
Abstract
We consider a variant of the clustering problem for a complete weighted graph. The aim is to partition the nodes into clusters maximizing the sum of the edge weights within the clusters. This problem is known as the clique partitioning problem, being NP-hard in the general case of having edge weights of different signs. We propose a new method of estimating an upper bound of the objective function that we combine with the classical branch-and-bound technique to find the exact solution. We evaluate our approach on a broad range of random graphs and real-world networks. The proposed approach provided tighter upper bounds and achieved significant convergence speed improvements compared to known alternative methods.
Similar content being viewed by others

1 Introduction
Clustering is one of the fundamental problems in data analysis and machine learning (Jain et al. 1999). In general terms, clustering means grouping similar objects together. At the same time, many real-world systems could be represented as networks (Newman 2018) or graphs. Traditionally, the word “graph” refers to the mathematical model of the underlying network, but we will use these terms interchangeably as synonyms. Graphs are a powerful mathematical model often used to study a broad range of objects and their relations. So, the clustering of real-world objects is often modeled and formulated mathematically as the clustering of vertices of a graph. If it is possible to quantify the similarity between objects, one can construct a complete graph where vertices correspond to the objects, and edge weights represent their similarity. In this case, the clustering problem could be formulated as a clique partitioning problem (Grötschel and Wakabayashi 1989, 1990).
Formally, given a complete weighted graph, the clique partitioning problem (CPP) is to find such a partition of vertices into groups (or clusters or modules) that maximizes the sum of weights of edges connecting vertices within the same groups. Obviously, this problem is not trivial only when the graph has both positive and negative edge weights. In the literature, this problem is known under different names, including clique partitioning, correlation clustering, and signed graph clustering (Hausberger et al. 2022).
In a more general case, when a system could still be represented as a network of connections between nodes, but similarities between objects are not given, the clustering problem spawned a separate field of research known as community detection in networks (Fortunato 2010). There are many approaches to community detection, but one of the most widely adopted is to define a similarity or a strength of the connection between nodes and then optimize the sum of these strengths within clusters. Probably the most well-known quality function of such partitioning is modularity (Girvan and Newman 2002; Newman and Girvan 2004; Newman 2006). For each pair of nodes, a modularity score is defined as a normalized difference between actual edge weight and expected weight in a random graph that preserves node degrees. Modularity of a partition is then just a sum of modularity scores of pairs of nodes placed in the same cluster. The problem of finding an optimal partition in terms of modularity can now be formulated as the clique partitioning problem in a graph whose edge weights correspond to modularity scores.
There are many real-world applications of CPP. The most famous, including those studied in original works by Grötschel and Wakabayashi (1989), come from biology, group technology (Oosten et al. 2001; Wang et al. 2006), and transportation (Dorndorf et al. 2008). Community detection done through modularity maximization solved as CPP could apply to areas ranging from geo-informatics (Belyi et al. 2016, 2017) and tourism management (Xu et al. 2021) to biochemistry (Guimerà and Nunes Amaral 2005) and the study of social networks (Girvan and Newman 2002). The practical usefulness of the problem continues to attract researchers’ attention. However, solving CPP is hard.
NP-hardness of CPP has been known since Wakabayashi (1986). And the same result was later proven for modularity maximization too (Brandes et al. 2008). Thus, most of the scholars’ efforts have been aimed at developing heuristic approaches that allow finding relatively good solutions relatively quickly. Among such approaches were simulated annealing and tabu search (de Amorim et al. 1992; Gao et al. 2022), ejection chain and Kernighan-Lin heuristic (Dorndorf and Pesch 1994), noising method (Charon and Hudry 2006), neighborhood search (Brusco and Köhn 2009; Brimberg et al. 2017), iterative tabu search (Palubeckis et al. 2014), and their combinations (Zhou et al. 2016). Usually, graphs considered in operational research are not too big, comprising hundreds to a few thousands of nodes, and the quality of approximate solutions is high (Zhou et al. 2016; Hu et al. 2021; Lu et al. 2021). At the same time, in network science, graphs could be extremely large, spanning over millions of nodes. Therefore, an extensive search for the solutions close to optimal is not feasible for such networks, and often methods able to provide reasonably good solutions in manageable time are favored (Blondel et al. 2008). However, some methods try to stay within reasonable time limits while delivering solutions close to optimal (Sobolevsky et al. 2014; Sobolevsky and Belyi 2022; Aref et al. 2023).
Given the NP-hardness of CPP, exact solutions are rarely proposed. Most of the existing approaches utilize the branch-and-bound method (Dorndorf and Pesch 1994; Jaehn and Pesch 2013) or cutting plane technique (Grötschel and Wakabayashi 1989; Oosten et al. 2001). Many use both methods through the means of optimization software packages that internally implement them (Du et al. 2022). Usually, such works propose some extra steps to make the problem easier to solve with standard packages (Miyauchi et al. 2018; Lorena 2019; Belyi and Sobolevsky 2022). A few approaches were proposed for slight variations of CPP with different constraints, like branch-and-price for the capacitated or graph-connected version (Mehrotra and Trick 1998; Benati et al. 2022) or branch-and-price-and-cut method for CPP with minimum clique size requirement (Ji and Mitchell 2007). Integer programming models for clustering proved to be a useful tool (Pirim et al. 2018), and the vast majority of approaches try to solve CPP formulated as an integer linear programming (ILP) problem (Grötschel and Wakabayashi 1989; Oosten et al. 2001; Miyauchi et al. 2018; Du et al. 2022). Researchers used similar methods in network science to maximize modularity (Agarwal and Kempe 2008; Aloise et al. 2010; Dinh and Thai 2015; Lorena 2019). In their seminal work, Agarwal and Kempe (2008) proposed solving the relaxation of ILP to linear programming (LP) problem and then rounding solution to integers. They described a rounding algorithm that can provide a feasible solution to the initial problem, which (after applying local-search post-processing), in many cases, could achieve high modularity. In the most recent work, Aref et al. (2022) propose the Bayan algorithm grounded in an ILP formulation of the modularity maximization problem and relying on the branch-and-cut scheme for solving the problem to global optimality. While finding the global maximum is unfeasible for large networks, studies in community detection showed that just providing the upper bound on achievable modularity could be useful by itself, and a few approaches were proposed recently (Miyauchi and Miyamoto 2013; Sobolevsky et al. 2017).
In this work, we present a new method for finding an upper bound on values that the objective function of CPP could reach. By further developing the idea proposed by Sobolevsky et al. (2017), we base our approach on combining known upper bounds of small subnetworks to calculate the upper bound for the whole network. We describe how to use obtained upper bounds to construct the exact solution of CPP. The proposed method is similar to the algorithm of Jaehn and Pesch (2013) and its further development by Belyi et al. (2019). However, by significantly improving the upper bound’s initial estimates and recalculation procedure, it achieves a decrease of a couple of orders of magnitude in computational complexity and execution time. Moreover, we show that our algorithm can find exact solutions to problems that the algorithm from Jaehn and Pesch (2013) could not. In the end, we discuss possible directions of future research and show how adding new subnetworks could improve upper bound estimates.
