
Abstract
In this paper, we study the effects on the survival rate in the employment of a scheme that facilitates gradual retirement through working time reductions. We use information on the entire labour market career and other observables to control for the selection and take dynamic treatment assignment into account. We also estimate a competing risks model considering different (possibly selective) pathways to early retirement. We find that participation in the scheme prolongs employment during the first 2 (4) years for men (women). However, when individuals become eligible for early retirement, the effect reverses. This suggests that TC initially improves the work–life balance, but that it eventually decreases labour market attachment and signals to employers a preference for early retirement. The institutional environment in which part-time participants are entitled to full-time pensions reinforces the latter process. Participation in TC seems also to generate a slight, statistically insignificant, improvement in health.




Similar content being viewed by others


Notes
See Internet Appendix B for an overview of such schemes in the countries mentioned in the text.
Ahn (2016) studies the effect of working time reductions on healthier life style, but does not directly measure the effect on health.
Internet Appendix can be found here: https://sites.google.com/site/researchandreaalbanese/InternetAppendix_TC.
There is some evidence that declining productivity with age or deferred compensation schemes induces a pay-productivity gap for older workers (e.g. Hellerstein and Neumark 2007; Aubert and Crépon 2003, 2006; Ilmakunnas and Maliranta,2005) and in particular in Belgium (Cataldi et al. 2012; Vandenberghe et al. 2013). By contrast, no pay-productivity gap is found by Cardoso et al. (2011) and van Ours and Stoeldraijer (2011).
This procedure has been criticised by Fredriksson and Johansson (2008).
A third regime existed in which one could completely stop working, but since it was hardly used and our interest is in gradual retirement, we do not further consider this regime.
All € in the text are indexed by the CPI and expressed in constant 2004 euros.
The statutory retirement age for women was raised by 1 year every 3 years from 60 before 1997 to 65 from 2009 onwards.
The legal age of eligibility is 60, but this age has been lowered in most sectors to 58. Moreover, in restructuring firms and for arduous professions, the age condition could drop to 50, 52 or 55, depending on the agreement in the corresponding industrial committee in which the labour market conditions are bargained.
“Canada Dry” refers to publicity for the drink Canada Dry: “It has the colour of Whisky, but it is not Whisky”. So, the Canada Dry scheme has features of a bridge pension, but it is not the same.
First, to restore the representativeness within the cohorts we reweigh the units within each cohort by \( W_{cr}^{c} = \frac{{N_{cr} }}{{N_{c} }} * \frac{{n_{c} }}{{n_{cr} }} \) (where \( N_{c} \) and \( n_{c} \) are the size of the cohort in the population and in the sample). To make the cohorts representative for the population, we weigh them a second time: \( SW_{cr} = W_{cr}^{c} * \frac{{N_{c} }}{N} * \frac{n}{{n_{c} }} \), so that \( W_{cr} = \frac{{N_{cr} }}{N} * \frac{n}{{n_{cr} }} \).
In principle, we could also consider TC that started in later years, but these additional treatments would not be helpful in identifying the long-run effects in which we are particularly interested.
As explained in Sect. 5.1.1, we start the treatment one quarter before the actual take-up of the TC, which occurs in 2003 or 2004. Therefore, the last exogenous quarter before the start of the selection into treatment is 2002Q3 (2004Q3).
54.3% of the treated is in the 50% TC regime, the remainder in the 20% TC regime.
The variables referred to the employment history are not combined to keep information coming from different sources and periods with missing information separate.
If \( \hat{h}_{s} \) is an estimate of the hazard at time s, then the Kaplan–Meier estimator of the survival rate at time t is given by \( \prod\nolimits_{s = 1}^{t} {(1 - \hat{h}_{s} )} \), where \( \hat{h}_{s} \) is non-parametrically estimated by the ratio of the number of individuals leaving a state at time s to the number of individuals who did not yet leave the state prior to s.
