
Abstract
In the present article we consider a type of matrices stemming in the context of the numerical approximation of distributed order fractional differential equations (FDEs). From one side they could look standard, since they are real, symmetric and positive definite. On the other hand they cause specific difficulties which prevent the successful use of classical tools. In particular the associated matrix-sequence, with respect to the matrix-size, is ill-conditioned and it is such that a generating function does not exists, but we face the problem of dealing with a sequence of generating functions with an intricate expression. Nevertheless, we obtain a real interval where the smallest eigenvalue belongs to, showing also its asymptotic behavior. We observe that the new bounds improve those already present in the literature and give more accurate pieces of spectral information, which are in fact used in the design of fast numerical algorithms for the associated large linear systems, approximating the given distributed order FDEs. Very satisfactory numerical results are presented and critically discussed, while a section with conclusions and open problems ends the current work.
Similar content being viewed by others


1 Introduction
When considering the numerical approximation of fractional differential equations (FDEs), due to the nonlocal nature of the involved operators, the matrices are intrinsically dense, even in the case where the approximation technique is of local nature (Finite Differences, Finite Elements, Finite Volumes, Isogeometric Analysis etc.); see [14, 18,19,20, 22, 25, 34,35,36,37] and references therein. The same situation is present also in the context of distributed order FDEs (see [21] and references therein). When employing equispaced gridding, the resulting structures have the advantage of being of Toeplitz nature, so that the cost of a matrix-vector multiplication is almost linear i.e. of \(O(n\log n)\) arithmetic operations, where n is the matrix order and the constant hidden in the big O is very moderate (we refer to [8, 23] and to the references there reported). These computational features, joint with the usually large dimensions of the considered linear systems, lead to the search for suitable iterative solvers: typically the most successful iterative procedures belong to the class of preconditioned Krylov methods, to the algorithms of multigrid type, or to clever combinations of them [8, 10,11,12, 23, 29, 31].
A crucial piece of information for an appropriate design of an efficient solver of such a kind is the precise knowledge of the asymptotic behavior of the minimal eigenvalue, which in the positive definite case is also related to the asymptotic spectral conditioning: in our setting we emphasize that the considered matrices are real, symmetric, and positive definite.
In this work, starting from [5, 21], we improve the bounds present in the literature. We take into account the techniques already developed in [4, 6]: the additional difficulty, in the present setting, relies on the fact that the generating function is not fixed but rather depends on the matrix order n, which is somehow a challenging novelty with respect to the classical work on the subject [4, 6, 27].
In reality, in technical terms, we consider the real-valued symbol
with \(h\equiv \frac{1}{n}\). In this article we obtain a real interval where the smallest eigenvalue of the Toeplitz matrix \(A_{n}\equiv T_{n}(f_{n})\) belongs to. Recall that if f is a complex-valued function on the unit circle \({\mathbb {T}}\) or, equivalently, on \([-\pi ,\pi ]\) with Fourier coefficients \(\hat{f}_j\) (\(j\in {\mathbb {Z}}\)), then \(T_{n}(f)\) stands for the matrix \((\hat{f}_{j-k})_{j,k=1}^{n}\). The function f is then called the generating function or the symbol of \(T_{n}(f)\). In our case not only the matrix dimension of \(A_{n}\) but also the symbol \(f_{n}\) depends on n.
Based on the spectral information, few algorithmic proposals are also discussed, starting from those presented in [12, 13, 21] and being of the type mentioned before: preconditioned conjugate gradient (PCG) algorithms, multigrid solvers (typically the V-cycle), and combinations of them, that is, a V-cycle where the smoothing iterations (one step) incorporate the proposed PCG choices.
The work is organized as follows. Section 2 contains the setting of the problem regarding the minimal eigenvalue of \(A_{n}\) and its study and solution. Section 3 is devoted to numerical experiments concerning the solution of large linear systems with coefficient matrix \(A_{n}\), including few evidences of the spectral clustering at one of the proposed preconditioned matrix-sequences.
