
Abstract
3D-AVS2 is the 3D extension of AVS2 (audio video coding standard 2), which is under the development of AVS Working Group. Besides including all efficient techniques in AVS2, it has developed extensive 3D coding tools consist of disparity compensated prediction and the inter-view motion information inheritance. In these inter-view techniques, disparity vector (DV) plays a critical role to eliminate inter-view redundancy. Global disparity vector (GDV) is first proposed as the DV derivation method in 3D-AVS2, which is calculated by averaging all the disparity vectors of \(16\times 16\) block in the latest previous coded frame. The prediction accuracy of GDV may be however limited by the lack of local adaptivity. Thus we propose the local disparity vector (LDV) and its improved sub-candidate local disparity vector (SCLDV) derivation scheme to make full use of local information. In addition, utilizing depth map to refine DV can further improve our derivation scheme. Experimental results show that the proposed SCLDV derivation method can provide 1.34% and 0.92% BD-rate saving in low delay P (LDP), and 1.00% and 0.73% BD-rate saving in random access (RA) for the compressed views and synthesized views compared with the GDV scheme, respectively. It also shows that our LDV scheme can be further improved by depth refinement.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Driven by the enormous development of three-dimensional (3D) video techniques and increasing popularity in 3D video content, 3D video services such as 3D television [1] and free viewpoint television [2] (FTV) become more and more popular. To better support various 3D video applications, the working group of China audio video coding standard [3] (AVS) begins to develop a 3D or multi-view video oriented coding standard. In 2014, the 3D Ad hoc Group is established to develop 3D-AVS2 standard on top of AVS2 [4], which aims to provide high coding efficiency for multi-view plus depth (MVD) video data and support high quality depth-based image rendering for auto-stereoscopic.
Since all cameras capture the same scene simultaneously from different views, compared with conventional 2D video compression, eliminating the statistical redundancy among different views in the same instant, i.e., inter-view redundancy, is a considerable and fundamental problem in multi-view and three-dimensional (3D) video coding. To exploit the inter-view correlation, disparity vector (DV) is required to identify pixels of the same object in two different views to utilize texture or motion information in coded view for the current. Such inter-view techniques can be employed as new modes to further improve the compression efficiency.
Besides including all efficient coding tools in 2D video, 3D-AVS2 has developed extensive 3D coding tools consist of disparity compensated prediction (DCP) and the inter-view motion information inheritance. Since the accuracy of DV has direct impact on the efficacy of these inter-view techniques, how to efficiently derive an effective DV needs to be carefully explored.
In 3D-AVS2, global disparity vector [5] (GDV) is first proposed as the DV derivation method, which is calculated by averaging all the disparity vectors of \(16\times 16\) block in the latest previous coded frame. The global disparity vector exploits the global information and a constant DV is used for the whole picture, however, the prediction accuracy of GDV may be limited by the lack of local adaptivity. Hence, we propose a novel local disparity vector (LDV) [6] derivation scheme fully utilizing the neighbouring information to replace the GDV in 3D-AVS2. Then the improved versions of sub-candidate LDV (SCLDV) [7] and depth refinement of LDV [10] are also considered to further improve the accuracy, which have been adopted by MV-AVS2 in 59th AVS meeting [7] and 3D-AVS2 in 60th AVS meeting [10], respectively.
In this paper, the DV derivation schemes especially local disparity vector (LDV) derivation schemes in 3D-AVS2 is fully explained. The rest of this paper is organized as follows. In Sect. 2, the global disparity vector (GDV) scheme is introduced. The technical details of the proposed local disparity vector (LDV) and its improved versions are described in Sect. 3. The experimental results are presented and analysed in Sect. 4. At last, Sect. 4 concludes the paper.
2 Global Disparity Vector Derivation Scheme
In 3D-AVS2, the global disparity vector (GDV) [5] derivation scheme is proposed by considering the inter-similarity between the current frame with the frame that coded before.

