
Abstract
With the increase in the volume of climate model simulations for past, present and future climate, from various institutions across the globe, there is a need for efficient and robust methods for model comparison and/or evaluation. This manuscript discusses common empirical orthogonal function analysis with a step-wise algorithm, which can be used for the above objective. The method looks for simultaneous diagonalisation of several covariance matrices in a step-wise fashion ensuring thus simultaneous monotonic decrease of the eigenvalues in all groups, and allowing therefore for dimension reduction. The method is applied to a number of tropospheric and stratospheric fields from the main four reanalysis products, and also to several historical climate model simulations from CMIP6, the Coupled Model Intercomparison Project (Phase 6). Monthly means as well as winter daily gridded data are considered over the Northern Hemisphere. The method shows consistency between mass fields as well as mid-tropospheric and stratospheric fields of the reanalyses, but also reveals significant differences in the 2 m surface-air temperature in terms of explained variance. CMIP6 models, on the other hand, show differences reflected in the percentage of explained variance of the leading common EOFs with inter-group variation ranging from 5–10% in the troposphere to about 25% in the stratosphere. Higher order statistics within the leading common modes of variability, in addition to further merits of the method are also discussed.
Similar content being viewed by others

1 Introduction
Several reanalysis products are produced by a number of weather centres across the globe such as the National Center for Environmental Prediction (NCEP; Kalnay et al. 1996), European Centre for Medium Range Weather Forecasts (ECMWF) with its ERA5 (Hersbach et al. 2020) and ERA-Interim (ERAi; Dee et al. 2011), reanalyses, and Japan Meteorological Agency (JMA) with its Japanese Reanalysis (JRA55; Kobayashi et al. 2015). These reanalyses constitute a valuable database used in countless investigations such as forecasting/hindcasting experiments, climate analysis, and downscaling especially in poorly observed areas, e.g. the Sahara desert. Another equally important database is that of the CMIP6, the Coupled Model Intercomparison Project (Phase 6), produced by the World Climate Research Programme (WCRP). The objective of CMIP6 is to allow studies that can lead to a better understanding of past, present and future climate change resulting from natural or anthropogenic radiative forcing within a multimodel context.Footnote 1
The existence of such rich gridded databases call for the need to have a robust and efficient method to compare the reanalyses and/or CMIP6 model simulations and that helps towards model evaluation. In the climate research literature model evaluation is commonly studied using conventional empirical orthogonal function (EOF) method (Jolliffe 2002; Hannachi et al. 2007) to compare, e.g. the prominent modes of variability of different models. These EOFs and associated principal components (PCs) are model dependent making comparison difficult. In other investigations, such as the identification of forced response or climate change experiments, the researcher computes the EOFs of the models’ ensemble mean and then proceeds by projecting the individual models outputs onto these ‘mean’ EOFs, (e.g., Venzke et al. (1999)), which do not embed variability across the different members of the ensemble. In addition, the obtained time series resulting from the ‘mean’ EOFs are not near uncorrelatedness.
An alternative and robust method to address the problem described above is the common EOF method (Flury 1984), which is a generalization of PC analysis (Jolliffe 2002; Hannachi 2021) to two or more groups and attempts to simultaneously diagonalise several covariance matrices. Common EOFs provide a natural basis to compare models’ time series and their explained variance, and allow intuitive model evaluation, following various perspectives, e.g. linear and/or nonlinear. Apart from its usefulness in model comparison/evaluation, the common EOF method enjoys another advantage, namely the benefit of combining the information from all different groups compared to analysing individual groups separately or using ensemble mean EOFs. Common EOFs can also be applied to one sample, in which the groups represent different time periods (e.g., T-mode) allowing for investigation of the relative importance of the source of variation over time.
Notwithstanding its potentials, common EOF analysis was not given consideration in climate research. Basic methods such as those based on pairwise comparison were considered in the literature (e.g. Preisendorfer 1988; Bretherton et al. 1992). Other used methods include the projection onto the modes of variability of say observations (e.g. reanalyses). To the best of our knowledge only two studies considered common EOFs, which go back more than two decades (Frankignoul et al. 1995; Sengupta and Boyle 1998), which were based on the original Flury and Gautschi (1986) (FG86)’s algorithm. These studies, however, were limited in terms of size and capacity of the method. Frankignoul et al. (1995), for example, compared pairs of thermocline depth field, over the tropical Atlantic, between a given model and observations. Sengupta and Boyle (1998), on the other hand, compared NCEP reanalysis and five ECMWF Atmospheric Model Intercomparison Project (AMIP) simulations of 200 hPa monthly velocity potential. Due to limited computational resources, they had to truncate their field using spectral resolution of T10 in order to solve the problem. This is quite similar to using the dominant PCs (instead of the whole fields) prior to applying common EOFs, and this defies the objective of the common EOF method, which is to explore original or higher resolution gridded data.
The FG86 algorithm has two major drawbacks. Although the algorithm seems efficient for low dimension, it becomes extremely slow as the dimension of the problem increases. For example, with 5 groups and 100 variables the computational time of FG86 becomes prohibitively large (e.g. Browne and McNicholas 2014a; Pepler 2014). The other major drawback is related to the fact that the eigenvalues in different groups are not simultaneously decreasing. This makes common EOFs unsuitable for dimension reduction. Precisely, most available algorithms (e.g. De Lathauwer 2003; Browne and McNicholas 2014a, b) find common EOFs in an arbitrary order by focusing only on simultaneous diagonalisation, and are therefore not suitable for dimension reduction, which is a major common goal in data analysis, particularly for high dimensional problems as in weather and climate. This is because the estimated common eigenvectors do not have the same ranking in all groups regarding the accounted percentage of explained variance (e.g. Pepler 2014). We introduce common EOF method using a stepwise algorithm that simultaneously decreases the eigenvalues, and thereby overcoming the above drawbacks, and apply it to several reanalysis products and model simulations from CMIP6. Comparison to similar existing methods like for example the common basis function approach (Lee et al. 2019) or a distinct EOF analysis (Bayr and Dommenget 2014; Wang et al. 2015) and using coupled CMIP6 simulations goes beyond the scope of the present paper and is left for future research. The paper is organized as follows. Sections 2 and 3 describe respectively the methodology and data. Application to Reanalyses and 9 models from the AMIP simulations are given in Sect. 4. Section 5 discusses the results, and a summary and conclusion are given in the last section.
