
Abstract
Hydraulic transmission systems are widely used in industry because of their high output power and compact structure. To cope with the ambiguity and uncertainty in the process of hydraulic system health monitoring, this paper adopts the combination of cloud model and Dempster–Shafer evidence theory for multi-sensor data fusion from three levels: data layer, feature layer, and decision layer, which effectively avoids the problem of high conflict of evidence in Dempster–Shafer theory and completes the assessment of health status of a complex hydraulic system. Firstly, the cloud parameters are calculated to establish the expert knowledge base. Secondly, the membership matrix is used to obtain the basic probability assignments of the evidence. Then, the fusion decision of combining the same type of sensors with evidence iterations is used to improve the efficiency of fusion, and finally, Dempster's rule is performed to obtain the hydraulic system health status assessment results. The feasibility and effectiveness of this method are verified on a real data set.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
Hydraulic systems have become indispensable transmission systems in many fields under their high stability, high transmission ratio, and adaptability to complex operating conditions [1]. To ensure the reliability of hydraulic systems operating in harsh environments, it is necessary to monitor the condition health of hydraulic system components [2]. The first is a model-based approach based on the modeling of the physical and structural information of the hydraulic system, which usually has poor monitoring results due to the inability to obtain enough detailed information about the complex structure. The second is a statistical approach based on historical measurement data and fault characteristic information [3], including the deep learning approach [4], which has become popular in recent years, the shortcoming of this approach is that it requires a large amount of historical data and has high requirements for data completeness and certainty [5]. Therefore, considering the problems of uncertainty and randomness in the operation of hydraulic systems, the above methods are not better applicable. Dempster–Shafer (D–S) evidence theory is a means of decision-making based on expert experience and has good advantages in the problem of ambiguity [6]. However, in the process of multi-sensor fusion, the evidence theory often suffers from the problem of conflicting or even contradictory evidence from multiple sources [7]. In this paper, we use the improved D-S evidence theory combined with the cloud model, which organically combines the fuzziness and randomness in the concept of uncertainty using cloud model [8], and calculates the cloud parameters of each state parameter as well as the affiliation degree; then, the basic probability assignment matrix of each evidence in D–S theory is obtained from the affiliation degree of each state parameter; further, to solve the problem of high conflict of evidence in D–S evidence theory, the isomorphic sensor evidence is averaged and iterated, and finally, dempster rule evidence synthesis is performed for heterogeneous sensors to obtain the evaluation results of hydraulic system health status.
2 Materials and Methods
2.1 Cloud Model Characteristics
Let \(U\) be a quantitative domain of arbitrary dimension expressed through exact numerical values, \(C\) be a qualitative concept within this domain, \(x\) be a quantitative value, a random realization of \(C\), \(x\in U\), and x be a random number with a stable tendency for the determinacy \(\mu (x)\in [\mathrm{0,1}]\) of \(C\).
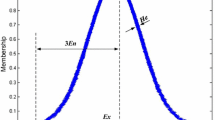
Then the distribution of \(x\) over the theoretical domain \(U\) is called a cloud, and each \(x\) is called a cloud drop. The normal cloud model expresses the numerical characteristics of a qualitative concept in terms of a set of mutually independent parameters that together reflect the uncertainty and wholeness of the concept, thus enabling better quantitative analysis [9]. The numerical characteristics of a cloud usually contain three parameters: expectation \({E}_{x}\), entropy \({E}_{n}\), and superb entropy \({H}_{e}\). \(\lambda\) is a constant value determined according to the ambiguity and randomness of specific different parameters.
2.2 D–S Evidence Theory
D–S evidence theory is an imprecise inference theory approach that addresses uncertainty due to lack of knowledge, and uses the “identification fram” \(\Theta\) to represent the set of data to be fused, and gives a function \(m:\) \({2}^{\Theta }\to\) [0,1] if it satisfies
Then \(m\) is called the set of basic credibility of such identification frame \(\Theta\), if \(A\) is contained in the identification frame \(\Theta\), \(m(A)\) is called the basic credibility function of \(A\). The basic credibility function \(m(A)\) represents the magnitude of the credibility of \(A\) itself.