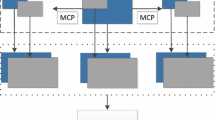
Global disparity vector derivation scheme.
More specifically, there are three prediction modes in one coded frame, as shown in Fig. 1, intra prediction, motion compensation prediction (MCP) and disparity compensation prediction (DCP). If the block is disparity compensated, the disparity vector can be acquired. It is assumed that the disparity vectors are typically highly correlated in temporary direction. When coding the current frame, the previously coded frame’s disparity vectors information can be used to derive current frame’s disparity vector.
There are many ways to derive the global disparity vector (GDV) in current frame. In 3D-AVS2 standard, GDV [5] is calculated by averaging all disparity vectors of block \(16\times 16\) in the latest previous coded frame, performed as formula 1.
where \(\varvec{\varOmega }\) indicates the set of all DVs in the \(16\times 16\) blocks of latest previously coded frame, and N is size of \(\varvec{\varOmega }\).
It is a two dimensional vector that explicitly transmitted for each texture picture and all blocks in the same picture share this vector. The benefit of GDV lies in low coding complexity and it replaces zero-dv in following inter-view techniques in 3D-AVS2:
-
The predictor of disparity vector (PDV) in inter prediction mode: When reference picture is an interview reference in inter prediction and the predictor of the disparity vector (PDV) is zero vector, replace the PDV with GDV.
-
Inter-view motion information inheritance techniques: GDV instead of the zero vector is used to find a corresponding block in the reference view so that motion information of this block can be inherited by the current block.

Local-adapted neighboring region (LANR).

3 Local Disparity Vector (LDV) Derivation Scheme
The GDV can be derived with low coding complexity and performs better than zero-disparity vector, however, the GDV exploits the global information and a constant DV is used for the whole picture. The prediction accuracy of GDV may be limited by the lack of local adaptivity. In order to further improve the coding efficiency of 3D-AVS2, a more accurate DV which adapts to the content is strongly desired.
3.1 LDV Derivation Based on LANR
Disparity vectors also present high spatial correlations, it can be easily inferred that if a block is coded by inter-view prediction, its neighboring blocks also coded by inter-view prediction may have a similar disparity vector. Based on this, we propose an improved local disparity vector [6] (LDV), where the local-adapted neighboring region (LANR) is defined to explore the content-based adaptivity.
As shown in Fig. 2, the LANR of current prediction unit (PU) is defined as its left, above left, above and above right blocks, which are already compressed and their coding information can be used to derive the DV for current PU. In the Fig. 2, W and H indicate the width and height of current PU. The parameter R is utilized to adaptively adjust the range of LANR.
Subsequently, the LDV can be calculated by averaging all the DVs of \(4\times 4\) blocks in the LANR as follows,
where \({\varvec{\varOmega }}_{{\varvec{R}}}\) indicates the set of all DVs in the LANR given R, and \(N_R\) is size of \({\varvec{\varOmega }}_{{\varvec{R}}}\).
Furthermore, the range of LANR can adaptively expand for maximum information utilization. The algorithm of the proposed method is shown in Algorithm 1. Firstly we examine whether a non-zero LDV is derived by initializing \(R=1\). If not, R would be continually increased by a step of 1 to expand the LANR until a non-zero LDV is acquired or the R reaches the maximum fixed \(R_M\). \(R_M\) is a parameter which can be defined by users in configuration file and suggested to be 4 in 3D-AVS2. Finally, if the derived LDV is non-zero, it will replace the GDV in 3D-AVS2.

Sub-candidate local-adapted neighboring region (SCLANR)

3.2 Sub-candidate LDV (SCLDV) Derivation Scheme
Averaging all DVs in the whole neighboring region can be inaccuracy when the parameter R becomes larger. In order to fully use the statistical similarity, the neighboring region has been expanded and divided into five spatial neighbouring candidate region. We introduce them as the sub-candidate local-adapted neighboring regions [7] (SCLANR), which include the left (a 1), above left (b 1), above (b 2), above right (b 0) and below left (a 0) coded blocks of current prediction unit (PU), as shown in Fig. 3. W and H also indicate the width and height of current PU. The parameter R is utilized to adaptively adjust the range of SCLANR.
Unlike deriving LDV using all the neighboring regions, we advance a priority search method where each candidate region is checked in a certain defined order to decide whether the dvs are derived or not within it. If dvs can be acquired in one candidate region, the search processing will terminate. Otherwise, the five candidate areas are automatically expanded by increasing the parameter R to continue searching until the dvs are found or the maximum area size is reached. And all the dvs we find in this candidate region are averaged to derive the final LDV, presented as formula 3.
where \({\varvec{\varOmega }}_{{\varvec{SC}}_{{\varvec{R}}}}\) indicates the set of all DVs in one sub-candidate local-adapted region (SCLANR) given R, and \(N_R\) is size of \({\varvec{\varOmega }}_{{\varvec{SC}}_{{\varvec{R}}}}\).
The searching-order can be arranged in many ways. In 3D-AVS2, the scheme of a 1, b 1, b 2, b 0, a 0 is employed. The algorithm is similar with Algorithm 1, but we only averaging the dvs in one candidate region, as shown in Algorithm 2. In this way, the non-zero sub-candidate LDV (SCLDV) is derived and it will replace GDV in all inter-view techniques such as inter-view motion information inheritance.
3.3 Depth Refinement of LDV
Utilizing depth information, our proposed LDV derivation scheme can be further improved. In the current multi-view or three-dimensional (3D) system, 1D linear camera arrangement scenario is most commonly used, as shown in Fig. 4. Depth to disparity mapping can be defined as formula 4 in which f means focal length of two cameras, c means the translation between two cameras, d means the depth value of current point, and the function \(DV_{Depth}\) means depth to DV conversion.

