
Abstract
Speech perception ability in noise is one of the most practical measures of success with a cochlear implant; however, with experience, this ability can change dramatically over time, making it a less than ideal tool for comparing performance among different processing strategies. This study examined performance on a spectral discrimination task and compared it to speech perception in noise. An adaptive procedure was used to determine the spectral-ripple density that subjects could discriminate. A closed-set, forced-choice adaptive procedure was used to determine speech reception thresholds for words in two-talker babble and in speech-shaped, steady-state noise. Spectral-ripple thresholds (ripples/octave) were significantly correlated with speech reception thresholds (dB SNR) in noise for 29 cochlear implant users (r = −0.55, p = 0.002 in two-talker babble; r = −0.62, p = 0.0004 in steady-state noise), demonstrating that better spectral resolution was associated with better speech perception in noise. A significant correlation was also found between the spectral-ripple discrimination ability and word recognition in quiet (r = 0.50, p = 0.009). In addition, test–retest reliability for spectral-ripple discrimination was good, and no learning was observed. The present study demonstrates that the spectral-ripple discrimination test, which is time efficient and nonlinguistic, would be a useful tool to evaluate cochlear implant performance with different signal processing strategies.
Similar content being viewed by others
INTRODUCTION
Understanding speech in noise is one of the most difficult tasks for cochlear implant (CI) users. Poor frequency selectivity, frequency discrimination, and electrode discrimination contribute to poor speech perception for CI users (Donaldson and Nelson 2000; Nelson et al. 1995; Henry et al. 2000). Also, several researchers have shown that the loss of fine spectral information, spectral smearing, and poor auditory segregation affect CI users’ ability to perceive speech in quiet and noise (Fu et al. 1998; Fu and Nogaki 2005; Hong and Turner 2006; Litvak et al. 2006). Results using normal hearing subjects listening to CI simulations showed that 16 to 20 channels of processing were required to optimize speech perception in noise (Dorman et al. 1998; Friesen et al. 2001). Shannon et al. (1995) and Dorman and Loizou (1997, 1998), however, have shown that CI users have only 3–9 functional channels. Furthermore, Loizou and Poroy (2001) showed that CI users need a larger spectral contrast for vowel identification than normal hearing listeners, and similar effects have been observed in the hearing impaired (Leek et al. 1987). Parikh and Loizou (2005) additionally reported that background noise reduces spectral contrast, making it even more difficult for CI users to hear speech in noise. Thus, we expect that CI users with better spectral resolution will have better speech understanding in noise.
A time efficient, nonlinguistic measure of spectral peak resolution has been developed by Henry and Turner (2003, 2005). The spectral shape of the ripple sounds had a full-wave rectified sinusoidal shape. They evaluated the ability of subjects to discriminate a reversal in the phase of the rippled shape (Supin et al. 1994). They found that CI users could discriminate 0.13–1.66 ripples/octave with an average of 0.62 ripples/octave. Furthermore, they found significant correlations between spectral resolution threshold and both vowel and consonant recognition (r = 0.52, p = 0.01 for vowels; r = 0.60, p = 0.003 for consonants).
In the present study, we hypothesized that a similar relationship would exist between spectral discrimination ability and speech perception in noise for CI users. We employed a similar test using spectral ripples logarithmically spaced in the frequency domain with an amplitude envelope determined by a sinusoid on a decibel scale. The speech reception thresholds (SRTs) for spondees in two-talker babble and speech-shaped noise were also measured. In this way, we evaluate the predictive power of the spectral-ripple test in the practical task of speech understanding in noise. In addition, test–retest reliability was evaluated for the spectral-ripple and speech-in-noise tasks. If the spectral-ripple test is reliable and shows predictive power for speech understanding in noise for a group of CI subjects, the test could be useful as a clinical tool to evaluate the performance of individual CI users with different processing strategies. In addition, the speech-in-noise tests might also be useful tools for evaluating processing strategies.