For an arbitrary set, D–S evidence inference gives a notion of credibility function
Suppose there exists an \(A\) contained in this recognition framework \(\Theta\), then give the following definition:
where \(pl\) is called \(Bel's\) likelihood function, and Dou is called \(Bel's\) doubt function. Then according to this definition, we can call \(pl(A)\) the seeming truth of \(A\), and \(Dou(A)\) can be called the doubtfulness of \(A\). According to the plausibility synthesis law proposed by Dempster, then we give the synthesis law for two plausibility degrees
Using \({m}_{1},{m}_{2},\dots ,{m}_{n}\) to represent the credibility distribution function of \(n\) data, and these \(n\) data are independent of each other, then multiple credibilities can be written in the following form after fusion:
2.3 Improved D–S Evidence Theory Based on Cloud Model
The flow chart of improved D–S evidence theory based on the cloud model for hydraulic system health condition assessment is shown in Fig. 54.1. It mainly includes the calculation of cloud model feature parameters, the establishment of cloud model knowledge base, the calculation of membership function and basic probability assignment, the fusion of D–S evidence, and the fusion result by fusion decision.

Block diagram of multi-sensor data fusion in hydraulic system
Suppose that there are n classes of faults in the expert system knowledge base of the system: \({F}_{1},{F}_{2},{F}_{3},...{F}_{n}\), each class of faults has m characteristic parameters: \({x}_{i1},{x}_{i2},...,{x}_{im}\), where \({x}_{ij}\left(j=\mathrm{1,2},..m\right)\) denotes the jth parameter of the ith class of faults. In industry, there are two main types of parameters for industrial equipment, discrete and continuous parameters, so these two can be modeled separately. The required a priori knowledge is obtained through historical information to construct the fault knowledge base.
For the modeling of continuous parameters, since the values of variables are different under different fault conditions, the cloud with the main action region as the bilateral constraint region can be used to approximate the modeling. If the value interval in the fault signal measured under the rth fault mode is [\({C}_{\mathrm{min}}(r),{C}_{\mathrm{max}}(r)\)], the median value of the constraint can be adopted as the expected value, and the specific cloud model parameters are calculated as follows:
For the modeling of discrete parameters, the cloud model of the expert system fault knowledge base can be established directly by experimentally measuring the mathematical expectation and standard deviation of the variable parameters (see 54.2–54.4). For the characteristic variables of discrete parameters, the membership degree is calculated as follows, which is the same as continuous parameters.
where \({\mu }_{ij}\left(k\right)\) is the membership degree of the jth characteristic parameter of a fault signal obtained by the measurement with respect to the jth characteristic pattern of the i-th class of faults in the expert knowledge base, \({E}_{xij}\) denotes the expectation value previously obtained in the expert knowledge base, and \({E}_{nij}^{\prime}\) is a normal random number generated with the entropy \({E}_{nij}\) as the expectation and the superentropy \({H}_{eij}\) as the standard deviation and the normal random number generated. This leads to the affiliation matrix
To improve the credibility and accuracy of the fusion results, the membership degree matrix \({R}_{m\times n}\) is normalized.
The uncertainty of the actual measurement signal due to the errors caused by the circumstances such as the measurement environment and the measurement method in the actual project is represented by the variable \(\theta\). Where \(max\left({\mu }_{i1},{\mu }_{i2},\dots ,{\mu }_{nm}\right)\) denotes the maximum value of each element in each row of the membership degree matrix.
