
Abstract
Evaluation of long-term temporal and spatial climatic change in mountainous regions is a critical challenge because of the interactive effects of multiple land and climatic factors and processes. Here we present the application of the statistical framework to the assessment of changes of climatic conditions, using data from 17 meteorological stations across the East River watershed near Crested Butte, Colorado, USA, and spanning the period from 1966 to 2021. The framework is developed based on (1) a time-series analysis of daily, monthly, and yearly averaged meteorological parameters (temperature, relative humidity, precipitation, wind speed, etc.), (2) evaluation and time series analysis of potential evapotranspiration (ETo), actual evapotranspiration (ET), aridity index (AI), standard precipitation index (SPI) and standard precipitation-evapotranspiration index (SPEI), and (3) a temporal-spatial climatic zonation of the studied area based on the hierarchical clustering and PCA analysis of the SPEI, because the SPEI can be considered an integrative characteristic of the changes of climatic conditions. The Budyko model, with the application of the Penman–Monteith equation for the estimation of ETo, was used to determine the ET. The time series analysis of the AI is used to identify the periods with energy limited and water limited conditions. Hierarchical clustering of site locations for the three temporal segments of the SPEI showed a significant temporal-spatial shifts, indicating that dynamic climatic processes drive zonation patterns. Therefore, the watershed climatic zonation requires periodic re-evaluation based on the structural time series analysis of meteorological and water balance data.
Similar content being viewed by others

1 Introduction
Evaluation of long-term temporal and spatial features of climatic change in mountainous regions is particularly challenging due to strong gradients in energy budgets, topographic complexity and heterogeneous soils and vegetation. This limits our ability to predict the consequences of global change for the ecology and ecosystem services of mountainous regions. Various meteorological (such as temperature and precipitation) and hydrological variables (such as evapotranspiration), as well as various drought indices, which are derived from meteorological and hydrological variables, are amongst the metrics used to characterize climatic changes. For example, to assess spatiotemporal drought variability, researchers commonly use such indices, as the Standardized Precipitation Index (SPI), the Standard Precipitation-Evapotranspiration Index (SPEI), the Compound Index (CI), the Z Index, the Palmer Drought Severity Index (PDSI), etc. (e.g., Bonaccorso et al. 2003; Vicente-Serrano et al. 2010; Beguería et al. 2014; Jiang et al. 2015; WHO 2016). These index values are indicators of the frequency of specific conditions across extended time-series. In this paper, we performed a statistical analysis of SPI and SPEI, but the developed approach is applicable for other climatic indices.
The SPI is a drought index that is used for estimating wet or dry conditions based on a single precipitation time series (McKee et al. 1993, 1995; Edwards and McKee 1997; Guttman 1998, 1999; Guenang and Kamga 2014). The SPI is expressed as a standard deviation that the observed precipitation would deviate from the long-term mean. The application of SPI relies on two assumptions: (a) the variability of precipitation is much greater than that of other variables, such as temperature or ETo, and (b) the other variables are effectively stationary, i.e., they have no pronounced temporal trend (Mckee et al. 1993). The SPI indicates the frequency of the precipitation value in the corresponding month as estimated from the entire precipitation record. The World Meteorological Organization (WMO) has recommended SPI as a starting point for meteorological drought monitoring (https://www.droughtmanagement.info/indices/). However, SPI cannot reflect how other meteorological parameters, such as temperature or relative humidity, interact with precipitation to influence drought characteristics.
The SPEI is generally an extension of the SPI, and has been formulated to capture the effect of the meteorological water balance given as the difference between precipitation and ETo time trends (Vicente-Serrano et al. 2010a,b). The Global SPEI database, SPEIbase, offers long-term, robust information about drought conditions at global scales, with a 0.5-degree spatial resolution and a monthly time resolution (Global SPEI database 2020). The SPEI can be used for determining the onset, duration and magnitude of drought conditions with respect to normal conditions across a variety of natural and managed systems, with time-scales between 1 and 48 months. Like other climatic indices, SPEI can be used to assess drought severity according to its intensity and duration, and can identify the onset and end of drought episodes. Statistical analysis showed that SPEI is more sensitive to drought assessment than SPI, and could more accurately reflect dry/wet alternations in complex regions (e.g., Stagge et al. 2014; Liu et al. 2021).
Taking into account the need to analyze the long-term temporal and spatial climatic changes in the mountainous area, the goal of this paper is to present a statistical framework to: (1) conduct a time-series analysis of meteorological parameters (air temperature, dewpoint temperature, relative humidity, precipitation, and wind speed), using the data for 17 locations of meteorological stations at the East River watershed, Colorado, USA, as a case study, (2) calculate and analyze time series of water balance parameters–potential evapotranspiration, aridity index, actual evapotranspiration, SPI and SPEI, and (3) perform a climatic zonation of the watershed area for different segments of the temporal trends SPEI, by means of the hierarchical k-means clustering and Principal Component Analysis.
The 17 locations of meteorological stations represent significant variance in energy (elevation/aspect), geologic and topographic complexity, subsurface properties, and vegetation, which influence the interactions between precipitation and ET and therefore provide a valuable test case to track the ability of these indices to define climatic zonation across a mountainous watershed. We analyzed the meteorological datasets for the period from 1966 to 2021.
The structure of the paper is as follows: Sect. 2 presents a description of the study area, the sources of meteorological data, and data used for calculations. Section 3 presents a flow chart of the statistical approach, the methods and equations used for calculations of the ETo, ET, AI, SPI and SPEI, as well as the approach used for the hierarchical cluster analysis and ordination. Section 4 includes (a) the results of the time-series analysis to assess the timings of breakthroughs, i.e., abrupt changes or shifts of meteorological and water balance parameters, (b) calculations of SPI and SPEI, and hierarchical clustering, i.e., subdivision/partitioning of meteorological stations. Section 5 includes conclusions and directions of future research.
2 Study area characterization and data used for calculations
2.1 Study area of the East River watershed
2.1.1 Location and topography
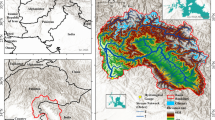
The study area is the East River watershed, which is a representative headwater basin in the Upper Colorado River Basin, Colorado, USA (Fig. 1). The watershed is located northeast of the town of Crested Butte, Colorado, and covers an area of ~ 300 km2 at an average elevation of 3266 m. The East River watershed is a typical example of watersheds in mountainous areas, with pronounced gradients in hydrology, geomorphology, biome type or life zone (montane, subalpine, alpine). A summary of geographic coordinates, types of the land cover at these locations, and elevations is given in Table 1, and locations of the meteorological stations will be shown on the maps given in Sect. 4.2 below. Detailed information about geological and hydrological conditions of the East River watershed can be found at https://watershed.lbl.gov/community-observatory/additional-site-information/. The East River watershed serves as a testbed for the US Department of Energy Watershed Function Scientific Focus Area, SFA (Hubbard et al. 2018; Community Watershed 2022), hosting 150 + investigators, conducting research in various fields of earth sciences, ecohydrogeology, climate and other scientific disciplines.