2 Problem formulation and existing solution approaches
We consider the following problem. Given a complete weighted undirected graph \(G=(V, E, W)\), where \(V=\{1\dots n\}\) is a set of vertices, \(E=\{\{i, j\}\mid i,j\in V, i\ne j\}\) is a set of edges, \(W=\{w_{ij} \in \mathbb {R} \mid \{i,j\} \in E, w_{ij}=w_{ji}\}\) is a set of weights of edges, find such a partition of its vertices V into clusters (represented by a mapping function \(C: V \rightarrow \mathbb {N}\) from vertices into cluster labels \(c_v=C(v)\)) that sum of edge weights within the clusters is maximized:
We denote this sum as Q and will refer to it as the partition quality function or CPP objective function. Note that this problem can be defined for any graph by adding edges with zero weight, ignoring loop edges, and averaging the weights of incoming and outgoing edges. We will say that in a given partition, an edge is included (because its weight is included in the sum in Eq. (1)) if it connects two nodes from the same cluster. Otherwise, we will say that it is excluded. Also, we use the words graph/network and vertex/node interchangeably here and throughout the rest of the text.
Grötschel and Wakabayashi (1989) showed that CPP can be formulated as the following integer linear programming (ILP) problem. For every edge \(\{i, j\}\), we define a binary variable \(x_{ij}\) that equals 1 when the edge is included and 0 otherwise. Then the objective of CPP is to
Constraints are called triangle inequalities and ensure consistency of partition, i.e., if both edges \(\{i, j\}\) and \(\{j, k\}\) are included, then edge \(\{i, k\}\) must be included too.
ILP formulation (2) has been employed by many algorithms for CPP and its variants. In their article, Grötschel and Wakabayashi (1989) empirically showed that many constraints are not saturated in the optimal solution and are redundant for the problem. More recently, Dinh and Thai (2015) derived a set of redundant constraints in formulation (2) for modularity optimization, then Miyauchi and Sukegawa (2015) generalized Dinh and Thai’s results to the general case of CPP, and recently Koshimura et al. (2022) proposed even more concise formulation of ILP. Developing their idea further, Miyauchi et al. (2018) proposed an exact algorithm that solves a modified ILP problem and then performs simple post-processing to produce an optimal solution to the original problem.
Extending the results of Grötschel and Wakabayashi (1990), Oosten et al. (2001) studied the polytope of (2) and described new classes of facet-defining inequalities that could be used in a cutting plane algorithm. Sukegawa et al. (2013) proposed a size reduction algorithm for (2) based on the Lagrangian relaxation and pegging test. They showed that for some instances of CPP, their algorithm, which minimizes the duality gap, can find an exact solution. For the other cases, they provided an upper bound of the solution. Even without an exact solution, knowing an upper bound could be useful by itself (Miyauchi and Miyamoto 2013). For example, it allows estimating how good a particular solution found by a heuristic is. The most common way to obtain upper bounds is to solve the problem (2) with relaxed integrity constraints (i.e., when constraints \(x_{ij}\in \{0,1\}\) are replaced with \(x_{ij}\in [0,1]\)). We refer to this version of the problem as the relaxed problem (2). In this case, the problem becomes an LP problem and can be solved in polynomial time using existing methods (Miyauchi and Miyamoto 2013).
Looking at the problem from a different angle, Dorndorf and Pesch (1994) and Jaehn and Pesch (2013) did not use formulation (2). Instead, they approached CPP as a combinatorial optimization problem and employed constraint programming to solve it. In some sense, our approach combines both ideas: we will show how to obtain tight upper bounds by solving another linear programming problem and then use the branch-and-bound method to solve CPP.
3 Upper bound estimation
In the general case of CPP, there is no theoretical limit on what values the quality function can reach since edge weights could be arbitrarily large. For modularity scores, however, Brandes et al. (2008) proved that \(-1/2\le Q \le 1\). In practice, though, for every network \(G=(V, E, W)\), a trivial upper bound \(\overline{Q}\) could be obtained simply as a sum of all positive edges:
But even this threshold is usually quite far above the actual maximum. To further reduce this upper bound, Jaehn and Pesch (2013) used triples of vertices in which two edges are positive (i.e., have positive weights) and one is negative (i.e., has negative weight). However, their approach considered only edge-disjoint triples , i.e., triples of nodes that have no more than one common node and thus no shared edges. In what follows, we are developing a similar idea and generalizing it further. We show how any subgraph, for which we know the upper bound of its partition quality function, could be used to reduce the upper bound for the whole network. Furthermore, we also show how to account for overlaps of such subgraphs. We start by introducing a few definitions.

Illustration of definitions: a original network; b penalizing subnetworks (two triangles and a chain); c reduced subnetworks; d permissible linear combination of reduced subnetworks with all weights \(\lambda \) equal to 1. Colors indicate one of the possible optimal partitions. While subnetworks’ optimal partitions do not determine the optimal partition of the network, their penalties could be used to estimate the network’s penalty
Definition 1
A subnetwork \(S=(V^*\subseteq V, E^*, W^*)\) is a complete network built on a subset of nodes of the original network \(G=(V, E, W)\) defined in Sect. 2, where each edge \(\{i, j\}\in E^*\) has weight \(w^*_{ij}\in W^*\) such that \(|w^*_{ij} |\le |w_{ij} |\), \(w_{ij}\in W\) and \(w^*_{ij} \cdot w_{ij}\ge 0\), i.e., weights of subnetwork’s edges have smaller or equal absolute values and the same sign (unless the weight is zero) as weights in the original network.
For example, networks in Fig. 1b, c are subnetworks of a network in Fig. 1a. For small networks with just a few nodes or with a simple structure, it is often easy to find the exact solution of CPP, e.g., by considering all possible partitions. For some more complex networks, when finding the exact solution is already complicated, it might still be possible to prove tighter upper bound estimates \(Q_{max}\) than the trivial one (\(Q(C)\le Q_{max} < \overline{Q}\) for any partition C). Our idea is to find such networks among subnetworks of the original graph G and use their upper bound estimates to prove an estimate for G.
Definition 2
For subnetwork S with an upper bound estimate \(Q_{max}\), its penalty (P) is the difference between the trivial upper bound of the objective function given by formula (3) and \(Q_{max}\): \(P=\overline{Q}(S)-Q_{max}\).
We call a subnetwork with a positive penalty a penalizing subnetwork. For example, it is easy to see the best partitions of subnetworks in Fig. 1b: we either keep all vertices in one cluster, including the negative edge or split them into two clusters, excluding the negative edge and the smallest positive edge. This way, we know the optimal value of objective function Q, which we can use as a sharp upper bound. Then the penalty is just the difference between the sum of positive edge weights and this value of Q. We call any subnetwork of a given penalizing subnetwork S having the same penalty as S a reduced subnetwork. For example, subnetworks in Fig. 1c are reduced subnetworks of their counterparts from Fig. 1b. The benefit of using them will become clearer by the end of this section.
Definition 3
Given a set of subnetworks \(\{S_k=(V_k, E_k, W_k) \mid k=1\dots K\}\) of graph G, their permissible linear combination \(S^L=(V^L, E^L, W^L)\) with non-negative coefficients \(\lambda _k\) is a subnetwork of the original network G with all the same nodes \(V^L=\bigcup _{k=1}^K{V_k}\) and edge weights equal to linear combinations \(w^L_{ij}=\sum _{k=1}^K{\lambda _k w^{*k}_{ij}}\) of the corresponding weights \(w^{*k}_{ij}= {\left\{ \begin{array}{ll} w^{k}_{ij} &{} \text {if } \{i, j\}\in E_k\\ 0 &{} \text {otherwise} \end{array}\right. }\).
