
Abstract
We propose a Jacobi-style distributed algorithm to solve convex, quadratically constrained quadratic programs (QCQPs), which arise from a broad range of applications. While small to medium-sized convex QCQPs can be solved efficiently by interior-point algorithms, high-dimension problems pose significant challenges to traditional algorithms that are mainly designed to be implemented on a single computing unit. The exploding volume of data (and hence, the problem size), however, may overwhelm any such units. In this paper, we propose a distributed algorithm for general, non-separable, high-dimension convex QCQPs, using a novel idea of predictor–corrector primal–dual update with an adaptive step size. The algorithm enables distributed storage of data as well as parallel, distributed computing. We establish the conditions for the proposed algorithm to converge to a global optimum, and implement our algorithm on a computer cluster with multiple nodes using message passing interface. The numerical experiments are conducted on data sets of various scales from different applications, and the results show that our algorithm exhibits favorable scalability for solving high-dimension problems.






Similar content being viewed by others
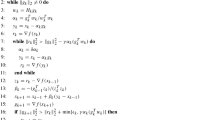


Notes
For more information, we refer the readers to our implementation codes programmed in C available online at https://github.com/BigRunTheory/A-Distributed-Algorithm-for-Large-scale-Convex-QCQPs.
Young’s inequality states that if a and b are two non-negative real numbers, and p and q are real numbers greater than 1 such that \(\frac{1}{p} + \frac{1}{q} = 1\), then \(ab < \frac{a^p}{p} + \frac{b^q}{q}\).
References
Aholt, C., Agarwal, S., Thomas, R.: A QCQP approach to triangulation. In: European Conference on Computer Vision. Springer, pp. 654–667 (2012)
Basu, K., Saha, A., Chatterjee, S.: Large-scale quadratically constrained quadratic program via low-discrepancy sequences. In: Advances in Neural Information Processing Systems, pp. 2297–2307 (2017)
Bose, S., Gayme, D.F., Chandy, K.M., Low, S.H.: Quadratically constrained quadratic programs on acyclic graphs with application to power flow. IEEE Trans. Control Netw. Syst. 2(3), 278–287 (2015)
Breiman, L., et al.: Arcing classifier. Ann. Stat. 26(3), 801–849 (1998)
Chatterjee, S., Saha, A., Basu, K.: Constrained multi-slot optimization for ranking recommendations (2018). US Patent App. 15/400738
Chen, G., Teboulle, M.: A proximal-based decomposition method for convex minimization problems. Math. Program. 64(1–3), 81–101 (1994)
Golub, G.H., Van Loan, C.F.: Matrix Computations. Johns Hopkins University Press, Baltimore (2013)
Hastie, T., Tibshirani, R., Friedman, J.: The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer, Berlin (2009)
Horn, R.A., Johnson, C.R.: Matrix Analysis. Cambridge University Press, Cambridge (2012)
Huang, K., Sidiropoulos, N.D.: Consensus-ADMM for general quadratically constrained quadratic programming. IEEE Trans. Signal Process. 64(20), 5297–5310 (2016)
Huang, Y., Palomar, D.P.: Randomized algorithms for optimal solutions of double-sided QCQP with applications in signal processing. IEEE Trans. Signal Process. 62(5), 1093–1108 (2014)
IBM ILOG CPLEX optimization studio CPLEX Parameters Reference, Version 12 Release 8 (1987–2017)
IBM ILOG CPLEX optimization studio CPLEX User’s Manual, Version 12 Release 7 (1987–2017)
Kalbat, A., Lavaei, J.: A fast distributed algorithm for decomposable semidefinite programs. In: 54th IEEE Conference on Decision and Control, pp. 1742–1749 (2015)
Lancaster, P., Farahat, H.K.: Norms on direct sums and tensor products. Math. Comput. 26(118), 401–414 (1972)
Lanckriet, G.R., Cristianini, N., Bartlett, P., Ghaoui, L.E., Jordan, M.I.: Learning the kernel matrix with semidefinite programming. J. Mach. Learn. Res. 5(Jan), 27–72 (2004)
Lobo, M.S., Vandenberghe, L., Boyd, S., Lebret, H.: Applications of second-order cone programming. Linear Algebra Appl. 284(1–3), 193–228 (1998)
Nemirovski, A.: Interior point polynomial time methods in convex programming. Lecture Notes (2004)
Nesterov, Y., Nemirovskii, A.: Interior-Point Polynomial Algorithms in Convex Programming. SIAM, Philadelphia (1994)
O’donoghue, B., Chu, E., Parikh, N., Boyd, S.: Conic optimization via operator splitting and homogeneous self-dual embedding. J. Optim. Theory Appl. 169(3), 1042–1068 (2016)
Pakazad, S.K., Hansson, A., Andersen, M.S., Rantzer, A.: Distributed semidefinite programming with application to large-scale system analysis. IEEE Trans. Autom. Control 63(4), 1045–1058 (2018)
Rabaste, O., Savy, L.: Mismatched filter optimization for radar applications using quadratically constrained quadratic programs. IEEE Trans. Aerosp. Electron. Syst. 51(4), 3107–3122 (2015)
Rockafellar, R.T.: Convex Analysis. Princeton University Press, Princeton (2015)
Acknowledgements
