
Abstract
Monitoring systems in sheet metal forming cannot rely on direct measurements of the physical condition of interest because the space between the die component and the material is inaccessible. Therefore, in order to gain further insight into the forming or stamping process, sensors must be used to detect auxiliary quantities such as acoustic emission and force that relate to the physical quantities of interest. While it is known that changes in force data are related to physical parameters of the process material, lubricant used, and geometry, the changes in data over large stroke series and their relationship to wear are the subject of this paper. Previously, force data from different wear conditions (artificially introduced into the system and not occurring in an industry-like environment) were used as input for clustering and classifying high and low wear force data. This paper contributes to fill the current research gap by isolating structural properties of data as indicators of wear growth to quantify the wear evolution during ongoing production in industry-like scenarios. The selected methods represent either established methods in sheet metal forming force data analysis, dimensionality reduction for local structure separation or generic feature extraction. The study is conducted on a set of four experiments with each containing about 3000 strokes.
Similar content being viewed by others

Introduction
Sheet metal forming comprises various processes in which a force is applied to a piece of sheet metal to plastically deform the material into the desired shape and change its geometry without removing material. They are typically used in areas where high production rates and low costs are required while maintaining stable quality, such as in the aerospace and automotive industries (Klocke, 2014). Current trends towards shorter production cycles, increased competition and rising production rates superimpose increasing pressure on the industry to innovate and further reduce costs by eliminating defects during production.
With the increasing availability of data in the industry, the focus has shifted to research questions that focus on the processing and modeling of data and their relationship to physical quantities of interest to provide powerful systems that assist engineers and operators in the effective design and operation of the process (Klocke et al., 2017). As a result, data-driven monitoring of sheet metal forming processes, a tool that can minimize unexpected production line downtime, has become a major focus of recent research.
By design, sheet metal forming and stamping are performed in large quantities with identical process settings and therefore provide data sets with a large number of operations, but without variation of the process or tooling, except for the continuously increasing wear of the active tool components. Constant and direct measurements of physical quantities of interest, such as wear increase or product quality, are not possible in most scenarios. The resulting digital representation of forming and stamping operations consists of multivariate, nonlinear, and transient time series accompanied by metadata including process and system parameters.
Researchers have already proven that force signals from punching operations are influenced by numerous disturbance variables that affect the process (Jin & Shi, 1999), and that the characteristics derived by domain-specific feature engineering as well as generic features are related to specific process and system parameters of the designed process (Kubik et al., 2021). In addition, they have been shown to contain information about the progression of wear (Voss et al., 2017), quality characteristics of the resulting workpieces (Havinga & Van Den Boogaard, 2017), machine errors, feed errors, and thickness variations (Bassiuny et al., 2007). The high sensitivity of force signals to changes in punch wear condition has also recently been demonstrated by the use of classification techniques to correctly evaluate the wear condition of the tool (Kubik et al., 2022) at a given time, while also a continuous monitoring approach has been introduced through the use of autoencoder (AE) (Niemietz et al., 2021). In most studies, the extraction of meaningful features from high-dimensional time series data has been shown to be a critical step in aggregating information about the physical state of the process. Compared to more generic feature extraction, the extraction of features based on the expertise of process experts generally leads to improved interpretability of models derived from these features. Nevertheless, generic features often lead to less redundancy in the feature set and more accurate models (Zhang et al., 2018). The focus is set on the analysis of sequences of time series data that contain characteristic seasonal patterns, where each profile represents a forming operation. Within these patterns, both stroke-to-stroke variations and long-term variations in large series of consecutive forming operations can be identified (Bergs et al., 2020).
The summary of the research results suggests that force signals can be used to provide adequate insight into the process and to develop applications for monitoring and quality prediction. However, while it was shown in (Kubik et al., 2022) that force data can be attributed to various punch wear states, no model could be found that links the continuous wear evolution to quantifiable indicators such as trends, variations or events in force data over large stroke series. This is of particular importance, as a monitoring system should not only be able to distinguish different wear states, but also to relate different wear states to each other in a certain metric. The innovation of the presented approach is that the wear evolution is tracked in an industry-like setting and linked to the discussed structural properties of the reduced feature spaces calculated for large time series data sets. The present work deals with the processing of successive punch stroke series and the derivation of a continuous univariate wear estimator to evaluate the wear increase in real time during production. This is done by conducting experiments under industry-like conditions, starting with an unworn punch and observing the actual wear evolution over time.
The methodology extends the findings of domain-specific feature engineering technique and extraction of feature templates introduced in (Kubik et al., 2021; Niemietz et al., 2020) to large stroke series and incorporates not only established dimensionality reduction methods such as principle component analysis (PCA) (Jolliffe, 2005), but also innovative approaches to highlight local structures in the data with uniform manifold approximation and projection (UMAP) (McInnes et al., 2018) and to automatically learn features from time series data with autoencoder (AE). The univariate wear estimators are derived from the reduced feature spaces computed in combinations of different feature sets and four experiments. For a comprehensive study, the following aspects are investigated and discussed: (i) the effect of spectral, statistical, and temporal feature sets, (ii) the effect of domain-specific feature engineering, and (iii) the differences in representation learning and dimensionality reduction techniques and in the associated wear increases using field data from experiments with approximately 12,000 strokes performed on a fine-blanking press.
Problem statement
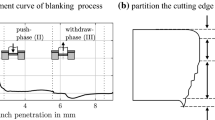
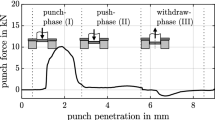
In this study, fine-blanking is considered as an exemplary process for sheet metal forming in general. The process is characterized by the so-called flow shear process, which leads to a clean cut, and takes place in a compressive stress dominated process area (Klocke, 2014). and uses triple-acting presses in which the V-ring force and the counterforce are generated hydraulically and the main punching force can be either mechanical or hydraulic. The cutting force in fine-blanking is shown schematically in Fig. 1 and visualizes different characteristic process phases (Schmidt et al., 2006)

