
Abstract
This paper explores how to identify a reduced order model (ROM) from a physical system. A ROM captures an invariant subset of the observed dynamics. We find that there are four ways a physical system can be related to a mathematical model: invariant foliations, invariant manifolds, autoencoders and equation-free models. Identification of invariant manifolds and equation-free models require closed-loop manipulation of the system. Invariant foliations and autoencoders can also use off-line data. Only invariant foliations and invariant manifolds can identify ROMs, and the rest identify complete models. Therefore, the common case of identifying a ROM from existing data can only be achieved using invariant foliations. Finding an invariant foliation requires approximating high-dimensional functions. For function approximation, we use polynomials with compressed tensor coefficients, whose complexity increases linearly with increasing dimensions. An invariant manifold can also be found as the fixed leaf of a foliation. This only requires us to resolve the foliation in a small neighbourhood of the invariant manifold, which greatly simplifies the process. Combining an invariant foliation with the corresponding invariant manifold provides an accurate ROM. We analyse the ROM in case of a focus type equilibrium, typical in mechanical systems. The nonlinear coordinate system defined by the invariant foliation or the invariant manifold distorts instantaneous frequencies and damping ratios, which we correct. Through examples we illustrate the calculation of invariant foliations and manifolds and at the same time show that Koopman eigenfunctions and autoencoders fail to capture accurate ROMs under the same conditions.
Similar content being viewed by others

1 Introduction
There is a great interest in the scientific community to identify explainable and/or parsimonious mathematical models from data. In this paper we classify these methods and identify one concept that is best suited to accurately calculate reduced order models (ROM) from off-line data. A ROM must track some selected features of the data over time and predict them into the future. We call this property of the ROM invariance. A ROM may also be unique, which means that barring a (nonlinear) coordinate transformation, the mathematical expression of the ROM is independent of who and when obtained the data as long as the sample size is sufficiently large and the distribution of the data satisfies some minimum requirements.

Two cases of data distribution. The blue dots (initial conditions) are mapped into the red triangles by the nonlinear map \({\varvec{F}}\) given by Eq. (36). a Data points are distributed in the neighbourhood of the solid green curve, which is identified as an approximate invariant manifold. b Initial conditions are well-distributed in the neighbourhood of the steady state and there is no obvious manifold structure. For completeness, the second invariant manifold is denoted by the dashed line (Color figure online)
Not all methods that identify low-dimensional models produce ROMs. In some cases the data lie on a low-dimensional manifold embedded in a high-dimensional, typically Euclidean, space as in Fig. 1a. In this case the task is to parametrise the low-dimensional manifold and fit a model to the data in the coordinates of the parametrisation. The choice of parametrisation influences the form of the model. It is desired to use a parametrisation that yields a model with the least number of parameters. Approaches to reduce the number of parameters include compressed sensing (Billings 2013; Brunton et al. 2014, 2016; Champion et al. 2019; Donoho 2006) and normal form methods (Cenedese et al. 2022; Read and Ray 1998; Yair et al. 2017). The methods to obtain a parametrisation of the manifold include diffusion maps (Coifman and Lafon 2006), isomaps (Tenenbaum et al. 2000), autoencoders (Cenedese et al. 2022; Champion et al. 2019; Kalia et al. 2021; Kramer 1991) and equation-free models (Kevrekidis et al. 2003; Kevrekidis and Samaey 2009).
The main focus of this paper is genuine ROMs, where we need to find structure in a cloud of data as illustrated in Fig. 1b. An invariant manifold provides such structure, since all trajectories starting from the manifold stay on the manifold for all times. However an invariant manifold is not defined by the dynamics on it but by the dynamics in its neighbourhood (Cabré et al. 2003; de la Llave 1997; Fenichel 1972). This means that identifying a manifold must also involve identifying the dynamics in its neighbourhood, which is regularly omitted, such as in Cenedese et al. (2022). We find that resolving the nearby dynamics is the same as identifying an invariant foliation, as explained in Sect. 2.2.
Invariant foliations (Szalai 2020) can also be used to find structure in data like in Fig. 1b. An invariant foliation consists of a family of leaves (manifolds) that map onto each other under the dynamics of our system as in Fig. 4a. Each leaf of the foliation has a parameter from a space which has the dimensionality of the phase space minus the dimensionality of a leaf. As the leaves map onto each other, so do the parameters, which then defines a low-dimensional map or ROM. A leaf that maps onto itself is an invariant manifold. Invariant foliations are also useful to find suitable initial conditions for ROMs (Roberts 1989).
A natural question is if we have exhausted all possible concepts that identify structure in dynamic data. To address this, we systematically explore how a physical (or any other data producing) system can be related to a mathematical model. This allows us to categorise ROM concepts and choose the most suitable one for a given purpose. Through this process we arrive at the definitions of four cases: invariant foliations, invariant manifolds, autoencoders and equation-free models, and uncover their relations to each other.
We find that not all methods are applicable to off-line produced data. Indeed, calculating an invariant manifold requires actively probing the mathematical model (Haller and Ponsioen 2016). If a model is not available, the physical system must be placed under closed-loop control, such as in control-based continuation (Barton 2017; Sieber and Krauskopf 2008), which can currently identify equilibria or periodic orbits, but potentially it could also be used to find invariant manifolds of those equilibria and periodic orbits. Equation-free models were developed to recover inherently low-order dynamics from large systems by systematically probing the system input (Kevrekidis et al. 2003; Kevrekidis and Samaey 2009). However, not all systems can be put under closed-loop control, mainly because either setting up the required high-speed control loop is too costly or time consuming, or the system is simply inaccessible to the data analyst. In this case, the data collection is carried out separately from the data analysis without instant feedback to the system. We call this case open-loop or off-line data collection. We conclude that invariant foliations and autoencoders can be fitted to off-line data, but only invariant foliations produce genuine ROMs.
Surprisingly, invariant foliations were not explored for ROM identification before paper (Szalai 2020). Here, we propose a two-stage process, which finds an invariant foliation, that captures a low-order model and then finds a transverse and locally defined invariant foliation, whose fixed leaf is the invariant manifold with the same dynamics as the globally defined invariant foliation. This ensures that we take into account all data when the low-order dynamics is uncovered, and at the same time also produce a familiar structure, which is the corresponding invariant manifold. As per remark 15, this process may be simplified at the possible cost of losing some accuracy.
Another contribution of the paper is that we resolve the problem with high-dimensional data, which requires the approximation of high-dimensional functions, when invariant foliations are identified. We use polynomials that have compressed tensor coefficients (Grasedyck et al. 2013), and whose complexity scales linearly, instead of combinatorially with the underlying dimension. Compressed tensors in the hierarchical Tucker format (HT) (Hackbusch and Kühn 2009) are amenable to singular value decomposition (Grasedyck 2010), hence by calculating the singular values we can check the accuracy of the approximation. In addition, compressed tensors can be truncated if some singular values are near zero without losing their accuracy. However for our purpose, the most important property is that within an optimisation framework a HT tensor is linear in each of its parameter matrices (when the rest of the parameters are fixed), which gives us a convex cost function. Indeed, when solving the invariance equation of the foliation, we use a block coordinate descent method, the Gauss–Southwell scheme (Nutini et al. 2015), which significantly speeds up the solution process. We also note that optimisation of each coefficient matrix of a HT tensor is constrained to a matrix manifold; hence, we use a trust-region method designed for matrix manifolds (Boumal 2022; Conn et al. 2000) when solving for individual matrix components.
A ROM is usually represented in a nonlinear coordinate system; hence, the quantities predicted by the ROM may not behave the same way as in Euclidean frames. This is particularly true for instantaneous frequencies and damping ratios of decaying vibrations. In Sect. 3, we take the distortion of the nonlinear coordinate system into account and derive correct values of instantaneous frequencies and damping ratios.
The structure of the paper is as follows. We first discuss the type of data assumed for ROM identification. Then, we define what a ROM is and go through all possible connections between a data producing system and a ROM. We then classify the uncovered conceptual connections along two properties: whether they are applicable to off-line data or produce genuine ROMs. Next, we discuss instantaneous frequencies and damping ratios in nonlinear frames. In Sect. 4, we summarise the proposed and tested numerical algorithms and describe their implementation details. Finally, we discuss three example problems. We start with a conceptual model that illustrates the non-applicability of autoencoders to genuine model order reduction. We then use a nonlinear ten-dimensional mathematical model to create synthetic data sets. Here we demonstrate the accuracy of our method to full state-space data, but also highlight problems with phase-space reconstruction from scalar signals. Finally, we analyse vibration data from a jointed beam, for which there is no accurate physical model due to the frictional interface in the joint.
1.1 Set-Up
The first step on our journey is to characterise the type of data we are working with. We assume a real n-dimensional Euclidean space, denoted by X (a vector space with an inner product \(\left\langle \cdot ,\cdot \right\rangle _{X}:X\times X\rightarrow {\mathbb {R}}\)), which contains all our data. We further assume that the data are produced by a deterministic process, which is represented by an unknown map \({\varvec{F}}:X\rightarrow X\). In particular, the data are organised into \(N\in {\mathbb {N}}^{+}\) pairs of vectors from space X, that is
that satisfy
where \(\varvec{\xi }_{k}\in X\) represents a small measurement noise, which is sampled from a distribution with zero mean. Equation (1) describes pieces of trajectories if for some \(k\in \left\{ 1,\ldots ,N\right\} \), \({\varvec{x}}_{k+1}={\varvec{y}}_{k}\). The state of the system can also be defined on a manifold, in which case X is chosen such that the manifold is embedded in X according to Whitney’s embedding theorem (Whitney 1936). It is also possible that the state cannot be directly measured, in which case Takens’ delay embedding technique (Takens 1981) can be used to reconstruct the state, which we will do subsequently in an optimal manner (Casdagli 1989). As a minimum, we require that our system is observable (Hermann and Krener 1977).
For the purpose of this paper we also assume a fixed point at the origin, such that \({\varvec{F}}\left( {\varvec{0}}\right) ={\varvec{0}}\) and that the domain of \({\varvec{F}}\) is a compact and connected subset \(G\subset X\) that includes a neighbourhood of the origin.
2 Reduced Order Models
We now describe a weak definition of a ROM, which only requires invariance. There are two ingredients of a ROM: a function connecting vector space X to another vector space Z of lower dimensionality and a map on vector space Z. The connection can go two ways, either from Z to X or from X to Z. To make this more precise, we also assume that Z has an inner product \(\left\langle \cdot ,\cdot \right\rangle _{Z}:Z\times Z\rightarrow {\mathbb {R}}\) and that \(\dim Z<\dim X\). The connection \({\varvec{U}}:X\rightarrow Z\) is called an encoder and the connection \({\varvec{W}}:Z\rightarrow X\) is called a decoder. We also assume that both the encoder and the decoder are continuously differentiable and their Jacobians have full rank. Our terminology is borrowed from computer science (Kramer 1991), but we can also use mathematical terms that calls \({\varvec{U}}\) a manifold submersion (Lawson 1974) and \({\varvec{W}}\) a manifold immersion (Lang 2012). In accordance with our assumption that \({\varvec{F}}\left( {\varvec{0}}\right) ={\varvec{0}}\), we also assume that \({\varvec{U}}\left( {\varvec{0}}\right) ={\varvec{0}}\) and \({\varvec{W}}\left( {\varvec{0}}\right) ={\varvec{0}}\).
Definition 1
Assume two maps \({\varvec{F}}:X\rightarrow X\), \({\varvec{S}}:Z\rightarrow Z\) and an encoder \({\varvec{U}}:X\rightarrow Z\) or a decoder \({\varvec{W}}:Z\rightarrow X\).
-
1.
The encoder-map pair \(\left( {\varvec{U}},{\varvec{S}}\right) \) is a ROM of \({\varvec{F}}\) if for all initial conditions \({\varvec{x}}_{0}\in G\subset X\), the trajectory \({\varvec{x}}_{k+1}={\varvec{F}}\left( {\varvec{x}}_{k}\right) \) and for initial condition \({\varvec{z}}_{0}={\varvec{U}}\left( {\varvec{x}}_{0}\right) \) the second trajectory \({\varvec{z}}_{k+1}={\varvec{S}}\left( {\varvec{z}}_{k}\right) \) are connected such that \({\varvec{z}}_{k}={\varvec{U}}\left( {\varvec{x}}_{k}\right) \) for all \(k>0\).
-
2.
The decoder-map pair \(\left( {\varvec{W}},{\varvec{S}}\right) \) is a ROM of \({\varvec{F}}\) if for all initial conditions \({\varvec{z}}_{0}\in H=\left\{ {\varvec{z}}\in Z:{\varvec{W}}\left( z\right) \in G\right\} \), the trajectory \({\varvec{z}}_{k+1}={\varvec{S}}\left( {\varvec{z}}_{k}\right) \) and for initial condition \({\varvec{x}}_{0}={\varvec{W}}\left( {\varvec{z}}_{0}\right) \) the second trajectory \({\varvec{x}}_{k+1}={\varvec{F}}\left( {\varvec{x}}_{k}\right) \) are connected such that \({\varvec{x}}_{k}={\varvec{W}}\left( {\varvec{z}}_{k}\right) \) for all \(k>0\).
Remark 2
In essence, a ROM is a model whose trajectories are connected to the trajectories of our system \({\varvec{F}}\). We call this property invariance. It is possible to define a weaker ROM, where the connections \({\varvec{z}}_{k}={\varvec{U}}\left( {\varvec{x}}_{k}\right) \) or \({\varvec{x}}_{k}={\varvec{W}}\left( {\varvec{z}}_{k}\right) \) are only approximate, which is not discussed here.
The following corollary can be thought of as an equivalent definition of a ROM.
Corollary 3
The encoder-map pair \(\left( {\varvec{U}},{\varvec{S}}\right) \) or decoder-map pair \(\left( {\varvec{W}},{\varvec{S}}\right) \) is a ROM if and only if either invariance equation
hold, where \(H=\left\{ {\varvec{z}}\in Z:{\varvec{W}}\left( z\right) \in G\right\} \).

