
Abstract
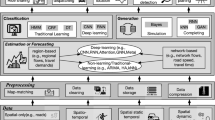
This paper aims at metro station clustering based on passenger flow data. Compared with existing clustering methods that only use boarding or alighting data of each station separately, we focus on higher granularity origin-destination (O-D) path flow data, and provide more flexible and insightful clustering results. In particular, we regard the metro system as a network, with each station as a node. The real-time passenger flows over time between different O-D paths serve as directed edges between nodes. Compared with traditional networks, our edges are temporal curves, and can be regarded as functional data. For this functional data-edged graph, we are the first to develop a novel community detection approach for node clustering. Our method is based on functional factorization. First a dual time-warped sparse nonnegative functional factorization is proposed for extracting patterns of the functional edges. Then the passenger flow of each O-D path can be regarded as a linear combination of different extracted passenger flow patterns. Based on it, we construct a multi-view directed and weighted network, where each view represents one particular pattern, and the factorization coefficient of each O-D path on this pattern is treated as the weight of this directed edge in this particular view. Then a novel community detection algorithm based on nonnegative matrix tri-factorization is constructed according to the topological structure of the multi-view network. The fusion of different views can be either subjectively determined or objectively learnt in a data-driven way, which gives flexibility of the clustering algorithm to emphasize on different travel patterns. Two real datasets of Singapore and Hong Kong metro systems are used to validate the proposed method.