Standard errors are cluster robust to take into account correlation between the same individuals in the two samples. The bootstrap is implemented with 500 repetitions and the confidence intervals (CI) assume normality.
In Internet Appendix A, we perform a cost-benefit analysis of the TC scheme under a set of assumptions. Overall, the existing scheme does not pass the cost-benefit test.
Albanese and Cockx (2018) find that the effects on labour market outcomes of wage subsidies for older workers are consistent with this pay-productivity gap.
Since we have argued in Sect. 5.1.2 that by matching on past employment history we can capture the selection on fixed unobservables, such as work motivation, this explanation therefore assumes that employers falsely perceive that workers who participate in TC are less motivated and/or less productive.
For the population eligible for time credit, health issues only seem to matter to a minor extent: see the discussion in Sect. 6.3.
As the monthly subsidy is lump-sum, we have also estimated treatment heterogeneity with respect to labour market earnings at selection. The results are very similar to the different response by TC regime as two thirds of the treated high earnings group take the 50% regime (Fig. 7—symmetric figures for the low earnings group). Results are available in Internet Appendix C.
This is a less strong assumption than the exogenous censoring of Fredriksson and Johansson (2008).
To have an idea of the size of the ATT relative to the counterfactual of no treatment, we report the level of the survival rates of the treated and (reweighted) control units in Fig. 6 of Appendix 4.
This is because in the data only the period during which the sickness insurance pays out the replacement income are registered. Prior to 1 month, the payments during sickness absence are due by the employer.
In cases that the population of the substratum was smaller than the population, the complete population was sampled.
References
Ahn T (2016) Reduction of working time: does it lead to a healthy lifestyle? Working time and health behaviors. Health Econ 25(8):969–983
Albanese A, Cockx B (2018) Permanent wage cost subsidies for older workers. An effective tool for employment retention and postponing early retirement? Labour Econ. https://doi.org/10.1016/j.labeco.2018.01.005
Aubert P, Crépon B (2003) La productivité des salariés âgés: une tentative d’estimation. Économie et statistique 368(1):95–119
Aubert P, Crépon B (2006) Are older workers less productive? Firm-level evidence on age-productivity and age-wage profiles. Mimeo, INSEE, Paris
Berg PB, Hamman MK, Piszczek M, Ruhm C (2015) Can policy facilitate partial retirement? Evidence from Germany. IZA discussion paper no. 9266, IZA, Bonn
Busso M, DiNardo J, McCrary J (2014) New evidence on the finite sample properties of propensity score reweighting and matching estimators. Rev Econ Stat 96(5):885–897
Cameron AC, Trivedi PK (2005) Microeconometrics: methods and applications. Cambridge University Press, Cambridge
Cardoso AR, Guimarães P, Varejão J (2011) Are older workers worthy of their pay? An empirical investigation of age-productivity and age-wage nexuses. De Econ 159(2):95–111
Cataldi A, Kampelmann S, Rycx F (2012) Does it pay to be productive? The case of age groups. Int J Manpow 33:264–283
Charles K, Decicca P (2007) Hours flexibility and retirement. Econ Inq 45(2):251–267
Claes T (2012) La prépension conventionnelle (1974–2012). Courrier hebdomadaire du CRISP 2154(29):5–94
Crépon B, Ferracci M, Jolivet G, van den Berg G (2009) Active labor market policy effects in a dynamic setting. J Eur Econ Assoc 7(2–3):595–605
Devisscher S (2004) The career break (time credit) scheme in Belgium and the incentive premiums by the Flemish Government. Discussion paper, IDEA Consult, Brussels
Devisscher S, Sanders D (2008) Ageing and life-course issues: the case of the career break scheme (Belgium) and the life-course regulation (Netherlands). In: OECD, modernising social policy for the new life course. OECD Publishing, Paris. https://doi.org/10.1787/9789264041271-5-en
Elsayed A, de Grip A, Fouarge D, Montizaan R (2015) Gradual retirement, financial incentives, and labour supply of older workers: evidence from a stated preference analysis. IZA discussion paper no. 9430, IZA, Bonn