2 The problem and its solution
Let \(h\equiv \frac{1}{n}\) and consider the function \(f_{n}:[-\pi ,\pi ]\rightarrow {\mathbb {R}}\) given by
Note that \(f_{n}\) coincides with the function \({\hat{F}}_{n}\) used in [5]. We employ the notation \(A_{n}\equiv T_{n}(f_{n})\), that is, we consider the \(n \times n\) Toeplitz matrix with the symbol \(f_n\). Using that
we obtain
To simplify the previous expression, we consider now the function g given for \(\sigma >0\) by
Then we infer the relation \(nf_{n}(\theta )=g(n|\theta |)+r_{n}(\theta )\) where \(r_{n}(\theta )=O(n\theta ^{2}+|\theta |)\) as \(n\rightarrow \infty \).
We now establish a connection with the simple-loop method [3, 4]. Consider the Toeplitz matrix \(T_{n}(a)\) with symbol \(a:{\mathbb {T}}\rightarrow {\mathbb {R}}\) given by
where \(t=\mathrm {e}^{\mathrm {i}\theta }\). For a symbol b, let \(\lambda _{j}(T_{n}(b))\) and \(\psi _{j}(T_{n}(b))\) be its jth eigenvalue and normalized eigenfunction, respectively. Since a is real-valued, its eigenvalues must be real and we arrange them in increasing order, that is,
It is well-known that (see, for example, [4, 7]) that
where \(s\equiv \frac{\pi }{n+1}\) and \(c_{n}\) is bounded when \(n\rightarrow \infty \). The constant \(c_{n}\) can be calculated from the relation \(\Vert \psi _{1}(T_{n}(a))\Vert _{2}=1\), see Fig. 1.

The constant \(c_{n}\) in Eq. (2.2) for different values of n. The horizontal gridlines correspond to the value of \(c_{n}\) for some selected numbers n in order to enhance the convergence
2.1 Upper bound for \(\lambda _{1}(A_{n})\)
Theorem 2.1
We have
where the constant \(k_{1}\) is given by
and can be numerically approximated as 12.9301.
Proof
Let \(\langle \cdot ,\cdot \rangle \) be the inner product of the Hilbert space \(L^{2}({\mathbb {T}})\). Note that the essential ranges of the symbols \(n^{2} a\) and \(n f_{n}\) have a similar behavior in an interval of the type \(\big [0,O\big (\frac{1}{n}\big )\big ]\). Hence using the well-known formula
we obtain
where
It is easy to see that \(\lim _{n\rightarrow \infty }n\,\mathcal I_{1}(n)<\infty \). Indeed
Here the notation \(f\sim g\) means \(\lim _{n\rightarrow \infty }\frac{f(n)}{g(n)}=1\). Using (2.2), a similar calculation produces
Note that the last integral does not depend on n. Therefore, the numerical value of \(c_{n}\) is \(c_{n}=\frac{\pi }{\sqrt{2}}\approx 2.2214\), which agrees with the Fig. 1. For the second integral in (2.3) we recall that \(r_{n}(\theta )=O(n\theta ^{2}+|\theta |)\) and write \(\mathcal I_{2}(n)=O(\Phi (n))\) where
which combined with (2.5) produces
Finally, combining (2.3), (2.4), (2.5), and (2.6) we obtain the thesis. \(\square \)
2.2 Lower bound for \(\lambda _{1}(A_{n})\)
In this part we will implement the trick used in [6] which works as follows. Let \(b\in C({\mathbb {T}})\) and \(q_{n}:{\mathbb {T}}\rightarrow {\mathbb {C}}\) given by
Since \(T_{n}(q_{n})\) is the zero matrix we clearly have \(T_{n}(a)=T_{n}(a+q_{n})\). Thus instead of working with \(T_{n}(a)\) we can use \(T_{n}(a+q_{n})\) which under a swiftly selected symbol \(q_{n}\) can be advantageous.
Theorem 2.2
We have
where the constant \(k_{2}\) is given by
which can be approximated numerically as 2.2945.