The location of the East River Watershed within the Colorado River basin
Figure 2 shows a barplot of the elevations of meteorological stations along with the photographs of three meteorological stations, Almont, representing the lowest elevation, Billy Barr–median elevation, and Mexican Cut–highest elevation. These three locations represent different climatic conditions within the East River watershed in terms of the elevation, a landcover, as well as temperature, precipitation, and other meteorological and water balance parameters, and were used to present typical results of calculations in the main body of the paper. The results of calculations for other locations are given in the attached Supplemental Information (SI).

Barplot of elevations of meteorological stations. Photographs of the meteorological stations, for which the plots are shown in the main body of the paper, are from https://watershed.lbl.gov/community-observatory/
2.1.2 Climate and biome zones
The East River watershed area is defined as having a continental, subarctic climate with long, cold winters and short, cool summers. Excursions in river discharge are driven primarily by snowmelt in late spring to early summer, with mid‐ to late‐summer monsoonal rainfall inducing rapid but punctuated increases in flow. The watershed comprises several biome zones–montane, subalpine, and alpine life zones, which collectively include aspen, meadow, mixed conifer, sagebrush, willow, grasses, sedges, and a diversity of forbs. The area is characterized by variable climatic conditions across the drainage watersheds, with quite variable rainfall and temperature. The watershed has a mean annual temperature of ∼0 °C, with average minimum and maximum temperatures of − 9.2 and 9.8 °C, respectively; winter and growing seasons are distinct and greatly influence the hydrology and biogeochemistry of the watershed. An average precipitation is 1200 mm yr−1, the majority of which falls as snow, which is typical for the Upper Colorado River Basin. A typical feature of the East River watershed is that air reaches the mountains, and then moves up the windward side of a mountain and cools. As a result, humidity increases and orographic clouds and precipitation can develop.
2.2 Data used for calculations
Meteorological datasets for the period from January 1966 to December 2021 were downloaded from two major climatic databases: (1) PRISM database (PRISM 2022), which is part of the Northwest Alliance for Computational Science and Engineering at the Oregon State University (the abbreviation PRISM stands for “Parameter-elevation Regressions on Independent Slopes Model), and (2) NOOA Reanalysis database (2022). These databases provide the most complete meteorological datasets, which were calculated using modern weather forecasting models and data assimilation.
The PRISM database was used to provide time series datasets of monthly precipitation, air temperature (minimum, mean, and maximum), vapor pressure deficit (minimum and maximum), and dewpoint temperature (mean) for the period from January 1966 to December 2021. The wind dataset for the same period (with a 3-h frequency) was downloaded from the NCEP/NCAR Reanalysis database with the application of the function “NCEP.gather” in the R package ‘RNCEP” (Kemp 2020). A function “NCEP.aggregate” of the package ‘RNCEP” was used to convert the 3-h time series of wind velocity into the monthly wind velocity. (The citations to the R packages that are central to this study are given at the end of the Reference list.)
Monthly data of relative humidity were calculated using the air temperature (Ta) and dewpoint temperature (Td), based on the formula given by (Alduchov and Eskridge 1996; Buck 1981; Lawrence 2005)
where air temperature and dewpoint temperature are given in °C, and RH is in percent.
3 Methods of data analysis
3.1 Workflow flowchart
The developed statistical framework of the data analysis includes a sequence of three main phases, which are summarized in the flowchart in Fig. 3. Phase I of the data analysis involves an exploration data analysis: plotting time trends of temperature, precipitation, and relative humidity, estimation of the time series structural breakpoints, basic statistics, and cumulative probability distribution functions; Phase II is concerned with calculations of ETo, ET, SPI, and SPEI; and Phase III includes hierarchical k-means cluster analysis of SPEI, averaging of the SPEI time trends for each cluster, and plotting hierarchical clustering trees-dendrograms and 2D PCA (PCA stands for Principal Component Analysis) maps, and zonation maps for periods before and after the time series breaks. Preparation of the datasets for calculations was conducted using the methods given in the paper by Faybishenko et al. (2022). Monthly data of all variables were converted to yearly averaged time series data using the function “apply.monthly” of the “xts” library in R (Ryan et al. 2020). This function is applied to non-overlapping time periods, such as monthly time series, and it is different from a rolling function in that it used to subset the data based on the specified time period (in this case it is the year), and returns a vector of values for each period in the original data. Other R libraries applied for data manipulation are: zoo (Zeileis and Grothendieck 2005) and dplyr (Wickham et al. 2021).

