
Abstract
With the development of neural networks, more and more complex and excellent relation classification models are constantly proposed. Although they can be compressed by some model compression methods at the cost of effectiveness, they are still insufficient to deploy on resource-constrained devices. Knowledge distillation can transfer the excellent predictive abilities of superior models to lightweight models, but the gap between models limits its effects. Due to the huge gaps between relation classification models, it is painstakingly difficult to select and train a superior teacher model to guide student models when we use knowledge distillation to get a lightweight model. Therefore, how to obtain a lightweight relation classification model with high effectiveness is still a hot research topic. In this paper, we construct an alternate distillation framework with three modules. The weight adaptive external distillation module is built based on an adaptive weighting module based on cosine similarity. The progressive internal distillation module allows the model to be its own teacher to guide its own training. Finally, a combination module based on the attention mechanism combines the above two modules. On SemEval-2010 Task 8 and WiKi80 datasets, we demonstrate the great effect of our approach on improving the relation classification effectiveness of lightweight models.
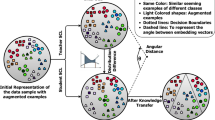
Graphical Abstract
The complex relation classification models compressed at the cost of effectiveness are still insufficient to deploy on resource-constrained devices. Besides, due to the significant differences between relation classification models, it is challenging to find a suitable teacher model for knowledge distillation. In this paper, we propose an alternate distillation framework (including external distillation and internal distillation) to obtain lightweight relation classification models with high effectiveness. Our approach effectively transfers the excellent predictive capability of complex models to lightweight models even when there is a significant gap between them






Similar content being viewed by others


References
Shen Y, Huang, X (2016) Attention-based convolutional neural network for semantic relation extraction. In: Calzolari N, Matsumoto Y, Prasad R (eds) COLING 2016, 26th International conference on computational linguistics, proceedings of the conference: technical papers, December 11-16, 2016, Osaka, Japan, pp 2526–2536. https://aclanthology.org/C16-1238/
Wang Z, Yang B (2020) Attention-based bidirectional long short-term memory networks for relation classification using knowledge distillation from BERT. IEEE intl conf on dependable, autonomic and secure computing, intl conf on pervasive intelligence and computing 2020, pp 562–568. https://doi.org/10.1109/DASC-PICom-CBDCom-CyberSciTech49142.2020.00100
Jiang Z, Xu W, Araki J, Neubig G (2020) Generalizing natural language analysis through span-relation representations. In: Jurafsky D, Chai J, Schluter N, Tetreault JR (eds) Proceedings of the 58th annual meeting of the association for computational linguistics, ACL 2020, Online, July 5-10, 2020, pp 2120–2133. https://doi.org/10.18653/v1/2020.acl-main.192
Tuo M, Yang W (2023) Review of entity relation extraction. J Intell Fuzzy Syst 44(5):7391–7405. https://doi.org/10.3233/JIFS-223915
Alt C, Hübner M, Hennig L (2019) Improving relation extraction by pre-trained language representations. https://doi.org/10.24432/C5KW2W
Wu S, He Y (2019) Enriching pre-trained language model with entity information for relation classification. In: Zhu W, Tao D, Cheng X, Cui P, Rundensteiner EA, Carmel D, He Q, Yu JX (eds) Proceedings of the 28th ACM international conference on information and knowledge management, CIKM 2019, Beijing, China, November 3-7, 2019, pp 2361–2364. https://doi.org/10.1145/3357384.3358119