Depth to disparity vector mapping in 1D linear camera arrangement
In 3D-AVS2, texture layer is coded before depth layer for each view. The true depth value d is not available yet when coding current texture block, thus an estimated depth value derived from the corresponding depth picture of the reference view is required in formula 4 to obtain the DV. Depth oriented neighbouring block based disparity vector [8] (DoNBDV) is proposed in 3D-HEVC by using the derived NBDV to locate the corresponding depth block in the reference view. Converting the max depth of four corners in derived depth block into refined disparity can further improve the accuracy of NBDV. Motivated by this, the derived LDV in Sect. 3.2 can also be used to locate the depth block in base view and refined [9, 10] by utilizing the depth map information.
In details, for current block B in the current picture, first employing the derived LDV locates the depth block \(DB_1\) in the corresponding depth picture of the reference view shown in Fig. 5. The maximum value of four corners of \(DB_1\) is considered as the estimated depth to derive the DV (donated as \(DV_1\)) as shown in formula 5.
\(dm_1\) is the max value of four corners of \(DB_1\). Then the depth refinement of LDV is derived.
The performance can be promoted by more steps refinement using depth map. Take two-step depth refinement as an example, after deriving the one-step depth refinement dv \(DV_1\), another depth block \(DB_2\) is re-located in the corresponding depth picture of reference view by \(DV_1\) as shown in Fig. 5. And we use the maximum value of four corner of \(DB_2\) to derive the two-step depth refinement of LDV (denoted as \(DV_2\)) as shown in formula 6 where \(dm_2\) is the max value of four corners of \(DB_2\).
The derived depth-refined LDV can enhance the accuracy of DV and be applyed in techniques such as the disparity vector predictor, inter-view motion information inheritance to further improve the compression efficiency of 3D-AVS2.