Flowchart of the statistical framework of three phases of the data analysis
3.2 Detecting breakpoints and segmentation of time series
In statistical studies, time series structural breaks (also termed change-points, or breakthrough points, or simply breakpoints) are commonly defined as unexpected (or sudden) changes over time, i.e., time series shifts (Antoch et al. 2019; Hansen 2001). We applied the strucchange package in R for analyzing time series for trend structural changes (Zeileis et al. 2002). The algorithms is based on the determination of the time series of structural changes, i.e., breakpoints or shifts, of time series based on the evaluation of the F-statistics (Chow test statistics), by means of assessing deviations in the classical linear regression model. In general, the algorithm for computing the optimal breakpoints given the number of breaks is based on a dynamic programming approach of Bellman's “principle of optimality." Details about the underlying theory can be found in Bai and Perron (2003), and Zeileis et al. (2010). The application of the function “breakpoints” of the strucchange package for the minimal number of observations from 150 to 200 days in each time series segment showed that both the residual sum of squares (RSS) and the Bayesian Information Criterion (BIC) function drop sharply up to 2 breakpoints (Figure SI-1, see Supplemental Information), indicating that the time series can be divided into three segments. The function “breakdate” is then used to determine the corresponding dates of the time series breakpoints, which were then converted to the POSIXct scale of time (Grolemund and Wickham 2011; Eddelbuettel 2020). The function “confint” is applied to determine the confidence intervals (CIs) of breakpoints. The breakpoints and their CIs are then visualized by vertical lines on time series plots given in Sect. 4 and plots in SI.
A comparison of the ranges of calculated parameters for different segments of time series of meteorological parameters and calculated ET, SPI, and SPEI are demonstrated in Sect. 4, using (a) box-and-whisker plots, (b) calculations of the Empirical Cumulative Distribution Functions, using the “ecdf” function of the library “stats” in R (R Core Team 2022), and (c) statistical Kolmogorov–Smirnov (KS) two-sample testing of “stats”. The KS test is a nonparametric statistical test for comparing two samples, based on the differences in both location and shape of the empirical cumulative distribution functions of the samples. The “ks.test “ function returns the test statistic and the p-value. The p-value < 0.05 is used to reject the null hypothesis that the time series before and after the break are drawn from the same continuous distribution.
3.3 Calculations of ETo, ET, SPI, and SPEI.
3.3.1 Calculations of ETo
Calculations of ETo were performed using Thornthwaite (1948), Hargreaves (1994), and Penman–Monteith (Allen et al. 1998) equations.
The Thornthwaite formula (1948) is given by
where Tmi is the average monthly temperature (oC); if the monthly averaged Tmi < 0, then ETo = 0; N is the number of days in the month being calculated, L is the average sunshine hours of the month (which was determined from the site latitude given in Table 1), the exponent a is determined from
with I being the Annual Heat Index given by
Thornthwaite equation is an empirical model, and is based on the assumption that temperature and radiation are correlated. However, over the course of a year, air temperature tends to lag behind radiation.
The Hargreaves formula is given by (Hargreaves and Allen 2003)
where Tm is monthly temperature (oC), and Rs is the global solar radiation at the land surface, given in the units of water evaporation, mm/day.
The Penman–Monteith (PM) equation is based on a combination of turbulent transfer and energy-balance models, and is given by
where ETo is the reference evapotranspiration (mm day−1), Rn is the net radiation (MJ m−2 day−1), G is the soil heat flux density (MJ m−2 day−1), T is air temperature at 2 m height (°C), u2 is wind speed at 2 m height (m s−1), es is saturation vapor pressure (kPa), ea is actual vapor pressure (kPa), (es—ea) is saturation vapor pressure deficit (kPa), \({\Delta }\) is slope of the vapor pressure curve (kPa °C−1), and γ is psychrometric constant (kPa °C−1).
