
Abstract
Sanskrit, the “sacred language” of Ancient India, is a morphologically rich Indo-Iranian language that has received some attention in NLP during the last decade. This paper describes a system for the tokenization and morphosyntactic analysis of Sanskrit. The system combines a fixed morphological rule base with a statistical selection of the most probable analysis of an input text. After an introduction into the research history and the linguistic peculiarities of Sanskrit that are relevant to the task, the paper describes the present architecture of the system and new extensions that increase its accuracy when analyzing morphologically ambiguous forms. The algorithms are tested on a gold-annotated data set of 3,587,000 words.
This is a preview of subscription content, log in via an institution.
Buying options
Tax calculation will be finalised at checkout
Purchases are for personal use only
Learn about institutional subscriptionsNotes
- 1.
- 2.
In a recent research project, the Aṣṭādhyāyī has been fully annotated on the morphological, lexical and word-semantic level to make it easier accessible for Western researchers without knowledge of Sanskrit [25]. A web platform that gives access to this database is available at http://panini.phil-fak.uni-duesseldorf.de/panini/.
- 3.
The rules of the Aṣṭādhyāyī are not given in the order in which they need to be applied for generating a valid Sanskrit word. Instead, it is generally assumed that their order minimizes the resulting rule base. The Indian grammar uses the concept of anuvṛtti (“following”) rules for regulating the order in which rules and their elements are applied. These rules are not part of the text of the Aṣṭādhyāyī, but are recorded – and heavily discussed – in the commentary literature; refer to [4, 187ff.] for details about rule order in the Aṣṭādhyāyī, and to [26] for the proof of minimality in a subset of Pāṇinian rules.
- 4.
Refer to page Subsect. 3.3 for the phonological phenomenon of Sandhi.
- 5.
The GRETIL web repository (http://gretil.sub.uni-goettingen.de/) contains less than 20 million strings. Several of the texts are not usable for automatic processing due to excessive formatting of their editors, as described in Sect. 3.6.
- 6.
The following abbreviations are used in this paper: Nom.: nominative; Acc.: accusative; Ins.: instrumental; Dat.: dative; Gen.: genitive; Loc.: locative; Voc.: vocative; Co.: compound; Sg.: singular; Du.: dual; Pl.: plural; Msc.: masculine; Fem.: feminine; Neu.: neuter; Ind.: indeclinable; Pres.: present; Impf.: imperfect; Perf.: perfect tense; Proh.: prohibitive (a kind of imperative that is only used in negated phrases); PastPart.: past participle, frequently with a passive sense; PresPart.: present participle
Ambiguities in a morphological analysis are expressed by a regex-style notation, with | denoting the operator OR and round brackets a set of options. So, (Nom.|Acc.|Voc.)Pl. Neu.means that a form is a neuter plural either in nominative or accusative or vocative.
The plus operator + is used to separate elements of compounds, the ampersand sign & to indicate Sandhi at word boundaries (Sect. 3.3).
Further abbreviations: tri: trigram based model for morphological disambiguation; crf: Conditional Random Fields; me: Maximum Entropy.
- 7.
Note that the word bahuvrīhi is itself an example of a bahuvrīhi compound. In its “default interpretation” as a so-called tatpuruṣa (“his man”, an instance of relational compounding) compound, it means just “much rice.”.
- 8.
From a purely grammatical point of view, the sentence can also be translated as “... destroyed by these bad actions.” Numerous references of the bahuvrīhi solution with unambiguous case endings (e.g., in Nom. Pl. Msc.) make the proposed interpretation much more plausible.
- 9.
Though slightly outdated, the grammar of Stenzler still provides a good introduction into Sanskrit Sandhi rules [33, 3ff.].
- 10.
Refer to [24, 1ff.] for a detailed linguistic description with several examples. Brockington locates the epics, especially the Mahābhārata, in a continuum “of dialects and language registers from classical or Pāṇinian Sanskrit at one end to colloquial MIA [Middle Indo-Aryan] at the other” [3, 83] and makes this linguistic situation responsible for the irregular application of Sandhi in epic texts.
- 11.
- 12.
A quantitative evaluation of the reuse of Pāṇinian vocabulary is presented in [11].
- 13.
A member of a low caste.
- 14.
- 15.
As these data are only checked by one annotator and have not been adjudicated, they should rather be called semi-gold annotations.
- 16.
The Mahābhārata and the Rāmāyaṇa are the two central epic texts written in Sanskrit. The term Purāṇa (“old (story)”) denotes a group of works dealing with virtually everything; refer to Rocher for an introduction [28].
- 17.
The TTRs found in the third column of Table 1 are obtained by calculating the TTRs for each text, and then averaging these values over the topic levels. Because text lengths have not been used as normalizing factors, the TTRs of underrepresented topic levels such as śruti or Buddhist literature are most probably too high.
- 18.
The one-solution case predicts the correct morphological category in about 99.8 % of all cases. The errors are caused by irregular word forms.
- 19.
