
Abstract
Small-sample classification is a challenging problem in computer vision and has many applications. In this paper, we propose an image-text dual model to improve the classification performance on small-sample dataset. The proposed dual model consists of two sub-models, an image classification model and a text classification model. After training the sub-models respectively, we design a novel method to fuse the two sub-models rather than simply combining the two models’ results. Our image-text dual model aims to utilize the text information to overcome the problem of training deep models on small-sample datasets. To demonstrate the effectiveness of the proposed dual model, we conduct extensive experiments on LabelMe and UIUC-Sports. Experimental results show that our model is superior to other models. In conclusion, our proposed model can achieve the highest image classification accuracy among all the referred models on LabelMe and UIUC-Sports.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
With the wide use of the internet, the image data on the network is increasing dramatically. How to retrieve and understand the image data correctly is a hot and difficult problem in the current research of computer vision. In recent years, with the development of deep learning, learning and extracting semantic information of massive images using convolutional neural network provides an effective solution for image understanding. However, we usually consider too much about the ideal situation but ignore the actual cases. In many applications, there is no sufficiently large amount of data but only small amount of labeled data, e.g., LabelMe dataset [12] and UIUC-Sports dataset [8]. The two datasets consist of 8 classes. Each class has more than 130 and less than 326 images. The total numbers of images in the two datasets are much smaller than that of other image datasets, such as Flickr [3] and MS COCO [10], which are frequently used in many image classification tasks. However, a large number of labeled samples are required in supervised learning. Adding annotations to data will cost a lot of manpower. On the other hand, the efficiency of artificially image tagging is very unstable and the results can easily be affected. Generally speaking, manual annotation is not only laborious but also easy to get subjective and individual tagging errors. Therefore, how to achieve similar performance on the small-sample dataset as on the large dataset is an important problem in the field of computer vision. Moreover, how to learn semantic information from small amount of labeled samples, among others, is one striking challenge. Motivated by this observation, this paper aims to study image semantic learning on small-sample datasets. The category of the images can be regarded as a general description. Hence, the image classification task is one of the fundamental tasks.
To tackle the challenges, we decompose the problem of image classification into two manageable sub-problems. An image classification model is trained on the given images, and a text classification model is built on the annotations. On top of the two classification models, we introduce a fusion process to learn the connection between the two sub-models.
The main contribution of our paper is to present an image-text dual model. Comparing with some existing models for image classification on small-sample datasets, our model achieves the best performance in terms of classification accuracy on LabelMe dataset and UIUC-Sports dataset [8, 12, 16, 17]. Our model can also save computational resources significantly.
2 Related Work
The method based on topic model to learn semantic features is the direction that researchers have been focused on recently [2, 4, 6, 14, 16, 17]. A topic model refers to a statistical model that discovers or learns abstract topics of documents, which origins from natural language processing (NLP) [2, 4]. In recent years, with the fast developing of neural network research, the research about neural topic model, which is the topic model based on neural network [6], and image classification based on neural topic model has been started [2, 4, 6, 14, 16, 17].
Larochelle et al. proposed a model at the 2012’s NIPS conference, the model named Document Neural Autoregressive Distribution Estimator (DocNADE) [6], can obtain good topic features. The model assumes that the generation of each word is only associated with the words that generated before it, and the document is the product of a set of conditional probabilities, which is generated by a feedforward neural network. The advantage is that the method models the relationship between words and the calculation of latent variables does not require complex approximate reasoning as other probabilities generation models. Zheng et al. presented the SupDocNADE, a shallow model based on the DocNADE [16, 17]. The model got 83.43% accuracy on LabelMe and 77.29% accuracy on UIUC-Sports [8, 12, 16, 17]. Recently, there has been remarkable progress in the direction under big data with the development of deep learning, however there is still room for improvement in this area. AlexNet trained on ImageNet obtained perfect performance for image classification [5]. Zhou et al. [18] proposed a method of extracting features trained on Places dataset. The model is similar to AlexNet, and got perfect performance on several datasets. Zisserman et al. proposed VGG-Net [15], which achieved the first place on the localization task of ILSVR and the second place on the classification task of ILSVR. However, the models mentioned above are all deep models. Since deep models have a large number of parameters needed to be trained, the models can not be trained adequately on small-sample datasets, therefore, the performance will be constrained. To tackle this problem, we utilize the semantic of annotations to learn images’ deep semantic features and improve the performance of image classification on small-sample dataset.