Note that the Thornthwaite and Hargreaves equations are derived to calculate the potential evapotranspiration, which is the cumulative amount of evaporation and transpiration that would occur if a sufficient water source is available. The Penman–Monteith equation is used to calculate the reference evapotranspiration, which is the amount of evaporation and transpiration from a “reference surface,” i.e., a hypothetical grass surface. Calculations of ETo were provided using the library “SPEI” in R. The day length is determined using the function “DayLength” from the library “solrad” (Seyednasrollah 2018).
3.3.2 Calculations of ET using the Budyko model
Budyko (1974) hypothesized that a functional relationship between the actual evapotranspiration, ET, and the two climate variables—precipitation, P, and ETo is given by
where AI is the Aridity Index given by
The Budyko model is subject to the limiting conditions (Wang et al. 2016; Sposito 2017): under wet conditions, ET is energy limited by ETo, and under dry conditions, ET is water limited by P.
The Budyko equation provides a concise and accurate representation of the relationship between annual evapotranspiration and long-term-average water and energy balance at a catchment scale, and has achieved iconic status in soil and hydrological studies (Sposito 2017).
3.3.3 Calculations of SPI and SPEI
The first step in calculations of SPI and SPEI is to choose a particular probability distribution among several typical distributions for the precipitation P (for calculations of SPI) and the difference (P-ETo) used for calculations of SPEI. We tested the application of the gamma, Weibull, lognormal, and logistic distributions, and found that the gamma distribution fits best the long-term time series of both precipitation and the difference (P-ETo).
The SPI and SPEI are usually computed for different time scales, and expressed in units of the standard deviation. Positive SPI and SPEI values indicate wet conditions, and negative values indicate dry conditions (Lloyd-Hughes and Saunders 2002). Calculations of the SPI and SPEI were conducted using the time scale period of 12 months, with the application of the R library “SCI” (Gudmundsson and Stagge 2016).
3.4 Hierarchical k-means clustering analysis and mapping
A clustering analysis is generally provided to classify studied locations on the basis of a set of measured variables into a number of different groups such that similar locations are placed in the same group (Kaufman and Rousseeuw 1990; Maechler et al. 2021). Hierarchical clustering, which is one of the most popular modern clustering techniques, is aimed to build a hierarchy of clusters. The application of this technique is useful as it provides flexibility in selecting from the hierarchical tree (i.e., a dendrogram) how many clusters can be selected and/or how many elements of the studied system can be included in each cluster. In this paper, we applied a univariate clustering of the SPEI time series, assuming that the SPEI is a comprehensive measure of the climatic water balance of the studied area.
Hierarchical clustering is provided using the Hartigan and Wong algorithm (Hartigan and Wong 1979), with the application of the function ‘hkmeans’ in the R library ‘factoextra’ (Kassambara and Mundt 2020). The results are presented in the forms of the cluster dendrogram and the PCA plot for the three segments of SPEI time series, which are shown in Sect. 4.2. The optimal number of clusters was determined using the “elbow” method, using the function “kmeans” of the R package “stats.” Figure SI-2 shows that the optimal number of clusters is 5. The function “fviz_cluster” of the R package “factoextra” was used to visualize the results. Mapping was conducted with the application of the R libraries “ggmap,” “ggrepel,” and “ggplot2” (Kahle and Wickham 2013; Wickham 2016; Slowikowski 2021).
4 Results
4.1 Time series trends and structural breakpoints
4.1.1 Meteorological parameters
The temporal warming trends, structural breakpoints and their 95% CIs for Almont, Billy Barr and Mexican Cut locations are shown in Fig. 4, and for all other locations in SI-3. The corresponding boxplots are shown in Fig. 5, showing the minimum, lower-hinge (first quartile), median, upper-hinge (third quartile), and maximum of the temperature before and after the breaks. These results show that the median temperature of the 3rd segment in comparison with the 1st segment increased by 1.8 °C at Almont (from 3.3 to 5.1 °C), 1.6 °C at Billy Barr (from 0.5 to 2.5 °C), and 1.5 °C at Mexican Cut (from -0.8 to 0.7 °C).