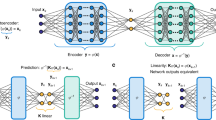
Commutative diagrams of a invariant foliations, b invariant manifolds, and connection diagrams of c autoencoders and d equation-free models. The dashed arrows denote the chain of function composition(s) that involves \({\varvec{F}}\), the continuous arrows denote the chain of function composition(s) that involves map \({\varvec{S}}\). The encircled vector space denotes the domain of the invariance equation, and the boxed vector space is the target of the invariance equation
Proof
Let us assume that (2) holds, and choose an \({\varvec{x}}_{0}\in X\) and let \({\varvec{z}}_{0}={\varvec{U}}\left( {\varvec{x}}_{0}\right) \). First we check whether \({\varvec{z}}_{k}={\varvec{U}}\left( {\varvec{x}}_{k}\right) \), if \({\varvec{x}}_{k}={\varvec{F}}^{k}\left( {\varvec{x}}_{0}\right) \), \({\varvec{z}}_{k}={\varvec{S}}^{k}\left( {\varvec{z}}_{0}\right) \) and (2) hold. Substituting \({\varvec{x}}={\varvec{F}}^{k}\left( {\varvec{x}}_{0}\right) \) into (2) yields
Now in reverse, assuming that \({\varvec{z}}_{k}={\varvec{U}}\left( {\varvec{x}}_{k}\right) \), \({\varvec{z}}_{k}={\varvec{S}}^{k}\left( {\varvec{z}}_{0}\right) \), \({\varvec{x}}_{k}={\varvec{F}}^{k}\left( {\varvec{x}}_{0}\right) \) and setting \(k=1\) yields that
which is true for all \({\varvec{x}}_{k-1}\in G\), hence (2) holds. The proof for the decoder is identical, except that we swap \({\varvec{F}}\) and \({\varvec{S}}\) and replace \({\varvec{U}}\) with \({\varvec{W}}.\) \(\square \)
Now the question arises if we can use a combination of an encoder and a decoder? This is the case of the autoencoder or nonlinear principal component analysis (Kramer 1991) and the equation-free model (Kevrekidis et al. 2003; Kevrekidis and Samaey 2009). Indeed, there are four combinations of encoders and decoders, which are depicted in diagrams Fig. 2a–d. We name these four scenarios as follows.
Definition 4
We call the connections displayed in Fig. 2a–d, invariant foliation, invariant manifold, autoencoder and equation-free model, respectively.

a Autoencoder. Encoder \({\varvec{U}}\) maps data to parameter space Z, then the low-order map \({\varvec{S}}\) takes the parameter forward in time and finally the decoder \({\varvec{W}}\) brings the new parameter back to the state space. This chain of maps denoted by solid purple arrows must be the same as map \({\varvec{F}}\) denoted by the dashed arrow. The two results can only match between two manifolds \({\mathcal {M}}\) and \({\mathcal {N}}\) and not elsewhere in the state space. Manifold \({\mathcal {M}}\) is invariant if and only if \({\mathcal {M}}\subset {\mathcal {N}}\), which is not guaranteed by this construction. b Equation-free model. The only difference from the autoencoder is the reversal of the arrow under \({\varvec{F}}\), hence \({\varvec{S}}\left( {\varvec{z}}\right) ={\varvec{U}}\left( {\varvec{F}}\left( {\varvec{W}}\left( {\varvec{z}}\right) \right) \right) \) (Color figure online)
As we walk through the dashed and solid arrows in diagram Fig. 2a, we find the two sides of the invariance Eq. (2). If we do the same for diagram Fig. 2b, we find Eq. (3). This implies that invariant foliations and invariant manifolds are ROMs. The same is not true for autoencoders and equation-free models. Reading off diagram Fig. 2c, the autoencoder must satisfy
Equation (4) is depicted in Fig. 3a. Since the decoder \({\varvec{W}}\) maps onto a manifold \({\mathcal {M}}\), Eq. (4) can only hold if \({\varvec{x}}\) is chosen from the preimage of \({\mathcal {M}}\), that is, \({\varvec{x}}\in {\mathcal {N}}={\varvec{F}}^{-1}\left( {\mathcal {M}}\right) \). For invariance, we need \({\varvec{F}}\left( {\mathcal {M}}\right) \subset {\mathcal {M}}\), which is the same as \({\mathcal {M}}\subset {\mathcal {N}}\) if \({\varvec{F}}\) is invertible. However, the inclusion \({\mathcal {M}}\subset {\mathcal {N}}\) is not guaranteed by Eq. (4). The only way to guarantee \({\mathcal {M}}\subset {\mathcal {N}}\), is by stipulating that the function composition \({\varvec{W}}\circ {\varvec{U}}\) is the identity map on the data. A trivial case is when \(\dim Z=\dim X\) or, in general, when all data fall onto a \(\dim Z\)-dimensional submanifold of X. Indeed, the standard way to find an autoencoder (Kramer 1991) is to solve
Unfortunately, if the data are not on a \(\dim Z\)-dimensional submanifold of X, which is the case of genuine ROMs, the minimum of \(\sum _{k=1}^{N}\left\| {\varvec{W}}\left( {\varvec{U}}\left( {\varvec{x}}_{k}\right) \right) -{\varvec{x}}_{k}\right\| ^{2}\) will be far from zero and the location of \({\mathcal {M}}\) as the solution of (5) will only indicate where the data are in the state space. It is customary to seek a solution to (5) under the normalising condition that \({\varvec{U}}\circ {\varvec{W}}\) is the identity and hence \({\varvec{S}}={\varvec{U}}\circ {\varvec{F}}\circ {\varvec{W}}\).
The equation-free model in diagram Fig. 2d is identical to the autoencoder Fig. 2c if we replace \({\varvec{F}}\) with \({\varvec{F}}^{-1}\) and \({\varvec{S}}\) with \({\varvec{S}}^{-1}\). Reading off diagram Fig. 2d, the equation-free model must satisfy
Equation (6) immediately provides \({\varvec{S}}\), for any \({\varvec{U}},\) \({\varvec{W}}\), without identifying any structure in the data.
Only invariant foliations, through Eq. (2) and autoencoders through Eqs. (4) and (5) can be fitted to off-line data. Invariant manifolds and equation-free models require the ability the manipulate the input of our system \({\varvec{F}}\) during the identification process. Indeed, for off-line data, produced by Eq. (1), the foliation invariance Eq. (2) turns into an optimisation problem
and the autoencoder Eq. (4) turns into
For the optimisation problem (7) to have a unique solution, we need to apply a constraint to \({\varvec{U}}\). One possible constraint is explained in remark 7. In case of the autoencoder (8), the constraint, in addition to the one restricting \({\varvec{U}}\), can be that \({\varvec{U}}\circ {\varvec{W}}\) is the identity, as also stipulated in Cenedese et al. (2022).

a Invariant foliation: a leaf \({\mathcal {L}}_{{\varvec{z}}}\) is being mapped onto leaf \({\mathcal {L}}_{{\varvec{S}}\left( {\varvec{z}}\right) }\). Since the origin \({\varvec{0}}\in Z\) is a steady state of \({\varvec{S}}\), the leaf \({\mathcal {L}}_{{\varvec{0}}}\) is mapped into itself and therefore it is an invariant manifold. b Invariant manifold: a single trajectory, represented by red dots, starting from the invariant manifold \({\mathcal {M}}\) remains on the green invariant manifold (Color figure online)
2.1 Invariant Foliations and Invariant Manifolds
An encoder represents a family of manifolds, called foliation, which is the set of constant level surfaces of \({\varvec{U}}\). A single level surface is called a leaf of the foliation; hence, the foliation is a collection of leaves. In mathematical terms, a leaf with parameter \({\varvec{z}}\in Z\) is denoted by
All leaves are \(\dim X-\dim Z\)-dimensional differentiable manifolds, because we assumed that the Jacobian \(D{\varvec{U}}\) has full rank (Lawson 1974). The collection of all leaves is a foliation, denoted by
where \(H={\varvec{U}}\left( G\right) \). The foliation is characterised by its co-dimension, which is the same as \(\dim Z\). Invariance Eq. (2) means that each leaf of the foliation is mapped onto another leaf, in particular the leaf with parameter \({\varvec{z}}\) is mapped onto the leaf with parameter \({\varvec{S}}\left( {\varvec{z}}\right) \), that is
Due to our assumptions, leaf \({\mathcal {L}}_{{\varvec{0}}}\) is an invariant manifold, because \({\varvec{F}}\left( {\mathcal {L}}_{{\varvec{0}}}\right) \subset {\mathcal {L}}_{{\varvec{0}}}\). This geometry is illustrated in Fig. 4a.
We now characterise the existence and uniqueness of invariant foliations about a fixed point. We assume that \({\varvec{F}}\) is a \(C^{r}\), \(r\ge 2\) map and that the Jacobian matrix \(D{\varvec{F}}\left( {\varvec{0}}\right) \) has eigenvalues \(\mu _{1},\ldots ,\mu _{n}\) such that \(\left| \mu _{i}\right| <1\), \(i=1,\ldots ,n\). To select the invariant manifold or foliation we assume two \(\nu \)-dimensional linear subspaces E of X and \(E^{\star }\) of X corresponding to eigenvalues \(\mu _{1},\ldots ,\mu _{\nu }\) such that \(D{\varvec{F}}\left( {\varvec{0}}\right) E\subset E\) and for the adjoint map \(\left( D{\varvec{F}}\left( {\varvec{0}}\right) \right) ^{\star }E^{\star }\subset E^{\star }\).
Definition 5
The number
is called the spectral quotient of the left-invariant linear subspace \(E^{\star }\) of \({\varvec{F}}\) about the origin.
Theorem 6
Assume that \(D{\varvec{F}}\left( {\varvec{0}}\right) \) is semisimple and that there exists an integer \(\sigma \ge 2\), such that \(\beth _{E^{\star }}<\sigma \le r\). Also assume that
for all \(m_{k}\ge 0\), \(1\le k\le n\) with at least one \(m_{l}\ne 0\), \(\nu +1\le l\le n\) and with \(\sum _{k=0}^{n}m_{k}\le \sigma -1\). Then in a sufficiently small neighbourhood of the origin there exists an invariant foliation \({\mathcal {F}}\) tangent to the left-invariant linear subspace \(E^{\star }\) of the \(C^{r}\) map \({\varvec{F}}\). The foliation \({\mathcal {F}}\) is unique among the \(\sigma \) times differentiable foliations and it is also \(C^{r}\) smooth.
Proof
The proof is carried out in Szalai (2020). Note that the assumption of \(D{\varvec{F}}\left( {\varvec{0}}\right) \) being semisimple was used to simplify the proof in Szalai (2020), therefore it is unlikely to be needed. \(\square \)
Remark 7
Theorem 6 only concerns the uniqueness of the foliation, but not the encoder \({\varvec{U}}\). However, for any smooth and invertible map \({\varvec{R}}:Z\rightarrow Z\), the encoder \(\tilde{{\varvec{U}}}={\varvec{R}}\circ {\varvec{U}}\) represents the same foliation and the nonlinear map \({\varvec{S}}\) transforms into \(\tilde{{\varvec{S}}}={\varvec{R}}\circ {\varvec{S}}\circ {\varvec{R}}^{-1}\). If we want to solve the invariance Eq. (2), we need to constrain \({\varvec{U}}\). The simplest such constraint is that
where \({\varvec{W}}_{1}:Z\rightarrow X\) is a linear map with full rank such that \(E^{\star }\cap \ker {\varvec{W}}_{1}^{\star }=\left\{ {\varvec{0}}\right\} \). To explain the meaning of Eq. (11), we note that the image of \({\varvec{W}}_{1}\) is a linear subspace \({\mathcal {H}}\) of X. Equation (11) therefore means that each leaf \({\mathcal {L}}_{{\varvec{z}}}\) must intersect subspace \({\mathcal {H}}\) exactly at parameter \({\varvec{z}}\). The condition \(E^{\star }\cap \ker {\varvec{W}}_{1}^{\star }=\left\{ {\varvec{0}}\right\} \) then means that the leaf \({\mathcal {L}}_{{\varvec{0}}}\) has a transverse intersection with subspace \({\mathcal {H}}\). This is similar to the graph-style parametrisation of a manifold over a linear subspace.
Remark 8
Eigenvalues and eigenfunctions of the Koopman operator (Mezić 2005, 2021) are invariant foliations. Indeed, the Koopman operator is defined as \(\left( {\mathcal {K}}{\varvec{u}}\right) \left( {\varvec{x}}\right) ={\varvec{u}}\left( {\varvec{F}}\left( {\varvec{x}}\right) \right) \). If we assume that \({\varvec{U}}=\left( {\varvec{u}}_{1},\ldots ,{\varvec{u}}_{\nu }\right) \) is a collection of functions \({\varvec{u}}_{j}:X\rightarrow {\mathbb {R}}\), \(Z={\mathbb {R}}^{\nu }\), then \({\varvec{U}}\) spans an invariant subspace of \({\mathcal {K}}\) if there exists a linear map \({\varvec{S}}\) such that \({\mathcal {K}}\left( {\varvec{U}}\right) ={\varvec{S}}{\varvec{U}}\). Expanding this equation yields \({\varvec{U}}\left( {\varvec{F}}\left( {\varvec{x}}\right) \right) ={\varvec{S}}{\varvec{U}}\left( {\varvec{x}}\right) \), which is the same as the invariance Eq. (2), except that \({\varvec{S}}\) is linear. The existence of linear map \({\varvec{S}}\) requires further non-resonance conditions, which are
for all \(m_{k}\ge 0\) such that \(\sum _{k=0}^{n}m_{k}\le \sigma -1\). Equation (12) is referred to as the set of internal non-resonance conditions, because these are intrinsic to the invariant subspace \(E^{\star }\). In many cases \({\varvec{S}}\) represents the slowest dynamics, hence even if there are no internal resonances, the two sides of (12) will be close to each other for some set of \(m_{1},\ldots ,m_{\nu }\) exponents and that causes numerical issues leading to undesired inaccuracies. We will illustrate this in Sect. 5.2.
Now we discuss invariant manifolds. A decoder \({\varvec{W}}\) defines a differentiable manifold
where \(H=\left\{ {\varvec{z}}\in Z:{\varvec{W}}\left( {\varvec{z}}\right) \in G\right\} \). Invariance Eq. (3) is equivalent to the geometric condition that \({\varvec{F}}\left( {\mathcal {M}}\right) \subset {\mathcal {M}}\). This geometry is shown in Fig. 4b, which illustrates that if a trajectory is started on \({\mathcal {M}}\), all subsequent points of the trajectory stay on \({\mathcal {M}}\).
Invariant manifolds as a concept cannot be used to identify ROMs from off-line data. As we will see below, invariant manifolds can still be identified as a leaf of an invariant foliation, but not through the invariance Eq. (3). Indeed, it is not possible to guess the manifold parameter \({\varvec{z}}\in Z\) from data. Introducing an encoder \({\varvec{U}}:X\rightarrow Z\) to calculate \({\varvec{z}}={\varvec{U}}\left( {\varvec{x}}\right) \), transforms the invariant manifold into an autoencoder, which does not guarantee invariance.
We now state the conditions of the existence and uniqueness of an invariant manifold.
Definition 9
The number
is called the spectral quotient of the right-invariant linear subspace E of map \({\varvec{F}}\) about the origin.
Theorem 10
Assume that there exists an integer \(\sigma \ge 2\), such that \(\aleph _{E}<\sigma \le r\). Also assume that
for all \(m_{k}\ge 0\) such that \(\sum _{k=0}^{\nu }m_{k}\le \sigma -1\). Then, in a sufficiently small neighbourhood of the origin there exists an invariant manifold \(\mathcal {{\mathcal {M}}}\) tangent to the invariant linear subspace E of the \(C^{r}\) map \({\varvec{F}}\). The manifold \({\mathcal {M}}\) is unique among the \(\sigma \)-times differentiable manifolds and it is also \(C^{r}\) smooth.
Proof
The theorem is a subset of theorem 1.1 in Cabré et al. (2003). \(\square \)
Remark 11
To calculate an invariant manifold with a unique representation, we need to impose a constraint on \({\varvec{W}}\) and/or \({\varvec{S}}\). The simplest constraint is imposed by
where \({\varvec{U}}_{1}:Z\rightarrow X\) is a linear map with full rank such that \(E\cap \ker {\varvec{U}}_{1}^{\star }=\left\{ {\varvec{0}}\right\} \). This is similar to a graph-style parametrisation (akin to theorem 1.2 in Cabré et al. (2003)), where the range of \({\varvec{U}}_{1}\) must span the linear subspace E. Constraint (14) can break down for large \(\left\| {\varvec{z}}\right\| \), when \({\varvec{U}}_{1}D{\varvec{W}}\left( {\varvec{z}}\right) \) does not have full rank. A globally suitable constraint is that \(D{\varvec{W}}^{\star }\left( {\varvec{z}}\right) D{\varvec{W}}\left( {\varvec{z}}\right) ={\varvec{I}}\).
For linear subspaces E and \(E^{\star }\) with eigenvalues closest to the complex unit circle (representing the slowest dynamics), \(\beth _{E}=1\) and \(\aleph _{E}\) is maximal. Therefore the foliation corresponding to the slowest dynamics requires the least smoothness, while the invariant manifold requires the maximum smoothness for uniqueness.
Table 1 summarises the main properties of the three conceptually different model identification techniques. Ultimately, in the presence of off-line data, only invariant foliations can be fitted to the data and produce a ROM at the same time.
2.2 Invariant Manifolds Represented by Locally Defined Invariant Foliations
As discussed before, we cannot fit invariant manifolds to data, instead we can fit an invariant foliation that contains our invariant manifold (which is the leaf containing the fixed point \({\mathcal {L}}_{{\varvec{0}}}\) at the origin). This invariant foliation only needs to be defined near the invariant manifold and therefore we can simplify the functional representation of the encoder that defines the foliation. In this section we discuss this simplification.
To begin with, assume that we already have an invariant foliation \({\mathcal {F}}\) with an encoder \({\varvec{U}}\) and nonlinear map \({\varvec{S}}\). Our objective is to find the invariant manifold \({\mathcal {M}}\), represented by decoder \({\varvec{W}}\) that has the same dynamics \({\varvec{S}}\) as the foliation. This is useful if we want to know quantities that are only defined for invariant manifolds, such as instantaneous frequencies and damping ratios. Formally, we are looking for a simplified invariant foliation \(\hat{{\mathcal {F}}}\) with encoder \(\hat{{\varvec{U}}}:X\rightarrow {\hat{Z}}\) that together with \({\mathcal {F}}\) form a coordinate system in X. (Technically speaking, \(\left( {\varvec{U}},\hat{{\varvec{U}}}\right) :X\rightarrow Z\times {\hat{Z}}\) must be a isomorphism.) In this case our invariant manifold is the zero level surface of encoder \(\hat{{\varvec{U}}}\), i.e. \({\mathcal {M}}=\hat{{\mathcal {L}}}_{0}\in \hat{{\mathcal {F}}}\). Naturally, we must have \(\dim Z+\dim {\hat{Z}}=\dim X\).