Proof
In our case instead of working with the symbol \(nf_{n}\) we will use
where \(p(\sigma )\equiv \sum _{j=1}^{\infty } p_{j}\cos (\sigma j)\), \(p_{j}\) are real constants, and \(r_{n}\) is given in (2.1). Let \(t=\mathrm {e}^{\mathrm {i}\theta }\). Then we can write
which clearly shows the form (2.7). Additionally, the function p is \(2\pi \)-periodic, even, and satisfies \(\int _{0}^{\pi }p(\sigma )\mathrm{d}\sigma =0\). We thus deduce \(T_{n}(p(n|\theta |))=0\), and hence
Keeping in mind that, for any real-valued symbol \(\beta \), the smallest eigenvalue of \(T_{n}(\beta )\) must be greater than or equal to the infimum of \(\beta \), we obtain
where in the last line we used the variable change \(\sigma =n|\theta |\). Then we obtain
for a sufficiently large constant M. Thus we have
In order to obtain a neat lower bound for \(\lambda _{1}(A_{n})\), we need to choose the coefficients \(p_{j}\) in such a way that
be maximal. Since p is \(2\pi \)-periodic and g is strictly increasing with \(g(0)=0\) and \(g(\infty )=\infty \), the infimum of \(g+p\) must be in the interval \([0,\pi ]\), and consequently we infer that
Consider the integral
which satisfies \(k_{2}\geqslant m\), and take p as
It is immediate that the function p is \(2\pi \)-periodic, \([g(\sigma )+p(\sigma )]_{\sigma \in [-\pi ,\pi ]}\equiv k_{2}\), \(g(\sigma )+p(\sigma )\geqslant k_{2}\) for \(\sigma \notin [-\pi ,\pi ]\), which implies \(m=k_{2}\). This combined with (2.8) proves the theorem. \(\square \)
Finally, combining the Theorems 2.1 and 2.2 we obtain
for every sufficiently large n.
Remark 2.1
In [5] the authors proved that \(\lambda _{1}(A_{n})=O\big (\frac{1}{n}\big )\). The next section will show that our bounds are more precise.
3 Few selected numerical experiments
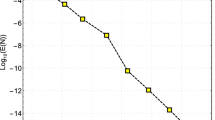
The current section is divided into two parts. In the first we discuss our theoretical results regarding the bounds on the minimal eigenvalue of \(A_{n}\) as a function of the matrix order n in comparison with the bounds present in the literature. Regarding [21], based on [26], the only relevant observation is that the minimal eigenvalue of \(T_{n}^{-1}(|\theta |^{2})h^\alpha T_{n}(|\theta |^{2-\alpha })\) is well separated from zero, for any choice of \(\alpha \in (0,2)\), and this provides a qualitative indication that the minimal eigenvalue of \({A_{n} \over n}\) converges to zero with a speed of \({1 \over n^{2}}\). Concerning [5], the latter claim is indeed proved formally, but the constants are not computed, while in the present article we improve the findings, by determining quite precise lower and upper bounds (see Fig. 2).

The second part is devoted to exploiting the spectral information for the use and the design of specialized iterative algorithms, when solving large linear systems having \(\frac{1}{n}A_{n}\) as coefficient matrix. In Table 1 we employ the standard conjugate gradient (CG), since the coefficient matrix is positive definite, but we do not expect optimality due to the ill-conditioning of the related matrix-sequence. We then use the preconditioned conjugate gradient (PCG) with Strang and Frobenius optimal preconditioners (see [8, 9, 23, 28] taking the preconditioner in the algebra of the circulant matrices and in the algebra of sine transforms, containing the Finite Difference discrete Laplacian \(T_{n}(2-2\cos \theta )\)). Also in this case it is nontrivial to obtain optimality, due to the ill-conditioning of the involved matrices, which grows to infinity as the matrix size tends to infinity.
Few observations are in order: the considered matrix \(A_{n}\) is real, symmetric, and Toeplitz and the \(\tau \) algebra is again inherently real, symmetric, and with Toeplitz generator [9]. The latter statement represents a qualitative explanation of the fact that the \(\tau \) preconditioners perform substantially better than the analogs in the circulant algebra (see Table 1): the theoretical ground to the preceding qualitative remark relies in the notion of good algebras developed in [30].