Similar content being viewed by others


Notes
Note that the following inference can be applied to cases with unequally spaced time points as well.
References
Ben P, Williams AH, Maheswaranathan N, Yu B, Santhanam G, Ryu SI, Baccus SA, Shenoy K, Ganguli S (2017) Time-warped PCA: simultaneous alignment and dimensionality reduction of neural data. In: Computational and systems neuroscience
Bonami P, Kilinç M, Linderoth J (2012) Algorithms and software for convex mixed integer nonlinear programs. Mixed integer nonlinear programming. Springer, New York, pp 1–39
Chen C, Chen J, Barry J (2009) Diurnal pattern of transit ridership: a case study of the New York City subway system. J Transp Geogr 17:176–186
Chen P-Y, Hero AO (2017) multilayer spectral graph clustering via convex layer aggregation: theory and algorithms. IEEE Trans Signal Inf Process Over Netw 3:553–567
Chiou J-M, Chen Y-T, Yang Y-F (2014) Multivariate functional principal component analysis: a normalization approach. Stat Sin 1571–1596
Daubechies I, Defrise M, De Mol C (2004) An iterative thresholding algorithm for linear inverse problems with a sparsity constraint. Commun Pure Appl Math J Issued Courant Inst Math Sci 57:1413–1457
Di C-Z, Crainiceanu CM, Caffo BS, Punjabi NM (2009) Multilevel functional principal component analysis. Ann Appl Stat 3:458
Fortunato S (2010) Community detection in graphs. Phys Rep 486:75–174
Gan Z, Yang M, Feng T, Timmermans H (2018) Understanding urban mobility patterns from a spatiotemporal perspective: daily ridership profiles of metro stations. Transportation 1–22
Han Q, Xu K, Airoldi E (2015) Consistent estimation of dynamic and multi-layer block models. In: International conference on machine learning. PMLR, pp 1511–1520
Huang H-C, Chuang Y-Y, Chen C-S (2012) Affinity aggregation for spectral clustering. In: 2012 IEEE conference on computer vision and pattern recognition. IEEE, pp 773–780
Huang X, Chen D, Ren T, Wang D (2021) A survey of community detection methods in multilayer networks. Data Mining and Knowledge Discovery 35:1–45
Jeong S, Li X, Yang J, Li Q, Tarokh V (2017) Dictionary learning and sparse coding-based denoising for high-resolution task functional connectivity mri analysis. International workshop on machine learning in medical imaging. Springer, New York, pp 45–52
Kim M-K, Kim S-P, Heo J, Sohn H-G (2017) Ridership patterns at subway stations of Seoul capital area and characteristics of station influence area. KSCE J Civ Eng 21:964–975
Kuang D, Ding C, Park H (2012) Symmetric nonnegative matrix factorization for graph clustering. In: Proceedings of the 2012 SIAM international conference on data mining. SIAM, pp 106–117
Kumar A, Rai P, Daume H (2011) Co-regularized multi-view spectral clustering. Adv Neural Inf Process Systems 24:1413–1421
Li B, Solea E (2018) A nonparametric graphical model for functional data with application to brain networks based on fMRI. J Am Stat Assoc 113:1637–1655
Liu J, Wang C, Gao J, Han J (2013) Multi-view clustering via joint nonnegative matrix factorization. In: Proceedings of the 2013 SIAM international conference on data mining. SIAM, pp 252–260
Liu X, Cheng H-M, Zhang Z-Y (2019) Evaluation of community detection methods. IEEE Trans Knowl Data Eng 32:1736–1746
Mei J, De Castro Y, Goude Y, Hébrail G (2017) Nonnegative matrix factorization for time series recovery from a few temporal aggregates. In: International conference on machine learning. pp 2382–2390
Ng AY, Jordan MI, Weiss Y (2002) On spectral clustering: analysis and an algorithm. In: Advances in neural information processing systems. pp 849–856
Pan J, Yao Q (2008) Modelling multiple time series via common factors. Biometrika 365–379
Paynabar K, Zou C, Qiu P (2016) A change-point approach for phase-I analysis in multivariate profile monitoring and diagnosis. Technometrics 58:191–204
Poussevin M, Tonnelier E, Baskiotis N, Guigue V, Gallinari P (2015) Mining ticketing logs for usage characterization with nonnegative matrix factorization. Big data analytics in the social and ubiquitous context. Springer, New York, pp 147–164
Qiao X, James G, Lv J (2015) Functional graphical models. Technical report. University of Southern California, Tech. rep
Ramlau-Hansen H (1983) Smoothing counting process intensities by means of kernel functions. Ann Stat 453–466
Reades J, Zhong C, Manley E, Milton R, Batty M (2016) Finding pearls in London’s oysters. Built Environ 42:365–381
Solea E, Dette H (2021) Nonparametric and high-dimensional functional graphical models. arXiv preprint arXiv:2103.10568
Solea E, Li B (2020) Copula Gaussian graphical models for functional data. J Am Stat Assoc 1–13
Sun L, Axhausen KW (2016) Understanding urban mobility patterns with a probabilistic tensor factorization framework. Transp Res Part B Methodol 91:511–524
Wan Y, Meila M (2016) Graph clustering: block-models and model free results. Adv Neural Inf Process Syst 2478–2486
Wang J-L, Chiou J-M, Muller H-G (2016) Functional data analysis. Ann Rev Stat Appl 3:257–295
Wang W, Lo S, Liu S (2014) Aggregated metro trip patterns in urban areas of Hong Kong: evidence from automatic fare collection records. J Urban Plan Develop 141:05014018
Xia R, Pan Y, Du L, Yin J (2014) Robust multi-view spectral clustering via low-rank and sparse decomposition. In: Proceedings of the AAAI conference on artificial intelligence, vol 28
Xu Q, Mao B, Bai Y (2016) Network structure of subway passenger flows. J Stat Mech Theory Exp 2016:033404
Yildirimoglu M, Kim J (2018) Identification of communities in urban mobility networks using multi-layer graphs of network traffic. Transp Res Part C Emerg Technol 89:254–267
Yuan M, Lin Y (2007) Model selection and estimation in the Gaussian graphical model. Biometrika 19–35
Zhan K, Nie F, Wang J, Yang Y (2018) Multiview consensus graph clustering. IEEE Trans Image Process 28:1261–1270
Zhang C, Hoi SC, Tsung F (2020) Time-warped sparse non-negative factorization for functional data analysis. ACM Trans Knowl Discov Data (TKDD) 14:1–23
Zhang C, Yan H, Lee S, Shi J (2018) Weakly correlated profile monitoring based on sparse multi-channel functional principal component analysis. IISE Trans 50:878–891
Zhang T (2011) Sparse recovery with orthogonal matching pursuit under RIP. IEEE Trans Inf Theory 57:6215–6221
Zhao B, Zhai S, Wang YS, Kolar M (2021) High-dimensional functional graphical model structure learning via neighborhood selection approach. arXiv preprint arXiv:2105.02487
Zhong C, Manley E, Arisona SM, Batty M, Schmitt G (2015) Measuring variability of mobility patterns from multiday smart-card data. J Comput Sci 9:125–130
Zhou F, Torre F (2009) Canonical time warping for alignment of human behavior. Adv Neural Inf Process Syst 2286–2294
Zhu H, Strawn N, Dunson DB (2016) Bayesian graphical models for multivariate functional data. J Mach Learn Res 17:1–27
Zong L, Zhang X, Liu X, Yu H (2018) Weighted multi-view spectral clustering based on spectral perturbation. In: Proceedings of the AAAI conference on artificial intelligence, vol 32
Acknowledgements
This paper was supported by the NSFC Grant 71901131, 71932006 and 72271138, the BNSF Grant 9222014, the Hong Kong RGC General Research Funds 16216119 and Foshan HKUST Projects FSUST20-FYTRI03B.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Albrecht Zimmermann.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
1.1 Additional empirical analysis of numerical studies
1.1.1 Additional figures

