
Abstract
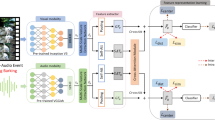
Existing research on audio–text retrieval is limited by the size of the dataset and the structure of the network, making it difficult to learn the ideal features of audio and text resulting in low retrieval accuracy. In this paper, we construct an audio–text retrieval model based on contrastive learning and collaborative attention mechanism. We first reduce model overfitting by implementing audio augmentation strategies including adding Gaussian noise, adjusting the pitch and changing the time shift. Additionally, we design a co-attentive mechanism module that the audio data and text data guide each other in feature learning, effectively capturing the connection between the audio modality and the text modality. Finally, we apply the contrastive learning methods between the augmented audio data and the original audio, allowing the model to effectively learn a richer set of audio features. The retrieval accuracy of our proposed model is significantly improved on publicly available datasets AudioCaps and Clotho.





Similar content being viewed by others


Data availability
The data that support the findings of this study are available on request from the corresponding author. The data are not publicly available due to privacy restrictions.
References
Jiang, Q.Y., Li, W. J.: Deep cross-modal hashing. In: Proceedings of the IEEE conference on computer vision and pattern recognition. (2017) p. 3232–3240.
Li, C., Deng, C., Li, N., et al.: Self-supervised adversarial hashing networks for cross-modal retrieval. Proceedings of the IEEE conference on computer vision and pattern recognition. 4242–4251 (2018)
Wu, L., Wang, Y., Shao, L.: Cycle-consistent deep generative hashing for cross-modal retrieval[J]. IEEE Trans. Image Process. 28(4), 1602–1612 (2018)
Yu, Y., Tang, S., Raposo, F., et al.: Deep cross-modal correlation learning for audio and lyrics in music retrieval. ACM Transact. Multimed. Comput. Commun. Appl. (TOMM) 15(1), 1–16 (2019)
Lou, S., Xu, X., Wu, M., et al.: Audio-Text Retrieval in Context. In: ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022: 4793–4797
Liu, J., Zhu, X., Liu, F., et al.: Opt: omni-perception pre-trainer for cross-modal understanding and generation. https://arxiv.org/abs/2107.00249, (2021)
Manco, I., Benetos, E., Quinton, E., et al.: Contrastive audio-language learning for music[J]. https://arxiv.org/abs/2208.12208, (2022)
Won, M., Oramas, S., Nieto, O., et al.: Multimodal metric learning for tag-based music retrieval. In: ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021: 591–595
Won, M., Salamon, J., Bryan, N. J., et al.: Emotion Embedding Spaces for Matching Music to Stories[J]. https://arxiv.org/abs/2111.13468, (2021)
Zhang, Hongli.: "Voice keyword retrieval method using attention mechanism and multimodal information fusion." Scientific Programming 2021 (2021)
Mei, X., Huang, Q., Liu, X., et al.: An encoder-decoder based audio captioning system with transfer and reinforcement learning. https://arxiv.org/abs/2108.02752, (2021)
Kuzminykh, I., Shevchuk, D., Shiaeles, S., et al.: Audio interval retrieval using convolutional neural networks. Internet of Things, Smart Spaces, and Next Generation Networks and Systems, pp. 229–240. Springer, Cham (2020)
Koepke, A. S., Oncescu, A. M., Henriques, J., et al.: Audio retrieval with natural language queries: A benchmark study. IEEE Transact on Multimedia, (2022)
Abel, A., Hussain, A.: Novel two-stage audiovisual speech filtering in noisy environments[J]. Cogn. Comput. 6(2), 200–217 (2014)
Almajai, I., Milner, B.: Visually derived wiener filters for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 19(6), 1642–1651 (2010)
Khan, M.S., Naqvi, S.M., Wang, W., et al.: Video-aided model-based source separation in real reverberant rooms. IEEE Trans. Audio Speech Lang. Process. 21(9), 1900–1912 (2013)
Liang, Y., Naqvi, S.M., Chambers, J.A.: Audio video based fast fixed-point independent vector analysis for multisource separation in a room environment[J]. EURASIP J. Adv. Sig. Process. 2012(1), 1–16 (2012)
Maganti, H.K., Gatica-Perez, D., McCowan, I.: Speech enhancement and recognition in meetings with an audio–visual sensor array[J]. IEEE Trans. Audio Speech Lang. Process. 15(8), 2257–2269 (2007)
Rivet, B., Girin, L., Jutten, C.: Mixing audiovisual speech processing and blind source separation for the extraction of speech signals from convolutive mixtures. IEEE Trans. Audio Speech Lang. Process. 15(1), 96–108 (2006)
Sadeghi, M., Alameda-Pineda, X.: Mixture of inference networks for VAE-based audio-visual speech enhancement. IEEE Trans. Signal Process. 69, 1899–1909 (2021)
Sadeghi, M., Alameda-Pineda, X.: Robust unsupervised audio-visual speech enhancement using a mixture of variational autoencoders. In: ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 7534–7538
Ideli, E.: Audio-visual speech processing using deep learning techniques. Applied Sciences: School of Engineering Science, (2019)
