
Abstract
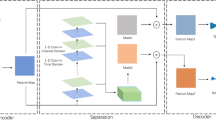
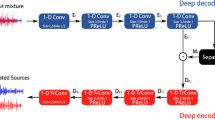
Resilient speech separation in multi-talker situations remains a challenge, particularly in real-time and low latency applications. Modern speech separation systems strive to separate loud, reverberant voice mixes, especially for hearing-impaired individuals. Several single channel and speaker-independent speech separation algorithms have recently been developed using deep learning. To overcome the limitation of a lengthy time window to attain appropriate frequency resolution, and long latency in processing the spectrograms, this paper addresses single-channel speech separation to extract and improve desired speech quality from mixed audio using state-of-the-art deep neural networks which is convolutional- time-domain audio separation network (Conv-TasNet). A novel monaural speech separation model by modifying an encoder-decoder pair of Conv-TasNet using wavelet transform (WT-Conv-TasNet) is presented here, which can be applied to hearing aids. From the perspective of isolating two and three speakers’ combinations using the LibriSpeech dataset, the proposed WT-Conv-TasNet system surpasses earlier time–frequency masking systems. Additionally, it has been shown that the proposed model lowers the computing cost of speech separation, and minimizes the output's minimum delay, as it is smaller in size. Therefore, it is well suited to real-time implementation requiring low power, low computing cost of speech separation, and minimum output delay, for example, hearing devices, telecommunication systems automatic speech recognition, and acoustic-based control.











Similar content being viewed by others

Data availability
The data is available in.wav format on https://www.openslr.org/12 and freely available for experimental research purposes.
References
Agarwal, D., & Bansal, A. (2020). Non-adaptive and adaptive filtering techniques for fingerprint pores extraction. In Advances in data and information sciences (pp. 643–654). Springer.
Agrawal, J., Gupta, M., & Garg, H. (2023). A review on speech separation in cocktail party environment: Challenges and approaches. Multimedia Tools and Applications, 82(20), 1–33.
Akansu, A. N., & Haddad, R. A. (2001). Wavelet transform. In Multiresolution signal decomposition (2nd ed., pp. 391–442). Academic Press.
Alzubaidi, L., Bai, J., Al-Sabaawi, A., Santamaría, J., Albahri, A. S., Al-dabbagh, B. S. N., Fadhel, M. A., Manoufali, M., Zhang, J., Al-Timemy, A. H., Duan, Y., Abdullah, A., Farhan, L., Lu, Y., Gupta, A., Albu, F., Abbosh, A., & Gu, Y. (2023). A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. Journal of Big Data, 10(1), 46.
Borgström, B. J., Brandstein, M. S., Ciccarelli, G. A., Quatieri, T. F., & Smalt, C. J. (2021). Speaker separation in realistic noise environments with applications to a cognitively-controlled hearing aid. Neural Networks, 140, 136–147.
Chen, Z., Luo, Y., & Mesgarani, N. (2017, March). Deep attractor network for single-microphone speaker separation. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 246–250). IEEE.
Chiang, H. T., Wu, Y. C., Yu, C., Toda, T., Wang, H. M., Hu, Y. C., & Tsao, Y. (2021). Hasa-net: A non-intrusive hearing-aid speech assessment network. In 2021 IEEE automatic speech recognition and understanding workshop (ASRU) (pp. 907–913). IEEE.
Deng, C., Zhang, Y., Ma, S., Sha, Y., Song, H., & Li, X. (2020). Conv-TasSAN: Separative adversarial network based on Conv-TasNet. In INTERSPEECH (pp. 2647–2651).
Desjardins, J. L., & Doherty, K. A. (2014). The effect of hearing aid noise reduction on listening effort in hearing-impaired adults. Ear and Hearing, 35(6), 600–610.
Esra, J. S., & Sukhi, Y. (2023). Speech separation methodology for hearing aid. Computer Systems Science and Engineering, 44(2), 1659–1678.
Fan, X., Yang, B., Chen, W., & Fan, Q. (2021). Deep neural network based noised Asian speech enhancement and its implementation on a hearing aid app. Transactions on Asian and Low-Resource Language Information Processing, 20(5), 1–14.
Fu, S. W., Tsao, Y., Hwang, H. T., & Wang, H. M. (2018). Quality-Net: An end-to-end non-intrusive speech quality assessment model based on BLSTM. arXiv preprint arXiv:1808.05344.
Green, T., Hilkhuysen, G., Huckvale, M., Rosen, S., Brookes, M., Moore, A., Naylor, P., Lightburn, L., & Xue, W. (2022). Speech recognition with a hearing-aid processing scheme combining beamforming with mask-informed speech enhancement. Trends in Hearing. https://doi.org/10.1177/23312165211068629
Han, C., O’Sullivan, J., Luo, Y., Herrero, J., Mehta, A. D., & Mesgarani, N. (2021). Automatic speech separation enables brain-controlled hearable technologies. In Brain–computer interface research (pp. 95–104). Springer.
Isik, Y., Roux, J. L., Chen, Z., Watanabe, S., & Hershey, J. R. (2016). Single-channel multi-speaker separation using deep clustering. arXiv preprint arXiv:1607.02173.