The authors would like to acknowledge the support of National Science Foundation Grant CMMI-1832688 and the Emerging Frontiers grant from the School of Industrial Engineering at Purdue University. Specially, we wish to thank Professor Jong-Shi Pang of University of Southern California for the helpful comments and discussions. In addition, we would like to thank Purdue Rosen Center for Advanced Computing for providing the computing resources and technical support.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1: Step-size update rule for \(\rho ^{k+1}\)
With a given scalar \(0 \le \epsilon _0 < 1\), and a series of positive scalars \(\epsilon _1, \ldots , \epsilon _8 > 0\) that satisfy \(\sum _{s=1}^8 \epsilon _s \le 1 - \epsilon _0\), we define the following function \(\rho : {\mathbb {X}} \times {\mathbb {R}}^{n_2} \times {\mathbb {R}}_+^{m_1} \times {\mathbb {R}}^{m_2} \rightarrow (0, +\infty )\) to update the adaptive step size \(\rho ^{k+1}\) in Algorithm 1 at each iteration k:
where
-
(i)
\(\rho _1 = \left\{ \begin{array}{ll} \displaystyle \frac{\epsilon _1}{\Vert P_0 \Vert _F}, &{}\text {if }\Vert P_0 \Vert _F \not = 0 \\ \epsilon _1, &{}\text {if }\Vert P_0 \Vert _F = 0, \end{array} \right.\) with \(\Vert \cdot \Vert _F\) representing the Frobenius norm of a matrix;
-
(ii)
\(\rho _2({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k) = \min _i\{\rho _{2i}({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k)\}\), where
$$\begin{aligned} \rho _{2i}({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k) {:}{=}\left\{ \begin{array}{ll} \displaystyle \frac{-b_i + \sqrt{b_i^2 + 4 a_i c_i}}{2 a_i}, &{}\text {if }a_i> 0 \\ \displaystyle \frac{c_i}{b_i}, &{}\text {if }a_i = 0, b_i > 0 \\ M, &{}\text {if }a_i = 0, b_i = 0, \end{array} \right. \end{aligned}$$for all \(i = 1, \dots , m_1\), with \(a_i = |\frac{1}{2} ({\mathbf {x}}^k)^T P_i {\mathbf {x}}^k + {\mathbf {q}}_i^T {\mathbf {x}}^k + {\mathbf {c}}_i^T {\mathbf {u}}^k + r_i |\ge 0\), and \(b_i = \lambda _i^k \ge 0\). For \(c_i\), if \(\Vert P_i \Vert _F \not = 0\), \(c_i = \frac{\epsilon _2}{m_1 \Vert P_i \Vert _F} > 0\); otherwise \(c_i = \frac{\epsilon _2}{m_1} > 0\). The constant \(M > 0\) can be any fixed, arbitrarily large scalar;
-
(iii)
\(\rho _{3}({\mathbf {x}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k) =\)
$$\begin{aligned} \left\{ \begin{array}{ll} \displaystyle \min \left\{2 \epsilon _3, \frac{-b + \sqrt{b^2 + 4 a c}}{2 a}\right\}, &{}\text {if }a> 0 \\ \displaystyle \min \left\{2 \epsilon _3, \frac{c}{b}\right\}, &{}\text {if }a = 0, b > 0 \\ 2 \epsilon _3, &{}\text {if }a = 0, b = 0, \end{array} \right. \end{aligned}$$where \(a = \Vert P_0 {\mathbf {x}}^k + {\mathbf {q}}_0 + \sum _{i=1}^{m_1} \lambda _i^k (P_i {\mathbf {x}}^k + {\mathbf {q}}_i) + A^T \varvec{\gamma }^k\Vert _2 \ge 0\), \(b = 2 \Vert {\mathbf {x}}^k \Vert _2 \ge 0\) and \(c = \frac{2 \epsilon _3}{\Vert P \Vert _F} > 0\) with \(P \in {\mathbb {R}}^{m_1 n_1 \times n_1}\) denoting the stacked matrix \(\left( \begin{array}{c}P_1 \\ \vdots \\ P_{m_1}\end{array}\right)\);
-
(iv)
\(\rho _4 = \left\{ \begin{array}{ll} \displaystyle \frac{\epsilon _4}{\Vert Q \Vert _F}, &{}\text {if }\Vert Q \Vert _F \not = 0 \\ \epsilon _4, &{}\text {if }\Vert Q \Vert _F = 0 \end{array} \right.\), where \(Q \in {\mathbb {R}}^{m_1 \times n_1}\) denotes matrix \(\left( \begin{array}{c}{\mathbf {q}}_1^T \\ \vdots \\ {\mathbf {q}}_{m_1}^T\end{array}\right)\), with the \({\mathbf {q}}_i\)’s being the vectors in the linear terms of \({\mathbf {x}}\) in the QCQP (8);
-
(v)
\(\rho _5({\mathbf {x}}^k) = \left\{ \begin{array}{ll} \displaystyle \frac{\epsilon _5}{\Vert {\mathbf {x}}^k \Vert _2 \Vert P \Vert _F}, &{}\text {if }\Vert {\mathbf {x}}^k \Vert _2 \not = 0 \\ \epsilon _5, &{}\text {if }\Vert {\mathbf {x}}^k \Vert _2 = 0 \end{array} \right.\);
-
(vi)
\(\rho _6 = \left\{ \begin{array}{ll} \displaystyle \frac{\epsilon _6}{\Vert C \Vert _F}, &{}\text {if }\Vert C \Vert _F \not = 0 \\ \epsilon _6, &{}\text {if }\Vert C \Vert _F = 0 \end{array} \right.\), where \(C \in {\mathbb {R}}^{m_2 \times n_2}\) denotes matrix \(\left( \begin{array}{c}{\mathbf {c}}_1^T \\ \vdots \\ {\mathbf {c}}_{m_2}^T\end{array}\right)\), with the \({\mathbf {c}}_j\)’s being the vectors in the linear terms of \({\mathbf {u}}\) in the QCQP (8);
-
(vii)
\(\rho _7 = \left\{ \begin{array}{ll} \displaystyle \frac{\epsilon _7}{\Vert A \Vert _F}, &{}\text {if }\Vert A \Vert _F \not = 0 \\ \epsilon _7, &{}\text {if }\Vert A \Vert _F = 0 \end{array} \right.\), where A is the matrix in the linear constraint \(A {\mathbf {x}} + B {\mathbf {u}} = {\mathbf {b}}\) in (8);
-
(viii)
\(\rho _8 = \left\{ \begin{array}{ll} \displaystyle \frac{\epsilon _8}{\Vert B \Vert _F}, &{}\text {if }\Vert B \Vert _F \not = 0 \\ \epsilon _8, &{}\text {if }\Vert B \Vert _F = 0 \end{array} \right.\), where B is the matrix in the linear constraint \(A {\mathbf {x}} + B {\mathbf {u}} = {\mathbf {b}}\) in (8).