METHODS
Thirty-one CI subjects were tested with the spectral-ripple task. They were 41–81 years old (mean = 58 years, 16 males and 15 females), and all were native speakers of American English. Twenty-five subjects were unilateral users and the other six subjects were bilateral users (S21, S28, S29, S30, S32, S33). Twenty-nine of the original group of 31 CI subjects were tested for speech perception in noise. Twenty-six subjects were also tested with Consonant–Nucleus–Consonant (CNC) words (Peterson and Lehiste 1962). Fifty CNC words were presented in quiet. Individual subject information is listed in Table 1. The use of human subjects in this study was reviewed and approved by the University of Washington Institutional Review Board.
All subjects listened to the stimuli using their own speech processor set to a comfortable listening level. Six bilateral users were tested with both implants functioning. Cochlear implant speech processor settings were the same in both experiments. Sounds were presented in the free field in a double-walled, sound-treated booth (IAC). Stimuli were presented using custom MATLAB programs via a Macintosh G5 computer and a Crown D45 amplifier. A single loudspeaker (B&W DM303), positioned 1 m from the subject, presented the target stimuli at an average level of 65 dBA for the spectral-ripple, SRT, and CNC word test.
Experiment 1: Measuring the spectral-ripple threshold
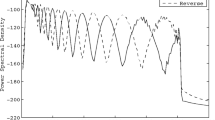
Two-hundred pure-tone frequency components were summed to generate the rippled noise stimuli. The amplitudes of the components were determined by a full-wave rectified sinusoidal envelope on a logarithmic amplitude scale. The ripple peaks were spaced equally on a logarithmic frequency scale. The stimuli had a bandwidth of 100–5,000 Hz and a peak-to-valley ratio of 30 dB. The level of the stimuli was 65 dBA. The starting phases of the components were randomized for each presentation. The ripple stimuli were generated with 14 different densities, measured in ripples per octave. The ripple densities differed by ratios of 1.414 (0.125, 0.176, 0.250, 0.354, 0.500, 0.707, 1.000, 1.414, 2.000, 2.828, 4.000, 5.657, 8.000, and 11.314 ripples/octave). Standard (reference stimulus) and inverted (ripple phase reversed test stimulus) ripple stimuli were generated. For standard ripples, the phase of the full-wave rectified sinusoidal spectral envelope was set to zero radians, and for inverted ripples, it was set to π / 2. The stimuli had 500 ms total duration and were ramped with 150 ms rise/fall times. Stimuli were filtered with a long-term, speech-shaped filter (Byrne et al. 1994). These stimuli differed from those used by Henry et al. (2005) (Turner, personal communication) in that our spectral shape was sinusoidal on a logarithmic amplitude axis (a dB scale), whereas the Henry et al. study had a sinusoidal shape on a linear amplitude axis. Logarithmic amplitude ripples were used in this study with the rationale that logarithmic amplitude is closer to the perceptual scale of loudness. The first panel of Figure 1 shows both types of ripple stimuli. The logarithmic amplitude ripples are thinner than the linear amplitude ripples, creating relatively wider dips and enabling slightly more ease for discrimination with log-amplitude ripples. Ripple stimuli with 2 ripples/octave and 2.828 ripples/octave are also shown in the second and third panels of Figure 1.

The figure shows the spectra of spectral-ripple stimulus from 100 to 800 Hz. Linear and logarithmic amplitude ripples with 1 ripple/octave are shown in the first panel. Standard and inverted ripples with 2 and 2.828 ripples/octave (with logarithmic amplitude) are shown in the second and third panels, respectively.