Notice that the tridiagonal \(\tau \) discrete Finite Difference Laplacian \(\Delta _{n}\) is optimal: the related linear system solution is extremely cheap both in a sequential model (via the Thomas algorithm) and in a parallel model of computation (via e.g. classical multigrid methods [17]). We also notice the remarkable difference between the performance of the optimal \(\tau \) preconditioner and of the optimal circulant preconditioner. The reason is spectral (plus the good algebra argument [30]). The minimal eigenvalue of the optimal circulant preconditioner is averaged, due to a Cesàro sum effect [9, 28], and hence it behaves as \({1\over n}\) (instead of \(1\over n^{2}\)) and this explains the reason why the number of iterations grows as \(\sqrt{n}\), in the light of the classical results on conjugate gradient methods [1]. On the other hand, the optimal \(\tau \) preconditioner matches very well the extremal eigenvalues of \(A_{n}\) (see e.g. [9]).
Thus, as a conclusion, we deduce that the preconditioners \(C_{S,n}\) (Strang-Circulant), \(\tau _{N,n}\) (Natural-\(\tau \)), \(\tau _{F,n}\) (Frobenius-Optimal \(\tau \)), and \(\Delta _{n}\) (Discrete FD Laplacian) are all optimal in the sense that the iteration count is bounded by constants independent of the matrix size n and the cost per iteration is that of the Fast Fourier Transform, which amounts to \(O(n\log n)\) arithmetic operations (for a formal notion of optimality see [2]). As the data indicate, the preconditioners \(\tau _{N,n}\), \(\tau _{F,n}\) are the best, but also \(\Delta _{n}\) is of interest given its sparsity.
In Tables 2, 3 and 4 the minimal and maximal eigenvalues of the considered preconditioned matrices are reported to highlight the efficiency of the proposed preconditioner. For sure, both the data regarding the preconditioners \(\tau _{N,n}\) and \(\tau _{F,n}\) deserve further attention. The outliers analysis reported in Tables 5 and 6, respectively, seems to show a strong cluster at 1. For sure, a weak clustering is observed, being the outliers percentage decreasing as long as n increases: we notice that the weak clustering can be deduced theoretically using the GLT theory [16], while the strong clustering is nontrivial given the ill-conditioning of \(A_{n}\).
The last choice is a multigrid method designed with the use of the spectral information available. In fact, the projector and the restriction operators are those classically used when dealing with the standard discrete Laplacian \(\Delta _{n}=T_{n}(2-2\cos \theta )\). Indeed, even if \(\frac{1}{n}A_{n}\) is dense and seemingly there are no similarities with \(\Delta _{n}\), from a spectral point of view both matrix-sequences have minimal eigenvalue collapsing to zero as \(1\over n^{2}\), up to some moderate constants.
More precisely, the transfer operators are designed, in a very standard way, as the product of the Toeplitz matrix generated by the symbol \(2+2\cos \theta \) and a proper cutting matrix (see e.g. [15, 17]). A purely algebraic multigrid is considered, so that matrices at coarser levels are obtained by projection via the transfer operators according to the Galerkin condition. When setting smoothers, we tested several choices by considering a standard Gauss-Seidel iteration, or PCG with sine transform preconditioners, according to the natural approach and the Frobenius optimal choice: \(\nu _{\text {pre}}\) steps are applied for the presmoother and \(\nu _{\text {post}}\) steps for the postsmoother, respectively.
As it can be seen in Table 7, the numerical results with the multigrid choice are fully satisfactory, as well: the method is optimal [2] in the sense that the iteration count is bounded by a constant independent of n and the cost per iteration is proportional to that of the matrix-vector product.
A special mention deserves a last test in which we set as presmoother the PCG with Finite Difference discrete Laplacian preconditioner with \(\nu _{\text {pre}}=1\), and as postsmoother the PCG with Natural-\(\tau \) or Frobenius-Optimal \(\tau \) preconditioner with \(\nu _{\text {post}}=1\), but only at the finest level. In all the coarser levels the smoothers are simply chosen as one iteration of the standard Gauss-Seidel iteration, so further reducing the computational cost. The number of required iterations is 3 as for the case \(\gamma \).
Though the efficiency is comparable with those of the preconditioned PCG in Table 1 in the present unilevel setting, multigrid could become the most promising choice in the multilevel one, due to the theoretical barriers studied in [24, 32, 33], regarding the non optimality of the PCG with matrix-algebra preconditioners in the multilevel context.