\(\Box\)
While the rules to update the step-size \(\rho ^{k+1}\) may appear to be very cumbersome, the calculations are actually quite straightforward. Since the Frobenius norm of all matrices can be obtained in advance, the values of \(\rho _1\), \(\rho _4\), \(\rho _6\), \(\rho _7\) and \(\rho _8\) are pre-determined. Given a current solution \(({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\), \(\rho _2\), \(\rho _{3}\) and \(\rho _5\) can also be easily calculated. The minimum of all the \(\rho _s\)’s then determines the value of the adaptive step size \(\rho ^{k+1}\).
Appendix 2: Proofs in Sect. 3
1.1 Proof of Proposition 1
We first prove the inequality (24). Consider the linear approximation of the Lagrangian function of a QCQP, as defined in (21), with a given point \(\zeta ^k \equiv ({\mathbf {x}}^k, \lambda ^k, \gamma ^k)\). Let \(\widehat{{\mathbf {z}}} = ({\mathbf {y}}^{k+1}, {\mathbf {v}}^{k+1})\), the \((k+1)\)th iteration of the primal predictor of \({\mathbf {x}}^k\) and \({\mathbf {u}}^k\) in the PC\(^2\)PM algorithm, as given in (14a) and (16a), respectively. By Lemma 2, we know that \(\widehat{{\mathbf {z}}}\) is the unique minimizer of the corresponding proximal minimization problem in (22b). By defining \(\bar{{\mathbf {z}}} = ({\mathbf {x}}^k, {\mathbf {u}}^k)\) and \({\mathbf {z}} = ({\mathbf {x}}^{k+1}, {\mathbf {u}}^{k+1})\), and using Lemma 1, we have that
which leads to the following expanded inequality
Now consider the \({\mathcal {R}}\) function at a different given point \(\zeta ^{k+1} \equiv ({\mathbf {y}}^{k+1}, \mu ^{k+1}, \varvec{\nu }^{k+1})\). With a slight abuse of notation, we now let \(\widehat{{\mathbf {z}}} = ({\mathbf {x}}^{k+1}, {\mathbf {u}}^{k+1})\), the primal correctors at the \((k+1)\)th iteration of the PC\(^2\)PM algorithm. Also letting \({\mathbf {z}} = ({\mathbf {x}}^*, {\mathbf {u}}^*)\), but keeping \(\bar{{\mathbf {z}}} = ({\mathbf {x}}^k, {\mathbf {u}}^k)\), by (22c) in Lemmas 2 and 1, we have that:
which leads to the following expanded inequality
The final piece to derive inequality (24) is to utilize Lemma 3. Let \(({\mathbf {x}}^*, {\mathbf {u}}^*, \varvec{\lambda }^*, \varvec{\gamma }^*)\) be a saddle point of QCQP (8), and again, \(\zeta ^{k+1} = ({\mathbf {y}}^{k+1}, \mu ^{k+1}, \varvec{\nu }^{k+1})\). By Lemma 3, we have that
Multiplying both sides by \(2 \rho ^{k+1}\) and expanding the \({\mathcal {R}}\) function, we have that
Adding the three inequalities (51), (52) and (54) yields the inequality (24) in Proposition 1.
To prove the second inequality, (25), in Proposition 1, we use a similar approach as above, just replacing the linear approximation function \({\mathcal {R}}\) with the original Lagrangian function \({\mathcal {L}}\). More specifically, let \(\widehat{{\mathbf {z}}} = (\varvec{\mu }^{k+1}, \varvec{\nu }^{k+1})\). By (22a) in Lemma 2, we know that
Letting \(\bar{{\mathbf {z}}} = (\varvec{\lambda }^k, \varvec{\gamma }^k)\) and choosing a specific \({\mathbf {z}} = (\varvec{\lambda }^{k+1}, \varvec{\gamma }^{k+1})\), we use Lemma 1 to obtain that
which yields the following expanded inequality:
Similarly, again with some abuse of notation, letting \(\widehat{{\mathbf {z}}} = (\varvec{\lambda }^{k+1}, \varvec{\gamma }^{k+1})\), by (22d) in Lemma 2, we have that
By choosing \({\mathbf {z}}\) to be \((\varvec{\lambda }^*, \varvec{\gamma }^*)\), while keeping \(\bar{{\mathbf {z}}}\) at \((\varvec{\lambda }^k, \varvec{\gamma }^k)\), we have from Lemma 1 that
which yields the following expanded inequality:
Adding the two inequalities (57) and (60) leads to the second inequality, (25), in Proposition 1. \(\Box\)
1.2 Proof of Theorem 1
By adding the two inequalities (24) and (25) in Proposition 1, we have that
Next, we establish an upper bound for each term of the term from (a) to (l) in (61) using the adaptive step size \(\rho ^{k+1} = \rho ({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\), as defined in (49).