2 Methodology
2.1 Motivation
EOF analysis (Lorenz 1956; Jolliffe 2002; Hannachi 2007, 2021) finds an optimal decomposition of space-time fields into orthogonal spatial patterns (EOFs) and uncorrelated time series or PCs, using efficient algorithms such as the singular value decomposition, SVD, (Golub and van Loan 1996). In this context EOF analysis deals with one sample of data, i.e. one data matrix, hence the one sample method. Given a sample of n observations of p-dimensional variables, \(\mathbf{x}_t = (x_{t1}, \ldots , x_{tp})^T\), \(t=1, \ldots n\), assumed to be anomalies with respect to some background field, the \(n \times p\) data matrix \(\mathbf{X}\) is given by \(\mathbf{X}^T = \left[ \mathbf{x}_1, \ldots , \mathbf{x}_n \right]\), where \(\mathbf{x}^T\) denotes the transpose of \(\mathbf{x}\). The sample covariance matrix \(\mathbf{S}\) is then estimated by:
The diagonalisation of \(\mathbf{S}\), i.e. \(\mathbf{S}=\mathbf{E} {\varvec{\Lambda }}^2\mathbf{E}^T\), where \({\varvec{\Lambda }}^2 = diag( \lambda _1^2, \ldots , \lambda _p^2)\), yields the EOFs \(\mathbf{E}=[\mathbf{e}_1, ...,\mathbf{e}_p]\) and associated eigenvalues \(\lambda _1^2, \ldots , \lambda _p^2\).
With more than one covariance matrix the motivation is to find how much do these models share common modes of variability. In other words, we seek to identify common EOFs of several groups of datasets. These “common” EOFs simultaneously diagonalise the different covariance matrices, and with explained variances that depend on the indiviual matrices. The algorithm presented here is based on power iteration. It is an efficient stepwise algorithm that can find a (specified) limited number of common EOFs. The next two subsections introduce the algorithm, but readers who are unfamiliar with technical background can skip to the results section.
2.2 Common EOF analysis and the FG86 algorithm
We now assume we have m groups of data matrices \(\mathbf{X}_1, \ldots , \mathbf{X}_m\), with respective sample \(p \times p\) covariance matrices \(\mathbf{S}_1, \ldots , \mathbf{S}_m\). In application, interpolation may be used to yield same resolution of the data sets (see Sect. 3). The common EOF analysis looks for simultaneous (approximate) diagonalisation of those matrices, i.e.
where \(\mathbf{B} = \left[ \mathbf{b}_1, \ldots , \mathbf{b}_p \right]\) is the common \(p \times p\) orthonormal matrix of \(\mathbf{S}_k, k=1, \ldots m\), and \({\varvec{\Lambda }}_k^2 = diag ( \lambda _{k1}^2, \ldots , \lambda _{kp}^2)\), \(k=1,\ldots m\), are \(p \times p\) positive diagonal matrices. A simple interpretation of common EOFs is sketched in Fig. 1. The two samples are shown by filled ellipses along with their individual EOFs. The common EOFs provide directions that approximately diagonalise the respective covariance matrices (Fig. 1).

Schematic of a simple case illustrating the common EOF method (center) that combines information of two groups (left and right)

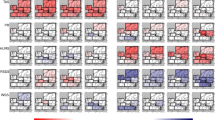
Leading two common EOFs, EOF1 (left) and EOF2 (right), of monthly T2m anomalies from the four reanalyses ERA5, ERAi, JRA55 and NCEP

Percentage of explained variance of the first 15 common modes of variability of monthly T2m from the analysis with the four reanalysis products ERA5, ERAi, JRA55 and NCEP

Leading two common modes of variability, EOF1 (top leftl) and EOF2 (top right) and a quantile-quantile plot of common EOF1 time series (bottom panel) of winter daily T2m from the four reanalyses

Percentage of explained variance of the leading 15 common EOFs of monthly Z500 anomalies from the CMIP6 models
In the original problem, Flury (1984, 1988) formulated the problem of common PC analysis based on normality assumption \(\mathcal{N}({\varvec{\mu }}_k, {\varvec{\Sigma }}_k)\), \(k=1, \ldots m\), of m p-variate random vectors, with the hypothesis \({\varvec{\Sigma }}_k = \mathbf{B} {\varvec{\Lambda }}_k^2 \mathbf{B}^T\), where \({\varvec{\Lambda }}_k\), \(k=1, \ldots m\), are diagonal matrices, and \(\mathbf{B}\) is an orthonormal matrix. Given the sample covariance matrices \(\mathbf{S}_1, \ldots , \mathbf{S}_m\), which follow a Wishart distribution (Chatfield and Collins 1980; Anderson 2003), the likelihood function can be shown to take the form:
where \(|\mathbf{A}|\) and \(\text{ tr }(\mathbf{A})\) stand respectively for the determinant and trace of the matrix \(\mathbf{A}\), and \(n_1, \ldots n_k\) are positive weights (taken to be 1 in most cases). The maximum likelihood was then used (Flury 1984, 1988) to obtain a basic system of equations satisfied by \(\mathbf{B}\) and \({\varvec{\Lambda }}_k^2\), \(k=1,\ldots m\):
In computational terms, Flury and Gautschi (1986, FG86) considered the following measure, (Hadamard’s inequality):
as deviation from diagonality, which is valid for positive definite symmetric matrices, see for example Noble and Daniel (1977), and proposed minimizing the function \(\prod _{k=1}^m \varphi ( \mathbf{B}^T \mathbf{S}_k \mathbf{B})\), that is:
The FG86 algorithm is based on a sequence of Jacobi diagonalzation and has two levels; an outer level (F-level) and an inner level (G-level). The F-level constructs a converging sequence of orthogonal matrices by minimizing Eq. (6) whereas the G-level solves iteratively Eq. (4). Whereas the algorithm was shown to converge, it gets very slow with increasing dimension. Another main criticism of FG86 is that the method focuses on simultaneous covariance matrices diagonalisation, but is not connected to dimensionality reduction (e.g. Schott 1988; Trendafilov 2010), a main goal of climate data analysis. This is because there is no guarantee the obtained eigenvalues are simultaneously ordered in all groups. This is important when comparing common EOFs’ time series, or investigating, e.g. the dynamics, e.g. probability density functions (PDFs) or flow regimes (Hannachi et al. 2017).