The intuition here is that we re-weight and combine several subnetworks to get one. With some abuse of notation, it can be written that \(S^L=\sum _{k=1}^K \lambda _k S_k\), where multiplying a subnetwork by a scalar means multiplying all edge weights by this scalar, and summing subnetworks means uniting vertex sets and summing corresponding edge weights. For example, the network in Fig. 1d is a permissible linear combination of reduced subnetworks from Fig. 1c.
Now it is easy to see that the following proposition holds:
Lemma 1
(Summation lemma) Consider a set of subnetworks of graph G \(\{S_1, S_2,..., S_K\}\) with penalties \(P_1, P_2,..., P_K\), and a permissible linear combination \(S^L=\sum _{k=1}^K{\lambda _k S_k}\) with non-negative \(\lambda _k\). Then \(S^L\) has a penalty greater or equal to \(\sum _{k=1}^K{\lambda _k P_k}\).
Proof
Indeed, for each subnetwork \(S_k\) denote the upper bound estimate corresponding to \(P_k\) as \(Q_{max}^k\). Then for any partition C of the subnetwork \(S^L\), score Q can be expressed as \(Q(S^L, C) = \sum _{1\le i<j\le n \mid \{i, j\}\in E^L, c_i=c_j}{w^L_{ij}} = \sum _{1\le i<j\le n \mid \{i, j\}\in E^L, c_i=c_j}{\sum _{k=1}^K{\lambda _k w^{*k}_{ij}}} = \sum _{k=1}^K{\lambda _k \sum _{1\le i<j\le n \mid \{i, j\}\in E_k, c_i=c_j}{w^{k}_{ij}}} = \sum _{k=1}^K{\lambda _k Q(S_k, C)} \le \sum _{k=1}^K{\lambda _k Q_{max}^k}\), so \(Q^L_{max}=\sum _{k=1}^K{\lambda _k Q_{max}^k}\) is an upper bound for subnetwork \(S^L\), and since for the trivial upper bounds (3) \(\overline{Q}(S^L) = \sum _k{\lambda _k \overline{Q}(S_k)}\), \(S^L\) has penalty \(P^L = \overline{Q}(S^L)-Q^L_{max} = \sum _{k=1}^K{\lambda _k \overline{Q}(S_k)}-\sum _{k=1}^K{\lambda _k Q_{max}^k} = \sum _{k=1}^K{\lambda _k \left( \overline{Q}(S_k)-Q_{max}^k\right) } = \sum _{k=1}^K{\lambda _k P_k}\). \(\square \)
Summation lemma allows us to prove a stronger result:
Theorem 1
Consider graph G, a set of its subnetworks \(\{S_1, S_2,..., S_K\}\) with penalties \(P_1, P_2,..., P_K\), and a permissible linear combination \(S^L=\sum _{k=1}^K{\lambda _k S_k}\) with non-negative \(\lambda _k\). Then G has a penalty greater or equal to \(\sum _{k=1}^K{\lambda _k P_k}\).
Proof
Network G can be represented as a sum \(G = S^L + R\) of \(S^L\) and some residual subnetwork R, with edge weights \(w^R_{ij} = w_{ij} - w^{*L}_{ij}\), where \(w^{*L}_{ij}\) are equal to the edge weights \(w^L_{ij}\) of \(S^L\), if edge \(\{i, j\}\) belongs to \(S^L\), and zero otherwise. Then, \(\overline{Q}(G) = \overline{Q}(S^L) + \overline{Q}(R)\), and for any partition C, \(Q(G, C) = Q(S^L, C) + Q(R, C)\). From the summation lemma, we have the following: \(Q(S^L, C) \le \overline{Q}(S^L) - \sum _k{\lambda _k P_k}\). So, \(Q(G, C) \le Q(R, C) + \overline{Q}(S^L) - \sum _k{\lambda _k P_k} \le \overline{Q}(R) + \overline{Q}(S^L) - \sum _k{\lambda _k P_k} = \overline{Q}(G) - \sum _k{\lambda _k P_k} = Q_{max}\), and G has penalty \(P = \overline{Q}(G) - Q_{max} = \sum _k{\lambda _k P_k}\). \(\square \)
This result provides a framework for constructing tight upper bounds by combining penalties of smaller subnetworks. Having a set of penalizing subnetworks \(\{S_1, S_2,..., S_K\}\) with their penalties \(P_1, P_2,..., P_K\), we can construct a linear programming problem to find the penalty of the whole network. LP problem can be formulated as follows:
Constraints ensure that the linear combination of subnetworks remains a subnetwork, i.e., satisfies the condition \(|w^*_{ij} |\le |w_{ij} |\). Here comes the benefit of using reduced subnetworks: having smaller edge weights \(|w^{*k}_{ij} |\) while keeping the same penalty \(P_k\) allows the possibility of finding larger coefficients \(\lambda _k\), and thus larger global penalty P. Note that this is not an integer problem and could be efficiently solved with modern optimisation software packages in polynomial time (Lee and Sidford 2015; Cohen et al. 2021). A large penalty P found this way leads to a tight upper bound \(Q_{max}=\overline{Q}-P\).

Penalizing subnetworks: a Chain; b Star
3.1 Chains
Our method primarily focuses on a particular case of penalizing subnetworks that we call chains.
Definition 4
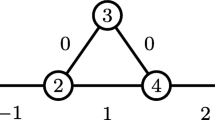
A chain of length k is a subnetwork consisting of k nodes relabeled within a chain \(1^*,\dots ,k^*\), connected by positive edges \(\{1^*, 2^*\}, \{2^*, 3^*\},\dots ,\{(k-1)^*, k^*\}\) and a negative edge \(\{1^*, k^*\}\). When \(k=3\), we call the chain a triangle.
Figure 2a illustrates a chain in a general case, and in Fig. 1b, we show triangles and a chain of length 4.
It is always easy to find the exact solution of CPP for a chain. Indeed, in the optimal partition, nodes \(1^*\) and \(k^*\) appear either in the same cluster or different ones. In the first case, the negative edge \(\{1^*, k^*\}\) is included in the total score, and in the second case, one of the positive edges must be excluded. So, depending on which value is larger \(|w^*_{1^*,k^*} |\) or \(\min _{i=1,\dots ,k-1}(w^*_{i^*,(i+1)^*})\), the optimal split of the chain will be into one or two clusters with the objective function value equal to \(\sum _{i=1,\dots ,k-1}{w^*_{i^*,(i+1)^*}} - \min (w^*_{1^*,2^*},\dots ,w^*_{(k-1)^*,k^*},|w^*_{k^*,1^*} |)\), where \(\min (w^*_{1^*,2^*},\dots ,w^*_{(k-1)^*,k^*},|w^*_{k^*,1^*} |)=P\) is that chain’s penalty. Then to construct a reduced chain, we can set the weight of each positive edge to P and the weight of the negative edge to \(-P\). Repeating the same reasoning, one can easily see that this chain has the same penalty P. In some sense, this is the best reduction possible because assigning a smaller absolute value to any weight in the original chain would lead to a smaller penalty.
Using chains alone, we can already calculate a non-trivial upper bound: find as many chains as possible, reduce them, construct an LP problem, and solve it using an appropriate method to obtain penalty P. Then the upper bound is the difference \(Q_{max} = \overline{Q} - P\). By as many as possible, we mean as many as we can find and a solver can handle in a reasonable time (in our experiments, we used all penalizing chains with three and four nodes). The following algorithm formalizes these steps.