-
(a)
First, we want to show that
$$\begin{aligned} \text {(a)} \le \epsilon _1 \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(62)To prove this (and several inequalities below), we first show an extension of the Young’s inequalityFootnote 3 on vector products that will play a key role in the following proof. Given any two vectors \({\mathbf {z}}_1, {\mathbf {z}}_2 \in {\mathbb {R}}^n\), we have that
$$\begin{aligned} {\mathbf {z}}_1^T {\mathbf {z}}_2 = \sum _{j=1}^n z_{1j} z_{2j} = \sum _{j=1}^n \Big (\frac{1}{\delta } z_{1j}\Big ) \Big (\delta z_{2j}\Big ) \le \sum _{j=1}^n \Big |\frac{1}{\delta } z_{1j} \Big |\Big |\delta z_{2j} \Big |, \end{aligned}$$(63)where \(\delta\) is a non-zero real number. Applying Young’s inequality on each summation term with \(p = q = 2\), we obtain that
$$\begin{aligned} {\mathbf {z}}_1^T {\mathbf {z}}_2 \le \sum _{j=1}^n \left[ \frac{1}{2} \Big (\frac{1}{\delta } z_{1j}\Big )^2 + \frac{1}{2} \Big (\delta z_{2j}\Big )^2\right] = \frac{1}{2 \delta ^2} \Vert {\mathbf {z}}_1 \Vert _2^2 + \frac{\delta ^2}{2} \Vert {\mathbf {z}}_2 \Vert _2^2. \end{aligned}$$(64)Applying (64) on (a) yields
$$\begin{aligned} \text {(a)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert P_0 ({\mathbf {y}}^{k+1} - {\mathbf {x}}^k) \Vert _2^2\Big ) \nonumber \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| P_0 \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \nonumber \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert P_0 \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(65)The second inequality holds due to the property that given a matrix \(A \in {\mathbb {R}}^{m \times n}\) and a vector \({\mathbf {z}} \in {\mathbb {R}}^n\), \(\Vert A {\mathbf {z}} \Vert _2 \le {\left| \left| \left| A \right| \right| \right| }_2 \Vert {\mathbf {z}} \Vert _2\) (see Theorem 5.6.2 in [9]), where we use the notation \({\left| \left| \left| \cdot \right| \right| \right| }_2\) to denote the matrix norm \({\left| \left| \left| A \right| \right| \right| }_2 {:}{=}\underset{{\mathbf {z}} \not = {\mathbf {0}}}{\sup } \frac{\Vert A {\mathbf {z}} \Vert _2}{\Vert {\mathbf {z}} \Vert _2}\). The last inequality holds due to the property \({\left| \left| \left| A \right| \right| \right| }_2 \le \Vert A \Vert _F\) [7], where \(\Vert A \Vert _F {:}{=}\big (\sum _{i=1}^m \sum _{j=1}^n |A_{ij} |^2\big )^{\frac{1}{2}}\) denotes the Frobenius norm. From (65), if \(\Vert P_0 \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert P_0 \Vert _F}\) yields
$$\begin{aligned} \text {(a)} \le \rho ^{k+1} \Vert P_0 \Vert _F \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(66)Since \(\rho ^{k+1} \le \rho _1 = \frac{\epsilon _1}{\Vert P_0 \Vert _F}\), we obtain (62). If, on the other hand, \(\Vert P_0 \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(a)} \le \rho ^{k+1} \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(67)Since \(\rho ^{k+1} \le \rho _1 = \epsilon _1\), (62) is also obtained.
-
(b)
Here we want to show that
$$\begin{aligned} \sum _{i=1}^{m_1} \text {(b)}_i \le \epsilon _2 \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(68)Applying (64) on each term \(\text {(b)}_i\) yields
$$\begin{aligned} \begin{aligned} \text {(b)}_i &\le 2 \rho ^{k+1} \mu _i^{k+1} \Big (\frac{1}{2 \delta _i^2} \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \frac{\delta _i^2}{2} {\left| \left| \left| P_i \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\ &\le 2 \rho ^{k+1} \mu _i^{k+1} \Big (\frac{1}{2 \delta _i^2} \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \frac{\delta _i^2}{2} \Vert P_i \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(69)-
If \(\Vert P_i \Vert _F \not = 0\), then letting \(\delta _i^2 = \frac{1}{\Vert P_i \Vert _F}\) yields
$$\begin{aligned} \begin{aligned} \text {(b)}_i &\le \rho ^{k+1} \mu _i^{k+1} \Vert P_i \Vert _F \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\ &\le \rho ^{k+1} {\tilde{\mu }}_i^{k+1} \Vert P_i \Vert _F \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ), \end{aligned} \end{aligned}$$(70)where \({\tilde{\mu }}_i^{k+1} {:}{=}\lambda _i^k + \rho ^{k+1} |\frac{1}{2} ({\mathbf {x}}^k)^T P_i {\mathbf {x}}^k + {\mathbf {q}}_i^T {\mathbf {x}}^k + {\mathbf {c}}_i^T {\mathbf {u}}^k + r_i |\ge \mu _i^{k+1}\). If we can bound \(\rho ^{k+1} {\tilde{\mu }}_i^{k+1} \le \frac{\epsilon _2}{m_1 \Vert P_i \Vert _F}\), then we can achieve
$$\begin{aligned} \text {(b)}_i \le \frac{\epsilon _2}{m_1} \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(71)By substituting \(a_i = |\frac{1}{2} ({\mathbf {x}}^k)^T P_i {\mathbf {x}}^k + {\mathbf {q}}_i^T {\mathbf {x}}^k + {\mathbf {c}}_i^T {\mathbf {u}}^k + r_i |\ge 0\), \(b_i = \lambda _i^k \ge 0\) and \(c_i = \frac{\epsilon _2}{m_1 \Vert P_i \Vert _F} > 0\), we can rewrite \(\rho ^{k+1} {\tilde{\mu }}_i^{k+1} - \frac{\epsilon _2}{m_1 \Vert P_i \Vert _F}\) as \(a_i(\rho ^{k+1})^2 + b_i \rho ^{k+1} - c_i\), which is simply a quadratic function of \(\rho ^{k+1}\) with parameters \(a_i\), \(b_i\) and \(c_i\). To bound \(\rho ^{k+1} {\tilde{\mu }}_i^{k+1} \le \frac{\epsilon _2}{m_1 \Vert P_i \Vert _F}\) is equivalent to find proper values of \(\rho ^{k+1}\) that keep the quadratic function stay below zero.
-
If \(a_i = 0\) and \(b_i = 0\), then \(\rho ^{k+1} \in (0, +\infty )\).
-
If \(a_i = 0\) and \(b_i > 0\), then \(\rho ^{k+1} \in (0, \frac{c_i}{b_i}]\).
-
If \(a_i > 0\), then \(\rho ^{k+1} \in (0, \frac{-b_i + \sqrt{b_i^2 + 4 a_i c_i}}{2 a_i}]\).
Since \(\rho ^{k+1} \le \rho _2({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k) \le \rho _{2i}({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k)\), it satisfies all the above three conditions, we then obtain (71), and hence (68).