The ripple resolution threshold was determined using a three-interval forced-choice, two-up and one-down adaptive procedure, converging on 70.7% correct (Levitt 1971). Each test run started with 0.176 ripples per octave and moved in equal ratio steps of 1.414. The presentation level was roved within trials (8 dB range in 1 dB steps) to minimize level cues. Subjects were asked to click on an on-screen button that was labeled 1, 2, and 3 after they were presented the stimuli. One stimulus (i.e., inverted ripple sound, test stimulus) was different from two others (i.e., standard ripple sound, reference stimulus). The subject’s task was to discriminate the test stimulus from the reference stimuli. Feedback was not provided. The threshold was estimated by averaging the ripple spacing (the number of ripples/octave) for the final 8 of 13 reversals. Subjects did at least six test runs. To evaluate test–retest reliability, 20 subjects repeated the test and did two sets of six runs on separate days. Thresholds were determined by averaging the threshold from six runs.
Experiment 2: Measuring the speech recognition threshold in two-talker babble and steady-state noise
In this experiment, subjects were asked to identify one randomly chosen spondee word out of a closed-set of 12 equally difficult spondees (Harris 1991). The spondees, two-syllable words with equal emphasis on each syllable, were recorded by a female talker [fundamental frequency range: 212–250 Hz (Turner et al. 2004)]. Two background noises were used: two-talker babble and steady-state, speech-shaped noise. The two-talker babble consisted of a male voice saying “Name two uses for ice.” and a female voice saying “Bill might discuss the foam.” These sentences were taken from the SPIN test (Bilger et al. 1984). The female talker for the babble was different from the female talker for the spondees. The other background noise was a speech-shaped, steady-state noise. The same background noises were used on every trial, and the onset of the spondees was 500 ms after the onset of the background noise. The two-talker babble and steady-state noise had a duration of 2.0 s. The 12-alternative forced-choice task used one-up, one-down adaptive tracking, converging on 50% correct. The level of the target speech was 65 dBA. The noise level was varied with a step size of 2 dB. Feedback was not provided. The threshold was estimated by averaging the signal-to-noise ratio (SNR) for the final 10 of 14 reversals. As in experiment 1, 29 subjects completed six test runs. Sixteen of those subjects completed two sets of six runs to provide a measure of test–retest reliability.
RESULTS
The spectral-ripple threshold
The spectral-ripple thresholds for each subject are shown in the upper panel of Figure 2. The mean threshold was 1.73 ripples/octave with a 95% confidence interval of ±0.34 ripples/octave. Large variability was observed among subjects, whose performance ranged from 0.60 to 4.87 ripples/octave. The lower panel of Figure 2 shows the distribution of spectral-ripple thresholds. The Lilliefors test (Lilliefors 1967) shows that the distribution was close to normal (p = 0.05).

The upper panel shows spectral-ripple thresholds for 31 subjects. Error bars represent ±95% confidence interval. The lower panel shows the distribution of mean spectral-ripple thresholds for 31 subjects.
Figure 3 shows the psychometric functions showing percent correct versus spectral-ripple threshold for S02, S10, and S35, representing poor, average, and good performers, respectively. As the ripple density increased, there was a monotonic decrease in the ability to discriminate the standard and inverted ripple stimuli. The psychometric functions were monotonic and close to linear on a logarithmic scale (from 0–80% correct), demonstrating that the use of an adaptive procedure using equal ratio steps of ripples per octave was appropriate. The lower ripple densities sometimes had large error bars (±1 SD) because they were visited only a few times.

Psychometric function of the performance for S02, S10, and S35. Error bars represent ±1 SD.
A one-way repeated-measures analysis of variance (ANOVA) (six repetition times) showed there was no effect of repetition number (F 5,150 = 0.21, p = 0.96), suggesting there was no learning over the course of the six repeated runs. A paired t test between the first and last threshold obtained in the test session supported this result, showing no significant learning effect between the first and sixth test run. The mean first threshold was 1.75 ripples/octave, and the mean sixth threshold was 1.76 ripples/octave (N = 31, p = 0.95).