The parameter 3 for the window size was chosen after comparing disambiguation results for window sizes between 1 and 7. Window sizes above 3 did not consistently increase the accuracy, but required higher training times.
- 20.
The final Sandhi ṃ has been transformed into the pausa form m.
- 21.
Used in the Java implementation of the OpenNLP package; settings: smoothing factor: 0.001, 100 iterations.
- 22.
Used in the C++ implementation from http://www.chokkan.org/software/crfsuite/; settings: L2 regularization: 2.0, one-dimensional architecture.
References
Adler, M., Elhalad, M.: An unsupervised morpheme-based HMM for Hebrew morphological disambiguation. In: Proceedings of the 21st International Conference on Computational Linguistics, pp. 665–672 (2006)
Bloch, J.: Indo-Aryan from the Vedas to Modern Times. Librarie d’Amérique et d’Orient, Paris (1965)
Brockington, J.: The Sanskrit Epics. Brill, Leiden (1998)
Cardona, G.:
 . A Survey of Research. Mouton, The Hague - Paris (1976)
. A Survey of Research. Mouton, The Hague - Paris (1976)Emeneau, M.: Dravidian and indo-aryan: the indian linguistic area. In: Emeneau, M.B. (ed.) Language and Linguistic Area, pp. 167–196. Stanford University Press, Stanford (1980)
Gillon, B.S.: Review of “Natural Language Processing: A Paninian Perspective" by A. Bharati, V. Chaitanya, and R. Sangal. Prentice-Hall of India 1995. Computational Linguistics 21(3), 419–421 (1995)
Gillon, B.S.: Word order in classical Sanskrit. Indian Linguist. 57(1–4), 1–35 (1996)
Hellwig, O.: \(\mathtt{{SadnskritTagger}}\): a stochastic lexical and POS tagger for Sanskrit. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) Sanskrit CL 2007/2008. LNCS, vol. 5402, pp. 266–277. Springer, Heidelberg (2009)
Hellwig, O.: Etymological trends in the Sanskrit vocabulary. Literary Linguist. Comput. 25(1), 105–118 (2010)
Hellwig, O.: Performance of a lexical and POS tagger for Sanskrit. In: Jha, G.N. (ed.) SCL. LNCS, vol. 6465, pp. 162–172. Springer, Heidelberg (2010)
Hellwig, O., Petersen, W.: What’s
 got to do with it? The use of
got to do with it? The use of  -headers from the Aṣṭādhyāyī in Sanskrit literature from the perspective of corpus linguistics. In: Proceedings of the WCS 2015 (forthcoming)
-headers from the Aṣṭādhyāyī in Sanskrit literature from the perspective of corpus linguistics. In: Proceedings of the WCS 2015 (forthcoming)Huet, G.: A functional toolkit for morphological and phonological processing, application to a Sanskrit tagger. J. Funct. Program. 15(04), 573–614 (2005)
Kiparsky, P.: On the architecture of
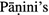 grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. Lecture Notes in Computer Science, vol. 5402, pp. 33–94. Springer, Heidelberg (2009)
grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. Lecture Notes in Computer Science, vol. 5402, pp. 33–94. Springer, Heidelberg (2009)Knauth, J., Alfter, D.: A dictionary data processing environment and its application in algorithmic processing of Pali dictionary data for future NLP tasks. In: Proceedings of the 5th Workshop on South and Southeast Asian NLP, pp. 65–73 (2014)
Kneser, R., Ney, H.: Improved backing-off for m-gram language modeling. In: Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pp. 181–184 (1995)
Kulkarni, A., Shukla, D.: Sanskrit morphological analyser: some issues. Indian Linguist. 70(1–4), 169–177 (2009)
Kulkarni, M.: Phonological overgeneration in paninian system. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. LNCS, vol. 5402, pp. 306–319. Springer, Heidelberg (2009)
Lafferty, J.D., McCallum, A., Pereira, F.C.N.: Conditional random fields: probabilistic models for segmenting and labeling sequence data. In: Proceedings of the Eighteenth International Conference on Machine Learning, pp. 282–289 (2001)
Lee, J., Naradowsky, J., Smith, D.A.: A discriminative model for joint morphological disambiguation and dependency parsing. In: Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, vol. 1, pp. 885–894 (2011)
Mayrhofer, M.: Kurzgefaßtes etymologisches Wörterbuch des Altindischen. Carl Winter Universitätsverlag, Heidelberg (1982)
Mishra, A.: Simulating the
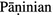 system of Sanskrit grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. LNCS, vol. 5402. Springer, Heidelberg (2009)
system of Sanskrit grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. LNCS, vol. 5402. Springer, Heidelberg (2009)Mittal, V.: Automatic Sanskrit segmentizer using finite state transducers. In: Proceedings of the ACL 2010 Student Research Workshop, pp. 85–90. Association for Computational Linguistics, Stroudsburg (2010)