In the previous methods, there were two ways to learn the connections between image and the corresponding annotations. One was to input the joint features of images and annotations into a classification model, the other was to input the features of images and annotations to the classification models separately. Summarizing the existing methods, the classification models on small-sample dataset mostly utilize traditional methods not deep models. This is because the deep models can not be trained reliably on small-sample dataset. Hence, we propose an image-text dual model in order to utilize the annotations’ semantic information to overcome the insufficient training problem. By comparing with some recently proposed methods, we find that our semantic information can achieve significant improvement in terms of image classification accuracy.
The main contribution of our paper is to propose an image-text dual model. The model utilizes two models to respectively learn image and text features and fuse the two models’ results in the end. Our model can utilize annotations’ semantic information to improve the performance of image classification model. The proposed dual model achieves 97.75% classification accuracy on LabelMe dataset [12] and 99.51% classification accuracy on UIUC-Sports dataset [6].
3 Image-Text Dual Model
In order to utilize annotations’ semantic information to improve the performance of the image classification model, we propose a simple yet effective image-text dual model. It decomposes the traditional image classification model into two models.
Image model: It is an end-to-end network fine-tuned by VGG16 [15], which gives the image classification results.
Text model: It is an end-to-end neural network as well, it gives the annotations classification results.
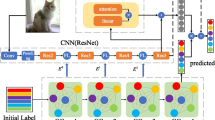
Ultimately, we propose a method to fuse the image classification results and the annotations classification results to predict the final class that the input image belongs to. The architecture of the proposed image-text dual model is shown in Fig. 1.

Illustration of the image-text dual model. Images and annotations are trained respectively. On top of the two classification models, we add another fusion processing to merge the two models’ results. To learn the connection between the two models, we propose a method in the fusion process.

Illustration of image classification model. We take only the convolutional layers of VGG16 and drop the FC layers. On top of the convolutional layers, we add two FC layers. When fine-tune the model, we freeze the first four convolution blocks and fine-tune the fifth convolution block and new FC layers
3.1 Image Model
Instead of simply jointing the image features and annotations features as input of one model, we train two models respectively. We use transfer learning [13] to build the model. Transfer learning allows to utilize known relevant task data to solve new unknown tasks. We use VGG16 [15] as pre-trained model and fine-tune the model on our pre-processed datasets [8, 12]. The structure of our image model is shown in Fig. 2.
Implementation details. The model consists of five convolutional blocks and two full-connected(FC) layers. The convolutional blocks consist of 3 \(\times \,\)3 stride 1 convolutions and ReLU. Between two convolutional blocks, there is 2 \(\times \) 2 stride 2 maxpooling. The stack of convolutional layers is followed by two FC layers: the first contains 512 channels, the second is a soft-max layer with 8 channels (one for each class).
3.2 Text Model
To learn the semantic information of the annotations, we build a text classification model consisted of three FC layers as shown in Fig. 3. There are many ways to build word embedding. We applied the word2vec [7, 11] and bag of words model to build the text vectors. The two methods work well in text classification tasks. And we further attempt to use PCA [1] to reduce word vecotrs to lower dimensions.
Implementation details. The model consists of three FC layers: the first contains 64 channels, the second contains 512 channels, the third is a soft-max layer with 8 channels (one for each class).
3.3 Fusion Models
We get the soft-max layer’s output \(P_{img}(c)\) of the image model and the soft-max layer’s output \(P_{text}(c)\) of the text model. \(P_{img}(c)\) and \(P_{text}(c)\) are all of eight dimensions. Each of the dimensions represents the probability of the sample belongs to a specific class. The final result \(c_{final}\) is predicted by merging the two models’ results. Simple way of fusion is to add the two models’ results together. However this fusion strategy can not get good results. We propose a method to combine the results of the two models as shown in (1). \(\lambda \) is a regularization parameter that controls the balance between the two sub-models. The range of values of \(\lambda \) is between 0 to 1.

Illustration of text classification model.
4 Experiment Results and Discussions
To evaluate the proposed image-text dual model, we conducted extensive quantitative and qualitative evaluations on LabelMe dataset and UIUC-Sports dataset [8, 12]. The two datasets contain images’ annotations and are popular classification benchmarks. We provided a quantitative comparison between SupDocNADE, Fu-L, Mv-sLDA [9, 16, 17]. Following Li et al. [9], we randomly extracted five subsets of LabelMe dataset [12] and five subsets of UIUC-Sports dataset [8]. We used the mean classification accuracy of the five subsets to measure the performance of image classification.