4 Conclusions
In the current article we have considered a type of matrix stemming when considering the numerical approximations of distributed order FDEs (see [5, 21] for example). The main contribution relies on explicit bounds for the minimal eigenvalue of the involved matrices. In fact the new presented bounds improve those already present in the literature and give a more accurate spectral information. The latter knowledge has been used in the design of fast numerical algorithms for the associated linear systems approximating the given distributed order FDEs: an interesting challenge is to consider a d-dimensional version of the considered FDE (see [21]), in order to show how the presented techniques and numerical methods can be adapted and extended in d-level setting with \(d\geqslant 2\).
References
Axelsson, O., Lindskog, G.: On the rate of convergence of the preconditioned conjugate gradient method. Numer. Math. 48(5), 499–523 (1986)
Axelsson, O., Neytcheva, M.: The algebraic multilevel iteration methods-theory and applications. In: Proceedings of the Second International Colloquium on Numerical Analysis, pp. 13–24. VSP, Utrecht (1994)
Bogoya, M., Böttcher, A., Grudsky, S.M., Maximenko, E.A.: Eigenvalues of Hermitian Toeplitz matrices with smooth simple-loop symbols. J. Math. Anal. Appl. 422, 1308–1334 (2015)
Bogoya, M., Böttcher, A., Grudsky, S.M., Maximenko, E.A.: Eigenvectors of Hermitian Toeplitz matrices with smooth simple-loop symbols. Linear Algebra Appl. 493, 606–637 (2016)
Bogoya, M., Grudsky, S.M., Mazza, M., Serra-Capizzano, S.: On the spectrum and asymptotic conditioning of a class of positive definite Toeplitz matrix-sequences, with application to fractional-differential approximations. arXiv:2112.02685 (2021)
Böttcher, A., Grudsky, S.M.: On the condition numbers of large semi-definite Toeplitz matrices. Linear Algebra Appl. 279(1/3), 285–301 (1998)
Böttcher, A., Grudsky, S.M.: Spectral properties of banded Toeplitz matrices. Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA (2005)
Chan, R., Jin, X.: An introduction to iterative Toeplitz solvers. Society for Industrial and Applied Mathematics (SIAM) (2007)
Di-Benedetto, F., Serra-Capizzano, S.: A unifying approach to abstract matrix algebra preconditioning. Numer. Math. 82(1), 57–90 (1999)
Donatelli, M., Garoni, C., Manni, C., Serra-Capizzano, S., Speleers, H.: Robust and optimal multi-iterative techniques for IgA Galerkin linear systems. Comput. Methods Appl. Mech. Engrg. 284, 230–264 (2015)
Donatelli, M., Garoni, C., Manni, C., Serra-Capizzano, S., Speleers, H.: Symbol-based multigrid methods for Galerkin B-spline isogeometric analysis. SIAM. J. Numer. Anal. 55(1), 31–62 (2017)
Donatelli, M., Mazza, M., Serra-Capizzano, S.: Spectral analysis and structure preserving preconditioners for fractional diffusion equations. J. Comput. Phys. 307, 262–279 (2016)
Donatelli, M., Mazza, M., Serra-Capizzano, S.: Spectral analysis and multigrid methods for finite volume approximations of space-fractional diffusion equations. SIAM J. Sci. Comput. 40(6), A4007–A4039 (2018)
Ervin, V., Roop, J.: Variational formulation for the stationary fractional advection dispersion equation. Numer. Methods Partial Differ. Equ. 22(3), 558–576 (2006)
Fiorentino, G., Serra-Capizzano, S.: Multigrid methods for Toeplitz matrices. Calcolo 28(3–4), 283–305 (1992)
Garoni, C., Serra-Capizzano, S.: Generalized Locally Toeplitz sequences: Theory and applications, vol. I. Springer, Cham (2017)
Hackbusch, W.: Multigrid methods and applications, Springer Series in Computational Mathematics, vol. 4. Springer, Berlin (1985)
Hejazi, H., Moroney, T., Liu, F.: Stability and convergence of a finite volume method for the space fractional advection-dispersion equation. J. Comput. Appl. Math. 255, 684–697 (2014)
Lin, Z., Wang, D.: A finite element formulation preserving symmetric and banded diffusion stiffness matrix characteristics for fractional differential equations. Comput. Mech. 62(2), 185–211 (2018)