Monier-Williams, M.:
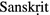 -English Dictionary, 3rd edn. Munshiram Manoharlal Publishers Pvt. Ltd., New Delhi (1988)
-English Dictionary, 3rd edn. Munshiram Manoharlal Publishers Pvt. Ltd., New Delhi (1988)Oberlies, T.: A Grammar of Epic Sanskrit. De Gruyter (2003)
Petersen, W., Soubusta, S.: Structure and implementation of a digital edition of the Aṣṭādhyāyī. In: Kulkarni, M. (ed.) Recent Researches in Sanskrit Computational Linguistics, pp. 84–103. D.K. Printworld, New Delhi (2013)
Petersen, W.: Zur Minimalität von
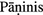 Śivasūtras: eine Untersuchung mit Methoden der formalen Begriffsanalyse. Ph.D. thesis, Universität Düsseldorf (2008)
Śivasūtras: eine Untersuchung mit Methoden der formalen Begriffsanalyse. Ph.D. thesis, Universität Düsseldorf (2008)Ratnaparkhi, A.: Maximum Entropy Models for Natural Language Ambiguity Resolution. Ph.D. thesis, University of Pennsylvania (1998)
Rocher, L.: The
 , A History of Indian Literature, vol. II, Fasc. 3. Otto Harrassowitz, Wiesbaden (1986)
, A History of Indian Literature, vol. II, Fasc. 3. Otto Harrassowitz, Wiesbaden (1986)Scharfe, H.: Grammatical Literature. A History of Indian Literature, Volume 5, Fasc. 2, Otto Harrassowitz, Wiesbaden (1977)
Shacham, D., Wintner, S.: Morphological disambiguation of Hebrew: a case study in classifier combination. In: Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pp. 439–447. Association for Computational Linguistics, Prague (2007)
Shukla, P., Kulkarni, A., Shukl, D.: Geeta: Gold standard annotated data, analysis and its application. In: Proceedings of ICON (2013)
Staal, J.: Word Order in Sanskrit and Universal Grammar. Foundations of Language, Supplementary Series, vol. 5. D. Reidel Publishing Company, Dordrecht (1967)
Stenzler, A.F.: Elementarbuch der Sanskrit-Sprache. Max Mälzer, Breslau (1872)
Witzel, M.: Early indian history: linguistic and textual parametres. In: Erdosy, G. (ed.) The Indo-Aryans of Ancient South Asia. Language, Material Culture and Ethnicity, vol. 1, pp. 85–125. Walter de Gruyter, Berlin (1995)
Yuret, D., Türe, F.: Learning morphological disambiguation rules for Turkish. In: Proceedings of HLT-NAACL (2006)
 . A Survey of Research. Mouton, The Hague - Paris (1976)
. A Survey of Research. Mouton, The Hague - Paris (1976) got to do with it? The use of
got to do with it? The use of  -headers from the Aṣṭādhyāyī in Sanskrit literature from the perspective of corpus linguistics. In: Proceedings of the WCS 2015 (forthcoming)
-headers from the Aṣṭādhyāyī in Sanskrit literature from the perspective of corpus linguistics. In: Proceedings of the WCS 2015 (forthcoming)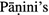 grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. Lecture Notes in Computer Science, vol. 5402, pp. 33–94. Springer, Heidelberg (2009)
grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. Lecture Notes in Computer Science, vol. 5402, pp. 33–94. Springer, Heidelberg (2009)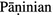 system of Sanskrit grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. LNCS, vol. 5402. Springer, Heidelberg (2009)
system of Sanskrit grammar. In: Huet, G., Kulkarni, A., Scharf, P. (eds.) SCL. LNCS, vol. 5402. Springer, Heidelberg (2009)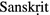 -English Dictionary, 3rd edn. Munshiram Manoharlal Publishers Pvt. Ltd., New Delhi (1988)
-English Dictionary, 3rd edn. Munshiram Manoharlal Publishers Pvt. Ltd., New Delhi (1988)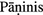 Śivasūtras: eine Untersuchung mit Methoden der formalen Begriffsanalyse. Ph.D. thesis, Universität Düsseldorf (2008)
Śivasūtras: eine Untersuchung mit Methoden der formalen Begriffsanalyse. Ph.D. thesis, Universität Düsseldorf (2008) , A History of Indian Literature, vol. II, Fasc. 3. Otto Harrassowitz, Wiesbaden (1986)
, A History of Indian Literature, vol. II, Fasc. 3. Otto Harrassowitz, Wiesbaden (1986)Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Hellwig, O. (2015). Morphological Disambiguation of Classical Sanskrit. In: Mahlow, C., Piotrowski, M. (eds) Systems and Frameworks for Computational Morphology. SFCM 2015. Communications in Computer and Information Science, vol 537. Springer, Cham. https://doi.org/10.1007/978-3-319-23980-4_3
Download citation
DOI: https://doi.org/10.1007/978-3-319-23980-4_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-23978-1
Online ISBN: 978-3-319-23980-4
eBook Packages: Computer ScienceComputer Science (R0)