-
-
If \(\Vert P_i \Vert _F = 0\), then letting \(\delta _i^2 = 1\) yields
$$\begin{aligned} \begin{aligned} \text {(b)}_i \le&\rho ^{k+1} \mu _i^{k+1} \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\ \le&\rho ^{k+1} {\tilde{\mu }}_i^{k+1} \Big (\Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(72)Similarly, if we can bound \(\rho ^{k+1} {\tilde{\mu }}_i^{k+1} \le \frac{\epsilon _2}{m_1}\), then we can also achieve (71). By substituting \(a_i = |\frac{1}{2} ({\mathbf {x}}^k)^T P_i {\mathbf {x}}^k + {\mathbf {q}}_i^T {\mathbf {x}}^k + {\mathbf {c}}_i^T {\mathbf {u}}^k + r_i |\ge 0\), \(b_i = \lambda _i^k \ge 0\) and \(c_i = \frac{\epsilon _2}{m_1} > 0\), we can rewrite \(\rho ^{k+1} {\tilde{\mu }}_i^{k+1} - \frac{\epsilon _2}{m_1}\) as \(a_i(\rho ^{k+1})^2 + b_i \rho ^{k+1} - c_i\). The same analysis can be followed as discussed in the case of \(\Vert P_i \Vert _F \not = 0\).
-
-
(c)
Next, we want to show that
$$\begin{aligned} \text {(c)} \le \epsilon _3 \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(73)By using P to denote \(\left( \begin{array}{c}P_1 \\ \vdots \\ P_{m_1}\end{array}\right)\), we can rewrite
$$\begin{aligned} \text {(c)} = \rho ^{k+1} \Big \{(\varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1})^T \Big [I_{m_1 \times m_1} \otimes ({\mathbf {x}}^k + {\mathbf {y}}^{k+1})^T\Big ] P ({\mathbf {y}}^{k+1} - {\mathbf {x}}^k)\Big \}, \end{aligned}$$(74)where \(\otimes\) denotes the Kronecker product; that is, given a matrix \(A \in {\mathbb {R}}^{m_1 \times n_1}\) and a matrix \(B \in {\mathbb {R}}^{m_2 \times n_2}\), \(A \otimes B {:}{=}\left( \begin{array}{ccc}a_{11} B&{}\cdots &{}a_{1 m_1} B \\ \vdots &{}&{}\vdots \\ a_{m_1 1} B&{}\cdots &{}a_{m_1 n_1} B\end{array}\right)\). Applying (64) to (74) yields
$$\begin{aligned} \begin{aligned} \text {(c)}&\le \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 \\&\quad + \frac{\delta ^2}{2} {\left| \left| \left| I_{m_1 \times m_1} \otimes ({\mathbf {x}}^k + {\mathbf {y}}^{k+1})^T \right| \right| \right| }_2^2 {\left| \left| \left| P \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\&\le \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert {\mathbf {x}}^k + {\mathbf {y}}^{k+1} \Vert _2^2 \Vert P \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(75)Since we have the property that \({\left| \left| \left| A \otimes B \right| \right| \right| }_2 = {\left| \left| \left| A \right| \right| \right| }_2 {\left| \left| \left| B \right| \right| \right| }_2\) (see Theorem 8 in [15]), the last inequality holds due to
$$\begin{aligned} {\left| \left| \left| I_{m_1 \times m_1} \otimes ({\mathbf {x}}^k + {\mathbf {y}}^{k+1})^T \right| \right| \right| }_2^2 = {\left| \left| \left| I_{m_1 \times m_1} \right| \right| \right| }_2^2 {\left| \left| \left| ({\mathbf {x}}^k + {\mathbf {y}}^{k+1})^T \right| \right| \right| }_2^2, \end{aligned}$$(76)together with \({\left| \left| \left| I_{m_1 \times m_1} \right| \right| \right| }_2 = 1\) and \({\left| \left| \left| ({\mathbf {x}}^k + {\mathbf {y}}^{k+1})^T \right| \right| \right| }_2 \le \Vert ({\mathbf {x}}^k + {\mathbf {y}}^{k+1})^T \Vert _F = \Vert {\mathbf {x}}^k + {\mathbf {y}}^{k+1} \Vert _2\). Note that \(\Vert P \Vert _F \not = 0\), otherwise the QCQP is simply a QP.
-
If \(\Vert {\mathbf {x}}^k + {\mathbf {y}}^{k+1} \Vert _2 \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert {\mathbf {x}}^k + {\mathbf {y}}^{k+1} \Vert _2 \Vert P \Vert _F}\) yields
$$\begin{aligned} \begin{aligned} \text {(c)} \le&\frac{1}{2} \rho ^{k+1} \Vert {\mathbf {x}}^k + {\mathbf {y}}^{k+1} \Vert _2 \Vert P \Vert _F \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\ \le&\frac{1}{2} \rho ^{k+1} \Vert {\mathbf {x}}^k + \tilde{{\mathbf {y}}}^{k+1} \Vert _2 \Vert P \Vert _F \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ), \end{aligned} \end{aligned}$$(77)where \({\tilde{y}}_j^{k+1} {:}{=}x_j^k + \rho \Big |\big [P_0 {\mathbf {x}}^k + {\mathbf {q}}_0 + \sum _{i=1}^{m_1} \lambda _i^k \big (P_i {\mathbf {x}}^k + {\mathbf {q}}_i\big ) + A^T \varvec{\gamma }^k\big ]_j \Big |\ge y_j^{k+1}\). If we can bound \(\rho ^{k+1} \Vert {\mathbf {x}}^k + \tilde{{\mathbf {y}}}^{k+1} \Vert _2 \le \frac{2 \epsilon _3}{\Vert P^T \Vert _F}\), then (73) can be obtained. We first bound
$$\begin{aligned}&\rho ^{k+1} \Vert {\mathbf {x}}^k + \tilde{{\mathbf {y}}}^{k+1} \Vert _2 - \frac{2 \epsilon _3}{\Vert P \Vert _F} \nonumber \\&\quad \le \rho ^{k+1} \Big [2 \Vert {\mathbf {x}}^k \Vert _2 + \rho ^{k+1} \Vert P_0 {\mathbf {x}}^k + {\mathbf {q}}_0 + \sum _{i=1}^{m_1} \lambda _i^k \big (P_i {\mathbf {x}}^k + {\mathbf {q}}_i\big ) + A^T \varvec{\gamma }^k \Vert _2\Big ] \nonumber \\&\qquad - \frac{2 \epsilon _3}{\Vert P \Vert _F}. \end{aligned}$$(78)By substituting \(a = \Vert P_0 {\mathbf {x}}^k + {\mathbf {q}}_0 + \sum _{i=1}^{m_1} \lambda _i^k \big (P_i {\mathbf {x}}^k + {\mathbf {q}}_i\big ) + A^T \varvec{\gamma }^k \Vert _2 \ge 0\), \(b = 2 \Vert {\mathbf {x}}^k \Vert _2 \ge 0\) and \(c = \frac{2 \epsilon _3}{\Vert P \Vert _F} > 0\), we can bound \(\rho ^{k+1} \Vert {\mathbf {x}}^k + \tilde{{\mathbf {y}}}^{k+1} \Vert _2 - \frac{2 \epsilon _3}{\Vert P \Vert _F}\) using \(a (\rho ^{k+1})^2 + b \rho ^{k+1} - c\), which is simply a quadratic function of \(\rho ^{k+1}\) with parameters a, b and c. Bounding \(\rho ^{k+1} \Vert {\mathbf {x}}^k + \tilde{{\mathbf {y}}}^{k+1} \Vert _2 \le \frac{2 \epsilon _3}{\Vert P \Vert _F}\) can be guaranteed by finding the proper values of \(\rho ^{k+1}\) that keep the quadratic function stay below zero.