Approximate invariant foliation. The linear map \({\varvec{U}}^{\perp }\) and the nonlinear map \({\varvec{U}}\) create a coordinate system, so that in this frame the invariant manifold \({\mathcal {M}}\) is given by \({\varvec{U}}^{\perp }{\varvec{x}}={\varvec{W}}_{{\varvec{0}}}\left( {\varvec{z}}\right) \), where \({\varvec{z}}={\varvec{U}}\left( {\varvec{z}}\right) \). We then allow to shift manifold \({\mathcal {M}}\) in the \({\varvec{U}}^{\perp }\) direction such that \({\varvec{U}}^{\perp }{\varvec{x}}-{\varvec{W}}_{{\varvec{0}}}\left( {\varvec{z}}\right) =\hat{{\varvec{z}}}\), which creates a foliation parametrised by \(\hat{{\varvec{z}}}\in {\hat{Z}}\). If this foliation satisfies the invariance equation in a neighbourhood of \({\mathcal {M}}\) with a linear map \({\varvec{B}}\) as per Eq. (16), then \({\mathcal {M}}\) is an invariant manifold. In other words, nearby blue dashed leaves are mapped towards \({\mathcal {M}}\) by linear map \({\varvec{B}}\) the same way as the underlying dynamics does (Color figure online)
The sufficient condition that \({\mathcal {F}}\) and \(\hat{{\mathcal {F}}}\) form a coordinate system locally about the fixed point is that the square matrix
is invertible. Let us represent our approximate (or locally defined) encoder by
where \({\varvec{W}}_{0}:Z\rightarrow {\hat{Z}}\) is a nonlinear map with \(D{\varvec{W}}_{0}\left( {\varvec{0}}\right) ={\varvec{0}}\), \({\varvec{U}}^{\perp }:X\rightarrow {\hat{Z}}\) is an orthogonal linear map, \({\varvec{U}}^{\perp }\left( {\varvec{U}}^{\perp }\right) ^{\star }={\varvec{I}}\) and \({\varvec{U}}^{\perp }{\varvec{W}}_{0}\left( {\varvec{z}}\right) ={\varvec{0}}\). Here, the linear map \(\varvec{U^{\perp }}\) measures coordinates in a transversal direction to the manifold and \({\varvec{W}}_{0}\) prescribes where the actual manifold is along this transversal direction, while \({\varvec{U}}\) provides the parametrisation of the manifold. All other leaves of the approximate foliation \(\hat{{\mathcal {F}}}\) are shifted copies of \({\mathcal {M}}\) along the \({\varvec{U}}^{\perp }\) direction as displayed in Fig. 5. A locally defined foliation means that \(\hat{{\varvec{z}}}=\hat{{\varvec{U}}}\left( {\varvec{x}}\right) \in {\hat{Z}}\) is assumed to be small; hence, we can also assume linear dynamics among the leaves of \(\hat{{\mathcal {F}}}\), which is represented by a linear operator \({\varvec{B}}:{\hat{Z}}\rightarrow {\hat{Z}}\). Therefore, the invariance Eq. (2) becomes
Once \({\varvec{B}}\), \({\varvec{U}}^{\perp }\) and \({\varvec{W}}_{0}\) are found, the final step is to reconstruct the decoder \({\varvec{W}}\) of our invariant manifold \({\mathcal {M}}\).
Proposition 12
The decoder \({\varvec{W}}\) of the invariant manifold \({\mathcal {M}}=\left\{ {\varvec{x}}\in X:\hat{{\varvec{U}}}\left( {\varvec{x}}\right) ={\varvec{0}}\right\} \) is the unique solution of the system of equations
Proof
First we show that conditions (17) imply \(\hat{{\varvec{U}}}\left( {\varvec{W}}\left( {\varvec{x}}\right) \right) ={\varvec{0}}\). We expand our expression using (15) into \(\hat{{\varvec{U}}}\left( {\varvec{W}}\left( {\varvec{x}}\right) \right) ={\varvec{U}}^{\perp }{\varvec{W}}\left( {\varvec{z}}\right) -{\varvec{W}}_{0}\left( {\varvec{U}}\left( {\varvec{W}}\left( {\varvec{z}}\right) \right) \right) \), then use Eq. (17), which yields \(\hat{{\varvec{U}}}\left( {\varvec{W}}\left( {\varvec{x}}\right) \right) ={\varvec{0}}\). To solve Eq. (17) for \({\varvec{W}}\), we decompose \({\varvec{U}}\), \({\varvec{W}}\) into linear and nonlinear components, such that \({\varvec{U}}\left( {\varvec{x}}\right) =D{\varvec{U}}\left( 0\right) {\varvec{x}}+\widetilde{{\varvec{U}}}\left( {\varvec{x}}\right) \) and \({\varvec{W}}\left( {\varvec{z}}\right) =D{\varvec{W}}\left( 0\right) {\varvec{z}}+\widetilde{{\varvec{W}}}\left( {\varvec{z}}\right) \). Expanding Eq. (17) with the decomposed \({\varvec{U}}\), \({\varvec{W}}\) yields
The linear part of Eq. (18) is
hence \(D{\varvec{W}}\left( 0\right) ={\varvec{Q}}^{-1}\begin{pmatrix}{\varvec{I}}\\ {\varvec{0}} \end{pmatrix}\). The nonlinear part of (18) is
which can be solved by the iteration
Iteration (19) converges for \(\left| {\varvec{z}}\right| \) sufficiently small, due to \(\widetilde{{\varvec{U}}}\) \(\left( {\varvec{x}}\right) ={\mathcal {O}}\left( \left| {\varvec{x}}\right| ^{2}\right) \) and \({\varvec{W}}_{0}\left( {\varvec{z}}\right) ={\mathcal {O}}\left( \left| {\varvec{z}}\right| ^{2}\right) \). \(\square \)
As we will see in Sect. 5, this approach provides better results than using an autoencoder. Here we have resolved the dynamics transversal to the invariant manifold \({\mathcal {M}}\) up to linear order. It is essential to resolve this dynamics to find invariance, not just the location of data points.
Remark 13
More consideration is needed in case \(\hat{{\varvec{U}}}\left( {\varvec{x}}_{k}\right) \) assumes large values over some data points. This either requires to replace \({\varvec{B}}\) with a nonlinear map or we need to filter out data points that are not in a small neighbourhood of the invariant manifold \({\mathcal {M}}\). Due to \({\varvec{B}}\) being high-dimensional, replacing it with a nonlinear map leads to numerical difficulties. Filtering data is easier. For example, we can assign weights to each term in our optimisation problem (7) depending on how far a data point is from the predicted manifold, which is the zero level surface of \(\hat{{\varvec{U}}}\). This can be done using the optimisation problem
where
is the bump function and \(\kappa >0\) determines the size of the neighbourhood of the invariant manifold \({\mathcal {M}}\) that we take into account.
Remark 14
The approximation (16) can be made more accurate if we allow matrix \({\varvec{U}}^{\perp }\) to vary with the parameter of the manifold \({\varvec{z}}={\varvec{U}}\left( {\varvec{x}}\right) \). In this case the encoder becomes
This does increase computational costs, but not nearly as much as if we were calculating a globally accurate invariant foliation. For our example problems, we find that this extension is not necessary.
Remark 15
It is also possible to eliminate a-priori calculation of \({\varvec{U}}\). We can assume that \({\varvec{U}}\) is a linear map, such that \({\varvec{U}}{\varvec{U}}^{\star }={\varvec{I}}\) and treat it as an unknown in representation (15). The assumption that \({\varvec{U}}\) is linear makes sense if we limit ourselves to a small neighbourhood of the invariant manifold \({\mathcal {M}}\) by setting \(\kappa <\infty \) in (20), as we have already assumed a linear dynamics among the leaves of the associated foliation \(\hat{{\mathcal {F}}}\) given by linear map \({\varvec{B}}\). Once \({\varvec{B}}\), \({\varvec{U}},\) \({\varvec{U}}^{\perp }\) and \({\varvec{W}}_{0}\) are found, map \({\varvec{S}}\) can also be fitted to the invariance Eq. (2). The equation to fit \({\varvec{S}}\) to data is
which is a straightforward linear least squares problem, if \({\varvec{S}}\) is linear in its parameters. This approach will be further explored elsewhere.
3 Instantaneous Frequencies and Damping Ratios
Instantaneous damping ratios and frequencies are usually defined with respect to a model that is fitted to data (Jin et al. 2020). Here we take a similar approach and stress that these quantities only make sense in an Euclidean frame and not in the nonlinear frame of an invariant manifold or foliation. The geometry of a manifold or foliation depends on an arbitrary parametrisation; hence, uncorrected results are not unique. Many studies mistakenly use nonlinear coordinate systems, for example one by the present author (Szalai et al. 2017) and colleagues (Breunung and Haller 2018; Ponsioen et al. 2018). Such calculations are only asymptotically accurate near the equilibrium. Here we describe how to correct this error.
We assume a two-dimensional invariant manifold \({\mathcal {M}}\), parametrised by a decoder \({\varvec{W}}\) in polar coordinates \(r,\theta \). The invariance Eq. (3) for the decoder \({\varvec{W}}\) can be written as
Without much thinking (as described in (Szalai et al. 2017; Szalai 2020)), the instantaneous frequency and damping could be calculated as
respectively. The instantaneous amplitude is a norm \(A\left( r\right) =\left\| {\varvec{W}}\left( r,\cdot \right) \right\| _{A}\), for example
where \(\left\langle \cdot ,\cdot \right\rangle _{X}\) is the inner product on vector space X.
The frequency and damping ratio values are only accurate if there is a linear relation between \(\left\| {\varvec{W}}\left( r,\cdot \right) \right\| _{A}\) and r, for example
and the relative phase between two closed curves satisfies
Equation (25) means that the instantaneous amplitude of the trajectories on manifold \({\mathcal {M}}\) is the same as parameter r, hence the map \(r\mapsto R\left( r\right) \) determines the change in amplitude. Equation (26) stipulates that the parametrisation in the angular variable is such that there is no phase shift between the closed curves \({\varvec{W}}\left( r_{1},\cdot \right) \) and \({\varvec{W}}\left( r_{2},\cdot \right) \) for \(r_{1}\ne r_{2}\). If there would be a phase shift \(\gamma \), a trajectory that within a period moves from amplitude \(r_{1}\) to \(r_{2}\), would misrepresent its instantaneous period of vibration by phase \(\gamma \), hence the frequency given by \(T\left( r\right) \) would be inaccurate. In fact, one can set a continuous phase shift \(\gamma \left( r\right) \) among the closed curves \({\varvec{W}}\left( r,\cdot \right) \), such that the frequency given by \(T\left( r\right) \) has a prescribed value. The following result provides accurate values for instantaneous frequencies and damping ratios.
Proposition 16
Assume a decoder \({\varvec{W}}:\left[ 0,r_{1}\right] \times \left[ 0,2\pi \right] \rightarrow X\) and functions \(R,T:\left[ 0,r_{1}\right] \rightarrow {\mathbb {R}}\) such that they satisfy invariance Eq. (21).
-
1.
A new parametrisation \(\tilde{{\varvec{W}}}\) of the manifold generated by \({\varvec{W}}\) that satisfies the constraints (25) and (26) is given by
$$\begin{aligned} \tilde{{\varvec{W}}}\left( r,\theta \right) ={\varvec{W}}\left( t,\theta +\gamma \left( t\right) \right) ,\;t=\kappa ^{-1}\left( r\right) , \end{aligned}$$where
$$\begin{aligned} \gamma \left( r\right)&=-\int _{0}^{r}\frac{\int _{0}^{2\pi }\left\langle D_{1}{\varvec{W}}\left( \rho ,\theta \right) ,D_{2}{\varvec{W}}\left( \rho ,\theta \right) \right\rangle _{X}\textrm{d}\theta }{\int _{0}^{2\pi }\left\langle D_{2}{\varvec{W}}\left( \rho ,\theta \right) ,D_{2}{\varvec{W}}\left( \rho ,\theta \right) \right\rangle _{X}\textrm{d}\theta }\textrm{d}\rho , \end{aligned}$$(27)$$\begin{aligned} \kappa \left( r\right)&=\sqrt{\frac{1}{2\pi }\int _{0}^{2\pi }\left\langle {\varvec{W}}\left( r,\theta \right) ,{\varvec{W}}\left( r,\theta \right) \right\rangle _{X}\textrm{d}\theta } \end{aligned}$$(28)and \(\left\langle \cdot ,\cdot \right\rangle _{X}\) is the inner product on vector space X.
-
2.
The instantaneous natural frequency and damping ratio are calculated as
$$\begin{aligned} \omega \left( r\right)&=T\left( t\right) +\gamma \left( t\right) -\gamma \left( R\left( t\right) \right)&\left[ \textrm{rad}/\textrm{step}\right] , \end{aligned}$$(29)$$\begin{aligned} \zeta \left( r\right)&=-\frac{\log \left[ r^{-1}\kappa \left( R\left( t\right) \right) \right] }{\omega \left( r\right) }&\left[ -\right] . \end{aligned}$$(30)where \(t=\kappa ^{-1}\left( r\right) \).
Proof
A proof is given in “Appendix C”. \(\square \)
Remark 17
The transformed expressions (29), (30) for the instantaneous frequency and damping ratio show that any instantaneous frequency can be achieved for all \(r>0\) if \(R\left( r\right) \ne r\) by choosing appropriate functions \(\rho ,\gamma \). For example, zero frequency is achieved by solving
which is a functional equation. For an \(\epsilon >0\), fix \(\gamma \left( R\left( \epsilon \right) \right) =0\), \(\gamma \left( \epsilon \right) =T\left( \epsilon \right) \) and some interpolating values in the interior of the interval \(\left[ R\left( \epsilon \right) ,\epsilon \right] \), then use contraction mapping to arrive at a unique solution for function \(\gamma \).
Remark 18
The same calculation applies to vector fields, \(\dot{{\varvec{x}}}={\varvec{f}}\left( {\varvec{x}}\right) \), but the final result is somewhat different. Assume a decoder \({\varvec{W}}:\left[ 0,r_{1}\right] \times \left[ 0,2\pi \right] \rightarrow X\) and functions \(R,T:\left[ 0,r_{1}\right] \rightarrow {\mathbb {R}}\) such that they satisfy the invariance equation
The instantaneous natural frequency and damping ratio is calculated by
where \(t=\kappa ^{-1}\left( r\right) \). All other quantities are as in proposition 16. A proof is given in “Appendix C”.
Remark 19
Note that proposition 16 also applies if we create a different measure of amplitude, for example \(\hat{{\varvec{W}}}\left( r,\theta \right) ={\varvec{w}}^{\star }\cdot {\varvec{W}}\left( r,\theta \right) \), where \({\varvec{w}}^{\star }\) is a linear map. Indeed, in the proof we did not use that \({\varvec{W}}\) is a manifold immersion, it only served as Euclidean coordinates of points on the invariant manifold. Hence, the transformed function \(\hat{{\varvec{W}}}\) gives us the same frequencies and damping ratios as \({\varvec{W}}\), but at linearly scaled amplitudes.
The following example illustrates that if a system is linear in a nonlinear coordinate system, we can recover the actual instantaneous damping ratios and frequencies using proposition 16. This is the case of Koopman eigenfunctions (as in remark 8), or normal form transformations where all the nonlinear terms are eliminated.
Example 20
Let us consider the linear map
and the corresponding nonlinear decoder
In terms of the polar invariance Eq. (21), the linear map (33) translates to \(T\left( r\right) =\omega _{0}\) and \(R\left( r\right) =\textrm{e}^{\zeta _{0}\omega _{0}}r\). If we disregard the nonlinearity of \({\varvec{W}}\), the instantaneous frequency and the instantaneous damping ratio of our hypothetical system would be constant, that is \(\omega \left( r\right) =\omega _{0}\) and \(\zeta \left( r\right) =\zeta _{0}\). Using proposition 16, we calculate the effect of \({\varvec{W}}\) and find that
Finally, we plot expressions (29) and (30) in Fig. 6a, b, respectively. It can be seen that frequencies and damping ratios change with the vibration amplitude (red lines), but they are constant without taking the decoder (34) into account (blue lines).
The geometry of the re-parametrisation is illustrated in Fig. 7.


