
Abstract
Morphology is the process of analyzing the internal structure of words. Grammatical features and properties are used for this analysis. Like other Dravidian languages, Tamil is a highly agglutinative language with a rich morphology. Most of the current morphological analyzers for Tamil mainly use segmentation to deconstruct the word to generate all possible candidates and then either grammar rules or tagging mismatch is used during post processing to get the best candidate. This paper presents a morphological engine for Tamil that uses grammar rules and an annotated corpus to get all possible candidates. A support vector machines classifier is employed to determine the most probable morphological deconstruction for a given word. Lexical labels, respective frequency scores, average length and suffixes are used as features. The accuracy of our system is 98.73 % and a F-measure of .943, which is more than the same reported by other similar research.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
References
Jayan, J.P., Rajeev, R., Rajendran, S.: Morphological analyzer and morphological generator for Malayalam - Tamil machine translation. Int. J. Comput. Appl. (0975 – 8887) 13(8), 15–18 (2011)
Au-kbc.org. Tamil Morphological Analyzer (2015)
Selvam, M., Natarajan, A.M.: Improvement of rule based morphological analysis and POS tagging in Tamil language via projection and induction techniques. Int. J. Comput. 3(4), 357–367 (2009)
Anand Kumar, M., Dhanalakshmi, V., Soman, K.P., Rajendran, S.: A sequence labeling approach to morphological analyzer for Tamil language. Int. J. Comput. Sci. Eng. 2(6), 1944–1951 (2010)
Parameshwari, K.: An implementation of APERTIUM morphological analyzer and generator for Tamil. Probl. Parsing Indian Lang. 11, 41–44 (2011)
Akilan, R., Naganathan, E.R.: Morphological analyzer for classical Tamil texts: a rule-based approach. Int. J. Innov. Sci. Eng. Technol. 1(5), 563–568 (2014)
Shah, R., Dhillon, P.S., Liberman, M., Foster, D., Maamouri, M., Ungar, L.: A new approach to lexical disambiguation of Arabic text. In: Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, Massachusetts, pp. 725–735, 09–11 October 2010
Koehn, P., Knight, K.: Empirical methods for compound splitting. In: Proceedings of the Tenth Conference on European Chapter of the Association for Computational Linguistics, Budapest, Hungary, 12–17 April 2003
Nuhman, M.A.:
 , Revised edn, pp. 93–260. Poobalasingam Publications, Sri Lanka (2010)
, Revised edn, pp. 93–260. Poobalasingam Publications, Sri Lanka (2010)Naavalar, A.:
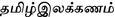 , 10th edn, pp. 88–180. Poobalasingam Publications, Sri Lanka (2008)
, 10th edn, pp. 88–180. Poobalasingam Publications, Sri Lanka (2008)
 , Revised edn, pp. 93–260. Poobalasingam Publications, Sri Lanka (2010)
, Revised edn, pp. 93–260. Poobalasingam Publications, Sri Lanka (2010)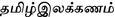 , 10th edn, pp. 88–180. Poobalasingam Publications, Sri Lanka (2008)
, 10th edn, pp. 88–180. Poobalasingam Publications, Sri Lanka (2008)Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Mokanarangan, T. et al. (2016). Tamil Morphological Analyzer Using Support Vector Machines. In: Métais, E., Meziane, F., Saraee, M., Sugumaran, V., Vadera, S. (eds) Natural Language Processing and Information Systems. NLDB 2016. Lecture Notes in Computer Science(), vol 9612. Springer, Cham. https://doi.org/10.1007/978-3-319-41754-7_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-41754-7_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-41753-0
Online ISBN: 978-3-319-41754-7
eBook Packages: Computer ScienceComputer Science (R0)