Thus, the basic probability assignment function can be computationally determined as
where \(m\left({\Theta }_{j}\right)\) denotes the basic probability assignment of the jth evidence uncertainty in the test sample, and \(m\left({F}_{ij}\right)\) denotes the basic probability assignment of the jth characteristic parameter of the fault signal obtained from the measurement compared to the jth characteristic value of the ith fault in the expert knowledge base. The basic probability assignment matrix \({M}_{m\times (n+1)}\) for m rows and n + 1 columns can be obtained after considering both measurement data and uncertainty
In order to solve the problems of low sensitivity among fault features, high conflict among fused evidence and large uncertainty, this study determines the weights of fused evidence by two aspects and reallocates the weights by the uncertainty coefficient \({\omega }_{j}^{\sigma }\) and the overall support coefficient \({\omega }_{j}^{s}\) of the evidence, respectively, so as to mitigate the conflict problem among the evidence, and after that, use Dempster's rule for evidence fusion. Let \({\omega }_{j}\) be the weight coefficient of the jth fault feature measured after fusing the evidence, then \({\omega }_{j}\) should satisfy the condition that
In the actual industry, there will be errors when measuring and collecting data due to the layout location of heterogeneous sensors, environmental conditions, and other factors, and the weight coefficient determined by the uncertainty brought by the sensor measurement and the fusion evidence is defined as the uncertainty coefficient. Let the relative measurement error of the sensor be \({\chi }_{j}\), then
where \(E\left({x}_{j}\right)\), \({\sigma }_{j}^{2}\) denote the mean and variance of the jth fault characteristic parameter, respectively. The overall support coefficient indicates the mutual support between the evidence and the evidence, and the overall support of the evidence is determined by the distance between the evidence, assuming the existence of two pieces of evidence \({m}_{j}\) and \({m}_{d}\), and defining the distance function as
Then the overall support of the evidence is
where the larger \(\eta \left({m}_{j}\right)\) indicates that the higher the support of the evidence in the overall evidence, the less conflict with other evidence, and thus the greater the weight of the evidence in the final fusion. The overall support coefficient of the evidence is calculated as
In order to reduce the number of evidence in the final fusion, reduce the running time and improve the fusion efficiency, after obtaining the basic probability assignment matrix and the fusion weight coefficients, the combined evidence iterations are performed on the homogeneous sensor information, and then the final fusion is performed by the Dempster combination rule after the iterations to obtain the decision results. Let there be j pieces of evidence generated by the feature parameters obtained from the homogeneous sensors, the average iterative evidence is calculated as
3 Results and Discussion
This work uses a publicly available real dataset of complex hydraulic systems, which has been publicly released by the UC Irvine Machine Learning Repository [2, 10]. The author has developed a hydraulic test bench to measure the state data of this hydraulic system through multiple real and virtual sensors, from which the characteristics of the hydraulic system under different faults are analyzed. This study is illustrated with one of the cooling state health states, which are divided into three operating states: Close to Total Failure (CTF), Reduced Efficiency (RE), and Full Efficiency (FE). For each condition, 150 sets of data are selected for the calculation to obtain a priori knowledge, and 60 sets of data are selected as tests to verify the results.
3.1 Cloud Model Parameters Calculation
The actual industry faces the problem of inconsistent sensor sampling rate, to unify the data length, this paper adopts the unified data length utilizing time–frequency domain feature extraction, 24 common time–frequency domain features are selected in this paper [11], and finally, the cloud model feature matrix data of the cooling condition of the hydraulic system of 3*24 is obtained, and the value of super entropy is taken as a constant value of 0.1, as shown in Table 54.1. Due to space limitation, only the first five parameters of a set of test data are shown in all the following tables.
3.2 Calculation of the Basic Probability Assignment Matrix
According to the obtained cloud model parameters, calculate the membership degree of each parameter relative to the corresponding parameter of the cooling state of the hydraulic system, calculate the uncertainty of each piece of evidence, to obtain the basic probability assignment matrix of the hydraulic system as shown in Table 54.2.
3.3 Iteration of Homogeneous Sensor Merging Evidence
The same sensors in this dataset are iterated to merge evidence, 8 heterogeneous sensor evidence information are obtained, and finally, these 8 shreds of evidence are fused by applying Dempster’s rule to obtain the cooling condition health assessment of this hydraulic system, as shown in Table 54.3, and the final fusion result of this test data is FE.
3.4 Experimental Results
The 60 sets of data of the cooling condition of each type of hydraulic system are subjected to the above experimental calculation, and the final operating condition classification results are shown in Fig. 54.2. It can be seen that the classification accuracy of the three operating states of the cooling condition of this hydraulic system reached 100%, and achieved quite good classification results, which proved the feasibility and effectiveness of the improved D–S evidence theory based on the cloud model.

