
Abstract
The Bank of England Inflation Attitudes Survey asks individuals about their inflation perceptions and expectations in eight intervals including an indifference limen. This paper studies fitting a mixture normal distribution to such interval data, allowing for multiple modes. Bayesian analysis is useful since ML estimation may fail. A hierarchical prior helps to obtain a weakly informative prior. The No-U-Turn Sampler speeds up posterior simulation. Permutation invariant parameters are free from the label switching problem. The paper estimates the distributions of public inflation perceptions and expectations in the UK during 2001Q1–2017Q4. The estimated means are useful for measuring information rigidity.











Similar content being viewed by others

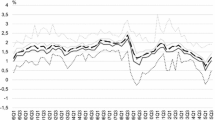
Notes
Interval data lose some quantitative information, however. If the first or last interval has an open end, then one cannot draw a histogram nor compute its mean. Moreover, one cannot find the median if it lies in the first or last interval with an open end. To solve the problem, one can assume the minimum or maximum of the population distribution, or fit a parametric distribution to the frequency distribution.
If intervals represent durations, then we apply survival analysis.
Since May 2011, the survey asks further questions with more intervals to those who have chosen either category 1 or 8.
Nonparametric kernel density estimation for numerical data does not apply directly to interval data.
Since these panels are not histograms but bar charts, the multiple modes may be spurious. Without knowing the width of the indifference limen, one cannot draw a histogram.
If such estimates seem unreasonable, then one can impose a subjective prior on the lower bound of the indifference limen, which will change the results further.
Fitting a mixture of four normal distributions gives similar results, though error bands are wider.
One may think that numerical data are easier to analyze than interval data. This is not the case if one considers the rounding problem seriously, since some respondents round to integers but others round to multiples of 5 or 10; see Manski and Molinari (2010). To account for such rounding in numerical data on inflation expectations from the Opinion Survey on the General Public’s Views and Behavior conducted by the Bank of Japan, Kamada et al. (2015) introduce point masses at multiples of 5. Binder (2017) interprets heterogeneous rounding as a measure of uncertainty. The rounding problem is irrelevant to our interval data.
A generalized Gibbs sampler by Liu and Sabatti (2000) does not work well in our context.
With covariates, our model extends an ordered probit model by allowing for some known cutpoints and a mixture normal distribution. Lahiri and Zhao (2015) use a hierarchical ordered probit (HOPIT) model, which reduces to an ordered probit model if no covariate is available.
The result seems robust to other priors on \(\beta _0\); e.g., a half-Cauchy prior with a large-scale parameter.
There were five trial surveys quarterly from November 1999 to November 2000.
We set an extremely high target rate to eliminate divergent transitions as much as possible in all 136 quarters. In practice, it can be much lower in most quarters, and the results are almost identical as long as there is no divergent transition.
This increases the maximum number of leapfrog steps from \(2^{11}-1=2047\) to \(2^{13}-1=8191\).
Normal mixture models with \(K \ge 3\) are not identifiable from our data.
The nor1mix package for R is useful for calculating quantiles of a mixture normal distribution.
A noisy information model gives the same regression model if \(\{y_t\}\) is AR(1); see Coibion and Gorodnichenko (2015, sec. I.B).
The full sample periods are 1987Q4–2017Q4 for the change in the log oil price and 1971Q2–2017Q4 for the change in the log exchange rate.
Coibion and Gorodnichenko (2015, pp. 2664–2665) obtain similar results using data on forecasts of various macroeconomic variables from the Survey of Professional Forecasters.
For US consumers, Coibion and Gorodnichenko (2015, p. 2662) report that \(\beta =.705\) for inflation expectations relative to the CPI, which implies \(\lambda \approx .413\). Thus, information rigidities in inflation expectations among individuals in the UK and USA seem not too different, though the two results may not be directly comparable.
Since the leapfrog method preserves volume, its Jacobian of transformation is 1; see Neal (2011, pp. 117–122). To justify the Metropolis step, the proposal should be \((\varvec{\theta }',-\varvec{z}')\) rather than \((\varvec{\theta }',\varvec{z}')\), but this is unnecessary in practice since \(H(\varvec{\theta }',\varvec{z}')=H(\varvec{\theta }',-\varvec{z}')\) and we discard \(\varvec{z}'\) anyway; see Neal (2011, p. 124). Since the Hamiltonian is approximately constant during the leapfrog method, the acceptance probability is close to 1 if \(\epsilon \) is small.