Time series graphs of yearly (grey color) temperature for Almont, Billy Barr, and Mexican Cut meteorological stations, determined as a 12-month moving-window mean. Vertical solid lines indicate structural breakpoints, separating the temporal segments, and vertical dashed lines are the 95% CIs of breakpoints. Blue dashed lines are mean temperature for each temporal segment

Boxplots of yearly averaged temperature for Almont, Billy Barr, and Mexican Cut meteorological stations for the three time series segments
Figures 6 and 7 show that the precipitation increased in the 2nd segment following the decrease to the same (for Almont) or lower levels (Billy Barr and Mexican Cut) in the 3rd segment. The median precipitation dropped from the 2nd to the 3rd segment at Billy Barr by 306 mm/yr (from 1295 to 989 mm/yr) and at Mexican Cut even more significantly—by 530 mm/yr from 1816 to 1286 mm/yr. The same pattern of increasing and then decreasing precipitation was observed for all stations, except NRCS 1141, where precipitation dropped in the 2nd segment, and then again in the 3rd segment (Figure SI-4).

Time series graphs of yearly (grey color) precipitation for Almont, Billy Barr, and Mexican Cut meteorological stations, determined as a 12-month moving-window mean. Vertical solid lines indicate structural breakpoints, separating the temporal segments, and vertical dashed lines are the 95% CIs of breakpoints. Blue dashed lines are mean precipitation for each temporal segment

Boxplots of yearly averaged precipitation for Almont, Billy Barr, and Mexican Cut meteorological stations for the three time series segments
Based on the results of the two-sample KS test, the null hypothesis Ho that the temperature and precipitation trends for each pair of segments (i.e., for the 1st and 2nd segments, and the 2nd and 3rd segments) are from the same distribution can be rejected for all locations (Tables 2 and 3).
The graphs of the dewpoint temperature are the same for all locations: Td dropped in the 2nd segment compared to the 1st, and then increased to either the same or higher levels in the 3rd segment (Figures SI-5). Relative humidity decreased in the 3rd segment compared to the 1st segment at all locations (Figure SI-6).
4.1.2 Time series of ETo, AI, and ET
The ETo was calculated using the Thornthwaite, Hargreaves, and Penman–Monteith equations. For further calculations, we used the Penman–Monteith model that provides more reliable Eo, comparable with those determined from field observations by Tokunaga et al. (2016, 2019) and numerical CLM (Community Land Model) modeling by Tran et al. (2019). Graphs of the time series of ETo, which were calculated from the Penman–Monteith equation, depict the pattern of decreasing ETo in the 2nd segment, followed by the increase in the 3rd segment to the level above that in the 1st segment for all stations (Figure SI–7).
Figure 8 shows the time series graphs of AI for Almont, Billy Barr and Mexican Cut. On these plots, the horizontal lines of AI = 1 are separating the periods of limited energy (AI < 1) and periods of limited water (AI > 1). For example, at Almont, climatic conditions are characterized as water limited for the period from 1966 to 2021, at Billy Barr—as intermittent energy and water limited until 2011, and then mostly water limited, and Mexican Cut—as energy limited for the whole period from 1966 to 2021, with a few short periods of water limited. Figure SI-8 shows the calculated time series of AI for all locations.

Graphs of yearly averaged AI for Almont, Billy Barr, and Mexican Cut. Red color: AI > 1, which corresponds to water limited conditions, and green color: AI < 1, which corresponds to energy limited conditions. Vertical dashed lines are 95% CI around the breakpoints. Horizontal dashed blue lines are mean values of AI for each segment
The Budyko curve, i.e., the relationship of ET/P vs AI, with the points representing the yearly averaged ET/P vs AI for Almont, Billy Barr, and Mexican Cut, is shown in Fig. 9. The Almont points are located entirely within the water limited part of the Budyko curve; the Billy Barr points are within the energy limited part before the temporal break, and in the water limited part after the break; and the Mexican Cut points are mostly within the energy limited part with a few points in the water limited part of the Budyko curve.