Geometry of the decoder (34). The blue grid represents the polar coordinate system with maximum radius \(r=1\). The red curves are the images of the blue concentric circles under the decoder \({\varvec{W}}\). The red dots are images of the intersection points of the blue circles with the blue radial lines under \({\varvec{W}}\). The red dots do not fall onto the radial blue lines, which indicates a phase shift. The green curves correspond to the images of the blue concentric circles under the re-parametrised decoder \(\tilde{{\varvec{W}}}\) for the same parameters as the red curves. The amplitudes of the green curves are now the same as the amplitude of the corresponding blue curves. Due to the re-parametrisation, there is no phase shift between the black dots and the blue radial lines, on average (Color figure online)
4 ROM Identification Procedures
Here we describe our methodology of finding invariant foliations, manifolds and autoencoders. These steps involve methods described so far and further methods from the appendices. First we start with finding an invariant foliation together with the invariant manifold that has the same dynamics as the foliation.
- F1.:
-
If the data are not from the full state space, especially when it is a scalar signal, we use a state-space reconstruction technique as described in “Appendix B”. At this point we have data points \({\varvec{x}}_{k},{\varvec{y}}_{k}\in X\), \(k=1,\ldots ,N\).
- F2.:
-
To ensure that the solution of (7) converges to the desired foliation, we calculate a linear approximation of the foliation. We only consider a small neighbourhood of the fixed point, where the dynamics is nearly linear. Hence, we define the index set \({\mathcal {I}}_{\rho }=\left\{ k\in \left\{ 1,\ldots ,N\right\} :\left| {\varvec{x}}_{k}\right| <\rho \right\} \) with \(\rho \) sufficiently small, but large enough that it encompasses enough data for linear parameter estimation.
- 1.:
-
First we fit a linear model to the data using a create a least-squares method (Boyd and Vandenberghe 2018). The linear map is assumed to be \({\varvec{y}}_{k}={\varvec{A}}{\varvec{x}}_{k}\), where the coefficient matrix is calculated as
$$\begin{aligned} {\varvec{K}}&=\sum _{k\in {\mathcal {I}}_{\rho }}\left| {\varvec{x}}_{k}\right| ^{-2}{\varvec{x}}_{k}\otimes {\varvec{x}}_{k}^{T},\\ {\varvec{L}}&=\sum _{k\in {\mathcal {I}}_{\rho }}\left| {\varvec{x}}_{k}\right| ^{-2}{\varvec{y}}_{k}\otimes {\varvec{x}}_{k}^{T},\\ {\varvec{A}}&={\varvec{L}}{\varvec{K}}^{-1}. \end{aligned}$$Matrix \({\varvec{A}}\) approximates the Jacobian \(D{\varvec{F}}\left( {\varvec{0}}\right) \), which then can be used to identify the invariant subspaces \(E^{\star }\) and E.
- 2.:
-
The linearised version of foliation invariance (2) and manifold invariance (3) are
$$\begin{aligned} {\varvec{S}}_{1}{\varvec{U}}_{1}&={\varvec{U}}_{1}{\varvec{A}}\;\text {and}\\ {\varvec{W}}_{1}{\varvec{S}}_{1}&={\varvec{A}}{\varvec{W}}_{1}, \end{aligned}$$respectively. We also need to calculate the linearised version of our locally defined foliation (16), that is
$$\begin{aligned} {\varvec{B}}{\varvec{U}}_{1}^{\perp }={\varvec{U}}_{1}^{\perp }{\varvec{A}}. \end{aligned}$$To find the unknown linear maps \({\varvec{U}}_{1}\), \({\varvec{W}}_{1}\), \({\varvec{U}}_{1}^{\perp }\), \({\varvec{S}}_{1}\) and \({\varvec{B}}\) from \({\varvec{A}}\), let us calculate the using real Schur decomposition of \({\varvec{A}}\), that is \({\varvec{A}}{\varvec{Q}}={\varvec{Q}}{\varvec{H}}\) or \({\varvec{Q}}^{T}{\varvec{A}}={\varvec{H}}{\varvec{Q}}^{T}\), where \({\varvec{Q}}\) is unitary and \({\varvec{H}}\) is in an upper Hessenberg matrix, which is zero below the first subdiagonal. The Schur decomposition is calculated (or rearranged) such that the first \(\nu \) column vectors, \({\varvec{q}}_{1},\ldots ,{\varvec{q}}_{\nu }\) of \({\varvec{Q}}\) span the required right invariant subspace E and correspond to eigenvalues \(\mu _{1},\ldots ,\mu _{\nu }\). Therefore we find that \({\varvec{W}}_{1}=\left[ {\varvec{q}}_{1},\ldots ,{\varvec{q}}_{\nu }\right] \). In addition, the last \(n-\nu \) column vectors of \({\varvec{Q}}\), when transposed, define a left-invariant subspace of \({\varvec{A}}\). Therefore we define \({\varvec{U}}_{1}^{\perp }=\left[ {\varvec{q}}_{\nu +1},\ldots ,{\varvec{q}}_{n}\right] ^{T}\) and \({\varvec{B}}_{1}={\varvec{U}}_{1}^{\perp }{\varvec{A}}{\varvec{U}}_{1}^{\perp T}\), which provides the initial guesses \({\varvec{U}}^{\perp }\approx {\varvec{U}}_{1}^{\perp }\) and \({\varvec{B}}\approx {\varvec{B}}_{1}\) in optimisation (20). In order to find the left-invariant subspace of \({\varvec{A}}\) corresponding to the selected eigenvalues, we rearrange the Schur decomposition into \(\hat{{\varvec{Q}}}^{T}{\varvec{A}}=\hat{{\varvec{H}}}\hat{{\varvec{Q}}}^{T}\), where \(\hat{{\varvec{Q}}}=\left[ \hat{{\varvec{q}}}_{1},\ldots ,\hat{{\varvec{q}}}_{n}\right] \) (using ordschur in Julia or Matlab) such that \(\mu _{1},\ldots ,\mu _{\nu }\) now appear last in the diagonal of \(\hat{{\varvec{H}}}\) at indices \(\nu +1,\ldots ,n\). This allows us to define \({\varvec{U}}_{1}=\left[ \hat{{\varvec{q}}}_{n-\nu },\ldots ,\hat{{\varvec{q}}}_{n}\right] ^{T}\) and \({\varvec{S}}_{1}={\varvec{U}}_{1}{\varvec{A}}{\varvec{U}}_{1}^{T}\) which provides the initial guess for \(D{\varvec{U}}\left( {\varvec{0}}\right) ={\varvec{U}}_{1}\) and \(D{\varvec{S}}\left( {\varvec{0}}\right) ={\varvec{S}}_{1}\).
- F3.:
-
We solve the optimisation problem (7) with the initial guess \(D{\varvec{U}}\left( {\varvec{0}}\right) ={\varvec{U}}_{1}\) and \(D{\varvec{S}}\left( {\varvec{0}}\right) ={\varvec{S}}_{1}\) as calculated in the previous step. We also prescribe the constraints that \(D{\varvec{U}}\left( {\varvec{0}}\right) \left( D{\varvec{U}}\left( {\varvec{0}}\right) \right) ^{T}={\varvec{I}}\) and that \({\varvec{U}}\left( {\varvec{W}}_{1}{\varvec{z}}\right) \) is linear in \({\varvec{z}}\). The numerical representation of the encoder \({\varvec{U}}\) is described in “Appendix A.3”.
- F4.:
-
We perform a normal form transformation on map \({\varvec{S}}\) and transform \({\varvec{U}}\) into the new coordinates. The normal form \({\varvec{S}}_{n}\) satisfies the invariance equation \({\varvec{U}}_{n}\circ {\varvec{S}}={\varvec{S}}_{n}\circ {\varvec{U}}_{n}\) (c.f. Equation (2)), where \({\varvec{U}}_{n}:Z\rightarrow Z\) is a nonlinear map. We then replace \({\varvec{U}}\) with \({\varvec{U}}_{n}\circ {\varvec{U}}\) and \({\varvec{S}}\) with \({\varvec{S}}_{n}\) as our ROM. This step is optional and only required if we want to calculate instantaneous frequencies and damping ratios. In a two-dimensional coordinate system, where we have a complex conjugate pair of eigenvalues \(\mu _{1}={\overline{\mu }}_{2}\), the real valued normal form is
$$\begin{aligned} \begin{pmatrix}z_{1}\\ z_{2} \end{pmatrix}_{k+1}=\begin{pmatrix}z_{1}f_{r}\left( z_{1}^{2}+z_{2}^{2}\right) -z_{2}f_{r}\left( z_{1}^{2}+z_{2}^{2}\right) \\ z_{1}f_{i}\left( z_{1}^{2}+z_{2}^{2}\right) +z_{2}f_{r}\left( z_{1}^{2}+z_{2}^{2}\right) \end{pmatrix}, \end{aligned}$$(35)which leads to the polar form (21) with \(R\left( r\right) =r\sqrt{f_{r}^{2}\left( r^{2}\right) +f_{i}^{2}\left( r^{2}\right) }\) and \(T\left( r\right) =\tan ^{-1}\frac{f_{i}\left( r^{2}\right) }{f_{r}\left( r^{2}\right) }\). This normal form calculation is described in Szalai (2020).
- F5.:
-
To find the invariant manifold, we calculate a locally defined foliation (15) and solve the optimisation problem (20) to find the decoder \({\varvec{W}}\) of invariant manifold \({\mathcal {M}}\). The initial guess in problem (20) is such that \({\varvec{U}}^{\perp }={\varvec{U}}_{1}^{\perp }\) and \({\varvec{B}}={\varvec{B}}_{1}\). We also need to set a \(\kappa \) parameter, which is assumed to be \(\kappa =0.2\) throughout the paper. We have found that results are not sensitive to the value of kappa except for extreme choices, such as \(0,\infty \).
- F6.:
-
In case of an oscillatory dynamics in a two-dimensional ROM, we recover the actual instantaneous frequencies and damping ratios using proposition (16).
The procedure for the Koopman eigenfunction calculation is the same as steps F1-F6, except that \({\varvec{S}}\) is assumed to be linear. To identify an autoencoder, we use the same setup as in Cenedese et al. (2022). The numerical representation of the autoencoder is described in “Appendix A.2”. We carry out the following steps
- AE1.:
-
We identify \({\varvec{W}}_{1}\), \({\varvec{S}}_{1}\) as in step F2 and set \({\varvec{U}}={\varvec{W}}_{1}^{T}\) and \(D{\varvec{S}}\left( {\varvec{0}}\right) ={\varvec{S}}_{1}\)
- AE2.:
-
Solve the optimisation problem
$$\begin{aligned} \arg \min _{{\varvec{U}},{\varvec{W}}_{nl}}\sum _{k=1}^{N}\left\| {\varvec{y}}_{k}\right\| ^{-2}\left\| {\varvec{W}}\left( {\varvec{U}}{\varvec{y}}_{k}\right) -{\varvec{y}}_{k}\right\| ^{2}, \end{aligned}$$which tries to ensure that \({\varvec{W}}\circ {\varvec{U}}\) is the identity, and finally solve
$$\begin{aligned} \arg \min _{{\varvec{S}}}\sum _{k=1}^{N}\left\| {\varvec{x}}_{k}\right\| ^{-2}\left\| {\varvec{W}}\left( {\varvec{S}}\left( {\varvec{U}}\left( {\varvec{x}}_{k}\right) \right) \right) -{\varvec{y}}_{k}\right\| ^{2}. \end{aligned}$$ - AE3.:
-
Perform a normal form transformation on \({\varvec{S}}\) by seeking the simplest \({\varvec{S}}_{n}\) that satisfies \({\varvec{W}}_{n}\circ {\varvec{S}}_{n}={\varvec{S}}\circ {\varvec{W}}_{n}\). This is similar to step F4, except that the normal form is in the style of the invariance equation of a manifold (3).
- AE4.:
-
Same as step F6, but applied to nonlinear map \({\varvec{S}}_{n}\) and decoder \({\varvec{W}}\circ {\varvec{W}}_{n}\).
5 Examples
We are considering three examples. The first is a caricature model to illustrate all the techniques discussed in this paper and why certain techniques fail. The second example is a series of synthetic data sets with higher dimensionality, to illustrate the methods in more detail using a polynomial representations of the encoder with HT tensor coefficients (see “Appendix A.3”). This example also illustrates two different methods to reconstruct the state space of the system from a scalar measurement. The final example is a physical experiment of a jointed beam, where only a scalar signal is recorded and we need to reconstruct the state space with our previously tested technique.
5.1 A Caricature Model
To illustrate the performance of autoencoders, invariant foliations and locally defined invariant foliations, we construct a simple two-dimensional map \({\varvec{F}}\) with a node-type fixed point using the expression
where
the near-identity coordinate transformation is
and the state vector is defined as \({\varvec{x}}=\left( x_{1},x_{2}\right) \). In a neighbourhood of the origin, transformation \({\varvec{V}}\) has a unique inverse, which we calculate numerically. Map \({\varvec{F}}\) is constructed such that we can immediately identify the smoothest (hence unique) invariant manifolds corresponding to the two eigenvalues of \(D{\varvec{F}}\left( 0\right) \) as
We can also calculate the leaves of the two invariant foliations as
To test the methods, we created 500 times 30 points long trajectories with initial conditions sampled from a uniform distribution over the rectangle \(\left[ -\frac{4}{5},\frac{4}{5}\right] \times \left[ -\frac{1}{4},-\frac{1}{4}\right] \) to fit our ROM to.
We first attempt to fit an autoencoder to the data. We assume that the encoder, decoder and the nonlinear map \({\varvec{S}}\) are
where \(\lambda ,h\) are polynomials of order-5. Our expressions already contain the invariant subspace \(E=\textrm{span}\left( 1,0\right) ^{T}\), which should make the fitting easier. Finally, we solve the optimisation problem (8). The result of the fitting can be seen in Fig. 8a as depicted by the red curve. The fitted curve is more dependent on the distribution of data than the actual position of the invariant manifold, which is represented by the blue dashed line in Fig. 8a. Various other expressions for \({\varvec{U}}\) and \({\varvec{W}}\) were also tried that do not assume the direction of the invariant subspace E with similar results.
To calculate the invariant foliation in the horizontal direction, we assume that
where u is an order-5 polynomial which lacks the constant and linear terms. The exact expression of \({\varvec{U}}\) is not a polynomial, because it is the second coordinate of the inverse of function \({\varvec{V}}\). The fitting is carried out by solving the optimisation problem (7). The result can be seen in Fig. 8b, where the red curves are contour plots of the identified encoder \({\varvec{U}}\) and the dashed blue lines are the leaves as defined by Eq. (37). Figure 8c is produced in the same way as Fig. 8b, except that the encoder is defined as \({\varvec{U}}\left( x_{1},x_{2}\right) =x_{2}+h\left( x_{1},x_{2}\right) \) and the blue lines are the leaves given by (38).

