends Optim. 1(4), 241–433 (2015)
Zheng, Y., Fantuzzi, G., Papachristodoulou, A., Goulart, P., Wynn, A.: Chordal decomposition in operator-splitting methods for sparse semidefinite programs. Math. Program. 180(1), 489–532 (2020)
Acknowledgements
This publication was supported by the Institute of Operations Research at the Karlsruhe Institute of Technology (KIT). We also want acknowledge the members of the Vienna Graduate School of Computational Optimization (VGSCO) for their valuable discussion and input, in particular Prof. Günther Raidl, who suggested the experiments conducted in Sect. 5.6. Finally, we want to thank the anonymous referees for their diligence and for suggesting the experiments conducted in Sect. 5.7.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Gabl, M. Sparse conic reformulation of structured QCQPs based on copositive optimization with applications in stochastic optimization. J Glob Optim 87, 221–254 (2023). https://doi.org/10.1007/s10898-023-01283-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10898-023-01283-y