An example of a network for which the upper bound constructed using chains does not match the optimal objective function value. Original network (a) has only three chains (b). After reducing them (c) and constructing optimal permissible linear combination (d) by solving an LP problem, the best penalty is 16.5, and the upper bound is \(33-16.5=16.5\). However, it is easy to see (by considering all possibilities) that the best partition of the original network has a score of 15 and a penalty of 18. Colors indicate one of the possible optimal partitions
We note here that while adding more chains, in general, helps to construct tighter upper bounds, it is possible that even after considering all chains, the upper bound will not become sharp, i.e., it will not reach the optimal value of the objective function. We show an example of such a network in Fig. 3. Moreover, we proved that solution to relaxed problem (2) (i.e., when constraints \(x_{ij}\in \{0,1\}\) are replaced with \(x_{ij}\in [0,1]\)) always finds at least as tight upper bounds as considering only chains as penalizing subnetworks (see Appendix A). Nevertheless, we will show that chains alone can already give a tight upper bound for many networks while the resulting LP problem is smaller and faster to solve. Furthermore, the main advantage of our framework is that it allows us to use not only chains but any penalizing subnetworks.
3.2 Stars
To show an example of penalizing subnetworks that can help to construct upper bounds tighter than those found by solving the relaxed problem (2), we introduce one more class of penalizing subnetworks that we call stars. The intuition comes from the example in Fig. 3. A star is a network that has three nodes i, j, k connected to each other by edges with weight \(-p\), and a node m connected to i, j, k via simple non-overlapping paths consisting of edges with weight p, for some positive number p (see Fig. 2b). The solution of relaxed problem (2) for a star gives a penalty of 1.5p. So it follows that the actual penalty is at least 2p, and it is easy to see how it can be achieved.
4 Branch and bound
Here we describe how to use the method proposed in the previous section inside a general branch-and-bound technique to solve CPP. In each step of branch and bound, we select an edge of the network and fix it, i.e., consider two possibilities: (1) This edge is included, i.e., lays within some cluster, so its weight is included in the total sum of the objective function. So, the two nodes that it connects belong to the same cluster in the final partition. (2) This edge is excluded, i.e., it connects nodes belonging to different clusters in the final partition, and so its weight is not included in the objective function score. In each of these two cases, we recalculate the estimate of what the objective function score could be, and if the upper bound is equal to or smaller than the value achieved by some already known feasible solution, then the case cannot lead to a better solution, so it is fathomed. Then, for each case that is not fathomed, the same steps are repeated recursively. This procedure creates a binary search tree that is being traversed depth-first.
There are a few things we need to consider at each step. First, we must ensure that constraints imposed by edge inclusion or exclusion are not contradictory. That means we need to propagate transitivity condition: if edges between a and b, and b and c are included, then the edge between a and c must be included too; and if edge \(\{a,b\}\) is included and edge \(\{b,c\}\) is excluded, then edge \(\{a,c\}\) must be excluded. To ensure this, we use the following algorithm.

The correctness of this algorithm follows from the observation that when the transitivity condition is satisfied, nodes connected by included edges form cliques, and every node is connected to all nodes in such a clique via the same type of edges (included, excluded, or non-fixed). Fixing edge \(\{a, b\}\) may break this property, and Algorithm 2 restores it. The time complexity of this algorithm is \(O(n^2)\), where \(n=|V |\) is the number of nodes in G because the number of all possible edges between sets A, B, X, Y is not greater than the total number of edges, which is \(n(n-1)/2\). However, in practice, in many cases, we do not need to fix many edges, so sets A, B, X, Y are small enough so that their sizes could be considered constant, as well as the number of edges between them, then the complexity of the algorithm is dominated by the first loop over all nodes, and thus this algorithm runs in linear time O(n).

A second consideration is that we want to update our upper bound estimate after each edge fixation. We do so by noting that if we include a negative or exclude a positive edge \(\{i, j\}\), then \(|w_{ij} |\) should be added to the network’s penalty since \(Q\le \overline{Q}-|w_{ij} |\) in this case. However, any fixation of edge \(\{i, j\}\) changes the penalties of some subnetworks in which it is present, so the penalty of each affected subnetwork needs to be recalculated. Fortunately, it is easy to do for chains and stars. If we include a negative edge or exclude a positive one, then adding \(|w_{ij} |\) to the network’s total penalty entirely accounts for any penalty incurred by this edge in any chain containing it, so we should stop considering such chains. We do the same for stars, but the reason is a bit less apparent. We stop considering stars containing edge \(\{i, j\}\) because their penalties are accounted for by weight \(|w_{ij} |\) added to the total penalty and by penalties of chains that do not go through \(\{i, j\}\). In contrast, if we exclude a negative or include a positive edge \(\{i, j\}\), the total penalty is not affected directly. To account for such fixation, we need to exclude this edge from the constraints in LP formulation (4).
In our experiment, we implemented the branch-and-bound algorithm using only chains to calculate upper bounds. Separately, we implemented a version where we included stars to estimate the initial upper bound. In the rest of this section, we will present algorithms for chains only. They could be easily generalized to use stars too. However, in our experiments, the benefit of tighter upper bounds obtained from solving the LP problem with stars was offset by the larger LP problem that was slower to solve.

Moreover, it appeared that instead of solving the LP problem at each step, it is often expedient to use a much faster greedy technique that produces less tight upper bounds. The idea is to use a good set of chains with their weights \(\lambda \) already found at previous steps, and instead of constructing and solving the LP problem for the whole network, construct a residual subnetwork \(R = G - S^L\) and find new chains in it using a simple heuristic: find a (random) chain and subtract it from R (with weight \(\lambda =1\)), then find another (random) chain and subtract it, repeat this process, until there are no more chains. This procedure is formalized in Algorithm 3.
This method works quickly, but it accumulates inefficiencies. To deal with them, after considering some number of levels (e.g. four) in the branch-and-bound search tree, we still solve the complete LP problem to update chains and their weights. For that purpose, we can use a slightly adjusted Algorithm 1 that takes into account fixed edges.
Now we are ready to present Algorithm 4 - the main workhorse of branch and bound: a recursive function that explores each node of the tree, i.e., tries to include and exclude an edge and calls itself recursively to explore the search tree further.
Two more notes before we can finally formulate the main procedure: (1) The order in which we consider edges influences performance quite a lot. However, calculating penalty change after fixing each edge on every step is too computationally expensive. So, we used edge weights as an approximation. The reasoning here is that excluding a heavy positive edge would cause a higher loss in partition score. (2) For some most simple cases, even the heuristic of Algorithm 3 can already find an upper bound that matches a feasible solution proving its optimality. So to avoid spending time on solving the LP problem, we try a few (e.g. three) times to calculate the initial upper bound using the heuristic.
The following algorithm describes the main procedure of the branch-and-bound method that calls the functions presented above to find a CPP solution.

Since both our method and the method by Jaehn and Pesch (2013) implement the standard branch-and-bound technique, they both have a similar recursive structure with the same steps. However, each step of the two methods is implemented differently: (1) We use Combo (Sobolevsky et al. 2014) to obtain lower bounds, while Jaehn and Pesch use a heuristic by Dorndorf and Pesch (1994). Our experiments show that Combo is more efficient, agreeing with recent results (Aref et al. 2023). (2) We use a more efficient algorithm 2 for constraints propagation. (3) The order in which we consider edges is different. (4) And, most importantly, we use methods introduced above to calculate much tighter upper bounds using penalizing subnetworks.