Comparison of idealized cutting force-time curves of fine- and shear-blanking with a visualization of the corresponding process phases (fine-blanking 1–2, shear-blanking 1–4). \(F_{S,\max }\) indicates the maximal cutting force. (Schmidt et al. 2006)
The fine-blanking process
Phase 1 or the elastic phase begins with the first occurrence of a cutting force \(F_S\). The counter punch force \(F_G\), which is (in theory) kept constant throughout the cutting process, has been present since the beginning of the cutting process and is countered in phase 1 by the continuously increasing cutting force \(F_S\). After the cutting force \(F_S\) has exceeded the counter punch force \(F_G\), the cutting punch and counter punch begin to move downwards, causing elastic deformation of the sheet metal material. Phase 1 ends when the maximum elastic deformation of the sheet material or its shear flow limit is exceeded. Phase 2, also known as the cutting phase, begins with the onset of plastic flow of the sheet material. It is characterized by the penetration of the cutting punch as a result of a further increase in the cutting force \(F_S\). Two opposing mechanisms act on the cutting force during this phase. As the forming process continues, sliding dislocations accumulate at obstacles in the crystal lattice of the sheet material and lead to work hardening in the cutting gap (Klocke, 2014). As a result, the deformation resistance and the required cutting force increase. As a second effect, the force-transmitting residual material cross section in the cutting area of the sheet material decreases continuously due to the progressive cutting process until the material is completely penetrated (Schmidt et al., 2006). Until the maximum cutting force \(F_{S,\max }\) is reached, the effect of work hardening is dominant. After the maximum cutting force \(F_{S,\max }\) is reached, the decrease of the remaining cross section is predominant and the cutting force decreases rapidly. Phase 2 is finished when the maximum plastic deformation of the sheet material is exceeded and the material breaks. The plateau within the cutting force curve shown in Fig. 1 represents the residual cutting force \(F_S\) required to compensate for the counter punch force \(F_G\) after phase 2 has ended. Phase 3, the fracture phase, and phase 4, the oscillating phase, are characteristic for the shearing process, but do not occur in the idealized cutting force-time curve of the fine-blanking process (Schmidt et al., 2006).
Wear in fine-blanking
The wear of tool components does not proceed linearly with time, but follows a non-linear pattern. It starts in the early run-in phase with an unstable wear rate, continues in the middle phase with a stable low wear rate and ends in the third phase, which is characterized by accelerated wear leading to the failure of the punch (Behrens et al., 2016) (see Fig. 2). Initially, the surfaces of the punch and the workpiece are in contact. When a sliding motion begins, an enormous stress is applied to the very small area of the interfering surface asperities, causing them to fail and the abrasive wear phase begins. This abrasive wear phase is the first phase, the running-in phase, where the abrasion increases rapidly and deteriorates the surface of the punch very quickly. Under heat and pressure, these abrasive particles stick to the surface and lead to the more stable phase of adhesive wear. The force and the stresses during fine-blanking increase due to the strong adhesion and the altered tribology of the punch, resulting in an accelerated wear rate in the third stage. The third phase is usually accompanied by fatigue wear and can lead to cracking and breakage of the punch (Lind et al., 2010).