Figure 4 shows the average thresholds of the first six repetitions plotted against the average thresholds of the second six repetitions for 20 subjects. The average of the first six was 1.77 ripples/octave, and the average of the second six was 1.87 ripples/octave. A paired t test revealed that there was no significant improvement between the first and second six repetitions (p = 0.36). The intraclass correlation between the thresholds from the first and second six repetitions was 0.89 (p = 0.00001), which reveals promising retest stability of the spectral-ripple test. Without one outlying point (the best performer), a paired t test showed that there was still no significant improvement between the first and second six repetitions (p = 0.41). Also, the intraclass coefficient was still 0.77 (p = 0.00002) without it.

Reliability of the spectral-ripple test. The relationship between the spectral-ripple thresholds determined by the first six repetitions and the second six repetitions for 20 subjects are shown. The dotted diagonal line represents y=x.
The SRT in noise
Mean SRT in two-talker babble was −6.81 dB (95% confidence interval of ±2.02 dB), and SRT in steady-state noise was −7.84 dB (95% confidence interval of ±1.70 dB). A 2 × 6, repeated-measures ANOVA (two noise backgrounds, six repetition times) demonstrated that there was an effect of repetition number (F 5,130 = 7.33, p = 0.0001), no effect of the noise background (F 1,26 = 3.21, p = 0.85), and no interaction between repetition number and noise background (F 5,130 = 1.72, p = 0.14). The Lilliefors test (Lilliefors 1967) shows that the distribution of SRTs is normal in steady-state noise (p = 0.001 for normality), but not in two-talker babble (p = 0.04 for non-normality), which showed a positive skew.
Sixteen subjects who completed two sets of six repetitions for the SRT in noise test showed a significant improvement in two-talker babble between the first and second six repetitions (the average of the first and second six repetitions was −7.18 and −9.49 dB SNR, respectively; mean difference = −2.31 dB SNR; 95% confidence interval = ±1.10 dB SNR; p = 0.0005), but only a trend in steady-state noise (the average of the first and second six repetitions was −7.77 and −8.69 dB SNR, respectively; mean difference = −0.92 dB SNR; 95% confidence interval = ±1.12 dB SNR; p = 0.10).
Figure 5 shows the mean threshold for SRTs in both types of noise as a function of trial number, calculating the mean at each repetition. There was a learning effect in SRT for two-talker babble from the 1st to 12th test runs. This effect was smaller, and in fact, not statistically significant for steady-state noise. Drennan et al. (2007) reported that normal-hearing listeners presented with vocoded speech using randomized temporal fine structure (a cochlear implant simulation with 100% randomization of fine structure) showed a similar greater learning effect with two-talker babble than with speech-shaped, steady-state noise, which is consistent with the present study.

Effects of learning for the speech perception in noise task. The figure shows mean SRTs as a function of trial number for spondees in two-talker babble and steady-state noise. Error bars show ±95% confidence interval based on data from 16 subjects.
Correlations
In Figure 6, the spectral-ripple threshold was correlated with performance on speech perception in two-talker babble (left panel) and steady-state noise (right panel) for 29 subjects (data from the first six repetitions for both tests). Significant negative correlations were found for both in two-talker babble (r = −0.55, p = 0.002) and in steady-state noise (r = −0.62, p = 0.0004). Without the best performer, significant correlations were still found between the spectral-ripple threshold and SRTs in two-talker babble (r = −0.53, p = 0.0038) and in steady-state noise (r = −0.57, p = 0.0015).

Spectral-ripple discrimination is correlated with speech perception in noise. The figure shows the relationship between the spectral-ripple thresholds and SRTs in two-talker babble (left panel) and steady-state noise (right panel) using data from the first six repetitions. Linear regressions are represented by the dotted lines.
A significant correlation was found between the ripple threshold and CNC word recognition score in quiet (r = 0.50, p = 0.009). Highly significant correlations were also found among the SRTs in both types of noise and CNC scores (for two-talker babble: r = −0.83, p = 0.00001 and for steady-state noise: r = −0.73, p = 0.0001).