Eurofound (2001) Progressive retirement in Europe. European observatory of working life. Dublin. http://www.eurofound.europa.eu/observatories/eurwork/comparative-information/progressive-retirement-in-europe
Fredriksson P, Johansson P (2008) Dynamic treatment assignment: the consequences for evaluations using observational data. J Bus Econ Stat 26(4):435–445
Frölich M, Huber M, Wiesenfarth M (2017) The finite sample performance of semi- and nonparametric estimators for treatment effects and policy evaluation. Comput Stat Data Anal 115:91–102
Gielen A (2009) Working hours flexibility and older workers’ labor supply. Oxf Econ Pap 61(2):240–274
Graf N, Hofer H, Winter-Ebmer R (2011) Labor supply effects of a subsidized old-age part-time scheme in Austria. J Labour Mark Res 44(3):217–229
Gustman A, Steinmeier T (1984) Partial retirement and the analysis of retirement behavior. Ind Labor Relat Rev 37(3):403–415
Hellerstein JK, Neumark D (2007) Production function and wage equation estimation with heterogeneous labor: evidence from a new matched employer–employee data set. In: Hard-to-measure goods and services: essays in Honor of Zvi Griliches. University of Chicago Press, Chicago, Illinois, pp 31–71
Hirano K, Imbens GW, Ridder G (2003) Efficient estimation of average treatment effects using the estimated propensity score. Econometrica 71(4):1161–1189
Honig M, Hanoch G (1985) Partial retirement as a separate mode of retirement behavior. J Hum Resour 20(1):21–46
Horvitz DG, Thompson DJ (1952) A generalization of sampling without replacement from a finite universe. J Am Stat Assoc 47(260):663–685
Huber M, Lechner M, Wunsch C (2013) The performance of estimators based on the propensity score. J Econom 175(1):1–21
Huber M, Lechner M, Wunsch C (2016) The effect of firms’ phased retirement policies on the labor market outcomes of their employees. ILR Rev 69(5):1216–1248. https://doi.org/10.1177/0019793916644755
Hurd MD (1996) The effect of labor market rigidities on the labor force behavior of older workers. In: Wise D (ed) Advances in the economics of aging. University of Chicago Press, Chicago, pp 11–60
Ilmakunnas P, Maliranta M (2005) Technology, labour characteristics and wage-productivity gaps. Oxf Bull Econ Stat 67(5):623–645
Imbens G, Wooldridge J (2009) Recent developments in the econometrics of program evaluation. J Econ Lit 47(1):5–86
Kantarcı T, van Soest A (2008) Gradual retirement: preferences and limitations. De Econ 156(2):113–144
Lechner M, Strittmatter A (2017) Practical procedures to deal with common support problems in matching estimation. Econom Rev. https://doi.org/10.1080/07474938.2017.1318509
Lechner M, Wunsch C (2008) What did all the money do? On the general ineffectiveness of recent West German labour market programmes. Kyklos 61(1):134–174
Lechner M, Miquel R, Wunsch C (2011) Long-run effects of public sector sponsored training in West Germany. J Eur Econ Assoc 9(4):742–784
Machado CS, Portela M (2012) Hours of work and retirement behavior. IZA discussion paper no. 6270, IZA, Bonn
Manski C, Lerman SR (1977) The estimation of choice probabilities from choice based samples. Econometrica 45(8):1977–1988
OECD (2017) OECD.StatExtracts. www.stats.oecd.org. Retrieved 1 June 2017
Picchio M (2015) Is training effective for older workers? IZA World of Labor 2015, p 121
Rudolf R (2014) Work shorter, be happier? Longitudinal evidence from the korean five-day working policy. J Happiness Stud 15(5):1139–1163
Schmid G (1998) Transitional labour markets: a new European employment strategy. WZB discussion paper, no. FS I, pp 98–206
Shao J (2003) Impact of the bootstrap on sample surveys. Stat Sci 18(2):191–198
Van Looy P, Kovalenko M, Mortelmans D, De Preter H (2014) Working hours-reduction in the move to full retirement: how does this affect retirement preferences of 50 + individuals in Flanders? : Steunpunt WSE/Antwerpen. Steunpunt WSE/Antwerpen: CELLO, Universiteit Antwerpen, Leuven
van Ours J, Stoeldraijer L (2011) Age, wage and productivity in Dutch manufacturing. De Econ 159(2):113–137
Vandenberghe V, Waltenberg F, Rigo M (2013) Ageing and employability. evidence from Belgian firm level data. J Prod Anal 40:111–136
Vikström J (2017) Dynamic treatment assignment and evaluation of active labor market policies. Labour Econ 49(C):42–54