The three stages of wear increase in sheet metal forming tool components (Behrens et al. 2016)

Data preprocessing steps of the unsupervised feature extraction: segmentation of continuous force data, elimination of sensor errors by tilt and drift corrections, segmentation into logical segments, feature extraction and projection
Experimental setting and data preprocessing
The data used in this paper are based on the stamping force signal of the fine-blanking process. Stamping force is the force that is applied on the sheet metal to start the plastic deformation. In the current setup, the stamping force is measured using a piezoelectric mechanism (Gautschi, 2002). Additionally, scanning electron microscope (SEM) images of the punch edges have to be processed to approximate the current wear condition observed in the experiments.
Experimental setup
The analysis of the stamping system requires an industry-like setup. Thus, a commercially available fine-blanking production line Feintool XFT 2500 Speed is used for this research. The fine-blanking process typically begins with a 1–20 mm thick and 50–250 mm wide metal coil being unrolled by a decoiler. To relieve the residual stresses, the metal sheet is fed into a leveler (Klocke, 2014). A lubricant film is subsequently applied on the metal sheet, which is followed by the actual blanking process. The press can be configured for up to 140 strokes/min.
In this study, all experiments were performed with the same speed of 50 strokes/min and lubrication setup, while the used lubricant changed throughout the experimental samples. X5CrNi18-10 is used as semi-finished product. In total, almost 12,000 strokes have been acquired with a sensor sample frequency of 10 kHz within individual experiments, see Table 1 for details and (Niemietz, 2022) for the raw data.
Domain-specific signal preprocessing
Figure 3 illustrates the steps of data processing. For preprocessing and artifact removal, drift and tilt correction is performed, assuming that the force should always be set to 0 at the beginning as well as at the end (drift correction) and that no increase in force should be visible when the tool is open (tilt correction), see Fig. 3.
To include domain knowledge in the feature extraction process, the signal is divided into logical segments based on the different phases of the forming process (see Fig. 3). The clamping (C) segment is characterized by the first peak and represents the time during which the sheet is clamped between the tool components. The blanking (B) segment is identified by the global maximum and refers to the actual blanking process. Finally, the segments pre-stripping (P) (minor vibrations that occur only to a limited extent during fine-blanking) and stripping (S) represent the process of stripping off the sheet from the punch and are characterized by the global minimum of the signal.
Features are extracted from the entire signal as well as from the individual segments using the Python library TSFEL (Barandas et al., 2020). An overview can be found in Table 2. In addition, six manually selected features that are easy for humans to interpret and reasonable from a domain perspective are examined. Namely, the maximum \(M^+\), the minimum \(M^-\), the mean M, and the index t of the total signal as well as the area under the curve of the blank and stripping segments \(I^b\) and \(I^e\), respectively, are selected (see Fig. 4).

Selected human-interpretable features alongside with the global average of the signal (blue curve) and the timestamps of the blanking segment (left) and stripping segment (right) (Color figure online)
Wear quantification
For each test, the die components are examined at four characteristic edges (see Fig. 5) after approximately 1000, 2000, and 3000 strokes using SEM images at \(\times \) 100 magnification. Standard image processing methods are used to identify the damaged punch surface. Figure 6 shows the basic steps to isolate the coating-free area from the rest of the image. The first step is to increase the contrast of the SEM images and blur the images using a simple median blur method. Then, worn areas are detected by setting a global threshold for the gray level to classify each pixel as either worn or not worn. Due to geometric differences in the worn areas, some pixels are still not classified correctly. This is solved with a contour detection algorithm, and the detected area is filled in white. The relative amount of pixels in each image is calculated and set as a relative wear estimate in the last step. All image processing steps are performed using the Python image processing library OpenCV (Bradski, 2000). To obtain a wear approximation for each stroke executed, the values of the calculated wear estimate are linearly interpolated.