5 Computational experiment
We considered both proprietary solvers and open-source solutions to solve the LP problem that arises when calculating the upper bound estimate. Based on the results of the comparison of some of the most popular open-source solvers (Gearhart et al. 2013), we picked COIN_OR CLP (Forrest and Hall 2012) as an open-source candidate for our experiments. Then, after it showed results similar to and often even better than proprietary solutions, we stayed with it as our linear programming solver. Another argument in favour of an open-source solution was that we wanted our results to be freely available to everyone. Our code and the datasets generated and analysed in this section are available on GitHub.Footnote 1 To find an initial solution of CPP, we used the algorithm Combo (Sobolevsky et al. 2014), whose source code is also freely available. All programs were implemented in C++, compiled using Clang 13.1.6, and ran on a laptop with a 3.2 GHz CPU and 16 GB RAM.
Among the recent works, there are two methods for solving CPP exactly that show the best results. Our method extends and improves upon the one by Jaehn and Pesch (2013). The other one is by Miyauchi et al. (2018), whose main idea was to provide a way of significantly reducing the number of constraints in problem (2) for networks with many zero-weight edges. So they tested their algorithm only on networks with many zero-weight edges, which is the hard case for our method because a chain cannot be penalizing if it has non-fixed edges with weight zero. Thus, the comparison with their results would be unfair. Therefore we mostly adopted the testing strategy of Jaehn and Pesch (2013) and compared results with their method, which is much more similar in spirit to ours.
We note that Jaehn and Pesch (2013) did not make their implementation available, and our attempts to re-implement their method did not show any improvements compared to already reported results, sometimes falling behind significantly. Therefore, below, we compare our results with the results from their original paper. Although we use a modern laptop, running our algorithm on a computer from 2011 with similar characteristics to the one used by Jaehn and Pesch (2013) decreases the performance only by a factor from 1.5 to 3, which is expected for a simple single-threaded program without heavy memory usage, like our algorithm. So, we believe the difference in laptop configuration cannot lead to misjudgments in our comparison.
Also, following Jaehn and Pesch (2013), we report times for solving ILP problem 2 using CPLEX Optimization Studio 20.1. We use the version of problem 2 without redundant constraints as proposed by Koshimura et al. (2022). We tried incorporating custom propagation techniques into CPLEX but could not achieve performance gains compared to default settings. Finally, we note that there exists a benchmark for evaluating heuristic approaches adopted, for example, by Hu et al. (2021) and Lu et al. (2021), but it consists of instances too large to be solved exactly, and therefore we did not use it.
We tested our approach on both real-world and artificial networks. The real-world networks were collected from previous studies found in the literature, and artificial networks are random graphs generated according to specified rules. Jaehn and Pesch (2013) considered two sets of real-world networks. The first set studied by Grötschel and Wakabayashi (1989) was obtained by reducing an object clustering problem to CPP. Some of the networks were published in the article’s appendix, but some were only referenced, so we could not find Companies network. For the network UNO, we got the same results as Grötschel and Wakabayashi (1989), and they are slightly different from the results of Jaehn and Pesch (2013), probably because of the typo in the data. Jaehn and Pesch (2013) mentioned this issue. We present results for these networks in Table 1. In all the tables that follow: in column Nodes, we show the number of nodes considered by the branch-and-bound technique; t indicates execution time in seconds; n is the network’s size; \(\overline{Q}\) is a trivial upper bound estimate (3); \(Q_{min}\) represents the initial value obtained by a heuristic (Combo in our case); \(Q_{max}\) is the upper bound obtained on the first step by using penalizing chains in our algorithm and using triangles in the method of Jaehn and Pesch (2013); \(Q_{opt}\) is the optimal solution; asterisk (\(^*\)) indicates the results of the algorithm proposed here; \(t^{CPLEX}\) is execution time for CPLEX; results of Jaehn and Pesch (2013) (\(\overline{Q}\), \(Q_{min}\), \(Q_{max}\), Nodes, t) are taken from their article; better values are shown in bold.
It could be seen that all instances were solved by our method within a second. Combo had already found the optimal solution in all cases, and our method was applied only to prove its optimality. There are a few cases where the method of Jaehn and Pesch (2013) was faster due to the quick heuristic they use to construct upper bounds, while our approach had to solve the LP problem. However, we would notice that we did not have to use branch and bound for any network except Workers because the constructed upper bound was already equal to the lower bound found by Combo.
The second set of real-world networks arises from a part-to-machine assignment problem, which is often encountered in group technology, and was studied by Oosten et al. (2001). Unfortunately, they did not publish their networks and only provided citations to sources. Nevertheless, we obtained five out of the seven networks they considered. These networks are particularly hard to solve because they are bipartite, which means that every triple of nodes has an edge with zero weight, so there are no triangles. Just as Oosten et al. (2001) and Jaehn and Pesch (2013), we quickly solved three easy problems, but unlike them, we also solved MCC and BOC problems, although, CPLEX showed even better time. Summary statistics are present in Table 2, but neither Oosten et al. (2001) nor Jaehn and Pesch (2013) reported their execution time.
To generate random graphs, we repeated the procedures described by Jaehn and Pesch (2013). Similarly, we created four sets of synthetic networks. The first set consists of graphs with n vertices where n ranges from 10 to 23. In the original paper by Jaehn and Pesch (2013), authors used only networks of sizes up to 20 nodes, but we extended all four datasets with networks of 21–23 nodes for better comparison with CPLEX. In the first dataset, edge weights were selected uniformly from the range \([-q, q]\). For every n and every q from a set \(\{1, 2, 3, 5, 10, 50, 100\}\) we generated five random graphs, resulting in 35 graphs for each n or 490 graphs in total. Results for this set are shown in Table 3. Each value corresponds to a sum over 35 instances. Because our networks are different from those generated by Jaehn and Pesch (2013), first, after each experiment, we divided \(\overline{Q}\), \(Q_{min}\), and \(Q_{max}\) by \(Q_{opt}\) and operated with relative numbers instead of absolute values of the objective function. Second, we ran every experiment ten times with different random instances and reported the mean and the unbiased standard deviation estimate (as \(mean \pm std.\)).
As seen from Table 3, for this set of random graphs, our approach significantly outperformed Jaehn and Pesch (2013) on networks of all sizes. While averages of our trivial estimates \(\overline{Q}^{*}\) are pretty close to \(\overline{Q}\), indicating that generated random instances were similar to those used by Jaehn and Pesch (2013), our estimates of upper bounds were always more than \(20\%\) closer to the optimal solution. For the largest instances with 20 nodes, our approach considered about 1800 times fewer nodes and completed more than 250 times faster. On the other hand, we can see that for larger instances CPLEX starts to perform even faster than the proposed method.
Graphs in the second set were generated using a procedure that is supposed to resemble the process of creating similarity networks of Grötschel and Wakabayashi (1989). First, for every graph with n vertices, we fixed a parameter p. Then, for each vertex, we created a binary vector of length p, picking 0 or 1 with an equal probability of 0.5. Finally, the weight of the edge between vertices i and j was set to p minus doubled the number of positions where vectors of i and j differ. For every n from 10 to 30 and p from the set \(\{1, 2, 3, 5, 10, 50, 100\}\) we generated 5 instances of random graphs. We show results for this set in Table 4. As previously, in every experiment, results are summed up over 35 instances, and we report the mean and standard deviation calculated over ten experiment runs.
Again, we can see that our approach gave a very significant speedup in execution time compared to the method of Jaehn and Pesch (2013). Comparable execution time for smaller instances could be explained by the simplicity of these networks, where even straightforward but fast methods work well. We can see that again, similar to results of Jaehn and Pesch (2013), the largest instances are faster solved by CPLEX. That can suggest that for now our method is better suited for smaller networks. In our future research on this problem, we will try to address this by applying column and row generation methods to speed up the solution of underlying LP problems.
