
Abstract
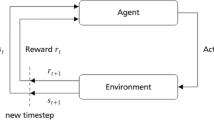
This study aims to develop a weight-adjustment scheme for a double exponentially weighted moving average (dEWMA) controller using deep reinforcement learning (DRL) techniques. Under the run-to-run control framework, the weight adjustment of the dEWMA is formulated as a Markovian decision process in which the candidate weights are viewed as the DRL agent’s decision action. Accordingly, a composite control strategy integrating DRL and dEWMA is proposed. Specifically, a well-trained DRL agent serves as an auxiliary controller that produces the preferred weights of the dEWMA. The optimized dEWMA serves as a master controller to provide a suitable recipe for the manufacturing process. Furthermore, two classical deterministic policy-gradient algorithms are leveraged for automatic weight tuning. The simulation results show that the proposed scheme outperforms existing RtR controllers in terms of disturbance rejection and target tracking. The proposed scheme has significant practical application prospects in smart semiconductor manufacturing.

















Similar content being viewed by others


Data availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
Espadinha-Cruz P, Godina R, Rodrigues EM (2021) A review of data mining applications in semiconductor manufacturing. Processes 9(2):305
Moyne J, Del Castillo E, Hurwitz AM (2018) Run-to-run control in semiconductor manufacturing, CRC press
Liu K, Chen Y, Zhang T, Tian S, Zhang X (2018) A survey of run-to-run control for batch processes. ISA Trans 83:107–125
Wang HY, Pan TH, Wong DS-H, Tan F (2019) An extended state observer-based run to run control for semiconductor manufacturing processes. IEEE Trans Semicond Manuf 32(2):154–162
Khakifirooz M, Chien C-F, Fathi M, Pardalos PM (2019) Minimax optimization for recipe management in high-mixed semiconductor lithography process. IEEE Trans Industr Inf 16(8):4975–4985
Fan S-KS, Jen C-H, Hsu C-Y, Liao Y-L (2020) A new double exponentially weighted moving average run-to-run control using a disturbance-accumulating strategy for mixed-product mode. IEEE Trans Autom Sci Eng 18(4):1846–1860
Zhong Z, Wang A, Kim H, Paynabar K, Shi J (2021) Adaptive cautious regularized run-to-run controller for lithography process. IEEE Trans Semicond Manuf 34(3):387–397
Tom M, Yun S, Wang H, Ou F, Orkoulas G, Christofides PD (2022) Machine learning-based run-to-run control of a spatial thermal atomic layer etching reactor. Comput Chem Eng 168:108044
Chen L, Chu L, Ge C, Zhang Y (2023) A general tool-based multi-product model for high-mixed production in semiconductor manufacturing. Int J Product Res 61(23):8062–8079. https://doi.org/10.1080/00207543.2022.2164088
Gong Q, Yang G, Pan C, Chen Y, Lee M (2017) Performance analysis of double EWMA controller under dynamic models with drift. IEEE Trans Components Pack Manuf Technol 7(5):806–814
Su C-T, Hsu C-C (2004) A time-varying weights tuning method of the double EWMA controller. Omega 32(6):473–480
Wu W, Maa C-Y (2011) Double EWMA controller using neural network-based tuning algorithm for mimo non-squared systems. J Process Control 21(4):564–572
Arulkumaran K, Deisenroth MP, Brundage M, Bharath AA (2017) Deep reinforcement learning: a brief survey. IEEE Signal Process Mag 34(6):26–38
Ziya T, Karakose M (2020) Comparative study for deep reinforcement learning with cnn, rnn, and lstm in autonomous navigation. In: 2020 International conference on data analytics for business and industry: way towards a sustainable economy (ICDABI), IEEE, pp. 1–5
Arena P, Fortuna L, Frasca M, Patané L (2009) Learning anticipation via spiking networks: application to navigation control. IEEE Trans Neural Networks 20(2):202–216
Tang G, Kumar N, Yoo R, Michmizos K (2021) Deep reinforcement learning with population-coded spiking neural network for continuous control. In: Conference on robot learning, PMLR, pp. 2016–2029
Song Z, Yang J, Mei X, Tao T, Xu M (2021) Deep reinforcement learning for permanent magnet synchronous motor speed control systems. Neural Comput Appl 33:5409–5418
Song D, Gan W, Yao P, Zang W, Qu X (2022) Surface path tracking method of autonomous surface underwater vehicle based on deep reinforcement learning. Neural Comput Appl 35:1–21
Spielberg S, Tulsyan A, Lawrence NP, Loewen PD, Bhushan Gopaluni R (2019) Toward self-driving processes: a deep reinforcement learning approach to control. AIChE Journal 65(10):e16689