Characteristic edges at which the tool components’ wear have been assessed

Processing of a SEM image to a wear approximation
Wear approximation methodology
The method was developed to use structural properties of feature (sub)spaces as estimators of wear progression in a completely unsupervised scenario. Features of time series are used to reduce the amount of data that must be processed by computationally intensive algorithms. Features can be either the raw signal itself, an aggregation of features computed by a fixed set of rules, or features learned individually for each time series. All approaches result in different feature spaces with different structural properties. By selecting different techniques for computing features generated from the time series, this study attempts to identify redundancies and patterns that arise in and between each feature space. Finally, a set of univariate wear estimators derived from the structural properties of each feature space is calculated and compared to the wear increase observed in the SEM images to identify the most suitable approach.
As mentioned above, the methodology combines feature extraction with domain-specific preprocessing of the signal to isolate each process phase by applying four different feature templates using the TSFEL-library not only on the complete signal but also on process specific segments. Next, dimensionality reduction techniques are used to condense the information of partially redundant large feature sets. Dimensionality reduction in general is used to transform data from a high-dimensional space to a low-dimensional space such that the low-dimensional representation preserves most of the important features of the input data.
In this study, three different dimensionality reduction methods are selected, which all have different characteristics. PCA is known to preserve the global properties of the input feature space in the generated subspace while omitting local structures in the input data, and has been widely used for force data in manufacturing. In contrast, UMAP is known to preserve local features while distorting global features of the input space. Finally, AEs are able to learn features from raw time series data and provide a generic way to compute learned features fast, once the AE is trained. This is especially important since some feature templates are known to be very computationally intensive.
Autoencoder
AEs are a type of artificial neural networks (ANN) that are used for dimension reduction and denoising among various other applications. They consist of a (commonly) nonlinear transformation to a low-dimensional representation space (encoding) and a back- transformation to the space of the data set (decoding). AEs learn appropriate low-dimensional representations.
Here, an AE is designed with three fully connected layers with fifteen, two and fifteen units using the Python Keras package. The hidden layer with two units results in the two-dimensional representation for each input time series. The ReLU activation function is used for the hidden layers and hyperbolic tangent (tanh) for the output layer of the decoder. The training of the AE is done through the optimizer adam by minimizing the mean squared error loss over 300 episodes with a batch-size of 50 and the input is the cleaned force raw data. In contrast to the PCA approach mentioned above, this method uses the raw sensor signal as input instead of a feature set to take advantage of the AEs’ ability to learn generic features themselves. Because tanh takes values between − 1 and 1, all signal values are scaled accordingly.
Univariate wear estimation
The application of dimension reduction techniques based either on feature sets (PCA, UMAP) or raw force data (AE) results in a multivariate sequence that contains much of the variation in the original data set. Next, the correlation between structural properties of the subspaces with the wear increase of the punch is computed to evaluate the suitability of each approach to estimate the wear state. In this study, four different estimators are derived, each of which resembles specific structural properties of the computed subspaces.
-
1.
Distance to reference point The estimator is based on the Euclidean distance of each stroke to the first stroke of a series. Thus, the estimator reflects the amount of global variation in each subspace with respect to the first stroke.
-
2.
Cumulative stroke-wise The estimator is based on the local change between subsequent strokes, based on the Euclidean distance. The distance is smoothed with a rolling average using a window length of five.
-
3.
Cumulative rolling variance This estimator is based on the changing local variance indicating stable processes. The window length of the rolling variance is set to 20.
-
4.
Combined estimation This estimator combines the first two to incorporate the global amount of variation (1.) as well as local changes in subsequent strokes (2.).
All of the estimators are computed separately for each interval of tool-inspections listed in Table 1 and concatenated afterwards, while the transition between these distances is accounted for. The complete methodology is visualized in Fig. 7.

Aspects and methods for the identification of patterns that are linked to the wear coefficient
Results
While evaluating the results of the proposed methodology, the following set of questions is considered:
-
1.
How do the considered feature spaces relate to each other?
-
2.
Is a similar behavior observable for all four conducted experiments?
-
3.
How does the domain-specific preprocessing of the signal influence the pattern?
-
4.
Are structural properties of the computed subspaces related to the wear increase?
The results are presented in the next subsections, with each subsection providing a discussion of the results regarding the questions in chronological order.
Experiment execution
For experiments \(E_1\) and \(E_3\), irregularities have been recorded during the experiment execution. While during the first 700 strokes of \(E_1\) a lubrication error was recorded, a sequence of stroke data of about 1000 strokes are missing for \(E_3\). Therefore, in the following result evaluation, the performance of both experiments are considered with these obstacles in mind.
Evaluation of feature spaces
First, the Pearson correlation coefficients are computed for the principal components based on the four experiments, four feature sets, and five process segments considered in this study, see Fig. 8.
The first correlation matrix shows the correlations of the first three principal components of each experiment using the combined feature template with the manually selected features. For all experiments, the first component shows the highest correlation with the manually selected features, except for some outliers. Only experiment \(E_1\) shows a lower correlation with a part of the features. The lowest correlation is observed for the total amount of applied stripping force, represented by \(I^e\). Of particular interest are the correlations of the components with t, where t represents the stroke index and thus the sequence. They indicate the change of signals over time and represent the non-stationary behavior of the signal changes. The high correlations of the first component and only low correlations of the second and third components indicate that a large part of the non-stationary behavior of the data is captured in the first principal component. The second correlation matrix displays the average correlations between the principle components based on each feature template with the complete set of manually selected features for all experiments. Again, a common pattern between all experiments except for \(E_1\) can be identified, where most of the correlations are found in the first component, while the correlations of the other components are negligible. The third matrix shows the correlations for the principle components of each segment based on the combined feature template to the manually selected features for each experiment. All segments show similar correlation patterns for each experiment, while again \(E_1\) shows a different pattern, consistently for all considered segments. Additionally, the clamping segment shows a different correlation pattern with the selected features, but also consistent throughout all experiments \(E_1\) to \(E_4\).
The findings indicate that the lubrication error in \(E_1\) significantly skews the pattern observable in all other experiments and it is therefore expected that the wear estimation of \(E_1\) will perform poorly. A low correlation between the amount of applied pulling force during the stripping phase and the principle components derived from features computed from the complete signal indicates that local information is lost for all of the experiments and hints that considering local segments can be beneficial if such information is important. Additionally, since the correlation structure of the feature sets remains considerably stable throughout all considered feature templates, all feature spaces seem to cover the basic information of the manually selected features for each experiment equally. Lastly, the similarity between the correlation structure of the complete signal’s components and the components of the blanking segment is expected, since the complete signal is dominated by the blanking signal’s behavior. The difference in correlation structure of the pre-stripping and stripping segments indicates a general difference in included information within the subspaces.
To compare the explained variance ratio (EVR) of the principle components based on four feature sets for each experiment, Fig. 9 shows the cumulative EVR for the first 60 principle components. For each feature set, differences between each experiment can be observed, while the general pattern between the feature spaces remains the same, indicating that the amount of information in the feature spaces in total is similar after reduction in subspace with PCA.