The third set consists of graphs created using the same procedure as for the first set, but then the weight of each edge was set to zero with \(40\%\) probability in the first subset (Table 5) and \(80\%\) in the second subset (Table 6).
These subsets appeared to be the easiest to solve. Here again, our method was faster than its competitor, but by a smaller margin primarily because, for such an easy set, there was little room for improvement. While the simplicity of this set for both methods is surprising because the abundance of zero-weight edges means fewer triangles and chains, our results confirm the conclusion of Jaehn and Pesch (2013) that zeroing out edges at random only makes instances easier to solve.
As we mentioned in Sect. 4, we used only chains to estimate upper bounds in our algorithms. However, as we proved in Corollary 1, this approach cannot provide an upper bound tighter than the solution of the relaxed problem (2). Therefore, to show how our method could be extended, we did an experiment where we also used stars to estimate upper bounds. We applied our algorithm to maximize the modularity of two well-studied real-world networks: a social network of frequent associations between 62 dolphins (Lusseau et al. 2003) and a co-appearance network of characters in Les Miserables novel (Knuth 1993). It took a couple of minutes to construct a set of stars and solve the initial LP problem. However, for both networks, found solutions (\(Q_{max}\)) were already equal to the feasible solutions found by Combo, which proved their optimality, while the solutions of relaxed problem (2) give higher values of upper bounds (Miyauchi and Miyamoto 2013). These results make us believe that further improvements to our algorithm will allow us to achieve even better performance for more difficult networks.
6 Conclusions
We propose a two-stage method, providing an efficient solution for the clique partitioning problem in some cases. First, we define penalizing subnetworks and use them to calculate the upper bounds of the clique quality function. In many cases, our method is much faster than other methods for upper-bounds estimation, and for many networks, it finds tighter upper bounds. Second, we present an algorithm that uses found upper bounds in the branch-and-bound technique to solve the problem exactly. Our experiments showed that the proposed algorithm drastically outperforms some previously known approaches even when using only a single class of penalizing subnetworks that we call chains. Moreover, the proposed heuristic, which allows finding upper bounds using chains quickly, works much faster than a well-known alternative approach leveraging a linear programming problem, while the resulting upper bounds are tight enough for many networks to find the exact solution efficiently.
We also provide a framework for using more general penalizing subnetworks when chains are not effective enough. E.g., we introduce another class of subnetworks called stars that can help find upper bounds much tighter than those found by chains and even by a linear programming-based method. Constructing more diverse sets of penalizing subnetworks and improving the efficiency of incorporating them into the method can further improve finding exact solutions to the clique partitioning problem. Since some larger graph instances are still solved faster by standard packages like CPLEX, we plan to incorporate column and row generation methods and cutting plane techniques into our algorithm. We believe that future work in this direction could provide efficient solutions for the clique partitioning and its particular case—a modularity maximization problem—for a broader range of networks, including larger ones.
Data availability
Code, data and materials are available at https://github.com/Alexander-Belyi/best-partition.
References
Agarwal G, Kempe D (2008) Modularity-maximizing graph communities via mathematical programming. Eur Phys J B 66(3):409–418. https://doi.org/10.1140/epjb/e2008-00425-1
Aloise D, Cafieri S, Caporossi G et al (2010) Column generation algorithms for exact modularity maximization in networks. Phys Rev E 82(4):46,112. https://doi.org/10.1103/PhysRevE.82.046112
Aref S, Chheda H, Mostajabdaveh M (2022) The Bayan algorithm: detecting communities in networks through exact and approximate optimization of modularity. arXiv preprint
Aref S, Mostajabdaveh M, Chheda H (2023) Heuristic modularity maximization algorithms for community detection rarely return an optimal partition or anything similar. In: Computational science—ICCS 2023. Springer, Cham
Belyi A, Sobolevsky S (2022) Network size reduction preserving optimal modularity and clique partition. In: Gervasi O, Murgante B, Hendrix EMT et al (eds) Computational science and its applications—ICCSA 2022. Springer, Cham, pp 19–33. https://doi.org/10.1007/978-3-031-10522-7_2
Belyi A, Rudikova L, Sobolevsky S et al (2016) Flickr service data and community structure of countries. In: International congress on computer science: information systems and technologies: materials of international scientific congress, Republic of Belarus, Minsk, pp 851–855
Belyi A, Bojic I, Sobolevsky S et al (2017) Global multi-layer network of human mobility. Int J Geogr Inf Sci 31(7):1381–1402. https://doi.org/10.1080/13658816.2017.1301455. arxiv:1601.05532
Belyi AB, Sobolevsky SL, Kurbatski AN et al (2019) Improved upper bounds in clique partitioning problem. J Belarusian State Univ Math Inform 3:93–104. https://doi.org/10.33581/2520-6508-2019-3-93-104
Benati S, Ponce D, Puerto J et al (2022) A branch-and-price procedure for clustering data that are graph connected. Eur J Oper Res 297(3):817–830. https://doi.org/10.1016/j.ejor.2021.05.043
Blondel VD, Guillaume JL, Lambiotte R et al (2008) Fast unfolding of communities in large networks. J Stat Mech Theory Exp 2008(10):P10,008. https://doi.org/10.1088/1742-5468/2008/10/p10008
Brandes U, Delling D, Gaertler M et al (2008) On modularity clustering. IEEE Trans Knowl Data Eng 20(2):172–188. https://doi.org/10.1109/TKDE.2007.190689
Brimberg J, Janićijević S, Mladenović N et al (2017) Solving the clique partitioning problem as a maximally diverse grouping problem. Optim Lett 11(6):1123–1135. https://doi.org/10.1007/s11590-015-0869-4
Brusco MJ, Köhn HF (2009) Clustering qualitative data based on binary equivalence relations: neighborhood search heuristics for the clique partitioning problem. Psychometrika 74(4):685. https://doi.org/10.1007/s11336-009-9126-z
Charon I, Hudry O (2006) Noising methods for a clique partitioning problem. Discrete Appl Math 154(5):754–769. https://doi.org/10.1016/j.dam.2005.05.029
Cohen MB, Lee YT, Song Z (2021) Solving linear programs in the current matrix multiplication time. J ACM. https://doi.org/10.1145/3424305
de Amorim SG, Barthélemy JP, Ribeiro CC (1992) Clustering and clique partitioning: simulated annealing and tabu search approaches. J Classif 9(1):17–41. https://doi.org/10.1007/BF02618466
Dinh TN, Thai MT (2015) Toward optimal community detection: from trees to general weighted networks. Int Math 11(3):181–200. https://doi.org/10.1080/15427951.2014.950875
Dorndorf U, Pesch E (1994) Fast clustering algorithms. ORSA J Comput 6(2):141–153. https://doi.org/10.1287/ijoc.6.2.141