Ideli, E., Sharpe, B., Bajić, I. V., et al.: Visually assisted time-domain speech enhancement. 2019 IEEE global conference on signal and information processing (GlobalSIP). IEEE, 2019: 1–5
Adeel, A., Ahmad, J., Larijani, H., et al.: A novel real-time, lightweight chaotic-encryption scheme for next-generation audio-visual hearing aids. Cogn. Comput. 12(3), 589–601 (2020)
Adeel, A., Gogate, M., Hussain, A.: Towards next-generation lipreading driven hearing-aids: A preliminary prototype demo[C]//Proceedings of the International Workshop on Challenges in Hearing Assistive Technology (CHAT-2017), Stockholm, Sweden. 2017, 19
Afouras, T., Chung, J. S., Zisserman. A.: My lips are concealed: Audio-visual speech enhancement through obstructions[J]. https://arxiv.org/abs/1907.04975, (2019)
Arriandiaga, A., Morrone, G., Pasa, L., et al.: Audio-visual target speaker enhancement on multi-talker environment using event-driven cameras. In: 2021 IEEE International Symposium on Circuits and Systems (ISCAS). IEEE, 2021: 1–5
Wu, Z., Xiong, Y., Yu, S. X., et al.: Unsupervised feature learning via non-parametric instance discrimination. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 3733–3742
Ye, M., Zhang, X., Yuen, P. C., et al.: Unsupervised embedding learning via invariant and spreading instance feature. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6210–6219
Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding[J]. https://arxiv.org/abs/1807.03748, (2018)
Tian, Y., Krishnan, D., Isola, P.: Contrastive multiview coding. In: European conference on computer vision. Springer, Cham, 2020: 776–794
Jia, C., Yang, Y., Xia, Y., et al.: Scaling up visual and vision-language representation learning with noisy text supervision. In: International Conference on Machine Learning. PMLR, 2021: 4904–4916.
Li, J., Selvaraju, R., Gotmare, A., et al.: Align before fuse: Vision and language representation learning with momentum distillation. Adv. Neural. Inf. Process. Syst. 34, 9694–9705 (2021)
Wang, W., Bao, H., Dong, L., et al.: Vlmo: Unified vision-language pre-training with mixture-of-modality-experts[J]. https://arxiv.org/abs/2111.02358, (2021)
Shen, D., Zheng, M., Shen, Y., et al.: A simple but tough-to-beat data augmentation approach for natural language understanding and generation. arXiv preprint arXiv:2009.13818, (2020)
Fang, H., Wang, S., Zhou, M., et al.: Cert: Contrastive self-supervised learning for language understanding. https://arxiv.org/abs/2005.12766, (2020)
Wu, X., Gao, C., Zang, L., et al.: Esimcse: Enhanced sample building method for contrastive learning of unsupervised sentence embedding[J]. https://arxiv.org/abs/2109.04380, (2021)
Li, W., Gao, C., Niu, G., et al.: Unimo: Towards unified-modal understanding and generation via cross-modal contrastive learning[J]. https://arxiv.org/abs/2012.15409, (2020)
Zhang, H., Koh, J. Y., Baldridge, J., et al.: Cross-modal contrastive learning for text-to-image generation. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 833–842
Liu, J., Zhu, X., Liu, F., et al.: OPT: Omni-perception pre-trainer for cross-modal understanding and generation[J]. arXiv preprint arXiv:2107.00249, (2021)
Seo, P. H., Nagrani, A., Arnab, A., et al:. End-to-end generative pretraining for multimodal video captioning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 17959–17968
Guu, K., Lee, K., Tung, Z., et al.: REALM: Retrieval-Augmented Language Model Pre[J]. Training, 2020.
Mei, X., Liu, X., Sun, J., et al.: On Metric Learning for Audio-Text Cross-Modal Retrieval[J]. https://arxiv.org/abs/2203.15537, (2022)
Chen, T., Kornblith, S., Norouzi, M., et al.: A simple framework for contrastive learning of visual representations. In: International conference on machine learning. PMLR, 2020: 1597–1607
Kim, C. D., Kim, B., Lee, H., et al.: Audiocaps: Generating captions for audios in the wild. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 119–132
Drossos, K., Lipping, S., Virtanen, T.: Clotho: An audio captioning dataset[C]//ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020: 736–740
Bogolin, S. V., Croitoru. I., Jin, H., et al.: Cross modal retrieval with querybank normalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 5194–5205.
Funding
The research conducted in this paper was financially supported by a fund from Hunan Provincial Central South University of Forestry and Technology, with the fund project number being CX202202081.
Author information
Authors and Affiliations
Contributions
Tao Hu, Xuyu Xiang wrote the main manuscript text and Jiaohua Qin, Yun Tan provided experimental ideas. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Communicated by B. Bao.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Hu, T., Xiang, X., Qin, J. et al. Audio–text retrieval based on contrastive learning and collaborative attention mechanism. Multimedia Systems 29, 3625–3638 (2023). https://doi.org/10.1007/s00530-023-01144-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00530-023-01144-4