-
If \(a = 0\) and \(b = 0\), then \(\rho ^{k+1} \in (0, +\infty )\).
-
If \(a = 0\) and \(b > 0\), then \(\rho ^{k+1} \in (0, \frac{c}{b}]\).
-
If \(a > 0\), then \(\rho ^{k+1} \in (0, \frac{-b + \sqrt{b^2 + 4 a c}}{2 a}]\).
Since \(\rho ^{k+1} \le \rho _3({\mathbf {x}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\), it satisfies all the above three conditions, we obtain (73).
-
-
If \(\Vert {\mathbf {x}}^k + {\mathbf {y}}^{k+1} \Vert _2 = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} (c) \le \frac{1}{2} \rho ^{k+1} \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \end{aligned}$$(79)Since \(\rho ^{k+1} \le \rho _3({\mathbf {x}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k) \le 2 \epsilon _3\), (73) is also obtained.
-
-
(d)
To show that
$$\begin{aligned} \text {(d)} \le \epsilon _4 \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ), \end{aligned}$$(80)by letting \(Q = \left( \begin{array}{c}{\mathbf {q}}_1^T \\ \vdots \\ {\mathbf {q}}_{m_1}^T\end{array}\right)\), we can rewrite that
$$\begin{aligned} \text {(d)} = 2 \rho ^{k+1} \Big [(\varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1})^T Q^T ({\mathbf {y}}^{k+1} - {\mathbf {x}}^k)\Big ]. \end{aligned}$$(81)$$\begin{aligned} \begin{aligned} \text {(d)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| Q \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \big (\frac{1}{2 \delta ^2} \Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert Q \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\big ). \end{aligned} \end{aligned}$$(82)-
If \(\Vert Q \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert Q \Vert _F}\) yields
$$\begin{aligned} \text {(d)} \le \rho ^{k+1} \Vert Q \Vert _F \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(83)Since \(\rho ^{k+1} \le \rho _4 = \frac{\epsilon _4}{\Vert Q \Vert _F}\), we obtain (80).
-
If \(\Vert Q \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(d)} \le \rho ^{k+1} \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(84)Since \(\rho ^{k+1} \le \rho _4 = \epsilon _4\), (80) is also obtained.
-
-
(e)
Similarly, to show
$$\begin{aligned} \text {(e)} \le \epsilon _4 \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ), \end{aligned}$$(85)we can rewrite that
$$\begin{aligned} \text {(e)} = 2 \rho ^{k+1} \Big [(\varvec{\mu }^{k+1} - \varvec{\lambda }^k)^T Q ({\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1})\Big ]. \end{aligned}$$(86)Applying (64) to (86) yields that
$$\begin{aligned} \begin{aligned} \text {(e)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| Q \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \frac{\delta ^2}{2} \Vert Q \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(87)-
If \(\Vert Q \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert Q \Vert _F}\) yields
$$\begin{aligned} \text {(e)} \le \rho ^{k+1} \Vert Q \Vert _F \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(88)Since \(\rho ^{k+1} \le \rho _4 = \frac{\epsilon _4}{\Vert Q \Vert _F}\), we obtain (85).
-
If \(\Vert Q \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(e)} \le \rho ^{k+1} \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(89)Since \(\rho ^{k+1} \le \rho _4 = \epsilon _4\), (85) is also obtained.
-
-
(f)
To show
$$\begin{aligned} \text {(f)} \le \epsilon _5 \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ), \end{aligned}$$(90)we can rewrite
$$\begin{aligned} \text {(f)} = 2 \rho ^{k+1} \Big \{(\varvec{\mu }^{k+1} - \varvec{\lambda }^k)^T \Big [I_{m_1 \times m_1} \otimes ({\mathbf {x}}^k)^T\Big ] P ({\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1})\Big \}. \end{aligned}$$(91)Applying (64), we have that
$$\begin{aligned} \begin{aligned} \text {(f)}&\le 2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 \\&\quad + \frac{\delta ^2}{2} {\left| \left| \left| I_{m_1 \times m_1} \otimes ({\mathbf {x}}^k)^T \right| \right| \right| }_2^2 {\left| \left| \left| P \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ) \\&\le 2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \frac{\delta ^2}{2} \Vert {\mathbf {x}}^k \Vert _2^2 \Vert P \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(92)Similarly, the last inequality holds due to
$$\begin{aligned} {\left| \left| \left| I_{m_1 \times m_1} \otimes ({\mathbf {x}}^k)^T \right| \right| \right| }_2^2 = {\left| \left| \left| I_{m_1 \times m_1} \right| \right| \right| }_2^2 {\left| \left| \left| ({\mathbf {x}}^k)^T \right| \right| \right| }_2^2. \end{aligned}$$-
If \(\Vert {\mathbf {x}}^k \Vert _2 \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert {\mathbf {x}}^k \Vert _2 \Vert P \Vert _F}\) yields
$$\begin{aligned} \text {(f)} \le \rho ^{k+1} \Vert {\mathbf {x}}^k \Vert _2 \Vert P \Vert _F \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(93)Since \(\rho ^{k+1} \le \rho _5({\mathbf {x}}^k) = \frac{\epsilon _5}{\Vert {\mathbf {x}}^k \Vert _2 \Vert P \Vert _F}\), we obtain (90).