Dorndorf U, Jaehn F, Pesch E (2008) Modelling robust flight-gate scheduling as a clique partitioning problem. Transp Sci 42(3):292–301. https://doi.org/10.1287/trsc.1070.0211
Du Y, Kochenberger G, Glover F et al (2022) Solving clique partitioning problems: a comparison of models and commercial solvers. Int J Inf Technol Decis Mak 21(01):59–81. https://doi.org/10.1142/S0219622021500504
Forrest J, Hall J (2012) COIN-OR Linear Programming (CLP) v1.14.8
Fortunato S (2010) Community detection in graphs. Phys Rep 486:75–174. https://doi.org/10.1016/j.physrep.2009.11.002
Gao J, Lv Y, Liu M et al (2022) Improving simulated annealing for clique partitioning problems. J Artif Intell Res 74:1485–1513. https://doi.org/10.1613/jair.1.13382
Gearhart JL, Adair KL, Detry RJ et al (2013) Comparison of open-source linear programming solvers. Sandia Natl Lab SAND2013-8847
Girvan M, Newman MEJ (2002) Community structure in social and biological networks. Proc Natl Acad Sci 99(12):7821–7826. https://doi.org/10.1073/pnas.122653799
Grötschel M, Wakabayashi Y (1989) A cutting plane algorithm for a clustering problem. Math Program 45(1):59–96. https://doi.org/10.1007/BF01589097
Grötschel M, Wakabayashi Y (1990) Facets of the clique partitioning polytope. Math Program 47(1):367–387. https://doi.org/10.1007/BF01580870
Guimerà R, Nunes Amaral LA (2005) Functional cartography of complex metabolic networks. Nature 433(7028):895–900. https://doi.org/10.1038/nature03288
Hausberger F, Faraj MF, Schulz C (2022) A distributed multilevel memetic algorithm for signed graph clustering. arXiv preprint arXiv:2208.13618
Hu S, Wu X, Liu H et al (2021) A novel two-model local search algorithm with a self-adaptive parameter for clique partitioning problem. Neural Comput Appl 33(10):4929–4944. https://doi.org/10.1007/s00521-020-05289-5
Jaehn F, Pesch E (2013) New bounds and constraint propagation techniques for the clique partitioning. Discrete Appl Math 161(13):2025–2037. https://doi.org/10.1016/j.dam.2013.02.011
Jain AK, Murty MN, Flynn PJ (1999) Data clustering: a review. ACM Comput Surv 31(3):264–323. https://doi.org/10.1145/331499.331504
Ji X, Mitchell JE (2007) Branch-and-price-and-cut on the clique partitioning problem with minimum clique size requirement. Discrete Optim 4(1):87–102. https://doi.org/10.1016/j.disopt.2006.10.009
Knuth DE (1993) The Stanford GraphBase: a platform for combinatorial computing. AcM Press, New York
Koshimura M, Watanabe E, Sakurai Y et al (2022) Concise integer linear programming formulation for clique partitioning problems. Constraints 27:99–115. https://doi.org/10.1007/s10601-022-09326-z
Lee YT, Sidford A (2015) Efficient inverse maintenance and faster algorithms for linear programming. In: 2015 IEEE 56th annual symposium on foundations of computer science, pp 230–249. https://doi.org/10.1109/FOCS.2015.23
Lorena LHN, Quiles MG, Lorena LAN (2019) Improving the performance of an integer linear programming community detection algorithm through clique filtering. In: Misra S, Gervasi O, Murgante B et al (eds) Computational science and its applications—ICCSA 2019. Springer, Cham, pp 757–769. https://doi.org/10.1007/978-3-030-24289-3_56
Lu Z, Zhou Y, Hao JK (2021) A hybrid evolutionary algorithm for the clique partitioning problem. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2021.3051243
Lusseau D, Schneider K, Boisseau OJ et al (2003) The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav Ecol Sociobiol 54(4):396–405. https://doi.org/10.1007/s00265-003-0651-y
Mehrotra A, Trick MA (1998) Cliques and clustering: a combinatorial approach. Oper Res Lett 22(1):1–12. https://doi.org/10.1016/S0167-6377(98)00006-6
Miyauchi A, Miyamoto Y (2013) Computing an upper bound of modularity. Eur Phys J B 86(7):302. https://doi.org/10.1140/epjb/e2013-40006-7
Miyauchi A, Sukegawa N (2015) Redundant constraints in the standard formulation for the clique partitioning problem. Optim Lett 9(1):199–207. https://doi.org/10.1007/s11590-014-0754-6
Miyauchi A, Sonobe T, Sukegawa N (2018) Exact clustering via integer programming and maximum satisfiability. In: Proceedings of the AAAI conference on artificial intelligence, vol 32(1)
Newman MEJ (2006) Modularity and community structure in networks. Proc Natl Acad Sci 103(23):8577–8582. https://doi.org/10.1073/pnas.0601602103
Newman M (2018) Networks. Oxford University Press, Oxford
Newman MEJ, Girvan M (2004) Finding and evaluating community structure in networks. Phys Rev E 69(2):26,113. https://doi.org/10.1103/PhysRevE.69.026113
Oosten M, Rutten JHGC, Spieksma FCR (2001) The clique partitioning problem: facets and patching facets. Networks 38(4):209–226. https://doi.org/10.1002/net.10004
Palubeckis G, Ostreika A, Tomkevičius A (2014) An iterated tabu search approach for the clique partitioning problem. Sci World J. https://doi.org/10.1155/2014/353101
Pirim H, Eksioglu B, Glover FW (2018) A novel mixed integer linear programming model for clustering relational networks. J Optim Theory Appl 176(2):492–508. https://doi.org/10.1007/s10957-017-1213-1
Sobolevsky S, Belyi A (2022) Graph neural network inspired algorithm for unsupervised network community detection. Appl Netw Sci 7(63):1–19. https://doi.org/10.1007/s41109-022-00500-z
Sobolevsky S, Campari R, Belyi A et al (2014) General optimization technique for high-quality community detection in complex networks. Phys Rev E Stat Nonlinear Soft Matter Phys. https://doi.org/10.1103/PhysRevE.90.012811. arXiv:1308.3508
Sobolevsky S, Belyi A, Ratti C (2017) Optimality of community structure in complex networks. arXiv preprint arXiv:1712.05110
Sukegawa N, Yamamoto Y, Zhang L (2013) Lagrangian relaxation and pegging test for the clique partitioning problem. Adv Data Anal Classif 7(4):363–391. https://doi.org/10.1007/s11634-013-0135-5
Wakabayashi Y (1986) Aggregation of binary relations: algorithmic and polyhedral investigations. PhD thesis, Doctoral Dissertation. University of Augsburg
Wang H, Alidaee B, Glover F et al (2006) Solving group technology problems via clique partitioning. Int J Flex Manuf Syst 18(2):77–97. https://doi.org/10.1007/s10696-006-9011-3
Xu Y, Li J, Belyi A et al (2021) Characterizing destination networks through mobility traces of international tourists: a case study using a nationwide mobile positioning dataset. Tour Manag. https://doi.org/10.1016/j.tourman.2020.104195
Zhou Y, Hao JK, Goëffon A (2016) A three-phased local search approach for the clique partitioning problem. J Comb Optim 32(2):469–491. https://doi.org/10.1007/s10878-015-9964-9
Acknowledgements
We thank Daniel Bretsko and Margarita Mishina for their careful review of the paper and constructive comments and suggestions.
Funding
Open access publishing supported by the National Technical Library in Prague. The work of Alexander Belyi and Stanislav Sobolevsky was partially supported by the MUNI Award in Science and Humanities (MASH Belarus) of the Grant Agency of Masaryk University under the Digital City project (MUNI/J/0008/2021). The work of Alexander Belyi was also partially supported by the National Research Foundation (prime minister’s office, Singapore), under its CREATE program, Singapore-MIT Alliance for Research and Technology (SMART) Future Urban Mobility (FM) IRG. The work of Stanislav Sobolevsky was also partially supported by ERDF “CyberSecurity, CyberCrime and Critical Information Infrastructures Center of Excellence” (No. CZ.02.1.01/0.0/0.0/16_019/0000822).
