
Abstract
In several examples it has been observed that a module category of a vertex operator algebra (VOA) is equivalent to a category of representations of some quantum group. The present article is concerned with developing such a duality in the case of the Virasoro VOA at generic central charge; arguably the most rudimentary of all VOAs, yet structurally complicated. We do not address the category of all modules of the generic Virasoro VOA, but we consider the infinitely many modules from the first row of the Kac table. Building on an explicit quantum group method of Coulomb gas integrals, we give a new proof of the fusion rules, we prove the analyticity of compositions of intertwining operators, and we show that the conformal blocks are fully determined by the quantum group method. Crucially, we prove the associativity of the intertwining operators among the first-row modules, and find that the associativity is governed by the 6j-symbols of the quantum group. Our results constitute a concrete duality between a VOA and a quantum group, and they will serve as the key tools to establish the equivalence of the first-row subcategory of modules of the generic Virasoro VOA and the category of (type-1) finite-dimensional representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\).
Similar content being viewed by others
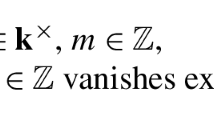
1 Introduction
1.1 Conformal field theories, vertex operator algebras, and quantum groups
Two-dimensional conformal field theories (CFT) are an outstanding example of extremely fruitful interaction of physics and mathematics [DFMS97, Gaw99, Hua12, Nah00]. Their physical applications include string theory [GSW87] and critical phenomena in planar statistical physics [Mus10], and they are among the best understood examples of quantum field theories. In mathematics, ideas from CFT have been instrumental to the Monster simple group [FLM89], tensor categories [BKJ01], subfactors [Kaw15], moduli spaces [FBZ04], the geometric Langlands program [Fre07], and conformally invariant random geometry [BB04], among others.
As with quantum field theories in general, the mathematical axiomatization and construction of CFTs are vast challenges, but CFTs possess remarkable structure that has enabled a highly successful algebraic axiomatization based on vertex operator algebras (VOA) [Kac97, LL04, Hua12]. A VOA is essentially the chiral symmetry algebra of a CFT as envisioned in the seminal work of Belavin, Polyakov, and Zamolodchikov [BPZ84a, BPZ84b]. The symmetry algebra always contains the Virasoro algebra responsible for the conformal symmetry itself. Virasoro vertex operator algebras are thus fundamental in that they incorporate only and exactly the minimal amount of symmetry that any CFT possesses. At special choices of the central charge c, a key parameter of CFTs, there may actually exist two different Virasoro VOAs: the universal Virasoro VOA [LL04] (maximally large) and its irreducible quotient, the minimal Virasoro VOA [Wan93]. At generic values of c, however, the universal Virasoro VOA itself is irreducible, and we call it a generic Virasoro VOA. The topic of this article is such generic Virasoro VOAs.
Generic Virasoro VOAs have been studied very little in comparison with many other VOAs. The main reason is that they fail most structural properties that have enabled significant progress. In particular, they are far from rational VOAs [FZ92, Zhu96], which possess a semisimple category of modules with finitely many simple objects. Generic Virasoro VOAs admit first of all infinitely many simple modules, and many more indecomposable but not irreducible ones. We are lacking even the description of the general indecomposable modules, let alone the category of such modules equipped with the desired structures of a tensor product and braiding. In a notable recent progress [CJH+21], the category of \(C_1\)-cofinite modules of the generic Virasoro VOA was studied, and the tensor product constructed in it.
An intriguing aspect of conformal field theories, and of the corresponding VOAs, is a hidden quantum group symmetry. In a number of prominent examples, a representation category of a suitable quantum group has been found to agree with a module category of a VOA—often together with the tensor products and braiding in the categories. The case of (VOAs based on) Wess–Zumino–Witten (WZW) CFTs at various levels have been treated in [Dri89, KL94a, McR16], and the corresponding quantum group was a q-deformation of the finite dimensional Lie algebra of the corresponding WZW theory. Another well studied example is the triplet W-algebra of logarithmic CFT [FGST06b, FGST06a, NT11, KS11, TW13, GN21, CLR21], whose representation category is equivalent to that of the restricted quantum group of \(\mathfrak {sl}_{2}\). Though not as much as a categorical equivalence, a certain structure related to a quantum group has been also observed in the context of Liouville CFT [TV14].
1.1.1 First row subcategory of modules for the generic Virasoro VOA
The category of all modules of the generic Virasoro VOA being hopelessly complicated, we focus here on a subcategory we call the first row subcategory. It is the semisimple category whose infinitely many simple modules are the irreducible Virasoro highest weight modules “in the first row of the Kac table”, i.e., with highest weights \(h=h_{1,s}\), \(s \in {\mathbb {Z}}_{> 0}\), when \(h_{r,s}\), \(r,s \in {\mathbb {Z}}_{> 0}\), denote the usual Kac labeled highest weights [Kac79]. These correspond to a certain infinite set of (chiral) primary fields in a CFT, which has been found to be relevant in particular to questions in conformally invariant random geometry—the two simplest of these primary fields after the identity, with Kac labeled conformal weights \(h_{1,2}\) and \(h_{1,3}\), correspond to SLE-type curves’ starting points [BB03b, Dub07] and boundary visit points [BB03a, JJK16, Dub15], respectively. For such SLE applications, the generic Virasoro VOA corresponds to generic values of the key parameter \(\kappa >0\) of SLEs [Wer04, RS05, Law08], and is completely natural.
By contrast to the general Kac labeled highest weights \(h_{r,s}\), \(r,s \in {\mathbb {Z}}_{> 0}\), at the first row highest weights \(h_{1,s}\), \(s\in {\mathbb {Z}}_{> 0}\) one has truly explicit expressions of singular vectors in the Virasoro Verma module, by the Benoit–St. Aubin (BSA) formula [BSA88]. Correspondingly the BPZ partial differential equations [BPZ84a] for the correlation functions of these primary fields are explicit. This is a feature that facilitates the analysis of the first row subcategory, but resorting to the explicit partial differential equations does not in principle seem essential.
Our analysis of this first row subcategory of the generic Virasoro VOA is based on a quantum group method of [KP20], which is a concrete and practical version of the hidden quantum group symmetry [MR89, PS90, RRRA91, FW91, SV91, Var95, GRAS96] developed with applications [KP16, JJK16] to random geometry in mind. The corresponding quantum group is \({\mathcal {U}}_q (\mathfrak {sl}_2)\), a q-deformation of \(\mathfrak {sl}_2\), at a deformation parameter q which is not a root-of-unity. Correspondingly the category of (type-1) finite-dimensional representations of this quantum group is semisimple, with infinitely many irreducible representations, and it is equipped with tensor products and braiding [Lus93, BKJ01].
We consider it noteworthy that our VOA without extended symmetries of Lie group type (present, e.g., in WZW models) has a quantum group counterpart in this way, and that our VOA, which is irrational with very complicated representation theory, corresponds to a quantum group with extremely well-behaved category of finite-dimensional representations (albeit with infinitely many irreducibles). The case more often seen before has been rational VOAs with good module categories, and complicated root-of-unity quantum groups whose representation categories are “semisimplified” for certain purposes.
In general terms, our main results are that the first row subcategory of modules of the generic Virasoro VOA is stable under fusion, and detailed calculations of the fusions with the quantum group method.
1.1.2 Methods
After reviewing the characterization and construction of intertwining operators among the first row modules, we show that the intertwining operators and their arbitrary compositions are the correlation functions obtained with the quantum group method. A priori, the compositions of intertwining operators of a VOA are formal series, but this shows that they are actual analytic functions given by explicit integral formulas. In particular one obtains convergence of the series, and straightforward methods of analytic continuation.
Showing associativity of tensor products of modules of VOAs is generally a very difficult task, and one of the main obstacles to constructing the appropriate tensor category of modules of a VOA [HL92, HL94, HL95a, HL95b, HL95c, Hua95, Hua05, HLZ14, HLZ10a, HLZ10b, HLZ10c, HLZ10d, HLZ10e, HLZ11a, HLZ11b], see also [HKJL15, Section 2] for a review. The difficulties lie partly in the fact that the formal series are not even supposed to correspond to single-valued functions, so nontrivial branch choices are inevitable, and yet the convergence and analyticity of the formal series is far from obvious. The explicit analytic expressions from the quantum group method enable our proof of associativity. It is also the explicit expressions that show the equivalence of the tensor categories of the finite-dimensional representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\) and of the first-row modules of the generic Virasoro VOA. The operator product expansion (OPE) coefficients of the corresponding primary fields, in particular, are explicit, and involve the quantum 6j-symbols.
The braiding in the tensor category of VOA modules makes the multivaluedness of the functions even more manifest. We will postpone the construction of the braiding in the first row subcategory to a subsequent article, but the key to it is similarly the explicit analytical expressions that are amenable to analytic continuation.
1.1.3 Novelty and advantages of the approach
Our results provide a very satisfactory VOA to quantum group duality for the fundamentally important generic Virasoro VOA, especially when combined with the follow-up work establishing the equivalence of the tensor categories of the first row modules of the VOA and of (type-1) finite-dimensional representations of the quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\). The formulation is practical, and in particular allows us to perform VOA calculations with very straightforward linear algebra in finite-dimensional representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\).
Conversely the method sheds light onto the quantum group method of [KP20]. Notably, VOA techniques can be used to systematize the calculation of general series expansion coefficients of the correlation functions obtained from the method. Moreover, the result gives a rather satisfactory characterization of the space of solutions to BSA PDEs obtained from the quantum group method: it says that the obtained solutions are exactly the linear span of the conformal blocks, which can be described combinatorially, and in this sense all solutions relevant to CFTs are included. By contrast, direct analytical description of the solution space is complicated already in the particular case involving only second order BSA PDEs [FK15a].
Underlying the method and the results is the key observation that the intertwining operators in the first row subcategory for the generic Virasoro VOA are described by explicit analytic functions, not just formal series.
1.1.4 Related works
The recent article [CJH+21] also treats the question about the tensor products in a subcategory of modules for the generic universal Virasoro VOA. The category of all \(C_1\)-cofinite modules considered there is more general than the first row category considered in the present article. Our approach is thus less general, but it is fully explicit, and additionally shows the intimate relationship with the quantum group.
Very recently, in [GN21], a ribbon tensor equivalence was established between a module category of the Virasoro VOA at a central charge lying in a specific series and a module category of the quantum \(\mathrm {SL}_{2}\) at a root of unity. That article employs results about tensor categories directly, and specifically the fact that the tensor categories in question have a distinguished generator. The first row subcategory of the generic Virasoro VOA is also generated (as a tensor category) by a single module. With the methods of [GN21] one could therefore expect to obtain a complementary viewpoint to the relationship of the \({\mathcal {U}}_q (\mathfrak {sl}_2)\) and our first row subcategory, which would be directly category theoretical but not as explicit about the correlation functions as our approach.
The setting of the article [TV14] involves the same VOA and the same quantum group as the present work, and the authors also observed a duality between modules of the two. The modules of both are, however, different from what we consider here. In other words, the results of us and [TV14] thus pertain to different CFTs despite the fact that the VOA and the quantum group are the same.
The quantum group method of [KP20] relies on tensor products of finite-dimensional representations of the quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\) at generic values of the deformation parameter q when the representation theory is semisimple. Questions about it often reduce to the commutant of the quantum group on the tensor product representation, via a general q-Schur-Weyl duality. This approach to calculations with the quantum group method has been developed in particular by Flores and Peltola, in a series of articles [FP18b, FP18a, FP20, FP21]. The commutant is a generalization of Temperley-Lieb algebas, and Flores and Peltola have developed specific representation theoretic tools that are suitable for explicit calculations in the quantum group method. Some of the calculations in the present article, especially related to the 6j symbols, are closely parallel to such a q-Schur-Weyl duality approach. The results we need are, however, sufficiently concrete and tractable directly, so we do not need to introduce the commutant algebra and its presentation by generators and relations.
Ideas of reconstructing intertwining operators for the Virasoro VOA from integral formulas appeared already in the seminal article [Fel89], and more recently [KKP19] contains a conjecture of a special case of the precise relationship between the quantum group method and the generic Virasoro VOA that we establish here.
As a future perspective, it would be desirable to develop the method to a more systematic one and facilitate generalizations in particular to non-semisimple, root of unity cases. For that purpose, we view the theories of twisted (co)homologies [AK11, TW14] and Nichols algebras [Len21] as particularly promising.
2 Background on the Quantum Group Method
In this section we review the method of [KP20], by which one construct functions of relevance to conformal field theories from vectors in tensor product representations of a quantum group. In Sect. 3 we select specific vectors in such representations, which will correspond to the conformal blocks that are crucial to all of our main results: the construction (Sect. 4) of the intertwining operators among the first-row modules of the generic Virasoro VOA, their compositions (Sect. 5), and associativity (Sect. 6).
The textbook [Kas95] uses conventions similar to ours about the quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\). Our specific choices and notations are identical to [KP20].
2.1 The quantum group
The quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\) is the Hopf algebra defined as follows. Fix a non-zero complex number \(q \in {\mathbb {C}}\setminus \left\{ 0 \right\} \).
2.1.1 Definition of the quantum group
As an algebra, \({\mathcal {U}}_q (\mathfrak {sl}_2)\) is generated by elements
subject to relations
The Hopf algebra structure on \({\mathcal {U}}_q (\mathfrak {sl}_2)\) is uniquely determined by the coproduct, an algebra homomorphism \({\Delta }:{\mathcal {U}}_q (\mathfrak {sl}_2)\rightarrow {\mathcal {U}}_q (\mathfrak {sl}_2)\otimes {\mathcal {U}}_q (\mathfrak {sl}_2)\), whose values on the generators are
2.1.2 Representations of the quantum group
We consider the representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\) which continuously q-deform the finite-dimensional representations of \(\mathfrak {sl}_2\). These are specified by a highest weight \(\lambda \in {\mathbb {N}}\). The \((\lambda +1)\)-dimensional representation \({\mathsf {M}}_{\lambda }\) of \({\mathcal {U}}_q (\mathfrak {sl}_2)\) has a basis \((u_{j}^{(\lambda )})_{j=0}^\lambda \) in which the generator K acts diagonally
and the generators E and F act as raising and lowering operators
where we used the q-integers defined by
The representations \({\mathsf {M}}_{\lambda }\), \(\lambda \in {\mathbb {N}}\), are irreducible if q is not a root of unity, as we will assume throughout the present article.
2.1.3 Tensor product representations
Using the coproduct \({\Delta }:{\mathcal {U}}_q (\mathfrak {sl}_2)\rightarrow {\mathcal {U}}_q (\mathfrak {sl}_2)\otimes {\mathcal {U}}_q (\mathfrak {sl}_2)\), we can equip the tensor product \({\mathsf {V}}' \otimes {\mathsf {V}}''\) of any two representations \({\mathsf {V}}', {\mathsf {V}}''\) of \({\mathcal {U}}_q (\mathfrak {sl}_2)\) with the structure of a representation. Coassociativity of \({\Delta }\) ensures that we can unambiguoulsy define triple tensor products such as \({\mathsf {V}}' \otimes {\mathsf {V}}'' \otimes {\mathsf {V}}'''\), as well as further iterated tensor products. One should note, however, that due to the lack of cocommutativity of \({\Delta }\), we can not canonically identify \({\mathsf {V}}' \otimes {\mathsf {V}}''\) with \({\mathsf {V}}'' \otimes {\mathsf {V}}'\). In the category of modules that we will consider, such identifications can be done by braiding, but the choice of braiding direction must be specified.
The rest of the section assumes that q is not a root of unity,
Then the tensor products of the representations \({\mathsf {M}}_{\lambda }\), \(\lambda \in {\mathbb {N}}\), are completely reducible, and the Clebsch–Gordan decomposition is the same as for \(\mathfrak {sl}_2\)
see, e.g., [KP20, Lemma 2.4]. Let us therefore define the selection rule set associated to \(\mu , \lambda \in {\mathbb {N}}\) as the set of those \(\sigma \) such that a copy of \({\mathsf {M}}_{\sigma }\) is contained in \({\mathsf {M}}_{\lambda } \otimes {\mathsf {M}}_{\mu }\), i.e.,
Note the symmetries
The most convenient formulation of the Clebsch–Gordan rule for our purposes is in terms of the following embedding.
Lemma 2.1
Let \(\mu , \lambda \in {\mathbb {N}}\). Then we have
In the case \(\sigma \in \mathrm {Sel}(\mu ,\lambda )\), any \({\mathcal {U}}_q (\mathfrak {sl}_2)\)-module map \({\mathsf {M}}_{\sigma } \rightarrow {\mathsf {M}}_{\lambda } \otimes {\mathsf {M}}_{\mu }\) is proportional to the embedding
which is uniquely determined by
Proof
This follows directly from, e.g., [KP20, Lemma 2.4]. \(\quad \square \)
Since for \(\sigma \in \mathrm {Sel}(\mu ,\lambda )\) the multiplicity of the irreducible representation \({\mathsf {M}}_{\sigma }\) in the tensor product \({\mathsf {M}}_{\lambda } \otimes {\mathsf {M}}_{\mu }\) is one, there exist a unique \({\mathcal {U}}_q (\mathfrak {sl}_2)\)-module map
The projection
from \({\mathsf {M}}_{\lambda } \otimes {\mathsf {M}}_{\mu }\) to its unique subrepresentation isomorphic to \({\mathsf {M}}_{\sigma }\) then agrees with the composition of \({\hat{\pi }}_{ {\lambda } , {\mu }}^{\;{\sigma }}\) with the embedding \({\iota }_{ \;{\sigma }}^{{\lambda } , {\mu }}\),
2.2 The correspondence with functions
Throughout this section, we parametrize q by \(\kappa \) via
and assume that \(\kappa \in (0,\infty ) \setminus {\mathbb {Q}}\). Then q has unit modulus, but is not a root of unity.
For \(\lambda \in {\mathbb {N}}\), we write
for the conformal weight of a module in the “first row of the Kac table” (see Sect. 4).
For \(N \in {\mathbb {N}}\), let us denote by
the chamber of N ordered real variables. We also fix parameters \(\lambda _1 , \ldots , \lambda _N \in {\mathbb {N}}\), and sometimes refer to all of them collectively as
We are interested in functions \(F :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) that satisfy certain properties motivated by conformal field theory: N linear partial differential equations, asymptotics as two variables approach each other, as well as translation invariance, homogeneity, and sometimes covariance under more general Möbius transformations.
Specifically, for each \(j \in \left\{ 1,\ldots ,N \right\} \), we define a Benoit–Saint-Aubin partial differential operator
of order \(\lambda _j+1\), where
The parameters \(\lambda _1 , \ldots , \lambda _N \in {\mathbb {N}}\) as well as the number of variables N are implicit in this notation. Note that with a fixed j, the operators \({\mathscr {L}}^{(j)}_{n}\) satisfy the Witt algebra commutation relations
The correspondence involves the representation of the quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\) constructed as the tensor product of the irreducible representations \({\mathsf {M}}_{\lambda _1} , \ldots , {\mathsf {M}}_{\lambda _N}\). The tensorands are ordered from left to right in the reverse order of the index, and we use the shorthand notation
for this ordering convention. Similarly we denote, e.g.,
For the projection \({\pi }_{ {\lambda _{j+1}} , {\lambda _{j}}}^{\;{\tau }}\) of (2.4) applied in the two consecutive tensorands with indices \(j, j+1\), we use the notation
and when the projection \({\hat{\pi }}_{ {\lambda _{j+1}} , {\lambda _{j}}}^{\;{\sigma }}\) is applied instead (thus reducing the number of tensorands by one), we use the notation
Within the tensor product (2.8), we are primarily concerned with the subspace
consisting of highest weight vectors.
Theorem 2.2
[KP20] There is a family of linear mappings \({\mathcal {F}}:{\mathcal {H}}_{\underline{{\lambda }}} \rightarrow {\mathcal {C}}^\infty ({\mathfrak {X}}_N)\) indexed by \(\underline{{\lambda }}\in \bigsqcup _{N \in {\mathbb {N}}} {\mathbb {N}}^N\), normalized so that for \(N=1\) and any \(\lambda _1 \in {\mathbb {N}}\) we have \({\mathcal {F}}[u_{0}^{(\lambda _1)}](x_1) \equiv 1\), and with the following properties:
-
(PDE)
For any \(u \in {\mathcal {H}}_{\underline{{\lambda }}}\) the function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) satisfies
$$\begin{aligned} {\mathscr {D}}^{(j)} F (x_1 , \ldots , x_N) \, = \, 0&\\ \text { for all }j=1,\ldots ,N\text { and }(x_1 , \ldots , x_N) \in {\mathfrak {X}}_N&\, . \end{aligned}$$ -
(COV)
For any \(u \in {\mathcal {H}}_{\underline{{\lambda }}}\) the function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) is translation invariant,
$$\begin{aligned} F (x_1 + t , \ldots , x_N + t) \, = \, F (x_1 , \ldots , x_N)&\nonumber \\ \text { for all }(x_1 , \ldots , x_N) \in {\mathfrak {X}}_N\text { and }t \in {\mathbb {R}}\,&. \end{aligned}$$(2.10)If, moreover, u is a Cartan eigenvector, \(u \in {\mathcal {H}}_{\underline{{\lambda }}} \cap \mathrm {Ker}(K - q^{\sigma })\), then the function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) is translation invariant and homogeneous,
$$\begin{aligned} F (s x_1 + t , \ldots , s x_N + t) \, = \, s^{h(\sigma ) - \sum _{i=1}^N h(\lambda _i)} \; F (x_1 , \ldots , x_N)&\nonumber \\ \text { for all }(x_1 , \ldots , x_N) \in {\mathfrak {X}}_N\text { and }t \in {\mathbb {R}}, s>0 \,&. \end{aligned}$$(2.11)Finally, if u lies in a trivial subrepresentation, \(u \in {\mathcal {H}}_{\underline{{\lambda }}} \cap \mathrm {Ker}(K-1)\), then the function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) is fully Möbius-covariant in the sense that for any \((x_1 , \ldots , x_N) \in {\mathfrak {X}}_N\) and any \({\mathfrak {M}}(z) = \frac{az+b}{cz+d}\) such that \({\mathfrak {M}}(x_1)< \cdots < {\mathfrak {M}}(x_N)\), we have
$$\begin{aligned} F ( {\mathfrak {M}}(x_1) , \ldots , {\mathfrak {M}}(x_N) ) \, = \, \prod _{i=1}^N {\mathfrak {M}}'(x_i)^{-h(\lambda _i)} \; F (x_1 , \ldots , x_N) . \end{aligned}$$(2.12) -
(ASY)
If \(u \in {\mathcal {H}}_{\underline{{\lambda }}}\) lies in the subrepresentation corresponding to the irreducible \({\mathsf {M}}_{\tau }\) in the tensor product of the j:th and \(j+1\):th factors, i.e., if \( u = {\pi }_{ \{{j} , {j+1}\}}^{\;\;{\tau }} (u) \), then the function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) has the expansion
$$\begin{aligned}&F(x_1, \ldots , x_j , x_{j+1} , \ldots , x_N) \\&\quad = \; B\, (x_{j+1}-x_j)^{{\Delta }} \, \Big ( {\hat{F}} \big ( x_1, \ldots , \xi , \ldots , x_N \big ) + {\mathfrak {o}}(1) \Big ) \qquad \text { as }x_{j} , x_{j+1} \rightarrow \xi , \end{aligned}$$where \({\hat{F}} = {\mathcal {F}}[{\hat{u}}]\) with
$$\begin{aligned} {\hat{u}} = \;&{{\hat{\pi }}}_{ \{{j} , {j+1}\}}^{\;\;{\tau }} (u) \; \in \; \Big ( \big ( \bigotimes _{i>j+1} {\mathsf {M}}_{\lambda _i} \big ) \otimes {\mathsf {M}}_{\tau } \otimes \big ( \bigotimes _{i<j} {\mathsf {M}}_{\lambda _i} \big ) \Big ) , \end{aligned}$$and \(B= B_{ {\lambda _{j+1}} , {\lambda _j}}^{\;{\;\;\tau }} = \dfrac{1}{((\lambda _j+\lambda _{j+1}-\tau )/2)!} \prod _{p=1}^{(\lambda _j+\lambda _{j+1}-\tau )/2} \dfrac{\Gamma ( 1\!+\!\dfrac{4}{\kappa } p ) \Gamma ( 1\!-\!\dfrac{4}{\kappa } (1\!+\!\lambda _j-p) ) \, \Gamma ( 1\!-\!\dfrac{4}{\kappa } (1\!+\!\lambda _{j+1}-p) ) }{\Gamma ( 1+\dfrac{4}{\kappa } ) \, \Gamma ( 2-\dfrac{2}{\kappa } (4-2p + \lambda _j + \lambda _{j+1} + \tau ) )}\) and \({\Delta }= {\Delta }_{ {\lambda _{j+1}} , {\lambda _j}}^{\;{\;\;\tau }} = h(\tau ) - h(\lambda _j) - h(\lambda _{j+1})\).