-
If \(\Vert {\mathbf {x}}^k \Vert _2 = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(f)} \le \rho ^{k+1} \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(94)Since \(\rho ^{k+1} \le \rho _5({\mathbf {x}}^k) = \epsilon _5\), (90) is also obtained.
-
-
(g)
To show
$$\begin{aligned} \text {(g)} \le \epsilon _6 \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ), \end{aligned}$$(95)By letting \(C = \left( \begin{array}{c}{\mathbf {c}}_1^T \\ \vdots \\ {\mathbf {c}}_{m_2}^T\end{array}\right)\), we can rewrite
$$\begin{aligned} \text {(g)} = 2 \rho ^{k+1} \Big [(\varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1})^T C ({\mathbf {v}}^{k+1} - {\mathbf {u}}^k)\Big ]. \end{aligned}$$(96)Applying (64), we have that
$$\begin{aligned} \begin{aligned} \text {(g)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| C \right| \right| \right| }_2^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert C \Vert _F^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(97)-
If \(\Vert C \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert C \Vert _F}\) yields
$$\begin{aligned} \text {(g)} \le \rho ^{k+1} \Vert C \Vert _F \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ). \end{aligned}$$(98)Since \(\rho ^{k+1} \le \rho _6 = \frac{\epsilon _6}{\Vert C \Vert _F}\), we obtain (95).
-
If \(\Vert C \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(g)} \le \rho ^{k+1} \Big (\Vert \varvec{\lambda }^{k+1} - \varvec{\mu }^{k+1} \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ). \end{aligned}$$(99)Since \(\rho ^{k+1} \le \rho _6 = \epsilon _6\), (95) is also obtained.
-
-
(h)
Next, we want to show that
$$\begin{aligned} \text {(h)} \le \epsilon _6 \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(100)Similarly, we can rewrite
$$\begin{aligned} \text {(h)} = 2 \rho ^{k+1} \Big [(\varvec{\mu }^{k+1} - \varvec{\lambda }^k)^T C ({\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1})\Big ]. \end{aligned}$$(101)Applying (64) on the above equality leads to
$$\begin{aligned} \begin{aligned} \text {(h)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| C \right| \right| \right| }_2^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \frac{\delta ^2}{2} \Vert C \Vert _F^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(102)-
If \(\Vert C \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert C \Vert _F}\) yields
$$\begin{aligned} \text {(h)} \le \rho ^{k+1} \Vert C \Vert _F \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(103)Since \(\rho ^{k+1} \le \rho _6 = \frac{\epsilon _6}{\Vert C \Vert _F}\), we obtain (100).
-
If \(\Vert C \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(h)} \le \rho ^{k+1} \Big (\Vert \varvec{\mu }^{k+1} - \varvec{\lambda }^k \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(104)Since \(\rho ^{k+1} \le \rho _6 = \epsilon _6\), (100) is also obtained.
-
-
(i)
To show
$$\begin{aligned} \text {(i)} \le \epsilon _7 \Big (\Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ), \end{aligned}$$(105)we apply (64) on the rewriting of (i), which leads to
$$\begin{aligned} \begin{aligned} \text {(i)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| A \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert A \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(106)-
If \(\Vert A \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert A \Vert _F}\) yields
$$\begin{aligned} \text {(i)} \le \rho ^{k+1} \Vert A \Vert _F \Big (\Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(107)Since \(\rho ^{k+1} \le \rho _7 = \frac{\epsilon _7}{\Vert A \Vert _F}\), we obtain (105).
-
If \(\Vert A \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(i)} \le \rho ^{k+1} \Big (\Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^k \Vert _2^2\Big ). \end{aligned}$$(108)Since \(\rho ^{k+1} \le \rho _7 = \epsilon _7\), (105) is also obtained.
-
-
(j)
Similarly, to show
$$\begin{aligned} \text {(j)} \le \epsilon _7 \Big (\Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(109)we apply (64) on the rewriting of (j), which yields
$$\begin{aligned} \begin{aligned} \text {(j)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| A \right| \right| \right| }_2^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \frac{\delta ^2}{2} \Vert A \Vert _F^2 \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(110)-
If \(\Vert A \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert A \Vert _F}\) yields
$$\begin{aligned} \text {(j)} \le \rho ^{k+1} \Vert A \Vert _F \Big (\Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(111)Since \(\rho ^{k+1} \le \rho _7 = \frac{\epsilon _7}{\Vert A \Vert _F}\), we obtain (109).
-
If \(\Vert A \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(j)} \le \rho ^{k+1} \Big (\Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \Vert {\mathbf {y}}^{k+1} - {\mathbf {x}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(112)Since \(\rho ^{k+1} \le \rho _7 = \epsilon _7\), (109) is also obtained.
-
-
(k)
Next, to show
$$\begin{aligned} \text {(k)} \le \epsilon _8 \Big (\Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ), \end{aligned}$$(113)we apply (64) on the rewriting of (k):
$$\begin{aligned} \begin{aligned} \text {(k)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| B \right| \right| \right| }_2^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \frac{\delta ^2}{2} \Vert B \Vert _F^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(114)-
If \(\Vert B \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert B \Vert _F}\) yields
$$\begin{aligned} \text {(k)} \le \rho ^{k+1} \Vert B \Vert _F \Big (\Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ). \end{aligned}$$(115)Since \(\rho ^{k+1} \le \rho _8 = \frac{\epsilon _8}{\Vert B \Vert _F}\), we obtain (113).
-
If \(\Vert B \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(k)} \le \rho ^{k+1} \Big (\Vert \varvec{\gamma }^{k+1} - \varvec{\nu }^{k+1} \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^k \Vert _2^2\Big ). \end{aligned}$$(116)Since \(\rho ^{k+1} \le \rho _8 = \epsilon _8\), (113) is also obtained.