SG-MRT: The corresponding estimated \({\textbf{U}}\) of Fig. 4

SG-MRT: The corresponding estimated \({\textbf{B}}^{m}\) of Fig. 4


HK-MTR: The corresponding estimated \({\textbf{U}}\) of Fig. 7

HK-MRT: The corresponding estimated \({\textbf{B}}^{m}\) of Fig. 7
1.1.2 Single-view analysis for Singapore dataset
To further explore the spatial dependence relationship of different stations for each particular passenger flow, we consider network community detection based on each single view. The clustering results under different C for each view are shown in Table 5. In particular, it is noted that except that View 6 selects \(C=3\) clusters, other views all select \(C=4\) clusters. This may indicate for afternoon peak pattern, passenger travel distributions are simpler than those of other patterns. The corresponding \({\textbf{U}}\), \({\textbf{B}}\) and clustering results for each view are shown in Figs. 12, 13, 14, 15, 16, 17, 18, 19, 20 and 21. The results are also interpretable and can reveal some interesting phenomena:
-
1.
For View 5 representing morning peak, the red circle cluster represents general business zones or traffic hubs. The green square cluster represents residential zones of the three LRT lines, where passengers tend to go to the mixed commercial-business zones, denoted by the black up-triangle cluster. The blue diamond cluster represents general residential zones, where passengers tend to go to the red circle cluster for work or transfer.
-
2.
For View 3 representing late morning peak, the results are different from View 5. The black up-triangle cluster represents northeast residential zone. The red circle cluster represents northwest residential zone. Passengers in these two zones tend to only travel in each local cluster, with no interaction. The blue diamond cluster represents other mixed residential-business zones, and the green square cluster represents the commercial-business zones. These two zones will have dense trips to the first two residential zones. All the trips in the late morning peaks are also contributed by commuters, who work in residential areas. Yet they commute late because their office hours are a bit late.
-
3.
For View 8 representing noon peak, the results are a bit similar to View 3. The blue diamond cluster represents east residential zones. The black up-triangle cluster represents the northwest residential zones. The green square cluster represents the mixed residential-business zones. The red circle cluster represents the business or commercial zones with larger passenger riderships than the other three clusters.
-
4.
For View 6 representing early afternoon peak, the red circle cluster represents the commercial zones or places with traffic hubs, which attract people working or living around to come. The blue diamond cluster represents the business zones. The green square cluster represents the residential zones.
-
5.
For View 1 representing late afternoon peak, the results are a bit similar to those of View 4. The green square cluster represents the northeast residential zones with local traffic flows. The blue diamond cluster represents the northwest residential zones on the LRT line with local traffic flows. The red circle cluster represents general mixed residential-business zones with passengers travelling to the other three clusters. The black up-triangle cluster represents commercial-business zones.
-
6.
The results of View 9 and View 10 are similar, since both these two views represent evening peaks. The green square cluster represents the northwest residential zones. The blue diamond cluster represents the northeast residential zones. The red circle cluster represents the mixed residential-business zones. The black up-triangle cluster represents commercial zones or places with traffic hubs, where passengers tend to go to the other three clusters.
-
7.
For View 2 representing the midnight passenger flow, the red circle cluster represents the west commercial zones or places with traffic hubs, where there are still passengers travelling to the west residential zone, which is the black up-triangle cluster. Correspondingly, the blue diamond cluster represents the east and central commercial zones or places with traffic hubs, where there are still passengers travelling to the east and north residential zone, which is the green square cluster.
-
8.
For View 7 representing normal travel patterns with afternoon skewness, the results are quite different from other views. This is because the passengers with this travel pattern are most visitors (such as tourists) or old people who do not work. The red circle cluster represents the most busy zones with commercial places and interesting places. The blue diamond cluster represents not-so-busy yet still attractive zones. The green square cluster and black up-triangle clusters indicate residential zones on the main MRT lines and LRT lines.
-
9.
For View 4 representing normal travel patterns with morning skewness, the blue diamond cluster represents the northeast residential zone who has local traffic flows. The black up-triangle cluster represents the northwest residential zone. The green square cluster represents general mixed residential-business zones with passengers travelling to the other two residential clusters. The red circle cluster represents commercial-business zones or traffic hubs with passengers travelling to the other three clusters.
Overall, for different passenger flow patterns, the clustering results are quite distinct. This is because for urban centres, like Singapore and Hong Kong, each city zone usually has multiple functions, and serves for different functions in different time periods of a day. As such, dynamic station clustering according to different functions is more reasonable and can give instructive information for understanding city land use.