The Budyko curve, i.e., the relationship of ET/P vs AI, with the points representing the yearly averaged ET/P vs AI for Almont, Billy Barr, and Mexican Cut
Figure 10 shows the time series graphs of ET for Almont, Billy Barr, and Mexican Cut, and Figure SI-9, the ET graphs for all locations. The graphs show that the temporal patterns of ET are the same for all stations: an increase in the 2nd segment compared to the 1st, followed by the decrease of ET in the 3rd segment practically to the same level as that in the 1st segment.

Graphs of yearly averaged ET (based on monthly data) for all meteorological stations, calculated from the Budyko model. Vertical dashed lines are 95% CI around the breakpoints. Horizontal dashed blue lines are mean values for each segment
4.1.3 SPEI and SPI time series
Figure 11 shows the time series of yearly averaged SPEI for Almont, Billy Barr and Mexican Cut, showing the shifts from wetted to drought climatic conditions. Figure SI-10 demonstrates the SPEI graphs for all locations, also indicating the shift from wetted conditions in the 2nd segment to drought conditions in the 3rd segment.

Graphs of yearly averaged SPEI (12-month averaged). Blue: wetted condtions, and red: drought conditions. Vertical dashed lines are 95% CI around the breakpoints. Horizontal dashed black horizontal lines are mean values for each segment
Time series plots of SPI are shown in Figure SI–11. A linear regression between SPEI and SPI for all locations is shown in Fig. 12, which illustrates the 95% confidence and 95% prediction intervals for the relationship SPEI = f(SPI). As expected, a prediction interval is wider than a confidence interval. Although the majority of the data points are beyond the 95% confidence interval, most of the points are within the 95% prediction interval. A prediction interval accounts for both the uncertainty in estimating the mean, plus random variations of the individual values. A prediction interval is an estimate of an interval in which a future observation will fall, with a certain probability, and this interval will not converge to a single value as the sample size increases.

Regression analysis of the relationship between SPEI and SPI, showing 95% confidence and 95% prediction intervals
4.2 Hierarchical clustering and zonation mapping
To reduce the effect of the high frequency fluctuations of the graphs of SPEI, hierarchical clustering was performed based on the cumulative distribution curves of SPEI for each of the three segments shown in Fig. 13. Figure 14 shows the results of the hierarchical clustering (left) and corresponding PCA plots for the three segments of SPEI time series for all locations. Based on the results of clustering, Fig. 15 shows the maps of the spatial zonation of meteorological stations. Figures 14 and 15 clearly indicate different clustering and zonation patterns for the three temporal segments. Table 4 lists the clusters for the three temporal segments of SPEI. This table indicates that 7 out 17 locations remained in the same cluster for all three segments, but combinations of the meteorological stations into the clusters are different for the three segments. Thus, the watershed climatic zonation requires periodic re-evaluation based on the results of the structural time series analysis.

Cumulative distribution curves of SPEI for the three segments of SPEI time series

Left: Hierarchical clustering, and right: PCA plots of the 17 locations for the three segments of SPEI time series