References
Albert JH, Chib S (1993) Bayesian analysis of binary and polychotomous response data. J Am Stat Assoc 88:669–679. https://doi.org/10.2307/2290350
Alston CL, Mengersen KL (2010) Allowing for the effect of data binning in a Bayesian normal mixture model. Comput Stat Data Anal 54:916–923. https://doi.org/10.1016/j.csda.2009.10.003
Armantier O, Bruine de Bruin W, Potter S, Topa G, van der Klaauw W, Zafar B (2013) Measuring inflation expectations. Ann Rev Econ 5:273–301. https://doi.org/10.1146/annurev-economics-081512-141510
Betancourt M, Girolami M (2015) Hamiltonian Monte Carlo for hierarchical models. In: Upadhyay SK, Singh U, Dey DK, Loganathan A (eds) Current trends in Bayesian methodology with applications, chap 4. CRC Press, Boca Raton, pp 79–102
Biernacki C (2007) Degeneracy in the maximum likelihood estimation of univariate Gaussian mixtures for grouped data and behavior of the EM algorithm. Scand J Stat 34:569–586. https://doi.org/10.1111/j.1467-9469.2006.00553.x
Binder CC (2017) Measuring uncertainty based on rounding: new method and application to inflation expectations. J Monet Econ 90:1–12. https://doi.org/10.1016/j.jmoneco.2017.06.001
Blanchflower DG, MacCoille C (2009) The formation of inflation expectations: an empirical analysis for the UK. Working Paper 15388, National Bureau of Economic Research. https://doi.org/10.3386/w15388
Chen MH, Dey DK (2000) Bayesian analysis for correlated ordinal data models. In: Dey DK, Ghosh SK, Mallick BK (eds) Generalized linear models: a Bayesian perspective, chap 8. Marcel Dekker, New York, pp 133–157
Chib S, Greenberg E (1995) Understanding the Metropolis–Hastings algorithm. Amn Stat 4:327–335. https://doi.org/10.1080/00031305.1995.10476177
Coibion O, Gorodnichenko Y (2015) Information rigidity and the expectations formation process: a simple framework and new facts. Am Econ Rev 105:2644–2678. https://doi.org/10.1257/aer.20110306
Cowles MK (1996) Accelerating Monte Carlo Markov chain convergence for cumulative-link generalized linear models. Stat Comput 6:101–111. https://doi.org/10.1007/BF00162520
Frühwirth-Schnatter S (2004) Estimating marginal likelihoods for mixture and Markov switching models using bridge sampling techniques. Econom J 7:143–167. https://doi.org/10.1111/j.1368-423x.2004.00125.x
Frühwirth-Schnatter S (2006) Finite mixture and Markov switching models. Springer, New York
Gelman A, Carlin JB, Stern HS, Dunson DB, Vehtari A, Rubin DB (2014) Bayesian data analysis, 3rd edn. CRC Press, Boca Raton
Geweke J (2007) Interpretation and inference in mixture models: simple MCMC works. Comput Stat Data Anal 51:3529–3550. https://doi.org/10.1016/j.csda.2006.11.026
Gronau QF, Sarafoglou A, Matzke D, Ly A, Boehm U, Marsman M, Leslie DS, Forster JJ, Wagenmakers EJ, Steingroever H (2017) A tutorial on bridge sampling. J Math Psychol 81:80–97. https://doi.org/10.1016/j.jmp.2017.09.005
Hall AR (2005) Generalized method of moments. Oxford University Press, Oxford
Hoffman MD, Gelman A (2014) The No-U-Turn Sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. J Mach Learn Res 15:1593–1623
Jeffreys H (1961) Theory of probability, 3rd edn. Clarendon Press, Oxford
Kamada K, Nakajima J, Nishiguchi S (2015) Are household inflation expectations anchored in Japan? Working paper 15-E-8, Bank of Japan
Kiefer J, Wolfowitz J (1956) Consistency of the maximum likelihood estimator in the presence of infinitely many incidental parameters. Ann Math Stat 27:887–906. https://doi.org/10.1214/aoms/1177728066
Lahiri K, Zhao Y (2015) Quantifying survey expectations: a critical review and generalization of the Carlson–Parkin method. Int J Forecast 31:51–62. https://doi.org/10.1016/j.ijforecast.2014.06.003