Absolute values of the Pearson correlation coefficients for the first three principal components of the combined feature template to the engineered features (top), averaged correlation over all engineered features for all feature sets and experiments (mid), and averaged correlation over all data sets for all segments using the combined feature template (bottom)

Cumulative explained variance ratio of the first 60 principal components for all feature templates and respecting data sets

First two components of all experiments E using PCA (a), UMAP (b), and AE (c). The results for PCA and UMAP are based on the combined feature set

First two components of experiment \(E_2\) using PCA (a), UMAP (b), each with four different feature sets, and of each segment using the combined feature set (c)
Qualitative evaluation of the subspace structure
After evaluating the correlation structure of the signals’ features, common patterns are identified in two-dimensional plots of the first two principal components on a qualitative basis. Figure 10 shows the two-dimensional plots of all data sets using the combined feature template of all models evaluated. Figure 11 shows the two-dimensional plots of only experiment \(E_2\) using PCA and UMAP with four different feature templates, and for all segments considered. Both plots show the significant correlation with time and stroke index. Figure 10 shows that UMAP and PCA have very different properties when the feature size is reduced to a few dimensions. Whereas PCA tends to maintain the global structure of the input feature set, UMAP can detect local differences in the data, often resulting in more and clearly separated clusters. The flat AE used in this study is still able to capture similar information to both algorithms, but tends to learn highly correlated features, especially for \(E_1\) and \(E_2\).
The different feature templates and their effects can be seen in Fig. 11. The spectral feature template shows strong similarities to the combined feature template, for both UMAP and PCA, indicating that most of the information in the spectral set dominates the representation of the combined feature set. Again, UMAP shows better cluster separability, while PCA is more coherent and shows fewer clusters overall. The different segments clamping, blanking, pre-stripping, and stripping show a large influence on the resulting plot. While the plot of the blanking segment bears a strong resemblance to the plot of the full signal, which is intuitive since the original signal is dominated by the blanking segment, the rest of the signal shows a very different structure with a different number of clusters or level of variation. This indicates that the information contained in the local structure of the original signal may contain additional information (see pre-stripping and stripping). It has already been pointed out in Sect. 2 that during the stripping phase, the different wear conditions have a considerable influence on the measured signal. In the first 1000 strokes, a strong deviation from one stroke to the next can be observed, which decreases until the end of the test run, see Fig. 11.
Figure 12 shows the UMAP plots of the last 1500 strokes of \(E_2\) and all templates sets. Here, the correlation with time and the change in local variance are shown by the red and yellow arrows. The plots show that the chosen dimensionality reduction methods result in considerably different low-dimensional representations, showing a consistent correlation with time, sometimes directly related to the amount of variation. In the next chapter, the relationship between the different representations, their variations and the approximated wear increase is examined and related to the dimensionality reduction method used, the feature templates, and the estimator approach.
Connecting wear and structural properties of the reduced feature spaces
In this chapter, four different univariate estimates that quantify the range of variation from the beginning to the end of the experiment are mapped onto the approximated wear increase derived by SEM image processing of the tool edges. Recalling Sect. 4.2, four estimation methods, namely distance to reference point, cumulative stroke-wise change, cumulative rolling variance and a combination of the first two, were defined. Each of the measures attempts to capture different structural aspects of the low-dimensional projections of the force signal. While the cumulative stroke-wise change attempts to quantify the amount of local absolute variation that increases each time a subsequent stroke is projected to a different position, the distance to a reference point encompasses a global structural property. For the latter, only the distance to the reference points is important, regardless of the positioning of the subsequent strokes. The cumulative rolling variance quantifies the variation of the distance to a reference point through several successive strokes, thus combining local and global structural aspects in a different way.
Identifying the specific structural features associated with the increase in wear leads to a more understandable and interpretable monitoring system than simply classifying wear levels. In the following, the results are presented and discussed in terms of the impact of each of these aspects and the quality of the resulting estimates.
Impact of feature spaces
Figure 13 shows the comparison between the four different feature sets evaluated in this work for all experiments and the estimates derived from UMAP and PCA embeddings. The results show that the performance of the approaches depends strongly on the experiment. Recall that experiment \(E_3\) lacks a critical amount of data from process execution, which seems to lead to poorer performance in contrast to the other experiments. When using the cumulative estimation of stroke variance and cumulative rolling-variance, the effect of varying feature templates is much smaller compared to the distance to reference points. Since the estimator for distance to reference points is more sensitive to global structure changes, while the other two are more sensitive to local structure in the input spaces, it can be concluded that a change in feature template mainly affects the global structure, whereas the local structure remains similar. The feature template Temp leads to slightly better results than the other feature templates in most experiments. For the other feature templates, the wear estimators perform similarly, with some exceptions. In general, the feature template Stat leads to the worst estimates. The feature templates Comb and Spec lead to very similar good estimates in most cases.