4.1 Datasets Description
The LabelMe dataset [12] collected by Aude Oliva, Antonio Torralba. LabelMe dataset [12] has eight classes: coast, forest, highway, inside city, open country, street, tall building. For each class in one of our subsets, 200 images were randomly selected and split evenly in the training and test sets, yielding 1600 images.
The UIUC-Sports dataset [8] collected by L. Li and F. Li. It contains 1792 images, classified into eight classes. Each subset we constructed consists of 1720 images: badminton (300 images), bocce (130 images), croquet (300 images), polo (190 images), rockclimbing (190 images), rowing (250 images), sailing (180 images), snowboarding (190 images). The images are randomly selected and split evenly in the training and test sets.
4.2 Performance Analysis
In this section, we analyze our proposed dual model on LabelMe dataset [12] and UIUC-Sports dataset [8] with baseline models shown in Fig. 4.
The mean image classification accuracy of our single image model on LabelMe [12] is 80.9% and on UIUC-Sports [8] is 70.7%. Our single image model can get better performance than single image classification model in Fu-L and Mv-sLDA [9].

The vertical axis presents the classification accuracy and the horizontal axis represents the value of the weight \(\lambda \) in (1).
We use word2vec [7, 11] and bag of words to build text vectors. However, word2vec [7, 11] in our task does not have good performance. The reason is that word2vec fits for sentences but not for separate words. Furthermore, only less than 1000 words in total can not train by neural network sufficiently to get a good word2vec embedding. In our work, we choose the bag of words model to build the text vectors. We further attempted to use PCA [1] to reduce word vectors to lower dimensions. The mean text classification accuracy on LabelMe dataset without PCA [1] is 95.13%. The accuracy is 94.73% after reducing to 480 dimensions with PCA. The accuracy is 93.78% after reducing to 240 dimensions. The model without PCA is always higher than the model with PCA [1]. This is due to the fact that the dimension of the original vectors is not high for the neural model to train. Therefore, without dimension reduction, better result can be obtained. The mean text classification accuracy on UIUC-Sports dataset [8] without PCA [1] is 99.35%. The aforementioned text classification model also can get better performance than the text classification models in Fu-L, Mv-sLDA [9].
Figure 4 shows the trend of image classification accuracy with different values of \(\lambda \). When \(\lambda \) is 0, the model is the text classification model. When \(\lambda \) is 1, the model is the image classification model. Good performance can be obtained when \(\lambda \) falls in [0.4, 0.5] on LabelMe and can be obtained when \(\lambda \) falls in [0.2, 0.3] on UIUC-Sports. As illustrated in Fig. 4, the dual model achieves significant improvement than the single models. It exhibits that our image-text dual model reliably effective. These experimental results demonstrate that the proposed dual model can overcome the insufficient training of deep models on small-sample datasets. The idea that utilizing annotations’ semantic information to improve image classification model’s capability is proved to be feasible. As reason that the probability values of classes from image classification model’s soft-max layer are much bigger than the values of text classification model’s, so the dual model’s accuracy drops rapidly when \(\lambda \) is equal or greater than 0.5.
As shown in Tables 1 and 2, we can conclude that the proposed image-text dual model can get the highest image classification accuracy on LabelMe dataset when \(\lambda \) is 0.46 and on UIUC-Sports dataset when \(\lambda \) is 0.26.
4.3 Experimental Results
In this section, we describe quantitative comparison between our dual model and other methods. The classification results are illustrated in Table 3. Our dual model obtains an accuracy of 97.75% on the LabelMe [12] dataset and 99.51% on UIUC-Sports dataset. This is significantly superior to other models’ performance on the two datasets as shown in Table 3.
We compare the proposed image-text dual model with the SupDocNADE [16, 17], which uses the image-text joint embedding during training and inputs images only during test stage. Since using the code published by the author can not get the accuracy in paper, we compare directly with the results found in the corresponding paper [16, 17]. The reported accuracy is 83.43% on LabelMe and 77.29% on UIUC-Sports for SupDocNADE [16, 17], which is lower than our image-text dual model as shown in Table 3. Therefore, we can conclude that training the image and text separately can yield better results. In addition, the max iteration number for training SupDocNADE [16, 17] is 3000. Our image model only needs 350 epochs to train at most, 100 epochs to fine-tune and the text model also only needs 100 epochs at most, as our models’ parameters are less than SupDocNADE’. For the reason that we decompose one model into two sub-models and use fine-tune during training the image model. What’ more, the two sub-models can be trained parallelly at the same time. Our single image model’s accuracy is lower than SupDocNADE because deep models have the problems of insufficient training and the single image model don’t utilize the annotations. The final result shows that our model can learn the semantic information of images’ annotations better.