Experimental results
4 Conclusions
In this paper, a hydraulic system health assessment method based on the cloud model and D–S evidence theory is proposed to address the problem of ambiguity and randomness of each assessment state quantity in hydraulic system health state assessment. To cope with the problem of the inconsistent sampling rate of hydraulic system acquisition sensors in the industry, a time–frequency domain feature analysis is performed to unify the data length; then, a multi-source information uncertainty fusion method for hydraulic system condition monitoring is constructed using the cloud model from quantitative to qualitative modeling and using D–S evidence theory to obtain the assessment results of hydraulic system health status. The validity and feasibility of the method are verified by real data sets to provide a basis for the condition maintenance of the hydraulic system.
References
P. Guo, J. Wu, X. Xu, Y. Cheng, Y. Wang, Health condition monitoring of hydraulic system based on ensemble support vector machine, in 2019 Prognostics and System Health Management Conference (PHM-Qingdao) (2019), pp. 1–5. https://doi.org/10.1109/PHM-Qingdao46334.2019.8942981
N. Helwig, E. Pignanelli, A. Schuetze, Ieee, Condition Monitoring of a Complex Hydraulic System using Multivariate Statistics (2015 IEEE International Instrumentation and Measurement Technology Conference, 2015), pp. 210–215
T.M.A. Manghai, R. Jegadeeshwaran, G. Sakthivel, R. Sivakumar, D.S. Kumar, IEEE, Condition monitoring of hydraulic brake system using rough set theory and fuzzy rough nearest neighbor learning algorithms, in 2019 Ieee International Symposium on Smart Electronic Systems (IEEE Computer Soc, Los Alamitos (in English), 2019), pp. 229–232
C. Konig, A.M. Helmi, Sensitivity analysis of sensors in a hydraulic condition monitoring system using CNN models. Sensors 20(11), 3307. https://doi.org/10.3390/s20113307
L. Wang, K. N. Teng, W. M. Lv, System level health condition assessment method of complex equipment under uncertainty based on D-S evidence theory, in 2014 International Conference on Management Science & Engineering, H. Lan Ed., (International Conference on Management Science and Engineering-Annual Conference Proceedings, IEEE, New York, 2014), pp. 435–441
G.Z. Zhao, A.G. Chen, G.X. Lu, W. Liu, Data fusion algorithm based on fuzzy sets and D-S theory of evidence, (in English). Tsinghua Sci. Technol. 25(1), 12–19. https://doi.org/10.26599/tst.2018.9010138
F.Y. Xiao, A new divergence measure for belief functions in D-S evidence theory for multisensor data fusion (in English). Inf. Sci. 514, 462–483. https://doi.org/10.1016/j.ins.2019.11.022
S. Kaparthi, A. Mann, D.J. Power, An overview of cloud-based decision support applications and a reference model (in English). Stud. Inform. Control 30(1), 5–18. https://doi.org/10.24846/v30i1y202101
Y. Li, A. Wang, X. Yi, Based on normal cloud model and D-S evidence theory comprehensive evaluation of operation state of fire control system, in 2019 International Conference on Sensing, Diagnostics, Prognostics, and Control (SDPC), (2019), pp. 877–883. https://doi.org/10.1109/SDPC.2019.00167
S.S. Chawathe, Condition Monitoring of Hydraulic Systems by Classifying Sensor Data Streams (2019 IEEE 9th Annual Computing and Communication Workshop and Conference, 2019), pp. 898–904
Y. Lei, Z. He, Y. Zi, Q. Hu, Fault diagnosis of rotating machinery based on multiple ANFIS combination with GAS. Mech. Syst. Signal Proc. 21(5), 2280–2294 (2007). https://doi.org/10.1016/j.ymssp.2006.11.003
Acknowledgements
The research is supported by Beijing Natural Science Foundation (grant number L212033), and the National Key Research and Development Program of China (grant number 2019YFB1705502).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Mei, S., Yuan, M., Cui, J., Dong, S., Zhao, J. (2022). Health Condition Assessment of Hydraulic System Based on Cloud Model and Dempster–Shafer Evidence Theory. In: Liu, G., Cen, F. (eds) Advances in Precision Instruments and Optical Engineering. Springer Proceedings in Physics, vol 270. Springer, Singapore. https://doi.org/10.1007/978-981-16-7258-3_54
Download citation
DOI: https://doi.org/10.1007/978-981-16-7258-3_54
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-7257-6
Online ISBN: 978-981-16-7258-3
eBook Packages: Physics and AstronomyPhysics and Astronomy (R0)