2.3 Series expansions of the functions
The method of Theorem 2.2 in fact yields not only smooth functions, but analytic functions which have Frobenius series expansions on the codimension one boundaries of the chamber \({\mathfrak {X}}_N\). These Frobenius series will be important in Sects. 5 and 6. We start with a general definitions about the assumptions we use on parametrized power series, and then state the series expansion results. The proofs are left to “Appendix A”.
2.3.1 Controlled parametrized power series
We will need to expand the functions of Sect. 2.2 as power series recursively one variable at a time. Therefore, we will treat one of the variables as the variable of the power series, and the other variables as parameters. In order to be able to perform the natural operations on the power series, we need the following type of control of the power series coefficients locally uniformly over the the parameters.
Definition 2.3
Let \(\Omega \subset {\mathbb {R}}^m\) be an open set and \(c_k :\Omega \rightarrow {\mathbb {C}}\) smooth functions for \({k \in {\mathbb {N}}}\). For \(R>0\), we say that \((c_k)_{k \in {\mathbb {N}}}\) are locally uniformly R -controlled power series coefficients if for every compact \(K\subset \Omega \) and every multi-index \(\alpha \in {\mathbb {N}}^m\) we have
As simpler terminology, in the above situation we may just say that the power series
parametrized by \(y \in \Omega \) is locally uniformly R-controlled. Note that by the Cauchy-Hadamard formula for the radius of convergence, this implies in particular that for any \(y \in \Omega \) the radius of convergence of the power series itself and its coefficientwise derivatives with respect to the parameters y have radius of convergence at least R.
2.3.2 Analyticity and Frobenius series statements
The analyticity statement in a single variable for the functions from Theorem 2.2 is the following.
Lemma 2.4
Let \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) be the function associated to any \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\), and let \((x_1, \ldots , x_N) \in {\mathfrak {X}}_N\), and let \(j \in \left\{ 1,\ldots ,N \right\} \). Then we have a power series expansion
in the j:th variable. For fixed \(x_j \in {\mathbb {R}}\) and \(R>0\), viewing the other variables \((x_i)_{i \ne j}\) as parameters, on the subset \(\Omega \subset {\mathbb {R}}^{N-1}\) defined by the conditions \(x_1< \cdots < x_N\) and \(\min _{i \ne j} |x_i - x_j| > R\), the power series is locally uniformly R-controlled.
The proof is elementary, but it is instructive as a preparation for the consideration of the Frobenius series, so we give it in “Appendix A”.
The Frobenius series statement that we will use is the following. Variants of this formulation with obvious modifications to the statement and proof could be done as well.
Lemma 2.5
Let \(j \in \left\{ 2,\ldots ,N \right\} \). Suppose that \(\tau \in \mathrm {Sel}(\lambda _{j-1},\lambda _j)\) and that \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\) is such that \(u = {\pi }_{ \{{j-1} , {j}\}}^{\;\;{\tau }} (u)\). The function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) associated to u has a Frobenius series expansion in the variable \(z=x_j-x_{j-1}\)
where the indicial exponent is \({\Delta }= h(\tau ) - h(\lambda _{j}) - h(\lambda _{j-1})\). For fixed \(R>0\), viewing the other variables \((x_i)_{i \ne j}\) as parameters, on the subset \(\Omega \subset {\mathbb {R}}^{N-1}\) defined by the conditions \(x_1< \cdots < x_N\) and \(\min _{i \ne j, j-1} |x_i - x_{j-1}| > R\), the power series part of this Frobenius series is locally uniformly R-controlled, and for \(0<z<R\) the Frobenius series converges to the function F on the left hand side.
Remark 2.6
The leading coefficient \(c_0\) of the Frobenius series in Lemma 2.5 is related to the value of the function associated to \({\hat{u}} = {{\hat{\pi }}}_{ \{{j-1} , {j}\}}^{\;\;{\tau }} (u)\) as follows
where \(B= B_{ {\lambda _{j}} , {\lambda _{j-1}}}^{\;{\;\;\tau }}\) is as in Theorem 2.2. This can be seen from the (ASY) part of Theorem 2.2 (or more directly from the proofs).
The proof of Lemma 2.5 is based on an elaboration of ideas from [KP20], in particular those leading to part (ASY) of Theorem 2.2. Since this result will be crucially relied on in the present article, we outline the proof in “Appendix A”.
3 Construction of Conformal Block Vectors for the Quantum Group
In this section we construct specific vectors in tensor product representations of the quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\), which will correspond to our basis of “conformal blocks”. More precisely, in the subsequent sections, compositions of intertwining operators in the first row category of modules for the generic Virasoro VOA will be obtained from these vectors via the quantum group method of Sect. 2.
3.1 The quantum 6j-symbols
The embeddings \({\iota }_{ \;{\sigma }}^{{\lambda } , {\mu }} \; :\; {\mathsf {M}}_{\sigma } \, \hookrightarrow \; {\mathsf {M}}_{\lambda } \otimes {\mathsf {M}}_{\mu }\) in Lemma 2.1 can be combined in different ways, and the relationships between the choices are given by the quantum 6j-symbols.
Lemma 3.1
Let \(\lambda _1 , \lambda _2 , \lambda _3 \in {\mathbb {N}}\). Then for any \(\sigma \in {\mathbb {N}}\), the space
has one basis consisting of
and another basis consisting of
Proof
Clearly the given maps are \({\mathcal {U}}_q (\mathfrak {sl}_2)\)-module maps \({\mathsf {M}}_{\sigma } \rightarrow {\mathsf {M}}_{\lambda _3} \otimes {\mathsf {M}}_{\lambda _2} \otimes {\mathsf {M}}_{\lambda _1}\). It follows straightforwardly from coassociativity and Clebsch–Gordan decompositions that the two collections both span and are linearly independent. \(\quad \square \)
The expansions of the elements of the second basis of Lemma 3.1 with respect to the first basis are denoted as in the following:

The coefficients \(\Big \{ \begin{array}{ccc} {\lambda _3} &{} {\lambda _2} &{} {\nu } \\ {\lambda _1} &{} {\sigma } &{} {\kappa } \end{array}\Big \}\) in these expansions are called the quantum 6j symbols.
3.2 The construction of the conformal block vectors
Fix
throughout. Note that compared to Sect. 2 we now have two additional labels, \(\lambda _{0}\) and \(\lambda _{\infty }\). They will later be seen to have the interpretations of labels of primary fields at the origin and at infinity.
Definition 3.2
A sequence
is said to be \(\underline{{\lambda }}\)-admissible, if we have
The following picture should serve as a visual guide to what is going on at the level of representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\) (and in fact at the level of modules of the generic Virasoro VOA in later sections); the \(\underline{{\lambda }}\)-admissibility of the sequence \({\underline{{\varsigma }}}\) exactly ensures that the selection rules are satisfied at every vertex of this picture:

We seek to associate a conformal block to such an admissible sequence, and for that purpose we will first associate to it a suitable vector
Our convention is that tensor products are formed in the order with the indices increasing from right to left, i.e., the space above is
Above we have placed the parentheses to illustrate the idea according to which the vector \(u_{{\underline{{\varsigma }}}}\) is chosen. The construction of the vector is done with the composition

of embeddings

Namely, we take \(u_{{\underline{{\varsigma }}}}\) to be the image of the highest weight vector \(u_0^{(\lambda _{\infty })} \in {\mathsf {M}}_{\lambda _{\infty }}\) under this composition of embeddings,
Lemma 3.3
The vector \(u_{{\underline{{\varsigma }}}}\) in (3.3) satisfies
Proof
These properties are satisfied by the vector \(u_0^{(\lambda _{\infty })} \in {\mathsf {M}}_{\lambda _{\infty }}\), and the mapping applied on this vector in (3.3) is a \({\mathcal {U}}_q (\mathfrak {sl}_2)\)-module map. \(\quad \square \)
More formally, the reason for the choice of \(u_{{\underline{{\varsigma }}}}\) is the following projection conditions. We use partial compositions of the following sequence

of projections

Proposition 3.4
For each \(j=1,\dots , N\), denote by \({P}^{(j)} (u_{{\underline{{\varsigma }}}}) \in \big ( \bigotimes _{i \ge j} {\mathsf {M}}_{\lambda _i} \big ) \otimes {\mathsf {M}}_{{\varsigma }_{j-1}}\) the image of \(u_{{\underline{{\varsigma }}}}\) under the composition of the first \(j-1\) projections above. The following conditions hold for the vector \(u_{{\underline{{\varsigma }}}}\) in (3.3):
for each \(j=1,\ldots ,N\). Moreover, \(u_{{\underline{{\varsigma }}}}\) is up to a multiplicative constant the unique vector in \(\big ( \bigotimes _{j=1}^N {\mathsf {M}}_{\lambda _j} \big ) \otimes {\mathsf {M}}_{\lambda _{0}}\) for which the above conditions hold.
Proof
The conditions for vector \(u_{{\underline{{\varsigma }}}}\) follow directly from its construction, using the relationships \({\pi }_{ {\lambda } , {\mu }}^{\;{\sigma }} \circ {\iota }_{ \;{\sigma }}^{{\lambda } , {\mu }} = {\iota }_{ \;{\sigma }}^{{\lambda } , {\mu }}\) and \({\hat{\pi }}_{ {\lambda } , {\mu }}^{\;{\sigma }} \circ {\iota }_{ \;{\sigma }}^{{\lambda } , {\mu }} = \mathrm {id}_{{\mathsf {M}}_{\sigma }}\) between the projections and embeddings.
Uniqueness (up to multiplicative constants) can be shown by an induction over N, using the multiplicity-free branching rule (2.1). \(\quad \square \)
4 Generic Virasoro VOA
This section introduces the main algebraic structure of the present work, the generic Virasoro vertex operator algebra. We also define its modules and intertwining operators between modules.
From the point of view of physics, vertex operator algebras serve as the chiral algebras of conformal field theories, and the case of the Virasoro VOA is appropriate for the case with conformal symmetry alone. The modules of a VOA correspond to the (conformal families of) fields in the CFT. Intertwining operators are the building blocks of the correlation functions of these fields.
This section is organized as follows. In Sect. 4.1 we introduce notation and fix conventions about formal series. In Sect. 4.2 we introduce the Virasoro algebra and its highest weight representations, as well as the VOAs based on them. Sect. 4.3 contains the general definition of modules and intertwining operators of VOAs, and Sect. 4.4 concentrates on the specific case of the first row modules of the generic Virasoro VOA. The specific result about the fusion rules, in particular, is given in Sect. 4.4. Much of the topic of this section can be found in textbooks. To the extent possible, in our presentation we follow [LL04] in Sects. 4.1–4.2, and [Xu98, Li99] in Sects. 4.1–4.3. The more specific fusion rule statement of Sect. 4.4 has been obtained through a different method in [FZ12].
4.1 Some notational conventions
Let us first fix some notational conventions.
4.1.1 General conventions
When a statement depends on a real number m (integer, natural number, ...), we use the quantifier “for \(m \gg 0\)” (resp. “for \(m \ll 0\)”) to mean that the statement holds for all sufficiently large m (resp. sufficiently small m), i.e., that there exists some \(m_0\) such that the statement holds for all \(m > m_0\) (resp. for all \(m<m_0\)).
4.1.2 Formal series
We will have to consider various types of formal series: polynomials, Laurent polynomials, formal power series, formal Laurent series, and formal series of yet more general types. The formal series are formal sum expressions with terms which are a coefficient times a power of a formal variable. The coefficients are always taken to lie in some complex vector space, and consequently also the spaces of formal series are naturally vector spaces with addition and scalar multiplication defined coefficientwise.
Let V be a vector space, and let \({\mathfrak {z}}\) be a formal variable.
The space of formal power series with coefficients in V is
and the space of polynomials is the subspace \(V[{\mathfrak {z}}] \subset V[[{\mathfrak {z}}]]\) consisting of those formal power series \(\sum _{n \in {\mathbb {N}}} v_n \, {\mathfrak {z}}^n\) which only have finitely many non-zero coefficients, i.e., \(v_n = 0\) for all \(n \gg 0\).
Similarly the space of formal Laurent series with coefficients in V is
and space of Laurent polynomials is the subspace \(V[{\mathfrak {z}}^{\pm 1}] \subset V[[{\mathfrak {z}}^{\pm 1}]]\) consisting of those formal Laurent series \(\sum _{m \in {\mathbb {Z}}} v_m \, {\mathfrak {z}}^m\) which only have finitely many non-zero coefficients, i.e., \(v_m = 0\) for \(|m| \gg 0\). The residue of a formal Laurent series is defined as
The space of general formal series with coefficients in V is
Elements of any of the above are typically denoted by e.g. \(f({\mathfrak {z}}) = \sum _{i} v_i \, {\mathfrak {z}}^i\), to explicitly indicate the formal variable \({\mathfrak {z}}\), and to emphasize the analogue with functions.
Series with several formal variables are defined by considering series in one variable with coefficients in a vector space of formal series of other variables, and natural identifications are made without comment: we set, e.g., \(V[[{\mathfrak {z}},{\mathfrak {w}}]] = \big ( V[[{\mathfrak {z}}]] \big ) [[{\mathfrak {w}}]] = \big ( V[[{\mathfrak {w}}]] \big )[[{\mathfrak {z}}]]\).
4.1.3 Binomial expansion convention
We follow the commonly used binomial expansion convention according to which the power of a binomial in formal variables is always expanded in non-negative integer powers of the second variable: for example if \({\mathfrak {z}}, {\mathfrak {w}}\) are two formal variables and \(\beta \in {\mathbb {C}}\), we interpret
The convention does require some caution: for instance for \(n \in {\mathbb {Z}}_{> 0}\) the two series
are not equal, but are different Laurent series expansions of the same rational function function. The series on the left is in \({\mathbb {C}}[[{\mathfrak {z}}^{\pm 1},{\mathfrak {w}}]]\) and is convergent in the region \(|{\mathfrak {z}}|>|{\mathfrak {w}}|\), while the series on the right is in \({\mathbb {C}}[[{\mathfrak {z}},{\mathfrak {w}}^{\pm 1}]]\) and is convergent in the region \(|{\mathfrak {w}}|>|{\mathfrak {z}}|\). In the case of non-integer \(\beta \), note that non-integer powers are placed on only one of the formal variables, leading to different branch choice issues when specializing the formal variables to actual complex values.
4.1.4 The formal delta function
The formal delta-function in the formal variable \({\mathfrak {z}}\) is the formal Laurent series
If \({\mathfrak {z}}, {\mathfrak {w}}, {\mathfrak {u}}\) are formal variables, with the binomial expansion convention we interpret
4.1.5 Multiplication of formal series
In the case when \(V = A\) is an associative algebra, e.g., \(V = {\mathbb {C}}\) or \(V=\mathrm {End}(W)\) for some vector space W, multiplication of formal series of particular types may be meaningful: e.g. the product \(a({\mathfrak {z}}) \, b({\mathfrak {z}})\) of two formal power series \(a({\mathfrak {z}}), b({\mathfrak {z}}) \in A[[{\mathfrak {z}}]]\) is well-defined in \(A[[{\mathfrak {z}}]]\) (there are finitely many contributions to the coefficient of any \({\mathfrak {z}}^n\)), and the product \(f({\mathfrak {z}}) \, g({\mathfrak {z}})\) of a general series \(f({\mathfrak {z}}) \in A\{{\mathfrak {z}}\}\) with a Laurent polynomial \(g({\mathfrak {z}}) \in A[{\mathfrak {z}}^{\pm 1}]\) is well-defined in \(A\{{\mathfrak {z}}\}\) (there are finitely many contributions to the coefficient of any \({\mathfrak {z}}^\alpha \)).
Likewise, suitable formal series with complex coefficients can be multiplied with suitable series with coefficients in complex vector spaces: e.g., the multiplication of a Laurent polynomial \(r({\mathfrak {z}}) \in {\mathbb {C}}[{\mathfrak {z}}^{\pm 1}]\) with a formal power series \(h({\mathfrak {z}}) \in V[[{\mathfrak {z}}]]\) is well-defined in \(V[[{\mathfrak {z}}^{\pm 1}]]\) (there are finitely many contributions to the coefficient of any \({\mathfrak {z}}^m\)).
Where well-defined, we use any such products without explicit comment in what follows.
4.2 Generic Virasoro vertex operator algebra
4.2.1 Virasoro algebra
The Virasoro algebra is the complex Lie algebra
with the Lie bracket determined by
To describe the relevant representations of \(\mathfrak {vir}\), we introduce the Lie subalgebras
The universal enveloping algebra of \(\mathfrak {vir}\) is denoted by \({\mathcal {U}}(\mathfrak {vir})\).
4.2.2 Verma module
For \(c,h \in {\mathbb {C}}\), the Verma module \(M(c,h)\) of central charge c and conformal weight h is defined as the quotient of the universal enveloping algebra by the left ideal generated by the elements \(C-c1\), \(L_0-h1\), and \(L_n\) for \(n>0\), i.e.
By construction, the vector \({\bar{w}}_{c,h} := [1] \in M(c,h)\) satisfies
and it is a cyclic vector, i.e., it generates the whole representation, \({\mathcal {U}}(\mathfrak {vir}) {\bar{w}}_{c,h} = M(c,h)\).
Owing to the Poincaré–Birkhoff–Witt (PBW) theorem, as a vector space the Verma module is isomorphic to \({\mathcal {U}}(\mathfrak {vir}_{<0})\); a PBW basis for \(M(c,h)\) consists of vectors
where \(k \in {\mathbb {N}}\) and \(0 < n_1 \le n_2 \le \cdots \le n_k\).
The central element C acts as the scalar c on \(M(c,h)\). The element \(L_0\) is diagonalizable and has eigenvalues \(h+d\), \(d \in {\mathbb {N}}\), and we use this to define a grading of the Verma module
The homogeneous subspaces in this grading are finite-dimensional, since the basis elements (4.7) are eigenvectors of \(L_0\), with eigenvalues \(h+d\), where \(d = n_1 + \cdots + n_k\).
The Verma module has a filtration associated with the PBW basis, which we will use extensively. For each \(p\in {\mathbb {Z}}_{\ge 0}\), we define the subspace
spanned by basis vectors (4.7) with “PBW word-length” at most p. The PBW filtration is the increasing sequence of subspaces
which clearly has the property that \(\bigcup _{p \in {\mathbb {N}}} {\mathscr {F}}^{p}M(c,h) = M(c,h)\). Note furthermore that each subspace \({\mathscr {F}}^{p}M(c,h)\) is itself a representation of the Lie subalgebra \(\mathfrak {vir}_{\ge 0} \subset \mathfrak {vir}\).
4.2.3 Highest weight modules
If \(\chi \) is a non-zero vector in a representation \({\mathcal {W}}\) of \(\mathfrak {vir}\), which for some \(\eta \in {\mathbb {C}}\) and \(c \in {\mathbb {C}}\) satisfies
then we call \(\chi \in {\mathcal {W}}\) a singular vector.
If a singular vector \(\chi \in {\mathcal {W}}\) generates the whole representation,
then it is called a highest weight vector, the representation \({\mathcal {W}}\) is called a highest weight representation, and the \(L_0\)-eigenvalue \(\eta \) and the C-eigenvalue c of \(\chi \) are called its conformal weight and central charge, respectively. As an example, the Verma module \(M(c,h)\) is a highest weight representation and \({\bar{w}}_{c,h}\) its highest weight vector. Note that a highest weight vector in a given representation is necessarily unique up to non-zero scalar multiples.
By construction the Verma module \(M(c,h)\) has the universal property that for any highest weight representation \({\mathcal {W}}\) with the same central charge c and highest weight h, there exists a surjective \({\mathcal {U}}(\mathfrak {vir})\)-module map

As a consequence, any highest weight representation is isomorphic to a quotient of a Verma module by a proper subrepresentation (possibly zero). In particular, a highest weight representation \({\mathcal {W}}\) with highest weight h also admits a \({\mathbb {N}}\)-grading by eigenvalues of \(L_0-h \, \mathrm {id}_{{\mathcal {W}}}\), and the homogeneous subspaces \(\mathrm {Ker}\big ( L_0 - (h+d) \, \mathrm {id}_{{\mathcal {W}}} \big )\) are finite-dimensional. The PBW filtration of a Verma module is also inherited to its quotient: letting \({\mathscr {F}}^{p}{\mathcal {W}}\) denote the image of \({\mathscr {F}}^{p}M(c,h)\) under the above surjection, we obtain an increasing filtration
Since the surjection is a \({\mathcal {U}}(\mathfrak {vir})\)-module map, each \({\mathscr {F}}^{p}{\mathcal {W}}\) is a representation of \(\mathfrak {vir}_{\ge 0}\).
The unique irreducible highest weight representation with given c, h is the quotient of the Verma module \(M(c,h)\) by its maximal proper subrepresentation. A basic fact is that all subrepresentations of Verma modules are generated by singular vectors, and that at most two singular vectors are needed to generate a given subrepresentation [FF90], see also [IK11, Chapter 6].
The easiest example of a non-trivial submodule of a Verma module appears when \({h=0}\): the vector \(L_{-1}{\bar{w}}_{c,0}\) is a singular vector in the Verma module \(M(c,0)\) and thus generates a proper subrepresentation \({\mathcal {U}}(\mathfrak {vir})L_{-1}{\bar{w}}_{c,0} \subset M(c,0)\). This easy case will be relevant for the universal Virasoro vertex operator algebra, but we first give other examples that are the building blocks of the module category that we study.
4.2.4 The Kac table and its first row
The highest weights h for which the Verma module \(M(c,h)\) is not irreducible form what is called the Kac table: these highest weights \(h_{r,s}\) are indexed by two positive integers r, s.
Let us parametrize central charges c by \(\kappa \) viaFootnote 1
Then an explicit formula for the Kac table highest weights is
We will be interested in highest weight modules with conformal weights in the first row of the Kac table, i.e., with \(r=1\). These conformal weights are exactly the ones in (2.5); we have
Lemma 4.1
[FF90] Assume \(\kappa \not \in {\mathbb {Q}}\) and \(\lambda \in {\mathbb {N}}\), and let c and \(h(\lambda )\) be as in (4.9) and (4.10). Then the maximal proper subrepresentation of the Verma module \(M(c,h(\lambda ))\) is isomorphic to the Verma module \(M(c,\,h(\lambda )+1+\lambda )\). In particular, the irreducible highest weight representation with highest weight \(h(\lambda )\) is the quotient
Proof
See, e.g., [FF90] or [IK11, Section 5.3.1]. With the above assumptions, the Verma module \(M(c,h(\lambda ))\) falls in “class I” following the terminology of Iohara and Koga [IK11]. \(\quad \square \)
The singular vector in \(M(c,h(\lambda ))\) that generates the maximal proper subrepresentation \(M(c,\,h(\lambda )+1+\lambda ) \subset M(c,h(\lambda ))\) is given by the explicit formula of [BSA88],
4.2.5 Virasoro vertex operator algebras
A vertex operator algebra is an \({\mathbb {N}}\)-graded vector space
equipped with two distinguished non-zero vectors,
as well as a vertex operator map
all subject to axioms which are explicitly given in, e.g., [LL04].