There were no significant correlations between duration of implantation and either spectral-ripple threshold (r = −0.13, p = 0.47) or SRT in both types of noise (SRT in two-talker babble: r = 0.16, p = 0.41; SRT in steady-state noise: r = −0.03, p = 0.88). Also, there were no significant correlations between duration of hearing loss and either spectral-ripple threshold (r = −0.10, p = 0.62) or SRT in both types of noise (SRT in two-talker babble: r = 0.20, p = 0.31; SRT in steady-state noise: r = 0.19, p = 0.33).
DISCUSSION
The present study demonstrated a relationship between spectral resolving power and speech perception in noise for CI users. In both two-talker babble and steady-state noise, there was a negative correlation between the spectral-ripple threshold and SRTs in noise, showing that, as expected, CI users who had better spectral resolving power had better speech understanding in noise. Previous studies investigating relationships between speech perception in noise and spectral resolution in CI users showed that diminished frequency resolution, broad activation patterns, and the limited ability to fully utilize the spectral information provided affects speech perception in noise (Friesen et al. 2001; Fu et al. 1998; Fu and Nogaki 2005; Hong and Turner 2006; Litvak et al. 2006). All these previous studies suggest that reduced spectral resolution might contribute to reduced speech perception in noise in CI users. The present study confirms this hypothesis.
Henry et al. (2005) found a relationship between the spectral-ripple threshold and vowel and consonant recognition in quiet for normal-hearing, hearing-impaired, and CI subjects. Their CI subjects had spectral-ripple discrimination ability ranging from 0.13 to 1.66 ripples/octave. The spectral-ripple threshold of our CI subjects, excluding the best performer, ranged from 0.60 to 3.33 ripples/octave. These thresholds were better than Henry et al.’s previous results. There are two potential reasons for this difference: (1) We employed ripples which were sinusoidal in a decibel amplitude space, whereas Henry et al. used ripples which were sinusoidal in a linear amplitude space. Thus, the gaps between the ripple peaks were broader in our study, making the task easier (see Fig. 1); and (2) it is possible that our subjects, as a group, had better spectral resolution capabilities as they were, in general, highly successful users of cochlear implants, not necessarily a cross-section of the implanted population.
CI subjects in the present study showed lower SRTs (i.e., better speech perception ability) in steady-state noise than in two-talker babble (difference = 1.03 dB, p = 0.059), which is consistent with previous studies (Qin and Oxenham, 2003; Turner et al. 2004; Hong and Turner 2006). The spectra of two types of maskers were not matched, but they had similar spectra and equivalent overall level. In Qin and Oxenham (2003) study, normal-hearing listeners who were presented with cochlear implant simulations with 24, 8, and 4 channels showed lower SRTs in steady-state noise than in male single-talker masker by 1.9, 2.2, and 3.2 dB, respectively. Other than the unmatched spectra, there were a number of additional differences in methodology between our studies and those of Qin and Oxenham: (1) the present study used the same background noise trial to trial, whereas Qin and Oxenham used varying background noises; (2) the present study tested listeners for more repetitions, providing more opportunity for learning the background noise, hence the possibility of better performance with babble backgrounds; (3) the present study used two-talker interference but Qin and Oxenham used single-talker interference; and (4) the present study used spondees, single words, whereas Qin and Oxenham used HINT sentences for target speech.
As noted in the results, test–retest analysis revealed that the spectral-ripple test was reliable and does not show a significant learning effect. Only one out of 20 subjects who did two sets of six repetitions for the ripple test showed a significant improvement in the second six repetitions compared to the first six repetitions. A repeated-measures ANOVA demonstrated that there was no effect of repetition number (F 11,209 = 0.80, p = 0.64) throughout the 12 ripple test runs. These results suggest that the ripple test is a reliable test of spectral discrimination performance and further, as the test shows no learning, it is a potentially valuable tool for evaluation of spectral resolution ability as part of a clinical trial. The test has the added attraction that performance is correlated with speech recognition in quiet and in noise.