Alt C, Hübner M, Hennig L (2019) Fine-tuning pre-trained transformer language models to distantly supervised relation extraction. In: Korhonen A, Traum DR, Màrquez L (eds) Proceedings of the 57th conference of the association for computational linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, vol 1: Long papers, pp 1388–1398. https://doi.org/10.18653/v1/p19-1134
Yang W, Xiao Y (2022) Structured pruning via feature channels similarity and mutual learning for convolutional neural network compression. Appl Intell 52(12):14560–14570. https://doi.org/10.1007/s10489-022-03403-9
Tsubota K, Aizawa K (2023) Comprehensive comparisons of uniform quantization in deep image compression. IEEE Access 11:4455–4465. https://doi.org/10.1109/ACCESS.2023.3236086
Tian X, Zheng B, Li S, Yan C, Zhang J, Sun Y, Shen T, Xiao M (2021) Hard parameter sharing for compressing dense-connection-based image restoration network. J Electronic Imaging 30(5). https://doi.org/10.1117/1.jei.30.5.053025
Hong Y, Leu J, Faisal M, Prakosa SW (2022) Analysis of model compression using knowledge distillation. IEEE Access 10:85095–85105. https://doi.org/10.1109/ACCESS.2022.3197608
Hong Y, Dai H, Ding Y (2022) Cross-modality knowledge distillation network for monocular 3d object detection. In: Avidan S, Brostow GJ, Cissé M, Farinella GM, Hassner T (eds) Computer vision - ECCV 2022 - 17th European conference, Tel Aviv, Israel, October 23-27, 2022, proceedings, Part X. Lecture notes in computer science, vol 13670, pp 87–104. https://doi.org/10.1007/978-3-031-20080-9_6
Wang C, Zhong J, Dai Q, Qi Y, Shi F, Fang B, Li X (2023) Multi-view knowledge distillation for efficient semantic segmentation. J Real Time Image Process 20(2):39. https://doi.org/10.1007/s11554-023-01296-6
Xu K, Feng Y, Huang S, Zhao D (2015) Semantic relation classification via convolutional neural networks with simple negative sampling. In: Màrquez L, Callison-Burch C, Su J, Pighin D, Marton Y (eds) Proceedings of the 2015 conference on empirical methods in natural language processing, EMNLP 2015, Lisbon, Portugal, September 17-21, 2015, pp 536–540. https://doi.org/10.18653/v1/d15-1062
Lee S, Na S (2022) Jbnu-cclab at semeval-2022 task 12: Machine reading comprehension and span pair classification for linking mathematical symbols to their descriptions. In: Emerson G, Schluter N, Stanovsky G, Kumar R, Palmer A, Schneider N, Singh S, Ratan S (eds) Proceedings of the 16th international workshop on semantic evaluation, SemEval@NAACL 2022, Seattle, Washington, United States, July 14-15, 2022, pp 1679–1686. https://doi.org/10.18653/v1/2022.semeval-1.231
Hinton, G.E., Vinyals, O., Dean, J (2015) Distilling the knowledge in a neural network. arXiv:1503.02531
Lee J, Seo S, Choi YS (2019) Semantic relation classification via bidirectional LSTM networks with entity-aware attention using latent entity typing. Symmetry 11(6):785. https://doi.org/10.3390/sym11060785
Liu Y, Wen F, Zong T, Li T (2023) Research on joint extraction method of entity and relation triples based on hierarchical cascade labeling. IEEE Access 11:9789–9798. https://doi.org/10.1109/ACCESS.2022.3232493
Zhu J, Qiao J, Dai X, Cheng X (2017) Relation classification via target-concentrated attention cnns. In: Liu D, Xie S, Li Y, Zhao D, El-Alfy EM (eds) Neural information processing - 24th international conference, ICONIP 2017, Guangzhou, China, November 14-18, 2017, proceedings, part II. Lecture notes in computer science, vol 10635, pp 137–146. https://doi.org/10.1007/978-3-319-70096-0_15
Wang L, Cao Z, Melo G, Liu Z (2016) Relation classification via multi-level attention cnns. In: Proceedings of the 54th annual meeting of the association for computational linguistics, ACL 2016, August 7-12, 2016, Berlin, Germany, vol 1: long papers. https://doi.org/10.18653/v1/p16-1123
Xu Y, Mou L, Li G, Chen Y, Peng H, Jin Z (2015) Classifying relations via long short term memory networks along shortest dependency paths. In: Màrquez L, Callison-Burch C, Su J, Pighin D, Marton Y (eds) Proceedings of the 2015 conference on empirical methods in natural language processing, EMNLP 2015, Lisbon, Portugal, September 17-21, 2015, pp 1785–1794. https://doi.org/10.18653/v1/d15-1206