UMAP representations of the last 1500 strokes of \(E_2\) and all feature templates. The red arrows indicate long-term variations of the representations with stroke index. The yellow arrow represents the short-term stroke-to-stroke based variations within restricted time intervals

RMSE between the wear estimates and the wear approximation using the four different feature templates with PCA as well as UMAP and the distance to reference points (top), the cumulative stroke-wise change in the signal (middle), and the cumulative rolling variance (bottom) based on the original force signal

RMSE between the wear estimates and the wear approximation for data of the complete signal (O) in comparison to the segments corresponding to the process phases (C, B, P, S) using the distance to reference points (top), the cumulative stroke-wise change in the signal (middle), and the combination of both estimators (bottom). The results for PCA and UMAP are based on the combined feature set
Impact of local segments
Figure 14 shows the performance of the estimators with respect to the local segments in the force signal. A first observation is the similarity of the results for experiments \(E_2\) and \(E_4\) and the significant deviations for the other two experiments. For \(E_2\) and \(E_4\), the best results for all projection methods were obtained with the distance to reference points measure and the stripping segment. For \(E_1\) and \(E_3\), on the other hand, other segments, e.g., clamping or pre-stripping, led to the best wear estimates. The same observations can be made for the results of the cumulative stroke-wise change. PCA shows very good performance for the stripping segments of \(E_2\) and \(E_4\), while no clear pattern is evident for UMAP in terms of segment suitability. Interestingly, AE performs well for the stripping segments, but best for the blanking segments for \(E_2\) and \(E_4\). From a fine-blanking perspective, the respective blanking and stripping segments are both stages in the fine-blanking process that are strongly affected by changes in wear condition. Therefore, good results for both segments are appropriate. Good results for the clamping and pre-stripping segments could indicate that the data are biased because, from a theoretical point of view, the segments in question should not contain detailed information on wear condition. In addition, AE seems to be particularly suitable for quantifying variations and changes in the blanking segment, compared to the other methods, which perform significantly worse for the blanking segments.
Impact of projection methods
Figure 16 shows a comparison between the methods for computing the low-dimensional projection. Of particular interest is the comparison of performances between the feature engineering-based approaches PCA and UMAP on the one hand, and AE, which automatically learns to extract valuable features, on the other hand. In addition to these three methods, a baseline reference is given by a simple approximation of the wear increase using a linear function from 0 to the maximum wear value. First, on experiment \(E_1\), the linear approximation is almost always more accurate than all other estimators, indicating the influence of the skewed data resulting from the lubrication error in the beginning of experiment \(E_1\). In general, a better overall performance of the cumulative approaches can be observed, using the stroke-wise change and the rolling variance. The distance to reference points is better than the linear reference approximation only for some of the experiments and segments presented, namely for the original and stripping segments of \(E_2\) and \(E_4\). Regarding the cumulative stroke-wise change for both \(E_2\) and \(E_4\), AE performs best for the blanking, whereas PCA performs best for the stripping segment. Similar trends are observed for the combined estimator. UMAP generally performs worst for the cumulative stroke-wise change, while PCA and AE can achieve better results than the linear wear approximation.
Estimator comparison
Figure 16 compares the performance of the four estimation approaches for PCA, UMAP, and AE. For PCA, the distance to reference point estimator performs worst in all trials, while the combined and stroke-wise estimators perform best in most cases. This is in contrast to UMAP, where the distance to reference point estimator performs better than its competitors. This observation is consistent to the before mentioned properties of UMAP that allow UMAP to isolate local changes, while skewing global structure. Therefore, local structure gains more significance. In both methods, the rolling variance estimator is able to achieve good results in all trials, while it does not achieve the best results in any of the trials. For AE, the distance to reference point and the cumulative stroke-wise approaches perform worse than the other two methods in most cases. Figure 17 shows the approximate wear for each estimator for selected experiments and methods. Here, the combined estimator highly overlaps to the measured wear increase for PCA, while the distance to reference points estimator shows much better performance on UMAP.