The SRT tests were also found to be reliable; however, some learning effects were observed. A repeated-measure ANOVA demonstrated that there was an effect of repetition number in two-talker babble (F 11,165 = 6.17, p = 0.0001), but not in steady-state noise (F 11,165 = 1.57, p = 0.11; see Figure 5). In evaluating the speech-in-noise results from a clinical point of view, as a test to evaluate clinically meaningful improvements for hearing in noise, the findings suggest that the speech in steady-state, speech-shaped noise would be a better test of performance because the learning effects are minimal. However, two-talker babble has the attractive feature of being a more realistic, cocktail-party-like background. Improvements of more than 2.5 dB from one set of six repetitions to the second set could be considered a meaningful clinical improvement, as the mean improvement from the first to the second set of six repetitions was 2.3 dB. More conservatively, a few subjects improved by 5 dB from the first to second sets, so a difference of 5 dB or greater would be clinically significant. We speculate further that if listeners heard 12 repetitions of speech in babble before receiving a treatment, additional improvements due to learning would be slight. Further study would be required to confirm this.
Because the SRT in babble improves over time, we speculated that stronger correlations might result from comparing the acute ripple threshold with more stabilized, chronic SRT data. Figure 7 shows that highly significant negative correlations were also found between the ripple threshold measured from the first six repetitions and SRTs in noise measured from the second six repetitions for 16 subjects (r = −0.74, p = 0.0009 for two-talker babble; r = −0.83, p = 0.0001 for steady-state noise). Without the best performer, significant correlations were still found between the spectral-ripple threshold and SRTs in two-talker babble (r = −0.61, p = 0.0165) and in steady-state noise (r = −0.72, p = 0.0023). This finding suggests the intriguing possibility that the ripple threshold could predict not only acute speech perception but also the longer-term performance on speech perception tasks after learning has occurred. The current study demonstrated that the CI user’s spectral resolving power measured by the ripple threshold test was significantly correlated with speech perception in quiet and in noise, suggesting that it would be a useful tool for clinical trials of CI performance with different signal processing strategies.

Spectral-ripple discrimination correlates well with speech perception in noise after more experience with the speech perception task. The figure shows the relationship between the spectral-ripple thresholds using data from the first six repetitions and SRTs in two-talker babble (left panel) and steady-state noise (right panel) using data from the second six repetitions. Linear regressions are represented by the dotted lines.
References
Bilger RC, Nuetzel JM, Rabinowitz WM, Rzeczkowski C. Standardization of a test of speech perception in noise. J. Speech. Hear. Res. 27:32–48, 1984.
Byrne D, Dillon H, Tran K, Arlinger S, et al. An international comparison of long-term average speech spectra. J. Acoust. Soc. Am. 96:2108–2120, 1994.
Donaldson GS, Nelson DA. Place-pitch sensitivity and its relation to consonant recognition by cochlear implant listeners using the MPEAK and SPEAK speech processing strategies. J. Acoust. Soc. Am. 107:1645–1658, 2000.
Dorman MF, Loizou PC. Speech intelligibility as a function of the number of channels of stimulation for normal-hearing listeners and patients with cochlear implants. Am. J. Otolaryngol. 18:113–114, 1997.
Dorman MF, Loizou PC. The identification of consonants and vowels by cochlear implant patients using a 6-channel Continuous Interleaved Sampling processor and by normal-hearing subjects using simulations of processors with two to nine channels. Ear Hear. 19:162–166, 1998.
Dorman MF, Loizou PC, Fitzke J, Tu Z. The recognition of sentences in noise by normal-hearing listeners using simulations of cochlear-implant signal processors with 6–20 channels. J. Acoust. Soc. Am. 104:3583–3585, 1998.
Drennan WR, Won JH, Dasika VK, Rubinstein JT. Effects of temporal fine-structure on the lateralization of speech and on speech understanding in noise. J. Assoc. Res. Otolaryngol. 2007.
Friesen LM, Shannon RV, Baskent D, Wang X. Speech recognition in noise as a function of the number of spectral channels: Comparison of acoustic hearing and cochlear implants. J. Acoust. Soc. Am. 110:1150–1163, 2001.