2.3 Stepwise algorithm
To overcome the above weaknesses we propose to use here the stepwise algorithm (Trendafilov 2010; Hannachi et al. 2006). The original formulation of common EOFs is based on a matrix optimization problem, e.g. the likelihood Eq. (3) (Flury 1984). This can be reformulated and cast into the following minimization problem:
If the eigenvalues are to decrease monotonically simultaneously in all groups the above matrix minimization problem is to be transformed into a vectorized form (Trendafilov 2010), and the j’th vector \(\mathbf{b}_j\) is then obtained by:
where \({\varvec{{{\mathcal {B}}}}}_{j-1} = [\mathbf{b}_1, \ldots \mathbf{b}_{j-1}]\) and \({\varvec{{{\mathcal {B}}}}}_0 = \mathbf{0}\). The procedure (Trendafilov 2010) is similar to the stepwise method applied to simplified EOFs (Hannachi et al. 2006), and is based on projecting the gradient of the objective function, Eq. (8), onto the orthogonal of the space spanned by the common EOFs identified in the previous step. Noting \(n = \sum _{k=1}^m n_k\), the optimality conditions of Eq. (8) yields the following set of equations:
for the first leading mode \(\mathbf{b}_1\), and for subsequent modes, i.e. for \(j=2, \ldots p\), we get:
Keeping in mind that \({\varvec{{{\mathcal {B}}}}}_0 =\mathbf{0}\), the above two equations can simply be written in one single compact form as:
for \(j=1, \ldots p\). These equations are then solved using a standard power method (Golub and van Loan 1996).
3 Data
The data considered in this paper consist of two sets. The first set is composed of reanalyses from four sources, namely the ERA5 and ERAi reanalyses, both produced by the ECMWF, the JRA55 reanalysis from the Japan Meteorological Agency (JMA) and the NCEP/NCAR reanalysis from the National Center for Environmental Prediction (NCEP). The data have been produced at different resolutions in time and space, namely hourly at T639 with 137 levels up to 0.01 hPa for ERA5, 6-hourly at TL255 resolution with 60 levels up to 0.1 hPa for ERAi, 3-hourly at TL319 with 60 levels up to 0.1 hPa for JRA55, and 6-hourly at T62 with 28 levels up to 3 hPa for NCEP/NCAR. Monthly mean and daily winter (December-January-February, DJF) data are considered for the period 1979–2018. The analysed fields include 2 m surface-air temperature (T2m), sea level pressure (SLP), 500 hPa (Z500) and 10 hPa (Z10) geopotential heights. The second set is composed of CMIP6 data. SLP, Z500 and Z10 (T2m is not provided) from 9 general circulation models (GCMs) from different modelling centres have been selected for the analysis. Table 1 provides a list of these models i’th more details. All simulations are taken from the historical AMIP experiment, which is an atmosphere only climate simulation that is initialised by historical sea surface temperature and sea ice concentration data (Eyring et al. 2016). The data are first restricted to the northern hemisphere and then bilinearily interpolated to a \(1.25^\circ \times 1.25^\circ\) latitude-longitude grid as a requirement in addition to consistency and easy comparison. The data are then further reduced by considering every other grid point, i.e. \(2.5^\circ \times 2.5^\circ\) north of \(20^\circ N\), and no area weighting was applied. Anomalies with respect to the monthly and daily seasonal cycle are obtained for monthly and DJF daily data respectively.
4 Results
4.1 Application to reanalysis data
Common EOFs of the 4 covariance matrices of the Reanalyses are determined. Figure 2 shows the leading two common EOFs of monthly mean T2m reanalyses. The leading common EOF shows mostly a monopole pattern characterised by large loadings over the Arctic, and small loadings over Europe and US. The second common EOF shows a dipole with centres located respectively over Northern Russia, stretching to Scandinavia and eastern Canada/Greenland. The associated percentage of explained variance shows an inter-group variation of 5 and 3% for the first and second common EOFs respectively (Table 2). This can also be seen in the scree plot for the four reanalysis datasets in Fig. 3. The error bar \(\lambda ^2 \pm \delta \lambda ^2\), estimated using the standard error due to sampling \(\delta \lambda ^2 = \lambda ^2 \sqrt{2/n}\) (e.g., (North et al. 1982)), are reported in Table 2. Overall, the leading eigenvalue is well separated from the rest of the spectrum. As the figure shows, the algorithm successfully extracts the eigenvalues, which decrease simultaneously monotonically in all groups. Interestingly, the resulted ranking of explained variance for common EOF1 across the reanalyses follows the models’ resolution. Low-ranked eigenvalues of the reanalyses (Fig. 3) tend to be barely distinguishable. High-order statistics can also be evaluated within the low-dimensional space spanned by the leading common EOFs. The skewness, indicating the distributions’ asymmetry around the mean value, varies between 0.2 (ERA5) to 0.6 (JRA55 and NCEP) and the excess kurtosis, providing information about distribution peakedness and outliers, is of the order 1.5 (see Table 2). For a sample size n, the variance of the sample skewness and kurtosis are given by \(\sigma ^2_{skew}=6n(n-1)/((n-2)(n+1)(n+3))\) and \(\sigma ^2_{kurt} = 4\sigma ^2_{skew} (n^2-1)/((n-3)(n+5))\), which can be approximated by 6/n and 24/n, respectively, for large n (e.g. Crawley 2015). For monthly data (\(n=480\)), the skewness of common EOF1 time series of ERAi, JRA55 and NCEP T2m are significant at more than \(1\%\) level, and at 5%w for ERA5, the excess kurtosis is positive (leptokurtic) and significant, reflecting peakedness of the probability distribution.