Maps of the areal zonation of meteorological stations for the three segments of SPEI time series
5 Conclusions
A statistical framework has been developed to assess long-term temporal and spatial variability of meteorological parameters (temperature, dewpoint, precipitation, relative humidity, and wind speed), as well as calculated time series of ETo, ET, SPI, and SPEI. Calculations were conducted for the period from 1966 to 2021 for 17 locations of meteorological stations located within the East River Watershed, Colorado, which is a typical watershed in the Upper Colorado River Basin.
The statistical analysis included the segmentation of meteorological and calculated time series datasets time series into three segments, based on the evaluation of structural breakpoints (i.e., shifts) of, and zonation of the studied locations by means of hierarchical and PCA clustering of the SPEI time series segments. Time series segmentation analysis and zonation demonstrate considerable changes in climatic conditions with time and space. The response to changing climate forcing is non-uniform across the watershed. A significant shift in the cluster arrangements for the temporal segments indicate that zonation patterns are driven by dynamic climatic processes, which are variable through time and space. Therefore, the watershed climatic zonation requires periodic re-evaluation based on the structural time series analysis of meteorological data.
Examples of directions of future research include the assessment of the redistribution of the water and energy limited regions across the East River watershed, a comparison of the time series breakpoints for different meteorological and water balance parameters, application of other programming languages, such as Python or MATLAB, and the application of the statistical framework to other watershed areas.
References
Alduchov OA, Eskridge RE (1996) Improved Magnus form approximation of vapor pressure. J Appl Meteorol Climatol 35(4):601–609
Allen RG, Pereira LS, Raes D, Smith M (1998) Crop evapotranspiration—guidelines for computing crop water requirements—FAO Irrigation and drainage paper 56. FAO, Rome (ISBN 92-5-104219-5)
Antoch J, Hanousek J, Horváth L, Hušková M, Wang S (2019) Structural breaks in panel data: large number of panels and short length time series. Economet Rev 38(7):828–855. https://doi.org/10.1080/07474938.2018.1454378
Bai J, Perron P (2003) Computation and analysis of multiple structural change models. J Appl Economet 18:1–22
Buck AL (1981) New equations for computing vapor pressure and enhancement factor. J Appl Meteorol 20(12):1527–1532
Community Watershed (2022) https://watershed.lbl.gov/community-observatory/. Accessed 9 Dec 2022
Global SPEI database (2020) https://spei.csic.es/database.html. Accessed 9 Dec 2022
Guenang GM, Kamga FM (2014) Computation of the standardized precipitation index (SPI) and its use to assess drought occurrences in cameroon over recent decades. J Appl Meteorol Climatol. https://doi.org/10.1175/JAMC-D-14-0032.1
Guttman NB (1999) accepting the standardized precipitation index: a calculation algorithm. J Am Water Resources Assoc 35(2):311–322
Guttman NB (1998) comparing the palmer drought index and the standardized precipitation index. J Am Water Resour Assoc 34(1):113–121
Edwards DC, McKee TB (1997) Characteristics of 20th century drought in the United States at multiple time scales. Climatology report no. 97-2, Colorado State Univ., Ft. Collins
Faybishenko B, Versteeg R, Pastorello G, Dwivedi D, Varadharajan C, Agarwal D (2022) Challenging problems of quality assurance and quality control (QA/QC) of meteorological time series data. Stoch Env Res Risk Assess 36:1049–1062
Hansen B (2001) The new econometrics of structural change: dating breaks in U.S. labour productivity. J Econ Perspect 15(4):117–128
Hargreaves GH (1994) Defining and using reference evapotranspiration. J Irrig Drain Eng 120:1132–1139
Hargreaves GH, Allen RG (2003) History and evaluation of Hargreaves evapotranspiration equation. J Irrig Drain Eng 129(1):53–63
Hubbard SS, Williams KH, Agarwal D, Banfield J, Beller H, Bouskill N, Brodie E, Carroll R, Dafflon B, Dwivedi D, Falco N, Faybishenko B, Maxwell R, Nico P, Steefel C, Steltzer H, Tokunaga T, Tran PA, Wainwright H, Varadharajan C (2018) The East River, Colorado, Watershed: a mountainous community testbed for improving predictive understanding of multiscale hydrological–biogeochemical dynamics. Vadose Zone J 17:180061. https://doi.org/10.2136/vzj2018.03.0061
Kaufman L, Rousseeuw P (1990) Finding groups in data: an introduction to cluster analysis. Wiley, New York
Lawrence MG (2005) The relationship between relative humidity and the dewpoint temperature in moist air: a simple conversion and applications. Bull Am Meteor Soc 86(2):225–233
Liu C, Yang C, Yang Q et al (2021) Spatiotemporal drought analysis by the standardized precipitation index (SPI) and standardized precipitation evapotranspiration index (SPEI) in Sichuan Province. China. Sci Rep 11:1280. https://doi.org/10.1038/s41598-020-80527-3
Lloyd-Hughes B, Saunders MA (2002) A drought climatology for Europe. Int J Climatol. https://doi.org/10.1002/joc.846