Fujimoto S, Hoof H, Meger D (2018) Addressing function approximation error in actor-critic methods. In: International conference on machine learning, PMLR, pp. 1587–1596
Nian R, Liu J, Huang B (2020) A review on reinforcement learning: introduction and applications in industrial process control. Comput Chem Eng 139:106886
Dutta D, Upreti SR (2022) A survey and comparative evaluation of actor-critic methods in process control. Can J Chem Eng 100(9):2028–2056
Panzer M, Bender B (2022) Deep reinforcement learning in production systems: a systematic literature review. Int J Prod Res 60(13):4316–4341
Deng J, Sierla S, Sun J, Vyatkin V (2022) Reinforcement learning for industrial process control: a case study in flatness control in steel industry. Comput Ind 143:103748
Li C, Zheng P, Yin Y, Wang B, Wang L (2023) Deep reinforcement learning in smart manufacturing: a review and prospects. CIRP J Manuf Sci Technol 40:75–101
Gheisarnejad M, Khooban MH (2020) An intelligent non-integer PID controller-based deep reinforcement learning: Implementation and experimental results. IEEE Trans Industr Electron 68(4):3609–3618
Lawrence NP, Forbes MG, Loewen PD, McClement DG, Backström JU, Gopaluni RB (2022) Deep reinforcement learning with shallow controllers: an experimental application to PID tuning. Control Eng Pract 121:105046
Shalaby R, El-Hossainy M, Abo-Zalam B, Mahmoud TA (2023) Optimal fractional-order PID controller based on fractional-order actor-critic algorithm. Neural Comput Appl 35(3):2347–2380
Qin H, Tan P, Chen Z, Sun M, Sun Q (2022) Deep reinforcement learning based active disturbance rejection control for ship course control. Neurocomputing 484:99–108
Zheng Y, Tao J, Sun Q, Sun H, Chen Z, Sun M, Xie G (2022) Soft actor-critic based active disturbance rejection path following control for unmanned surface vessel under wind and wave disturbances. Ocean Eng 247:110631
Yu J, Guo P (2020) Run-to-run control of chemical mechanical polishing process based on deep reinforcement learning. IEEE Trans Semicond Manuf 33(3):454–465
Ma Z, Pan T (2021) A quota-ddpg controller for run-to-run control. In: China automation congress (CAC). IEEE 2021: 2515–2519
Ma Z, Pan T (2023) Distributional reinforcement learning for run-to-run control in semiconductor manufacturing processes. Neural Comput Appl 35:19337–19350. https://doi.org/10.1007/s00521-023-08760-1
Li Y, Du J, Jiang W (2021) Reinforcement learning for process control with application in semiconductor manufacturing. arXiv preprint arXiv:2110.11572
Ma Z, Pan T (2022) Adaptive weight tuning of EWMA controller via model-free deep reinforcement learning. IEEE Trans Semicond Manuf 36(1):91–99
Tseng S-T, Chen P-Y (2017) A generalized quasi-MMSE controller for run-to-run dynamic models. Technometrics 59(3):381–390
Castillo ED (1999) Long run and transient analysis of a double EWMA feedback controller. IIE Trans 31(12):1157–1169
Acknowledgements
This work was supported in part by National Natural Science Foundation of China (No. 62273002, No. 61873113).
Author information
Authors and Affiliations
Contributions
Zhu Ma was contributed to conceptualization, writing—original draft, software. Tianhong Pan was contributed to supervision, validation, resources, writing—review and editing.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
DDPG is a policy-based and augmented actor-critic algorithm that consolidates the advantages of the policy gradient and deep Q-network (DQN) algorithms. In contrast to TD3, only the critic network Q and target-critic network \(Q^{'}\) were used for the algorithm implementation.
Within minibatch N, the critic network was trained by minimizing the loss function \(L(\theta )\), denoted as
where \(Y_i=r_i(s_{i},a_{i})+\gamma {Q^{'}}(s_{i+1},a_{i+1}\mid {\theta ^{'}}))\).
In addition, the calculation of the target action can be expressed as \(a_{t+1}=\mu ^{'}(s_{t+1}\mid {\phi ^{'}})\).
When training DDPG-dEWMA, we adopted the same state, action, and reward as described in Sect. 3. The training procedure for DDPG-dEWMA is presented in Algorithm 3. Compared with the TD3-dEWMA scheme, there are differences only in the DRL agent, which are not described in detail here.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ma, Z., Pan, T. DRL-dEWMA: a composite framework for run-to-run control in the semiconductor manufacturing process. Neural Comput & Applic 36, 1429–1447 (2024). https://doi.org/10.1007/s00521-023-09112-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-023-09112-9