Let \(c \in {\mathbb {C}}\) be given. The vector \(L_{-1}{\bar{w}}_{c,0}\) is a singular vector in the Verma module \(M(c,0)\) of highest weight \(h=0\). Consider the highest weight representation obtained as the quotient of the Verma module by the proper subrepresentation \({\mathcal {U}}(\mathfrak {vir})L_{-1}{\bar{w}}_{c,0} \subset M(c,0)\) generated by this singular vector,
It is known [LL04, Theorem 6.1.5] that the vector space \(V_{c}\) can be equipped with the structure of a vertex operator algebra (VOA), uniquely fixed by the following. The vacuum vector is \({\mathsf {1}}= [{\bar{w}}_{c,0}]\), the conformal vector is \(\omega = L_{-2} {\mathsf {1}}= [L_{-2} {\bar{w}}_{c,0}]\), and the Laurent modes of the vertex operator
corresponding to the conformal vector are the Virasoro generators \(L_n\), \(n\in {\mathbb {Z}}\) (acting as endomorphisms of \(V_c\)). This vertex operator algebra \(V_c\) is known as the universal Virasoro vertex operator algebra with central charce c.
The irreducible highest weight representation of the Virasoro algebra with highest weight \(h=0\) can be also obtained as the quotient of \(V_c\) by its maximal proper submodule. A simple vertex operator algebra can be formed as the corresponding quotient of the universal Virasoro VOA \(V_c\) [LL04, Theorem 6.1.5], and we refer to this as the simple Virasoro vertex operator algebra with central charce c. For generic central charges, \(c = c(\kappa )\) with \(\kappa \notin {\mathbb {Q}}\), the representation \(V_c\) is in fact already irreducible by itself (case \(\lambda =0\) of Lemma 4.1), so the simple Virasoro VOA coincides with the universal Virasoro VOA \(V_c\). In this article we focus on the generic case: specifically we assume that \(c=c(\kappa )\) as in (4.9) with
For clarity, we then call \(V_c\) the generic Virasoro vertex operator algebra, although it is also both the universal Virasoro VOA and the simple Virasoro VOA. As a warning we already point out that, despite being a simple VOA, the generic Virasoro VOA \(V_c\) fails many key properties assumed in most VOA theory: \(V_c\) is not \(C_2\)-cofinite, it has infinitely many simple modules, it has modules which are not completely reducible, etc.
It is instructive to contrast the generic case we consider with what happens for rational central charges c—which are relevant, e.g., for minimal models of CFT. For typical rational central charges the representation \(V_c\) is not irreducible, and correspondingly the universal Virasoro VOA and the simple Virasoro VOA are different. The simple Virasoro VOA has been studied extensively in these cases, and is a model case of a well-behaved VOA: it is in particular \(C_2\)-cofinite, has finitely many simple modules, has semisimple category of modules closed under fusion, satisfies Verlinde’s formula, etc. The failure of such good properties for the generic Virasoro VOA is probably one of the main reasons the generic Virasoro VOA has not been extensively studied yet.
4.3 Modules and intertwining operators for VOAs
We introduce the notions of modules and intertwining operators for a general vertex operator algebra \(V\).
4.3.1 Modules for vertex operator algebras
A module for a vertex operator algebra \(V\) is a vector space \(W\) equipped with a linear map
subject to the following conditions. For \(v\in V\), let us denote by \(v^{W}_{(n)} \in \mathrm {End}(W)\) the coefficient of \(\varvec{\zeta }^{-1-n}\) in the formal series \(Y_{W}(v, \varvec{\zeta })\), so that
For the coefficients of the series associated to the conformal vector \(\omega \in V\), we use the notation \(L^{W}_{n} := \omega ^{W}_{(1+n)}\), \(n\in {\mathbb {Z}}\) so that \(Y_{W} (\omega , \varvec{\zeta }) = \sum _{n \in {\mathbb {Z}}} \varvec{\zeta }^{-2-n} L^{W}_{n} \). When the module \(W\) is sufficiently clear from the context, we even omit the superscript and denote simply \(L_{n} = L^{W}_{n}\). The required conditions then read:
-
We have \(Y_{W} ({\mathsf {1}}, \varvec{\zeta }) = \mathrm {id}_{W}\).
-
For any \(v_1 , v_2 \in V\), the following Jacobi identity holds:
$$\begin{aligned}&\varvec{\zeta }_0^{-1} \, \delta \Big ( \frac{\varvec{\zeta }_1- \varvec{\zeta }_2}{\varvec{\zeta }_0} \Big ) \, Y_{W} (v_1 , \varvec{\zeta }_1) \, Y_{W} (v_2 , \varvec{\zeta }_2) - \varvec{\zeta }_0^{-1} \, \delta \Big ( \frac{\varvec{\zeta }_2- \varvec{\zeta }_1}{-\varvec{\zeta }_0} \Big ) \, Y_{W} (v_2 , \varvec{\zeta }_2) \, Y_{W} (v_1 , \varvec{\zeta }_1) \nonumber \\&\quad = \; \varvec{\zeta }_2^{-1} \, \delta \Big ( \frac{\varvec{\zeta }_1- \varvec{\zeta }_0}{\varvec{\zeta }_2} \Big ) \, Y_{W} \big ( Y(v_1 , \varvec{\zeta }_0) v_2 , \, \varvec{\zeta }_2\big ) . \end{aligned}$$(4.15) -
The operator \(L^{W}_{0} \in \mathrm {End}(W)\) is diagonalizable, its eigenspaces \(W_{(\eta )} := \mathrm {Ker}\big ( L^{W}_{0} - \eta \, \mathrm {id}_{W} \big )\) are finite-dimensional, and \(W_{(\eta )} = \left\{ 0 \right\} \) when \(\mathfrak {Re}(\eta ) \ll 0\).
A module \(W\) thus has an \(L^{W}_0\)-eigenspace decomposition
The coefficients of the module vertex operator (4.14) respect this decomposition in the following sense.
Lemma 4.2
For any homogeneous element \(v\in V_{(d)}\) of the vertex operator algebra and any \(m \in {\mathbb {Z}}\) and \(\eta \in {\mathbb {C}}\) we have
Proof
This is a standard result; it follows from
which in turn follows from applying the Jacobi identity (4.15) in the case that \(v_{1}=\omega \) and \(v_{2}=v\). (Similar calculations will be done in some more detail in a more general case in Lemma 4.6 and Corollary 4.7, for example.) \(\quad \square \)
4.3.2 Contragredient modules
Suppose that \(W\) is a module for a vertex operator algebra \(V\). Considering the duals \(W_{(\eta )}^* = \mathrm {Hom}(W_{(\eta )},{\mathbb {C}})\) of the finite-dimensional \(L^W_{0}\)-eigenspaces \(W_{(\eta )}\) in the decomposition (4.16), the restricted dual (also called graded dual) is the space
It can be equipped with the structure of a \(V\)-module [FHL93, Xu98] so that the module vertex operator \(Y_{W'}( \cdot , \varvec{\zeta })\) on \(W'\) is defined by the formula
This \(V\)-module \(W'\) is called the contragredient module of \(W\). Double contragredients are isomorphic to the original modules, \(W'' \cong W\).
Lemma 4.3
We have \(L_{n}^{W'} = (L_{-n}^{W})^\top \) for any \(n \in {\mathbb {Z}}\), i.e., for any \(w' \in W'\) and \(w\in W\) we have
Proof
Taking \(v= \omega \) and using \(e^{\varvec{\zeta }L_{1}} (-\varvec{\zeta }^{-2})^{L_{0}} \omega = \varvec{\zeta }^{-4} \, \omega \), this is just the equality of the coefficients of \(\varvec{\zeta }^{-2-n}\) in the defining formula above. \(\quad \square \)
4.3.3 Intertwining operators
As an analogy to that the tensor product of modules over a Hopf algebra is governed by the coproduct structure, the fusion product of modules of a VOA \(V\) is governed by the notion of intertwining operators.
Definition 4.4
Let \(W_{1}, W_{0}, W_{\infty }\) be three modules for a VOA \(V\), with respective module vertex operators \(Y_{W_{1}} (\cdot , \varvec{\zeta }), Y_{W_{0}} (\cdot , \varvec{\zeta }) , Y_{W_{\infty }} (\cdot , \varvec{\zeta })\). An intertwining operator of type \(\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \) is a linear map
satisfying the Jacobi identity
and the translation property
for all \(v\in V\) and \(w\in W_{1}\).
The space of intertwining operators of type \(\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \) is a vector space, which we will denote by
It is known that spaces of intertwining operators admit the following symmetry.
Proposition 4.5
[HL95b] Let \(W_{0}\), \(W_{1}\), and \(W_{\infty }\) be modules of a VOA \(V\). Then, we have linear isomorphisms
The next lemma is useful for calculations with intertwining operators, and it is in fact equivalent to the property (4.18).
Lemma 4.6
Let \({\mathcal {Y}}(\cdot , {\varvec{x}})\) be an intertwining operator of type \(\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \). Then, for any \(p,q \in {{\mathbb {Z}}}\), \(v\in V\), \(w\in W_{1}\), we have
Proof
Take the terms in (4.18) proportional to \(\varvec{\xi }^{-q-1}\) to obtain
We further multiply \(\varvec{\zeta }^{p}\) and take the residue with respect to \(\varvec{\zeta }\) to obtain
This proves the assertion. \(\quad \square \)
From the above formulas, we get the following equations for intertwining operators, which give the basis of many recursive constructions with respect to the PBW filtration (4.8) that we will use.
Corollary 4.7
Let \({\mathcal {Y}}(\cdot , {\varvec{x}})\) be an intertwining operator of type \(\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \).
-
(1)
For any \(w\in W_{1}\), \(n\in {{\mathbb {Z}}}\), we have
$$\begin{aligned}&{\mathcal {Y}}(L_{n}^{W_{1}} \, w, \, {\varvec{x}}) \\&\quad = \; \mathrm {Res}_{\varvec{\zeta }} \Big ( Y_{W_{\infty }} (\omega , \varvec{\zeta }) \, {\mathcal {Y}}(w, {\varvec{x}}) \, (\varvec{\zeta }-{\varvec{x}})^{n+1} - {\mathcal {Y}}(w, {\varvec{x}}) \, Y_{W_{0}}(\omega , \varvec{\zeta }) \, (-{\varvec{x}}+\varvec{\zeta })^{n+1} \Big ) \\&\quad = \; \sum _{k=0}^{\infty } \left( {\begin{array}{c}n+1\\ k\end{array}}\right) \, (-{\varvec{x}})^{k} \, L_{n-k}^{W_{\infty }} \, {\mathcal {Y}}(w, {\varvec{x}}) - \sum _{k=0}^{\infty } \left( {\begin{array}{c}n+1\\ k\end{array}}\right) \, (-{\varvec{x}})^{n-k+1} \, {\mathcal {Y}}(w, {\varvec{x}}) \, L_{k-1}^{W_{0}} . \end{aligned}$$ -
(2)
For any \(w\in W_{1}\), \(n\in {{\mathbb {Z}}}\), we have
$$\begin{aligned} L_{n}^{W_{\infty }} \, {\mathcal {Y}}(w, {\varvec{x}}) - {\mathcal {Y}}(w, {\varvec{x}}) \, L_{n}^{W_{0}} = \;&\sum _{k=0}^{\infty } \left( {\begin{array}{c}n+1\\ k\end{array}}\right) \, {\varvec{x}}^{n-k+1} \, {\mathcal {Y}}(L_{k-1}^{W_{1}} \, w, {\varvec{x}}) . \end{aligned}$$ -
(3)
For any \(w\in W_{1}\), we have
$$\begin{aligned} L_{-1}^{W_{\infty }} \, {\mathcal {Y}}(w, {\varvec{x}}) - {\mathcal {Y}}(w, {\varvec{x}}) \, L_{-1}^{W_{0}} = \frac{\mathrm {d}}{\mathrm {d}{{\varvec{x}}}} {\mathcal {Y}}(w,{\varvec{x}}). \end{aligned}$$
Remark 4.8
From here on, we will not use as careful notation as above to indicate in which modules the different \(L_n\)’s act. We will instead abuse the notation slightly and write
in, e.g., parts (2) and (3) above.
Proof of Corollary 4.7
Recall that \(L_{n}=\omega _{(n+1)}\), \(n\in {{\mathbb {Z}}}\). By setting \(v=\omega \), \(p=0\), \(q=n+1\), we see (1). By setting \(v=\omega \), \(p=n+1\), \(q=0\), we see (2). In particular the latter gives
and the right hand side here equals \(\frac{\mathrm {d}}{\mathrm {d}{{\varvec{x}}}} {\mathcal {Y}}(w,{\varvec{x}})\) by the translation property (4.19) of intertwining operators. \(\quad \square \)
4.4 Modules and intertwining operators for the generic Virasoro VOA
We now discuss modules and intertwining operators focusing on the case of the generic Virasoro VOA \(V_{c}\), and describe the subcategory of modules that is the topic of this article. We continue to parametrize the central charge \(c\le 1\) by \(\kappa >0\) as in (4.9). Throughout we make the genericity assumption that \(\kappa \notin {\mathbb {Q}}\).
4.4.1 Modules
Suppose that \({\mathcal {W}}\) is a representation of the Virasoro algebra where C acts as \(c \, \mathrm {id}_{{\mathcal {W}}}\), and \(L_0\) acts diagonalizably with finite-dimensional eigenspaces and eigenvalues with real part bounded from below. Then \({\mathcal {W}}\) has a unique structure of a module for the universal Virasoro VOA \(V_{c}\) such that
i.e., \(\omega ^{{\mathcal {W}}}_{(m)} = L_{m-1} \in \mathrm {End}({\mathcal {W}})\), see, e.g., [LL04, Theorem 6.1.7].
In particular any of the Verma modules \(M_{\lambda }=M(c,h(\lambda ))\), \(\lambda \in {\mathbb {N}}\), and their irreducible quotient representations
in Lemma 4.1 becomes a module for the generic Virasoro VOA \(V_c\). We call these \(Q_{\lambda }\), \(\lambda \in {\mathbb {N}}\) first row modules, and we denote the module vertex operators in them simply by
Irreducible highest weight representations are self-dual in the following sense.
Lemma 4.9
Let \({\mathcal {W}}\) be an irreducible highest weight representation of Virasoro algebra, viewed as a module for the universal Virasoro VOA \(V_{c}\). Then the contragradient module \({\mathcal {W}}^{\prime }\) is isomorphic to \({\mathcal {W}}\).
Proof
Let \({\bar{w}}\in {\mathcal {W}}_{(h)}\) be a highest weight vector in \({\mathcal {W}}\), and choose \({\bar{w}}' \in {\mathcal {W}}_{(h)}^*\) such that \(\langle {\bar{w}}' , {\bar{w}}\rangle = 1\). From Lemma 4.3 we see that \({\bar{w}}' \in {\mathcal {W}}'\) is a singular vector with highest weight h in \({\mathcal {W}}'\). Then, \({\mathcal {W}}'\) contains the subrepresentation \({\mathcal {U}}(\mathfrak {vir}) {\bar{w}}' \subset {\mathcal {W}}'\), which is a highest weight representation with the same highest weight h. Since \({\mathcal {W}}\) is irreducible, there is a surjective module homomorphism \({\mathcal {U}}(\mathfrak {vir}){\bar{w}}^{\prime } \twoheadrightarrow {\mathcal {W}}\), which in particular implies that \(\mathrm {dim}(({\mathcal {U}}(\mathfrak {vir}){\bar{w}}^{\prime })_{(\eta )})\ge \mathrm {dim}({\mathcal {W}}_{(\eta )})\) for all \(\eta \in {\mathbb {C}}\). On the other hand, by construction, we have \(\mathrm {dim}({\mathcal {W}}'_{(\eta )}) = \mathrm {dim}({\mathcal {W}}_{(\eta )})\), \(\eta \in {\mathbb {C}}\). Therefore we get that
and we can conclude that \({\mathcal {U}}(\mathfrak {vir}){\bar{w}}^{\prime }={\mathcal {W}}^{\prime }\simeq {\mathcal {W}}\). \(\quad \square \)
Corollary 4.10
The first-row modules are self-dual, \(Q_{\lambda }' \cong Q_{\lambda }\) for any \(\lambda \in {\mathbb {N}}\).
4.4.2 Intertwining operators among highest weight modules
Let us now suppose that \(W_{1}\), \(W_{0}\), \(W_{\infty }\) are three modules for the universal Virasoro VOA \(V_{c}\), and that each of \(W_{1}\), \(W_{0}\), and \(W_{\infty }'\) are highest weight modules (note also that by Lemma 4.9, the contragredient \(W_{\infty }'\) is a highest weight module for example if \(W_{\infty }\) itself is an irreducible highest weight module). Let \({\bar{w}}_{1}\), \({\bar{w}}_{0}\), \({\bar{w}}_{\infty }'\) be highest weight vectors in \(W_{1}\), \(W_{0}\), \(W_{\infty }'\), respectively, and denote the corresponding highest weights by \(h_{1}, h_{0}, h_{\infty }\).
For an intertwining operator operator \({\mathcal {Y}}\in {\mathcal {I}}\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \), define
and call this the initial term of the intertwining operator \({\mathcal {Y}}\). The initial term defines a linear map
We make a few simple general observations in this setup.
Lemma 4.11
The initial term of any \({\mathcal {Y}}\in {\mathcal {I}}\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \) is of the form
Proof
Using Corollary 4.7(2) for \(n = 0\), Lemma 4.3, and the eigenvector equations \(L_0 {\bar{w}}_{1}= h_{1}\, {\bar{w}}_{1}\), \(L_0 {\bar{w}}_{0}= h_{0}\, {\bar{w}}_{0}\), \(L_0 {\bar{w}}_{\infty }' = h_{\infty }\, {\bar{w}}_{\infty }'\), we calculate
Thus the initial term satisfies \({\varvec{x}}\frac{\mathrm {d}}{\mathrm {d}{{\varvec{x}}}} \mathrm {Init}[{\mathcal {Y}}] ({\varvec{x}}) = (h_{\infty }- h_{1}- h_{0}) \, \mathrm {Init}[{\mathcal {Y}}] ({\varvec{x}})\). The solution space of this differential equation is one dimensional and spanned by \({\varvec{x}}^{h_{\infty }- h_{1}- h_{0}}\), so the assertion follows. \(\quad \square \)
The following straightforward proposition contains a key idea, that of an induction based on PBW-filtrations, so we do it in detail here. In later proofs (including our main results), we will then not always write out explicitly all of the cases, as the ideas are similar.
Proposition 4.12
An intertwining operator \({\mathcal {Y}}\in {\mathcal {I}}\left( {\begin{array}{c}W_{\infty }\\ W_{1} \; W_{0}\end{array}}\right) \) is uniquely determined by its initial term \(\mathrm {Init}[{\mathcal {Y}}] ({\varvec{x}})\). In particular, by Lemma 4.11 we thus have
i.e., if a non-zero intertwining operators exists, it is unique up to a multiplicative constant.
Proof
Suppose that \(\mathrm {Init}[{\mathcal {Y}}]({\varvec{x}}) = 0\). We will prove that then \(\langle {w}_{\infty }' , \; {\mathcal {Y}}({w}_{1}, {\varvec{x}}) \, {w}_{0}\rangle = 0\) for all \({w}_{\infty }' \in W_{\infty }'\), \({w}_{1}\in W_{1}\), \({w}_{0}\in W_{0}\). It will follow that \({\mathcal {Y}}= 0\). From this we can conclude that the initial term indeed determines the interwining operator.
The proof of the above is done by induction with respect to the total PBW word length for the PBW filtrations of the three highest weight representations \(W_{1}\), \(W_{0}\), \(W_{\infty }^{\prime }\). So assume that \(\langle {w}_{\infty }' , \; {\mathcal {Y}}({w}_{1}, {\varvec{x}}) \, {w}_{0}\rangle = 0\) whenever \({w}_{\infty }' \in {\mathscr {F}}^{p_1} W_{\infty }'\), \({w}_{1}\in {\mathscr {F}}^{p_2} W_{1}\), \({w}_{0}\in {\mathscr {F}}^{p_3} W_{0}\) are such that the total word lengths satisfy \(p_1 + p_2 + p_3 \le p\). Now let \(n>0\), and consider any such \({w}_{\infty }', {w}_{1}, {w}_{0}\). From Corollary 4.7(2) we get that
where each term of the second expression vanished by the induction hypothesis (note that also \(L_{n} {w}_{0}\in {\mathscr {F}}^{p_3-1} W_{0}\) and \(L_{k-1} {w}_{1}\in {\mathscr {F}}^{p_2} W_{1}\) above). Similarly we get
Finally, using Corollary 4.7(1–3), we similarly get
These three cases complete the induction step, by establishing that \(\langle {w}_{\infty }' , \; {\mathcal {Y}}({w}_{1}, {\varvec{x}}) \, {w}_{0}\rangle \) vanishes also whenever \({w}_{\infty }' \in {\mathscr {F}}^{p_1} W_{\infty }'\), \({w}_{1}\in {\mathscr {F}}^{p_2} W_{1}\), \({w}_{0}\in {\mathscr {F}}^{p_3} W_{0}\) are such that the total word lengths satisfy \(p_1 + p_2 + p_3 \le p+1\). \(\quad \square \)
4.4.3 Intertwining operators among first row modules
To find all intertwining operators among the first row modules \(Q_{\lambda }\), in view of Proposition 4.12 it suffices to determine when non-zero intertwining operators can exist. We call the conditions for the existence selection rules.Footnote 2
The singular vectors (4.12) lead to necessary conditions. Fix \(\lambda \in {\mathbb {N}}\), and introduce the corresponding polynomial of \(h_{\infty }, h_{0}\)
Lemma 4.13
Suppose that \(W_{0}\), \(W_{\infty }\) are modules for \(V_{c}\) such that \(W_{0}\) and \(W_{\infty }'\) are highest weight modules with highest weights \(h_{0}\) and \(h_{\infty }\), respectively. For each \(\lambda \in {\mathbb {N}}\), the linear map
where \(\pi _{\lambda }:M_{\lambda }\rightarrow Q_{\lambda }\) is the canonical projection, is an embedding of the space of intertwining operators. Furthermore, this embedding is an isomorphism if and only if the highest weights satisfy the polynomial equation
Proof
It is clear that for any \({\mathcal {Y}}\in {\mathcal {I}}\left( {\begin{array}{c}W_{\infty }\\ Q_{\lambda } \; W_{0}\end{array}}\right) \), the formula \({\mathcal {Y}}(\pi _{\lambda }(\cdot ), {\varvec{x}})\) indeed gives an intertwining operator of type \(\left( {\begin{array}{c}W_{\infty }\\ M_{\lambda } \; W_{0}\end{array}}\right) \), so the map is well-defined.
For its injectivity, observe the following. The initial terms satisfy \(\mathrm {Init}[{\mathcal {Y}}(\cdot ,{\varvec{x}})]=\mathrm {Init}[{\mathcal {Y}}(\pi _{\lambda }(\cdot ),{\varvec{x}})]\). Now if \({\mathcal {Y}}(\pi _{\lambda }(\cdot ),{\varvec{x}})=0\), we have \(\mathrm {Init}[{\mathcal {Y}}(\cdot ,{\varvec{x}})]=0\), which by Proposition 4.12 implies that also \({\mathcal {Y}}(\cdot ,{\varvec{x}})=0\). Injectivity follows.