Identifying invariant objects in Eq. (36). The data contain 500 trajectories of length 30 with initial conditions picked from a uniform distribution; a fitting an autoencoder (red continuous curve) does not reproduce the invariant manifold (blue dashed curve), instead it follows the distribution of data; b invariant foliation in the horizontal direction; c invariant foliation in the vertical direction; d an invariant manifold is calculated as the leaf of a locally defined invariant foliation. The green line is the invariant manifold. Each diagram represents the box \(\left[ -\frac{4}{5},\frac{4}{5}\right] \times \left[ -\frac{1}{4},-\frac{1}{4}\right] \); the axes labels are intentionally hidden (Color figure online)
As we have discussed in Sect. 2.2, a locally defined encoder can also be constructed from a decoder. In the expression of the encoder (15) we take
and \({\varvec{U}}^{\perp }=\left( 0,1\right) \), where h is an order-9 polynomial without constant and linear terms. The expressions for \({\varvec{U}}\) and \({\varvec{S}}\) were already found as (42), hence our approximate encoder becomes
We solve the optimisation problem (20) with \(\kappa =0.13\). We do not reconstruct the decoder \({\varvec{W}}\), as it is straightforward to plot the level surfaces of \(\hat{{\varvec{U}}}\) directly. The result can be seen in Fig. 8d, where the green line is the approximate invariant manifold (the zero level surface of \(\hat{{\varvec{U}}}\)) and the red lines are other level surfaces of \(\hat{{\varvec{U}}}\).
In conclusion, this simple example shows that only invariant foliations can be fitted to data and autoencoders give spurious results.
5.2 A Ten-Dimensional System
To create a numerically challenging example, we construct a ten-dimensional differential equation from five decoupled second-order nonlinear oscillators using two successive coordinate transformations. The system of decoupled oscillators is denoted by \(\dot{{\varvec{x}}}={\varvec{f}}_{0}\left( {\varvec{x}}\right) \), where the state variable is in the form of
and the dynamics is given by
The first transformation brings the polar form of Eq. (43) into Cartesian coordinates using the transformation \({\varvec{y}}={\varvec{g}}\left( {\varvec{x}}\right) \), which is defined by \(y_{2k-1}=r_{k}\cos \theta _{k}\) and \(y_{2k}=r_{k}\sin \theta _{k}\). Finally, we couple all variables using the second nonlinear transformation \({\varvec{y}}={\varvec{h}}\left( {\varvec{z}}\right) \), which reads
and where \({\varvec{y}}=\left( y_{1},\ldots ,y_{10}\right) \) and \({\varvec{z}}=\left( z_{1},\ldots ,z_{10}\right) \). The two transformations give us the differential equation \(\dot{{\varvec{z}}}={\varvec{f}}\left( {\varvec{z}}\right) \), where
The natural frequencies of our system at the origin are
and the damping ratios are the same \(\zeta _{1}=\cdots =\zeta _{5}=1/500\).
We select the first natural frequency to test various methods. We also test the methods on three types of data. Firstly, full state space information is used, secondly the state space is reconstructed from the signal \(\xi _{k}=\frac{1}{10}\sum _{j=1}^{10}z_{k,j}\) using principal component analysis (PCA) as described in “Appendix B.1” with 16 PCA components, and finally the state space is reconstructed from \(\xi _{k}\) using a discrete Fourier transform (DFT) as described in “Appendix B.2”. When data are recorded in state space form, 1000 trajectories 16 points long each with time step \(\Delta T=0.1\) were created by numerically solving (45). Initial conditions were sampled from unit balls of radius 0.8, 1.0, 1.2 and 1.4 about the origin. The Euclidean norm of the initial conditions was uniformly distributed. The four data sets are labelled ST-1, ST-2, ST-3, ST-4 in the diagrams. For state space reconstruction, 100 trajectories, 3000 points each, with time step \(\Delta T=0.01\) were created by numerically solving (45). The initial conditions for these data were similarly sampled from unit balls of radius 0.8, 1.0, 1.2 and 1.4 about the origin, such that the Euclidean norm of the initial conditions are uniformly distributed. The PCA reconstructed data are labelled PCA-1, PCA-2, PCA-3, PCA-4, and the DFT reconstructed data are labelled DFT-1, DFT-2, DFT-3, DFT-4.
The amplitude for each ROM is calculated as \(A\left( r\right) =\sqrt{\frac{1}{2\pi }\int \left( {\varvec{w}}^{\star }\cdot {\varvec{W}}\left( r,\theta \right) \right) ^{2}\textrm{d}\theta }\), where \({\varvec{w}}^{\star }=\frac{1}{10}\left( 1,1,\ldots ,1\right) \) for the state-space data and \({\varvec{w}}^{\star }\) is calculated in “Appendices B.1, B.2” when state-space reconstruction is used. We can also attach an amplitude to each data point \({\varvec{x}}_{k}\) through the encoder and the decoder. If the ROM assumes the normal form (35), the radial parameter r is simply calculated as \(r_{k}=\left\| {\varvec{U}}\left( {\varvec{x}}_{k}\right) \right\| \), hence the amplitude is \(A\left( r_{k}\right) \).

Instantaneous frequencies and damping ratios of differential Eq. (45) using invariant foliations. The first column shows the data density with respect to the amplitude \(A\left( r\right) \), the second column is the instantaneous frequency and the third column is the instantaneous damping. The first row corresponds to state space data, the second row shows PCA reconstructed data, and the third row is DFT reconstructed data. The data density is controlled by sampling initial conditions from different sized neighbourhoods of the origin

Histograms of the fitting error (46) for the data sets ST-1, PCA-1 and DFT-1 as a function of vibration amplitude. The distribution appears uniform with respect to the amplitude
Figure 9 shows the result of our calculation for the three types of data. In the first column data density is displayed with respect to amplitude \(A\left( r\right) \) in the ROM. Lower amplitudes have higher densities, because trajectories exponentially converge to the origin. In Fig. 9 we also display the identified instantaneous frequencies and damping ratios. The results are then compared to the analytically calculated frequencies and damping ratios labelled by VF.
State space data give the closest match to the analytical reference (labelled as VF). We find that the PCA method cannot embed the data in a 10-dimesional space, only an 16-dimensional embedding is acceptable, but still inaccurate. Using a perfect reproducing filter bank (DFT) yields better results, probably because the original signal can be fully reconstructed and we expect a correct state-space reconstruction at small amplitudes. Indeed, the PCA results diverge at higher amplitudes, where the state space reconstruction is no longer valid. The author has also tried non-optimal delay embedding, with inferior results. None of the techniques had any problem with the less the challenging Shaw-Pierre example (Shaw and Pierre 1994; Szalai 2020) (data not shown).
Figure 10 shows the accuracy of the data fit as a function of the amplitude \(A\left( r\right) \). The relative error displayed is defined by
It turns out that the error is roughly independent of the amplitude, except for data set ST-1, which has lower errors at low amplitudes. The accuracy is the highest for state space data, while the accuracy of the DFT reconstructed data is slightly worse than for the PCA reconstructed data. In contrast, the comparison with the analytically calculated result is worse for the PCA data than for the DFT data. The reason is that PCA reconstruction cannot exactly reproduce the original signal from the identified components while the DFT method can.

ROM by Koopman eigenfunctions. The same quantities are calculated as in Fig. 9, except that map \({\varvec{S}}\) is assumed to be linear. There is some variation in the frequencies and damping ratios with respect to the amplitude due to the corrections in Sect. 3, but accurate values could not be recovered as the linear approximation does not account for near internal resonances, as in formula (12)
When restricting map \({\varvec{S}}\) to be linear, we are identifying Koopman eigenfunctions. Despite that linear dynamics is identified we should be able to reproduce the nonlinearities as illustrated in Sect. 3. However, we also have near internal resonances as per Eq. (12), which make certain terms of encoder \({\varvec{U}}\) large, which are difficult to find by optimisation. The result can be seen in Fig. 11. The identified frequencies and damping ratios show little variation with amplitude and mostly capture the average of the reference values. Fitting the Koopman eigenfunction achieves maximum and average values of \(E_{rel}\) at \(8.66\%\) and \(0.189\%\) over data set ST-1, respectively. Better accuracy could be achieved using higher rank HT tensor coefficients in the encoder, which would significantly increase the number of model parameters. In contrast, fitting the invariant foliation to the same data set yields maximum and the average values of \(E_{rel}\) at \(2.21\%\) and \(0.0118\%\), respectively (also illustrated in Fig. 10a). This better accuracy is achieved with a small number of extra parameters that make the two-dimensional map \({\varvec{S}}\) nonlinear.

Data analysis by autoencoder. An autoencoder can recover system dynamics if all data are on the invariant manifold. For the solid line MAN, data were artificially forced to be on an a-priori calculated invariant manifold. However if the data are not on an invariant manifold, such as for data set ST-1, the autoencoder calculation is meaningless. The dotted line VF-1 represents the analytic calculation for the first natural frequency, and the dash-dotted VF-2 depicts the analytic calculation for the second natural frequency of vector field (45)
Knowing that autoencoders are only useful if all the dynamics is on the manifold, we have synthetically created data consisting of trajectories with initial conditions from the invariant manifold of the first natural frequency. We used 800 trajectories, 24 points each with time-step \(\Delta t=0.2\) starting on the manifold. Fitting an autoencoder to these data yields a good match in Fig. 12, the corresponding lines are labelled MAN. Then we tried dataset ST-1, that matched the reference best when calculating an invariant foliation. However, our data do not lie on a manifold and it is impossible to make \({\varvec{W}}\circ {\varvec{U}}\) close to the identity on our data. In fact the result (blue dashed line) is closer to the second mode of vibration (green dash-dotted curve), which seems to be the dominant vibration of the system.
5.3 Jointed Beam
It is challenging to accurately model mechanical friction; hence data-oriented methods can play a huge role in identifying dynamics affected by frictional forces. Therefore we analyse the data published in Titurus et al. (2016). The experimental setup can be seen in Fig. 13. The two halves of the beam were joined together with an M6 bolt. The two interfaces of the beams were sandblasted to increase friction, and a polished steel plate was placed between them; finally the bolt was tightened using four different torques: minimal torque so that the beam does not collapse under its own weight (denoted as 0 Nm), 1 Nm, 2.1 Nm and 3.1 Nm. The free vibration of the steel beam was recorded using an accelerometer placed at the end of the beam. The vibration was initiated using an impact hammer at the position of the accelerometer. Calibration data for the accelerometer are not available. For each torque value a number of 20 s long signals were recorded with sampling frequency of 2048 Hz. The impacts were of different magnitude so that the amplitude dependency of the dynamics could be tracked. In Titurus et al. (2016), a linear model was fitted to each signal and the first five vibration frequencies and damping ratios were identified. These are represented by various markers in Fig. 14. In order to make a connection between the peak impact force and the instantaneous amplitude we also calculated the peak root mean square (RMS) amplitude for signals with the largest impact force for each tightening torque and found that the average conversion factor between the peak RMS amplitude and the peak impact force was 443, which we used to divide the peak force and plot the equivalent peak RMS in Fig. 14. We also band filtered each trajectory with a 511 point FIR filter with 3 dB points at 30 Hz and 75 Hz and estimated the instantaneous frequency and damping ratios from two consecutive vibration cycles, which are then drawn as thick semi-transparent lines in Fig. 14 for each trajectory. It is worth noting that the more friction there is in the system, the less reproducible the frequencies and damping ratios become when using short trajectory segments for estimation.

a Experimental setup. b Schematic of the jointed beam. The width of the beam (not shown) is 25 mm. All measurements are in millimetres
To calculate the invariant foliation we used a 10-dimensional DFT reconstructed state space, to include all five captured frequencies, as described is “Appendix B.2”. We chose \(\kappa =0.2\) in the optimisation problem (20) when finding the invariant manifold. The result can be seen in Fig. 14. Since we do not have the ground truth for this system, it is not possible to tell which method is more accurate, especially that our naive alternative calculation (thick semi-transparent lines) displays a wide spread of results.

Instantaneous frequencies and damping ratios of the jointed beam set-up in Fig. 13. Solid red lines correspond to the invariant foliation of the system with minimal tightening torque, blue dashed lines with tightening torque of 2.1 Nm and green dotted lines with tightening torque of 3.1 Nm. The markers of the same colour show results calculated in Titurus et al. (2016) using curve fitting. a Data density with respect to amplitude \(A\left( r\right) \), b instantaneous frequency, c instantaneous damping ratio (Color figure online)

The fitting error to the invariant foliation can be assessed from the histograms in Fig. 15. The distribution of the error is very similar to the synthetic model, which is nearly uniform with respect to the vibration amplitude. It is also clear that there is no real difference in the fitting error for different tightening torques, which indicates that frictional dynamics can be accurately characterised using invariant foliations.
As a final test, we also assess whether the measured signal is reproduced by the invariant foliation \(\left( {\varvec{U}},{\varvec{S}}\right) \) in Fig. 16. For this we apply the encoder \({\varvec{U}}\) to our original signal \({\varvec{x}}_{k}\), \(k=1,\ldots ,N\) and compare this signal to the one produced by the recursion \({\varvec{z}}_{k+1}={\varvec{S}}\left( {\varvec{z}}_{k}\right) \), where \({\varvec{z}}_{1}={\varvec{U}}\left( {\varvec{x}}_{1}\right) \). The instantaneous amplitude error in both cases of Fig. 16a, c was mostly due to high frequency oscillations that was not completely filtered out by the encoder \({\varvec{U}}\) at the high amplitudes. The phase error seemed to have only accumulated for the lowest tightening torque (0 Nm) in Fig. 16b. This is to be expected over long trajectories, since the fitting procedure only minimises the prediction error for a single time step. Unfortunately, accumulating phase error is rarely shown in the literature, where only short trajectories are compared, in contrast to the 28685 and 25149 time-steps that are displayed in Fig. 16b, d, respectively.