Leading two common EOFs, EOF1 (left) and EOF2 (right), of monthly Z500 anomalies of the CMIP6 models

Scree plot showing the percentage of explained variance of the leading 15 common EOFs of winter daily Z10 anomalies from the CMIP6 models

Leading two common EOFs, EOF1 (left) and EOF2 (right) of winter daily Z10 anomalies from the CMIP6 models

Scatter plot of the trajectory of winter daily Z10 anomalies for CES (a), Had (b), and MPI (c) models within the leading two common EOFs of the CMIP6 models

Quantile–quantile plot of common EOF1 time series of winter daily Z10 anomalies of CMIP6 ensemble means and ERA5
For the DJF daily T2m data the percentage of explained variance of common EOF1 has an inter-group variation of 5% and are all separated (Table 2). Figure 4 (top) shows the leading two common EOFs. Common EOF1 reflects a dipole with centres located over the Arctic and Siberia. The associated time series show a slight decreasing trend during the second half of the record. Common EOF2 shows an elongated centre over the Arctic, Greenland and Alaska, and two opposite centres sitting respectively over Canada and Eurasia, plus another small centre over East Asia. These centres of action occur mostly over northern land masses, which control the T2m. The skewness becomes more prominent compared to monthly data, particularly for the leading mode for all reanalyses (see Table 2). The excess kurtosis associated with common EOF1 is positive and significant, but non-significant (i.e. mesokurtic) for common EOF2. The leptokurtic distributions have fatter tails than the Gaussian and yield greater probability of extremes. These results are summarized by a quantile-quantile (QQ) plot shown in Fig. 4 (bottom) for the 4 reanalysis products. The negative skewness is reflected by the deviation of the left side of the curves below the diagonal line. Note that the deviation below the diagonal line of the right side of the curves indicates thinner (right) tail than the normal distribution (see, e.g. Hannachi et al. 2003).
For the SLP, Z500 and Z10 anomalies, the difference between the four reanalysis products is minimal for both monthly and winter daily time scales (not shown). The eigenvalues and associated time series are quite comparable. The leading common EOF of SLP anomalies, for example, reflects the standard Arctic Oscillation, AO (Thompson and Wallace 1998). The AO pattern becomes more prominent with Z500 anomalies, and with Z10 anomalies one gets the conventional AO with one single (nearly) zonally symmetric centre over the polar region representing the variability of the stratospheric polar vortex. The second mode of Z10 shows a dipole sitting over Scandinavia and Western Canada/Alaska (e.g. Iqbal et al. 2019). The two leading patterns of Z10 explain respectively around 68 and 13% of monthly variability, and are significantly skewed and strongly leptokurtic, favouring thus a weaker polar vortex and vortex displacement over western Canada/Alaska relating to sudden stratospheric warming (SSW). On winter daily time scales the two leading patterns explain about 56 and 17% respectively. They are also significantly skewed, and the four time series associated with the leading pattern are mesokurtic, and significant negative excess kurtosis is observed with the second pattern.

Percentage of explained variance of the leading 15 common EOFs of the reanalyses monthly SLP anomalies, along with the same percentages obtained using conventional EOF analysis of individual (reanalyses) SLP anomalies. Notice the large change obtained with common EOF analysis compared to those obtained from EOF analysis

As in Fig. 11, but for CMIP6 monthly SLP anomalies derived using EOF (a) and common EOF (b) analyses

Common EOF analysis in T-mode applied to ERA5 T2m, SLP, Z500 and Z10 anomalies showing the leading common PC (top) and the associated patterns of T2m (middle left), SLP (middle right), Z500 (bottom left) and Z10 (bottom right) anomalies
4.2 Application to CMIP6 data
All but two models (GFDL, INM) have more than one ensemble member. We have investigated both the ensemble mean and ensemble members by (randomly) choosing one ensemble member from each of the 7 models. Note that the Z500 of Had and ACCESS are not defined in many locations as the pressure surface crosses high mountains.
For monthly SLP anomalies of the ensemble mean, the percentage of explained variance associated with the leading common EOF, has an inter-group variation of about 10%, with the largest value obtained with MPI (44%) and the smallest with MIR (35%). Common EOF1 (not shown) represents the AO, and common EOF2 has a main centre located over the North Pacific, with an inter-group variation of percentage of explained variance of 10%. Only MPI and Had show significant skewness of the time series of common EOF1. All models, however, show positive excess kurtosis. The results from the common EOF analysis based on ensemble members are similar to those of the ensemble mean in various aspects. Only two models (ACCESS and MPI) show significant skewness of common EOF1 time series.
For Z500 the largest difference in the percentage of explained variance is also obtained with common EOF1 (Fig. 5), with an inter-group variation of 7%. Except for few exceptions it is interesting that there is a tendency for higher resolved models to explain more variance in the first mode. Figure 6 shows the leading two common EOFs of monthly Z500 anomalies. Common EOF1 describes also the AO pattern with a weakened North Atlantic centre, which is shifted over western Europe whereas common EOF2 projects onto the Pacific North America (PNA) pattern (Wallace and Gutzler 1981). The two leading modes show significant skewness only with ESM and MIR. The excess kurtosis of the leading common mode is largely positive for all models.
For stratospheric monthly time scales, the inter-group variation of the percentage of explained variance of Z10 common EOF1 has increased significantly reaching 15%. Common EOF1 shows a anomaly center over the polar region whereas common EOF2 displays a dipole over Eurasia and Canada (not shown). For the ensemble members the inter-group variation of explained variance for common EOF1 varies within a range of about 20%, with the largest value (about 71%) obtained with ESM, and the smallest (around 52%) with GFDL. The skewness is not uniform across the models. For the ensemble mean all models show significant positive skewness of common EOF1, and the models’ distributions are again significantly leptokurtic. Note also that for the leading common pattern of the ensemble members, skewness is significantly positive for all models except MPI, which yields a stronger polar vortex compared to the other models.
For tropospheric DJF daily data, SLP and Z500 common EOF1 project onto the AO. Z500 common EOF2 projects onto the PNA, and for SLP it shows a tripole with centres located respectively over western Canada/Aleutian, Scandinavia/Russia and the Mediterranean (not shown). Table 3 shows the percentage of explained variance of the leading two common EOFs along with their skewness and kurtosis based on an ensemble member of each model for SLP and Z500 anomalies. For example, whereas monthly fields show largely leptokurtic structure (peaked distribution), the daily data shifts to more platykurtic structure. Notice the significant skewness of Z500, and the negative excess kurtosis for most models. Negative excess kurtosis, in particular, may provide support for nonlinear regime behaviour (Sura and Hannachi 2015; Hannachi 2010).