The embedding is an isomorphism if and only if all intertwining operators \({\mathcal {Y}}\in {\mathcal {I}}\left( {\begin{array}{c}W_{\infty }\\ M_{\lambda } \; W_{0}\end{array}}\right) \) factor through the irreducible quotient in the sense that we have \({\mathcal {Y}}(w, {\varvec{x}})=0\) for all \(w\) in the maximal proper submodule of \(M_{\lambda }\). As in Proposition 4.12, we see that the factorization is equivalent to the single condition \(\langle {\bar{w}}_{\infty }' , \, {\mathcal {Y}}( S_\lambda {\bar{w}}_{c,h(\lambda )} , \, {\varvec{x}}) \, {\bar{w}}_{0}\rangle = 0\), where \(S_{\lambda } {\bar{w}}_{c,h(\lambda )}\) is the singular vector defined in (4.12); just note that the singular vector generates the maximal proper submodule of \(M_{\lambda }\), which is isomorphic to \(M(c,h(\lambda )+\lambda +1)\).
Let \({\bar{w}}_{0}\) and \({\bar{w}}_{\infty }'\) be highest weight vectors in \(W_{0}\) and \(W_{\infty }'\), respectively, and let \({\bar{w}}_{\lambda }\) be a highest weight vector in \(M_{\lambda }\). Denote the initial term of \({\mathcal {Y}}\) by
By Lemma 4.11, we must have
Again by a calculation using the formulas of Corollary 4.7 (in fact the special case \({w}_{\infty }'={\bar{w}}_{\infty }'\) and \({w}_{0}= {\bar{w}}_{0}\) of the last calculation in the proof of Proposition 4.12), we get for any \(n>0\)
where we introduced the differential operator
Recursively used, this allows to reduce the following expression to a differential operator acting on the initial term
With induction on k, starting from \(f({\varvec{x}}) = A \, {\varvec{x}}^{\Delta }\) and using the explicit differential operators \({\mathscr {L}}_{-n}\), we find
From the formula (4.12) for the singular vector \(S_\lambda {\bar{w}}_{c,h(\lambda )}\), using (4.21), we get
The vanishing \(\langle {\bar{w}}_{\infty }' , {\mathcal {Y}}( S_\lambda {\bar{w}}_{1}, {\varvec{x}}) {\bar{w}}_{0}\rangle = 0\) therefore amounts to a differential equation for the initial term \(f({\varvec{x}}) = \mathrm {Init}[{\mathcal {Y}}]({\varvec{x}})\). With the explicit formula \(f({\varvec{x}}) = A \, {\varvec{x}}^{\Delta }\), this differential equation simplifies to
The intertwining operator \({\mathcal {Y}}\) is non-zero only if \(A \ne 0\), and in this case the desired factorization is equivalent to \(P_\lambda (h_{0},h_{\infty }) = 0\). \(\quad \square \)
For fixed \(\lambda \in {\mathbb {N}}\) and \(h_{0}\in {\mathbb {C}}\), the equation \(P_\lambda (h_{0}, h_{\infty })\) is a degree \(\lambda +1\) polynomial equation for \(h_{\infty }\). It is possible to find the roots by a direct calculation [FZ12]. With the quantum group method, the following easier argument works as well.
Proposition 4.14
Let \(\lambda \in {\mathbb {N}}\) and \(\mu \in {\mathbb {Q}}\). Then we have the factorization
Proof
Recall from (4.10) that \(h(\mu )\) is a quadratic polynomial in \(\mu \), specifically \(h(\mu ) = \frac{1}{\kappa } \mu ^2 + \big ( \frac{2}{\kappa }-\frac{1}{2} \big ) \mu \). Note also that
Recalling that \(\kappa \notin {\mathbb {Q}}\), we see in particular that if \(\rho \in {\mathbb {Q}}\), then all \(h(\rho +m)\), \(m \in {\mathbb {Z}}\), are distinct.
First fix \(\lambda \in {\mathbb {N}}\) and \(\ell \in \left\{ 0,1,\ldots ,\lambda \right\} \). Now if \(\mu \in {\mathbb {N}}\) is such that \(\mu \ge \lambda \), then we have \(\sigma = \lambda +\mu -2\ell \in \mathrm {Sel}(\lambda ,\mu )\), so we may consider the non-zero vector \(u = {\iota }_{ \;{\sigma }}^{{\lambda } , {\mu }} \big ( u_{0}^{(\sigma )} \big ) \in {\mathsf {M}}_{\lambda } \otimes {\mathsf {M}}_{\mu }\). The associated function
satisfies the BSA PDEs \({\mathscr {D}}^{(j)} F(x_0,x_1) = 0\), for \(j=0,1\), where \({\mathscr {D}}^{(j)}\) is given by (2.6). From the translation and scaling covariance and asymptotics given in Theorem 2.2 it follows that in this case the function must be simply
where \(\Delta = h(\lambda +\mu -2\ell ) - h(\lambda ) - h(\mu )\) and \(B = B_{ {\lambda + \mu - 2\ell } , {\lambda }}^{\;{\;\;\mu }} \ne 0\).
But the BSA PDE for a function of the above form reads
We conclude that \(P_\lambda \big ( h(\mu ) , h(\lambda +\mu -2\ell ) \big ) = 0\). Now observe that both \(\mu \mapsto h(\mu )\) and \(\mu \mapsto h(\lambda +\mu -2\ell )\) are quadratic polynomials in \(\mu \), so also \(\mu \mapsto P_\lambda \big ( h(\mu ) , h(\lambda +\mu -2\ell ) \big )\) is a polynomial in \(\mu \). We have just shown that this polynomial vanishes for all integers \(\mu \ge \lambda \), so it must be identically zero:
Now let \(\lambda \in {\mathbb {N}}\) and \(\mu \in {\mathbb {Q}}\) be fixed. Consider the polynomial \(h_{\infty }\mapsto P_\lambda \big ( h(\mu ) , h_{\infty }\big )\) of degree \(\lambda +1\). From the above we see that \(h_{\infty }= h(\lambda +\mu -2\ell )\) are roots of this polynomial, when \(\ell = 0, 1, \ldots , \lambda \). Since \(\kappa \not \in {\mathbb {Q}}\), these \(\lambda +1\) roots are distinct, and so we must have
From the defining formula (4.20) one sees that the leading term of this polynomial of \(h_{\infty }\) is \((h_{\infty })^{1+\lambda }\), so the constant of proportionality above is in fact 1. \(\quad \square \)
The following theorem states that there is always a nontrivial intertwining operator among an arbitrary triple of Verma modules. The theorem can be seen as a particular case of a more general one in [Li99]. For self-containedness, we give the proof for the case of our interest in “Appendix B”.
Theorem 4.15
For \(h_{1},h_{0},h_{\infty }\in {\mathbb {C}}\),
The fusion rules among first row modules of the generic Virasoro VOA now follow from Lemma 4.13, Proposition 4.14 and Theorem 4.15.
Corollary 4.16
Let \(\lambda , \mu , \nu \in {\mathbb {N}}\). Then,
Proof
Recall that the first row modules are self-dual (Corollary 4.10). We consider the following sequence of embeddings
where we used the symmetry in Proposition 4.5. Then, due to Lemma 4.13, the composed embedding is an isomorphism if and only if the highest weights satisfy the conditions
It is an easy manipulation of the factorization in Proposition 4.14 to see that these conditionsFootnote 3 are equivalent to \(\nu \in \mathrm {Sel}(\lambda ,\mu )\). \(\quad \square \)
5 Compositions of Intertwining Operators
Intertwining operators, defined in the previous section, give 3-point correlation functions of conformal field theories (or alternatively, in a geometric interpretation, amplitudes in a pair-of-pants Riemann surface with three parametrized boundary components [Hua12]). Importantly, they serve as the building blocks of more general correlation functions. Namely, for a multipoint correlation function (or an amplitude on a Riemann surfaces with more than three parametrized boundary components), one forms an appropriate composition of intertwining operators.
An intertwining operator is a formal series, with coefficients that are linear operators between modules of the VOA. Compositions of intertwining operators are then a priori formal series in several formal variables, also with coefficients that are (composed) linear operators between modules. To get actual correlation functions, however, one considers suitable matrix elements of the formal series of linear operators, and crucially, one must then address the convergence of the corresponding series.
In this section, we first study properties of the compositions of the intertwining operators between modules of the first row subcategory for the generic Virasoro VOA as formal power series. Then we establish analoguous properties for the functions obtained by the quantum group method—specifically the ones corresponding to the conformal block vectors of Sect. 3. The main result of this section (Theorem 5.9) is that the formal series of the composition of intertwining operators coincide with suitable power series expansions of the actual conformal block functions, and that these series are convergent in the appropriate domains.
More precisely, the section is organized as follows. In Sect. 5.1 we fix our normalization of the intertwining operators, and in Sect. 5.2 we introduce the specific spaces of formal series that will be used. Section 5.3 contains the proofs of two key properties; that (the highest weight matrix elements of) compositions of the intertwining operators satisfy a system of partial differential equations, and that the formal series solutions to this PDE system are unique (up to scalar multiples). In Sect. 5.4 we detail a recursive series expansion procedure for the quantum group functions, and use this and the partial differential equations to prove the main result (Theorem 5.9) that the formal series of the composition of intertwining operators converge to the functions corresponding to the conformal block vectors. In Sect. 5.5 we comment on some first applications of the result.
5.1 Fusion rules and normalized intertwining operators
A comparison of Corollary 4.16 and Lemma 2.1 directly gives
Definition 5.1
When \(\lambda _{\infty }\in \mathrm {Sel}(\lambda _{1},\lambda _{0})\) so that nonzero intertwining operators exist, we denote by
the unique intertwining operator normalized so that
where
are as in Theorem 2.2.
The above normalization of the intertwining operator \({\mathcal {Y}}_{\lambda _{1} \, \lambda _{0}}^{\;\lambda _{\infty }}\) is chosen so that that the “matrix element” \(\left\langle {{\bar{w}}}_{\lambda _{\infty }},{\mathcal {Y}}_{\lambda _{1} \, \lambda _{0}}^{\;\lambda _{\infty }} ( {{\bar{w}}}_{\lambda _{1}} , {\varvec{x}}) \, {{\bar{w}}}_{\lambda _{0}}\right\rangle = \mathrm {Init}[{\mathcal {Y}}_{\lambda _{1} \, \lambda _{0}}^{\;\lambda _{\infty }}] ({\varvec{x}}) = B \, {\varvec{x}}^{\Delta }\) between highest weight vectors formally coincides with the function \(x \mapsto {\mathcal {F}}[u_{{\underline{{\varsigma }}}}](0,x)\) constructed with the quantum group method from the conformal block vector \(u_{{\underline{{\varsigma }}}} \in {\mathsf {M}}_{\lambda _{1}} \otimes {\mathsf {M}}_{\lambda _{0}}\) corresponding to \({{\underline{{\varsigma }}}= (\lambda _{0}, \lambda _{1}, \lambda _{\infty })}\) as in Sect. 3.
5.2 Space of formal series
For a sequence \(\underline{{\lambda }}= (\lambda _{0},\lambda _{1}\dots ,\lambda _{N},\lambda _{\infty }) \in {\mathbb {N}}^{N+2}\), and a \(\underline{{\lambda }}\)-admissible sequence \({\underline{{\varsigma }}}= ({\varsigma }_0 , {\varsigma }_1 , \ldots , {\varsigma }_{N-1}, {\varsigma }_{N})\), we consider the composition of intertwining operators
which is a priori a formal series in \({\varvec{x}}_1 , \ldots , {\varvec{x}}_N\) with coefficients that are linear maps \({Q_{{\varsigma }_0} \rightarrow Q_{{\varsigma }_N}}\). We consider in particular the “matrix element” between highest weight states
As in the proof of Proposition 4.12, the general matrix elements
with \(w_{i}\in Q_{\lambda _{i}}\), \(i=0,1,\dots , N\), and \(w_{\infty }^{\prime }\in Q_{\lambda _{\infty }}^{\prime }\), can be determined by a recursion using the Jacobi identity (4.18) (in the specific form of Corollary 4.7) from this matrix element (5.2); this particular matrix element serves a role analogous to the initial term of an intertwining operator. A priori, (5.2) is a formal series in \({\varvec{x}}_1 , \ldots , {\varvec{x}}_n\) with complex coefficients, i.e., an element of \({\mathbb {C}}\{{\varvec{x}}_1 , \ldots , {\varvec{x}}_n\}\). But in fact the series has a more particular structure: it is essentially a formal power series (with non-negative powers!) in the ratios of the variables.
Lemma 5.2
The series (5.2) belongs to the space
with \(\Delta _{i}=h({\varsigma }_{i})-h(\lambda _{i})-h({\varsigma }_{i-1})\) for \(i=1,\dots , N\).
We make a preliminary to prove Lemma 5.2. For each \(\lambda \in {\mathbb {N}}\) and \(n\in {\mathbb {N}}\), we set \(Q_{\lambda }(n):=(Q_{\lambda })_{(h(\lambda )+n)}\) as the eigenspace of \(L_{0}\) corresponding to the eigenvalue \(h(\lambda )+n\). Suppose that a triple \((\lambda _{\infty },\lambda _{1},\lambda _{0})\) satisfies the selection rule \(\lambda _{\infty }\in \mathrm {Sel}(\lambda _{1},\lambda _{0})\), and take the intertwining operator \({\mathcal {Y}}_{\lambda _{1} \, \lambda _{0}}^{\;\lambda _{\infty }}\) of type \(\left( {\begin{array}{c}Q_{\lambda _{\infty }}\\ Q_{\lambda _{1}} \; Q_{\lambda _{0}}\end{array}}\right) \). For \(w\in Q_{\lambda _{1}}(k)\), \(k\in {\mathbb {N}}\), using Corollary 4.7(2) for \(L_0\) like in Lemma 4.2, we find that \({\mathcal {Y}}_{\lambda _{1} \, \lambda _{0}}^{\;\lambda _{\infty }} (w,{\varvec{x}})\) takes the form
where \(w_{(m)}Q_{\lambda _{0}}(n)\subset Q_{\lambda _{\infty }}(k-m+n-1)\) for \(m\in {\mathbb {Z}}\), \(n \in {\mathbb {N}}\).
We prove a slightly more general result than Lemma 5.2:
Lemma 5.3
Let \(w\in Q_{{\varsigma }_{0}}(n)\), \(n\in {\mathbb {N}}\). Then, the formal series defined by
lies in the space
Proof
We prove this by induction on N. When \(N=1\), we have
Here, since \(({{\bar{w}}}_{\lambda _{1}})_{(m)} w\subset Q_{{\varsigma }_{1}}(-m+n-1)\), the matrix element \(\langle {{\bar{w}}}_{{\varsigma }_{1}}^{\prime }, ({{\bar{w}}}_{\lambda _{1}})_{(m)}w\rangle \) vanishes unless \(m=n-1\). Therefore, we can see that
which is the \(N=1\) case.
Then assume that the assertion holds for \(N\le k-1\) with some \(k>1\). Then, we have
Again, since \(({{\bar{w}}}_{\lambda _{1}})_{(m)}w\in Q_{{\varsigma }_{1}}(-m+n-1)\), the matrix element vanishes unless \(m\le n-1\). In other words, we have the expansion
where we set \(\underline{{\lambda }}^{\prime } = ({\varsigma }_{1},\lambda _{2},\ldots ,\lambda _{k},\lambda _{\infty })\) and \({\underline{{\varsigma }}}^{\prime }=({\varsigma }_{1},\dots ,{\varsigma }_{k})\). By the induction hypothesis, each coefficient \(C^{\underline{{\lambda }}^{\prime }}_{{\underline{{\varsigma }}}^{\prime }}\left( ({{\bar{w}}}_{\lambda _{1}})_{(n-\ell -1)}w;{\varvec{x}}_{2},\dots ,{\varvec{x}}_{k}\right) \) lies in
Consequently, we have the desired result at \(N=k\). \(\quad \square \)
5.3 System of differential equations
Due to the quotienting out of the singular vector in the first row module \(Q_{\lambda } = M_{\lambda } \, \big / \, {\mathcal {U}}(\mathfrak {vir}) S_\lambda {\bar{w}}_{c,h(\lambda )}\), the matrix element \(C^{\underline{{\lambda }}}_{{\underline{{\varsigma }}}}({\varvec{x}}_{1},\dots , {\varvec{x}}_{N})\) satisfies a certain system of differential equations. Given a sequence \(\underline{{\lambda }}=(\lambda _{0},\dots ,\lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\), we introduce the differential operators
for \(j=1,\dots , N\) and \(n\in {\mathbb {Z}}\), and
for \(j=1,\dots , N\). These differential operators \(\widetilde{{\mathscr {L}}}_{n}^{(j)}\) and \(\widetilde{{\mathscr {D}}}^{(j)}\) essentially correspond to how the differential operators \({\mathscr {L}}^{(j)}_{n}\) and \({\mathscr {D}}^{(j)}\) of (2.7) and (2.6) act on translation invariant functions; see Lemma 5.7 for a precise statement. Notice that the actions of \(\widetilde{{\mathscr {L}}}_{n}^{(j)}\) and \(\widetilde{{\mathscr {D}}}^{(j)}\) on the space
of formal series are canonically determined in such a way that
and the factors \((x_i-x_j)^n\) are expanded as the following formal power series
i.e., \((x_i-x_j)^n \mapsto ({\varvec{x}}_i-{\varvec{x}}_j)^n\) for \(i>j\) but \((x_i-x_j)^n \mapsto (-{\varvec{x}}_j+{\varvec{x}}_i)^n\) for \(i<j\).
The following standard lemma will be instrumental for us. We include the details here to concretely demonstrate the source of the specific power series expansions above.
Lemma 5.4
Let \(\underline{{\lambda }}=(\lambda _{0},\dots ,\lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\) be a sequence and \({\underline{{\varsigma }}}=({\varsigma }_{0},\dots , {\varsigma }_{N})\) be \(\underline{{\lambda }}\)-admissible. Then, the matrix element \(C^{\underline{{\lambda }}}_{{\underline{{\varsigma }}}}({\varvec{x}}_{1},\dots , {\varvec{x}}_{N})\) solves the following system of differential equations
Proof
Fix \(j \in \left\{ 1,\ldots ,N \right\} \). For \(w\in Q_{\lambda _j}\), consider
Then we can use Corollary 4.7(1) to calculate \(X(L_{-p} w;{\varvec{x}}_{1},\dots , {\varvec{x}}_{N})\), for \(p>0\),
In the first term, we use
from Corollary 4.7(2), to commute \(L_{-p-k}\) to the left, where it annihilates the highest weight vector \({{\bar{w}}}_{{\varsigma }_{N}}^{\prime } \in Q_{\lambda _N}'\). The first term thus becomes
which is indeed expanded in non-negative powers of \({\varvec{x}}_{j}/{\varvec{x}}_{i}\), \(i>j\). Similarly in the second term, by commuting \(L_{k-1}\) to the right and simplifying, the commutator contributions become
which is expanded in non-negative powers of \({\varvec{x}}_{i}/{\varvec{x}}_{j}\), \(i<j\). However, for \(k=0\) and \(k=1\), the highest weight vector \({{\bar{w}}}_{{\varsigma }_{0}} \in Q_{\lambda _0}\) is not annihilated by \(L_{k-1}\), so also the following two further terms remain
After simplifications (the first one still using Corollary 4.7), these two can be written as
By combining everything, we get
Using this auxiliary observation, the assertion then follows easily from the formula (4.12) for the singular vector \(S_{\lambda _j} {\bar{w}}_{c,h(\lambda _j)} \in M_{\lambda _j}\), and the fact that its canonical projection in \(Q_{\lambda _j}\) vanishes, \(S_{\lambda _j} {{\bar{w}}}_{\lambda _j} = 0\). \(\quad \square \)
The coefficient of the monomial \({\varvec{x}}_{N}^{\Delta _{N}}\cdots {\varvec{x}}_{1}^{\Delta _{1}}\) in
is easy to trace in the calculations above. Ultimately because of the chosen normalizations of the intertwining operators, this coefficient is
In particular \(C^{\underline{{\lambda }}}_{{\underline{{\varsigma }}}}({\varvec{x}}_{1},\dots , {\varvec{x}}_{N})\) is a non-zero solution to the system of differential equations above.
Theorem 5.5
In the space of formal series of the form (5.3), the solution space
of the above system of differential equations is one-dimensional,
Proof
Since Lemma 5.4 ensures the existence of a nonzero solution, it suffices to show that solutions are unique up to a multiplicative constant. We prove this by induction on N. When \(N=1\), observe that for any \(n \in {\mathbb {Z}}\) we have
where \(P_{\lambda _1}\) is the polynomial (4.20). Recall that by the genericity \(\kappa \notin {\mathbb {Q}}\), we have
if and only if \(n=0\). This shows that \(\mathrm {Ker}\widetilde{{\mathscr {D}}}^{(1)} = {\mathbb {C}}\, {\varvec{x}}_{1}^{\Delta _{1}}\), and proves one-dimensionality.
For the induction step, assume the uniqueness of solutions up to multiplicative constants for \(N-1\) variables. We regard
as a subspace of the space
and on the latter we introduce a \({\mathbb {Z}}\)-grading so that the degree of a monomial is
The grading also gives rise to the corresponding notion of a degree of an operator acting on the latter space.
Now let \(C({\varvec{x}}_{1},\dots , {\varvec{x}}_{N}) \in \bigcap _{j=1}^N \mathrm {Ker}\, \widetilde{{\mathscr {D}}}^{(j)}\) be a non-zero solution. Expand it according to the grading above as
where \(d \in {\mathbb {Z}}\) is the lowest degree with a non-vanishing coefficient, \(C_{d} ({\varvec{x}}_{2},\dots , {\varvec{x}}_{N}) \ne 0\). We express the action of \(\widetilde{{\mathscr {L}}}_{-p}^{(1)}\), \(p\in {\mathbb {Z}}\), explicitly as
in order to manifest the degree of each contribution. Let us denote the first term in this expansion by
which is an operator of degree \(-p\) and involves no other variables besides \({\varvec{x}}_1\). It is readily seen that, if \(p\ge 0\), the difference \(\widetilde{{\mathscr {L}}}_{-p}^{(1)}-\underline{\widetilde{{\mathscr {L}}}}{\,}_{-p}^{(1)}\) is a sum of operators of degrees strictly greater than \(-p\). Therefore, when we set
this is of degree \(-\lambda _{1}-1\) and the difference \(\widetilde{{\mathscr {D}}}^{(1)}-\underline{\widetilde{{\mathscr {D}}}}{\,}^{(1)}\) is a sum of operators of degree strictly greater than \(-\lambda _{1}-1\). Specifically, let us expand \(\widetilde{{\mathscr {D}}}^{(1)}\) as
Recall the polynomial (4.20). It is again straightforward that the action of \(\underline{\widetilde{{\mathscr {D}}}}{\,}^{(1)}\) on the monomial \({\varvec{x}}_{1}^{\Delta _{1}+n}\), \(n\in {\mathbb {Z}}\), gives
Having assumed the generic case \(\kappa \notin {\mathbb {Q}}\), from the factorization in Proposition 4.14, we see that the factor \({P_{\lambda _{1}} \big (h(\lambda _{0}),h({\varsigma }_{1})+n \big )}\) vanishes if and only if \(n=0\). This observation gives first of all an indicial equation: the lowest degree term in \(\widetilde{{\mathscr {D}}}^{(1)} \, C = 0\) is
and its vanishing is only possible if \(d = 0\). Moreover, the same observation gives a recursion to determine the coefficients of higher degree, \(C_n\) for \(n > d = 0\). Indeed, plugging in the series expansions for both C and \(\widetilde{{\mathscr {D}}}^{(1)}\), the differential equation \(\widetilde{{\mathscr {D}}}^{(1)} C = 0\) for the solution C becomes
For each \(k=1,2,\dots \), the equality of the components of degree \(-\lambda _{1}-1+k\) gives
where we used the property that \(P_{\lambda _{1}}(h(\lambda _{0}),h({\varsigma }_{1})+k)\ne 0\) for \(k=1,2,\dots \). The apparent dependence of the right hand side on \({\varvec{x}}_{1}\) is checked to be cancelled by considering the degrees of the operators involved. This formula implies that, for each \(k=1,2\dots \), the coefficient \(C_{k}\) is determined by the finitely many previous coefficients \(C_{0}, C_{1},\dots , C_{k-1}\). Recursively, we conclude that each \(C_{k}\), \(k=1,2,\dots , \) is determined by the initial coefficient \(C_{0}\).