-
-
(l)
Last, to show
$$\begin{aligned} \text {(l)} \le \epsilon _8 \Big (\Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ), \end{aligned}$$(117)we apply (64) on the rewriting of (l):
$$\begin{aligned} \begin{aligned} \text {(l)} \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \frac{\delta ^2}{2} {\left| \left| \left| B \right| \right| \right| }_2^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ) \\ \le&2 \rho ^{k+1} \Big (\frac{1}{2 \delta ^2} \Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \frac{\delta ^2}{2} \Vert B \Vert _F^2 \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned} \end{aligned}$$(118)-
If \(\Vert B \Vert _F \not = 0\), then letting \(\delta ^2 = \frac{1}{\Vert B \Vert _F}\) yields
$$\begin{aligned} \text {(l)} \le \rho ^{k+1} \Vert B \Vert _F \Big (\Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(119)Since \(\rho ^{k+1} \le \rho _8 = \frac{\epsilon _8}{\Vert B \Vert _F}\), we obtain (117).
-
If \(\Vert B \Vert _F = 0\), then letting \(\delta ^2 = 1\) yields
$$\begin{aligned} \text {(l)} \le \rho ^{k+1} \Big (\Vert \varvec{\nu }^{k+1} - \varvec{\gamma }^k \Vert _2^2 + \Vert {\mathbf {v}}^{k+1} - {\mathbf {u}}^{k+1} \Vert _2^2\Big ). \end{aligned}$$(120)Since \(\rho ^{k+1} \le \rho _8 = \epsilon _8\), (117) is also obtained.
-
The summation of terms \(\text {(a)}\) to \(\text {(l)}\) can now be bounded as:
Substituting it back into (61), we have that for all \(k \ge 0\),
which implies for all \(k \ge 0\):
It further implies that the sequence \(\{\Vert {\mathbf {x}}^k - {\mathbf {x}}^* \Vert _2^2 + \Vert {\mathbf {u}}^k - {\mathbf {u}}^* \Vert _2^2 + \Vert \varvec{\lambda }^k - \varvec{\lambda }^* \Vert _2^2 + \Vert \varvec{\gamma }^k - \varvec{\gamma }^* \Vert _2^2\}\) is monotonically decreasing and bounded below by 0; hence the sequence must be convergent to a limit, denoted by \(\xi\):
Taking the limit on both sides of (122) yields:
Additionally, (124) also implies that \(\{({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\}\) is a bounded sequence, and there exists a sub-sequence \(\{({\mathbf {x}}^{k_j}, {\mathbf {u}}^{k_j}, \varvec{\lambda }^{k_j}, \varvec{\gamma }^{k_j})\}\) that converges to a limit point \(({\mathbf {x}}^{\infty }, {\mathbf {u}}^{\infty }, \varvec{\lambda }^{\infty }, \varvec{\gamma }^{\infty })\). We next show that the limit point is indeed a saddle point and is also the unique limit point of \(\{({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\}\). Given any \({\mathbf {x}} \in {\mathbb {X}}\) and \({\mathbf {u}} \in {\mathbb {R}}^{n_2}\), we have:
The positive semi-definiteness of each \(P_i\) for all \(i = 0, 1, \dots , m\) guarantees the non-positiveness of \((\varDelta )\), which makes the last inequality hold. Applying Lemma 1 on (22c) with \(\widehat{{\mathbf {z}}} = ({\mathbf {x}}^{k+1}, {\mathbf {u}}^{k+1})\), \(\bar{{\mathbf {z}}} = ({\mathbf {x}}^k, {\mathbf {u}}^k)\) and \({\mathbf {z}} = ({\mathbf {x}}, {\mathbf {u}})\) yields:
Adding the above two inequalities yields
Taking the limits over an appropriate sub-sequence \(\{k_j\}\) on both sides and using (125), we have:
Similarly, given any \(\varvec{\lambda } \in {\mathbb {R}}_+^{m_1}\) and \(\varvec{\gamma } \in {\mathbb {R}}^{m_2}\), applying Lemma 1 on (22d) with \(\widehat{{\mathbf {z}}} = (\varvec{\lambda }^{k+1}, \varvec{\gamma }^{k+1})\), \(\bar{{\mathbf {z}}} = (\varvec{\lambda }^k, \varvec{\gamma }^k)\) and \({\mathbf {z}} = (\varvec{\lambda }, \varvec{\gamma })\) yields
Taking the limits over an appropriate sub-sequence \(\{k_j\}\) on both sides and using (125), we have:
Therefore, we show that \(({\mathbf {x}}^{\infty }, {\mathbf {u}}^{\infty }, \varvec{\lambda }^{\infty }, \varvec{\gamma }^{\infty })\) is indeed a saddle point of the Lagrangian function \({\mathcal {L}}({\mathbf {x}}, {\mathbf {u}}, \varvec{\lambda }, \varvec{\gamma })\). Then (124) implies that
Since we have argued (after Eq. (125)) that there exists a bounded sequence of \(\{({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\}\) that converges to \(({\mathbf {x}}^{\infty }, {\mathbf {u}}^{\infty }, \varvec{\lambda }^{\infty }, \varvec{\gamma }^{\infty })\); that is, there exists \(\{k_j\}\) such that \(\lim _{k_j \rightarrow +\infty } \Vert {\mathbf {x}}^{k_j} - {\mathbf {x}}^{\infty } \Vert _2^2 + \Vert {\mathbf {u}}^{k_j} - {\mathbf {u}}^{\infty } \Vert _2^2 + \Vert \varvec{\lambda }^{k_j} - \varvec{\lambda }^{\infty } \Vert _2^2 + \Vert \varvec{\gamma }^{k_j} - \varvec{\gamma }^{\infty } \Vert _2^2 = 0\), which then implies that \(\xi = 0\). Therefore, we show that \(\{({\mathbf {x}}^k, {\mathbf {u}}^k, \varvec{\lambda }^k, \varvec{\gamma }^k)\}\) converges globally to a saddle point \(({\mathbf {x}}^{\infty }, {\mathbf {u}}^{\infty }, \varvec{\lambda }^{\infty }, \varvec{\gamma }^{\infty })\). \(\Box\)
Rights and permissions
About this article

Cite this article
Chen, R., Liu, A.L. A distributed algorithm for high-dimension convex quadratically constrained quadratic programs. Comput Optim Appl 80, 781–830 (2021). https://doi.org/10.1007/s10589-021-00319-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10589-021-00319-x