Mao, Z., Karniadakis, G.: A spectral method (of exponential convergence) for singular solutions of the diffusion equation with general two-sided fractional derivative. SIAM J. Numer. Anal. 56(1), 24–49 (2018)
Mazza, M., Serra-Capizzano, S., Usman, M.: Symbol-based preconditioning for Riesz distributed-order space-fractional diffusion equations. Electr. Trans. Num. Anal. 54, 499–513 (2021)
Meerschaert, M., Tadjeran, C.: Finite difference approximations for fractional advection-dispersion flow equations. J. Comput. Appl. Math. 172(1), 65–77 (2004)
Ng, M.: Iterative methods for Toeplitz systems. Oxford University Press (2004)
Noutsos, D., Serra-Capizzano, S., Vassalos, P.: Matrix algebra preconditioners for multilevel Toeplitz systems do not insure optimal convergence rate. Theoret. Comput. Sci. 315(2–3), 557–579 (2004)
Pedas, A., Tamme, E.: On the convergence of spline collocation methods for solving fractional differential equations. J. Comput. Appl. Math. 235(12), 3502–3514 (2011)
Serra-Capizzano, S.: New PCG based algorithms for the solution of Hermitian Toeplitz systems. Calcolo 32, 53–176 (1995)
Serra-Capizzano, S.: On the extreme eigenvalues of Hermitian (block) Toeplitz matrices. Linear Algebra Appl. 270, 109–129 (1998)
Serra-Capizzano, S.: A Korovkin-type theory for finite Toeplitz operators via matrix algebras. Numer. Math. 82(1), 117–142 (1999)
Serra-Capizzano, S.: The rate of convergence of Toeplitz based PCG methods for second order nonlinear boundary value problems. Numer. Math. 81(3), 461–495 (1999)
Serra-Capizzano, S.: Toeplitz preconditioners constructed from linear approximation processes. SIAM J. Matrix Anal. Appl. 20(2), 446–465 (1999)
Serra-Capizzano, S.: Convergence analysis of two-grid methods for elliptic Toeplitz and PDEs matrix-sequences. Numer. Math. 92(3), 433–465 (2002)
Serra-Capizzano, S.: Matrix algebra preconditioners for multilevel Toeplitz matrices are not superlinear. Special issue on structured and infinite systems of linear equations. Linear Algebra Appl. 343/344, 303–319 (2002)
Serra-Capizzano, S., Tyrtyshnikov, E.: Any circulant-like preconditioner for multilevel matrices is not superlinear. SIAM J. Matrix Anal. Appl. 21(2), 431–39 (1999)
Tian, W., Zhou, H., Deng, W.: A class of second order difference approximations for solving space fractional diffusion equations. Math. Comput. 84(294), 1703–1727 (2015)
Wang, H., Du, N.: A superfast-preconditioned iterative method for steady-state space-fractional diffusion equations. J. Comput. Phys. 240, 49–57 (2013)
Xu, K., Darve, E.: Isogeometric collocation method for the fractional Laplacian in the 2D bounded domain. Computer Methods in Applied Mechanics and Engineering 364, 112,936 (2020)
Zeng, F., Mao, Z., Karniadakis, G.: A generalized spectral collocation method with tunable accuracy for fractional differential equations with end-point singularities. SIAM J. Sci. Comput. 39(1), A360–A383 (2017)
Funding
Open access funding provided by Università degli Studi dell’Insubria within the CRUI-CARE Agreement
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Michiel E. Hochstenbach.
Communicated by Michiel E. Hochstenbach.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this article was revised: The funding note was missing.
Received... Accepted... Published online on... Recommended by \(\ldots \) The first author was partially supported by Universidad del Valle. The second author was partially supported by the CONACYT project “Ciencia de Frontera” FORDECYT-PRONACES/61517/2020. The third and the fourth authors are partially supported by the National Agency INdAM-GNCS.
The original online version of this article was revised: The funding note was missing.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bogoya, M., Grudsky, S.M., Serra–Capizzano, S. et al. Fine spectral estimates with applications to the optimally fast solution of large FDE linear systems. Bit Numer Math 62, 1417–1431 (2022). https://doi.org/10.1007/s10543-022-00916-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10543-022-00916-0