Note that \(C_{0}\) belongs to the space
The next task is to show that the formal series \(C_{0}\) solves the desired system differential equations. Those differential equations involve the differential operators
for \(2 \le j \le N\). These differential operators \(\widetilde{{\mathscr {L}}}'{}_{-p}^{(j)}\) do not involve the variable \({\varvec{x}}_1\), and they can be viewed either as operators on the space \({\mathbb {C}}[{\varvec{x}}_N] \, [[{\varvec{x}}_{N-1}/{\varvec{x}}_{N}]]\cdots [[{\varvec{x}}_{2}/{\varvec{x}}_{3}]] [{\varvec{x}}_2^{-1}] \; {\varvec{x}}_{N}^{\Delta _{N}}\cdots {\varvec{x}}_{2}^{\Delta _{2}}\) or as operators on the space \(\big ({\mathbb {C}}[{\varvec{x}}_N] \, [[{\varvec{x}}_{N-1}/{\varvec{x}}_{N}]]\cdots [[{\varvec{x}}_{2}/{\varvec{x}}_{3}]] [{\varvec{x}}_2^{-1}] \, {\varvec{x}}_{N}^{\Delta _{N}}\cdots {\varvec{x}}_{2}^{\Delta _{2}}\big ) [[{\varvec{x}}_1]]\, [{\varvec{x}}_1^{-1}] \, {\varvec{x}}_{1}^{\Delta _{1}}\), in which case they obviously have degree 0. In the latter space, the difference \(\widetilde{{\mathscr {L}}}_{-p}^{(j)}-\widetilde{{\mathscr {L}}}'{}_{-p}^{(j)}\) can be straightforwardly simplified to the form
where the first line is a degree zero operator, and all the terms on the second line have strictly positive degrees. We thus see that
where \(\mathrm {h.o.t.}\) contains only terms of strictly positive degree. Now the vanishing of the degree zero term in the differential equation \(\underline{\widetilde{{\mathscr {D}}}}{\,}^{(j)} \Big ( \sum _{n=0}^\infty {\varvec{x}}_{1}^{\Delta _{1}+n} \, C_{n}({\varvec{x}}_{2},\dots , {\varvec{x}}_{N}) \Big ) = 0\) implies the differential equation
for \(C_0\), where
The initial coefficient \(C_{0}({\varvec{x}}_2,\ldots ,{\varvec{x}}_N)\) therefore solves the system of differential equations \({\widetilde{{\mathscr {D}}}'{}^{(j)}\, C_{0}=0}\) for \(j=2,\dots , N\), which is a system of the original form with one fewer variable. By the induction hypothesis, such a \(C_{0}\) is unique up to multiplicative constants. Since a solution C is determined by its initial coefficient \(C_0\), we conclude that the solution C is also unique one up to multiplicative constants. \(\quad \square \)
5.4 Functions from the quantum group method
In this subsection we do the exactly analoguous steps for the functions from the quantum group method as were done for the highest weight matrix elements of compositions of intertwining operators in the previous subsection. The conclusions have an identical appearance, and this is in fact what will allow us to show the equality of the two. While Sect. 5.3 dealt with formal power series, we will now be working with functions.
We use the quantum group method of Sect. 2, with the difference that we first use \(N+1\) variables, labeled \(x_0, x_1, \ldots , x_{N}\). After some initial observations, we will in fact set \(x_0 = 0\).
5.4.1 Translation invariance
We first note that the differential operators \({\mathscr {L}}^{(j)}_{n}\) of (2.7) preserve translation invariance.
Lemma 5.6
If \(F \in {\mathcal {C}}^\infty ({\mathfrak {X}}_{N+1})\) is translation invariant,
then so is \({\mathscr {L}}^{(j)}_{n}F\), for any \(j \in \left\{ 0,1,\dots , N \right\} \) and \(n\in {\mathbb {Z}}\).
Proof
Let us set \({\mathbb {L}}_{-1}:=\sum _{i=0}^{N}\frac{{\partial }}{{\partial }x_{i}}\). Then, a smooth function F is translation invariant if and only if \({\mathbb {L}}_{-1}F=0\). The desired result follows from the fact that each operator \({\mathscr {L}}^{(j)}_{n}\), \(j=0,1,\dots , N\), \(n\in {\mathbb {Z}}\) commutes with \({\mathbb {L}}_{-1}\). \(\quad \square \)
We introduce the restricted chamber
of N variables. To a given translation invariant function \(F \in {\mathcal {C}}^{\infty } ({\mathfrak {X}}_{N+1})\), we associate a corresponding function on \({\mathfrak {X}}_{N}^{+}\) by
For typographical reasons, when the function F is given by a lengthy expression, we place the tilde symbol as a superscript, \({\widetilde{F}} = F^{\thicksim }\).
Lemma 5.7
Fix \(j \in \left\{ 1,\ldots ,N \right\} \). Let \(F\in {\mathcal {C}}^{\infty }({\mathfrak {X}}_{N+1})\) be a translation invariant function. Then we have
for any \(k\in {\mathbb {N}}\) and \(n_{1},\dots , n_{k}\in {\mathbb {Z}}\).
Proof
If F is translation invariant, then its partial derivative w.r.t. \(x_{0}\) can be rewritten as
Consequently, we observe that
which admits the specialization at \(x_{0}=0\) and gives \(\big ( {\mathscr {L}}^{(j)}_{n} F \big )^{\thicksim } = \widetilde{{\mathscr {L}}}_{n}^{(j)} {\widetilde{F}}\). The assertion is then obtained from Lemma 5.6 by induction on k. \(\quad \square \)
The following simple corollary of this lemma yields differential equations of the same form as those in Sect. 5.3.
Corollary 5.8
Fix a sequence \(\underline{{\lambda }}= (\lambda _{0},\lambda _{1},\dots , \lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\) and a \(\underline{{\lambda }}\)-admissible sequence \({\underline{{\varsigma }}}=({\varsigma }_{0},\dots ,{\varsigma }_{N})\). Let \(u_{{\underline{{\varsigma }}}} \in \big ( \bigotimes _{j=1}^N {\mathsf {M}}_{\lambda _j} \big ) \otimes {\mathsf {M}}_{\lambda _{0}}\) be the corresponding conformal block vector (3.3), and let \(F={\mathcal {F}}[u_{{\underline{{\varsigma }}}}]\in {\mathcal {C}}^{\infty }({\mathfrak {X}}_{N+1})\) denote the corresponding function obtained by the quantum group method of Sect. 2.2. Then F is translation invariant, and the associated function \({\widetilde{F}}\) on \({\mathfrak {X}}_{N}^{+}\) solves the system of differential equations \(\widetilde{{\mathscr {D}}}^{(j)}{\widetilde{F}}=0\), \(j=1,\dots , N\).
5.4.2 Series expansions of the functions
Fix again a sequence \(\underline{{\lambda }}= (\lambda _{0},\lambda _{1},\dots , \lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\) and a \(\underline{{\lambda }}\)-admissible sequence \({\underline{{\varsigma }}}=({\varsigma }_{0},\dots ,{\varsigma }_{N})\), and let \({\widetilde{F}} :{\mathfrak {X}}_{N}^{+} \rightarrow {\mathbb {C}}\) be the function given by
where \(u_{{\underline{{\varsigma }}}} \in \big ( \bigotimes _{j=1}^N {\mathsf {M}}_{\lambda _j} \big ) \otimes {\mathsf {M}}_{\lambda _{0}}\) is the corresponding conformal block vector of (3.3). We will expand this function as a series recursively, one variable at a time, starting from \(x_1\). The series expansion in \(x_1\) is the Frobenius series at 0 given by Lemma 2.5,
and the other variables \((x_2, \ldots , x_N) \in {\mathfrak {X}}_{N-1}^+\) are treated as parameters. When the other variables stay in the open subset
the Frobenius series in locally uniformly R-controlled.
The differential operators \(\widetilde{{\mathscr {L}}}_{n}^{(j)}\) and \(\widetilde{{\mathscr {D}}}^{(j)}\) of (5.4) and (5.5) are composed of
-
differentiations \(\frac{\partial }{\partial {x_1}}\) with respect to the power series variable \(x_1\);
-
differentiations \(\frac{\partial }{\partial {x_i}}\) with respect to the parameters \(x_i\), for \(i=2,\ldots ,N\);
-
multiplication operators by \((x_i-x_j)^n\) for \(i \ne j\) and by \(x_i^n\).
If \(i,j>1\), then the multiplication by \((x_i-x_j)^n\) acts on the coefficients \(c_k \in {\mathcal {C}}^\infty ({\mathfrak {X}}_{N-1}^{+;R})\) by a multiplication by a smooth (and in particular locally bounded) function. By contrast \({(x_i-x_1)^n}\) for \(i = 2, \ldots , N\) is expanded as a power series \((x_i-x_1)^n = \sum _{j=0}^\infty (-1)^j \, \left( {\begin{array}{c}n\\ j\end{array}}\right) \, x_i^{n-j} x_1^j\), which is itself locally uniformly R-controlled power series in \(x_1\) on \({\mathfrak {X}}_{N-1}^{+;R}\), and the multiplication operator involves a convolution of the coefficients of the power series.
By Lemma A.1, each one of the above constituent operators preserves the space of locally uniformly R-controlled series and acts naturally coefficientwise when \((x_2, \ldots , x_N) \in {\mathfrak {X}}_{N-1}^{+;R}\). Therefore the constituent operators can be composed, and the operators \(\widetilde{{\mathscr {L}}}_{n}^{(j)}\) and \(\widetilde{{\mathscr {D}}}^{(j)}\) also act on the space of locally uniformly R-controlled series, and they also act naturally coefficientwise, when \((x_2, \ldots , x_N) \in {\mathfrak {X}}_{N-1}^{+;R}\). For different values of \(R>0\), the actions of \(\widetilde{{\mathscr {L}}}_{n}^{(j)}\) and \(\widetilde{{\mathscr {D}}}^{(j)}\) on power series parametrized by \({\mathfrak {X}}_{N-1}^{+;R}\) are consistent (coefficient functions are obtained by restrictions to the smaller subset), so they give rise to a natural action on power series parametrized simply by \({\mathfrak {X}}_{N-1}^{+} = \bigcup _{R>0} {\mathfrak {X}}_{N-1}^{+;R}\).
It will turn out in the analysis below that the coefficient functions \(c_k \in {\mathcal {C}}^\infty ({\mathfrak {X}}_{N-1}^{+})\) are themselves (essentially) given by functions from the quantum group method, and they therefore admit Frobenius series expansions of their own. Recursively in the number of variables, this allows us to uniquely associate to \({\widetilde{F}}\) a power series in the space (5.3),
The following is our main result about the equality of the quantum group functions and (the highest weight matrix elements of) the compositions of intertwining operators of the first row subcategory of the generic Virasoro VOA.
Theorem 5.9
For any \(\underline{{\lambda }}= (\lambda _{0},\lambda _{1},\dots , \lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\) and any \(\underline{{\lambda }}\)-admissible sequence \({\underline{{\varsigma }}}=({\varsigma }_{0},\dots ,{\varsigma }_{N})\), the function \({\mathcal {F}}[u_{{\underline{{\varsigma }}}}]\) admits a series expansion
which is convergent for any \((x_1, \ldots , x_N) \in {\mathfrak {X}}_N^+\). As a formal series, this coincides with the matrix element (5.2) of the composition of intertwining operators,
Proof
We employ an induction over the number of variables N. The case of \(N=1\) is obvious; the function is
This function gives the same one term power series in \({\mathbb {C}}{\varvec{x}}^{\Delta _{1}}\) as the matrix element \(C^{\underline{{\lambda }}}_{{\underline{{\varsigma }}}}({\varvec{x}})\).
Assume that the assertion is true when the number of variables is strictly less than N. Then use Lemma 2.5 to obtain a Frobenius expansion of \({\widetilde{{\mathcal {F}}}}[u_{{\underline{{\varsigma }}}}]\) at \(x_{1}=0\),
Note that by Remark 2.6, the initial coefficient \({\widetilde{F}}_{0}\) coincides with \(B_{ {\lambda _{1}} , {\lambda _{0}}}^{\;{{\varsigma }_{1}}} {\widetilde{{\mathcal {F}}}}[u_{{\underline{{\varsigma }}}'}]\), where \({{\underline{{\varsigma }}}'=({\varsigma }_{1},\dots ,{\varsigma }_{N})}\) is a \(({\varsigma }_{1},\lambda _{2},\dots ,\lambda _{N},\lambda _{\infty })\)-admissible sequence.
We apply \(\widetilde{{\mathscr {D}}}^{(1)}\) to both sides of the expansion (5.8). Because the operators act coefficientwise, we may employ similar arguments as in the proof of Theorem 5.5. We find that \({\widetilde{F}}_{n}\), \(n\ge 1\), are determined recursively as
where \({\mathscr {R}}^{(1)}_{j}\), \(j \in {\mathbb {N}}\), are differential operators given by exactly the same formulas as in the proof of Theorem 5.5, but now acting on the space \({\mathcal {C}}^\infty ({\mathfrak {X}}_{N-1}^{+})[[{\varvec{x}}_1^{\pm 1}]] \, {\varvec{x}}_1^{\Delta _1}\).
In particular, \({\widetilde{F}}_{n}\), \(n\ge 1\), are determined by \({\widetilde{F}}_{0}\) via the same relations as \(C_{n}\), \(n\ge 1\), are determined by \(C_{0}\). It also follows that all higher coefficients \(F_{n}\), \(n\ge 1\), are analytic on \({\mathfrak {X}}_{N-1}^{+}\). By the induction hypothesis, \({\widetilde{F}}_{0}\) is expanded in
and coincides with \(C_{0}\). Therefore, each \({\widetilde{F}}_{n}\), \(n\ge 0\) is expanded in
and coincides with \(C_{n}\). Finally, from the expansion (5.8), we conclude that \({\widetilde{{\mathcal {F}}}}[u_{{\underline{{\varsigma }}}}]\) is expanded in
and coincides with \(C^{\underline{{\lambda }}}_{{\underline{{\varsigma }}}}\). The convergence of this series at any \((x_1 , \ldots , x_N) \in {\mathfrak {X}}_{N}^{+}\) is clear by an inductive application of Lemma 2.5. \(\quad \square \)
5.5 Some applications
Let us quickly comment on applications of the above result to the analysis of the PDE system and to the quantum group method itself.
5.5.1 On the solution spaces to BPZ differential equations
By Theorem 5.9, for every \(u \in \big ( \bigotimes _{j=1}^N {\mathsf {M}}_{\lambda _j} \big ) \otimes {\mathsf {M}}_{\lambda _{0}}\) such that \(E u = 0\) we associate a formal series representing the function \({\widetilde{{\mathcal {F}}}}[u] :{\mathfrak {X}}_{N}^+ \rightarrow {\mathbb {C}}\),
By convergence of the series (pointwise) in \({\mathfrak {X}}_{N}^+\), the series uniquely determines the function \({\widetilde{{\mathcal {F}}}}[u]\), and by translation invariance it therefore also determines \({\mathcal {F}}[u] :{\mathfrak {X}}_{N+1} \rightarrow {\mathbb {C}}\).
For fixed \(\underline{{\lambda }}= (\lambda _{0},\lambda _{1},\dots , \lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\), any \(\underline{{\lambda }}\)-admissible sequence \({\underline{{\varsigma }}}=({\varsigma }_{0},\dots ,{\varsigma }_{N})\) gives a solution to the (same) system of BPZ partial differential equations of BSA form,
with homogeneity
for any \(s>0\) and \((x_0, x_1, \ldots , x_N) \in {\mathfrak {X}}_{N+1}\).
For different \({\underline{{\varsigma }}}\), the corresponding formal series in \({\mathbb {C}}\{ {\varvec{x}}_1 , \ldots , {\varvec{x}}_N \}\) are clearly linearly independent, since the sequences \((\Delta _1, \ldots ,\Delta _N)\) of exponents \(\Delta _{i}=h({\varsigma }_{i})-h(\lambda _{i})-h({\varsigma }_{i-1})\), \(i=1,\ldots ,N\), are distinct in the generic case. In particular the conformal block type solutions \({\mathcal {F}}[u_{{\underline{{\varsigma }}}}]\), for \({\underline{{\varsigma }}}\) admissible, are linearly independent solutions to the system of differential equations.
As an application, we therefore get that the dimension of the solution space is at least the number of conformal blocks, which is a combinatorial and well understood quantity.
Corollary 5.10
Let \(\underline{{\lambda }}= (\lambda _{0},\lambda _{1},\dots , \lambda _{N},\lambda _{\infty })\in {\mathbb {N}}^{N+2}\). Then we have
5.5.2 Differential equations at infinity
From the perspective of CFT, the (PDE) part of Theorem 2.2 has the interpretation that for \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\), the function \({\mathcal {F}}[u]\) satisfies partial differential equations stemming from degeneracies of primary fields at the points \(x_0, x_1, \ldots , x_N\). When we take u to moreover satisfy \(K.u = q^{\lambda _\infty } \, u\), it is natural to expect the function \({\mathcal {F}}[u]\) to satisfy a further differential equation of order \(\lambda _\infty + 1\), associated with the field at infinity. It is possible to give a direct proof of this property from the quantum group method, but such a proof is not entirely trivial. By contrast, a very simple proof can be obtained as an application of the results of this section.
For the statement, we introduce the following differential operators at infinity
Corollary 5.11
Let \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\cap \mathrm {Ker}(K-q^{\lambda _{\infty }})\), \(\lambda _{\infty }\in {\mathbb {N}}\). The function \({\mathcal {F}}[u]\) satisfies the differential equation \({\mathscr {D}}^{(\infty )} \, {\mathcal {F}}[u] = 0\), where
Proof
Note that any \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\cap \mathrm {Ker}(K-q^{\lambda _{\infty }})\) is a linear combination of \(u_{{\underline{{\varsigma }}}}\), where \({\underline{{\varsigma }}}\) ranges over the \(\underline{{\lambda }}\)-admissible sequences. By linearity, it suffices to prove the statement for \(u = u_{{\underline{{\varsigma }}}}\).
To simplify, we make use of the fact that the representation \({\mathsf {M}}_{0}\) is the unit for tensor products of representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\), as seen from (2.1). Explicitly, we use the isomorphism
We set \(u'_{{\underline{{\varsigma }}}} = \big ( \big ( \bigotimes _{j=1}^N \mathrm {id}_{{\mathsf {M}}_{\lambda _j}} \big ) \otimes {\iota }_{ \;{\lambda _0}}^{{\lambda _0} , {0}} \big ) (u_{{\underline{{\varsigma }}}})\), and note that the function
satisfies the first order differential equation \(0 = \frac{\partial }{\partial {z}} \, {\mathcal {F}}[u'_{{\underline{{\varsigma }}}}]\) by the (PDE) property of Theorem 2.2. Therefore it is constant as a function of z. When we specialize to \(z=0\), Theorem 5.9 states that this function is given by
On the other hand, by the (ASY) property of Theorem 2.2 and the observation that \({B_{ {\lambda _{0}} , {0}}^{\;{\,\lambda _{0}}} = 1}\), we can determine the value of the constant, and we find
It now suffices to prove the differential equation for the above expression involving a composition of intertwining operators. Recall that \(Q_{\lambda _\infty }' \cong Q_{\lambda _\infty }\), so \(S_{\lambda _\infty } {{\bar{w}}}_{\lambda _\infty }' = 0\), and therefore
We can commute the Virasoro generators \(L_{p_m}\) to the right by Corollary 4.7 in the form (5.6) again. For \(p_m>0\) we have \(L_{p_m} {{\bar{w}}}_{\lambda _0} = 0\), so after commutation we find the desired differential equation. \(\quad \square \)
By contrast, to prove Corollary 5.11 directly using the quantum group method, one would have to introduce an auxiliary variable \(x_{N+1}\) and an auxiliary vector
as in [KP20, Section 5.2], conjugate by an appropriate exponentiatial of \({\mathscr {L}}^{(N+1)}_{1}\), and take a complicated limit \(x_{N+1} \rightarrow +\infty \). The proof above is a significant simplification.
5.5.3 Full series expansions of the functions from the quantum group method
The property (ASY) in Theorem 2.2 gives the explicit leading coefficient of the Frobenius series expansion of a function obtained by the quantum group method, in the limit \(x_j-x_{j-1} \rightarrow 0\). The main result of this section allows to express also all of the higher order coefficients of this Frobenius series as matrix elements of compositions of intertwining operatorsFootnote 4, making their calculation tractable by algebraic and combinatorial techniques. This is perhaps the most important direct application of the results of this section to the quantum group method.
6 Associativity of Intertwining Operators
In this section we will prove one of the main results of the paper, the associativity of the intertwining operators among the modules of the first row subcategory. This result is essentially the associativity in an appropriate tensor category.
From the point of view of correlation functions of conformal field theories, associativity amounts to the fact that the same correlation function admits series expansions in different regimes, and the resulting series represent the same function on the overlap of the domains where they converge. A geometric interpretation of this property is that different pair-of-pants decompositions of the same Riemann surface can be used interchangeably.
In VOA theory, associativity is a statement about the case \(N=2\) only, but involving the full intertwining operators, not merely a matrix element that gives a particular correlation function. Starting from the \(N=2\) case, it is then possible to inductively obtain coincidence of various expansions of multipoint correlation functions (or interchangeability of pair-of-pants decompositions of multiply punctured spheres).
From the point of view of VOA intertwining operators, we will be comparing a priori entirely different formal series, and it is far from obvious that they should represent the same function. Indeed, to obtain coincidence, we cannot separate a given conformal block from the rest: the expansion of a single conformal block in another regime will involve all possible conformal blocks, so a carefully devised linear combination is needed. The appropriate coefficients of the linear combination will be the 6j-symbols of the underlying quantum group.
A key subtlety is that the analytic functions represented by the series are multivalued (when extended to their natural complex domains), and the correct coincidence statements necessarily involve branch choices. In our setup, the quantum group method and the ordering of the variables on the real line leads to convenient branch choices which facilitate the statement. The multivaluedness, in turn, is closely related to braiding properties, which feature crucially in the analysis of CFT correlation functions, and form a key structure of the underlying tensor category.
In the previous sections, the quantum group has been used mainly through the fusion rules of the VOA modules, which matched the selection rules for \({\mathcal {U}}_q (\mathfrak {sl}_2)\) representations. The selection rules themselves, however, are not sensitive to the deformation parameter q. By contrast, the results of this section will involve the specific 6j symbols, and they will lead to the specific braiding properties. The associativity result therefore gives more profound evidence for the equivalence of the first row subcategory of the generic Virasoro VOA and the category of (type-one) finite-dimensional representations of \({\mathcal {U}}_q (\mathfrak {sl}_2)\).
This section is organized as follows. In Sect. 6.1 we introduce the setup and give the precise formulation of the associativity statement, Theorem 6.1. The proof of that statement is divided in two parts. Section 6.2 contains the proof of a particular case involving a highest weight matrix element. In Sect. 6.3, an inductive construction starting from that particular case is used to finish the proof of the general case.