SG-MRT: Clustering results for view \(m=1\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=2\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=3\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=4\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=5\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=6\): 3 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=7\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=8\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=9\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

SG-MRT: Clustering results for view \(m=10\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=1\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=2\): 3 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=3\): 3 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=4\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=5\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=6\): 3 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=7\): 3 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)
1.1.3 Single-view analysis for Hong Kong dataset
We also consider network community detection based on each single view. The clustering results under different C for each view are shown in Table 6. In particular, Views 1, 4, 5 and 9 select \(C=4\) clusters, while the other views select \(C=3\) clusters. Their corresponding \({\textbf{U}}\), \({\textbf{B}}\) and clustering results are shown in Figs. 22, 23, 24, 25, 26, 27, 28, 29 and 30. The results are also interpretable and we can draw the following conclusions:
-
1.
For View 2 representing morning peak, the blue diamond cluster represents residential zones and the two port stations (Lo Wu and Lok Ma Chau), where passengers take MTR to business zones for work. The red circle cluster represents mixed residential-business zones. The green square cluster represents business zones or two amusement parks (Disneyland and Ocean park) where attract lots of travellers every day.
-
2.
For View 1 representing late morning peak, the results are quite different from View 2. There are four clusters. The red circle cluster represents commercial zones or amusement places. From the corresponding \({\textbf{B}}\) we can see this cluster has few passengers travelling to other places but attracts passengers from other places to come. The black up-triangle cluster represents residential-commercial zones which also has few passengers. It is interesting to find that even for Lo Wu and Lok Ma Chau, which are port stations connecting mainland to Hong Kong, there is no passenger flow peak around 9am. This indicates the morning commuting peak has passed. The green square cluster represents mixed residential-business zones with passengers travelling to each of the four clusters. The blue diamond cluster represents mixed commercial-business zones.
-
3.
For View 9 representing noon peak, the results are clear and easily interpretable. The blue diamond cluster represents north residential zones. The green square cluster represents other residential zones. Passengers of these two clusters either travel interactively or go to commercial zones. The black up-triangle cluster represents business zones, and the red circle cluster represents commercial zones (including amusement parks).
-
4.
For View 8 representing afternoon peak, the red circle cluster represents general residential zones. The green square cluster represents mixed commercial-business zones. The blue diamond cluster represents commercial zones or places with traffic hubs. These clustering results are also very similar to those of the SG-MRT dataset based on afternoon peak, i.e., View 6.
-
5.
For View 7 representing evening peak, the red circle cluster represents amusement parks or business zones, especially industrial zones where companies’ opening hours are a bit early. The blue diamond cluster represents residential zones. The green square cluster represents mixed business-commercial zones or places with traffic hubs, where passengers would go to residential or other commercial zones after work.
-
6.
For View 3 representing night peak, the results are similar to those of View 7. The blue diamond cluster represents business zones, especially for white collars, where companies’ opening hours are a bit late. The red circle cluster represents residential zones. The green square cluster still represents mixed business-commercial zones or places with traffic hubs.
-
7.
For View 4 representing midnight peak, the results are a bit complex. The blue diamond cluster represents residential zones. The red circle cluster represents the most busy nightlife places, such as central business or commercial zones, Disneyland, or places with traffic hubs. The green square cluster represents mixed residential-commercial zones. The black up-triangle cluster represents mixed commercial-business zones yet without as many passenger throughput as the red circle cluster.
-
8.
For View 6 representing morning-skewed normal travel pattern, the green square cluster represents residential zones. The red circle cluster represents mixed commercial-residential zones, or places with traffic hubs. The blue diamond cluster represents the most busy commercial zones.
-
9.
For View 5 representing afternoon-skewed normal travel pattern, the results are very clear. The black up-triangle cluster represents north residential zone. The blue diamond cluster represents west residential zones. The green square cluster represents east residential zones, and the red circle cluster represents the central zones. Each cluster has local trips inside.