Xu Y, Jia R, Mou L, Li G, Chen Y, Lu Y, Jin Z (2016) Improved relation classification by deep recurrent neural networks with data augmentation. In: Calzolari N, Matsumoto Y, Prasad R (eds) COLING 2016, 26th international conference on computational linguistics, proceedings of the conference: technical papers, December 11-16, 2016, Osaka, Japan, pp 1461–1470. https://aclanthology.org/C16-1138/
Ebrahimi J, Dou D (2015) Chain based RNN for relation classification. In: Mihalcea R, Chai JY, Sarkar A (eds) NAACL HLT 2015, The 2015 conference of the north american chapter of the association for computational linguistics: human language technologies, Denver, Colorado, USA, May 31 - June 5, 2015, pp 1244–1249. https://doi.org/10.3115/v1/n15-1133
Zhao K, Xu H, Cheng Y, Li X, Gao K (2021) Representation iterative fusion based on heterogeneous graph neural network for joint entity and relation extraction. Knowl Based Syst 219:106888. https://doi.org/10.1016/j.knosys.2021.106888
Tian Y, Chen G, Song Y, Wan X (2021) Dependency-driven relation extraction with attentive graph convolutional networks. In: Zong C, Xia F, Li W, Navigli R (eds) Proceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing, ACL/IJCNLP 2021, (vol 1: long papers), virtual event, August 1-6, 2021, pp 4458–4471. https://doi.org/10.18653/v1/2021.acl-long.344
Li J, Katsis Y, Baldwin T, Kim H, Bartko A, McAuley JJ, Hsu C (2022) SPOT: knowledge-enhanced language representations for information extraction. In: Hasan MA, Xiong L (eds) Proceedings of the 31st ACM International conference on information & knowledge management, Atlanta, GA, USA, October 17-21, 2022, pp 1124–1134. https://doi.org/10.1145/3511808.3557459
Cho JH, Hariharan B (2019) On the efficacy of knowledge distillation, pp 4793–4801. https://doi.org/10.1109/ICCV.2019.00489
Chen G, Choi W, Yu X, Han TX, Chandraker M (2017) Learning efficient object detection models with knowledge distillation. In: Guyon I, Luxburg U, Bengio S, Wallach HM, Fergus R, Vishwanathan SVN, Garnett R (eds) Advances in neural information processing systems 30: annual conference on neural information processing systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp 742–751. https://proceedings.neurips.cc/paper/2017/hash/e1e32e235eee1f970470a3a6658dfdd5-Abstract.html
Huang M, You Y, Chen Z, Qian Y, Yu K (2018) Knowledge distillation for sequence model. In: Yegnanarayana B (ed) Interspeech 2018, 19th annual conference of the international speech communication association, Hyderabad, India, 2-6 September 2018, pp 3703–3707. https://doi.org/10.21437/Interspeech.2018-1589
Gotmare A, Keskar NS, Xiong C, Socher R (2019) A closer look at deep learning heuristics: learning rate restarts, warmup and distillation. In: 7th international conference on learning representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. https://openreview.net/forum?id=r14EOsCqKX
Yim J, Joo D, Bae J, Kim J (2017) A gift from knowledge distillation: fast optimization, network minimization and transfer learning. In: 2017 IEEE conference on computer vision and pattern recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pp 130–7138. https://doi.org/10.1109/CVPR.2017.754
Park W, Kim D, Lu Y, Cho M (2019) Relational knowledge distillation, pp 3967–3976. https://doi.org/10.1109/CVPR.2019.00409. http://openaccess.thecvf.com/content_CVPR_2019/html/Park_Relational_Knowledge_Distillation_CVPR_2019_paper.html
Liu Y, Cao J, Li B, Yuan C, Hu W, Li Y, Duan Y (2019) Knowledge distillation via instance relationship graph. In: IEEE conference on computer vision and pattern recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pp 7096–7104. https://doi.org/10.1109/CVPR.2019.00726
Liu Y, Shu C, Wang J, Shen C (2020) Structured knowledge distillation for dense prediction. IEEE Trans Pattern Anal Mach Intell PP:1–1