In the winter stratosphere, the difference across daily data is more prominent in terms of both the percentage of explained variance and the significance of high order statistics. Table 4 is like Table 3, but for Z10 anomalies, for both ensemble mean and ensemble members. Figure 7 shows a scree plot of Z10 anomalies based on ensemble members. The range of inter-group variation of explained variance of common EOF1 is about 20% for the ensemble mean and 25% for the ensemble member analysis. Figure 8 shows the obtained leading two common EOFs of Z10 anomalies showing respectively a positive AO and a dipole located over Eurasia and North America. Notice, in particular, that most models show highly significant skewness and negative excess kurtosis (Table 4). CES, Had, and MPI show particularly large negative excess kurtosis for both the leading two common EOFs, in addition to their skewness. In particular, the positive skewness, as seen in the ensemble mean, reflects excursions towards a weaker polar vortex exemplified by SSW also reflected by the negative excess kurtosis (e.g. Christiansen 2009). Note also that the significant skewness of common EOF2 (Fig. 8) in some models (e.g. ACCESS, ESM, Had) means preference for vortex displacement over Canada (e.g Hannachi et al. 2011). Figure 9 shows scatter plots of the time series of the leading two common modes of variability of Z10 anomalies. These scatter plots largely show the strong non-Gaussian character with particular flatness of the PDF, also associated with the nonlinear behaviour of the winter stratospheric polar vortex.
4.3 Case of reanalysis-CMIP6 data
Lastly, we have also compared the reanalysis and CMIP6 data, and we only discuss the case with ERA5 for conciseness. On monthly time scales, for example, the application of common EOFs to ERA5 and CMIP6 Z500 anomalies yields the AO as the leading common mode of variability, and PNA as the common EOF2 (not shown). The range of inter-group variation of the percentage of explained variance is about 8 and 5% for common EOF1 and EOF2, respectively. These are larger than those obtained with the CMIP6 models only. Only two models show significant skewness (ESM, MIR) of the leading common mode of variability, and all models are highly and coherently leptokurtic. On winter daily time scales, the range of inter-group variation of the percentage of explained variance of the leading common EOFs goes from 10% in the troposphere to about 25% in the stratosphere. In terms of hogh-order statistics of Z10 anomalies some models show stronger skewness (e.g. Had, ESM, GFDL) and excess kurtosis (e.g., ACCESS, MIR, MPI) than ERA5. A quantile-quantile plot of common EOF1 time series of winter daily Z10 anomalies from the ensemble mean CMIP6 models and ERA5 is shown in Fig. 10. The positive skewness is now reflected by the deviation of the right side of the curves above the diagonal line. Note, in particular, the strong skewness of Had and ESM models with large positive extremes. ERA5 has also large skewness but with less outliers.
5 Discussion
The application of common EOFs to Reanalyses show great degree of coherence of large-scale flow over the period 1979-2018 as shown from the common EOFs and associated PCs of the mass field, mid-tropospheric and stratospheric geopotential heights. The largest (smallest) explained variance of common EOF1 are obtained with NCEP (ERA5). Differences, however, are observed in the explained variance between the Reanalyses in the T2m, for which the inter-group variation of the percentage of explained variance is about 5%, a significant amount, particularly for winter daily time scales. Differences across the Reanalyses are suggested to result from the data assimilation scheme and the parametrization of the land-surface processes. The leading mode of DJF daily T2m has a dipole structure over the Arctic and Siberia. The associated time series exhibit a slight decreasing trend for all four reanalysis fields during the second half of the record reflecting a slight warming over the Arctic and cooling over Siberia. Panagiatopoulos et al. (2005) found, using station-based observations over Siberia, a decreasing trend of the Siberian high index between late 1970’s and 2000. However, the Siberian high has witnessed fast recovery starting around mid 1990s (Jeong et al. 2011). Also, Li et al. (2020) showed that Eurasian temperatures in the fall witnessed significant cooling over the period 2004–2018, associated with strengthening of the Pacific Decadal Oscillation and Siberian high.
The CMIP6 models show varying degrees of differences. In the troposphere the inter-group percentage of explained variance varies within a range of 5% mostly with the few leading common modes of variability based on SLP and Z500 anomalies. The common leading mode reflects the AO whereas the second mode reflects in general a PNA (with Z500) or a Pacific mode (with SLP). The largest difference in the percentage of explained variance takes place in the stratosphere, with a inter-group variation going from 15% for monthly time series to about 25% for winter daily data. The leading common mode of variability shows a clear polar center reflecting the variability of the polar vortex whereas the second mode has a dipole with centres of action located respectively over Russia/Scandinavia and North America. High-order statistics of the obtained time series have also been analysed. The winter daily T2m from reanalysis shows large negative skewness, indicating a tendency towards warmer Arctic and colder Siberia (e.g. Li et al. 2020). For the CMIP6 models, on monthly time scales, the simulations have varying degrees of skewness, with tendency for large amplitude of \(-AO\) (MPI, Had), and most models show large positive excess kurtosis. For Z10 this tends to favour weaker polar vortex, except for MIR and MPI models, which have positive but weak skewness.
On daily time scales, the outstanding feature is the change of kurtosis for several models. The excess kurtosis of SLP and Z500 anomalies, are negative for the leading two common EOFs for several models. Few models show positive excess kurtosis (CES, GFDL). Positive excess kurtosis combined with skewness is contingent with high probability of extremes. Negative excess kurtosis may provide support for nonlinear regimes. This is also the case for daily winter Z10 anomalies. The CES, Had and MPI models stand out with a particularly robust negative excess kurtosis. A preliminary investigation of clustering within the leading two common EOFs using gap statistics (Tibshirani et al. 2001; Hannachi et al. 2011), reveals clustering with a number of clusters between 2 and 3. Further results, however, go beyond the scope of this paper and are left for future research.