Liu JS, Sabatti C (2000) Generalized Gibbs sampler and multigrid Monte Carlo for Bayesian computation. Biometrika 87:353–369. https://doi.org/10.1093/biomet/87.2.353
Lombardelli C, Saleheen J (2003) Public expectations of UK inflation. Bank Engl Q Bull 43:281–290
Mankiw NG, Reis R (2002) Sticky information versus sticky prices: a proposal to replace the new Keynesian Phillips curve. Q J Econ 117:1295–1328. https://doi.org/10.1162/003355302320935034
Mankiw NG, Reis R, Wolfers J (2004) Disagreement about inflation expectations. In: Gertler M, Rogoff K (eds) NBER macroeconomics annual 2003, vol 18. MIT Press, Cambridge, pp 209–248
Manski CF (2004) Measuring expectations. Econometrica 72:1329–1376. https://doi.org/10.1111/j.1468-0262.2004.00537.x
Manski CF, Molinari F (2010) Rounding probabilistic expectations in surveys. J Bus Econ Stat 28:219–231. https://doi.org/10.1198/jbes.2009.08098
Meng XL, Schilling S (2002) Warp bridge sampling. J Comput Graph Stat 11:552–586. https://doi.org/10.1198/106186002457
Murasawa Y (2013) Measuring inflation expectations using interval-coded data. Oxf Bull Econ Stat 75:602–623. https://doi.org/10.1111/j.1468-0084.2012.00704.x
Nandram B, Chen MH (1996) Reparameterizing the generalized linear model to accelerate Gibbs sampler convergence. J Stat Comput Simul 54:129–144. https://doi.org/10.1080/00949659608811724
Nardo M (2003) The quantification of qualitative survey data: a critical assessment. J Econ Surv 17:645–668. https://doi.org/10.1046/j.1467-6419.2003.00208.x
Neal RM (2011) MCMC using Hamiltonian dynamics. In: Brooks S, Gelman A, Jones GL, Meng XL (eds) Handbook of Marcov Chain Monte Carlo, handbooks of modern statistical methods, chap 5. Chapman & Hall/CRC, Boca Raton, pp 113–162
Papaspiliopoulos O, Roberts GO, Sköld M (2003) Non-centered parameterisations for hierarchical models and data augmentation. In: Bernardo JM, Bayarri MJ, Berger JO, Dawid AP, Heckerman D, Smith AFM, West M (eds) Bayesian statistics, vol 7. Oxford University Press, Oxford, pp 307–326
Papaspiliopoulos O, Roberts GO, Sköld M (2007) A general framework for the parametrization of hierarchical models. Stat Sci 22:59–73. https://doi.org/10.1214/088342307000000014
Pesaran MH, Weale M (2006) Survey expectations. In: Elliot G, Granger CWJ, Timmermann A (eds) Handbook of economic forecasting, chap 14, vol 1. Elsevier, Amsterdam, pp 715–776. https://doi.org/10.1016/S1574-0706(05)01014-1
R Core Team (2018) R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/. Accessed 19 June 2018
Richardson S, Green PJ (1997) On Bayesian analysis of mixtures with an unknown number of components (with discussion). J R Stat Soc Ser B (Stat Methodol) 59:731–792. https://doi.org/10.1111/1467-9868.00095
Sinclair P (ed) (2010) Inflation expectations. Routledge, London
Stan Development Team (2018) RStan: the R interface to Stan. http://mc-stan.org/, R package version 2.17.3. Accessed 19 June 2018
Terai A (2010) Estimating the distribution of inflation expectations. Econ Bull 30:315–329
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
I thank three referees and Naohito Abe for useful comments. This work was supported by JSPS KAKENHI Grant Number JP16K03605.
Appendix: HMC methods and the NUTS
Appendix: HMC methods and the NUTS
Understanding an HMC method requires some knowledge of physics. The Boltzmann (Gibbs, canonical) distribution describes the distribution of possible states in a system. Given an energy function E(.) and the absolute temperature T, the pdf of a Boltzmann distribution is \(\forall x\),
where k is the Boltzmann constant. One can think of any pdf f(.) as the pdf of a Boltzmann distribution with \(E(x):=-\ln f(x)\) and \(kT=1\).