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Methods and algorithms were developed by AB and SS. Computational experiments and their analysis were performed by AB. The first draft of the manuscript was written by AB, and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethics approval
Not applicable.
Consent to participate
Not applicable.
Consent for publication
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A
Appendix A
Theorem 2
Solution of the relaxed problem (2) (i.e., when constraints \(x_{ij}\in \{0,1\}\) are replaced with \(x_{ij}\in [0,1]\)) for any chain (see Definition 4) always finds upper bound equal to the maximum of Q for this chain.
Proof
Consider a chain with k nodes and edge weights \(w_{1,2}, w_{2,3},\dots , w_{k-1,k}, -w_{1,k}\), where \(w_{1,2}, w_{2,3}, \dots , w_{k-1,k}, w_{1,k} > 0\) (see Fig. 2a). Let \(w_{m,m+1} = \min _{i\in \{1..k-1\}}w_{i,i+1}\). There are two cases:
1. \(w_{1,k} < w_{m,m+1}\)
In this case, the optimal clique partition is to assign all nodes to one clique, i.e., to include the negative edge \(\{1, k\}\), \(Q_{opt} = w_{1,2} + w_{2,3} +\dots + w_{k-1,k} - w_{1,k}\). So, we want to show that \(w_{1,2} + w_{2,3} +\dots + w_{k-1,k} - w_{1,k} \ge x_{1,2}w_{1,2} + x_{2,3}w_{2,3} +\dots + x_{k-1,k}w_{k-1,k} - x_{1,k}w_{1,k}\), for all \(x_{ij}\in [0,1]\) satisfying triangle inequalities of the problem (2). After regrouping, we get: \((1-x_{1,2})w_{1,2}+(1-x_{2,3})w_{2,3}+\dots +(1-x_{k-1,k})w_{k-1,k} \ge (1-x_{1,k})w_{1,k}\). Since all \(w_{i,i+1}>w_{1,k}>0\) and \(0 \le x_{i,j} \le 1\), it is enough to show that \(1-x_{1,2}+1-x_{2,3}+\dots +1-x_{k-1,k} \ge 1-x_{1,k}\).
From the constraints of problem (2), we have:
\(1 \ge x_{1,2} + x_{2,k} - x_{1,k} \Leftrightarrow 1 - x_{1,2} \ge x_{2,k} - x_{1,k}\),
\(1 \ge x_{2,3} + x_{3,k} - x_{2,k} \Leftrightarrow 1 - x_{2,3} \ge x_{3,k} - x_{2,k}\),
\(\cdots \)
\(1 \ge x_{k-2,k-1} + x_{k-1,k} - x_{k-2,k} \Leftrightarrow 1 - x_{k-2,k-1} \ge x_{k-1,k} - x_{k-2,k}\).
After summing them, we get
\(1-x_{1,2} + 1-x_{2,3} +\dots + 1-x_{k-2,k-1} \ge x_{k-1,k} - x_{1,k}\),
and by adding 1 to both sides and moving \(x_{k-1,k}\) to the left, we get the needed inequality.
2. \(w_{m,m+1} \le w_{1,k}\)
In this case, an optimal solution is to split all nodes into two groups by excluding negative and the ‘cheapest’ positive edges, \(Q_{max} = w_{1,2} + w_{2,3} +\dots + w_{m-1,m} + w_{m+1,m+2} +\dots + w_{k-1,k}\). Now, we want to show that \(w_{1,2} + w_{2,3} +\dots + w_{m-1,m} + w_{m+1,m+2} +\dots + w_{k-1,k} \ge x_{1,2}w_{1,2} + x_{2,3}w_{2,3} +\dots + x_{k-1,k}w_{k-1,k} - x_{1,k}w_{1,k}\). After rearranging, we have: \((1-x_{1,2})w_{1,2}+(1-x_{2,3})w_{2,3}+\dots +(1-x_{m-1,m})w_{m-1,m} + (1-x_{m+1,m+2})w_{m+1,m+2}+\dots +(1-x_{k-1,k})w_{k-1,k}\)
\( + x_{1,k}w_{1,k} \ge x_{m,m+1}w_{m,m+1}\). Since all \(w_{i,i+1}\ge w_{m,m+1}>0\), \(w_{1,k} \ge w_{m,m+1}\) and \(0 \le x_{i,j} \le 1\), it is enough to show that \(1-x_{1,2} + 1-x_{2,3} +\dots + 1-x_{m-1,m} + 1-x_{m+1,m+2} +\dots + 1-x_{k-1,k} + x_{1,k} \ge x_{m,m+1}\). But we have already shown that \(1-x_{1,2}+1-x_{2,3}+\dots +1-x_{k-1,k} \ge 1-x_{1,k}\), so \(1-x_{1,2} + 1-x_{2,3} +\dots + 1-x_{m-1,m} + 1-x_{m+1,m+2} +\dots + 1-x_{k-1,k} + x_{1,k} \ge 1-(1-x_{m,m+1}) = x_{m,m+1}\). \(\square \)
Corollary 1
Solution of the relaxed problem (2) always finds an upper bound on Q that is the same as or tighter than the upper bound \(Q_{max} = \overline{Q}(G) - \sum _k{\lambda _k P_k}\) obtained by solving problem (4) for some set of chains \(\{S_k\}\) with penalties \(\{P_k\}\).
Proof
Following the proof of Theorem 1, network G could be represented as sum \(G = S^L + R\) of the linear combination of chains \(S^L\) and some residual subnetwork R with edge weights \(w^{*R}_{ij} = w_{ij} - w^*_{ij}\), and for any partition, \(Q(G) = Q(S^L) + Q(R)\). So, for the optimal solution \(\{x_{ij}\}\) of the relaxed problem (2), we have: \( \sum _{i<j}{w_{ij}\cdot x_{ij}} = \sum _{i<j}{x_{ij}\cdot (w^{*R}_{ij} + w^*_{ij})} =\)
\(\sum _{i<j}{x_{ij}\cdot w^{*R}_{ij} + \sum _{i<j}{x_{ij}\cdot \sum _k{\lambda _k w^{*k}_{ij}}}} \le \sum _{w^{*R}_{ij}>0}{w^{*R}_{ij}} + \sum _k{\lambda _k\cdot \sum _{i<j}{x_{ij}\cdot w^{*k}_{ij}}} \le \sum _{w^{*R}_{ij}>0}{w^{*R}_{ij}} + \sum _k{\lambda _k\cdot Q_{opt}(S^L)} = \)
\(\overline{Q}(R) + \sum _k{\lambda _k\cdot \left( \sum _{w^{*k}_{ij}>0}{w^{*k}_{ij}} - P_k\right) } = \)
\(\overline{Q}(R) + \overline{Q}(S^L) - \sum _k{\lambda _k P_k} = \overline{Q}(G) - \sum _k{\lambda _k P_k} \). \(\square \)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Belyi, A., Sobolevsky, S., Kurbatski, A. et al. Subnetwork constraints for tighter upper bounds and exact solution of the clique partitioning problem. Math Meth Oper Res 98, 269–297 (2023). https://doi.org/10.1007/s00186-023-00835-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00186-023-00835-y
Keywords
- Clustering
- Graphs
- Clique partitioning problem
- Community detection
- Modularity
- Upper bounds
- Exact solution
- Branch and bound
- Linear programming