Acknowledgements
We acknowledge financial support for this research project from the programme Society and Future of the Belgian Science Policy (contract no. TA/00/044) and from the special Research Fund of Ghent University for providing a scholarship to Andrea Albanese (code 01SF3612).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendices
Appendix 1: (Endogenous) stratification of the sample
The population is stratified for each gender in 9 birth cohorts defined in Table 3. The reference periods by birth cohort were chosen in order to observe sufficient transitions in and out of private sector employment for both treatment and control groups, determined so as to evaluate the 2002 reform mentioned in the main text on the basis of a difference-in-differences strategy (Albanese and Cockx 2018). Each of these 18 strata is subsequently endogenously stratified in five substrata:
- 1.
The population exiting salaried employment in the private sector within the reference period;
- 2.
The population entering salaried employment in the private sector within the reference period and not contained in substratum 1;
- 3.
The population employed throughout the reference period as salaried workers in the private sector and earning a gross wage lower than €100 per day at the start of this period;
- 4.
The population employed throughout the reference period as salaried workers in the private sector and earning at least €100 per day at the start of this period;
- 5.
The population that was not employed as salaried workers in the private sector during the reference period, i.e. individuals who were out of the labour force, unemployed, self-employed or working in the public sector.
In each of the 18 strata, a random sample of 2000 individuals is drawn from this substratum, while the sample size was 1500 for substratum 4 and 5.Footnote 26 The size of the population is known for each substratum, so that it was straightforward to construct the appropriate weights to make inferences regarding the population.
Appendix 2: Sample selection mechanism
In order to enhance the comparability of treated and control groups, we impose that members of both groups should satisfy criteria slightly stricter than those that determine eligibility to TC (cf. Sect. 3):
- 1.
Being employed in a firm with at least 20 employees at the end of 2002 (2003);
- 2.
Have at least 5 years of tenure in the same firm at the end of 2002 (2003);
- 3.
Have at least 20 years of private sector labour market experience at the end of 2002 (2003);
- 4.
Being full-time employed in all four quarters of 2002 (2003);
- 5.
Being employed in the private sector in t = 0, i.e. at the end of 2003Q3 (2004Q3);
- 6.
Not being on sick leave at the end of 2003Q3 (2004Q3).
Table 4 shows the sample size evolution and represented population after imposing these selection criteria. The fifth selection criterion is imposed at the end of each assignment period into treatment, because it is automatically satisfied for the members of the treatment groups, so that it is natural to impose it on the members of the control groups as well. The other criteria are slightly more restrictive than the TC eligibility conditions, so that a few treated individuals are eliminated from our initial selection. We are slightly more restrictive for the following reasons:
- 1.
Eligibility conditions 1–4 are uniformly imposed at the end of the year preceding the contractual start of the TC so that the same conditions apply to all treated and control units;
- 2.
Because the data contain only basic information about firm characteristics, we aim at restricting the analysis to sufficiently large firms in which the use of TC does not require the consent of the employer (cf. Sect. 3 of the paper). If no consent is required, it is less likely that the use of TC is selective in firm characteristics, which therefore enhances the internal validity of the evaluation. However, according to the rules, no consent is required in firms with more than 10 employees. Nevertheless, we include only firms that employ at least 20 workers. This is because the available data on firm size are grouped in intervals that do not allow identifying firms with strictly more than 10 employees;
- 3.