6.1 The setup and statement of associativity
Fix \(\lambda _{0},\lambda _{1},\lambda _{2},\lambda _{\infty }\in {\mathbb {N}}\). For arbitrary \(w_{0} \in Q_{\lambda _{0}}\), \(w_{1} \in Q_{\lambda _{1}}\), \(w_{2} \in Q_{\lambda _{2}}\), \(w_{\infty }' \in Q_{\lambda _{\infty }}^{\prime }\), and \({\varsigma }\in \mathrm {Sel}(\lambda _{0},\lambda _{1})\), we will consider the formal series
which is a special case \(N=2\) of the series in Sect. 5, and we will compare it with the formal series
for \({\mu }\in \mathrm {Sel}(\lambda _{1},\lambda _{2})\cap \mathrm {Sel}(\lambda _{0},\lambda _{\infty })\). The idea will be to substitute actual values \(x_1 , x_2 \in {\mathbb {R}}\) so that
The first series (6.1) will correspond to an expansion in the regime \(0 < x_1 \ll x_2\), and the second (6.2) to and expansion in the regime \(0 < x_2-x_1 \ll x_1\). As discussed in Sect. 5, the series (6.1) is in the space
Similarly we will see that the series (6.2) is in the space
The goal of this section is to prove the following associativity of intertwining operators.
Theorem 6.1
Fix \(\lambda _{0},\lambda _{1},\lambda _{2},\lambda _{\infty }\in {\mathbb {N}}\). For arbitrary \(w_{0} \in Q_{\lambda _{0}}\), \(w_{1} \in Q_{\lambda _{1}}\), \(w_{2} \in Q_{\lambda _{2}}\), \(w_{\infty }' \in Q_{\lambda _{\infty }}^{\prime }\), and \({\varsigma }\in \mathrm {Sel}(\lambda _{0},\lambda _{1})\), the series
converges when \(0< x_1 < x_2\), and the series
converges when \(0< x_2-x_1 < x_1\), and in the (nontrivial) overlap of these domains, the analytic functions represented by these two series coincide.
The proof of Theorem 6.1 consists of two main steps: the special case of the matrix element of highest weight vectors, and the recursion on the PBW filtration to establish the general case. We address the two in separate subsections below.
In the rest of the section, sums over \({\mu }\) are always taken over the same set of values satisfying the two selection rules above. For brevity, we omit this from the notation and write just
6.2 The special case with highest weight vectors
The first step in the proof of Theorem 6.1 is to consider the special case where instead of general vectors \(w_{0} \in Q_{\lambda _{0}}\), \(w_{1} \in Q_{\lambda _{1}}\), \(w_{2} \in Q_{\lambda _{2}}\), \(w_{\infty }' \in Q_{\lambda _{\infty }}^{\prime }\), we use the highest weight vectors \({\bar{w}}_{\lambda _{0}} \in Q_{\lambda _{0}}\), \({\bar{w}}_{\lambda _{1}} \in Q_{\lambda _{1}}\), \({\bar{w}}_{\lambda _{2}} \in Q_{\lambda _{2}}\), \({\bar{w}}_{\lambda _{\infty }}' \in Q_{\lambda _{\infty }}^{\prime }\). This is analogous to the initial term of an intertwining operator, and the highest weight matrix element considered in the context of compositions of intertwining operators. The precise statement we want to prove is the following.
Proposition 6.2
Let \(\lambda _{0},\lambda _{1},\lambda _{2},\lambda _{\infty }\in {\mathbb {N}}\). For arbitrary \({\varsigma }\in \mathrm {Sel}(\lambda _{0},\lambda _{1})\), the two series
converges when \(0< x_1 < x_2\), and the series
converges when \(0< x_2-x_1 < x_1\), and in the (nontrivial) overlap of these domains, the analytic functions represented by these two series coincide.
The first of the two series is exactly of the form considered in Sect. 5, and by Theorem 5.9 we have
where \(u_{{\underline{{\varsigma }}}} \in {\mathsf {M}}_{\lambda _2} \otimes {\mathsf {M}}_{\lambda _1} \otimes {\mathsf {M}}_{\lambda _0}\) is the conformal block vector (3.3)
For the purposes of comparing with the other series in the associativity statement, we decompose this vector using the defining property (3.1)
of 6j-symbols, to get
For the corresponding function, we get the decomposition
where each term on the right hand side has a good Frobenius series expansion in the variable \(x_2-x_1\), by virtue of the submodule projection property \({\widehat{u}}_{{\underline{{\mu }}}} = {\pi }_{ \{{1} , {2}\}}^{\;\;{{\mu }}} ({\widehat{u}}_{{\underline{{\mu }}}})\) and Lemma 2.5. Specifically, for any \({\mu }\), in the region \(0< x_2-x_1 < x_1\), we have
where \({\widehat{{\Delta }}}({\mu }) = h({\mu }) - h(\lambda _2) - h(\lambda _1)\) and the leading coefficient is
with \({\widehat{{\Delta }}}'({\mu }) = h(\lambda _\infty ) - h({\mu }) - h(\lambda _0)\). To prove Proposition 6.2 therefore amounts to showing that the series (6.3) coincides with the other expression with VOA intertwining operators,
where one substitutes \({\varvec{x}}=x_1\) and \({\varvec{y}}= x_2-x_1\). For this, the strategy is again to show that both expressions satisfy the same differential equation, and that the series solutions to it are unique up to multiplicative constants. The most straightforward approach would be to use more than one differential equation (e.g., inductively, as in Sect. 5), but in the current case we can in fact bypass the need for all but one differential equation by using a priori homogeneity information.
The appropriate differential operator now is
where for \(n \in {\mathbb {Z}}\) we set
Analogously to Sect. 5, these differential operators act on the one hand on spaces of smooth functions of x and y, and on the other hand on spaces \({\mathbb {C}}[{\varvec{x}}]\,[[{\varvec{y}}/{\varvec{x}}]] \, [{\varvec{y}}^{-1}] \; {\varvec{x}}^{{\widehat{{\Delta }}}'({\mu })} {\varvec{y}}^{{\widehat{{\Delta }}}({\mu })}\) of formal series (for any \({\mu }\)) via
and the factors \((-x-y)^n\) are expanded as the following formal power series
These differential operators \(\widehat{{\mathscr {D}}}^{(2)}\) and \(\widehat{{\mathscr {L}}}_{n}^{(2)}\) are obtained from \(\widetilde{{\mathscr {D}}}^{(2)}\) and \(\widetilde{{\mathscr {L}}}_{n}^{(2)}\) by changing variables from \(x_1, x_2\) to \(x=x_1, y=x_2-x_1\). In particular the following is obvious from the property \(\widetilde{{\mathscr {D}}}^{(2)} \, {\mathcal {F}}[{\widehat{u}}_{{\underline{{\mu }}}}](0,x_1,x_2) \, = \, 0\), which itself is obtained from the (PDE) part of Theorem 2.2 using Lemma 5.6.
Lemma 6.3
For any \({\mu }\) we have
Next we show the analoguous property of the formal series.
Proposition 6.4
For each \({\mu }\in \mathrm {Sel}(\lambda _{1},\lambda _{2})\cap \mathrm {Sel}(\lambda _{0},\lambda _{\infty })\), the formal series
lies in \({\mathbb {C}}[[{\varvec{y}}/{\varvec{x}}]] \, {\varvec{y}}^{{\widehat{{\Delta }}}({\mu })} \, {\varvec{x}}^{{\widehat{{\Delta }}}'({\mu })}\), and it satisfies the differential equation
Proof
We expand the intertwining operator \({\mathcal {Y}}_{\lambda _{2} \, \lambda _{1}}^{\;{\mu }}({\bar{w}}_{\lambda _{2}},{\varvec{y}})\) so that
where each \(({\bar{w}}_{\lambda _{2}})_{(n)}\in \mathrm {Hom}(Q_{\lambda _{1}},Q_{{\mu }})\) is of degree \(-n-1\), \(n\in {\mathbb {Z}}\). In particular, we have \(({\bar{w}}_{\lambda _{2}})_{(n)}{\bar{w}}_{\lambda _{1}}\in Q_{{\mu }}(-n-1)\), \(n\in {\mathbb {Z}}\), implying that \(({\bar{w}}_{\lambda _{2}})_{(n)}{\bar{w}}_{\lambda _{1}}=0\) unless \(n\le -1\). Furthermore, we expand each part \({\mathcal {Y}}_{{\mu } \, \lambda _{0}}^{\;\lambda _{\infty }}(({\bar{w}}_{\lambda _{2}})_{(n)}{\bar{w}}_{\lambda _{1}}, {\varvec{x}})\), \(n\le -1\) so that
where \(\left( ({\bar{w}}_{\lambda _{2}})_{(n)}{\bar{w}}_{\lambda _{1}}\right) _{(m)}\in \mathrm {Hom}(Q_{\lambda _{0}},Q_{\lambda _{\infty }})\), \(m\in {\mathbb {Z}}\) is of degree \(-n-m-2\). Therefore, the matrix element
vanishes unless \(-n-m-2=0\). Consequently, we see that the series \({\widehat{C}}^{\underline{{\lambda }}}_{{\mu }}({\varvec{x}},{\varvec{y}})\) is expanded as
The differential equation follows from the quotienting out of the singular vector \(S_{\lambda _2} {\bar{w}}_{c,h(\lambda _2)}\) of the Verma module \(M(c,h(\lambda _2))\) given by (4.12); in \(Q_{\lambda _2}\) we have \(S_{\lambda _2} {\bar{w}}_{\lambda _{2}} = 0\) and therefore
To see that this gives the differential equation of the asserted form, the key is to observe that for any \(w_2\in Q_{\lambda _{2}}\) and \(p>0\), we have
which in turn follows by a calculation based on the formulas of Corollary 4.7. The calculation is otherwise very similar to that in the proof of Lemma 5.4, except that part (a) of Corollary 4.7 has to be used twice here. \(\square \)
By the chosen normalization of the intertwining operators, the coefficient of \({\varvec{y}}^{{\widehat{{\Delta }}}({\mu })}\,{\varvec{x}}^{{\widehat{{\Delta }}}'({\mu })}\) in \({\widehat{C}}^{\underline{{\lambda }}}_{{\mu }}({\varvec{x}},{\varvec{y}})\) is \(B_{ {{\mu }} , {\lambda _{0}}}^{\;{\,\lambda _\infty }} \, B_{ {\lambda _{1}} , {\lambda _{2}}}^{\;{\;{\mu }}}\). In particular, \({\widehat{C}}^{\underline{{\lambda }}}_{{\mu }}({\varvec{x}},{\varvec{y}})\) is non-zero.
The remaining core ingredient is a suitable uniqueness statement for series form solutions of the PDE. Two aspects of the statement here are worth noting. First, we will have a uniqueness statement separately for every \({\mu }\), in an appropriate space of formal series. Different \({\mu }\) would give other linearly independent solutions, but due to different characteristic exponents, the forms of the series are different. Second, although we require just one differential equation, we obtain uniqueness, because we additionally fix the total homogeneity degree. Alternatively it would be possible to start without the homogeneity requirement, using instead further differential equations that can also be established in the present case.
Proposition 6.5
For each \({\mu }\in \mathrm {Sel}(\lambda _{1},\lambda _{2}) \cap \mathrm {Sel}(\lambda _{0},\lambda _{\infty })\), subspace
consisting of the solutions to the above differential equation is one-dimensional,
Proof
Since \({\widehat{C}}^{\underline{{\lambda }}}_{{\mu }}\) is a non-zero solution in this space of formal series, it suffices to show that solutions are unique up to multiplicative constant.
For the present purpose, we introduce a \({\mathbb {Z}}\)-grading of the space \({\mathbb {C}}[{\varvec{x}}]\,[[{\varvec{y}}/{\varvec{x}}]] \, [{\varvec{y}}^{-1}] {\varvec{x}}^{{\widehat{{\Delta }}}'({\mu })} \, {\varvec{y}}^{{\widehat{{\Delta }}}({\mu })}\): for \(n,m\in {\mathbb {Z}}\), a monomial \({\varvec{y}}^{{\widehat{{\Delta }}}({\mu }) + n} \, {\varvec{x}}^{{\widehat{{\Delta }}}'({\mu }) + m}\) is declared to be of degree n. The degrees of operators are determined accordingly.
For each \(p>0\), the operator
is of degree \(-p\), and the difference
is a sum of terms of degrees strictly greater than \(-p\). Therefore, we can decompose the action of \(\widehat{{\mathscr {D}}}^{(2)}\) on \({\mathbb {C}}[{\varvec{x}}]\,[[{\varvec{y}}/{\varvec{x}}]] \, [{\varvec{y}}^{-1}] \; {\varvec{x}}^{{\widehat{{\Delta }}}'({\mu })} \, {\varvec{y}}^{{\widehat{{\Delta }}}({\mu })}\) so that
where \(\deg \widehat{{\mathscr {R}}}^{(2)}_{k} = -\lambda _{2}-1+k\) for \(k \ge 1\), and
is a differential operator of degree \(-\lambda _{2}-1\).
We also have
for any \(n \in {\mathbb {Z}}\), and we recall that \(P_{\lambda _{2}}(h(\lambda _{1}),h(\mu )+n)=0\) if and only if \(n=0\).
Let us expand a series \({\widehat{C}}\in {\mathbb {C}}[[{\varvec{y}}/{\varvec{x}}]] \; {\varvec{x}}^{{\widehat{{\Delta }}}'({\mu })} \, {\varvec{y}}^{{\widehat{{\Delta }}}({\mu })}\) so that
Requiring the differential equation \(\widehat{{\mathscr {D}}}^{(2)} \, {\widehat{C}}= 0\) and considering the terms of different degrees separately, we obtain the recursion relations that determines all higher coefficients \({\widehat{C}}_{k}\), \(k>0\), by
Therefore, a solution is uniquely determined by its leading coefficient \({\widehat{C}}_0\). \(\quad \square \)
Putting the above ingredients together, we can prove Proposition 6.2.
Proof of Proposition 6.2
By linearity on \({\mathcal {F}}\) and decomposition of \(u_{{\underline{{\varsigma }}}}\), we found
According to Theorem 5.9, the left hand side is given by the series
On the right hand side, change variables to \(x=x_1, \, y=x_2-x_1\), and recall from Lemma 6.3 that each term \({\mathcal {F}}[{\widehat{u}}_{{\underline{{\mu }}}}](0,x,x+y)\) satisfies the differential equation \(\widehat{{\mathscr {D}}}^{(2)} \, {\mathcal {F}}[{\widehat{u}}_{{\underline{{\mu }}}}](0,x,x+y) = 0\) and by Lemma 2.5 has a Frobenius series of the form (6.3). By homogeneity, property (COV) in Theorem 2.2, it is easy to see that the coefficients are of the form \({\widehat{C}}_n (x) = c_n \, x^{{\widehat{{\Delta }}}'({\mu })-n}\). The power series part of the Frobenius series in variable y is locally uniformly R-controlled in the domain defined by \(x>R\), so by arguments similar to the proof of Theorem 5.9 we get that the differential operator \(\widehat{{\mathscr {D}}}^{(2)}\) acts naturally coefficientwise on the series. The uniqueness up to multiplicative constant of series solutions stated in Proposition 6.5 then shows that the series expansion is
since the leading coefficients on both sides are \({\widehat{C}}_0 (x) = B_{ {\lambda _{2}} , {\lambda _{1}}}^{\;{\;\;{\mu }}} \, B_{ {{\mu }} , {\lambda _{0}}}^{\;{\,\lambda _\infty }} \; x^{{\widehat{{\Delta }}}'({\mu })} \). \(\quad \square \)
6.3 Reduction to the initial terms
Here, we present a proof of Theorem 6.1. The proof is by induction on the total PBW length, broadly similarly to Proposition 4.12. In fact, since the proof splits to many similar cases, we only provide the details about one. Proposition 6.2 from above will serve as the base case of the induction.
Proof of Theorem 6.1
Recall that all the modules \(Q_{\lambda _{i}}\), \(i=0,1,2\) and \(Q_{\lambda _{\infty }}^{\prime }\) admit the PBW filtration;
Fix \(p\in {\mathbb {N}}\) and assume that the claim in Theorem 6.1 is true for any \(w_{i}\in {\mathscr {F}}^{p_{i}}Q_{\lambda _{i}}\), \(i=0,1,2\) and \(w_{\infty }^{\prime }\in {\mathscr {F}}^{p_{\infty }}Q_{\lambda _{\infty }}^{\prime }\) with \(p_{0}+p_{1}+p_{2}+p_{\infty }\le p\). Note also that the base case \(p_0 = p_1 = p_2 = p_\infty = 0\) is covered by Proposition 6.2.
Let us first consider increasing \(p_0\) by one, by applying \(L_{-n}\), \(n>0\), on \(w_0 \in {\mathscr {F}}^{p_{0}}Q_{\lambda _{0}}\). The Jacobi identity, as formulated in Corollary 4.7, yields the following
Each of the terms of the right hand side have a total PBW word length \(\le p\), so the induction hypothesis can be applied to each of them. By the induction hypothesis, the right hand side power series represents the same analytic function as the following series
when the two series are evaluated at \({\varvec{x}}_1 = x_1\), \({\varvec{x}}_2 = x_2\), and \({\varvec{x}}= x_1\), \({\varvec{y}}= x_2-x_1\), respectively. It remains to check that the expression inside the parentheses in (6.6) coincides with
For this, we first commute \(L_{-n}\) to the left with the formula of Corollary 4.7,
The first term here is indeed present in (6.6), so we focus on the second term. Also the \(\ell =0\) contribution in the second term is
which also appears in (6.6). We rewrite the remaining terms by commuting \(L_{\ell -1}\) to the right inside the intertwiner, leading to a contribution
Again the first term appears in (6.6), so it remains to treat the last term. The \(k=0\) contribution of it is just
Both of these again appear in (6.6). In the remaining terms, we interchange the order of summations and change to a new summation variable \(m=\ell -k\) to express them as
This equals the remaining term in (6.6).
There are in principle three more cases to consider: the application of \(L_{-n}\) on \(w_1 \in {\mathscr {F}}^{p_{1}}Q_{\lambda _{1}}\), on \(w_2 \in {\mathscr {F}}^{p_{2}}Q_{\lambda _{2}}\), and on \(w_\infty ' \in {\mathscr {F}}^{p_{\infty }}Q_{\lambda _{\infty }}'\). The calculations are similar to the case above, so we omit the details here. \(\quad \square \)
Notes
This parametrization of the central charges \(c \le 1\) by \(\kappa >0\) arises naturally in the context Schramm-Loewner Evolutions (SLE). It is a 2-to-1 parametrization (except at \(c=1\) and \(\kappa =4\)): the values \(\kappa \) and \(\kappa '=\frac{16}{\kappa }\) give rise to the same c. In these two cases with the same central charge c we will introduce different categories of modules for the same vertex operator algebra. What we call “the first row of the Kac table” for \(\kappa '\) becomes instead “the first column of the Kac table” for \(\kappa \)—notice that \(h_{r,s}(\kappa ') = h_{s,r}(\kappa )\) in the formula below. Thus with this 2-to-1 parametrization also the latter category becomes covered even if we explicitly only treat the former.
These selection rules turn out to take exactly the same form as the selection rules which determine when an irreducible representation of the quantum group \({\mathcal {U}}_q (\mathfrak {sl}_2)\) appears in the tensor product of two others.
It can also be seen that two of these conditions imply the other one.
Specifically, the method as presented in this section, applies to the coefficients of the Frobenius series corresponding to \(x_1-x_0 \rightarrow 0\). The general case of expansions as \(x_j-x_{j-1} \rightarrow 0\) for \(j>1\) will be obtained by associativity, which is addressed in the next section.
At various stages of the construction, the superscripts to \({\mathbb {M}}\) are meant to indicate in which of the modules \(W_{0}\), \(W_{1}\), \(W_{\infty }\) we restrict attention to only the one-dimensional subspaces \(W_{0}(0)\), \(W_{1}(0)\), \(W_{\infty }(0)\) of highest weight vectors.