Xu X, Zou Q, Lin X, Huang Y, Tian Y (2020) Integral knowledge distillation for multi-person pose estimation. IEEE Signal Process Lett 27:436–440. https://doi.org/10.1109/LSP.2020.2975426
Yoon D, Park J, Cho D (2020) Lightweight deep CNN for natural image matting via similarity-preserving knowledge distillation. IEEE Signal Process Lett 27:2139–2143. https://doi.org/10.1109/LSP.2020.3039952
Zhao H, Sun X, Dong J, Yu H, Wang G (2022) Multi-instance semantic similarity transferring for knowledge distillation. Knowl Based Syst 256:109832. https://doi.org/10.1016/j.knosys.2022.109832
Jeong Y, Park J, Cho D, Hwang Y, Choi SB, Kweon IS (2022) Lightweight depth completion network with local similarity-preserving knowledge distillation. Sensors 22(19):7388. https://doi.org/10.3390/s22197388
Sanh V, Debut L, Chaumond J, Wolf T (2019) Distilbert, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108
Jiao X, Yin Y, Shang L, Jiang X, Chen X, Li L, Wang F, Liu Q (2020) Tinybert: Distilling BERT for natural language understanding. In: Cohn T, He Y, Liu Y (eds) Findings of the association for computational linguistics: EMNLP 2020, Online Event, 16-20 November 2020. Findings of ACL, vol EMNLP 2020, pp 4163–4174. https://doi.org/10.18653/v1/2020.findings-emnlp.372
Kim K, Ji B, Yoon D, Hwang S (2021) Self-knowledge distillation with progressive refinement of targets. In: 2021 IEEE/CVF international conference on computer vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pp 6547–6556. https://doi.org/10.1109/ICCV48922.2021.00650
Hendrickx I, Kim SN, Kozareva Z, Nakov P, Séaghdha DÓ, Padó S, Pennacchiotti M, Romano L, Szpakowicz S (2010) Semeval-2010 task 8: multi-way classification of semantic relations between pairs of nominals. In: Erk K, Strapparava C (eds) Proceedings of the 5th international workshop on semantic evaluation, SemEval@ACL 2010, Uppsala University, Uppsala, Sweden, July 15-16, 2010, pp 33–38. https://aclanthology.org/S10-1006/
Han X, Gao T, Yao Y, Ye D, Liu Z, Sun M (2019) Opennre: an open and extensible toolkit for neural relation extraction. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019 - System Demonstrations, pp 169–174. https://doi.org/10.18653/v1/D19-3029
Zeng D, Liu K, Lai S, Zhou G, Zhao J (2014) Relation classification via convolutional deep neural network. In: Hajic J, Tsujii J (eds) COLING 2014, 25th international conference on computational linguistics, proceedings of the conference: technical papers, August 23-29, 2014, Dublin, Ireland, pp 2335–2344. https://aclanthology.org/C14-1220/
Cho K, Merrienboer B, Gülçehre Ç, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Moschitti A, Pang B, Daelemans W (eds) Proceedings of the 2014 conference on empirical methods in natural language processing, EMNLP 2014, October 25-29, 2014, Doha, Qatar, A Meeting of SIGDAT, a Special Interest Group of The ACL, pp 1724–1734. https://doi.org/10.3115/v1/d14-1179
Chen X, Zhang N, Xie X, Deng S, Yao Y, Tan C, Huang F, Si L, Chen H (2022) Knowprompt: Knowledge-aware prompt-tuning with synergistic optimization for relation extraction. In: Laforest F, Troncy R, Simperl E, Agarwal D, Gionis A, Herman I, Médini L (eds) WWW ’22: The ACM Web conference 2022, virtual event, Lyon, France, April 25 - 29, 2022, pp 2778–2788. https://doi.org/10.1145/3485447.3511998
Acknowledgements
This research is supported by the National Natural Science Foundation of China (NSFC) (grant numbers U19A2061, 42050103, 62076108), the Natural Science Foundation of Jilin Province (grant number 20220101114JC), and the Interdisciplinary Integration and Innovation project of Jilin University (grant number JLUXKJC2021ZZ04).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Yuxin Ye is contributed equally to this work.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Wang, Z., Li, K. & Ye, Y. Improving relation classification effectiveness by alternate distillation. Appl Intell 53, 28021–28038 (2023). https://doi.org/10.1007/s10489-023-04964-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-023-04964-z