Fu QJ, Shannon RV, Wang X. Effects of noise and spectral resolution on vowel and consonant recognition: acoustic and electric hearing. J. Acoust. Soc. Am. 104:3586–3596, 1998.
Fu QJ, Nogaki G. Noise susceptibility of cochlear implant users: the role of spectral resolution and smearing. J Assoc. Res. Otolaryngol. 6:19–27, 2005.
Harris RW. Speech audiometry materials compact disk. Provo, UT, Brigham Young University, 1991.
Henry BA, McKay CM, McDermott HJ, Clark GM. The relationship between speech perception and electrode discrimination in cochlear implantees. J. Acoust. Soc. Am. 108:1269–1280, 2000.
Henry BA, Turner CW. The resolution of complex spectral patterns in cochlear implant and normal hearing listeners. J. Acoust. Soc. Am. 113:2861–2873, 2003.
Henry BA, Turner CW, Behrens A. Spectral peak resolution and speech recognition in quiet: normal hearing, hearing impaired, and cochlear implant listeners. J. Acoust. Soc. Am. 118:1111–1121, 2005.
Hong RS, Turner CW. Pure-tone auditory stream segregation and speech perception in noise in cochlear implant recipients. J. Acoust. Soc. Am. 120:360–374, 2006.
Leek M, Dorman M, Summerfield Q. Minimum spectral contrast for vowel identification by normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Am. 81:148–154, 1987.
Levitt H. Transformed up-down methods in psychoacoustics. J. Acoust. Soc. Am. 49:467–477, 1971.
Lilliefors H. On the Kolmogorov–Smirnov test for normality with mean and variance unknown. J. Am. Stat. Assoc. 62:399–402, 1967.
Litvak L, Spahr T, Saoji A, Fridman G. Relationship between perception of spectral ripple and speech recognition in cochlear implant and vocoder listeners. 29th Annual MidWinter Research Meeting of the ARO. 85, 2006.
Loizou PC, Poroy O. Minimum spectral contrast needed for vowel identification by normal hearing and cochlear implant listeners. J. Acoust. Soc. Am. 110:1619–1627, 2001.
Nelson DA, Van Tassell DJ, Schroder AC, Soli S, Levine S. Electrode ranking of place pitch and speech recognition in electrical hearing. J. Acoust. Soc. Am. 98:1987–1999, 1995.
Parikh G, Loizou PC. The influence of noise on vowel and consonant cues. J. Acoust. Soc. Am. 118:3874–3888, 2005.
Peterson G, Lehiste I. Revised CNC lists for auditory tests. J. Speech. Hear. Disord. 27:62–70, 1962.
Qin MK, Oxenham AJ. Effects of simulated cochlear-implant processing on speech reception in fluctuating maskers. J. Acoust. Soc. Am. 114:446–454, 2003.
Shannon RV, Zeng FG, Kamath V, Wygonski J, Ekelid M. Speech recognition with primarily temporal cues. Science. 270:303–304, 1995.
Supin AY, Popov VV, Milekhina ON, Tarakanov MB. Frequency resolving power measured by rippled noise. Hear. Res. 78:31–40, 1994.
Turner CW, Gantz BJ, Vidal C, Behrens A, Henry BA. Speech recognition in noise for cochlear implant listeners: benefits of residual acoustic hearing. J. Acoust. Soc. Am. 115:1729–1735, 2004.
Acknowledgments
The authors are grateful to the subjects for their dedicated efforts. This work was supported by NIH grants R01-DC007525 and P30-DC004661 and by the Cochlear Corporation. We also appreciate the assistance of Robby Kang, Jeff Longnion, Chad Ruffin, and Jonathan Kopelovich in data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Won, J.H., Drennan, W.R. & Rubinstein, J.T. Spectral-Ripple Resolution Correlates with Speech Reception in Noise in Cochlear Implant Users. JARO 8, 384–392 (2007). https://doi.org/10.1007/s10162-007-0085-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10162-007-0085-8