Reconstruction error of the foliation. a, b Reconstructing the first signal of the series of experimental data with 0 Nm tightening torque. c, d Reconstructing the first signal of the series of experimental data with 3.1 Nm tightening torque. The compared values are calculated through the encoder \({\varvec{z}}={\varvec{U}}\left( {\varvec{x}}_{k}\right) \) and the reconstructed values are from the iteration \({\varvec{z}}_{k+1}={\varvec{S}}\left( {\varvec{z}}_{k}\right) \). The amplitude error (\(\left\| {\varvec{z}}\right\| \)) is minimal; however, over time phase error accumulates; hence direct comparison of a coordinate (\(z_{1}\)) can look unfavourable
6 Discussion
The main conclusion of this study is that only invariant foliations are suitable for ROM identification from off-line data. Using an invariant foliation avoids the need to use resonance decay (Ehrhardt and Allen 2016), or waiting for the signal to settle near the most attracting invariant manifold (Cenedese et al. 2022), thereby throwing away valuable data. Using invariant foliations can make use of unstructured data with arbitrary initial conditions, such as impact hammer tests. Invariant foliations produce genuine ROMs and not only parametrise a-priori known invariant manifolds, like other methods (Cenedese et al. 2022; Champion et al. 2019; Yair et al. 2017). We have shown that the high-dimensional function required to represent an encoder can be represented by polynomials with compressed tensor coefficients, which significantly reduces the computational and memory costs. Compressed tensors are also amenable to further analysis, such as singular value decomposition (Grasedyck 2010), which gives way to mathematical interpretations of the decoder \({\varvec{U}}\). The low-dimensional map \({\varvec{S}}\) is also amenable to normal form transformations, which can be used to extract information such as instantaneous frequencies and damping ratios.
We have tested the related concept of Koopman eigenfunctions, which differs from an invariant foliation in that map \({\varvec{S}}\) is assumed to be linear. If there are no internal resonances, Koopman eigenfunctions are theoretically equivalent to invariant foliations. However in numerical settings unresolved near internal resonances become important and therefore Koopman eigenfunctions become inadequate. We have also tried to fit autoencoders to our data (Cenedese et al. 2022), but apart from the artificial case where the invariant manifold was pre-computed, it performed even worse than Koopman eigenfunctions.
Fitting an invariant foliation to data is extremely robust when state space data are available. However, when the state space needed to be reproduced from a scalar signal, the results were not as accurate as we hoped for. While Takens’ theorem allows for any generic delay coordinates, in practice a non-optimal choice can lead to poor results. We were expecting that the embedding dimension at least for low-amplitude signals would be the same as the attractor dimension. This is, however, not true if the data also include higher amplitude points. Despite not being theoretically optimal, we have found that perfect reproducing filter banks produce accurate results for low-amplitude signals and at the same time provide a state-space reconstruction with the same dimensionality as that of the attractor. Future work should include exploring various state-space reconstruction techniques in combination with fitting an invariant foliation to data.
We did not fully explore the idea of locally defined invariant foliations in remark 15, which can lead to computationally efficient methods. Further research can also be directed towards cases, where the data are on a high-dimensional submanifold of an even higher-dimensional vector space X. This is where an autoencoder and invariant foliation may be combined.
Data Availability
The datasets generated and/or analysed during the current study are available in the FMA repository, https://github.com/rs1909/FMA.
References
Absil, P.A., Mahony, R., Sepulchre, R.: Optimization Algorithms on Matrix Manifolds. Princeton University Press (2009)
Absil, P.A., Malick, J.: Projection-like retractions on matrix manifolds. SIAM J. Optim. 22(1), 135–158 (2012)
Barton, D.A.W.: Control-based continuation: bifurcation and stability analysis for physical experiments. Mech. Syst. Signal Process. 84, 54–64 (2017)
Bellman, R.E.: Adaptive Control Processes. Princeton University Press (2015)
Bergmann, R.: Manopt.jl: optimization on manifolds in Julia. J. Open Source Softw. 7(70), 3866 (2022)
Beyn, W.-J., Thümmler, V.: Phase Conditions, Symmetries and PDE Continuation, pp. 301–330. Springer, Dordrecht (2007)
Billings, S.A.: Nonlinear System Identification: “NARMAX” Methods in the Time, Frequency, and Spatio-Temporal Domains. Wiley (2013)
Boumal, N.L: An introduction to optimization on smooth manifolds. To appear with Cambridge University Press (2022)
Boyd, S., Vandenberghe, L.: Introduction to Applied Linear Algebra: Vectors, Matrices, and Least Squares. Cambridge University Press (2018)
Breunung, T., Haller, G.: Explicit backbone curves from spectral submanifolds of forced-damped nonlinear mechanical systems. Proc. R. Soc. Lond. A Math. Phys. Eng. Sci. 474(2213), 20180083 (2018)
Broomhead, D.S., King, G.P.: Extracting qualitative dynamics from experimental data. Physica D 20(2), 217–236 (1986)
Brunton, S.L., Tu, J.H., Bright, I., Kutz, J.N.: Compressive sensing and low-rank libraries for classification of bifurcation regimes in nonlinear dynamical systems. SIAM J. Appl. Dyn. Syst. 13(4), 1716–1732 (2014)
Brunton, S.L., Proctor, J.L., Kutz, J.N., Bialek, W.: Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc. Natl. Acad. Sci. U.S.A. 113(15), 3932–3937 (2016)
Cabré, X., Fontich, E., de la Llave, R.: The parameterization method for invariant manifolds I: manifolds associated to non-resonant subspaces. Indiana Univ. Math. J. 52, 283–328 (2003)
Cabré, X., Fontich, E., de la Llave, R.: The parameterization method for invariant manifolds iii: overview and applications. J. Differ. Equ. 218(2), 444–515 (2005)
Casdagli, M.: Nonlinear prediction of chaotic time series. Physica D 35(3), 335–356 (1989)
Cenedese, M., Axås, J., Bäuerlein, B., Avila, K., Haller, G.: Data-driven modeling and prediction of non-linearizable dynamics via spectral submanifolds. Nat. Commun. 13, 872 (2022)
Champion, K., Lusch, B., Nathan Kutz, J., Brunton, S.L.: Data-driven discovery of coordinates and governing equations. Proc. Natl. Acad. Sci. U.S.A. 116(45), 22445–22451 (2019)
Coifman, R.R., Lafon, S.: Diffusion maps. Appl. Comput. Harmon. Anal. 21(1), 5–30 (2006)
Conn, A.R., Gould, N.I.M., Toint, P.L.: Trust Region Methods. MPS-SIAM Series on Optimization. SIAM (2000)
de la Llave, R.: Invariant manifolds associated to nonresonant spectral subspaces. J. Stat. Phys. 87(1), 211–249 (1997)
Donoho, D.L.: Compressed sensing. IEEE Trans. Inf. Theory 52(4), 1289–1306 (2006)
Ehrhardt, D.A., Allen, M.S.: Measurement of nonlinear normal modes using multi-harmonic stepped force appropriation and free decay. Mech. Syst. Signal Process. 76–77, 612–633 (2016)
Elbrachter, D., Perekrestenko, D., Grohs, P., Bolcskei, H.: Deep neural network approximation theory. IEEE Trans. Inf. Theory 67(5), 2581–2623 (2021)
Fenichel, N.: Persistence and smoothness of invariant manifolds for flows. Indiana Univ. Math. J. 21, 193–226 (1972)
Grasedyck, L.: Hierarchical singular value decomposition of tensors. SIAM J. Matrix Anal. Appl. 31(4), 2029–2054 (2010)
Grasedyck, L., Kressner, D., Tobler, C.: A literature survey of low-rank tensor approximation techniques. GAMM-Mitteilungen 36(1), 53–78 (2013)
Hackbusch, W., Kühn, S.: A new scheme for the tensor representation. J. Fourier Anal. Appl. 15, 706–722 (2009)
Haller, G., Ponsioen, S.: Nonlinear normal modes and spectral submanifolds: existence, uniqueness and use in model reduction. Nonlinear Dyn. 86(3), 1493–1534 (2016)
Hermann, R., Krener, A.: Nonlinear controllability and observability. IEEE Trans. Autom. Control 22(5), 728–740 (1977)
Hornik, K.: Approximation capabilities of multilayer feedforward networks. Neural Netw. 4(2), 251–257 (1991)
Jin, M., Chen, W., Brake, M.R.W., Song, H.: Identification of instantaneous frequency and damping from transient decay data. J. Vib. Acoust. Trans. ASME 142(5), 051111 (2020)
Kalia, M., Brunton, S.L., Meijer, H.G.E., Brune, C., Kutz, J.N.: Learning normal form autoencoders for data-driven discovery of universal,parameter-dependent governing equations (2021)
Kevrekidis, I.G., Gear, C.W., Hyman, J.M., Kevrekidis, P.G., Runborg, O., Theodoropoulos, C.: Equation-free, coarse-grained multiscale computation: enabling microscopic simulators to perform system-level analysis. Commun. Math. Sci. 1(4), 715–762 (2003)
Kevrekidis, I.G., Samaey, G.: Equation-free multiscale computation: algorithms and applications. Annu. Rev. Phys. Chem. 60(1), 321–344 (2009)
Kramer, M.A.: Nonlinear principal component analysis using autoassociative neural networks. AIChE J. 37(2), 233–243 (1991)
Lang, S.: Fundamentals of Differential Geometry. Graduate Texts in Mathematics. Springer, New York (2012)
Lawson, H.B., Jr.: Foliations. Bull. Am. Math. Soc. 80, 369–418 (1974)
Mezić, I.: Spectral properties of dynamical systems, model reduction and decompositions. Nonlinear Dyn. 41(1–3), 309–325 (2005)
Mezić, I.: Koopman operator, geometry, and learning of dynamical systems. Not. Am. Math. Soc. 68(7), 1087–1105 (2021)
Nutini, J., Schmidt, M., Laradji, I.H., Friedlander, M., Koepke, H.: Coordinate descent converges faster with the gauss-southwell rule than random selection. In: Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37, ICML’15, pp. 1632–1641 (2015)
Orr, G.B., Müller, K.R.: Neural Networks: Tricks of the Trade. Lecture Notes in Computer Science. Springer, Berlin (2003)
Ortega, J.M., Ortega, J.R.W., Rheinboldt, W.C.: Iterative Solution of Nonlinear Equations in Several Variables. Classics in Applied Mathematics. SIAM (1970)
Oseledets, I.V.: Tensor-train decomposition. SIAM J. Sci. Comput. 33(5), 2295–2317 (2011)
Pecora, L.M., Moniz, L., Nichols, J., Carroll, T.L.: A unified approach to attractor reconstruction. Chaos Interdiscip. J. Nonlinear Sci. 17(1), 013110 (2007)
Perez-Garcia, D., Verstraete, F., Wolf, M.M., Cirac, J.I.: Matrix product state representations. Quantum Info. Comput. 7(5), 401–430 (2007)
Petersen, P., Raslan, M., Voigtlaender, F.: Topological properties of the set of functions generated by neural networks of fixed size. Found. Comput. Math. 21(2), 375–444 (2021)
Ponsioen, S., Pedergnana, T., Haller, G.: Automated computation of autonomous spectral submanifolds for nonlinear modal analysis. J. Sound Vib. 420, 269–295 (2018)
Read, N.K., Ray, W.H.: Application of nonlinear dynamic analysis to the identification and control of nonlinear systems - iii. n-dimensional systems. J. Process Control 8(1), 35–46 (1998)
Roberts, A.J.: Appropriate initial conditions for asymptotic descriptions of the long-term evolution of dynamical systems. J. Aust. Math. Soc. Ser. B 31, 48–75 (1989)
Roberts, A.J.: Boundary conditions for approximate differential equations. J. Aust. Math. Soc. Ser. B 34, 54–80 (1992)
Shaw, S.W., Pierre, C.: Normal-modes of vibration for nonlinear continuous systems. J. Sound Vib. 169(3), 319–347 (1994)
Sieber, J., Krauskopf, B.: Control based bifurcation analysis for experiments. Nonlinear Dyn. 51, 365–377 (2008)
Strang, G., Nguyen, T.: Wavelets and Filter Banks. Wellesley-Cambridge Press (1996)
Szalai, R.: Invariant spectral foliations with applications to model order reduction and synthesis. Nonlinear Dyn. 101(4), 2645–2669 (2020)
Szalai, R., Ehrhardt, D., Haller, G.: Nonlinear model identification and spectral submanifolds for multi-degree-of-freedom mechanical vibrations. Proc. R. Soc. A 473, 20160759 (2017)
Takens, F.: Detecting strange attractors in turbulence. In: Rand, D., Young, L.-S. (eds.) Dynamical Systems and Turbulence, Warwick 1980, pp. 366–381. Springer, Berlin (1981)
Tenenbaum, J.B., De Silva, V., Langford, J.C.: A global geometric framework for nonlinear dimensionality reduction. Science 290(5500), 2319–2323 (2000)
Titurus, B., Yuan, J., Scarpa, F., Patsias, S., Pattison, S.: Impact hammer-based analysis of nonlinear effects in bolted lap joint. In: Proceedings of ISMA2016 including USD2016, ISMA2016, pp. 789–802 (2016)
Uschmajew, A., Vandereycken, B.: The geometry of algorithms using hierarchical tensors. Linear Algebra Appl. 439(1), 133–166 (2013)
Vizzaccaro, A., Shen, Y., Salles, L., Blahoš, J., Touzé, C.: Direct computation of nonlinear mapping via normal form for reduced-order models of finite element nonlinear structures. Comput. Methods Appl. Mech. Eng. 384, 113957 (2021)
Whitney, H.: Differentiable manifolds. Ann. Math. 37(3), 645–680 (1936)
Wolpert, D.H., Macready, W.G.: No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1(1), 67–82 (1997)
Yair, O., Talmon, R., Coifman, R.R., Kevrekidis, I.G.: Reconstruction of normal forms by learning informed observation geometries from data. Proc. Natl. Acad. Sci. U.S.A. 114(38), E7865–E7874 (2017)
Acknowledgements
I would like to thank Branislaw Titurus for supplying the data of the jointed beam. I would also like to thank Sanuja Jayatilake, who helped me collect more data on the jointed beam, which eventually was not needed in this study. Discussions with Alessandra Vizzaccaro, David Barton and his research group provided great inspiration to complete this research. A.V. has also commented on a draft of this manuscript.
Author information
Authors and Affiliations
Contributions
The author carried out all the work related to the manuscript, including, but not limited to design of the research, writing the paper, preparing figures and writing the necessary computer code.
Corresponding author
Ethics declarations
Conflict of interest
The author has no relevant financial or non-financial interests to disclose. No funds, grants, or other support was received.
Additional information
Communicated by Paul Newton.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Implementation details
In this appendix we deal with how to represent invariant foliations, locally defined invariant foliations and autoencoders. We also describe our specific techniques to carry out optimisation on these representations.
1.1 Dense Polynomial Representation
The nonlinear map \({\varvec{S}}\), the polynomial part of the locally defined invariant foliation \({\varvec{W}}_{0}\) and the decoder part an autoencoder are represented by dense polynomials, that we define here.
A polynomial \({\varvec{P}}:Z\rightarrow X\) of order d is represented as a linear combination of monomials formed from the coordinates of vectors of Z. First we define what we mean by a monomial and how we order them. Given a basis in Z with \(\nu =\dim Z\), we can represent each vector \({\varvec{z}}\in Z\) by \({\varvec{z}}=\left( z_{1},z_{2},\ldots ,z_{\nu }\right) \). Then we define non-negative integer vectors \({\varvec{m}}=\left( m_{1},\ldots ,m_{\nu }\right) \in {\mathbb {N}}^{\nu }\) and finally define a monomial of \({\varvec{z}}\) by \({\varvec{z}}^{{\varvec{m}}}=z_{1}^{m_{1}}z_{2}^{m_{2}}\cdots z_{\nu }^{m_{\nu }}\). We also need an ordered set of integer exponents, which is denoted by