RMSE between the wear estimates and the wear approximation for the methods using PCA, UMAP, AE, and a linear wear approximation for the distance to reference points (top), the cumulative stroke-wise change in the signal (2nd), the cumulative rolling variance (3rd), and the combined method (bottom). The results for PCA and UMAP are based on the combined feature template

RMSE between the wear estimates and the wear approximation for the different variation quantification methods using PCA (top), UMAP (middle), and AE (bottom). The results for PCA and UMAP are based on the combined feature template
The poor performance of the estimator for the distance to reference point on the stripping segments of \(E_1\) can be explained by the recorded lubrication error. A reduction in lubrication has a strong effect on the frictional forces during stripping and thus on the measured force signal. In Fig. 10, the scatter plot on the upper left shows the global distribution of the data and shows a strong deviation from the other experiments. Since the estimator for the distance to reference point mainly captures global structural properties, the poor performance of this estimator is understandable. On the other hand, the estimators based on stroke-wise change or variance do not seem to be negatively affected by the error. This is a very interesting fact, as it shows that the different estimators indeed handle severe local or global structural changes differently.
Discussion
In general, the results for both non-skewed experiments show that a much better approximation can be achieved by using cumulative methods based on stroke-wise variations or variance. The combination of both distance to reference point and cumulative stroke-wise estimators provides the most consistent results across experiments and models. The fact that the estimators perform significantly better than linear estimators in most cases, and in some cases can approximate the wear increase with high accuracy, demonstrates the applicability of extracting structural measures from auxiliary sensor signals to serve as estimators for real physical conditions. Moreover, AE offers the advantage that features can be extracted automatically and does not require exhaustive feature engineering approaches, which can incur additional computational costs, and works well in most of the considered cases. Another important finding is that the UMAP approach performs poorly in most cases. Nevertheless, UMAP is known to capture well the local behavior of the considered data set, so the estimators derived from UMAP may reflect reasonable behavior, but are not strongly related to the wear increase in most cases.