Joder, C., Weninger, F., Eyben, F., Virette, D., & Schuller, B. (2012). Real-time speech separation by semi-supervised nonnegative matrix factorization. In Latent variable analysis and signal separation: 10th international conference, LVA/ICA 2012, Tel Aviv, Israel, 12–15 March 2012. Proceedings 10 (pp. 322-329). Springer.
Kadıoğlu, B., Horgan, M., Liu, X., Pons, J., Darcy, D., & Kumar, V. (2020, May). An empirical study of Conv-TasNet. In ICASSP 2020–2020 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 7264–7268). IEEE.
Kolbæk, M., Yu, D., Tan, Z. H., & Jensen, J. (2017). Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(10), 1901–1913.
Li, H., Chen, K., Wang, L., Liu, J., Wan, B., & Zhou, B. (2022). Sound Source separation mechanisms of different deep networks explained from the perspective of auditory perception. Applied Sciences, 12(2), 832.
Luo, Y. (2021). End-to-end speech separation with neural networks. Columbia University.
Luo, Y., Han, C., &Mesgarani, N. (2021, June). Ultra-lightweight speech separation via group communication. In ICASSP 2021–2021 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 16–20). IEEE.
Luo, Y., & Mesgarani, N. (2018, April). Tasnet: Time-domain audio separation network for real-time, single-channel speech separation. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 696–700). IEEE.
Luo, Y., & Mesgarani, N. (2019). Conv-TasNet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(8), 1256–1266.
Munoz, A., Ertlé, R., & Unser, M. (2002). Continuous wavelet transform with arbitrary scales and O(N) complexity. Signal Processing, 82(5), 749–757.
Nakamura, T., & Saruwatari, H. (2020). Time-domain audio source separation based on Wave-U-Net combined with discrete wavelet transform. In ICASSP 2020–2020 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 386–390). IEEE.
Nwe, T. L., & Li, H. (2007). Exploring vibrato-motivated acoustic features for singer identification. IEEE Transactions on Audio, Speech, and Language Processing, 15(2), 519–530.
O’Grady, P. D., Pearlmutter, B. A., & Rickard, S. T. (2005). Survey of sparse and non‐sparse methods in source separation. International Journal of Imaging Systems and Technology, 15(1), 18–33.
Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015, April). LibriSpeech: An ASR corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP) (pp. 5206–5210). IEEE.
Pedersen, M. S. (2006). Source separation for hearing aid applications. IMM, Informatikog Matematisk Modelling, DTU.
Qian, Y. M., Weng, C., Chang, X. K., Wang, S., & Yu, D. (2018). Past review, current progress, and challenges ahead on the cocktail party problem. Frontiers of Information Technology & Electronic Engineering, 19, 40–63.
Sifuzzaman, M., Islam, M. R., & Ali, M. Z. (2009). Application of wavelet transform and its advantages compared to Fourier transform. Journal of Physical Sciences, 13, 121–134.
Singh, L. K., Garg, H., & Khanna, M. (2022). Performance evaluation of various deep learning based models for effective glaucoma evaluation using optical coherence tomography images. Multimedia Tools and Applications, 81(4), 1–45.
Subakan, Y. C., & Smaragdis, P. (2018). Generative adversarial source separation. In 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 26–30). IEEE.
Tang, C., Luo, C., Zhao, Z., Xie, W., & Zeng, W. (2021). Joint time-frequency and time domain learning for speech enhancement. In Proceedings of the twenty-ninth international conference on international joint conferences on artificial intelligence (pp. 3816–3822).
Wang, K., Huang, H., Hu, Y., Huang, Z., & Li, S. (2021). End-to-end speech separation using orthogonal representation in complex and real time-frequency domain. In Proceedings of Interspeech 2021 (pp. 3046–3050).
Wang, L., Zheng, W., Ma, X., & Lin, S. (2021). Denoising speech based on deep learning and wavelet decomposition. Scientific Programming. https://doi.org/10.1155/2021/8677043
Wei, S., Wang, F., & Jiang, D. (2019). Sparse component analysis based on an improved ant K-means clustering algorithm for underdetermined blind source separation. In 2019 IEEE 16th international conference on networking, sensing and control (ICNSC) (pp. 200–205). IEEE.
Williamson, D. S., Wang, Y., & Wang, D. (2015). Complex ratio masking for monaural speech separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(3), 483–492.
Wirsing, K. (2020). Time frequency analysis of wavelet and Fourier transform. In Wavelet theory. InTechOpen.
Yin, J., Liu, Z., Jin, Y., Peng, D., & Kang, J. (2017). Blind source separation and identification for speech signals. In 2017 International conference on sensing, diagnostics, prognostics, and control (SDPC) (pp. 398–402). IEEE.
Yuan, C. M., Sun, X. M., & Zhao, H. (2020). Speech separation using convolutional neural network and attention mechanism. Discrete Dynamics in Nature and Society, 2020(6), 1–10.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sector.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Agrawal, J., Gupta, M. & Garg, H. Monaural speech separation using WT-Conv-TasNet for hearing aids. Int J Speech Technol 26, 707–720 (2023). https://doi.org/10.1007/s10772-023-10045-w
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10772-023-10045-w