One step refinement derives \(DV_1\), then using \(DV_1\) can re-derive \(DV_2\).
4 Experimental Results
To verify the efficiency of our proposed LDV derivation schemes, all of them have been implemented on RFD8.0 [11], the latest reference software of 3D-AVS2. And it is tested strictly in accordance with the common test conditions [12] of 3D-AVS2, where the low delay P (LDP) and random access (RA) configurations are used for simulation.
The commonly used BD-rate index [13] is utilized for comparing the performance of two different schemes. A negative value of the BD-rate indicates coding gains over the anchor. In following tables, the first and second column represent the BD-rate performance considering Y-PSNR of view 1 and 2 (dependent view). The third and fourth column represent the BD-rate performance considering Y-PSNR of the coded texture views over the bitrates of texture data and over the bitrates of texture data and depth data. The last column represents the BD-rate performance considering Y-PSNR of the synthesized texture views over the bitrates of texture data and depth data.
It should be noted that since GDV and SCLDV have been involved in RFD8.0. In Sect. 4.1, we close SCLDV and set GDV as anchor. In Sect. 4.2, the anchor is RFD8.0 with GDV and SCLDV opening.
4.1 Results of Sub-candidate LDV (SCLDV) Derivation
In this section, LDV derived in SCLANR [7] in Sect. 3.2 is tested. \(R_M\) is defined in suggested value 4. The searching order of candidate region is the left (a 1), above left (b 1), above(b 2), above right (b 0), and below left (a 0), which is advised in 3D-AVS2. If non-zero LDV can be derived, it will replace GDV in disparity vector predictor and inter-view motion information inheritance.
Tables 1 and 2 demonstrate that proposed SCLDV can reach 0.61% and 0.37% BD-rate saving in LDP, and 0.73% and 0.61% BD-rate saving in RA for the compressed views and synthesized views, respectively. It can be concluded that LDV is more accurate than GDV because of content-adaptivity.
4.2 Results of Depth Refinement of LDV
Depth map can be utilized to further improve the DV accuracy, depth refinement of SCLDV in this section is tested. RFD8.0 is the anchor, where GDV and SCLDV have already involved. Furthermore, we consider both one step and second step refinement.
Tables 3 and 4 illustrate that one step depth-based refinement can reach 1.34% and 0.92% BD-rate saving in LDP, and 1.00% and 0.73% BD-rate saving in RA for the compressed views and synthesized views, respectively. Tables 5 and 6 show that two step depth-based refinement can reach 1.37% and 0.97% BD-rate saving in LDP, and 1.05% and 0.78% BD-rate saving in RA for the compressed views and synthesized views, respectively.
From the results above, it can be confirmed that depth information does help to improve the accuracy of LDV and brings a appealing gain. It can also be noticed that more steps of depth refinement are employed, the better the performance improvements obtained. However, these improvements taper off as more steps are used, which can be easily inferred that the DV may be accurate enough with ample depth refinement.
5 Conclusion
In this paper, we have discussed different disparity vector derivation schemes in 3D-AVS2. Disparity vector plays a fundamental and crucial role in all inter-view techniques, how to derive an efficient DV is essential. Global disparity vector (GDV) can be derived with low coding complexity, the prediction accuracy of GDV may be however limited by the lack of local adaptivity. Therefore, we propose the local disparity vector (LDV) to fully utilize local information and further put forward sub-candidate local disparity vector (SCLDV) to achieve higher accuracy. Depth value can be converted into disparity vector using camera parameters. Derived local disparity vector (LDV) can locate the corresponding depth block in reference view to obtain estimated depth value to refine itself. The experimental results show that proposed LDV performs better than GDV with 0.61% and 0.37% BD-rate saving in low delay P configuration, 0.73% and 0.61% BD-rate saving in random access configuration for the compressed vies and synthesized views, respectively. It can be further improved by depth refinement and more steps of refinement can achieve better results.
References
Fehn, C., Cooke, E., Schreer, O., Kauff, P.: 3D analysis and image-based rendering for immersive TV applications. Sig. Process. Image Commun. 17(9), 705–715 (2002)
Tanimoto, M.: Overview of free viewpoint television. Sig. Process. Image Commun. 21(6), 454–461 (2006)
Fan, L., Ma, S., Wu, F.: Overview of AVS video standard. In: 2004 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, pp. 423–426. IEEE Press (2004)
AVS Workgroup: Information Technology - Advanced Media Coding Part2: Video 3D Extension WD, AVS Doc. AVS-M2245 (2015)
Ma, J., Zhang, Y., Zhang, N., Fan, X., Zhao, D.: An effective method for obtaining disparity vector. In: Document M3582. 51st AVS Meeting, Fuzhou, China (2014)
Mao, Q., Wang, S., Su, J., Zhang, X., Zhang, X., Ma, S.: A local-adapted disparity vector derivation scheme for 3D-AVS. In: 2016 Visual Communications and Image Processing (VCIP), Chengdu, pp. 1–4. IEEE Press (2016)
Mao, Q., Su, J., Cui, J., Wang, S., Luo, F., Ma, S.: CE: a local-adapted disparity vector derivation scheme. In: Document M4072. 59th AVS Meeting, Haikou, China (2016)
Chang, Y.-L., Wu, C.-L., Tsai, Y.-P., Lei, S.: CE1.h: Depth-Oriented Neighboring Block Disparity Vector (DoNBDV) With Virtual Depth Retrieval. In: Document JCT3V-C0131. The Third JCT-3V Meetings, Geneva, Switzerland (2013)
Zhang, J., Chen, J., Lee, J.Y., Park, M.W.: Depth based two-step disparity vector derivation for AVS2-3D. In: 2016 Visual Communications and Image Processing (VCIP), Chengdu, pp. 1–4. IEEE Press (2016)
Mao, Q., Su, J., Cui, J., Wang, S., Luo, F., Ma, S.: CE: a local-adapted disparity vector derivation scheme. In: Document M4125. 60th AVS Meeting, Beijing, China (2017)
Wang, S.: AVS2-P2-3D: Describe of the RFD 8.0 platform. In: Document N2385. 59th AVS Meeting, Haikou, China (2017)
Wang, S.: AVS2-P2-3D: RFD Common Test Condition and Software reference configuration. In: Document N2247. 55th AVS Meeting, Beijing, China (2015)
Bjontegaard, G.: Calculation of average PSNR differences between RD-curves. In: Document VCEG-M33 ITU-T Q6/16, Austin, TX, USA (2001)
Acknowledgement
This research was supported by grants from NVIDIA and the NVIDIA DGX-1 AI Supercomputer.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Mao, Q., Wang, S., Ma, S. (2017). Local Disparity Vector Derivation Scheme in 3D-AVS2. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10667. Springer, Cham. https://doi.org/10.1007/978-3-319-71589-6_26
Download citation
DOI: https://doi.org/10.1007/978-3-319-71589-6_26
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71588-9
Online ISBN: 978-3-319-71589-6
eBook Packages: Computer ScienceComputer Science (R0)