While regulations do not impose that the labour market experience should be accumulated in the private sector, we do because we do not have information on early experience outside the private sector;
- 4.
We impose full-time employment in the last year prior to contractual assignment into treatment, while for the 50% TC regime the requirement is only to have worked at least 75% of a full-time job. This is done to consider only individuals who are eligible to both regimes;
- 5.
Finally, we impose the last condition on sickness in 2003Q3 (2004Q3) because we want to contrast the impact of the benchmark outcome, i.e. survival in employment, to a more restrictive variant that considers survival in employment without being on sick leave. If we would not impose this, some of the selected individuals would not be in the risk set of this second outcome at the start of the evaluation period. Imposing this condition only very marginally affects the sample selection. Finally, note that we do not impose the age condition, because our sample only contains individuals older than 50.
Appendix 3: Empirical strategy
3.1 Notation
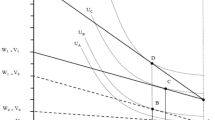
Let \( t \in \left\{ {1,2, \ldots \bar{T}} \right\} \) denote the number of years since sample selection and \( l \in \left\{ { 1, 2, \ldots ,\bar{L}} \right\} \) the elapsed number of years in employment at this start. \( \bar{T} \) and \( \bar{L} \) are the maximum number of years in employment, respectively, after and before selection. In the data, \( l \ge 5 \), because this is an eligibility condition for the TC and a sample selection criterion (Table 1). The random time since sample selection until the start of the treatment, i.e. entry in TC, is denoted by \( S \) and its realization by \( s \), where \( s \in \left\{ {0,1, \ldots ,\bar{S}} \right\} \) and \( \bar{S} \le \bar{T} \). \( Y_{l + t} \left( s \right) \) is equal to one in case employment is left in year \( l + t \) and treatment started in year \( l + s \), and zero otherwise. \( Y_{l + t} \left( \infty \right) \) denotes the potential outcome in year \( l + t \) if never treated and \( Y_{l + t} \) the observed outcome. \( \bar{Y}_{l + t} \left( s \right) \equiv \left\{ {Y_{1} \left( s \right),Y_{2} \left( s \right), \ldots , Y_{l + t} \left( s \right)} \right\} \) and \( \bar{Y}_{l + t} \equiv \left\{ {Y_{1} , Y_{2} , \ldots , Y_{l + t} } \right\} \) denote, respectively, the sequence of potential and of observed outcomes. Figure 5 provides a graphical representation of the introduced notation.

Graphical representation of the notation
We aim at identifying the average treatment effect on the treated (ATT) of treatment starting \( s \) years after sample selection against the counterfactual of never being treated on the residual survival in employment until year \( t > s \), given survival in employment until sample selection:
This extends the ATT as a parameter of interest to the evaluation of a stock sample. Since in a stock sample individuals may have a different elapsed duration, the conditional expectation is taken across these elapsed durations, conditional on being employed for at least 5 years to take into account that one needs at least 5 years of tenure to be eligible for TC. Observe that \( E[\bar{Y}_{L + t} \left( . \right) = 0|S = .,\bar{Y}_{L + s} \left( . \right) = 0] = \Pr [T > L + t|S = .,T > L + s] \) holds, i.e. the conditional probability of surviving \( L + t \) years in employment given survival until \( L + s \). In case \( L = 0 \), Eq. (1) reduces to the corresponding expression in Vikström (2017) for a flow sample.
3.2 Identification
In order to identify \( {\text{ATT}}_{t} (s) , \) we use two identifying assumptions: CIA and no anticipation (NAA). These assumptions can be formalized as follows:
and
The latter condition means that individuals do not alter their behaviour in response to a future assignment to the treatment. Based on these assumptions (Fredriksson and Johansson 2008; Crépon et al. 2009; Vikström 2017) prove that for l = 0 \( {\text{ATT}}_{t} \left( s \right) \) can be identified by successively using the not yet treated at \( l + t \) to estimate the exit rate under no treatment at \( l + t \) for those treated at \( l + s \). Vikström (2017) generalizes by explicitly allowing for selectivity on time-varying observables in subsequent assignments into treatment. We follow his approach. Because the identification proof is not affected for different values of \( l \), we refer the reader to Vikström (2017).