Lastly, further merits of the method are worth mentioning. For example, an interesting feature of the method is the structure of the obtained spectra. Figure 11 shows examples of scree plots of SLP anomalies from the reanalyses obtained using both common and conventional EOFs. The common EOF spectra show a clear jump/break or ‘elbow’, where the values change abruptly from around 40% to about 10%, then a different rate of decrease afterwards. An elbow in the spectra is quite useful in the analysis. It helps towards physical interpretation, and also suggests a guideline for truncation or dimension reduction (Hannachi 2007). For example, here the analysis suggests that the leading one or two commom EOFs are the most sensible common modes of variability. Note, however, that this is less prominent in the conventional EOF analysis (Fig. 11). This feature carries over to the CMIP6 models (Fig. 12). Moreover, as the formulation involves a logarithm (Eq. 8), the method can be applied to fields with different scalings, which are absorbed by the diagonal matrices (Eq. 2). Common EOFs can also be used in the T-mode, rather like canonical covariance analysis (Bretherton et al. 1992; Wallace et al. 1992). This is demonstrated by Fig. 13, showing the leading common PC and associated patterns of monthly ERA5 T2m, SLP, Z500 and Z10 anomalies. It is interesting that the pattern of T2m (Fig. 13) associates, not with common T2m EOF1 but with common EOF2 (Fig. 2). The T2m pattern is associated more with the North Atlantic Oscillation, NAO, (Stendel et al. 2016) (Fig. 13, middle right and bottom left), and with the AO (polar vortex slightly shifted towards Siberia) with a slight dipolar structure with the weaker centre located over western Canada/North Pacific (Fig. 13, bottom right). The common PC (Fig. 13, top) has positive skewness (significant at 15% level) and is highly leptokurtic, i.e. extreme events are associated favourably with negative NAO and a weakening of the polar vortex (associated with SSW), which is concomitant with warming over Canadian Arctic Archipelago and Greenland, and cooling over northern Eurasia (Fig. 13).
6 Summary and conclusion
The volume of climate data including Reanalyses and model simulations is witnessing an unprecedented increase begging for efficient tools of analyses and evaluation. We presented here common EOF method and applied it to Reanalyses and CMIP6 simulations. The approach is based on a step-wise algorithm seeking simultaneous diagonalisation of multiple covariance matrices. Unlike the Jacobi diagonalization of FG86, our method uses a fast/economic power iteration, which can find a limited number of eigenelements helping thus towards dimension reduction. Beside its usefullness in the T-mode application, the method can also be applied to fields with different scaling.
The application to the data reveals differences in various aspects, but also agreement in others. Whereas the large scale mass field and upper air geopotential height fields are quite consistent between the reanalysis products, the T2m fields do differ following the leading common EOF pattern. The leading (DJF daily) T2m common mode of variability shows highly significant skewness for all Reanalyses varying between about \(-0.8\) (JRA55) and \(-0.4\) (NCEP) concurrent with extreme warm and cold temperatures over the polar region and Siberia respectively. The CMIP6 models commonly identify the AO as the leading mode of variability for the mass and height fields and the PNA as the second common EOF of Z500. Unlike the Reanalyses, the AMIP models show large inter-group variation of the percentage of explained variance (up to 25%) in the stratosphere. This may be explained by the differences in resolving the upper atmosphere. Large variation is also observed in the high-order statistics also mainly in the Z10 field. The T-mode application suggests a link between a dipolar structure of T2m (opposite polarity between Greenland/Canadian Archipellago and northern Eurasia/Siberia), the NAO and the polar vortex.
Data availability
Enquiries about data availability should be directed to the authors.
References
Anderson TW (2003) An introduction to multivariate statistical analysis, 3rd edn. Whiley Interscience, New York, p 747
Bayr T, Dommenget D (2014) Comparing the spatial structure of variability in two datasets against each other on the basis of EOF-modes. Clim Dyn 42:1631–1648. https://doi.org/10.1007/s00382-013-1708-x
Bretherton CS, Smith C, Wallace JM (1992) An intercomparison of methods for finding coupled patterns in climate data. J Clim 5:541–560. https://doi.org/10.1175/1520-0442(1992)005<0541:AIOMFF>2.0.CO;2
Browne RP, McNicholas PD (2014a) Estimating common principal components in high dimensions. Adv Data Anal Classif 8:217–226. https://doi.org/10.1007/s11634-013-0139-1
Browne RP, McNicholas PD (2014b) Orthogonal Stiefel manifold optimization for eigen-decomposed covariance parameter estimation in mixture models. Stat Comput 24:203–210. https://doi.org/10.1007/s11222-012-9364-2
Chatfield C, Collins AJ (1980) Introduction to multivariate analysis. Springer, Berlin, p 249
Christiansen B (2009) Is the atmosphere interesting? A projection pursuit study of the circulation in the northern hemisphere winter. J Clim 22:1239–1254. https://doi.org/10.1175/2008JCLI2633.1
Crawley MJ (2015) Statistics: an introduction using R, 2nd edn. Wiley, New York, p 357
Danabasoglu G (2019) NCAR CESM2-WACCM model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.10041. version = 20190220
De Lathauwer L (2003) Simultaneous matrix diagonalization: the overcomplete case. ICA 03. In: Fourth international symposium on independent component analysis and blind signal separation, Nara, Japan, pp 821–825