Wear estimates and the wear approximation for the methods using PCA (top), UMAP (middle) based on the \(E_2\) experimental data and combined feature set, and AE (bottom) based on the \(E_4\) experimental data set
Conclusion
This paper discusses the current state of research on monitoring sheet metal forming processes in manufacturing, focusing on short- and long-term process signal variations. Research has shown that force signal variations or signal anomalies are related to changes in physical conditions and increasing wear. Nevertheless, which part of the signal, which structural properties of the data distribution, which type of variation can provide a valuable basis for estimating the characteristics of a manufacturing process with respect to wear, has not been adequately explored. In fact, current studies often use data sets, where a specific wear state is artificially introduced by the manipulation of tool components. The force data of the strokes executed in different wear stages are classified into different classes, while not taking the relation between the different wear states into account. The understanding of the relationship between wear conditions is a preliminary for complex monitoring tools that work in industrial settings and the next stage after pure classification of wear stages.
The results of this study demonstrate the importance of examining short- and long-term variations in force sensor data from sheet metal forming processes in relation to physical quantities of interest such as wear. The present study first focused on a descriptive approach to observe variations in low-dimensional representations of force data, and then investigated actual estimators representing wear increase during fine-blanking. It was found that in the context of the experiments conducted, both PCA and a flat AE as dimensionality reduction techniques have the potential to capture important global structure that can be used in the outlined approach. In the next step, more experimental data with context have to be obtained. Additionally, a study to compare established dimensionality and representation learning methods has to be conducted for sheet metal forming time series data. Furthermore, a convolutional AE-based approach in combination with class activation maps (CAM) can provide an explainable representation learning approach to further localize important structures in time series data.
Data availability
The authors guarantee no restriction of availability of data and code.
References
Barandas, M., Folgado, D., Fernandes, L., Santos, S., Abreu, M., Bota, P., Liu, H., Schultz, T., & Gamboa, H. (2020). Tsfel: Time series feature extraction library. SoftwareX, 11, 100456.
Bassiuny, A., Li, X., & Du, R. (2007). Fault diagnosis of stamping process based on empirical mode decomposition and learning vector quantization. International Journal of Machine Tools and Manufacture, 47(15), 2298–2306.
Behrens, B.-A., Bouguecha, A., Vucetic, M., & Chugreev, A. (2016). Advanced wear simulation for bulk metal forming processes. In MATEC Web of Conferences, vol. 80, (p. 04003). EDP Sciences.
Bergs, T., Niemietz, P., Kaufman, T., & Trauth, D. (2020). Punch-to-punch variations in stamping processes. In 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), (pp. 000213–000218). IEEE.
Bradski, G. (2000). The OpenCV Library. Dr. Dobb’s Journal of Software Tools.
Gautschi, G. (2002). Piezoelectric sensors. In Piezoelectric sensorics, (pp. 73–91). Springer.
Havinga, J., & Van Den Boogaard, T. (2017). Estimating product-to-product variations in metal forming using force measurements. In AIP Conference Proceedings, vol. 1896, (p. 070002). AIP Publishing LLC.
Jin, J., & Shi, J. (1999). Feature-preserving data compression of stamping tonnage information using wavelets. Technometrics, 41(4), 327–339.
Jolliffe, I. (2005). Principal component analysis. Encyclopedia of Statistics in Behavioral Science.
Klocke, F. (2014). Manufacturing processes 4: Forming. Springer.
Klocke, F., Kamps, S., Mattfeld, P., Shirobokov, A., Stauder, J., Trauth, D., Bassett, E., Jurke, B., Bönsch, C., Gärtner, R., et al. (2017). Assistenzsysteme in der produktionstechnik. In Proceedings of the 29th Aachener Werkzeugmaschinen-Kolloquium (AWK): Aachen May 18th and 19th, (pp. 265–287).
Kubik, C., Hohmann, J., & Groche, P. (2021). Exploitation of force displacement curves in blanking-feature engineering beyond defect detection. The International Journal of Advanced Manufacturing Technology, 113(1), 261–278.
Kubik, C., Knauer, S. M., & Groche, P. (2022). Smart sheet metal forming: Importance of data acquisition, preprocessing and transformation on the performance of a multiclass support vector machine for predicting wear states during blanking. Journal of Intelligent Manufacturing, 33(1), 259–282.
Lind, L., Peetsalu, P., Põdra, P., Adoberg, E., Veinthal, R., & Kulu, P. (2010). Description of punch wear mechanism during fine blanking process. In Proc. 7th International Conference DAAAM Baltic Industrial Engineering, (pp. 504–509).
McInnes, L., Healy, J., & Melville, J. (2018). Umap: Uniform manifold approximation and projection for dimension reduction. http://arxiv.org/abs/1802.03426.
Niemietz, P. (2022). Series of Time Series representing Fine-blanking Punch Force Strokes with Wear assessment.https://doi.org/10.7910/DVN/OYNDZO
Niemietz, P., Pennekamp, J., Kunze, I., Trauth, D., Wehrle, K., & Bergs, T. (2020). Stamping process modelling in an internet of production. Procedia Manufacturing, 49, 61–68.
Niemietz, P., Unterberg, M., Trauth, D., & Bergs, T. (2021). Autoencoder based wear assessment in sheet metal forming. In IOP Conference Series: Materials Science and Engineering, vol. 1157, (p. 012082). IOP Publishing.
Schmidt, R., Band, B. E., Lyss, F. T. A., & Birzer, F. (2006). Umformen und Feinschneiden. Carl Hanser Fachbuchverlag.
Voss, B. M., Pereira, M. P., Rolfe, B. F., & Doolan, M. C. (2017). A new methodology for measuring galling wear severity in high strength steels. Wear, 390, 334–345.
Zhang, G., Li, C., Zhou, H., & Wagner, T. (2018). Punching process monitoring using wavelet transform based feature extraction and semi-supervised clustering. Procedia Manufacturing, 26, 1204–1212.
Acknowledgements
Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy—EXC-2023 Internet of Production—390621612.
Funding
Open Access funding enabled and organized by Projekt DEAL. Funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation) under Germany’s Excellence Strategy—EXC-2023 Internet of Production—390621612.
Author information
Authors and Affiliations
Contributions
All authors PN, MJKK, DT and TB contributed equally to the work.
Corresponding author
Ethics declarations
Competing interest
The authors have no competing interests.
Ethical approval
The authors declare that there are no conflicts with the ethical standards by Springer and the research conducted in this research paper.
Consensus to participate
A consent was obtained from all individuals included in the study.
Consent to publish
The publisher has the consent to the authors to publish the given article.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Niemietz, P., Kornely, M.J.K., Trauth, D. et al. Relating wear stages in sheet metal forming based on short- and long-term force signal variations. J Intell Manuf 33, 2143–2155 (2022). https://doi.org/10.1007/s10845-022-01979-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10845-022-01979-0