3.3 Estimation and inference
Vikström derives the Inverse Probability Weighting (IPW) estimator, introduced by Horvitz & Thompson (1952) and Hirano et al. (2003), to estimate the \( {\text{ATT}}_{t} \left( s \right) \) defined in (1). We follow this approach for the following reasons: (1) Busso et al. (2014) find in their Monte Carlo simulation that the normalized IPW estimator is one of the best performing matching estimators in the presence of good overlap. Other Monte Carlo simulations of Huber et al. (2013) and Frölich et al. (2017) confirm the good performance of the IPW estimator, although it does not outperform other propensity score-based and nonparametric estimators; (2) it is easy to integrate the endogenous sampling weights. This merely requires to include an additional weight in the estimation; (3) compared to other matching estimators, the IPW estimator is simple and computationally fast.
We provide the most general estimator that does not only allow to take into account selective (on observables) right censoring as a consequence of individuals not yet treated getting treated (Vikström 2017), but also more general forms of selective right censoring that may involve both treated individuals and those not yet treated. For instance, we consider a competing risk framework, with estimations of the treatment effect on different exit destinations when terminating employment. We distinguish between exits to bridge pensions, statutory early retirement and “other” exit routes.
To write down the estimator, we denote the random censoring duration since sample selection for individual \( i \) by \( C_{i} \). Generalizing Vikström’s formula (see his Appendix A.2) for the endogenous sampling weights \( W_{cr,i} \) and taking the elapsed employment duration \( l_{i} \) into account, we obtain:
where
where \( X_{i} \) denotes the vector of predetermined explanatory variables, \( W_{l,k\left( s \right),i}^{C} \left( s \right) \) and \( W_{l,k\left( \infty \right),i}^{C} \left( s \right) \) are the IPW weights in year \( l_{i} + k \) for individual \( i \) treated in year \( l_{i} + s \) and not yet treated in year \( l_{i} + k \), respectively. \( p_{t} \left( {X_{i} ,l_{i} } \right) \) and \( c_{t} \left( {X_{i} ,l_{i} } \right) \) denote the conditional probability of entering the treatment, respectively, censoring state after \( l_{i} + t \) years conditional on still being employed in \( l_{i} + t - 1 \). In other words, they represent the discrete hazard of entering treatment, respectively, censoring in year \( l_{i} + t \).
To clarify the intuition of the estimator defined in Eq. (4), consider first the case without right censoring, i.e. \( C_{i} = \infty \), \( W_{l,k\left( s \right),i}^{C} \left( s \right) = 1 \) and \( W_{l,k\left( \infty \right),i}^{C} \left( s \right) = \frac{{p_{s} \left( {X_{i} ,l_{i} } \right)}}{{1 - p_{s} \left( {X_{i} ,l_{i} } \right)}}\frac{1}{{\mathop \prod \nolimits_{m = s + 1}^{k} \left[ {1 - p_{m} \left( {X_{i} ,l_{i} } \right)} \right]}} \). Apart from the weights, the first sequence of products in (4) is the standard Kaplan–Meier survivor estimator for the treated group. This represents the conditional survival rate in employment until year \( l_{i} + t \), conditional on treatment and survival in employment until year \( l_{i} + s \), i.e. the product of one minus the discrete hazards from employment between \( l_{i} + s + 1 \) and \( l_{i} + t \). The second sequence of products is a similar Kaplan–Meier estimator for the control group (or individuals not yet treated), which estimates the survival rate of the treated in the counterfactual of no treatment. In order to make these control units comparable to the treated, they are reweighted using the standard IPW weights \( \frac{{p_{s} \left( {X_{i} ,l_{i} } \right)}}{{1 - p_{s} \left( {X_{i} ,l_{i} } \right)}} \) in a static evaluation approach, where \( p_{s} \left( {X_{i} ,l_{i} } \right) \) is the estimated propensity score (PS) for an individual treated in year \( l_{i} + s \). However, to take into account that individuals who are not yet treated will gradually be treated, we must consider that this may change the composition of the control group over time. Hence, Vikström (2017) shows that we must in addition weight the control units by \( \frac{1}{{\mathop \prod \nolimits_{m = s + 1}^{k} \left[ {1 - p_{m} \left( {X_{i} ,l_{i} } \right)} \right]}} \), i.e. by the inverse of the probability of not yet being treated in each period between \( l_{i} + s + 1 \) and \( l_{i} + t \).