Dee DP, Uppala SM, Simmons AJ, Berrisford P, Poli P, Kobayashi S, Andrae U, Balmaseda MA, Balsamo G, Bauer P, Bechtold P, Beljaars ACM, van de Berg L, Bidlot J, Bormann N, Delsol C, Dragani R, Fuentes M, Geer AJ, Haimberger L, Healy SB, Hersbach H, Hólm EV, Isaksen L, Kållberg P, Köhler M, Matricardi M, McNally AP, Monge-Sanz BM, Morcrette JJ, Park BK, Peubey C, de Rosnay P, Tavolato C, Thépaut JN, Vitart F (2011) The ERA-Interim reanalysis: configuration and performance of the data assimilation system. Q J R Meteorol Soc 137(656):553–597. https://doi.org/10.1002/qj.828
Dix M, Bi D, Dobrohotoff P, Fiedler R, Harman I, Law R, Mackallah C, Marsland S, O’Farrell S, Rashid H, Srbinovsky J, Sullivan A, Trenham C, Vohralik P, Watterson I, Williams G, Woodhouse M, Bodman R, Dias FB, Domingues C, Hannah N, Heerdegen A, Savita A, Wales S, Allen C, Druken K, Evans B, Richards C, Ridzwan SM, Roberts D, Smillie J, Snow K, Ward M, Yang R (2019) CSIRO-ARCCSS ACCESS-CM2 model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.4239. version = 20191108
(EC-Earth) EEC (2019) EC-Earth-Consortium EC-Earth3 model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.4529. version = 20200203
Eyring V, Bony S, Meehl GA, Senior CA, Stevens B, Stouffer RJ, Taylor KE (2016) Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geosci Model Dev 9(5):1937–1958. https://doi.org/10.5194/gmd-9-1937-2016
Flury BN (1984) Common principal components in k groups. J Am Stat Assoc 79:892–898. https://doi.org/10.2307/2288721
Flury BN (1988) Common Principal Components and Related Mutivariate Models. Wiley, New York
Flury BN, Gautschi W (1986) An algorithm for simultaneous orthogonal transformation of several positive definite symmetric matrices to nearly diagonal form. SIAM J Sci Stat Comput 7:169–184. https://doi.org/10.1137/0907013
Frankignoul C, Février S, Sennéchael N, Verbeek J, Braconnot P (1995) An intercomparison between four tropical ocean models. Tellus A Dyn Meteorol Oceanogr 47(3):351–364. https://doi.org/10.3402/tellusa.v47i3.11522
Golub GH, van Loan CF (1996) Matrix computation, 3d edn. The John Hopkins University Press, Baltimore
Hannachi A (2007) Pattern hunting in climate: a new method for finding trends in gridded climate data. Int J Climatol 27(1):1–15. https://doi.org/10.1002/joc.1375
Hannachi A (2010) On the origin of planetary-scale extra-tropical winter circulation regimes. J Atmos Sci 67(5):1382–1401. https://doi.org/10.1175/2009JAS3296.1
Hannachi A (2021) Pattern identification and data mining in weather and climate. Springer, Berlin, p 600
Hannachi A, Stephenson DB, Sperber KR (2003) Probability-based methods for quantifying nonlinearity in the ENSO. Clim Dyn 20:241–256. https://doi.org/10.1007/s00382-002-0263-7
Hannachi A, Jolliffe IT, Stephenson DB, Trendafilov N (2006) In search of simple structures in climate: simplifying EOFs. Int J Climatol 26(1):7–28. https://doi.org/10.1002/joc.1243
Hannachi A, Jolliffe IT, Stephenson DB (2007) Empirical orthogonal functions and related techniques in atmospheric science: a review. Int J Climatol 27(9):1119–1152. https://doi.org/10.1002/joc.1499
Hannachi A, Mitchell LGD, Charlton-Perez A (2011) On the use of geometric moments to examine the continuum of sudden stratospheric warmings. J Atmos Sci 68(3):657–674. https://doi.org/10.1175/2010JAS3585.1
Hannachi A, Straus DM, Franzke CLE, Corti S, Woollings T (2017) Low-frequency nonlinearity and regime behavior in the Northern Hemisphere extratropical atmosphere. Rev Geophys 55(1):199–234. https://doi.org/10.1002/2015RG000509
Hersbach H, Bell B, Berrisford P, Hirahara S, Horányi A, Muñoz-Sabater J, Nicolas J, Peubey C, Radu R, Schepers D, Simmons A, Soci C, Abdalla S, Abellan X, Balsamo G, Bechtold P, Biavati G, Bidlot J, Bonavita M, De Chiara G, Dahlgren P, Dee D, Diamantakis M, Dragani R, Flemming J, Forbes R, Fuentes M, Geer A, Haimberger L, Healy S, Hogan RJ, Hólm E, Janisková M, Keeley S, Laloyaux P, Lopez P, Lupu C, Radnoti G, de Rosnay P, Rozum I, Vamborg F, Villaume S, Thépaut JN (2020) The ERA5 global reanalysis. Q J Roy Meteorol Soc 146(730):1999–2049. https://doi.org/10.1002/qj.3803
Huan G, John JG, Blanton C, McHugh C, Nikonov S, Radhakrishnan A, Rand K, Zadeh NT, Balaji V, Durachta J, Dupuis C, Menzel R, Robinson T, Underwood S, Vahlenkamp H, Bushuk M, Dunne KA, Dussin R, Gauthier PP, Ginoux P, Griffies SM, Hallberg R, Harrison M, Hurlin W, Lin P, Malyshev S, Naik V, Paulot F, Paynter DJ, Ploshay J, Reichl BG, Schwarzkopf DM, Seman CJ, Shao A, Silvers L, Wyman B, Yan X, Zeng Y, Adcroft A, Dunne JP, Held IM, Krasting JP, Horowitz LW, Milly P, Shevliakova E, Winton M, Zhao M, Zhang R (2018) NOAA-GFDL GFDL-CM4 model output amip. https://doi.org/10.22033/ESGF/CMIP6.8494. version=20180701
Iqbal W, Hannachi A, Hirooka T, Chafik L, Harada Y (2019) Troposphere–stratosphere dynamical coupling in regard to the North Atlantic eddy-driven jet variability. J Meteorol Soc Jpn 97(3):657–671. https://doi.org/10.2151/jmsj.2019-037
Jeong JH, Ou T, Linderholm HW, Kim BM, Kim SJ, Kug JS, Chen D (2011) Recent recovery of the Siberian High intensity. J Geophys Res Atmos 116(D23):102. https://doi.org/10.1029/2011JD015904
Jolliffe IT (2002) Principal component analysis, 2nd edn. Springer, New York
Jungclaus J, Bittner M, Wieners KH, Wachsmann F, Schupfner M, Legutke S, Giorgetta M, Reick C, Gayler V, Haak H, de Vrese P, Raddatz T, Esch M, Mauritsen T, von Storch JS, Behrens J, Brovkin V, Claussen M, Crueger T, Fast I, Fiedler S, Hagemann S, Hohenegger C, Jahns T, Kloster S, Kinne S, Lasslop G, Kornblueh L, Marotzke J, Matei D, Meraner K, Mikolajewicz U, Modali K, Müller W, Nabel J, Notz D, Peters K, Pincus R, Pohlmann H, Pongratz J, Rast S, Schmidt H, Schnur R, Schulzweida U, Six K, Stevens B, Voigt A, Roeckner E (2019) MPI-M MPI-ESM1.2-HR model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.6463. version = 20190710
Kalnay E, Kanamitsu M, Kistler R, Collins W, Deaven D, Gandin L, Iredell M, Saha S, White G, Woollen J, Zhu Y, Chelliah M, Ebisuzaki W, Higgins W, Janowiak J, Mo KC, Ropelewski C, Wang J, Leetmaa A, Reynolds R, Jenne R, Joseph D (1996) The NCEP/NCAR 40-year reanalysis project. Bull Am Meteorol Soc 77(3):437–472. https://doi.org/10.1175/1520-0477(1996)077<0437:TNYRP>2.0.CO;2