References
Aomoto, K., Kita, M.: Theory of Hypergeometric functions. Springer, Berlin (2011)
Bauer, M., Bernard, D.: SLE, CFT and zig-zag probabilities. In: Proceedings of the conference ‘Conformal Invariance and Random Spatial Processes’, Edinburgh (2003)
Bauer, M., Bernard, D.: Conformal field theories of stochastic Loewner evolutions. Commun. Math. Phys. 239(3), 493–521 (2003)
Bauer, M., Bernard, D.: Conformal transformations and the SLE partition function martingale. Annales Henri Poincaré 5(2), 289–326 (2004)
Bakalov, B., Kirillov Jr, A.: Lectures on Tensor Categories and Modular Functors, volume 21 of University Lecture Series. American Mathematical Society (2001)
Belavin, A.A., Polyakov, A.M., Zamolodchikov, A.B.: Infinite conformal symmetry in two-dimensional quantum field theory. Nucl. Phys. B 241, 333–380 (1984)
Belavin, A.A., Polyakov, A.M., Zamolodchikov, A.B.: Infinite conformal symmetry of critical fluctuations in two dimensions. J. Stat. Phys. 34, 763–774 (1984)
Benoit, L., Saint-Aubin, Y.: Degenerate conformal field theories and explicit expressions for some null vectors. Phys. Lett. B 215(3), 517–522 (1988)
Creutzig, T., Jiang, C., Hunziker, F.O., Ridout, D., Yang, J.: Tensor categories arising from the Virasoro algebra. Adv. Math. 380, 107601 (2021)
Creutzig, T., Lentner, S., Rupert, M.: Characterizing braided tensor categories associated to logarithmic vertex operator algebras (2021). arXiv:2104.13262
Di Francesco, P., Mathieu, P., Sénéchal, D.: Conformal Field Theory. Springer, New York (1997)
Drinfeld, V.G.: Quasi-Hopf algebras. Algebra i Analiz 1(6), 114–148 (1989)
Dubédat, J.: Commutation relations for SLE. Commun. Pure Appl. Math. 60(12), 1792–1847 (2007)
Dubédat, J.: SLE and Virasoro representations: fusion. Commun. Math. Phys. 336(2), 761–809 (2015)
Frenkel, E., Ben-Zvi, D.: Vertex Algebras and Algebraic Curves, volume 88 of Mathematical Surveys and Monographs, 2nd edn. American Mathematical Society (2004)
Felder, G.: BRST approach to minimal models. Nucl. Phys. B 317(1), 215–236 (1989). Erratum ibid., 324(2):548, 1989
Feigin, B.L., Fuchs, D.B.: Representations of the Virasoro algebra. In: Representation of Lie groups and related topics, volume 7 of Adv. Stud. Contemp. Math., pp. 465–554. Gordon and Breach, New York (1990)
Feigin, B.L., Gainutdinov, A.M., Semikhatov, A.M., Tipunin, I.Y.: The Kazhdan-Lusztig correspondence for the representation category of the triplet W-algebra in logarithmic CFT. Theor. Math. Phys. 148, 1210–1235 (2006)
Feigin, B.L., Gainutdinov, A.M., Semikhatov, A.M., Tipunin, I.Y.: Modular group representations and fusion in logarithmic conformal field theories and in the quantum group center. Commun. Math. Phys. 265, 47–93 (2006)
Frenkel, I.B., Huang, Y.-Z., Lepowsky, J.: On Axiomatic Approaches to Vertex Operator Algebras and Modules, volume 104 of Memoirs of the American Mathematical Society. American Mathematical Society (1993)
Flores, S.M., Kleban, P.: A solution space for a system of null-state partial differential equations. Parts I–IV. Commun. Math. Phys. 333(1), 389–434, 333(1), 435–481, 333(2), 597–667, 333(2), 669–715 (2015)
Frenkel, I., Lepowsky, J., Meurman, A.: Vertex Operator Algebras and the Monster. Academic Press, New York (1989)
Flores, S.M., Peltola, E.: Generators, projectors, and the Jones-Wenzl algebra (2018). arXiv:1811.12364
Flores, S.M., Peltola, E.: Standard modules, radicals, and the valenced Temperley-Lieb algebra (2018). arXiv:1801.10003
Flores, S.M., Peltola, E.: Higher-spin quantum and classical Schur-Weyl duality fo \({sl}_2\) (2020). arXiv:2008.06038
Flores, S.M., Peltola, E.: Monodromy invariant CFT correlation functions of first column kac operators (2021) (in preparation)
Frenkel, E.: Lectures on the Langlands program and conformal field theory. In: Frontiers in Number Theory, Physics, and Geometry II, pp. 387–533. Springer (2007)
Felder, G., Wieczerkowski, C.: Topological representation of the quantum group \(U_{q}(sl_{2})\). Commun. Math. Phys. 138(3), 583–605 (1991)
Frenkel, I.B., Zhu, Y.: Vertex operator algebras associated to representations of affine and Virasoro algebras. Duke Math. J. 66, 123–168 (1992)
Frenkel, I., Zhu, M.: Vertex algebras associated to modified regular representations of the Virasoro algebra. Adv. Math. 229, 3468–3507 (2012)
Gawȩdzki, Krzysztof: Lectures on conformal field theory. In: Quantum fields and strings: a course for mathematicians (IAS Princeton). volume 1–2, pp. 727–805. American Mathematical Society, Providence (1999)
Gannon, T., Negron, C.: Quantum SL(2) and logarithmic vertex operator algebras at (p,1)-central charge (2021). arXiv:2104.12821
Gómez, C.G., Ruiz-Altaba, M., Sierra, G.: Quantum Groups in Two-Dimensional Physics. Cambridge University Press, Cambridge (1996)
Green, M.B., Schwarz, J.H., Witten, E.: Superstring Theory I, II. Cambridge University Press, Cambridge (1987)
Huang, Y.-Z., Kirillov, A., Jr., Lepowsky, J.: Braided tensor categories and extensions of vertex operator algebras. Commun. Math. Phys. 337, 1143–1159 (2015)
Huang, Y.-Z., Lepowsky, J.: Toward a theory of tensor products for representations of a vertex operator algebra. In: Proceedings of 20th International Conference on Differential Geometric Methods in Theoretical Physics, New York, 1991, vol. 1, pp. 344–354. World Scientific (1992)
Huang, Y.-Z., Lepowsky, J.: Tensor products of modules for a vertex operator algebra and vertex tensor categories. In: Lie Theory and Geometry, in Honor of Bertram Kostant, pp. 349–383. Birkhäuser, Boston (1994)
Huang, Y.-Z., Lepowsky, J.: A theory of tensor products for module categories for a vertex operator algebra, I. Selecta Mathematica, New Series 1(4), 699–756 (1995)
Huang, Y.-Z., Lepowsky, J.: A theory of tensor products for module categories for a vertex operator algebra, II. Selecta Mathematica, New Series 1(4), 757–786 (1995)
Huang, Y.-Z., Lepowsky, J.: A theory of tensor products for module categories for a vertex operator algebra, III. J. Pure Appl. Algebra 100, 141–171 (1995)
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, II: Logarithmic formal calculus and properties of logarithmic intertwining operators (2010). arXiv:1012.4196
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, III: Intertwining maps and tensor product bifunctors (2010). arXiv:1012.4197
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, IV: Constructions of tensor product bifunctors and the compatibility conditions (2010). arXiv:1012.4198
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, V: Convergence condition for intertwining maps and the corresponding compatibility condition (2010). arXiv:1012.4199
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, VI. Expansion condition, associativity of logarithmic intertwining operators, and the associativity isomorphisms (2010). arXiv:1012.4202
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, VII: Convergence and extension properties and applications to expansion for intertwining maps (2011). arXiv:1110.1929
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory, VIII: Braided tensor category structure on categories of generalized modules for a conformal vertex algebra, (2011). arXiv:1110.1931
Huang, Y.-Z., Lepowsky, J., Zhang, L.: Logarithmic tensor category theory for generalized modules for a conformal vertex algebra, I: Introduction and strongly graded algebras and their generalized modules. In: Conformal Field Theories and Tensor Categories, pp. 169–248. Springer, Berlin (2014)
Huang, Y.-Z.: A theory of tensor products for module categories for a vertex operator algebra, IV. J. Pure Appl. Algebra 100, 173–216 (1995)
Huang, Y.-Z.: Differential equations and intertwining operators. Commun. Contemp. Math. 7, 375–400 (2005)
Huang, Y.-Z.: Two-Dimensional Conformal Geometry and Vertex Operator Algebras, vol. 148. Springer, Berlin (2012)
Iohara, K., Koga, Y.: Representation theory of the Virasoro algebra. Springer Monographs in Mathematics. Springer, Berlin (2011)
Jokela, N., Järvinen, M., Kytölä, K.: \({\rm SLE}\) boundary visits. Ann. Henri Poincaré 17(6), 1263–1330 (2016). arXiv:1311.2297 (2013)
Kac, V.G.: Contravariant form for infinite-dimensional Lie algebras and superalgebras. In: Group Theoretical Methods in Physics, pp. 441–445. Springer (1979)
Kac, V.: Vertex algebras for beginners. University Lecture Series, vol. 10. American Mathematical Society, Providence (1997)
Kassel, C.: Quantum Groups, volume 155 of Graduate Texts in Mathematics. Springer, Berlin (1995)
Kawahigashi, Y.: Conformal field theory, tensor categories and operator algebras. J. Phys. A Math. Theor. 48, 303001 (2015)
Karrila, A., Kytölä, K., Peltola, E.: Conformal blocks, \(q\)-combinatorics, and quantum group symmetry. Ann. Inst. Henri Poincaré D 6(3), 449–487 (2019). https://doi.org/10.4171/aihpd/88. arXiv:1709.00249
Kazhdan, D., Lusztig, G.: Tensor structures arising from affine Lie algebras I-IV. J. Am. Math. Soc. 6(4), 905–947, 6(4), 949–1011, 7(2), 335–381, 7(2), 383–453 (1994)
Kytölä, K., Peltola, E.: Pure partition functions of multiple SLEs. Commun. Math. Phys. 346(1), 237–292 (2016). arXiv:1506.02476
Kytölä, K., Peltola, E.: Conformally covariant boundary correlation functions with a quantum group. J. Eur. Math. Soc. 22, 55–118 (2020). https://doi.org/10.4171/JEMS/917.. arXiv:1408.1384
Kondo, H., Saito, Y.: Indecomposable decomposition of tensor products of modules over the restricted quantum universal enveloping algebra associated to \(sl_{2}\). J. Algebra 330, 103–129 (2011)
Lawler, G.F.: Conformally invariant processes in the plane. Number 114 in Mathematical Surveys and Monographs. American Mathematical Society (2008)
Lentner, S.D.: Quantum groups and Nichols algebras acting on conformal field theories. Adv. Math. 378, 107517 (2021)
Li, H.: Determining fusion rules by \(A(V)\)-modules and bimodules. J. Algebra 212, 515–556 (1999)
Lepowsky, J., Li, H.: Introduction to Vertex Operator Algebras and Their Representations. Birkhäuser, Boston (2004)
Lusztig, G.: Introduction to Quantum Groups. Birkhäuser, Boston (1993)
McRae, R.: Non-negative integral level affine lie algebra tensor categories and their associativity isomorphisms. Commun. Math. Phys. 346, 349–395 (2016)
Moore, G., Reshetikhin, N.: A comment on quantum group symmetry in conformal field theory. Nucl. Phys. B 328(3), 557–574 (1989)
Mussardo, G.: Statistical Field Theory: An Introduction to Exactly Solved Models in Statistical Physics. Oxford University Press, Oxford (2010)
Nahm, W.: Conformal field theory: a bridge over troubled waters. In: Quantum field theory - a twentieth century profile. In: Hindustani Book Agency and Indian National Science Academy, pp. 571–604 (2000)
Nagatomo, K., Tsuchiya, A.: The triplet vertex operator algebra \(W(p)\) and the restricted quantum group at root of unity. Adv. Stud. Pure Math. 61, 1–49 (2011)
Pasquier, V., Saleur, H.: Common structures between finite systems and conformal field theories through quantum groups. Nucl. Phys. B 330(2), 523–556 (1990)
Ramirez, C., Ruegg, H., Ruiz-Altaba, M.: The contour picture of quantum groups in conformal field theories. Nucl. Phys. B 364(1), 195–233 (1991)
Rohde, S., Schramm, O.: Basic properties of SLE. Ann. Math. 161(2), 883–924 (2005)
Schechtman, V.V., Varchenko, A.N.: Quantum groups and homology of local systems. In: Fujiki, A., Kato, K., Kawamata, Y., Katsura, T., Miyaoka, Y. (eds). ICM-90 Satellite Conference Proceedings, Tokyo, pp. 182–197(1991). Springer, Japan
Teschner, J., Vartanov, G.: \(6j\) symbols for the modular double, quantum hyperbolic geometry, and supersymmetric gauge theories. Lett. Math. Phys. 104, 527–551 (2014)
Tsuchiya, A., Wood, S.: The tensor structure on the representation category if the \({\cal{W}}_{p}\) triplet algebra. J. Phys. A Math. Theor. 46, 445203 (2013)
Tsuchiya, A., Wood, S.: On the extended W-algebra of type \({\mathfrak{sl}}_{2}\) at positive rational level. Int. Math. Res. Not. 2015(14), 5357–5435 (2014)
Varchenko, A.: Multidimensional hypergeometric functions and representation theory of Lie algebras and quantum groups, volume 21 of Advanced Series in Mathematical Physics. World Scientific, Singapore (1995)
Wang, W.: Rationality of Virasoro vertex operator algebras. Int. Math. Res. Not. 1993(7), 197–211 (1993)
Werner, W.: Random planar curves and Schramm-Loewner evolutions. In: Lectures on Probability Theory and Statistics, pp. 107–195. Springer, Berlin (2004)
Xu, X.: Introduction to Vertex Operator Superalgebras and Their Modules, volume 456 of Mathematics and Its Applications. Springer, Berlin (1998)
Zhu, Y.: Modular invariance of characters of vertex operator algebras. J. Am. Math. Soc. 9, 237–302 (1996)
Acknowledgements
SK is supported by the Grant-in-Aid for JSPS Fellows (No. 19J01279).
KK wishes to thank Eveliina Peltola and Steven Flores for discussions and for sharing their relevant work with us, Steven Flores and David Radnell for contributions to our study group, and Yi-Zhi Huang for accepting the invitation to give a minicourse in Helsinki and for sharing valuable insights.
KK also wishes to thank the organizers of the conference “The Mathematical Foundations of Conformal Field Theory and Related Topics” for hospitality. Numerous discussions at the conference, particularly with Ingo Runkel, Shashank Kanade, Jinwei Yang, and Robert McRae, were very helpful for this work.
Open Access
This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funding
Open Access funding provided by Aalto University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by C. Schweigert.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A. Proofs of analyticity and Frobenius series
This appendix is devoted to indicating how the results of [KP20] can be strengthened so as to yield the analyticity and series expansion properties needed in the present article, and for some elementary power series estimates employed in the proofs of the main results in Sects. 5 and 6.
1.1 A.1. Elementary power series estimates
In Sects. 5.4 and 6.2, we needed that three types of operations preserved a suitable space of parametrized power series, and that these operations could be performed essentially “coefficientwise”. Specifically, we needed
-
differentiation of the power series itself;
-
multiplication of the power series by another power series;
-
differentiation of the power series with respect to parameters.
The setup is that we consider power series in a variable z, of the form
where the coefficients \(c_k\) depend smoothly on parameters \(y \in \Omega \), where \(\Omega \subset {\mathbb {R}}^m\) is an open set. The main assumption is that for some \(R>0\), the parametrized power series is locally uniformly R-controlled in the sense of Definition 2.3. For concretely working with the power series, it is useful to note that the property of being locally uniformly R-controlled is equivalent to the following: for every compact \(K \subset \Omega \), every multi-index \(\alpha \), and every \(0< R_0 < R\), there exists a \(M<\infty \) such that
This in particular ensures that for every \(y \in \Omega \), the radius of convergence of (A.1) is at least R, and for any \(R_0<R\) and any compact subset \(K \subset \Omega \), the convergence is uniform over \(|z| \le R_0\) and \(y \in K\).
Crucial for us is that the locally uniformly R-controlled power series are stable under differentiation of the power series, multiplication by another locally uniformly R-controlled power series, and differentiation with respect to the parameters \(y \in \Omega \). The first two are in essence just familiar operations on ordinary power series—only the last one involves dependence on the parameters y. The proofs are all elementary.
Lemma A.1
Let \(\Omega \subset {\mathbb {R}}^m\) be an open set, and let \(R>0\).
-
(a)
If \((c_k)_{k \in {\mathbb {N}}}\) are locally uniformly R-controlled, then also \({\big ( (k+1) c_{k+1} \big )_{k \in {\mathbb {N}}}}\) are locally uniformly R-controlled and for any \(z \in {\mathbb {C}}\) with \(|z|<R\) and any \(y \in \Omega \) we have
$$\begin{aligned} \frac{\mathrm {d}}{\mathrm {d}{z}} \sum _{k=0}^\infty c_k(y) \, z^k = \sum _{k=0}^\infty (k+1) \, c_{k+1}(y) \, z^{k} . \end{aligned}$$ -
(b)
If \((c_k)_{k \in {\mathbb {N}}}\) and \((d_k)_{k \in {\mathbb {N}}}\) are locally uniformly R-controlled, then also the convoluted coefficients \({\big ( \sum _{j=0}^k c_{k-j} d_j \big )_{k \in {\mathbb {N}}}}\) are locally uniformly R-controlled and for any \(z \in {\mathbb {C}}\) with \(|z|<R\) and any \(y \in \Omega \) we have
$$\begin{aligned} \Big ( \sum _{k=0}^\infty d_k(y) \, z^k \Big ) \Big ( \sum _{k=0}^\infty c_k(y) \, z^k \Big ) = \sum _{k=0}^\infty \bigg ( \sum _{j=0}^k c_{k-j}(y) \, d_j(y) \bigg ) \, z^{k} . \end{aligned}$$ -
(c)
If \((c_k)_{k \in {\mathbb {N}}}\) are locally uniformly R-controlled and \(j \in \left\{ 1,\ldots ,m \right\} \), then also the coefficients \({\big ( \partial _j c_{k} \big )_{k \in {\mathbb {N}}}}\) are locally uniformly R-controlled and for any \(z \in {\mathbb {C}}\) with \(|z|<R\) and any \(y \in \Omega \) we have
$$\begin{aligned} \frac{\partial }{\partial {y_j}} \sum _{k=0}^\infty c_k(y) \, z^k = \sum _{k=0}^\infty (\partial _j c_{k}) (y) \, z^{k} . \end{aligned}$$
Proof
The statements (a) and (b) at a fixed parameter y are textbook power series results based on the estimates (A.2), and the explicit calculations yield locally uniformly R-controlledness by the same characterization.
For property (c), note first that arbitrary partial derivatives of the coefficients satisfy the same estimate (A.2), so it is clear that any partial derivatives of the coefficients remain locally uniformly R-controlled. It suffices to check that the the partial derivative of the series is the series with partial derivative coefficients. Fix \(y \in \Omega \) and choose a small \(r>0\) so that the closed ball \({\overline{B}}_r(y) \subset \Omega \). First fix \(R'<R_0<R\) and consider \(|z| \le R'\). Since \({\overline{B}}_r(y) \subset \Omega \) is compact, we may choose \(M<\infty \) such that for all \(k \in {\mathbb {N}}\) and \(y \in {\overline{B}}_r(u)\) we have both \(|c_k(y)| \le M \, R_0^{-k}\) and \(\big | \partial _j c_k(y) \big | \le M \, R_0^{-k}\). The partial derivative of the power series with respect to the j:th parameter \(y_j\) at \(y=(y_1,\ldots ,y_m)\) is
For \(\delta <r\) the integral above is bounded by the same \(M \, R_0^{-k}\) (since the integrand is, and the integration is taken over the unit integral), so for \(|z| \le R'<R_0\) the power series terms are dominated by \(M \, \big ( \frac{R'}{R_0} \big )^k\), which are summable. Moreover, as \(\delta \rightarrow 0\), the integrands are tending pointwise w.r.t. s to the constant \((\partial _j c_k)(y)\), and they are bounded by the above. With these observations, we can apply dominated convergence to interchange the limit \(\delta \rightarrow 0\) with both the series and the interal, and the assertion (c) follows. \(\quad \square \)
1.2 A.2. Power series for the functions from the quantum group method
We now outline the proofs of Lemmas 2.4 and 2.5. For convenience, we also recall their statements here.
Lemma
(Lemma 2.4) Let \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) be the function associated to any \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\), and let \((x_1, \ldots , x_N) \in {\mathfrak {X}}_N\), and let \(j \in \left\{ 1,\ldots ,N \right\} \). Then we have a power series expansion
in the j:th variable. For fixed \(x_j \in {\mathbb {R}}\) and \(R>0\), viewing the other variables \((x_i)_{i \ne j}\) as parameters, on the subset \(\Omega \subset {\mathbb {R}}^{N-1}\) defined by the conditions \(x_1< \cdots < x_N\) and \(\min _{i \ne j} |x_i - x_j| > R\), the power series is locally uniformly R-controlled.
Proof
The construction in [KP20] expresses \(F = {\mathcal {F}}[u]\) as a finite linear combination of integrals
where the integrands are branches of the multivalued function
and where the integration surfaces \(\Gamma \) are collections of non-intersecting loops (for details see [KP20]). Most importantly, the integration surfaces \(\Gamma \) are compact, and the integrands \((w_1, \ldots , w_\ell ) \mapsto f(x_1, \ldots , x_N ; w_1 , \ldots , w_\ell )\) are continuous on them.
Fix \(R>0\) and a compact subset \(K \subset \Omega _R = \left\{ (x_i)_{i \ne j} \in {\mathbb {R}}^{N-1} \big | \min _{i \ne j} |x_i - x_j| > R \right\} \). When \((x_i)_{i \ne j} \in K\), without changing the homotopy class of \(\Gamma \), it is possible to arrange so that none of the \(\ell \) coordinates of \(\Gamma = \Gamma _K\) intersects the closed ball \({\overline{B}}_{R}(x_j)\) of radius R centered at \(x_j\). For notational convenience, let us keep the coordinates \(x_i\), \(i \ne j\), fixed and omit them from the notation, and consider only the dependence of the integrand f on the j:th variable (denoted \(z_j\); we will perform power series expansions around \(z_j=x_j\)) and the integration variables \(w_1, \ldots , w_\ell \). From the explicit formula for f, it is clear that for any \((w_1, \ldots , w_\ell ) \in \Gamma \), the function \(z_j \mapsto f(z_j ; w_1 , \ldots , w_\ell )\) is analytic in an open set containing \({\overline{B}}_{R}(x_j)\), and has a convergent power series expansion
where the Taylor coefficients obey the Cauchy integral based estimates
In particular we get the uniform estimate
for all \((w_1, \ldots , w_\ell ) \in \Gamma \), with the finite constant \(C_K\) taken as the maximum of \(\big | f(z_j ; w_1 , \ldots , w_\ell ) \big |\) over the compact set \({\overline{B}}_{R}(x_j) \times K \times \Gamma _K\) (the middle factor is for the implicit parameters \(x_i\), \(i \ne j\)). Then for
we can use a power series expansion with coefficients
which satisfy \(|c_k| \le C_K \, |\Gamma _K| \, R^{-k}\). The series converges to \(G(z_j)\) whenever \({|z_j-x_j|<R}\), by virtue of the error term estimate
From the above explicit estimate for coefficients \((c_k)_{k\in {\mathbb {N}}}\), we see that \(z_j \mapsto G(z_j)\) is given by a locally uniformly R-controlled power series parametrized by \(\Omega _R\). The same holds for the finite linear combination \(z_j \mapsto F(z_j)\) of such terms. \(\quad \square \)
The Frobenius series statement that we will use is the following. Variants of this formulation with obvious modifications to the statement and proof could be done as well.
Lemma
(Lemma 2.5) Let \(j \in \left\{ 2,\ldots ,N \right\} \). Suppose that \(\tau \in \mathrm {Sel}(\lambda _{j-1},\lambda _j)\) and that \(u\in {\mathcal {H}}_{\underline{{\lambda }}}\) is such that \(u = {\pi }_{ \{{j-1} , {j}\}}^{\;\;{\tau }} (u)\). The function \(F = {\mathcal {F}}[u] :{\mathfrak {X}}_N \rightarrow {\mathbb {C}}\) associated to u has a Frobenius series expansion in the variable \(z=x_j-x_{j-1}\)
where the indicial exponent is \({\Delta }= h(\tau ) - h(\lambda _{j}) - h(\lambda _{j-1})\). For fixed \(R>0\), viewing the other variables \((x_i)_{i \ne j}\) as parameters, on the subset \(\Omega \subset {\mathbb {R}}^{N-1}\) defined by the conditions \(x_1< \cdots < x_N\) and \(\min _{i \ne j, j-1} |x_i - x_{j-1}| > R\), the power series part of this Frobenius series is locally uniformly R-controlled, and for \(0<z<R\) the Frobenius series converges to the function F on the left hand side.
Proof
The idea of the proof is otherwise similar to that of Lemma 2.4, except that a part of the integration surface needs to be separated from the rest and that part of the surface also undergoes scaling proportional to variable \(x_j-x_{j-1}\) of the Frobenius series.
Again for notational simplicity, we suppress the fixed variables \(x_i\), \(i \ne j\), from the notation. By translation invariance we can moreover assume \(x_{j-1}=0\), so that the Frobenius series variable is simply \(x_j\) and notation with scalings centered at \(x_{j-1}\) simplifies.
With the methods of [KP20, Sections 3.4, 4.2, and 4.3], the assumption \(u = {\pi }_{ \{{j-1} , {j}\}}^{\;\;{\tau }} (u)\) implies that the function \(x_j \mapsto F(x_j) = {\mathcal {F}}[u](\ldots ,x_j,\ldots )\) can be written as a finite linear combination of integrals
where the surface \(\Gamma '\) is compact and can be kept fixed as \(x_j \downarrow 0\), and where and \(x_j \Gamma _0\) stands for a scaling by a factor \(x_j>0\) of a fixed surface \(\Gamma _0\) (same for all terms in the linear combination and for all sufficiently small \(x_j>0\)) of dimension \(m = \frac{1}{2} \big (\lambda _{j-1} + \lambda _{j} - \tau \big )\), and the integrand \(f(x_j; w'_1,\ldots ,w'_m, w_1, \ldots , w_\ell )\) is as in Lemma 2.4. (now all of \(w'_1,\ldots ,w'_m, w_1, \ldots , w_\ell \) are in the same role as \(w_1, \ldots , w_\ell \) originally). With a change of variables to unit scale, \(t_r = w'_r / x_j\) for \(r=1,\ldots ,m\), both integration surfaces become constant, and the dependence on \(x_j\) is entirely in the integrand: we find
We will compare \(f(x_j ; x_j t_1,\ldots , x_j t_m, w_1, \ldots , w_\ell )\) with (we omit all of the fixed arguments \(x_i\), \(i \ne j\), for brevity)
where
because \({\hat{f}}( \ ; w_1 , \ldots , w_\ell )\) is the integrand whose integral on \(\Gamma '\) yields the asserted leading asymptotic coefficient.
The ratio
contains factors (we set \(x_{j-1}=0\))
out of which we extract in particular the powers of the scaling factor \(x_j\), which combined with the factor \(x_j^m\) from the change of variables produce the correct overall scaling by
The \(t_a\)-dependent factors are yet to be integrated over \(\Gamma _0\). The ratio can naturally also be rearranged (by appropriately splitting the factor \((w_r-0)^{-\frac{4}{\kappa } {\hat{\lambda }}_{j-1}}\) in the denominator) to contain factors
which can be expanded as power series in \(x_j\) with unit constant coefficient, all having a radius of convergence at least a fixed positive multiple of the distance \(R'\) of \(x_{j-1}\) to the contours in \(\Gamma '\), when \((t_1 , \ldots , t_m)\) lies on the compact set \(\Gamma _0\). All remaining factors in the ratio cancel directly.