If individuals are right censored before exiting to the destination of interest and this is selective (i.e. depends on \( X \)), then this may similarly gradually change the composition of, not only the control group, but also of the treatment group over time. We therefore need to weight both treated and control samples by \( \frac{1}{{\mathop \prod \nolimits_{m = s + 1}^{k} \left[ {1 - c_{m} \left( {X_{i} ,l_{i} } \right)} \right]}} \), i.e. the probability of not yet being right censored in each period between \( l_{i} + s + 1 \) and \( l_{i} + t \).
In contrast to Vikström (2017), the discrete hazards to treatment and censoring depend on the elapsed employment duration \( l_{i} \) at sample selection. Observe that we can only proxy for this elapsed employment duration, because prior to 1998 we only have annual (instead of quarterly) information on private sector employment and no information on self-employment, nor on employment in the public sector. Given that we selected individuals with at least 5 years of tenure and 20 years of experience in the private sector, we believe that the bias induced by using this proxy is negligible.
We estimate separate ATTs for individuals entering treatment in 2003 and 2004. Subsequently, like Vikström, we pool these analyses to have more precise estimates. This is done by averaging the estimated ATTs in each survival year, using the endogenous sampling weights to take into account the size of the two different treated groups in the population.
where \( n_{s} \equiv \mathop \sum \nolimits_{i} W_{cr,i} *1\left( {S_{i} = s} \right) \).
As a lack of overlap of the PS can bias the estimator and increase the variance (Lechner and Strittmatter 2017), we trim treated units who, due to their very high PS, do not have a correspondent control unit. In particular, we remove treated units with a PS above the 99.9 percentile of the control units. After trimming, we are left with about 99% of the treated units, counting 1212 and 755 men and women. Huber et al. (2013) propose to remove the control units with a weight higher than 4% of the total. However, because the sample of control units is large, this additional trimming is not required. In the four analyses (2003 and 2004, men and women), the highest relative weight is only 0.17% of the total sample.
To take into account that the PS in the weights \( W_{l,k\left( . \right),i}^{C} \left( s \right) \) is estimated, we bootstrap the standard errors. As our data come from an endogenously stratified sample, we augment the standard bootstrap method and implement a stratified bootstrap by randomly drawing for each replication \( n_{cr} \) individuals within each cohort–stratum \( cr \). This is valid because the bootstrap randomly samples individuals within each cohort–stratum (for a review on bootstrap and stratified data see, for example, Shao 2003). To take individual serial correlation into account, we resample the same individuals (i.e. clusters) in the two analyses (2003 and 2004 sample) within each replication.
In general, once conditioned on the eligibility conditions, the selectivity into treatment on the observables is low for 2003. The pseudo-R-squared of a standard logit model is 0.068 and 0.026 for men and women. The selectivity is slightly higher in 2004. The corresponding pseudo-R-squared is 0.127 and 0.084. This indicates that, once the eligibility conditions are imposed, the sample becomes relatively homogenous. The IPW estimator performs well in balancing the distribution of the covariates. In our worst scenario (women selected in 2004), after reweighting the control units by \( W_{l,1\left( \infty \right),i}^{C} \left( s \right) \), the median Standardized Bias (SB) is as low as 1.2%, the highest SB is 2.9%, the pseudo-R-squared of the reweighted sample is 0 and the Wald test for the joint significance of the variables after the reweighting has a p-value of 1.