Kobayashi S, Ota Y, Harada Y, Ebita A, Moriya M, Onada H, Kamahori KOH, Kobayashi C, Endo H, Miyakoi K, Takahashi K (2015) The JRA-55 reanalysis: general specifications and basic characteristics. J Meteorol Soc Jpn Ser II 93(1):5–48. https://doi.org/10.2151/jmsj.2015-001
Lee J, Sperber K, Gleckler P, W BCJ, E TK, (2019) Quantifying the agreement between observed and simulated extratropical modes of interannual variability. Clim Dyn 52:4057–4089. https://doi.org/10.1007/s00382-018-4355-4
Li B, Li Y, Chen Y, Zhang B, Shi X (2020) Recent fall Eurasian cooling linked to North Pacific sea surface temperatures and a strengthening Siberian high. Nat Commun 11:5202. https://doi.org/10.1038/s41467-020-19014-2
Lorenz EN (1956) Empirical orthogonal functions and statistical weather prediction. Science Report 1, Statistical Forecasting Project, Department of Meteorology, MIT, p 49
Noble B, Daniel JW (1977) Applied linear algebra. Prentice Hall, Hoboken, p 477
North GR, Bell T, Cahalan R, Moeng F (1982) Sampling errors in the estimation of empirical orthogonal functions. Mon Weather Rev 110(7):699–706. https://doi.org/10.1038/s41467-020-19014-2
Panagiatopoulos F, Shahgedanova M, Hannachi A, Stepenson DB (2005) Observed trends and teleconnections of the Siberian high: a recently declining center of action. J Clim 18(9):1411–1422. https://doi.org/10.1175/JCLI3352.1
Pepler PT (2014) The identification and application of common principal components. Stellenbosch University, Stellenbosch
Preisendorfer RW (1988) Principal component analysis in meteorology and oceanography. Elsevier, Amsterdam
Ridley J, Menary M, Kuhlbrodt T, Andrews M, Andrews T (2019) MOHC HadGEM3-GC31-LL model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.5853. version = 20190617
Schott JR (1988) Common principal component subspaces in two groups. Biometrika 75(2):229–236
Sengupta S, Boyle JS (1998) Using common principal components for comparing GCM simulations. J Clim 11(5):816–830. https://doi.org/10.1175/1520-0442(1998)011<0816:UCPCFC>2.0.CO;2
Sura P, Hannachi A (2015) Perspectives of non-Gaussianity in atmospheric synoptic and low-frequency variability. J Clim 28(13):5091–5114. https://doi.org/10.1175/JCLI-D-14-00572.1
Swart NC, Cole JN, Kharin VV, Lazare M, Scinocca JF, Gillett NP, Anstey J, Arora V, Christian JR, Jiao Y, Lee WG, Majaess F, Saenko OA, Seiler C, Seinen C, Shao A, Solheim L, von Salzen K, Yang D, Winter B, Sigmond M (2019) CCCma CanESM5 model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.3535. version = 20190429
Stendel M, van den Besselaar E, Hannachi A, Kent E, Lefebvre C, Rosenhagen G, Schenk F, van der Schrier, Woollings T (2016) Recent change—atmosphere. In: Quante Colijn (ed) North Sea Region climate change assessment. Springer, Berlin–Heidelberg, pp 55–84
Tatebe H, Watanabe M (2018) MIROC MIROC6 model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.5422. version = 20191016
Thompson DWJ, Wallace JM (1998) The Arctic oscillation signature in the wintertime geopotential height and temperature fields. Geophys Res Lett 25(9):1297–1300. https://doi.org/10.1029/98GL00950
Tibshirani R, Walther G, Hastie T (2001) Estimating the number of clusters in a data set via the gap statistic. J Roy Stat Soc Ser B (Stat Methodol) 63(2):411–423. https://doi.org/10.1111/1467-9868.00293
Trendafilov N (2010) Stepwise estimation of common principal components. Comput Stat Data Anal 54(12):3446–3457. http://oro.open.ac.uk/49279/
Venzke S, Allen MR, Sutton RT, Rowell DP (1999) The atmospheric response over the North Atlantic to decadal changes in sea surface temperature. J Clim 12:2562–2584
Volodin E, Mortikov E, Gritsun A, Lykossov V, Galin V, Diansky N, Gusev A, Kostrykin S, Iakovlev N, Shestakova A, Emelina S (2019) INM INM-CM5-0 model output prepared for CMIP6 CMIP amip. https://doi.org/10.22033/ESGF/CMIP6.4935. version = 20190610
Wallace JM, Gutzler DS (1981) Teleconnections in the geopotential height field during the Northern Hemisphere winter. Mon Weather Rev 109(4):784–812. https://doi.org/10.1175/1520-0493(1981)109<0784:TITGHF>2.0.CO;2
Wallace JM, Smith C, Bretherton CS (1992) Singular value decomposition of wintertime sea surface temperature and 500-mb height anomalies. J Clim 5(6):561–576. https://doi.org/10.1175/1520-0442(1992)005<0561:SVDOWS>2.0.CO;2
Wang G, Dommenget D, Frauen C (2015) An evaluation of the CMIP3 and CMIP5 simulations in their skill of simulating the spatial structure of SST variability. Clim Dyn 44:95–114. https://doi.org/10.1007/s00382-014-2154-0
Acknowledgements
We acknowledge the modeling groups, the Program for Climate Model Diagnosis and Intercomparison (PCMDI) and the WCRP’s Working Group on Coupled Modelling (WGCM) for their roles in making available the WCRP CMIP6 multi-model dataset. Thanks are also due to the European Centre for Medium Weather Forecasting, ECMWF, for providing the ERA5 and ERA interim reanalyses, the Japan Meteorological Agency for providing JRA55 reanalyses, and the National Center for Environmental Prediction for providing NCEP reanalyses. Two anonymous reviewers provided constructive comments that helped improve the manuscript. The computations were performed on resources provided by the Swedish National Infrastructure for Computing (SNIC) at the National Supercomputer Centre (NSC). This research is supported by a faculty-funded PhD program. We declare no conflict of interest.
Funding
Open access funding provided by Stockholm University.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hannachi, A., Finke, K. & Trendafilov, N. Common EOFs: a tool for multi-model comparison and evaluation. Clim Dyn 60, 1689–1703 (2023). https://doi.org/10.1007/s00382-022-06409-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00382-022-06409-8