The ordering of \({\mathfrak {M}}_{c,d}\) is such that \({\varvec{m}}<{\varvec{n}}\) if there exists \(k\le \nu \) and \(m_{j}<n_{j}\) for all \(j=1,\ldots ,k\). The cardinality of set \({\mathfrak {M}}_{c,d}\) is denoted by \(\#\left( \nu ,c,d\right) \). Therefore we can also write that \({\mathfrak {M}}_{c,d}=\left\{ {\varvec{m}}_{1},{\varvec{m}}_{2},\ldots ,{\varvec{m}}_{\#\left( \nu ,c,d\right) }\right\} \). Using the ordered notation of monomials, a polynomial \({\varvec{P}}\) containing terms at least order c up to order-d is represented by a matrix \(\underline{{\varvec{P}}}\in {\mathbb {R}}^{n\times \#\left( \nu ,c,d\right) }\), such that
We also call such polynomials order-\(\left( c,d\right) \) polynomials. For optimisation purposes order-\(\left( c,d\right) \) polynomials form an Euclidean manifold and therefore no constraint is placed on matrix \(\underline{{\varvec{P}}}\).
1.2 Autoencoder Representation
A polynomial autoencoder of order d (as defined in Cenedese et al. 2022) is represented by an orthogonal matrix \(\underline{{\varvec{U}}}\in {\mathbb {R}}^{n\times \nu }\) (\(\underline{{\varvec{U}}}^{T}\underline{{\varvec{U}}}={\varvec{I}}\)) and an order-\(\left( 2,d\right) \) polynomial \({\varvec{W}}\), represented by matrix \(\underline{{\varvec{W}}}\in {\mathbb {R}}^{n\times \#\left( \nu ,2,d\right) }\). The associated encoder is given by \({\varvec{U}}\left( {\varvec{x}}\right) =\underline{{\varvec{U}}}^{T}{\varvec{x}}\) and the decoder is given by \({\varvec{W}}\left( {\varvec{z}}\right) ={\varvec{U}}{\varvec{z}}+{\varvec{W}}\left( {\varvec{z}}\right) \), which must satisfy the additional constraint \({\varvec{U}}\left( {\varvec{W}}\left( {\varvec{z}}\right) \right) ={\varvec{z}}\), that in terms of our matrices means \(\underline{{\varvec{U}}}^{T}\underline{{\varvec{W}}}={\varvec{0}}\). In summary, we have the constraints
which turns the admissible set of matrices \(\underline{{\varvec{U}}},\,\underline{{\varvec{W}}}\) into a matrix manifold. We call this manifold the orthogonal autoencoder manifold and denote it by \( OAE _{n,\nu ,\#\left( \nu ,2,d\right) }\). In paper (Cenedese et al. 2022), the authors also consider the case when the decoder is decoupled from the encoder. In this case \({\varvec{W}}\left( {\varvec{z}}\right) \) does not include the orthogonal matrix \({\varvec{U}}\) and therefore \({\varvec{W}}\left( {\varvec{z}}\right) \) is represented by matrix \(\underline{{\varvec{W}}}\in {\mathbb {R}}^{n\times \#\left( \nu ,1,d\right) }\), which also includes linear terms. The constraint on matrices \(\underline{{\varvec{U}}},\,\underline{{\varvec{W}}}\) is therefore different
where matrix \({\varvec{M}}\) represents the identity polynomial with respect to the monomials \({\mathfrak {M}}_{1,d}\). We call the resulting matrix manifold the generalised orthogonal autoencoder manifold and denote it by \( GOAE _{{\varvec{M}},n,\nu ,\#\left( \nu ,1,d\right) }\). Unfortunately, this generalised autoencoder leads to an ill-defined optimisation problem. Indeed, if all the data are on an invariant manifold (the only sensible case), then the directions encoded by \({\varvec{U}}\) are not defined by the data, because any transversal direction is equally suitable for projecting the data. In our numerical test \({\varvec{U}}\) quickly degenerated and led to spurious results. Nevertheless, due to the similar formulation we treat both cases at the same time, because \( OAE _{n,m,l}\) is a particular case of \( GOAE _{{\varvec{M}},n,m,l}\) with \({\varvec{M}}\) being equal to zero. The details of how projections and retractions are calculated for \( GOAE _{{\varvec{M}},n,m,l}\) are presented in Sect. A.5.1.
1.3 Compressed Polynomial Representation with Hierarchical Tensor Coefficients
To represent encoders of invariant foliations we need to approximate high-dimensional functions. Dense polynomials are not suitable to represent high-dimensional functions, because the number of required parameters increase combinatorially. One approach is to use multi-layer neural networks (Elbrachter et al. 2021; Hornik 1991); however, their training can be problematic (Orr and Müller 2003). Standard training methods take a long time and they rarely reach the global minimum (and there is no free lunch Wolpert and Macready 1997). In addition, the approximation can overfit the data, that is the accuracy on unseen data can be significantly worse than on the training data. In terms of the geometry of neural networks, they do not form a differentiable manifold and therefore parameters may tend to infinity without minimising the loss function (Petersen et al. 2021).
To represent encoders we still use polynomials, except that the polynomial coefficients are represented by compressed tensors in the hierarchical Tucker (HT) format. This tensor format was introduced in Hackbusch and Kühn (2009) and demonstrated to solve many problems (Grasedyck et al. 2013) that would normally wrestle with the ’curse of dimensionality’ (Bellman 2015). In chemistry and physics a somewhat different but related format, the matrix product state (Perez-Garcia et al. 2007) is frequently used and in other problems a particular type of HT representation the tensor train format (Oseledets 2011) is used. However, the most important property of HT tensors is that they form a smooth quotient manifold and therefore suitable to use in optimisation problems (Uschmajew and Vandereycken 2013).
To define the format, we partly follow the notation of Uschmajew and Vandereycken (2013) in our definitions. First, we need to define the dimension tree.
Definition 21
Given an order d, a dimension tree T is a non-trivial rooted binary tree whose nodes can be labelled by subsets of \(\left\{ 1,2,\ldots ,d\right\} \) such that
-
1.
the root has the label \(t_{r}=\left\{ 1,2,\ldots ,d\right\} \), and
-
2.
every node \(t\in T\), which is not a leaf has two descendants, \(t_{1}\) and \(t_{2}\) that form an ordered partition of t, that is,
$$\begin{aligned} t_{1}\cup t_{2}=t\quad \text {and}\quad \mu <\nu \;\text {for all}\;\mu \in t_{1},\nu \in t_{2}. \end{aligned}$$
The set of leaf nodes is denoted by \(L=\left\{ \left\{ 1\right\} ,\left\{ 2\right\} ,\ldots ,\left\{ d\right\} \right\} \).
Definition 22
Let T be a dimension tree and \({\varvec{k}}=\left( k_{t}\right) _{t\in T}\) a set of positive integers. The hierarchical Tucker format for \({\mathbb {R}}^{n_{0}\times n_{1}\times \cdots \times n_{d}}\) is defined as follows
-
1.
For a leaf node \(U_{t}\) is an orthonormal matrix, such that \(U_{t}\in {\mathbb {R}}^{k_{t}\times n_{t}}\) with elements \(U_{t}\left( i;j\right) \), where \(i=1\ldots k_{t}\), \(j=1\ldots n_{t}\)
-
2.
For not a leaf node with \(t=t_{1}\cup t_{2}\) we define
$$\begin{aligned}{} & {} U_{t}\left( p;i_{1},\ldots ,i_{\left| t_{1}\right| },j_{1},\ldots ,j_{\left| t_{2}\right| }\right) \nonumber \\{} & {} \quad =\sum _{q=1}^{k_{t_{1}}}\sum _{r=1}^{k_{t_{2}}}B_{t}\left( p,q,r\right) U_{t_{1}}\left( q;i_{1},\ldots ,i_{\left| t_{1}\right| }\right) U_{t_{2}}\left( r;j_{1},\ldots ,j_{\left| t_{2}\right| }\right) , \end{aligned}$$(49)where \(\left| t\right| \) stands for the number of indices in label t.
The definition is recursive, hence data storage for \(U_{t}\) is only required for the leaf nodes, and for non-leaf nodes only storing \(B_{t}\) is sufficient. In other words, the set of matrices
fully specifies a HT tensor. For each node, apart from the root node \(t_{r}\), one can apply a transformation, which does not change the resulting tensor. That is, for \(t\ne t_{r}\) define \({\tilde{U}}_{t}=A_{t}U_{t}\) and \({\tilde{B}}_{t}=B_{t}\times _{2,3}A_{t_{1}}^{-1}\otimes A_{t_{2}}^{-1}\), where \(A_{t}\in {\mathbb {R}}^{k_{t}\times k_{t}}\) are invertible matrices. Without restricting generality, we can stipulate that the leaf nodes \(U_{t}\) and matricisation of \(B_{t}\) with respect to the first index are also orthogonal matrices, which means that transformations \(A_{t}\) must be unitary to preserve orthogonality. This identity transformation defines an equivalence relation between parametrisations of a HT tensor and therefore the HT format is a quotient manifold as described in (Boumal, 2022, chapter 7). Using a quotient manifold would prevent us from optimising for the matrices \(U_{t}\), \(B_{t}\) individually, as we need to treat the whole HT tensor as a single entity. In addition, we could not find any example in the literature, where a HT tensor was treated as a quotient manifold. Instead, we simply assume a simpler structure, that is, \(B_{t_{r}}\) is on a Euclidean manifold and the rest of the coefficients \(B_{t}\) and \(U_{t}\) are orthogonal matrices and therefore elements of Stiefel manifolds, which is the running example in Boumal (2022). This way we have the HT format as an element of a product manifold, where each coefficient matrix remains independent of each other. It is also possible to calculate singular values of HT tensors. Vanishing singular values indicate that the required quantity is well-approximated and that the HT tensor can be simplified to include less terms. This further adds to our ability to identify parsimonious models. In what follows, we use balanced dimension trees and up to rank six matrices \(U_{t}\), \(B_{t}\) for simplicity.
Using notation (49), we can write the encoders as
where \({\varvec{U}}^{1}\) is an orthogonal matrix, similarly element of a Stiefel manifold. We also apply the constraint that \({\varvec{U}}\left( {\varvec{W}}_{1}{\varvec{z}}\right) \) must be linear. This simply means that for the nonlinear terms of \({\varvec{U}}\) the data must not include components in the \({\varvec{W}}_{1}\) direction. This can be achieved by projecting our data, that is \(\hat{{\varvec{x}}}={\varvec{U}}_{1}^{\perp }{\varvec{x}}\), where \({\varvec{U}}_{1}^{\perp }\) is obtained in step F2 of the invariant foliation identification process of Sect. 4 and consists of row vectors that are orthogonal to the column vectors of \({\varvec{W}}_{1}\). Therefore our constrained encoder assumes the form of
1.4 Optimisation Techniques
Given our compressed representation of the encoder in the form (50), we can now discuss how to solve the optimisation problem (7).
HT tensors, which make up the parametrisation of the encoder \({\varvec{U}}\), depend linearly on each matrix \(B_{t}^{d}\), \(U_{t}^{d}\) individually. Therefore, it is beneficial to carry out the optimisation for each matrix component individually, and cycle through all matrix components a number of times until convergence is reached. This is called batch coordinate descent (Ortega et al. 1970). The complicating factor in this approach is that the encoder also appears as an inner function of map \({\varvec{S}}\) and therefore the dependence of the objective function becomes nonlinear on matrices \(B_{t}\), \(U_{t}\). For optimisation in each coordinate we use the second order trust-region method (Conn et al. 2000) as we can explicitly calculate the Hessian of the objective function with respect to each matrix \(B_{t}^{d},U_{t}^{d}\) and the parameters of \({\varvec{S}}\). We only take a limited number of steps with the trust region method, as we cycle through all parameter matrices. The algorithm cycles through each tensor and the parameters of \({\varvec{S}}\) in a given order, but for each tensor of order d, only the coefficient matrix for which the gradient of the objective function is the largest is optimised for. This is a variant of the Gauss–Southwell algorithm (Nutini et al. 2015). We found that this technique, as it eliminates unnecessary optimisation steps for parameters that do not influence the objective function much, converges relatively fast. Attempts to use off-the-shelf optimisers were fruitless, due to computational costs.
To identify locally defined foliations we use the Riemannian trust region method and for identifying autoencoders, we use the Riemannian BFGS quasi-Newton technique from software package (Bergmann 2022).
1.5 Projections and Retractions on Matrix Manifolds
As we perform optimisation on matrix manifolds, we also require an orthogonal projection from the ambient space to the tangent space to the manifold and a retraction (Absil et al. 2009; Boumal 2022). The advantage of optimising on a manifold instead of using standard constrained optimisation is that retractions and projections are generally easier to evaluate than solving the constraints using generic methods.
Let us assume that our matrix manifold \({\mathcal {M}}\) is embedded into the Euclidean space \({\mathcal {E}}\). As computers deal with lists of numbers, we only have a cost function defined on \({\mathcal {E}}\), which we denote by \({\overline{F}}:{\mathcal {E}}\rightarrow {\mathbb {R}}\), instead on the manifold \(F:{\mathcal {M}}\rightarrow {\mathbb {R}}\). Carrying out optimisation on \({\mathcal {M}}\) therefore requires various corrections when we use cost function \({\overline{F}}\). The gradient \(\nabla F\) on \({\mathcal {M}}\) is a map from \({\mathcal {M}}\) to the tangent bundle \(T{\mathcal {M}}\). Generally \({\overline{F}}\) does not map into \(T{\mathcal {M}}\), therefore a projection is necessary. In particular, for a specific point \({\varvec{p}}\in {\mathcal {M}}\), the projection is the linear map \({\varvec{P}}_{{\varvec{p}}}:T_{{\varvec{p}}}{\mathcal {E}}\rightarrow T_{{\varvec{p}}}{\mathcal {M}}\) and the gradient is calculated as
A simple gradient descent method would move in the direction of the gradient, however that is not necessarily on manifold \({\mathcal {M}}\), so we need to bring the result back to \({\mathcal {M}}\) using a retraction. A retraction is a map \(R_{{\varvec{p}}}\left( {\varvec{X}}\right) :T{\mathcal {M}}\rightarrow {\mathcal {M}}\) for which \(DR_{{\varvec{p}}}\left( {\varvec{0}}\right) {\varvec{Y}}={\varvec{Y}}\). A retraction is supposed to approximate the so-called exponential map on the tangent space, which produces the geodesics along the manifold in the direction of the tangent vector \({\varvec{X}}\) up to the length of \({\varvec{X}}\). A second-order approximation of the exponential retraction is the solution of the minimisation problem
Projection like retractions are explained in detail in Absil and Malick (2012). Using a retraction we can pull back our result onto the manifold. The Hessian of F can be defined in terms of a second order retraction R. If we assume that \({\tilde{F}}\left( {\varvec{p}},{\varvec{X}}\right) ={\overline{F}}\left( R_{{\varvec{p}}}\left( {\varvec{P}}_{{\varvec{p}}}{\varvec{X}}\right) \right) \), then the Hessian is
The expression of the Hessian can be simplified in many ways, which is described, e.g. in Boumal (2022).
In what follows we detail two matrix manifolds that do not appear in the literature and are specific to our problems. We also use the Stiefel manifold of orthogonal matrices that is covered in many publications (Boumal 2022). In particular, we use the so-called polar retraction of the Stiefel manifold, which is equivalent to Eq. (51). For our specific matrix manifolds we solve (51).
1.5.1 Autoencoder Manifold