We also compare the proposed model requiring both images and annotations during test stage, i.e., Fu-L and Mv-sLDA [9]. Fu-L and Mv-sLDA all utilize traditional methods but not deep learning [9]. The structure of Fu-L is similar to our model. Fu-L builds two separate traditional models on image modal and text modal. Then Fu-L utilizes the third model to fuse the two models. Mv-sLDA builds a traditional model can classify both image modal and image modal. After training separately, it fuses the results of image model and text model. As shown in Table 3, our model’s image classification accuracy achieves the best performance for the reason that we introduce the deep models to the small-sample datasets.
5 Conclusions
In this paper, we proposed an image-text dual model for the task of small-sample image classification. The proposed method decomposes the image classification model into two manageable ones, i.e., an image classification model and a text classification model. Furthermore, we propose a method to fuse the two sub-models. Extensive quantitative and qualitative results demonstrate the effectiveness of our proposed model. Compared to some recently proposed models, our method can better incorporate the semantic information of the annotations. Therefore, we can get higher image classification accuracy. Moreover, our image-text dual model needs few epochs to train because it contains the few parameters. In our work, the two sub-models can be trained at the same time also contributes to saving the computational efficiency. In addition, the structure of our dual model can be extended to other modalities, e.g. image-sketch, image-video, text-video.
References
Bishop, C.M.: Pattern Recognition and Machine Learning. Springer, New York (2006)
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent dirichlet allocation. JMLR 3(1), 993–1022 (2003)
Hare, J.S., Lewis, P.H.: Automatically annotating the MIR Flickr dataset: experimental protocols, openly available data and semantic spaces. In: ACM MIR, pp. 547–556. ACM (2010)
Hofmann, T.: Probabilistic latent semantic indexing. In: ACM SIGIR, pp. 50–57. ACM (1999)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS, pp. 1097–1105 (2012)
Larochelle, H., Lauly, S.: A neural autoregressive topic model. In: NIPS, pp. 2708–2716 (2012)
Le, Q., Mikolov, T.: Distributed representations of sentences and documents. In: ICML, pp. 1188–1196 (2014)
Li, L., Li, F.: What, where and who? classifying events by scene and object recognition. In: IEEE ICCV, pp. 1–8. IEEE (2007)
Li, X., Li, R., Feng, F., Cao, J., Wang, X.: Multi-view supervised latent dirichlet allocation. Acta Electron. Sin. 42(10), 2040–2044 (2014)
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013)
Oliva, A., Torralba, A.: Modeling the shape of the scene: a holistic representation of the spatial envelope. IJCV 42(3), 145–175 (2001)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE TKDE 22(10), 1345–1359 (2010)
Putthividhya, D., Attias, H.T., Nagarajan, S.S.: Topic regression multi-modal latent dirichlet allocation for image annotation. In: IEEE CVPR, pp. 3408–3415. IEEE (2010)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Zheng, Y., Zhang, Y., Larochelle, H.: Topic modeling of multimodal data: an autoregressive approach. In: IEEE CVPR, pp. 1370–1377 (2014)
Zheng, Y., Zhang, Y., Larochelle, H.: A deep and autoregressive approach for topic modeling of multimodal data. IEEE TPAMI 38(6), 1056–1069 (2016)
Zhou, B., Lapedriza, A., Xiao, J., Torralba, A., Oliva, A.: Learning deep features for scene recognition using places database. In: NIPS, pp. 487–495 (2014)
Acknowledgement
This work was supported in part by the National Natural Science Foundation of China (NSFC) under Grant 61773071, Grant 61628301, Grant 61402047 and Grant 61563030, in part by the Beijing Nova Program Grant Z171100001117049, in part by the Beijing Natural Science Foundation (BNSF) under Grant 4162044, and in part by the CCF-Tencent Open Research Fund.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhu, F. et al. (2017). Image-Text Dual Model for Small-Sample Image Classification. In: Yang, J., et al. Computer Vision. CCCV 2017. Communications in Computer and Information Science, vol 772. Springer, Singapore. https://doi.org/10.1007/978-981-10-7302-1_46
Download citation
DOI: https://doi.org/10.1007/978-981-10-7302-1_46
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7301-4
Online ISBN: 978-981-10-7302-1
eBook Packages: Computer ScienceComputer Science (R0)