We again conclude that after extracting the overall scaling factor \(x_j^{\Delta }\), the integrand in \(H(x_j)\) admits a power series expansion in \(x_j\), with the k:th coefficient bounded by \(p(k) (C R')^{-k}\), where p(k) is a polynomial and \(C>0\) is a fixed constant. By arguments similar to the previous case, a term by term integration of this yields a power series for \(x_j^{-\Delta } \, H(x_j)\). The proof of the existence of a convergent Frobenius series expansion with some positive radius of convergence is complete once one notices that the integral of the constant coefficient of the power series factorizes to integrals over \(\Gamma _0\) and \(\Gamma '\), the former yielding the beta-function coefficient B and the latter yielding the function with one fewer variable and labels \(({\hat{\lambda }}_i)_{1 \le i \le N : \, i \ne j}\).
The remaining part of the assertion is the uniform R-controlledness on compact subsets of the domain determined by \(\min _{i \ne j, j-1} |x_i - x_{j-1}| > R\). For any such compact subset, from the start we can choose \(\Gamma '\) so that for some \(\varepsilon >0\), on \(\Gamma '\) we have \(|w_r| \ge (1 + \varepsilon ) R\) for all r, i.e., \(R' \ge (1+\varepsilon )R\). Moreover, \(\Gamma _0\) can be chosen so that on \(\Gamma _0\) we have \(|t_a| \le 1 + \varepsilon /2\) for all a. With such choices, the constant above is \(C \ge \frac{1}{1+\varepsilon /2}\), and the estimates indeed yield uniform R-controlledness. \(\quad \square \)
Appendix B. Construction of the intertwining operators for Verma modules
Our goal is to show the following theorem (Theorem 4.15):
Theorem B.1
For \(h_{1},h_{0},h_{\infty }\in {\mathbb {C}}\),
An intertwining operator in this case is unique up to multiplicative constants if exists (Proposition 4.12). Hence, we only have to prove the existence. We apply the construction in [Li99] to the generic Virasoro VOA to obtain an intertwining operator among Verma modules; we include this so as to be self-contained, and also because we believe that the concrete case of the Virasoro VOA is instructive. The procedure is divided into two parts: in the former part, we will construct a linear map
and in the latter part, we will show that this linear map \({\mathcal {Y}}\) is indeed an intertwining operator of the desired type.
1.1 B.1. Construction of a linear map
For convenience, we write \(W_{0}:=M(c,h_{0})\), \(W_{1}:=M(c,h_{1})\) and \(W_{\infty }:=M(c,h_{\infty })\). For each \(k\in {\mathbb {N}}\), we also write \(W_{0}(k):=(W_{0})_{(h_{0}+k)}\), \(W_{1}(k):=(W_{1})_{(h_{1}+k)}\) and \(W_{\infty }(k):=(W_{\infty })_{(h_{\infty }+k)}\) for the eigenspaces of \(L_{0}\).
Before constructing the linear map (B.1), it is instructive to observe anticipated properties. First of all, defining a linear map (B.1) is equivalent to defining its matrix elements
Second, if \({\mathcal {Y}}\) gives an intertwining operators of the desired type, it is expanded as
Hence, for our purpose of constructing an intertwining operator, it is natural to specify the linear map (B.1) in terms of the family of infinitely many bilinear functionals
labeled by \(m\in {\mathbb {Z}}\). We will actually incorporate these bilinear functionals, by introducing the affinization \({\widehat{W}}_{1}:={\mathbb {C}}[t^{\pm 1 }]\otimes W_{1}\), into a single bilinear functional
Finally, as we have seen in Proposition 4.12, an intertwining operator among highest weight modules is determined uniquely by the initial term. Therefore, the desired bilinear functional should be determined recursively by the value at \(({\bar{w}}_{c,h_{\infty }}, (t^{-1}\otimes {\bar{w}}_{c,h_{1}})\otimes {\bar{w}}_{c,h_{0}})\).
1.1.1 Step 1
The first step is to fix an initial term. Taking a constant \(B\in {\mathbb {C}}\backslash \{0\}\), we define a bilinear functionalFootnote 5
by \({\mathbb {M}}^{(\infty , 1, 0)} \left( {\bar{w}}_{c,h_{\infty }}, {\bar{w}}_{c,h_{1}}\otimes {\bar{w}}_{c,h_{0}}\right) := B\).
1.1.2 Step 2
We extend the bilinear functional \({\mathbb {M}}^{(\infty , 1, 0)}\) so that an arbitrary vector from \(W_{1}\) can be inserted.
Proposition B.2
There exists a unique bilinear functional
which coincides with \({\mathbb {M}}^{(\infty , 1, 0)}\) on the subspace
and which has the property that
for any \(n>0\) and \({w}_{1}\in (W_{1})_{(h)}\).
Proof
The proof is by induction with respect the PBW filtration \(({\mathscr {F}}^{p}W_{1})_{p \in {\mathbb {N}}}\) of \(W_{1}\). We recursively define
for \(p \in {\mathbb {N}}\), and we show consistency and the desired property.
The zeroth level of the filtration is just the highest weight subspace, \({\mathscr {F}}^{0}W_{1}= W_{1}(0)\), so the required coincidence with \({\mathbb {M}}^{(\infty , 1, 0)}\) fully determines \({\mathbb {M}}^{(\infty , 0)}_{0}\), and provides the base case for the recursion.
Suppose then that \({\mathbb {M}}^{(\infty , 0)}_{p}:W_{\infty }(0)\times ({\mathscr {F}}^{p}W_{1}\otimes W_{0}(0))\rightarrow {\mathbb {C}}\) are well-defined and consistent for \(p \le r-1\). We want to define \({\mathbb {M}}^{(\infty , 0)}_{r}:W_{\infty }(0)\times ({\mathscr {F}}^{r}W_{1}\otimes W_{0}(0))\rightarrow {\mathbb {C}}\) according to the required property, by setting
for \(n>0\) and \({w}_{1}\in {\mathscr {F}}^{r-1}W_{1}\cap (W_{1})_{(h)}\). For well-definedness, it suffices to show that
for any \(m,n>0\) and \({w}_{1}\in {\mathscr {F}}^{r-2}W_{1}\). We may assume that \({w}_{1}\in (W_{1})_{(h)}\). Note that
Hence we have
Therefore \({\mathbb {M}}^{(\infty , 0)}_{r}\) is well-defined. Consistency is clear from the construction: for \(s \le r\) the map \({\mathbb {M}}^{(\infty , 0)}_{r}\) coincides with \({\mathbb {M}}^{(\infty , 0)}_{s}\) on the subspace \(W_{\infty }(0)\times ({\mathscr {F}}^{s}W_{1}\otimes W_{0}(0))\). \(\quad \square \)
1.1.3 Step 3
As we anticipated, we now consider the affinization of \(W_{1}\), \({\widehat{W}}_{1}:={\mathbb {C}}[t^{\pm 1}]\otimes W_{1}\). Let us also introduce a \({\mathbb {Z}}\)-grading of it as
We extend the bilinear functional \({\mathbb {M}}^{(\infty , 0)}\) to
by
for \(n\in {\mathbb {Z}}\) and \({w}_{1}\in W_{1}(k)\). In particular, \({\widehat{{\mathbb {M}}}}^{(\infty , 0)}\) vanishes unless \(t^{n}\otimes {w}_{1}\in {\widehat{W}}_{1}\) is of degree 0.
1.1.4 Step 4
The following fact will be used to extend the bilinear functional \({\widehat{{\mathbb {M}}}}^{(\infty , 0)}\) so that arbitrary vectors from \(W_{0}\) can be inserted.
Proposition B.3
For \(m,n\in {\mathbb {Z}}\), and \({w}_{1}\in W_{1}\), we set
Then, this gives a representation of the Virasoro algebra of central charge 0 on \({\widehat{W}}_{1}\). Furthermore, \(L_{m}\) has degree \(-m\), i.e., when \({w}_{1}\in W_{1}\) is homogeneous, we have
Proof
Note that, for any \(m,n,p\in {\mathbb {Z}}\) and \({w}_{1}\in W_{1}\),
Therefore,
Here, we use the following identity:
Hence, we have
which implies that the action defines a representation of the Virasoro algebra of central charge 0. The latter property regarding the degree is obvious from the definition. \(\quad \square \)
Now we define the bilinear functional \({\widehat{{\mathbb {M}}}}^{(\infty )}:W_{\infty }(0)\times ({\widehat{W}}_{1}\otimes W_{0}) \rightarrow {\mathbb {C}}\) by
for \(n\in {\mathbb {Z}}\), \({w}_{1}\in W_{1}\) and \(y\in {\mathcal {U}}(\mathfrak {vir}_{<0})\), where \(\sigma \) is the anti-involution of \({\mathcal {U}}(\mathfrak {vir})\) defined by \(\sigma (X):=-X\), \(X\in \mathfrak {vir}\).
1.1.5 Step 5
Finally we extend the bilinear functional to the whole space \(W_{\infty }\times ({\widehat{W}}_{1}\otimes W_{0})\). For that purpose, we define an action of the Virasoro algebra on \({\widehat{W}}_{1}\otimes W_{0}\) by the so-called coproduct action:
Then \({\widehat{W}}_{1}\otimes W_{0}\) becomes a representation of the Virasoro algebra of central charge c.
Note that the tensor product \({\widehat{W}}_{1}\otimes W_{0}\) is naturally \({\mathbb {Z}}\)-graded so that
We extend \({\widehat{{\mathbb {M}}}}^{(\infty )}\) to a bilinear functional \({\widehat{{\mathbb {M}}}}:W_{\infty }\times ({\widehat{W}}_{1}\otimes W_{0}) \rightarrow {\mathbb {C}}\) by
where \(\theta \) is the anti-involution of \({\mathcal {U}}(\mathfrak {vir})\) defined by \(\theta (L_{n})=L_{-n}\), \(n\in {\mathbb {Z}}\) and \(\theta (C)=C\).
Now we define the linear map (B.1) that is meant to be an intertwining operator of the desired type.
Definition B.4
Define a linear map
by the matrix elements
where \({w}_{0}\in W_{0}\), \({w}_{1}\in W_{1}\) and \({w}_{\infty }\in W_{\infty }\) are arbitrary, and \(\Delta =h_{\infty }-h_{1}-h_{0}\).
1.2 B.2. Some properties of the linear map
We are going to show that the linear map \({\mathcal {Y}}\) constructed in Definition B.4 gives an intertwining operator. We begin with collecting some immediate properties.
Lemma B.5
Let \(w\in {\widehat{W}}_{1}\otimes W_{0}\). Then we have:
-
(1)
If \(w\in ({\widehat{W}}_{1}\otimes W_{0})(k)\) and \({w}_{\infty }\in W_{\infty }(l)\), we have \({\widehat{{\mathbb {M}}}}\left( {w}_{\infty }, w\right) =0\) unless \(k=l\).
-
(2)
For any \(y\in \mathfrak {vir}_{<0}\), we have \({\widehat{{\mathbb {M}}}}\left( {\bar{w}}_{c,h_{\infty }}, yw\right) =0\).
-
(3)
For any \(y\in \mathfrak {vir}_{0}\), we have \({\widehat{{\mathbb {M}}}}\left( {\bar{w}}_{c,h_{\infty }}, yw\right) ={\widehat{{\mathbb {M}}}}\left( y{\bar{w}}_{c,h_{\infty }},w\right) \).
Proof
(1): Writing \({w}_{\infty }=y{\bar{w}}_{c,h_{\infty }}\) with \(y\in {\mathcal {U}}(\mathfrak {vir}_{<0})\), we have \(\theta (y)w\in ({\widehat{W}}_{1}\otimes W_{0})(k-l)\). Hence it suffices to show that
unless \(k\ne 0\). We may further assume that \(w= (t^{n}\otimes {w}_{1})\otimes y'{\bar{w}}_{c,h_{0}}\) with \(y'\in {\mathcal {U}}(\mathfrak {vir}_{<0})\) to find
Since by assumption \(\deg (\sigma (y')(t^{n}\otimes {w}_{1}))=k\), this value vanishes unless \(k=0\) from the definition (B.2) of \({\widehat{{\mathbb {M}}}}^{(\infty , 0)}\).
(2): It is sufficient to consider the case \(y=L_{-n}\), \(n>0\), and \(w=(t^{m}\otimes {w}_{1})\otimes y_{2}{\bar{w}}_{c,h_{0}}\), \(m\in {\mathbb {Z}}\), \({w}_{1}\in W_{1}\), \(y_{2}\in {\mathcal {U}}(\mathfrak {vir}_{<0})\). Then, since \(L_{-n}y_{2}\in {\mathcal {U}}(\mathfrak {vir}_{<0})\), we observe that
(3): The assertion is obvious for \(y=C\), so it suffices to consider the case of \(y=L_{0}\). First, we assume that \(w=(t^{n}\otimes {w}_{1})\otimes {\bar{w}}_{c,h_{0}}\in {\widehat{W}}_{1}\otimes W_{0}(0)\), where \({w}_{1}\in W_{1}(k)\) is homogeneous. In this case,
Then consider a general vector \({w}_{0}\in W_{0}\), and write it as \({w}_{0}= y' {\bar{w}}_{c,h_{0}}\) for \(y' \in {\mathcal {U}}(\mathfrak {vir}_{<0})\). For \(n\in {\mathbb {Z}}\) and \({w}_{1}\in W_{1}\), we have
Note that \([L_{0},y']\in U(\mathfrak {vir}_{<0})\) and \(\sigma ([L_{0},y'])=-[\sigma (y'),L_{0}]\). Hence, we have
This finishes the proof. \(\quad \square \)
Proposition B.6
The bilinear functional \({\widehat{{\mathbb {M}}}}\) is \(\theta \)-invariant in the sense that
Proof
Let us write \({w}_{\infty }=y_{+}{\bar{w}}_{c,h_{\infty }}\), where \(y_{+}\in {\mathcal {U}}(\mathfrak {vir}_{<0})\). Since it follows from the PBW theorem that \({\mathcal {U}}(\mathfrak {vir})=({\mathcal {U}}(\mathfrak {vir}_{<0}) \, {\mathcal {U}}(\mathfrak {vir}_{0}))\oplus {\mathcal {U}}(\mathfrak {vir})\mathfrak {vir}_{>0}\), we can uniquely write \(yy_{+}=y_{1}+y_{2}\), \(y_{1}\in {\mathcal {U}}(\mathfrak {vir}_{<0}) \, {\mathcal {U}}(\mathfrak {vir}_{0})\), \(y_{2}\in {\mathcal {U}}(\mathfrak {vir})\mathfrak {vir}_{>0}\). Since \(y_{2}\) annihilates the highest weight vector,
From the definition of \({\widehat{{\mathbb {M}}}}\) and (3) of Lemma B.5 (note that \(\theta |_{{\mathcal {U}}(\mathfrak {vir}_{0})}=\mathrm {id}_{{\mathcal {U}}(\mathfrak {vir}_{0})}\)), we have
Notice also that \(\theta (y_{2})\in \mathfrak {vir}_{<0}{\mathcal {U}}(\mathfrak {vir})\). Then, (2) of Lemma B.5 gives \({\widehat{{\mathbb {M}}}}({\bar{w}}_{c,h_{\infty }}, \theta (y_{2})w)=0\). Therefore, we have
as desired. \(\quad \square \)
1.3 B.3. Translation property
We show that the linear map \({\mathcal {Y}}\) satisfies the Jacobi identity (4.18) and the translation property (4.19). Let us begin with the easier one; the translation property.
Proposition B.7
For \({w}_{1}\in W_{1}\), we have
Proof
We take arbitrary vectors \({w}_{0}\in W_{0}(k)\), \({w}_{1}\in W_{1}(l)\) and \({w}_{\infty }\in W_{\infty }(m)\) and consider the matrix element
Due to (1) of Lemma B.5, the coefficient \({\widehat{{\mathbb {M}}}}({w}_{\infty }, (t^{n}\otimes L_{-1}{w}_{1})\otimes {w}_{0})\) vanishes unless \(n=k+l-m\). Hence, we have
Recall that the action of \(L_{0}\) on \((t^{n-1}\otimes {w}_{1})\otimes {w}_{0}\), \(n\in {\mathbb {Z}}\) reads
Rearranging the terms, we get
Employing the \(\theta \)-invariance (Proposition B.6) of the bilinear functional \({\widehat{{\mathbb {M}}}}\), we obtain
Here, we again observe the identity
to conclude the desired result. \(\quad \square \)
1.4 B.4. Jacobi identity
We next show the Jacobi identity (4.18). Since the Virasoro VOA is generated by the conformal vector \(\omega \), it suffices to show the Jacobi identity for \(v=\omega \). For convenience, we introduce the generating series \(L(\varvec{\zeta })=\sum _{n\in {\mathbb {Z}}}L_{n}\varvec{\zeta }^{-n-2}\) whose coefficients are understood as the action of the Virasoro algebra on any representation. The following commutation relations are sometimes useful:
where c is the central charge of representations under consideration.
In our setting, it is convenient to formulate the Jacobi identity in terms of matrix elements. We will therefore prove the following.
Proposition B.8
For \({w}_{0}\in W_{0}\), \({w}_{1}\in W_{1}\) and \({w}_{\infty }\in W_{\infty }\), we have
In the following proof, it will be convenient to use the notation
for \({w}_{1}\in W_{1}\). Then applying the bilinear functional \({\widehat{{\mathbb {M}}}}\) coefficientwise to formal series in \({\varvec{x}}\), we may understand
for \({w}_{0}\in W_{0}\), \({w}_{1}\in W_{1}\) and \({w}_{\infty }\in W_{\infty }\). The following formula derived from Proposition B.3 will be also useful:
The strategy of proving Proposition B.8 is to reduce the Jacobi identity to the commutativity and the associativity. Let us first observe the commutativity.
Lemma B.9
For any \({w}_{0}\in W_{0}\), \({w}_{1}\in W_{1}\) and \({w}_{\infty }\in W_{\infty }\), we have
Proof
From the property of the contragredient module (Lemma 4.3) and the \(\theta \)-invariance of the bilinear functional \({\widehat{{\mathbb {M}}}}\) (Proposition B.6), we can see that
Hence, we have
Therefore, the proof amounts to showing the identity
in \({\widehat{W}}_{1}\{{\varvec{x}}\}\), which is straightforward from (B.5). \(\quad \square \)
We next state the associativity.
Proposition B.10
For any \({w}_{0}\in W_{0}\), there exists \(k\in {\mathbb {N}}\) (depending on \({w}_{0}\)) such that
holds for any \({w}_{1}\in W_{1}\) and \({w}_{\infty }\in W_{\infty }\).
The proof of Proposition B.10 requires some preliminaries.
Lemma B.11
Let \({w}_{1}\in W_{1}\). Then, we have
Proof
Assuming that \({w}_{1}\in W_{1}(k)\) is homogeneous, we can see that both sides coincide with
\(\square \)
Lemma B.12
For any \({w}_{1}\in W_{1}\) and \(i\in {\mathbb {N}}\), we have
Proof
Note that the assertion is equivalent to that
holds for any \({w}_{1}\in W_{1}\), \(i\in {\mathbb {N}}\) and \(m\in {\mathbb {Z}}\). We show this in several different ranges of m.
When \(m\in {\mathbb {N}}\), we have
by changing the variables as \(\varvec{\zeta }_{1}=\varvec{\zeta }_{0}+{\varvec{x}}\). Note that the formal series
does not involve any negative powers of \(\varvec{\zeta }_{1}\), and hence its residue with respect to \(\varvec{\zeta }_{1}\) vanishes. Therefore we can subtract the residue for free to obtain
where we used the commutativity (Lemma B.9) in the last equality. We also use the identity
to obtain
This in particular implies (B.6) in the case when \(m\in {\mathbb {N}}\).
We show (B.6) when \(m<0\) by induction. When \(m=-1\), we see that
We divide the sum into the part of \(r=0\) and those of \(r=1,\dots , i\). For the former case, we apply Lemma B.11, and for the latter cases, we can already apply (B.6) to obtain
Therefore (B.6) holds for \(m\ge -1\).
Suppose that \(k\in {\mathbb {Z}}_{> 0}\) is such that (B.6) holds for \(m\ge -k\). In particular, we have
for any \({w}_{1}\in W_{1}\), and \(i\in {\mathbb {N}}\). We differentiate both sides in terms of \({\varvec{x}}\). The derivative of the left hand side (LHS) becomes
On the other hand, the derivative of the right hand side (RHS) is
Here we used the commutation relation (B.4) at \(n=-1\) in the last equality. Comparing these, due to the induction hypothesis, we obtain
Hence, (B.6) holds also at \(m=-k-1\).
In conclusion, we have shown that (B.6) holds for arbitrary \({w}_{1}\in W_{1}\), \(i\in {\mathbb {N}}\) and \(m\in {\mathbb {Z}}\), which is equivalent to the desired result. \(\quad \square \)
Proof of Proposition B.10
We introduce another filtration on \(W_{0}\) as
In particular, each subspace \(G^{d}W_{0}\) is finite dimensional.
For \(d,r\in {\mathbb {N}}\), we name the following statement:
\({\mathbf {P}}[d;r]\): There exists \(k\in {\mathbb {N}}\) depending on d such that
holds for any \({w}_{0}\in G^{d}W_{0}\), \({w}_{1}\in W_{1}\) and \({w}_{\infty }\in {\mathscr {F}}^{r}W_{\infty }\).
To prove Proposition B.10, we employ the induction in \(p,r\in {\mathbb {N}}\). The statement \({\mathbf {P}}[0;0]\) is true due to Lemma B.12.
Assume that \({\mathbf {P}}[d;r]\) is true. For \({w}_{0}\in G^{d}W_{0}\), \({w}_{1}\in W_{1}\), \({w}_{\infty }\in {\mathscr {F}}^{r}W_{\infty }\) and \(n>0\) such that \(L_{-n}{w}_{0}\in G^{d+1}W_{0}\), we have
Using the commutation relation (B.4), we get
On the other hand, we have
Using the identities
we obtain
By induction hypothesis \({\mathbf {P}}[d;r]\), there exists \(m\in {\mathbb {N}}\) depending on d and n such that
Since \(G^{d+1}W_{0}\) is finite dimensional, we can maximize such m so that it depends only on \(d+1\), implying that \({\mathbf {P}}[d+1;r]\) is also true.
Next, we apply \(L_{-n}\) with \(n>0\) at \({w}_{\infty }\in {\mathscr {F}}^{r}W_{\infty }\). On one hand, we have
Note that the rational function \(\left( {\begin{array}{c}n+1\\ 3\end{array}}\right) (\varvec{\zeta }_{0}+{\varvec{x}})^{n-2}\) appearing in the last line is a polynomial of \(\varvec{\zeta }_{0}\) and \({\varvec{x}}\) for all \(n>0\). On the other hand, we have
Here we again used the identities from (B.7). Since \(L_{n}{w}_{0}\in G^{d}W_{0}\), we can apply the induction hypothesis \({\mathbf {P}}[d;r]\) to conclude that there exists \(m\in {\mathbb {N}}\) depending on d such that
holds, implying that \({\mathbf {P}}[d;r+1]\) is also true. \(\quad \square \)
Proof of Proposition B.8
The Jacobi identity is equivalent to having both of the commutativity (Lemma B.9) and the associativity (Proposition B.10). In [LL04], this equivalence is shown only for module maps, but the same arguments work for intertwining operators. \(\quad \square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Koshida, S., Kytölä, K. The Quantum Group Dual of the First-Row Subcategory for the Generic Virasoro VOA. Commun. Math. Phys. 389, 1135–1213 (2022). https://doi.org/10.1007/s00220-021-04266-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00220-021-04266-w