Appendix 4: Supplementary tables and figures

Survival rate in employment (benchmark) and competing risks—men (a) and women (b). Survival function of the treated and control units controlling for the dynamic selection on observables (Vikström 2017) by gender (a men and b women). The survival rates are expressed in percentage points (pp) and defined as (from left to right and top to bottom) (1) employment, (2) employment without exit to a bridge pension, (3) employment without exit to a statutory pension before the normal retirement age and (4) employment without exit to other non-employment statuses. In the competing risk analyses (2–4), the exits from employment to other destinations, apart from the one considered, are right censored. Reported estimates are pooled over the 2003 and 2004 samples. Year eight only uses information from the 2003 sample. The pooled sample is composed of 1227 (762) treated and 29,791 (9658) control units (men and women)


ATT of treated men and women in 50% (a, b) or 20% (c, d) TC scheme—competing risk (CR) and baseline (non-CR) framework. ATT of treated in the 50% TC (a, b) or 20% TC (c, d) on the survival rate controlling for the dynamic selection on observables (Vikström 2017). The ATTs are differentiated by gender: a men and b women. The estimates are expressed in percentage points (pp) differences in the survival rate in (from left to right and top to bottom) (1) employment, (2) employment without exit to a bridge pension, (3) employment without exit to a statutory pension before the normal retirement age and (4) employment without exit to other non-employment statuses. In the competing risk analyses (2–4), the exits from employment to other destinations, apart from the one considered, are right censored. Reported estimates are pooled over the 2003 and 2004 samples. Year eight only uses information from the 2003 sample. The pooled sample is composed of 567 (375) treated and 29,791 (9658) control units (men and women). Standard errors are obtained by a stratified bootstrap (clustering by individual) with 500 repetitions and 95% confidence intervals (CI) by assuming normality

ATT on survival in employment—heterogeneous effects by age. ATT on the survival rate in employment estimated by controlling for the dynamic selection on observables (Vikström 2017). Heterogeneous effects by age in year 0: younger (below the age of 56.5) and older workers (at least 56.5 years old). The estimates of the ATT’s are the percentage points (pp) differences between the survival rate of the treated in case of treatment and the estimated survival rate of the treated in the counterfactual of no treatment. Estimates are pooled over the 2003 and 2004 samples. Year eight only uses information from the 2003 sample. Standard errors are obtained by a stratified bootstrap (clustering by individual) with 500 repetitions and 95% confidence intervals (CI) by assuming normality

Validation test: working days and employment pre-treatment (no IPW weights). Validation test without using IPW weights: ATT on the yearly working days (panel above) and yearly employment (panel below—defined as working at least 260 days over the year) before the treatment (t = − 15, … t = − 6). Population: Men (left), women (right). Estimates are pooled over the 2003 and 2004 samples. Standard errors are clustered by individual and 95% confidence intervals (CI)

Validation test: working days and employment pre-treatment (IPW weights). Validation test using IPW weights: ATT on the yearly working days (panel above) and yearly employment (panel below—defined as working at least 260 days over the year) before the treatment (t = − 15, … t = − 6). Population: men (left), women (right). Estimates are pooled over the 2003 and 2004 samples. Standard errors are clustered by individual and 95% confidence intervals (CI). Standard errors are obtained by a stratified bootstrap (clustering by individual) with 500 repetitions and 95% confidence intervals (CI) by assuming normality
Rights and permissions
About this article

Cite this article
Albanese, A., Cockx, B. & Thuy, Y. Working time reductions at the end of the career: Do they prolong the time spent in employment?. Empir Econ 59, 99–141 (2020). https://doi.org/10.1007/s00181-019-01676-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-019-01676-7
Keywords
- Part-time work
- Older workers
- Inverse probability weighting
- Dynamic selection into treatment
- Endogenous sampling