HK-MTR: Clustering results for view \(m=8\): 3 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)

HK-MTR: Clustering results for view \(m=9\): 4 clusters of stations with \({\textbf{U}}\) and \({\textbf{B}}\)
In summary, these above results of the HK-MTR dataset also reflect the necessity of analysing station clusters from different views based on different passenger flow patterns. Furthermore, both Singapore and Hong Kong share some common clustering results due to they are both urban centres and citizens have similar living and travel habits. Yet they still have some difference due to their different land use distributions.
1.2 Optimization of Eq. (5)
The optimization of (4) can follow a similar way as Zhang et al. (2020), with three main steps as below.
1.2.1 Estimation of \(\varvec{\phi }_{ijk}\)
We temporally assume that \(d_{ijk}^{m_1}\), \(d_{ijk}^{m_2}\) and \({\textbf{v}}_{m}\) are fixed, and only focus on estimating \(\varvec{\phi }_{ijk}\). This is the exact sparse recovery problem with \(l_{0}\) regularization, and can be solved via greedy variable selection with orthogonal matching projections (OMP, Zhang (2011)). In particular, for each step, define the current set of selected basis functions is \({\mathcal {M}}\), and its current approximation residuals for \({\textbf{x}}_{ijk}\) and \({\textbf{y}}_{ijk}\) are \({\textbf{e}}_{ijk}^{1}\) and \({\textbf{e}}_{ijk}^{2}\) respectively, with the stacked residual \({\textbf{r}}_{ijk}=[{\textbf{e}}_{ijk}^{1},{\textbf{e}}_{ijk}^{2}]\). OMP selects the next basis function to be added in \({\mathcal {M}}\), whose normalized best deformation is able to reduce the current representation residual most:
here \(d_{ijk}^{m}({\textbf{v}}_{m})=\left[ d_{ijk}^{m_1}({\textbf{v}}_{m}),d_{ijk}^{m_2}\left( {\textbf{v}}_{m(L_{jk}^-)}\right) \right] \) are the stacked best deformations for \({\textbf{r}}_{ijk}\), which will be solved in detail later. After each selection step, \({\mathcal {M}}\) is updated as \(\{{\mathcal {M}}, m\}\). Then OMP projects \({\textbf{x}}_{ijk}\) and \({\textbf{y}}_{ijk}\) into the space spanned by the updated selected aligned bases \({\mathcal {M}}\), to find their updated coefficients as \(\varvec{\phi }_{ijk}=\mathop {\mathrm {arg\,min}}\limits _{\varvec{\phi }_{ijk}} \Vert {\textbf{x}}_{ijk}-\sum _{m \in {\mathcal {M}}}\phi _{ijk}^{m}d_{ijk}^{m_1}({\textbf{v}}_{m})\Vert _{2}^{2}+\Vert {\textbf{y}}_{ijk}-\sum _{m \in {\mathcal {M}}}\phi _{ijk}^{m}d_{ijk}^{m_2}({\textbf{v}}_{m(L_{jk}^-)})\Vert _{2}^{2}\).
Then the residuals are updated as \({\textbf{e}}_{ijk}^{1} \leftarrow {\textbf{x}}_{ijk}-\sum _{m\in {\mathcal {M}}}\phi _{ijk}^{m}d_{ijk}^{m_1}({\textbf{v}}_{m})\) and \({\textbf{e}}_{ijk}^{2} \leftarrow {\textbf{y}}_{ijk}-\sum _{m\in {\mathcal {M}}}\phi _{ijk}^{m}d_{ijk}^{m_2}\left( {\textbf{v}}_{m(L_{jk}^-)}\right) \) for (S-1) in the next step. The iteration continues until \(\max _{m \not \in {\mathcal {M}}} \frac{\langle {\textbf{r}}_{ijk},d_{ijk}^{m}({\textbf{v}}_{m})\rangle }{\Vert d_{ijk}^{m}({\textbf{v}}_{m})\Vert _{2}} \le \epsilon \) where \(\epsilon \) is a small positive constant.
1.2.2 Estimation of deformation function