The two matrices \({\varvec{p}}_{1}=\underline{{\varvec{U}}}\in {\mathbb {R}}^{n\times m}\), \({\varvec{p}}_{2}=\underline{{\varvec{W}}}\in {\mathbb {R}}^{n\times l}\) that satisfy the constraints (47) represent an orthogonal autoencoder form the matrix manifold \({\mathcal {M}}= GOAE _{{\varvec{M}},n,m,l}\), which is defined by the zero-level set of submersion
For \({\mathcal {M}}\) to be a manifold the derivative \(D{\varvec{h}}\) must have full rank. Indeed, we calculate that
and substitute \({\varvec{X}}_{1}={\varvec{p}}_{1}{\varvec{A}}\), \({\varvec{X}}_{2}={\varvec{p}}_{1}{\varvec{B}}\), which yields
Since \({\varvec{A}}\) and \({\varvec{B}}\) are arbitrary matrices, the range of \(D{\varvec{h}}\) is the full set of symmetric and general matrices, that is, \(D{\varvec{h}}\) has full rank; hence \({\mathcal {M}}\) is an embedded manifold.
Tangent space. The tangent space \(T_{\left( {\varvec{p}}_{1},{\varvec{p}}_{2}\right) }{\mathcal {M}}\) is defined as the null space of \(D{\varvec{h}}\left( {\varvec{p}}\right) \), that is
We define \({\varvec{p}}^{\perp }\in {\mathbb {R}}^{n\times \left( n-m\right) }\) by \({\varvec{p}}^{\perp T}{\varvec{p}}^{\perp }={\varvec{I}}\) and \({\varvec{p}}^{T}{\varvec{p}}^{\perp }={\varvec{0}}\), hence the direct sum of ranges of \({\varvec{p}}\) and \({\varvec{p}}^{\perp }\) span \({\mathbb {R}}^{n}\). To characterise the tangent space we decompose \({\varvec{X}}_{1}={\varvec{p}}_{1}{\varvec{A}}_{1}+{\varvec{p}}_{1}^{\perp }{\varvec{B}}_{1}\), \({\varvec{X}}_{2}={\varvec{p}}_{1}{\varvec{A}}_{2}+{\varvec{p}}_{1}^{\perp }{\varvec{B}}_{2}\), and find that
For (53) to equal zero, \({\varvec{A}}_{1}\) must be antisymmetric, \({\varvec{B}}_{1}\), \({\varvec{B}}_{2}\) can be arbitrary and \({\varvec{A}}_{2}=-{\varvec{B}}_{1}^{T}{\varvec{p}}_{1}^{\perp T}{\varvec{p}}_{2}\).
Normal space. We use \({\varvec{X}}_{1}={\varvec{p}}_{1}{\varvec{A}}_{1}+{\varvec{p}}_{1}^{\perp }{\varvec{B}}_{1}\), \({\varvec{X}}_{2}=-{\varvec{p}}_{1}{\varvec{B}}_{1}^{T}{\varvec{p}}_{1}^{\perp T}{\varvec{p}}_{2}+{\varvec{p}}_{1}^{\perp }{\varvec{B}}_{2}\) to represent an element of the tangent space and \({\varvec{Y}}_{1}={\varvec{p}}_{1}{\varvec{K}}_{1}+{\varvec{p}}_{1}^{\perp }{\varvec{L}}_{1}\), \({\varvec{Y}}_{2}={\varvec{p}}_{1}{\varvec{K}}_{2}+{\varvec{p}}_{1}^{\perp }{\varvec{L}}_{2}\) to represent an arbitrary element of the ambient space. For \(\left( {\varvec{Y}}_{1},{\varvec{Y}}_{2}\right) \) to be a normal vector in \(N_{\left( {\varvec{p}}_{1},{\varvec{p}}_{2}\right) }{\mathcal {M}}\) equation
must hold for all \({\varvec{B}}_{1}\), \({\varvec{B}}_{2}\) and \({\varvec{A}}_{1}\) antisymmetric matrices. Therefore we expand (53) into
To explore what parameters are allowed, we consider (54) term-by-term. If we set \({\varvec{B}}_{1}={\varvec{0}}\), \({\varvec{B}}_{2}={\varvec{0}}\), then what remains is \(\left\langle {\varvec{A}}_{1},{\varvec{K}}_{1}\right\rangle =0\) for all \({\varvec{A}}_{1}\) anti-symmetric. This constraint holds if and only if \({\varvec{K}}_{1}\) is symmetric. Now we set \({\varvec{A}}_{1}={\varvec{0}},{\varvec{B}}_{1}={\varvec{0}}\), which leads to \(\left\langle {\varvec{B}}_{2},{\varvec{L}}_{2}\right\rangle =0\) for all \({\varvec{B}}_{2}\), hence we must have \({\varvec{L}}_{2}={\varvec{0}}\). Finally we set \({\varvec{A}}_{1}={\varvec{0}},{\varvec{B}}_{2}={\varvec{0}}\), which gives us
or in index notation
Now we differentiate (55) with respect to \({\varvec{B}}_{1}\), which gives
In conclusion the normal space is given by matrices of the form
where \({\varvec{K}}_{1}\) symmetric and \({\varvec{K}}_{2}\) is a general matrix.
Projection to tangent space. A projection is an operation that removes a vector from the normal space from any input such that the result becomes a tangent vector. Therefore we need to solve equation
where \(\left( {\varvec{Y}}_{1},{\varvec{Y}}_{2}\right) \) is in the normal space \(N_{\left( {\varvec{p}}_{1},{\varvec{p}}_{2}\right) }{\mathcal {M}}\). Using the representation (56) of the normal space, we find that the equation to solve is
It remains to evaluate \(D{\varvec{h}}\), which yields
The solution of Eq. (57) is
and therefore the required projection is written as
Projective retraction. The retraction we calculate is the orthogonal projection onto the manifold (51). This is a second order retraction according to Absil and Malick (2012). In our case, the projection is defined as
where we can assume that \(m<l\) and \(m<n\). Using constrained optimisation we define the auxiliary objective function
where \(\varvec{\alpha }\in {\mathbb {R}}^{m\times m}\), \(\varvec{\beta }\in {\mathbb {R}}^{m\times l}\) are Lagrange multipliers. We can also write the augmented cost function in index notation, that is
To find the stationary point of g, we take the derivatives
which must vanish. Let us define \(\varvec{\sigma }={\varvec{I}}+\varvec{\alpha }+\varvec{\alpha }^{T}\); hence the equations to solve become
We can eliminate unknown variables \(\varvec{\sigma }\), \(\varvec{\beta }\) and \({\varvec{p}}_{2}\) by solving the equations, that is
The equation for the remaining \({\varvec{p}}_{1}\) then becomes
Equation (58) means that \({\varvec{q}}_{1}+{\varvec{q}}_{2}{\varvec{M}}^{T}-{\varvec{q}}_{2}{\varvec{q}}_{2}^{T}{\varvec{p}}_{1}\in \textrm{range}\,{\varvec{p}}_{1}\), therefore there exists matrix \({\varvec{a}}\) such that
The solution of Eq. (59) is not unique, because for any unitary transformation \({\varvec{T}}\), \({\varvec{p}}_{1}\mapsto {\varvec{p}}_{1}{\varvec{T}}\) and \({\varvec{a}}\mapsto {\varvec{T}}^{T}{\varvec{a}}\) are also a solution. We use Newton’s method in combination with the Moore–Penrose inverse of the Jacobian to find a solution of (59). Finally, the retraction is set to the solution of (59)
where \({\varvec{q}}_{1}=\tilde{{\varvec{p}}}_{1}+{\varvec{X}}_{1}\), \({\varvec{q}}_{2}=\tilde{{\varvec{p}}}_{2}+{\varvec{X}}_{2}\).
State-Space Reconstruction
When the full state of the system cannot be measured, but it is still observable from the output, we need to employ state-space reconstruction. We focus on the case of a real valued scalar signal \(z_{j}\in {\mathbb {R}}\), \(j=1\ldots ,M\), sampled with frequency \(f_{s}\), where j stands for time. Takens’ embedding theorem (Takens 1981) states that if we know the box counting dimension of our attractor, which is denoted by n, the full state can almost always be observed if we create a new vector \({\varvec{x}}_{p}=\left( z_{p},z_{p+\tau _{1}},\ldots ,z_{p+\tau _{d-1}}\right) \in {\mathbb {R}}^{d}\), where \(d>2n\) and \(\tau _{1},\ldots ,\tau _{d-1}\) are integer delays. The required number of delays is a conservative estimate, in many cases \(n\le d<2n+1\) is sufficient. The general problem, how to select the number of delays d and the delays \(\tau _{1},\ldots ,\tau _{d-1}\) optimally (Kramer 1991; Pecora et al. 2007), is a much researched subject.
Instead of selecting delays \(\tau _{1},\ldots ,\tau _{d-1}\), we use linear combinations of all possible delay embeddings, which allows us to consider the optimality of the embedding in a linear parameter space. We create vectors of length L,
where s is the number of samples by which the window is shifted forward in time with increasing p. Our reconstructed state variable \({\varvec{x}}_{p}\in {\mathbb {R}}^{d}\eqsim X\) is then calculated by a linear map \({\varvec{T}}:{\mathbb {R}}^{L}\rightarrow {\mathbb {R}}^{d}\), in the form \({\varvec{x}}_{p}={\varvec{T}}{\varvec{u}}_{p}\) such that our scalar signal is returned by \(z_{ps+\ell }\approx {\varvec{v}}\cdot {\varvec{x}}_{p}\) for some \(\ell \in \left\{ 1,\ldots ,L\right\} \). We assume that the signal has m dominant frequencies \(f_{k}\), \(k=1,\ldots ,m\), with \(f_{1}\) being the lowest frequency. We define \(w=\left\lfloor \frac{f_{s}}{f_{1}}\right\rfloor \) as an approximate period of the signal, where \(f_{s}\) is the sampling frequency and set \(L=2w+1\). This makes each \({\varvec{u}}_{p}\) capture roughly two periods of oscillations of the lowest frequency \(f_{1}\).
In what follows we use two approaches to construct the linear map \({\varvec{T}}\).
1.1 Principal Component Analysis
In Broomhead and King (1986) it is suggested to use Principal Component Analysis to find an optimal delay embedding. Let us construct the matrix
where \({\varvec{u}}_{p}\) are the columns of \({\varvec{V}}\). Then calculate the singular value decomposition (or equivalently Jordan decomposition) of the symmetric matrix in the form
where \({\varvec{H}}\) is a unitary matrix and \(\varvec{\Sigma }\) is diagonal. Now let us take the columns of \({\varvec{H}}\) corresponding to the d largest elements of \(\varvec{\Sigma }\), and these columns then become the d rows of \({\varvec{T}}\). In this case, we can only achieve an approximate reconstruction of the signal by defining
where \(T_{k\ell }\) is the element of matrix \({\varvec{T}}\) in the k-th row and \(\ell \)-th column. The dot product \(z_{ps+\ell }\approx {\varvec{v}}\cdot {\varvec{x}}_{p}\) approximately reproduces our signal. The quality of the approximation depends on how small the discarded singular values in \(\varvec{\Sigma }\) are.
1.2 Perfect Reproducing Filter Bank
We can also use discrete Fourier transform (DFT) to create state-space vectors and reconstruct the original signal exactly. Such transformations are called perfect reproducing filter banks (Strang and Nguyen 1996). The DFT of vector \({\varvec{u}}_{p}\) is calculated by \(\hat{{\varvec{u}}}_{p}={\varvec{K}}{\varvec{u}}_{p}\), where matrix \({\varvec{K}}\) is defined by its elements
where \(p=1,\ldots ,w\) and \(q=1,\ldots ,2w+1\). Note that \({\varvec{K}}^{T}{\varvec{K}}={\varvec{I}}\frac{2w+1}{2}\), hence the inverse transform is \({\varvec{K}}^{-1}=\frac{2}{2w+1}{\varvec{K}}^{T}\). Let us denote the \(\ell \)-th column of \({\varvec{K}}\) by \({\varvec{c}}_{\ell }\), which creates a delay filter
that delays the signal by \(\ell \) samples. Separating \({\varvec{c}}_{\ell }\) into components, such that
we can create a perfect reproducing filter bank, that is the vector
when summed over its components, the input \(z_{ps+\ell }\) is recovered. The question is how to create an optimal decomposition (60). As we assumed that our signal has m frequencies, we can further assume that we are dealing with m coupled nonlinear oscillators, and therefore we can set \(d=2m\). We therefore divide the resolved frequencies of the DFT, which are \({\tilde{f}}_{k}=k\frac{f_{s}}{2w+1}\), \(k=0,\ldots ,w\) into m bins, which are centred around the frequencies of the signal \(f_{1},\ldots ,f_{m}\). We set the boundaries of these bins as
and for each bin labelled by k, we create an index set
which ensures that all DFT frequencies are taken into account without overlap, that is \(\cup _{k}{\mathcal {I}}_{k}=\left\{ 0,1,\ldots ,w\right\} \) and \({\mathcal {I}}_{p}\cap {\mathcal {I}}_{q}=\emptyset \) for \(p\ne q\). This creates a decomposition (60) in the form of
with the exception of \({\varvec{v}}_{1}\), for which we also set \(v_{1,1}=c_{\ell ,1}\) to take into account the moving average of the signal and to make sure that \(\sum {\varvec{v}}_{k}={\varvec{c}}_{\ell }\). Here \(v_{k,l}\) stands for the l-th element of vector \({\varvec{v}}_{k}\). Finally, we define the transformation matrix
where each row is normalised such that our separated signals have the same amplitude. The newly created signal is then
where \({\varvec{T}}={\varvec{H}}{\varvec{K}}\) and the original signal can be reproduced as
Proof of Proposition 16
Proof of proposition 16
First we explore what happens if we introduce a new parametrisation of the decoder \({\varvec{W}}\) that replaces r by \(\rho \left( r\right) \) and \(\theta \) by \(\theta +\gamma \left( \rho \left( r\right) \right) \), where \(\rho :{\mathbb {R}}^{+}\rightarrow {\mathbb {R}}^{+}\) is an invertible function with \(\rho \left( 0\right) =0\) and \(\gamma :{\mathbb {R}}^{+}\rightarrow {\mathbb {R}}\) with \(\gamma \left( 0\right) =0\). This transformation creates a new decoder \(\tilde{{\varvec{W}}}\) of \({\mathcal {M}}\) in the form of
Equation (61) is not the only re-parametrisation, but this is the only one that preserves the structure of the polar invariance Eq. (21). After substituting the transformed decoder, invariance Eq. (21) becomes
where
In the new coordinates, the instantaneous frequency \(\omega \left( r\right) \) and damping ratio \(\zeta \left( r\right) \) become
Before we go further, let us introduce the notation
where \({\varvec{x}},{\varvec{y}}:\left[ 0,2\pi \right] \rightarrow X\) and \(\left\langle \cdot ,\cdot \right\rangle _{X}\) is the inner product on vector space X. The norm of function \({\varvec{x}}\) is then defined by \(\left\| {\varvec{x}}\right\| =\sqrt{\left\langle {\varvec{x}},{\varvec{x}}\right\rangle }\).
We now turn to the phase constraint given by Eq. (26). We choose a fixed \(\epsilon >0\), substitute \(r_{1}=\rho \left( r+\epsilon \right) \), \(r_{2}=\rho \left( r\right) \) and the phase shift \(\gamma =\gamma \left( \rho \left( r+\epsilon \right) \right) -\gamma \left( \rho \left( r\right) \right) \) into Eq. (26) and find the objective function
where we also divided by \(\epsilon \). We then need to find the value of \(\gamma \left( \rho \left( r+\epsilon \right) \right) \) that minimises J for a fixed \(\epsilon \). A necessary condition for a local minimum of J is that the derivative \(J^{\prime }=0\), that is,
To find a continuous parametrisation, let us now take the limit \(\epsilon \rightarrow 0\) to get
We can also remove the constant phase shift and use \(t=\rho \left( r\right) \) to find the phase condition
Integrating Eq. (65) leads to the phase shift
Note that phase conditions are commonly used in numerical continuation of periodic orbits (Beyn and Thümmler 2007), for slightly different reasons.
The next quantity to fix is the amplitude constraint given by Eq. (25). In the new parametrisation, Eq. (25) can be written as
If we define \(\kappa \left( r\right) =\left\| {\varvec{W}}\left( r,\cdot \right) \right\| \), then we have
Finally, substituting (66), (68) into Eqs. (63), (64) completes the proof. \(\square \)
Proof of remark 18
In case of a vector field \({\varvec{f}}:X\rightarrow X\), and invariance equation
the instantaneous frequency and damping ratios with respect to the coordinate system defined by the decoder \({\varvec{W}}\), are
respectively. However the coordinate system defined by \({\varvec{W}}\) is nonlinear, which needs correcting. As in the proof of proposition 16, we assume a coordinate transformation
and find that invariance Eq. (32) becomes
When substituting (70) into (71) we find
Comparing (72) and (32) we extract that
Recognising that \(t=\rho \left( r\right) =\kappa ^{-1}\left( r\right) \) and replacing T with \({\tilde{T}}\), R with \({\tilde{R}}\) in formulae (69) proves remark 18. \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Szalai, R. Data-Driven Reduced Order Models Using Invariant Foliations, Manifolds and Autoencoders. J Nonlinear Sci 33, 75 (2023). https://doi.org/10.1007/s00332-023-09932-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00332-023-09932-y
Keywords
- Invariant foliation
- Invariant manifold
- Reduced order model
- Instantaneous frequency
- Tensor approximation
- Machine learning