McKee TB, Doesken NJ, Kleist J (1995) Drought monitoring with multiple time scales. In: 9th conference on applied climatology. American Meteorological Society, Dallas, pp 233–236
McKee TB, Doesken NJ, Kleist J (1993) The relationship of drought frequency and duration of time scales. In: 8th conference on applied climatology. American Meteorological Society, Anaheim, pp 179–186
NOOA Reanalysis Database (2022) https://psl.noaa.gov/data/gridded/reanalysis/ and https://www.ecmwf.int/en/about/media-centre/focus/2020/fact-sheet-reanalysis). Accessed 9 Dec 2022
PRISM (2022) PRISM Climate Group, Oregon State University, https://prism.oregonstate.edu. Data created 4 Feb 2014. Accessed 12 Sep 2022
Stagge JH, Tallaksen LM, Xu C-Y, van Lanen HAJ (2014) Standardized precipitation-evapotranspiration index (SPEI): sensitivity to potential evapotranspiration model and parameters. In: Hydrology in a changing world: environmental and human dimensions, Proceedings of FRIEND-Water 2014, Montpellier, France, October 2014. IAHS Publ., p 363
Thornthwaite CW (1948) An approach toward a rational classification of climate. Geogr Rev 38:55–94. https://doi.org/10.2307/2107309
Tokunaga TK, Wan J, Williams KH, Brown W, Henderson A, Kim Y, Tran AP, Conrad ME, Markus B, Carroll RWH, Dong W, Xu Z, Lavy A, Gilbert B, Romero S, Christensen JN, Faybishenko B, Arora B, Siirila-Woodburn ER, Versteeg R, Raberg JH, Peterson JE, Hubbard SS (2019) Depth- and time-resolved distributions of snowmelt-driven hillslope subsurface flow and transport and their contributions to surface waters. Water Resour Res. https://doi.org/10.1029/2019WR025093
Tokunaga TK, Kim Y, Conrad ME, Bill M, Hobson C, Williams KH, Dong W, Wan J, Robbins MJ, Long PE, Faybishenko B, Christensen JN, Hubbard SS (2016) Deep vadose zone respiration contributions to carbon dioxide fluxes from a semiarid floodplain. Vadose Zone J. https://doi.org/10.2136/vzj2016.02.0014
Tran AP, Rungee J, Faybishenko B, Dafflon B, Hubbard SS (2019) Assessment of spatiotemporal variability of evapotranspiration and its governing factors in a mountainous watershed. Water 11(2):243. https://doi.org/10.3390/w11020243
Wang C, Wang S, Fu B (2016) Advances in hydrological modeling with the Budyko framework: a review. Prog Phys Geog 40:409–430
Zeileis A, Shah A, Patnaik I (2010) Testing, monitoring, and dating structural changes in exchange rate regimes. Comput Stat Data Anal 54(6):1696–1706. https://doi.org/10.1016/j.csda.2009.12.005
R software packages
Eddelbuettel D (2020) Anytime: anything to 'POSIXct' or 'Date' converter. R package version 0.3.9
Grolemund G, Wickham H (2011) Dates and times made easy with lubridate. J Stat Softw 40(3):1–25
Gudmundsson L, Stagge JH (2016) SCI: standardized climate indices such as SPI. SRI or SPEIR package version 1.0-2
Kahle D, Wickham H (2013) ggmap: spatial visualization with ggplot2. R J 5(1):144–161
Kassambara A, Mundt F (2020) factoextra: extract and visualize the results of multivariate data analyses. R package version 1.0.7
Kemp MU (2020) Package: RNCEP: Obtain, Organize, and Visualize NCEP Weather Data, Version: 1.0.1
Maechler M, Rousseeuw P, Struyf A, Hubert M, Hornik K (2021) cluster: cluster, analysis basics and extensions. R package version 2.1.2
R Core Team (2022) R: a language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. http://www.R-project.org/
Ryan JA, Ulrich J, Bennett R, Joy C (2020) xts: eXtensible Time Series, R package version: 0.12.1
Seyednasrollah B (2018) solrad: to calculate solar radiation and related variables based on location, time and topographical conditions. R package version 1.0.0
Slowikowski K (2021) ggrepel: automatically position non-overlapping text labels with 'ggplot2'. R package version 0.9.1
Wickham H (2016) ggplot2: elegant graphics for data analysis. Springer, New York
Wickham H, François R, Henry L, Müller K (2021) dplyr: a grammar of data manipulation. R package version 1.0.7
Zeileis A, Leisch F, Hornik K, Kleiber C (2002) strucchange: an R package for testing for structural change in linear regression models. J Stat Softw 7(2):1–38
Zeileis A, Grothendieck G (2005) zoo: S3 infrastructure for regular and irregular time series. J Stat Softw 14(6):1–27
Acknowledgements
The work was conducted as part of the Watershed Function Scientific Focus Area at Lawrence Berkeley National Laboratory, and was supported by the U.S. Department of Energy (DOE) Environmental Systems Science Program, DOE Office of Science, Office of Biological and Environmental Research, under Contract Number DE-AC02-05CH11231. Critical comments and suggestions of two autonomous reviewers are vey much appreciated.
Funding
The work was funded by the U.S. Department of Energy (DOE) Environmental Systems Science Program, DOE Office of Science, Office of Biological and Environmental Research, under Contract Number DE-AC02-05CH11231.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

{kind=link}
Cite this article
Faybishenko, B., Arora, B., Dwivedi, D. et al. Statistical framework to assess long-term spatio-temporal climate changes: East River mountainous watershed case study. Stoch Environ Res Risk Assess 37, 1303–1319 (2023). https://doi.org/10.1007/s00477-022-02327-7
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00477-022-02327-7