Now we talk about how to estimate \(d_{ijk}^{m_1}({\textbf{v}}_m)\) and \(d_{ijk}^{m_2}\left( {\textbf{v}}_{m(L_{jk}^-)}\right) \). Here we use \(d_{ijk}^{m_1}({\textbf{v}}_m)\) for illustration, and \(d_{ijk}^{m_2}({\textbf{v}}_m)\) can be estimated in the exactly same way. In particular, denote the components of \({\textbf{e}}_{ijk}^{1}\) as \(e_{ijk}^{1}(t_{l}),l=1,\ldots ,n_{ijk}^{1}\), and the components of \({\textbf{v}}_{m}\) as \(v_{m}(t_s),s=1,\ldots ,n\). The deformation (or time warping) \(d_{ijk}^{m_1}({\textbf{v}}_m)\) here can be regarded as a typical mapping function that assigns each point in \({\textbf{v}}_{m}\) to one point in \({\textbf{e}}_{ijk}^{1}\) with preserved time order, and \(d_{ijk}^{m_1}(\cdot )\) can be expressed by a list of non-decreasing pairs of indices \((t_{s},t_{l})\) with constraints on neighboring pairs. Following Zhang et al. (2020), denote a list of binary indicator vectors \(({\textbf{z}}_{1}^{1},\ldots ,{\textbf{z}}_{n_{ijk}^{1}}^{1})\), where \({\textbf{z}}_{l}^{1} \in {\mathcal {R}}^{n\times 1},l=1,\ldots ,n_{ijk}^{1}\), with \(z_{ls}^{1}\in \{0,1\}\) and \(\sum _{s=1}^{n}z_{ls}^{1}=1\). We can represent a mapping as \(d({\textbf{v}}_{m}) = ({\textbf{z}}_{1}^{1^T}{\textbf{v}}_{m},\ldots ,{\textbf{z}}_{n_{ijk}^{1}}^{1})\), or as a matrix multiplication \(d^{1}({\textbf{v}}_{m}) = {\textbf{Z}}^{1^T}{\textbf{v}}_{m}\) with \({\textbf{Z}}^{1}=[{\textbf{z}}_{1}^{1},\cdots ,{\textbf{z}}_{n_{ijk}^{1}}^{1}]\in {\mathcal {R}}^{n\times n_{ijk}^{1}}\) (Zhou and Torre , 2009).
To further guarantee that the mapping preserves the time order, additional linear constraints are imposed: if \(v_{m}(t_{s})\) is assigned to \(x_{ijk}(t_{l})\), \(v_{m}(t_{s^\prime })\) is assigned to \(x_{ijk}(t_{l^\prime })\), and \(l<l^{\prime }\), then we require \(s \le s^{\prime }\). This indicates \(\{s; z_{ls}^{1}=1 \} \le \{s^{\prime }; z_{(l+1)s^{\prime }}^{1}=1\}\) for \(l=1,\ldots ,n_{ijk}^{1}-1\), where s and \(s^{\prime }\) are the indices satisfying \(z_{ls}^{1}=1\) and \(z_{(l+1)s^{\prime }}^{1}=1\). This constraint can be implemented as a set of linear constraints by considering the positional binary notation. Consequently, the warping selection process can be formulated as the following integer programming:
By considering the positional binary notation, the position constraint of (S-2) can be transferred to a set of linear constraints. Then the above optimization becomes a 0-1 convex programming problem, and can be solved easily via standard algorithms (Bonami et al. , 2012).
1.2.3 Estimation of \({\textbf{v}}_{m}\)
Based on the estimated \(\varvec{\phi }_{ijk}\), \({\textbf{Z}}_{ijk}^{m_1}\) and \({\textbf{Z}}_{ijk}^{m_2}\), we may update \({\textbf{v}}_{m}\) using standard NMF estimation algorithms, by reformulating the objective function of solving \({\textbf{v}}_{m}\) as
Then the projected gradient descent (PGD) method can be used to update \({\textbf{v}}_{m} = P[{\textbf{v}}_{m}-\rho \nabla f({\textbf{v}}_{m})]\), where
is the gradient of the function with respect to \({\textbf{v}}_{m}\) evaluated on the current \({\textbf{v}}_{m}\), and \(P[{\textbf{v}}]\in {\mathcal {R}}^{n\times 1}\) is the element-wise gradient projection onto the nonnegative constraint set with \(P[v]=v \text { if } v \ge 0 \) and \(P[v]=0\) otherwise. Finally, we normalize \({\textbf{v}}_{m} = {\textbf{v}}_{m}/\Vert {\textbf{v}}_{m}\Vert _{2}\). The detailed algorithm is shown in Algorithm A.2.

Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, C., Zheng, B. & Tsung, F. Multi-view metro station clustering based on passenger flows: a functional data-edged network community detection approach. Data Min Knowl Disc 37, 1154–1208 (2023). https://doi.org/10.1007/s10618-023-00916-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-023-00916-w