The Hamiltonian is an energy function that sums the potential and kinetic energies of a state. An HMC method treats \(-\ln p(\varvec{\theta }|\varvec{y})\) as the potential energy at position \(\varvec{\theta }\) and introduces an auxiliary momentum \(\varvec{z}\) drawn randomly from \({\mathrm {N}}(\varvec{0},\varvec{\varSigma })\), whose kinetic energy is \(-\ln p(\varvec{z}) \propto \varvec{z}'\varvec{\varSigma }^{-1}\varvec{z}/2\) with mass matrix \(\varvec{\varSigma }\). The resulting Hamiltonian is
An HMC method draws from \(p(\varvec{\theta },\varvec{z}|\varvec{y})\), which is a Boltzmann distribution with energy function \(H(\varvec{\theta },\varvec{z})\).
The Hamiltonian is constant over (fictitious) time t by the law of conservation of mechanical energy, i.e., \(\forall t \in \mathbb {R}\),
or
Thus, Hamilton’s equation of motion is \(\forall t \in \mathbb {R}\),
The Hamiltonian dynamics says that \((\varvec{\theta },\varvec{z})\) moves on a contour of \(H(\varvec{\theta },\varvec{z})\), i.e., \(p(\varvec{\theta },\varvec{z}|\varvec{y})\).
Conceptually, given \(\varvec{\varSigma }\) and an initial value for \(\varvec{\theta }\), an HMC method proceeds as follows:
- 1.
Draw \(\varvec{z}\sim {\mathrm {N}}(\varvec{0},\varvec{\varSigma })\) independently from \(\varvec{\theta }\).
- 2.
Start from \((\varvec{\theta },\varvec{z})\) and apply Hamilton’s equations of motion for a certain length of (fictitious) time to obtain \((\varvec{\theta }',\varvec{z}')\), whose joint probability density equals that of \((\varvec{\theta },\varvec{z})\).
- 3.
Discard \(\varvec{z}\) and \(\varvec{z}'\), and repeat.
This gives a reversible Markov chain on \((\varvec{\theta },\varvec{z})\), since the Hamiltonian dynamics is reversible; see Neal (2011, p. 116). The degree of serial dependence or speed of convergence depends on the choice of \(\varvec{\varSigma }\) and the length of (fictitious) time in the second step. The latter can be fixed or random, but cannot be adaptive if it breaks reversibility.
In practice, an HMC method approximates Hamilton’s equations of motion in discrete steps using the leapfrog method. This requires choosing a step size \(\varepsilon \) and the number of steps L. Because of approximation, the Hamiltonian is no longer constant during the leapfrog method, but adding a Metropolis step after the leapfrog method keeps reversibility. Thus, given \(\varvec{\varSigma }\) and an initial value for \(\varvec{\theta }\), an HMC method proceeds as follows:
- 1.
Draw \(\varvec{z}\sim {\mathrm {N}}(\varvec{0},\varvec{\varSigma })\) independently from \(\varvec{\theta }\).
- 2.
Start from \((\varvec{\theta },\varvec{z})\) and apply Hamilton’s equations of motion approximately by the leapfrog method to obtain \((\varvec{\theta }',\varvec{z}')\).
- 3.
Accept \((\varvec{\theta }',\varvec{z}')\) with probability \(\min \{\exp (-H(\varvec{\theta }',\varvec{z}'))/\exp (-H(\varvec{\theta },\varvec{z})),1\}\).Footnote 22
- 4.
Discard \(\varvec{z}\) and \(\varvec{z}'\), and repeat.
The degree of serial dependence or speed of convergence depends on the choice of \(\varvec{\varSigma }\), \(\varepsilon \), and L. Moreover, the computational cost of each iteration depends on the choice of \(\varepsilon \) and L.
The NUTS developed by Hoffman and Gelman (2014) adaptively chooses L while keeping reversibility. Though the algorithm of the NUTS is complicated, it is easy to use with Stan, a modeling language for Bayesian computation with the NUTS (and other methods). Stan tunes \(\varvec{\varSigma }\) and \(\varepsilon \) adaptively during warm-up. The user only specifies the data, model, and prior. One can call Stan from other popular languages and softwares such as R, Python, MATLAB, Julia, Stata, and Mathematica. The NUTS often has better convergence properties than other popular MCMC methods such as the Gibbs sampler and M–H algorithm.
Rights and permissions
About this article

Cite this article
Murasawa, Y. Measuring public inflation perceptions and expectations in the UK. Empir Econ 59, 315–344 (2020). https://doi.org/10.1007/s00181-019-01675-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00181-019-01675-8